
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как я делал комикс-игру по Лавкрафту

Привет, Хабр! Это будет история о тернистом пути разработки 2D-квеста в сеттинге миров Говарда Филлипса Лавкрафта, который целиком оформлен в виде интерактивного комикса. Ну то есть все в игре, начиная... | https://habr.com/ru/post/431218/ | null | ru | null |
# Натуральный Geektimes — делаем пространство чище
Читая Geektimes я постоянно хотел отключить редакторов, ведь они делают из саморегулирующегося сообщества со свободно возникающими статьями очередной адми или что-то подобное.
После того, как пару дней назад на главной странице я увидел пост "[Школьник расшарил обн... | https://habr.com/ru/post/391233/ | null | ru | null |
# Подробный разбор простого приложения на Rust
Начнём с самого простого и, при этом, самого важного вопроса...
Что мы будем разрабатывать?
---------------------------
Первый этап, практически, любой разрабо... | https://habr.com/ru/post/692470/ | null | ru | null |
# Объекты Java
Под впечатлениями от [habrahabr.ru/blogs/java/134102](http://habrahabr.ru/blogs/java/134102/).
Недавно мне приходилось немного поковыряться внутри JVM. Довольно интересный опыт. Текст в вышеупомянутом топике не совсем сходится с моим опытом, но я не считаю себя обладателем абсолютной истины. Ниже я п... | https://habr.com/ru/post/134910/ | null | ru | null |
# Все о Cisco FastLocation
Чем дальше погружаюсь в тему Wi-Fi позиционирования, тем очевиднее становится факт, что основная задача заключается не в достижении необходимой точности, а в получении необходимого количества замеров! Почему я так думаю?
Требования к плотности размещения точек доступа с каждым годом увели... | https://habr.com/ru/post/311722/ | null | ru | null |
# Я спарсил больше 1000 топовых Github-профилей по машинному обучению и вот что я узнал
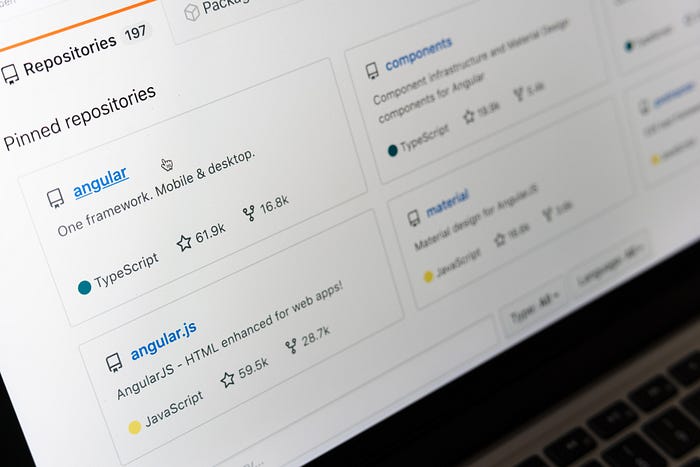
При поиске по ключевой фразе «машинное обучение» (речь идет об англоязычном ключе «machine learning» — прим. перев.) я нашел 246632 репозиториев по машинному обучению. Поск... | https://habr.com/ru/post/541352/ | null | ru | null |
# Автоэнкодеры в Keras, Часть 5: GAN(Generative Adversarial Networks) и tensorflow
### Содержание
* Часть 1: [Введение](https://habrahabr.ru/post/331382/)
* Часть 2: [*Manifold learning* и скрытые (*latent*) переменные](https://habrahabr.ru/post/331500/)
* Часть 3: [Вариационные автоэнкодеры (*VAE*)](https://habrah... | https://habr.com/ru/post/332000/ | null | ru | null |
# Знакомьтесь: FreeCAD
[FreeCAD](https://sourceforge.net/apps/mediawiki/free-cad/index.php?title=Main_Page) — параметрический трехмерный редактор, позволяющий создавать объемные модели и чертежи их проекций.
Текущая версия FreeCAD — 0.12, но можно также скачать бета-версию 0.13 и попытаться ее скомпилировать.
Fr... | https://habr.com/ru/post/145985/ | null | ru | null |
# Использование Razor за пределами ASP.NET
Итак, вчера [Microsoft выпустила ASP.NET MVC3 RTM](http://microgeek.ru/blogs/aspnet/1089/), который включает в себя новый движок представлений Razor. Как вы наверняка уже знаете, Razor не содержит каких-то компонентов, специфичных для web, а значит, его можно использовать и в... | https://habr.com/ru/post/111837/ | null | ru | null |
# Аналоги в Python и JavaScript. Часть первая
Привет, Хабр! Представляю вашему вниманию перевод статьи ["Equivalents in Python and JavaScript. Part 1"](https://djangotricks.blogspot.com/2018/06/equivalents-in-python-and-javascript-part-1.html).
