
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Практическое использование multiple bounds generic в Java
Не сильно ошибусь, если предположу, что мало кто активно использует эту возможность языка. Для тех кто не помнит, что это такое можно почитать [здесь](https://docs.oracle.com/javase/tutorial/java/generics/bounded.html). Я же переду к практике.
Наткнулся на п... | https://habr.com/ru/post/344054/ | null | ru | null |
# Полноценный lazyload на node.js
С выходом Node.js 6.0 мы из коробки получили готовый набор компонентов для организации честного ленивого загрузчика. В данном случае я имею в виду lazyload, который пытается найти и загрузить нужный модуль только в момент запроса его по имени и находится в глобальной области видимости... | https://habr.com/ru/post/283086/ | null | ru | null |
# Кунг-фу стиля Linux: организация работы программ после выхода из системы
Если вы пользуетесь Linux с ранних дней появления этой ОС (или если, вроде меня, начинали с Unix), то вам не надо очень быстро и в больших количествах изучать то новое, что появляется в системе по мере её развития и усложнения. Вы можете разбир... | https://habr.com/ru/post/533336/ | null | ru | null |
# Блиц-проверка алгоритмов машинного обучения: скорми свой набор данных библиотеке scikit-learn
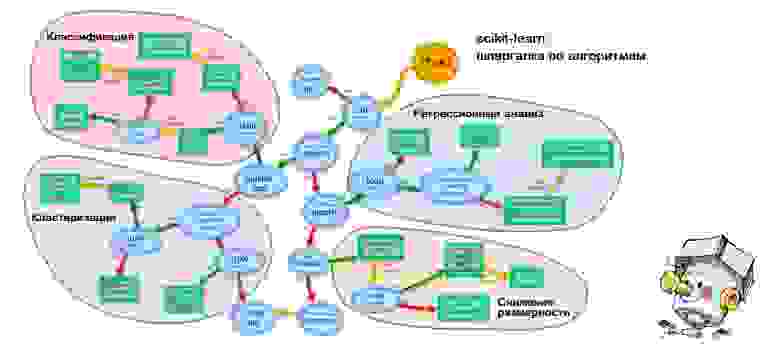
Глобальная паутина изо дня в день пополняется статьями о популярных, наиболее употребляемых алгоритмах ... | https://habr.com/ru/post/475552/ | null | ru | null |
# Баг движка Google Chrome с падением от 16 символов уже используют для создания игр
[](https://habrastorage.org/files/12b/987/6f9/12b9876f988e412584b12762df26eae8.png)19 сентября [получила](http://habrahabr.ru/post/267229/) ог... | https://habr.com/ru/post/384459/ | null | ru | null |
# Как добавить поиск на свой Hugo сайт
Hugo - **статический** генератор сайтов, но что же делать если хочется добавить интерактивный элемент? Система поиска - важная, а зачастую и необходимая функция на сайте, но написать её используя только Hugo попросту не получиться, исходя из природы инструмента. Потому придётся п... | https://habr.com/ru/post/678506/ | null | ru | null |
# Бэкап Linux и восстановление его на другом железе
Я работаю в организации с маленьким штатом, деятельность тесно связана с IT и у нас возникают задачи по системному администрированию. Мне это интересно и частенько я беру на себя решение некоторых.
На прошлой неделе мы настраивали FreePBX под debian 7.8, нанимали ... | https://habr.com/ru/post/251659/ | null | ru | null |
# Deep dive into PostgreSQL internal statistics. Алексей Лесовский
Расшифровка доклада 2015 года Алексея Лесовского "Deep dive into PostgreSQL internal statistics"
**Disclaimer от автора доклада:** *Замечу что доклад этот датирован ноябрем 2015 года — прошло больше 4 лет и прошло много времени. Рассматриваемая в докл... | https://habr.com/ru/post/505440/ | null | ru | null |
# Ежедневная архивация веб-проектов
Вот такую вещь я сделал сегодня. А перед этим — ещё год назад, работая в веб-студии.
Предлагается вашему вниманию bat-скрипт для ежедневной архивации home-директории вашего сайта и базы данных (MySQL).
*Требования:* **Windows** (у меня на работе — 2000), команда **mysqldump** ... | https://habr.com/ru/post/17633/ | null | ru | null |
# Играючи BASH'им дальше
Первая статья [И. BASH'им в начало](https://habrahabr.ru/post/335960)
Вдохновившись отзывами на первую статью я продолжил разработку piu-piu. В игре появилось интро\меню, р... | https://habr.com/ru/post/337896/ | null | ru | null |
# Как Clojure помогает ускорить написание Selenium-тестов
 Привет, читатель! Если доводилось писать Selenuim-тесты чуть сложнее чем на пару полей ввода и одну кнопку, то эта статья может пригодиться.
