
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Pool объектов для Unity3d
Все знают что операции создания и удаления объектов не дешевые. Например создавать каждый раз пулю и уничтожать, довольно накладно для тех же мобильных устройств. Может стоит не уничтожать пулю, а скрывать ее. Вот решил поделится своей реализацией Pool Manager.
#### Структуры
Для начал... | https://habr.com/ru/post/255499/ | null | ru | null |
# Просто еще одна Qt обертка для gRPC и protobuf

Не так давно я озадачился тем, что нет достаточно удобных и простых враппера и генератора для protobuf и gRPC, основанных и полностью совместимых с Qt. Натыкался на статьи, в т.ч. зде... | https://habr.com/ru/post/467893/ | null | ru | null |
# Почему обзоры кода — это хорошо, но недостаточно

Обзоры кода однозначно нужны и полезны. Это возможность передать знания, обучение, контроль выполнения задачи, улучшение качества и оформления к... | https://habr.com/ru/post/520390/ | null | ru | null |
# Поиск по сайту с Reindexer — это просто. Или как сделать «instant search» по всему Хабрахабр-у
Всем привет,
В предыдущей [статье](https://habrahabr.ru/post/346884/) я писал о том, что мы сделали новую in-memory БД — быструю и с богатыми функциональными возможностями — [Reindexer](https://github.com/Restream/reindex... | https://habr.com/ru/post/354034/ | null | ru | null |
# Habrahabr в PDF-варианте для электронной книги
Часто зависая на Хабре и не только много раз ловил себя на мысли, что информация и статьи гораздо эффективнее воспринимаются с телефона или планшета, когда читаешь в удобной позе, или даже не дома — в транспорте, командировках, и т.п. Описание игр с напильником для ориг... | https://habr.com/ru/post/257539/ | null | ru | null |
# STM32L-DISCOVERY + FDD
Для того что бы подключить STM32L-DISCOVERY к FDD тебе понадобится 4 провода и 2 джампера.

Всё что нужно знать о Floppy Disk Drive
---------------------------------------
* [F... | https://habr.com/ru/post/221023/ | null | ru | null |
# Использование parse_transform
**Disclaimer:** Описываемый инструмент имеет спорную репутацию. Я не призываю использовать его где ни попадя, только знакомлю с используемыми понятиями, дабы уменьшить некоторым трепет перед технологией.
Написанные исходники, а также текстовую копию статьи можно найти [на гитхабе](ht... | https://habr.com/ru/post/140374/ | null | ru | null |
# Автоматизация тестирования мобильных приложений. Часть 1: проверки, модули и базовые действия
Приложениями Badoo и Bumble пользуются миллионы людей по всему миру, и мы стремимся доставлять им новую функцион... | https://habr.com/ru/post/546188/ | null | ru | null |
# Что ученые должны знать о железе для написания быстрого кода

*[источник изображения](https://www.flickr.com/photos/153311384@N03/)*
Программирование сегодня используется во многих областях науки, где отдельным ученым часто прих... | https://habr.com/ru/post/529204/ | null | ru | null |
# JavaScript loader без define
Привет Хабр!
Всем известно решение задачи загрузки скриптов.
Например Curl.JS, Require.JS, + популярные frameworks умеют это тоже.
**MAIN UPDATE:** В комментариях всё обсудили. Спасибо [azproduction](http://habrahabr.ru/users/azproduction/) и [nuit](http://habrahabr.ru/users/nui... | https://habr.com/ru/post/145618/ | null | ru | null |
# Защита секретов с помощью технологии SRAM PUF
Команда *Racoon Security* постоянно находится в поиске новых технологий для применения в исследованиях и контрактном производстве. В очередной раз просматривая список докладов прошедших выставок *Embedded World 2019* и *Embedded World 2020*, мы наткнулись на документ от ... | https://habr.com/ru/post/563880/ | null | ru | null |
# MapServer -> Google Maps
**От автора**
Эта статья-заготовка для другой, большей статьи, но публикуется впервые. Она, возможно, несколько сложновата для восприятия для специалиста не знакомого с MapServer и цифровой картографией, постараюсь этот пробел восполнить в дальнейшем.
**Задача:**
Демонстрация пользо... | https://habr.com/ru/post/48012/ | null | ru | null |
# Пишем свой синхронный/асинхронный клиент-сервер
Всем привет.
В этой статье рассмотрим принцип многопоточного TCP сервера приложений в котором реализуем синхронные и асинхронные вызовы, а также разграничение доступа к процедурам и сжатие данных.
С чего все начиналось.
Все началось с непростого выбора с чего ... | https://habr.com/ru/post/190548/ | null | ru | null |
# Android Bluetooth Low Energy (BLE) — готовим правильно, часть #1 (scanning)
### Содержание
Часть #1 (scanning), вы здесь.
[Часть #2 (connecting/disconnecting)](https://habr.com/ru/post/537526/).
[Часть #3 (read/write)](https://habr.com/ru/post/538768/)
[Часть #4 (bonding)](https://habr.com/ru/post/539740/)
В по... | https://habr.com/ru/post/536392/ | null | ru | null |
# Анимированные меню на jQuery [часть 2]
*По мотивам [этого](http://habrahabr.ru/blogs/ui_design_and_usability/65917/) перевода.*
На одном из текущих проектов мы хотели добавить эффект на иконки меню — приподнимание в момент наведения мышкой. Я поэкспериментировал, используя встроенный в jquery эффект animate, на и... | https://habr.com/ru/post/66333/ | null | ru | null |
# PHPCleanArchitecture — Что нового?
Этот пост является дополнением [предыдущего](https://habr.com/ru/post/504590/). В нём я расскажу о новых возможностях [инструмента](https://github.com/Chetkov/php-clean-architecture) (~~с блэкджеком и шлюпками~~ с примерами и картинками).
](https://habr.com/ru/company/ruvds/blog/532140/)
> Can I just once again state my love for [WireGuard] and hope it gets merged soon? Maybe the code isn't perfect, but I've skimmed it, and co... | https://habr.com/ru/post/532140/ | null | ru | null |
# Скрипт для Notepad++ на Python
#### Введение
Думаю, многим известен [Notepad++](http://notepad-plus-plus.org/) — удобная бесплатная утилита, выступающая в качестве «продвинутой» замены стандартному Блокноту Windows. Как и при работе в любом текстовом редакторе, в Notepad++ время от времени возникает необходимость а... | https://habr.com/ru/post/135822/ | null | ru | null |
# Ещё один взгляд на вопрос «нужна ли дефрагментация для SSD»
Несомненно, вопрос, вынесенный в заголовок статьи, не нов, поднимался не раз и по нему достигнут консенсус «не особо нужна, и даже может быть вредна».
Однако [недавнее обсуждение](https://habr.com/ru/company/ruvds/blog/493696/#comment_21429898) в коммент... | https://habr.com/ru/post/494614/ | null | ru | null |
# Making a DIY thermal camera based on a Raspberry Pi

