
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Структура DNS пакета

Предисловие
===========
Решил как то написать снифер DNS, так сказать just for fun. Просто посмотреть какие адреса в моей системе резолвятся. Протокол старый, документации должно быть много. Много. Но все ста... | https://habr.com/ru/post/478652/ | null | ru | null |
# Новые возможности в WinAPI на Windows 11
С выходом новой операционной системы, у Microsoft изменились приоритеты в дизайне - теперь у интерфейса появились анимации, да и в целом он стал менее острым. В данной статье я поделюсь некоторыми фишками, с которыми столкнулся в процессе работы с WinAPI.
Все параметры в это... | https://habr.com/ru/post/658067/ | null | ru | null |
# Shrimp: масштабируем и раздаем по HTTP картинки на современном C++ посредством ImageMagic++, SObjectizer и RESTinio

Предисловие
===========
Наша небольшая команда занимается развитием двух OpenSource инструментов для C++разрабо... | https://habr.com/ru/post/416387/ | null | ru | null |
# Простой Telegram-бот на Flask с информированием о погоде
Всем привет, в этой статье я расскажу как сделать простейшего телеграмм бота на Python для отправки текущей погоды в Москве.
Статья расчитана на новичков в Python, которые бы хотели узнать больше о том, как взаимодействовать с внешними сервисами по API.
Техн... | https://habr.com/ru/post/495036/ | null | ru | null |
# Precise timestamp
Пока идёт горячее обсуждение быть или нет быть **jigsaw** в **java 9** и в каком виде ему быть — не стоит забывать про полезняшки, которые несёт с собой девятка — и одна из них — повышение точности **Clock.systemUTC()** — [JDK-8068730](https://bugs.openjdk.java.net/browse/JDK-8068730).
Что же был... | https://habr.com/ru/post/328334/ | null | ru | null |
# Создаём отзывчивые письма для будущего без медиа-запросов
Создавая HTML код для email, приходится иметь дело с изрядным количеством больных вопросов. И вряд ли для кого то будет приемлемо, если нам к тому же ещё и придётся следить за новыми email-клиентами и размерами устройств, которые появляются каждую неделю. Под... | https://habr.com/ru/post/259793/ | null | ru | null |
# На каких серверах держится Архив Интернета?
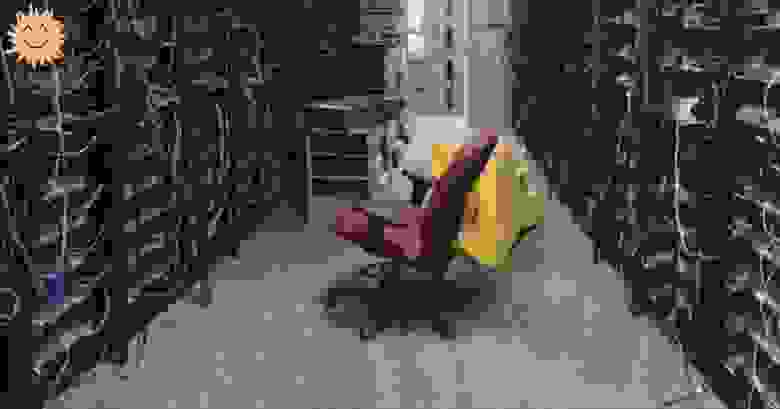
*Фото 1. Один из дата-центров Internet Archive в Сан-Франциско*
[Internet Archive](https://archive.org/) — некоммерческая организация, которая с 1996 года сохраняет копии веб-страни... | https://habr.com/ru/post/549520/ | null | ru | null |
# Поиск похожих групп и пабликов Вконтакте
На днях удалось провернуть интересную штуку. Для всех групп Вконтакте с числом подписчиков от 5000 до 10 000 (~100 000 групп) был построен полный граф, в котором веса рёбер равнялись пересечению аудиторий групп.

[Реализация итераторов в C# (часть 1)](http://habrahabr.ru/blogs/net/136828/).
Теперь, когда вы имеете в своём багаже общее представление о том, что стоит за итераторами, вы уже можете ответить на некоторые вопросы их использования. Вот сценарий, основанный на реальных события... | https://habr.com/ru/post/136864/ | null | ru | null |
# #00 — И целого байта мало… | Приглашение на Revision Online 2020
Дамы, господа, как бодрость духа?
От лица [**=RMDA**=](https://rmda.su/) приглашаю вас на [**Revision Online 2020**](https://2020.revision-party.net). Как вы отлично знаете, коронавирус лютует, отменены не только крупные мировые конференции, но даже... | https://habr.com/ru/post/492984/ | null | ru | null |
# JUCE — Кроссплатформенный C++ фреймворк для разработки приложений с пользовательским интерфейсом

Приветствую хабросообщество!