Несмотря на то что Python и Javascript довольно сильно отличаются, сущес... | https://habr.com/ru/post/416617/ | null | ru | null |
# Сети для самых маленьких. Часть девятая. Мультикаст
**Все выпуски**
[8.1. Сети для самых маленьких. Микровыпуск №3. iBGP](http://linkmeup.ru/blog/65.html)
[8. Сети для самых маленьких. Часть восьмая. BGP и IP SLA](http://linkmeup.ru/blog/65.html)
[7. Сети для самых маленьких. Часть седьмая. VPN](http://linkmeu... | https://habr.com/ru/post/217585/ | null | ru | null |
# Пока смерть не разлучит нас или всё о static в C++

Всем привет. На одном из код-ревью я столкнулся с мыслью, что многие, а чего скрывать и я сам, не то чтобы хорошо понимаем когда нужно использовать ключевое слова **static**. В ... | https://habr.com/ru/post/527044/ | null | ru | null |
# Swift + VK.API, или история о SwiftyVK

Сегодня я хочу вам рассказать о том, как однажды познакомился с языком программирования Swift и решил написать на нем приложение для социальной сети ВКонтакте под OSX (которое, к со... | https://habr.com/ru/post/269741/ | null | ru | null |
# PHP и Temporal Coupling
Про архитектуру приложений на PHP было написано не один десяток статей, но на данной проблеме больше акцентируют внимание разработчики Java и C#. Суть ее заключается в жесткой зависимости одного свойства на другом.
Представим следующую ситуацию:
**Использование сеттера**
```
php
class... | https://habr.com/ru/post/281330/ | null | ru | null |
# Домашний кластер на Dask
Я недавно проводил исследование, в рамках которого было необходимо обработать несколько сотен тысяч наборов входных данных. Для каждого набора — провести некоторые расчеты, результаты всех расчетов собр... | https://habr.com/ru/post/499086/ | null | ru | null |
# Создание игр для NES на ассемблере 6502: ветвление и циклы

**Оглавление**
Оглавление
----------
### Часть I: подготовка
* [Введение](https://habr.com/ru/post/596449/)
* [1. Краткая история NES](https://habr.com/ru/post/596449/)
... | https://habr.com/ru/post/599369/ | null | ru | null |
# Пулы потоков: ускоряем NGINX в 9 и более раз
Как известно, для обработки соединений NGINX использует [асинхронный событийный подход](/post/260065/). Вместо того, чтобы выделять на каждый запрос отдельный поток или процесс (как это делают серверы с традиционной архитектурой), NGINX мультиплексирует обработку множеств... | https://habr.com/ru/post/260669/ | null | ru | null |
# Автоматическая авторизация на карте Strava Heatmap

Данный пост является ответом на недавнюю [аналогичную статью](https://habr.com/ru/post/450124/). Попробую рассказать, как можно автоматизировать описанные в ней действия. И как по... | https://habr.com/ru/post/451620/ | null | ru | null |
# OSINT в Telegram

[Протокол](https://core.telegram.org/api) Telegram известен своей доступностью и открытостью. У него есть множество публичных реализаций: [tdlib/td](https://github.com/tdlib/td), [rubenlagus/TelegramApi](https://g... | https://habr.com/ru/post/486322/ | null | ru | null |
# Jenkins Scripting Pipeline — генерация стадий выполнения
Всем привет! В интернете довольно много статей, связанных с Declarative Jenkins pipeline, и совсем немного о Jenkins Scripting Pipeline, хотелось бы восполнить этот пробел.
