
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как отформатировать текст в Интернет по ширине с переносами
Большинство сайтов в интернете используют выравнивание текста влево и не используют переносы. Дизайнеры [утверждают](https://maxwellforbes.com/posts/web-justified-text/), что возможности браузеров по форматированию текста далеки от возможностей настольных и... | https://habr.com/ru/post/661689/ | null | ru | null |
# syslog-ng+MySQL+Net Source
Задача: Поднять syslog сервер, с хранением логов в SQL базе и cделать возможным
скидывать туда логи с других клиентов *роутеров например*
Что нужно: unix like ОС (хотя даже на ОС семейства Windows это можно сделать), syslog-ng, MySQL и понятие, для чего это на фиг нужно.
Предупре... | https://habr.com/ru/post/56926/ | null | ru | null |
# Статистические тесты в R. Часть 2: Тесты качественных данных
Эта статья — продолжение первой части. В этой серии статей я рассматриваю применение набирающего популярность языка программирования R для решения распространенных статистических задач.
В данной и следующей статье я показываю как выбрать для обработки к... | https://habr.com/ru/post/168877/ | null | ru | null |
# Как работает JS: WebRTC и механизмы P2P-коммуникаций
**[Советуем почитать] Другие 19 частей цикла**Часть 1: [Обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [О внутреннем устройстве V8 и оптимизации кода](https://habrahabr.ru/company/ruvds/blog... | https://habr.com/ru/post/416821/ | null | ru | null |
# Разнообразие версий Microsoft SQL Server и какая из них последняя?
В свое время из-за немного громоздкой политики по выпуску обновлений для Microsoft SQL Server путался какой же из дистриубтивов нужно установить и откуда его скачать. Углубившись в данную тематику, в интернете нашел замечательные систематизирующие ре... | https://habr.com/ru/post/281194/ | null | ru | null |
# Три относительно честных способа создания Flutter проекта

Итак, с презентацией Google первой стабильной версии [**Flutter**](https://flutter.io/), которая случилась 4 дека... | https://habr.com/ru/post/437716/ | null | ru | null |
# Избавление от шаблонного кода: как будет выглядеть источник данных?
В [предыдущей статье](https://habr.com/ru/company/psb/blog/588332/) мы начали разбирать, как избавиться от шаблонного многострочного кода в iOS-приложении. В результате сформировали первоначальное представление о том, какие основные архитектурные су... | https://habr.com/ru/post/589731/ | null | ru | null |
# Проектирование кластеров Kubernetes: как выбрать оптимальную стратегию автомасштабирования

[Pyramids of Egypt by acrosstars22](https://www.deviantart.com/comeonovercn/art/Egypt-piramid-529480169)
Масштабирование нод и узлов в к... | https://habr.com/ru/post/650591/ | null | ru | null |
# Переход от 2-х звенки к архитектуре служб в парадигме SOA
В данной статье я бы хотел поделиться своим опытом организации перехода от классической 2-х звенки к парадигме SOA, также затронуть некоторые аспекты деплоя в рамках enterprise-решения и интеграции со смежными службами, написанными на Java
##### Предистори... | https://habr.com/ru/post/223385/ | null | ru | null |
# Elixir
Erlang является уникальной по своим возможностям платформой, и не смотря на это, язык до сих пор является экзотикой. Причин существует несколько. Например, тугая арифметика, непривычность синтаксиса, функциональность. Это не недостатки. Это просто вещи, с которыми большинство программистов не могут или не хот... | https://habr.com/ru/post/115372/ | null | ru | null |
# VPN-сервер на Linux — решение проблемы с MPPE и клиентами, не поддерживающими шифрование данных
Так уж исторически сложилось, что связка pptpd + pppd — довольно популярное решение для раздачи интернета в локальных сетях, во многом благодаря наличию клиента pptp в windows начиная с 98 «из коробки». Более того, этот к... | https://habr.com/ru/post/56496/ | null | ru | null |
# Ubuntu 9.10 и catalyst: исправляем медленное развёртывание окна
В свежеустановленной ubuntu у ~~счастливых~~^Wпользователей проприетарного драйвера от ati(catalyst), при включенных эффектах, очень долго разворачивается окно. Для исправления нужно поставить «иксы» с патчем *nobackflill*(отключается инициализация фона... | https://habr.com/ru/post/74671/ | null | ru | null |
# Как сделать pda версию WordPress без плагинов
Существует множество способов сделать **pda версию блога**, созданного на движке **WordPress**. Плагины и прочее… Но всё оно мне не подходило, так как настраивать в них какие-то функции или внешний вид — невозможно! Рыться в этом коде можно очень долго, а толку в итоге н... | https://habr.com/ru/post/37192/ | null | ru | null |
# Самодельный SD Card Shield для Arduino
Приветствую, %username%!
