
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Введение в SuperCollider
В этой небольшой статье вкратце расскажу о том, что такое SuperCollider и продемонстрирую примеры его использования. SuperCollider — это open-source кроссплотформенное клиент-серверное приложение, среда разработки и язык программирования для аудиосинтеза в реальном (и не только) времени. Пер... | https://habr.com/ru/post/123133/ | null | ru | null |
# Создаем ListView с Context Action Bar как в новом Gmail
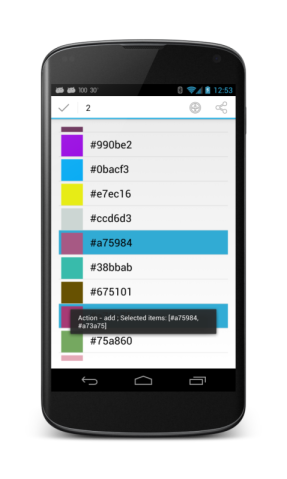
#### Что хотим получить
Сделать плавно работающий список с возможностью выделения рядов как кликом на иконку ряда, так и долгим нажатием на него. Также, дабы выд... | https://habr.com/ru/post/185004/ | null | ru | null |
# ЖЖ в БД (скрипт на Groovy)
В продолжении темы маленьких скриптов на groovy — еще один.
Предыдущие: [Большие письма](http://habrahabr.ru/blogs/google/110738/) в Gmail, [Упражнение](http://habrahabr.ru/blogs/development/108431/) на сложение (LATEX)
Новый скрипт показывает основы работы с XML и базой данных в Gro... | https://habr.com/ru/post/113941/ | null | ru | null |
# Bypassing LinkedIn Search Limit by Playing With API
***[Because [my extension](https://adam4leos.github.io/) got a lot of attention from the foreign audience, I translated [my original article](https://habr.com/en/post/462167/) into English]***.
Limit
-----
Being a top-rated professional network, LinkedIn, unfor... | https://habr.com/ru/post/466801/ | null | en | null |
# Кодогенерация в Dart. Часть 1. Основы
Известно, что для программиста очень хорошо быть *ленивым*, потому что **делать больше с меньшими затратами — ключ к прогрессу**. Никто не любит делать одно и то же снова и снова. Это утомительно, скучно, да и совсем не креативно. Повторяя одно и то же действие мы часто делаем о... | https://habr.com/ru/post/445824/ | null | ru | null |
# Выполнение внешнего файла из БД Oracle с целью получения информации о дисковом пространстве
Зачастую для тех или иных нужд возникает необходимость выполнить команду OS из pl/sql или даже sql внутри Oracle Database.
Ниже описывается один из способов и его применение в задаче определения доступного дискового прост... | https://habr.com/ru/post/191870/ | null | ru | null |
# Градиентный бустинг с CATBOOST (часть 3/3)
В предыдущих частях мы рассматривали задачу бинарной классификации. Если классов более чем два, то используется MultiClassification, параметру loss\_function будет присвоено значение MultiClass. Мы можем запустить обучение на нашем наборе данных, но мы получим те же самые р... | https://habr.com/ru/post/648939/ | null | ru | null |
# Развитие KodiCMS
Всем привет. С момента написания последней статьи в системе произошло много изменений, о которых хотелось бы рассказать.
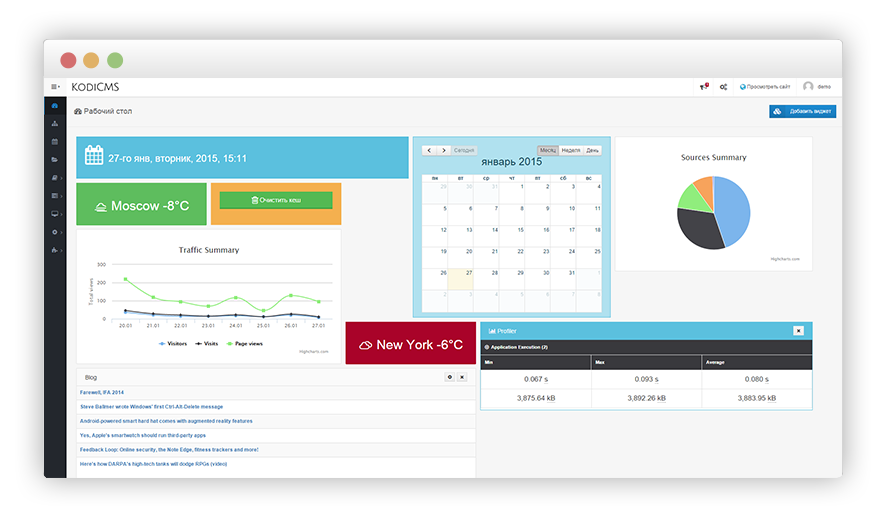
К сожалению, в статье минимум технической информации, но все равно данная статья... | https://habr.com/ru/post/248937/ | null | ru | null |
# Автоматный практикум — 1. Пример «Дисплей», разработка ОА и УА
*[Тесты в предыдущей статье](https://habrahabr.ru/post/341888/) убедительно показали высокую эффективность «автоматной» реализации примера «Дисплей» по сравнению с условно названной «неавтоматной» версией. Вкратце итог: обе реализации автоматные, но разн... | https://habr.com/ru/post/342048/ | null | ru | null |
# У вас нет разрешения на доступ к API. OpenCart
Содержание
* [1. Простой случай](#prostoi)
* [2. Случай клиента](#klient)
* [3.](https://byurrer.ru/u-vas-net-razresheniya-na-dostup-k-api-opencart.html#%D0%92%20%D1%87%D0%B5%D0%BC%20%D0%BF%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC%D0%B0?) [В чем проблема?](#problema)
* [4.]... | https://habr.com/ru/post/548324/ | null | ru | null |
# 10 библиотек, о которых должен знать каждый Android-разработчик

В 2015 году мы уже публиковали [статью](https://infinum.co/the-capsized-eight... | https://habr.com/ru/post/425397/ | null | ru | null |
# Удаленное управление мышью с помощью .NET Remoting
Пару лет назад я решил испытать Remoting в сочетании с winapi и сделать удаленное управление мышью. Решение должно состоять из 2 приложений, взаимодействующих через .NET Remoting. Серверное приложение должно быть в виде службы Windows.
