
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Разбираем лямбда-выражения в Java

*От переводчика: LambdaMetafactory, пожалуй, один из самых недооценённых механизмов Java 8. Мы открыли его для себя совсем недавно, но уже по достоинству оценили его возможности. В версии 7.0... | https://habr.com/ru/post/432418/ | null | ru | null |
# Как определить HTTP_REFERER flash'ки
Предыстория такова. Есть на некоем ресурсе флеш-виджет которые выполняет какие-то операции с пользовательским контентом. В моем конкретном случае, это фотографии. Задача стояла следующим образом. Необходимо собирать статистику показов с внешних ресурсов, т.е. сколько раз и где фл... | https://habr.com/ru/post/148284/ | null | ru | null |
# Переход на ReactiveCocoa v.4

Если вы когда – либо интересовались [фреймворком ReactiveCocoa](https://github.com/ReactiveCocoa/ReactiveCocoa), то заметили, что есть небольшое количество постов на тем... | https://habr.com/ru/post/281106/ | null | ru | null |
# Telegram-бот на Java для самых маленьких — от старта до бесплатного размещения на heroku

### В следующих сериях
Это первая статья в моей серии «для самых маленьких» — [следующая](https://habr.com/ru/post/646017/) посвящена Tele... | https://habr.com/ru/post/528694/ | null | ru | null |
# Решение японских кроссвордов в Wolfram Mathematica

Японский кроссворд — это известная головоломка, ответом которой является рисунок. Что это такое и как это решать, можно почитать на [Википедии](http://r... | https://habr.com/ru/post/204784/ | null | ru | null |
# Операции сравнения в C++20
Встреча в Кёльне прошла, стандарт C++20 приведён к более или менее законченному виду (по крайней мере до появления особых примечаний), и я хотел бы рассказать об одном из грядущих нововведений. Речь пойдёт о механизме, который обычно называют *operator<=>* (стандарт определяет его как «опе... | https://habr.com/ru/post/465575/ | null | ru | null |
# Перехватываем запуск любого приложения в Windows и пытаемся ничего не сломать
Если вы много занимаетесь отладкой приложений под Windows — вы, возможно, слышали о таком замечательном механизме, как [Image File Execution Options](https://msdn.microsoft.com/en-us/library/a329t4ed(v=vs.100).aspx) (**IFEO**). Одна из пре... | https://habr.com/ru/post/335736/ | null | ru | null |
# Автоматическая система полива сада на Home Assistant, ESP8266 и MiFlora

Некоторое время назад у моей семьи появился дом с небольшим садом в очень теплом и засушливом месте, и перед нами встала проблема регулярного полива.
Хотел... | https://habr.com/ru/post/497606/ | null | ru | null |
# Простейшая игра на Arduino с дисплеем 1602 — Часть #2
ЧАСТЬ #2 от начала до конца
===========================
Продолжаем делать игру на arduino и в дальнейшем всунем эту игру в программу, которую я делаю для машины и на наших полученных знаниях создадим вторую игру, для забавы ради и сделаем правильную музыку для н... | https://habr.com/ru/post/425367/ | null | ru | null |
# Настоящие ассоциативные массивы в JavaScript
Использование литерала объекта, как простого средства для хранения пар ключ-значение давно стало обычным делом в JavaScript. Тем не менее, литерал объекта всё же не является настоящим ассоциативным массивом и по этому, в некоторых ситуациях, его использование может привес... | https://habr.com/ru/post/259529/ | null | ru | null |
# Hetzner dedicated или в поисках дешевого хостинга
Хочу рассказать о том, как я озадачился поиском недорогого хостинга с поддержкой Java.
В начале решил, что неплохо бы купить железку, поставить ее дома, дать ей хороший канал и радоваться жизни. Но потом решил подсчитать примерную ежемесячную стоимость такого реше... | https://habr.com/ru/post/116017/ | null | ru | null |
# Настраиваем приватный Docker-репозиторий
 Docker одна из горячих тем в разработке. Большинство новых проектов строится именно на Docker. Как минимум, он отлично зарекомендовал себя для распространения ПО, например, наша систе... | https://habr.com/ru/post/320884/ | null | ru | null |
# 5 неочевидных возможностей FastAPI: упрощаем работу с бэкендом на Python
API (Application Programming Interface) — технология, позволяющая соединить функциональность разных компьютерных программ. API можно... | https://habr.com/ru/post/714688/ | null | ru | null |
# Kali Linux 2.0

