
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Скриптовый (script) 3D редактор OpenSCAD
Введение
--------
В настоящие время существует большой выбор мощных, универсальных 3D-редакторов для создания и анимирования 3D-сцен, которые в подавляющим случае можно отнести к программам с графическим интерфейсом. Такой подход к созданию 3D сцен имеет одновременно как бол... | https://habr.com/ru/post/651923/ | null | ru | null |
# Multilingual Text-to-Speech Models for Indic Languages
In this article, we shall provide some background on how multilingual multi-speaker models work and test an Indic [TTS model](https://github.com/snake... | https://habr.com/ru/post/674358/ | null | en | null |
# Из Excel в MySQL. Небольшая функция на PHP (fixed)
#### Введение
Здравствуй, **$habrauser**!
Бывает так, что вам нужно импортировать файл Excel в базу MySQL, но готового решения нигде нет. Вот и я, когда меня попросил друг поискать легкий способ импорта, сперва решил ~~загуглить~~ поискать решение. Увы, запрос *... | https://habr.com/ru/post/178089/ | null | ru | null |
# Автоматизация автоматизированного тестирования или Сила batch файлов
*— Почему не работаешь?
— Оно тестируется*
Привет, Хабролюди.
Решил поделиться с вами своим опытом на тавтологическую тему – автоматизация автоматизированного тестирования. Как мы все знаем, чтобы не тратить время на регрессионные тесты у... | https://habr.com/ru/post/100792/ | null | ru | null |
# Lego Mindstorms для программиста
Мне очень нравится играть в Lego. Нравится собирать роботов и машинки.
А ещё мне очень нравится програмировать. Нравится писать программы и фреймворки.
А не так давно я нашел способ совместит... | https://habr.com/ru/post/74222/ | null | ru | null |
# [The Old New Thing] Могу ли я использовать свой стек как угодно?
В Windows стек растет от больших адресов к меньшим. Иногда это определяется архитектурно, а иногда это просто принятое соглашение. Значение указателя стека (регистр процессора), является указателем на значение в верхней части стека. А значения, располо... | https://habr.com/ru/post/435814/ | null | ru | null |
# Установка и работа с менеджером пакетов для Maс OS X (MacPort и Homebrew)
Менеджер пакетов в Mac OS X позволит нам легко работать с пакетам посторонних разработчиков. В этом топике рассмотрим два таких менеджера: MacPort и Homebrew.
#### 1. MacPort
[Официальний сайт](http://www.macports.org/)
На этом же сайте... | https://habr.com/ru/post/151023/ | null | ru | null |
# Генерация окружения на основе звука и музыки в Unity3D. Часть 2. Создание 2D трассы из музыки
Аннотация
---------
Всем привет. Относительно недавно я написал статью [Генерация окружения на основе звука и музыки в Unity3D](https://habr.com/company/everydaytools/blog/429872/), в которой привел несколько примеров игр,... | https://habr.com/ru/post/432134/ | null | ru | null |
# Многострочный textarea placeholder, который работает в Firefox
[](http://habrahabr.ru/post/268947/)
Понадобилось сделать многострочный placeholder в textarea. Выяснилось, что Firefox, в отличие от всех других совреме... | https://habr.com/ru/post/268947/ | null | ru | null |
# Создание плагина для Clang Static Analyzer для поиска целочисленных переполнений

*Автор статьи: [0x64rem](https://habr.com/ru/users/0x64rem/)*
Вступление
----------
Полтора года назад у меня по... | https://habr.com/ru/post/473412/ | null | ru | null |
# Миграция микросервиса с геоданными с MS SQL на PostgreSQL
### Проблема
Не секрет, что тема перехода в IT-сфере на технологии, не требующие дорогостоящего лицензирования становится всё более актуальной. В то же время, очевидно и стремление компаний попасть в Реестр отечественного ПО, чтобы получить разного рода преф... | https://habr.com/ru/post/701060/ | null | ru | null |
# Секрет Великого Искоренителя
В недавнем выпуске ТВ-шоу «Удивительные люди» победа была присуждена человеку, продемонстрировавшему, казалось бы, невозможное – извлечение в уме, за 5 минут, корня 9999-й степени из числа, состоящего (по заявлению ведущего) из 80000 цифр.
 «Mozilla Hacks Weekly» увидал гиперссылку «[Morris.js](http://oesmith.github.com/morris.js/)», пошёл по ней, почитал, порадовался — а теперь и вам поведаю.
**Morris** — это легк... | https://habr.com/ru/post/139326/ | null | ru | null |
# Дистанционное управление системой отопления
Интернет вещей (IoT, Internet of Things) является многообещающим направлением, как уверяют аналитики. Одним из главных трендов IoT является автоматизация жилья или, как любят выражаться маркетологи, создание «умного дома».
Оставим в покое словесные упражнения и рассмотр... | https://habr.com/ru/post/358796/ | null | ru | null |
# Обход блокировок adblock, и блокировка обхода блокировки
В статье рассматривается один из эффективных методов противодействию adblock, и обход этого метода. Этот круг вечен – но, похоже, рекламщики вырвались вперёд!