Сервер аналогичен RAdmin се... | https://habr.com/ru/post/124491/ | null | ru | null |
# Разработка приложения на Android с помощью Xamarin и F#

Привет!
Недавно Xamarin объявил [конкурс на разработку](http://blog.xamarin.com/contest-build-your-first-f-mobile-app/) мобильного приложе... | https://habr.com/ru/post/228783/ | null | ru | null |
# Создание WebCron плагина для Joomla 4 (Task Scheduler Plugin)
Эта статья - дополненный перевод статьи [How to Create Joomla Task Scheduler Plugin](https://www.techfry.com/joomla/how-to-create-joomla-task-scheduler-plugin).
В Joomla! появился планировщик задач начиная с версии 4.1. Он помогает автоматизировать повто... | https://habr.com/ru/post/676902/ | null | ru | null |
# Как выбрать язык программирования?

Именно таким вопросом задалась команда Почты Mail.Ru перед написанием очередного сервиса. Основная цель такого выбора — высокая эффективность процесса разработки в рамках выбранного язы... | https://habr.com/ru/post/273341/ | null | ru | null |
# Небольшое тестирование двух библиотек для работы с ZIP архивами (язык C#)
Не раз приходилось работать с zip архивами с помощью C#, в моих случаях — это было скачивание архива с базой, потом извлекал б... | https://habr.com/ru/post/113236/ | null | ru | null |
# Использование камеры Fish eye на Raspberry Pi 3 с ROS — часть 2
Добрый день уважаемые читатели Хабра! Это вторая часть рассказа об использовании fish eye камеры на Raspberry Pi 3. Первую часть можно найти [здесь](https://habr.com/post/417251/). В этой статье я расскажу о калибровке fish eye камеры и применении камер... | https://habr.com/ru/post/429894/ | null | ru | null |
# Реализация схемы разделения секретной визуальной информации в MATLAB
##### Введение
Всем доброго времени суток!
Уверен, что многие из вас уже интересовались методами разделения секретной визуальной информации. Если это так, то вы наверняка знакомы с работой Мони Наора и Ади Шамира, посвященной визуальной криптог... | https://habr.com/ru/post/226859/ | null | ru | null |
# Загрузка треков со Spotify с помощью питона
Здравствуйте, дорогие пользователи хабра! Сегодня я расскажу как используя python можно скачивать треки со спотифая. Основано это на загрузки видео с ютуба. Да-да мы будем искать песни на ютубе и качать их оттуда. Ссылка на GitHub с репозиторием и интересным бонусом в конц... | https://habr.com/ru/post/582170/ | null | ru | null |
# Организация интерфейса в Unity с UI Canvas
В Unity есть хорошая система для создания пользовательского интерфейса UI Canvas. По ней написано довольно много обучающего материала, но большинство гайдов рассказывает только о том, какие кнопки нажать и какой код написать, чтобы все заработало. В качестве примеров обычно... | https://habr.com/ru/post/472770/ | null | ru | null |
# Долой абсолютные единицы в иконках-спрайтах
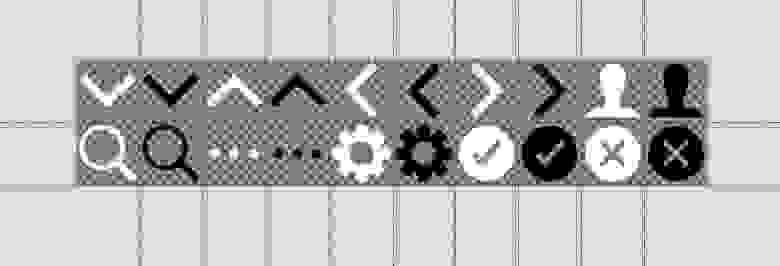
Спрайты — классный способ сократить количество запросов к серверу. Можно упаковать кучу иконок в один спрайт и прописать в CSS смещения для каждой иконки. Однако, очень неудобн... | https://habr.com/ru/post/245331/ | null | ru | null |
# Нахождения минимального расстояния до кривой с помощью API Яндекс.Карт
Здравствуйте уважаемые читатели.