Прошло уже более двух лет с момента выхода дистрибутива Kali 1.0. Сегодня вышла 2.0 версия этого дистрибутива.
Краткий экскурс: Kali linux представляет из себя дистрибутив, содержащий множество утилит дл... | https://habr.com/ru/post/264541/ | null | ru | null |
# Как обрабатывать alert, prompt и confirm в Selenium 4
В этом посте рассмотрим обработку модальных окон alert, prompt и confirm в Selenium.
### О чем вообще речь?
Рис.1 Vox-модель c графическими паттернамиВ качестве п... | https://habr.com/ru/post/648507/ | null | ru | null |
# Лень, нетерпение и самомнение — три главных добродетели программиста. С днем рождения, Ларри Уолл
*«Мне кажется, я иногда вижу сны на Perl`e»*
— Ларри Уолл
1. Ларри всегда по определению прав по поводу того, как Perl должен себя вести. Это значит, что у него финальное право вето на основные функциональные воз... | https://habr.com/ru/post/310938/ | null | ru | null |
# Превращаем старый телефон на Android в резервный сервер с помощью UrBackup/Linux Deploy. Часть 1
[](https://habr.com/ru/company/ruvds/blog/564166/)
Сегодня я покажу вам, как запустить полноценный резервный сервер на рутованном теле... | https://habr.com/ru/post/564166/ | null | ru | null |
# FreeSWITCH пример из жизни…
Доброе время суток %username%.
Хочется за ранее предупредить, всех кто в принципе будет прав, данная система этот как стрельба по воробьям из пушки, но хотелось чего то этакого. Так же некоторые элементы в данной схеме не поднимались с нуля, они уже были и использовались в решении дру... | https://habr.com/ru/post/132868/ | null | ru | null |
# Авторизация с помощью клиентских SSL сертификатов в IOS и Android
Протокол безопасной передачи данных SSL (Secure Sockets Layer) помимо обеспечения безопасной передачи данных так же позволяет реализовать авторизацию клиентов при помощи клиентских SSL сертификатов. Данная статья является практическим руководством по ... | https://habr.com/ru/post/194530/ | null | ru | null |
# Parallel Extensions для .net 3.5
Количество ядер у процессоров растет год от года. Но многие программы до сих пор умеют использовать только одно. В небольшой заметке хочу рассказать о дополнении... | https://habr.com/ru/post/45732/ | null | ru | null |
# Visual Studio 2019 .NET productivity
Your friendly neighborhood .NET productivity team (aka. Roslyn) focuses a lot on improving the .NET coding experience. Sometimes it’s the little refactorings and code fixes that really improve your workflow. You may have seen many [improvements in the previews](https://devblogs.m... | https://habr.com/ru/post/447462/ | null | en | null |
# MIDI-router на Raspberry Pi
Хочу рассказать о том, как решить проблему, которая наверняка знакома любителям аппаратных синтезаторов.
Что делать, если хочется состыковать MIDI-контроллер и синтезатор, но у одного из них есть только USB разъем и нет MIDI? Причем, по понятным причинам хочется все это сделать не исполь... | https://habr.com/ru/post/440294/ | null | ru | null |
# Кратко о DOCSIS или есть ли жизнь в КТВ?

