
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Feathers — UI фреймворк на основе Starling для мобильных и десктоп приложений

Поводом, для написания данного поста, послужил выход новой версии **[UI фреймворка Feathers](http://feathersui.com).**
Являясь AS3 разра... | https://habr.com/ru/post/184232/ | null | ru | null |
# Заметка: Контроль звуковых выходов для программ
Иногда надо иметь отдельный виртуальный "выход" для звука из некоторых программ. Например, на стриме через OBS. Эта программа не поддерживает такое "нативно", но это возможно сделать с помощью PulseAudio.
Делается это с помощью `null sinks` и `модуля loopback`, про ко... | https://habr.com/ru/post/565816/ | null | ru | null |
# Terminal Keynote – показываем презентации в терминале
Terminal Keynote – это, скрипт, созданный Хавьером Нориа (Xavier Noria) для показа своих презентаций на BaRuCo 2012 и RailsClub 2012. Вся его суть в возможности пок... | https://habr.com/ru/post/151512/ | null | ru | null |
# Tarantool vs Redis: что умеют in-memory технологии

В этой статье я хочу сравнить Redis и Tarantool. У меня нет цели сделать громогласный вывод «Tarantool лучше!» или «Redis круче!». Я хочу понять их сходства и отличия, разобрать... | https://habr.com/ru/post/550062/ | null | ru | null |
# Рекомендации после установки Ubuntu 16.10
13 Октября компания Canonical представила Ubuntu 16.10. 16.10 является промежуточным релизом между LTS выпусками и по своей сути служит для отладки и тестирования новых возможностей.
.
Что такое рантайм?
> [**Среда выполнения/рантайм**](https://ru.wikipedia.org/wiki/%D0%A1%D1%80%D0%B5%D0%B4%D0%B0_%D0%B2%D1%8B%D0%BF%D0%BE%D0%BB%D0%BD%D0%B5%D0%BD%D0%B8%D1%8F)(runtime) в... | https://habr.com/ru/post/676102/ | null | ru | null |
# Stream API: универсальная промежуточная операция
Я разрабатываю бесплатную библиотеку [StreamEx](https://github.com/amaembo/streamex), которая расширяет стандартное Java 8 Stream API, добавляя туда новые операции, коллекторы и источники стримов. Обычно я не добавляю всё подряд, а всесторонне рассматриваю каждую поте... | https://habr.com/ru/post/262139/ | null | ru | null |
# STM32 + DHT11
Попал мне в руки датчик температуры и влажности DHT11. Измеряет влажность в пределах 20-90% и температуру от 0 до 50°С. Погрешность измерения влажности 5%, температуры 2°С. Время захвата 1 сек. Интерфейс связи single wire ([datashit](http://www.micro4you.com/files/sensor/DHT11.pdf)). Столь скромные пар... | https://habr.com/ru/post/160017/ | null | ru | null |
# Фишки XAML-разработчика: встраиваемые конвертеры
Разберём интересный и нестандартный сценарий использования конвертеров — *Inline Converter*.

Наверно, некоторые разработчики сталкивались с той проблемой, что при ... | https://habr.com/ru/post/276185/ | null | ru | null |
# Кортежи (tuple) в C#
Кортежи появились в C# начиная с версии 7.0 с целью обеспечения работы с наборами значений. Основное предназначение кортежей - обобщение нескольких элементов в структуру с упрощенным синтаксисом. Для использования кортежей необходим тип System.ValueTuple. Для использования кортежей в более ранни... | https://habr.com/ru/post/573088/ | null | ru | null |
# Port Knocking для Windows
Мне довольно часто приходится настраивать "одинокие" терминальные сервера(и не только терминальные) в "Облаках", с "легким, быстрым" доступом к нему по RDP.
Все объяснения для пол... | https://habr.com/ru/post/697490/ | null | ru | null |
# Визуальные карты сетей кластеров K8s для оценки их производительности
[](https://habr.com/ru/company/ruvds/blog/712536/)
Создание производительных сервисов и систем — основа любого бизнеса. Ежедневно появляются кучи новых техноло... | https://habr.com/ru/post/712536/ | null | ru | null |
# Открытый курс машинного обучения. Тема 6. Построение и отбор признаков
Сообщество Open Data Science приветствует участников курса!
В рамках курса мы уже познакомились с несколькими ключевыми алгоритмами машинного обучения. Однако перед тем как переходить к более навороченным алгоритмам и подходам, хочется сделать ... | https://habr.com/ru/post/325422/ | null | ru | null |
# Мониторинг запросов в Greenplum
О чем статья?
-------------
Всем привет. Меня зовут Дмитрий, я системный архитектор в компании Arenadata, проектирую и разрабатываю системы мониторинга запросов ADCC (Arena... | https://habr.com/ru/post/564552/ | null | ru | null |
# Выращивание искусственного интеллекта на примере простой игры

