
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Паттерн «VIP слушатель»
Признаюсь честно, описание этого паттерна мне не встречалось, соответственно его название я выдумал. Если у кого есть информация о правильном названии, буду очень рад услышать. Паттерн не привязан к языку но в данной статье я буду использовать `C#`.
Картинка для привлечения внимания:

Добрый день, %username%!
Как-то мы с компанией друзей решили сделать интернет радио, но как оказалось, выделяемого места на VPS недостаточно для большого архива музы... | https://habr.com/ru/post/270415/ | null | ru | null |
# OpenStack — разворачиваем «руками» Kilo
Привет всем Хабралюдям!
В прошлой [статье](http://habrahabr.ru/post/261715/), я рассказывал о том, как можно быстро развернуть тестовую среду при помощи DevStack. В этой публикации я расскажу как развернуть своё «облако» OpenStack на двух машинах (Controller, Compute) в ком... | https://habr.com/ru/post/262049/ | null | ru | null |
# Как ManyChat на PHP8 переезжал
Привет, меня зовут Максим, я бэкенд-разработчик в ManyChat.
Эта статья — о нашем переходе на PHP8. Однажды мы решили немного поисследовать — посмотреть, чего нам будет стоить возможный переход на новую версию, и запланировать эти работы на следующий год, сразу на 8.1. Перспектива пер... | https://habr.com/ru/post/586008/ | null | ru | null |
# Учимся писать модуль ядра (Netfilter) или Прозрачный прокси для HTTPS
Эта статья нацелена на читателей, которые начинают или только хотят начать заниматься программированием модулей ядра Linux и сетевых приложений. А также может помочь разобраться с прозрачным проксированием HTTPS трафика.
Небольшое оглавление, ч... | https://habr.com/ru/post/138328/ | null | ru | null |
# Yet another kaspersky crackme
Сей раз ЛК выпустила на свет шесть крякми, два из которых были написаны на ~~человеческом языке~~ С. Приступим к анализу. [Линк](https://events.kaspersky.com/crackme/tasks), [архив](https://web.archive.org/web/20171126124003/https://events.kaspersky.com/crackme/tasks), [семпл из статьи]... | https://habr.com/ru/post/343342/ | null | ru | null |
# Вышла Opera 9.2
Вышла финальная версия [Opera 9.20](http://www.opera.com/download/).
Основные нововведения:
* появилась панель *Быстрого набора* (Speed Dial), которая появляется при открытии новой вкладки и [показывает](http://www.opera.com/img/products/desktop/screenshots/speeddial.jpg) до 9 миниатюр наиболее... | https://habr.com/ru/post/6689/ | null | ru | null |
# Maven vs Gradle различия использования в Java-проектах
В данной статье разберемся в практических различиях инструментов для сборки Maven и Gradle. Ведь современным разработчикам катастрофически не хватает времени на погружение во все ... | https://habr.com/ru/post/649987/ | null | ru | null |
# Решаем проблему с кешированием динамического JavaScript кода на фронтенд WordPress
В процессе разработки анти-спам плагина [CleanTalk](https://cleantalk.org) для WordPress мы стокнулись с проблемой кеширования динамического JavaScript кода на фронтенде сайтов. А именно, если разместить JavaScript содержащий какие ли... | https://habr.com/ru/post/281955/ | null | ru | null |
# Игровой сервер на Scala + Akka

Когда-то давно я уже поднимал тему применения Scala в игровом сервере. Тогда это был совсем простой пример использующий только Scala. С тех времен много воды утекло. S... | https://habr.com/ru/post/229045/ | null | ru | null |
# Part 2: Upsetting Opinions about Static Analyzers
By writing the article "Upsetting Opinions about Static Analyzers" we were supposed to get it off our chest and peacefully let it all go.... | https://habr.com/ru/post/523692/ | null | en | null |
# .NET в unmanaged окружении: вызов управляемого кода из неуправляемого
Как вы, наверное, помните из моей [предыдущей статьи](http://habrahabr.ru/blogs/net/58031/), взаимодействие unmanaged и managed кода представляет определенную проблему, даже для опытных разработчиков. Причина этого — необходимость понимать, какие ... | https://habr.com/ru/post/58240/ | null | ru | null |
# Создаем slack-бот на Python в Yandex.Cloud
Мы не любим отвлекаться от текущей работы, копаться в трекере задач и почте, чтобы найти нужный тикет или письмо от клиента. Нас беспокоят пропущенные напоминания ... | https://habr.com/ru/post/564684/ | null | ru | null |
# Практика IronScheme

