
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Разработка программы в Multimedia Builder на примере утилиты для удаленной работы с кассовым ПО

Как вы все уже поняли, я просто обычный инженер, но я всегда стремлюсь к тому, чтобы сделать свою работу и коллег намного удобнее.
... | https://habr.com/ru/post/242807/ | null | ru | null |
# Книга Безопасность в PHP (часть 4). Недостаток безопасности на транспортном уровне (HTTPS, TLS и SSL)

[Книга «Безопасность в PHP» (часть 1)](https://habrahabr.ru/company/mailru/blog/310726/)
[Книга «Безопасность в PHP» (часть 2)]... | https://habr.com/ru/post/352444/ | null | ru | null |
# Валидация в JavaScript с помощью Valid8
Часто приходится «насыщать» интерфейсы с помощью JavaScript. В основном работаю через jQuery, всё нравится, но одна беда – валидация. Постоянно приходится изобретать «велосипед», искать в сети обрывки кода; а ведь хочется написать пару строчек без углубления в детали. Радость ... | https://habr.com/ru/post/128321/ | null | ru | null |
# Внедрение зависимостей в GO
Идея [внедрения зависимости](https://en.wikipedia.org/wiki/Dependency_injection) проста: объект, зависящий от другого объекта, делегирует управление его жизненным циклом внешнему коду.
Здесь объект самостоятельно управляет жизненным циклом своей зависимости:
```
func NewGreeter(name str... | https://habr.com/ru/post/541676/ | null | ru | null |
# Модифицируем Bluetooth-стек для улучшения звука на наушниках без кодеков AAC, aptX и LDAC
*Перед прочтением этой статьи рекомендуется ознакомиться с предыдущей статьёй: [Аудио через Bluetooth: максимально подробно о профилях, кодеках и устройствах](https://habr.com/ru/post/427997/) / [in English](https://habr.com/en... | https://habr.com/ru/post/455316/ | null | ru | null |
# Проблемы использования SVG-кнопок в браузерах
Данная статья является продолжением статьи [Рисуем кнопку в SVG](http://habrahabr.ru/blogs/svg/110869/), в которой рассматривались проблемы создания SVG-изображений, предназначенных для использования в качестве кнопок на веб-страницах. Здесь я перейду непосредственно к в... | https://habr.com/ru/post/111682/ | null | ru | null |
# Рендеринг WEB-страницы: что об этом должен знать front-end разработчик
Приветствую вас, уважаемые хабравчане! Сегодня я бы хотел осветить вопрос рендеринга в веб-разработке. Конечно, на эту тему уже написано много статей, но, как мне показалась, вся информация довольно разрознена и отрывочна. По крайней мере, чтобы ... | https://habr.com/ru/post/224187/ | null | ru | null |
# Blazor WebAssembly: Drag and Drop в SVG
[Demo](https://alexeyboiko.github.io/BlazorDraggableDemo/) | [GitHub](https://github.com/AlexeyBoiko/BlazorDraggableDemo)
 систему в btrfs
Новый GRUB может обрабатывать /boot раздел в формате btrfs, так что теперь не нужно иметь отдельный раздел отформатированный в ext2/3/4.
Далее предполагаем, что вся ваша файловая система представлена одной партицией. Если же у вас под каждый разде... | https://habr.com/ru/post/139590/ | null | ru | null |
# PHP-AMQP Что нового у Друзей?
При построении социальной сети по типу шардинга встает проблема обмена данными между шардами. Традиционная репликация в данном случае не подходит по разным причинам. Тема шардинга — это отельная большая тема и не является предметом данной статьи.
В данной архитектуре для реализации ... | https://habr.com/ru/post/73904/ | null | ru | null |
# Сообщество Go в Казани и наши митапы

2-го декабря 2018 прошёл [первый](https://www.meetup.com/Golang-Kazan/events/256726987/) проведённый [Казанским Go сообществом](https://vk.com/golang_kazan) митап.
5-го января следующего год... | https://habr.com/ru/post/433916/ | null | ru | null |
# Отключение pip search
Вчера, при попытке найти интересующий меня пакет через pip я получил довольно объёмное сообщение об ошибке `xmlrpc.client.Fault`.