Сердцем любого backend являются данные. Существует два сценария использования данных. В одном из них данные изменяются редко, но при этом... | https://habr.com/ru/post/668524/ | null | ru | null |
# Разновидности объектно-ориентированного программирования (ОПП) в JavaScript. Часть 2
> **Для будущих студентов курса "**[**JavaScript Developer. Basic"**](https://otus.pw/pZGk/)**и всех желающих подготовили перевод полезной статьи.**
>
> **Приглашаем также посмотреть открытый урок на тему**[**"Прототипное наследова... | https://habr.com/ru/post/532946/ | null | ru | null |
# Автоматизация SSH-доступа к нодам Kubernetes с помощью Fabric и интеграции от CoreOS
Несмотря на то, что Kubernetes представляет мир, в котором SSH не так нужен в повседневном использовании для деплоя и управления приложениями, по-прежнему бывают случаи, когда SSH полезен для сбора статистики, отладки и исправления ... | https://habr.com/ru/post/328648/ | null | ru | null |
# Как победить на собеседовании. Несколько крайне полезных советов для разработчиков
*От автора: я разработал и провёл десятки собеседований по программированию. Здесь я расскажу, как меня обыграть*
Будем честными, боль... | https://habr.com/ru/post/302364/ | null | ru | null |
# Как начать программировать в Adobe Illustrator. Часть вторая
Этот пост — продолжение [первой части](https://habr.com/ru/post/452586/), где был представлен скрипт Expand Clipping Mask и детально описано, что и как он делает, а также попутно рассмотрены основные принципы создания подобных программ в целом. В этой част... | https://habr.com/ru/post/452614/ | null | ru | null |
# Сохранение данных для ESP32/Arduino в удаленной базе MySQL и не только
Любой любительский проект имеет дело с теми или иными данными, которые могут модифицироваться, генерироваться и, соответственно, требуют некоего хранения. В эт... | https://habr.com/ru/post/655537/ | null | ru | null |
# IoT и хакатон Azure Machine Learning: как мы делали проект вне конкурса

Не так давно состоялся очередной [хакатон](https://events.techdays.ru/machine-learning/2015-11/) от Microsoft. На этот раз, он был посвящен [машинно... | https://habr.com/ru/post/387857/ | null | ru | null |
# Использование преимуществ TypeScript в JavaScript разработке
Язык программирования [TypeScript](https://www.typescriptlang.org/) от Microsoft привносит многие преимущества статической типизации в JavaScript. Несмотря на то, что он не прове... | https://habr.com/ru/post/340036/ | null | ru | null |
# Hardening на практике
> В преддверии старта курса ["**Administrator Linux. Professional**"](https://otus.pw/SUPl/) подготовили статью, автором которой является Александр Колесников. Если вам интересно узнать подробнее об обучении на курсе, приходите на [демо-день курса.](https://otus.pw/bojm/)
>
>

Как известно, основной проблемой в тестировании является отчетность по прогонам. Некоторые компании собирают данные в отдельном хранилище. Вместо того, чтобы вручную организовыв... | https://habr.com/ru/post/695814/ | null | ru | null |
# Top 10 Bugs Found in C++ Projects in 2019

Another year is drawing to an end, and it's a perfect time to make yourself a cup of coffee and reread the reviews of bugs collected across open-source ... | https://habr.com/ru/post/481188/ | null | en | null |
# Mikrotik RouterOS + PHP скрипт на сайте. Расширение возможностей
Во времена ROS 5.x была потребность поднимать туннель к роутеру с белым динамическим адресом. В ROS 5 мы задавали не имя, а IP-адрес. Варианта 2: сервис DDNS, реализацию которого рассмотрим вкратце и второй о котором и будет рассказ.
Появилась идея... | https://habr.com/ru/post/267293/ | null | ru | null |
# Alice — REST Мониторинг RabbitMQ
Собственно столкнулся с проблемой, что при использовании [RabbitMQ](http://rabbitmq.com) необходимо мониторить сервер. Системную утилиту rabbitmqctl можно запускать из командной строки, но запустить ее из приложения не получилось. Что-то связанное с окружением эрланга.
После небо... | https://habr.com/ru/post/71328/ | null | ru | null |
# Автоматизация HTTP запросов в контексте Spring
### Предыстория
Несколько месяцев назад поступила задача по написанию HTTP API работы с продуктом компании, а именно обернуть все запросы с помощью RestTemplate и последующим перехватом информации от приложения и модификации ответа. Примерная реализация сервиса по рабо... | https://habr.com/ru/post/464089/ | null | ru | null |
# Тестирование PostgreSQL с HugePages в Linux
Ядро Linux предоставляет широкий спектр параметров конфигурации, которые могут повлиять на производительность. Главное — выбрать правильную конфигурацию для вашего приложения и рабочей нагрузки. Как и любой другой базе данных, PostgreSQL необходима оптимальная настройка яд... | https://habr.com/ru/post/435558/ | null | ru | null |
# Добавляем ORM в проект за четыре шага
Представим, что вашему проекту срочно понадобился ORM, и вы хотите внедрить его как можно быстрее. В этой статье я хочу рассказать, как это можно сделать всего за четыре шага на примере использования open source проекта [Apache Cayenne](https://cayenne.apache.org).

