
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как отличить начинающего профессионала от умудренного хоббиста в цифровой схемотехнике?
В чем главное отличие между FPGA-хоббистом, ностальгирующим по КР580ИК80 на пенсии - и начинающим микроархитектором, о... | https://habr.com/ru/post/593377/ | null | ru | null |
# Сдвиг блока
Здравствуйте.
Есть идея к добавлению в спецификацию CSS.
Свойство skew сдвигает один указанный угол или сторону блока по горизонтали или вертикали на установленное смещение. Сдвиг стороны сдвигает оба угла этой стороны, образуя параллелограмм. Текст и внутренние элементы сохраняют своё положения (в... | https://habr.com/ru/post/22213/ | null | ru | null |
# Как сделать быстрое веб-приложение или 8 советов разработчикам по оптимизации кода
Легкая и быстрая — вот два слова, на которые мы молимся, создавая Diafan.CMS. У нас нет больших библиотек на случай атомной войны, а всё новое добавляется по необходимости. Общая логика системы доработана и отполирована за многие годы... | https://habr.com/ru/post/300930/ | null | ru | null |
# Тестовая ферма из Android-устройств: как собрать, отладить и не взорвать офис

У нас был небольшой бюджет и большие проблемы с рутинным тестированием в match3-игре, у которой накопилось более 1500 уровней. А вот чего у нас не был... | https://habr.com/ru/post/579210/ | null | ru | null |
# Программирование nes/dendy скроллинг фона
В интернете много статей показывающих как скролить фон на два экрана (скажем так это стандартно), а вот как скролить фон на несколько экранов вперед как например в марио, или чип и дейле мало где можно найти а если и находиться такое в интернете то объяснение как это сделать... | https://habr.com/ru/post/715994/ | null | ru | null |
# Как настроить интеграцию между kafka и rabbitmq (путешествие туда и обратно)
Данная статья будет полезна тем, кто столкнулся с проблемой интеграции kafka и rabbitmq. Материал не претендует на подробный туториал, но поможет помочь настроить рабочий процесс. Я расскажу, как отправить сообщение в rabbitmq и получить ег... | https://habr.com/ru/post/659545/ | null | ru | null |
# Эдвард руки — С++
Я искал, с чем бы сравнить программирование на С++ и я вспомнил фильм 1990 года режиссера Тима Бертона — [«Эдвард руки-ножницы»](http://ru.wikipedia.org/wiki/%D0%AD%D0%B4%D0%B2%D0%B0%D1%80%D0%B4_%D0%A0%D1%83%D0%BA%D0%B8-%D0%BD%D0%BE%D0%B6%D0%BD%D0%B8%D1%86%D1%8B)
Была ли у вас идея (у программистов) сделать мир лучше?
Одном... | https://habr.com/ru/post/695502/ | null | ru | null |
# Squzy — бесплатная open-source self-host система мониторинга с инцидентами и уведомлениями
Однажды знойным зимним вечером к нам пришла идея написать приложение для проверки Sitemap фирмы, в которой мы работаем, с возможностью нотификации при возникновении ошибки.
Постепенно эта идея перешла к реализации, там поя... | https://habr.com/ru/post/512452/ | null | ru | null |
# Загрузка stage слоя DWH. Часть 1
Доброго дня. Меня зовут Иван Клименко, я разработчик потоков обработки данных в компании Аскона. В этом цикле статей я расскажу опыт внедрения инструмента Apache Nifi для формирования DWH.
Данная статья посвящена первому этапу внедрения Apache NIFI - начальным потокам выгрузки, вне... | https://habr.com/ru/post/599911/ | null | ru | null |
# Тонкости работы в командной строке Windows
Недавно я вырос из лютого эникея в очень большой компании, до скромного сисадмина надзирающего за сетью в 10 ПК. И, как очень ленивый сисадмин, столкнулся с задачами по автоматизации своей деятельности. Полгода назад я еще не знал, что в командной строке Windows есть конвей... | https://habr.com/ru/post/218759/ | null | ru | null |
# Распределенное хранилище данных в концепции Data Lake: установка CDH
Продолжаем делиться опытом по организации хранилища данных, о котором начали рассказывать в [предыдущем посте](https://habr.com/company/neoflex/blog/413149/). На этот раз хотим поговорить о том, как мы решали задачи по установке CDH.
 о новом проекте SpringSource: [spring-social](http://www.springsource.org/spring-social). Сегодня я хочу рассказать (вернее показать на примере) как можно данную библиотеку и... | https://habr.com/ru/post/108824/ | null | ru | null |
# Оптимизация с помощью замыканий
Дано — раз в секунду дергается AJAX'ом скрипт, в нем несколько вызовов одной функции (назовем ее updater) с разными аргументами. Функция в соответствии с аргументами апдейтит некоторый набор DOM-элементов (меняет контент, скрывает, показывает) на текущей странице. Используется jQuery,... | https://habr.com/ru/post/63119/ | null | ru | null |
# Динамические формы в ASP.NET MVC
Часто у пользователя требуется узнать информацию о нескольких дополнительных объектах, число которых заранее не известно. Для это используют динамические формы, поля которых создаются javascript кодом на клиентской машине. В asp.net mvc работая в связке Controller-View мы работаем с ... | https://habr.com/ru/post/88766/ | null | ru | null |
# Zone.js или как Dart спас Angular