Ка... | https://habr.com/ru/post/386417/ | null | ru | null |
# C++11 и 64-битные ошибки
Мы решили сделать небольшую паузу в тематике статического анализа кода. Ведь блог C++ читают и те, кто пока еще не использует эту технологию. А межд... | https://habr.com/ru/post/215939/ | null | ru | null |
# Экспорт UI дизайн-интерфейсов из Figma в Xcode iOS/Android Studio, в виде .xib/xml
[**FigmaConvertXib**](https://github.com/mrustaa/FigmaConvertXib)это инструмент для экспорта элементов дизайна из проекта Figma,
в среду разработки, с точностью 90%. В результате конвертации будут созданы файлы **xib / xml**, и уже... | https://habr.com/ru/post/645883/ | null | ru | null |
# Показать все, что скрыто
Привет, %username%. Сегодня речь пойдет об очередной интересной железяке — о гибкой видеокамере mt1010.

###### *Сначала матчасть =)*
Если верить всемогущей Википедии, то:
`Эндоскоп (от др.-греч.... | https://habr.com/ru/post/128799/ | null | ru | null |
# Линейная регрессия. Разбор математики и реализации на python
Тема линейной регресии рассмотрена множество раз в различных источниках, но, как говорится, "нет такой избитой темы, которую нельзя ударить еще раз". В данной статье рассмотрим указанную тему, используя как математические выкладки, так и код python, пытаяс... | https://habr.com/ru/post/659415/ | null | ru | null |
# WWDC19: Приступим к работе с Test Plan для XCTest
Привет, Хабр! Представляю вашему вниманию перевод статьи [«WWDC19: Getting Started with Test Plan for XCTest»](https://shashikantjagtap.net/wwdc19-getting-started-with-test-plan-for-xctest/) автора Shashikant Jagtap.
, который позволит обнаруживать целые классы багов на этапе компиляции. Во-вто... | https://habr.com/ru/post/425873/ | null | ru | null |
# Опыт еще одного инженерного расследования
##### Нам представилась возможность провести еще одно небольшое, но крайне поучительное тактическое занятие
Тематику этого поста навеяла рассылка от Шерлока Омса — периодически там размещаются истории о нетривиальных инженерных задачах, возникших при диагностировании различ... | https://habr.com/ru/post/231373/ | null | ru | null |
# AngularJS + UI Router: проверка авторизации и прав доступа
Если ваше приложение предполагает авторизацию пользователей и/или проверку прав доступа, то вам придется либо изобретать велосипед, либо гуглить в поисках подходящего решения. В принципе, я тоже это делал. В итоге я принял приемлемым для себя описанный ниже ... | https://habr.com/ru/post/245049/ | null | ru | null |
# Карта самоорганизации (Self-orginizing map) на TensorFlow
Привет, Хабр! Недавно начал свое знакомство с библиотекой глубокого обучения (Deep Learning) от Google под названием TensorFlow. И захотелось в качестве эксперимента написать карту самоорганизации Кохонена. Поэтому решил заняться ее созданием используя станда... | https://habr.com/ru/post/334810/ | null | ru | null |
# Миграция базы данных в Zend Framework: Akrabat_Db_Schema_Manager
В процессе работы над одним огромным проектом на Zend Framework, возникла необходимость миграции баз данных и перемещение между версиями, т.е. кроме update, был необходим так называемый downdate. Немного погуглив натолкнулся на интересную статью Роба А... | https://habr.com/ru/post/148843/ | null | ru | null |
# Обновление Kubernetes-кластера без простоя
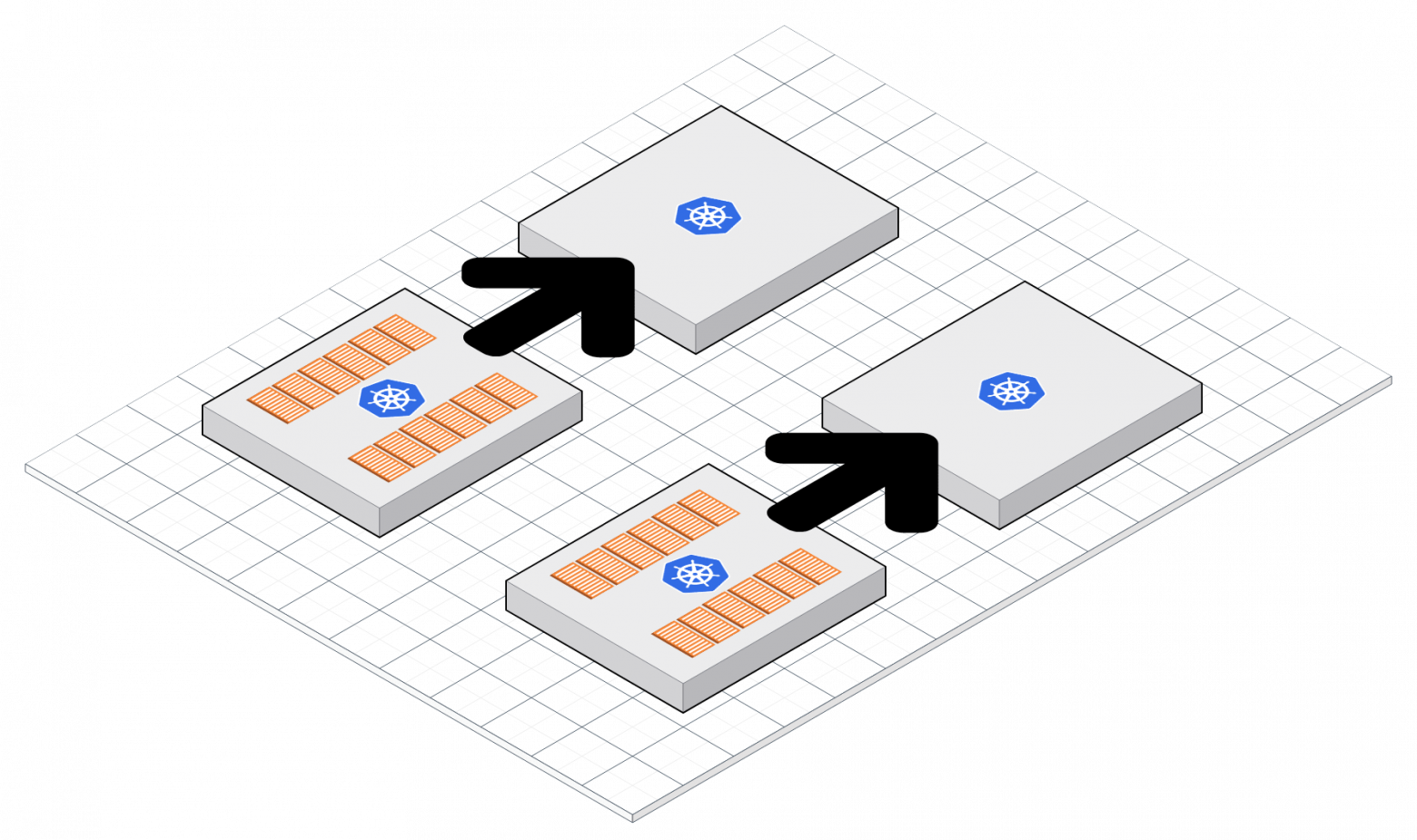
*Процесс обновления для вашего Kubernetes-кластера*