На... | https://habr.com/ru/post/308228/ | null | ru | null |
# Пишем свой плагин для XBMC. Пока без блекджека и всех остальных

Всем привет. Речь в топике пойдёт о создании плагина (программного дополнения, аддона) к замечательной программе [XBMC](http://xbmc.org/). Уровень сложнос... | https://habr.com/ru/post/166097/ | null | ru | null |
# Кроссбаузерный скроллинг
На сегодняшний день эффекты при скроллинге набрали достаточно большую популярность (так называемый [параллакс](http://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D1%80%D0%B0%D0%BB%D0%BB%D0%B0%D0%BA%D1%81)). Но, к сожалению, эти эффекты нейтивно не поддерживаются мобильными устройствами. Не так давно ... | https://habr.com/ru/post/147351/ | null | ru | null |
# Слияние Rails и Merb: Год спустя (часть 1 из 6)
*Шесть последовательных статей о слиянии Rails и Merb были опубликованы на [www.engineyard.com](http://www.engineyard.com) с декабря 2009 до апреля 2010 года. Это первая из них.*
Сегодня ровно год с того дня, как мы объявили о слиянии Rails и Merb. Тогда было много ... | https://habr.com/ru/post/87907/ | null | ru | null |
# Как написать UI-тесты с использованием Instagram-аккаунтов и не получить блок
Привет, Хабр. Довольно часто при покрытии различных сервисов автотестами (selenium или appium) нам приходится использовать аккаунты других социальных сетей. Это может понадобиться, например, если мы тестируем регистрацию на нашем сервисе ч... | https://habr.com/ru/post/344408/ | null | ru | null |
# WAI-ARIA: стандарт доступности активных интернет-приложений
WAI-ARIA (Web Accessibility Initiative — Accessible Rich Internet Applications) — стандарт доступности активных Интернет-приложений, определяет подходы к тому, чтобы сделать содержимое сайтов и интернет-приложения более доступными для людей с ограниченными ... | https://habr.com/ru/post/40730/ | null | ru | null |
# Автоматический контроль времени жизни общих C++-QML объектов
Речь пойдет об объектах, используемых в C++ и QML одновременно, верхушкой иерархии наследования которых является QObject. Насколько мне известно, реализации механизма автоматического контроля времени жизни таких объектов на уровне библиотеки не существует.... | https://habr.com/ru/post/274915/ | null | ru | null |
# Представляем Kubernetes CCM (Cloud Controller Manager) для Яндекс.Облака

В продолжение к недавнему [релизу CSI-драйвера](https://habr.com/ru/company/flant/blog/486190/) для Яндекс.Облака мы публикуем ещё один Open Source-проект дл... | https://habr.com/ru/post/490356/ | null | ru | null |
# Руководство разработчика Prism — часть 4, разработка модульных приложений
> **Оглавление**
>
> 1. [Введение](http://habrahabr.ru/post/176851/)
> 2. [Инициализация приложений Prism](http://habrahabr.ru/post/176853/)
> 3. [Управление зависимостями между компонентами](http://habrahabr.ru/post/176861/)
> 4. [Разработ... | https://habr.com/ru/post/176863/ | null | ru | null |
# Преимущества Common Lisp
Лисп часто рекламируют как язык, имеющий преимущества перед остальными из-за того, что он обладает некоторыми уникальными, хорошо интегрированными и полезными фичами.
Далее следует попытка выдел... | https://habr.com/ru/post/143490/ | null | ru | null |
# Теоретические структуры данных и их применение в JavaScript. Ч1. Пары
> «Плохие программисты думают о коде. Хорошие программисты думают о структурах данных и их взаимосвязях», — Линус Торвальдс, создатель Linux.
Примем в качестве аксиомы, что очень часто решение любой задачи в программировании сводится к выбору пр... | https://habr.com/ru/post/493692/ | null | ru | null |
# DIY-метаданные: как мы собрали велосипед, который везет на себе технологические данные компании
Привет, Хабр! Меня зовут Ткачев Константин, и я работаю архитектором в Леруа Мерлен.
В этой статье я хочу рас... | https://habr.com/ru/post/701448/ | null | ru | null |
# Dagaz: Подробности
***В «пи» цифр не пересчитать,
«е» — бесконечно столь же.
А если их с конца писать, какое будет больше?