Я фронтенд-разработчик в компании Wrike, пишу на JavaScript и на Dart, который компилируется в JavaScript. Сегодня я хочу рассказать о библиотеке Zone.js, лежащей в основе Angular 2.
И... | https://habr.com/ru/post/310422/ | null | ru | null |
# Оформление кода, оптимизация процесса проверки качества кода
#### JavaScript, the winning style

Код написанный в одном стиле, имеет много преимуществ: меньше мелких ошибок, многие ошибки легко обнаружит... | https://habr.com/ru/post/189872/ | null | ru | null |
# Автоматизация управления Let's Encrypt SSL сертификатами используя DNS-01 challenge и AWS
Пост описывает шаги для автоматизации управления SSL сертификатами от **[Let's Encrypt CA](https://letsencrypt.org/)** используя *[DNS-01 challenge](https://letsencrypt.org/docs/challenge-types/)* и *AWS*.
**[acme-dns-route53]... | https://habr.com/ru/post/451848/ | null | ru | null |
# Особенности использования SailsJS для начинающих (Часть 1)

#### Синопсис
Эта статья содержит полезные для новичков методы и способы разработки на SailsJS, которые могут быть неизвестны или непонятны тем... | https://habr.com/ru/post/228253/ | null | ru | null |
# Мониторинг кластера Kubernetes при помощи Prometheus
Здравствуйте, коллеги.
Мы только что отдали в перевод интересную книгу Брендана Бёрнса, рассказывающую о паттернах проектирования для распределенных систем
 Кроме того, у на... | https://habr.com/ru/post/421175/ | null | ru | null |
# Что делать, если поймал HardFault?
Что делать, если поймал HardFault? Как понять, каким событием он был вызван? Как определить строчку кода, которая привела к этому? Давайте разбираться.
Всем привет! Сложно найти программиста микроконтроллеров, который ни разу не сталкивался с тяжелым отказом. Очень часто он ника... | https://habr.com/ru/post/511924/ | null | ru | null |
# Гайд по миграции с Vue 2 на Vue 3. Часть 2
Эта статья — перевод оригинальной статьи Andy Li из Vue Mastery "[Vue 3 Migration Changes: Replace, Rename, and Remove (Pt. 2)](https://www.vuemastery.com/blog/migration/)".
Также я веду телеграм канал “[Frontend по-флотски](https://t.me/frontend_pasta)”, где рассказываю п... | https://habr.com/ru/post/571774/ | null | ru | null |
# Не возможно обновить (UPDATE) ту же таблицу, которую используешь в SELECT-запросе
Сегодня наткнулся на очень неприятный баг в MySQL. При выполнении следующего запроса в MySQL 5.0.45:
`UPDATE `files` SET `file_md5` =
(
SELECT MD5( `file_blob` )
FROM `files`
WHERE `id`= 6
)
WHERE `id` = 6`
Полу... | https://habr.com/ru/post/49531/ | null | ru | null |
# PHP-Дайджест № 107 – свежие новости, материалы и инструменты (9 – 23 апреля 2017)
[](https://habrahabr.ru/company/zfort/blog/327198/)
Предлагаем вашему вниманию очередную подборку со ссылками на новости ... | https://habr.com/ru/post/327198/ | null | ru | null |
# ОС Аврора 4.0.2 для разработчиков: обзор и примеры исходного кода
Релиз ОС Аврора 4.0.2 — первый [сертифицируемый](https://auroraos.ru/blog/tpost/8rslf01231-novoe-pokolenie-rossiiskoi-mobilnoi-os-a) выпуск четвёртого поколения операционной системы, именно он теперь будет использоваться на устройствах в актуальных пр... | https://habr.com/ru/post/696574/ | null | ru | null |
# Формат JPEG XL будет полным по Тьюрингу без ограничения 1024*1024 пикселей

