
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# SYN-флудим со спуффингом на 14 mpps или нагрузочная вилка V 2.0
Что-то меня пробило на написание заметок последнее время, поэтому пока энтузиазм не спал раздаю долги.
Год назад я пришёл на хабр со статьёй "[TCP(syn-flood)-netmap-generator производительностью 1,5 mpps](http://habrahabr.ru/post/183692/)", после кот... | https://habr.com/ru/post/229733/ | null | ru | null |
# Как машинное обучение помогает проекту «ЗабастКом» анализировать новости и освещать трудовые конфликты

В посте расскажу о моем успешном взаимодействии с некоммерческим проектом [ЗабастКом](https://www.zabastcom.org/), который поддер... | https://habr.com/ru/post/707760/ | null | ru | null |
# Knockoutjs. «Растим» дерево

Судя по частоте появления статей, [KnockoutJS](http://knockoutjs.com/) набирает [популярность](http://habrahabr.ru/search/?q=knockoutjs) на Хабре. Внесу и я свою лепту. Хочу осветить тему не... | https://habr.com/ru/post/165565/ | null | ru | null |
# Реализация паттерна Observer средствами PHP 5.3
Прочитав недавно нововведения PHP 5.3, я обратил внимание на несколько интересных особенностей, скомпоновав которые можно получить реализацию шаблона проектирования Observer, гораздо красивее, чем имеющиеся в pear и symfony, причём вся реализация займёт всего несколько... | https://habr.com/ru/post/106426/ | null | ru | null |
# Return oriented programming. Собираем exploit по кусочкам
**Введение**
В этой статье мы попробуем разобраться как работает Return Oriented эксплоит. Тема, в принципе, так себе заезженная, и в инете валяется немало публикаций, но я постараюсь писать так, чтобы эта статья не была их простой компиляцией. По ходу нам... | https://habr.com/ru/post/255519/ | null | ru | null |
# Django своими руками часть 1: Собираем шаблоны для jinja2
#### Введение
В этом посте хотелось бы описать создание небольшого фреймворка с системой плагинов как django. Только с использованием внешних компонентов. Jinja2 для шаблонов, bottle для получения переменых среды, вместо ORM будет использоваться pymongo, а с... | https://habr.com/ru/post/144717/ | null | ru | null |
# STM32: FreeRTOS и пьезокерамический излучатель