> Уверен, что вы перестанете играть в «мясо», ибо то, что я вам сейчас расскажу, покажется вам очень интересным, хотя бы потому, что многих специальных терминов вы не поймёте.
>
> Ярослав Гашек
[Ч... | https://habr.com/ru/post/267119/ | null | ru | null |
# REST API на Symfony, FOSRestBundle + GlavwebDatagridBundle
Всем привет! В прошлой статье я рассказал о нашем опыте в REST API со сборкой на [FOSRestBundle + JMSSerializer](https://habrahabr.ru/post/302902/). Сегодня я поделюсь нашим подходом к разработке REST API на FOSRestBundle + GlavwebDatagridBundle.
Новые за... | https://habr.com/ru/post/303366/ | null | ru | null |
# Настройка Wifi в Linux при помощи Adhoc на примере Ubuntu
Эта тема уже не раз поднималась, но хорошей и легкой инструкции я так и не нашел.
Данная статья расчитана на новичков в мире Linux поэтому тут используются наиболее легкие методы настройки.
Для начала ставим пакеты:
`sudo apt-get install wireless-to... | https://habr.com/ru/post/88281/ | null | ru | null |
# Тест Йохансена на коинтеграцию
Цель данной статьи - поделиться результатами сравнительного анализ двух тестов на коинтеграцию, теста Энгла-Гренджера и теста Йохансена. Для этого нам понадобится рассмотреть соотношение между двумя и более переменными, понять, что такое VAR процесс, как перейти к VECM модели, в чем за... | https://habr.com/ru/post/686314/ | null | ru | null |
# Биткоин-кошельки: зачем и как хранить свои приватные ключи
*Перевод статьи*[*Bitcoin Wallets*](https://www.swanbitcoin.com/bitcoin-wallets-not-your-keys-not-your-bitcoin)*подготовлен биткоинером*[*Tony ₿*](https://twitter.com/TonyCrusoe)
Итак, вы приобрели немного биткоинов, и теперь столкнулись со следующим вопрос... | https://habr.com/ru/post/530676/ | null | ru | null |
# Embedded Linux. Отладка ядра
Придя в embedded linux из мира микроконтроллеров, такого привычного инструмента отладки кода, как пошаговая отладка кода на целевой железке с помощью аппаратного программатора, - очень не хватало. В предыдущих статьях описано, как мы учились дебажить загрузчик u-boot: [1](https://habr.co... | https://habr.com/ru/post/592671/ | null | ru | null |
# Уязвимость в Telegram позволяет скомпрометировать секретные чаты
### Публикация к юбилею Telegram
В секретных чатах Telegram используется «сквозное шифрование», и что? End to end encryption Telegram слабо защищает переписку пользователей. Простой пример: злоумышленник достал приватный ключ.pgp Алисы, естественно, ч... | https://habr.com/ru/post/419551/ | null | ru | null |
# Взлом игрового архива трэш-клона GTA 3 и использование Kaitai для упрощения распаковки
Эта статья продолжает идею предыдущей ["Как у меня получилось взломать и распаковать ресурсы старой игры для PSX"](https://habr.com/ru/post/347382/) здесь я также попытаюсь с точки зрения "новичка в реверс-инжиниринге" описать ход... | https://habr.com/ru/post/689354/ | null | ru | null |
# Динамическая визуализация геокодированных данных (Twitter) с помощью R
##### «Новый год шагает по стране»
Я являюсь ярым фанатом геосоциальных сервисов. Они позволяют наглядно увидеть физическую реализацию социального пространства. Это то, о чем писал [Бурдьё](http://ru.wikipedia.org/wiki/%D0%91%D1%83%D1%80%D0%B4%D... | https://habr.com/ru/post/165305/ | null | ru | null |
# Паттерны проектирования для iOS разработчиков. Observer, часть I
#### Вместо предисловия
Прошло уже 17 лет с тех пор, как вышла легендарная книга Банды Четырех, посвященная Паттернам проектирования (Design patterns). Несмотря на столь солидный срок, тяжело оспорить актуальность описанных в ней методик. Паттерны про... | https://habr.com/ru/post/126968/ | null | ru | null |
# Беда “войти в айти” или курсы тестировщика отзывы: 5-минутный тест на перспективы в QA
В телеграм-канале для желающих стать тестировщиками автор опубликовал следующий пост, но дальше ситуация чуть вышла из-под контроля.
> *Как вы относитесь к различным психологическим тестам? Скорее всего, так же как и я - отрицате... | https://habr.com/ru/post/598481/ | null | ru | null |
# Улучшаем процесс ведения проекта в Git
Привет! Я давно заметил, что процесс добавления нового кода в проект в большинстве команд может быть не всегда стандартизирован. Из-за этого могут возникнуть сложности в коммуникации разработчиков как на уровне описания добавленного кода, так и понимания, какое влияние несет но... | https://habr.com/ru/post/664190/ | null | ru | null |
# Пример создания простой 2D игры для Android с использованием игрового движка Unity
Введение
========