Если вы когда-нибудь сталкивались с задачей описанной в топике, то наверное удивлены, тем что в посте будет что-либо кроме ссылки на описание метода getClosestPoint(), потому сразу скажу, что мое решение конечн... | https://habr.com/ru/post/127999/ | null | ru | null |
# Статистическая регуляризация некорректных обратных задач им. Турчина (часть 1)
Привет, Хабр! Сегодня мы хотим рассказать, чем занимается [лаборатория методов ядерно-физических экспериментов](https://research.jetbrains.org/groups/npm), входящая в [JetBrains Research](https://research.jetbrains.org/).
Где JetBrains... | https://habr.com/ru/post/497820/ | null | ru | null |
# Автоматическая отсылка анонсов в твиттер
Недавно, при работе над проектом на Джанго, понадобилось автоматически отправлять в твиттер заголовок и укороченную ссылку для публикуемых статей от имени пользователя.
Как оказалось, делается это совсем несложно.
Я сразу решил не изобретать велосипед и воспользоваться... | https://habr.com/ru/post/88811/ | null | ru | null |
# Небольшой скрипт для Naumen Phone Outsourcing
Есть задача, в начале каждого месяца выгружать из недр Naumen Phone Outsourcing (для простоты, буду звать его далее NPO) записи разговоров за предыдущий месяц с сортировкой по проектам и по дням месяца. Как это реализовать?
В NPO всё это добро хранится по адресу "/opt... | https://habr.com/ru/post/178799/ | null | ru | null |
# EMC DPO: как защитить свои товары от подделок
Представим ситуацию: вы приходите в магазин, скажем, дорогих часов, покупаете понравившийся товар, с нетерпением идете домой, чтобы открыть заветную коробочку, открываете ее, и, вдруг, выясняется, что купленный товар — дешевая подделка.
Знакомо? Что делать и кто винов... | https://habr.com/ru/post/322696/ | null | ru | null |
# «Фича» в IPSEC реализации VPN роутеров Draytek
[Draytek](http://www.draytek.com) — относительно новая в российском сегменте компания, занимающая нишу недорогих компактных роутеров All-in-one. [Здесь](http://www.thg.ru/network/draytek_vigor_2820vn/index.html) и [здесь](http://www.thg.ru/network/draytek_vigor_2910vg/i... | https://habr.com/ru/post/102915/ | null | ru | null |
# Добавляем поддержку Flatpak в Compose Desktop
Те, кто делали мультиплатформенное приложение с помощью Compose Multiplatform, наверное уже сталкивались с тем, в как публиковать приложение. Для Linux на текущий момент доступны следующие форматы: *Deb* - "нативные" пакеты для [Debian](https://www.debian.org/index.ru.ht... | https://habr.com/ru/post/701078/ | null | ru | null |
# Создать динамический компонент теперь проще: изменения в Angular 13
Бывают ситуации, когда компонент необходимо добавить на страницу динамически. Например, тултип или баннер. В такие моменты на помощь приходит Angular, который умеет создавать компоненты в рантайме и рендерить их. Для этого разработчик может воспольз... | https://habr.com/ru/post/652855/ | null | ru | null |
# И ещё один Steam Windows Client Local Privilege Escalation 0day
В предыдущей серии
------------------
Не так давно [я опубликовал](https://habr.com/ru/company/pm/blog/462479/) описание уязвимости для Steam. Я получил много отзывов от читателей. Valve не проронили ни слова, а HackerOne прислал огромное слезливое пис... | https://habr.com/ru/post/464367/ | null | ru | null |
# Что делать, если у вас много сторонних репозиториев
Прежде чем читать этот пост откройте консоль и выполните следующие команды
```
ls /etc/apt/sources.list.d | wc -l
```
Если у вас вдруг появилась надпись
```
"ls" не является внутренней или внешней командой, исполняемой программой или пакетным файлом.