*В формате JPEG XL это изображение занимает [59 байт](https://twitter.com/jonsneyers/status/1375828696846721031)*
Оказывается, [полным по Тьюрингу](h... | https://habr.com/ru/post/564370/ | null | ru | null |
# Увеличиваем производительность Zend Framework'а, собирая его классы в один файл
 Каждый раз когда вы запускаете ссылку, и на сервере ее обрабатывает ZendFramwork, происходят неприятные издержки производительности пр... | https://habr.com/ru/post/46742/ | null | ru | null |
# Template + jQuery + MVC = jsMVC
Разрабатывая сайты мне всегда хотелось облегчить себе жизнь, так я познакомился с jQuery. Все было бы хорошо если бы проекты не погружались в зыбучую смесь UI и js кода. Следующим этапом стало то что мы выделили UI Шаблоны в отдельные файлы, код стал более чистым, но, черт побери, все... | https://habr.com/ru/post/43898/ | null | ru | null |
# Политики управления рабочими нагрузками в Kubernetes

[Control by Matthias-Haker](https://www.deviantart.com/matthias-haker/art/Control-548364683)
В Kubernetes с помощью политик можно предотвратить развертывание определенных раб... | https://habr.com/ru/post/646463/ | null | ru | null |
# Большие изображения на сайте для пользователей с Retina Display — retina.js
Новый iPad уже появился в магазинах, не говоря уже про братьев iPhone 4S и iPhone 4, которыми многие давно и успешно пользуются, а вот сайтов, учитывающих возможности отображения дисплеями этих устройств картинок в высоком разрешении, пока н... | https://habr.com/ru/post/144573/ | null | ru | null |
# Трюки в консоли. Крутые однострочники
Много говорилось об удовольствии, которое испытываешь при работе в консоли. Это не случайно: [так задумано отцами-основателями Unix](https://habr.com/ru/company/vdsina/blog/552536/). Возника... | https://habr.com/ru/post/559464/ | null | ru | null |
# Взлом reCAPTCHA v2
Назойливая игра - разметка данных для google. Если, занимаетесь сбором доступной информации с ресурсов, не принадлежащим вам, и не сумели реализовать решение для преодоления этой преграды, советы от начинающего разработчика вам помогут. Опишу один из способов, основанный на детекторе объектов, хор... | https://habr.com/ru/post/546464/ | null | ru | null |
# минилинукс
###### Лирическая часть
Кто из нас в детстве не разбирал игрушки, чтоб посмотреть, что же там такое внутри. Я не был исключением. Прошло всего несколько лет, и одной из игрушек стал линукс. Из абстрактного желания «сломать и посмотреть» оно формализовалось в несколько вполне конкретных задач, одной из ко... | https://habr.com/ru/post/59988/ | null | ru | null |
# Дампим память и пишем maphack

