
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Бюджетная реализация Modbus TCP в серии Simatic S7-300/400 при помощи Logo
Классические линейки контроллеров Siemens, а именно — Simatic S7-300 и Simatic S7-400, поддерживают протокол Modbus TCP как в качестве клиента, так и в качестве сервера. Эта поддержка не лишена одного существенного недостатки, она платная, и ... | https://habr.com/ru/post/655465/ | null | ru | null |
# Таргетинг пользователей: регион, город, улица
Иногда в своих проектах мне хотелось прикрутить некоторую географическую базу, с помощью которой я бы разделял пользователей ресурса по их месту пребывания. Но п... | https://habr.com/ru/post/221989/ | null | ru | null |
# Разбор естественного языка: под капотом

#### API синтаксического анализатора
Продолжаю свой [предыдущий пост](http://habrahabr.ru/post/255073/). Время сфокусироваться на деталях внутреннего устройства синтаксического ан... | https://habr.com/ru/post/255711/ | null | ru | null |
# Клиент у руля, или почему провайдеру следует передать штурвал
Изначально наша [компания](https://1cloud.ru/blog/how-to-create-iaas-provider) задумывалась как «магазин облачных решений», но затем курс был взят на IaaS. Это было сделано потому, что того захотел рынок — такую потребность выразили пользователи. Почему п... | https://habr.com/ru/post/335246/ | null | ru | null |
# Все облака — в одном окошке
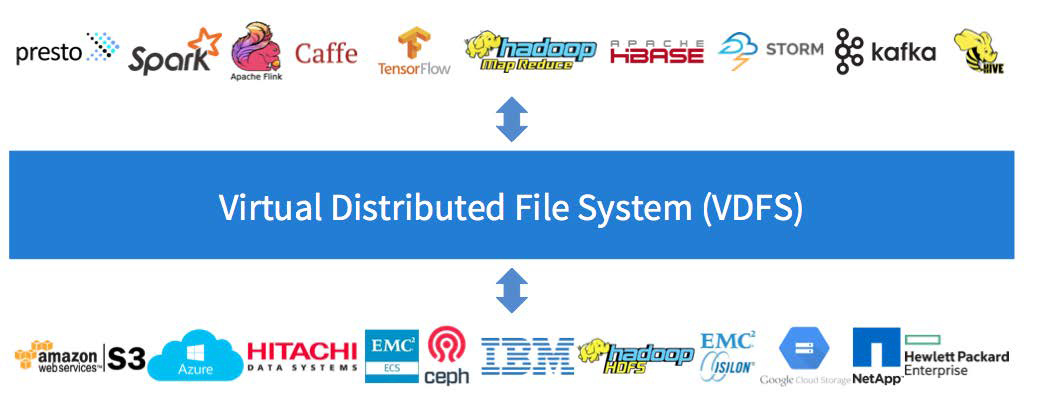
В наше время почти у каждого скопилось несколько гигабайт (или терабайт) резервных копий и личных документов. Всё это зачастую хранится в зашифрованном виде на нескольких накопителях и в нескольких обла... | https://habr.com/ru/post/678818/ | null | ru | null |
# Мессенджер от госкомпании «Крымтехнологии» взломали за три минуты
После [сегодняшней блокировки Telegram](https://geektimes.ru/post/300005/) многие пользователи задаются вопросом, что делать дальше. Установки VPN и прокси-серверов... | https://habr.com/ru/post/411539/ | null | ru | null |
# Брайан Кребс раскрыл личность автора червя Mirai
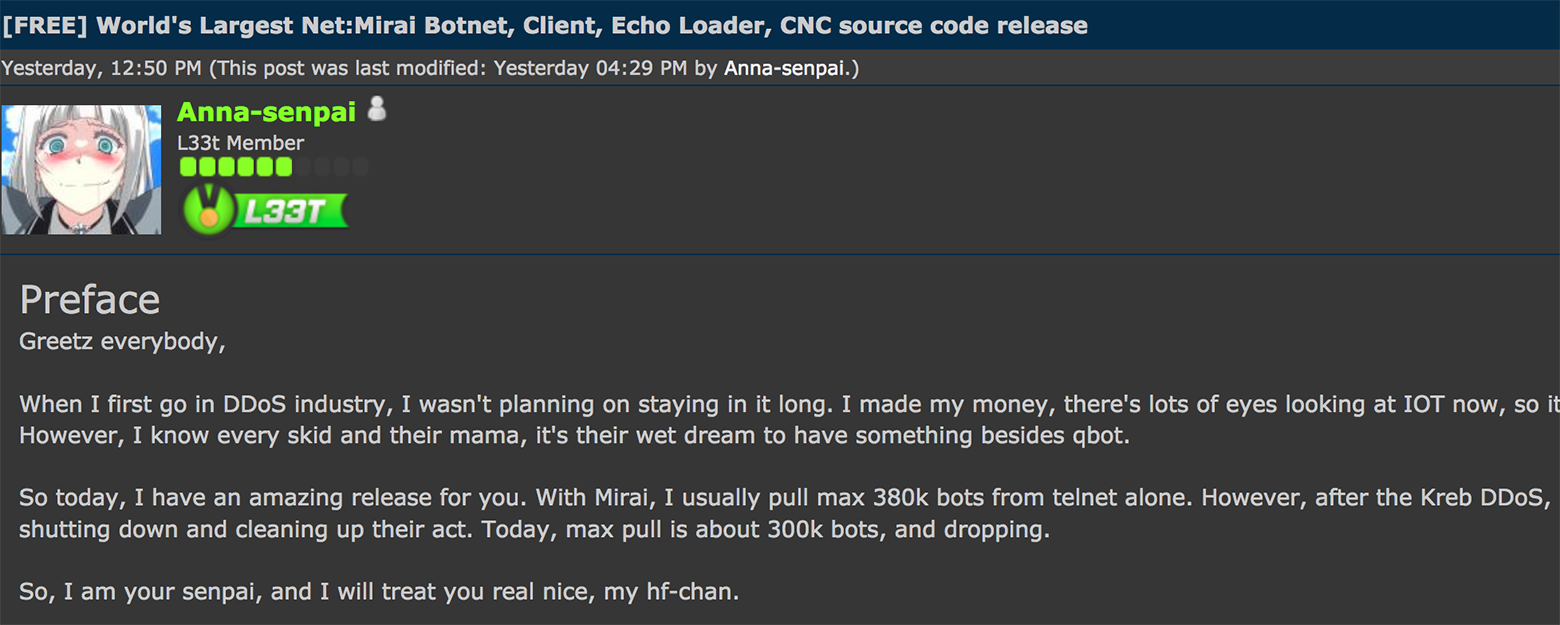
Червь и ботнет Mirai (яп. «будущее») в камерах, цифровых приставках (DVR) и других устройствах интернета вещей наделали немало шуму в сентябре-октябре прошлого года. Червь ... | https://habr.com/ru/post/400877/ | null | ru | null |
# Kubernetes для тех, кому за 30. Николай Сивко (2018г)