Наверно каждый кто профессионально разрабатывает ПО или просто увлека... | https://habr.com/ru/post/209956/ | null | ru | null |
# Снова про шаблоны C++ в микроконтроллерах
Вступление
----------
Идея использования шаблонов языка C++ для программирования контроллеров не является чем-то новым, в сети доступно большое количество материалов. Кратко напомню основные преимущества: перенос значительной части ошибок из runtime в compile-time за счет ... | https://habr.com/ru/post/540064/ | null | ru | null |
# Обновление MS16-072 ломает Group Policy. Что с этим делать?

Ничего не предвещало беды в прошлый «вторник обновлений» (14 июня): бюллетень обновлений содержал лишь сухой списо... | https://habr.com/ru/post/304202/ | null | ru | null |
# Приводим в порядок задачи с помощью Todoist
Совсем недавно я ввел для себя практику планировать задачи на предстоящую неделю. Недавно, потому что мой список задач, которые нужно сделать, выглядит как куча мусора, в котором тяжело ориентироваться. Разбирать эту груду для меня скорее было занятием неприятным, чем увле... | https://habr.com/ru/post/586180/ | null | ru | null |
# 6 лучших практик безопасности для Go
***Перевод статьи подготовлен специально для студентов курса [«Разработчик Golang»](https://otus.pw/gOgh/).***

---
Популярность Golang за последние годы существенно увеличилась. Успешные пр... | https://habr.com/ru/post/488724/ | null | ru | null |
# Вывод типов в программировании
При написании алгоритмов зачастую возникает ситуация, когда какая-то функция нуждается в вызове с тем же количеством аргументов, но с не совпадающими типами. Решаем.
Надуманный пример на C++:
```
#include
#include
using namespace std;
void a(int x)
{
cout<<"number\n";
}
void... | https://habr.com/ru/post/309074/ | null | ru | null |
# Очень удобный абстрактный адаптер для RecyclerView своими руками
Когда-то, на заре моей карьеры Android-разработчиком, я просматривал примеры уже имеющихся приложений и в прекрасном, словно солнышко весной, [U2020](https://github.com/JakeWharton/u2020) я нашел пример очень удобного адаптера. Имя его [BindableAdapter... | https://habr.com/ru/post/269057/ | null | ru | null |
# Заметка о Redux и Zustand

Привет, друзья!
На днях мне на глаза попалась [статья](https://blog.openreplay.com/building-a-shopping-cart-in-react-with-redux-toolkit-and-redux-persist), посвященная разработке корзины товаров на [Reac... | https://habr.com/ru/post/683726/ | null | ru | null |
# Запросы в PostgreSQL: 7. Сортировка и слияние
В предыдущих статьях я писал про [этапы выполнения запросов](https://habr.com/ru/company/postgrespro/blog/574702/), про [статистику](https://habr.com/ru/company/postgrespro/blog/576100/), про два основных вида доступа к данным — [последовательное сканирование](https://ha... | https://habr.com/ru/post/582058/ | null | ru | null |
# Изучаю Akka.NET: Сервер простой онлайн игры
Привет, Хабр! Решил я значит попробовать переписать тот сервер что делал с MS Orleans на Akka.NET просто чтобы попробовать и эту технологию тоже. Если вам интересно что получилось до добро пожаловать под кат.
Исходники
---------
[gitlab.com/VictorWinbringer/msorleanson... | https://habr.com/ru/post/500232/ | null | ru | null |
# Ингредиенты IoT деликатесов быстрого приготовления: Intel Edison + Intel XDK + JavaScript + Grove Kit
Насколько быстро можно создать устройство для Интернета вещей (IoT), которое управляется через браузер, получает и передает информацию, учитывая, что вы никогда не работали с микроконтроллерами, а только занимались ... | https://habr.com/ru/post/260259/ | null | ru | null |
# Redux: попытка избавиться от потребности думать во время запросов к API, часть 2
Мы хотим создать пакет, который позволит нам избавиться от постоянного создания однотипных reducer'ов и action creator'ов для каждой модели, получаемой по API.
Первая часть — [вот эта вот](https://habrahabr.ru/users/geoolekom/topics/) ... | https://habr.com/ru/post/330634/ | null | ru | null |
# IOptions и его друзья
Во время разработки часто возникает потребность для вынесения параметров в конфигурационные файлы. Да и вообще — хранить разные конфигурационный константы в коде является признаком дурного тона. Один из вариантов хранения настроек — использования конфигурационных файлов. .Net Core из коробки ум... | https://habr.com/ru/post/507442/ | null | ru | null |
# Повороты экрана в Android без боли

**Важно!**
Изначально в статье была реализация с ошибкой. Ошибку исправил, статью немного поправил.
Предисловие
-----------
Истинное понимание проблем каждо... | https://habr.com/ru/post/328512/ | null | ru | null |
# JavaScript: заметка об операторе конвейера

Привет, друзья!
