
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# GOSTIM: P2P F2F E2EE IM за один вечер с ГОСТ-криптографией
Будучи разработчиком [PyGOST](http://www.pygost.cypherpunks.ru/) библиотеки (ГОСТовые криптографические примитивы на чистом Python), я нередко получаю вопросы о том, как на коленке реализовать простейший безопасный обмен сообщениями. Многие считают прикладну... | https://habr.com/ru/post/452200/ | null | ru | null |
# AppCode 2019.2: Swift 5.1, анализ покрытия кода тестами, отображение дизассемблированного кода и другое
Астрологи объявили неделю релизов в JetBrains, количество публикаций в блоге выросло втрое! На самом деле, это тоже релизный пост, так что если вы участвовали в EAP, вы уже обо всем знаете.
Если нет — обязательн... | https://habr.com/ru/post/461949/ | null | ru | null |
# Поддержка чистой шары для обмена файлами с помощью Powershell
В каждой организации есть сетевой ресурс для обмена данными между пользователями, в который доступ имеют все. Что делать, когда пользователи сами не удаляют временные файлы из своих папок в «обмене» и ресурс начинает занимать слишком много места?
Задач... | https://habr.com/ru/post/186358/ | null | ru | null |
# GitLab + K8s + Werf
### Интро
Всем привет! Это мой первый пост на Хабре. Хотел написать сюда давно, первый блин комом - не бейте.
Сегодня хочу рассказать о связке GitLab + K8S + Werf и как с помощью него быстро собрать и задеплоить свое приложение в одну команду. Этот пост будет иметь формат мини-туториала.
Думаю... | https://habr.com/ru/post/679826/ | null | ru | null |
# Сайты-майнеры научились прятать браузер на компьютерах пользователей
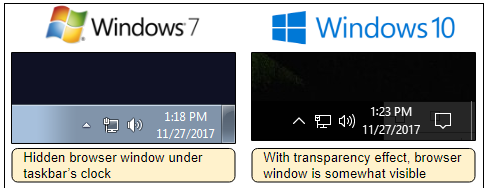
Всё бóльшую популярность у злоумышленников получает партнёрская программа Coinhive по майнингу криптовалюты в браузерах пользователей (и другие JS-майнеры). Ниче... | https://habr.com/ru/post/408525/ | null | ru | null |
# Установка GPU версии HPL с OpenBLAS
Для попадания в список ТОП 50, 100, 500 HPC (High Performance Computing) комплексов подходят результаты тестирования, полученные с помощью бенчмарка HPL (High Performance Linpack).
Бенчмарк Linpack (Linear Algebra PACKage) реализует алгоритм решения СЛАУ методом LU разложения. ... | https://habr.com/ru/post/497878/ | null | ru | null |
# Room + RxJava2 Flowable получение пустого списка при отсутствии данных
Когда я начал использовать Room для работы с БД, я задавался вопросом, как же более правильно сформировать подписку на изменения данных в таблице БД, чтобы если при подписке не было данных, то наш репозиторий сразу возвращал пустой список, а не ж... | https://habr.com/ru/post/591819/ | null | ru | null |
# In App Purchase с помощью Soomla. Быстро и просто

В последнее время пришлось интегрировать внутриигровые покупки в свою игру и встал вопрос, а какой же плагин для этого использовать под Unity3D? Есть такие вещи как OpenIA... | https://habr.com/ru/post/263899/ | null | ru | null |
# Знакомство со стеком DLMS/COSEM для микроконтроллеров семейства MSP430 компании Texas Instruments