Мартин Гарднер «Крестики-нолики»***
Для этой статьи, я хотел выбрат... | https://habr.com/ru/post/429494/ | null | ru | null |
# Проектирование синхронных схем. Быстрый старт с Verilog HDL
 На просторах рунета можно найти достаточно много статей с введением в Verilog HDL. Все они описывают синтаксис и семантику языка, но, к сожалению, не раскрывают... | https://habr.com/ru/post/137643/ | null | ru | null |
# 4 революционных возможности JavaScript из будущего
JavaScript, с момента выхода стандарта ECMAScript 6 (ES6), быстро и динамично развивается. Благодаря тому, что теперь новые версии стандарта [ECMA-262](https://tc39.es/ecma262/) выходят ежегодно, и благодаря титаническому труду всех производителей браузеров, JS стал... | https://habr.com/ru/post/510900/ | null | ru | null |
# svn tips
Сегодня занимался устройством проекта и возился с svn — решил поделиться некоторыми советами:
**Автоматическая заливка кода на сервер из репозитория после коммита**
**Версионирование файлов настроек (Settings.php/xml/yml)**
**Храниение жирных и малоизменчивых сторонних библиотек в репозитории с быс... | https://habr.com/ru/post/26753/ | null | ru | null |
# Роспотребнадзор закупает SEO услуги на 280т.р и настаивает на использовании SEOPult
Сегодня нашли в нашей [системе поиска по госзаказам](http://tender-consalt.ru/tenders) такой [тендер](http://zakupki.gov.ru/Tender/ViewPurchase.aspx?PurchaseId=558668): на право заключения Государственного контракта на продвижение са... | https://habr.com/ru/post/73941/ | null | ru | null |
# Ещё один Telegram-бот для видеонаблюдения
В данной статье мы рассмотрим основные принципы работы telegram-бота для видеонаблюдения.
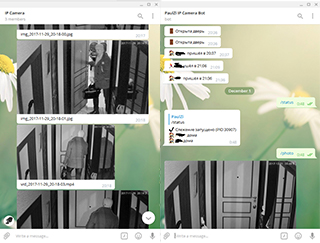
Прочитав [статью о созданном телеграм-боте из подручных материалов](https://habrahabr.ru/post/341... | https://habr.com/ru/post/343616/ | null | ru | null |
# Proxmox 4. День второй. Thin-LVM
Добрый день, друзья. После ранее опубликованной [статьи](https://habrahabr.ru/post/315086/) много воды утекло, было поднято несколько серверов, несколько уже на новой 5-ой версии. Были и кластеры и CEPH и даже репликация с двумя нодами (появилась функция в 5-ке). Для себя принял реше... | https://habr.com/ru/post/339676/ | null | ru | null |
# Рецепты от CHEFa: автоматизированное развёртывание сред бизнес-приложений с использованием HPE OneView
Информационные технологии становятся неотъемлемой частью продуктов и услуг нового стиля IT, в котором бизнес ожидает получить запрошенные ресурсы под новые приложения почти мгновенно. IT ресурсы, в парадигме новых ... | https://habr.com/ru/post/273605/ | null | ru | null |
# ASP.NET MVC Урок 9. Configuration и загрузка файлов
**Цель урока.** Научиться использовать файл конфигурации Web.config. Application section, создание своих ConfigSection и IConfig. Научиться загружать файлы, использование file-uploader для загрузки файла, последующая обработка файла.
В этом уроке мы рассмотрим ... | https://habr.com/ru/post/176069/ | null | ru | null |
# Экспорт ключа SignalCom в OpenSSL
*У вас стоит задача интегрироваться с удалённым сервисом, который работает по ГОСТу и "только через КРИПТО-КОМ", а вы хотите использовать OpenSSL с gost? На форуме "Сигнал-КОМ" вы видите кучи сообщений, что "ключи из формата КРИПТО-КОМ нельзя конвертировать в формат OpenSSL-гост-сов... | https://habr.com/ru/post/317406/ | null | ru | null |
# Оver-provisioning ресурсов в кластерах на базе mesos

Разработчики Apache mesos [заявляют](http://mesos.apache.org/documentation/latest/oversubscription/), что mesos научился делать overprovisioning начиная с версии ... | https://habr.com/ru/post/276773/ | null | ru | null |
# Автоматизация создания объектов при помощи конвейера
Привет, Хабр!