В какой-то момент при использовании кластера Kubernetes возникает потребность в обновлении работающих нод. Оно может включать в себя о... | https://habr.com/ru/post/489164/ | null | ru | null |
# Alpha-blending за одно умножение на пиксель на Windows Mobile
Те, кто занимался графикой на Windows Mobile, наверняка слышали о графической библиотеке [GapiDraw](http://gapidraw.com/). Если заглянуть в их [Feature List](http://gapidraw.com/features.php), то в разделе High Performance можно обнаружить следующие слова... | https://habr.com/ru/post/128773/ | null | ru | null |
# Как написать (игрушечную) JVM
> Статья про KVM оказалась интересной для читателей, поэтому сегодня публикуем новый перевод статьи Serge Zaitsev: как работает Java Virtual Machine под капотом.
Нравится нам это или нет, но Java — один из наиболее распространенных и широко используемых языков программирования. Однако ... | https://habr.com/ru/post/533244/ | null | ru | null |
# Как сделать простое «главное меню» для игры в Unreal Engine 4. Часть 1
*Этот туториал – моя первая «статья» по Unreal Engine 4. Сам я относительно недавно начал осваивать данный движок и разработку игр в общем и сейчас работаю над созданием более-менее простой игры. Недавно закончил базовую версию меню для своего пр... | https://habr.com/ru/post/334426/ | null | ru | null |
# PSGI — интерфейс между web-серверами и web-приложениями на perl
Не так давно появилась спецификация интерфейса между web-серверами и приложениями/фреймворками на perl **PSGI — Perl Web Server Gateway Interface Specification**. PSGI добавляет слой абстракции, позволяющий не заботиться о конкретном способе подключения... | https://habr.com/ru/post/78377/ | null | ru | null |
# Apt-cacher как корпоративный сервер обновлений для Ubuntu/Kubuntu/*buntu
#### Замена apt-mirror`у
apt-cacher — утилита для Debian-подобных дистрибутивов использующих apt в качестве установщика пакетов. Она кеширует файлы, которые скачивает пользователь с офф. зеркала обновлений и при следующем запросе выдает их из ... | https://habr.com/ru/post/46449/ | null | ru | null |
# Быстрое целочисленное деление на константу
На всех CPU операция деления выполняется сравнительно медленно, с этим ничего поделать нельзя. Но если делитель константа, то деление можно заменить на умножение на какую-то другую константу (обратное число, которое вычисляется во время компиляции). Тогда код будет чуть быс... | https://habr.com/ru/post/147096/ | null | ru | null |
# Ещё одна статья о декораторах в python, или немного о том, как они работают и как они могут поменять синтаксис языка
Декораторы в python являются одной из самых часто используемых возможностей языка. Множество библиотек и, особенно, веб-фреймворков предоставляют свой функционал в виде декораторов. У неопытного pytho... | https://habr.com/ru/post/587066/ | null | ru | null |
# Атаки HTML5: что нужно знать

Все последние версии браузеров поддерживают HTML5, следовательно, индустрия находится на пике готовности принять технологию и адаптироваться к ней. Сама технология создана та... | https://habr.com/ru/post/223501/ | null | ru | null |
# Deferred для Javascript (Prototype)

Продолжая тему [Deferred](http://twistedmatrix.com/projects/core/documentation/howto/async.html) для JavaScript предлагаю ... | https://habr.com/ru/post/60956/ | null | ru | null |
# Старые песни о главном. Java и исходящие запросы