Керамический пьезоизлучатель (buzzer) — простая деталь, наравне со светодиодом требующая минимального набора ресурсов для управления и настолько же легко подключаемая к... | https://habr.com/ru/post/316990/ | null | ru | null |
# Android Data Binding for RecyclerView: flexible way
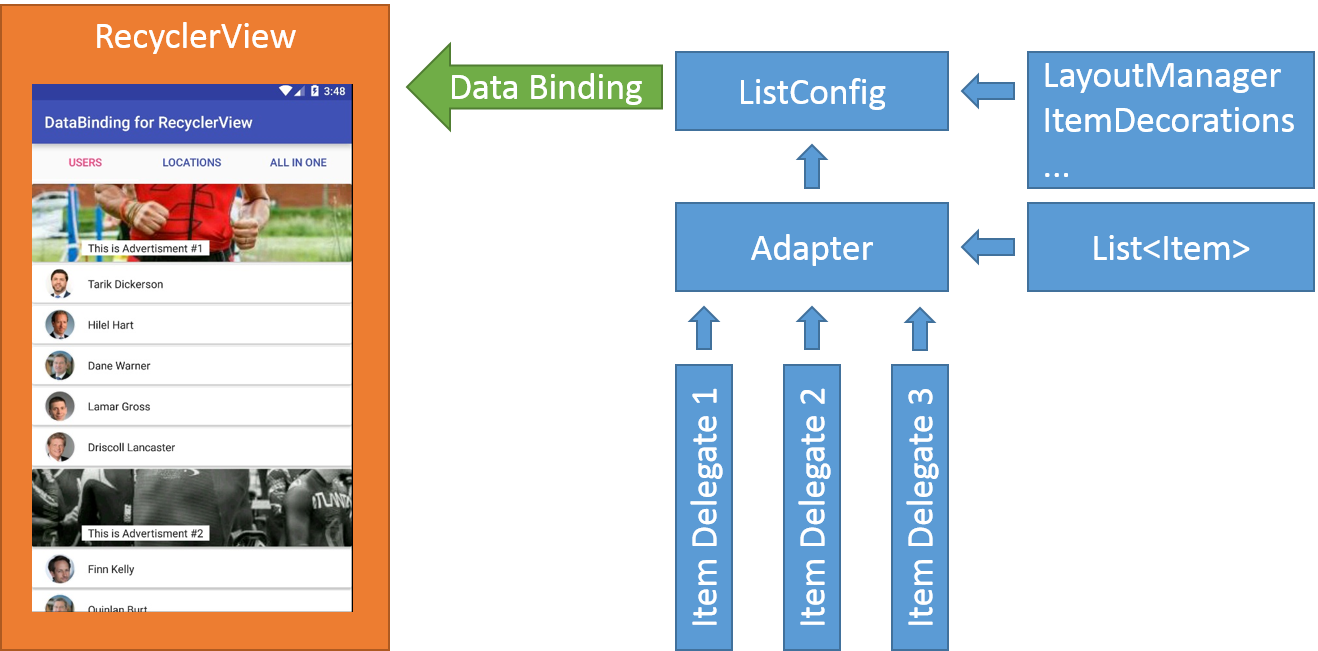
Со времени первого анонса на Google IO 2015 новой библиотеки [Data Binding Library](https://developer.android.com/topic/libraries/data-binding/index.html) прошло немало ... | https://habr.com/ru/post/308872/ | null | ru | null |
# Использование Atomics.wait(), Atomics.notify() и Atomics.waitAsync()
Статические методы [Atomics.wait()](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/wait) и [Atomics.notify()](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/notify)... | https://habr.com/ru/post/522952/ | null | ru | null |
# Jabber WebCam Bot
Эта идея пришла мне как-то случайно. Получить снимок с вэб камеры, которая находится дома, находясь на работе или в другом городе и при этом не расшаривать камеру через вэб… И не коннектиться по ssh… Забавно… Что, если получить его одним запросом в джаббере! Звучит бредово, но я занялся реализацией... | https://habr.com/ru/post/56684/ | null | ru | null |
# Создание таблицы субъектов РФ в формате Geography T-SQL (SQL Server)
В процессе подготовки инструмента для автоматического определения субъекта РФ по точке (тип данных Point) потребовалась таблица вида "Субъект РФ" - "geography::Object".
Предыстория: есть большой автопарк (>1000 ТС), который отправляет свои координ... | https://habr.com/ru/post/563110/ | null | ru | null |
# Смарт контракты Ethereum: что делать при ошибке в смартконтракте или техники миграции
При написании смартконтрактов важно помнить, что после загрузки в блокчейн, они уже не могут быть изменены, а следовательно, не могут быть внесены какие-либо улучшения или исправлены какие-то найденные ошибки! Все мы знаем, что оши... | https://habr.com/ru/post/339102/ | null | ru | null |
# Виджет для Android на JavaScript за 15 минут на примере Хабра-Кармы
Сразу говорю, кармавиджет — вовсе не основная цель статьи. В этой статье я хочу представить широкой общественности способ быстрого создания информационных виджетов для Android на JavaScript всего лишь на примере кармы и рейтинга хабра. Виджет будет ... | https://habr.com/ru/post/143001/ | null | ru | null |
# Рисуем знак рубля в Android приложении
В последнее время перед разработчиками все чаще ставится задача использовать символ рубля в тексте. Однако, символ рубля [был утвержден относительно недавно](http://ru.wikinews.org/wiki/%D0%91%D0%B0%D0%BD%D0%BA_%D0%A0%D0%BE%D1%81%D1%81%D0%B8%D0%B8_%D1%83%D1%82%D0%B2%D0%B5%D1%80... | https://habr.com/ru/post/231203/ | null | ru | null |
# Особенности валидации моделей на Xgboost
Машинное обучение все чаще используется аналитиками для упрощения работы при решении текущих задач, для реализации новых проектов или для выявления каких-либо ошиб... | https://habr.com/ru/post/573040/ | null | ru | null |
# Собираем логи из Nginx с помощью nginx-clickhouse, отправляем в Clickhouse и отображаем в Grafana
Я из компании Luxoft. В этой статье будет рассматриваться проект [nginx-clickhouse](https://github.com/mintance/nginx-clickhouse), который будет читать логи nginx, отправлять их в clickhouse. Для просмотра аналитики по ... | https://habr.com/ru/post/477498/ | null | ru | null |
# t1ha = Fast Positive Hash
Just about the fastest portable 64-bit hash function with decent quality.
This is a translation of the original [article](https://habr.com/ru/post/339160/) by [Leonid Yuriev](https://habr.com/ru/users/yleo/).
**Instead of a Disclaimer**I will omit the definition of hash functions along w... | https://habr.com/ru/post/439156/ | null | en | null |
# Как мы сжимаем данные в больших проектах
Привет! Меня зовут Александр Кленов, и я работаю в Tarantool. В апреле вышел Tarantool 2.10 Enterprise Edition – обновленная версия платформы in-memory вычислений. В... | https://habr.com/ru/post/672760/ | null | ru | null |
# Фаззинг сокетов: Apache HTTP Server. Часть 3: результаты
> *Прим. Wunder Fund:* наш СТО [Эмиль](https://youtu.be/662q9FVqp50) по совместительству является известным white-hat хакером и специалистом по информационной безопасности, и эту статью он предложил как хорошее знакомство с фаззером afl и вообще с фаззингом ка... | https://habr.com/ru/post/651559/ | null | ru | null |
# Две стороны WebView: о быстром запуске проектов и краже персональных данных
Привет, Хабр!
Меня зовут Евгений, я Full Stack JS разработчик, текущий стек Node.js + React + React Native. В разработке я более 10 лет. В мобильной разработке пробовал разные инструменты от Cordova до React Native. Получив опыт работы с... | https://habr.com/ru/post/440710/ | null | ru | null |
# AMS и магический кристалл