```
то... | https://habr.com/ru/post/148445/ | null | ru | null |
# Построение масштабируемых приложений на TypeScript. Часть 2.5 — Работа над ошибками и делегаты
Часть 1: [Асинхронная загрузка модулей](http://habrahabr.ru/post/184942/)
Часть 2: [События или зачем стоит изобретать собственный велосипед](http://habrahabr.ru/post/185160/)
К сожалению, московская жара серьезно по... | https://habr.com/ru/post/185290/ | null | ru | null |
# Карты из шестиугольников в Unity: поиск пути, отряды игрока, анимации
[Части 1-3: сетка, цвета и высоты ячеек](https://habr.com/post/424257/)
[Части 4-7: неровности, реки и дороги](https://habr.com/post/424491/)
[Части 8-11: вода, объекты рельефа и крепостные стены](https://habr.com/post/425463/)
[Части 12-... | https://habr.com/ru/post/426481/ | null | ru | null |
# Геометрические объекты и балуны в Рамблер-Картах
Те, кто уже пользовался API карт других разработчиков, думаю, без труда разберутся и с API Рамблер-Карт. Набор классов и методов достаточно стандартный и очевидный.
... | https://habr.com/ru/post/149258/ | null | ru | null |
# Начало дружбы с VkNet
 Я много дружу с библиотекой [VkNet](https://vknet.github.io/vk/). Но, к сожалению, документация по работе с ней достаточно устарела. Так что я решил поделиться и создать маленький туториал по основам работы с эт... | https://habr.com/ru/post/438874/ | null | ru | null |
# Инженерные требования к радио-тракту станции сотовой связи
Когда приходишь к радиоинженеру с просьбой что-то спроектировать, он задает вопрос: какие нужны параметры? Основные параметры, которые его интересуют:
* коэффициент шума приемника;
* мощность передатчика;
* линейность приемного тракта (IP1, IP3);
* линейнос... | https://habr.com/ru/post/587786/ | null | ru | null |
# Unity «Best» Practices
Эта статья родилась из внутреннего доклада для коллег, которые уже достаточно давно занимаются разработкой игр, но только недавно прикоснулись к Unity. Здесь мы собрали фишки и особе... | https://habr.com/ru/post/649687/ | null | ru | null |
# Meta-Object Protocol в Perl6
В некоторых языках программирования существует интерфейс для создания класса не через его определение, а через выполнение некоего кода. Этот API называется Meta-Object Protocol или MOP.
В Perl 6 есть MOP, позволяющий создавать классы, роли и грамматики, добавлять методы и атрибуты и д... | https://habr.com/ru/post/265199/ | null | ru | null |
# Iteraptor: библиотека для глубокого прозрачного мап-редьюса
Структуры данных *Elixir* — иммутабельны. Это здорово с точки зрения уверенности в том, что наши данные не будут искорежены до неузнаваемости в каком-то другом нерелевантном куске кода, но это немного раздражает, когда нам нужно изменить глубоко вложенную с... | https://habr.com/ru/post/482478/ | null | ru | null |
# Ускоряем фронтенд. Когда много запросов к серверу — это хорошо
В этой статье описываются некоторые методы ускорения загрузки фронтенд-приложений, чтобы реализовать отзывчивый, быстрый пользовательский интерфейс.
Мы обсудим общую архитектуру фронтенда, как обеспечить предварительную загрузку необходимых ресурсов и... | https://habr.com/ru/post/490210/ | null | ru | null |
# Разбор строки адреса (улица [дом]) средствами Golang и Postgis
Hi, %habrauser%.
Столкнулся я на днях с интересной задачей — пользователь вводит строку, которая может быть улицей с домом, просто улицей или вообще не улицей, а нам надо узнать имел ли он ввиду улицу с домом и соответствующее ему подсказать.
> —... | https://habr.com/ru/post/225481/ | null | ru | null |
# Как сжать плоского кота
Однажды в студеную зимнюю пору… ровно год назад, у нас появилась нетривиальная задача. Есть экран на электронных чернилах, есть процессор 16МГц (да-да, во встраиваемой электронике, особенно сверхнизкого энергопотребления, встречаются и такие) и совсем нет памяти. Ну, т.е. килобайтов 8 RAM и 2... | https://habr.com/ru/post/273047/ | null | ru | null |
# Выделите свой сайт в Speed Dial
Настольная версия браузера Opera, начиная с версии 11.10, позволяет владельцам сайтов определять, как их сайт будет отображаться в миниатюрах Экспресс-панели. По-умолчанию, для отображения используется скриншот целой веб-страницы. Теперь появилась возможность указывать значок через CS... | https://habr.com/ru/post/115705/ | null | ru | null |
# Об опыте перевода проекта asp.net mvc на .net 4 (mvc 2)
Здравствуйте! В этой статье я расскажу о своем опыте перевода проекта asp.net mvc на .net 4. В сети есть пост под названием [ASP.NET MVC 2 Brings Breaking Changes](http://www.infoq.com/news/2010/03/ASP-MVC-Break). Здесь вы можете ознакомиться с основными нововв... | https://habr.com/ru/post/96825/ | null | ru | null |