Если убрать часть подробностей о стеке вызовов, то выглядело оно так:
```
$ pip search opencv
ERROR: Exception:
Traceback (most recent call last):
File "/home/u... | https://habr.com/ru/post/533484/ | null | ru | null |
# Мейнтейнеры не масштабируются
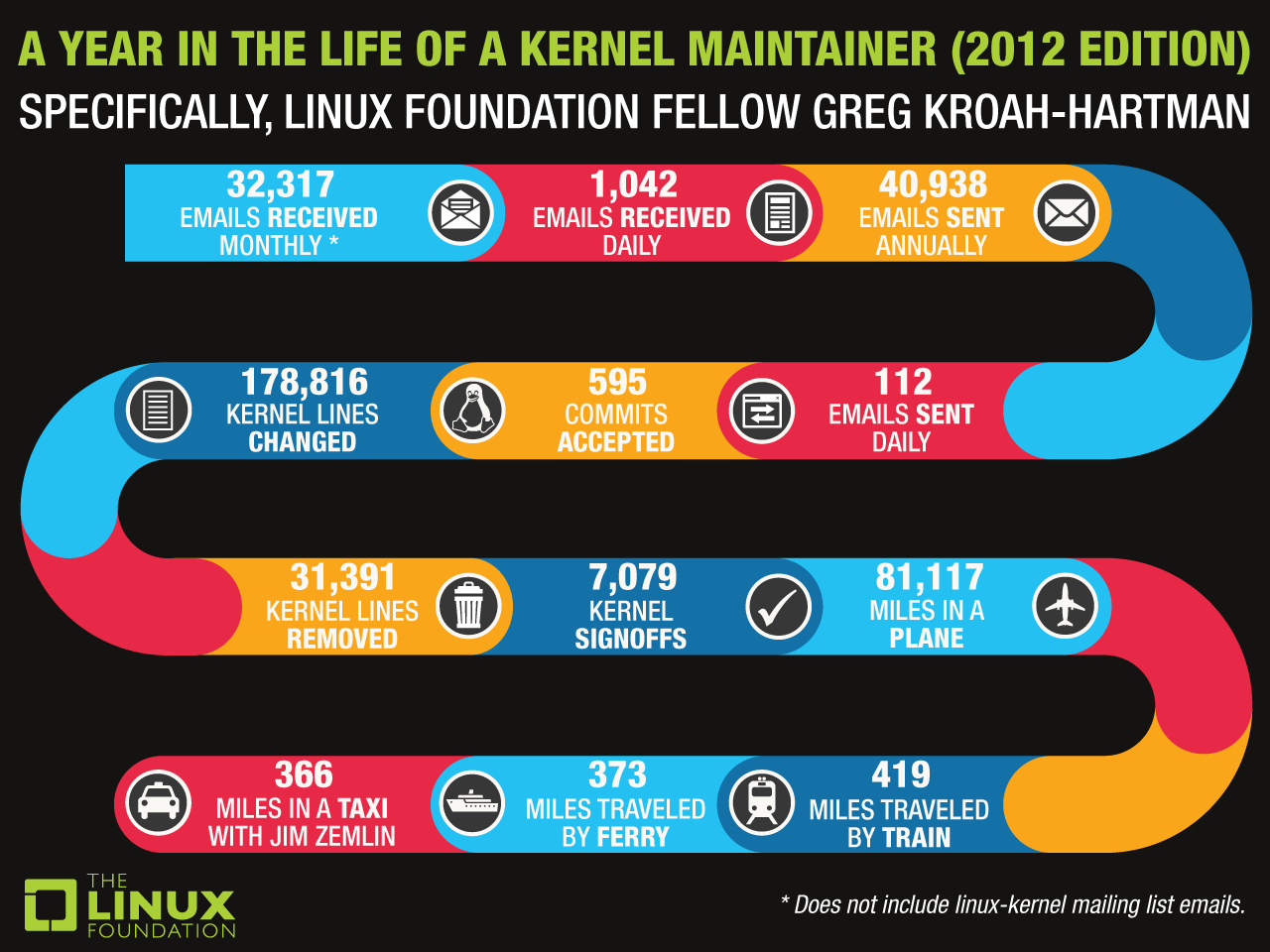
Система разработки и поддержки ядра Linux не так идеальна, как хотелось бы. Почему бы не улучшить нынешнюю систему, используя в качестве эксперимента успешный опыт других пр... | https://habr.com/ru/post/320092/ | null | ru | null |
# Построение полноценного MVC веб-сайта на ExpressJS
NB: Это материал для тех, кто уже ознакомился с теоретической основой node.js и хочет, как говорится, с места в карьер — поскорей окунуться в разработку с применением это... | https://habr.com/ru/post/192256/ | null | ru | null |
# Малоизвестные Git-команды

У Git есть строгие обязательства по обратной совместимости: многие продвинутые возможности скрыты за разнообразными опциями, а не применяются как поведение по умолчанию. К счастью, Git также под... | https://habr.com/ru/post/318508/ | null | ru | null |
# Сопоставляем с образцом как Pythonista
Одним из самых нашумевших нововведений Python 3.10 стало так называемое *структурное сопоставление с образцом* (structural pattern matching). Этот мощный инструмент берёт своё начало в функциональных языках программирования, а в последнее время постепенно появляется и во многих... | https://habr.com/ru/post/677126/ | null | ru | null |
# Комплексный твик реестра для Windows 7 + бонус: Перенос пользовательских данных
#### Быстрая настройка Windows
Установка операционной системы Windows стала обыденным делом для многих пользователей. Кто-то использует оригинальные образы, а кто-то экспериментирует со сборками — разницы особой нет. Если идти стандартн... | https://habr.com/ru/post/240609/ | null | ru | null |
# PyQt4 — Сигналы и события
**События**
События это важная часть GUI программирования. События генерируются пользователями или же системой. Когда мы вызываем метод exec() приложение запускает основной цикл. Он получаем события и отправляет их объектам. Trolltech представляет уникальный механизм сигналов и слотов. ... | https://habr.com/ru/post/31690/ | null | ru | null |
# Javascript: исходный код и его отображение при отладке
Программисты делятся на две категории: те, которые используют отладчик при разработке, и те, которые обходятся без него. В этом посте я попытался обобщить, какие типы сущностей можно выявить в исходном коде JS-программы, и как эти типы выглядят под отладчиком. J... | https://habr.com/ru/post/524526/ | null | ru | null |
# Contextual Emotion Detection in Textual Conversations Using Neural Networks
Nowadays, talking to conversational agents is becoming a daily routine, and it is crucial for dialogue systems to generate responses as human-like as possible. As... | https://habr.com/ru/post/439850/ | null | en | null |
# Генерим PDF бочками
#### Предыстория
На хабре [неоднократно](http://habrahabr.ru/blogs/development/30018/) [упоминались](http://habrahabr.ru/blogs/webdev/111188/) различные [инструменты](http://habrahabr.ru/blogs/webdev/128292/) и способы создания скриншотов WEB страниц.
Хочу поделиться собственным «велосипедом... | https://habr.com/ru/post/128078/ | null | ru | null |
# Альтернатива Emacs Lisp'у

Вы когда-нибудь искали альтернативу Emacs Lisp'у? Давайте попробуем добавить в Emacs ещё один язык программирования.
