
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# [NeoQuest2017] 6 планета или «Слишком много всего…»
Есть мнение, что после драки кулаками не машут. Но первый в моей жизни ctf [NeoQuest2017](http://neoquest.ru/about.php) показал, что бумажная ИБ от практической отличается достаточно сильно и с ходу флаги взять не получится. Хотя, как оказалось, подобрался я к флаг... | https://habr.com/ru/post/324360/ | null | ru | null |
# Эпидемия «умного червя» под WordPress
Месяц назад стало известно о новой [критической уязвимости](http://habrahabr.ru/blogs/wordpress/66829/) в WordPress 2.8.3, позволяющей легко изменить администраторский пароль в удалённом режиме. Сразу же [вышел](http://wordpress.org/development/2009/08/2-8-4-security-release/) W... | https://habr.com/ru/post/68905/ | null | ru | null |
# Как использовать USB-камеру с ROS на Raspberry Pi или BeagleBone Blue — для потокового стрима видео на большой компьютер

Эта инструкция о том как подключить USB-камеру к Raspberry Pi или BeagleBone Blue и использовать ее с ROS (... | https://habr.com/ru/post/414859/ | null | ru | null |
# Генерация уникального идентификатора пользователя средствами Nginx
Приветствую Вас, хабрачитатели!
Расскажу об одной задачке, которая встала передо мной, и как я ее решил.
*Сразу оговорюсь — часовой поиск в G и в Я удовлетворяющего результата не принес, но за следующий час было реализовано собственное решение.... | https://habr.com/ru/post/135777/ | null | ru | null |
# Разработка игры Breakout на Svelte
На MDN есть туториал ["2D игра на чистом JavaScript"](https://developer.mozilla.org/ru/docs/Games/Tutorials/2D_Breakout_game_pure_JavaScript), в котором изучаются основы использования элемента HTML5 .
 (GitHub: [voronianski/melchior.js](https://github.com/voronianski/melchior.js), Лицензия: *MIT*, npm: [melchiorjs](https://www.npmjs.org/package/melchiorjs)) от Dmitri Voronianski представл... | https://habr.com/ru/post/237933/ | null | ru | null |
# Рисуем фракталы Мандельброта с помощью языка GIMP Script-Fu
[](https://habr.com/ru/company/skillfactory/blog/542884/)
Программа GNU Image Manipulation Program ([GIMP](https://www.gimp.org/)) – моё решение проблемы редактирования ... | https://habr.com/ru/post/542884/ | null | ru | null |
# Фронтенд-новости №13. Релиз Vue 2.7, табы против пробелов Prettier, W3C — некоммерческая организация
Дайджест новостей и полезных статей из мира фронтенд-разработки за неделю 27 июня–3 июля.
### 🧍♂️Досту... | https://habr.com/ru/post/675032/ | null | ru | null |
# Автозапуск приложения Node.js на CentOS 6.2
Для автозапуска приложений Node.js есть много способов, но после некоторых поисков мне удалось отыскать такое решение, которое и работает, и не представляет большой трудности.
Сперва я испробовал [forever](https://github.com/nodejitsu/forever) — работает превосходно, но... | https://habr.com/ru/post/243429/ | null | ru | null |
# Кросс-компиляция и отладка C++ Windows-приложения под Linux
Показали мне недавно интересное приложение, под которое можно разрабатывать плагины. Приложение оказалось очень полезным для научной работы, но вот незадача — приложение разработано под Windows, у меня стоит Ubuntu. Windows для разработки под это приложение... | https://habr.com/ru/post/162171/ | null | ru | null |
# Релиз Phalcon 2.1.0 beta 1
Мы рады представить вам первый бета-релиз **Phalcon 2.1**!
Релизы 2.1.x будут поддерживаться в течении более длительного периода, 2.1 будет нашей первой версией с долгострочной поддержкой ([LTS](https://en.wikipedia.org/wiki/Long-term_support)).
В 2.0.x мы ввели несколько новых фич и... | https://habr.com/ru/post/266521/ | null | ru | null |
# Как сделать процессорный звук в Жигулях
Обычно люди идут в магазин автозвука и покупают компоненты. Я же сначала спаял цифровой аудиопроцессор, а компоненты поставил какие есть.
