
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Мощность статистических тестов на единичный корень
Цель данной статьи — поделиться результатами сравнительного исследования мощности статистических тестов на единичные корни [Дики-Фуллера (ADF)](https://habr.com/ru/post/314330/) и [Квятковского, Филлипса, Шмидта и Шина (KPSS)](https://habr.com/ru/post/457794/): в сл... | https://habr.com/ru/post/530688/ | null | ru | null |
# We need to go deeper: диплинки и кодогенерация
Привет! Мы написали свою систему диплинков на основе кодогенерации. В этой статье поговорим, как мы упростили работу с диплинками и смогли отловить устаревшие, добавили мониторинг и как собрали все диплинки в одной статье в конфлюенсе.
Диплинк — это uri на конкретный р... | https://habr.com/ru/post/673850/ | null | ru | null |
# Определение кодировки текста в PHP, часть 2 — биграммы
[В прошлой статье](http://habrahabr.ru/blogs/php/107945/) был реализован алгоритм автоматического определения кодировки текста на основе частот распределения символов. [В комментариях отметили](http://habrahabr.ru/blogs/php/107945/#comment_3411483): если использ... | https://habr.com/ru/post/127658/ | null | ru | null |
# RAML-роутинг в Play Framework

[Play framework](https://www.playframework.com/documentation/2.5.x/Home) — очень гибкий инструмент, но информации о том, как изменить [формат route-файла](https://www.playframework.com/doc... | https://habr.com/ru/post/332638/ | null | ru | null |
# Жжем и зажигаем! Логически
История про то как добавить терминалу (Uni-Ubi) то, чего у него не было от рождения с помощью M5Stack на ESP32?
Uni-Ubi и M5StackВ наши ковид... | https://habr.com/ru/post/592545/ | null | ru | null |
# Работа с моделями данных в javascript
Здравствуйте, Хабралюди.
Мал по-малу из моего опыта и наших проектов родилась небольшая библиотека для работы с моделями в джаваскрипте. Она так и называется — [Model.js](http://mcmlxxxiii.github.io/Model.js).
Я расскажу вам вкратце об этой библиотеке и этим постом запраши... | https://habr.com/ru/post/178811/ | null | ru | null |
# Безопасный Android для ребёнка
Подозреваю, что многие из читателей этой публикации в детстве не носили с собой мобильный телефон, или начали носить его только в старших классах — как ни странно, обыденные на сегодняшний момент мобильники появились не так давно. И даже после их появления в течение долгого времени моб... | https://habr.com/ru/post/410213/ | null | ru | null |
# Доступный, но неприступный мобильный интернет
*— Кросс-пост из моего [блога](http://absolvo.ru/2008-06-28/dostupnyj-no-nepristupnyj-mobilnyj-internet/)*
Сегодня мобильный интернет уже не редкость, а удобный инструмент. Его можно повстречать практически везде. В пробке можно заметить у соседа ноутбук на переднем с... | https://habr.com/ru/post/28079/ | null | ru | null |
# Music on the Commodore PET and the Faulty Robots
After completion of the [System Beeps](https://shiru8bit.bandcamp.com/album/system-beeps), I wasn’t planning to make another stand alone album release with the pseudo polyphonic music, as I felt the topic had been explored enough. This, however, wouldn’t mean I couldn... | https://habr.com/ru/post/650905/ | null | en | null |
# Топ ошибок со стороны разработки при работе с PostgreSQL
[HighLoad++](https://www.highload.ru/) существует давно, и про работу с PostgreSQL мы говорим регулярно. Но у разработчиков все равно из месяца в месяц, из года в год возникают одни и те же проблемы. Когда в маленьких компаниях без DBA в штате случаются ошибки... | https://habr.com/ru/post/455248/ | null | ru | null |
# HMVC в пространстве имен
В последнее время очень много говорится о схеме проектирования [MVC](http://ru.wikipedia.org/wiki/MVC), почти все популярные PHP-фреймворки уже давно перешли на эту схему. Что же касается [Kohana](http://kohanaframework.org/), то начиная с версии 3, реализована иерархическая схема MVC – [HMV... | https://habr.com/ru/post/170739/ | null | ru | null |
# QQuickRenderControl, или как подружить QML с чужим OpenGL контекстом. Часть I
Недавний [релиз Qt 5.4](http://habrahabr.ru/post/245521/), помимо прочего, предоставил в распоряжение разработчиков один, на мой взгляд, очень любопытный инструмент. А именно, разработчики Qt сделали [QQuickRenderControl](http://doc-snapsh... | https://habr.com/ru/post/247477/ | null | ru | null |
# Устанавка pyload в качестве standalone качалки для ReadyNAS DUO v2
Для закачки торрентов ReadyNAS-ом на родном сайте в addons есть transmission, и поставить его не проблема.
Но, в тоже время простой ftp/http качалки, к моему сожалению и удивлению я там не нашел. Это недоразумение я предлагаю исправить.
, а мы в свою очередь подготовили топик про основы для этого творчеств... | https://habr.com/ru/post/133276/ | null | ru | null |
# Создание USB-гаджета с нуля или еще одна лампа настроения
Как-то на глаза попалась статья про [лампу настроения](http://habrahabr.ru/blogs/DIY/65616/). Будучи очень далеким от электротехники и абсолютно незнакомым с принципом работы микроконтроллеров, полученных из топика данных ну никак не хватало для понимания все... | https://habr.com/ru/post/95789/ | null | ru | null |
# Как использовать Python для «выпаса» ваших неструктурированных данных
Здравствуйте, уважаемые читатели.
В последнее время мы прорабатываем самые разные темы, связанные с языком Python, в том числе, проблемы извлечения и анализа данных. Например, нас заинтересовала книга [«Data Wrangling with Python: Tips and Tool... | https://habr.com/ru/post/302520/ | null | ru | null |
# v3.14.1592-beta2: все, что вы хотели знать о семантическом версионировании
Усилия и деньги, вкладываемые в продвижение языка Go, часто приносят пользу и другим разработчикам. В конце прошлого года на сайте [gopheracademy](h... | https://habr.com/ru/post/281593/ | null | ru | null |
# Создание подключений VPN на шлюзах Zyxel