В этой статье:
* Потенциальные преимущества, которые будут получены при возможности расширя... | https://habr.com/ru/post/331134/ | null | ru | null |
# Создание собственных команд в GIT
Эта статья предназначена для тех, кто уже имеет начальный уровень работы с Git и BitBucket. В статье рассматриваются примеры в Git Bash version 2.33.0, API BitBucket 2.0, [https://bitbucket.org](https://bitbucket.org/)
 в качестве java-хостинга.
В прошлый раз мы [разобрались](http://habrahabr.ru/post/145203/) как создавать приложения в облаке OpenShift. В наше распоряжение предоставлен бесплатный хостинг с сервером... | https://habr.com/ru/post/145289/ | null | ru | null |
# Как регулировать мощность переменного тока
Решил как-то отец собрать для дачи некое устройство, в котором, по его заверению, можно будет варить сыр. Устройство сие вид имело могучий и представляло из себя железный короб, подозрительно напоминающий старую стиральную машинку. Внутрь короба (все также добротно!) были в... | https://habr.com/ru/post/549446/ | null | ru | null |
# Инфраструктура открытых ключей: Удостоверяющий Центр на базе утилиты OpenSSL и SQLite3 (Посткриптум)
В одном из комментариев, присланным участником [garex](https://habr.com/ru/users/garex/), в ответ на [заявление](https://habr.com/pos... | https://habr.com/ru/post/415423/ | null | ru | null |
# Тестирование автоматизации Ansible с помощью Molecule Часть 1
В статье много информации об Ansible. Давайте посмотрим, как тестировать роли с помощью Molecule, Docker и Testinfra.
Molecule – это проект R... | https://habr.com/ru/post/711432/ | null | ru | null |
# Ускоряем разработку ч.1 (Расиширяем Zend_Db_Table)
Доброго времени суток. Многие согласятся с тем, что Zend Framework — это отличный инструмент, который позволяет сильно сократить время разработки проекта (и не только), но всё-равно часто приходится делать copy-paste методов в разных местах (контроллерах, моделях и ... | https://habr.com/ru/post/71553/ | null | ru | null |
# Решение задания с pwnable.kr 19 — unlink. Переполнение буфера в куче

В данной статье разберемся с уязвимостью переполнение буфера в куче, а также решим 19-е задание с сайта [pwnable.kr](https://pwnable.kr/index.php).
**Орг... | https://habr.com/ru/post/463227/ | null | ru | null |
# Создание изображений с использованием генеративно-состязательных нейронных сетей (GAN) на примере ЭКГ
Для создания изображений с помощью GAN я буду использовать [Tensorflow.](https://www.tensorflow.org/)
Генеративно-состязательная сеть (GAN) — это модель машинного обучения, в которой две нейронные сети соревнуются... | https://habr.com/ru/post/709036/ | null | ru | null |
# HolyJS 2019: Разбор задач от компании SEMrush (Часть 2)

Это вторая часть разбора задач от нашего стенда на конференции [HolyJS](https://holyjs-piter.ru/), прошедшей в Санкт-Петербурге 24-25 мая. Для большего контекста рекомендуе... | https://habr.com/ru/post/453466/ | null | ru | null |
# Собеседование Golang разработчика (теоретические вопросы), Часть II. Что там с конкурентностью?
Привет, Хабр! Это вторая статья цикла, о процессе собеседования Golang разработчика. Первую часть вы можете п... | https://habr.com/ru/post/670974/ | null | ru | null |
# Разбираемся с объектами в JavaScript
*В этом материале автор — фронтенд-разработчик — сделал обзор основных способов создания, изменения и сравнения объектов JavaScript.*
Объекты — одно из основных понятий в JavaScript. Когда... | https://habr.com/ru/post/419193/ | null | ru | null |
# Logging. «Из коробки»
Ведение логов применяется в каждом программном продукте, дожившем до стадии продакшена. Erlang предоставляет программистам целую экосистему, которая включает и механизмы слежения за приложением. В этой части я рассмотрю именно функционал «из коробки».
#### 0. Как это работает
Как и другие в... | https://habr.com/ru/post/115209/ | null | ru | null |
# Извлечение NTLM hash пользователя из процесса lsass.exe с помощью уязвимого драйвера
Приветствую вас, дорогие читатели! Сегодня я хочу рассказать о том, как с помощью уязвимого драйвера получить NTLM hash пользователя. NTLM hash находится в памяти процесса lsass.exe операционной системы Windows. Процесс lsass.exe от... | https://habr.com/ru/post/649689/ | null | ru | null |
# Дистанционное управление презентацией со смартфона
Делал я недавно доклад (на [Percona Live](http://www.percona.com/live/mysql-conference-2012/)). И как-то ночью (jet-lag все-таки) подумал, что неплохо бы как-нибудь видеть свои комментарии к слайдам — подсказки — и переключать слайды не подходя к ноутбуку. Чудо-устр... | https://habr.com/ru/post/132331/ | null | ru | null |
# Ночные созерцатели. Глава первая
> Предлагаю вашему вниманию пятничный, совсем не технический, а точнее сказать совсем художественный текст. Возможно хабр не подходящее место для подобного, и все же именно здесь я хочу его презентовать, поскольку сам по себе уже не первый десяток лет являюсь разработчиком.
>
> ... | https://habr.com/ru/post/488290/ | null | ru | null |
# Теория категорий на JavaScript. Часть 1. Категория множеств

Абстракция – это одна из основных техник в ИТ. Любой язык программирования или моделирования, любая парадигма программирования (процедурная, функциональная, ООП... | https://habr.com/ru/post/313254/ | null | ru | null |
# PyQt5 для начинающих
Привет, Хабр! Сегодня я вас хочу научить делать интерфейс на Python 3&PyQt5.
