
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Замена фискального накопителя ККТ Кассир 57Ф
**Производилась замена ФН по истечении строка в обычном режиме через утилиту ТестФР (TestFR).**
Этапы:
* установить точное время на ККТ до открытия смены - сначала нужно установить точное время на компьютере windows - Дата и время > Часы для различных часовых поясов > В... | https://habr.com/ru/post/574160/ | null | ru | null |
# Конечные автоматы на практике: Symfony Workflow
В университетские времена я столкнулся с такой математической абстракцией, как конечный автомат (КА). Эта модель была полезна для понимания и создания комбинированной логики. Спустя 15 лет КА вернулся в мою жизнь в виде компонента Symfony Workflow. В этой статье я расс... | https://habr.com/ru/post/702078/ | null | ru | null |
# Безопасное криптопрограммирование. Часть 1
В данном посте мы бы хотели познакомить пользователей Хабра с базовыми правилами программирования криптографических алгоритмов. Этот набор правил под названием «Стандарт криптографического программирования» (“Cryptography coding standard”) был создан в 2013 году по инициати... | https://habr.com/ru/post/268113/ | null | ru | null |
# Активное шумоподавление звука затвора в камере мобильного устройства
Камеры мобильных устройств Android/iOS/etc. при фотосъёмке издают характерный звук срабатывания затвора. В некоторых странах это требуется законодательно. Но что делать, если нашей программе нужно всё-таки беззвучно снять фотографию, пусть даже нез... | https://habr.com/ru/post/224055/ | null | ru | null |
# Как сократить код Canvas API в Svelte
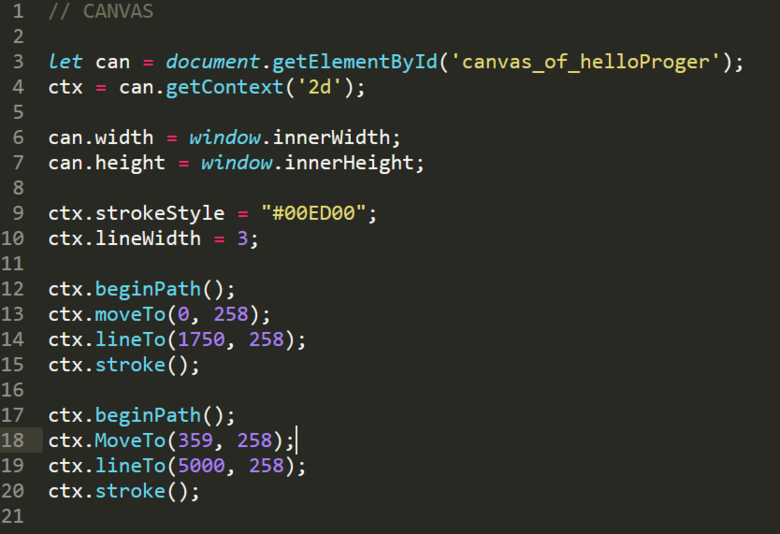Разработчик из консалтинговой компании в области разработки This Dot Labs рассказывает, как использовать canvas в Svelte и как превратить многословный API Canvas в краткий, более декларативный. По... | https://habr.com/ru/post/681866/ | null | ru | null |
# Танцы с бубном для блондинок, или о tabbed menus и хитрой работе с графикой
Собственно, перепал мне не так давно небольшой заказец. Вроде и несложный — а потанцевать с бубном немного пришлось. А всё из-за того, что заказчик оказался немного «падкой на дизайн блондинкой» (образно говоря), и требовал строгого соответс... | https://habr.com/ru/post/52547/ | null | ru | null |
# Mysql PARTITION BY YEAR(date) / MONTH(date) / DAYOFWEEK(date)
Зачастую мне приходится иметь дело с таблицами которые содержат редко или даже никогда ни обновляемые данные. Хорошим примером таких данных являются различные логи. Некоторые таблицы регулярно очищаются от устаревших данных, а в некоторых приходится храни... | https://habr.com/ru/post/159131/ | null | ru | null |
# Пример разработки небольшого python+PyQt4 приложения для учетной системы
Часто приходится разрабатывать приложения для корпоративной системы которые должны были функционировать еще вчера, не требующие строго соответствия корпоративным стандартам. Такими приложениями могут представлять cms к сайтам, gui для сервисов ... | https://habr.com/ru/post/73643/ | null | ru | null |
# Как мы добавили оттенок совершенства в инструмент для анализа производительности Linux Perf GUI (Hotspot)
В ходе выполнения одного из наших проектов мы усовершенствовали профилировщик Linux Perf GUI разработкой его новой функциональности.