VPN шлюзы Zyxel Zywall серий VPN, ATP и USG обладают обширными возможностями создания защищенных виртуальных сетей (VPN) для подключения как конечных пользователей (узел-сеть), так и созд... | https://habr.com/ru/post/503094/ | null | ru | null |
# Сервер WhatsApp обслуживает более миллиона TCP-соединений
Разработчики популярной программы WhatsApp Messenger [сообщили в блоге](http://blog.whatsapp.com/index.php/2011/09/one-million/), что провели оптимизацию серверного бэкенда для улучшения производительности, аптайма и масштабируемости. В результате им удалось ... | https://habr.com/ru/post/129035/ | null | ru | null |
# The Modal — правильные модальные окна
Очень часто модальные окна и диалоги делаются при помощи плагинов jQuery. Например, [SimpleModal](http://www.ericmmartin.com/projects/simplemodal/) или [jqModal](http://dev.iceburg.net/jquery/jqModal/). К сожалению, все они, в варианте по умолчанию, работают неправильно.
Что ... | https://habr.com/ru/post/148515/ | null | ru | null |
# DaData.ru превращает гуиды в адреса и знает всех пацанов на раёне

*[DaData.ru](https://dadata.ru/?utm_source=habr&utm_medium=post&utm_campaign=267997) — сервис автоматической проверки и исправления контактных данных (ФИО,... | https://habr.com/ru/post/267997/ | null | ru | null |
# Работа с GeoJSON в среде Node.js: практическое знакомство
[GeoJSON](https://tools.ietf.org/html/rfc7946) — это стандартизованный формат представления географических структур данных, основанный на JSON. Существует множество замечательных [инструментов](http://geojson.io/) для визуализации GeoJSON-данных. При этом дан... | https://habr.com/ru/post/489828/ | null | ru | null |
# Flutter + Socket.io — Обмен информацией в режиме реального времени
Когда скорость имеет решающее значение, когда необходимо иметь возможность обмениваться информацией мгновенно, есть несколько способы добиться этого, отправка множества сетевых запросов на сервер не всегда решает эту задачу, так как часто нам нужно п... | https://habr.com/ru/post/568356/ | null | ru | null |
# EDuke32 — Open Source движок Duke Nukem 3D
[](http://www.eduke32.com)
[EDuke32](http://www.eduke32.com) — движок культового PC шутера от 1-го лица Duke Nukem 3D для Windows, Linux и OS X, который доб... | https://habr.com/ru/post/89321/ | null | ru | null |
# Go += управление версиями пакетов
*Статья написана в феврале 2018 года*
В Go необходимо добавить версионирование пакетов.
Точнее, нужно добавить концепцию версионирования в рабочий словарь разработчиков Go и в инструменты, чтобы все употребляли одинаковые номера версий при упоминании, какую именно программу с... | https://habr.com/ru/post/442272/ | null | ru | null |
# Behind the scene of TOP-1 supercomputer
Это история о том, как мы c [mildly\_parallel](https://habrahabr.ru/users/mildly_parallel/) ~~замедляли~~ ускоряли расчеты на самом мощном суперкомпьютере [в мире](http://www.top500.org/).