Я не являюсь каким-то очень известным экспертом, однако мне очень интересен процесс обработки данных, а также написания кода для обработки этих самых данных. В процессе написания различных методов обработки этих самых данных у меня родилась идея час... | https://habr.com/ru/post/539512/ | null | ru | null |
# Планировщик путешествий своими руками за пару часов

*Автор: Сергей Матвеенко*
Однажды ко мне пришел инвестор одного проекта и сказал: «Давай сделаем планировщик путешествий по картам Google!» Я согласился. Тогда инвест... | https://habr.com/ru/post/301310/ | null | ru | null |
# Прореживание таймфреймов (криптовалюты, форекс, биржи)
Некоторое время назад передо мной была поставлена задача написать процедуру, которая выполняет прореживание котировок рынка Форекс (точнее, данных таймфреймов).
Формулировка задачи: данные поступают на вход с интервалом в 1 секунду в таком формате:
* Назва... | https://habr.com/ru/post/418757/ | null | ru | null |
# Свой сервер мониторинга с nagios и cacti
Под катом советы по быстрому развертыванию «системы мониторинга» посредством nagios и cacti.
Предположим имеется девственно чистый сервер с предустановленным debian lenny. А нам предстоит сделать из этой бесформенной массы луна-парк с блэк джеком и девочками. Хм, хотя нет,... | https://habr.com/ru/post/88293/ | null | ru | null |
# Функциональное программирование с точки зрения EcmaScript. Композиция, каррирование, частичное применение
Привет, Хабр!
Сегодня мы продолжим наши изыскания на тему функционального программирования в разрезе EcmaScript, на спецификации которого основан JavaScript. В предыдущей статье мы разобрали основные понятия:... | https://habr.com/ru/post/475324/ | null | ru | null |
# R: пакет ellipse для визуализации доверительных областей
Здравствуйте.
В последнем посте из R-хаба [«Визуализация двумерного гауссиана на плоскости»](http://habrahabr.ru/post/199060/) был описан алгоритм построения доверительного эллипса по ковариационной матрице. Алгоритм сопровождался примером и R-скриптом. ... | https://habr.com/ru/post/199282/ | null | ru | null |
# Мой опыт работы с необычным подходом к построению группы React приложений
* Вступление
* О системе
* Плюсы и минусы
* Возможные улучшения
* Заключение
### Вступление
Прежде чем начать, хочу уведомить что у меня нет желания как то оскорбить или продвинуть свою точку зрения как истинную. Все системы, приложения, мод... | https://habr.com/ru/post/589903/ | null | ru | null |
# Spring Security — пример REST-сервиса с авторизацией по протоколу OAuth2 через BitBucket и JWT
В [предыдущей](https://habr.com/ru/post/497588/) статье мы разработали простое защищенное веб приложение, в котором для аутентификации пользователей использовался протокол OAuth2 с Bitbucket в качестве сервера авторизаци... | https://habr.com/ru/post/528410/ | null | ru | null |
# Data-Oriented архитектура
В архитектуре программного обеспечения существует один малоизвестный паттерн, заслуживающий большего внимания. Архитектура, ориентированная на данные, (*data-oriented architectur... | https://habr.com/ru/post/590675/ | null | ru | null |
# Python и статистический вывод: часть 2
Предыдущий пост см. [здесь](https://habr.com/ru/post/556798/).
Выборки и популяции
-------------------
В статистической науке термины «выборка» и «популяция» имеют особое значение. Популяция, или генеральная совокупность, — это все множество объектов, которые исследователь хо... | https://habr.com/ru/post/556806/ | null | ru | null |
# Первые эксперименты со смешанным Litex+Verilog проектом для ПЛИС
В [предыдущей статье](https://habr.com/ru/post/594817/) мы начали осваивать построение шинно-ориентированных систем на базе среды Litex (которая всё делает на Питоне) с внедрением собственных модулей на Верилоге. Статья так разрослась, что практические... | https://habr.com/ru/post/596321/ | null | ru | null |
# Теперь ONLYOFFICE может всё: добавляем плагины в редакторы документов
Что если бы вы могли добавить в редакторы документов любые функции, какие вам хочется? Теперь вы можете: в редакторах ONLYOFFICE появилась возможность подключения плагинов. Несколько примеров мы написали сами — все их можно посмотреть в нашем откр... | https://habr.com/ru/post/314716/ | null | ru | null |
# MagOS в промышленном применении
*При выполнении этой работы ставилась задача минимизации времени на обслуживание сети из большого количества Linux машин.*
[1. Базовое описание основных принципов](#1)
[1.1. Применение MagOS.](#1-1)
[1.2. Технологии.](#1-2)
[1.3. Выбор базового дистрибутива.](#1-3)
[2. ... | https://habr.com/ru/post/270337/ | null | ru | null |
# Яндекс.Пробки: получаем области покрытия пробками + альтернативный пробочный гаджет
 Не так давно Яндекс стал отдавать данные о пробках для большого количества других регионов, кроме Москвы, Питера, Киева и ... | https://habr.com/ru/post/87294/ | null | ru | null |
# Состоялся новый релиз Kubernetes-платформы Deckhouse — v1.26.0
Новая стабильная версия Deckhouse — [v1.26.0](https://github.com/deckhouse/deckhouse/releases/tag/v1.26.0) — включает почти 60 изменений, исправлений и улучшений. Это второе по счету крупное обновление платформы [Deckhouse](https://github.com/deckhouse/d... | https://habr.com/ru/post/589223/ | null | ru | null |
# Подсветка синтаксиса в Ruby
В проектах, ориентированных на IT аудиторию время от времени возникает задача подсветки синтаксиса исходных файлов. Недавно, я захотел посмотреть как эта задача решается в Ruby.