Hi everyone!
Winter has arrived, and so I had to check the thermal insulation of my ~~out of town residence~~ dacha. And it just turned out a famous Chinese marketplace... | https://habr.com/ru/post/441050/ | null | en | null |
# Nokia Lumia 630 Dual Sim протестировано на себе
Давно жаждал пощупать windows phone 8, однако количество сим-карт в подобных аппаратах было равно единице, а для работы требовалось минимум наличие двух слотов. Ходил я с красным (это важно) Philips Xenium 732 и радовался что у меня под конец дня зарядка на уровне 40%.... | https://habr.com/ru/post/226005/ | null | ru | null |
# Поднимаем свой полноценный игровой Minecraft сервер с мини-играми. Часть 2. Устанавливаем карту для лобби сервера

[Часть 1. Выбираем и устанавливаем сервер](https://habr.com/ru/post/496498/)
[Часть 3. Устанавливаем мини-игры](h... | https://habr.com/ru/post/496700/ | null | ru | null |
# Rosetta Flash — кодирование SWF для вызова из JSONP
**Michele Spagnuolo**, специалист по безопасности Google, написал утилиту, которая может закодировать любой SWF-файл любым словарем.
Зачем это нужно? Все очень просто — такой файл можно передать в качестве параметра callback в JSONP на сайте, с которого вам нужн... | https://habr.com/ru/post/229639/ | null | ru | null |
# Джаббер чат на веб-странице
Прочитав пост на хабре про [онлайн чат для сайта через джаббер](http://habrahabr.ru/blogs/im/68300/), мне стало интересно — а как оно работает и как такое можно сделать самому, без готовых приложений. В итоге у меня получилась очень простая заготовка «чата для сайта через джаббер». К сожа... | https://habr.com/ru/post/69693/ | null | ru | null |
# Что значит быть программистом?

Привет, хабровчане! В прошедшую субботу, **12 сентября, айтишники по всему миру отмечали 256 день в году — День программиста**. Мы в [OTUS](https://otus.ru/?utm_source=habr&utm_medium=affilate&utm_ca... | https://habr.com/ru/post/519082/ | null | ru | null |
# GUI для подключения сетевых томов через SSH
Моё приложение является обычной «мордой» к [консольному приложению sshfs](http://pqrs.org/macosx/sshfs/index.html) и доступно для скачивания по адресу [code.google.com/p/sshfs-gui](http://code.google.com/p/sshfs-gui/). Оно было написано мной для обучения программированию п... | https://habr.com/ru/post/80401/ | null | ru | null |
# Использование MongoDB в Java EE 6