На этот раз предлагаю немного позаниматься магией (почему нет?) и создать магический кристалл для наших повседневных нужд. Использовать его мы будем по прямому назначению — для прорицания р... | https://habr.com/ru/post/390025/ | null | ru | null |
# Пишем чат-бот на Python + PostgreSQL и Telegram
Пошаговое руководство написания чат-бота на языке Python.
---------------------------------------------------------
* Установим Python и библиотеки;
* Получим вопросы и ответы из БД PostgreSQL;
* Подключим морфологию;
* Подключим чат-бот к каналу Telegram.
Colaborato... | https://habr.com/ru/post/593065/ | null | ru | null |
# Разработка изоморфного RealWorld приложения с SSR и Progressive Enhancement. Часть 2 — Hello World
В [предыдущей части](https://habrahabr.ru/post/348964/) туториала мы узнали что такое проект **RealWorld**, определились целями туториала, выбрали стек технологий и написали простой веб-сервер на **Express** в качестве... | https://habr.com/ru/post/349354/ | null | ru | null |
# Простенький скрипт поиска возможно осиротевших файлов проекта
Леность ли моя тому причиной или болезненная неприязнь к комбайнам, но у меня как-то не сложились отношения с большими толстыми довольными IDE. Довольствуюсь простым ламповым Geany и несколькими самописными скриптами, количество коих растёт по мере необхо... | https://habr.com/ru/post/337140/ | null | ru | null |
# Все, что вы хотели знать о Sigma-правилах. Часть 3
Эта статья — завершение цикла материалов ([первая часть](https://habr.com/ru/company/pt/blog/510480/), [вторая часть](https://habr.com/ru/company/pt/blog/513032/)), посвященного синтаксису Sigma-правил. Ранее мы рассмотрели пример простого Sigma-правила и подробно о... | https://habr.com/ru/post/515532/ | null | ru | null |
# Новые возможности werf: CI/CD на основе werf и Argo CD
В этой статье мы рассмотрим новый экспериментальный режим совместной работы Open Source-утилиты werf и инструмента для непрерывной доставки Argo CD, объединяющий в себе возможности и удобства обоих проектов в рамках одного CI/CD-процесса. Сейчас идет активная ра... | https://habr.com/ru/post/666100/ | null | ru | null |
# Удаленный доступ к IP камерам. Часть 2. Мобильное приложение

В предыдущей [статье](https://habr.com/ru/post/597363) я рассказывал о простом [сервере](https://github.com/vladpen/python-rtsp-server) для работы с камерами видеонаблюден... | https://habr.com/ru/post/654915/ | null | ru | null |
# Использование PowerShell с $PSStyle