([*Иллюстрация*](http://vk.com/phkdesign))
Одна из задач, с которой сталкиваются 99,9% разработчиков, — это обращение к сторонним endpoint’ам. Это могут быть как внешние API, так... | https://habr.com/ru/post/423591/ | null | ru | null |
# Анонс Rust 1.2
Сегодня [завершаются](http://www.rust-lang.org/install.html) циклы стабильного Rust 1.2 и бета-Rust 1.3! Читайте дальше об основных изменениях или переходите к более подробным [release notes](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-120-august-2015).
Что вошло в стабильный ... | https://habr.com/ru/post/264387/ | null | ru | null |
# Разработка собственного плагина для сервера Minecraft
Еще с детства я начал покорять бесконечные просторы Minecraft. Естественно о разработке в то время никакой речи не шло. Но с недавних пор загорелся идеей создать о свой проект серверов.
На Java до этого никогда не писал, но есть бекграунд на других языках, поэто... | https://habr.com/ru/post/676248/ | null | ru | null |
# Эффективный email как суперсила рекрутера и эйчара
История про рекрутера Марию
---------------------------
Жила-была девушка Мария. Маша работала в рекрутинге вот уже 3 с хвостиком года. Она была опытным и смелым рекрутером, и закрывала за месяц около 4-5 вакансий уровня Middle/Senior. Соискатели и кандидаты очень ... | https://habr.com/ru/post/540576/ | null | ru | null |
# Оптимизация ресурсов в Android. Ускорение сборки и уменьшение размера APK
> *Привет. Меня зовут*[*Кирилл Розов*](http://twitter.com/kirill_rozov)*и вы если вы интересуетесь разработкой под Android, то скорее всего слышали о*[*Telegram канале "Android Broadcast"*](https://t.me/android_broadcast)*, с ежедневными новос... | https://habr.com/ru/post/578154/ | null | ru | null |
# Обновлены Docker-образы с clickhouse-exporter и clickhouse_fdw
Эта новость — о двух Open Source-решениях с непростой судьбой: clickhouse-exporter и clickhouse\_fdw. Именно открытость и сила сообщества помогли им выжить, несмотря на перипетии судьбы (смену разработчиков).
Нам же они были важны, поскольку оба исполь... | https://habr.com/ru/post/551564/ | null | ru | null |
# Методы Монте-Карло для марковских цепей (MCMC). Введение
Привет, Хабр!
Напоминаем, что ранее мы анонсировали книгу "[Машинное обучение без лишних слов](https://habr.com/ru/company/piter/blog/481332/)" — и теперь она уже [в продаже](https://www.piter.com/collection/new/product/mashinnoe-obuchenie-bez-lishnih-slov)... | https://habr.com/ru/post/491268/ | null | ru | null |
# OS X, Vagrant и Parallels Desktop. Строим свои коробки с помощью veewee
В этой заметке я хочу поделиться своим опытом по созданию свой Vagrant boxes в OS X с системой виртуализации Parallels Desktop. Если есть интерес, добро пожаловать под cut.
Про [Vagrant](http://www.vagrantup.com) и [Chef](http://www.getchef.c... | https://habr.com/ru/post/213351/ | null | ru | null |
# Как и зачем разворачивать приложение на Apache Spark в Kubernetes
Для частого запуска Spark-приложений, особенно в промышленной эксплуатации, необходимо максимально упростить процесс запуска задач, а также ... | https://habr.com/ru/post/549052/ | null | ru | null |
# Судебное разбирательство между Google и Oracle: анализируется происхождение нескольких строк кода
Многие знают, что назревающий возможный скандал между крупными игроками IT-рынка Google и Oracle, подспудной причиной которого стала популярная платформа Android, вылился в суд между корпорациями, который начался в поне... | https://habr.com/ru/post/142499/ | null | ru | null |
# Рецепт разработки бота под Telegram

Добрый день, уважаемые читатели Хабрахабра!
В этом топике я хочу поделиться с вами опытом разработки бота под Telegram за 4 дня. Этот бот переводит все голосовые сообщения, которые п... | https://habr.com/ru/post/316824/ | null | ru | null |
# Защита .net приложения от посторонних глаз
«Как защитить код своего .net приложение?» – один из тех вопросов, который можно часто услышать на различных форумах.
Самый распространённый вариант – обфускация. С одной стороны — прост в использовании, а с другой — не достаточно надёжно прячет исходники. Предложу свой... | https://habr.com/ru/post/244031/ | null | ru | null |
# Видеопроигрыватель для сайтов обучающих иностранным языкам

Некоторое время назад я разработал ряд плагинов для javascript-видеопроигрывателя [MedialElement](http://... | https://habr.com/ru/post/210146/ | null | ru | null |
# Room: Один ко многим
Всем привет. На дворе 2018 и уже почти год как Google активно работает над [Architecture Components](https://developer.android.com/topic/libraries/architecture/release-notes.html). [Неплохая документация](https://developer.android.com/topic/libraries/architecture/index.html) и [примеры](https://... | https://habr.com/ru/post/349280/ | null | ru | null |
# Ищем дубликаты фотографий с помощью Perl
За 20 лет у меня скопилось несколько тысяч фотографий: праздники, свадьбы, рождение детей, и прочее, прочее... Понятно что снималось всё это на разные цифровики, присылалось почтой, сливалось через ICloud и GDrive, FTP, самба и т.п. По итогу всё это превратилось в дикий хаос ... | https://habr.com/ru/post/578874/ | null | ru | null |
# OpenMCAPI: одновременный запуск Linux и RTOS на многоядерных процессорах