Для Ruby существует решение [CodeRay](http://coderay.rubychan.de/) которое позволяет подсвечивать синтаксис ... | https://habr.com/ru/post/48614/ | null | ru | null |
# Настройка push-нотификаций для своего сервиса
В этой публикации мы рассмотрим пример интеграции платформы подписки на push-уведомлений [PushAll](https://pushall.ru/) с [сервисом мониторинга сайтов ХостТрекер](http://www.host-tracker.com). Эта информация будет полезна тем, кому необходимо быстро настроить push для св... | https://habr.com/ru/post/334038/ | null | ru | null |
# Offline-first приложение с Hoodie & React. Часть первая: браузерная база данных
Современный веб позволяет решать часть задач которые раньше были прерогативой нативных мобильных приложений. Мы с вами создадим веб-приложение (сайт) которое будет загружаться и сохранит полную функциональность даже в отсутствии интернет... | https://habr.com/ru/post/309166/ | null | ru | null |
# Управляем Windows Server (Core) с помощью веб-интерфейса Project Honolulu от Microsoft
Совсем недавно Microsoft выпустила WebUI для управления Windows Server. Мы поставили его и хотим поделиться впечатлениями.
В этой статье мы рассказали и показали:
* как развернуть Honolulu на Windows Server Core и сделать до... | https://habr.com/ru/post/339372/ | null | ru | null |
# Детектирование дампа памяти процесса LSASS. SOC наносит ответный удар
Привет, я [@Gamoverr](/users/gamoverr), работаю аналитиком угроз в Angara Security. А теперь к делу!
Angara SOC спешит дополнить [стат... | https://habr.com/ru/post/679592/ | null | ru | null |
# Luxon — новая библиотека для работы с датами от команды Moment.js

Казалось бы, зачем нужна еще одна библиотека для работы с датами и временем когда есть всем известная библиотека Moment?! Тем интереснее, что альтернатива предлож... | https://habr.com/ru/post/433850/ | null | ru | null |
# iOS in-app purchases, часть 6: как реализовать скидки introductory offer, promotional offer, offer code
Привет! Я Андрей, тимлид мобильной разработки в [Adapty](https://adapty.io/?utm_source=habr.com&utm_medium=referral&utm_campaign=blogpost_ios-iap_promooffers), я делаю [SDK под iOS](https://github.com/adaptyteam/A... | https://habr.com/ru/post/578180/ | null | ru | null |
# Пропаганда тоталитарного режима, антисемитизм и гомофобия в учебнике по программированию 2019 года? — Это возможно
Кликбейтный заголовок? К сожалению, всё указанное и даже более в обозреваемой ниже книге есть. Что за книга? «Простой Python просто с нуля».