В PowerShell 7.2 появилась автоматическая переменная `$PSStyle` для новой функции под названием PSAnsiRendering. В этой статье я покажу, как можно использовать ANSI-рендеринг для управления офор... | https://habr.com/ru/post/652711/ | null | ru | null |
# Cocos2d-x — Обработка действий
От автора перевода
------------------
Как вы уже поняли, эта статья — простой перевод официальной [документации](http://www.cocos2d-x.org/docs/programmers-guide/actions/index.html) к движку Cocos2d-x. Если вы здесь впервые, можете глянуть [предыдущую статью](https://habrahabr.ru/post/... | https://habr.com/ru/post/339794/ | null | ru | null |
# Система типов — лучший друг программиста

Я устал от [одержимости примитивами](https://blog.ploeh.dk/2011/05/25/DesignSmellPrimitiveObsession/) и от чрезмерного использования примитивных типов для моделирования функциональной облас... | https://habr.com/ru/post/697926/ | null | ru | null |
# NAT на Cisco. Часть 1
Добрый день, коллеги!
судя по многочисленным вопросам на форуме (ссылка в конце поста), от слушателей и коллег, работа NAT на маршрутизаторах Cisco (firewall'ы я опущу, [Fedia](https://habrahabr.ru/users/fedia/) достаточно подробно его работу расписал в своей серии статей про Cisco ASA) плох... | https://habr.com/ru/post/108931/ | null | ru | null |
# Java Puzzlers NG S02: всё чудесатее и чудесатее
Тагир Валеев ([lany](https://habr.com/ru/users/lany/)) и Барух Садогурский ([jbaruch](https://habr.com/ru/users/jbaruch/)) собрали новую коллекцию Java-паззлеров и спешат ими поделиться.
В основе статьи – расшифровка их выступления на осенней конференции JPoint 201... | https://habr.com/ru/post/352438/ | null | ru | null |
# Об облаках Amazon и транспорте MPLS
В ходе разработки одного проекта на базе облачных услуг Amazon пришлось столкнуться с одной проблемой, описания которой в открытом доступе найти не удалось — значительные задержки при обращении к сервису Amazon RDS. Однако помочь разобраться с ней мне помогли знания в технологиях ... | https://habr.com/ru/post/175023/ | null | ru | null |
# Checking FreeRDP with PVS-Studio

FreeRDP is an open-source implementation of the Remote Desktop Protocol (RDP), a proprietary protocol by Microsoft. The project supports multiple platforms, inc... | https://habr.com/ru/post/444246/ | null | en | null |
# Как я делал serverless поиск для мейлинг листов OpenJDK
Совсем недавно мне захотелось поискать какую-то информацию в [amber-dev](https://mail.openjdk.org/pipermail/amber-dev/) мейлинг листе. Оказывается, что никакого встроенного поиска тут нет. Нужно либо пользоваться гуглом и использовать **site:** оператор, либо и... | https://habr.com/ru/post/692512/ | null | ru | null |
# Как не дать программисту написать плохой код