В последнее время протокол DLMS/COSEM стал активно применяться в приборах учета (счетчики электрической энергии, тепла, вод... | https://habr.com/ru/post/302180/ | null | ru | null |
# Языковая механика профилирования памяти
Прелюдия
--------
Это третья из четырех статей в серии, которая даст представление о механике и дизайне указателей, стеков, куч, escape analysis и семантики значения/указателя в Go. Этот пост посвящен профилированию памяти.
Оглавление цикла статей:
1. [Language Mechanic... | https://habr.com/ru/post/511176/ | null | ru | null |
# Colada — удобная работа с коллекциями
**Colada** — библиотека для *удобной* и *безопасной* работы с коллекциями в PHP.
Это, прежде всего, работа в объектно-ориентированном стиле (что из коробки в PHP довольно неудобно). Немодифицируемые коллекции, защита от NPE (Null Pointer Exception) при помощи опциональных зна... | https://habr.com/ru/post/151558/ | null | ru | null |
# Новости из мира OpenStreetMap № 511 (28.04.2020-04.05.2020)
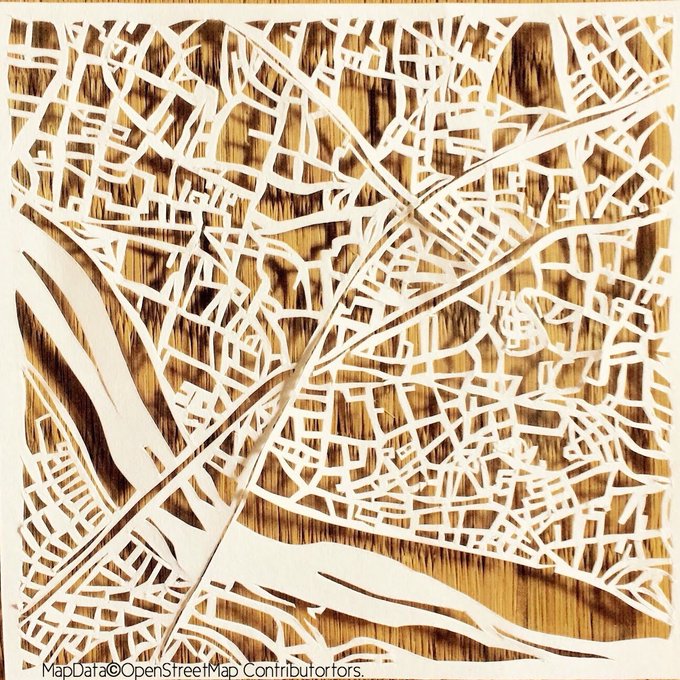
Одна из работ UtaArts, выполненная на основе карты OSM [1](#wn511_22391) | [あいかうたう / 切り絵の地図屋](https://twitter.com/utaarts) | map d... | https://habr.com/ru/post/502392/ | null | ru | null |
# Как и зачем защищать доступ в Интернет на предприятии — часть 2
В первой части я рассказал почему стоит защищать доступ в Интернет и что должны уметь технические решения. В этой же расскажу, что есть в арсенале Cisco и типовых способах решения задачи.
Как правило выбор делается между решениями классов «прокси-сер... | https://habr.com/ru/post/232863/ | null | ru | null |
# Адаптивные таблицы в вебе
Таблица — удобный и один из самых эффективных способов подачи ТЕКСТОВОЙ информации: на минимуме пространства размещено максимум данных. И что не менее важно — эти данные доступны не только для восприятия, но и для анализа (СРАВНЕНИЯ). Основная сложность таблиц при верстке — их адаптивность ... | https://habr.com/ru/post/680976/ | null | ru | null |
# JVM TI: как сделать плагин для виртуальной машины

Хотели бы вы добавить в JVM какую-нибудь полезную фичу? Теоретически каждый разработчик может внести свой вклад в OpenJDK, однако на практике любые нетривиальные изменения в HotS... | https://habr.com/ru/post/458812/ | null | ru | null |
# Измеряем расходы на память у Postgres процессов
*Это вольный перевод* [*поста*](https://blog.anarazel.de/2020/10/07/measuring-the-memory-overhead-of-a-postgres-connection/) *одного из сильных разработчиков Postgres - Andres Freund. Кроме того что разработчик сильный, так еще и статья довольно интересная и раскрывает... | https://habr.com/ru/post/562222/ | null | ru | null |
# История создания RaspberryPi микрокомпьютера

Поздравляем разработчиков RaspberryPi — недавно они [преодолели барьер в 2 млн проданных плат](http://habrahabr.ru/post/202514/).
И в честь этого знаменат... | https://habr.com/ru/post/202764/ | null | ru | null |
# Mockito. Из чего он приготовлен и как его подавать?
[](https://habr.com/ru/company/skillfactory/blog/541762/)
Думаю, многим довелось выпить какой-нибудь напиток, который глубоко впился в наши вкусовые рецепторы, что нам хочется п... | https://habr.com/ru/post/541364/ | null | ru | null |
# Оптический коммутатор TP-Link T2600G-28SQ для сервис-провайдеров: подробный обзор
Расширение больших городов и образование агломераций — один из важных трендов социального развития сегодня. Одна только Москва в 2019 году должна расшириться на 4 млн квадратных метров жилья (и это не считая 15 населенных пунктов, кото... | https://habr.com/ru/post/460421/ | null | ru | null |
# Item-based коллаборативная фильтрация своими руками