MongoDB — документо-ориентированная NoSQL СУБД, не требующая описания схемы таблиц. Больше о ней можно узнать на [оф. сайте](http://www.mongodb.org/), а в данной статье я опишу пример использов... | https://habr.com/ru/post/123502/ | null | ru | null |
# Как я Марс спасал или небольшой квест на питоне
Привет, Мир!
Август 2018
-----------
На улице стоит жаркое лето, плавно подходящее к концу, а я сижу в прохладной комнате с ноутбуком и серфлю интернет в поиске интересных вещей. Потеряв надежду найти что-либо стоящее внимания, вдруг, натыкаюсь в одной из довольно ... | https://habr.com/ru/post/435286/ | null | ru | null |
# SCADA «BortX» с поддержкой языка управления в рамках ANSI /ISA-88 для ESP8266
Признаюсь честно — очень люблю cовременные микроконтроллеры. В частности, производства китайского производителя **Espressif Systems** с интерфейсом Wi-Fi. Речь, естественно, идет о **ESP8266** и **ESP32**, которые обладают большим потенциа... | https://habr.com/ru/post/518916/ | null | ru | null |
# JavaScript — заполняем нишу между микросервисами и объектами — «нано-сервисы»
Кто из нас не хочет сделать большое приложение с правильной архитектурой? Все хотят.
Чтобы была гибкость, переиспользуемость и четкость логики. Чтобы были домены, сервисы, их взаимодействие.
И даже иногда хочется чтобы было почти как в... | https://habr.com/ru/post/346976/ | null | ru | null |
# Как плохо настроенная БД позволила захватить целое облако с 25 тысячами хостов
Привет, Хабр!
Я не так давно в ИТ, но в последнее время увлёкся темой кибербезопасности. Особенно интересна профессия пентестера. Во время сёрфинга увидел [классную статью «How a badly configured DB allowed us to own an entire cloud of... | https://habr.com/ru/post/520138/ | null | ru | null |
# Миграции баз данных — интеграция с вашим приложением
 Данная статья посвящена практическому использованию библиотеки [Migraton](http://codeigniter.com/user_guide/libraries/migration.html), появившейся в обновлении CodeIgniter верс... | https://habr.com/ru/post/133395/ | null | ru | null |
# Распараллеливаем код в R за пару минут
Если верить стереотипам, то язык R – это что-то узкоспециализированное для статистики и машинного обучения. Второй стереотип – что код на чистом R не очень быстрый: во-первых, потому что интерпретируемый, во-вторых, потому что исполняется последовательно. Безусловно, стереотипы... | https://habr.com/ru/post/527178/ | null | ru | null |
# Node.js: разрабатываем бота для Telegram

Привет, друзья!
В данном туториале мы разработаем простого бота для [Telegram](https://web.telegram.org/k/). Сначала зарегистрируем и кастомизируем бота с помощью *BotFather*, затем напи... | https://habr.com/ru/post/665124/ | null | ru | null |
# Запуск приложений в Android Virtual Device на удаленном Linux-сервере
В процессе работы над одним проектов возникла ситуация, когда необходимо проводить в автоматическом режиме ряд операций из мобильного приложения. Поскольку набор входных данных, которые вводит пользователь для работы приложения меняется, была необ... | https://habr.com/ru/post/244443/ | null | ru | null |
# Qt/Objective-C++11 или сборка Qt-проекта с помощью GCC-4.7 и Clang
Всем доброго хабрадня!
Сегодня я расскажу уважаемым хабражителям об очередном извращении — о сборке проекта, написанного на Qt, под Mac OS X компиляторо... | https://habr.com/ru/post/144707/ | null | ru | null |
# Проблемы, возникающие при разработке android-приложений
Введение
--------
Доброго времени суток. В этой статье вы узнаете о том, какие проблемы могут возникнуть при разработке android-приложений. На написание этой статьи меня побудили комментарии из прошлой статьи, кстати вот она: [моя первая статья](https://habrah... | https://habr.com/ru/post/322116/ | null | ru | null |
# Приватбанк начинает разворичавать сеть бесплатного WiFi на Украине
Как заявил в подкасте на itc.ua **Александр Витязь**, руководитель «Центра Электронного Бизнеса» ПриватБанка с завтрашнего дня (20 октября) приватбанк начинает разворачивать сеть бесплатных вай-фай хотспотов на базе своих отделений и банкоматов на Ук... | https://habr.com/ru/post/72806/ | null | ru | null |
# Ruby Together – фонд развития языка Ruby

Пару раз проскочив в условном Ruby Weekly, сайт инициативы Ruby Together не зацепил моего внимания, хотя должен был. Давайте разберемся, на что нам предлагают потратить свой трудов... | https://habr.com/ru/post/253703/ | null | ru | null |
# Как в Магическом Электротехническом практика по Java прошла и немного про Lumia 710
Так уж получилось, что я стал победителем [конкурса от Microsoft](http://habrahabr.ru/special/microsoft/imaginecup/) и получил в качестве приза Nokia Lumia 710. После того, как на совместимость с мобильным IE были проверены все мои с... | https://habr.com/ru/post/230585/ | null | ru | null |
# GLPI и последние обновления временных зон в Windows
##### История одного подвига
Несколько недель назад GLPI ни с того, ни с сего стал зависать на загрузке страницы заявки. Жалоба поступила от моих сослуживцев, когда я находился в отпуске. Открыв страницу в браузере я не обнаружил проблемы, о чем уведомил своих кол... | https://habr.com/ru/post/241215/ | null | ru | null |
# Ведется массовая атака криптором Wana decrypt0r 2.0
В настоящий момент можно наблюдать масштабную атаку трояном-декриптором "Wana decrypt0r 2.0"
Атака наблюдается в разных сетях совершенно никак не связанных между ссобой.