Потребности заказчика можно выразить следующими характеристиками желаемого... | https://habr.com/ru/post/525560/ | null | ru | null |
# Первый взгляд на RPG: оказывается, это не только ролевые игры
Многие из вас слышали об одном из старейших языков программирования COBOL, а также о том, что как сильно сейчас нужны COBOL-программисты для поддержки старого кода. Существует еще один «старожил», о котором знают немногие, который используется сейчас и бу... | https://habr.com/ru/post/345064/ | null | ru | null |
# Каррируем на C++
Привет, хабр.
Сидел я как-то вечером, ждал, пока соберется свежая ревизия clang, и смотрел на код *одного своего проекта*, в котором встречались не очень красивые вещи вроде
```
std::transform (someContainer.begin (), someContainer.end (), std::back_inserter (otherContainer),
[this] (const... | https://habr.com/ru/post/238879/ | null | ru | null |
# HowTo: DMARC
Недавно пришлось столкнуться со спамящим php-скриптом. Виновник был найден и уничтожен, дыра закрыта… Оставался вопрос с блэклистами. В частности перестала доходить почта на Gmail (reject).
Решил я настроить почту «как надо» — SPF, DKIM и попробовать настроить DMARC.
Оговорюсь сразу — я даже не пр... | https://habr.com/ru/post/253705/ | null | ru | null |
# Уроки по SDL 2: Урок 4 — Растяжка PNG
Всем привет! Это четвертый урок по SDL 2. Я решил объеденить два урока в один, так как в оригинале они маленькие. Но их можно найти [тут](http://lazyfoo.net/tutorials/SDL/05_optimized_surface_loading_and_soft_stretching/index.php) и [тут](http://lazyfoo.net/tutorials/SDL/06_exte... | https://habr.com/ru/post/456656/ | null | ru | null |
# Vue 3: CompositionAPI + Typescript эксперименты
В прошлой статье меня упрекнули, что я при живом Vue 3 пишу про "устаревший" Vue 2. Отговорившись тем, что Vue 3 еще не production-ready, я понемногу начал его смотреть и изучать. И поскольку я заядлый любитель типизации и различных фичей с сахарком, то рассматривать V... | https://habr.com/ru/post/557928/ | null | ru | null |
# Как из-за открытой базы ClickHouse могли пострадать персональные данные пациентов и врачей (обновлено)
Я много пишу про обнаружение свободно доступных баз данных практически во всех странах мира, но новостей про российские базы данных, оставленные в открытом доступе почти нет. Хотя недавно и [писал](https://habr.com... | https://habr.com/ru/post/444114/ | null | ru | null |
# Повторяющийся набор полей в Hibernate

Проблему, решения которой я сегодня хотел бы описать — это повторяющийся набор полей в Hibernate сущностях. Конечно, её можно было бы решить с помощью нормализации БД, но это неудо... | https://habr.com/ru/post/180703/ | null | ru | null |
# Контест на определение сбоев
Cтартовал первый контест для разработчиков от Brand Analytics!
**Задача контеста:** написать приложение, которое будет определять сбои и сможет выделять сервисы и аспекты в публичных сообщениях соцмедиа о сбоях.
**Призовой фонд** - 500 тысяч рублей.
**Срок подачи решений** до 17 авгус... | https://habr.com/ru/post/679810/ | null | ru | null |
# Маленькие победы
В течение своей карьеры я имел опыт работы над многими масштабными проектами, от проработки стратегий компании, выбора идеальных продуктов, реорганизации ключевых алгоритмов user-flow и информационного проектирования, до разработки систем с нуля.
Работать над такими крупными проектами чаще всего ... | https://habr.com/ru/post/556948/ | null | ru | null |
# Использование Drag&Drop; в HTML 5

Долгое время для создания Drag&Drop функционала использовались JavaScript-функции, однако браузеры не всегда корректно могли отображать результат. В HTML 5 есть способ грамотной поддер... | https://habr.com/ru/post/187582/ | null | ru | null |
# PHP сказ про то, как некромант инквизитора обманул
Как говорится: в сказке ложь, да в ней намек.
Все делалось не процесса ради а под конкретные нужды. Надеюсь шаблон окажется полезным. Код шаблона под катом.