Мы в okmeter.io в какой-то момент поняли, что нам тоже нужен k8s в production, хотя у нас нет даже CI/CD, но есть задача делить общий пул серверов между приложениями и достаточ... | https://habr.com/ru/post/519504/ | null | ru | null |
# Про ScalaCheck. Генераторы (Часть 2)
**Часть 2. Генераторы**
В [вводной](https://habrahabr.ru/post/319456/) статье серии вы, надеюсь уже, успели познакомиться с генераторами. В этом туториале мы закрепим полученные знания, научимся писать собственные (в том числе рекурсивные) генераторы. Хотя он и посвящен генерато... | https://habr.com/ru/post/320104/ | null | ru | null |
# Скрытый редирект на ER.RU

Во время тестирования [Brief.ly](http://habrahabr.ru/blogs/startup/120140/) [API](http://habrahabr.ru/blogs/wordpress/123750/) открылся маленький казус на... | https://habr.com/ru/post/134636/ | null | ru | null |
# RestAPI для веб-приложения на PHP или познаем дзен в чистоте
В нынешней разработке все стремятся к чистоте. Чистый код и прозрачный для любого Джуниора паттерн – безусловно залог успешного долгоиграющего проекта, который еще не скоро соберутся переписывать.
В данной статье расскажу, как в течении нескольких лет я... | https://habr.com/ru/post/280121/ | null | ru | null |
# Настройка WebRTC + Eclipse 4.3 + ubuntu 13.10
Добрый день, хабрапользователи!
Выкладываю небольшую шпаргалку по настройке WebRTC + Eclipce 4.3 + ubuntu 13.10. Это может быть полезно тем, кто решил попробовать себя в написании кода на С++ для webrtc.
Скажу сразу, что у Google есть неплохая документация для того... | https://habr.com/ru/post/204068/ | null | ru | null |
# С чем нам пришлось столкнуться при использовании утилиты Csync2

Csync2 — достаточно старая утилита, которая предназначена для синхронизации файлов между серверами. Она позволяет настроить синхронизацию файлов по приоритетам, либо ... | https://habr.com/ru/post/504762/ | null | ru | null |
# Alpine.js на конкретном примере
Возможно, вы уже слышали про Alpine.js. Если нет, то это "Vue.js на минималках". "Angular 1 для миллениалов". Называйте, как хотите, главное, чтобы вам было понятно.
Зачем нам еще один фреймворк? Ну, Alpine хорошо вписывается в свою нишу. По факту, он – альтернатива большим фреймворк... | https://habr.com/ru/post/504650/ | null | ru | null |
# Как работает Android, часть 3
[](https://habrastorage.org/web/6fc/be8/301/6fcbe8301203480fa934d7660ac531cf.png)
В этой статье я расскажу о компонентах, из которых состоят приложения под Android, и об идеях, которые стоят за эт... | https://habr.com/ru/post/338494/ | null | ru | null |
# Hermitage — решение ваших проблем с хранением и обработкой изображений
Всем привет! Буду краток: в обмен на пять минут вашего времени отдел PHP-разработки компании Лайв Тайпинг расскажет вам о собственном микросервисе для хранения и обработки загружаемых изображений. Он называется [Hermitage](https://github.com/Live... | https://habr.com/ru/post/310340/ | null | ru | null |
# Атака BitErrant с коллизиями SHA-1: создаём разные .exe с одинаковым файлом .torrent

23 февраля 2017 года сотрудники компании Google и Центра математики и информатики в Амстердаме представили [первый алгоритм генерации ко... | https://habr.com/ru/post/357944/ | null | ru | null |
# Introducing One Ring — an open-source pipeline for all your Spark applications
If you utilize Apache Spark, you probably have a few applications that consume some data from external sources and produce some intermediate result, that is about to be consumed by some applications further down the processing chain, and ... | https://habr.com/ru/post/486466/ | null | en | null |
# Как построить пирамиду в багажнике или Test-Driven Development приложений на Spring Boot
*Spring Framework* часто приводят как пример [Cloud Native](https://pivotal.io/spring-app-framework) фреймворка, созданного для работы в облаке, разработки [Twelve-Factor приложений](https://12factor.net/), микросервисов, и одно... | https://habr.com/ru/post/431306/ | null | ru | null |
# Жизнь верстальщика в Linux
Большинство fronted-разработчиков, используют ОС Windows или OS X в связи с отсутствием полноценного Photoshop. Но как быть тем, кто неравнодушен к Nix системам? Сейчас и попробуем выяснить, интересующихся прошу под кат.
В качестве системы я использую Fedora 22, проделать тоже самое в л... | https://habr.com/ru/post/268719/ | null | ru | null |
# Введение в компоненты derby 0.6