В этой небольшой заметке я хочу рассказать вам об одном интересном предложении по дальнейшему совершенствованию всеми нами любого JavaScript, а именно: об [`операторе к... | https://habr.com/ru/post/713768/ | null | ru | null |
# #PostgreSQL. Ускоряем деплой в семь раз с помощью «многопоточки»
Всем привет! Мы на проекте ГИС ЖКХ используем PostgreSQL и недавно столкнулись с проблемой долгого выполнения SQL скриптов из-за быстрого увеличения объема данных в БД. В феврале 2018 года на PGConf я рассказал, как мы решали эту проблему. Слайды презе... | https://habr.com/ru/post/351160/ | null | ru | null |
# Собеседование по Javascript, мой опыт. Часть вторая
> *“*И есть еще белые, белые дни, белые горы и белый лед.
> Но все, что мне нужно - это несколько слов и место для шага вперед.*”*
>
> *(Виктор Цой)*
>
>
Введение
--------
Это вторая часть статьи, где будут вопросы, которые мне задавали и ответы на них. Я н... | https://habr.com/ru/post/651527/ | null | ru | null |
# Esp8266 управление через интернет по протоколу MQTT

Всем привет! В этой статье будет подробно рассказано и показано как буквально за 20 минут свободного времени настроить дистанционное управление модулем esp8266 с помощ... | https://habr.com/ru/post/393277/ | null | ru | null |
# Краш-курс по интерфейсам в Go
Интерфейсы в Go представляют собой одну из отличительных особенностей языка, формирующих способ решения задач. При схожести с интерфейсами в других языках, интерфейсы Go всё же имеют важные отличия и это поначалу приводит к избыточному переиспользованию интерфейсов и путанице в том, как... | https://habr.com/ru/post/276981/ | null | ru | null |
# Асинхронный UI: будущее веб-интерфейсов
В то время как Ajax стал мейнстримом, пользовательские интерфейсы по-прежнему не могут похвастаться мгновенной отзывчивостью к действиям пользователя. Причина в том, что многие разработчики привыкли мыслить в терминологии «запрос/ответ» и думают, что UI должен работать паралле... | https://habr.com/ru/post/132834/ | null | ru | null |
# Web Scraping
Введение
--------
Всем привет. Недавно у меня возникла идея о том, чтобы поделиться с интересующимся кругом лиц о том как пишутся скраперы. Так как большинству аудитории знаком Python все дальнейшие примеры будут написаны на нём.
Данная часть рассчитана для того, чтобы познакомить тех, кто ещё не проб... | https://habr.com/ru/post/488720/ | null | ru | null |
# Configuration file htaccess
Let’s begin from a far distance with the goal that the novices can see how the file described in the article works. To work the website on the Internet, you need not just a PC and access to the network, yet additionally, extraordinary programming introduced on it, which gives access to in... | https://habr.com/ru/post/460459/ | null | en | null |
# Пример использования Java утилиты javap
JDK поставляется с рядом полезных утилит, размещенных в каталоге инструментов bin. Для тех, кто хочет декомпилировать байт-код, особый интерес *представляет* Java утилита *javap*.
Утилита командной строки *javap,* также известный как дизассемблер файлов классов Java, выводит ... | https://habr.com/ru/post/592161/ | null | ru | null |
# Новости из мира OpenStreetMap № 466 (18.06.2019-24.06.2019)
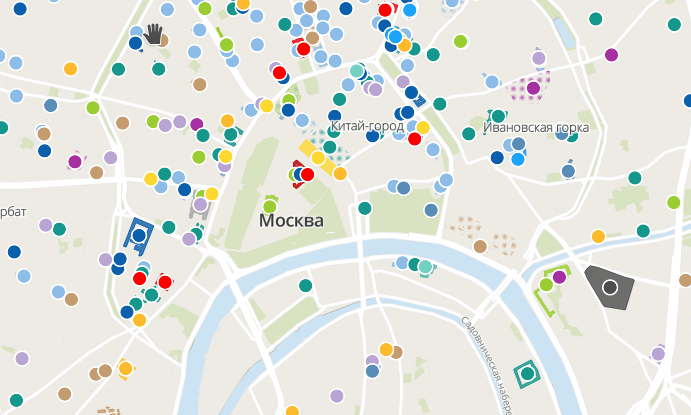
Места в Москве, которые связаны с террором во время СССР [1](#wn466_20339) | NextGIS | Map data OpenStreetMap contributors, ODbL
Картографир... | https://habr.com/ru/post/458460/ | null | ru | null |
# Работа с API КОМПАС-3D → Урок 16 → Управляющие символы
Продолжаем цикл статей по работе с API САПР КОМПАС-3D. Управляющие символы уже несколько раз встречались нам на предыдущих уроках цикла. Тогда каждый раз говорилось, что выводимые строки не должны их содержать, так как КОМПАС обрабатывает их особым образом. Тепе... | https://habr.com/ru/post/457702/ | null | ru | null |