В этой статье я дам рекомендации по созданию платёжных форм, которые будут выгодно отличаться от форм ваших конкурентов. Каждый пункт рекомендаций будет сопровождаться примером ко... | https://habr.com/ru/post/527796/ | null | ru | null |
# Дорога в ад JavaScript-зависимостей
Каждый JavaScript-проект начинается с благих намерений, заключающихся в том, что его создатели обещают себе не использовать слишком много NPM-пакетов в ходе его разработки. Но даже если разработчики прилагают немалые усилия к тому, чтобы сдержать это обещание, NPM-пакеты постепенн... | https://habr.com/ru/post/499668/ | null | ru | null |
# Jii: Active Record для Node.js с API от Yii 2
Вступление
==========
Привет всем хабровчанам, любителям Yii и Node.js.
Это вторая статья про фреймворк [Jii](http://www.jiiframework.ru/) ([GitHub](https://github.com/jiis... | https://habr.com/ru/post/260569/ | null | ru | null |
# Построение орбит небесных тел средствами Python

### Системы отсчёта для определения орбиты
Для нахождения траекторий относительных движений в классической механике используется предположение об абсолютности времени во всех систем... | https://habr.com/ru/post/419911/ | null | ru | null |
# Читаем ключевой контейнер КриптоПро
Речь пойдет о PFX, который можно экспортировать из КриптоПро, как бы все хорошо, но данный контейнер нельзя использовать в OpenSSL и в других криптографических средствах из-за некой PBE с OID 1.2.840.113549.1.12.1.80.
Также есть известная утилита [P12FromGostCSP](http://soft.liss... | https://habr.com/ru/post/693600/ | null | ru | null |
# Альтернатива mysql_pconnect для драйвера mysqli в php 5.3
В качестве драйвера для соединения с базой я использовал mysqli. Проблема началась, когда я добавил на свой тестовый сервер > 500 000 записей в одну таблицу. Соединение с базой стало занимать от 1 до 10 секунд, несмотря на то, что в настройках стояло:
```
... | https://habr.com/ru/post/129482/ | null | ru | null |
# HTML-формы. Взгляд бэкенд-разработчика
При подготовке материала по Symfony Form я решил уделить некоторое внимание теоретической части по работе с формами со стороны клиента – что они из себя представляют, как ведут себя браузеры при отправке, в каком формате путешествуют, в каком виде поступают на сервер.
Вводн... | https://habr.com/ru/post/236837/ | null | ru | null |
# Написание современного JavaScript кода
JavaScript-разработчик из Франции, Себастьян Кастель, поделился мыслями о том, как на его взгляд должен выглядеть JavaScript код в 2017 году.
А вы помните те времена, когда JavaScript был языком, который использовали только для оживления страниц сайта? Это время уже прошло, ... | https://habr.com/ru/post/330534/ | null | ru | null |
# Авто-регистрация тестов на С средствами языка
Сравнительно недавно была статья [«Полуавтоматическая регистрация юнит-тестов на чистом С»](http://habrahabr.ru/post/240565/), в которой автор продемонстрировал ре... | https://habr.com/ru/post/252439/ | null | ru | null |
# Реализация простейшей стратегии инвестирования на базе API MOEX (Московской биржи)
### Введение
В это горячее время криптовалют стоит помнить не только о высоких мгновенных спекулятивных доходах, но и о том, что ваши деньги могут работать и зарабатывать всю вашу жизнь. Являясь приверженцем фундаментального анализа ... | https://habr.com/ru/post/343688/ | null | ru | null |
# Приостанавливаем выполнение приложения, если пропало соединение с сетью
Под катом, небольшая заметка о том, как приостановить выполнение вашего приложения при обрыве связи с интернетом и продолжить — когда она будет восстановлена.
Представим, что ваше, гипотетическое приложение, должно выполнить очередь http зап... | https://habr.com/ru/post/436426/ | null | ru | null |
# React hooks, как не выстрелить себе в ноги. Часть 1: работа с состоянием
Статья поможет новичкам понять как работать с хуками, а также будет полезна и опытным разработчикам. Этой статьей открываю серию стат... | https://habr.com/ru/post/667706/ | null | ru | null |
# Кидхак Prehistorik 2: анлочим уровни
#### Любителям этой замечательной игры посвящается...
[](http://plewick.deviantart.com/art/Prehistorik-2-282430653)
… Если таковые еще есть. Впрочем, я уверен, ... | https://habr.com/ru/post/220167/ | null | ru | null |
# Как легко запустить свой сайт-сообщество с помощью платформы Flarum
В этой статье хочу рассказать почему мне понадобилась платформа для сообщества, какие варианты реализации я нашел и за что выбрал именно Flarum. Также в статье есть пошаговая инструкция для новичков по установке данной платформы на свой хостинг.