Прежде всего, хочу сразу отметить, что я не являюсь профессиональным разработчиком. В этой статье я постараюсь изложить... | https://habr.com/ru/post/283186/ | null | ru | null |
# Про Flutter, кратко: Основы

После доклада [Юры Лучанинова](https://www.youtube.com/watch?v=Y3kk4Qu79Qc&list=PLnkLrCUX4Qh4RH-BltBk03Eet1U... | https://habr.com/ru/post/430918/ | null | ru | null |
# Как мы внедряли INDE в наше Android приложение
Применение готовых библиотек в приложениях освобождает программистов от непроизводительного труда по изобретению велосипедов, сокращает время выхода приложения на рынок и бл... | https://habr.com/ru/post/236833/ | null | ru | null |
# HMI на основе Node-red и Scadavis.io
В связи с ростом популярности концепции IoT и развитием сопутствующих технологий многие производители программного обеспечения для промышленной автоматизации используют эти подходы в своих продуктах. Доступ к SCADA-системам через web-интерфейс — идея не новая. Еще лет 10 назад Ci... | https://habr.com/ru/post/507748/ | null | ru | null |
# Эволюция конфигурации .NET

Каждый программист представлял — ну или может хочет представить — себя пилотом самолета, когда у тебя есть огромный проект, к нему огромная панель датчиков, метрик и переключателей, с помощью которых м... | https://habr.com/ru/post/514652/ | null | ru | null |
# Обзор выделенных серверов Kimsufi и SoYouStart
Год назад вышла [статья](http://habrahabr.ru/post/167117/), которая подвигла меня приобрести сервер в [Kimsufi](http://www.kimsufi.com/) – это подразделение крупного французского хостера [OVH](http://www.ovh.com/), специализирующееся на дешёвых серверах, зачастую на ста... | https://habr.com/ru/post/210992/ | null | ru | null |
# Анимация в MooTools. Основы и не только.
В данном топике я собираюсь свести все свои знания об анимации в MooTools воедино и рассмотреть темы, более углубленные, чем просто примеры использования плагинов. Теоретическая информация справедлива не только для MooTools, но и для других фреймворков. Начинающим будет интер... | https://habr.com/ru/post/43379/ | null | ru | null |
# Как сэкономить на спотовых инстансах EC2 с помощью Scylla
Спотовые инстансы могут сэкономить вам много денег. Но что если вы работаете с сервисами с сохранением состояния, например, базами данных NoSQL? Основная проблема заключается в том, что в таком случае каждая нода в кластере должна сохранять некоторые параметр... | https://habr.com/ru/post/345480/ | null | ru | null |
# SQL и XPath против РосРеестра
Уже несколько лет РосРеестр выдаёт данные в формате XML, а с недавних пор – только в XML. И это замечательно! Ведь это удобный, человек-читаемый и машино-читаемый формат, для работы с которым существует огромное количество инструментов. Но Кадастровым Инженерам почему то, подавай данные... | https://habr.com/ru/post/307294/ | null | ru | null |
# MAC-адреса бывают разные
*Эпиграф: Если у человека нет чувства юмора, у него по крайней мере должно быть чувство, что у него нет чувства юмора.*
Не далее как сегодня с коллегами вычисляли неблагополучно подключенное устройство с целью отключить порт на коммутаторе в воспитательных целях.
В нашем случае мы физи... | https://habr.com/ru/post/324200/ | null | ru | null |
# Адаптивные email'ы
Сегодня пользователи все чаще читают электронные письма на мобильных устройствах. Каково бывает просмотр большого HTML-email'а на телефоне? Приходится много масштабировать и скрол... | https://habr.com/ru/post/190814/ | null | ru | null |
# Тестирование производительности приложений как часть ежедневного цикла разработки
### Введение
Каждый продукт в какой-то момент приходит в ту точку, когда вопросы производительности начинают выходить на пе... | https://habr.com/ru/post/586666/ | null | ru | null |
# Безопасность в iOS приложениях
Добрый день, Хабр! Представляю вашему вниманию перевод статьи про базовые основы безопасности конфиденциальных данных в iOS приложениях [«Application Security Musts for every iOS App»](https://medium.com/swift2go/application-security-musts-for-every-ios-app-dabf095b9c4f) автора Arlind ... | https://habr.com/ru/post/430532/ | null | ru | null |
# Масштабируем кластер Kubernetes до 7500 нод

