
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Советы Google по кодированию на языке Python. Часть вторая: советы по форматированию исходного кода

Доброго времени суток. Вот и пришло время для публикации второй части так понравившегося многим хабровчанам перевода ... | https://habr.com/ru/post/180509/ | null | ru | null |
# Как НАДЕЖНО защитить in-App Purchase от ломалок
Совсем недавно я писал статью [Как защитить in-App Purchase от ломалок](http://habrahabr.ru/post/143738/) . Прошло немного времени, а хакеры на месте не сидят. Тот метод защиты оказывается можно обойти, не очень сложно. Под катом метод, который намного надежнее.
Пе... | https://habr.com/ru/post/145524/ | null | ru | null |
# Docotic.Pdf: Какие проблемы PVS-Studio обнаружит в зрелом проекте?

Качество для нас важно. И о PVS-Studio мы наслышаны. Все это привело к желанию проверить Docotic.Pdf и узнать, что еще можно улучшить.
[... | https://habr.com/ru/post/425741/ | null | ru | null |
# Руководство по SQL: Как лучше писать запросы (Часть 2)
Продолжение статьи [Руководство по SQL: Как лучше писать запросы (Часть 1)](https://habr.com/ru/post/465547/)
От запроса к планам выполнения
------------------------------
 ... | https://habr.com/ru/post/465975/ | null | ru | null |
# NeoQUEST-2015: HeartBleed, Android и немного реверса
 Привет, Хабр! Близится лето, а вместе с ним — «очная ставка» NeoQUEST-2015. [Регистрация](http://neoquest.ru/timeline.php?year=2015) на мероприятие уже открыта, и вход — б... | https://habr.com/ru/post/258169/ | null | ru | null |
# Работа с API Яндекс.Метрика на Python
**Всем любителям Python и Яндекс.Метрики доброго дня!**
Некоторые знают, что с некоторых пор я заделался Web-разработчиком, впрочем это громко сказано. Мой сайт с занимательными задачками, кстати, если кому интересно, попасть туда можно вот по [этой ссылке](http://ru-brains.o... | https://habr.com/ru/post/187384/ | null | ru | null |
# Магический круг: CSS головоломка
Доброго времени суток, уважаемые хабравчане. Недавно [Hugo Giraudel](https://twitter.com/HugoGiraudel), он же CSS гоблин, SASS хакер и Margin псих опубликовал в своем блоге очень интересную [CSS задачку](http://hugogiraudel.com/2014/02/19/the-magic-circle-a-css-brain-teaser/) на смыш... | https://habr.com/ru/post/214917/ | null | ru | null |
# Wi-Fi сети: проникновение и защита. 2) Kali. Скрытие SSID. MAC-фильтрация. WPS

[Первая часть цикла](http://habrahabr.ru/post/224955/) была очень живо встречена хабрасообществом, что вдохновило меня на ус... | https://habr.com/ru/post/225483/ | null | ru | null |
# Новости из мира OpenStreetMap № 463 (28.05.2019-03.06.2019)
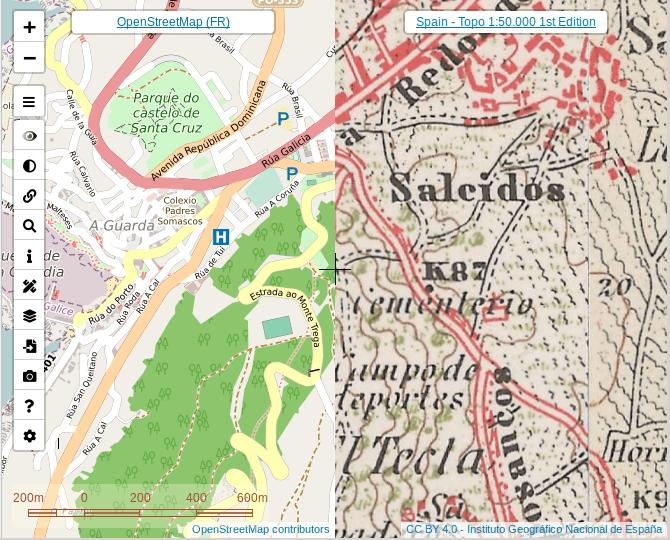
*Multimapas- это сочетание множества исторических, топографических, спутниковых и дорожных карт [1](#wn461_20136) | CC BY 4.0 Национальный гео... | https://habr.com/ru/post/455455/ | null | ru | null |
# Маски, картины, тайные покупатели и анализ продаж: разбираем решения задач для Go-разработчиков
3 апреля на платформе All Cups прошло отборочное соревнование на курс «[Продвинутая разработка микросервисов на Go](https://route256.ozon.ru/go-developer)» — это уже второй поток бесплатных курсов для разработчиков от Ozo... | https://habr.com/ru/post/660489/ | null | ru | null |
# Android. Surface
Дисклеймер
----------
Данная статья предназначена для начинающих андроид разработчиков с небольшим опытом работы с видео и/или камерой, особенно тех кто начал разбирать примеры [grafika](https://github.com/google/grafika) и кому они показались сложными — здесь будет рассмотрен похожий код с упрощен... | https://habr.com/ru/post/480878/ | null | ru | null |
# Детерминированный метод факторизации чисел, основанный на использовании mod 6 и mod 4
О! Сколько нам открытий чудных
Готовит просвещение дух,
И опыт, сын ошибок трудных,
И гений, парадоксов друг,
И случай, бог изобретатель…
А.С. Пушкин
### Вместо вступления
Надеюсь представить решение проблемы... | https://habr.com/ru/post/301094/ | null | ru | null |