 Робин Хэнсон кратко обсуждает деградацию программ:
> Программное обеспечение изначально было разработано для одного набора задач, инструментов и с... | https://habr.com/ru/post/442064/ | null | ru | null |
# RESTful запросы на основе паттерна «Команда»
На протяжении многих лет традиционным подходом было включение библиотек Alamofire (AFNetworking) в состав iOS приложения для осуществления RESTful запросов к бэк... | https://habr.com/ru/post/697262/ | null | ru | null |
# Рецепты для ELFов

На русском языке довольно мало информации про то, как работать с ELF-файлами (Executable and Linkable Format — основной формат исполняемых файлов Linux и многих Unix-систем). Не претендуем на полное покрытие... | https://habr.com/ru/post/460247/ | null | ru | null |
# Из Rails 4 в Rails 5: как это было
 Жил-был поставщик облачных сервисов и захотелось ему не отставать от прогресса. И решил он обновиться с Rails 4.2.8 до Rails 5.0.2. А как это было, что по пути отвалилось, что по лбу вдарил... | https://habr.com/ru/post/326706/ | null | ru | null |
# Конструирование типов в Scala
При построении многослойных («enterprise») систем часто оказывается, что создаются `ValueObject`'ы (или case class'ы), в которых хранится информация о каком-либо экземпляре сущности, обрабатываемом системой. Например, класс
```
case class Person(name: String, address: Address)
```
... | https://habr.com/ru/post/222553/ | null | ru | null |
# Аскетичный вебъ: прототип барахолки на go и js
[](https://habrastorage.org/webt/3g/h3/-6/3gh3-6swyq65srharlejw1xeuek.png)
Всем привет, хочу поделиться результатом размышлений на тему — каким может быть современное веб-прило... | https://habr.com/ru/post/435908/ | null | ru | null |
# Современный подход к наблюдаемости
Эпоха монолитных приложений почти прошла. Современные системы разделены на множество компонентов. Даже в самом простом приложении может быть много микросервисов, а у тех е... | https://habr.com/ru/post/703056/ | null | ru | null |
# Внедрение кода в Silverlight
В свободное время я занимаюсь разработкой [Snoop'a](http://snoopwpf.codeplex.com/). Это отличное подспорье WPF разработчикам, которое не имеет хороших бесплатных аналогов в... | https://habr.com/ru/post/128189/ | null | ru | null |
# Локализация своих скриптов на BASH
Создание меню на BASH — задача сама по себе не сложная: "case тебе в руки и echo в спину". Решая её в очередной раз, мне захотелось добавить возможность отображать текст на других языках. Осталось решить, как сделать сам процесс локализации меню более удобным. Если оно большое, то ... | https://habr.com/ru/post/539586/ | null | ru | null |
# Не все патчи одинаково полезны
Эта заметка продолжает разбор улучшений производительности, которые могли бы стать явью, если бы не разные "но". Предыдущая часть о `StringBuilder`-е находится [здесь](https://habr.com/ru/post/436746/).
Здесь мы рассмотрим несколько "улучшений", отклонённых из-за непонимания тонкостей... | https://habr.com/ru/post/433174/ | null | ru | null |
# Пишем плагин для Netbeans. Часть первая
Представьте ситуацию: вы программируете в среде разработки и вам необходимо кому-то отправить небольшой кусок кода из редактора. Вы выделяете нужный кусок, копируете его, открываете браузер, заходите на pastebin, вставляете код, копируете ссылку, а затем отправляете её адресат... | https://habr.com/ru/post/146788/ | null | ru | null |
# Vue.js для проекта на Bitrix
Привет, Хабр!
Меня зовут Дмитрий Матлах. Я тимлид в AGIMA. Мы с коллегами обратили внимание, что в сообществе часто возникает вопрос о том, как совместить на одном проекте Bitrix-компоненты и реактивные фронтовые движки. Мы неоднократно сталкивались с подобными задачами, и поэтому я ре... | https://habr.com/ru/post/584130/ | null | ru | null |
# Межпроцедурный анализ и оптимизации (I)
Одной из самых интересных и важных компонент современного оптимизирующего компилятора является межпроцедурный анализ и оптимизации. Хороший стиль программирования и необходимость разделения работы между разработчиками диктует необходимость разбиения большого проекта на отдельн... | https://habr.com/ru/post/199112/ | null | ru | null |
# История двух стандартных библиотек Си
Сегодня мне пришел баг-репорт от пользователя Debian, который скормил какую-то ерунду в утилиту [scdoc](https://git.sr.ht/~sircmpwn/scdoc) и получил `SIGSEGV`. Исследование проблемы позволило мне провести отличное сравнение между `musl libc` и `glibc`. Для начала посмотрим на ст... | https://habr.com/ru/post/520920/ | null | ru | null |
# 30 вредных советов для php-разработчиков
Я не стал сильно заморачиваться и расписывать очевидные факты, но большинство моментов, которые меня пугают в коде, тут изложены. Я постарался сделать список особо лаконичным, чтобы вам не пришлось вчитываться, но и максимум понятным, чтобы даже новички поняли что так делать ... | https://habr.com/ru/post/309450/ | null | ru | null |
# Arduino контролирует в подвале температуру, влажность и затопление и выдает данные на веб-страницу
Всем привет.
Хочу поделиться опытом создания системы контроля и предупреждения.