# Docker контейнер с данными на Postgres для интеграционного тестирования и лёгким расширением
Про использование `Docker` и `Docker-compose` последнее время написано очень много, например рекомендую [недавнюю статью на Хабре](https://habrahabr.ru/post/322440/), если вы до сих пор не прониклись. Это действительно очень... | https://habr.com/ru/post/328226/ | null | ru | null |
# Сортировка… хэш-таблицей (ещё подсчётом-деревом и HashMap'ом)
Три дня назад я задумался об объединении сортировки подсчётом и деревом. Обсудив её с коллегой, пришли к следующему решению: вместо TreeSet использовать HashMap (при чём здесь вообще TreeSet, можно посмотреть ниже). Но и этого мне показалось мало, так что... | https://habr.com/ru/post/418355/ | null | ru | null |
# Личные цели: контроль версий и красивая распечатка одним щелчком
Приветствую уважаемое сообщество! Как многие успели заметить, прошлый год давно кончился — успешно??? Чтобы с уверенностью судить об этом каждому лично для себя, полезно обзавестись "системой отчетности". Или, по выражению классика, [PAS](http://www.st... | https://habr.com/ru/post/137972/ | null | ru | null |
# Runscript — утилита для запуска python скриптов
Думаю многим знакома следующая ситуация. В вашем проекте есть различные действия, которые нужно выполнять время от времени. Для каждого действия вы создаёте отдельный скрипт на питоне. Чтобы далеко не лазить, скрипт кладёте в корень проекта. Через некоторое время вся к... | https://habr.com/ru/post/248871/ | null | ru | null |
# HPE инвестирует в контейнеры
Сегодня многие технологические компании обращают пристальное внимание на технологию контейнеров. В их числе – Google, IBM, Microsoft и конечно HPE. Контейнеры позволяют «упаковать» в один физический сервер намного больше приложений, чем это позволяют сделать виртуальные машины. Контейнер... | https://habr.com/ru/post/302892/ | null | ru | null |
# Рассказ о том, как создать хранилище и понять Redux
Redux — это интересный шаблон, и, по своей сути, он очень прост. Но почему его сложно понять? В этом материале мы рассмотрим базовые концепции Redux и разберёмся с внутренними механизмами хранилищ. Поняв эти механизмы, вы сможете освоиться со всем тем, что происход... | https://habr.com/ru/post/345340/ | null | ru | null |
# Простыми словами об ARMBIAN
По сути это процесс сборки Linux с описанием некоторых проблем с которыми можно столкнуться при использовании ARMBIAN. Ну и самое главное, из-за чего это понадобилось, это возможность каскадного монтирования файловой системы. Правда используется не AUFS, а Overlay2 поскольку в последних в... | https://habr.com/ru/post/702400/ | null | ru | null |
# Нельзя просто так взять и обратиться к фоновой странице
Всё дело — в политике безопасности, аналогичной кроссдоменной. Обращение к страницам других табов или к фоновой странице расширения сознательно ограни... | https://habr.com/ru/post/174745/ | null | ru | null |
# Создание игры Match-3 в Unity

Несколько лет назад на [SeishunCon](http://seishun-con.com/) я заново открыл для себя игры match-3. Я играл в Dr. Mario детстве, но такие более соревновательные игры, к... | https://habr.com/ru/post/329016/ | null | ru | null |
# JMeter: забудьте про BeanShell Sampler
С помощью стандартных элементов тест-плана в Jmeter можно сделать многое, но далеко не всё. Для расширения функциональности и реализации более сложной логики принято использовать BeanShell Sampler — как-то во всём мире так исторически сложилось. И во всём мире от этого периодич... | https://habr.com/ru/post/250731/ | null | ru | null |
# inter-AS Option AB (D)
Для того, чтобы прокинуть L3VPN между разными автономными системами, необходимо использовать опции протокола BGP — A, B или C. Если кто не знает, как работают эти опции, то прошу [сюда](https://habrahabr.ru/post/302600/). У каждой из данных опций есть как плюсы, так и минусы. Остановимся на ка... | https://habr.com/ru/post/303386/ | null | ru | null |
# 5 вещей, которые я узнал, доведя Snowpack до 20000 GitHub-звёзд
Меня зовут [Фред](https://twitter.com/FredKSchott). Я — создатель [Snowpack](https://snowpack.dev/). Для тех, кто не знаком с этим проектом, расскажу в двух словах о том, что он собой представляет. Это — инструмент для сборки фронтенда веб-сайтов, котор... | https://habr.com/ru/post/580276/ | null | ru | null |
# Подгон под MNIST-овский датасет
В интернете можно найти 1000 и 1 статью по тренингу мнистовского датасета для распознавания рукописных чисел. Однако когда дело доходит до практики и начинаешь распознавать собственные картинки, то модель справляется плохо или не справляется вовсе. Конечно же мы можем перевести картин... | https://habr.com/ru/post/668144/ | null | ru | null |
# Основы JavaScript для начинающих разработчиков
Материал, перевод которого мы сегодня публикуем, посвящён основам JavaScript и предназначен для начинающих программистов. Его можно рассматривать и как небольшой справочник по базовым конструкциям JS. Здесь мы, в частности, поговорим о системе типов данных, о переменных... | https://habr.com/ru/post/416375/ | null | ru | null |