*A ransomware spreading in th... | https://habr.com/ru/post/403837/ | null | ru | null |
# Фундаментальная теория тестирования
В тестировании нет четких определений, как в физике, математике, которые при перефразировании становятся абсолютно неверными. Поэтому важно понимать процессы и подходы. В данной статье разберем основные определения теории тестирования.

> 2. [Инициализация приложений Prism](http://habrahabr.ru/post/176853/)
> 3. [Управление зависимостями между компонентами](http://habrahabr.ru/post/176861/)
> 4. [Разработка мод... | https://habr.com/ru/post/176869/ | null | ru | null |
# О конвертировании образа из VMWare в XenServer
В целом процедура конвертирования простая и понятная. Она [подробно и красиво описана](http://support.citrix.com/article/CTX116603) на сайте Citrix.
После нескольких недель конвертирования различных виртуальных серверов могу сделать несколько дополнений:
1. Нужно... | https://habr.com/ru/post/53624/ | null | ru | null |
# Введение в отладку на примере Firefox DevTools, часть 4 из 4
[Первая часть: знакомство с отладчиком](https://habr.com/ru/post/586776/)
[Вторая часть: узнаём значение переменной без console.log](https://habr.com/ru/post/587516/)
[Третья часть: стек вызовов](https://habr.com/ru/post/588981/)
---
Точки останова с... | https://habr.com/ru/post/592095/ | null | ru | null |
# iWebkit как способ оптимизировать свой сайт под iPhone
iWebkit как способ оптимизировать свой сайт под iPhone.
Вчера мной была замечена библиотека разработки сайтов оптимизированных для iPhone и iPod Touch под названием [PastryKit](http://habrahabr.ru/blogs/web_design/79406/), библиотека включает в себя сборник и... | https://habr.com/ru/post/79446/ | null | ru | null |
# Простая разработка IoT приложений на C# для Raspberry Pi и других одноплатников, на Linux

Многие привыкли легко и просто программировать микроконтроллеры на платформе Arduino или [nanoFramework](https://habr.com/ru/company/timeweb... | https://habr.com/ru/post/597601/ | null | ru | null |
# Распознавание номеров: от А до 9. Часть 3
Неделю назад мы опубликовали [статью](http://habrahabr.ru/post/222539/) про открытый сервер для распознавания изображений автомобильных номеров. Теперь, как и обещали, статья про то, как отправлять на него свои фотографии с номерами. Наша цель была, как вы помните, вовсе не ... | https://habr.com/ru/post/223441/ | null | ru | null |
# Троян, использующий вычислительные мощности ПК для генерации Bitcoin
Случилось мне вчера привезти из командировки один троянчик, **Trojan.Win32.Powp.rdf** (по классификации ЛК). Там я его победил, но флэшки он мне успел позаражать. Чтоб добро зря не проподало, решил поковырять его на досуге.
С наименованием зловр... | https://habr.com/ru/post/123244/ | null | ru | null |
# Ох уж эти QR коды
Пандемия, осеннее обострение, зима близко и QR коды на каждом шагу, роботы наступают, рутина работы затягивает. Хочешь покушать — покажи картинку. Скучную и квадратную, для робота, не для... | https://habr.com/ru/post/590587/ | null | ru | null |
# Приключения с ptrace(2)
 На Хабре уже [писали](https://habr.com/ru/post/111266/) про перехват системных вызовов с помощью `ptrace`; Алекса написал про это намного более развёрнутый пост, который я решил перевести.
---
### С чего... | https://habr.com/ru/post/439882/ | null | ru | null |
# Подробное введение в rvalue-ссылки для тех, кому не хватило краткого
Вместо КДПВ — короткая драма для привлечения внимания, основанная на реальных событиях. Ее можно смело пропустить и перейти к статье, которая поможет вам разобраться в rvalue-ссылках, конструкторах перемещения, универсальных ссылках, идеальной пере... | https://habr.com/ru/post/322132/ | null | ru | null |
# Параллельное программирование в Swift: Operations
В параллельном программировании в Swift: Основы Я представил множество низкоуровневых способов для управления параллелизмом в Swift. Первоначальная идея состояла в том, чтобы собрать все различные подходы, которые мы можем использовать в iOS в одном месте. Но при нап... | https://habr.com/ru/post/350096/ | null | ru | null |
# Lapis: сайт на Lua в конфигах Nginx
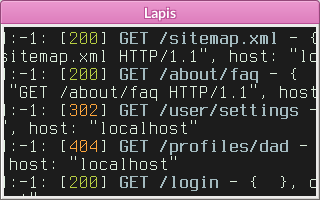
*Tl;dr Lapis(Lua) = RoR(Ruby) =... | https://habr.com/ru/post/240217/ | null | ru | null |
# Легкий сокращатель ссылок на JavaScript, Cloudflare Workers и c Telegram Bot'ом
Что делать если нужно быстро создать короткую ссылку? Конечно – использовать сокращатель ссылок. А что если при этом сделать эту ссылку читаемой? Еще и при этом использовать свой личный домен? А лучше было бы делать это без дополнительны... | https://habr.com/ru/post/545170/ | null | ru | null |
# Android: Bluetooth в качестве сервиса