В этой статье я поделюсь опытом выращивания простейшего искусственного интеллекта (ИИ) с использованием генетического алгоритма, а также расскажу про минимальны... | https://habr.com/ru/post/406673/ | null | ru | null |
# Ещё один формат хранения архивов: dar
Введение
--------
Есть известная поговорка, что системные администраторы делятся на три типа: тех, кто не делает бэкапы; тех, кто *уже* делает бэкапы и тех, кто делает и проверяет, что бэкапы рабочие.
Однако этого недостаточно, и сейчас для пользователя системы бэкапов важен... | https://habr.com/ru/post/215449/ | null | ru | null |
# История небольшого исследования легаси-кода
Хорошо, когда в команде есть кто-то более опытный, кто покажет что и как надо делать, какие грабли и за каким углом подстерегают, и где скачать лучшие чертежи велосипедов за 2007 год на DVD. Эта история о том, как желаемое было выдано за действительное, что получилось в ре... | https://habr.com/ru/post/450384/ | null | ru | null |
# Прощай, ViewState — 2, или В базу его!
Очередной раунд [нелёгкого](http://habrahabr.ru/blogs/net/60170/) [противостояния](http://habrahabr.ru/blogs/net/77187/) с ViewState. На этот раз попробуем сохранять его в БД SQL Server.
Немного повторим теорию. У нас есть класс [PageAdapter](http://msdn.microsoft.com/ru-ru/... | https://habr.com/ru/post/109417/ | null | ru | null |
# Настольные игры для Windows Phone: разведка боем
 Мне повезло работать в Саровском Технопарке – секретном месте на границе Нижегородской области и Мордовского заповедника, где среди снегов и умных ... | https://habr.com/ru/post/139769/ | null | ru | null |
# Хорошо ли вы знаете linear-gradient?
*Работа над переводом [статьи](http://habrahabr.ru/company/paysto/blog/251933/) о проекте singlediv.com показала, что некоторые инструменты CSS имеют более широкое применение, чем я привыкла думать. Но для того чтобы суметь найти это применение, необходимо четко понимать особенно... | https://habr.com/ru/post/256479/ | null | ru | null |
# Apache Bigtop и выбор Hadoop-дистрибутива сегодня
[](https://habr.com/ru/company/rostelecom/blog/499854/)
Наверное, ни для кого не секрет, что прошлый год для Apache Hadoop стал годом больших перемен. В прошлом году произошло слиян... | https://habr.com/ru/post/499854/ | null | ru | null |
# 7 мифов о Linq to Database
Linq появился в 2007 году, тоже же появился первый IQueryable-провайдер — Linq2SQL, он работал только с MS SQL Server, довольно сильно тормозил и покрывал далеко не все сценарии. Прошло почти 7 лет, появилось несколько Linq-провайдеров, которые работают с разными СУБД, победили почти все «... | https://habr.com/ru/post/230623/ | null | ru | null |
# Redux store: Расширение по «горизонтали»
 Когда приложение, использующее [Redux](http://redux.js.org/), разрастается до достаточно больших размеров, количество состояний увеличивается многократно. Для р... | https://habr.com/ru/post/335868/ | null | ru | null |
# Защищаем API – что важно знать?
В фундаменте каждой информационной защиты лежит глубокое понимание технологии целевой системы. В этой статье речь пойдет о защите API (Application Programming Interface) — в... | https://habr.com/ru/post/670500/ | null | ru | null |
# Разбираем iPhone Core Data Recipes. Часть 2
#### **Introduction**
Данная статья, вторая и заключительная статья из серии «Разбираем iPhone Core Data Recipes». Первую часть статьи, вы можете прочитать [тут](http://habrahabr.ru/blogs/macosxdev/136319/). Цель серии статей — помочь начинающему iOS разработчику, понять,... | https://habr.com/ru/post/136344/ | null | ru | null |
# Подключение GPRS-модема к Intel Edison

