
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Сервлеты и Reflection
Совсем недавно, в статье [Сервлеты — маленький трюк с Reflection](http://habrahabr.ru/blogs/java/119648/), разбирался прием, с помощью которого можно получить url вида:
`host/servletName/methodName.`
Если пойти дальше, то с помощью Reflection можно реализовать конструкцию следующего вида... | https://habr.com/ru/post/120715/ | null | ru | null |
# Обучение с подкреплением для самых маленьких
*В данной статье разобран принцип работы метода машинного обучения[«Обучение с подкреплением»](https://ru.wikipedia.org/wiki/Обучение_с_подкреплением) на примере физической системы. Алгоритм поиска оптимальной стратегии реализован в коде на Python с помощью метода [«Q-Lea... | https://habr.com/ru/post/308094/ | null | ru | null |
# Кастомизация radiobutton без JS
Однажды, у меня возникла задача, сделать на форме сайта выбор одного из нескольких цветов. Казалось бы, нет ничего проще. Элемент `radiobutton`, как нельзя лучше, подходит для этой задачи, нужно только чуть-чуть его кастомизировать. Тут-то и начинаются проблемы. Дело в том, что отрисо... | https://habr.com/ru/post/150760/ | null | ru | null |
# Строим отчеты и анализируем групповые политики с помощью PowerShell
Тема использования PowerShell для администрирования крайне актуальна, и на Хабре появляется все больше и больше статей на эту тему. Предыдущий [перевод с... | https://habr.com/ru/post/161533/ | null | ru | null |
# Заметка ленивого верстальщика о SCSS и Compass Framework
Я изготавливаю сайты «под ключ». Начиная от дизайна, кончая заливкой на хостинг. И самая нелюбимая мною часть этого увлекательного процесса — верстка дизайна в HTML. Вроде бы ничего сложного, но многие рутинные вещи очень утомляют. Поэтому я постоянно нахожусь... | https://habr.com/ru/post/111523/ | null | ru | null |
# Дорога к С++20
Сегодня завершилась летняя встреча комитета ISO WG21 C++, проходившая в Торонто с 10 по 15 июля. Вскоре нас наверняка ждёт [подробный отчёт от РГ21](https://stdcpp.ru/blog/20-iyulya-vstre... | https://habr.com/ru/post/333414/ | null | ru | null |
# Учебник по языку программирования D. Часть 3
Третья часть перевода [D Programming Language Tutorial](http://ddili.org/ders/d.en/index.html) от [Ali Çehreli](http://ddili.org/AliCehreli_resume.html). Содержание главы расчитано для начинающих и, как мне кажется, даже не раскрывает темы. Но это перевод одной из глав. ... | https://habr.com/ru/post/243595/ | null | ru | null |
# Concurrency: 6 способов жить с shared state

В многопоточном программировании много сложностей, основными из которых являются работа c разделяемым состоянием и эффективное использование предос... | https://habr.com/ru/post/216049/ | null | ru | null |
# Использование бесплатных утилит для кастомизации «Неизменяемых» компонентов Windows 8
Многие, если не сказать – большинство из вас уже, как я уверен, успели установить и оценить новые возможности в последней клиентской оп... | https://habr.com/ru/post/178359/ | null | ru | null |
# Неочевидная особенность в синтаксисе определения переменных
Предлагается совершенно невинный на вид кусок кода на C++. Здесь нет ни шаблонов, ни виртуальных функций, ни наследования, но создатели этого чудесного языка спрятали грабли посреди чистa поля.
> `struct A {
>
> A (int i) {}
>
> };
>
>
> ... | https://habr.com/ru/post/68796/ | null | ru | null |
# Именованные аргументы функции в C
В некоторых языках существует возможность вызова функции с именованными параметрами. Такой способ позволяет указать аргумент для определённого параметра, связав его с именем параметра, а не с позицией. Это возможно, например, в C# или Python.
Рассмотрим «игрушечный» пример на Py... | https://habr.com/ru/post/248385/ | null | ru | null |
# Решение проблемы кодировки в GSP-страницах (без Grails)
В какой-то момент проявилась одна заметная проблема, мешающая мне осуществить абсолютно 100% замену PHP на Groovy для веба без использования относительно тяжеловесного MVC-фреймворка Grails.
Это касается \*.gsp страниц (Groovy Server Pages), представляющих с... | https://habr.com/ru/post/129285/ | null | ru | null |
# (in)Finite War
We have a problem. The problem with testing. The problem with testing React components, and it is quite fundamental. It’s about the difference between `unit testing` and `integration testing`. It’s about... | https://habr.com/ru/post/436692/ | null | en | null |
# Kogito + Knime = new instance of match made in heaven?
Very often we've heard that some frameworks fit together so good, that they are considered as "match made in heaven". In this article I would like to share our experience regarding integration of those frameworks.
Introduction
------------
Recently we were inv... | https://habr.com/ru/post/660721/ | null | en | null |
# Аппаратный ЭЛТ-фильтр для картинок
[](https://habr.com/ru/company/ruvds/blog/695058/)
Всю мою жизнь мне нравятся средства отображения информации — в виде электронно-лучевых трубок. В них есть определённый романтизм и шарм. Недаро... | https://habr.com/ru/post/695058/ | null | ru | null |
# Проблема с безопасностью при использовании аутентификации формами в ASP.NET
Сообщает [Peter Vogel](http://visualstudiomagazine.com/forms/emailtoauthor.aspx?AuthorItem=%7BDD0073EE-E182-4F32-B5FB-3F183FCFA220%7D&ArticleItem=%7BD74E8DAD-34EF-460E-AF36-56058B6D51C0%7D)
Два исследователя безопасности, Тай Донг (Thai D... | https://habr.com/ru/post/104258/ | null | ru | null |
# Криптография в Java. Класс KeyPair
Привет, Хабр! Представляю вашему вниманию перевод 6, 7 и 8 статей автора Jakob Jenkov из [серии статей для начинающих](http://tutorials.jenkov.com/java-cryptography/index.html), желающих освоить основы криптографии в Java.
Оглавление:
-----------
1. [Java Cryptography](https://ha... | https://habr.com/ru/post/445560/ | null | ru | null |
# Встроенная поддержка FTP будет удалена в Firefox 90
Mozilla [объявила](https://blog.mozilla.org/addons/2020/04/13/what-to-expect-for-the-upcoming-deprecation-of-ftp-in-firefox/) о планах удалить встроенную... | https://habr.com/ru/post/552910/ | null | ru | null |
# Настройка WPA2 Enterprise c RADIUS