Под данным изречением-мемом, взятым с замечательной картинки [Владимира Филонова](https://www.facebook.com/pyhoster), поставит свою подпись каждый человек, имеющий хотя бы... | https://habr.com/ru/post/318564/ | null | ru | null |
# Поиск городских маршрутов в 15 городах и 3 виджета для сайтов — Смотри Карту.ру
Проект [SeeMap.ru — Городские Маршруты](http://www.seemap.ru/). За 9 месяцев, что прошли с моего [прошлого](http://habrahabr.ru/blogs/i_am_advertising/85285/) поста, была проделана огромная работа. Теперь поиск маршрутов работает **в 15 ... | https://habr.com/ru/post/107588/ | null | ru | null |
# Погодник на java для начинающих и постарше

Приветствую всех в этот прекрасный день ожидания праздника, это моя первая статья на хабре, в которой я хотел бы рассказа про открытый API погоды Яндекса.... | https://habr.com/ru/post/164101/ | null | ru | null |
# Вы не смотрите рекламу во время разработки? Непорядок
Дожили. Примерно такая реакция у меня была, когда на локальном проекте на [localhost](http://localhost) поверх всего вылезла реклама. Вот так вот:
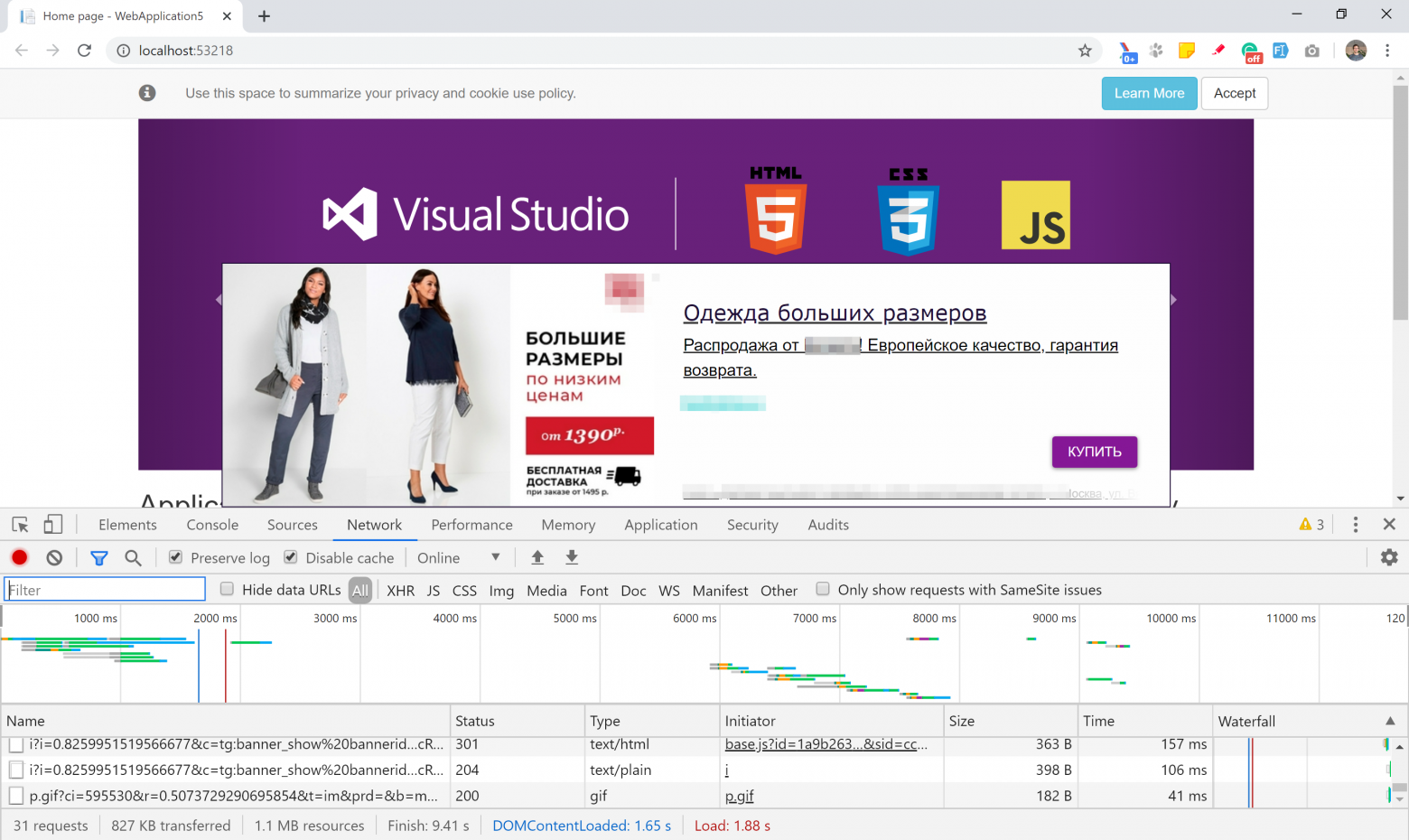
Так-то давно пора был... | https://habr.com/ru/post/489528/ | null | ru | null |
# Управление мультиваркой Redmond. Горячее ферментирование
Будучи поклонником здорового питания, увлёкся методом приготовления пищи с помощью горячего ферментирования. Смысл приготовления - щадящее нагревание в диапазоне 40-80 градусов в течение нескольких часов. Похоже на процесс "томления" из народных традиций. Для ... | https://habr.com/ru/post/599685/ | null | ru | null |
# Медиа-запросы в адаптивном дизайне 2018