Эта статья объяснит, как создать сеть передачи данных с использованием протокола PPP, подключив [GPRS-модуль](http://www.seeedstudio.com/wiki/GPRS_Shield_V2.0) к плате Intel Edison.
Устан... | https://habr.com/ru/post/383075/ | null | ru | null |
# Работа распределённой команды в условиях самоизоляции: как мы почти не заметили разницы

Режим самоизоляции многих вынудил работать из дома. Кому-то смена обстановки даётся легче, кому-то сложнее, а кто-то и вовсе не заметил бы раз... | https://habr.com/ru/post/500116/ | null | ru | null |
# Vector Drawable API. Возможности применения
2014 год был особенным для всех, кто занимается разработкой под Android — он принес одно из самых значимых обновлений Android за всю его историю, версию Android 5.0. С этим обновлением мы получили новый визуальный язык, детальные гайдлайны, множество новых API и инструмент... | https://habr.com/ru/post/267073/ | null | ru | null |
# Гадание на нейросетях: отметился ли в комментариях к посту сам автор

Поделюсь рассказом о небольшом проекте: как найти в комментариях ответы автора, заведомо не зная кто автор поста.
Свой проект я начинал с минимальными знани... | https://habr.com/ru/post/441850/ | null | ru | null |
# MastermindCMS2 vs Next.js
Вступление
----------
Подходит к концу 2021 г. и я думаю сейчас самое время подвести итоги как продвигалась веб разработка в условиях пандемии в мире и какие технологии сейчас используются для веб-программирования.
Сегодня я хотел бы затронуть тему фреймворков. И сделать небольшое сравне... | https://habr.com/ru/post/593361/ | null | ru | null |
# Условия if...else
###### Доброго времени суток Хабралюди!
Сегодня для меня великий день.
В вопросах я писал о краткой справке для новичков и профессионалов, думалось мне что я сейчас быстро окунусь в язык, сдела... | https://habr.com/ru/post/140152/ | null | ru | null |
# Пример разработки блога на Zend Framework 2. Часть 3. Работа с пользователями
Это третья (последняя?) часть статьи, посвященной разработке простого приложения при помощи Zend Framework 2. [В первой части](http://habrahabr.ru/post/192522/) я рассмотрел структуру ZendSkeletonApplication, [во второй части](http://habra... | https://habr.com/ru/post/192726/ | null | ru | null |
# Nuke: настраиваем сборку и публикацию .NET-проекта
Введение
--------
В настоящее время существует множество систем CI/CD. У всех есть определенные достоинства и недостатки и каждый выбирает себе наиболее подходящую под проект. Цель данной статьи - познакомить с Nuke на примере web-проекта, использующего уходящий на... | https://habr.com/ru/post/537460/ | null | ru | null |
# Sidecar for a Code splitting

Code splitting. Code splitting is everywhere. However, why? Just because there is **too much of javascript** nowadays, and not all are in use at the same point in time.
JS is a very *heavy* thing. Not... | https://habr.com/ru/post/450942/ | null | en | null |
# PHP-Дайджест № 80 – интересные новости, материалы и инструменты (14 – 28 февраля 2016)

Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
* [Э... | https://habr.com/ru/post/278137/ | null | ru | null |
# Разработка веб-приложений на встраиваемом портале
Java порталы это особый класс веб-приложений позволяющий разрабатывать достаточно сложные и при том модульные информационные системы, которые напоминают Сис... | https://habr.com/ru/post/521498/ | null | ru | null |
# Знакомьтесь с Ember Octane
Ember Octane — это новая редакция фреймворка Ember.js, а также лучший способ для команд создавать амбициозные веб-приложения.
20 декабря вышла новая версия Ember 3.15. И это Octane! Любопытно, что это значит для веб-разработки? Этот пост поможет вам сориентироваться.
Мы с гуглотранслейт... | https://habr.com/ru/post/482158/ | null | ru | null |
# Организация IPAM и переезд с phpIPAM в NetBox: советы и подводные камни
В [прошлой статье](https://habr.com/ru/company/rosbank/blog/654987/) я рассказал о том, как наладить кабель-менеджмент в NetBox — популярном опенсорс-инструменте для документирования инфраструктуры. В этом посте я перейду к тому, как организоват... | https://habr.com/ru/post/678124/ | null | ru | null |
# Уроки компьютерного зрения на Python + OpenCV с самых азов. Часть 8
[**Оглавление**](https://habr.com/ru/post/688316/).
На [прошлом уроке](https://habr.com/ru/post/676838/) мы углубились в изучение контуров. В частности, научились работать со структурой, которую возвращает функция выделения контуров, научились аппр... | https://habr.com/ru/post/687864/ | null | ru | null |
# +(AppStore *) Timera: архитектура приложения и особенности разработки
Настала пора поведать общественности о нашем приложении timera. C сегодняшнего дня его можно скачать в appstore.
Об архитектуре timera расскажет [heximal (Павел)](http://habrahabr.ru/users/heximal/), наш ios разработчик, у него сейчас read only... | https://habr.com/ru/post/212497/ | null | ru | null |
# Виртуальный хостинг для Django (FreeBSD + Apache + mod_python / mod_wsgi)
Создавая новый проект на Django, ты в очередной раз лезешь изменять конфигурации своего web-сервера. И вроде бы ничего страшного, да только конфигур... | https://habr.com/ru/post/138830/ | null | ru | null |
# Обнаружение сетевых устройств
Сканирование сети с построением списка устройств и их свойств, таких как перечень сетевых интерфейсов, с последующим снятием данных в системах мониторинга, если не вникать в происходящее, может показаться особой, компьютерной, магией. Как же это работает — под катом.
 для разработчиков на .NET.
Во первых — абстрагирование от конкретной СУБД.
Во вторых — отсутс... | https://habr.com/ru/post/74009/ | null | ru | null |
# Настройка IPv6 или IPv6 в массы

UPDATE: Так как все это писалось давно, то смысл использовать скрипты сильно теряется, осталось ради истории.
Все можно и наверно лучше настроить через inadyn.
Синтакси... | https://habr.com/ru/post/85777/ | null | ru | null |
# Eval или include?
Один из текущих проектов разрабатываю на собственном фреймворке, параллельно его обкатывая и дописывая. Зачем мне понадобилось изобретать велосипед, и чем он отличается от существующих, напишу когда буду представлять его общественности. Сейчас же хочется поделиться некоторыми мыслями по поводу прои... | https://habr.com/ru/post/24038/ | null | ru | null |
# Лучший технический вопрос, который мне задавали на собеседовании
Много воды утекло с тех пор, как я в последний раз участвовал в собеседовании по программированию как соискатель. Но до сих пор помню особенно полюбившийся мне вопрос с такого собеседования. Дело было в MemSQL, году так в 2013. (Они [даже успели переим... | https://habr.com/ru/post/662247/ | null | ru | null |
# Наследование шаблонов в PHP без использования сторонних библиотек
При разработке Web-приложений мы обязательно сталкиваемся с проблемами рендеринга HTML-страниц. Обычно эти проблемы решает шаблонизатор — собственно PHP или какой-нибудь парсер шаблонов. Если приложение большое и страницы содержат множество блоков, то... | https://habr.com/ru/post/134421/ | null | ru | null |
# PostgreSQL 16: Часть 1 или Коммитфест 2022-07
Август в релизном цикле PostgreSQL месяц особенный. Еще не вышла официально 15-я версия, но уже закончился [первый коммитфест](https://commitfest.postgresql.org/38/) 16-й версии. И мы можем посмотреть на самые интересные изменения.
Собираем сервер из [исходного кода](ht... | https://habr.com/ru/post/681164/ | null | ru | null |
# Работа с игровыми контроллерами