Подумал на днях, что для своего будущего 2х ядерного коптера (да и мало ли других проектов) неплохо бы потом сделать еще и черный ящик ([GPS](http://habrahabr.ru/blogs/arduino/109354)), а для этого надо много памяти и EEPROM не поможет, а поэтому сто... | https://habr.com/ru/post/115176/ | null | ru | null |
# Неблагодарный opensource: разработчик самого быстрого веб сервера удалил его репозиторий

Краткая суть ситуации: наш соотечественник [fafhrd91](https://habr.com/ru/users/fafhrd91/) на протяжении 3 лет практически самостоятельно (см. ... | https://habr.com/ru/post/484436/ | null | ru | null |
# Заставим клавишу Switch Display на ноутбуке работать по-своему!
Вам нравится как работает gnome-display-properties (это тот, который «Система -> Параметры -> Мониторы») и клавиша переключения монитора на ноутбуке? Да? Тогда можете проходить мимо, топик не для вас :)
Самое большое неудобство этого аплета — невозмо... | https://habr.com/ru/post/120782/ | null | ru | null |
# Qt обертка вокруг фреймворка gRPC в C++
Всем привет. Сегодня мы рассмотрим, как можно связать фреймворк gRPC в C++ и библиотеку Qt. В статье приведен код, обобщающий использование всех четырех режимов взаимодействия в gRPC. Помимо этого, приведен код, позволяющий использовать gRPC через сигналы и слоты Qt. Статья мо... | https://habr.com/ru/post/420237/ | null | ru | null |
# Как запустить Istio, используя Kubernetes в production. Часть 1
Что такое [Istio](https://istio.io)? Это так называемый Service mesh, технология, которая добавляет уровень абстракции над сетью. Мы перехватываем весь или часть трафика в кластере и производим определенный набор операций с ним. Какой именно? Например, ... | https://habr.com/ru/post/419319/ | null | ru | null |
# Деревья квадрантов и распознавание коллизий
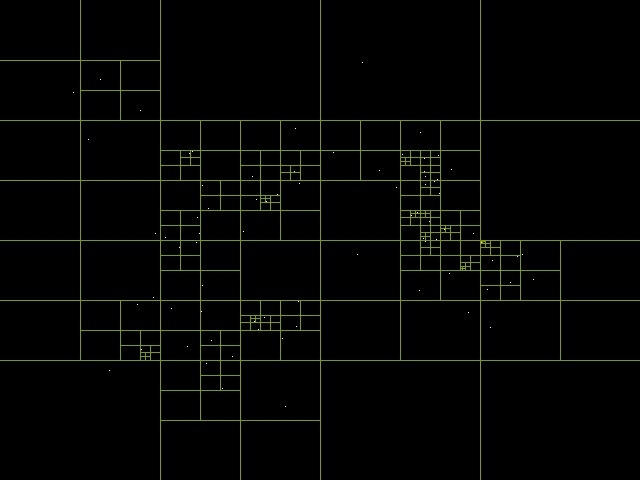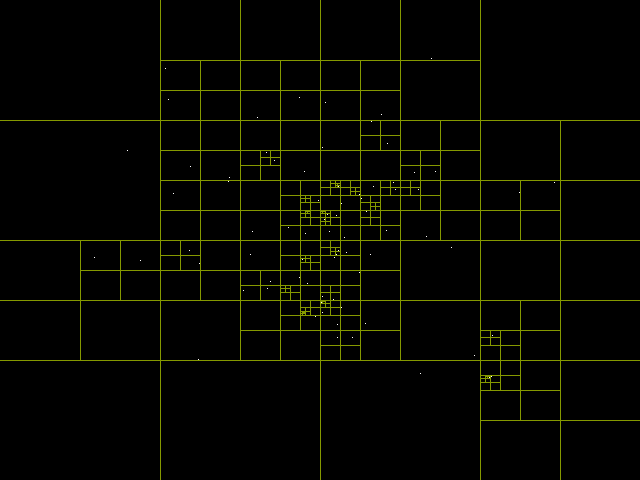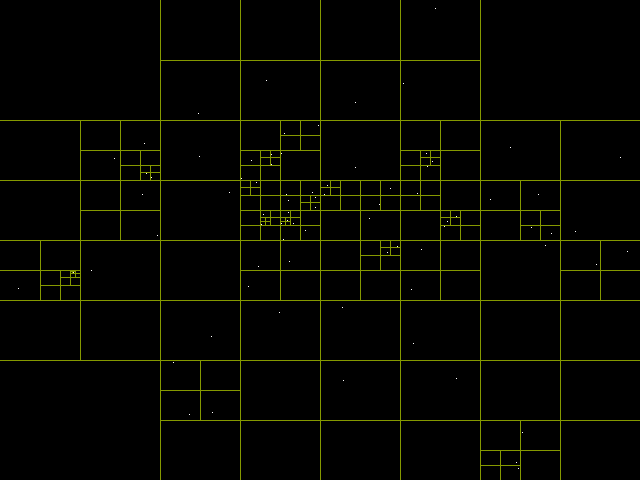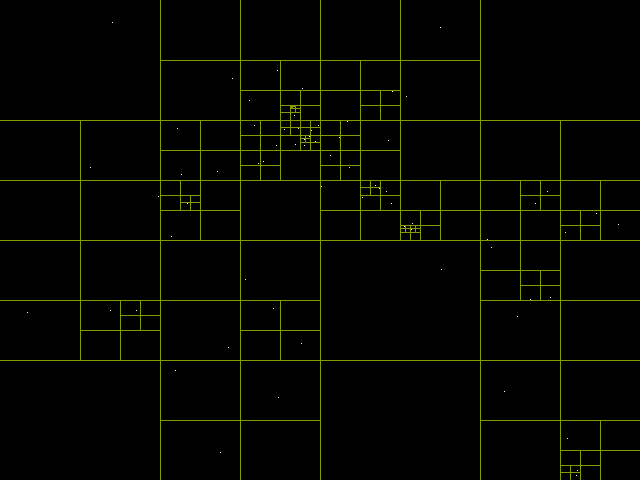
Эта неделя была короткой, в понедельник и вторник я продолжал работать над [системой 2D-освещения](https://pvigier.github.io/2019/07/28/vagabond-2d-light-system.h... | https://habr.com/ru/post/473066/ | null | ru | null |
# Сокращённые свойства

> Зачем задавать картинку через `background-image`, если можно просто написать `background`?