В апр... | https://habr.com/ru/post/340318/ | null | ru | null |
# Mikrotik Router OS, скрипт для динамического деления скорости (Версия 2)
#### Mikrotik Router OS, скрипт для динамического деления скорости (Версия 2)
Это вторая версия, первая лежит тут: [тут.](http://habrahabr.ru/blogs/sysadm/110745/)
На днях встала следующая проблема: делить скорость поровну между всеми польз... | https://habr.com/ru/post/111745/ | null | ru | null |
# Визуальный сахар для ActiveRecord
Каждый, кто разрабатывал приложение на RoR знает, что в консоли (./script/console) не слишком удобно просматривать ActiveRecord объекты, они имеют мягко говоря не читабельный вид
Например в моем последнем проекте есть модель Schema
> `# == Schema Information`
>
>
Соответ... | https://habr.com/ru/post/78732/ | null | ru | null |
# Xcode 11 и XCFrameworks: новый формат упаковки фреймворков
В жизни многих компаний, которые имеют и развивают свой стек библиотек и компонентов, наступает момент, когда объёмы этого стека становится сложно поддерживать.
В случае ра... | https://habr.com/ru/post/475816/ | null | ru | null |
# Как адаптировать UX/UI под permissions
Во многих проектах существует процессы аутентификации (в той или иной степени). Написано много “бест практис” во всех известных технологиях и т.д. и т.п.
Но вот пользователь сделал логин и? Ведь он далеко не всё может сделать. Как определить что он может видеть, а что нет. На... | https://habr.com/ru/post/439100/ | null | ru | null |
# Распределенный реестр для колесных пар: опыт с Hyperledger Fabric
Привет, я работаю в команде проекта РРД КП (распределенный реестр данных для контроля жизненного цикла колесных пар). Здесь я хочу поделиться опытом нашей команды в разработке корпоративного блокчейна для данного проекта в условиях ограничений, наклад... | https://habr.com/ru/post/489002/ | null | ru | null |
# Восстановление (импутация) данных с помощью Python
*Автор статьи — Виктория Ляликова.*
На данный момент Python является самым популярным языком программирования, который применяется для анализа данных или ... | https://habr.com/ru/post/681410/ | null | ru | null |
# Разработка своей системы биллинга на Django
При разработке большинства сервисов возникает потребность во внутреннем биллинге для аккаунтов сервиса. Так и в [нашем сервисе](http://bitcalm.com/) возникла такая задача. Готовые пакеты для её решения мы так и не смогли найти, в итоге пришлось разрабатывать систему биллин... | https://habr.com/ru/post/234861/ | null | ru | null |
# Спам-кампания “Love you” перенацелена на Японию
Изучая свежую [волну спама в России](https://habr.com/ru/company/eset/blog/437982/), мы обратили внимание на другую атаку. С середины января 2019 года известная [кампания “Love you”](https://isc.sans.edu/forums/diary/Heartbreaking+Emails+Love+You+Malspam/24512/) дорабо... | https://habr.com/ru/post/439068/ | null | ru | null |
# Google Drive папка для Linux
Введение
--------
Существуют различные дистрибутивы Linux. В Xubuntu используется среда рабочего стола Xfce с файловым менеджером [thunar](https://ru.wikipedia.org/wiki/Thunar) (фунар). Целью данного туториала является описание способа подключения Google Диска к фунару. Этот же способ [... | https://habr.com/ru/post/685758/ | null | ru | null |
# 12 млрд реквестов в месяц за 120$ на java
Когда Вы запускаете свой продукт — Вы совершенно не знаете, что произойдет после запуска. Вы можете так и остаться абсолютно никому не нужным проектом, можете получить небольшой ручеек клиентов или сразу целое цунами пользователей, если про Вас напишут ведущие СМИ. Не знали ... | https://habr.com/ru/post/316370/ | null | ru | null |
# Как посчитать количество звёзд на фото?
Всем привет!
Недавно я участвовал в олимпиаде по искусственному интеллекту на Python и там было много интересных задач, но самая интересная это про звезды на небе: *... | https://habr.com/ru/post/589003/ | null | ru | null |
# JavaScript фреймворки теперь можно хостить на Google
В блоге [AJAX Search API](http://googleajaxsearchapi.blogspot.com/) вчера был проанонсирован [AJAX Libraries API](http://code.google.com/apis/ajaxlibs/). Суть состоит в том, что Google теперь позволяет всем желающим использовать JavaScript фреймворки, размещенные ... | https://habr.com/ru/post/26344/ | null | ru | null |
# Как я год строил расширениe для браузера которое читает статьи голосом (с синхронизацией в подкаст)
[Не один раз](https://habr.com/post/275587) я пробовал использовать сторонние API для получения голоса из текста который мне интересно прочитать — можно переключить чтение на уши когда глаза устали, или слушать во вре... | https://habr.com/ru/post/358374/ | null | ru | null |
# Блокировка нежелательного DNS трафика