Самая большая проблема автозвука-установка динамиков в самых неподходящих местах: динамик который играет прямо в ногу, сабвуфер массирует... | https://habr.com/ru/post/313946/ | null | ru | null |
# Реализация оператора in в С++
Привет! Сегодня я надеюсь показать вам немного магии. Моим хобби является придумывание всяких казалось бы невозможных штук на С++, что помогает мне в изучении всевозможных тонкостей языка ну или просто развлечься. Оператор in есть в нескольких языках, например Python, JS. Но в С++ его н... | https://habr.com/ru/post/419579/ | null | ru | null |
# Анимация в Figma от 0 до постинга на Behance
Новичок в веб-дизайне? Восхищаешься красивыми анимированными кейсами на Behance, но не знаешь, как сделать анимацию и добавить видео в свою презентацию? Тогда эта статья специально для тебя: я пошагово расскажу, что надо делать!
### Проблемы
При подготовке презентации ... | https://habr.com/ru/post/704292/ | null | ru | null |
# Интеграция CKEditor в SonataAdminBundle
Собственно говоря, встраивается этот WYSIWYG редактор “легким движением руки”. Необходимо лишь загрузить его javascript код на страницу админки и добавить класс “ckeditor” к необходимому textarea полю. Но есть и один нехороший подводный камень, о котором я и написал в посте. ... | https://habr.com/ru/post/142304/ | null | ru | null |
# Android in-app purchases, часть 4: коды ошибок от Billing Library и как не облажаться с тестированием
Привет, я Влад, core разработчик [Adapty SDK для Android](https://adapty.io/sdk/android?utm_source=habr.com&utm_medium=referral&utm_campaign=blogpost_android_error-codes-and-testing). Продолжаю серию статей про то, ... | https://habr.com/ru/post/575866/ | null | ru | null |
# JSONB запросы в PostgreSQL
Ранее я писал, как включить поддержку jsonb в [postgres/psycopg2](http://schinckel.net/2014/05/24/python%2C-postgres-and-jsonb/). Сегодня экспериментировал с тем, как запрашивать данные в колонках типа JSON.
На эту тему есть [документация](http://www.postgresql.org/docs/9.4/static/funct... | https://habr.com/ru/post/254425/ | null | ru | null |
# Как начать использовать DI
Многократно сталкивался с мнением, что DI это нечто сложное, громоздкое, медленное, подходящее только для «больших» проектов, а потому его использование конкретно на текущей задаче (500+ классов моделей, 300+ классов контроллеров) неоправданно. Отчасти это связано с тем, что DI однозначно ... | https://habr.com/ru/post/191168/ | null | ru | null |
# Ruby 2.1 в деталях (Часть 2)

##### Refinements
Уточнения (refinements) больше не являются экспериментальной фичей и не выводят ворнинг, а также в их реализацию добавилось несколько деталей, делающих их ... | https://habr.com/ru/post/223209/ | null | ru | null |
# YOLOv7 pose vs MediaPipe при оценке позы человека
Поза YOLOv7 была представлена в репозитории YOLOv7 через несколько дней после первоначального выпуска в июле ‘22. Это одноступенчатая модель оценки позы для нескольких человек. Поза YOLOv7 уникальна, поскольку она отличается от обычных двухэтапных алгоритмов оценки п... | https://habr.com/ru/post/701268/ | null | ru | null |
# Java. Factory Method Pattern in Game Server
Game Server**Фабричный метод** - это порождающий шаблон проектирования, который предоставляет интерфейс для создания объектов в родительс... | https://habr.com/ru/post/571502/ | null | ru | null |
# Жизнь Конвея на F# + OpenGL
#### Почему F#?

Просто потому что он мне нравится. Решив пару десятков задач на [projecteuler](http://projecteuler.net/) я решил найти более практическое применение знаниям и написать нечто... | https://habr.com/ru/post/173419/ | null | ru | null |
# На злобу дня: кроссплатформенный клиент для Telegram на .NET Core и Avalonia
В этой статье я расскажу, как реализовать кроссплатформенное приложение на .NET Core и Avalonia. Тема Телеграма очень популярна в последнее время — тем интереснее будет сделать клиентское приложение для него.