CSS-свойство `background` — это сокращение целой группы свойств: `background-color`, `image`, `attachment`, `... | https://habr.com/ru/post/337274/ | null | ru | null |
# .NET и HashiCorp Vault: Использование секретов в настройках .NET Core приложения
Настройка
---------
Для работы нам понадобится настроенный к8s кластер, можно использовать [Minkube](https://minikube.sigs.... | https://habr.com/ru/post/707802/ | null | ru | null |
# Yet Another Android snake with Kivy, Python
Hello, there.
[UPD from 2021: I highly recommend following this tutorial with an utmost caution]
A lot of people want to start programming apps for Android, but they prefer not to use Android Studio and/or Java. Why? Because it's an overkill. «I just wanna create Sna... | https://habr.com/ru/post/465523/ | null | en | null |
# Java и Linux — особенности эксплуатации
Java — очень распространённая платформа, на ней пишут очень разные вещи, начиная от Big Data, заканчивая микросервисами, монолитами, enterprise и прочим. И, как правило, всё это развёртывают на Linux серверах. При этом, соответственно, те люди, которые пишут на Java, зачастую ... | https://habr.com/ru/post/358520/ | null | ru | null |
# «Домашка» по Yii2
Не так давно был написан [пост](http://habrahabr.ru/post/254179/) о «подводных камнях ~~и ракушках~~», в котором было «домашнее задание» — ответ на которое так никто и не прислал, но думаю многие задавались вопросом — как все таки связывать модели из разных модулей. Хочу вам предложить вариант реше... | https://habr.com/ru/post/256685/ | null | ru | null |
# Создаем приложение Art-pixel на Angular и Nest.js. Часть 2.1 (ESLint)
В процессе разработки приложения, поскольку у нас не было четкого технического задания и видения, у нас возник некий технический долг в виде any, в этой статье мы постараемся это исправить. Для тех кто пропустил, [начало](https://habr.com/ru/post/... | https://habr.com/ru/post/648881/ | null | ru | null |
# Используем CSS Flexible Box Layout Module. Часть 1: Введение
В данной статье мы рассмотрим использование модели [CSS Flex Box](http://www.w3.org/TR/2015/WD-css-flexbox-1-20150514/), предназначенной для дизайна пользовательского интерфейса в браузере. В этой модели дети контейнера flex (гибкий) могут располагаться в ... | https://habr.com/ru/post/262545/ | null | ru | null |
# Остановка неиспользуемых хостов через CloudWatch
Привет! 
Многие сталкивались с тем, что ресурсы системы простаивают. Обычная практика борьбы с простоем — удаление из системы этих ресурсов. С практической точки зре... | https://habr.com/ru/post/165215/ | null | ru | null |
# Советы и рецепты начинающему Android программисту
Добрый день, уважаемые хабраюзеры.
В данной статье я хочу поделиться своим опытом разработки под Android.
Требования к функционалу разрабатываемого продукта породили различные технические задачи, среди которых были как тривиальные, разжеванные во множестве блог... | https://habr.com/ru/post/240045/ | null | ru | null |
# Испорченный PDT
Привет. Данный топик, будет интересен только тем, кто знает, что такое Eclipse PDT и пользуется им ;)
Сама суть.
Есть два проекта, один благополучно работает с PDT, а второй не чем не отличаясь не хочет.
В чем проблема?