Одной из наиболее популярных техник для построения персонализированных рекомендательных систем (RS, чтобы не путать с ПиСи) является [коллаборативная... | https://habr.com/ru/post/232843/ | null | ru | null |
# Как автоматизировать с Jenkins сборку и раскатку артефактов модели метаданных для таблиц в хранилище
Все началось с того, что мы столкнулись с потребностью быстро и правильно формировать структуры EDWEX, JSON, DDL и затем раскатывать их на разных контурах реляционных БД. Под контурами я подразумеваю знакомые всем аб... | https://habr.com/ru/post/428101/ | null | ru | null |
# Пишем драйвер виртуального EEPROM для STM32F030
[](https://habr.com/ru/company/ruvds/blog/578690/)
Кто хотел сохранять какие-либо данные в FLASH микроконтроллера во время работы устройства сталкивались с особенностями работы с этим... | https://habr.com/ru/post/578690/ | null | ru | null |
# Обзор доступных библиотек для численного решения жёстких ОДУ
Создавая дополнения к отечественной математической программе [SMath Studio](http://en.smath.info/forum/), я нашёл в сети ряд библиотек, которые можно было бы использоват... | https://habr.com/ru/post/229435/ | null | ru | null |
# Сервер Игры на MS Orleans — часть 3: Итоги

Привет, Хабр! Я продолжаю изучать MS Orleans и делать простенькую онлайн игру с консольным клиентом и сервером работающим с Orleans грейнами. На этот раз я расскажу чем все закончилось и ... | https://habr.com/ru/post/499556/ | null | ru | null |
# Сводные таблицы в SQL
Сводная таблица – один из самых базовых видов аналитики. Многие считают, что создать её средствами SQL невозможно. Конечно же, это не так.
Предположим, у нас есть таблица с данными закупок нескольких видов товаров (Product 1, 2, 3, 4) у разных поставщиков (A, B, C):
 в Opera
Доброго всем времени суток! Буквально сегодня при использовании Web Workers столкнулся с проблемой в функции importScripts(), которая заключается в том, что Opera(использую версию 11.61) по каким-то своим внутренним причинам при повторном создании объекта Worker отказывается ... | https://habr.com/ru/post/138847/ | null | ru | null |
# Начинающим React-разработчикам: приложение со списком дел (покупок)
> **Будущих студентов курса** [**"React.js Developer"**](https://otus.pw/TOoG/) **приглашаем записаться на бесплатный демо-урок по теме** [**"Пишем приложение на React+Redux".**](https://otus.pw/mRDz/) **А также подготовили для вас перевод полезного... | https://habr.com/ru/post/531656/ | null | ru | null |
# Сапожник без сапог, или учет оборудования в ИТ-отделе. Часть I
 В народе есть замечательная крылатая фраза «Сапожник без сапог». Она в полной мере описывает ситуацию, в которой оказываются ИТ-отделы организа... | https://habr.com/ru/post/178013/ | null | ru | null |
# Как выигрывать в конкурсах репостов Вконтакте?

Мне захотелось узнать, реально ли выиграть в конкурсах репостов ВКонтакте.
Как это сделать? Ответ очевиден — надо участвовать во всех конкурсах и по теории вероятностей, ч... | https://habr.com/ru/post/331312/ | null | ru | null |
# Cocos2d-x — Диспетчер событий
От переводчика
--------------
Доброго времени суток! Эта статья представляет собой перевод [документации](http://www.cocos2d-x.org/docs/programmers-guide/event_dispatch/index.html) к движку Cocos2d-x.
В предыдущих частях мы уже рассмотрели большинство основных компонентов движка:
... | https://habr.com/ru/post/341066/ | null | ru | null |
# Поэтапное руководство по алгоритму автоматического размещения из CSS Grid

*Предлагаем вашему вниманию перевод статьи о [методике](https://www.sitepoint.com/a-step-by-step-guide-to-the-auto-placement-algorithm-in-css-grid/... | https://habr.com/ru/post/326098/ | null | ru | null |
# ООП в языке R (часть 2): R6 классы
В прошлой [публикации](https://habr.com/ru/post/453964/) мы разобрали S3 классы, которые являются наиболее популярными в языке R.
Теперь разберёмся с R6 классами, которые максимально приближённые к классическому объектно ориентированному программированию.