Достаточно давно занимаюсь разработкой на Vue.js, но вот упаковывать компоненты для публикации как то не приходилось. Недавно пришла идея интересного компонента, и я... | https://habr.com/ru/post/516250/ | null | ru | null |
# Разбор заданий конкурса «Конкурентная разведка» на PHDays IV
[](http://habrahabr.ru/company/pt/blog/225353/) Сегодня мы расскажем о некоторых практических аспектах сбора конфиденциальных данных на примере он... | https://habr.com/ru/post/225353/ | null | ru | null |
# Мониторинг служб Linux c помощью Prometheus
**Автор: Senior Devops. Ведущий специалист по инфраструктуре** [**Hostkey**](https://hostkey.ru/) **Никита Зубарев**
В [прошлой статье](https://habr.com/ru/compa... | https://habr.com/ru/post/696918/ | null | ru | null |
# Знакомство с Green-forest Framework

Хочу рассказать Java-сообществу Хабра о небольшом, но очень полезном (на личном опыте) фреймворке под названием [Green-forest](http://code.google.com/p/green-forest)... | https://habr.com/ru/post/168855/ | null | ru | null |
# Лучшие практики для деплоя высокодоступных приложений в Kubernetes. Часть 1
Развернуть в Kubernetes приложение в минимально рабочей конфигурации нетрудно. Но когда вы захотите обеспечить своему приложению м... | https://habr.com/ru/post/545204/ | null | ru | null |
# JavaScript: проверьте свою интуицию

На Хабре [уже](http://habrahabr.ru/post/84311/) [разминались](http://habrahabr.ru/post/84381/) и [развлекались](http://habrahabr.ru/post/136577) кажущимися нелогичнос... | https://habr.com/ru/post/208922/ | null | ru | null |
# Что с памятью моею стало
### Запомним на века: Повесть о работе с ПЗУ
[](https://habr.com/ru/company/ruvds/blog/648649/)
Помню, ещё в детстве, когда у меня появился первый компьютер, там на материнской плате была магическая микр... | https://habr.com/ru/post/648649/ | null | ru | null |
# Физика вращения 3д тел
Когда я раньше задумывался о вращении в 3д, мне было неуютно. Оно казалось сложным. Вспомнить, например, эффект Джанибекова с прецессией свободно вращающейся гайки. Настало время разобраться!
В статье Вас ждут математика, физика, а заодно численное моделирование и визуализация в libgdx.
Можн... | https://habr.com/ru/post/697534/ | null | ru | null |
# Основные проблемы разработки современных интерфейсов
Привет, Хабр! Представляю вашему вниманию перевод [поста](https://overreacted.io/the-elements-of-ui-engineering/) Дэна Абрамова [«The Elements of UI Engineering»](https://overreacted.io/the-elements-of-ui-engineering/) о современных проблемах и задачах, которые до... | https://habr.com/ru/post/435912/ | null | ru | null |
# Самодиагностика МЕМС акселерометра, гироскопа и компаса (self test)
Изучая спецификацию (datasheet) на МЕМС-датчик (акселерометр, гироскоп и проч.) мы сталкиваемся с такой процедурой, как самопроверка (self-test) или самодиагностика. Обычно в спецификациях есть описание, как это делать. Кому интересно: что это и как... | https://habr.com/ru/post/366461/ | null | ru | null |
# Правила работы с Tasks API. Часть 2
В этом посте я бы хотел поговорить о временами неправильном понимания концепции тасков. Также попытаюсь показать несколько неочевидностей при работе с **TaskCompletionSource** и просто выполненными (completed) тасками, их решение и истоки.
### Проблема
**Пусть у нас есть некий... | https://habr.com/ru/post/280344/ | null | ru | null |
# Шахматные алгоритмы, которые думают почти так же, как человек, только лучше
Когда создавались первые вычислительные машины, их воспринимали только как дополнение к человеческому разуму. И до недавнего врем... | https://habr.com/ru/post/544040/ | null | ru | null |
# Магия Dispatcher'ов и как сделать свой Main
Я думаю сейчас не осталось людей, незнакомых с корутинами в Kotlin. Волшебный инструмент, согласны? Ещё более волшебным в них я нахожу возможно вынести вычисление в другой поток:
```
fun main() = runBlocking {
println("Hello from ${Thread.currentThread().name}")
withC... | https://habr.com/ru/post/680946/ | null | ru | null |
# Как обмануть GPS Глонасс без вандализма
Сразу оговорюсь: мы не будем ломать приборы, глушить сигнал или сливать топливо через обратку. В данном посте хочу без лишних технических подробностей рассказать, как можно увеличить пробег по приборам мониторинга. При этом не меняя маршрут движения транспортных средств. Спосо... | https://habr.com/ru/post/302900/ | null | ru | null |
# Перевод: эффективный способ работы с памятью в Compact Framework
Оригинал статьи находится в блоге [Роба Тиффани](http://blogs.msdn.com/robtiffany/archive/2009/04/09/memmaker-for-the-net-compact-framework.aspx).
Кто-нибудь ещё помнит старые добрые времена DOS, когда мы проводили время, пытаясь выжать более 640Кб ... | https://habr.com/ru/post/60865/ | null | ru | null |
# Локализация приложений Node.js. Часть 1
***От переводчика:** Это девятая статья из [цикла о Node.js](https://hacks.mozilla.org/category/a-node-js-holiday-season/) от команды Mozilla Identity, которая занима... | https://habr.com/ru/post/197566/ | null | ru | null |
# INTEL (Altera) USB Byte Blaster на STM32
Зачастую если в устройстве есть программируемая логика, присутствует и процессор/микроконтроллер.