**.project Game**
`xml version="1.0" encoding="UTF-8"?
game
... | https://habr.com/ru/post/17262/ | null | ru | null |
# Создание аудиоплагинов, часть 6
Все посты серии:
[Часть 1. Введение и настройка](http://habrahabr.ru/post/224911/)
[Часть 2. Изучение кода](http://habrahabr.ru/post/225019/)
[Часть 3. VST и AU](http://habrahabr.ru/post/225457/)
[Часть 4. Цифровой дисторшн](http://habrahabr.ru/post/225751/)
[Часть 5. П... | https://habr.com/ru/post/226439/ | null | ru | null |
# Как мы искали утечку данных в SimilarWeb
Доброго времени суток.
Все началось пол года назад. Работаем небольшой командой над проектом, проект уже запустили в сеть и он успешно работал несколько месяцев. Зашла как-то речь по поводу статистики посещения, источников переходов пользователей и тому подобное. Менеджеры... | https://habr.com/ru/post/444770/ | null | ru | null |
# Автоматизация удаления забытых транзакций
### Предисловие
Достаточно нередко бывают ситуации, когда транзакция в MS SQL Server бывает забытой тем, кто ее запустил. Самый частый пример этому — запуск скрипта в SSMS, где явно открывается транзакция инструкцией begin tran, затем происходит ошибка, а вот commit или rol... | https://habr.com/ru/post/349798/ | null | ru | null |
# Можно ли обойтись без jsx и зачем?
Я уверен, большинство из вас, кто использует **react** используют **jsx**. Благодаря своему лаконичному синтаксису **jsx** улучшает читабельность шаблонов. Сравните:
```
render() {
return React.createElement('div', { className: 'block'}, 'Text of block');
}
// vs
render() {
... | https://habr.com/ru/post/317114/ | null | ru | null |
# Наследование реализации в С++. Реальная история
Привет, Хабр!
В поисках вдохновения, чем бы пополнить портфель издательства на тему С++, мы набрели на возникший словно из ниоткуда [блог](https://quuxplusone.github.io/blog/) Артура О'Дуайера, кстати, уже [написавшего](https://www.amazon.com/Mastering-17-STL-standa... | https://habr.com/ru/post/524882/ | null | ru | null |
# Использование вычислительных возможностей R для проверки гипотезы о равенстве средних
Возникла недавно потребность решить вроде бы классическую задачу мат. статистики.
Проводится испытание определенного push воздействия на группу людей. Необходимо оценить наличие эффекта. Конечно, можно делать это с помощью вероя... | https://habr.com/ru/post/441192/ | null | ru | null |
# Идеальный SAST. Тестируем парсеры
Пока индексируется github (спасибо лимиту в 5000 запросов в час), который нужен для получения данных для статьи, поговорим пока о тестировании лексеров и парсеров. Обсудим пожелания к процессу разработки грамматик, их тестирования и контроля качества так, что бы не превращаться в су... | https://habr.com/ru/post/533106/ | null | ru | null |
# Can I haz? Рассматриваем ФП-паттерн Has
Привет, Хабр.
Сегодня мы рассмотрим такой ФП-паттерн, как `Has`-класс. Это довольно любопытная штука по нескольким причинам: во-первых, мы лишний раз убедимся, что паттерны в ФП таки есть. Во-вторых, оказывается, что реализацию этого паттерна можно поручить машине, что вылило... | https://habr.com/ru/post/470197/ | null | ru | null |
# Если связь — просто жесть, то ее нужно закопать

Любой советский школьник, собиравший подобную схему знал, что без заземления — никак.
Нынешнее поколение Z, взращенное айфонами, сомнев... | https://habr.com/ru/post/448998/ | null | ru | null |
# Как мы пытались подружить VictoriaMetrics и Thanos (и у нас почти получилось)
Источник изображения — СоюзМультфильм ©Привет! ... | https://habr.com/ru/post/672908/ | null | ru | null |
# Используем стандартные элементы ListFragment по назначению
В одном из проектов столкнулся с тем, что в приложении нужно было отображать списки результатов для различных запросов (поиск по словам, датам, тегам и т.п.). Так как списки повторялись в разных Activity, самым очевидным решением было использовать фрагменты,... | https://habr.com/ru/post/246199/ | null | ru | null |
# Нейронная сеть с SoftMax слоем на c#
Привет, [в прошлой статье](http://habrahabr.ru/post/154369/) я рассказал про алгоритм обратного распространения ошибки и привел реализацию, не зависящую от функции ошибки и от функции активации нейрона. Было показано несколько простых примеров подмены этих самых параметров: миним... | https://habr.com/ru/post/155235/ | null | ru | null |
# Implementing Offline traceroute Tool Using Python
Hey everyone! This post was born from a question asked by an IT forum member. The summary of the question looked as follows:
* There is a set of text files containing routing tables collected from various network devices.
* Each file represents one device.
* Device... | https://habr.com/ru/post/539436/ | null | en | null |
# Как я парсил Хабр, часть 1: тренды
Когда был доеден новогодний оливье, мне стало нечего делать, и я решил скачать себе на компьютер все статьи с Хабрахабра (и смежных платформ) и поисследовать.