Не так давно мы рассказали о новой услуге Selectel — [облачных высокопроизводительных вычислениях на FPGA-ускорителях](https://blog.selectel.ru/fpga-uskoriteli-uxodyat-v-oblaka/?utm_source=b... | https://habr.com/ru/post/418403/ | null | ru | null |
# Первое знакомство с Home Assistant

Home Assistant – популярное приложение с открытым исходным кодом для организации умного дома. Первый опыт автора в работе с Home Assistant основывается на попытке интеграции в него ‘умной рисова... | https://habr.com/ru/post/471822/ | null | ru | null |
# OpenSceneGraph: Интеграция с фреймворком Qt

Введение
========
С одной стороны движок OpenSceneGraph и сам по себе обладает развитой подсистемой управления окнами, обработки событий пользовательского ввода, отправки и приема пол... | https://habr.com/ru/post/438654/ | null | ru | null |
# Как изучать исходные тексты
Бувально в тот момент, когда я (не очень успешно) вычитывал ошибки и опечатки в предыдущем посте, [bobry](https://habrahabr.ru/users/bobry/) предложил обсудить, как сделать в консоли историю (которая, Shift-PgUp).
Очевидным методом сделать что-то связанное с терминалами — посмотреть, ... | https://habr.com/ru/post/122027/ | null | ru | null |
# CQS (CQRS) со своим блэкджеком
Command-query separation (CQS) — это разделение методов на read и write.
Command Query Responsibility Segregation (CQRS) — это разделение модели на read и write. Предполагается в одну пишем, с нескольких можем читать. М — масштабирование.
Этот подход часто используют как способ о... | https://habr.com/ru/post/544034/ | null | ru | null |
# Integer и int
В этом топике я хочу описать некоторые базовые различия между примитивными типами и соответствующими им объектными на примере int и Integer. Различия эти достаточно простые и, если немного задуматься, то вполне логичные, но, как показал опыт, программист не всегда над этим задумывается.
Основное раз... | https://habr.com/ru/post/104231/ | null | ru | null |
# Расширение языка программирования (C++/Planning C). Волшебные сканеры и компилирующие макросы
Здравствуйте, уважаемые читатели.
Обычно, когда речь заходит о создании какого-либо расширения для существующего языка программирования, в воображении неминуемо начинают рождаться разнообразные сложные решения, включающие ... | https://habr.com/ru/post/572416/ | null | ru | null |
# Создание функции губки из MD5
> Привет, Хабр. В преддверии старта курса ["**Python Developer. Professional**"](https://otus.pw/yxxg/) подготовили перевод материала.
>
>

---
Во время своих исследований... | https://habr.com/ru/post/559210/ | null | ru | null |
# Проблема с кодировкой в Sprockets 3 при работе с HTML файлами
Я не так давно обновил один из проектов до Rails 4.2 и заметил интересный эффект: кодировка обработанных html файлов в ассетах меняется на ISO-8859-1.
Данная проблема актуальна для Sprockets 3.0.0 и 3.0.1.
Проблема нашлась в EncodingUtils#detect\_... | https://habr.com/ru/post/256523/ | null | ru | null |
# Шифрование с помощью Emoji
На очередной паре по «Информационной безопасности» преподаватель дал нам задание придумать собственный метод шифрования. В голову сразу пришла идея о довольном необычном (а может и нет) методе. Что из этого вышло, читайте под катом.

Системный администратор — человек ленивый. Обычно он старается сделать максимум работы, приложив минимум усилий, а для этого зачастую требуется автоматизировать многие ... | https://habr.com/ru/post/71525/ | null | ru | null |
# Songsterr — теперь на Android
C полгода назад [songsterr](http://habrahabr.ru/users/songsterr/) [писали](http://habrahabr.ru/blogs/startup/123465/) об итогах трех лет. А ныне команда рада оповестить Хабрахабр о выходе приложения для Android!
##### Основная функциональность
— Доступ к огромному каталогу табулату... | https://habr.com/ru/post/137098/ | null | ru | null |
# Операционная система с кибериммунитетом: кто, зачем и как создает KasperskyOS
Здравствуйте! Мы подразделение «Лаборатории Касперского», которое разрабатывает безопасную операционную систему KasperskyOS. Наша цель — создать ОС, у которой есть кибериммунитет, поэтому ей не страшно доверить управление умными автомобиля... | https://habr.com/ru/post/499746/ | null | ru | null |
# MSLibrary. Захват и верификация телефонных номеров с помощью регулярных выражений, для iOS и не только… Часть 2
В [первой части статьи](https://habrahabr.ru/post/278345/) разработчики библиотеки [MSLibrary](https://habrahabr.ru/users/mslibrary/) for iOS рассказали об особенностях структуры телефонных номеров с точ... | https://habr.com/ru/post/278359/ | null | ru | null |
# PayPal доигрался с заморозкой аккаунтов без объяснения. Подан групповой иск