В какой-то момент мне надоело разводить на платах разъем JTAG, он занимает много места на плате и по сути нужен только для разработки. В конечном устройстве он вообще без надоб... | https://habr.com/ru/post/534358/ | null | ru | null |
# STM32 Modular USB Composite device
Проект является логическим продолжением другого проекта на Хабре - [CDC+MSC USB Composite Device на STM32 HAL](https://habr.com/ru/post/335018/) и рассказыват как на STM32... | https://habr.com/ru/post/674662/ | null | ru | null |
# Vim в Windows и переключение раскладки клавиатуры
**UPD:** Это «историческая» версия топика. Новое решение проблемы смотреть [здесь](http://habrahabr.ru/post/175709/).
Проблема русской раскладки в Vim поднималась много раз. Одно из решений можно увидеть [здесь](http://habrahabr.ru/post/98393/), однако оно заставл... | https://habr.com/ru/post/162483/ | null | ru | null |
# Автоматическая система подсказок для онлайн-курсов
Я работаю в [JetBrains Research](https://research.jetbrains.org/ru/) в группе, занимающейся применением методов машинного обучения в области программной инженерии. В данной статье я расскажу об одном из наших проектов — автоматической системе подсказок для онлайн-ку... | https://habr.com/ru/post/504118/ | null | ru | null |
# Погружение в автотестирование на iOS. Часть 3. Жизненный цикл iOS приложения во время прогона тестов
Привет, Хабр!
В этой статье я расскажу про жизненный цикл iOS приложения во время прогона тестов, а в ч... | https://habr.com/ru/post/544254/ | null | ru | null |
# POST запрос, составное содержимое (multipart/form-data)

### Передача составных данных методом POST
В жизни любого программиста попадаются задачки, которые человека цепляют. Вот не нравится стандартный мето... | https://habr.com/ru/post/511114/ | null | ru | null |
# Настало время офигительных историй. Кастомные транзишены в iOS. [2/2]
В [прошлой статье](https://habr.com/ru/company/citymobil/blog/549284/) мы реализовали анимацию ZoomIn/ZoomOut для открытия и закрытия эк... | https://habr.com/ru/post/549288/ | null | ru | null |
# Использование технологии Direct2D для создания WinRT компонентов
 Эта статья продолжает серию наших рассказов, в которых мы делимся своим опытом разработки визуальных WinRT контролов в стиле Windows 8 UI.
В [прошлый ра... | https://habr.com/ru/post/150618/ | null | ru | null |
# Где порешать аналитические задачи от команд Яндекса? Контест и разбор
Сегодня начинается пробный раунд чемпионата по программированию [Yandex Cup](https://yandex.ru/cup/?utm_source=habr&utm_medium=article&utm_campaign=probniy). Это оз... | https://habr.com/ru/post/519846/ | null | ru | null |
# Как использовать Microsoft SQL для отчётов в Power BI. На примере Mindbox
Если вы хотите понимать, насколько эффективны вложения в рекламу, нужно всё измерять: письма, визиты, заказы, выручку. Важна и скорость получения этих метрик. Для наглядности можно строить красивые и понятные отчёты в Microsoft Power BI. А упр... | https://habr.com/ru/post/506740/ | null | ru | null |
# Напиши мне GraphQL сервер на C#
Как-то выдалась у меня пара выходных, и я набросал GraphQL сервер к нашей Docsvision платформе. Ниже расскажу, как все прошло.

#### Что за платформа Docsvision
Платформа ... | https://habr.com/ru/post/416501/ | null | ru | null |
# Визуализация изменения климата при помощи интерактивного генеративного искусства
Чтобы мотивировать людей активнее бороться с изменением климата необходимо постоянно искать новые креативные способы. Их мн... | https://habr.com/ru/post/524802/ | null | ru | null |
# Пишем клиент для Хабра под Android
Забегая вперед, вот что получилось:
12:56. Я буду делать это параллельно с написанием топика (так интересней). По ходу написания клиента поясняя все шаги. Итак,... | https://habr.com/ru/post/117885/ | null | ru | null |
# Пиксели, Excel, Kotlin и немного ностальгии…
Всем привет! Идея для этой статьи пришла еще месяц назад, но в силу занятости на работе времени катастрофически не хватало. Однажды вечером в YouTube я наткнулся на ролик о создании игры-платформера в стиле пиксельной графики. И тут мне вспомнились мои первые уроки информ... | https://habr.com/ru/post/542242/ | null | ru | null |
# Разработка доступных интерфейсов
[По данным Росстата](http://specialbank.ru/2016/10/18/stats_russia) 1 млн. человек имеют проблемы со зрением, начиная от астигматизма и заканчивая слепотой и с трудом могут пользоваться обычными сайтами. Попробуйте протестировать ваш ресурс на доступность: зажмурьте глаза, чтобы экр... | https://habr.com/ru/post/425447/ | null | ru | null |
# Абстрактная фабрика на пальцах
Написать данную статью меня заставили две причины. Совсем недавно я познакомился с паттерном Абстрактная фабрика. Как говорится – «Не умеешь сам, научи товарища». Известно, что один из лучших способов закрепления материала – это объяснение кому-либо ранее изученного. Вторая причина – в... | https://habr.com/ru/post/465835/ | null | ru | null |
# AmbilightUSB
Привет, strangers!