В повседневной практике разработчика встраиваемых систем приходится сталкиваться с необходимостью запуска двух и более разноплановых ОС на n-яде... | https://habr.com/ru/post/186806/ | null | ru | null |
# «Валидность» расширения для Firefox и пара мелочи
Привет!
На Хабре достаточно много статей на тему написания расширений для Mozilla Firefox.
Воспользовавшись поиском, можно найти информацию, например: [здесь](http://habrahabr.ru/blogs/firefox/71839/), [здесь](http://habrahabr.ru/blogs/firefox/72117/), [здесь](... | https://habr.com/ru/post/134413/ | null | ru | null |
# Мини API на Lumen

Цель этой публикации — создание простого API на Lumen и рассмотрение его отличий от старшего брата. Весь код доступен [здесь](https://github.com/buzdykg/Lumen).
Устанавливал я е... | https://habr.com/ru/post/257073/ | null | ru | null |
# Детекция объектов с помощью YOLOv5
Введение
--------
Иногда возникает необходимость быстро сделать кастомную модель для детекции, но разбираться в специфике компьютерного зрения и зоопарке моделей нет времени. Так появился краткий обзор проблемы детекции, и пошаговый туториал для обучения и инференса модели YOLOv5 ... | https://habr.com/ru/post/576738/ | null | ru | null |
# CI/CD используя Jenkins на Kubernetes
Добрый день.
На Хабре уже есть несколько статей о jenkins, ci/cd и kubernetes, но в данной я хочу сконцентрироваться не на разборе возможностей этих технологий, а на максимально простой их конфигурации для постройки ci/cd pipeline.
Я подразумеваю, что читатель имеет базовое по... | https://habr.com/ru/post/442614/ | null | ru | null |
# Пошаговая инструкция: как с Node.js организовать иконки из Figma в проекте

Эта статья подробно описывает создание небольшого скрипта на Node.js для выгрузки векторных иконок из Figma в проект, а также универсального компонента для р... | https://habr.com/ru/post/708286/ | null | ru | null |
# Создаем приложение на Node.JS, Express и Typescript с Jest, Swagger, log4js и Routing-controllers
Это пошаговая инструкция создания приложение на Node.JS, с использованием typescript и express. Новое приложение создается не часто, отсюда забываются шаги по его созданию. И я решил написать некую шпаргалку, в помощь с... | https://habr.com/ru/post/536512/ | null | ru | null |
# Генерация PDF для скачивания конфигов сервера
Есть [замечательный проект hiqpdf](http://www.hiqpdf.com/demo/ConvertHtmlToPdf.aspx).
Умеет html качественно в pdf или картинки превращать
Но по дефолту не учитывает тот факт, что в html можно вставлять js/iframe, которые могут быть использованы не по назначению. ... | https://habr.com/ru/post/354476/ | null | ru | null |
# UHCI, или самый первый USB