> `1. php</li- /\*\*
> - \* Cloak is a good thing when we need to hide some public methods and properti... | https://habr.com/ru/post/83263/ | null | ru | null |
# Интеграция средств VR в Unity3d

Проходит время и все меняется, в том числе и игры, точнее подход к их созданию. Сейчас появились новомодные штучки типа шлемов виртуальной реальности Oculus Rift, Sony Mor... | https://habr.com/ru/post/223295/ | null | ru | null |
# Rust: От &str; к Cow
Одной из первых вещей, которые я написал на Rust'е была структура с `&str` полем. Как вы понимаете, анализатор заимствований не позволял мне сделать множество вещей с ней и сильно ограничивал выразительность моих API. Эта статья нацелена на демонстрацию проблем, возникающих при хранении сырых &s... | https://habr.com/ru/post/282708/ | null | ru | null |
# Реализация на Python многопоточной обработки данных для парсинга сайтов
Процесс парсинга усложняется существенными затратами времени на обработку данных. Многопоточность поможет в разы увеличить скорость обработки данных. Сайт для парсинга — [«Справочник купюр мира»](http://banknotes.finance.ua/), где получим валюту... | https://habr.com/ru/post/323238/ | null | ru | null |
# IPv6, miredo, dynamic DNS AAAA
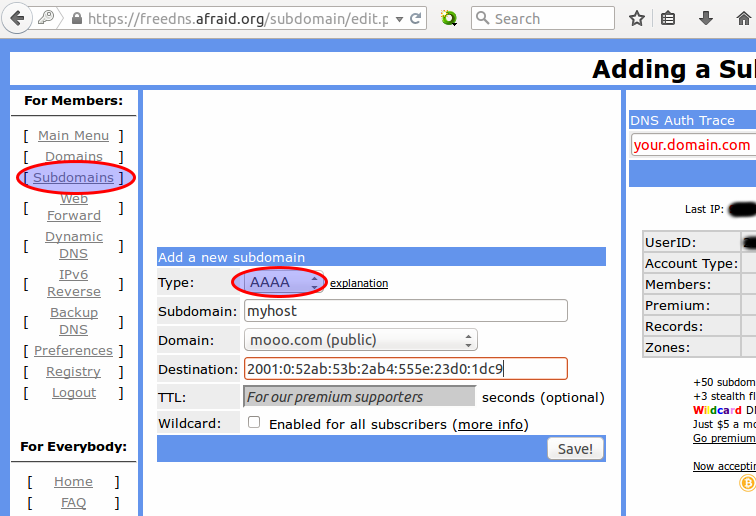
Захотелось странного — чтоб мои IPv6-enabled (miredo) хосты еще и динамически обновляемую DNS запись имели. Поизучав вопрос выяснил, что многие распространённые dyndns сервисы или не предост... | https://habr.com/ru/post/246341/ | null | ru | null |
# Об утечках памяти в iOS и методах борьбы с ними
 Среди проектов, над которыми мы [работаем](http://habrahabr.ru/blogs/macosxdev/110197/#habracut), пожалуй, нет ни одного, в котором было бы всё в порядке с памятью. Этот пост я посвя... | https://habr.com/ru/post/117485/ | null | ru | null |
# Виды репликации в MongoDB

Привет, хабровчане! Расшифровали для вас часть урока по MongoDB от Евгения Аристова, разработчика с 20-летним стажем и автора [онлайн-курса «Нереляционные базы данных»](https://otus.ru/lessons/nosql-bd/?u... | https://habr.com/ru/post/521302/ | null | ru | null |
# Извлечь максимум из новостей в интернете, часть 3
### Часть 3
#### Как я автоматизировал доставку аудиоподкастов на свой плеер
Продолжение статьи про новости - как я скачиваю подкасты. Предыдущие части [т... | https://habr.com/ru/post/551836/ | null | ru | null |
# Как мы игру «Камень – ножницы – бумага» на блокчейне Ethereum делали. Ч.2 Техническая
Учтя комментарии к моей [предыдущей статье](https://habr.com/post/358576/) я решил написать вторую часть, где будут более подробна рассмотрена техническая составляющая игры.
И так, начнём. Клиентскую часть мы сделали на javascr... | https://habr.com/ru/post/358772/ | null | ru | null |
# .Net коннектор для файлового менеджера elFinder
Есть такой замечательный, как мне кажется, файловый менеджер для веба под названием [elFinder](http://elrte.org/elfinder), который, также, интегрируется с WYSIWYG редактором [elRTE](http://elrte.org/).
Но, к сожалению, пользоваться им я не мог, потому что проекты у ... | https://habr.com/ru/post/107684/ | null | ru | null |
# Методы определения местоположения пользователя
#### **Предисловие**
Всем, кто когда-либо занимался написанием систем авторизации/регистрации пользователей, наверняка приходилось задаваться вопросом: «А как узнать о пользователе больше информации?». Для чего это нужно? В большинстве случаев, для идентификации именно... | https://habr.com/ru/post/193372/ | null | ru | null |
# Троян Troj/JSRedir-LK и уязвимость WordPress
Буквально сегодня закончила разбираться с интересной и новой для себя задачкой — подопечный сайт оказался в блэклисте яндекса. Причина — троян Troj/JSRedir-LK (по данным компании Sophos).