Установка PyQt5
---------------
Для того, чтобы установить PyQt5 в Windows или MacOS, откройте Командную строку или Терминал и введите:
```
pip3 install PyQt5
```
Для Linux, откройте Терминал и введите:
```
sudo apt... | https://habr.com/ru/post/651093/ | null | ru | null |
# Проблемы unsafe кода C#
В этой статье я покажу какие проблемы может вызвать unsafe код и пару примеров, как можно изменить значение константы, readonly поля и свойства без set метода.
Я не знаю насколько б... | https://habr.com/ru/post/707172/ | null | ru | null |
# CSS var в rgba или удобное использование цветов в Sass
Эта статья посвящена обзору моих наработок в Sass, которые облегчают жизнь при работе с цветами во время верстки. Мы рассмотрим 3 подхода, которые воедино принесут комфорт в работу с цветами.
**Задача:**
Быстрое изменение палитры цветов и их прозрачность(именн... | https://habr.com/ru/post/533084/ | null | ru | null |
# Смерть или эволюция. Что ждёт программирование в будущем?

Или ещё одна статья про ChatGPT. Этот чат-бот с ИИ пишет код на многих языках программирования, оптимизирует код, конвертирует код с одного языка программирования на друг... | https://habr.com/ru/post/709310/ | null | ru | null |
# OpenID у хабра
Только что заметил в хедере хабра такие строчки:
Хабр собирается стать провайдером OpenID? и когда это будет? | https://habr.com/ru/post/47500/ | null | ru | null |
# Пишем веб сервис используя gSOAP
#### О чем речь?
Иногда в старом и добром C++ возникает потребность в реализации SOAP сервисов. Конечно, истинные любители программирования бросаются писать сервер самостоятельно, я же предпочитаю не тратить время впустую и использовать готовые библиотеки. Сегодня я хочу осветить (с... | https://habr.com/ru/post/121853/ | null | ru | null |
# Как по маслу, или анимируем со скоростью 60 FPS на CSS 3
*Изображения и текст принадлежат их авторам.*
Анимация элементов в мобильных приложениях — это просто. *Правильная* анимация тоже может быть простой… если вы последуете представленным в статье советам.
Сегодня кто только не использует CSS 3 анимацию в своих ... | https://habr.com/ru/post/308006/ | null | ru | null |
# Телеграм бот для создания быстрого UI
В рамках своих проектов я часто сталкиваюсь с потребностью в разработке интерфейса и, так как я работаю с python, в моём арсенале присутствует большое количество разных библиотек, позволяющих генерировать интерфейс, начиная от страницы сайта и заканчивая сложной структурой окна.... | https://habr.com/ru/post/593067/ | null | ru | null |
# Построение потоковой stateful обработки данных на Akka
В одном из исследовательских проектов нам с коллегами пришла идея совместить [Akka Stream](https://doc.akka.io/docs/akka/current/stream/index.html), [Akka event sourcing (typed persistence)](https://doc.akka.io/docs/akka/current/typed/persistence.html) и [Akka c... | https://habr.com/ru/post/570012/ | null | ru | null |
# Аудит пользователей в AD через VBS с занесением в SharePoint при помощи PowerShell
##### Добрый день наблюдатели НЛО
Хотел описать, как собирал информацию о пользователях из AD и затем размещал информацию на SharePoint для удобочитаемости и в любой момент посмотреть о том, или ином пользователе нужную для нас инфор... | https://habr.com/ru/post/158183/ | null | ru | null |
# Беспроводные технологии передачи звука на базе Bluetooth: что же лучше?

С развитием технологий так привычные всем «ламповые» аналоговые наушники уходят в историю – их всё больше вытесняют беспроводные собратья на базе Bluetooth.... | https://habr.com/ru/post/433502/ | null | ru | null |
# LESS? — мнение обывателя-верстальщика или дизайнера со стажем
Приветствую всех! Меня зовут Сергей, я живу в Самаре, мне 37 и я бородат, но только тогда, когда сила созидания побеждает во мне все остальные физиологические процессы… Сегодня я поделюсь с вами своим опытом практического использования LESS. Что уж говори... | https://habr.com/ru/post/233467/ | null | ru | null |
# О некоторых неочевидных хаках при работе с entity framework и unique constraints

Пару лет назад, когда деревья были большие и зеленые, ~~ко мне пришли злые дотнетчики, и сказали — ага, попался!~~ пр... | https://habr.com/ru/post/160897/ | null | ru | null |
# Проверяем исходный код GIMP с помощью PVS-Studio

Чтобы проверить GIMP, для начала нужно научиться его компилировать. Это непростая задача, из-за которой поверка несколько раз откладыва... | https://habr.com/ru/post/233489/ | null | ru | null |
# PowerShell: обход и визуализация HTML-дерева из файла
Ранее я написал скрипт для программы-оболочки «Windows PowerShell» версии 5.1 (или для «PowerShell» версии 7), работающей в операционной системе «Windows 10». Этот скрипт получает текст из текстового файла с кодом на языке HTML (в кодировке UTF-8 без метки BOM) и... | https://habr.com/ru/post/682438/ | null | ru | null |
# Создание CRUD приложения на Symfony 2
#### Symfony 2.0
Недавно вышедшая версия фреймворка [Symfony 2](http://symfony.com) включает в себя много интересных фич. В данной статье хочу рассказать про создание [CRUD](http://ru.wikipedia.org/wiki/CRUD) приложений — очень часто встречающейся задачи создания веб-интерфейса... | https://habr.com/ru/post/125948/ | null | ru | null |
# Mysql2
Mysql2 — современная, простая и очень быстрая [Mysql библиотека (GEM) для Ruby.](http://github.com/brianmario/mysql2)