 на c#, и в этой статье я расскажу про [алгоритм обратного распространения ошибки](http://ru.wikipedia.org/wiki/Метод_обратного_расп... | https://habr.com/ru/post/154369/ | null | ru | null |
# Трюки CSS и JavaScript, которые вдохнут жизнь в ваш статический сайт
Последние несколько недель я работал над своим сайтом и хотел придать ему некоторый динамизм. Эта статья не о создании веб-страницы. Я покажу готовые сниппеты с объяснениями.
[
**NewLang** — это язык программирования высокого уровня, в котором можно сочетать стандартные алгоритмические конструкции с декларативным программированием и тензорными вычислениями для задач... | https://habr.com/ru/post/673176/ | null | ru | null |
# Получаем кривую плотности распределения вероятности… быстрее и точнее
Недавно на Хабре вышла [статья](https://habr.com/ru/post/585232/) за авторством [MilashchenkoEA](https://habr.com/ru/users/MilashchenkoEA/) , в которой автор восполняет обнаруженный им пробел в доступных материалах по методам построения кривых пло... | https://habr.com/ru/post/587372/ | null | ru | null |
# Dive into pyTorch
Всем привет. Меня зовут Артур Кадурин, я руковожу исследованиями в области глубокого обучения для разработки новых лекарственных препаратов в компании [Insilico Medicine](http://insilico.com/). В Insilico мы используем самые современные методы машинного обучения, а также сами разрабатываем и публик... | https://habr.com/ru/post/358096/ | null | ru | null |
# Модераторы Хабра в лицах: будем знакомы
Я никогда не мечтала быть модератором. Ну то есть, даже мысли не было: хочу или не хочу, в Хабре я занималась совершенно другими вещами. Однако жизнь любит шутить, и 12 июля 2017 года я стала ведущим менеджером по работе с пользователями. Эта должность предполагает кучу функци... | https://habr.com/ru/post/712800/ | null | ru | null |
# ООП в JavaScript

В данной статье мы поговорим об основных особенностях объектно-ориентированного программирования в JavaScript:
* создание объектов,
* функция-конструктор,
* инкапсуляция через замыкания,
* полиморфизм... | https://habr.com/ru/post/302518/ | null | ru | null |
# Mail.Ru для бизнеса: всё, что вы хотели и не стеснялись просить
[](http://habrahabr.ru/company/mailru/blog/223667/)
Вы, возможно, помните, как мы [анонсировали](http://habrahabr.ru/company/mailru/blog/18... | https://habr.com/ru/post/223667/ | null | ru | null |
# Организация кода в микросервисах и мой подход применения гексагональной архитектуры и DDD
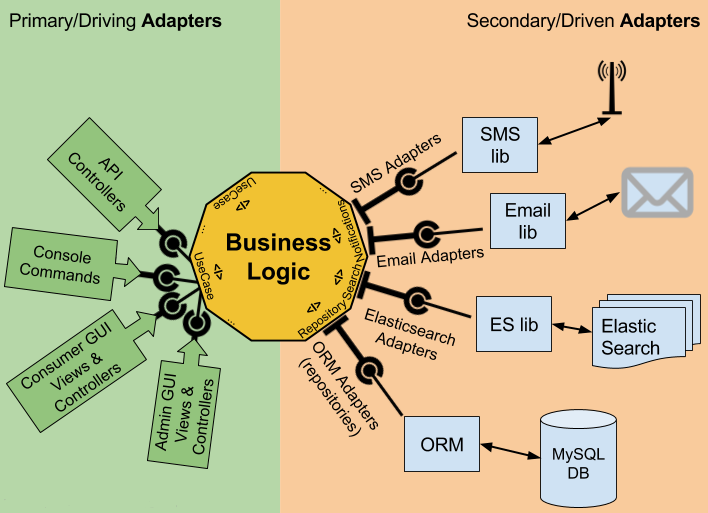
Привет, Хабр! В Монолите весь код должен быть в едином стиле, a в разных микросервисах можно использовать разные подходы, языки программиров... | https://habr.com/ru/post/493426/ | null | ru | null |
# Примеры кода для интернета вещей: умная поливалка
Недавно мы опубликовали [учебные примеры кода](https://software.intel.com/ru-ru/blogs/2015/11/04/announcing-18-new-how-to-intel-iot-code-samples) для различных проектов, которые формируют интернет вещей. Сегодня расскажем об автоматической системе полива. Построена о... | https://habr.com/ru/post/282756/ | null | ru | null |
# Подсвечиваем проблемные зоны на коленке с SonarQube и Docker Desktop
Привет, меня зовут Андрей Голяков, я руководитель бэкенд разработки компании Bimeister.