Уточню: в блэклисте оказались сразу два сайта, один из которых является поддомен... | https://habr.com/ru/post/184124/ | null | ru | null |
# Стандартные шаги исполнения запроса
По материалам статьи Craig Freedman: [The Building Blocks of Query Execution](https://techcommunity.microsoft.com/t5/sql-server-blog/the-building-blocks-of-query-execution/ba-p/383091)
### Что такое итератор?
SQL Server декомпозирует запросы, преобразуя их в набор стандартных бл... | https://habr.com/ru/post/655349/ | null | ru | null |
# Как это сделано: парсинг статей
Для меня всегда было некоей магией то, как Getpocket, Readability и Вконтакте парсят ссылки на страницы и предлагают готовые статьи к просмотру без рекламы, сайдбаров и ме... | https://habr.com/ru/post/200394/ | null | ru | null |
# Descriptive Programming в QuickTest Pro
QuickTest Professional – популярный инструмент для автоматизации функционального тестирования. В немалой степени его популярность обусловлена наличием в нем рекордера пользовательской активности, который позволяет записать действия пользователя и преобразовать их в скрипт.
... | https://habr.com/ru/post/69138/ | null | ru | null |
# Проклятые Земли. Освежаем геймплей
Приветик! Наверняка многие играли в замечательную игру от компании Nival Interactive - Проклятые Земли.
Такое бывает...Кто-то её помнит п... | https://habr.com/ru/post/685106/ | null | ru | null |
# Книга «Computer Science для программиста-самоучки. Все что нужно знать о структурах данных и алгоритмах»
[](https://habr.com/ru/company/piter/blog/711786/) Как дела, Хаброжители?
Книги Кори Альтхоффа вдохновили сотни тысяч л... | https://habr.com/ru/post/711786/ | null | ru | null |
# Espruino: JavaScript в микроконтроллере

«Зачем?», «Что за бред?», «Извращение!», «Фу-фу-фу» — вот некоторые из многих высказываний, которые мы услышали, когда выпустили плату [Iskra JS](http://amperka.ru/product/iskr... | https://habr.com/ru/post/392399/ | null | ru | null |
# Поиск декартова произведения с помощью LINQ
Постановка вопроса: **как найти декартово произведение *произвольного* количества последовательностей с помощью LINQ?**
Для начала, давайте убедимся, что мы знаем, о чем идет речь. Я буду обозначать последовательности как упорядоченные множества: `{a, b, c, d...}` Дека... | https://habr.com/ru/post/99128/ | null | ru | null |
# Вставка изображения из буфера обмена в редактор TinyMCE
Некоторое время назад у нас на проекте возникла необходимость вставить картинки из буфера обмена прямо в редактор. Задача оказалась нетривиальной, и простых решений не имела. По факту поиска в интернете было найдено всего два пути решения проблемы – либо менять... | https://habr.com/ru/post/124466/ | null | ru | null |
# Управление высокодоступными PostgreSQL кластерами с помощью Patroni. А.Клюкин, А.Кукушкин
**Расшифровка доклада/tutorial "Управление высокодоступными PostgreSQL кластерами с помощью Patroni". А.Клюкин, А.Кукушкин**
[Patroni](https://github.com/zalando/patroni) — это Python-приложение для создания высокодоступных Po... | https://habr.com/ru/post/504044/ | null | ru | null |
# И ещё раз про уникальные константы
Прочитав статью [«Вычислите длину окружности»](http://habrahabr.ru/company/abbyy/blog/252871), которая, в общем-то, крайне позабавила меня своим стилем, и узнав для себя кое-что новое, я стал несколько сомневаться в достаточной подробности предложенной информации. Всё-таки компилят... | https://habr.com/ru/post/254077/ | null | ru | null |
# Работа NSFetchRequest и NSFetchedResultsController, а также зачем тут продуктовый рынок
Здравствуйте! Эта статья нацелена на разработчиков, у которых есть минимальный навык работы с `Core Data Framework`. Напомню, что `Core Data` — это фреймворк для хранения данных на устройстве и взаимодействия с ними. На эту тему ... | https://habr.com/ru/post/309624/ | null | ru | null |
# svnconfbackup: скрипт для резервного копирования конфигурационных файлов
Несколько лет назад передо мной встала задача резервного копирования конфигурационных файлов. Да не простого, а такого, чтоб в любой момент можно было бы просмотреть что и когда изменилось. Я знал о существовании [csvbackup](http://www.opennet.... | https://habr.com/ru/post/83120/ | null | ru | null |
# Как я взломал свою ip-камеру и нашел там бекдор
Время пришло. Я купил себе второе IoT устройство в виде дешевой ip-камеры. Мои ожидания относящиеся к безопасности этой камеры были не высоки, это была самая дешевая камера из всех. Но она смогла меня удивить.