# Апокалипсис грядёт
Есть такая проблема — в 2038м году [количество секунд с начала эпохи Unix Time перевалит за величину signed int и исчезнет.](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B1%D0%BB%D0%B5%D0%BC%D0%B0_2038_%D0%B3%D0%BE%D0%B4%D0%B0) Это как проблема 2000 года, только намного сложнее, потому что ... | https://habr.com/ru/post/485546/ | null | ru | null |
# Поддержка подогретого бэкапа средствами двух MikroTik'ов
[В прошлой статье](http://habrahabr.ru/post/135541/) я рассказал о возможном способе снимать централизованные резервные копии конфигураций с маршрутизаторов MikroTik. Казалось бы на этом можно и успокоиться, но для некоторых филиалов руководство требует сиюмин... | https://habr.com/ru/post/140866/ | null | ru | null |
# Hascgi y или пароли в открытом доступе
CPanel, панель управления хостингом, при создании аккаунта выводит примерно такое:
```
| Domain: masterrr.name
| Ip: 123.456.789.123
| HasCgi: y
| UserName: charlettte
| PassWord: bsd8M1F279G2yTG
```
```
| CpanelMod: x3
| HomeRoot: /homedir
| Quota: infinity Meg
| NameServe... | https://habr.com/ru/post/138127/ | null | ru | null |
# Ваш ход, товарищ .NET, или опять Реверси под nanoCAD
Некоторое время назад у нас было большое событие — выход релиза nanoCAD 3.5. Ключевым нововведением этой версии стало открытое API, о котором и пойдёт речь в данной статье.
Как известно лучший способ что-то изучить – сделать это. Когда-то я писал Реверси под na... | https://habr.com/ru/post/135173/ | null | ru | null |
# Делать хорошо, делая плохо: написание «злого» кода с помощью Go, часть 1
#### *Вредные советы для Go-программиста*

После десятилетий программирования на Java, последние несколько лет я в основном р... | https://habr.com/ru/post/460645/ | null | ru | null |
# Интересные вопросы на знание C# и механизмов .NET
Предлагаю Вам ряд вопросов по C# и .NET в целом, которые могут пригодиться для проведения собеседования или просто помогут лучше понять, как работает платформа .NET. Здесь не будет обычных вопросов о том, чем отличаются ссылочные типы от значимых и тп. Я постарался в... | https://habr.com/ru/post/328504/ | null | ru | null |
# Интересная задачка
Вот такая простенькая задачка поставила меня в тупик:
`var a=2
b=a++ + (--a * ++a)
//Чему равно b?`
Исходя из приоритета операций скобки () имеют наивысший приоритет, значит сначала должно выполняться выражение в скобках, затем все остальное?
Напишите ваш вариант ответа, а потом зап... | https://habr.com/ru/post/77397/ | null | ru | null |
# Пост ненависти к Могучему Шеллу
Написал я как-то давно один простой скрипт, удаляющий в указанной директории все поддиректории с заданными именами:
```
Remove-Item * -Force -Recurse -Include name1,name2,name3 -ErrorAction SilentlyContinue
```
Давно им не пользовался, а тут он понадобился. Запускаю — ничего не уд... | https://habr.com/ru/post/514608/ | null | ru | null |
# Делаем SharePoint Web Part используя xml/xsl
В этой статье я расскажу, как сделать SharePoint WebPart, ~~используя блокнот~~ используя только xml и xsl.
Про разработку web part-ов уже писалось ранее, там же писалось, зачем, собственно, они нужны: [habrahabr.ru/blogs/sharepoint/57992](http://habrahabr.ru/blogs/sha... | https://habr.com/ru/post/58134/ | null | ru | null |
# Недооценённые итераторы
Речь пойдет о стандартной библиотеке шаблонов STL. Будут рассмотрены существующие типы итераторов и их классификация, а также будут предложены несколько новых обёрток над итераторами. Которые позволят в некоторых случаях избежать лямбда-выражений, которых до С++11 как бы и нет.
### Вступит... | https://habr.com/ru/post/122283/ | null | ru | null |
# Лабиринты Бильбо Беггинса

Нет в русском языке нарицательного существительного, которое не годилось бы для фамилии еврея.
И нет на Хабре статьи, которую нельзя было бы сделать игрушкой под iPad.
Для доказательств... | https://habr.com/ru/post/182980/ | null | ru | null |
# Простой монитор системы на Flask
Привет, Хабр!