# На GitHub появился форк движка Godot с возможностью экспорта проектов для PS Vita
Разработчик под никнеймом SonicMastr [опубликовал](https://github.com/SonicMastr/godot/releases/tag/3.5-rc5-vita1) версию игрового движка Godot 3.5 с поддержкой Sony PlayStation Vita. Пользователи получили возможность собирать проекты ... | https://habr.com/ru/post/679192/ | null | ru | null |
# Что нас ждет в WordPress 3.0 (обзор новых функций)
Очередная версия самой популярной платформы для блогов WordPress 3.0 должна выйти 1 мая в один день с проведением конференции WordCamp в San Francisco. При этом окончательный вариант всех новых функций был утвержден и «заморожен» 1 марта. Таким образом, все новинки ... | https://habr.com/ru/post/86395/ | null | ru | null |
# Visual Studio Code — эволюция кроссплатформенного редактора кода на примере версии для OS X
[Visual Studio Code](https://code.visualstudio.com/) — редактор кода, с поддержкой более 30 языков программирования и форматов фа... | https://habr.com/ru/post/268837/ | null | ru | null |
# Основы Интерактивных карт
Для визуализации интерактивных карт рассмотрим библиотеку - Folium.
Folium — это мощная библиотека визуализации данных в Python, которая была создана в первую очередь для того, чтобы помочь людям визуализировать гео-пространственные данные.
Folium - это библиотека с открытым исходным кодо... | https://habr.com/ru/post/664888/ | null | ru | null |
# Как найти количество всех букв на всех знаках вида «въезд в город Х» в стране? Точный способ ответить на такие вопросы
Недавно в рамках одного собеседования мне понадобилось решить задачу, условие которой приведено ниже:
> У лучшего в мире управляющего по имени Пенультимо родилась очередная гениальнейшая идея, pe... | https://habr.com/ru/post/516394/ | null | ru | null |
# 16 ядер и 30 Гб под капотом Вашего Jupyter за $0.25 в час
Если Вам не очень повезло, и на работе нет n-ядерного монстра, которого можно загрузить своими скриптами, то эта статья для Вас. Также если Вы привыкли запускать скрипты на всю ночь (и утром читать, что где-то забыли скобочку, и 6 часов вычислений пропали) — ... | https://habr.com/ru/post/280562/ | null | ru | null |
# Запись интернет-радио из консоли Linux
Технически реализовать это безобразие помогает Mplayer, который умеет очень многое из консоли. Помимо проигрывания музыки, Mplayer умеет записывать радиостанции (причем вовремя записи их не нужно слушать).
Для начала у вас должен быть установлен этот плеер. В операционной с... | https://habr.com/ru/post/165119/ | null | ru | null |
# Что делать если Instagram не дал доступ к API?
1 июня 2016 года Instagram [отключит](http://techcrunch.com/2015/11/17/just-instagram/) от своего API все приложения, которые не прошли модерацию. Что делать если вы в их числе?
### **Предыстория**
Мы делаем сервис для постинга в Instagram по расписанию и используе... | https://habr.com/ru/post/302150/ | null | ru | null |
# Enabling Apache Camel metrics in Spring Boot Actuator Prometheus
### Contents
* [Intro](#intro)
* [Popular approach](#popular_approach)
* [Problem](#problem)
* [Path to find the solution](http://path_to_find_solution)
* [Final solution](http://final_solution)
* [Conclusion](#conclusion)
### Intro
Once I had a tas... | https://habr.com/ru/post/657495/ | null | en | null |
# Курс по Ruby+Rails. Часть 3. Функциональное программирование
Привет! Сегодня мы поговорим про функциональное программирование. В Ruby реализован исключительно гибкий объектно-ориентированный стиль. И как бы... | https://habr.com/ru/post/692656/ | null | ru | null |
# Фильтруем людей или как заблюрить одного человека на видео
Добрый день. Хочу предложить вам небольшую статью о своей работе с кинектом.
Сейчас я делаю небольшую часть рекламного проекта, где используется кинект. Одной из задач является «наложение фильтра» на одного человека в толпе. Об этом и поговорим.
В раб... | https://habr.com/ru/post/127802/ | null | ru | null |
# Lubuntu OpenStar Linux edition 10.04

Lubuntu OpenStar Linux edition 10.04 специально доработанная операционная система Linux для слабых компьютеров с целью замены Windows XP на предприятих.
... | https://habr.com/ru/post/94724/ | null | ru | null |
# Определение наличия Acrobat-плагина в броузере
Столкнулся с проблемой определения наличия плагина. Гуглёж дал результаты не сразу. Основная проблема была в пятой строке.