Получилось несколько интересных сюжетов. Первый из них — это развитие формата и тематики статей за 12 лет существования с... | https://habr.com/ru/post/346198/ | null | ru | null |
# «Привет, мир»: разбираем каждый шаг хэш-алгоритма SHA-256

SHA-2 (Secure Hash Algorithm), в семейство которого входит SHA-256, — это один самых известных и часто используемых алгоритмов хэширования. В тексте подробно покажем каждый... | https://habr.com/ru/post/530262/ | null | ru | null |
# Легенды на SH-3
Приветствую всех!
Думаю, многие из нас хоть раз слышали о клавиатурных КПК. И как-то так получилось, что едва ли не самым узнаваемым аппаратом подобного класса стал HP Jornada 720.

Но сегодня речь пойдёт о... | https://habr.com/ru/post/706016/ | null | ru | null |
# Взлом игры Clocktower — The First Fear
Давайте возьмём отличную японскую игру в жанре survival horror, разберёмся, как она работает, переведём её на английский и сделаем с ней ещё кое-что.
Введение
--------
ClockTower (известная в Японии как Clocktower — The First Fear) — это игра, изначально выпущенная Human En... | https://habr.com/ru/post/332882/ | null | ru | null |
# Пакеты(packages) в Fuelphp
В данной статье я бы хотел поделиться знаниями о том, как устроены, для чего нужны и что из себя представляют [packages](http://docs.fuelphp.com/general/packages.html)(далее пакеты) в [Fuelphp](http://docs.fuelphp.com/). Прошу помочь сравнить реализацию и возможности пакетов Fuelphp с ана... | https://habr.com/ru/post/156449/ | null | ru | null |
# Почему вы должны дать еще один шанс замыканию
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Why you should give the Closure function another chance»](https://medium.freecodecamp.org/why-you-should-give-the-closure-function-another-chance-31253e44cfa0) автора Cristi Salcescu.
В JavaScript функции могу... | https://habr.com/ru/post/352882/ | null | ru | null |
# Создание отказоустойчивой ИТ инфраструктуры. Часть 2. Установка и настройка кластера oVirt 4.3
Эта статья является продолжением предыдущей – «[Создание отказоустойчивой ИТ инфраструктуры. Часть 1 — подготовка к развёртыванию кластера oVirt 4.3](https://habr.com/ru/company/lenvendo/blog/483980/)».
В ней будет рассмо... | https://habr.com/ru/post/485208/ | null | ru | null |
# Neo4j VS MySQL
#### Предисловие
Будучи студентом третьего курса, я выбрал тему для курсовой роботы: «Графовые базы данных на примере Neo4j». Так как до того времени я изучал и использовал исключительно реляционные БД, мне было интересно, зачем вообще графовая БД и когда ее способности лучше применять? После просмот... | https://habr.com/ru/post/258179/ | null | ru | null |
# Оценка важности «фичей» для нелинейных моделей
Задачи, которые сегодня решает машинное обучение, зачастую являются комплексными и включают в себя большое количество признаков (фичей). Из-за сложности и мно... | https://habr.com/ru/post/540656/ | null | ru | null |
# Что можно положить в механизм Dependency Injection в Angular?
Почти каждый разработчик на Angular может найти в Dependency Injection решение своей проблемы. Это хорошо было видно в комментариях [к моей прошлой статье](https://habr.com/ru/company/tinkoff/blog/507906/). Люди рассматривали различные варианты работы с д... | https://habr.com/ru/post/516622/ | null | ru | null |
# Поиск стат. значимости в BigQuery или удаление шума
Всё началось с использования ML в BigQuery — оказалось это совсем не больно, и очень эффективно.
Мы в GFN.RU используем модель K-Means для поиска аномалий в работе сервиса. Ведь невозможно кожаному мешку смотреть десятки графиков по тысячам игр ежедневно. Пусть э... | https://habr.com/ru/post/588859/ | null | ru | null |
# Опыт применения GitHub Actions для создания CI/CD с бесплатным хостингом на Heroku
В рамках изучения ЯП Golang я решил сделать учебный проект на примере telegram-бота. Для этой цели я взял популярный для создания ботов [AP](https://go-telegram-bot-api.dev).
Написав реализацию нужной мне бизнес-логики, у меня возник... | https://habr.com/ru/post/571374/ | null | ru | null |
# Не IoT, а малина! Строим IoT-проект на Raspberry Pi с Windows 10 и DeviceHive
Привет, Хабр.
Наверное каждый разработчик на определенном этапе задумывался о собственном IoT-проекте. Internet of Things сейчас поистине вездесущ и многим из нас хочется попробовать свои силы. Но не все знают, с чего начать и за что б... | https://habr.com/ru/post/280294/ | null | ru | null |
# Настройка корректного завершения работы гостевой Windows 2003 в qemu-kvm Linux
Это не статья, а просто заметка для тех кто столкнулся с проблемой корректного выключения.
Я не претендую на оригинальность, но лекрство собранное по частям на просторах интернета мне помогло, надеюсь поможет и вам.