Недавно возникла необходимость сделать простой и расширяемый монитор использования системы для сервера на Debian. Хотелось строить диаграммы и наблюдать в реальном времени использование памяти, дисков и тп. Нашел много готовых решений, но в итоге сделал скрипт на pyt... | https://habr.com/ru/post/345848/ | null | ru | null |
# Проекты Python в рамках Google Summer of Code — gevent
Уже весна, а это значит… что скоро лето и очередное Google Summer of Code — возможность получить кучу опыта и даже какое-то материальное вознаграждение. Хочу рассказать об одном интересном проекте, которому вы сможете помочь во время летних каникул — [gevent](ht... | https://habr.com/ru/post/87793/ | null | ru | null |
# Мультиклассификация экстремально коротких текстов классическими методами машинного обучения
В мире коммерции существует множество применений классификации текста. Например, новости часто сгруппированы по темам, контент или товары часто помечаются по категориям, а пользователей можно разделить на группы, в зависимост... | https://habr.com/ru/post/584506/ | null | ru | null |
# Запись гитарных аккордов HTML+CSS (пока без барре)
Как обычно представляют гитарные аккорды на веб-страничках?
**Картинками!**
Вот только не всегда это уд... | https://habr.com/ru/post/53792/ | null | ru | null |
# Как не пропустить ни одного сообщения
Обработка событий — одна из самых распространенных задач в области бессерверных технологий. Сегодня расскажем о том, как создать надежный обработчик сообщений, который сведет к нулю их потерю. Кстати, примеры написаны на C# с использованием библиотеки Polly, но показанные подход... | https://habr.com/ru/post/358438/ | null | ru | null |
# Ускоряем рендеринг MatTable за несколько шагов
Часто бывает так, что большую часть приложения составляют различные списки и таблицы. Чтобы каждый раз не изобретать велосипед, я как и многие, чаще использовал [таблицы Angular Material](https://material.angular.io/components/table/overview).
Позже эти таблицы разра... | https://habr.com/ru/post/503844/ | null | ru | null |
# Как я Jest с помощью SWC ускорял
За последние пару лет не раз можно было услышать про новые инструменты сборки статики, такие как SWC, esbuild и Vite. Все они обещают нам next gen-оптимизацию времени сборки... | https://habr.com/ru/post/699582/ | null | ru | null |
# Поднимаем свой DNS-over-HTTPS сервер
Различные аспекты эксплуатации DNS уже неоднократно затрагивались автором в ряде [статей](https://kostikov.co/tag/dns) опубликованных в рамках блога. При этом, основной акцент всегда делался на повышение безопасности этого ключевого для всего Интернет сервиса.

> Зачем нужны кастомные свойства и как они работают?
В языках программирования есть переменные: вы что-нибудь один раз объявляете, присваиваете значение, а потом снова и снова используете. Если значение п... | https://habr.com/ru/post/337292/ | null | ru | null |
# Первая программа для OS X своими руками — менеджер буфера обмена
Больше года прошло с тех пор, как я увлекся программированием под платформу iOS. Наконец-то я нашел свободное время попробовать свои силы на платформе OS X. Если вы давно испытываете интерес к платформе OS X, но никак не соберетесь начать, эта статья д... | https://habr.com/ru/post/197348/ | null | ru | null |
# Новости Yii 2. №1
С тех пор, как расширения PHP фреймворка Yii переехали в отдельные репозитории и начали релизиться независимо, изменений на каждый релиз в них стало меньше и писать на хабре про каждое отдельно стало как-то не правильно. То же и про новости. Вроде и важно, но отдельно на статью не тянет. Однако, но... | https://habr.com/ru/post/316038/ | null | ru | null |
# rpm-gpg-repository-mirroring — Скрипт для скачивания RPM из репозиториев, для которых нельзя сделать yum proxy в Nexus
В некоторых организациях с серверов нет доступа в интернет. В таких случаях делают зеркала основных репозиториев.
Но что делать, если доступ с серверов ограничен, а нужные rpm пакеты нужно установи... | https://habr.com/ru/post/507370/ | null | ru | null |