Собственно аббревиатуру DOCSIS слышали многие, но далеко не все представляют что это и зачем оно нужно. Самые любопытные могли, даже просветится этим вопросом в википедии,... | https://habr.com/ru/post/102429/ | null | ru | null |
# Способы представления словарей для автоматической обработки текстов
Автоматический анализ текстов практически всегда связан с работой со словарями. Они используются для морфологического анализа, выделения персон (нужны словари личных имен и фамилий) и организаций, а также других объектов.
В общем виде словарь — м... | https://habr.com/ru/post/190694/ | null | ru | null |
# Отладка сложных веб-приложений — эффективная багодробилка на production-серверах
Всем привет!
Сегодня расскажу, как на боевых серверах во время нагрузки, в пыли и грязи, эффективно отлавливать узкие места в производительности больших веб-приложений на PHP, а также искать и устранять «нестандартные» ошибки. Многие... | https://habr.com/ru/post/144482/ | null | ru | null |
# Создание stateful навыка для Алисы на serverless функциях Яндекс.Облака и Питоне
Начнём с новостей. Вчера Яндекс.Облако анонсировало запуск сервиса бессерверных вычислений [Yandex Cloud Functions](https://cloud.yandex.ru/services/functions). Это значит: ты пишешь только код своего сервиса (например, веб-приложения и... | https://habr.com/ru/post/469723/ | null | ru | null |
# Ahead-of-Time компиляция и Blazor
В .NET 6 запланирована поддержка AOT компиляции для Blazor WebAssembly приложений. Давайте попробуем запустить в Preview 2 версии.
Анонса и инструкций пока что нету. Поэто... | https://habr.com/ru/post/548132/ | null | ru | null |
# Пишем PHP extension
А давайте сегодня взглянем на PHP немного с другой точки зрения, и напишем к нему расширение. Так как на эту тему уже были публикации на Хабре ([здесь](http://habrahabr.ru/blogs/php/98862/) и [здесь](http://habrahabr.ru/blogs/php/75388/)), то не будем углубляться в причины того, для чего это може... | https://habr.com/ru/post/125597/ | null | ru | null |
# Отладка Grunt-задания в WebStorm
*Вообще-то у меня PhpStorm, но, думаю, все будет работать и в WebStorm.*
Запускаем в командной строке
```
cd
node --debug-brk=64005 $(which grunt) img2base64
```
*Где **img2base64** — название нужного задания. Можно опустить этот параметр, чтобы запустились все задания.*
... | https://habr.com/ru/post/170441/ | null | ru | null |
# Распаковка Huawei TaiShan 2280v2

Серверы с процессорами на архитектуре arm64 старательно входят в нашу жизнь. В этой статье мы покажем распаковку, установку и небольшой тест нового сервера TaiShan 2280v2.
Распаковка
----------
... | https://habr.com/ru/post/496228/ | null | ru | null |
# Антипаттерны тестирования ПО
Введение
========
Есть несколько статей об антипаттернах разработки ПО. Но большинство из них говорят о деталях на уровне кода и фокусируются на конкретной технологии или языке программирования.
В этой статье я хочу сделать шаг назад и перечислить высокоуровневые антипаттерны тестиро... | https://habr.com/ru/post/358178/ | null | ru | null |
# Зонд Atlas RIPE
На конференции ENOG-4 мое внимание привлек стол, на котором лежали коробочки с наклейкой RIPE NCC, портом RJ-45 и хвостом USB. Вот такие:

Я был не в курсе что это и для чего нужно, по этому подошел ... | https://habr.com/ru/post/156155/ | null | ru | null |
# First DI: Первый DI на интерфейсах для Typescript приложений
Делюсь одной из своих библиотек которая называется First DI. Она уже много лет помогает мне решить проблему внедрения зависимостей в браузерных приложениях для таких библиотек как React, Preact, Mithril и другие. При написании First DI за основу была взята... | https://habr.com/ru/post/496860/ | null | ru | null |
# Принципы эмуляции на основе CHIP-8
Считается, что прежде чем начинать эмулировать сложные системы, нужно начать с чего-то простого, например с Chip-8. В этой статье я попытаюсь рассмотреть все аспекты того, как можно написать свою реализацию этого языка в виртуальной машине. Пойдет совсем любой язык программирования... | https://habr.com/ru/post/100916/ | null | ru | null |
# Throwable exception и ошибки в php7
В прошлом, обрабатывать фатальные ошибки было практически невозможно. Обработчик, установленный `set_error_handler` вызван не будет, скрипт просто будет завершен.
В PHP 7 при возникновении фатальных ошибок (E\_ERROR) и фатальных ошибок с возможностью обработки (E\_RECOVERABLE\... | https://habr.com/ru/post/261451/ | null | ru | null |
# Телеграм бот для поддержки своими руками
Представьте, что у вас есть свой канал в Телеге. Допустим, вы высказываете непопулярную политическую точку зрения и, соответственно, ловите хейт в личку со стороны ч... | https://habr.com/ru/post/539766/ | null | ru | null |
# Постепенно вводим TypeScript в ваш проект на React
Привет, Хабр!
В последнее время в области front-end особую популярность приобретает комбинация React+TypeScript. Соответственно, возрастает актуальность грамотной миграции с JavaScript на TypeScript, желательно в сжатые сроки. Сегодня мы хотели бы обсудить с вами... | https://habr.com/ru/post/504384/ | null | ru | null |
# Когда-то я внедрял ClickHouse в стартапе, где даже алерты мониторили индийцы — это был Дикий Запад
Однажды я работал дата-инженером в стартапе. Он быстро рос и в какой-то момент решился на покупку одной крупной компании. Там было больше сотни сотрудников — оказалось, почти все из Индии. Пока наши разработчики возили... | https://habr.com/ru/post/537138/ | null | ru | null |
# JupyterHub или как перестать бояться pip install
### …или рассказ о self service на JupyterHub для дата саентистов
Всем привет, сегодня я расскажу о том, как мы переехали на наш велосипед в виде JupyterHu... | https://habr.com/ru/post/689596/ | null | ru | null |
# Решаем задачу Best Reverser с PHDays 9
Здравствуйте!
Меня зовут Марат Гаянов, я хочу поделиться с вами моим решением задачи с конкурса [Best Reverser](https://www.phdays.com/ru/program/contests/best-reverser/), показать, как сделать кейген для этого кейса.
 и мон... | https://habr.com/ru/post/665950/ | null | ru | null |
# Как Magento 2 взаимодействует с Vue Storefront