*Фото Carles Rabada, Unsplash.com*
Мы заскейлили кластер Kubernetes до 7500 нод, создав масштабируемую архитектуру для крупных моделей, вроде [GPT-3](https://arxiv.org/abs/2005.1... | https://habr.com/ru/post/558168/ | null | ru | null |
# Установка Yggdrasil Network на Windows
Найти общую [информацию](https://habr.com/ru/post/547250/) о Yggdrasil на русском языке не составляет труда. Однако, как показала практика, многие пользователи сталкиваются с трудностями при установке клиента сети. По заявкам трудящихся рассмотрим в этой статье установку и нача... | https://habr.com/ru/post/567012/ | null | ru | null |
# Распознаем медицинские тексты
Это третья публикация в рамках цикла статей по изучению московской базы ковидных больных. В настоящей работе были созданы векторные представления медицинских терминов, которые... | https://habr.com/ru/post/581408/ | null | ru | null |
# Как проанализировать рынок фотостудий с помощью Python (3/3). Аналитика
Каждый, кто открывает свой бизнес, хочет угадать идеальный момент открытия, найти идеальное место и выполнить точные, эффективные действия для того, чтобы бизнес выжил и приумножился. Найти идеальные параметры невозможно, но оценить наилучшие во... | https://habr.com/ru/post/512848/ | null | ru | null |
# Создаем простую игру с Jetpack Compose для часов на Google WearOS
Библиотека Jetpack Compose значительно изменила подход к разработке нативных приложений и позволила декларативно описывать в коде интерфейсы... | https://habr.com/ru/post/705686/ | null | ru | null |
# HTTP Error 503. Service Unavailable: случай в поддержке хостинга
Работа в поддержке хостинга в основном однотипная, большинство запросов от клиентов решаются по проработанной схеме, но иногда всё же приходится сталкиваться с нетривиальными проблемами. Тогда главная задача инженера — найти тот самый — единственно вер... | https://habr.com/ru/post/510048/ | null | ru | null |
# Top 10 JavaScript Hack for Optimized Performance
JavaScript has been ruling the tech arena for more than two decades and helping developers simplifying complex tasks. It allows developers to implement complex task web pages in a most simplified manner. For most of the developers minified JavaScript file is the commo... | https://habr.com/ru/post/456544/ | null | en | null |
# Трехмерная визуализация в тренажерах подвижного состава на базе движка OpenSceneGraph

Чуть меньше года назад увидела свет [публикация](https://habr.com/ru/post/408885/), где мы рассказывали об учебно-лабораторном комплексе (УЛК)... | https://habr.com/ru/post/436276/ | null | ru | null |
# Why PVS-Studio Uses Data Flow Analysis: Based on Gripping Error in Open Asset Import Library

An essential part of any modern static code analyzer is data flow analysis. However, from an outsid... | https://habr.com/ru/post/543138/ | null | en | null |
# Робот, который таки ответит на вопрос о погоде в Токио (на самом деле — нет, но уже близко)
Собственно, после одного из недавних [постов](https://habrahabr.ru/company/ibm/blog/303666/) [@IBM](https://habrahabr.ru/users/ibm/) возникла идея скрестить ~~ежа с ужом~~ [Dialog](http://www.ibm.com/smarterplanet/us/en/ibmwa... | https://habr.com/ru/post/304282/ | null | ru | null |
# Итератор в шаблонизаторе doT.js по объектам с фильтрацией
Компактный (3.5 Кб) и быстрый шаблонизатор **doT.js** для браузеров и nodeJS до сих пор (v.1.0.1) имеет итерацию только по массивам. Это не всегда уд... | https://habr.com/ru/post/201592/ | null | ru | null |
# Python на примере демона уведомления о новых коммитах Git
Работая в команде я люблю быть в курсе активности участников. Поэтому было решено написать демона наблюдающего за поступлением новых коммитов в репозиторий *git*’а. Так как я работаю в *Ubuntu*, то уведомление было реализовано встроенным способом — библиотеко... | https://habr.com/ru/post/135408/ | null | ru | null |
# Checking Telegram Open Network with PVS-Studio