В июле 2010 года я написала статью [«Как использовать CSS3 медиа-запросы для создания мобильной версии вашего сайта»](https://www.smashingmagazine.com/2010/07/how-to-use-css3-media-qu... | https://habr.com/ru/post/349484/ | null | ru | null |
# Работа с ESP8266: Первоначальная настройка, обновление прошивки, связь по Wi-Fi, отправка-получение данных на ПК
На Хабре уже было пару статей о чипе ESP8266 китайской компании Espressif. [Статья №1](http://habrahabr.ru/company/coolrf/blog/235881/) и [Статья №2](http://habrahabr.ru/company/coolrf/blog/238443/). Не т... | https://habr.com/ru/post/362623/ | null | ru | null |
# Эффективное управление транзакциями в Spring
Всем добрый день!
Что ж, конец месяца у нас всегда интенсивные, вот и тут остался всего день до старта второго потока курса [«Разработчик на Spring Framework»](https://otus.pw/8LJd/) — замечательного и интересного курса, который ведёт не менее прекрасный и злой [Юрий](... | https://habr.com/ru/post/431508/ | null | ru | null |
# Как удалённо отлаживать через WinDbg не включая отладочный режим Windows
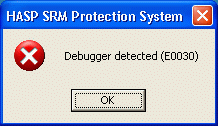 Иногда при анализе какой-нибудь ~~платной программы~~ малвари случается так, что она не хочет нормально работать, если в памяти есть отладчик или включён отлад... | https://habr.com/ru/post/327128/ | null | ru | null |
# Сопротивляйтесь добавлению в проект новых библиотек
Итак, вам понадобилось реализовать в проекте функциональность X. Теоретики разработки программного обеспечения в этот момент го... | https://habr.com/ru/post/275159/ | null | ru | null |
# Превращаем реактивные формы Angular в строго типизированные за одну минуту
Привет, Хабр! Представляю вашему вниманию перевод статьи ["Convert into Strongly Typed Angular Forms in a Minute"](https://indepth.dev/convert-into-strongly-typed-angular-forms-in-a-minute-2) автора Ajay Ojha.
. Мысль о статье у меня появилась после очередной просьбы знакомого тестировщика подсказать ему, что можно почитать по командам Linux пе... | https://habr.com/ru/post/481398/ | null | ru | null |
# DataIncrement — дополнение к возможностям phpMyAdmin
Когда используешь что-то вроде phpMyAdmin для работы с данными в базе, всегда неудобно что связанное поле отображает просто число из другой таблицы, вместо конкретных данных, которые там прячутся.
Например, в поле `country\_id` стоят числа, а не название страны... | https://habr.com/ru/post/425939/ | null | ru | null |
# Книга «ASP.NET Core в действии» в правильном переводе команды DotNetRu
Полтора года назад мы [рассказывали](https://habr.com/ru/company/jugru/blog/498932/) про опыт совместной работы нашего сообщества [**Do... | https://habr.com/ru/post/581224/ | null | ru | null |
# Как уменьшить количество измерений и извлечь из этого пользу
 Сначала я хотел честно и подробно написать о методах снижения размерности данных — [PCA](https://en.wikipedia.org/wiki/Principal_component_analysis), [ICA](https:... | https://habr.com/ru/post/275273/ | null | ru | null |
# Организуем собственный мини-тотализатор на матчи ЧЕ 2020 по футболу
Через несколько дней начнется чемпионат Европы по футболу - второй по значимости турнир среди сборных. Как и в любом другом турнире в нем будут как интересные, так и достаточно проходные для нейтрального болельщика матчи вроде “Дания - Финляндия” ил... | https://habr.com/ru/post/557254/ | null | ru | null |
# Автоматическое тестирование iOS приложений
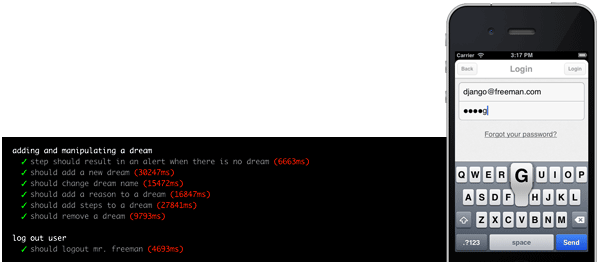
Бывает, наступает момент, когда нужно следить, не развалился ли лишний раз интерфейс мобильного приложения. Чтобы решить эту проблему используются автоматические т... | https://habr.com/ru/post/202910/ | null | ru | null |
# Всё, что вы хотели знать о PVS-Studio и не постеснялись спросить