*В статье пойдёт речь о вопросах расширенной аутентификации в беспроводной сети через WPA2 Enterprise. Для данной системы используется RADIUS сервер, поэтому рассмотрим краткий пример упрощённой ... | https://habr.com/ru/post/541474/ | null | ru | null |
# Локальный (offline) npm репозиторий

### Предыстория
Решив продаться задорого, я оказался у работодателя, где интернета нет не только в пром-контуре, но и в деве (ситуация на самом деле нередкая во многих, так сказать, "энтерпрайза... | https://habr.com/ru/post/453614/ | null | ru | null |
# Книга «Вероятностное программирование на Python: байесовский вывод и алгоритмы»
[](https://habr.com/ru/company/piter/blog/456562/) Привет, Хаброжители! Байесовские методы пугают формулами многих айтишников, но без анализа стати... | https://habr.com/ru/post/456562/ | null | ru | null |
# Ящик пива за лучшую сисадминскую байку и наш личный топ историй
Мы в [RUVDS](https://ruvds.com/) очень любим три вещи: сисадминов, байки и пиво.
В этот раз мы решили объединить эти любимые вещи и сделать конкурс лучших сисадминских баек: про работу, клиентов и забавные случаи из практики.
 — Light and Versatile Graphics Library также известная как LittleVGL.
Библиотека поддерживает большое количество микроконтроллеров, ... | https://habr.com/ru/post/510626/ | null | ru | null |
# Плавающая контентная область сайта.
Приветствую Хабр.
По мотивам cайта, сделанного сами знаете кем :)
В свое время увидел, такой эффект – слева сайта находятся ссылки, при клике на которые контентная область сайта плавно перемещается к указанному идентификатору. Эффект запомнился — решил повторить.
Для р... | https://habr.com/ru/post/46873/ | null | ru | null |
# Обзор маршрутизатора Draytek серии 2912. Часть первая
Сегодня на рынке широко представлены различные модели многофункциональных устройств, которые призваны максимально обеспечить малый или среднего размера офис сетевыми сервисами на базе одного устройства. Но среди них особняком, как и несколько лет назад, стоит про... | https://habr.com/ru/post/394687/ | null | ru | null |
# Универсальный NMEA 0183 Parser/Formatter на C# (+ порт на JAVA)
#### Префикс
Как бы банально это не звучало, но поискав готовое решение, которое могло бы (по моему разумению) полностью поддерживать работу с [NMEA](http://ru.wikipedia.org/wiki/NMEA) — сообщениями, я его не обнаружил.
Проштудировав [официальный ... | https://habr.com/ru/post/132493/ | null | ru | null |
# Анимации на лямбдах в C++11