# Exim + DKIM на примере FreeBSD 8.2
#### Что такое DKIM и как оно работает
**DKIM** (расшифровывается как *DomainKeys Identified Mail*) — метод идентификации письма по доменным ключам.
DKIM настраивается на почтовом сервере для того, чтобы подписывать исходящие письма цифровой подписью. Наличие такой подписи в за... | https://habr.com/ru/post/173605/ | null | ru | null |
# Пользователи: Windows 11 создает множество пустых папок в каталоге
Пользователи Windows 11 [находят](https://borncity.com/win/2021/11/01/auch-windows-11-flutet-ordner-mit-leerem-tmp-verzeichnismll/) в каталоге `C:\Windows\System32\config\systemprofile\AppData\Local` в среднем около 100 пустых временных папок, некото... | https://habr.com/ru/post/586786/ | null | ru | null |
# Понимаем JIT в PHP 8
***Перевод статьи подготовлен в преддверии старта курса [«Backend-разработчик на PHP»](https://otus.pw/DdoM/)***

---
### TL;DR
*Компилятор Just In Time в PHP 8 реализован как часть [расширения Opcache](ht... | https://habr.com/ru/post/509598/ | null | ru | null |
# Создание простого бота для WoW: продолжение
Это продолжение предыдущей статьи:
[Создание простого бота для онлайн-игры world of warcraft](http://habrahabr.ru/blogs/gdev/113258/)
В этой части я рассмотрю процесс взаимодействия с аукционером и почтовым ящиком. Если предыдущая часть была более общая, то эта часть... | https://habr.com/ru/post/113271/ | null | ru | null |
# Debian Lenny 5 «закончился». Переходим на Debian Squeeze 6!
 Как известно, полтора месяца назад (в феврале) закончилась поддержка 5-го Дебиана и он официально канул в лету, т.е. в архив archive.debian.org.
Что делать да... | https://habr.com/ru/post/142413/ | null | ru | null |
# Проектирование в PostgreSQL документо-ориентированного API: Комплексные запросы (Часть 4)
Хранение документов в Postgres немного проще, теперь у нас есть [серьезные процедуры сохранения](http://habrahabr.ru/post/272395/), возможность запускать [полнотекстовый поиск](http://habrahabr.ru/post/272411/), и некоторые про... | https://habr.com/ru/post/272675/ | null | ru | null |
# Безопасная загрузка в i.MX6
Безопасная загрузка в i.MX6
---------------------------
Разрабатывая любой проект для встроенных систем разработчик должен решать два дополнительных вопроса:
* Как защитить прошивку от подмены в изделии;
* Как защитить ПО от копирования.
В данной статье описано как защитить процессор... | https://habr.com/ru/post/488638/ | null | ru | null |
# CDC и логическая репликация для баз данных, реализованных на стеке open source-решений
Привет, Хабр! На связи СберТех — мы создаём Platform V, цифровую платформу Сбера для разработки бизнес-приложений.
В платформу входит более 60 продуктов на базе собственных сборок open source, доработанных до уровня enterprise по... | https://habr.com/ru/post/679028/ | null | ru | null |
# Модификация исходного кода android-приложения с использованием apk-файла
Так уж получилось, что приложение для чтения комиксов и манги, которое я использую на своем android-смартфоне, после обновления стало показывать рекламу в конце каждой главы комикса. Данное приложение пару лет назад было доступно на Google Play... | https://habr.com/ru/post/244457/ | null | ru | null |
# Как я создал лучший colorpicker
Эта статья посвящена тому, как я решил написать свой выбор цвета для сайта, потому что не устраивала кривая работа и тяжеловесность аналогов. Мой код не содержит ни одного плагина или библиотеки, поэтому он максимально простой и производительный.
Начнём с самого начала. Создаём базо... | https://habr.com/ru/post/537944/ | null | ru | null |
# Spring — эффективный роутинг

*[Виктор Васнецов, Рыцарь на распутье; fatcatart.com](https://fatcatart.com/?attachment_id=713&lang=en)*
Привет, Хабр! Здесь краткий пересказ [интересной баги c GitHub](https://github.com/spring-proje... | https://habr.com/ru/post/493448/ | null | ru | null |
# /etc/resolv.conf для Kubernetes pods, опция ndots:5, как это может негативно сказаться на производительности приложения

Не так давно мы запустили Kubernetes 1.9 на AWS с помощью Kops. Вчера, во время плавного выкатывания нового траф... | https://habr.com/ru/post/464371/ | null | ru | null |
# Humane API REST Protocol
Здравствуйте, меня зовут Дмитрий Карловский и я… как скульптор, отрезаю всё лишнее, чтобы оставить лишь самую мякотку, которая в наиболее лаконичной и практичной форме решает широкий круг задач. Вот лишь несколько спроектированных мною вещей:
* [MarkedText](https://habhub.hyoo.ru/#!author=n... | https://habr.com/ru/post/680376/ | null | ru | null |
# Kinect + 3D Display + HTML5
Особенности создания интерактивного 3D HTML5 приложения с использованием сенсора Kinect.
##### Задача
Продемонстрировать 3D фото и видео, отснятое в разных краях нашей большой Родины, на 3D дисплее, причем так, чтобы воспроизведение начиналось тогда, когда пользователь входил в опреде... | https://habr.com/ru/post/172225/ | null | ru | null |
# Создаем NUnit тесты в BDD стиле
Тихим пятничным вечером я заканчивал свой рабочий день покрывая тестами реализованную логику. Названия тестов я тщательно подбирал как и рекомендовал [Рой](http://www.amazon.com/Art-Unit-Te... | https://habr.com/ru/post/156325/ | null | ru | null |
# MySQL.com взломан и продан за 3000$
Вся подробная информация будет под катом.