У Вас может быть идеально настроено конечное сетевое оборудование, полный порядок в кластерах, могут быть пустыми магистрали и не нагруженное оборудование ядра сети, но если у Вас плохо раб... | https://habr.com/ru/post/110771/ | null | ru | null |
# Crossfilter.js, dc.js и D3.js для визуализации Данных
Приветствую ценителей красивой и функциональной визуализации данных! Предлагаю вашему вниманию небольшой обзор нескольких **JavaScript** библиотек, которые вкупе с [D3.js](http://d3js.org) позволят создать интерактивную визуализацию многомерных данных с возможнос... | https://habr.com/ru/post/189838/ | null | ru | null |
# Инструмент автоматизации управления версиями
Всем привет!
Всегда было интересно, что такое версии продукта и как ими управлять? Как автоматизировать управление версиями разработки? Прошу под кат.
Меня зовут Роман. Я разработ... | https://habr.com/ru/post/433994/ | null | ru | null |
# Математические вычисления и графики в LyX с использованием Sage
[LyX](http://www.lyx.org/) — это WYSIWYM процессор документов, который прозрачным образом работает с LaTeX. То есть пользователь создаёт в этом процессоре файлы \*.lyx, из которых потом создаются и компилируются \*.tex.
[Sage](http://www.sagemath.org... | https://habr.com/ru/post/95289/ | null | ru | null |
# Зачем (не)нужны геттеры?
Прошлая статья про [сеттеры/геттеры](https://habr.com/ru/post/469323/) как способ работы с сущностью (на примере Symfony в PHP) получила бурное обсуждение. В данной статье попробую выразить свои мысли отдельно по поводу геттеров: зачем и когда что-то получать, какую ответственность они решаю... | https://habr.com/ru/post/500416/ | null | ru | null |
# Почему нельзя установить размер шрифта у посещенной ссылки
Привет, Хабр! Представляю Вашему вниманию перевод статьи [«Why can’t I set the font size of a visited link?»](https://jameshfisher.com/2019/03/08/why-cant-i-set-the-font-size-of-a-visited-link/) автора Jim Fisher.