------------------
Обновление проекта [Лайтпак: Прокачан и открыт](http://habrahabr.ru/blogs/DIY/114291/)
Эта история о том, как сделать супер мега дешевую и простую ambilight подсветку для эвм. В роли дирижера будет выступать микроконтроллер ATtiny44, а в роли оркестра 4 RGB-свет... | https://habr.com/ru/post/100085/ | null | ru | null |
# Работа с набором параметров листа через API nanoCAD
При подготовке чертежа к печати необходимо настраивать большое количество параметров: принтер, формат бумаги, масштаб, область печати и т. д.
В nanoCAD в... | https://habr.com/ru/post/565514/ | null | ru | null |
# Погружение в драйвер: общий принцип реверса на примере задания NeoQUEST-2019

Как и все программисты, ты любишь код. Вы с ним — лучшие друзья. Но рано или поздно в жизни наступит такой момент, когда кода с тобой не будет. Да, в это сложно ... | https://habr.com/ru/post/446462/ | null | ru | null |
# Centrifuge набирает обороты
 Привет!
Пару месяцев назад я [опубликовал](http://habrahabr.ru/post/184262/) на Хабре статью, посвященную описанию open-source проекта [Centrifuge](https://github.com/FZambia/centrifuge). ... | https://habr.com/ru/post/194640/ | null | ru | null |
# Создание фреймворка для Canvas: объекты и мышь

Среди [вопросов на счёт Canvas](http://habrahabr.ru/blogs/canvas/119772/) чаще всего звучали вопросы по внутренностям фреймворков — как понять, что мышка находится на... | https://habr.com/ru/post/119773/ | null | ru | null |
# О том как я имя файла из С++ в Java передавал

В кроссплатформенных приложениях чего только не встретишь. Или напишешь. Вот, намедни ~~родили против шерсти очередного ежика~~ наступили на заботливо р... | https://habr.com/ru/post/148115/ | null | ru | null |
# GraphQL + SPQR + Spring Boot Starter 2021
Привет, Хабр!
**GraphQL** — это язык запросов к API-интерфейсам. Он отображает предоставляемые сервером данные, чтобы клиент смог выбрать именно то, что ему нужно. GraphQL **SPQR** призван упростить добавление GraphQL API в *любой* Java-проект. SPQR работает динамически, г... | https://habr.com/ru/post/594335/ | null | ru | null |
# Распознаем эмоции в приложении UWP с помощью API Project Oxford
[](http://habrahabr.ru/post/276411/)
Скорее всего, вы слышали хоть раз про необычный облачный сервис от Microsoft, который позволяет распознавать по фотографии эмоции... | https://habr.com/ru/post/276411/ | null | ru | null |
# GitLab в NAS

При наличии [работоспособного NAS с докером](https://habr.com/post/415779/), установка Gitlab не представляет особых сложностей.
Эта статья является лишь наглядным примером в рамках цикла про NAS. И показывает как пр... | https://habr.com/ru/post/418883/ | null | ru | null |
# Как Postgres хранит строки
Мне стало интересно разобраться, как PostgreSQL хранит данные на диске, и в процессе своего исследования я обнаружил несколько интересных фактов, которыми хочу с вами поделиться.
... | https://habr.com/ru/post/699812/ | null | ru | null |
# Статический анализ кода в PHP: регулярные выражения
Продолжая развивать тему статического анализа, который в общем случае занимается поиском любых дефектов в исходных кодах программ, давайте коснёмся проверки правильности регулярных выражений.