На одном из строительных объектов делали строение с бассейном, сауной, тренажёрным залом и комнатой отдыха. Все это было в приличных... | https://habr.com/ru/post/249201/ | null | ru | null |
# Как я мониторил РИП-12 от Bolid
Резервированные источники питания используются повсеместно. Они обеспечивают бесперебойным электропитанием приборы охранной и пожарной сигнализации, оборудование систем контроля доступа и другие системы. На нашем предприятии в качестве таких источников, как правило, используются прибо... | https://habr.com/ru/post/554780/ | null | ru | null |
# Библиотека, помогающая преодолеть концептуальный разрыв между ООП и БД во время тестирования при использовании ORM, — LinqTestable
Как известно, между объектно-ориентированной и реляционной моделью существует [концептуальный разрыв](https://en.wikipedia.org/wiki/Object-relational_impedance_mismatch), преодолеть кото... | https://habr.com/ru/post/269917/ | null | ru | null |
# Поиск данных в столбцах таблицы с пагинацией (front-часть)
### Введение
Всем добрый день. Меня зовут Александр. Сейчас я работаю в Мегафон front-end разработчиком. Проблемы поиска данных всегда отличались особенной сложностью и зачастую нестандартностью в подходах. Сегодня я бы хотел остановиться на одной интересно... | https://habr.com/ru/post/544384/ | null | ru | null |
# Сказ о том, как я с гидрой боролся
Проблемы третьего мира
----------------------
Вообще на этом фриланс-проекте я занимался вёрсткой - простенький дизайн в Figma, где ничто не предвещало беды. И вот, когда... | https://habr.com/ru/post/543906/ | null | ru | null |
# 1C-Битрикс на Raspberry Pi 2
 Наши коллеги и партнеры — веб-студия «Оробланко» — решили устроить интересный эксперимент: запустить 1С-Битрикс на микрокомпьютере Raspberry Pi 2. О чем и написали подробно [у себя в блоге](http... | https://habr.com/ru/post/276409/ | null | ru | null |
# Multicast вещание видеофайлов с помощью tsplay
Добрый день.
Возникла необходимость вещать видеофайлы в сеть (трейлеры фильмов). Первая мысль, которая возникла у меня в голове (и у вас тоже, наверное?) — это VLC. Установил VLC, настроил, запустил и результат: все работает. Через полчаса замечаю, что иногда подсыпа... | https://habr.com/ru/post/154349/ | null | ru | null |
# Произвольное число аргументов любых типов на C11 и выше с помощью _Generic и variadic макросов
), и я решил таки глянуть, как делать инъекции своего кода в Cocoa-приложения.
Общ... | https://habr.com/ru/post/65368/ | null | ru | null |
# Микроформаты в Википедии
Речь пойдёт об [hCard](http://ru.wikipedia.org/wiki/HCard) и [hCalendar](http://en.wikipedia.org/wiki/HCalendar) (англ.). Об использовании других микроформатов тоже можно говорить долго, но не в этот раз.
Сам топик частично анонс того, что появилось, частично попытка спросить совета, куда... | https://habr.com/ru/post/28655/ | null | ru | null |
# Валидация Kubernetes YAML на соответствие лучшим практикам и политикам
***Прим. перев.**: С ростом числа YAML-конфигураций для K8s-окружений всё более актуальной становится потребность в их автоматизированной проверке. Автор этого обзора не просто отобрал существующие решения для этой задачи, но и на примере Deploym... | https://habr.com/ru/post/511018/ | null | ru | null |
# TermKit: новая концепция консоли с графическим выводом
Командная оболочка (консоль) — пожалуй, самый архаичный элемент Unix, который остаётся почти в неизменном виде уже тридцать лет. Мы любим его, но кому-то кажется странным сидеть у монитора с миллионами пикселей, ежедневно глядя в консольное окошко образца 70-х г... | https://habr.com/ru/post/119550/ | null | ru | null |
# Хочу как у YouTube
Вы когда-нибудь задумывались как устроен ID видео на YouTube?
Возможно, вы уже знаете/нашли ответ, но, как показали обсуждения на Stack Overflow, многие понимают эту технологию неправильно. Если вам интересно изучить что-то новое, добро пожаловать под кат.