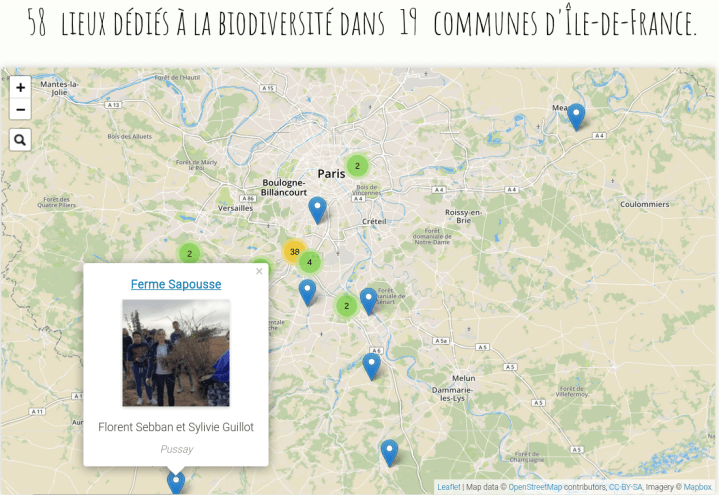
58 мест, где были высажены живые изгороди [1](#wn490_21443) | Map data OpenStreetMap contributors | Imagery Mapbox
Выборы в Совет Фо... | https://habr.com/ru/post/481390/ | null | ru | null |
# MVVM: новый взгляд
*Внимание!*
Более свежие и прогрессивные материалы по *MVVM* паттерну представлены в статье [Context Model Pattern via Aero Framework](http://habrahabr.ru/post/251347/) и подробно разобраны в [следующем цикле статей](http://habrahabr.ru/users/makeman/topics/)
**Предисловие**
Некоторое вре... | https://habr.com/ru/post/208326/ | null | ru | null |
# Именованные параметры Boost
Временами от C++ хочется более гибкого механизма параметризации функций. Например, есть у нас функция с двумя обязательными параметрами и большим количеством необязательных.
```
bool foo(int important, int& pOut, int sometimes = 1, int occasionally = 2, int rarely = 3)
{
//...
}
```
... | https://habr.com/ru/post/213015/ | null | ru | null |
# Опубликованы спецификации графического формата QOI, который в 20–50 раз быстрее PNG
Примерно месяц назад польский программист Доминик Шаблевски представил на суд публики новый графический формат QOI (Quite OK Image). Формат сжимает без потери качества, ориентируе... | https://habr.com/ru/post/596901/ | null | ru | null |
# Кривые линии на Google Maps
Думается мне, что скоро Google даст нам возможность нарисовать не только ломаную на своих картах, но и кривую. А с необходимостью нарисовать кривую линию я столкнулся уже сейчас, в процессе работы с одним проектом. И пришлось вертеться.
Я обычно очень люблю почитать на Хабре посты вида... | https://habr.com/ru/post/40503/ | null | ru | null |
# Частотный метод идентификации линейных динамических систем: теория и практика
В практиктических приложениях ТАУ часто необходимо точно и качественно идентифицировать объект управления. В этой статье речь пойдет об идентификации объекта управления частотным методом. Данный метод применим, когда есть возможность физич... | https://habr.com/ru/post/346812/ | null | ru | null |
# Установка Netbeans 7.0.1 в Mac OS X 10.7 Lion
Я совсем недавно стал обладателем MacBook Pro и пользователем Mac OS X.
Купил я этого «зверя» не забавы ради, а для того что бы работать. Ну и сразу же приступил к настройке системы: установка компиляторов, интерпретаторов, IDE, различных библиотек и расширений, а так... | https://habr.com/ru/post/125584/ | null | ru | null |
# Распараллеливание задач. Случай «идеальной параллельности». Часть 2
### Предлагаемые решения в .NET 4
Это вторая часть статьи, посвященной распараллеливанию идеальных циклов. В [первой части](http://habrahabr.ru/blogs/net/104078/ "Распараллеливание задач. Случай «идеальной параллельности». Часть 1") были рассмотрен... | https://habr.com/ru/post/104103/ | null | ru | null |
# Мультимедиа центр «Kodi» и Yocto Project

Введение в Yocto Project
-------------------------
Yocto Project — это совместный Open Source проект для упрощения разработки дистрибутивов для встраиваемых систем. Yocto содержит большое... | https://habr.com/ru/post/467443/ | null | ru | null |
# Подключаем онлайн-карты к навигатору на смартфоне. Часть 3 — OverpassTurbo
Превращаем созданный ранее скрипт в API для просмотра интерактивной карты с сайта OverpassTurbo.eu через навигационное приложение смартфона.
Содержание:
1 – [Вступление. Стандартные растровые карты](https://habr.com/ru/post/461031/)
2 – ... | https://habr.com/ru/post/461073/ | null | ru | null |
# Angular: оптимизация обработки событий