Тема регулярных выражений для PHP довольно щекотлива (примерно как ман... | https://habr.com/ru/post/260185/ | null | ru | null |
# Закачка файлов с depositfiles.com из консоли
*Пост не мой — просто попросили закинуть. Если понравилось, то почта автора для инвайта: ~~jeka.eee.12@gmail.com~~. Уже получено — спасибо!*
Функция для скриптов на bash, предназначенная для автоматизации скачивания файлов с файлообменника Depositefiles.com:
`down_d... | https://habr.com/ru/post/82703/ | null | ru | null |
# Особенности резолвера DNS в Windows 10 и DNS Leak
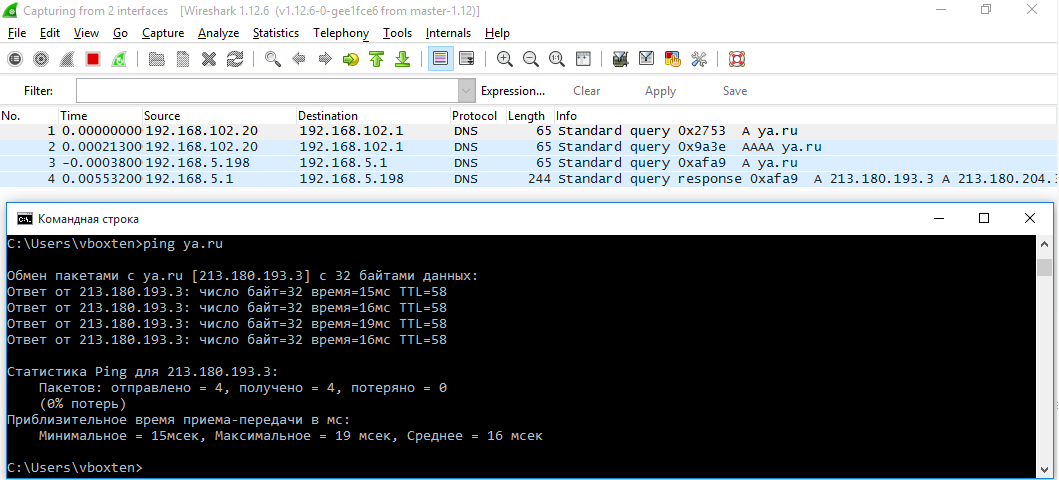
**TL;DR:** DNS-резолвер в Windows 10 отправляет запросы на все известные системе адреса DNS-серверов параллельно, привязывая запрос к интерфейсу, и ... | https://habr.com/ru/post/264503/ | null | ru | null |
# Расширяем функционал jQuery по работе со стилями
Работая с jQuery легкое неудобство доставляет применение большого количества свойств CSS правил к тегам. Решение этой задачи в большинстве случаев сводиться к повторению `$.(“селектор”).css(“свойство”, “значение”);`, что не есть хорошо, но несколько строк кода исправи... | https://habr.com/ru/post/114913/ | null | ru | null |
# Идеальное Vue приложение на Typescript
Пока Vue 3 официально еще не вышел, а в продакшене в основном 2 версия - я хочу поговорить о типизации и о том, что она все еще не идеальна во Vue. И сегодня мы попробуем создать идеальное приложение с типизацией на typescript сделав упор на code style, пропагандируя [vue style... | https://habr.com/ru/post/540798/ | null | ru | null |
# Об одном эвристическом методе детекции вирусных инжекций на сайтах
**!** Пост написал [RomanL](https://habrahabr.ru/users/romanl/), но за неимением необходимого количества кармы — опубликовать его не может.
Хочу рассказать об одном решении, как можно обнаружить внедрения полиморфного вирусного JavaScript-кода в с... | https://habr.com/ru/post/70615/ | null | ru | null |
# Пристрастные заметки о русских разработчиках САПР
Один из сооснователей ЗАО Нанософт, [Дмитрий Попов](http://www.nanocad.ru/about/dima/index.php), написал в facebook заметку из серии «САПР в России»… Понятно, что пристрастно, не претендуя на историческую точность. Но нам показалось, что интересно и вполне подойдет д... | https://habr.com/ru/post/234221/ | null | ru | null |
# Использование SQLCLR для увеличения производительности
Начиная c MS SQL Server 2005 в распоряжение разработчиков баз данных была добавлена очень мощная технология [SQL CLR](http://en.wikipedia.org/wiki/SQL_CLR).
Эта технология позволяет расширять функциональность SQL сервера с помощью .NET языков, например C# или... | https://habr.com/ru/post/88396/ | null | ru | null |
# Высокоуровневая репликация в СУБД Tarantool
Привет, я занимаюсь созданием приложений для СУБД [Tarantool](http://tarantool.io/ru) — это разработанная в Mail.ru Group платформа, совмещающая в себе высокопроизводительную СУБД и сервер приложений на языке Lua. Высокая скорость работы решений, основанных на Tarantool, д... | https://habr.com/ru/post/455146/ | null | ru | null |
# QuadBraces III
Доброго всем здравия!