Привет! Меня зовут Павел и я занимаюсь бэкенд разработкой. Как уже писал [AndreyHabr](https://habr.com/ru/users/andreyhabr/), многие из наших проектов основаны на стеке [Adobe Magento 2... | https://habr.com/ru/post/521692/ | null | ru | null |
# Как хотел срубить бабла с корпорации добра
У меня чудесная IT работа в русской провинции.
К тому же приличная зарплата. Даже по столичным меркам.
Несмотря на это, перед сном я мечтаю. Среди ... | https://habr.com/ru/post/145609/ | null | ru | null |
# В поисках компактного FizzBuzz на Python
source: http://www.mwctoys.com/REVIEW\_010413a.htmПришло время ... | https://habr.com/ru/post/593489/ | null | ru | null |
# Разработка приложений на Ruby on Rails в Visual Studio
Речь сегодня пойдет о том, как разрабатывать и отлаживать приложения на всеми уже давно любимом фрэймворке Ruby on Rails. Для ~~всех~~ меня лично с первого дня знакомства с Rails привычно стало использование следующей связки:
— Ubuntu
— Rvm
— Gedit +... | https://habr.com/ru/post/174103/ | null | ru | null |
# Новая операция кибершпионажа FinFisher: атаки MitM на уровне провайдера?
ESET выявила новые операции с применением шпионской программы FinFisher, также известной как FinSpy, некогда продаваемой правительственным структурам по всему миру. Помимо технических доработок FinFisher, зафиксирован новый, ранее неизвестный в... | https://habr.com/ru/post/338422/ | null | ru | null |
# Связный список в Swift
Сегодня мы поговорим, что такое связный список, что делает его таким особенным, как он работает, чем он отличается от обычного массива ([о котором я подробно писал в прошлой статье](https://habr.com/ru/post/665536/)), и попутно мы увидим, как связные списки хороши для решения определенного кла... | https://habr.com/ru/post/713162/ | null | ru | null |
# Как устроены технические стажировки Авито
Несколько раз в год мы набираем стажёров в технический департамент Авито. Они работают от шести месяцев до года и решают боевые задачи. По итогам большинство стажёров переходят в штат.
Нас зовут Станислав Юрков и Ирина Мулёва, мы набираем стажёров и помогаем им в процессе ... | https://habr.com/ru/post/492584/ | null | ru | null |
# Оптимизация OS X для продления жизни SSD
Привет, Geektimes! Если вы купили SSD и заинтересованы в том, чтобы твердотельный накопитель прослужил как можно дольше, то добро пожаловать под кат.
[](http://geektimes.ru/company/... | https://habr.com/ru/post/386517/ | null | ru | null |
# Добавление Quartz в Spring Boot
*И снова здравствуйте. Специально для студентов курса [«Разработчик на Spring Framework»](https://otus.pw/G4SU/) подготовили перевод интересной статьи.*