Прошла буквально пара недель, как я впервые начал писать на [Angular](https://angular.io/), и сразу же столкнулся с рядом специфических проблем. Из-за малого опыта работы с этим фреймворком, ... | https://habr.com/ru/post/353354/ | null | ru | null |
# Мой опыт настройки окружения для Web-разработки
Речь пойдет не о настройке денвера и не о том, как поставить LAMP-стек. Я решил рассказать о том, какое мы в своей команде используем окружение для разработки. Мы разрабатываем Web-сервисы и ERP-системы, но всё это, в сущности, ничто иное, как сайты. Просто сложные вну... | https://habr.com/ru/post/282884/ | null | ru | null |
# Пошаговое руководство по настройке DNS-сервера BIND в chroot среде для Red Hat (RHEL / CentOS) 7
*Перевод статьи подготовлен для студентов курса [«Безопасность Linux»](https://otus.pw/U1cp/). Интересно развиваться в данном направлении? Смотрите запись трансляции мастер-класса Ивана Пискунова [«Безопасность в Linux в... | https://habr.com/ru/post/461281/ | null | ru | null |
# Забудьте про div, семантика спасёт интернет
Давным-давно (лет пятнадцать назад) почти все делали сайты и не переживали о том, что под капотом. Верстали таблицами, использовали всё, что попадётся под руку ... | https://habr.com/ru/post/546500/ | null | ru | null |
# Операция TaskMasters: как мы разоблачили кибергруппировку, атакующую организации России и СНГ
[](https://habr.com/ru/company/pt/blog/451566/)
*Изображение: [Unsplash](https://unsplash.com/photos/FCrYdP8gohg)*
Осенью 2018 года эк... | https://habr.com/ru/post/451566/ | null | ru | null |
# Краткий очерк истории Lisp машин
Привет, Хабр!
В некоторых статьях я замечал, что авторы обещали рассказать про историю Lisp машин, но так и не рассказали. Возможно, эта короткая статья будет интересна любителям истории IT.
Да, на свете было мало машин с аппаратной поддержкой лямбда исчисления — около 7000 шту... | https://habr.com/ru/post/190082/ | null | ru | null |
# NativeScript, что за зверь и для чего он нужен?
Доброго времени суток, хабражители, меня зовут Владимир Миленко, я frontend-инженер в компании Иннософт, географически расположенной в городе Иннополис и являющейся резидентом особой экономической зоны г. Иннополис.
Сегодня я поведаю о таком звере, как NativeScript(... | https://habr.com/ru/post/318950/ | null | ru | null |
# Кто умнее тот и прав — Записки Хакера часть 1 из 5
Вашему вниманию предлагается увлекательное чтение, навеянное постами прошлой недели из жизни советских хакеров.
Всего планируется 5 выпусков, в зависимости от того, как хабрасообщество их воспримет.
Эти истории были подслушаны в вагоне поезда Москва-Питер прим... | https://habr.com/ru/post/86880/ | null | ru | null |
# Тестирование в 1C Bitrix
### Предисловие
Говоря о разработке сайтов с использованием CMS 1C Bitrix вопрос покрытия тестами поднимается редко. Главная причина в том, что большинство проектов обходится штатным функционалом, который предоставляется системой - его сложно (да и, в общем-то, незачем) тестировать.
Но со ... | https://habr.com/ru/post/667160/ | null | ru | null |
# Автогенерация CSS Sprites
Свершилось. Долгие бессонные ночи не прошли даром и мысль, [заявленная Вадимом aka pepelsbey](http://habrahabr.ru/blogs/client_side_optimization/52539/#comment_1395595), обрела более-менее физические очертания.
[sprites.webo.in](http://sprites.webo.in/) (сырая-сырая альфа-версия) — назва... | https://habr.com/ru/post/54283/ | null | ru | null |
# Лучший способ загрузки файлов в Ruby с помощью Shrine. Часть 1
*Это первая часть из серии постов о [Shrine](https://github.com/janko-m/shrine). Цель этой серии статей – показать преимущества Shrine над существующими загрузчиками файлов.*
---
Прошло уже больше года с того времени, как я начал разрабатывать Shrine... | https://habr.com/ru/post/328558/ | null | ru | null |
# Как создать email-письмо, которое увидит только Apple Watch
[](http://habrahabr.ru/company/pechkin/blog/258871/)
В блоге компании Litmus опубликован [материал](https://litmus.com/blog/how-to-send-hidden-version-email-apple... | https://habr.com/ru/post/258871/ | null | ru | null |
# Suggest.io: для людей с запросами