1. Скрипт для по... | https://habr.com/ru/post/145980/ | null | ru | null |
# О способах продвижения.
Вот такой, можно сказать, нестандартный способ продвижения встретил в Петербургском метро, на рекламных постерах с пивом были расклеены сообщения: “Русский хватит пить! Твой народ вымирает!”. Сама форма подачи не оригинальна, довольно часто встречается, но в данном случае заинтересовала не фо... | https://habr.com/ru/post/39518/ | null | ru | null |
# Побеждаем Android Camera2 API с помощью RxJava2 (часть 2)

Это вторая часть [статьи](https://habrahabr.ru/company/badoo/blog/330080/), в которой я показываю, как использование RxJava2 помогает строить логику поверх аси... | https://habr.com/ru/post/352318/ | null | ru | null |
# Чат-сервер на Ruby и Event Machine
Недавно передо мной стала задача написать небольшой чат-демон для крупного интернет-проекта. Эту задачу я решил с помощью Ruby и Event Machine. Подробности и маленький пример под катом.
После пробной версии чата, написанной на нативных сокетах Ruby, стало понятно что для достато... | https://habr.com/ru/post/61920/ | null | ru | null |
# Объект в футляре или Optional в Java 8 и Java 9. Часть 3: «Что добавилось в Java 9»
[](https://habrahabr.ru/post/347748/)
Это третья статья серии, посвящённая использованию класса Optional при обработке объектов с... | https://habr.com/ru/post/347748/ | null | ru | null |
# А вы можете решить эти три (обманчиво) простые задачи на Python?
С самого начала своего пути как разработчика программного обеспечения я очень любил копаться во внутренностях языков программирования. Мне всегда было интересно, как устроена та или иная конструкция, как работает та или иная команда, что под капотом у ... | https://habr.com/ru/post/509274/ | null | ru | null |
# Экспортируем данные OpenStreetMap с помощью визуального редактора на rete.js
В своей работе я часто сталкиваюсь с задачей по экспорту данных из OpenStreetMap. OSM — это восхитительный источник данных, откуда можно вытащить хоть [достопримечательности](https://habr.com/ru/post/414433/), хоть [районы города](https://h... | https://habr.com/ru/post/502714/ | null | ru | null |
# Техрадар от ThoughtWorks
Добрый день, меня зовут Павел Поляков, я Principal Engineer в каршеринг компании SHARE NOW, в Гамбурге в 🇩🇪 Германии. А еще я автор Telegram-канала [Хороший разработчик знает](https://t.me/gooddevknows), где рассказываю обо всем, что должен знать хороший разработчик.
Сегодня я хочу погово... | https://habr.com/ru/post/587184/ | null | ru | null |
# Из чего состоит набор для разработчиков NB-IoT DevKit?
Набор вышел в начале июня. Он поможет разобраться, в чем преимущества сети интернета вещей NB-IoT, и научит работать с ней. В комплект входит аппаратная часть, коннективити, то есть доступ к сети NB-IoT и доступ к IoT-платформам. Главная «фича» DevKit – демонстр... | https://habr.com/ru/post/508198/ | null | ru | null |
# Чего ждать от Java в 2020 году?
2020 уже в разгаре, давайте же обсудим, какие изменения в мире Java нас ожидают в этом году. В этой статье перечислю основные тренды Java и JDK. И буду рад дополнениям от читателей в комментариях.
Сразу оговорюсь, что статья носит скорее ознакомительный характер. Детали по каждой р... | https://habr.com/ru/post/488302/ | null | ru | null |
# Моделирование кинематики — это не сложно
Мне давно хочется заняться созданием роботов, но всегда не хватает свободных денег, времени или места. По этому я собрался писать их виртуальные модели!
Мощные инструменты, позволяющие это ... | https://habr.com/ru/post/313138/ | null | ru | null |
# Java, Spring, Kurento и медиасервисы

Существует уже немало медиа сервисов, но люди продолжают их создавать. Решил и я заняться изобретением своего велосипеда.
Натолкнувшись на проект [Kurento](http://www.kurento.org/), понял ч... | https://habr.com/ru/post/435580/ | null | ru | null |
# Сквозное тестирование DApp в связке с расширением Metamask
Всем привет! На связи снова QA Engineer Илья из компании Tourmaline Core и это вторая часть статьи про тестирование DApp.
В прошлый раз я рассказывал о том, как [можно тестировать](https://habr.com/ru/post/693566/) подключение и работоспособность блокчейн-... | https://habr.com/ru/post/708622/ | null | ru | null |
# Новая Zero-day уязвимость позволяет выполнение произвольного кода через журнал логирования log4j
Недавно обнаруженная уязвимость нулевого дня в широко используемой библиотеке логирования Java Apache Log4j легко эксплуатируется и позволяет злоумышленникам получить полный контроль над уязвимыми серверами.
 *дейс... | https://habr.com/ru/post/318200/ | null | ru | null |
# Основы программирования на SAS Base. Урок 3. Чтение текстовых файлов
В предыдущей [статье](https://habrahabr.ru/company/sas/blog/349726/) мы познакомились с понятием библиотеки SAS, научились назначать библиотеку для файла Excel, а также познакомились с процедурой, которая создает детализированные отчеты.