Против компании PayPal Holdings, Inc. [подан судебный иск](https://www.bloomberg.com/news/articles/2022-01-13/paypal-sued-for-freezing-customer-accounts... | https://habr.com/ru/post/645891/ | null | ru | null |
# Как случайно не рассказать секреты всему миру
В целом компания SpectralOps (сейчас принадлежит Check Point) занимается разработкой и развитием инструментов, уменьшающих вероятность публикации чувствительной... | https://habr.com/ru/post/675468/ | null | ru | null |
# Способ качественно изучить паттерны проектирования
Привет, Хабр! Когда я изучал паттерны проектирования, я делал это с помощью прочтения двух книг: простую и понятную книгу от Head First одновременно со сложной и менее понятной книгой от Банды Четырех. Ниже описан мой опыт того, как именно я это делал, плюс выводы, ... | https://habr.com/ru/post/586494/ | null | ru | null |
# Разработка системы заметок с нуля. Часть 3: знакомство с Neo4j, работа над микросервисами CategoryService и APIService
Мы продолжаем разрабатывать систему заметок с нуля. В третьей части серии материалов мы познакомимся с графовой базой Neo4j, напишем CategoryService и реализуем клиента к новому сервису в APIService... | https://habr.com/ru/post/582500/ | null | ru | null |
# Фасетные фильтры: как готовить и с чем подавать
О чем речь
==========
Как сделать фасетный поиск в интернет-магазине? Как формируются значения в фильтрах фасетного поиска? Как выбор значения в фильтре влияет на значения в соседних фильтрах? В поиске ответов дошел до пятой страницы поисковой выдачи Google. Исчерпыва... | https://habr.com/ru/post/517074/ | null | ru | null |
# Применение зашифрованных данных для машинного обучения без их расшифровки

Применение зашифрованных данных для машинного обучения без их расшифровки
В этой статье обсуждаются передовые криптографические методики. Это лишь обзо... | https://habr.com/ru/post/478514/ | null | ru | null |
# Визуализируем в R данные мониторинга температуры процессора Raspberry PI Zero W
Для автоматического обновления данных в рамках [небольшого проекта по визуализации погоды в регионах РФ](https://teletype.in/@weekly_charts/YodM2Y8SNmM) используется скрипт на языке R, который выполняется по расписанию (ежедневно каждые ... | https://habr.com/ru/post/689522/ | null | ru | null |
# Magento 2: импорт продуктов из внешних источников
Magento является e-commerce решением, т.е. больше нацелено на продажу продуктов, чем на сопутствующий продажам складской, логистический или финансовый учёт. Для сопутствующего лучше подходят другие приложения (например, ERP-системы). Поэтому достаточно часто в практи... | https://habr.com/ru/post/436020/ | null | ru | null |
# Разбираем email в Java
К моему последнему проекту, написанному на 80% на Java, надо было дописать модуль — парсер всех писем, проходящих через сервер. Религиозные мотивы модуля очень странные, но некоторыми деталями хотелось бы поделиться.
###### **В наличии имеются:**
Почтовый сервер Postfix со службой доставки... | https://habr.com/ru/post/153415/ | null | ru | null |
# Классификатор на word2vec
После недавнего диалога возник вопрос поиска классификаторов, способных работать с текстами на русском языке без костылей в виде сборки watson-го NLC и bing translator-а. Решено было свелосипедить макет. За основу взят word2vec для получения векторного представления примеров и пользовательс... | https://habr.com/ru/post/304672/ | null | ru | null |
# Watchdog на базе Arduino Nano
*Watchdog — это устройство, предназначенное для обнаружения и устранения проблем оборудования. Обычно для этого используется таймер, периодический перезапуск которого предотвращает отправку сигнала на перезагрузку.*

С каждым годом курсовые для моих студентов становятся все объемнее. Например, в этом году одним из заданий была разработка метеостанции, ведь только ленивый... | https://habr.com/ru/post/506414/ | null | ru | null |
# Nextcloud Talk

Talk — это расширение платформы Nextcloud, позволяет совершать защищенные аудио и видеозвонки, а также обмениваться текстовыми сообщениями через веб-интерфейс или мобильное приложе... | https://habr.com/ru/post/349556/ | null | ru | null |
# Винеровский хаос или Еще один способ подбросить монетку