#### API состоит из 2-х классов:
1. Mysql2::Client — соединение с базой
2. Mysql2::Result — результат запроса включающий в себя модуль Enumerable.
#### Установка:
`gem install mysql2`
... | https://habr.com/ru/post/102060/ | null | ru | null |
# STM32, C++ и FreeRTOS. Разработка с нуля. Часть 1
#### Введение
Не так давно мой отдел столкнулся с трудностями поиска новых инженеров программистов для разработки встроенного ПО. Опытным и умным не нравился уровень зарплаты, а молодых просто нет в нашем городе. Поэтому под патронажем нашей доблестной глобальной ко... | https://habr.com/ru/post/261807/ | null | ru | null |
# Tests as code с Allure TestOps и что из этого вышло
Внедрение автоматизированных практик тестирования — очень полезная штука. Однако при подходе к этой задаче возникает масса вопросов. Какую платформу выбра... | https://habr.com/ru/post/709902/ | null | ru | null |
# Ведение периодических сведений в информационных системах
Все разработчики информационных систем сталкиваются с периодической информацией, т.е. данными изменяющимися во времени. Например:
— Цены на товары
— Курсы валют
— Должности
и т.п. Также, одна периодическая информация меняется часто, другая — ред... | https://habr.com/ru/post/116140/ | null | ru | null |
# Дайджест интересных новостей и материалов из мира PHP № 47 (24 августа – 7 сентября 2014)

Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
* ... | https://habr.com/ru/post/235963/ | null | ru | null |
# Любопытный случай взаимной блокировки транзакций в базе данных при использовании TransactionScope
Привет, Хабр! Тем временем у нас [распродажа в честь черной пятницы](https://habr.com/ru/company/piter/news... | https://habr.com/ru/post/591121/ | null | ru | null |
# Определение пола по ФИО – когда точность действительно важна
Некоторое время назад меня заинтересовала задача определения пола человека по его ФИО. В тот момент я работал в области медицинского страхования, где эта проблема была действительно актуальна – расходы на одного застрахованного, а значит и тарифы, по котор... | https://habr.com/ru/post/274499/ | null | ru | null |
# Гибкая настройка графиков в JavaFX

JavaFX довольно странная штука. С одной стороны он кажется безумно продуманным и удобным настолько, что хочется использовать его где только можно. А с другой стороны он настолько топорны... | https://habr.com/ru/post/242009/ | null | ru | null |
# Как увеличить точность модели с 80% до 90%+ (мой опыт)
Привет, чемпион! Возможно, перед тобой сейчас стоит задача построить предиктивную модель, или ты просто фармишь Kaggle, и тебе не хватает идей, тогда эта статья будет тебе полезна!
Наверное, уже только ленивый не слышал про Data Science и то, как модели машинн... | https://habr.com/ru/post/598991/ | null | ru | null |
# Тюнинг Swift компилятора. Часть 2

Продолжение исследования способов ускорить компиляцию Swift. Издевательство над семантическим анализатором и неожиданные настройки проекта.
[Ссылка на первую часть](https://habrahabr.ru/post/316986/) для тех, кто пропуст... | https://habr.com/ru/post/317298/ | null | ru | null |
# Создание крюка-кошки в Unity. Часть 1

Крюки-кошки добавляют в игру забавные и интересные механики. Можно использовать их для перемещения по уровням, боёв на аренах и получения предметов. Но несмотря на кажу... | https://habr.com/ru/post/414887/ | null | ru | null |
# Дайджест интересных материалов из мира Drupal #3
Всем привет!
Мы отобрали для вас самое интересное и полезное из мира Drupal за первые недели 2015 года.

### По-русски
1. Во-первых, в тест... | https://habr.com/ru/post/248293/ | null | ru | null |
# Как мы в андроид приложение inDriver добавили поддержку Harmony OS
Все началось с того, что [министерство торговли США включило Huawei в список компаний, с которыми запрещено вести бизнес американским компаниям](https://habr.com/ru/news/t/452406/). Ответом Huawei стала операционная система Harmony OS для своих смарт... | https://habr.com/ru/post/497142/ | null | ru | null |
# Ищем убийцу на Прологе
Каждое воскресенье в нашей компании принято устраивать весёлые викторины, это одна из них.
Загадка
=======
Чтобы найти убийцу мистера Бодди, нужно узнать, где находился каждый человек и какое оружие было в комнате. Подсказки разбросаны по всей викторине (вы не можете ответить на первый воп... | https://habr.com/ru/post/434172/ | null | ru | null |
# Что заморозили на feature freeze 2019. Часть I. JSONPath

После [**комитфеста 2019-03**](https://commitfest.postgresql.org/22/) произошла заморозка функциональности (feature freeze). У нас это почти традиционная рубрика: о прошло... | https://habr.com/ru/post/448612/ | null | ru | null |
# Это ужасно бесит — подборка косяков, постоянно встречающихся от сайта к сайту, от приложения к приложению
Каждый день мы пользуемся десятками различных мобильных приложений и посещаем десятки, если не сотни, всевозможных сайтов. Часто при этом мы сталкиваемся с какими-то их неприятными особенностями — что-то сделано... | https://habr.com/ru/post/709494/ | null | ru | null |
# Избавьтесь от аннотаций в своих контроллерах!
В [предыдущей части](http://habrahabr.ru/post/227781/) этой серии мы понизили связанность симфонийского контроллера и фреймворка, удалив зависимость от базового класса контроллера из `FrameworkBundle`. А в этой части мы избавимся от некоторых неявных зависимостей, которы... | https://habr.com/ru/post/227787/ | null | ru | null |
# Полковнику никто не пишет. Отправка писем по SMTP после изменения политики Google. С примером на Python
Начало
------
Недавно Google [изменил политику](https://support.google.com/accounts/answer/6010255) по отношению к доступу к аккаунту из неизвестных источников. Давно приходили предупреждения, но я до последнего ... | https://habr.com/ru/post/675130/ | null | ru | null |
# JOOQ и его кроличья нора. Как выжить без Hibernate
В этой статье я не буду топить за JOOQ. Я предпочитаю Hibernate и всю силу Spring Data JPA, которая за ним стоит. Но статья будет не о них.