````
var isPDFInstalled = false;
if (window.ActiveXObject) {
var control;
try {
control = new ActiveXObject('AcroPDF.PDF');
... | https://habr.com/ru/post/13953/ | null | ru | null |
# Meet StoreKit 2
Всем привет, меня зовут Сурен, я SDK Engineer в qonversion.io.
Мы - data платформа для приложений с подписками. Наши мобильные SDK предоставляют интерфейс для работы со StoreKit и Google Billing Client, принимают пуши, отображают экраны, построенные в визуальном конструкторе экранов и многое другое.... | https://habr.com/ru/post/563280/ | null | ru | null |
# Установка Jenkins с помощью terraform в Kubernetes в Yandex Cloud с letsencypt
В этой статье будет следующее:
* Заведение DNS домена на reg.ru.
* Управление DNS зоной в Yandex DNS c помощью terraform.
* Создание Kubernetes в Yandex Cloud.
* Резервируем внешний статический IP адрес.
* Установка Jenkins c помощью ter... | https://habr.com/ru/post/683844/ | null | ru | null |
# Пишем XGBoost с нуля — часть 1: деревья решений

Привет, Хабр!
После многочисленных поисков качественных руководств о решающих деревьях и ансамблевых алгоритмах (бустинг, решающий лес и пр.) с их непосредственной реализацией на ... | https://habr.com/ru/post/438560/ | null | ru | null |
# Как разговорить Марусю: FAQ по созданию скиллов для голосового ассистента

Голосовые помощники как технология возникли благодаря развитию целого созвездия других технологий. И одним из таких голосовых помощников стала Маруся, отн... | https://habr.com/ru/post/533626/ | null | ru | null |
# Краткое введение в разработку приложений для микроконтроллеров stm32
Ко мне довольно часто обращаются люди с просьбой помочь им начать работу с микроконтроллерами семейства stm32. Отвечая на их вопросы и помогая им с проектами, я понял, что будет лучше написать статью, которая будет полезна всем желающим начать прог... | https://habr.com/ru/post/407045/ | null | ru | null |
# Обзор и доработка устройств от DreamSourseLab
Всех приветствую.
По следам предыдущих статей по логическим анализаторам на Хабре решил таки закончить свой "фундаментальный" труд.

Начну немного издалека.
Все началось в в начал... | https://habr.com/ru/post/452362/ | null | ru | null |
# Использование slots во Vue на примере сниппета товара
При работе с проектами где не используется SSR (Server Side Rendering) или внедрение его невозможно, возникает проблема, что некоторые функции или логика пишутся два раза для статических элементов которые распечатывает backend и для компонентов которые рендерит V... | https://habr.com/ru/post/422465/ | null | ru | null |
# О репозиториях замолвите слово

В последнее время на хабре, и не только, можно наблюдать интерес GO сообщества к луковой/чистой архитектуре, энтерпрайз паттернам и прочему DDD. Читая статьи на данную тему и разбирая примеры ... | https://habr.com/ru/post/524232/ | null | ru | null |
# Comparing PHP-FPM, NGINX Unit, and Laravel Octane
This article compares the performance of several different web servers for a Laravel-based application. What follows is a lot of graphs, configuration settings, and my personal conclusions which do not pretend to represent universal truth in any way.
I myself have b... | https://habr.com/ru/post/646397/ | null | en | null |
# Qt и SQLite и вообще, программирование БД в Qt
Добрый день.
Ниже пойдет речь о том, как использовать [SQLite](http://ru.wikipedia.org/wiki/Sqlite) в [Qt](http://ru.wikipedia.org/wiki/Qt). Автор постарался как можно подробнее рассматривать программирование баз данных в Qt.
Об этих двух замечательных продуктах ... | https://habr.com/ru/post/128836/ | null | ru | null |
# Насколько сложно написать свою операционную систему?

*Концептуальная плата [REX](https://dl.acm.org/doi/pdf/10.1145/1275462.1275470) и простой процессор WRAMP разработаны специально для обучения студентов компьютерной архитектур... | https://habr.com/ru/post/566734/ | null | ru | null |
# Выравнивание модального окна по центру
Мой первый пост.
Центрирование блока относительно другого блока относительно часто-попадающаяся задача, это очередное ее решение. Для меня оно стало самым универсальным и покрывающим все кейсы, с которыми я когда-либо сталкивался.
**Формулировка**
Центрировать модально... | https://habr.com/ru/post/252769/ | null | ru | null |
# Проектирование Базы Данных. Лучшие практики
*В преддверии старта очередного потока по курсу [«Базы данных»](https://otus.pw/3WyH/) подготовили небольшой авторский материал с важными советами по конструированию БД. Надеемся данный материал будет полезен для вас.*
. В связи с этим приглашаем всех желающих посетить бесплатный демо-урок по теме: [«Что нужно знать о JS тестировщику»](https://otus.p... | https://habr.com/ru/post/539296/ | null | ru | null |
# Общее представление об архитектуре Clean Swift
Привет, читатель!
В этой статье я расскажу об архитектуре iOS приложений — [Clean Swift](http://clean-swift.com). Мы рассмотрим основные теоретические моменты и разберем пример на практике.