Приветствую, дорогие читатели!
В одном из проектов мне понадобилось работать с [игровыми контроллерами](http://ru.wikipedia.org/wiki/%D0%98%D0%B3%D1%80%D0%BE%D0%B2%D0%BE%D0%B9_%D0%BA%D0%BE%D0... | https://habr.com/ru/post/124851/ | null | ru | null |
# Опыт разработки первой игры на Unity, часть 4
* [Ссылка на часть 1](https://habr.com/ru/post/593399/)
* [Ссылка на часть 2](https://habr.com/ru/post/593401/)
* [Ссылка на часть 3](https://habr.com/ru/post/594069/)
### Или о том, как я обманываю читателей
Дело в том, что я снова ошибся в планах - причем опять на то... | https://habr.com/ru/post/597819/ | null | ru | null |
# Js, трюки, наблюдения, бенчмарки и как Лиса уничтожает Хром. Я протестировал всё, что вам было лень
[](https://habr.com/ru/company/ruvds/blog/712386/)*Картинка, конечно, стронгли анрилейтед*
Разные трюки я тестировал на Google Chro... | https://habr.com/ru/post/712386/ | null | ru | null |
# Selenium для Python. Глава 6. Объекты Страницы
Продолжение перевода неофициальной документации Selenium для Python.
Оригинал можно найти [здесь](http://selenium-python.readthedocs.org/page-objects.html).
Содержание:
-----------
1. [Установка](http://habrahabr.ru/post/248559/)
2. [Первые шаги](http://habrah... | https://habr.com/ru/post/273115/ | null | ru | null |
# NVIDIA Jetson Nano: тесты и первые впечатления
Привет, Хабр.
Относительно недавно, в этом, 2019 году, NVIDIA [анонсировала одноплатный компьютер](https://habr.com/ru/post/444442/) совместимого с Raspberry Pi форм-фактора, ориентированный на AI и ресурсоемкие расчеты.

Краткое введение
----------------
Sony знала, что разработка для 3D-оборудования может становиться очень сложной. Поэтому в дизайне своей первой консоли она стремилась к *пр... | https://habr.com/ru/post/599869/ | null | ru | null |
# О применении RazorPages в консольных и десктопных приложениях
Иногда хочется автоматически создавать текстовые файлы, подставляя в шаблоны значения каких-то полей. Например, это могут быть исходники классов-хелперов на основе какого-то интерфейса, какие-то отчеты в XML, которые хотя и можно сгенерировать полностью п... | https://habr.com/ru/post/664712/ | null | ru | null |
# Применение оконных функций и CTE в MySQL 8.0 для реализации накопительного итога без хаков

***Прим. перев.**: в этой статье тимлид британской компании Ticketsolve делится решением своей весьма специфичной проблемы, демонстрируя пр... | https://habr.com/ru/post/510686/ | null | ru | null |
# Нейросети и трейдинг. Часть 2: набор «сделай сам»
*Продолжение статьи [здесь](https://habr.com/ru/post/562092/).
Добавить нейросеть в MetaTrader5 можно [тут](https://www.mql5.com/ru/blogs/post/746398).*
В [прошлой статье](https://habr.com/ru/post/494964/) я описал как получилось добиться от нейросети предсказ... | https://habr.com/ru/post/521960/ | null | ru | null |
# Настраиваем Out-Of-Memory Killer в Linux для PostgreSQL

Когда в Linux сервер базы данных непредвиденно завершает работу, нужно найти причину. Причин может быть несколько. Например, **SIGSEGV** — сбой из-за бага в бэкенд-сервере. Но ... | https://habr.com/ru/post/464245/ | null | ru | null |
# Covid-19: зачем мы сидим на карантине, и ответы на другие вопросы
Привет Хабр.
Изначально я не планировал публиковать здесь статью про коронавирус, аналитики на хабре уже более чем достаточно. Однако, читая разные местечковые форумы и соцсети, я с удивлением обнаружил сколько достаточно вредных мифов гуляет в сет... | https://habr.com/ru/post/495828/ | null | ru | null |
# FreeBSD Netgraph на примере Ethernet тоннеля
Всем привет.
Думаю многим системным администраторам, работающим с FreeBSD, известно о существовании ядерной подсистемы Netgraph. Но не многие знают/понимают как это работает, и что из этого можно построить.
Расскажу что это такое, а также разберу на простом примере ... | https://habr.com/ru/post/86553/ | null | ru | null |
# Добавляем Pattern Matching и параметризованные методы в Objective-C
Все больше и больше статей на тему «добавь функциональные ~~косты~~ плюшки в свой любимый императивный язык программирования». [Вот недавний пример для Java](http://habrahabr.ru/blogs/java/122919/).
В Objective-C не так давно были добавлены блоки... | https://habr.com/ru/post/123187/ | null | ru | null |
# Как я решил потихоньку учить питон, а попал в дебри CS188.1x Artificial Intelligence
#### Привет Хабр, или введение