Компании-разработчики, как правило, не особо спешат переходить на новый Си++. Главным образом из-за поддержки его компиляторами, а точнее ее полного или частичного отсутствия.... | https://habr.com/ru/post/230501/ | null | ru | null |
# Создание пользовательских слоев в SwiftUI. LayoutValueKey
В последние несколько недель мы рассмотрели многие аспекты создания пользовательских слоев с использованием нового **Layout** протокола в Swift UI, однако нам еще многое предстоит обсудить. На этой неделе мы узнаем, как использовать протокол **Layout Value Ke... | https://habr.com/ru/post/714778/ | null | ru | null |
# Установка Softether vpn-сервера в chroot окружение, под zte f-660 Iconbit 1003d
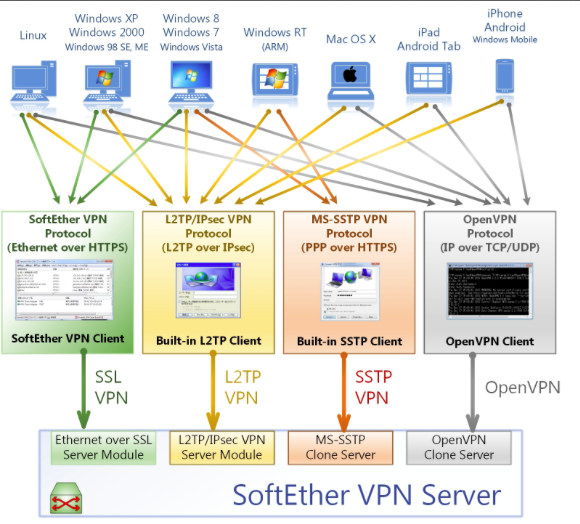
В предыдущем моем [материале](http://habrahabr.ru/post/211759/) я описывал процесс установки sip-proxy и базовых линукс ути... | https://habr.com/ru/post/212679/ | null | ru | null |
# Вариант управления компьютером на Windows из-под консоли Linux
Бывают попадаются задачи, когда надо что-то сделать из-под Linux-а на машине, на которой установлен Windows, но не через RDP или VNC. Или например, как в моём случае, основная машина на Linux и необходимо управлять группой серверов. И для простых задач, ... | https://habr.com/ru/post/181103/ | null | ru | null |
# Установка и настройка hyper-v server для тех, кто впервые его видит
#### *Вступление*
Сегодня я расскажу о том, как установить и настроить гипервизор hyper-v server от компании Microsoft, а так же о некоторых подводных камнях и способах их избежать.
Поводом для написания этот статьи стал материал [данного поста]... | https://habr.com/ru/post/146303/ | null | ru | null |
# Используем Webpack вместо Sprockets в Ruby on Rails
За работу frontend части приложения в Ruby on Rails отвечает библиотека [Sprockets](https://github.com/rails/sprockets), которая не дотягивает до потребностей современного frontend приложения. В чем именно не дотягивает можно почитать, например, [здесь](https://www... | https://habr.com/ru/post/282584/ | null | ru | null |
# Подключаемся к СУБД CUBRID через PHP
Итак Вы, я уверен, уже знаете, как в PHP подключаться и работать с определенными реляционными системами баз данных. В этом блоге я расскажу, как начать работу в PHP с [СУБД CUBRID](http://habrahabr.ru/company/cubrid/blog/117687/ "Знакомство с CUBRID — СУБД оптимизированная для Ве... | https://habr.com/ru/post/119514/ | null | ru | null |
# Type assertation without allocations
Всем привет. В дополнении к моей [предыдущей](https://habrahabr.ru/post/315566/) статье был интересный диалог с
[kirill\_danshin](https://habrahabr.ru/users/kirill_danshin/). В конце концов мы это сделали. Встречайте — [efaceconv](https://github.com/t0pep0/efaceconv), тулза для ... | https://habr.com/ru/post/315752/ | null | ru | null |
# Игрища с сервером jabber.ru
Среди активных ~~и пассивных~~ пользователей Линукс принято осуждать использование любых мессенджеров, кроме джаббера. Однако, мало кто знает, что сервер jabber.ru скрывает в себе множесто «веселых игр» вроде чтения приватной переписки в конференциях. Самые увлекательные развлечения, кото... | https://habr.com/ru/post/230735/ | null | ru | null |
# История борьбы за IOPS в самосборной SAN
Всем привет!
В одном из моих проектов используется нечто, немного похожее на частное облако. Это несколько серверов для хранения данных и несколько — бездисковых, отвечающих за виртуализацию. На днях я похоже что наконец поставил точку в вопросе выжимания максимальной прои... | https://habr.com/ru/post/158159/ | null | ru | null |
# Интересное применение WordCloud
Всем привет! Хочу продемонстрировать вам, как я использовал библиотеку WordCloud для создания подарка для друга/подруги. Я решил составить облако слов по переписке с челове... | https://habr.com/ru/post/580560/ | null | ru | null |
# OLPC, Афганистан. Первые прототипы педальных нетбуков
Как бы смешно не звучал заголовок, но это так.
Для использования нетбуков в деревнях и сельских районах.