# iOS: работа с галереей (Photos framework)
Привет, Хабр! В данной статье решил написать о том, как работать с галереей с помощью фреймворка Photos. В этой статье рассмотрим базовые возможности фреймворка: создание альбома, сохранение, удаление и загрузку фото. Если будут положительные отзывы, то в следующих частях на... | https://habr.com/ru/post/318810/ | null | ru | null |
# Использование Paint в качестве редактора уровней
Всю сознательную программистскую деятельность я увлекался созданием игр и не любил делать редакторы и прочие утилиты. Главным моим редактором почти всегда был Paint. Но для игр, в которых уровень статичен и состоит из тайлов (Марио подобные и прочие танчики), это боле... | https://habr.com/ru/post/195338/ | null | ru | null |
# Установка и настройка Debian Linux под Hyper-V
Давайте продолжим наши упражнения в виртуализации Linux систем под Hyper-V. Сегодня мы займемся установкой и настройкой Debian 6 под Hyper-V. Все что я буду писать ниже можно применять не только к Debian 6, но и к Debian 5 и к остальным дистрибутивам основанным на Debia... | https://habr.com/ru/post/115630/ | null | ru | null |
# Очередной универсальный интернет каталог средствами реляционной СУБД
Одним из главных требований к каталогу является возможность быстро искать и находить его элементы по различным критериям.
Существует множество подходов к реализации таких требований. Это и nosql решения и механизмы работы с json в реляционных СУБД... | https://habr.com/ru/post/595411/ | null | ru | null |
# Регулировка contentOffset с помощью UICollectionViewLayout
Один из распространенных UI элементов в iOS является `UICollectionView`.
Часто при построении таких коллекций возникает необходимость обновления данных, например добавления новых ячеек в коллекцию.
Рассмотрим простой пример - список новостей, вертикальный ... | https://habr.com/ru/post/666216/ | null | ru | null |
# Dart Code Metrics 4.0: команды, поддержка монорепозиториев и новые правила
В предыдущей [статье](https://habr.com/ru/company/wrike/blog/552012/) мы анонсировали [Dart Code Metrics](https://github.com/dart-... | https://habr.com/ru/post/573140/ | null | ru | null |
# Сравниваем производительность C# и C++ в задачах обработки изображений
Бытует мнение, что C# не место в вычислительных задачах, и мнение это вполне обоснованное: JIT-компилятор вынужден компилировать и оптимизировать код на лету в процессе выполнения программы с минимальными задержками, у него попросту нет возможнос... | https://habr.com/ru/post/532442/ | null | ru | null |
# Бюджетное SAN-хранилище на LSI Syncro, часть 1

[Вторая часть](https://habr.com/post/253741/)
Итак, продолжу свои [редкие](http://habrahabr.ru/post/209460/) [статьи](http://habrahabr.ru/post/209666/) на тему «как не пл... | https://habr.com/ru/post/252403/ | null | ru | null |
# Самая первая серьезная уязвимость в Blockchain и как получить публичный ключ Bitcoin ECDSA значение RSZ из файла RawTX
 В этой статье мы поговорим о извлечение значений подписи `ECDSA R, S, Z` из блокчейна ... | https://habr.com/ru/post/674736/ | null | ru | null |
# Использование ORM при разработке корпоративных приложений
Есть много [споров](http://habrahabr.ru/post/123293/) о плюсах и минусах [ORM](http://ru.wikipedia.org/wiki/ORM), попробуем сделать акцент на плюсах при его использовании в ERP приложениях.
Я 5 лет разрабатываю платформу для ERP, разработал три версии плат... | https://habr.com/ru/post/140713/ | null | ru | null |
# Окна на чистом WinAPI. Или просто о сложном
*Disclaimer*
Казалось бы, что WinAPI уходит в прошлое. Давно уже существует огромное количество кросс-платформенных фреймфорков, Windows не только на десктопах, да и сами Microsoft в свой магазин не жалуют приложения, которые используют этого монстра. Помимо этого стате... | https://habr.com/ru/post/352096/ | null | ru | null |
# Пишем простой парсер web страниц
Здравствуйте. Меня зовут Сережа. Я хочу рассказать о том, как я писал простейшего вэб паука.

Поскольку это некоммерческий проект, созданный исключительно на моём... | https://habr.com/ru/post/309428/ | null | ru | null |
# Что должен, но не знает про конкуренцию в PostgreSQL каждый разработчик?
Опыт показывает, что разработчики редко задумываются о проблемах, которые могут возникать при многопользовательском доступе к данным... | https://habr.com/ru/post/581854/ | null | ru | null |
# Обзор модульного и интеграционного тестирования Spring Boot
Модульное и интеграционное тестирование - неотъемлемая часть вашей повседневной жизни как разработчика. Однако для новичков Spring Boot написание содержательных тестов для своих приложений оказывается проблемой:
* С чего начать мои усилия по тестированию?