В последнее время мы усилили наше присутствие на различных профильных IT-конференциях в России и за рубежом. На большинстве меро... | https://habr.com/ru/post/431086/ | null | ru | null |
# Jedi — библиотека автодополнения для Python
Вот, набрел на просторах гитхаба на интересную библиотеку ([GitHub](https://github.com/davidhalter/jedi)). Дальше следует немного слов от автора.
Jedi — это инструмент, который можно использовать для автодополнения кода Python в IDE/редакторах. Jedi работает. Jedi быстр... | https://habr.com/ru/post/192610/ | null | ru | null |
# Задачка Python на синтаксический сахар
Я молодой разраб на python и только пришел на свою первую работу. На работе руководитель ИТ отдела иногда задает задачки python нам(разрабам), одна из них - это создание списка с нулями, такой же длины, как исходный итерируемый обьект python. Итерируемый обьект может быть как с... | https://habr.com/ru/post/570094/ | null | ru | null |
# (Не) любителям protothreads посвящается: Высокоуровневые функции для работы с 1-Wire
Подразумевается, что мы будем писать прошивку под «голое железо». В противном случае применение protothreads смысла не имеет, т.к. мультизадачность должна обеспечиваться средствами ОС. Подразумевается также, что нам необходимо реали... | https://habr.com/ru/post/326320/ | null | ru | null |
# Переходим на Fusion Drive (Mac OS X Mavericks)

***UPDATE: От одного из читателей поступила информация, что собраный по данной методике FD не работает должным образом — не переносит часто используемые фа... | https://habr.com/ru/post/200362/ | null | ru | null |
# Всемогущий FFmpeg: скриншаринг в WebRTC
Когда мы пишем статьи о своем сервере в комментариях очень часто находится читатель, который говорит:
"И зачем такой огород городить? Все это одной FFmpeg командой д... | https://habr.com/ru/post/568664/ | null | ru | null |
# ObjectScript — новый язык программирования
Сколько же существует всяких языков программирования, еще один? Ну можно и так сказать, а можно сказать и по другому: я программист и пишу программы на разных языках программирования для разных задач. В одних языках есть одни плюсы, в других — другие. Вот я и решил предложи... | https://habr.com/ru/post/152289/ | null | ru | null |
# Унифицируем поведение LINQ to IEnumerable и LINQ to IQueriable в части работы с null значениями. Часть вторая. Своя реализация IQueryProvider
В комментариях к [первой части](http://habrahabr.ru/post/256257/) мне справедливо сделали замечание, что я обещал унификацию IEnumerable и IQueryable, а сам спрятал их за само... | https://habr.com/ru/post/256403/ | null | ru | null |
# 30 новых ресурсов для android-разработчика (лето 2017)

Компания EDISON Software профессионально занимается разработкой Android-приложений. Вот некоторые крупные проекты:
* [Мобильные приложения ... | https://habr.com/ru/post/338904/ | null | ru | null |
# RaspberryPi + Pioneer System Remote
 В статье кратко описана шина Pioneer System Remote (SR), представлены схема подключения RaspberryPi к шине System Remote и CLI программа на языке C для RaspberryPi, управ... | https://habr.com/ru/post/226667/ | null | ru | null |
# Откуда этот конфиг? [Debian/Ubuntu]
Цель этого поста: показать технику отладки в debian/ubuntu, связанную с "поиском первоисточника" в системном конфигурационном файле.
Тестовый пример: после долгих издевательств над tar.gz копией установленной ОС и после её восстановления и установки апдейтов мы получаем сообщение... | https://habr.com/ru/post/461033/ | null | ru | null |
# ARM ассемблер (продолжение)
Доброго времени суток, хабражители. Вдохновившись статьёй [ARM аccемблер](http://habrahabr.ru/post/133808/), решил для интересующихся и таких же начинающих, как я, продолжить эту статью. Исходя из названия становится понятно, что перед тем, как читать эту статью, желательно прочесть вышеу... | https://habr.com/ru/post/188712/ | null | ru | null |
# Глупые трюки с ES6
*Это перевод [статейки](https://engineering.haus.com/dumb-es6-tricks-53ecadd1b29f) о некоторых не совсем очевидных прикольных возможностях, которые предоставляет ES6 стандарт JavaScript'а. В статье время от времени проходит нечто наркоманское, так что вполне возможно я не смог перевести всё достат... | https://habr.com/ru/post/313814/ | null | ru | null |
# PHP closures и передача аргументов по ссылке
Ради интереса я решил сделать механизм замыканий (closures) на PHP. Я знаю, что в PHP 5.3 такой механизм есть, поэтому подчёркиваю — чисто из академического интереса. И моя любознательность дала (по крайней мере, для меня — кто-то с этим уже мог иметь дело) свои плоды — п... | https://habr.com/ru/post/77282/ | null | ru | null |
# Поиск множества регулярных выражений при помощи библиотеки Hyperscan
В данной статье я бы хотел рассказать о собственном опыте оптимизации выполнения множества регулярных выражений при помощи системы [hyperscan](https://github.com/01org/hyperscan). Так вышло, что при разработке своего спам-фильтра [rspamd](https://r... | https://habr.com/ru/post/275507/ | null | ru | null |
# Статически безопасная динамическая типизация à la Python
Привет, Хабр.
На днях в одном моём хобби-проекте возникла задача написания хранилища метрик.
Задача сама по себе решается очень просто, но моя проблема с хаскелем (особенно в проектах для собственного развлечения) в том, что невозможно просто взять и решить ... | https://habr.com/ru/post/457930/ | null | ru | null |
# Язык сетевого программирования P4. Часть 1: обзор возможностей и настройка SONiC-P4