Многие, наверное, слышали о замечательном способе решения программистских задач под названием [метод утенка](https://ru... | https://habr.com/ru/post/325204/ | null | ru | null |
# Пришло время для открытых и свободных процессоров?
Раскрытие [уязвимостей Meltdown и Spectre](https://lwn.net/Articles/742702/) снова привлекло внимание к багам на аппаратном уровне. Многое сделано для улучшения (всё ещё слабой) безоп... | https://habr.com/ru/post/347874/ | null | ru | null |
# «Reader» monad through async/await in C#

[In my previous article](https://habr.com/ru/post/458692/) I described how to achieve the "Maybe" monad behavior using **async/await** operators. This time I am going to show how to imple... | https://habr.com/ru/post/461371/ | null | en | null |
# Умная новогодняя ёлка на ESP8266 и ws2811
В прошлом году я начал собирать новогоднюю ёлку очень поздно. Обычно стандартный для каждого конца года режим закрытия проектов в тот декабрь оказался особенно напряженным. В общем, ёлку мы с ребенком принялись наряжать за пару дней до нового года. И первый же сюрприз при ук... | https://habr.com/ru/post/409459/ | null | ru | null |
# Тесты визуальной регрессии. Перезагрузка
В своей предыдущей [статье](https://habr.com/ru/post/454464/) я рассказывал про опыт использования движка [Gemini](https://github.com/gemini-testing/gemini) для разработки визуальных тестов, точнее, тестов визуальной регрессии. Такие тесты проверяют, не «съехало» ли что-нибуд... | https://habr.com/ru/post/479040/ | null | ru | null |
# Определение процента схожести нарисованного 2d-полигона с заданным шаблоном
Приветствую, друзья.
Как вы знаете, в последнее время технология разработки игр для мобильных платформ развивается очень бурно. Игры пишутся на самых разных движках и языках, мы не будем в этой статье обсуждать, почему тот или иной язык/д... | https://habr.com/ru/post/190866/ | null | ru | null |
# Подробно о задачах Gradle

Перевод второй главы свободно распространяемой книги [Building and Testing with Gradle](http://www.gradleware.com/registered-access?content=books%2Fbuilding-and-testing%2F)
*... | https://habr.com/ru/post/167227/ | null | ru | null |
# Как проверить гипотезы и заработать на Swift с помощью сплит-тестов

Всем привет! Меня зовут Саша Зимин, я работаю iOS-разработчиком в лондонском офисе [Badoo](https://tech.badoo.com/ru/). В Badoo очень тесное взаимодействие с пр... | https://habr.com/ru/post/416841/ | null | ru | null |
# LISP-интерпретатор на чистом C
Я люблю язык C за его простоту и эффективность. Тем не менее, его нельзя назвать гибким и расширяемым. Есть другой простой язык, обладающий беспрецедентной гибкостью и расширяемостью, но проигрывающий C в эффективности использования ресурсов. Я имею в виду LISP. Оба языка использовалис... | https://habr.com/ru/post/150805/ | null | ru | null |
# Где формируем модель для UI при Domain Driven Design? Сравнение производительности различных архитектурных решений

Рассмотрим с точки зрения производительности варианты размещения логики по заполнению модели для трёх-уро... | https://habr.com/ru/post/279331/ | null | ru | null |
# И полгода не прошло: выпущена система управления версиями Git 2.29

Привет, %username%, сегодня отличная новость: в открытом доступе [появился](https://lkml.org/lkml/2020/10/19/692) выпуск распределенной ... | https://habr.com/ru/post/524514/ | null | ru | null |
# Корни разные нужны, корни разные важны
#### Вместо вступления
Прежде всего хочется выразить признательность всем, кто откликнулся на первую статью [об оптимизации кода на языке C/C++](https://habr.com/ru/post/515018/) на примере функции для вычисления квадратного корня из целого с округлением до ближайшего целого. ... | https://habr.com/ru/post/562572/ | null | ru | null |
# Об одной малоизвестной уязвимости в веб сайтах
Первое правило безопасности при разработке Веб приложений гласит: —
> Не доверять данным пришедшим от клиента.
Почти все это правило хорошо знают и соблюдают. Мы пропускаем через валидаторы данные форм, кукисы, даже URI.
Но недавно я с удивлением обнаружил, что ес... | https://habr.com/ru/post/166855/ | null | ru | null |
# Node.js в огне
Мы создаем новое поколение веб-приложения Netflix.com, использующего node.js. Вы можете узнать больше о нашем походе из [презентации](https://www.youtube.com/watch?v=gtjzjiTI96c&list=PLfXiENmg6yyUpIVY9XVOkbdmBPx6PUm9_), которую мы представили на NodeConf.eu несколько месяцев назад. Сегодня я хочу поде... | https://habr.com/ru/post/243945/ | null | ru | null |
# ASP.NET Push notifications с помощью SignalR
В качестве примера будем писать примитивный чат с мгновенным уведомлением всех клиентов с помощъю библиотеки [SignalR](https://github.com/SignalR/SignalR)
#### подготовка
Для этого в Visual Studio создадим пустой проект ASP.NET Empty Web Application
Сама библиотека... | https://habr.com/ru/post/135604/ | null | ru | null |
# Flutter. Разбираемся, как рисовать различные фигуры с помощью CustomClipper

Flutter предлагает различные виджеты для работы с определенным набором фигур, например, [ClipRect](https://api.flutter.dev/flutter/widgets/ClipRect-class.ht... | https://habr.com/ru/post/509384/ | null | ru | null |
# Создание мобильного приложения чата на React Native
Это вторая часть статьи (первая [тут](https://habr.com/ru/post/470756/)), посвященная созданию чата, используя apollo-server-koa и react-native. В ней будет рассмотрено создание мобильного приложения чата. В предыдущей части уже был создан бекенд для этого чата, по... | https://habr.com/ru/post/471712/ | null | ru | null |
# Hello World! в Adobe AIR
[Adobe AIR](http://www.adobe.com/devnet/air/) — это средство для разработки интерактивных приложений от Adobe. К особенностям можно отнести возможность разрабатывать кроссплатформенные приложения с использованием HTML/Ajax, Flex, Flash.