... | https://habr.com/ru/post/561520/ | null | ru | null |
# Внедряем Bootstrap 3 Datepicker в SonataAdminBundle
В этой маленькой заметке я расскажу о том, как подключить [удобный datepicker](http://eonasdan.github.io/bootstrap-datetimepicker/) в админку Symfony. По умолчанию datepicker в SonataAdminBundle выглядит так:
Иногда хочется занять свой ноутбук чем-нибудь полезным, да и так чтобы с работой помогало. Несколько лет назад, в университете сталкивался бегло с моделирование мет... | https://habr.com/ru/post/377845/ | null | ru | null |
# Как я стандартную библиотеку C++11 писал или почему boost такой страшный. Глава 3
 ### Краткое содержание предыдущих частей
Из-за ограничений на возможность использовать компиляторы C++ 11 и от безальтернативн... | https://habr.com/ru/post/417295/ | null | ru | null |
# PG Metricus — сбор метрик из plpgsql кода или как три строчки кода упростили жизнь
Начнем с того, что все [ваши объявления живут](https://habrahabr.ru/company/avito/blog/321796/) в базе PostgreSQL. До сих пор львиная часть бизнес-логики скрыта в хранимых процедурах, и не всегда их работу удобно контролировать.
[!... | https://habr.com/ru/post/323900/ | null | ru | null |
# Тай'Дзен: первые шаги
Уважаемое хабрасообщество, приветствую!
В этой статье я хотел бы немного поделиться своим скромным опытом на пути познания Тай’Дзен (или Tizen). Как приобщиться к Истине, я, в меру разумения своего, постарался описать в [предыдущей публикации](http://habrahabr.ru/post/205046/). Будучи верным... | https://habr.com/ru/post/213385/ | null | ru | null |
# Анонс Rust 1.8
Мы рады представить новую версию Rust — 1.8. Rust — это системный язык программирования, нацеленный на безопасную работу с памятью, скорость и параллельное выполнение кода.
Как обычно, вы можете [установить Rust 1.8](https://www.rust-lang.org/downloads.html) с соответствующей страницы официального ... | https://habr.com/ru/post/281152/ | null | ru | null |
# Реализация мгновенного поиска в Android с помощью RxJava

Я работаю над новым приложением, которое, как это обычно и происходит, связывается с бэкенд... | https://habr.com/ru/post/430394/ | null | ru | null |
# Консоли больше не нужны (но это не точно)
Доброго времени суток, уважаемые читатели. Я не знаю делал ли кто-то что-то подобное до меня, поэтому решил поделиться идеей моего [pet-проекта](https://strangebird.ru/) и отнять у вас немного времени.
Вначале был кролик
------------------
С детства я любил играть в игры,... | https://habr.com/ru/post/549628/ | null | ru | null |
# Skyforge: технологии рендеринга

Всем привет! Меня зовут Сергей Макеев, и я технический директор в проекте Skyforge в команде Allods Team, игровой студии Mail.Ru Group. Мне хотелось бы рассказать про технологии рендеринга... | https://habr.com/ru/post/248873/ | null | ru | null |
# Реализация свободного перемещения частиц на ReactJS
Приветствую! Хочу вам показать один из способов, как реализовать свободное перемещение частиц в указанном диапазоне. Для выполнения этой задачи я буду использовать ReactJS. Но сам алгоритм все равно будет общим, и вы можете его использовать где угодно.

Доброго времени суток, друзья!
Данная статья представляет собой небольшую подборку примеров работы с Canvas API, к которой удобно обращаться при необходимости вспомнить изученный материал.
Это ... | https://habr.com/ru/post/500530/ | null | ru | null |
# Архитектура масштабируемой почтовой системы
В этой статье мы рассматриваем один из вариантов реализации масштабируемой архитектуры большой почтовой системы.
6 декабря 2012 г. Google прекратил регистрацию новых аккаунтов для бесплатной версии Google Apps.
У клиентов [нашей компании](http://centos-admin.ru) пост... | https://habr.com/ru/post/167051/ | null | ru | null |
# Создатель Vue.js отвечает Хабру

Всех с пятницей!