---
В моей статье [«Specifications to the... | https://habr.com/ru/post/475996/ | null | ru | null |
# Генерация текста на русском по шаблонам
Когда я только начинал работать над своей текстовой игрой, решил, что одной из её главных фич должны стать красивые художественные описания действий героев. Отчасти хотел «сэкономить», поскольку в графику не умел. Экономии не получилось, зато получилась Python библиотека ([git... | https://habr.com/ru/post/471278/ | null | ru | null |
# Создание документации в .NET
Качественная документация – неотъемлемая часть успешного программного продукта. Создание полного и понятного описания всех функций и возможностей программы и программного ком... | https://habr.com/ru/post/102177/ | null | ru | null |
# Polygonal Mesh to B-Rep Solid Conversion: Algorithm Details and C++ Code Samples
Boundary representation (B-rep) is the primary method of representing modeled objects in most geometric kernels, including our C3D Modeler kernel. The core algorithms that edit models, such as applying fillet operations, performing cutt... | https://habr.com/ru/post/465237/ | null | en | null |
# Как автоматизировать рутинные операции с помощью Jupyter, Python и Selenium
Привет, Хабр! Меня зовут Николай Суворов, я [руководитель направления в МТС Digital](https://career.habr.com/companies/mts/vacancies). Занимаюсь продуктом [МТС Premium](https://premium.mts.ru/) – это единая подписка на сервисы МТС и партнеро... | https://habr.com/ru/post/695696/ | null | ru | null |
# Почему, зачем и когда нужно использовать ValueTask
Этот перевод появился благодаря хорошему комментарию [0x1000000](https://habr.com/ru/users/0x1000000/).

В .NET Framework 4 появилось пространство System.Threading.Tasks, а... | https://habr.com/ru/post/458828/ | null | ru | null |
# Экспорт метрик в Prometheus из логов PostgreSQL с помощью Vector
В этой статье я хочу рассказать о не совсем обычном использовании логов — о получении из лог-файлов метрик для Prometheus. Это может быть полезно, когда существующие экспортеры не предоставляют нужные метрики, а писать свой экспортер не хочется или оче... | https://habr.com/ru/post/678046/ | null | ru | null |
# Тестирование выгрузки 200 000 товаров на сайт из 1С
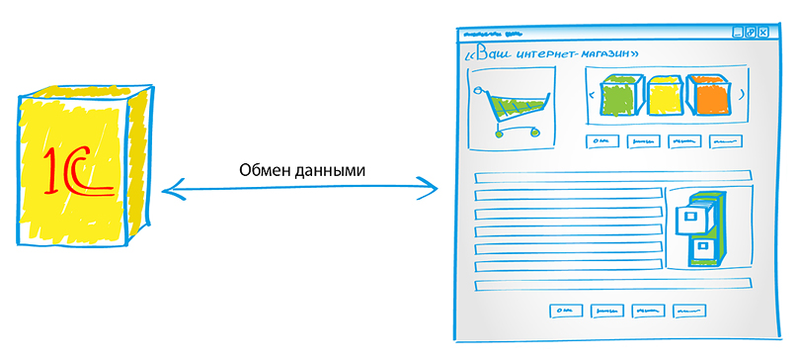
В одном из проектов перед нами стояла задача выгрузки из 1С на сайт большого количества товаров с периодичностью 2 раза в день. Хотим поделиться опытом, полученным пр... | https://habr.com/ru/post/163285/ | null | ru | null |
# «Прокачиваем» notepad.exe

Какая ассоциация связана у Вас с клавишей F5? Обновление страницы в браузере? Копирование файла из одной директории в другую? Запуск приложения из Visual Studio? А вот авто... | https://habr.com/ru/post/261507/ | null | ru | null |
# Адаптивная навигация: куда деть меню на смартфонах

Адаптировать свой сайт под мобильные устройства уже пытаются очень многие. Используют новые возможности CSS3 и на простых сайтах и на куда более сложных. В процессе во... | https://habr.com/ru/post/140801/ | null | ru | null |
# Расширения Firefox — Работа с настройками
Сегодня я хотел бы рассказать о том, как можно реализовать систему настроек для своего расширения. Начиная с определения опций и заканчивая добавлением в ваше расширение возможности менять настройки с помощью созданных вами диалоговых окон.
Первую статью, надеюсь из будущ... | https://habr.com/ru/post/72117/ | null | ru | null |
# Пасхальные яйца и Open Source
> «Пасхальное яйцо» (англ. Easter Egg) — секрет в компьютерной игре, фильме или программном обеспечении, заложенный создателями. Отличие пасхального яйца в игре от обычного игрового секрета состоит в том, что его содержание, как правило, не вписывается в общую концепцию, выглядит в конт... | https://habr.com/ru/post/434288/ | null | ru | null |
# Детектирование округлостей на изображении средствами MATLAB