Прошло практически ровно два года с момента моей [первой публикации о парсере QuadBraces](https://habrahabr.ru/post/266865/) — альтернативе MODX Evolution для простейших проектов, требующих шаблонизации. Это могут быть одностраничники с типовыми публикациями, портфолио, сайты-... | https://habr.com/ru/post/338018/ | null | ru | null |
# Python AI: как построить нейронную сеть и делать прогнозы
### Обзор искусственного интеллекта
Проще говоря, цель использования ИИ — заставить компьютеры думать так же, как люди. Это может показаться чем-то новым, но эта область родилась в 1950-х годах.
Представьте, что вам нужно написать программу на Python, котор... | https://habr.com/ru/post/671116/ | null | ru | null |
# Беспроводные технологии - это ловушка

Когда-то я был крестоносцем, борющимся с проводами. Я ненавидел хаос из кабелей и мою склонность бессознательно жевать их, когда они окажутся рядом с лицом. Но столкнувшись со сложным багом ... | https://habr.com/ru/post/666178/ | null | ru | null |
# 9 альтернатив плохой команде (шаблону проектирования)

### Что это и зачем?
При проектировании разработчик может столкнуться с проблемой: у существ и объектов могут быть разные способности в разных ... | https://habr.com/ru/post/439506/ | null | ru | null |
# Реализация свойств в С++
Всем привет! При реализации проектов разработчикам часто нужны классы, которые содержат только поля и не имеют никаких функций. Такие классы полезны для сохранения нужной информации с последующем их манипуляциями.
Первый подход в реализации таких классов основан на использовании С структу... | https://habr.com/ru/post/459212/ | null | ru | null |
# Samba 3 файловый сервер в домене Active Directory

Как обещал в [прошлой статье](http://habrahabr.ru/post/174407/), сегодня напишу как настроить файловый сервер на базе Samba 3 для пользователей домена Active Directory.... | https://habr.com/ru/post/174497/ | null | ru | null |
# XBMC 12.3 DSPlayer + SmoothVideo Project = мечты сбываются
Доброго всем здравия уважаемые хабражители.
Поискав немного по обоим темам [XBMC](http://habrahabr.ru/search/?q=XBMC) + [SVP](http://habrahabr.ru/search/?q=SVP) понял, что обе имеют достаточное количество поклонников и интересующихся.
Многие знают XBMC... | https://habr.com/ru/post/181598/ | null | ru | null |
# Виртуалка-камуфляж: Вредоносный подход к виртуализации

Виртуализация – это палка о двух концах
Победоносное развитие облаков в последние годы можно связать с постепенным совершенствованием сразу множества технологий, относящих... | https://habr.com/ru/post/559730/ | null | ru | null |
# Самые позорные ошибки в моей карьере программиста (на текущий момент)

Как говорится, если тебе не стыдно за свой старый код, значит, ты не растешь как программист — и я согласна с таким мнением. Я начала программировать для разв... | https://habr.com/ru/post/475662/ | null | ru | null |
# Гетерогенный пул процессоров в XenServer 6
Не так давно у заказчика появилась необходимость собрать пул виртуальных машин, который должен был состоять из серверов [HP ProLiant](http://welcome.hp.com/country/ru/ru/smb/servers.html) 6 и 5 поколений. Процессоры в этих серверах: Xeon **E5502** и **X3353**. Начиная с вер... | https://habr.com/ru/post/145665/ | null | ru | null |
# Скругление углов на чистом CSS с анти-алисингом
Вношу свои 5 копеек в проблему скругления уголков. Хочу предложить метод, который не революционный, а просто несколько усовершенствует другой.
Многие знаком... | https://habr.com/ru/post/63983/ | null | ru | null |
# Создание нестандартного компонента на основе ListView
Для приложения под Android мне понадобился элемент интерфейса, отдаленно напоминающий DatePicker. Он должен уметь:
* прокручивать список от начала и до конца (но не по кругу), так чтобы выделять центральный элемент.