Как и обещали, публикуем ответы Эвана Ю (Evan You) на вопросы, которые мы ~~долго и мучительно~~ собирали в [предыдущем посте](https://habrahabr.ru/post/349494/), а также русскоя... | https://habr.com/ru/post/350290/ | null | ru | null |
# Мой путь во Flask. Часть первая
Всем доброго времени суток. В программировании два года назад я был профан, и начал с *Python*, потому что с этим языком была связана моя диссертация, но понял, что не тяну в изучении сам и пошел на курсы, где научили основам *Python*, как делать блог-соцсеть на *Django*, как работать... | https://habr.com/ru/post/680180/ | null | ru | null |
# Linux LiveCD на базе CentOS и техники его использования в PXE-загрузке через Foreman
Получаем управляемую систему сборки и доставки LiveCD
-----------------------------------------------------
*Создатели дистрибутивов Linux предлагают пользователям пригодные для работы без установки образы операционных систем, одна... | https://habr.com/ru/post/663338/ | null | ru | null |
# Phalcon: Давайте учиться на примере

Совсем недавно на хабре [упоминался](http://habrahabr.ru/post/159217/) PHP MVC Framework написанный на языке C, где были описаны его преимущества и недос... | https://habr.com/ru/post/160311/ | null | ru | null |
# Книга «Безопасность веб-приложений»
[](https://habr.com/ru/company/piter/blog/569658/) Привет, Хаброжители! Среди огромного количества информации по сетевой и ИТ-безопасности практически не найти книг по безопасности веб-прилож... | https://habr.com/ru/post/569658/ | null | ru | null |
# XKB: перенастроим клавиши под себя любимого
В один прекрасный день надоедает нажимать Shift, чтобы вывелся символ **~** вместо **`**.
Надоедает тянуться до Esc, при этом клавишей CapsLock пользуетесь РЕДКО.
Надоедает смещать кисть вниз и нажимать Ctrl/Cmd/Win слабым мизинчиком, либо, не дай бог, тянуться до ни... | https://habr.com/ru/post/222285/ | null | ru | null |
# Почему мы выбрали MongoDB
Эта статья появилась на свет после прочтения материала [«Почему вы никогда не должны использовать MongoDB»](http://habrahabr.ru/post/231213/). Ниже — история о том, как мы постепенно отказались от MySQL и пришли к использованию MongoDB в качестве основного хранилища данных.
. В настоящий момент в мире больших данных существуют несколько основных игроков, на которых обращают внимание при выборе инструментария и... | https://habr.com/ru/post/530054/ | null | ru | null |
# Создание библиотеки в стиле Spring Data Repository своими руками при помощи Dynamic Proxy и Spring IoC
А что если бы можно было создать интерфейс, например, такой:
```
@Service
public interface GoogleSearchApi {
/**
* @return http status code for Google main page
*/
@Uri("https://www.google.com")
... | https://habr.com/ru/post/458548/ | null | ru | null |
# Как мы не выиграли хакатон
С 30 ноября по 2 декабря в Москве прошел [PicsArt AI hackathon](https://picsart.ai/ru/hack) c призовым фондом — 100,000$. Основной задачей было сделать AI решение для обработки фото или видео, которое можно будет использовать в приложение PicsArt. Коллега по работе(на тот момент) [Артур Ку... | https://habr.com/ru/post/433586/ | null | ru | null |
# Nginx — уходим на технические работы

Совсем недавно возникла интересная задача: реализовать закрытие доступа к веб-сайту из вне, на время технических работ. Мне показалось, что это довольно распрос... | https://habr.com/ru/post/139968/ | null | ru | null |
# ASP.NET Core RC2: встроенная поддержка модульности (application parts)
Будучи исторически погруженным в вопросы разработки модульных приложения на ASP.NET, первое что я сделал, когда вышел ASP.NET Core RC2 – постарался перевести на него свой модульный фреймворк ExtCore. И вот тут оказалось, что в новой версии все из... | https://habr.com/ru/post/301336/ | null | ru | null |
# Как парсить интернет по-гусиному
“Распарсить сайт” — словосочетание, которое повергало меня в уныние всего полгода назад. В моей голове сразу же проносились знакомые проблемы с настройкой фантома, или возней с селениумом. Мысли о возможной необходимости подменять useragent, пагинации и других действиях во время парс... | https://habr.com/ru/post/271425/ | null | ru | null |
# Квантовые траектории и с чем их едят
Эта небольшая заметка про то, как рисовать красивые картинки, ну и немного про физику, о которой редко говорят, про бомовскую квантовую механику.

Небольшое введение
------------------
Как ... | https://habr.com/ru/post/476948/ | null | ru | null |
# Kodein. Основы
Не нашел понятных гайдов для тех, кто `Kodein` видит в первый раз, а документация не во всех местах прозрачная и последовательная, поэтому хочу поделиться основными возможностями библиотеки с вами. Некоторые возможности библиотеки будут выпущены, но это в основном advanced часть. Здесь же вы найдете в... | https://habr.com/ru/post/431696/ | null | ru | null |
# Алгоритм ранжирования сегментов речной сети с использованием графов для геоинформационного анализа
Привет, Хабр.
В данной статье хотелось бы затронуть тему применения информационных технологий в Науках о Земле, а именно, в Гидрологии и Картографии. Под катом представлено описание алгоритма ранжирования водотоков и... | https://habr.com/ru/post/514526/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.