Как-то раз в одной [неглупой статье](http://habrahabr.ru/blogs/net/102177/) один [неглупый хабраюзер](http://maseal.habrahabr.ru/) рассказал одну [неглупую идею](h... | https://habr.com/ru/post/111463/ | null | ru | null |
# Организуем Asterisk IP телефонию в офисе без изучения Linux
В этой статье я расскажу по шагам об организации IP телефонии в офисе на 15 человек с помощью Asterisk в виде сборки Askozia, неттопа Intel NUC и телефонов Linksys и Yealink, заказанных с Ebay, а также прикину примерные затраты на организацию связи со своим... | https://habr.com/ru/post/194812/ | null | ru | null |
# Самые частые грабли при использовании printf в программах под микроконтроллеры
Время от времени в моих проектах приходится применять printf в связке с последовательным портом (UART или абстракция над USB, имитирующая последовательный порт). И, как обычно, времени между его применениями проходит много и я успеваю нап... | https://habr.com/ru/post/459420/ | null | ru | null |
# Подготовка к Spring Professional Certification. Spring Boot
Приветствую всех. Эта статья раскроет основные вопросы по теме "Spring Boot". Она ориентирована на начинающих разработчиков, и может быть полезной при подготовке к собеседованию. Она получилась достаточно компактной, по сравнению с остальными статьями.
**О... | https://habr.com/ru/post/471312/ | null | ru | null |
# Введение в Puppet
Puppet — это система управления конфигурацией. Он используется для приведения хостов к нужному состоянию и поддержания этого состояния.
Я работаю с Puppet уже больше пяти лет. На мой взгляд, его официальная документация хороша для тех, кто уже знаком с Puppet, а для новичка она сложна — сразу даёт... | https://habr.com/ru/post/507346/ | null | ru | null |
# PHP+SQL начинающим: Повышаем уровень программирования.
Данная статья сугубо практическая и затрагивает единственный аспект – как повысить уровень програмирования в PHP при работе с SQL базой данных (в дальнейшем мы постараемся затронуть и другие аспекты программирования) Сразу же стоит оговориться, что есть высокий ... | https://habr.com/ru/post/30651/ | null | ru | null |
# Smart IdReader SDK — встраиваем распознавание в проекты на Python и PHP
Мы, [Smart Engines](http://smartengines.ru/), продолжаем цикл статей про то, как встроить наши технологии распознавания ([паспортов](https://habr.com/ru/company/smartengines/blog/252703/), [банковских карт](https://habr.com/ru/company/smartengin... | https://habr.com/ru/post/472536/ | null | ru | null |
# Синхронизация времени в Linux: NTP, Chrony и systemd-timesyncd

Большинство людей следят за временем. Мы встаём вовремя, чтобы выполнить наши утренние ритуалы и отправиться на работу, сделать перерыв на обед, уложиться в сроки пр... | https://habr.com/ru/post/505314/ | null | ru | null |
# Flyway: управление миграциями баз данных
В этой статье я расскажу об одном из средств обеспечения версионности схем и управления миграциями БД — библиотеке [Flyway](http://code.google.com/p/flyway/). С поблемой версионности схемы базы данных рано или поздно приходится сталкиваться разработчикам любого приложения, оп... | https://habr.com/ru/post/141354/ | null | ru | null |
# Пишем игры на C++, Часть 1/3 — Написание мини-фреймворка
[Пишем игры на C++, Часть 2/3 — State-based программирование](http://habrahabr.ru/post/197280/)
[Пишем игры на C++, Часть 3/3 — Классика жанра](http://habrahabr.ru/post/197288/)
Здравствуй, Хабрахабр!
На хабре не очень много уроков по созданию игр, по... | https://habr.com/ru/post/197278/ | null | ru | null |
# Валидация электронных подписей на C# с использованием КРИПТО ПРО
Продолжая разговор на тему электронных подписей (далее ЭП), надо сказать о проверке. В предыдущей стать я разбирал более сложную часть задачи — создание подписи. В этой статье всё несколько проще. Большая часть кода это адаптация примеров из КРИПТО ПРО... | https://habr.com/ru/post/426645/ | null | ru | null |
# Гармонические колебания
На хабре было несколько статей по преобразованию Фурье и о всяких красивостях типа Цифровой Обработки Сигналов (ЦОС), но неискушённому пользователю совершенно не понятно, зачем всё это нужно и где, а главное как это применить.
Думаете, я сошел с ума? Я уже сталкивался с такой реакцией, когда впервые предложил развертывать кластеры Kubernetes с помощью Kubernetes.
Но я ... | https://habr.com/ru/post/562188/ | null | ru | null |
# Совместный доступ к Spark-датасетам из разных приложений — Redis нам в помощь
[Apache Spark](https://spark.apache.org/), универсальная платформа для крупномасштабной обработки данных, в сочетании с [Redis](https://github.com/RedisLabs/spark-redis) способна обеспечить ускоренные расчеты в реальном времени для таких з... | https://habr.com/ru/post/703136/ | null | ru | null |
# Автоопределение кодировки текста