[Части 4-7: неровности, реки и дороги](https://habr.com/post/424491/)
[Части 8-11: вода, объекты рельефа и крепостные стены](https://habr.com/post/425... | https://habr.com/ru/post/427003/ | null | ru | null |
# CodeIgniter Command Line library — небольшой ассистент для работы с CLI
Как вы наверное знаете, в php есть интересная функция для обработки данных, поступающих из командной строки: [getopt](http://php.net/manual/ru/function.getopt.php). Но есть одна маленькая проблема — она неправильно работает в CodeIgniter, да и н... | https://habr.com/ru/post/141448/ | null | ru | null |
# Генерация подземелий в Diablo 1

[Diablo 1](https://en.wikipedia.org/wiki/Diablo_(video_game)) — это классический roguelike 1996 года в жанре hack and slash. Это была одна из первых успешных попыток ... | https://habr.com/ru/post/460038/ | null | ru | null |
# W.Script языки. Часть 2 — высокоуровневые языки, или зачем нам в корпорации C++
Недавно я [опубликовал](http://habrahabr.ru/post/158013/) обзор написания программы Hello, world на корпоративном языке R.Script LLP. Данный язык считается у нас в корпорации низкоуровневым, так как является самым быстрым, среди использу... | https://habr.com/ru/post/158099/ | null | ru | null |
# Подключение к службе TFS без ввода учетных данных LiveID
Как правило, при подключении к службе [Team Foundation Service](http://tfs.visualstudio.com/) пользователь видит веб-страницу для входа с помощью учетной записи Microsoft, также называемой LiveID. Выполняя вход, пользователь может установить флажок сохранения ... | https://habr.com/ru/post/171209/ | null | ru | null |
# 2019-й по версии Chrome

Привет, Хабр! Сегодня мы попробуем объять необъятное и вспомнить всё, что нам принёс 2019-й год в вебе вообще и в Chrome, в частности, а также пригласить вас на серию вебинаров, посвящённых новым веб-технол... | https://habr.com/ru/post/488886/ | null | ru | null |
# Охота на Вампуса. Переосмысление классической игры для Алисы
Привет! Меня зовут Кирилл Богатов, я дизайнер голосовых интерфейсов в команде TORTU и заядлый геймер. Когда эти две страсти сталкиваются, рождаются необычные концепты для голосовых игр.
Месяц назад я выпустил игру «[Охота на Вампуса](https://dialogs.yande... | https://habr.com/ru/post/597815/ | null | ru | null |
# Chargebox на Arduino
Создания автомата для зарядки планшетов и телефонов
**Основные компоненты:**
* Arduino Uno
* LСD Display 2x16
* Coin Receiver Wei-Ya HI 07
* Реле

**Задача**
Создать автомат, который будет пр... | https://habr.com/ru/post/307518/ | null | ru | null |
# Исповедь Битрикс хейтера
Что-то много развелось в последнее время статей про [минусы](/post/280226/) битрикса, и их [опровержений](/post/282317/). Раз уж пошла такая пьянка, то и я добавлю свои 5 копеек.
В комментариях к статьям писали, что не хватает конкретики, примеров, более глубокого обзора.
Данная стать... | https://habr.com/ru/post/282333/ | null | ru | null |
# Big Data от A до Я. Часть 5.1: Hive — SQL-движок над MapReduce
Привет, Хабр! Мы продолжаем наш цикл статьей, посвященный инструментам и методам анализа данных. Следующие 2 статьи нашего цикла будут посвящены Hive — инструменту для любителей SQL. В предыдущих статьях мы рассматривали [парадигму MapReduce](https://hab... | https://habr.com/ru/post/283212/ | null | ru | null |
# Добавляйте единицы измерения в имена
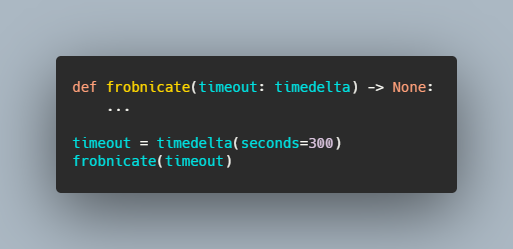
Есть одна ловушка читаемости кода, которой легко избежать, если вы о ней знаете; тем не менее она встречается постоянно: это отсутствующие единицы измерения. Рассмотрим три фрагмента кода на Py... | https://habr.com/ru/post/668832/ | null | ru | null |
# Testcontainers с Kotlin и Spring Data R2DBC
В этой статье мы оговорим о библиотеке **Testcontainers** и о том, как ее использовать для упрощения нашей жизни, когда дело доходит до интеграционного тестирования нашего кода.
В приведенном примере я буду использовать простое приложение, работающее с рецензиями некоторы... | https://habr.com/ru/post/710924/ | null | ru | null |
# Современная Web-платформа: как расслабиться и получать удовольствие? Практическое руководство, часть 1
### Всем привет!
Помните [эту статью](https://habrahabr.ru/post/312022/)? Раньше мы могли быстро собрать статичную HTML-страничку в каком-нибудь FrontPage и сайт был готов. С этим мог справится любой студент. В бо... | https://habr.com/ru/post/340530/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.