В этом топике я приведу альтернативный подход к задаче, решенной товарищем [VasG](https://habrahabr.ru/users/vasg/) [тут](http://habrahabr.ru/blogs/... | https://habr.com/ru/post/114335/ | null | ru | null |
# Новая уязвимость Wordpress — возможна DOS атака
Свежая уязвимость в Wordpress которая позволяет провести DOS атаку на блог жертвы используя файл wp-trackback.php
Для исправления этой уязвимости необходимо добавить следующий код в файл functions.php, который находится в папке шаблона блога:
`function ft_stop_tr... | https://habr.com/ru/post/72911/ | null | ru | null |
# Руководство по SEO JavaScript-сайтов. Часть 2. Проблемы, эксперименты и рекомендации
В [первой части](https://habrahabr.ru/company/ruvds/blog/350976/) перевода этой статьи мы говорили о том, как веб-мастер может взглянуть на свой ресурс глазами Google, и о том, над чем стоит поработать, если то, что увидит разработч... | https://habr.com/ru/post/351058/ | null | ru | null |
# Разработка игр с помощью Unity и 3D-камеры Intel RealSense

Процесс создания компьютерных игр включает набор стандартных задач, с которыми постоянно приходится сталкиваться разработчикам. Это, к примеру, учет физических з... | https://habr.com/ru/post/264577/ | null | ru | null |
# Тональное качество вибраций, или Почему барабаны не прямоугольные?
У науки есть огромное, бесконечное число достоинств, и одно из них состоит в том, что именно она способна кратко, точно и ёмко ответить на... | https://habr.com/ru/post/564456/ | null | ru | null |
# Использование mapbox-gl в React и Next.js
Введение
--------
В данной статье я хочу описать известные мне способы встраивания `mapbox-gl` в `React` приложение, на примере создания простого веб приложения содержащего карту на `Next.js` с использованием `Typescript`, код компонента карты можно также использовать в люб... | https://habr.com/ru/post/565636/ | null | ru | null |
# Почему стоит использовать тег <picture> вместо <img>

Использование изображений и анимаций в интерфейсах пользователя стало распространённой практикой в современных веб-приложениях. Хотя эти примеры современного дизайна дела... | https://habr.com/ru/post/555736/ | null | ru | null |
# Модификаторы private и private[this] в Scala
В Scala, помимо обычного модификатора доступа private существует также модификатор private[this]. Эти два модификатора довольно похожи друг на друга. К тому же в Java есть только простой private. Поэтому они легко могут вызвать путаницу или убежденность, что простой priva... | https://habr.com/ru/post/267305/ | null | ru | null |
# Как и зачем собирать Android приложение в docker контейнере
Добрый день, уважаемые читатели.
Я - Владимир, меня зовут девопс. Говорят, что девопс - это болезнь и я это вам сегодня докажу.
Ответа на вопрос "зачем?" вы тут не найдете, это кликбейт, я и сам не знаю. Все происходящее мотивируется девизом "бикоз ай к... | https://habr.com/ru/post/667006/ | null | ru | null |
# Букмарклеты: если XPath недоступен, а селекторов и методов навигации по DOM не хватает
Недавно я пытался написать несколько условно кроссбраузерных букмарклетов с выборками и навигацией средней сложности. Решил ограничиться последними версиями Google Chrome, Firefox и Internet Explorer. Приступив к проверке в послед... | https://habr.com/ru/post/262853/ | null | ru | null |
# Управляем Rhythmbox'ом по ssh