В один из вечеров школьного лета, у меня появилась потребность в мапхаке для DayZ Mod (Arma 2 OA). Поискав информацию по теме, я понял, что связываться с античитом Battleye не стоит, ибо не... | https://habr.com/ru/post/338734/ | null | ru | null |
# Простой кэш в памяти
#### Добрый день!
Понадобилось тут сделать совсем примитивный кэш, чтобы лишний раз в базу не лазить. При этом данные в базе статичные, и вопрос не столько в обновлении данных, сколько в том, когда их выбросить, чтобы просто не занимать память, ну и простота использования конечно важна. Сначала... | https://habr.com/ru/post/185616/ | null | ru | null |
# «Не отображается сайт»
Статья в помощь людям, у которых совсем не отображается их сайт.
Именно с такой проблемой я столкнулся, работая с сайтами клиентов. После того, как поступило еще несколько звонков в техническую поддержку, стало понятно, что «у меня не открывается сайт» — это результат не плохого интернета, ... | https://habr.com/ru/post/101691/ | null | ru | null |
# Say hello to the new Visual Studio terminal
Building on the momentum from the recently announced [Developer PowerShell](https://devblogs.microsoft.com/visualstudio/the-powershell-you-know-and-love-now-with-a-side-of-visual-studio/), we are excited to share the first preview of the new Visual Studio terminal. This ne... | https://habr.com/ru/post/468263/ | null | en | null |
# Ненормальное программирование. Разработка IF игр
Разработка игр
==============

Кто не мечтал попробывать разработать собственную игру. Мы будем создавать игру в стиле [**interactive fiction**](http://... | https://habr.com/ru/post/72310/ | null | ru | null |
# Webix 2.3. Весеннее обновление
Не так давно в [блоге](http://webix.com/blog/) разработчиков этой JavaScript библиотеки появился пост о релизе новой версии за номером 2.3. Обновления это хорошо, спору нет. Но, глядя в окно на позднемартовскую улицу, становится не вполне понятно, что же выбрать: разбираться с новыми д... | https://habr.com/ru/post/254103/ | null | ru | null |
# Интеграционные тесты на Flutter — это просто
Думаю, многие уже знакомы с Flutter и хотя бы ради интереса запускали простые приложения на нем. Настало время убедиться, что в них все работает как нужно, и в этом нам помогут интеграционные тесты.