В продолжение вводной части [habrahabr.ru/post/196248](http://habrahabr.ru/post/196248/), в этой статье я обзорно расскажу о механизме компонентной системы реализованной ... | https://habr.com/ru/post/197192/ | null | ru | null |
# Знакомство с трансформерами. Часть 3
[Первая](https://habr.com/ru/company/wunderfund/blog/592231/) и [вторая](https://habr.com/ru/company/wunderfund/blog/593713/) части перевода материала о трансформерах были посвящены теоретическим основам этого семейства нейросетевых архитектур, рассказу о способах их использовани... | https://habr.com/ru/post/594333/ | null | ru | null |
# Встраиваем вирусный exe в файл *.reg
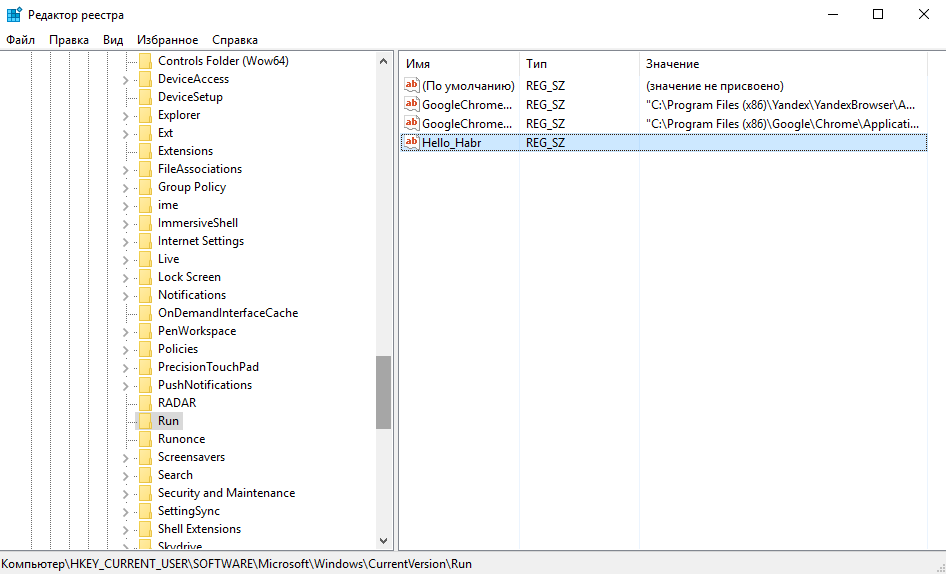Сравнительно недавно я выпустил экспериментальный проект под названием «EmbedExeLnk» — этот инструмент генерировал файл .lnk, содержащий встроенную полезную нагрузку EXE... | https://habr.com/ru/post/680378/ | null | ru | null |
# В Ubuntu Tweak появилась возможность восстанавливать рабочий стол
Ubuntu Tweak — это инструмент для ОС Ubuntu, который позволяет настроить систему, установки рабочего стола и ещё много чего.
В новой версии Ubuntu Tweak 0.5.6 beta появилась возможность сделать копию рабочего стола с его настройками и параметрами и... | https://habr.com/ru/post/102558/ | null | ru | null |
# Sphinx — Распределённый поиск. Выполнение REPLACE для distributed индекса
Статья нацелена на тех кто уже знает что такое Sphinx и SphinxQL
Цель: Обеспечить непрерывность работы поиска по сайту с помощью Sphinx в момент проведения технических работ над одной из нод Sphinx кластера.
Sphinx отличный инструмент дл... | https://habr.com/ru/post/222203/ | null | ru | null |
# Трансляция видео с мобильного устройства на YouTube
 Продолжая серию статей о возможностях Intel® INDE Media Pack, в этот раз я расскажу о том, как с помощью нашей библиотеки вы сможете добавить в прил... | https://habr.com/ru/post/227237/ | null | ru | null |
# Анализ языка VKScript: JavaScript, ты ли это?
TL;DR
=====
---
VKScript — это **не** JavaScript. Семантика этого языка кардинально отличается от семантики JavaScript. См. [заключение](#summary).
Что такое VKScript?
===================
---
**VKScript** — скриптовый язык программирования, похожий на JavaScript, ко... | https://habr.com/ru/post/464099/ | null | ru | null |
# Автоэнкодеры в Keras, Часть 2: Manifold learning и скрытые (latent) переменные
### Содержание
* Часть 1: [Введение](https://habrahabr.ru/post/331382/)
* **Часть 2: *Manifold learning* и скрытые (*latent*) переменные**
* Часть 3: [Вариационные автоэнкодеры (*VAE*)](https://habrahabr.ru/post/331552/)
* Часть 4: [*Con... | https://habr.com/ru/post/331500/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.