 на пальцах
Три переезда равно одному пожару. Выгребая старый ящик, пропахший ацетоном, с многослойной пылью на донышке (как хорошо, что жена не видела) я наткнулся на до боли знакомые мне компакт диски. Вот один из любимых фильмов детства… а вот моя когда-то любимая аркадная игрушка…
Стран... | https://habr.com/ru/post/269311/ | null | ru | null |
# GoLand 2020.2: улучшенная поддержка Go modules, дженерики и многое другое
Хабр, привет! Две недели назад мы выпустили GoLand 2020.2 и хотим рассказать про основные изменения в этом релизе.

Если коротко, то мы улучшили поддержку G... | https://habr.com/ru/post/515062/ | null | ru | null |
# Как работает Backend-Driven UI на мобильном клиенте
Привет всем, кто хочет изменять интерфейс мобильного приложения до выхода нового релиза, всем, кто хочет без лишних доработок на клиенте проводить А/B-тестирование, и всем, кто хочет забыть о срочных «новых пятничных промоакциях», которые нужны уже в понедельник. В... | https://habr.com/ru/post/661941/ | null | ru | null |
# Мониторинг воровства кабеля
Работаю в интернет-провайдере, в одном из районов города стали часто резать медный 25 парный кабель.
Злоумышленникам все просто — зашел в подъезд, поднялся на верхний этаж, обрезал кабель и вытащил из трубостоек, можно скручивать и продавать. Факт кражи будет заметен только тогда, ког... | https://habr.com/ru/post/188730/ | null | ru | null |
# HowToCode — Адаптация системного подхода к разработке для React и TypeScript
Наверное, каждый программист рано или поздно начинает задумываться о качестве своего кода. И, скорее всего, я не ошибусь, если скажу, что добрая половина разработчиков им вечно недовольна. Мне мой код тоже нравился редко: функции, казалось,... | https://habr.com/ru/post/545852/ | null | ru | null |
# Настройка резервного копирования в Ubuntu
Настройка резервного копирования в Ubuntu за 20 минут.
======================================================
Для работы над проектами использую svn, который находится на удаленном виртуальном выделенном хосте, под управлением ubuntu 8.04. Со временем объемы данных выросли,... | https://habr.com/ru/post/45912/ | null | ru | null |
# iOS Инструменты разработчика
Вступление
----------
Всем привет, меня зовут Григорий, последние 5 лет занимался программированием под iOS. Сейчас решил сменить сферу деятельности и ударился в веб, но чтобы добро не пропадало, хочу поделиться с сообществом своими наработками, накопившимися за это время. Библиотеки вы... | https://habr.com/ru/post/262615/ | null | ru | null |
# MLflow в облаке. Простой и быстрый способ вывести ML-модели в продакшен
[Robot factory by lucart](https://www.deviantart.com/lukart/art/Robot-factory-428963611)
MLflow — один из самых стабильных и легких инструментов, по... | https://habr.com/ru/post/565022/ | null | ru | null |
# Простой, надёжный и удобный мониторинг серверов на Linux
Если вы администрируете сервера на Linux, наверняка, вы находитесь в состоянии постоянного поиска простых, надежных и удобных инструментов для решения самых разных задач. Одна из них — наблюдение за состоянием машин. И, хотя инструментов для мониторинга предос... | https://habr.com/ru/post/324194/ | null | ru | null |
# VK notifer на java
Однажды мне довелось работать над проектом, заказчик которого поддерживал обратную связь исключительно с помощью социальной сети Вконтакте. Так как я — не особо активный пользователь данной социальной сети, то возникла проблема в плане скорости получения посланных мне сообщений. Так случилось, что... | https://habr.com/ru/post/144813/ | null | ru | null |
# Fabric — пара прикладных рецептов
Сегодня неожиданно понял, что скрипты — это сила (спустя несколько месяцев использования **fabric**). На самом деле 30 минут потраченные на написание адекватного сценария избавляют от многих совокупных часов повторения ненужных действий. Для упрощения жизни адептов **python**'а суще... | https://habr.com/ru/post/141271/ | null | ru | null |
# Основы борьбы с неявным дублированием кода
Код с одной и той же структурой в двух и более местах — верный признак необходимости рефакторинга. Если вам нужно будет что-нибудь изменить в одном месте, то, скорее всего, нужно также сделать **то же самое** и в других местах. Но есть близкая к 100% вероятность не найти эт... | https://habr.com/ru/post/197932/ | null | ru | null |
# Node.js + JQuery Ajax. Загрузка файлов на сервер
#### Введение
В данные статье я хочу вам рассказать о моем способе загрузки файлов на сервер Node.js с помощью JQuery Ajax. Да, я понимаю что есть уже и другие решения, например [JQuery File Upload](http://blueimp.github.io/jQuery-File-Upload/), но все таки иногда хо... | https://habr.com/ru/post/229743/ | null | ru | null |
# Nullable Reference types in C# 8.0 and static analysis

It's not a secret that Microsoft has been working on the 8-th version of C# language for quite a while. The new language version (C# 8.0) is... | https://habr.com/ru/post/455234/ | null | en | null |
# Зачем выставлять в Интернет интерфейс управления или атака на Cisco Smart Install
Недавно Cisco узнала о некоторых хакерских группировках, которые выбрали своими мишенями коммутаторы Cisco, используя при этом проблему неправильного использования протокола в Cisco Smart Install Client. Несколько инцидентов в разных с... | https://habr.com/ru/post/352996/ | null | ru | null |
# Golang+FFmpeg
Долго искал более-менее живую Golang-библиотеку для работы с rtsp.