Хочу поделиться опытом быстрого подсвечивания возможных проблемных зон объёмного и малознакомого кода.

**Примечание от переводчика**Первая часть находится здесь: [«Учебное пособие по Nim (часть 1)»](http://habrahabr.ru/post/271197/)
Перевод делался для себя, то есть коряво и на скорую руку. Формулировки некоторых фраз приходилось рожать в страшных муках, чтобы они хоть отдалённо бы... | https://habr.com/ru/post/271361/ | null | ru | null |
# Наследование, композиция, агрегация
Нередко случается, что решив разобраться с какой-то новой темой, понятием, инструментом программирования, я читаю одну за другой статьи на различных сайтах в интернете. И, если тема сложная, то эти статьи могут не на шаг не приблизить меня к понимаю. И вдруг встречается статья, ко... | https://habr.com/ru/post/354046/ | null | ru | null |
# Делаем радиоуправление для самолета

Прочитав [этот](http://habrahabr.ru/post/168219/) пост загорелся и я идеей склепать свой самолетик. Взял готовые [чертежи](http://forum.rcdesign.ru/f81/thread145233.html), заказал у... | https://habr.com/ru/post/180759/ | null | ru | null |
# Awesome-лист своими руками, или GitHub вместо блокнота
Привет, Хабр! Наверное, у каждого из нас есть такой файлик, куда мы припрятываем что-то полезное и интересное для себя. Какие-то ссылки на статьи, книги, репозитории, мануалы.... | https://habr.com/ru/post/496594/ | null | ru | null |
# Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС

Итак, в [первой статье цикла](https://habr.com/ru/post/452656/) говорилось, что для управления нашим оборудованием, реализованным средствами ПЛИС, ... | https://habr.com/ru/post/454938/ | null | ru | null |
# Изучаем ResponseEntity<?> и избавляемся от него в контроллерах Spring
Всем привет! Проверяя задания в учебном центре моей компании, обнаружил, что двумя словами описать то, как можно избавиться от ResponseE... | https://habr.com/ru/post/675716/ | null | ru | null |
# Надежный способ сокрытия ссылок сайта от поисковых роботов
В один из рабочих дней мне пришел список заданий. Отдельным пунктом была просьба найти способ надежного сокрытия внешних ссылок на сайте от поисковых систем.
В чем суть проблемы? Существует несколько способов спрятать ссылку от поисковых роботов, но у них ... | https://habr.com/ru/post/667016/ | null | ru | null |
# Разворачиваем Kubernetes на десктопе за несколько минут с MicroK8s
Начать работать с Kubernetes не всегда бывает просто. Не у всех есть необходимая для разворачивания полноценного кластера Kubernetes инфраструктура. Для локальной работы Kubernetes предлагет утилиту [Minikube](https://kubernetes.io/docs/setup/minikub... | https://habr.com/ru/post/439734/ | null | ru | null |
# Храним сессии на клиенте, чтобы упростить масштабирование приложения (3-я из 12 статей о Node.js от команды Mozilla Identity)
***От переводчика:** Это третья статья из [цикла о Node.js](https://hacks.mozill... | https://habr.com/ru/post/196018/ | null | ru | null |
# Оптимизация картинок для Google PageSpeed
Нет предела совершенству, и [Google PageSpeed](https://developers.google.com/speed/pagespeed/) тому доказательство. С его помощью меньше чем за минуту можно получить подробный отчет о производительности Web страницы. В подавляющем большинстве случаев PageSpeed подскажет, что... | https://habr.com/ru/post/258363/ | null | ru | null |
# Стековая машина на моноидах

Не так давно на Хабре появилась отличная и вдохновляющая [статья](https://habr.com/company/badoo/blog/428878/) про компиляторы и стековые машины. В ней показывается путь от простой реализации исполнител... | https://habr.com/ru/post/429530/ | null | ru | null |
# Использование R для «промышленной» разработки
Является продолжением [предыдущих публикаций](https://habrahabr.ru/post/341668/). Не секрет, что при упоминании R в числе используемых инструментов вторым по популярности является вопрос о возможности его применения в «промышленной разработке». Пальму первенства в России... | https://habr.com/ru/post/342254/ | null | ru | null |
# Фильтрация запросов на уровне DNS
Начиная с версии 9.8.1 DNS-сервера bind появилась новая возможность — DNS RPZ. Это интересный инструмент, который может оказаться весьма полезным для многих сисадминов. Странно, но в русскоязычном сегменте интернета эта тема совершенно не освещена. Спешу восполнить этот пробел.