Видео, демонстрирующее как пользователи заражаются:
##### Шаг 1:
Посещаем сайт [mysql.com](http://mysql.com)
##### Шаг 2:
Загружаем вредоносный скрипт: [mysql.com/common/js/s\_code\_remote.js?ver=20091011](http://mysql.com/comm... | https://habr.com/ru/post/129221/ | null | ru | null |
# Пятничный JS: игра в 0 строк JS и CSS
Возможно, многие из старожилов помнят эпидемию статей с заголовками вида "%something% в 30 строк JS". А также последовавший за ней эпичный пост "[Игра в 0 строк кода на чистом JS](https://habr.com/post/203048/)", после которого эпидемия резко сошла на нет. Полностью осознавая, ч... | https://habr.com/ru/post/419135/ | null | ru | null |
# Создание Comet-приложения с использованием Ajax Push Engine
#### Введение
В этой статье я хочу поделиться опытом построения Web-приложения, работающего в реальном времени. Не буду углубляться в теорию, так как обзоры технологий уже были на хабре, и в сети их при желании найти не проблема. Предлагаю заняться непосре... | https://habr.com/ru/post/116571/ | null | ru | null |
# Мультидоменность в Apache без лишних хлопот на локальном хосте
Интернет пестрит руководствами по настройке виртуальных хостов в Apache. Но, в большинстве случаев, создание такого поддомена представляется хлопотным делом.
По «стандартной» инструкции предлагается сделать следующее:
1. Создать папку для сайта
2.... | https://habr.com/ru/post/129900/ | null | ru | null |
# Ускорение запуска Firefox
Как известно, человек привыкает практически ко всему, в том числе и к неудобствам. Лично меня уже давно раздражает временной интервал между кликом на ярлык Firefox и появлением Его Лисичества, но я терпел. Однако, сегодня звёзды стали так, что решение случайно попало в мои руки.
Меняя ик... | https://habr.com/ru/post/57284/ | null | ru | null |
# Расстановка полей и отступов в CSS

В этой статье я хотел бы рассказать, как правильно расставлять **поля** (`padding`) и **отступы** (`margin`) в CSS.
Прежде всего давайте вспомним определение полей и отступов... | https://habr.com/ru/post/281008/ | null | ru | null |
# Почему я отказался от Rust
Когда я узнал, что появился новый язык программирования системного уровня, с производительностью как у С++ и без сборщика мусора, я сразу заинтересовался. Мне нравится решать задачи с помощью язы... | https://habr.com/ru/post/309968/ | null | ru | null |
# Тестировать только через public-методы плохо
В программировании и в TDD, в частности, есть хорошие принципы, которых полезно придерживаться: DRY и тестирование через public-методы. Они неоднократно оправдали себя на практике, но в проектах с большим legacy-кодом могут иметь «тёмную сторону». Например, ты можешь писа... | https://habr.com/ru/post/419873/ | null | ru | null |
# Chaos Engineering: искусство умышленного разрушения. Часть 3
***Прим. перев.**: Это продолжение цикла статей от технологического евангелиста из AWS (Adrian Hornsby) про довольно новую ИТ-дисциплину — chaos engineering, — в рамках которой инженеры проводят эксперименты, призванные смягчить последствия сбоев в система... | https://habr.com/ru/post/477994/ | null | ru | null |
# Упаковка булевых переменных для хранения и поиска в базе
Столкнулся с необходимостью хранить в базе формы, большая часть из которых являлась «галочками», то есть, по сути булевыми переменными. Создавать под тридцать галочек тридцать полей INT 1 не хотелось стал искать другой метод.
И нашел — битовый массив.
То... | https://habr.com/ru/post/37131/ | null | ru | null |
# Виртуальная АТС МТТ: обзор возможностей
Немного о том, что из себя представляет виртуальная АТС, какова её роль в офисной среде, а также о технических и интеграционных возможностях одного из самых продвинутых и актуальных решений в этой области.
АТС в облаке
------------
Виртуальные АТС, если говорить упрощённо, ... | https://habr.com/ru/post/661875/ | null | ru | null |
# Вейвлет деревья
*Succinct data structures* свежее веяние в алгоритмистике. В русскоязычной школе материала мало, нет даже устоявшегося перевода. Будем восполнять этот пробел. На правах первопроходцев терминологию будем вводить налету. Пусть, *скажем, компактные структуры данных.* На Хабре уже появилась хорошая ознак... | https://habr.com/ru/post/491368/ | null | ru | null |
# Нарушает ли React DOM-стандарты?
Существует довольно популярный сайт <https://custom-elements-everywhere.com> где показывается как работают веб-компоненты в разных фреймворках. Почти у всех фреймворков там красивый 100% результат, но у React там очень настораживающие 71%:
Движение является ключевой частью того, что дела... | https://habr.com/ru/post/705286/ | null | ru | null |
# Работа с геолокациями в режиме highload
При разработке ПО часто возникают интересные задачи. Одна из таких: работа с гео-координатами пользователей. Если вашим сервисом пользуются миллионы пользователей и запросы к РСУБД происходят часто, то выбор алгоритма играет важную роль. О том как оптимально обрабатывать больш... | https://habr.com/ru/post/228023/ | null | ru | null |
# Эмулятор игры «жизнь» на языке GLSL
Для начала небольшой ликбез: [раз](http://habrahabr.ru/blogs/python/111247/), [два](http://ru.wikipedia.org/wiki/Жизнь_(игра)), [три](http://habrahabr.ru/blogs/games/63848/).