Теория вероятности никогда не переставала меня удивлять, начиная ещё с того момента, как я впервые с ней столкнулся, и до сих пор. В разное время в разной степени меня наст... | https://habr.com/ru/post/343148/ | null | ru | null |
# Обратная сторона Spring
Неделя Spring на Хабре, судя по всему, открыта. Хочется сказать спасибо переводчику и комментаторам статьи ["Почему я ненавижу Spring"](https://habrahabr.ru/post/334118/), которая не смотря на сильный негативный посыл в названии вызвала ряд интересных дискуссий, а так же тем, кто отреагировал... | https://habr.com/ru/post/334448/ | null | ru | null |
# Установка и обновление сертификата Let's encrypt для почтового сервера Zimbra
В прошлый статьях нас попросили рассказать об установке и обновлении сертификатов Let’s Encrypt.
**Let’s Encrypt** — центр сертификации, предоставляющий бесплатные криптографические сертификаты X.509 для TLS шифрования (HTTPS). Процесс... | https://habr.com/ru/post/345844/ | null | ru | null |
# Bootstrap Dropdown Menus Enhancement
Мне очень нравятся выпадающие меню из Bootstrap. Благодаря простой и понятной семантике их легко и приятно использовать при верстке.
Но для полного счастья мне не хватало некоторой функциональности.
#### 1. radio и checkbox
В сети существует великое множество плагинов для... | https://habr.com/ru/post/175027/ | null | ru | null |
# Firebase-queue: стероиды для firebase
Про Firebase уже не раз писали на хабре. Ключевым преимуществом этой системы является то, что в некоторых случаях на ней можно построить завершенное веб-приложение работающее с данными в реальном времени. Располагая возможностью редактирования правил доступа к базе данных и тем ... | https://habr.com/ru/post/266355/ | null | ru | null |
# Чем живёт домашний интернет и статистика сервера доменных имён
Домашний роутер (в данном случае FritzBox) умеет многое регистрировать: сколько трафика когда ходит, кто с какой скоростью подключён и т.п. Узнать, что скрывается под непонятными адресатами, мне помог сервер доменных имён (DNS) в локальной сети.
В цел... | https://habr.com/ru/post/463851/ | null | ru | null |
# Сравнение встраиваемых ЯП по размеру в исполняемом файле
В рамках одного из моих SDK-проектов нам понадобилось добавить скриптование, которое бы оказало наименьший эффект на размер конечного бинарного файла, но при этом предоставляло хорошую фунциональность. Это дало старт проекту, который описан в этой статье. Прош... | https://habr.com/ru/post/524190/ | null | ru | null |
# Превращаем Sublime Text 2 в Notepad++
Сейчас огромную популярность набирает текстовой редактор **Sublime Text 2**. Я же в давние времена перешел на **Notepad++** и много лет им активно пользовался, радуясь и восхищаясь... | https://habr.com/ru/post/166971/ | null | ru | null |
# Julia и уравнения в частных производных
На примере типичнейших физических моделей закрепим навыки работы с функциями и познакомимся с быстрым, удобным и красивым визуализатором PyPlot, предоставляющим всю мощь питоновской Matplotlib... | https://habr.com/ru/post/429218/ | null | ru | null |
# Вызываем обработчики событий потокобезопасно без лишнего присваивания в C# 6
От переводчика
--------------
Часто начинающие разработчики спрашивают, зачем при вызове обработчика нужно копировать его в локальную переменную, а как показывает код ревью, даже опытные разработчики забывают об этом. В C# 6 разработчики я... | https://habr.com/ru/post/272571/ | null | ru | null |
# Повышаем производительность в компонентах-функциях React с помощью React.memo ()
Представляем вам перевод статьи Chidume Nnamdi, которая была опубликована на blog.bitsrc.io. Если вы хотите узнать, как избежать лишнего рендера и чем полезны новые инструменты в React, добро пожаловать под кат.