Никаких дополнительных аккумуляторов, только физическая сила человека.
Разработчики утверждаю... | https://habr.com/ru/post/72261/ | null | ru | null |
# PostrgreSQL: ускоряемся через intarray
Лет так 6 назад, когда слоник был только в 8.0, а я плотно сидел на MySql, часто слышал призывы сменить DB. Я помню как это было болезненно начать. Но после того, как решился, ни разу не жалел и на мускул уже вряд ли вернусь. Уж очень много тут плюсов, но пост не об этом.
Пр... | https://habr.com/ru/post/269823/ | null | ru | null |
# Telegram Site Helper 2.0 — чат помощник для сайта на основе Telegram

Здравствуйте. Меня зовут Андрей.
Летом прошлого года я опубликовал проект и статью "[Чат-помощник на сайт с помощью Telegram за 15 минут](https://ha... | https://habr.com/ru/post/302056/ | null | ru | null |
# За закрытой дверью фронтенда ЕФС
В этой статье мы расскажем о библиотеке компонентов Единой фронтальной системы (ЕФС) и как в целом устроен фронтенд платформы.
[](https://habrahabr.ru/company/efs/blog/325916/)
Одной и... | https://habr.com/ru/post/325916/ | null | ru | null |
# Используйте поиск по хешу, а не обыск массива
Довольно-таки часто встречается задача: проверить, совпадает ли строка с другими строками из набора. Например, вам нужно проверить каждое слово из сообщения на форуме на предмет того, не содержится ли оно в списке запрещённых. Распространённое решение: создать массив со ... | https://habr.com/ru/post/216865/ | null | ru | null |
# Самурайские инструменты QA: Python (requests)
Постоянно в сл... | https://habr.com/ru/post/669344/ | null | ru | null |
# Грокаем монады императивно
[Часть 1 Грокаем функторы](https://habr.com/ru/post/686768/)
[Часть 2 Грокаем монады](https://habr.com/ru/post/682340/)
Часть 3 Грокаем монады императивно
[Часть 4 Грокаем аппликативные функторы](https://habr.com/ru/post/707294/)
[Часть 5 Грокаем валидацию при помощи аппликативного... | https://habr.com/ru/post/684820/ | null | ru | null |
# Screensaver на J2ME или Назад в прошлое. Часть первая
Доброго времени суток!
#### Введение
На дворе третье января, а душа то и дело требует написать какую-нибудь программку. Недолго думая, я вспомнил, что когда-то предложил [поправочку](http://habrahabr.ru/blogs/JavaMobile/132185/#comment_4429466) автору топика ... | https://habr.com/ru/post/135672/ | null | ru | null |
# Байесовский анализ в Python
Этот пост является логическим продолжением моего первого поста о Байесовских методах, который можно найти [тут](http://habrahabr.ru/post/170545/).
Я бы хотел подробно рассказать о том, как проводить анализ на практике.
Как я уже упоминал, наиболее популярным средством, используемым ... | https://habr.com/ru/post/170633/ | null | ru | null |
# Пишем свой Orm под Android с канастой и сеньоритами, Часть 3-я
#### Вступление
После некоторого перерыва в разработке моего приложения под **Android**, в течение которого в моей голове формировались все новые и новые идеи, как сделать его красивее и удобнее, в конце января я вновь уселся за разработку. За время раз... | https://habr.com/ru/post/216419/ | null | ru | null |
# Как научиться работать в Blazor, делая что-то полезное. Часть II

Как я сказал в [первой части](https://habr.com/ru/company/first/blog/583042/) этой статьи, мы решили написать систему, которая преобразует команды для отправки много... | https://habr.com/ru/post/584836/ | null | ru | null |
# Развертываем свой сайт на Heroku
Здравствуй, Хабрахабр! Недавно у меня возникла необходимость развернуть свое Rails web-приложение на Heroku и я, к своему удивлению, не нашел почти ничего об этом на просторах не только Хабра, но и рунета в целом, поэтому я решил поделиться с вами своим опытом. Подробности о том, что... | https://habr.com/ru/post/232679/ | null | ru | null |
# DevConf 2015 — финальное голосование за доклады. Сделаем программу лучше и полезней
Коллеги — до конференции DevConf 2015 осталось меньше 2-х недель — [помогите выбрать достойные доклады](http://devconf.ru/offers/).
[](ht... | https://habr.com/ru/post/259593/ | null | ru | null |
# Спасение раздела в Debian, когда пошло, что-то не так
Добрый день, уважаемые!
Я вам раскажу исторую, которая могла привести к полной потери данных на виртуальной машине, но выход из ситуации все же был найден при помощи: parted
**Исходные данные:**
**ОС:** Debiab 9 64bit
**ФС:** ext4 без LVM
**Цель:**... | https://habr.com/ru/post/446252/ | null | ru | null |
# «65К методов хватит всем» или как бороться с лимитом DEX методов в Android
Это произошло внезапно. Только что вы писали код для своего приложения под андроид, вам это нравилось, и вы наслаждались процессом. Вы добавили крутую библиотеку чтобы получить дополнительные возможности и писать более простой код. Но вместо ... | https://habr.com/ru/post/230665/ | null | ru | null |
# Попытка создать java Framework для телеграм ботов
У меня иногда появлялось желание делать ботов для телеграм, так мой основной язык Java - выбор не велик и он меня не устраивает. Каждый раз нужно было придумывать какие-то схемы обработки приходящих апдейтов и мучаться с этим всем. Либо был другой выбор - всякие непо... | https://habr.com/ru/post/570660/ | null | ru | null |
# Откровения про отсутствующий Nested Inline от разработчика с очень маленьким Django