Продолжаю серию ([раз](http://habrahabr.ru/post/221027/), [два](http://habrahabr.ru/post/221703/), [три](http://habrahabr.ru/post/222399/), [четыре](http://habrahabr.... | https://habr.com/ru/post/224831/ | null | ru | null |
# Представляем .NET MAUI Preview 12
Сегодня мы выпускаем 12 превью-версию [.NET Multi-platform App UI](https://github.com/dotnet/maui) со многими улучшениями качества и некоторыми новыми возможностями. По мере того, как мы приближаемся к выпуску нашей первой стабильной версии, баланс работы начинает смещаться в сторон... | https://habr.com/ru/post/646617/ | null | ru | null |
# Написание бота для мессенджера Tox
На фоне общей увлеченности созданием ботов для Telegram я бы хотел рассказать об API не очень широко известного мессенджера Tox и показать на примере простого echo-бота, как можно так же легко и быстро создавать собственных.

На первый взгляд, такой вопрос как выбор свойства или метода кажется простым. Но это до тех пор, пока вы не столкнётесь с непониманием в своей команде. Хотя есть устоявшиеся практики, их формулировки достат... | https://habr.com/ru/post/541308/ | null | ru | null |
# Консольный скринкаст
Оказывается, записывать сессии работы в терминале — совсем просто. Программа [script](http://unixhelp.ed.ac.uk/CGI/man-cgi?script), входящая в пакет [util-linux-ng](ftp://ftp.kernel.org/pub/linux/utils/util-linux-ng/) может записать все ваши действия в файл. В выходном файле ( по умолчанию он на... | https://habr.com/ru/post/49385/ | null | ru | null |
# Программируем Windows 7: Taskbar. Часть 9 – PeekBitmap
Ранее я писал о возможности панели задач Windows 7 изменять preview для окна. Мы говорили о том, что в preview можно отображать как часть окна, так и собственное изображение. У Windows 7 есть такая приятная особенность, что если мы наведем курсор мыши на preview... | https://habr.com/ru/post/60791/ | null | ru | null |
# Сам себе сервис скриншотов
#### Все началось с ...
Несколько лет назад я только начал знакомиться с web-программированием, и одним из моих первых «проектов» был каталожек сайтов. Разработка велась для себя, в целях повышения опыта. Но т.к. аналогичных сайтов тьма-тьмущая, хотелось сделать что-то особенное. Я решил,... | https://habr.com/ru/post/111188/ | null | ru | null |
# Взломать Wi-Fi за 10 часов
Еще не так давно казалось, что беспроводная сеть, защищенная с помощью технологии WPA2, вполне безопасна. Подобрать простой ключ для подключения действительно возможно. Но если установить по-настоящему длинный ключ, то сбрутить его не помогут ни радужные таблицы, ни даже ускорения за счет ... | https://habr.com/ru/post/143834/ | null | ru | null |
# О чем не пишут в документации, или тонкости рефакторинга на .Net Core
Всем привет! Этим материалом мы открываем цикл из нескольких статей, посвященных длинной истории о том, как мы пришли с одной стороны к CD, а с другой — к high availability, основанной на избыточности.
Начнем по порядку. У нас есть API для мобиль... | https://habr.com/ru/post/348590/ | null | ru | null |
# Обнаружение мобильного вредоносного ПО в дикой природе
Смартфоны всё больше и больше проникают в нашу жизнь, для многих людей они стали незаменимым повседневным спутником. Эти гаджеты дают нам связь с другими людьми и ра... | https://habr.com/ru/post/251929/ | null | ru | null |
# Как я сделал свою сборку Gulp для быстрой, лёгкой и приятной вёрстки
Серьёзно и профессионально я начал заниматься вёрсткой в 2019 году, хотя до этого ещё со школы интересовался данной темой как любитель. ... | https://habr.com/ru/post/560894/ | null | ru | null |