Telegram Open Network (TON) is a platform by the same team that developed the Telegram messenger. In addition to the blockchain, TON provides a large set of services. The dev... | https://habr.com/ru/post/469915/ | null | en | null |
# Sanic — быстрее, чем кролики
Как известно, в великом множестве веб-фрейморков, существующих в экосистеме Python, очень легко заблудиться. С одной стороны, большой выбор - это хорошо, но с другой - это так ж... | https://habr.com/ru/post/676556/ | null | ru | null |
# Следим и вычисляем с Vue 3, или Как использовать watchEffect
Привет! Меня зовут Алексей, я frontend-специалист SimbirSoft. В этой статье разберем новый метод слежения за реактивными свойствами watchEffect.
С появлением Vue 3 c Composition API стало доступно два метода слежения — watch и watchEffect. Если «старый» м... | https://habr.com/ru/post/697910/ | null | ru | null |
# Пишем расширение для Chrome «загрузка аудиозаписей с Вконтакте»
В магазине расширений chrome наверняка уже есть загрузчики песен с вконтакте, но мы попробуем написать свой.
Наше расширение будет добавлять ссылку в каждую из песен раздела *Мои Аудиозаписи*, которая будет скачивать песню.
Выглядеть должно пример... | https://habr.com/ru/post/254005/ | null | ru | null |
# Vue + SSR + AMP — как подружить SPA с гугл страницами
Привет, хабрист!
Довольно давненько подружил свои приложения с гуглом.
Основная идея была - не создавая новых шаблонов, получить все страницы сайта AMP-friendly и, вообще, сделать ядро приложения AMP-ready.
Тут нас поджидает серьезная переработка стилей CSS и ... | https://habr.com/ru/post/599301/ | null | ru | null |
# Добавляем favicons для bookmarklets
Так как плагин [Favicon Picker 2](https://addons.mozilla.org/en-US/firefox/addon/3176) не поддерживает FireFox 3, а смотреть на пустые иконки букмарклетов стало грустно, я предпринял попытку исправить эту ситуацию.
Для работы нам понадобится расширение [Stylish](https://addons.... | https://habr.com/ru/post/27872/ | null | ru | null |
# Разбор WKB формата без сторонних библиотек
В процессе разботы над одной задачей в проекте [Карты Mail.Ru](http://maps.mail.ru) возникла необходимость чтения формата [WKB](http://en.wikipedia.org/wiki/Well-known_text). Коне... | https://habr.com/ru/post/167517/ | null | ru | null |
# Детектирование аппаратных Троянских угроз с помощью алгоритмов машинного обучения
Интро
-----
Все мы в какой-то степени подвержены Троянской угрозе сегодня. Любой девайс, который был куплен в ближайшем магазине под домом, может служить не только Вам, как потребителю, но и злоумышленнику в его целях. Потому угроза и... | https://habr.com/ru/post/533652/ | null | ru | null |
# Hello World! как ему следует быть на C в Linux
Очень многие начинающие программисты думают, что знают, как написать Hello World. Естественно, с этого примера ведь и начинается большинство учебников.
А давайте посмотрим, как это делается.
Обычно в учебнике по C эта программа выглядит примерно так:
`#include... | https://habr.com/ru/post/75971/ | null | ru | null |
# Гибкая система логирования на Go
Данная статья это адское изобретение нового велосипеда. Так что на продакшене использовать только на свой страх и риск. Я долго искал систему для ведения логов на Go которая удовлетворила бы мои запросы (гибкая, возможность уведомления на емейл, очень быстрая и хранение логов в муску... | https://habr.com/ru/post/270263/ | null | ru | null |
# Обработка ошибок в Express
Когда я только начинал работать с Express и пытался разобраться с тем, как обрабатывать ошибки, мне пришлось нелегко. Возникало такое ощущение, будто никто не писал о том, что мне было нужно. В итоге мне пришлось самому искать ответы на мои вопросы. Сегодня я хочу рассказать всё, что знаю ... | https://habr.com/ru/post/476290/ | null | ru | null |
# Джаваскриптовая библиотека MathJax преобразует математические формулы на языке MathML или LaTeX в красивые иллюстрации
Обратите внимание на вот эту иллюстрацию:
![[итог работы MathJax]](https://habrastorage.org/r/w1560/getpro/habr/post_images/8a8/f38/e5e/8a8f38e5e94c497954dedc3b0ae38d9e.png)
Красиво, правда? ... | https://habr.com/ru/post/79059/ | null | ru | null |
# Как развлечь себя с помощью vk api
В какой-то момент моей жизни я понял, что для счастья мне нужно создать 10 страниц-копий самого себя во Вконтакте и добавиться одновременно всеми в друзья к людям из френдлиста моей основной страницы. Для подробностей реализации идеи — прошу под кат.
, оставленой в песочнице. Тут, как и было обещано в заметке, будет более подробно рассказано о использовании обьектов **DataProxy**, **DataReader**.
Но для начала рассмотрим структуру, ко... | https://habr.com/ru/post/60549/ | null | ru | null |
# Анализ источников трафика для повышения конверсии
 В этой статье речь пойдет о том, как правильно анализировать источники трафика, например, с помощью... | https://habr.com/ru/post/210946/ | null | ru | null |
# Использование runit для своих сервисов
Супервизор сервисов [**runit**](http://smarden.org/runit/) позиционируется как замена стандартным скриптам инициализации Unix.
Но на практике оказалось, что runit идеален для управления сервисами безотносительно инициализации и т.п.
#### Введение
Супервизор берёт на себя... | https://habr.com/ru/post/83775/ | null | ru | null |
# Русификация библиотеки openGLCD для Arduino
Написание русскоязычного текста на графических дисплеях с контролером ks0108 или его аналогами все еще представляет существенные трудности. Библиотека openGLCD, которую рекомендуют официальные сайты Arduino, в [оригинальной комплектации](https://bitbucket.org/bperrybap/ope... | https://habr.com/ru/post/400749/ | null | ru | null |
# Опыт настройки и использования WSL (подсистемы Linux в Windows 10)
К написанию данной статьи меня побудил вопрос на Тостере, связанный с WSL. Я, после нескольких лет использования систем на ядре Linux, около полугода назад перешел к использованию Windows 10 на домашнем ПК. Зависимость от терминала и Linux окружения ... | https://habr.com/ru/post/412633/ | null | ru | null |
# SSR: когда, зачем и для чего. На примере Vue