Для ознакомления сделаем пример «Hello World!» с исп... | https://habr.com/ru/post/31360/ | null | ru | null |
# Написание виртуальной файловой системы на c++
Еще одна моя запись из песочницы, если будет время то переведу остальные части
Это перевод первой части статьи про написание VFS (виртуальной файловой системы) на c++ которую я нашел достаточно давно. Надеюсь вам понравится. :)
Вступление
==========
Когда я начал ... | https://habr.com/ru/post/64538/ | null | ru | null |
# Разработка простого чата на Socket.IO [2016] \ Node.js
Всем привет, дорогие хабрахабровцы! Недавно я начал изучать node.js и дошёл до самого интересного, а именно — [Socket.Io](http://socket.io/). Поизучав информацию в интернете, я так и не смог найти подробного «гайда» по данному модулю, поэтому пришлось копать сам... | https://habr.com/ru/post/307744/ | null | ru | null |
# Запланированные новые возможности C# 8.0

Все ранее представленные в минорных версиях C# средства, разработаны так, чтобы не сильно изменять язык. Они представляют собой скорее синтаксические улучшения и небольшие дополнения [к нов... | https://habr.com/ru/post/413065/ | null | ru | null |
# Чёрная археология датамайнинга: насколько опасны «сливы» больших данных
В 2014 году в сеть утекла большая, на 6 млн. записей, база паролей различных почтовых сервисов. Давайте посмотрим, насколько эти пароли актуальны сейчас, в 2015 году.

Изначальный текст на р... | https://habr.com/ru/post/495024/ | null | ru | null |
# О проверке захвата в Scala 3
Несколько дней назад в [твите](https://twitter.com/odersky/status/1491693322573864960) Мартина Одерски (Martin Odersky) была анонсирована новая экспериментальная фича под назван... | https://habr.com/ru/post/670102/ | null | ru | null |
# Извлекаем мета-информацию из Си/C++ кода при помощи (py)gccxml
До появления gccxml, был только один способ извлечь мета-информацию из Си/С++ кода. Для начала, необходимо было написать парсер, способный справиться с грамматикой язы... | https://habr.com/ru/post/138906/ | null | ru | null |
# Firefox: улучшения панели загрузок
Речь пойдет об особенностях новой панели загрузок в Firefox и расширении [Download Panel Tweaker](https://addons.mozilla.org/firefox/addon/download-panel-tweaker/), устраняющем некоторые из нежелательных особенностей.
В частности, о самом спорном, на мой взгляд, нововведении, из... | https://habr.com/ru/post/215175/ | null | ru | null |
# История одного приложения или Борьба за производительность
Если вы — профессиональный разработчик, то вам должно быть знакомым чувство, когда хочется сделать что-то не для денег, а для души. В один из таких вечеров мне захотелось немного отвлечься и написать именно такое приложение.
Мы находимся в Украине, где ло... | https://habr.com/ru/post/167001/ | null | ru | null |
# Симулятор x86 подобного процессора на машине Тьюринга
Привет, Хабр! В свободное от работы время по вечерам мне нравится воплощать в жизнь свои сумасшедшие идеи. В один из таких вечеров родилась мысль реализовать компилятор кода в машину Тьюринга. Осознав ~~всю тщетность бытия~~ сложность реализации, было принято реш... | https://habr.com/ru/post/665776/ | null | ru | null |
# GitLab: с выходом версии 12.1 мы прекращаем поддержку MySQL
Сейчас мы расскажем, почему, начиная с версии 12.1, GitLab перестанет поддерживать MySQL.
--------------------------------------------------------------------------------... | https://habr.com/ru/post/459182/ | null | ru | null |
# Стриминг в Rails 4

Что такое стриминг?