Изначально наткнулся на [github.com/nareix/joy4](https://github.com/nareix/joy4), но там оказался устаревший C-код и rtp был на Golang, а декодинг на FFmpeg. (~~немало deprecated варнингов~~).
Изначально форкнул ее, что-то поправи... | https://habr.com/ru/post/569162/ | null | ru | null |
# (Архив) Matreshka.js — MK.Array
**Статья устарела. В [новой документации](http://ru.matreshka.io/) содержится самая актуальная информация из этого поста. См. [Matreshka.Array](http://ru.matreshka.io/#Matreshka.Array).**
* [Введение](http://habrahabr.ru/post/196146/)
* [Наследование](http://habrahabr.ru/post/20007... | https://habr.com/ru/post/198212/ | null | ru | null |
# Анатомия KD-Деревьев

Эта статья полностью посвящена KD-Деревьям: я описываю тонкости построения KD-Деревьев, тонкости реализации функций поиска 'ближнего' в KD-Дереве, а также возможные 'подводные ... | https://habr.com/ru/post/312882/ | null | ru | null |
# Раскрываем магию MySQL или о строгости и мягкости MySQL
Очень часто в интернете встречаюсь со статьями, в которых приводят кучу примеров с якобы странным поведением MySQL по сравнению с другими БД. Чтобы стало понятно, о чём я говорю, приведу несколько примеров:
1. Деление на ноль возвращает NULL вместо ошибки
... | https://habr.com/ru/post/166411/ | null | ru | null |
# Как фильтровать Git логи
### Получение всех коммитов
```
git log
```
### Получение последних n коммитов
Мы можем получить последние n коммитов, выполнив команду "git log -n". Скажем, мы хотим получить пос... | https://habr.com/ru/post/651209/ | null | ru | null |
# Опыт использования «координаторов» в реальном «iOS»-проекте
Мир современного программирования богат на тренды, а для мира программирования [«iOS»](https://developer.apple.com/ios/)-приложений это справедливо вдвойне. Надеюсь, я не сильно ошибусь, утверждая, что одним из самых «модных» архитектурных шаблонов последни... | https://habr.com/ru/post/444038/ | null | ru | null |
# Пример реализации автоматизированного процесса резервного копирования и восстановления баз данных встроенными средствами
### Предисловие
В Интернете можно найти достаточно много примеров по созданию резервных копий баз данных, а также по их восстановлению. Приведем еще один пример встроенными средствами в MS SQL Se... | https://habr.com/ru/post/343554/ | null | ru | null |
# БД ClickHouse для людей, или Технологии инопланетян
**Алексей Лизунов, руководитель направления центра компетенций дистанционных каналов обслуживания дирекции информационных технологий МКБ**

В качестве альтернативы стеку ELK (E... | https://habr.com/ru/post/472912/ | null | ru | null |
# Первая бета Phalcon 1.0.0
Сегодня группа разработчиков Phalcon выпустила первую бета-версию фреймворка Phalcon 1.0.0. Для тех, кто не в курсе: Phalcon — это PHP-фреймворк, написанный на Си и работающий как расширение для PHP, прочитать про него на Хабре можно в статьях [Phalcon — скомпилированный PHP MVC Framework](... | https://habr.com/ru/post/171915/ | null | ru | null |
# Визуальный конфигуратор окон, написанный за один час
Решал интересную задачу – сделать визуальный редактор-конфигуратор окон.
Подробностями процесса разработки я с вами, коллеги, и поделюсь.
UPD. Добавил скриншоты.
UPD2. **Речь идет об окнах оффлайновых, застекленных, деревянных или пластиковых — через кот... | https://habr.com/ru/post/238065/ | null | ru | null |
# Анализ защиты Sony PlayStation 4

Поскольку никаких публичных заявлений касательно взлома PS4 не поступало уже давно, настало время нарушить тишину и рассказать немного о том, как далеко зашел прогр... | https://habr.com/ru/post/265235/ | null | ru | null |
# Профилирование памяти на STM32 и других микроконтроллерах: статический анализ размера стека
Привет, Хабр!
В [прошлой статье](https://habr.com/ru/post/443030/) и я сам упоминал, и в комментариях спрашивали — ок, хорошо, методом научного тыка мы подобрали размер стека, вроде ничего не падает, а можно как-то надёжне... | https://habr.com/ru/post/443544/ | null | ru | null |
# MODx — собственный ajax календарь событий/новостей 2
Выходные проходят сложно для моего здоровья, но я таки смог переписать свой [календарь событий](http://habrahabr.ru/blogs/modx/111155/) для ModX.