# Пишем ИИ для Виндиниума на одноплатных компьютерах. Часть 2: логика принятия решения
Серия статей по написанию ИИ для многопользовательской онлайн игры жанра рогалик.
[Часть 1](https://geektimes.ru/post/291823/).
[Часть 3](https://geektimes.ru/post/292495/).
*В этой части статьи рассмотрим подходы по созданию л... | https://habr.com/ru/post/405849/ | null | ru | null |
# Ищем простые числа до триллиона за тридцать минут
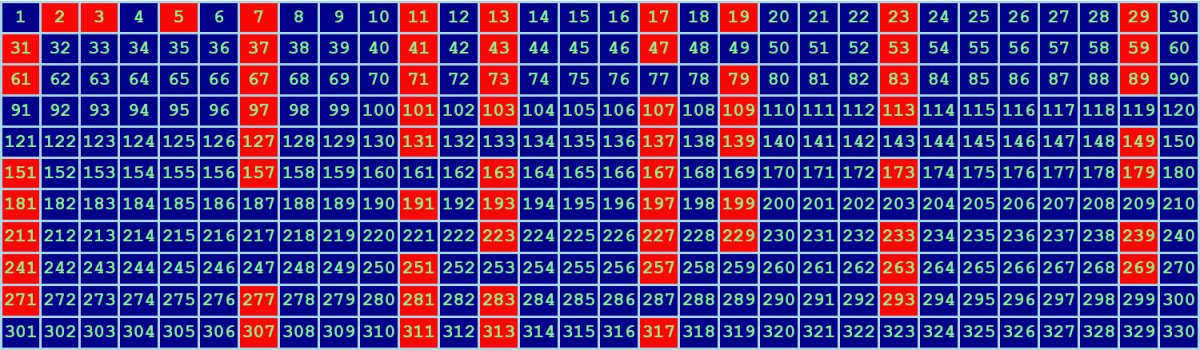
Поиск простых чисел — популярная задача среди программистов, увлекающихся математикой. Самый известный алгоритм, придуманный, по-видимому, больше двух тысяч лет назад, — [реше... | https://habr.com/ru/post/526924/ | null | ru | null |
# Ubuntu 17.10 повреждает BIOS на некоторых ноутбуках Lenovo, Acer и Toshiba
Компания Canonical отозвала вышедший в октябре дистрибутив Ubuntu 17.10 и [спрятала ссылку на сайте для скачиваний](https://github.com/canonical-websites/www... | https://habr.com/ru/post/409009/ | null | ru | null |
# re2c — компилятор регулярных выражений
Задача выделения из потока символов определенных лексем является весьма распространенной. Часто ее решают с помощью лексических анализаторов, конфигурируемых регулярными выражениями. Многие анализаторы построены по принципу генерации программного кода, который в свою очередь ре... | https://habr.com/ru/post/117843/ | null | ru | null |
# Configuring FT4232H using the ftdi_eeprom
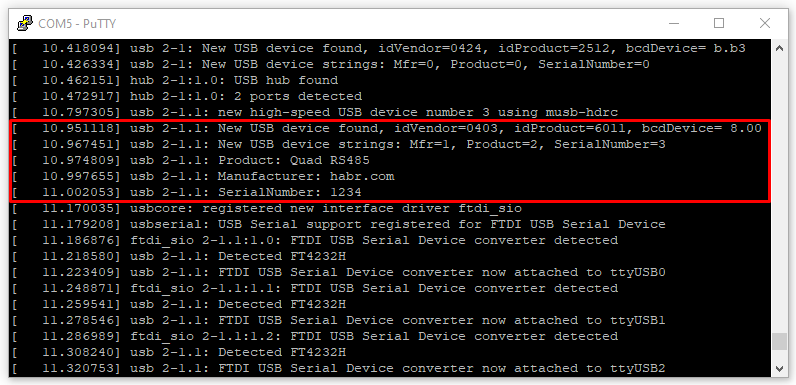
The [FT4232H](https://www.ftdichip.com/Products/ICs/FT4232H.htm) is USB 2.0 High speed to UART IC converter. The [FT4232H](https://www.ftdichip.com/Products/ICs/FT4232H.htm) has four UART po... | https://habr.com/ru/post/531504/ | null | en | null |
# Генерация строго-типизированных коллекций в PHP
Отсутствие коллекций — боль в заднице PHP. На данный момент нет удобного способа обеспечить безопасность типов для наборов объектов. Я постоянно создаю коллекции, но это означает, что нужно создавать новый класс каждый раз, когда нужна безопасность типов для набора дан... | https://habr.com/ru/post/671542/ | null | ru | null |
# Рейтинги автомобильных марок: пример анализа переменных с множественным откликом
[](https://habrastorage.org/webt/h2/ao/sb/h2aosb01wroheacfhj8ljd76gxs.png)
В анкетных маркетинговых исследованиях довольно часто встречаются вопросы, в ... | https://habr.com/ru/post/345296/ | null | ru | null |
# Безопасное динамическое обновление DNS записей в Windows домене из Linux (GSS-TSIG)
Необходимость в таком обновлении возникла у меня в такой ситуации: на линуксе поднят openvpn сервер, к нему коннектятся удаленные клиенты. Openvpn сервер сам динамически выдает адреса клиентам и, хотелось бы, чтобы он и создавал dns ... | https://habr.com/ru/post/221843/ | null | ru | null |
# Реверсинг Android клиента музыкального сервиса Zaycev.net и имплементация api на go
Строго говоря, к реверсингу данную статью можно отнести только с натяжкой.
Всем вам знаком такой сервис как zaycev.net. Не ошибусь, предположив, что каждый хоть раз качал с него музыку, либо через web-интерфейс, либо через мобильное... | https://habr.com/ru/post/301838/ | null | ru | null |
# Язык программирования SPL — пример решения задачи
В этой статье я расскажу о том, как можно в языке программирования SPL решить классическую задачу: получить список наиболее часто встречающихся в тексте слов. В качестве образца текста возьмем произведение Шекспира [Гамлет](http://erdani.com/tdpl/hamlet.txt).
Дале... | https://habr.com/ru/post/330678/ | null | ru | null |
# Делаем электронного консультанта из чата Post Hawk