Доброго времени суток, дорогой читатель! Меня просили написать про UHCI — хорошо, пишу.
Возможно, вам пригодиться эта статья, если, к примеру, вы не имеете достаточных навыков написания драйверов и чт... | https://habr.com/ru/post/429422/ | null | ru | null |
# Как генерировать осмысленные коммиты. Применяем стандарт Conventional Commits
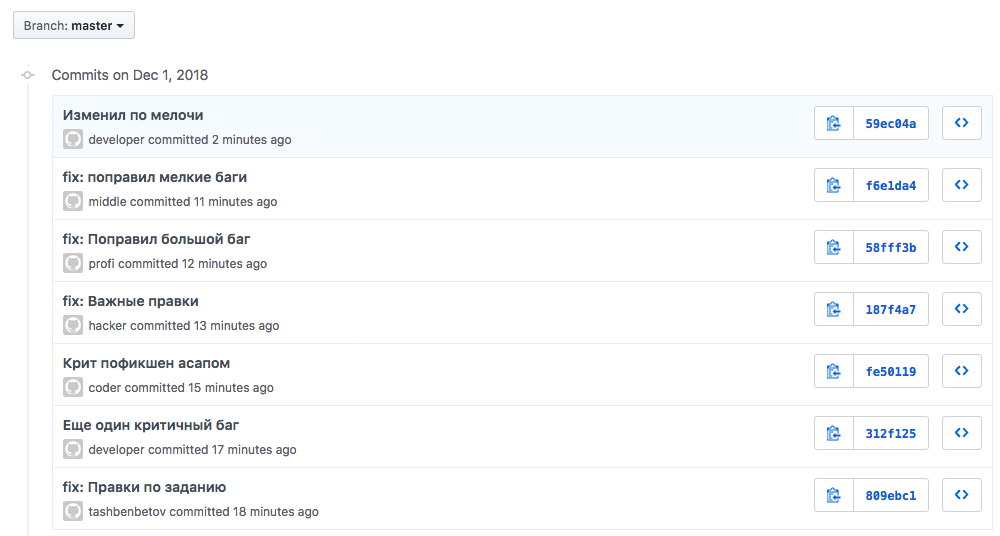
*Привычный хаос в названиях коммитов. Знакомая картина?*
Наверняка вы знаете **[git-flow](https://nvie.com/posts/a-successful-git-branching-model/)**... | https://habr.com/ru/post/431432/ | null | ru | null |
# Что нового можем делать с формами в 2022?
Эта статья — перевод оригинальной статьи Ollie Williams "[What’s New With Forms in 2022?](https://css-tricks.com/whats-new-with-forms-in-2022/)"
Также я веду телеграм канал “[Frontend по-флотски](https://t.me/frontend_pasta)”, где рассказываю про интересные вещи из мира раз... | https://habr.com/ru/post/691294/ | null | ru | null |
# Используем MSP430-Launchpad в качестве программатора
Здравствуйте! Я хочу поделиться с хабрасообществом одним необычным применением отладочной платы **MSP430-Launchpad**.
Руководство предназначено тем, кто уже имеет MSP430-Launchpad, освоил микроконтроллеры MSP430-ValueLine и задумывается о том, чтобы перейти на... | https://habr.com/ru/post/245425/ | null | ru | null |
# Грабли, эмулятор, аниматор (upd@21.06)
Недавно я занялся поиском хорошего инструмента для создания прототипов и анимации своих идей. В итоге исследование рынка превратилось в пересмотр специализаций инструментов своего арсенала и шлифовкой процесса проектирования нового продукта.
Чтобы понять, какой именно мне ну... | https://habr.com/ru/post/282103/ | null | ru | null |
# Рип сетевых словарей при помощи Node.js, ч. 2: динамические страницы; подключение NW.js
В [предыдущей части](https://habrahabr.ru/post/274475/) были описаны базовые операции и сопутствующие задачи при копировании сетевых словарей при помощи *Node.js*. В этой части описывается использование важного дополнительного ин... | https://habr.com/ru/post/277513/ | null | ru | null |
# Nano: И всё-таки его придётся выучить [1]
*Речь идёт о текстовом редакторе nano в Linux.*
Я не люблю nano и предпочитаю vim. Однако, в отсутствии vim, выбирая между vi и nano, я всё-таки предпочту nano, и... | https://habr.com/ru/post/106471/ | null | ru | null |
# Mooha — нодовый интерфейс для PHP
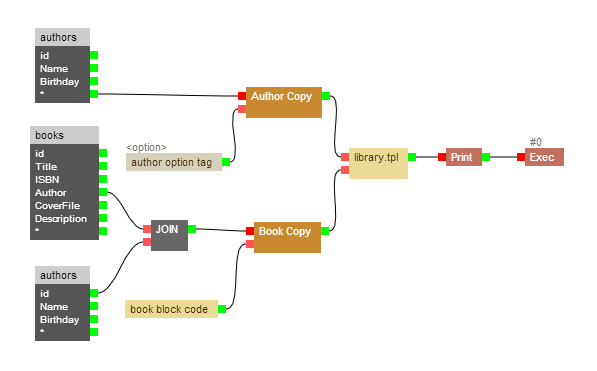
Мне часто приходилось сталкиваться с нодовыми интерфейсами в программах. Начиная с музыкальных модульных приложений, заканчивая пакетами для создания трехмерной графики.... | https://habr.com/ru/post/201646/ | null | ru | null |
# Сборка приложения среды arduino средствами CI github

Немного имея по работе дело с CI/CD (gitlab ce), не так давно на github наткнулся на actions, и решил попробовать, что же это за зверь такой.
Собирать JS или какие то д... | https://habr.com/ru/post/479718/ | null | ru | null |
# Проблемы релиз-менеджмента maven проектов при CI подходе к разработке ПО
Прочитав статью
[«Простой релиз-менеджмент средствами Git»](http://habrahabr.ru/post/159107/)
захотелось поделиться парой своих мыслей по поводу релиз-менеджмента maven проектов.
В этой заметке я не столько предложу решение проблем, ск... | https://habr.com/ru/post/160145/ | null | ru | null |
# Подключение датчиков KELLER к среде MATLAB
### Введение
Компания KELLER производит высокоточные датчики с цифровым выходом, которые подключаются к фирменному программному обеспечению для отображения и накопления показаний. Зачастую, пользователю необходимо интегрировать датчики в собственные системы мониторинга и у... | https://habr.com/ru/post/440966/ | null | ru | null |
# Я вам графония принес! Как нейросеть может улучшить разрешение в старых играх до HD

UPDATE: нашел баг при обучении, исправил, результаты стали существенно лучше, поэтому заменил картинки
Данная статья является вольным переводом [моей статьи на M... | https://habr.com/ru/post/508236/ | null | ru | null |
# Яндекс.Виджет + adjustIFrameHeight + MooTools