Напомню, сниппет берет события из указанной директории MODx и генерирует календарь с событиями по дням, которые ото... | https://habr.com/ru/post/111436/ | null | ru | null |
# Начинающему QA: полезные функции снифферов на примере Charles Proxy
Снифферы - это инструменты, позволяющие перехватывать, анализировать и модернизировать все запросы, которые через них проходят. Они полезны, когда из потока нужно извлечь какие-либо сведения или создать нужный ответ сервера. Так можно проводить моду... | https://habr.com/ru/post/554888/ | null | ru | null |
# Обработка событий в реальном масштабе времени с помощью SynapseGrid
Занимались мы как-то обработкой аудио на Java с помощью сложных алгоритмов. Каждый кусочек аудио должен был пройти длинную цепочку обработки (20-50 алгоритмов разной степени сложности). Потоки аудио поступали параллельно, алгоритмы работали параллел... | https://habr.com/ru/post/204596/ | null | ru | null |
# Пробуем IPv6 в домашней сети

Давно хотел пощупать что это такое. Много новостей связанных с ipv6 мелькает в интернете. Близится всемирный день запуска, прошлогодний день тестирования я как-то пропу... | https://habr.com/ru/post/141226/ | null | ru | null |
# Об удобной навигации и отладке C++ кода в Vim
Компания, где я работаю, разрабатывает программное обеспечение на C++ под Linux. Долгое время мы использовали Qt Creator, с редкими ребятами работающими из Emacs и Vim. Когда я сам попытался пересесть на Vim, я понял, что ситуация с плагинами для разработки на С++ очень ... | https://habr.com/ru/post/245681/ | null | ru | null |
# Будущее наступает на AMF 2014
Так получилось, что я не журналист и не блоггер. Не таскаю с собой дорогой фотоаппарат или камеру, и для повседневных фото-видеосъёмок мне хватало смартфона. Однако сегодня судьба закинула меня на Arab Media Forum 2014, где арабские журналисты и видные блоггеры рассуждали о SocialMedia ... | https://habr.com/ru/post/223505/ | null | ru | null |
# Dagger 2.11 & Android. Часть 2
В [предыдущей статье](https://habrahabr.ru/post/335940/) мы рассмотрели, как мы можем использовать специальный модуль dagger-android для предоставления зависимостей в активити и фрагменты, а также организацию разных скоупов.
В данной статье мы рассмотрим составляющие модуля, рассмотр... | https://habr.com/ru/post/336462/ | null | ru | null |
# Программная реализация умножения в полях Галуа
Захотелось мне как-то сделать более надёжной передачу информации через радиоканал. Это не какой-то промышленный проект, или что-то другое серьёзное. Это скорее для хобби и саморазвития. Сказалась травма детства — отсутствие нормально работающей радиоуправляемой машинки.... | https://habr.com/ru/post/528142/ | null | ru | null |
# Foreman — менеджер процессов для ваших веб-приложений
Все более популярной становится модель разработки веб-приложений, основанная на идее масштабирования с помощью процессов. Современное приложение представляет из себя на... | https://habr.com/ru/post/176947/ | null | ru | null |
# Алгоритм Левенберга — Марквардта для нелинейного метода наименьших квадратов и его реализация на Python
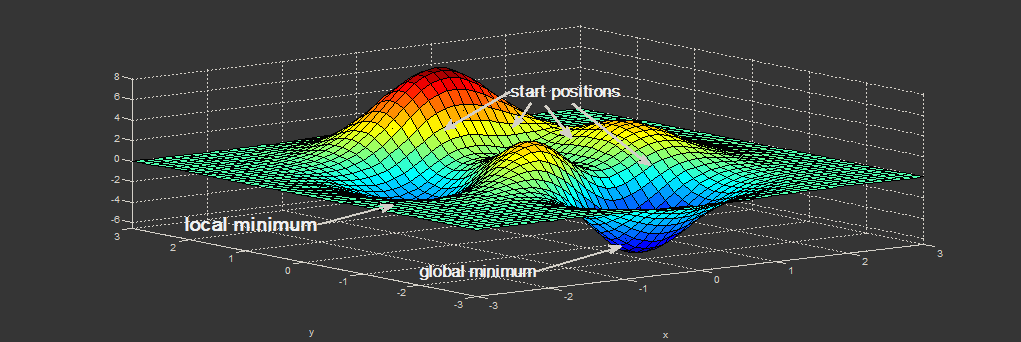
Нахождение экстремума(минимума или максимума) [целевой функции](https://ru.wikipedia.org/wiki/%D0%A... | https://habr.com/ru/post/308626/ | null | ru | null |
# Разбор задач викторины Postgres Pro на Highload++ 2017
На Higload++ 2017 года в Сколково наша компания Postgres Professional снова провела викторину с традиционной раздачей ништяков, в качестве которых выступили билеты на февральский [PgConf.Russia 2018](https://pgconf.ru/).
В этой статье разбираются вопросы викт... | https://habr.com/ru/post/342804/ | null | ru | null |
# Запуск OpenWRT 14.07 на Mikrotik и пример сборки Аsterisk c дополнительным модулем

В интернете много статей по запуску openwrt на устройствах Mikrotik через metarouter. Во всех них для сборки используется ревизия r... | https://habr.com/ru/post/249541/ | null | ru | null |
# Как я Хабр взломал
Всегда хотел взломать Хабр. Мечта такая, но как-то руки не доходили. И вот, вдохновившись статьей [о праведной борьбе](https://habr.com/ru/post/647515/) с Безумным Максом, я, как и автор поста, решил исследовать функционал Хабра на предмет уязвимостей.