([*Иллюстрация*](http://vk.com/phkdesign))
~~Once upon a time~~ Несколько лет назад, когда я только начинал работать с вебом на Java, мы работали с JSP. Вся страница генерировалась н... | https://habr.com/ru/post/425053/ | null | ru | null |
# Свой мессенджер Matrix-synapse в связке с Jitsi-meet. Часть 3
Всем Приветь. Как вы уже обратили внимание, порядок публикации нарушен. Изначально планировалось выпустить эту статью в качестве третьей части цикла, однако она стала второй. Это объясняется тем, что поднять один новый сервер для Matrix дешевле, чем неско... | https://habr.com/ru/post/540894/ | null | ru | null |
# Как мы пытались с NoSQL работать как с SQL с помощью Hibernate и Apache Phoenix
TL;DR;
------
Мы хотели реализовать пагинацию, и для этого нам пришлось форкнуть диалект для Hibernate.
В тот день ничего не предвещало ... | https://habr.com/ru/post/533724/ | null | ru | null |
# WebRTC стриминг в виртуальной реальности и вокруг нее

Виртуальная реальность нынче на пике моды. Оборудование, что во времена "Газонокосильщика" было уделом ~~сумасшедших ученых~~ гиков с большими деньгами ~~от Минобороны~~, сейча... | https://habr.com/ru/post/481698/ | null | ru | null |
# svn + bash = пишем консольный svn браузер
Для тех кто пользуется svn в командной строке, а так же для тех кто интересуется программированием bash-скриптов, в топике рассмотрен пример написания интерактивного bash-скрипта «svn-браузера», работающего в терминале и позволяющего делать несколько «ежедневных» операций с ... | https://habr.com/ru/post/104062/ | null | ru | null |
# Легко и просто проверяем Firefox с помощью PVS-Studio Standalone