*Автор статьи: [Дмитрий Шадрин](https://otus.pw/aZOm/)*
---
### Вступление
Хочется поделиться моим топом инструментов для тестирования, которые еженедельно помогают мне в эффективной работе и улуч... | https://habr.com/ru/post/501564/ | null | ru | null |
# Выводим состояние серверов из Zabbix на рабочий стол
Система мониторинга [Zabbix](http://www.zabbix.org) предоставляет замечательные возможности по мониторингу серверов под управлением ОС AIX, Linux, \*BSD, Windows, Mac OS X, сетевого оборудования, Web-приложений, а также любый железяк поддерживающих SNMP или хотя б... | https://habr.com/ru/post/104460/ | null | ru | null |
# DataGrip 2020.1: Конфигурации запуска, экспорт в Excel, результаты в редакторе и другое
Привет! Это наш первый релиз из дома. [**DataGrip**](https://www.jetbrains.com/datagrip/whatsnew/) и другие наши IDE с поддержкой баз данных теперь умеют больше.
, предлагаю взглянуть на новые фичи с позиции .NET.
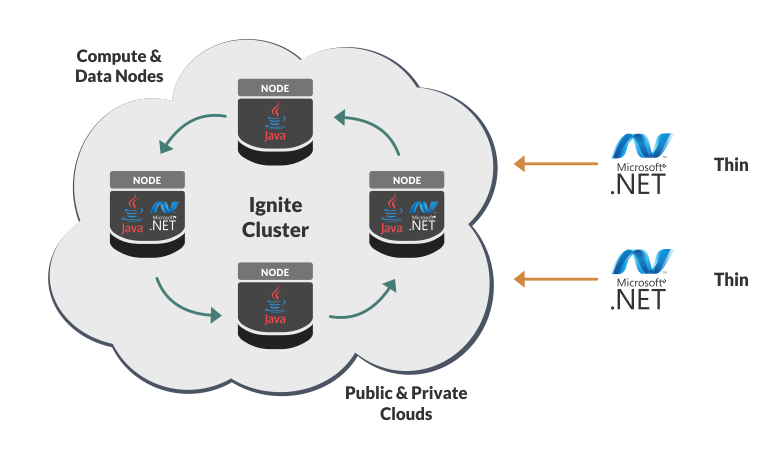
Thin .NET Cli... | https://habr.com/ru/post/347374/ | null | ru | null |
# Tableless justification или inline-blocks revisited
Все давно знают про кроссбраузерную реализацию инлайн-блоков, но не все знают, что данная реализация не такая уж и кроссбраузерная и полная, как кажется. Что, как и почему рассмотрим на простом примере: сделаем меню, пункты которого равномерно распределены по всей ... | https://habr.com/ru/post/81611/ | null | ru | null |
# Прокачиваем скрипты симуляции HDL с помощью Python и PyTest
Все делают это. Ну ладно, не все, но большинство. Пишут скрипты, чтобы симулировать свои проекты на Verilog, SystemVerilog и VHDL. Однако, написа... | https://habr.com/ru/post/537704/ | null | ru | null |
# Использование методов А/Б тестирования. Решение практического кейса в Python
Привет, Хабр! В данной статье будет рассмотрено применение логистической регрессии, причинного случайного леса (Causal Random Forest), метода CUPED для оценки изменения целевой переменной в Python при проведении А/Б тестов. Основное внимани... | https://habr.com/ru/post/708872/ | null | ru | null |
# Microsoft хакатон «IoT — интернет вещей» в Нижнем Новгороде
Повод, чтобы начать
===================
Я хочу рассказать про хакатон, который проводила компания Microsoft и Intel в Нижнем Новгороде в рамках Технологической экспедиции Microsoft Developer Tour. Так сказать из первых уст. Как участник. Думаю, так будет н... | https://habr.com/ru/post/255447/ | null | ru | null |
# Создаем удобный вьювер для vk.com при помощи Fluid.app с нотификацией о новых сообщениях в доке Mac OS X
Здравствуйте, хабражители!
Однажды после прочтения одной [статьи](http://habrahabr.ru/post/28706/), я загорелся желанием сделать подобную обертку для вконтактика с преферансом и куртизанками, тем более что с а... | https://habr.com/ru/post/174197/ | null | ru | null |
# Срочно обновляйте exim до 4.92 — идёт активное заражение
Коллеги, кто использует на своих почтовых серверах Exim версий 4.87...4.91 — срочно обновляйтесь до версии 4.92, предварительно остановив сам Exim во избежание взлома через CVE-2019-10149.
Потенциально уязвимы несколько миллионов серверов по всему миру, уяз... | https://habr.com/ru/post/455598/ | null | ru | null |
# Apollo Link. Настраиваем клиент GraphQL «под себя»
Сетевой уровень в Apollo Client и его отдельное использование
-------------------------------------------------------------
Возможно, вы встречали библиотеку, которая отвечает вашим потребностям, но не решает пару специфичных задач. И хотя эти задачи не относятся к... | https://habr.com/ru/post/335466/ | null | ru | null |
# USB Host, «Blue Pill», метод деления отрезка пополам и цена на водку в СССР
Написал недавно программный [USB-HOST на esp32](https://habr.com/ru/post/545364/) для работы с клавиатурой/мышкой/джойстиком. Процессор быстрый, но нежный, 5 вольт на ножках не выдерживает. Поэтому решил переписать на stm32f103c8t6, широко и... | https://habr.com/ru/post/548020/ | null | ru | null |
# Юзерскрипт для браузера — расширение возможностей файлообмена, а так же способ выживания пиратских сайтов при антипиратских законах
Сразу оговорюсь, ниже будут ссылки как на готовые скрипты, так и просто пока не реализованные в коде мысли. В статье рассмотрим возможности интеграции DC++ с торрент-сайтами, особенност... | https://habr.com/ru/post/230345/ | null | ru | null |
# Организация своего хоста виртуализации на Hetzner

*Proxmox Virtual Environment (Proxmox VE) — система виртуализации с открытым исходным кодо... | https://habr.com/ru/post/242031/ | null | ru | null |
# Factory Method Pattern
Привет, друзья. С вами [Alex Versus](https://www.udemy.com/user/sergei-1146/).
Ранее мы говорили про шаблоны проектирования [Одиночка](https://habr.com/ru/post/553298/) и [Стратегия](https://habr.com/ru/post/552278/), про тонкости реализации на языке **Golang**.
Сегодня расскажу про Фабри... | https://habr.com/ru/post/556512/ | null | ru | null |
# Боремся со Status 7. Как работает механизм OTA-обновлений и почему он дает сбои