Наверное, многие хоть раз в жизни писали эмулятор игры «жизнь».
Может быть для обучения программиров... | https://habr.com/ru/post/111332/ | null | ru | null |
# Расшифровка вредоносного JavaScript
Здравствуйте, уважаемые пользователи хабра. После того, как я опубликовал [данную статью](http://habrahabr.ru/blogs/infosecurity/136771/), у пользователей появился интерес, и они стали спрашивать меня в ЛС и в комментариях, а как именно расшифровываются данные скрипты и что же име... | https://habr.com/ru/post/137071/ | null | ru | null |
# Chaos Construction 2013: hackquest review-writeup
Как многие знают, [на этих выходных](http://habrahabr.ru/post/189658/) в Санкт-Петербурге проходил фестиваль компьютерного творчества, в т.ч. на которым был hackquest (по типу Capture The Flag). Так как у меня сейчас нет личного блога, решил поделиться решением задан... | https://habr.com/ru/post/189828/ | null | ru | null |
# AWS CloudWatch: собственные метрики (Custom Metrics)
Привет хабравчане!
Недавно сменил место работы, но всё так же поглощён облачными технологиями. И проектов у меня теперь будет гораздо больше, а с ними и статей, я над... | https://habr.com/ru/post/147046/ | null | ru | null |
# Какими будут контроллеры в PR2?
Привет! Продолжаем следить за развитием фреймворка [Symfony 2](http://symfony-reloaded.org/). В данном топике попытаемся проследить за дискуссией: каким будет механизм контро... | https://habr.com/ru/post/92066/ | null | ru | null |
# Конструктор плейлистов для Spotify
Статья о том, как [Spotify Web API](https://developer.spotify.com/documentation/web-api/) (SWA) и платформа [Google Apps Script](https://developers.google.com/apps-script?hl=ru) (GAS) позволили превратить библиотеку в гибкий конструктор плейлистов с бесплатным исполнением по распис... | https://habr.com/ru/post/537718/ | null | ru | null |
# Использование процессорной системы Nios II без процессорного ядра Nios II
В прошлом блоке статей про комплекс для удалённой отладки Redd, я показал, что работа с ним – это не только работа с ПЛИС. Мало того, ПЛИС – это всего лишь очень интересная, но всё-таки весьма специфичная часть комплекса. Основная же его часть... | https://habr.com/ru/post/496508/ | null | ru | null |
# NSA k8s security: Агентство национальной безопасности раскрывает секреты Kubernetes
N.B.
----
* Если желаете перейти сразу к делу, то пропускайте эту главу и переходите сразу к разбору (Руководство по безо... | https://habr.com/ru/post/681696/ | null | ru | null |
# Scripting Java с помощью JSR 223 — пример написания template engine в 20 строк из личного опыта
Статья посвящена Java девелоперам, которых жизнь заставила или пока только заставляет двигаться вперед, к светлому agile будущему. Препологается, что читатель знаком с Java, Javascript и слышал про JSR 223.
Многим очен... | https://habr.com/ru/post/151976/ | null | ru | null |
# Упали с AWS? Заезжайте без вопросов, документы потом, сейчас не до того
Пока я ехал на работу и слушал новый альбом Дельфина, кто-то блокировал IP адреса Amazon и Google целыми подсетями. Роскомнадзор назвал недостоверной информацию о блокировании сайтов, не имеющих отношения к Telegram, но арендующих IP-адреса на т... | https://habr.com/ru/post/353704/ | null | ru | null |
# Парсинг резюме
Те кто сталкивался с задачами автоматизированного анализа резюме, представляют современное состояние дел в этой области — существующие парсеры в основном ограничиваются выделением контактных данных и ещё нескольких полей, таких как «должность» и «город».
Для сколько-нибудь осмысленного анализа этог... | https://habr.com/ru/post/301936/ | null | ru | null |
# Выявляем признаки аудиомонтажа методами AI

Одной из задач фоноскопической экспертизы является установление подлинности и аутентичности аудио записи — другими словами, выявление признаков монтажа, искажения и изменения записи. У на... | https://habr.com/ru/post/514854/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.