Расскажу свою небольшую предысторию.
Как то в очередной раз надоело ковыр... | https://habr.com/ru/post/154959/ | null | ru | null |
# В мире антропоморфных животных: PVS-Studio проверил Overgrowth
Недавно в сети появилась новость о том, что был открыт исходный код игры Overgrowth. Мы не смогли пройти мимо и проверили его качество с помощью PVS-Studio. Давайте же вместе посмотрим, где больше интересного экшена: в игре или в её исходном коде!
-компилятор Питона, конкурирующий по производительности с промышленным решением? С учётом того, что он это сделает за две недели за зачёт по программированию.
Как оказалось, может, ... | https://habr.com/ru/post/674206/ | null | ru | null |
# Notepad++: проверка кода пять лет спустя

В этом году статическому анализатору PVS-Studio исполнилось 10 лет. Правда, стоит уточнить, что 10 лет назад он назывался Viva64. И есть ещё одна интерес... | https://habr.com/ru/post/330394/ | null | ru | null |
# Реализация счетчика наработки на микроконтроллере 1986BE92QI
Здравствуйте. Хочу поделиться алгоритмом и программной реализацией счетчика времени наработки изделия на микроконтроллере 1986BE92QI на языке Си.
Очень часто появляется необходимость отсчитывать время, отработанное некоторым устройством. Для ведения счетч... | https://habr.com/ru/post/571172/ | null | ru | null |
# Как строить красивые графики на Python с Seaborn
> *Будущих студентов курса* [***«Python Developer. Professional»***](https://otus.pw/VvSD/) *и всех желающих приглашаем принять участие в открытом вебинаре на тему* [***«Фреймворкирование и метаклассы».***](https://otus.pw/r5LF/) *А сейчас делимся традиционным перевод... | https://habr.com/ru/post/540526/ | null | ru | null |
# Настройка с нуля сервиса управления ИБП Network UPS Tools (NUT) для управления локально подключенным ИБП
Настройка Network UPS Tools на Linux на примере ИБП Eaton 5E650iUSB
===================================================================
Описание
--------
Сервис Linux NUT (Network UPS Tools) — это комплекс прог... | https://habr.com/ru/post/443736/ | null | ru | null |
# Сервис push-уведомлений Pushover для Android и iOS в связке с PHP