Довольно часто юзеры, привыкшие рутовать прошивки, устанавливать разного рода системный софт, менять ядра и по-другому издеваться над прошив... | https://habr.com/ru/post/260379/ | null | ru | null |
# Опасайтесь прозрачных пикселей

Если вы используете в своей игре спрайты с прозрачностью (а обычно так и бывает, как минимум для UI), то вам, вероятно, стоит уделить внимание к полностью прозрачным пикселям ... | https://habr.com/ru/post/328386/ | null | ru | null |
# Linux. Настройка клавиатуры
Для чего вообще специально настраивать клавиатуру?
Можно пользоваться и стандартными настройками, но иногда внесенные изменения дают возможность набирать быстрее (это, конечно, не слепая печать, но все же), совершать меньше ошибок, меньше переключать раскладку...
### Почему я захотел и... | https://habr.com/ru/post/486872/ | null | ru | null |
# Как выглядела разработка… ну скажем, в 80-х годах прошлого века
Уже много раз в исторических постах на Хабре я видел вопросы такого плана: «А как вообще выглядела разработка тогда, когда машины были большими»? Как был построен процесс, как устроена сборка, существовал ли отладчик (заменить на любой другой инструмент... | https://habr.com/ru/post/476588/ | null | ru | null |
# Тестирование в Java. TestNG

Наверняка все знакомы с таким понятием как [test-driven development(TDD)](http://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0_%D1%87%D0%B5%D1%80%D0%B5%D0%B7_%D1%... | https://habr.com/ru/post/121234/ | null | ru | null |
# Сравнение производительности версий PHP

В этой статье мы рассмотрим результаты нескольких бенчмарков, начиная с PHP 5 и вплоть до экспериментальной JIT-ветки (сейчас в разработке). На момент написания не... | https://habr.com/ru/post/326696/ | null | ru | null |
# DeepCode: взгляд со стороны

Не так давно DeepCode, статический анализатор, основанный на машинном обучении, стал поддерживать проверку C и C++ проектов. И теперь мы можем на практике взглянуть, ... | https://habr.com/ru/post/496536/ | null | ru | null |
# GSA: Препарируем Google Search Appliance в виртуальной машине

Последние годы, с интересом почитывая о персональных поисковых системах в веселых желтых коробках имени Google, я периодически гуглил по словам GSA, Google... | https://habr.com/ru/post/170801/ | null | ru | null |
# Смотрим часть чужого избранного ВКонтакте

*Кадры из фильма «50 оттенков серого»*
На этот раз с помощью незамысловатого куска кода на javascript заглянем в таинственные глубины человеческих предпочтений. А именно получи... | https://habr.com/ru/post/316562/ | null | ru | null |
# Структуры данных: бинарные деревья. Часть 1
Интро
-----
Этой статьей я начинаю цикл статей об известных и не очень структурах данных а так же их применении на практике.
В своих статьях я буду приводить примеры кода сразу на двух языках: на Java и на Haskell. Благодаря этому можно будет сравнить императивный и фу... | https://habr.com/ru/post/65617/ | null | ru | null |
# Weka проект для задачи распознавания тональности (сентимента)
Это перевод моей [публикации на английском языке](http://dmitrykan.blogspot.fi/2014/04/weka-template-project-for-sentiment.html).
Интернет полон статьями, заметками, блогами и успешными историями применения машинного обучения (machine learning, ML) для... | https://habr.com/ru/post/229779/ | null | ru | null |
# Применение Oracle Database для Технического анализа рынков
Эта статья про Oracle Database, PL/SQL, SQL, MATCH\_RECOGNIZE, MODEL clause, aggregate и pipelined functions.
В качестве функциональной области использован Технический анализ (ТА) рынков. Сначала небольшая поверхностная вводная о торговле на рынках, потом... | https://habr.com/ru/post/455050/ | null | ru | null |
# Прокачиваем PPTP-сервер или чем заменить Poptop