#... | https://habr.com/ru/post/177649/ | null | ru | null |
# Публичные свойства, геттеры и сеттеры или магические методы?
Как правило, мнения расходятся касательно того, хорошей ли практикой является использование публичных свойств в PHP классах или всё же стоит использовать геттеры и сеттеры (и хранить свойства приватными или защищёнными). Ещё одно, компромиссное мнение, сос... | https://habr.com/ru/post/197332/ | null | ru | null |
# Кластеризация nodejs web-сервера с помощью node-clusterize-cli
Последние полгода я занимаюсь разработкой достаточно большого web-приложения, под капотом которого ревет и дымится NodeJS. Когда дело дошло до деплоя на продакшн я задумался: «почему бы мне не использовать несколько тредов с инстансом приложения?».
Ре... | https://habr.com/ru/post/208914/ | null | ru | null |
# Китайская ошибка роутинга трафика России

В сентябре прошлого года третий по размеру российский мобильный оператор «Вымпелком» и China Telecom [подписали](http://www.comnews.ru/node/76819) соглашение о прямом присоединении... | https://habr.com/ru/post/356560/ | null | ru | null |
# PHP: Определение языка текста с помощью N-грамм. Часть 1
*Примечание*: я не смог по какой-то причине восстановить свой перевод, за который получил инвайт и он куда-то пропал. Поэтому публикую его снова.
Обычно, когда мы смотрим на текст, мы разбиваем его на слова и используем эти слова для определения языка, на к... | https://habr.com/ru/post/75509/ | null | ru | null |
# Обновление древовидной модели в Qt
Всем доброго времени суток! В этой статье я хочу рассказать про трудности, с которыми столкнулся при отображении и обновлении древовидной структуры с помощью QTreeView и QAbstractItemModel. Так же предложу велосипед, который я создал, чтобы обойти эти трудности.
Для отображения ... | https://habr.com/ru/post/250431/ | null | ru | null |
# Резервирование констант и Git hooks на C#
Позвольте мне рассказать вам историю. Жили-были два разработчика: Сэм и Боб. Они вместе работали над проектом, в котором была база данных. Когда разработчик хотел внести в неё изменения, он обязан был создать файл `stepNNN.sql`, где NNN — некоторое число. Чтобы избежать конф... | https://habr.com/ru/post/485218/ | null | ru | null |
# 7 распространенных ошибок в SQL-запросах, которые делал каждый (почти)
Сегодня SQL используют уже буквально все на свете: и аналитики, и программисты, и тестировщики, и т.д. Отчасти это связано с тем, что базовые возможности этого языка легко освоить.
Однако работая с большим количеством junior-ов, мы раз от раза ... | https://habr.com/ru/post/651965/ | null | ru | null |
# Поиск по дереву методом Монте-Карло и крестики-нолики
Так вышло, что для получение автомата по программированию бедным первокурам задали одну интересную задачу: написать программу, которая ищет по дереву методом Монте-Карло.
Конечно, всё началось с поиска информации в интернете. На великом и могучем русском языке б... | https://habr.com/ru/post/330092/ | null | ru | null |
# Пишем блог на микросервисах – часть 1 «Общее описание»
В этой статье хочу поделится нашими c [SergeyMaslov](https://habr.com/ru/users/sergeymaslov/) наработками решения типовых задач с использованием микросервисной архитектуры на примере задачи «создание блога» (в надежде, что читатель представляет как устроен блог ... | https://habr.com/ru/post/473514/ | null | ru | null |
# Функциональное программирование в Java
Сейчас появляются новые модные языки использующие парадигму функционального программирования. Тем не менее, в обычной Java
можно использовать функции для описания поведения объектов. Причём делать это можно полностью в рамках синтаксиса Java.