-------------------
Стриминг крутился около Rails начиная с версии 3.2, но он был ограничен исключительно [стримингом шаблонов](http://apidock.com/rails/ActionController/Streami... | https://habr.com/ru/post/187994/ | null | ru | null |
# Робот-тележка на ROS. Часть 6. Одометрия с энкодеров колес, карта помещения, лидар
Посты серии:
[8.Управляем с телефона-ROS Control, GPS-нода](https://habr.com/ru/post/474650/)
[7. Локализация робота: gmapping, AMCL, реперные точки на карте помещения](https://habr.com/ru/post/472984/)
[6. Одометрия с энкоде... | https://habr.com/ru/post/471028/ | null | ru | null |
# Microsoft открывает исходный код первых версий MS-DOS и Word

Не прошло и 40 лет, как компания Microsoft решила открыть для публики исходный код MS-DOS v1.1 и v2.0, а также одной из первых версий Wor... | https://habr.com/ru/post/217081/ | null | ru | null |
# Создание динамически изменяемого ландшафта для RTS на Unity3D
Давным-давно я имел радость играть в замечательнейшую RTS под названием «Периметр: Геометрия Воины» от отечественного разработчика K-D Labs. Это игра о том, как огромные летающие города под названием «Фреймы» бороздят просторы «Спанджа» — цепи соединенных... | https://habr.com/ru/post/269645/ | null | ru | null |
# Кластер PostgreSQL высокой надежности на базе Patroni, Haproxy, Keepalived
Привет, Хабр! Встала передо мной недавно задача: настроить максимально надежный кластер серверов PostgreSQL версии 9.6.
По задумке, хотелось получить кластер, который переживает выпадение любого сервера, или даже нескольких серверов, и уме... | https://habr.com/ru/post/322036/ | null | ru | null |
# Советы по именованию ресурсов в Android
Андроид позволяет держать все текстовые константы в xml файлах. Тоже самое касается и многих других вещей, например, идентификаторов. И если ваше приложение чуть сложнее HelloWorld, то неправильное поименование может сильно повлиять на производительность вашего труда и качеств... | https://habr.com/ru/post/111153/ | null | ru | null |
# Настраиваем отказоустойчивость Pi-Hole в связке с Mikrotik
В [прошлой статье](https://habr.com/ru/post/468621/) мы внедрили домашний сервер DoH с использованием Pi-Hole, чем не только пофильтровали большое количество рекламы, но и инкапсулировали наши DNS-запросы в HTTPS, что вывело их из поля фильтрации запросов оп... | https://habr.com/ru/post/556024/ | null | ru | null |
# Новые технологии баз данных, на которые стоит обратить внимание (часть 1)
В этой статье мы поговорим о трех свежих технологиях в сфере баз данных, которые нас заинтересовали:
* [TileDB](https://lucperkins.dev/blog/new-db-tech-1/#tiledb)
* [Materialize](https://lucperkins.dev/blog/new-db-tech-1/#materialize)
* [Pr... | https://habr.com/ru/post/513100/ | null | ru | null |
# Первый вклад в API браузера от Facebook

Наше положение, как владельцев популярного веб-сайта — и наша работа в поддержке популярной платформы React — дают нам уникальные возможности и понимание работы с браузером, которые мы ... | https://habr.com/ru/post/451900/ | null | ru | null |
# Теплый и ламповый VPN

Ничего не предвещало беды, как вдруг в 2 часа ночи раздался телефонный звонок.
— Алло, милый! У меня youtube не работает!
— Прекрасно, иди спать!
— Нууу! Там новая серия вышла!
— З... | https://habr.com/ru/post/153855/ | null | ru | null |
# React+Django как написать Hello World
#### Написание простого web приложения на react с бэкендом на Django, с БД на postgres, зайцем, nginx и всё завернуть в docker.
Для кого написана эта статья? По большому счету для самого себя, чтобы хоть как-то структурировать знания в своей черепушке. А также она будет полезна... | https://habr.com/ru/post/713490/ | null | ru | null |
# Кастомизация DateTime в SharePoint
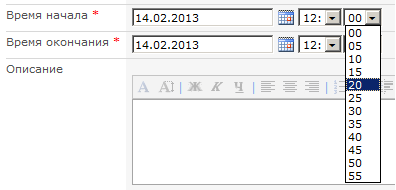Пользователи SharePoint знают, что создавая или редактируя какой-либо элемент, указывать время можно с интервалом в 5 минут. В большинстве случаев этого достаточно. Однако, встречаются та... | https://habr.com/ru/post/169167/ | null | ru | null |
# Есть ли жизнь без стандартов в JavaScript?
Предыстория
-----------
Начинается новый проект, собрана смышленая команда человек так из 7, намечен roadmap, согласованы сроки и бюджет ,- вроде бы все идет по плану, и счастью разработчиков нет предела. Так и слышны фразы: “Наконец-то не придется писать на (подставить an... | https://habr.com/ru/post/345326/ | null | ru | null |
# Way of Tanks. Путь от идеи к игре

Я всегда затрудняюсь ответить на вопрос: откуда берутся идеи для игр? Но в этот раз, я более-менее точно могу сказать, что эта идея родилась у меня когда я увидел баннер «World of Tanks» ... | https://habr.com/ru/post/249977/ | null | ru | null |
# Быстрый старт с WPF. Часть 1. Привязка, INotifyPropertyChanged и MVVM
Всем привет!