*— Стыдно признаться, но в нашей компании мы до сих пор используем Django…*
Так нач... | https://habr.com/ru/post/651179/ | null | ru | null |
# Архитектура Архитектуры. Шаг 7: Носом в пилотку
Продолжение. [К предыдущим постам и карте цикла.](https://habr.com/en/post/575106/#map)
Знаете, что случается, когда и архитектура вроде получилась и команда подобралась нормальная? Приходит [ПОЦ](https://en.wikipedia.org/wiki/Proof_of_concept). [Пилотная](https://e... | https://habr.com/ru/post/575106/ | null | ru | null |
# Настройка окружения нейронной сети Mask R-CNN
Доброго времени суток, в рамках изучения нейронных сетей, многие сталкиваются с трудностями по настройки окружения. С этой целью решил написать статью, дабы помочь жаждущим новичкам.
В рамках своей задачи воспользовался [архитектурой Mask R-CNN](https://github.com/mat... | https://habr.com/ru/post/503860/ | null | ru | null |
# Кэширование данных в приложениях с Spring 3, размещенных в AppEngine
В этой статье я расскажу как можно кэшировать в memcache значения, возвращаемые методами bean'ов. Для этого не потребуется писать код, достаточно добавить конфигурации в xml файлы Spring'а и разметить код с помощью аннотаций.
Итак поредставим чт... | https://habr.com/ru/post/98972/ | null | ru | null |
# Небольшое сравнение производительности СУБД «MongoDB vs ClickHouse»
Так как колоночная СУБД ClickHouse (внутренняя разработка Яндекс) стала доступна каждому, решил использовать эту СУБД заместо MongoDB для хранения аналитических данных. Перед использованием сделал небольшой тест производительности и хочу поделиться ... | https://habr.com/ru/post/320762/ | null | ru | null |
# Брейн-система
В последнее время набирают популярность различные виды интеллектуальных игр: «Что? Где? Когда?», «Мелотрек», «Брейн-ринг». Но для некоторых видов игр не обойтись без специальной системы, которая будет управлять ходом игры. Вот в рамках курсового проекта решили попробовать сделать свою брейн-систему.
... | https://habr.com/ru/post/394359/ | null | ru | null |
# SQLite теперь для мобильных приложений на С# под любую платформу