Многие знают о такой клёвой штуке как [Яндекс.Виджет](http://www.yandex.ru/catalog/).
Сделать свой функциональный виджет проще простого, достаточно написать серверный виджет и подключить его к Яндекс... | https://habr.com/ru/post/83083/ | null | ru | null |
# Машинное стереозрение для новичков: две камеры Raspberry Pi и Python
Стажируясь в правительственном технологическом агентстве Сингапура, автор работал над экспериментом по созданию альтернативы камере Intel... | https://habr.com/ru/post/652599/ | null | ru | null |
# Патчим всё, что ни попадя или Open source в действии
Возможно, многие сталкивались с ситуацией, когда программа или библиотека из дистрибутива не содержит некоторой (нужной вам) функциональности, которая была добавлена в следующей версии. Или содержит баг, который был исправлен в следующей версии (или его исправлени... | https://habr.com/ru/post/72609/ | null | ru | null |
# Как уменьшить размерность метрик в Prometheus, если вы не DevOps
Иногда команда разработки сталкивается с задачей, в которой у неё мало экспертного опыта, и через пробы и ошибки она находит неочевидное решение. Так произошло и с нами, когда понадобилось перенести сбор метрик из Infux в Prometheus. Их итоговая размер... | https://habr.com/ru/post/564686/ | null | ru | null |
# Переменные в CSS
Если вы разработчик, то вы точно хорошо знакомы с переменными, и возможно, они одни из ваших лучших друзей. По определению, переменная — это временное хранилище, которое содержит некое значение величины или информации.
Но каким образом это относится к тому CSS, который мы все знаем? Год назад на ... | https://habr.com/ru/post/141920/ | null | ru | null |
# Надёжный JavaScript: в погоне за мифом
JavaScript нередко называют «самым популярным языком», но, кажется, никто не отзывается о JS-разработке как о «самой безопасной», и количество подстерегающих проблем в экосистеме велико. Как эффективно их обходить?
.... | https://habr.com/ru/post/478852/ | null | ru | null |
# Как использовать Axios в React

В этой статье вы узнаете как использовать библиотеку **Axios** в React.
Рассмотрим все на примере запросов на сервер, отобразим полученные данные в таблице, сдалаем компонент проверки загрузки и ... | https://habr.com/ru/post/521902/ | null | ru | null |
# Картинки в теле страницы с помощью data: URL
*Примечание: ниже расположен перевод статьи [«Inline Images with Data URLs»](http://www.websiteoptimization.com/speed/tweak/inline-images/), в которой рассматривается вопрос о внедрении картинки на веб-страницы при помощи `data:URI`. Эта схема позволяет вставить код карти... | https://habr.com/ru/post/31500/ | null | ru | null |
# Новый вид развода — помоги девушке
Недавно обнаружил новый способ, которым мошенники [при содействии](http://habrahabr.ru/blogs/infosecurity/71257/) операторов зарабатывают себе на жизнь.
Суть в следующем: вам в аську/личку приходит сообщение от симпатичной девушки (для девушек думаю, сообщения приходят от парне... | https://habr.com/ru/post/82485/ | null | ru | null |
# Самостоятельная сборка cURL для iOS и Android
Добрый день!
Я занимаюсь разработкой приложения под iOS/Android, в котором используется библиотека cURL.
До недавнего времени мы использовали готовую сборку libcurl:
* для iOS с официального сайта
* для Android с пространств Интернета
При этом версии библиотеки... | https://habr.com/ru/post/184960/ | null | ru | null |
# Как линуксовый админ управлял детским хором с помощью системы распознавания нот под Ubuntu 16.04. Микрофон и аккорды
Что нужно, чтобы лето проходило весело? Нужна музыка! Но если музыка записана нотами на бумаге, а вы — обыкновенный системный администратор, и вам поручили задачу создать детский хор, то в качестве од... | https://habr.com/ru/post/460207/ | null | ru | null |
# Сбалансированное слияние сверху-вниз и снизу-вверх
[](https://habr.com/company/edison/blog/432646/)
В прошлой статье мы ознакомились [с реликтовыми сортировками слияния](https://habr.com/company/edison/blog/431964/) (вызывающих п... | https://habr.com/ru/post/432646/ | null | ru | null |
# Настройка BGP для обхода блокировок, или «Как я перестал бояться и полюбил РКН»
Ну ладно, про «полюбил» — это преувеличение. Скорее «смог сосуществовать с».
Как вы все знаете, с 16 апреля 2018 года Роскомнадзор крайне широкими мазками блокирует доступ к ресурсам в сети, добавляя в "Единый реестр доменных имен, указ... | https://habr.com/ru/post/354282/ | null | ru | null |
# Псевдо 3D эффект
В последнее время обратил внимание на ролики программ, в которых реализован так называемый псевдо 3D эффект: когда картинка приложения изменяется в зависимости от положения пользователя относительно телефона. Или телефона относительно пользователя: смотря с какой стороны вы находитесь :). Для достиж... | https://habr.com/ru/post/162081/ | null | ru | null |
# Как сделать BTC-транзакцию без сдачи из мелких монет