Вкратце, **push-уведомления** — это небольшие по объему важные сообщения от программы или сервиса, отображаемые операционной системой тогда, когда вы не... | https://habr.com/ru/post/159649/ | null | ru | null |
# Аналог фейсбучной ленты для Телеграма. Тупенький ИИ OLEG
Этот пост — о том, как я решил сделать систему коллаборативной фильтрации постов из пабликов Телеграма на основе машинного обучения.
И сделал: [OLEG AI](http://t.me/olegaibot)
Идея
----
В мире наступает революция ИИ, и в какой то момент мне стало казаться, ... | https://habr.com/ru/post/555726/ | null | ru | null |
# Поваренная книга разработчика: DDD-рецепты (5-я часть, Процессы)
Введение
========
В рамках предыдущих статей мы описали: [область применения](https://habr.com/post/426663/), [методологические основы](https://habr.com/post/428209/), [пример архитектуры](https://habr.com/ru/post/429750/) и [структуры](https://habr.c... | https://habr.com/ru/post/454668/ | null | ru | null |
# Как мы превратили задание для найма тестировщиков в интерактив для конференции и читателей «Хабра»
Месяц назад мы приняли участие в конференции [SQA Days](https://sqadays.com/ru/index). Наши эксперты выст... | https://habr.com/ru/post/559126/ | null | ru | null |
# Cicada 3301: кого и куда должны были отобрать загадки таинственной «Цикады»? Часть 1
[](https://habr.com/ru/company/ruvds/blog/714806/)
Рассуждая о крипоте в [прошлой статье](http://habr.com/ru/company/ruvds/blog/713396/), мы кос... | https://habr.com/ru/post/714806/ | null | ru | null |
# Паттерн: Сага
Привет, Хабр! Представляю вашему вниманию перевод статьи ["Pattern: Saga"](https://microservices.io/patterns/data/saga.html) автора Chris Richardson.
Ситуация
--------
Есть приложение, к которому применялся паттерн [Database per Service](https://microservices.io/patterns/data/database-per-service.htm... | https://habr.com/ru/post/427705/ | null | ru | null |
# Эмулятор PS2 на Android — ёжик плакал и кололся, но продолжал есть кактус
Привет всем читателям!
Я продолжаю тему программного эмулятора для PlayStation 1, PlayStation 2 и PlayStation Portable — Omega Red. Более подробно:
* [Редизайн пользовательского интерфейса эмулятора Omega Red (Вторая серия)](https://habr... | https://habr.com/ru/post/520744/ | null | ru | null |
# Сказ о курсовой
Здравствуйте. Я хочу рассказать о своей курсовой или к чему приводит любопытство.
Давно от нечего делать пишу программки под симбиан. И время от времени сталкивался со странностями при сборке. Все указывало на утилиту elf2e32. Ее задача — преобразование входного бинарного файла формата elf в другой,... | https://habr.com/ru/post/430794/ | null | ru | null |
# Быстрый ввод в Java
Доброго времени суток!
Данная статья будет полезна для прикладных программистов или людей, увлекающихся спортивным программированием. Она расскажет о быстром вводе данных на языке Java.
Я часто решаю задаче на сайте [www.spoj.pl](http://www.spoj.pl) и иногда сталкиваюсь с проблемами скорост... | https://habr.com/ru/post/91283/ | null | ru | null |
# Характер Kotlin
Привет, Хабр! Надеемся в обозримом будущем и до Kotlin добраться. Мимо этой статьи (февральская) пройти не смогли.
Читаем и комментируем!
Я только что дочитал книгу [Брюса Тейта](https://en.wikipedia.org/wiki/Bruce_Tate) "[Семь языков за семь недель](https://pragprog.com/book/btlang/seven-lang... | https://habr.com/ru/post/353946/ | null | ru | null |
# Как передать полиморфный объект в алгоритм STL
Как мы можем прочесть в первой главе книги [Effective C++](https://www.amazon.com/gp/product/0321334876/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0321334876&linkCode=as2&tag=fluentcpp-20&linkId=c827183fcb052e6a805d39ee7d66095), язык С++ является по сути ... | https://habr.com/ru/post/354198/ | null | ru | null |
# Возвращение в строй маршрутизатора Cisco с нерабочей CF или mini-flash картой
Как-то электрикам потребовалось провести плановые работы с отключением оборудования организации. По плану на ночь сотрудники выключают оборудование, электрики ночью работают, а утром сотрудники всё включают и радуются. Вечером отключили се... | https://habr.com/ru/post/335648/ | null | ru | null |
# Unity: 8 причин отказаться от Coroutine в пользу Async
Введение
--------
Когда речь заходит об асинхронных операциях в Unity, на ум первым делом приходит coroutine. И это не удивительно, так как большинство примеров в сети реализованы именно через них. Но мало кто знает, что Unity поддерживает работу с async/await ... | https://habr.com/ru/post/652483/ | null | ru | null |
# Cacheops
Некоторое время назад [я писал о системе кеширования](http://habrahabr.ru/blogs/algorithm/120471/). Помнится, я обещал продолжение, но сейчас решил, что строка кода лучше сотни комментариев, теорию оставим на потом. Поэтому сегодня у нас своего рода анонс с парой советов по использованию в одном флаконе. Вс... | https://habr.com/ru/post/129122/ | null | ru | null |
# История про хитрожо… индуса, encrypted procedures, DAC и «режим Бога»
На той неделе пришлось разбираться в логике работы одного бесплатного тула. Почти детективная история вышла с ее автором, который впоследствии оказался инд... | https://habr.com/ru/post/278737/ | null | ru | null |
# Наивный Байес, или о том, как математика позволяет фильтровать спам
Привет! В этой статье я расскажу про байесовский классификатор, как один из вариантов фильтрации спам-писем. Пройдемся по теории, затем закрепим практикой, ну и в конце предоставлю свой набросок кода на мною обожаемом языке R. Буду стараться излагат... | https://habr.com/ru/post/415963/ | null | ru | null |
# Ускоряем передачу данных в localhost
[](https://habrahabr.ru/post/320508)
Один из самых быстрых способ межпроцессного взаимодействия реализуется при помощи разделяемой памяти (Shared Memory). Но мне казало... | https://habr.com/ru/post/320508/ | null | ru | null |
# Заменяем бут-анимацию Android устройства на мелькающие логи Linux ядра
После разработки кастомного загрузчика для своего телефона мне захотелось реализовать вывод ядерных логов на дисплей, как это умеют делать десктопные дистрибутивы Linux. А всё потому, что лично мне при загрузке телефона намного интереснее наблюда... | https://habr.com/ru/post/310886/ | null | ru | null |
# Тестирование «РУСТЭК-платформа»
*В связи с уходом некоторых вендоров из России мы решили потестировать отечественные системы виртуализации. Одним из главных критериев для нас как облачного провайдера было наличие мультитенантности. Именно по этой причине среди прочих взяли на тестирование отечественную систему вирту... | https://habr.com/ru/post/709570/ | null | ru | null |
# Тонкости R. Как минута час экономит
Довольно часто enterprise задачи по обработке данных затрагивают данные, сопровождаемые временной меткой. В R такие метки, обычно хранятся как класс `POSIXct`. Выбор методов работы с таким типом данных по принципу аналогии может привести к большому разочарованию и убеждению о край... | https://habr.com/ru/post/322890/ | null | ru | null |
# Реализация HTTP server push с помощью Server-Sent Events
На эту тему было уже много статей, но раскрыта далеко не вся правда. Для тех, кто пропустил — читайте [Создание приложений реального времени с помощью Server-Sent Events](http://habrahabr.ru/blogs/javascript/120429/) .
#### Как же работает Server-Sent-Event... | https://habr.com/ru/post/122783/ | null | ru | null |
# Проброс DLNA в удаленную сеть
**Предыстория**:
Итак, появилась необходимость дать возможность просматривать фильмы с моего сервера на телевизоре. Ну казалось бы, поднимаем DLNA, например miniDLNA и проблема решена. Так и было, пока не появилась нужда дать такую же возможность родителям, которые живут в другом мес... | https://habr.com/ru/post/267149/ | null | ru | null |
# Инструкция: как расширить файловую систему в Linux. Часть 1