Недавно вышла новая версия [api](https://bitbucket.org/Slavenin/hawk_api) [Post Hawk](http://post-hawk.com) и [чат](https://bitbucket.org/Slavenin/hawk_chat) основанный н... | https://habr.com/ru/post/268673/ | null | ru | null |
# Xamarin.Forms для WPF и UWP разработчиков
[](http://habrahabr.ru/post/331308/)
Постараюсь коротко, но понятно, рассказать самое интересное о Xamarin. Самые основные концепты, которые необходимо знать UWP и WPF разработчикам... | https://habr.com/ru/post/331308/ | null | ru | null |
# Как spring-kafka обрабатывает сообщения и не мешает ли этому auto-commit?
[В предыдущей статье](https://habr.com/ru/post/558206/) мы рассмотрели как работает **KafkaConsumer** и как реализован механизм auto-commit.
В этой статье я хочу остановиться на том как получает и обрабатываются сообщения spring-kafka.
Сто... | https://habr.com/ru/post/570674/ | null | ru | null |
# Вышла deno 1.27. Подробности об улучшениях под катом
[Deno 1.27](https://github.com/denoland/deno/releases/tag/v1.27.0) выпущена с фичами и изменениями в списке ниже:
* Улучшение языкового сервера/IDE
* Улучшение совместимости с `npm`
* Онлайн-API `navigator.language`
* Улучшение `deno task`
* Проверка обновлений
*... | https://habr.com/ru/post/697752/ | null | ru | null |
# JOIN локальной коллекции и DbSet в Entity Framework
Чуть больше года при моём участии состоялся следующий "диалог":
**.Net App**: Эй, Entity Framework, будь любезен дай мне много данных!
**Entity Framework**: Прости, не понял тебя. Что ты имеешь ввиду?
**.Net App**: Да просто мне прилетела коллекция из 100k т... | https://habr.com/ru/post/435810/ | null | ru | null |
# Repaint для больших картинок
Repaint происходит средствами процессора, браузер тратит на это определенное время. При анимации это время негативно влияет на производительность. Я уперся в эту проблему, когда мне надо было анимировать листалку из картинок большого разрешения весом 100-200kB. Причем в ряде браузеров пр... | https://habr.com/ru/post/134653/ | null | ru | null |
# Построение карты сети
Построение карты сети — это длительный процесс. Исследование происходит за счет отслеживания откликов операционных систем на испорченные данные в заголовках сетевых протоколов. Этот по... | https://habr.com/ru/post/560452/ | null | ru | null |
# Разбираемся в Go: пакет encoding
*Перевод одной из статей Бена Джонсона из серии "Go Walkthrough" по более углублённому изучению стандартной библиотеки Go в контексте реальных задач.*
Пока что мы рассмотрели работу с потоками и слайсами байт, но мало какие программы просто гоняют байты туда сюда. Сами по себе байты... | https://habr.com/ru/post/309834/ | null | ru | null |
# Превью и Resize картинок на лету
Переделывал сайт заказчику на Netcat и с удивлением обнаружил, что кто-то ещё использует загрузку отдельных картинок для оригиналов и для превьюшек и как следствие отдельные столбцы в таблице БД. Куда ещё не шло создавать превьюшки на стороне сервера после загрузки оригинала.
Идея... | https://habr.com/ru/post/53912/ | null | ru | null |
# Производительность: нюансы против очевидностей
Приветствую, это текстовая версия моего доклада на [JPoint-2021](https://jpoint.ru/2021/talks/1ui7ta2itmzurm0vaqmyjw/). Как обычно я сделал упор на случаи из жизни и на повседневные вещи, используемые каждым разработчиком. Под кат приглашаются интересующиеся производите... | https://habr.com/ru/post/518744/ | null | ru | null |
# ChibiOS: легковесная RTOS

В этой статье я хочу представить и вкратце описать члена семейства ОС реального времени — ChibiOS.
#### Лицензия
В первую очередь про лицензирование. ChibiOS является свободной RTOS и имее... | https://habr.com/ru/post/181912/ | null | ru | null |
# Что же не так с ДЭГ в Москве?
Что же не так с ДЭГ в Москве
============================
Последние три дня я занимался тем, что анализировал результаты ДЭГ в Москве по одномандатным округам в Госдуму. У меня есть некоторые результаты, которыми я бы хотел поделиться с общественностью. Однако основная цель этого поста... | https://habr.com/ru/post/579350/ | null | ru | null |
# Три особенности JavaScript, о которых полезно знать каждому Java/C-разработчику

Иногда JavaScript может вводить разработчика в заблуждение, а иногда — доводить до белого каления из-за своей неполной консистентности. Есть... | https://habr.com/ru/post/257617/ | null | ru | null |
# SVN → Подключение внешних библиотек
Итак, сегодня речь пойдет о подключении внешних библиотек (суб-проектов) в основные проекты с использованием **Subversion**.
По старой доброй традиции, в качестве клиента для работы с **SVN** будет использоваться давно полюбившийся нам **TortoiseSVN**.
Как обычно, все описан... | https://habr.com/ru/post/15823/ | null | ru | null |
# Максимально простой в поддержке способ интеграции java-клиента с java-сервером
При решении повседневных задач с интерфейсом настольного приложения, реализованного на JavaFX, приходится в любом случае делать запрос на веб-сервер. После времен J2EE и страшной аббревиатуры RMI многое изменилось, а вызовы на сервер стал... | https://habr.com/ru/post/422073/ | null | ru | null |
# Nagare — пример использования фреймворка
В прошлом [посте](http://hemul.habrahabr.ru/blog/86595/) я презентовал [Nagare](http://www.nagare.org) — революционный (хоть и имеющий аналоги на [Smalltalk](http://www.seaside.st) и [CL](http://weblocks.viridian-project.de/)) питоновский web-фреймворк. Тот пост был несколько... | https://habr.com/ru/post/87908/ | null | ru | null |
# Разработка Action-able приложения для Slack

**От переводчика:** публикуем для вас [статью](https://medium.com/slack-developer-blog/tutorial-developing-an-action-able-app-4d5455d585b6) Томоми Имуры о том,... | https://habr.com/ru/post/431346/ | null | ru | null |
# Schema.org своими руками: настраиваем микроразметку без программиста

Программисты сейчас обиделись, а не надо. Они же попробуют справиться без вас, а потом придут... | https://habr.com/ru/post/486764/ | null | ru | null |
# Docker и аутентификация через Nginx