Устройство на ATtiny13, управляемое программой из 290 16-разрядных слов, написанной на ассемблере, запоминает коды шести кнопок пульта ДУ и включает/выключает три нагрузки. Схе... | https://habr.com/ru/post/455006/ | null | ru | null |
# Актуализируем учетные данные Active Directory
Многие помнят то чувство, когда компания расширяется до тех размеров, когда рабочих групп недостаточно, и поднимается первый домен Active Directory: «О, уж теперь-то все будет как следует!» Ан нет, домен потихонечку разрастается, создаются новые учетки, блокируются стары... | https://habr.com/ru/post/132591/ | null | ru | null |
# Создание отчётов с использованием SAP Query
Система SAP ERP содержит множество отчетов с огромным количеством полей. Для настройки отображения нужных полей существует механизм, позволяющий скрыть лишние поля, изменить порядок, выполнить сортировку, подвести промежуточные и общие итоги. Ко всему прочему, система позв... | https://habr.com/ru/post/218581/ | null | ru | null |
# Плата BLE400 и разработка под nRF51822
Для разработки под микроконтроллер nRF51822 существует несколько комплектов от Nordic Semiconductor, все они достаточно дороги зато обеспечивают возможность удобной работы без возни с программаторами. При этом у китайских производителей можно обнаружить платы облегчающие отладк... | https://habr.com/ru/post/348684/ | null | ru | null |
# Обучение OpenCV каскада Хаара
На хабре уже есть несколько статей и про то, что такое каскад Хаара ([раз](http://habrahabr.ru/post/133826/), [два](http://habrahabr.ru/post/134857/http://habrahabr.ru/post/134857/), [три](http://habrahabr.ru/post/67937/)). Есть даже одна, где затронут процесс обучения, но в отношении о... | https://habr.com/ru/post/208092/ | null | ru | null |
# OData + Angular.js + Bootstrap + JavaScript Grid = приложение за 5 минут
Предположим в некотором проекте появилась необходимость добавить некоторую форму опроса пользователей на веб сайте (детальная форма) и форму для просмотра и редактирования списка пользователей для администратора системы (списковая форма).
Ра... | https://habr.com/ru/post/252657/ | null | ru | null |
# Делаем полноценный JS-прелоадер для AJAX-приложения
Многие программисты оптимизируют JavaScript и CSS-код, чтобы страница грузилась быстрее.
Но не все они делают прелоадеры, которые дают пользователю эффект субъективно более быстрой загрузки.
**Способ №1. Дешево и сердито.**
Идея проста — необходимо помести... | https://habr.com/ru/post/46210/ | null | ru | null |
# Проверка теории шести рукопожатий