Начать решил с нового редактора, рассуждая с... | https://habr.com/ru/post/653007/ | null | ru | null |
# “Да кто это написал?!!”, или решение сложных задач простыми средствами
Каждый день тысячи программистов трудятся не покладая рук. Они пишут код, контактируют между собой и, как и любой человек, совершают ошибки. Проблемы в коде могут повысить уровень рисков и стать критическими для компании. И с целью выявления таки... | https://habr.com/ru/post/681370/ | null | ru | null |
# Измерение покрытия кода тестами в Android с помощью JaCoCo
Автор: Mike Gouline
<https://blog.gouline.net/2015/06/23/code-coverage-on-android-with-jacoco/>
Перевод: Семён Солдатенко
С тех пор как эта возможность появилась в Android Gradle плагине версии 0.10.0 было написано много статей об измерении покрытия... | https://habr.com/ru/post/280374/ | null | ru | null |
# Поддержка USB в KolibriOS: что внутри? Часть 5: уровень логического устройства
Обработка подключения устройства, начатая на [уровне поддержки хост-контроллеров](http://habrahabr.ru/company/kolibrios/blog/183... | https://habr.com/ru/post/200172/ | null | ru | null |
# Добавляем Last.fm радио в MPD плейлист
Здравствуй Xабраменш,
IchBin's. Все началось с того, что поддержка [last.fm](http://www.last.fm/) радио была настолько коряво реализована в [MPD](http://mpd.wikia.com/wiki/Music_Player_Daemon_Wiki), что я даже перестал эту функцию компилировать. Корявость ее заключалась в то... | https://habr.com/ru/post/144116/ | null | ru | null |
# Готовим простой блог на микросервисах, пишем свой микрофреймворк на php и запускаем все на Docker с примерами
А что если я скажу вам, что новый продукт можно сразу начинать писать на микросервисной архитектуре, а не заниматься распилом монолита? Это вообще нормально? Удобно? Хотите узнать ответ?
Задача: необходимо ... | https://habr.com/ru/post/302844/ | null | ru | null |
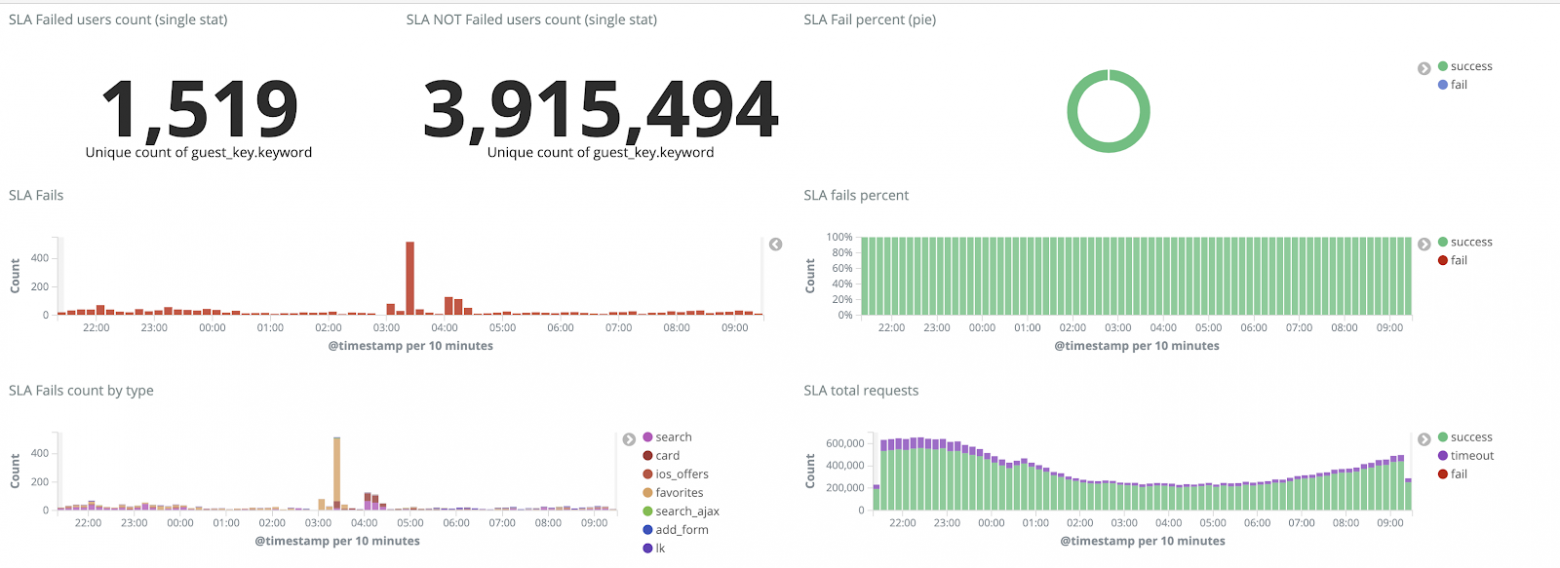
# Как мы в ЦИАН укрощали терабайты логов
Всем привет, меня зовут Александр, я работаю в ЦИАН инженером и занимаюсь системным администрированием и автоматизацией инфраструктурных процессов. В комментариях к... | https://habr.com/ru/post/478564/ | null | ru | null |
# Prisma — как подключить в Nest-проекте
### Prisma - установка в проект
Установка поддержки [Prisma](https://www.prisma.io/) в [NestJS](https://nestjs.com/)-проекте выполняется очень просто - при помощи **двух** команд.