Совсем недавно вышла новая версия библиотеки, которая будет полезна С# разработчикам, разрабатывающим или планирующим разрабатывать к... | https://habr.com/ru/post/228193/ | null | ru | null |
# Статистика пользователей Google Plus
Компания [Find People on Plus](http://www.findpeopleonplus.com) подготовила статистику по 947996 аккаунтам, которые зарегистрированы в новой социальной сети от Google.
[](https://habrastorag... | https://habr.com/ru/post/124214/ | null | ru | null |
# Резиновая верстка — линейная зависимость горизонтального положения DIV-ов
**Задача:** менять горизонтальное положение блочных элементов по линейной зависимости при изменении размера окна браузера.
**Решение:** термин «пропорциональность» подразумевает линейную зависимость двух параметров. Вспоминаем школьный курс... | https://habr.com/ru/post/28631/ | null | ru | null |
# Язык Go. Пишем эмулятор CHIP-8
Язык [Go](http://golang.org) отпразновал недавно первый год своей жизни. Интерпретатору [CHIP-8](http://chip8.com) стукнуло уже под сорок.
Любителям новых языков и старого железа посвящается этот пост — в нем мы будем писать эмулятор виртуальной машины CHIP-8 на языке Go.
О том, ... | https://habr.com/ru/post/109862/ | null | ru | null |
# Элементарная симуляция кастомного физического взаимодействия на python + matplotlib
Привет!
Тут мы опишем работу некоторого поля а затем сделаем пару красивых фичей (тут все ОЧЕНЬ просто).
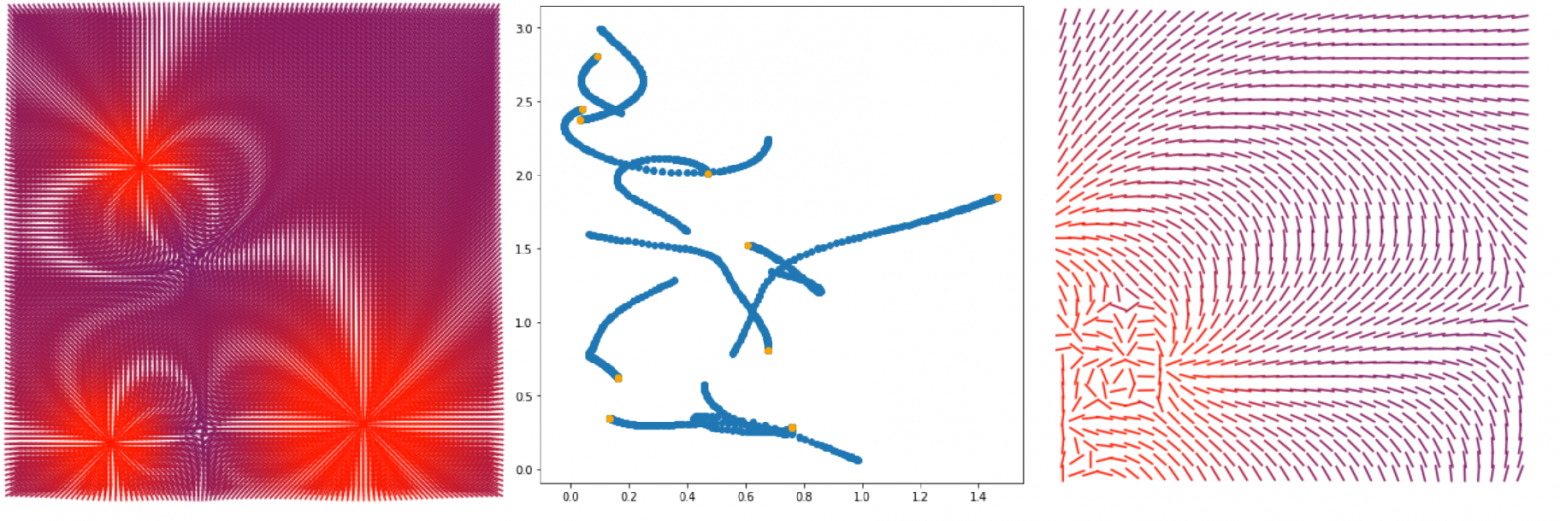
Что будет в этой статье.
Общий с... | https://habr.com/ru/post/467803/ | null | ru | null |
# Упрощаем работу с Check Point API с помощью Python SDK
Вся мощь взаимодействия с API раскрывается при совместном использовании с програмным кодом, когда появляются возможности динамически формировать API запросы и инструменты для... | https://habr.com/ru/post/505510/ | null | ru | null |
# Russian Code Cup 2012: подробный разбор задач с отборочного раунда (полуфинал)

В прошлую субботу, 16 июня, завершился отборочный раунд Russian Code Cup 2012. Задачи отборочного раунда посложнее, чем были... | https://habr.com/ru/post/146458/ | null | ru | null |
# PostgreSQL. Добавляем not null constraints в большие таблицы

Проекты развиваются, клиентская база увеличивается, базы данных разрастаются, и наступает момент, когда мы начинаем замечать, что некогда простые манипуляции над базам... | https://habr.com/ru/post/493954/ | null | ru | null |
# Сохранение пакетов Perl через local
В **perl** есть выражение **local**. Оно подменяет указанное значение **undef**-ом до конца блока. В качестве значения могут выступать глобальные хеши, массивы и скаляры, а так же элементы или срезы хешей и скаляров.
Проблема в том, что хеши пакетов **local** не сохраняет.
Под х... | https://habr.com/ru/post/585038/ | null | ru | null |
# Статистика Google Analytics на вашем сайте
Помню, как-то проскакивала пара записей ([здесь](http://dab512.habrahabr.ru/blog/26862/) и [здесь](http://habrahabr.ru/blogs/webdev/19564/)) по поводу импортирования данных из Google Analytics для отображения сводных диаграмм на сайте, в общем, как на [хабре](http://habraha... | https://habr.com/ru/post/42080/ | null | ru | null |
# Разработка через тестирование в iOS
#### **Содержание:**
* Разработка через тестирование – что это?
* Три закона TDD
* Примеры применения
* Преимущества и недостатки
* Литература и ссылки
#### **Разработка через тестирование – что это?**
> Разработка через тестирование (Test-driven development) — техника разработ... | https://habr.com/ru/post/263087/ | null | ru | null |
# Улучшаем allOf и anyOf в CompletableFuture