Одна из досадных проблем, которые встают при создании NAS, заключается в том, что не всякое программное обеспечение может работать с LDAP, а [некоторое](https://github.com/d0u9/youtube-dl-webui)... | https://habr.com/ru/post/456894/ | null | ru | null |
# Бэкапы для HashiCorp Vault с разными бэкендами
Недавно мы [публиковали статью](https://habr.com/ru/company/flant/blog/540836/) про производительность Vault с разными бэкендами, а сегодня расскажем, как дела... | https://habr.com/ru/post/558910/ | null | ru | null |
# Загрузка Linux с корнем на RAID
Для того, чтобы загрузить ядро linux с корневой файловой системой лежащей на RAID-массиве нужно передать ядру следующие параметры (рабочий пример для Grub). Значимыми для нас опциями являются первая и вторая строка параметров.
`title Gentoo Linux 3.0.8 Hardened
kernel (hd0,0)/li... | https://habr.com/ru/post/133059/ | null | ru | null |
# Использование Intel Movidius для нейронных сетей
Введение
--------
Мы занимаемся разработкой глубоких нейронных сетей для анализа фото, видео и текстов. В прошлом месяце мы купили для одного из проектов очень интересную штуковину:
[Intel Movidius Neural Compute Stick](https://developer.movidius.com/).

После прочтения предыдуших топиков про капчу, мне пришла идея сделать ребус капчу. Конечно, использовать её в реальных проектах не очень правильно, так как пользователь будет тратить время на решение ребуса, а вы н... | https://habr.com/ru/post/122081/ | null | ru | null |
# Распознавание цифр, для максимально маленьких (python/keras)
Этот пост я решил написать, для тех, кто также искал понятный код и рабочий пример, который можно было взять, вставить в гугл колаб(google colab) и сразу начать "играться" с кодом. Но не нашел. Для вас, друзья!
P.S весь код будет в конце.
Импортируем бэк... | https://habr.com/ru/post/705306/ | null | ru | null |
# Пишем Hex Viewer для Flipper Zero
Примерно месяц назад основная поставка Flipper'ов таки доехала до России. Вопреки моим ожиданиям, это не вызвало волну публикаций про создание приложений под него. Хорошие ... | https://habr.com/ru/post/700378/ | null | ru | null |
# Социальные игры: сервер, клиент и общая шина событий
Добрый день.
У меня выдалось свободное время, и я решил написать статью про несправедливо обойденный вниманием паттерн написания api. Он подходит в случае, если у Вас и клиент и сервер содержат сложное состояние, и есть необходимость его синхронизировать. На м... | https://habr.com/ru/post/188928/ | null | ru | null |
# Как мы ускорили наш DNS стек в 3 раза
Компании Cloudflare уже пошёл 6-й год и предоставление авторитативных DNS серверов было основной нашей инфраструктуры с самого начала. С тех пор мы выросли, став самым большим и быстрым поставщиком услуг DNS в Интернете, обслуживая около 100 000 сайтов из списка [Alex top 1M sit... | https://habr.com/ru/post/326372/ | null | ru | null |
# Qt: рисование по мотивам векторной графики
Qt предоставляет программисту очень богатые возможности, однако набор виджетов ограничен. Если ничего из имеющегося в наличии не подходит, приходится рисовать что-то свое. Простейший способ —... | https://habr.com/ru/post/425547/ | null | ru | null |
# Unity UIElements: первые впечатления в продакшн
Сегодня мы поделимся впечатлениями от работы с нашумевшим фреймворком от Unity — UIToolkit, известным также как UIElements. Мы рассмотрим его основные особенности без глубокого погружения в код. Стоит уточнить, что у команды ранее не было опыта работы с веб-версткой и ... | https://habr.com/ru/post/517726/ | null | ru | null |
# DotVVM — Коммуникация между клиентом и сервером
Это вторая статья из серии посвященная DotVVM. [Первая статья](https://habr.com/post/353606/) была скорее ознакомительной. Я старался на простом примере показать как работать в DotVVM на базовом уровне. Статья, по сути, не затрагивала самого важного: как это работает. ... | https://habr.com/ru/post/412951/ | null | ru | null |
# Анимация текстовых переходов
Эта статья — перевод оригинальной статьи "[Text Replace Transitions](https://nerdy.dev/text-replace-transitions)"
Также я веду телеграм канал “[Frontend по-флотски](https://t.me/frontend_pasta)”, где рассказываю про интересные вещи из мира разработки интерфейсов.
Вступление
----------
... | https://habr.com/ru/post/710276/ | null | ru | null |
# Вышел релиз GitLab 12.8 с обозревателем логов, NuGet и панелью управления соответствием требованиям

Новый релиз GitLab 12.8 посвящен подходу «единое место»: для всех ваших... | https://habr.com/ru/post/491780/ | null | ru | null |
# Визуальное представление выборов в Санкт-Петербурге — магия накрутки голосов
Привет!
В сентябре этого (2019) года прошли выборы Губернатора Санкт-Петербурга. Все данные о голосовании находятся в открытом доступе на сайте избирательной комиссии, мы не будем ничего ломать, а просто визуализируем информацию с этого ... | https://habr.com/ru/post/475258/ | null | ru | null |
# Применение Arm Mbed OS. Тонкая настройка