Три года назад мы уже проверяли Mozilla Firefox с помощью анализатора PVS-Studio. Тогда это было неудобно и затрудни... | https://habr.com/ru/post/226247/ | null | ru | null |
# Почему для SQL Server важна статистика
*Считанные дни остаются до старта нового потока по курсу [“MS SQL Server разработчик”](https://otus.pw/FSTK/). В преддверии старта курса продолжаем делиться с вами полезным материалом.*
За годы работы с SQL Server я обнаружила, что есть несколько тем, которые часто игнорируютс... | https://habr.com/ru/post/489366/ | null | ru | null |
# Когда «Zoë» !== «Zoë», или почему нужно нормализовывать Unicode-строки
Никогда не слышали о нормализации Unicode? Вы не одиноки. Но об этом надо знать всем. Нормализация способна избавить вас от множества проблем. Рано или поздно нечто подобное тому, что показано на следующем рисунке, случается с любым разработчиком... | https://habr.com/ru/post/445274/ | null | ru | null |
# Процедурная генерация лабиринтов в Unity
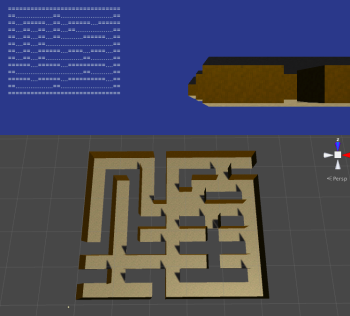
> *Примечание:* этот туториал написан для Unity 2017.1.0 и предназначен для опытных пользователей. Подразумевается, что вы уже хорошо знакомы с программирова... | https://habr.com/ru/post/353104/ | null | ru | null |
# Автоматическая установка и настройка PostgreSQL при помощи Wix#
Привет Хабр!
В связи со сложностью проекта, над которым я сейчас работаю, появилась необходимость развертывания и настройки PostgreSQL на каждой машине клиента. Клиентов у нашей компании много, поэтому было решено автоматизировать процесс настройки P... | https://habr.com/ru/post/276175/ | null | ru | null |
# Теневые стеки для пользовательского пространства
Стек вызовов (call stack) является излюбленной целью злоумышленников, пытающихся скомпрометировать запущенный процесс; если злоумышленник найдет способ перез... | https://habr.com/ru/post/658491/ | null | ru | null |
# Joker 2020: продолжение сезона онлайн-конференций
Только что, c 25 по 28 ноября 2020 года, прошла Java-конференция [Joker 2020](https://jokerconf.com). Это уже второй сезон конференций, проводимых [JUG Ru Group](https://jugru.org) в формате онлайн.
В онлайн-формате конференция стала лучше или хуже? Что нового орг... | https://habr.com/ru/post/529984/ | null | ru | null |
# Visual Studio Snippets
Одно время я очень фанател от CodeRush. Он позволял в два-три нажатия клавиши создать свойство у объекта или составить тело цикла. Набирать код институтских лабораторных было одно удовольствие.
Потом вышла 2008 студия с C# 3.0 и там были автоматические свойства. Мне все больше не нравилось,... | https://habr.com/ru/post/78530/ | null | ru | null |
# Вышла бета консольной утилиты GitHub CLI

Разработчики GitHub выпустили бета-версию консольной утилиты [GitHub CLI](https://github.com/cli/cli). Она позволяет создавать пул-реквесты и тикеты на GitHub, не выходя из консоли, где вы уже рабо... | https://habr.com/ru/post/488170/ | null | ru | null |
# 6 кнопок
Постановка задачи
=================
Сутки добрые, Хабраюзеры!
Пару недель назад представитель федерации по кикбоксингу нашего региона поставил мне задачу, сделать то, что позволит сократить время проведен... | https://habr.com/ru/post/178633/ | null | ru | null |
# Есть мнение: технология DANE для браузеров провалилась
Говорим о том, что собой представляет технология DANE для аутентификации доменных имен по DNS и почему она не получила широкого распространения в браузерах.
[](https://habr.c... | https://habr.com/ru/post/454322/ | null | ru | null |
# Отправляем магические ссылки с помощью Node.js
***Перевод статьи подготовлен в преддверии старта курса [«Разработчик Node.js»](https://otus.pw/qEXb/).***

---
Самый популярный метод входа в приложение – это предоставление логи... | https://habr.com/ru/post/507148/ | null | ru | null |
# Скачиваем Google Docs без браузера
Скриптик выглядит как-то так:
`#!/bin/bash
token=$(curl -s www.google.com/accounts/ClientLogin -d Email=user.name@gmail.com -d Passwd=qwerty -d accountType=GOOGLE -d service=writely -d Gdata-version=3.0 |cut -d "=" -f 2)
set $token
curl --silent --header "Gdata-Version:... | https://habr.com/ru/post/85298/ | null | ru | null |
# Супер кнопка для Манчкина