Живой поиск Suggest.io продолжает совершенствоваться.
Основные обновления:
* 1. Всвязи с увеличением числа пользователей внесены небольшие изменения в регистрацию/индексацию вновь подключаемых сайтов. Теперь индекс... | https://habr.com/ru/post/162289/ | null | ru | null |
# Обзор примитивов синхронизации — mutex и cond
Синхронизация нужна в любой малтитредной программе. (Если, конечно, она не состоит из локлесс алгоритмов на 100%, что вряд ли). Будь то приложение или компонента ядра современной операционной системы.
Меня всё нижесказанное, конечно, больше волнует с точки зрения разр... | https://habr.com/ru/post/278413/ | null | ru | null |
# Справочник методов console в JS
Со времён систематизации методов объекта console прошло достаточно много времени, некоторые браузеры получили поддержку недостающих ранее методов. Таблица вызывает естественный интерес у разраб... | https://habr.com/ru/post/253359/ | null | ru | null |
# Основы Irrlicht Engine для новичков
Хотелось бы рассказать о такой интересной вещи, как Irrlicht Engine. Для начала определимся что это вообще такое. Irrlicht — это мощный графический 3D движок, написанный на C++. Подходит сие чудо для разработки как простых 2D и 3D приложений, так и для игр. Как и любой другой движ... | https://habr.com/ru/post/191994/ | null | ru | null |
# Разработка HTML5-игр в Intel XDK. Часть 3. Знакомство со змейкой

[Часть 1](https://habrahabr.ru/company/intel/blog/281380/) » [Часть 2](https://habrahabr.ru/company/intel/blog/281453/) » [Часть 3](https://habrahabr.ru/com... | https://habr.com/ru/post/281523/ | null | ru | null |
# Как работает автозаполнение в браузерах и что важно учитывать веб-разработчику

Если человек пользуется автозаполнением в браузере, он ждёт, что сможет быстро заполнять формы на любом сайте, где посчитает нужным. Наладить такой мех... | https://habr.com/ru/post/686668/ | null | ru | null |
# Краткое сравнение библиотек отказоустойчивости на JVM
Независимо от того, внедряете ли вы микросервисы или нет, есть вероятность, что вы вызываете конечные точки HTTP. С HTTP-вызовами многое может пойти не так. Опытные разработчики планируют это и проектируют не только успешные пути. В общем отказоустойчивость (Faul... | https://habr.com/ru/post/645377/ | null | ru | null |
# Пятничный JS: минус без минуса
И вновь я приветствую всех в моей традиционной рубрике. Сегодня вы узнаете, что же такого особенного произошло 31 декабря 1969 года, ровно за миллисекунду до полуночи. Точнее, вы узнаете не только лишь это, но только к этому примеру я смог подобрать картинку, а развлекательная статья б... | https://habr.com/ru/post/352428/ | null | ru | null |
# Самая маленькая система управления перезагрузкой для Linux
*Делаем из мухи слона или кнопка для пингвина*
### Введение
После установки системы Gentoo Linux на свой нетбук я неожиданно обнаружил, что в сис... | https://habr.com/ru/post/703924/ | null | ru | null |
# .NET Core vs Node.js

Цель данной статьи — не выбор лучшей из двух платформ, а поиск сильных и слабых сторон каждой из них. Обе технологии прочно зарекомендовали себя в мире веб-разработки. Каждая из них имеет своих фанатов, получи... | https://habr.com/ru/post/506282/ | null | ru | null |
# Wi-Fi-модуль WF121 и HTTP-сервер впридачу