После того как с помощью **Arm Mbed OS** удалось [помигать светодиодом](https://habr.com/post/262839/), настало время протестировать и настроить другие важные сервисы. Далее рассказывает... | https://habr.com/ru/post/422413/ | null | ru | null |
# Введение в октодеревья
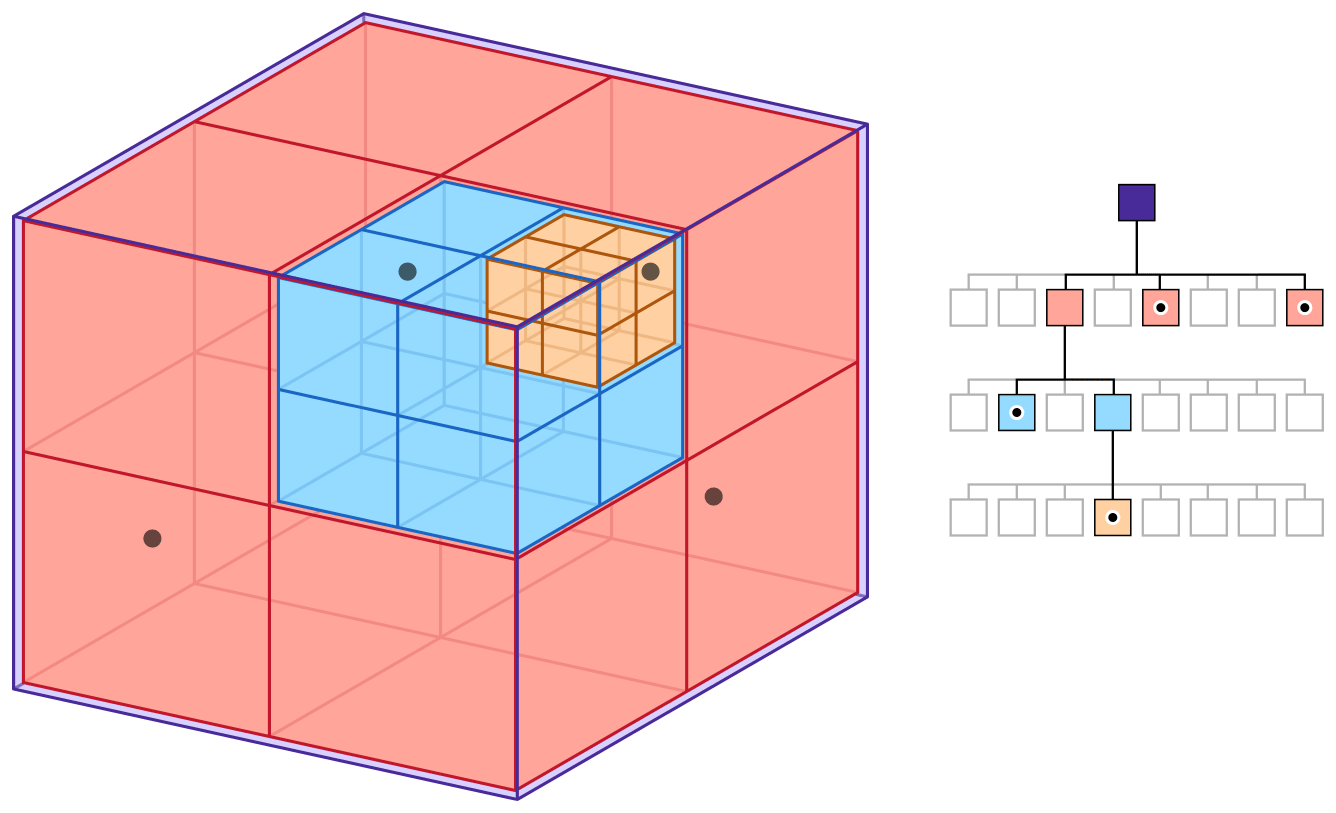
Что такое октодеревья? Если вам совершенно неизвестно это понятие, то рекомендую прочитать [статью в Википедии](https://ru.wikipedia.org/wiki/%D0%9E%D0%BA%D1%82%D0%BE%D0%B4%D0%B5%D... | https://habr.com/ru/post/334990/ | null | ru | null |
# Хитрые задачи по Java
Совсем недавно я сдал **OCA Java SE 7 Programmer I**. За время подготовки успел решить огромное количество задач и извлечь из них много тонких моментов языка. Самые интересные и ловкие — сохранял на будущее. И вот у меня накопилась небольшая личная коллекция, лучшую часть которой я здесь и опиш... | https://habr.com/ru/post/203796/ | null | ru | null |
# Связывание модели данных в C++ c представлением в QML на примере карты

*Этот пост участвует в конкурсе [„Умные телефоны за умные посты“](http://habrahabr.ru/company/Nokia/blog/132522/).*
Попробуем решить следующую задачу: по... | https://habr.com/ru/post/134302/ | null | ru | null |
# PHP-Дайджест № 72 – интересные новости, материалы и инструменты (5 – 18 октября 2015)

Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
* [Ко... | https://habr.com/ru/post/269039/ | null | ru | null |
# Вдогонку к предыдущему посту или О разных методах хранения конфигов
Настоящее приложение просто обязано быть конфигурируемым.
Новостная лента — не лента, если админка не позволяет указать, сколько же новостей выводить на главной. Блог — не блог, а унылый бложек, если нельзя тонко настроить миллион параметров — от... | https://habr.com/ru/post/78976/ | null | ru | null |
# Программа-помощник для освоения слепой печати на клавиатуре в Linux
Хочу показать и рассказать о небольшой программке, которая принесла пользу.
Однажды на работе мне написал друг. Диалог у нас состоялся примерно следующий:
— Привет, я тут обучаюсь технике слепой печати. Дело в том, что на линуксе нет программ... | https://habr.com/ru/post/266441/ | null | ru | null |
# Создание плагинов для AutoCAD с помощью .NET API (часть 1 – первые шаги)
Hello, Habr!
Решил рассказать о своем опыте работы с AutoCAD. Может быть, кому-то это поможет – ну или хотя бы интересным покажется.
```
public static string disclaimer = "Автор не является профессиональным разработчиком и не обладает глу... | https://habr.com/ru/post/235723/ | null | ru | null |
# Получаем информацию о программе и загружаем ее через CMD (man и apt-get для Windows?)

В данной статье речь пойдет об очень простом и удобном способе для получения данных (информации) о программным обеспечении и загру... | https://habr.com/ru/post/239443/ | null | ru | null |
# Создание аудиоплагинов, часть 11
Все посты серии:
[Часть 1. Введение и настройка](http://habrahabr.ru/post/224911/)
[Часть 2. Изучение кода](http://habrahabr.ru/post/225019/)
[Часть 3. VST и AU](http://habrahabr.ru/post/225457/)
[Часть 4. Цифровой дисторшн](http://habrahabr.ru/post/225751/)
[Часть 5. ... | https://habr.com/ru/post/227791/ | null | ru | null |
# Пишем конвертер для генератора мелодий от Nokia 3310
#### Любителям всего старого, но безумно интересного, добрый вечер!
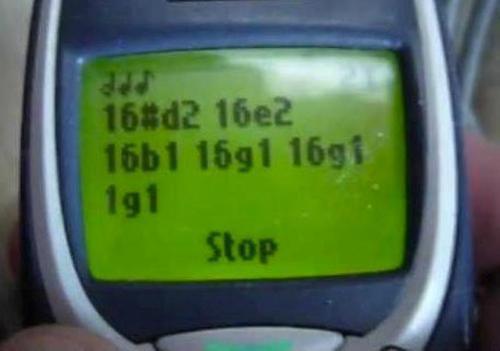
> Помните такой телефон — Nokia 3310? Разумеется, помните! А такую штуку как синтезатор мелодий в ... | https://habr.com/ru/post/245917/ | null | ru | null |
# Flexbox для интерфейсов во всей красе: Реализация Tracks (Часть 2)
*Продолжаем перевод статьи smashingmagazine, в котором подробно рассмотрены все нюансы разработки интерфейсов с помощью flexbox на примере сайта [Tracks](http://buildtracks.com/)*.
[Часть 1](http://habrahabr.ru/company/paysto/blog/271195/)
####... | https://habr.com/ru/post/271397/ | null | ru | null |
# Критерии 100% читаемости сайтов
Перевод статьи Oliver Reichenstein «[The 100% Easy-2-Read Standard](http://informationarchitects.jp/100e2r/)».
Большинство сайтов доверху наполнены мелким текстом, который больно читать. Но зачем? Нет причины вжимать так много информации в экран. Это глупая коллективная ошибка, кот... | https://habr.com/ru/post/48862/ | null | ru | null |
# Citrus: Набор стилей для AvaloniaUI

В комментариях к новостям об изменениях и улучшениях в новых версиях кроссплатформенного GUI-фреймворка [AvaloniaUI](http://github.com/avaloniaui) довольно часто можно увидеть [крит... | https://habr.com/ru/post/487000/ | null | ru | null |
# Используем GitLab в качестве удобного Helm-репозитория
GitLab – это мощный и в то же время простой инструмент для организации проектов. Как и любой крупный и самодостаточный продукт, GitLab постоянно развивается и дорабатывается. И сегодня хотелось бы обсудить новый функционал, который пока ещё находится в разработк... | https://habr.com/ru/post/667338/ | null | ru | null |
# Первые пять шагов для перелома ситуации с читерами в PvP-шутере
Мы прошли долгий путь от появления в игре первых читеров до полного пересмотра подхода к разработке, чтобы создавать защищенные по умолчанию... | https://habr.com/ru/post/547562/ | null | ru | null |
# Учим робота готовить пиццу. Часть 2: Состязание нейронных сетей

### Содержание
* [Часть 1: Получаем данные](https://habrahabr.ru/post/335444/)
В прошлой части, удалось распарсить сайт Додо-пиццы и загрузить данные об ингред... | https://habr.com/ru/post/337398/ | null | ru | null |
# Настройка наследования отступа для длинных строк
Речь пойдет о том, как vim «сворачивает» (делает то, что по английски называется wrap) длинные строки. Допустим, у вас есть очень длинная строка кода, которая начинается с некоторым отступом. Скорее всего, если вы используете `:set wrap` и `:set showbreak=->`, она выг... | https://habr.com/ru/post/138857/ | null | ru | null |
# Тестирование с Сodeception для чайников: 3 вида тестов
Целью данной статьи я ставил показать людям, не знакомым с тестированием, как можно действительно быстро начать тестировать, собрав все в одном месте с минимумом воды и на русском языке. Пусть это будет весьма примитивно. Пусть не очень интересно людям, которые ... | https://habr.com/ru/post/329418/ | null | ru | null |
# Расширения Entity Framework 6, о которых вы могли и не знать

Многие программисты делают записи, описывают трудности, красивые и не очень решения, с которыми приходится сталкиваться по долгу службы. Это может быть собстве... | https://habr.com/ru/post/320128/ | null | ru | null |
# Мониторинг Elasticsearch через боль и страдания

Мы наконец допинали функционал мониторинга elasticsearch до публичного релиза. Суммарно мы переделывали его три раза, так как результат нас не устраивал и не показывал проб... | https://habr.com/ru/post/315860/ | null | ru | null |
# Сервисная технология на основе REST + RPC API делаем в турбо режиме
Мы привыкли почему-то разделять REST и RPC, мне кажется это разделение искусственным. Просто REST строже и ограничен в методах, и это не всегда оправдано в сложном приложении.
Сделаем простую основу для написания сервисно-ориентированной архитект... | https://habr.com/ru/post/276781/ | null | ru | null |
# Говорим и показываем: как мы создали сервис синхронного просмотра видео ITSkino на основе VLC

О том, что самоизоляция — это не только «тук-тук-тук» в крышку гроба экономики, но и новые «горизонты возможностей», уже написано нема... | https://habr.com/ru/post/508370/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.