#### Введение
На сервере доступа в качестве pptp-сервера стоял проверенный Poptop последней стабильной версии (1.3.4). И все бы ничего, да вот только после повышения с... | https://habr.com/ru/post/142992/ | null | ru | null |
# Отслеживание исходящих ссылок с помощью Google Analytics
Google Analytics предоставляет широкие возможности по сбору и анализу статистики сайта, но, способ отслеживания исходящих ссылок, предлагаемый в справочном центре…
…мягко говоря, не очень удобен.
Поскольку сама возможность очень интересная, я решил все-т... | https://habr.com/ru/post/13849/ | null | ru | null |
# Делаем процесс разработки тяжеловесного программного обеспечения под микроконтроллеры более удобным (нет)
Сейчас уже никого не удивить микроконтроллерами с энергонезависимой (чаще всего Flash) памятью объемом 512 килобайт и более. Их стоимость постепенно снижается, а доступность напротив, растет. Наличие такого объе... | https://habr.com/ru/post/437848/ | null | ru | null |
# Maven, где мои артефакты? Еще одна статья про управление зависимостями
Легко жить с maven, когда есть доступ к центральному репозиторию, или у компании есть один корпоративный репозиторий. Все меняется, если работаешь в закрытом контуре, а количество репозиториев ближе к сотне. Под катом история о том, где искать по... | https://habr.com/ru/post/339902/ | null | ru | null |
# Кастомные социальные кнопки
Недавно участвовал в разработке одного проекта — фото конкурса. По задумке, рейтинг фото альбомов должен формироваться из суммы всех публикаций в социальных сетях: Facebook, Вконтакте, Twitter. Т.е. общий рейтинг фотоальбома расчитывается:
> Рейтинг фотоальбома = кол-во «Share» в Faceb... | https://habr.com/ru/post/116584/ | null | ru | null |
# Давайте обрабатывать звук на Go
> Дисклеймер: Я не рассматриваю какие-либо алгоритмы и API для работы со звуком и распознаванием речи. Эта статья о проблемах при работе с аудио и об их решении с помощью Go.