Напомн... | https://habr.com/ru/post/354284/ | null | ru | null |
# Решаем загадку круглых чисел на графике выборов 2018

Данная статья является ответом на вот эту статью ([Анализ результатов президентских выборов 2018 года. На федеральном и региональном уровне](https://habrahabr.ru/post/352424/)).... | https://habr.com/ru/post/354020/ | null | ru | null |
# Сайт про браузеры от Яндекса и как можно его использовать
Привет хабражители! Странно что замечательный небольшой ресурс [Яндекс.Браузеры](http://browser.yandex.ru/) до сих пор никак у нас не упомянут, даже в комментариях. А ведь он может пригодиться не только простым обывателям, но и разработчикам сайтов.
В рамках туториала мы напишем полноценный класс для отправки сообщений на GCM сервер, который:
* получает на вход массив данных для отправки
* формирует пакеты для отп... | https://habr.com/ru/post/161305/ | null | ru | null |
# Алгоритмы быстрого вычисления факториала
Понятие факториала известно всем. Это функция, вычисляющая произведение последовательных натуральных чисел от 1 до N включительно: N! = 1 \* 2 \* 3 \*… \* N. Факториал — быстрорастущая функция, уже для небольших значений N значение N! имеет много значащих цифр.
Попробуем р... | https://habr.com/ru/post/255761/ | null | ru | null |
# Онлайн видеостриминг с платы Orange Pi One

В данном посте будет приведён пример реализации онлайн видеостриминга с помощью вебкамеры и одноплатника Orange Pi One.
Ну начнём с того, что здесь используется:
1) [Платка]... | https://habr.com/ru/post/328892/ | null | ru | null |
# Traefik 2.0: обновление service mesh с поддержкой TCP и новым веб-интерфейсом
В минувший вторник компания Containous [представила](https://blog.containo.us/traefik-2-0-6531ec5196c2) крупное обновление к своему флагманскому Open Source-продукту — service mesh-решению Traefik — в виде версии 2.0.
 печатное издание замечательного учебника [Learn You a Haskell for Great Good!](http://learnyouahaskell.com) (онлайн-версия), написанного Miran Lipovača.
Я хочу пр... | https://habr.com/ru/post/123767/ | null | ru | null |
# geoDNS с помощью Powerdns и nginx
Обожаю задачи “на стыке технологий”, это одна из таких.
Задача:
* реализовать geoDNS\*
* c возможностью wildcard (\*.some.tst. A 1.2.3.4)
* с возможностью менять содержимое зон на ходу, добавлять новые зоны пачками
* без необходимости запускать громоздкие скрипты на каждый зап... | https://habr.com/ru/post/178727/ | null | ru | null |
# Курсы валют и аналитика – использование обменных курсов в Хранилище Данных
Привет! На связи Артемий – Analytics Engineer.
Сегодня хотел бы поговорить о вопросах конвертирования финансовых показателей в раз... | https://habr.com/ru/post/558238/ | null | ru | null |
# Cтреловидные формы элементов с помощью CSS3

В веб-дизайне элементы неправильной формы всегда вызывают интерес. Стреловидные формы и диагональные линии могут создать интересный визуальный поток и дать приятный результа... | https://habr.com/ru/post/135508/ | null | ru | null |
# Простой лидерборд на Unity3D с facebook-ом
После участия в Ludum Dare 31 у нас появилась игра, в которой можно соревноваться с друзьями и мы решили добавить к ней лидерборд, с авторизацией через Facebook. Какие сложности могут возникнуть и как сделать подобный в своей игре читайте под катом.
, и даже конце пообещал рассказать про настройку автодополнения для собственных скриптов.
Однако, прошло уже полтора года, а лично у... | https://habr.com/ru/post/115886/ | null | ru | null |
# Самодельный Bluetooth усилитель АБ класса с автоматизацией управления питанием
Всё началось с лени.
А точнее, с Веги 50у-122с, доставшейся в наследство вместе с акустикой Электроника 25ас-033. И вначале всё было хорошо. А потом, споткнувшись за провод, был убит ноут. После этого, в Веге появился BT модуль, а сама... | https://habr.com/ru/post/369323/ | null | ru | null |
# По дороге к 100% покрытия кода тестами в Go на примере sql-dumper

В этом посте я расскажу о том, как я писал консольную программу на языке Go для выгрузки данных из БД в файлы, стремясь покрыть весь к... | https://habr.com/ru/post/418565/ | null | ru | null |
# JavaScript: интересные возможности AbortController

Привет, друзья!
Представляю вашем вниманию адаптированный и дополненный перевод [этой замечательной статьи](https://whistlr.info/2022/abortcontroller-is-your-friend/).