Когда мы пользуемся Hibernate и Spri... | https://habr.com/ru/post/488522/ | null | ru | null |
# Storacle — децентрализованное хранилище файлов

Прежде чем начну, должен оставить [ссылку на предыдущую статью](https://habr.com/ru/post/495058/), чтобы было понятно о чем именно речь.
В этой статье х... | https://habr.com/ru/post/499954/ | null | ru | null |
# Пакетное действие SonataAdminBundle + Select2
Всем доброго времени суток!
Нынче многие бросают свой взгляд в сторону [EasyAdminBundle](https://github.com/EasyCorp/EasyAdminBundle), но я до сих пор использую и предпочитаю одну из лучших панелей администратора для Symfony.
### SonataAdminBundle
Система очень гибк... | https://habr.com/ru/post/687632/ | null | ru | null |
# Как реализованы конвейеры в Unix

В этой статье описана реализация конвейеров в ядре Unix. Я был несколько разочарован, что недавняя статья под названием «[Как работают конвейеры в Unix?](https://www.vegardstikbakke.com/how-do-pi... | https://habr.com/ru/post/495484/ | null | ru | null |
# Управляем стандартным плеером Sailfish OS с помощью голосовых команд
Многие знают и пользуются такими возможностями операционной системы Android, как Google Now и Google Assistant, которые позволяют не только вовремя получать полезную информацию и что-либо искать в интернете, но и управлять устройством с помощью гол... | https://habr.com/ru/post/313680/ | null | ru | null |
# SQL ключи во всех подробностях
В Интернете полно догматических заповедей о том, как нужно выбирать и использовать ключи в реляционных базах данных. Иногда споры даже переходят в холивары: использовать естественные или искусственные ключи? Автоинкрементные целые или UUID?
Прочитав шестьдесят четыре статьи, пролист... | https://habr.com/ru/post/348172/ | null | ru | null |
# Полезные сниппеты для Nginx конфигов

Доброго времени суток, уважаемые хабравчане! В [Elasticweb](http://habrahabr.ru/post/272241/) мы негласно ратуем за Nginx и, наверное, мы одни из немногих хостингов, которые не поддерж... | https://habr.com/ru/post/272381/ | null | ru | null |
# Pulseaudio в Ubuntu — звук по сети (и не только)
**Update/Disclaimer**: эта хня уже не актуальна т.к. в 8.04 оно завёрнуто в пульс по дефолту. В 7.10 есть какие-то макросы в asoundconf на эту тему. Остальные дистрибы тоже ползут в этом направлении.
Этой осенью я делал презентацию для OSU Open Source club про серв... | https://habr.com/ru/post/31035/ | null | ru | null |
# 10 самых распространенных ошибок Spring Framework
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Top 10 Most Common Spring Framework Mistakes»](https://www.toptal.com/spring/top-10-most-common-spring-framework-mistakes) автора Toni Kukurin.
Spring, вероятно, один из самых популярных Java-фреймворков, ... | https://habr.com/ru/post/465897/ | null | ru | null |
# К вопросу об Апофении, Телегонии и Путешествиях во времени (и функции с _ в начале)
> *В 1958 году немецкий нейропсихолог Клаус Конрад ввел термин «апофения» (от лат. apophene — высказывать суждение, делать явным; термин восходит к текстам религиозных откровений, где означает знание, достигаемое вне процесса познани... | https://habr.com/ru/post/505926/ | null | ru | null |
# 9 полезных трюков HTML
Приветствую, Хабр! Представляю вашему вниманию перевод статьи [«9 Extremely Useful HTML Tricks»](https://dev.to/razgandeanu/9-extremely-useful-html-tricks-463a) автора [Klaus](https://dev.to/razgandeanu).
У HTML есть много практических секретов, которые могут вам пригодиться.
**Нативка о... | https://habr.com/ru/post/480104/ | null | ru | null |
# Простой аудио плеер на GStreamer
Недавно мне понадобилось реализовать небольшой аудио плеер. Я, по различным причинам, выбрал библиотеку Gstreamer. И вот решил поделиться полученными знаниями. Надеюсь, приведенная ниже информация кому-то будет полезна.