* по мере удаления элемента от центра компон... | https://habr.com/ru/post/225649/ | null | ru | null |
# Пошаговый туториал по написанию Telegram бота на Ruby (native)
**Приветики-омлетики**, как-то недавно у меня появилась идея написать Telegram бота на **Ruby** на специфическую тематику, в двух словах этот бот должен был предоставлять участникам чата (где он присутствует) развлекательную тестовую игру, в случайное вр... | https://habr.com/ru/post/535618/ | null | ru | null |
# Симулятор призрака. От идеи стать программистом к готовой игре на IOS
*Прошло около 10 месяцев с тех пор, как я решил учить программирование, поскольку текущая работа инженером тех-поддержки попросту нагоняла апатию и ни к чему не вела. А чтобы сделать процесс обучения максимально интересным, я решил написать игру д... | https://habr.com/ru/post/266595/ | null | ru | null |
# Как сделать из мухи слона
Многим известна такая старая добрая игра со словами, сделать из мухи слона. Суть её в том, что нужно из начального слова сделать конечное, на каждом шаге меняя только одну букву, получая при этом на каждом шаге осмысленное существительное.
Известный автор книг по занимательной математике... | https://habr.com/ru/post/270845/ | null | ru | null |
# Как при помощи С++20 мы искоренили целый класс багов, возникавших во время выполнения
C++20 давно в ходу и поддерживается компилятором [MSVC](https://ru.wikipedia.org/wiki/Microsoft_Visual_C%2B%2B) с версии... | https://habr.com/ru/post/665966/ | null | ru | null |
# Разработка трехмерных игр для Windows 8 с помощью C++ и Microsoft DirectX

Разработка игр — постоянно актуальная тема: всем нравится играть в игры, их охотно покупают, поэтому их выгодно продавать. Но при разработке хорош... | https://habr.com/ru/post/241085/ | null | ru | null |
# CacheAccelerator для MODx Evo. Уменьшение в разы количества запросов к базе за счет кэширования динамических сниппетов
Всем привет. Я совсем недавно познакомился с MODx CMF. Осваиваю в данный момент версию Evolution. Система в целом довольно приятная и очень гибкая, однако, ознакомившись поближе, я обнаружил ряд нед... | https://habr.com/ru/post/113719/ | null | ru | null |
# Property в C++
Наверное, все любители языка C++, которые использовали другие языки, такие как C#, удивляются: почему же в плюсах нет property? Ведь это действительно удобное средство, позволяющее полностью контролировать доступ к членам класса. Недавно и я заинтересовался данным вопросом. Подумав, полистав Страустру... | https://habr.com/ru/post/121799/ | null | ru | null |
# Перенос толстого банк-клиента BSS в т.ч. на Windows 7 x64
Добрый день, сегодня я потратил много времени на перенос банк-клиента одного из банков, «идущего на острие прогресса» — называть его не буду. Использует этот банк очень распостраненный «толстый» BSS банк-клиент., написанный на Delphi в незапамятные времена. С... | https://habr.com/ru/post/184040/ | null | ru | null |
# Агрегаты в БД — многомерные суперагрегаты
В прошлой статье мини-цикла о работе с агрегатами я рассказывал, как организовать [эффективное многопоточное преобразование потока первичных данных](https://habr.com/ru/post/539638/) в данные агрегированные. Там мы рассматривали задачу "свертки" продаж в агрегаты вида **това... | https://habr.com/ru/post/540572/ | null | ru | null |
# Как продеть слона через игольное ушко. Обработка максимальных объемов данных за минимальное время

Чего только ни услышишь от апологетов тех же Java или C# про разработку на C/C++! Якобы этот язык устарел и на нем никто н... | https://habr.com/ru/post/258961/ | null | ru | null |
# ОС реального времени AQUA RTOS для МК AVR в среде BASCOM AVR
При написании для МК кода посложнее, чем «помигать лампочкой», разработчик сталкивается с ограничениями, присущими линейному программированию в стиле «суперцикл плюс прерывания». Обработка прерываний требует быстроты и лаконичности, что приводит к добавлен... | https://habr.com/ru/post/453708/ | null | ru | null |
# JNA: callbacks to Java
Мне понадобилось подключить наш проект на Яве к старой библиотеке на C. Одной из проблем было, что эта библиотека требует регистрации колбеков (callbacks), которые вызывает по ходу работы, и которые, я хотел бы имплементировать на стороне Явы.
JNI позволяет это всё делать, но муторно. Есть ... | https://habr.com/ru/post/113436/ | null | ru | null |
# Mathematics of Machine Learning based on Lattice Theory
This is a third article in the series of works (see also [first one](https://habr.com/en/post/509480/) and [second one](https://habr.com/en/post/510120/)) describing Machine Learning system based on Lattice Theory named 'VKF-system'. It uses structural (lattice... | https://habr.com/ru/post/510534/ | null | en | null |
# Ищем скрытые смыслы. Графовые нейронные сети на основе Spektral
Развитие методов глубокого машинного обучения привело к росту популярности нейронных сетей в задачах распознавания образов, машинного перевода... | https://habr.com/ru/post/681686/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.