Казалось бы, чего тут сложного. Даже сам rhythmbox обладает программой-спутником rhythmbox-client, которая принимает аргументом простые команды утравления этим замечательным проигрывателем. Но не в... | https://habr.com/ru/post/74544/ | null | ru | null |
# Шаблон Kotlin микросервисов
Для разработчиков не секрет, что создание нового сервиса влечет за собой немало рутиной настройки: билд скрипты, зависимости, тесты, docker, k8s дескрипторы. Раз мы выполняем эту работу, значит текущих шаблонов IDE недостаточно. Под катом мои попытки автоматизировать все до одной кросспла... | https://habr.com/ru/post/544538/ | null | ru | null |
# Как я нашел уязвимости в системе баг-трекинга Google и получил $15,600
Вы когда-нибудь слышали о Google Issue Tracker? Наверное, нет, если вы не являетесь сотрудником Google или разработчиком, который недавно сообщил о проблемах в инструментах Google. И я тоже не знал, пока не заметил, что мои сообщения об уязвимост... | https://habr.com/ru/post/341752/ | null | ru | null |
# Диспетчер лицензирования LMTOOLS. Вывод списка лицензий для пользователей продуктов Autodesk
Добрый день, уважаемые читатели.
> Я немного дописал сюда информации, потому-что с момента публикации прошло время и я развиваясь, понял свои ошибки, лишь хочу добавить, что это **не инструкция**. Это мой велосипед, котор... | https://habr.com/ru/post/467583/ | null | ru | null |
# 10 итераторов, о которых вы могли не знать
Одним из главных достоинств Python является выразительность кода. Не последнюю роль в этом играет возможность удобной работы с коллекциями и последовательностями различного вида: перебор элементов списка по одному, чтение файла по строкам, обработка всех ключей и значений в... | https://habr.com/ru/post/697390/ | null | ru | null |
# «А пошло оно всё!» или снова о Coursera и ему подобных
Привет хабровчанам!
-------------------

Во-первых, спасибо вам, хабровчане! Именно от вас я узнал о таком замечательном проекте, как Coursera.
Как-то кла... | https://habr.com/ru/post/153605/ | null | ru | null |
# Как я создаю приложения для браузера прямо в браузере

В 2013 году компания Canonical [пыталась собрать средства на выпуск смартфона Ubuntu Edge](https://habr.com/ru/post/187480). Особенностью продукта должна была стать возмож... | https://habr.com/ru/post/539816/ | null | ru | null |
# Раскрашиваем значки от гугла
Дизайн приложения — очень важная часть разработки. Google значительно его упрощает, предоставляя в свободном доступе около 150 готовых значков, заготовленных под разную плотность пикселей. Однако по умолчанию они серого цвета. Сделано это специально для того, чтобы дизайнер сам раскрасил... | https://habr.com/ru/post/226307/ | null | ru | null |
# Автоматизация изменений БД в .NET
Здравствуйте!
Я хотел бы рассказать о проектах [Migrator.Net](http://code.google.com/p/migratordotnet/) и [ECM7.Migrator](http://code.google.com/p/ecm7migrator/).
Migrator.Net — это механизм контроля версий базы данных, похожий на Migrations в Ruby on Rails. Migrator позволяет... | https://habr.com/ru/post/70884/ | null | ru | null |
# 7 странных особенностей Go
[](https://habr.com/ru/company/skillfactory/blog/522222/)
Когда человек начинает писать на непривычном языке программирования, он всегда обращает внимание на его особенности. Новичку бывает сложно понят... | https://habr.com/ru/post/522222/ | null | ru | null |
# Самую холодную капельку во Вселенной уронили с высокой колокольни
[](https://habr.com/ru/company/ruvds/blog/583058/)
И остались довольны результатом. Теперь хотят отправить ее на орбиту Земли.
Сегодня мы попр... | https://habr.com/ru/post/583058/ | null | ru | null |
# Flutter. MVVM. Начало
Доброго времени суток, дорогие читатели! Меня зовут [Сурен](https://habr.com/ru/users/avenumDev/), и я разработчик.
Поскольку моя предыдущая статья о том, [как бекендер в мобильную кроссплатформу лез](https://habr.com/ru/company/digdes/blog/588018/), не утонула в минусах, я решил продолжить ... | https://habr.com/ru/post/660411/ | null | ru | null |
# Микровселенная безумия, или Как устроены микрофронтенды в Dodo
*«Микрофронтенды в компании, которая доставляет пиццу? Серьёзно? Зачем? Да и куда? У вас же всего лишь приложенька с каталогом и заказом товара... | https://habr.com/ru/post/712320/ | null | ru | null |
# Мастерство Data Science: Автоматизированное конструирование признаков на Python