*И снова здравствуйте. В преддверии старта курса [«Разработчик Java»](https://otus.pw/lzgB/) подготовили для вас перевод полезного материала.*
---
В `CompletableFuture` есть два метод... | https://habr.com/ru/post/481804/ | null | ru | null |
# Техподдержка 3CX отвечает: быстрое бесплатное обновление до последней версии 3CX
Если вы в свое время приобрели лицензию 3CX, но по какой-то причине решили ее не обновлять, сейчас такой устаревшей системой следует пользоваться весьма аккуратно. Дело в том, что для активации лицензии и загрузки обновлений 3CX использ... | https://habr.com/ru/post/429292/ | null | ru | null |
# Домашний сервер — ESXi, паранойя
Доброго времени суток, уважаемые хабровчане!
На хабре много статей, про то настройку тех или иных кусочков домашнего сервера. Хотелось бы поделиться еще одним вариантом построения домашней сети, нацеленной на сисадмина или разработчика. На этот раз на базе ESXi.
Кого заинтерес... | https://habr.com/ru/post/118316/ | null | ru | null |
# Автоматы на службе распределенных транзакций
В этой заметке я расскажу о доменах, построенных на основе конечных автоматов, и распределенных транзакциях, реализованных при помощи таких доменов.

Такой подход я активно использую пр... | https://habr.com/ru/post/544042/ | null | ru | null |
# Режим высокой доступности HashiCorp Vault (HA)
Hashicorp Vault — open-source инструмент для управления секретами (пароли, ключи API и т.д.),
Vault может работать в режиме высокой доступности (HA) для защиты от сбоев за счет запуска нескольких серверов Vault. Vault обычно ограничивается пределами операций ввода-выво... | https://habr.com/ru/post/538392/ | null | ru | null |
# Менеджер транзакций для базы данных в оперативной памяти

В этот статье я хочу еще раз пройтись по особенностям работы транзакций в Tarantool, применительно к движку в памяти и дисковому движку. И главное — расскажу про новый мен... | https://habr.com/ru/post/540842/ | null | ru | null |
# Яндекс.Диск как файловая система

Недавно Яндекс [анонсировал](http://habrahabr.ru/company/yandex/blog/141458/) свой новый сервис, подобный DropBox'у. Многие его сразу же начали поливать из ведра, хотя, я думаю, зря.
... | https://habr.com/ru/post/142067/ | null | ru | null |
# Первое правило машинного обучения: начните без машинного обучения