Многие кошельки биткоина при выборе монет для отправки предпочитают ис... | https://habr.com/ru/post/465041/ | null | ru | null |
# Управление производительностью с Python 3.12
В Python 3.12 появилась поддержка perf profiling. В этой статье увидим, как это помогает сократить время выполнения Python-скрипта с 36 секунд до 0,8. Мы рассмотрим Linux-инструмент `perf`, графики Flame Graph, посмотрим на дизассемблированный код и займемся поиском ошиб... | https://habr.com/ru/post/712578/ | null | ru | null |
# Программирование игровых приложений на Corona SDK: часть 1
**Важно**Этот туториал рассчитан на людей, у которых есть опыт программирования на Lua, если нет, то отправляйтесь исправлять ситуацию. Но он отлично подойдет и д... | https://habr.com/ru/post/318256/ | null | ru | null |
# Основы Linux от основателя Gentoo. Часть 2 (5/5): Модули ядра
В заключительном отрывке второй части описаны основы управление модулями ядра Linux. Этот минимум неплохо знать всякому пользователю, однако, не стоит надеяться обнаружить в этом руководстве для начинающих информацию по сборке и конфигурированию модулей я... | https://habr.com/ru/post/107981/ | null | ru | null |
# Пишем платформер на Python, используя pygame
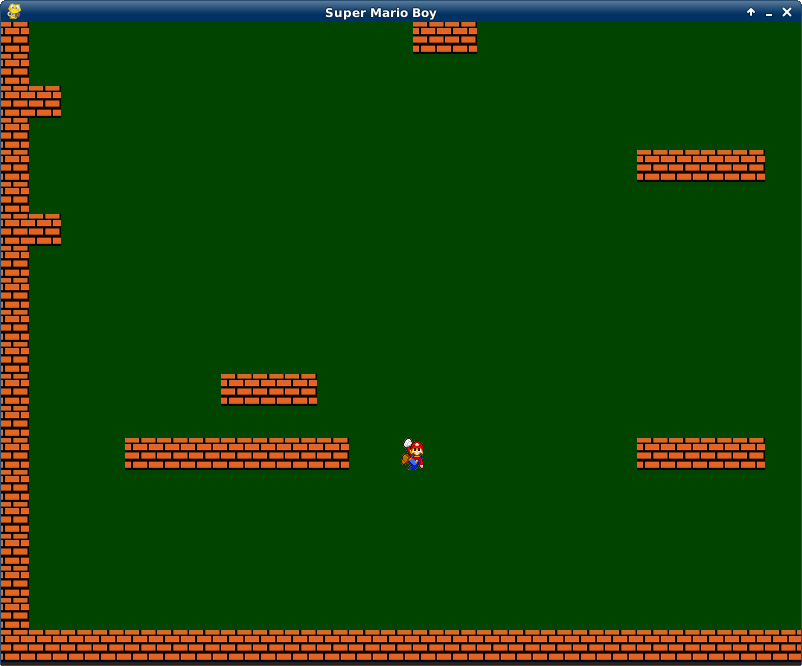
Сразу оговорюсь, что здесь написано для ~~самых маленьких~~начинающих.
Давно хотел попробовать себя в качестве игродела, и недавно выпал случай изучи... | https://habr.com/ru/post/193888/ | null | ru | null |
# Применение МЭМС гироскопов и акселерометров для отслеживания движений тела человека

Отслеживание движений тела человека — это задача, которая с переменным успехом решается уже не одну тысячу лет. Когда-то я читал историю... | https://habr.com/ru/post/253781/ | null | ru | null |
# Connecting to xxx.xxx.xx.xxx:443… failed: Unknown error или предупрежден — значит вооружен

В этом скриншоте, на первый взгляд, нет ничего необычного — просто упал сайт. Но это не так…
Скриншот сделан вчера в далеком от Моск... | https://habr.com/ru/post/328768/ | null | ru | null |
# Уроки по SDL 2: Урок 15 Многопоточность и Тиллинг
В этом уроке мы научимся запускать программу в несколько потоков, создавать полноценные уровни из мини изображения, так же научимся открывать несколько окон, скрывать и выводить вперед.

Вчера разработанное нами приложение [Coin Keeper](http://coinkeeper.me/ru) заняло третье место в топе платных приложений русского AppStore.
Интересно то, что мы разрабатывали его не на п... | https://habr.com/ru/post/132725/ | null | ru | null |
# Использование API Fmp Cloud для отбора акций по дивидендам на Nasdaq с помощью Python
> Акции с высокой дивидендной доходностью часто являются отличной инвестиционной стратегией для инвесторов, стремящихся получать приток денежных средств каждый год. В данной статье буден создан скрипт на Python для отбора их на бир... | https://habr.com/ru/post/549598/ | null | ru | null |
# Как посчитать синус быстро
и точно. Точнее, с заданной точностью, простите за каламбур.
Под катом я расскажу, как сделать это с использованием школьного курса алгебры и целочисленной арифметики, при чём здесь [полиномы Чебышёва](https://ru.wikipedia.org/wiki/%D0%9C%D0%BD%D0%BE%D0%B3%D0%BE%D1%87%D0%BB%D0%B5%D0%BD%D1... | https://habr.com/ru/post/577256/ | null | ru | null |
# Знакомство с Go, часть 2: пишем граббер изображений с балансировщиком и извращениями
#### Задание
Недавно я рассказывал, как выполнял секретную миссию и [с помощью Go загружал дамп цитат с «пустоты»](http://habrahabr.ru/post/197598/). Пришло время снова вступить в бой, на этот раз дело касается «Ататы», и не только... | https://habr.com/ru/post/198150/ | null | ru | null |
# UFOCTF 2017: декомпилируем Python в задании King Arthur (PPC600)

Приветствую тебя хабраюзер! Недавно, закончилась ежегодная олимпиада по информационной безопасности UFO CTF 2017. В этой статье будет райтап одного задания ... | https://habr.com/ru/post/325580/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.