Я опубликовал Java-библиотеку... | https://habr.com/ru/post/127076/ | null | ru | null |
# ESET обнаружила банкер BackSwap, использующий новый метод манипуляции браузером
Банковские трояны в последние годы теряют популярность среди киберпреступников. Одна из причин – развитие технологий защиты антивирусных вендоров и разработчиков веб-браузеров. Провести атаку с помощью банкера сложно, поэтому многие виру... | https://habr.com/ru/post/413307/ | null | ru | null |
# Применение паттерна observer в Redux и Mobx
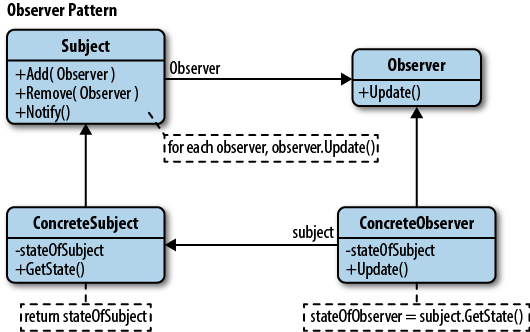
Паттерн "observer" известен наверное с момента появления самого ооп. Упрощенно можно представить что есть объект который хранит список слушателей и имеет метод "добавить", "удалить" и "опо... | https://habr.com/ru/post/348960/ | null | ru | null |
# Решаем проблемы с установкой Web Optimizer
[](http://code.google.com/p/web-optimizator/)После многочисленных установок приложения для автоматического ускорения сайтов — [Web Optimizer](http://code.google.com... | https://habr.com/ru/post/63753/ | null | ru | null |
# Неслучайный генератор случайных одноразовых кодов Тинькофф банка
Совершая очередную транзакцию в моем любимом банке Тинькофф, получил уже привычное сообщение:
> Никому не говорите код: 3131! Перевод с карты \*\*\*\*. Сумма \*\*\*.00 RUB
Если будут спрашивать — я вам его не говорил.
И снова взгляд зацепился за инт... | https://habr.com/ru/post/462071/ | null | ru | null |
# Как EA усложнили нам жизнь, или как мы чинили баг 12-летней давности
Иногда в программы закрадываются баги. Причем закрадываются так, что обнаружить их получается лишь через много-много лет после выпуска, когда чинить их уже нерентабельно. Иногда такие баги оказываются слишком критическими, чтобы их игнорировать. По... | https://habr.com/ru/post/333676/ | null | ru | null |
# Корпоративные сети могут быть взломаны с помощью Windows Update
Обновления Windows в последние дни становятся опасны для пользователей. Несколько дней назад желающие обновить свою операционную систему до Windows 10 [стали](http://www.zdnet.com/article/windows-10-scam-email-will-encrypt-your-files-for-ransom/) жертва... | https://habr.com/ru/post/264479/ | null | ru | null |
# Настройка отступов в VIM
Процесс смены Komodo IDE на VIM я начал с изучения всевозможных туториалов и хау ту, однако, что удивительно, ни в одном из них мне не удалось встретить человеческого описания процесса настройки отступов. В одних предлагали регулировать ширину отступа с помощью опции *tabstop*, в других — с ... | https://habr.com/ru/post/64224/ | null | ru | null |
# Как протестировать производительность серверов: подборка из нескольких open source бенчмарков
Продолжаем нашу серию материалов, посвященную тестированию производительности серверов. Сегодня поговорим о паре проверенных временем бенчмарках, которые до сих пор поддерживают и обновляют — NetPerf, HardInfo и ApacheBench... | https://habr.com/ru/post/476126/ | null | ru | null |
# Запуск сервера сборки Jenkins
Итак, в вашем репозитории накопилось количество сборок превысившее число 1. Настало время задуматься о DevOps(е). В этом тексте я напишу как развернуть локальный сервер сборки на основе Jenkins.
### Пролог
Зачем все это? Дело в том, что сам по себе репозиторий с кодом это Филькина гра... | https://habr.com/ru/post/695978/ | null | ru | null |
# Software renderer — 1: матчасть
Программный рендеринг (software rendering) — это процесс построения изображения без помощи GPU. Этот процесс может идти в одном из двух режимов: в реальном времени (вычисление большого числа кадров в секунду — необходимо для интерактивных приложений, например, игр) и в «оффлайн» режим... | https://habr.com/ru/post/243011/ | null | ru | null |
# Как работает JS: о внутреннем устройстве V8 и оптимизации кода
**[Советуем почитать] Другие 19 частей цикла**Часть 1: [Обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [О внутреннем устройстве V8 и оптимизации кода](https://habrahabr.ru/company/... | https://habr.com/ru/post/337460/ | null | ru | null |
# Обнаружение DDoS-атак «на коленке»
Приветствую, Хабр! Я работаю в небольшом интернет провайдере масштаба области. У нас транзитная сеть (это значит, что мы покупаем интернет у богатых провайдеров и продаем его бедным). Несмотря на небольшое количество клиентов и такое же небольшое количество трафика протекающего по ... | https://habr.com/ru/post/478238/ | null | ru | null |
# MockK — библиотека для mocking-а в Kotlin
 Kotlin пока еще очень новая технология и это значит, что существует множество возможностей сделать что-то лучше. Для меня этот путь был таким. Я начал пис... | https://habr.com/ru/post/341202/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.