Машинное обучение все больше переходит от моделей, разработанных вручную, к автоматически оптимизированным пайплайнам... | https://habr.com/ru/post/510420/ | null | ru | null |
# Как я патчил Zabbix
На днях, у меня наконец-то дошли руки до обновления Zabbix.
С момента прочтения статьи [Вышел Zabbix 2.2](http://habrahabr.ru/company/zabbix/blog/201500/) в соответствующем блоге, я не мог дождаться, когда же в Gentoo размаскируют версию 2.2. Практически не было такого нововведения в этой верс... | https://habr.com/ru/post/240169/ | null | ru | null |
# Ajax-запросы нативными средствами Joomla
Небольшая заметка о том, как делать ajax-запросы штатными средствами без использования дополнительных js-библиотек (jQuery, etc). Joomla 3 и Joomla 4 предоставляют небольшую обёртку для конструирования XMLHttpRequest. В целом синтаксис очень похож на тот же jQuery Ajax, поэто... | https://habr.com/ru/post/588651/ | null | ru | null |
# Панель оператора (HMI) с шиной I2C для Arduino
В рамках работы с неким ардуино-совместимым оборудованием(о нем в конце) понадобился мне экран с кнопками для управления и отображения текущей информации. То есть, была нужна панель оператора, она же HMI.
Решено было сделать HMI самостоятельно, а в качестве интерфейс... | https://habr.com/ru/post/401587/ | null | ru | null |
# Анализируем время ответа собеседника

С появлением мессенджеров коммуникация перешла на новый уровень — возможность мгновенного доступа к собеседнику воспринимается теперь как должное.
Но замечали ли вы, как на ваши ощущения от ... | https://habr.com/ru/post/541750/ | null | ru | null |
# Пишем простой модуль Magisk для Android
Введение
========
Одним вечером я устал менять TTL после перезагрузки устройства и подумал как можно было бы делать это автоматически. Android же Linux и на нем должен быть аналог systemd или он сам. В процессе исследований мой взор пал на Magisk.
На удивление разработать м... | https://habr.com/ru/post/478288/ | null | ru | null |
# Задача об определении принадлежности точки многоугольнику
Здравствуйте, уважаемые хабравчане!
В процессе разработки приложения под Android, которое предполагает взаимодействие пользователя с графическими примитивами (точками, линиями, эллипсами, прямоугольниками и т.д.), возникла довольно неприятная ситуация: по... | https://habr.com/ru/post/169317/ | null | ru | null |
# Книга «Роман с Data Science. Как монетизировать большие данные»
[](https://habr.com/ru/company/piter/blog/556962/) Привет, Хаброжители! Как выжать все из своих данных? Как принимать решения на основе данных? Как организовать ан... | https://habr.com/ru/post/556962/ | null | ru | null |
# Не только Яндексу. Микроразметка на крупнейших сайтах рунета: зачем ею пользуются и почему она пригодится и вам
Мы уже рассказали вам о мире семантической разметки — о том, [какие бывают словари](http://habrahabr.ru/company/yandex/blog/211638/), [почему столько стандартов синтаксиса](http://habrahabr.ru/company/yand... | https://habr.com/ru/post/246003/ | null | ru | null |
# Эволюция Docker. Часть 2.1
Вступление
----------
v0.1.0Данная статья является второй, в цикле по истории развития и изучению исходного кода Docker. В ней мы разберем, что представлял собой ... | https://habr.com/ru/post/574750/ | null | ru | null |
# Тесты на знание Python, PHP, Golang и DevOps: разбор викторины AvitoQuiz на Highload
Конференция Highload++ 2017 отгремела, и это было круто — как всегда. Мы пересматриваем доклады, вовсю пользуемся опытом, которым с нами поделились коллеги, и с удовольствием вспоминаем разные активности, которые проводились вне зон... | https://habr.com/ru/post/346520/ | null | ru | null |
# Возврат значения из powershell invoke-command агенту SQL-Server
При создании собственной методики управления резервными копиями на множестве серверов MS-SQL я потратил кучу времени на изучение механизма передачи значений в powershell при удаленных вызовах, поэтому пишу самому себе памятку, а вдруг кому-то еще пригод... | https://habr.com/ru/post/504890/ | null | ru | null |
# Google выпустила парсер HTML5 на чистом Си
Удачная возможность для веб-разработчиков выучить язык программирования Си — HTML5-парсер [Gumbo](https://github.com/google/gumbo-parser#gumbo---a-pure-c-html5-parser), реализованный в виде небольшой библиотеки C99 без внешних зависимостей. Парсер создан как строительный бл... | https://habr.com/ru/post/190044/ | null | ru | null |
# Установка NativeScript на Mac OS
Здравствуйте, уважаемые Хабравчане. Спешу поделиться с Вами своим небольшим опытом в казалось бы простом деле — установить NativeScript на Mac OS.
Недавно нам поступила заявка на изучение NativeScript с целью выявить положительные и отрицательные стороны данной технологии.
Ска... | https://habr.com/ru/post/327508/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.