Хочу рассказать о своем эксперименте по проверке [«Теории шести рукопожатий»](https://ru.wikipedia.org/wiki/Теория_шести_рукопожатий). На написание этого материала меня вдохновила статья [«Анализ... | https://habr.com/ru/post/273191/ | null | ru | null |
# Activiti — Business process engine
Activiti framework (Java) — описание потока задач на XML (bpm) и управление этим процессом. Здесь опишу основные базовые понятия и как строить простые бизнес процессы.
Основное понятие Activiti это процесс (process) и задача (task). Процесс это все задачи связанные между собой н... | https://habr.com/ru/post/416491/ | null | ru | null |
# Включаем IPv6 на dd-wrt
Если верить статистике на сайте [tunnelbroker.net](http://tunnelbroker.net/) то до исчерпания пула IPv4 адресов осталось полтора года. И я решил рассказать как перевести свой маршрутизатор под управлением dd-wrt на новый протокол. Тестировалось на Dir-320, но должно работать и на любом другом... | https://habr.com/ru/post/94952/ | null | ru | null |
# ASP.NET MVC Урок E. Тестирование
**Цель урока.** Научиться создавать тесты для кода. NUnit. Принцип применения TDD. Mock. Юнит-тесты. Интегрированное тестирование. Генерация данных.
##### Тестирование, принцип TDD, юнит-тестирование и прочее.
Тестирование для меня лично – это тема многих размышлений. Нужны или н... | https://habr.com/ru/post/176137/ | null | ru | null |
# Девушка с татуировкой ANSI
Специалисты по СУБД с сайта Oracle WTF [заинтересовались](http://oracle-wtf.blogspot.co.uk/2012/05/girl-with-ansi-tattoo.html), что же такое печатает в терминале юный хакер в фильме «Девушка с татуировкой дракона». По сюжету, это были запросы к базе данных полицейского отделения, с помощью... | https://habr.com/ru/post/145425/ | null | ru | null |
# Portable Areas как вариант модульности в MVC
Один из первых вопросов, которым я задался после знакомства с азами технологии MVC3, это способ выделения и повторного использования функционала в нескольких веб-проектах.
В WPF или WinForms все просто и понятно — обособленный функционал изолируется в модуль, модуль ко... | https://habr.com/ru/post/123819/ | null | ru | null |
# PHP библиотека для интеграции с API Новой Почты
Привет друзья.
Хочу поделиться [PHP библиотекой (SDK)](https://github.com/serj1chen/nova-poshta-sdk-php) для интеграции с API 2 Новой Почты (НП). Но сначала несколько слов о Новой Почте.
Новая Почта является лидером экспресс-доставки и перевозки грузов по всей У... | https://habr.com/ru/post/264209/ | null | ru | null |
# Применение Octave для вычисления центра вращения звездного поля
Я уже частично [говорил](http://habrahabr.ru/blogs/programming/132784/) о работе с FITS-файлами в Octave. Теперь расскажу о применении этого математического пакета для обработки конкретных данных, а именно: для вычисления центра вращения звездного поля ... | https://habr.com/ru/post/134352/ | null | ru | null |
# Хочу эту красивую штуку
Привет Хабр. Давно собирался написать эту статью и не то чтобы не доходили руки — просто сомневался в том, что здесь для нее подходящее место. К IT она имеет весьма косвенное отношение, скорее это жизненная история. История о том, как моя девушка стала уверенным пользователем linux. Дабы увел... | https://habr.com/ru/post/119755/ | null | ru | null |
# Добавление расчёта пути к схеме метро Москвы из Википедии
В процессе создания своей [схемы метро](https://habr.com/ru/post/556018) я использовал *SVG*-схему из [статьи](https://ru.wikipedia.org/wiki/%D0%9C%D0%BE%D1%81%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B8%D0%B9_%D0%BC%D0%B5%D1%82%D1%80%D0%BE%D0%BF%D0%BE%D0%BB%D0%B8%D1... | https://habr.com/ru/post/689966/ | null | ru | null |
# Как я стандартную библиотеку C++11 писал или почему boost такой страшный. Глава 2
 ### Краткое содержание предыдущих частей
Из-за ограничений на возможность использовать компиляторы C++ ... | https://habr.com/ru/post/417099/ | null | ru | null |
# Автоматический поворот изображения на мониторе
Исторически сложилось так, что у меня нет монитора. Вместо него я использую телевизор. Тридцати двух дюймовый телевизор. И нет, я еще не окосоглазил. Вполне комфортно за ним работается, заменяет мне сразу 2 монитора. Но есть у него одна неприятная особенность. Когда я о... | https://habr.com/ru/post/137650/ | null | ru | null |
# Операции с файлами в Perl 6
#### Директории
Вместо opendir и его друзей, в Perl 6 есть одна функция dir, которая возвращает список файлов из директории (по умолчанию, из текущей). Вместо тысячи слов:
```
# в директории Rakudo
> dir
build parrot_install Makefile VERSION parrot docs Configure.pl READM... | https://habr.com/ru/post/252509/ | null | ru | null |
# Быстрое создание CRUD с nest, @nestjsx/crud и TestMace

В настоящее время REST API стал стандартом разработки web-приложений, позволяя разбить разработку на независимые части. Для UI на данный момент используются различные популярн... | https://habr.com/ru/post/462585/ | null | ru | null |
# Идеальный UI фреймворк
Здравствуйте, меня зовут Дмитрий Карловский, и я… архитектор множества широко известных в узких кругах фреймворков. Меня никогда не устраивала необходимость из раза в раз решать одни и те же проблемы, поэтому я всегда стараюсь решать их в корне. Но прежде, чем их решить, нужно их обнаружить и ... | https://habr.com/ru/post/276747/ | null | ru | null |
# Избавляемся от дублирования сквозного кода в PHP: рефакторинг кода с АОП
Думаю, каждому программисту знаком принцип единственной ответственности,  ведь не зря он существует: соблюдая его, можно написать код лучше, он буде... | https://habr.com/ru/post/165329/ | null | ru | null |
# ROWCOUNT TOP
Рассматривая планы запроса для INSERT, UPDATE или DELETE, в том числе те, которые демонстрировались в некоторых статьях ранее, можно заметить, что почти все такие планы включают оператора TOP. Например, следующий ниже сценарий с оператором UPDATE создает показательный для демонстрации этого план:
```
C... | https://habr.com/ru/post/690228/ | null | ru | null |
# Google MAPs API в android или как работать с картами быстрее
Про использование Google MAPs API написано много статей, но основная часть из них устарела на столько, что глазам становится просто больно. Здесь хочу рассказать про замечательную библиотеку для работы со всеми MAPs API в частности Directions API, а так же... | https://habr.com/ru/post/341548/ | null | ru | null |
# Алгоритм проверки на простоту за O (log N)
#### Проверка на простоту
Чтобы определить, является ли данное число **N** простым, безусловно, достаточно написать простой цикл поиска делителей числа **N**:
```
bool prime(long long n){
for(long long i=2;i<=sqrt(n);i++)
if(n%i==0)
return false;
return true;
}
... | https://habr.com/ru/post/205318/ | null | ru | null |
# J-Bird
Весна навалилась на Крагуевац и нет покоя от котов и птиц. Птицы, скажете вы, при чем здесь птицы, и потянетесь к магической стреле. Стойте, я объясню…

Последний год iOS-игрушки перестали приносить деньги. Вообщ... | https://habr.com/ru/post/321648/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.