[AbortC... | https://habr.com/ru/post/673048/ | null | ru | null |
# Проверка счета Киевстар модема в Linux
Навеяно [этим](http://habrahabr.ru/blogs/telecom/98782/) топиком. Однажды у меня случился переезд и на новом месте проживания и мне потребовался срочно интернет. Насмотревшись рекламы Киевстара модем за 199 грн, я приобрел данный набор. Настройка в Ubuntu через NetworkManager н... | https://habr.com/ru/post/98837/ | null | ru | null |
# Гонка вооружений

В мае на Google I/O 2019 было объявлено о новом фреймворке для разработки декларативного UI под Android с названием Jetpack Compose. Через месяц на WWDC 2019 было объявлено о декларативном UI фреймворке под IOS ... | https://habr.com/ru/post/456770/ | null | ru | null |
# Разработка высоконагруженного WebSocket-сервиса
Как создать веб-сервис, который будет взаимодействовать с пользователями в реальном времени, поддерживая при этом несколько сотен тысяч коннектов одновременно?
Всем привет, меня зовут Андрей Клюев, я разработчик. Недавно я столкнулся с такой задачей – создать интера... | https://habr.com/ru/post/351012/ | null | ru | null |
# еще один велосипед или TreeDb — NoSQL Database startup
Хочу представить старт проекта, с рабочим названием TreeDb. Я не пиарюсь (еще далеко...) и размещаю свои мысли и рассуждения в личном блоге. Хочу в ответ получить адекватную критику, обсуждение идей, в общем все то, для чего нужны блоги ;). Просто, в последствии... | https://habr.com/ru/post/80928/ | null | ru | null |
# Реализация списка использованных библиотек с помощью DialogFragment в Android приложении
Часто при реализации мобильного приложения для Android c использованием в нем различных сторонних библиотек требуется их упомянуть в своем проекте, чтоб не нарушать права 3-х лиц и не попасть в бан с вашим проектом в магазине пр... | https://habr.com/ru/post/274859/ | null | ru | null |
# Пишем сложный, но интересный слайдер на JavaScript

Доброго времени суток, друзья! Решил вернуться к теме слайдеров. Вдохновением послужила [эта статья](https://www.hackdoor.io/articles/8MNPqDpV/build-a-full-featured-tinder-like-ca... | https://habr.com/ru/post/495022/ | null | ru | null |
# Блендинг террейна и меша в Unity
***Всем привет, в июне OTUS вновь запускает курс [«Разработчик игр на Unity»](https://otus.pw/YJ08/). В преддверии старта курса, мы подготовили перевод интересного материала по теме.***

---
Сег... | https://habr.com/ru/post/504554/ | null | ru | null |
# Когда файлы не хуже, чем memcached
Кеш на файлах не медленней memcached.
Нужда в memcached отпадает, если Вам нужен локальный (не распределённый) кеш размером не более свободной оперативки.
Кешеруем простой массив:
`$array = array();
for ($i = 0; $i < 1000; $i++) {
$array []= sha1($i);
}
echo ... | https://habr.com/ru/post/43412/ | null | ru | null |
# Прием платежей по банковским картам в приложениях — PayOnline Payment SDK
В конце лета PayOnline совместно с Microsoft анонсировали выход нового продукта — PayOnline Payment SDK, позволяющего разработчикам мобильных приложений интегрировать прием безналичных платежей в приложения Windows Store и Windows Phone. 12 се... | https://habr.com/ru/post/195854/ | null | ru | null |
# Yii 2.0.10
Вышла новая версия PHP-фреймворка Yii, включающая в себя [более 80 улучшений и исправлений](https://github.com/yiisoft/yii2/blob/2.0.10/framework/CHANGELOG.md). Инструкции по установке и обновлению можно найти [по адресу](http://www.yiiframework.com/download/). Стоит отметить, что в релиз вошли четыре неб... | https://habr.com/ru/post/313180/ | null | ru | null |
# Как заставить Apache работать или как я реализую создание миниатюр изображений в своих проектах
Здравствуйте, хабровчане.
Занимаясь созданием различных интернет-проектов уже порядочное время, часто был просто возмущён одним фактом — не все элементы системы несут на себе равную нагрузку. Я всегда придерживался мне... | https://habr.com/ru/post/239501/ | null | ru | null |
# Материалы в Unity: Акрил
Всем привет! Меня зовут Григорий Дядиченко, я СТО Foxsys, и я всё ещё люблю графику. В прошлый раз я рассказывал, что неплохим упражнением является сборка различных базовых материалов для тренировки в создании интересных эффектов. Давайте сегодня проведём такое упражнение вместе и разберём, ... | https://habr.com/ru/post/565662/ | null | ru | null |
# DDoS-атака на RDP-службы: распознать и побороть. Успешный опыт от Tucha
Расскажем вам прохладную историю о том, как «третьи лица» пытались помешать работе наших клиентов, и как эта проблема была решена.
Как всё началось
----------------
А началось всё с утра 31 октября, в последний день месяца, когда многим поза... | https://habr.com/ru/post/474470/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.