Прочитав статью [[HOW-TO] Add HTML button press functionality to the application](http://community.silabs.com/t5/Wireless-Knowledge-Base/HOW-TO-Add-HTML-button-press-functionalit... | https://habr.com/ru/post/280894/ | null | ru | null |
# Выпуск Rust 1.41.1: корректирующий выпуск
Команда Rust опубликовала новый корректирующий выпуск Rust, 1.41.1. Rust — это язык программирования, позволяющий каждому создавать надёжное и эффективное программное обеспечение.
Если вы установили предыдущую версию Rust средствами `rustup`, то для обновления до версии 1.4... | https://habr.com/ru/post/490132/ | null | ru | null |
# Как реализовать шаринг в социальные сети
Меня зовут Илья Степанов. Я – технический директор digital-агентства. Так как у нас много разных клиентских проектов, то мы постоянно сталкиваемся с новыми для нас задачами. Одной из таких оказалась реализация шаринга в социальные сети.
### Почему мы озадачились этой темой
... | https://habr.com/ru/post/574710/ | null | ru | null |
# Java Stream API на простых примерах
Стримы и коллекции чем-то похожи друг на друга, но у них разное назначение. Коллекции обеспечивают эффективный доступ к одиночным объектам, а стримы, наоборот, для прямог... | https://habr.com/ru/post/658999/ | null | ru | null |
# «Щадящая» балансировка между несколькими провайдерами на офисном шлюзе
Эта статья описывает конфигурацию шлюза под управлением Linux для балансировки трафика между каналами разных провайдеров.
, реализовать в конце каждой статьи ссылку на следующую и предыдущую. Нет ничего проще, дальше по большей части будет инструкция по использованию XSLT... | https://habr.com/ru/post/89262/ | null | ru | null |
# Механический дисплей из лего и Arduino
Если верить учебникам, то первые «телевизоры» были с механической развёрткой на [диске Нипкова](http://ru.wikipedia.org/wiki/%D0%94%D0%B8%D1%81%D0%BA_%D0%9D%D0%B8%D0%BF%D0%BA%D0%BE%D0%B2%D0%B0). Понятное дело, определение телевизора у каждого своё и для бытового применения меха... | https://habr.com/ru/post/135709/ | null | ru | null |
# Транслируем звук по сети с помощью Java
Стало мне интересно поэкспериментировать с передачей звука по сети.
Выбрал для этого технологию Java.
В итоге написал три компоненты — передатчик для Java SE, приемник для Java SE и приемник для Android.
В Java SE для работы со звуком использовались классы из пакета *... | https://habr.com/ru/post/242949/ | null | ru | null |
# Стилизация iOS-приложений: как мы натягиваем шрифты, цвета и изображения
[](http://habrahabr.ru/company/redmadrobot/blog/255381/)
В ходе работы над мобильным приложением разработчики получают от дизайнеров макеты, шрифты и... | https://habr.com/ru/post/255381/ | null | ru | null |
# Cisco Router + 2ISP + NAT. Доступность сервиса через 2ух провайдеров

Толчок. За ним ещё один, сильнее. Вот и всё. Перед глазами проносились альпийские луга, и девушка в бежевом сарафане, игриво кру... | https://habr.com/ru/post/117573/ | null | ru | null |
# Multithreading in Photon
**What this article is about**
In this article, we will talk about multithreading in the backend.
* how it is implemented
* how is it used
* what can be done
* what we invented ourselves
All these questions are relevant only if you develop something for the server side - modify the Serve... | https://habr.com/ru/post/559314/ | null | en | null |
# Персональные предложения для клиента – интеграция с платформой лояльности и начисление повышенных баллов
Рассмотрим взаимодействие с компанией SweetCard, которая представляет достаточно удобную платформу т... | https://habr.com/ru/post/582128/ | null | ru | null |
# Кофе с огурцами (Espresso + Cucumber)

Относительно не так давно появилась замечательная библиотека Espresso для тестирования UI Android приложений. Её преимущества над аналогами обозревались не один раз. Если вкратце,... | https://habr.com/ru/post/255763/ | null | ru | null |
# Как Android запускает MainActivity
Недавно я провел исследование о main() методе в Java и то, как он служит точкой входа для любого приложения Java. Это заставило меня задуматься, а как насчет Android-приложений? Есть ли у них основной метод? Как они загружаются? Что происходит за кулисами до выполнения onCreate()? ... | https://habr.com/ru/post/345120/ | null | ru | null |
# Telegram-бот для управления инфраструктурой
По мотивам статьи [Телеграмм-бот для системного администратора](https://habr.com/ru/post/317906/) (статья не моя, я только прочитал) захотел поделиться опытом создания Telegram-б... | https://habr.com/ru/post/483660/ | null | ru | null |
# Сага о типизации и тайпчекинге для JavaScript
Привет! Хочу поделиться своими мыслями по, казалось бы, простой теме — типизации. В частности, поговорить о тайпчекинге в JavaScript.
Часто люди воспринимают типизацию как эдакую серебряную пулю, которая защищает от всех проблем. Но это не так, часто ожидания от типиза... | https://habr.com/ru/post/541338/ | null | ru | null |
# Прекрати злоупотреблять массивами в PHP

Меня давно мучает мысль об одной проблеме — тотально злоупотребление массивами в PHP. Возможно корень проблемы в процедурном наследии PHP или... | https://habr.com/ru/post/279917/ | null | ru | null |
# Обработка файлов RAW, полученных с камеры Raspberry Pi HQ

Когда большинство людей делает фотографию, им просто нужно нажать кнопку спуска на фотокамере или телефоне, и готовое к просмотру изображен... | https://habr.com/ru/post/516658/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.