#### И так начнем
##### Для начала немного разберемся с осно... | https://habr.com/ru/post/204172/ | null | ru | null |
# Машинное обучение на языке R с использованием пакета mlr3
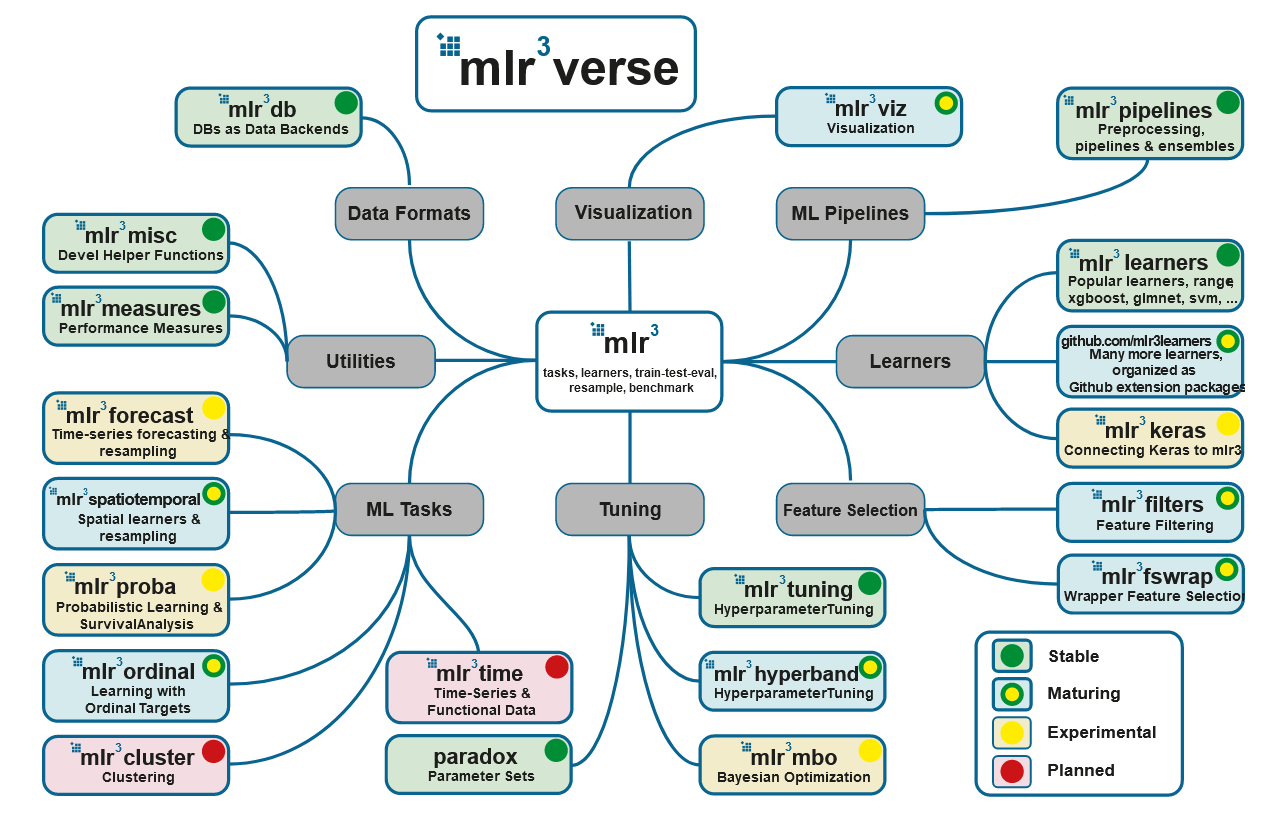
*Источник: <https://mlr3book.mlr-org.com/>*
Привет, Хабр!
В этом сообщении мы рассмотрим самый продуманный на сегодняшний день подход к машинному обучению на языке R ... | https://habr.com/ru/post/491566/ | null | ru | null |
# Как мы с женой повышали ее качество жизни с диабетом при помощи ИТ
*Всем привет! Меня зовут Андрей. Сегодня я расскажу о проекте, который делал для своей жены и при активном ее участии. Это устройство на Raspberry Pi с опенсорсным софтом для контроля сахара в крови с помощью данных мониторинга и команд, отдаваемых и... | https://habr.com/ru/post/685148/ | null | ru | null |
# Пишем расширение для Burp Suite с помощью Python
Привет, Хабр!
Думаю многие знают о таком инструменте, как Burp Suite от PortSwigger. Burp Suite – популярная платформа для проведения аудита безопасности ве... | https://habr.com/ru/post/546476/ | null | ru | null |
# Вся правда об ОСРВ. Статья #16. Сигналы

В этой статье будут рассмотрены сигналы, которые являются простейшими механизмами взаимодействия между задачами в Nucleus SE. Они предоставляют малозатратный способ передачи простых сообще... | https://habr.com/ru/post/427439/ | null | ru | null |
# AWS ECS scheduled task using terraform
Всем привет.
Не так давно AWS добавил новую возможность запускать scheduled task, что как по мне, является весьма удобной фичей для выполнения некоторых задач. К сожалению, пока (надеюсь только пока) HashiCorp не добавила возможность управлять ними как ресурсом в terraform. Но... | https://habr.com/ru/post/589173/ | null | ru | null |
# Machine Learning for your flat hunt. Part 1
Have you ever looked for a flat? Would you like to add some machine learning and make a process more interesting?