`phono` — прикладн... | https://habr.com/ru/post/424623/ | null | ru | null |
# Имя не гарантирует безопасность. Haskell и типобезопасность
Разработчики на Haskell много говорят о типобезопасности (type safety). Сообщество Haskell-разработчиков отстаивает идеи «описания инвариант на уровне системы типов» и «исключения недопустимых состояний». Звучит как вдохновляющая цель! Однако не совсем поня... | https://habr.com/ru/post/542724/ | null | ru | null |
# Определение технического лидера
Наша отрасль хорошо известна сложными терминами. Роли в процессе разработке программного обеспечения хороший тому пример. Такие должности как архитектор, технический лидер, тимлид и инже... | https://habr.com/ru/post/537930/ | null | ru | null |
# Ruby и C. Часть 3.
В прошлых частях([часть 1](http://habrahabr.ru/blogs/ruby/48928/),[часть 2](http://habrahabr.ru/blogs/ruby/49202/)) мы рассмотрели использование С для ускорения или расширения Ruby. Сейчас же мы узнаем как использовать Ruby интерпретатор в программах, написанных на С/С++.
В некоторых приложения... | https://habr.com/ru/post/50039/ | null | ru | null |
# Собственный провайдер пользователей для Keycloak
Интегрируя Keycloak в уже существующую систему, высока вероятность столкнуться с необходимостью во время аутентификации загружать пользователей из древней базы данных, где информация о них может храниться в довольно причудливом виде. Такая задача решается созданием со... | https://habr.com/ru/post/550704/ | null | ru | null |
# Планируете писать приложение на AngularJS? Пост вам в помощь
 Самые непристойные и отвратительные наши поступки, выходящие за всякие нормы морали и принципов, обычно начианаются со слов «А почему бы и нет?».... | https://habr.com/ru/post/215297/ | null | ru | null |
# CSS-Expressions on DOMReady (CSS+JS в одном файле)
Вероятно, многие из вас используя css-expressions сталкивались с проблемой периодического появления сообщения abort. В народе поговаривают, что связано это с изменением DOM-дерева до его готовности.
Я тоже сталкивался и, не долго думая, решил написать небольшую «... | https://habr.com/ru/post/87935/ | null | ru | null |
# Как сделать Змейку на чекбоксах и не только
В допандемическом 2020 Брайан Браун отправился на неделю в Recurse Center и разработал [Checkboxland](https://www.bryanbraun.com/checkboxland/). Эта библиотека J... | https://habr.com/ru/post/581924/ | null | ru | null |
# Как я писал свой «велосипед» для ротирования таблиц в Oracle и Postgre
Приветствую, Хабр!
В этой статье я расскажу о том, как мы боролись с проблемой быстрого роста размера таблиц в базе данных в высоконагруженной EMS системе. Свою изюминку добавляет то, что проблема решалась для двух баз данных: Oracle и Postgre... | https://habr.com/ru/post/240061/ | null | ru | null |
# HTML5-консоль от Google
HTML5-консоль, который вы могли видеть в одном из выступлений на майской конференции Google I/O, [работает в онлайне](http://www.htmlfivewow.com/demos/terminal/terminal.html) (судя по всему, только в браузере Chrome).
[
Я думаю не мало инженеров в АСУТП сталкивались с требованием заставить «что-то» работать по расписанию. Покажу как реализовал сделал расписание в составе сервер... | https://habr.com/ru/post/333412/ | null | ru | null |
# Извлечение данных при машинном обучении
Хотите узнать о трех методах получения данных для своего следующего проекта по ML? Тогда читайте перевод статьи Rebecca Vickery, опубликованной в блоге Towards Data Science на сайте Medium! Она будет интересна начинающим специалистам.
 порту и работа через usb-com адаптер.
При переходе с десктопа на лэптоп встала проблема подключения планшета Wacom Intuos. Моя модель достаточно старая и подключается через COM порт, который в лэптопах уже давно не используются. Покупать новый 6×8 дюймовый... | https://habr.com/ru/post/51441/ | null | ru | null |
# Онлайн кассы ОФД класс на Delphi
Создаем Свои класс для взаимодействия с ООФ КазакТелеком
--------------------------------------------------------
> Объявим вспомогательные типы
>
>
```
type
TSellBuy = class(TObject)
Sum : Double;
PaymentType : Integer;
PaymentTypeName : String;
end;
```
```
type
TNonNull... | https://habr.com/ru/post/685648/ | null | ru | null |
# Сам себе РКН или родительский контроль с MikroTik (ч.2)
[](https://habr.com/ru/company/ruvds/blog/583868/)
Вторая и заключительная статья в цикле организации родительского контроля на оборудовании MikroTik. [Ранее](https://habr.com/ru/company/ruvd... | https://habr.com/ru/post/583868/ | null | ru | null |
# Проектирование дашбордов для веб-аналитики e-commerce сайта. Часть 3: SEO-канал
В этой статье соберем дашборд для аналитики SEO-трафика. Данные будем выгружать через скрипты на python и через .csv файлы.
Что будем выгружать?
--------------------
Для аналитики динамики позиций поисковых фраз потребуется выгрузки ... | https://habr.com/ru/post/467019/ | null | ru | null |
# Реализация Unidirectional Data Flow в супераппе. Часть II
В [предыдущей статье](https://habr.com/ru/company/indriver/blog/571394/) я сформулировал нашу главную проблему при масштабировании Unidirectional Data Flow (UDF) — модуляризацию. Сегодня существует много UDF-фреймворков на Swift, но мало кто уточняет, как их ... | https://habr.com/ru/post/576660/ | null | ru | null |
# Тестируем вёрстку правильно
### Что не так с тестированием вёрстки
Мы часто им пренебрегаем. Написание функциональных, интеграционных и юнит-... | https://habr.com/ru/post/277457/ | null | ru | null |
# Идеальный график отпусков. Естественные алгоритмы. Поведение роя пчёл

Естественные (или эволюционные) алгоритмы – это направление в искусственном интеллекте, которое моделирует процессы естественного отбора, мутации и воспроизво... | https://habr.com/ru/post/513874/ | null | ru | null |
# Продвижение Java-стартапов
На сайте DZone собираются публиковать серию интервью о Java-стартапах.

Вот письмо одного из редакторов сайта:
`Java-Стартапы - Мы хотим услышать о Вас!
Сейчас вс... | https://habr.com/ru/post/142033/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.