Многие знают или, по крайней мере, слышали про настольную игру [Манчкин](http://ru.wikipedia.org/wiki/Манчкин_(игра))
В этой игре есть такое правило:
*«Когда в... | https://habr.com/ru/post/116550/ | null | ru | null |
# Computed Columns и nvarchar(max)
Недавно столкнулся с проблемным запросом, который делал отбор по столбцу с типом nvarchar(max). Про производительность отборов по nvarcar(max) я [уже писал](https://habr.com/ru/post/489182/), а сейчас решил сделать пост о том, как можно решить проблему, если фильтр по nvarchar(max) н... | https://habr.com/ru/post/577612/ | null | ru | null |
# Модульное тестирование для приложений на платформе IBM Notes/Domino
Коснусь темы, которая в мире Notes/Domino практически не известна — модульного (unit) тестирования, и представлю вашему вниманию инструмент на написания unit-тестов для Notes/Domino под язык LotusScript. Статья в большей степени рассчитана на тех, к... | https://habr.com/ru/post/346708/ | null | ru | null |
# Padding Oracle Attack или почему криптография пугает
Все мы знаем, что не следует самостоятельно реализовывать криптографические примитивы. Мы также в курсе, что даже если мы хитрым образом развернем порядок букв во всех словах сообщения, сдвинем каждую букву по алфавиту на 5 позиций и разбавим текст случайными фраз... | https://habr.com/ru/post/247527/ | null | ru | null |
# Внутренние и вложенные классы java. Часть 1
**Внутренние и вложенные классы java. Часть 1**
02.03.2017 — 2019 год
**Часть 1. Начало**

**Цель статьи:** Рассказать о внутренних, вложенных, локальных, анонимных классах.... | https://habr.com/ru/post/439648/ | null | ru | null |
# Поддельное BLE-устройство на nRF24l01
Данная статья на 90% основывается на заметке [«Bit-Banging» Bluetooth Low Energy](http://dmitry.gr/index.php?r=05.Projects&proj=11.%20Bluetooth%20LE%20fakery). Все началось с того, что потребовалось запустить распространенные сейчас трансиверы на чипе Nordic nRF24l01. В процессе... | https://habr.com/ru/post/245671/ | null | ru | null |
# Отслеживание лиц в реальном времени в браузере с использованием TensorFlow.js. Часть 5
Носить виртуальные аксессуары – это весело, но до их ношения в реальной жизни всего один шаг. Мы могли бы легко создат... | https://habr.com/ru/post/545336/ | null | ru | null |
# Делаем сайт для виртуальной реальности. Встраиваем монитор в монитор и размышляем о будущем

Несмотря на то, что понятие «виртуальная реальность» уже не первый год мелькает перед глазами, оно до сих пор остается загадко... | https://habr.com/ru/post/333400/ | null | ru | null |
# Как обойтись без WDS сервера, при установке Windows из WIM-образов по сети
Введение
========
Образы в [WIM](https://msdn.microsoft.com/en-us/library/windows/desktop/dd861280.aspx) формате, подготовленные в системе [MDT](https://msdn.microsoft.com/en-us/library/dn781292.aspx), компания Microsoft предлагает развертыв... | https://habr.com/ru/post/268827/ | null | ru | null |
# ControlValueAccessor и contenteditable в Angular
Вы когда-нибудь задумывались, как работает связка форм Angular и HTML элементов, через которые пользователь заносит данные?
С самого начала для этого использовали `ControlValueAccessor` — специальный интерфейс, состоящий всего из 4 методов:
```
interface ControlValu... | https://habr.com/ru/post/443714/ | null | ru | null |
# Dummy Origin: тестируем работу CDN

Перед тем как принять решение о работе с той или иной CDN хотелось бы убедиться, что она будет делать именно то, что мы от нее ожидаем. Конечно, вы прочитали документац... | https://habr.com/ru/post/328772/ | null | ru | null |
# Node.JS — формируем результирующий документ, используя другие HTTP-источники
Часто сервера на [Node.JS](http://nodejs.org/) используются как сервисы-агрегаторы, получающие динамические данные с других HTTP-источников и формирующие на основе этих данных агрегированный ответ.
Для обработки полученных данных удобно ... | https://habr.com/ru/post/102722/ | null | ru | null |
# Стал доступен эмулятор часов Pebble
В стане разработчиков приложений и циферблатов для Pebble случилась долгожданная радость: в облаке для разработки PebbleCloud стал доступен эмулятор часов, что позволяет теперь отлаживать написанное без постоянной загрузки в часы!
![image](https://habrastorage.org/r/w1560/getpr... | https://habr.com/ru/post/365013/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.