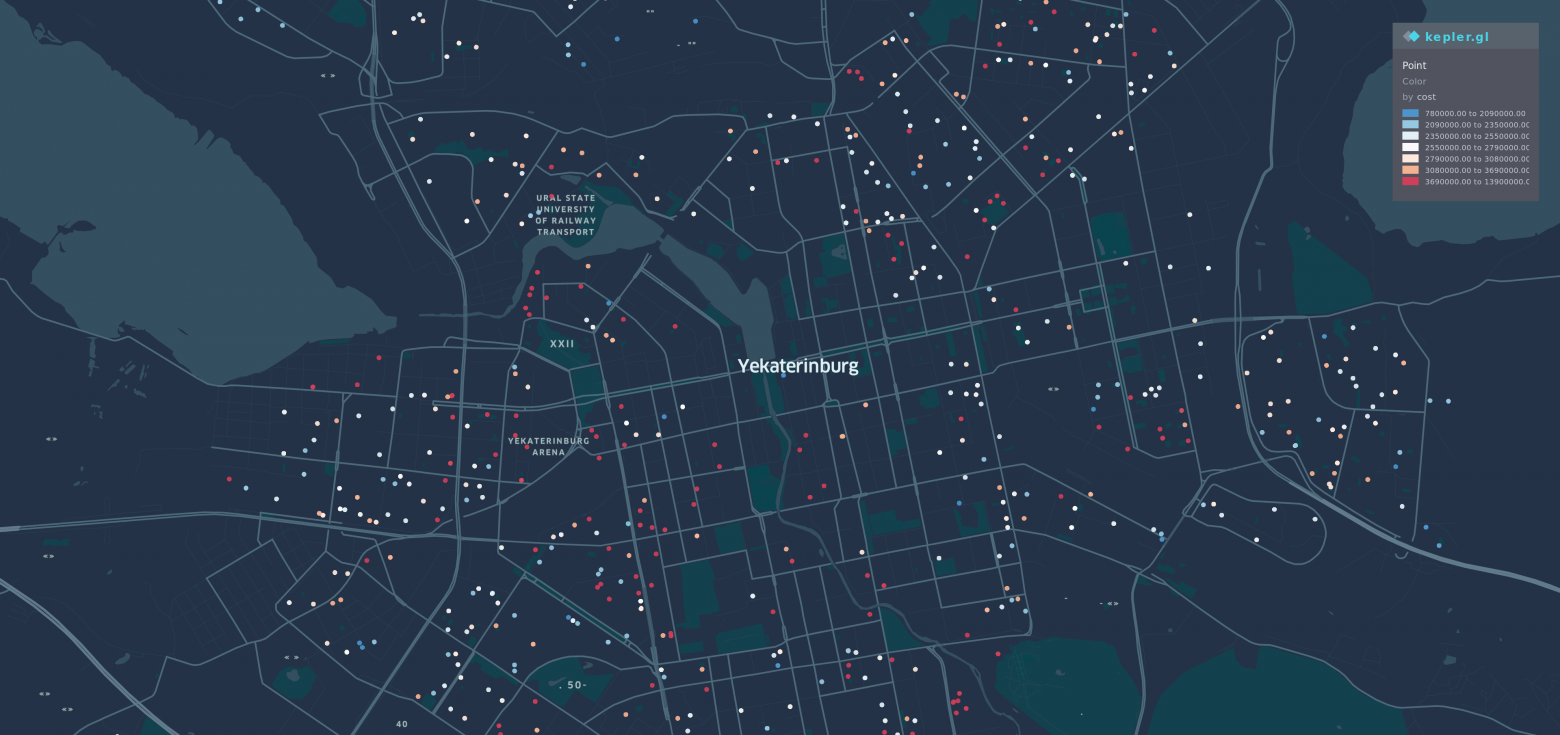
Today we will consider applying Machine Lea... | https://habr.com/ru/post/468053/ | null | en | null |
# Установка полноценного кластера Kubernetes на основе k3s
Большинство читателей уже так или иначе пробовали устанавливать Kubernetes с помощью kubespray или других средств автоматизации, доступных у большинства поставщиков облачных решений. Можно также всё делать с нуля с использованием kubectl, ведь сам процесс в пр... | https://habr.com/ru/post/551214/ | null | ru | null |
# Система фильтрации спама Rspamd
Система Rspamd разрабатывается как основная система фильтрации спама в Рамблер-Почте. Однако же, изначально я планировал сделать систему, которая бы не уступала по возможностям, гибкости и качеству работы Spamassassin'а, однако была бы лишена основных его недостатков: чрезмерного испо... | https://habr.com/ru/post/125007/ | null | ru | null |
# Эффективная генерация числа в заданном интервале

В подавляющем большинстве моих постов о генерации случайных чисел рассматривались в основном свойства различных схем генерации. Это может оказаться неожиданн... | https://habr.com/ru/post/455702/ | null | ru | null |
# Тайны кнопок в Android. Часть 1: Основы верстки
Приветствую, уважаемое сообщество.
В своем цикле статей по разработке Android-приложений я хочу поделиться с вами интересными и полезными приемами верстки сложных элементов управления. Мы рассмотрим как базовые приемы верстки, так и продвинутые способы ее оптимизаци... | https://habr.com/ru/post/206012/ | null | ru | null |
# Быстрый выбор случайных значений из больших таблиц MySQL по условию
Задача выбора случайных строчек из таблицы довольно часто возникает перед разработчиками.
В случае, если используется СУБД MySQL, обычно она решается примерно следующим способом:
`SELECT *
FROM users
WHERE role_id=5
ORDER BY rand()
... | https://habr.com/ru/post/207096/ | null | ru | null |
# Lingtrain Aligner. Написал приложение для создания параллельных книг, которое вас удивит

Здравствуй, читатель. Хотелось бы ненадолго отвлечь твое внимание от новостей и историй данной технической статьей. Поэтому пусть такой ... | https://habr.com/ru/post/564944/ | null | ru | null |
# Micro Men — история Клайва Синклера как памятка новым поколениям
Помнишь ZX-Spectrum, хабрачеловек?
Вот и англичане тоже помнят, да так помнят, что сняли художественный фильм по мотивам великого бум... | https://habr.com/ru/post/76397/ | null | ru | null |
# Как я визуальную новеллу препарировал
Привет, Хабр!
На днях я захотел достать ресурсы одной визуальной новеллы, созданной с помощью Ren'Py ~~(Да, да, того самого "Бесконечного Лета")~~. Опытным путем было установлено, что все они хранятся в файле archive.rpa. Я нашел готовые скрипты для распаковки на Github, но реш... | https://habr.com/ru/post/348320/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.