По разным причинам большинство из нас использует десктопные приложения, как минимум, браузер :) А у некоторых из нас возникает необходимость в написании своих. В этой статье я хочу пробежаться по процессу разработки несложного дескто... | https://habr.com/ru/post/427325/ | null | ru | null |
# Kubernetes в production: сервисы
Полгода назад мы закончили миграцию всех наших stateless сервисов в kubernetes. На первый взгляд задача достаточно простая: нужно развернуть кластер, написать спецификации приложений и вперед. Из-за од... | https://habr.com/ru/post/424229/ | null | ru | null |
# Analyzing the Code of ROOT, Scientific Data Analysis Framework
While Stockholm was holding the 118th Nobel Week, I was sitting in our office, where we develop the PVS-Studio static analyzer, working... | https://habr.com/ru/post/472492/ | null | en | null |
# Мигрируем БД в продакшене без даунтайма
В этой статье мы рассмотрим основные принципы миграции БД без даунтайма и дадим быстрые рецепты для наиболее распространенных случаев.
Как работает выкладка в прод?
-----------------------------
Давайте взглянем на типовой процесс выкладки веб-приложения в прод. Большинство ... | https://habr.com/ru/post/664028/ | null | ru | null |
# Парсинг сайтов или долгострои Московской области
Ознакомившись с рынком первичного жилья в Московской области, мы, конечно же, столкнулись с наличием обманутых дольщиков и проблемных объектов, так называемых «долгостроев». Естественно, встал вопрос, насколько вероятна такая ситуация.
Была поставлена цель выполнить ... | https://habr.com/ru/post/347996/ | null | ru | null |
# AngularJS vs. KnockoutJS
Добрый день уважаемые, хабрачеловеки.
В данной статье я хочу поделиться с вами своим опытом работы с такими фреймворками как [AngularJS](http://angularjs.org/) и [Knockout](http://knockoutjs.com/).
Cтатья будет интересна тем, кто хорошо знаком с JavaScript-ом и имеет представление хотя... | https://habr.com/ru/post/187808/ | null | ru | null |
# JScriptInclude Gear v 0.1.0 — механизм каскадного импорта скриптов/библиотек. (Реванш)
Доброго времени суток уважаемые хабражители.

Предлагаю Вашему вниманию пост-реванш, под названием **JScriptInclude Gear механизм... | https://habr.com/ru/post/148416/ | null | ru | null |
# Пишем приложения для Sony SmartWatch и SmartWatch 2
 **Sony SmartWatch** – достаточно интересный девайс своего времени, разработку под который почему-то обошли стороной на хабре. Ну раз так – давайте исправ... | https://habr.com/ru/post/210898/ | null | ru | null |
# Промокоды, случайно оставленные в исходном коде веб-сайта

Не так давно я обнаружил онлайн-магазин, нагло лгущий о количестве людей, просматривающих его товары. Его исходный код содержал функцию JavaScript, рандомизировавшую это чи... | https://habr.com/ru/post/564208/ | null | ru | null |
# Вышел Bootstrap 2.3
Это заняло много времени, друзья. Прошло около трех месяцев с последнего обновления, но не волнуйтесь, сегодня ожиданию наступил конец.
После многочисленных задержек, в том числе и на борьбу с гриппом, мы рады представить вам [Bootstrap 2.3](http://getbootstrap.com/).
#### И что нового?
Bo... | https://habr.com/ru/post/168959/ | null | ru | null |
# Набор регулярных выражений для MarkDown
Добрый день, уважаемые пользователи Хабра.
В этом посте хотел бы поделиться тем, с чем игрался долго и надеюсь это будет кому-то полезным.
Недавно столкнулся с тем, что в новом проекте надо было сделать подсветку синтаксиса для языка разметки MarkDown. В последнее время... | https://habr.com/ru/post/190304/ | null | ru | null |
# jQuery ColorPicker — выбираем цвет.
С удивлением обнаружил, что до сих пор не коснулся темы выбора цвета. Спешу исправить это недоразумение и расскажу о еще одном плагине к библиотеке **jQuery — ColorPicker**. Сразу хочу предупредить, плагин использует png-файлы, и в нашем любимом IE6 это аукается небольшими проблем... | https://habr.com/ru/post/42996/ | null | ru | null |
# Kafka в условиях повышенной нагрузки. Артём Выборнов (2017)

Kafka — распределённый брокер сообщений, нашедший широкое применение как универсальная шина для больших данных. Kafka позволяет как реализовать realtime-обработку большого ... | https://habr.com/ru/post/530714/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.