Эффективное использование машинного обучения — сложная задача. Вам нужны данные. Вам нужен надёжный конвейер, поддерживающий потоки данных. И больше всего вам нуж... | https://habr.com/ru/post/587508/ | null | ru | null |
# Без него не было бы YouTube, Instagram и Uber: пошаговая инструкция о том, как выжать максимум из Python
Языков в мире программирования масса, но корону по праву носит Python. Многие полюбили его за гибкость, лаконичность, бесчисленное количество модулей и поддержку сообщества. Именно этот язык стал основой для самы... | https://habr.com/ru/post/595739/ | null | ru | null |
# Все новинки Android 12. Обзор для разработчиков
> Привет. Меня зовут [Кирилл Розов](http://twitter.com/kirill_rozov) и вы если вы интересуетесь разработкой под Android, то скорее всего слышали о [Telegram канале "Android Broadcast"](https://t.me/android_broadcast), с ежедневными новостями для Android разработчиков, ... | https://habr.com/ru/post/560302/ | null | ru | null |
# Микрооптимизации важны: предотвращаем 20 миллионов системных вызовов
Эта публикация — логическое продолжение поста «[Как настройка переменной окружения TZ позволяет избежать тысяч системных вызовов](https://blog.packagec... | https://habr.com/ru/post/324466/ | null | ru | null |
# 4 главных вещи, которые я не знал перед выходом на стажировку в разработку
Всем привет! Меня зовут Даниил, и я программист-самоучка.
В разработку я хотел попасть давно, но, как это часто бывает, не слишком-то верил в свои силы. Я полагал, что мой поезд давно ушел, и мозги уже не те, чтобы освоить эту сложную про... | https://habr.com/ru/post/523730/ | null | ru | null |
# Laravel: создание фабрик и seeders при связях между моделями
В ситуациях, когда одна модель обязательно должна быть связана с другой моделью (например, статья и ее автор, компания и сотрудники и т.п.), большинство программистов допускают различные ошибки при создании фабрик (Factory) и сидов (Seeders) к этим моделям... | https://habr.com/ru/post/645055/ | null | ru | null |
# Errors that static code analysis does not find because it is not used
Readers of our articles occasionally note that the PVS-Studio static code analyzer detects a large number of errors that are insignificant and don't affect the application. It is really so. For the most part, important bugs have already been fixed... | https://habr.com/ru/post/460121/ | null | en | null |
# Строим свой Gmail с куртизанками и преферансом
#### Вместо предисловия
В один прекрасный, а может и не такой уж и прекрасный, день настигла паранойя и меня. Было принято решение бежать от Google подальше. При чем, бежать куда-нибудь на свою площадку, чтобы быть спокойным за сохранность своих любимых сервисов.
Ит... | https://habr.com/ru/post/197756/ | null | ru | null |
# Ломаем iOS-приложение! Часть 2
В [первой части](http://habrahabr.ru/post/199128/) мы изучили некоторые вопросы безопасности хранения и передачи *данных*. Теперь переходим к защите *исполняемого кода*. Мы будем модифицировать функционал iOS-приложения во время выполнения и проделаем реверс-инжиниринг. И снова, помнит... | https://habr.com/ru/post/199130/ | null | ru | null |
# Mozilla Firefox завибрирует
Этой зимою нам довелось заметить такие полезные новинки в мобильном Файерфоксе, как контроль за [зарядом аккумулятора](http://habrahabr.ru/blogs/firefox/135474/) и управление [мо... | https://habr.com/ru/post/137173/ | null | ru | null |
# Шифрование в EXT4. How It Works?
 Паранойя не лечится! Но и не преследуется по закону. Поэтому в Linux Kernel 4.1 добавлена поддержка шифрования файловой системы ext4 на уровне отдельных файлов и директорий. Зашифровать можно только пустую дире... | https://habr.com/ru/post/327682/ | null | ru | null |
# Rust 1.60.0: покрытие на основе исходного кода, новый синтаксис условной компиляции в Cargo, инкрементальная компиляция
Команда Rust публикует новую версию языка — 1.60.0. Rust — это язык программирования, позволяющий каждому создавать надёжное и эффективное программное обеспечение.
Если у вас есть предыдущая верси... | https://habr.com/ru/post/659905/ | null | ru | null |
# SafetyNet Attestation — описание и реализация проверки на PHP
В эту тему пришлось детально погрузиться во время работы над обеспечением стандартных механизмов верификации устройств для разных мобильных пла... | https://habr.com/ru/post/541934/ | null | ru | null |
# (псевдо)Наследование для компонентов ReactJS
Я хочу написать коротенький пост, про то, как я решил проблему наследования в ReactJS. Обычно, на форумах, люди советуют использовать миксины для наследования функционала, но, по-моему, это не совсем правильно. Все-таки трэйты/миксины и классы это не одно и то же, да еще ... | https://habr.com/ru/post/247347/ | null | ru | null |
# Находим опечатки в **kwargs
По мере разрастания проекта, в котором я сейчас принимаю активное участие, стал все чаще встречаться с подобными опечатками в именах аргументов у функции, как на картинке справа. Особенно дорого в ... | https://habr.com/ru/post/249423/ | null | ru | null |
# ORM в Android c помощью ORMLite
На данный момент для платформы Android существует несколько решений, позволяющих реализовать ORM-подход для работы с базой данных, но основных два. Это [ORMLite](http://ormlite.com) и [GreenDAO](http://greendao-orm.com/).
Для новичков стоит сделать отступление и рассказать что тако... | https://habr.com/ru/post/143431/ | null | ru | null |
# Почему наш стартап переехал с Flask на FastAPI
Продукт стартапа Datafold — платформа для мониторинга аналитических данных. Они подключаются к хранилищам данных и ETL и BI-системам, помогая дата-сайентистам и инженерам отслеживать потоки данных, их качество и аномалии
И однажды стартап решил поменять стек. Как так с... | https://habr.com/ru/post/575958/ | null | ru | null |
# Еще один Port knocking
Приветствую коллеги! В данной статье хочется описать свою доработку популярной технологии защиты сетевых рубежей под названием Port Knocking, реализованную на оборудовании MIKROTIK. ... | https://habr.com/ru/post/709022/ | null | ru | null |
# Разбираемся с цветами, палитрами, фильтрами CSS и не только
Этот материал — карманный справочник о том, как работать с цветом в CSS и вебе в целом. Он начинается с теоретических основ и содержит множество ... | https://habr.com/ru/post/581888/ | null | ru | null |
# SFINAE — это просто
TLDR: *как определять, есть ли в типе метод с данным именем и сигнатурой, а также узнавать другие свойства типов, не сойдя при этом с ума.*

Здравствуйте, коллеги.
Хочу рас... | https://habr.com/ru/post/205772/ | null | ru | null |
# Модели глубоких нейронных сетей sequence-to-sequence на PyTorch (Часть 4)
4 - Упакованные дополненные последовательности, маскировка, вывод и метод оценки BLEU
-------------------------------------------------------------------------------------
В этой части мы добавим несколько улучшений — упакованные дополненные ... | https://habr.com/ru/post/567998/ | null | ru | null |
# 3.2 Обработка событий

*От переводчика: данная статья является десятой в цикле переводов официального руководства по библиотеке SFML. Прошлую статью можно найти [тут.](https://habrahabr.ru/post/279957/ "Предыдущая статья: ... | https://habr.com/ru/post/280153/ | null | ru | null |
# Arduino, модуль Nokia 5110 LCD и любая картинка

Наверное, у меня, как и у всех Arduino-строителей, появилась какая-то бредовая идея в голове. Заказал в Китае все необходимые детали. Ждать пришлось очень долго, но тут ран... | https://habr.com/ru/post/247639/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.