Чаще всего задача расширить файловую систему возникает при работе с облачной инфраструктурой. Виртуализация позволяет экономить на дисковом пространстве и выделять... | https://habr.com/ru/post/679176/ | null | ru | null |
# Выявление скрытых зависимостей в данных для повышения качества прогноза в машинном обучении
План статьи
-----------
1. Постановка задачи.
2. Формальное описание задачи.
3. Примеры задач.
4. Несколько примеров на синтетических данных со скрытыми линейными зависимостями.
5. Какие ещё скрытые зависимости могут содержа... | https://habr.com/ru/post/339250/ | null | ru | null |
# Управление самобалансирующим роботом EduMip с помощью джойстика PS4 dualshock 4 через ROS
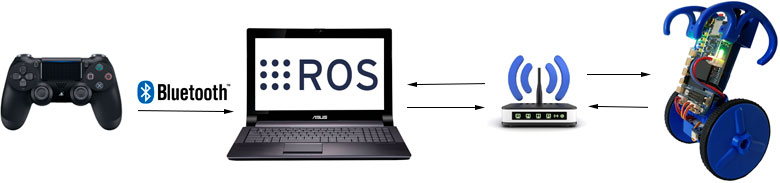
Это простой пример про то, как с помощью ROS можно связать несколько устройств по сети и пересылать данные управления.
Под катом в конц... | https://habr.com/ru/post/413901/ | null | ru | null |
# Интерполяция — мать анимации — Твинеры в Unity
Одним из неотъемлемых элементов игровых приложений, обеспечивающих красочный пользовательский опыт, является анимация. Основным компонентом Unity для анимации является **"Mecanim"**, имеющий более привычное название **"Аниматор"**. Это очень мощный инструмент, позволяющ... | https://habr.com/ru/post/572860/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.