**Первая** - устанавливает клиентскую часть Prisma:
`$ npm i @prisma/client`
... **вторая** ко... | https://habr.com/ru/post/653399/ | null | ru | null |
# Экспериментальная функция отладки .NET Core в Visual Studio Code
Сегодня мы выпускаем первую, экспериментальную и ознакомительную версию отладчика для [набора инструментов ASP.NET Core CLI](http://www.hanselman.com/blog/ExploringTheNewNETDotnetCommandLineInterfaceCLI.aspx) в составе редактора Visual Studio Code. Вна... | https://habr.com/ru/post/280143/ | null | ru | null |
# Удаленная отладка JavaScript с VS2015. Часть 2
*Предлагаю перевод статьи [«VS2015 Remote Debugging JavaScript – Part 2»](http://blogs.msdn.com/b/prakashpatel/archive/2015/11/04/vs2015-remote-debugging-javascript-part-2.aspx).*
#### Удаленная отладка JS, выполняющегося внутри Web Browser Control
Ранее мы обсуждал... | https://habr.com/ru/post/276897/ | null | ru | null |
# Проектирование Schemaless хранилища данных Uber Engineering с использованием MySQL
Designing Schemaless, Uber Engineering’s Scalable Datastore Using MySQL
-----------------------------------------------------------------------
*By Jakob Holdgaard Thomsen*
January 12, 2016
<https://eng.uber.com/schemaless-par... | https://habr.com/ru/post/354050/ | null | ru | null |
# Не только Аська в ICQ-клиентах
Начнем с главного: зачем мы написали этот пост?
Уже больше года у нас реализована возможность общения с друзьями из Facebook, не покидая ICQ. Так сложилось, что ни один неофициальный ICQ-клиент до сих пор не добавил к себе нашу серверную поддержку Facebook — при том, что возможность... | https://habr.com/ru/post/122241/ | null | ru | null |
# .NET-Хардкор в Москве
Конференция [DotNext 2015 Moscow](http://msk2015.dotnext.ru/) уже скоро! Мне посчастливилось быть в программном комитете этого замечательного мероприятия, так что я теперь в курсе закулисной деятельности: наблюдаю за общей организацией и помогаю готовить доклады. Организаторы долгими неделями т... | https://habr.com/ru/post/271915/ | null | ru | null |
# Хуки — это лучшее, что случилось с React
React — это [самая популярная фронтенд-библиотека](https://insights.stackoverflow.com/survey/2021?_ga=2.39987493.680762715.1636013141-1692851873.1636013141#section-most-popular-technologies-web-frameworks) из [экосистемы JavaScript](https://stackoverflow.blog/2018/01/11/bruta... | https://habr.com/ru/post/587728/ | null | ru | null |
# Функциональный Swift — это просто

В статьях о функциональном программировании много пишут о том, как ФП подход улучшает разработку: код становится легко писать, читать, разбивать на потоки и тестировать, построить плохую архи... | https://habr.com/ru/post/455359/ | null | ru | null |
# Разбираемся с launchMode Android Activity: standard, singleTop, singleTask и singleInstance
***Перевод статьи подготовлен специально для студентов [продвинутого курса по Android разработке](https://otus.pw/hPTK2/).***

---
Act... | https://habr.com/ru/post/493802/ | null | ru | null |
# Common Lisp IDE

Доброго времени суток, уважаемый читатель!
Перед каждым новичком в мире языка программирования [Common Lisp](https://ru.wikipedia.org/wiki/Common_Lisp)
возникает проблема выбора среды разработки — [I... | https://habr.com/ru/post/259737/ | null | ru | null |
# Почему важно проводить статический анализ открытых библиотек, которые вы добавляете в свой проект

Современные приложения строятся из сторонних библиотек ка... | https://habr.com/ru/post/520498/ | null | ru | null |
# Искусство парсинга или DOM своими руками
Привет, Хабр! Недавно я задался идеей создать простой язык разметки наподобие markdown, который отлично подходил бы для моих задач, а именно — быстрого написания лекций с форматированием и возможностью вставки математических формул «на лету», с применением одной лишь клавиату... | https://habr.com/ru/post/442964/ | null | ru | null |
# Туториал из руководства по Ember.js. Приложение Super Rentals. Часть 1.2
Продолжаем публиковать перевод туториала из официального руководства Ember.js. Туториал состоит из двух частей и это вторая половина первой части туториала. Напоминаем, что первую половину вы можете прочитать [по этой ссылке](https://habr.com/r... | https://habr.com/ru/post/482390/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.