Введение
--------
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то... | https://habr.com/ru/post/483166/ | null | ru | null |
# Quattro Wireless приходит конец
Я имею некоторый опыт разработки под Android. Как и многие разработчики из нашей необъятной родины, я не имел возможности публиковать платные приложения. После недолгих раздумий я решил вставить рекламу, а в качестве поставщика выбрал Quattro Wireless. Все было хорошо, но вот сегодня ... | https://habr.com/ru/post/102289/ | null | ru | null |
# Flutter и настольные приложения
Ни для кого не секрет то, что команда разработчиков Flutter стремится к тому, чтобы этот фреймворк позволял бы, пользуясь единой кодовой базой, создавать приложения для широкого разнообразия платформ. Сюда входят iOS, Android, Windows, Linux, macOS и веб. При этом такие приложения дол... | https://habr.com/ru/post/508128/ | null | ru | null |
# Драйвер виртуальных GPIO с контроллером прерываний на базе QEMU ivshmem для Linux

Трудно недооценить роль **GPIO**, особенно в мире встраиваемых систем ARM. Помимо того, что это крайне популярный матери... | https://habr.com/ru/post/303060/ | null | ru | null |
# λ-исчисление. Часть первая: история и теория
*Идею, короткий план и ссылки на основные источники для этой статьи мне подал хабраюзер [z6Dabrata](https://habrahabr.ru/users/z6dabrata/), за что ему огромнейшее спасибо.*
*UPD: в текст внесены некоторые изменения с целью сделать его более понятным. Смысловая составля... | https://habr.com/ru/post/215807/ | null | ru | null |
# Пример создания практичной Debug панели в Yii
Написать свою Debug-панель в Yii очень просто. Поэтому рассмотрим чуть практичную (с вызовом api PHPStorm) панель просмотра вьюшек.
Есть подробно разжеванная документация, c примером вывода списка вьюшек. Давайте ее приведем в более практичный вид.
1. Уберем дублик... | https://habr.com/ru/post/317562/ | null | ru | null |
# Yii 2.0.13
Состоялся релиз PHP фреймворка Yii версии 2.0.13. В него вошли более [90 улучшений и исправлений](https://github.com/yiisoft/yii2/blob/2.0.13/framework/CHANGELOG.md).
Обратите внимание, что в релиз попали изменения, которые могут повлиять на существующие приложения. Они описаны в [UPGRADE.md](https://git... | https://habr.com/ru/post/341614/ | null | ru | null |
# Сила дженериков в Swift. Часть 2
Добрый день, друзья. Специально для студентов курса [«iOS Разработчик. Продвинутый курс»](https://otus.pw/g6Xn/) мы подготовили перевод второй части статьи «Сила дженериков в Swift».

---
*Связа... | https://habr.com/ru/post/463789/ | null | ru | null |
# Как устроен ReactJS. Пакет React
Большинство людей, работающих во фронтенде, так или иначе сталкивались с реактом. Это JavaScript библиотека, помогающая создавать крутые интерфейсы, в последние годы набрала огромную популярность. При этом, не так много людей знает, как она работает внутри.
В этой серии статей мы по... | https://habr.com/ru/post/448122/ | null | ru | null |
# Недокументированные возможности оптического терминала ZTE ZXHN F660 от МГТС
По результатам собственных изысканий родилась идея набросать небольшой Q&A по работе с некоторыми недокументированными функциями оптического терминала ZTE ZXHN F660, устанавливаемого сейчас в квартиры фирмой МГТС.
 случилось невероятное — в [MongoDB](https://www.mongodb.com/) завезли честные [ACID транзакции](https://ru.wikipedia.org/wiki/ACID). С выходом четвёртой версии этой документ-ориентированной [СУБД](http... | https://habr.com/ru/post/417131/ | null | ru | null |
# [Видео] Доклады с митапа Android Paranoid
Android почти исполнилось десять лет.
Мы решили отметить это праздничным чаепитием со всеми, кто пришел в питерский офис Яндекса на второй митап Android Paranoid. Сказано — сделано. К нашему сожалению, маршмеллоу, шоколадное печенье и желейные бобы закончились еще 28 мар... | https://habr.com/ru/post/353370/ | null | ru | null |
# RESTinio — это асинхронный HTTP-сервер. Простой пример из практики: отдача большого объема данных в ответ

Недавно мне довелось поработать над приложением, которое должно было контролировать скорость своих исходящих подключений. На... | https://habr.com/ru/post/462349/ | null | ru | null |
# Запуск Hiri в Arch Linux через Docker
Что делать, если у вас не совсем такой Linux, как у создателя нужной вам софтины, а использовать виртуалку слишком накладно? Использовать Docker! А если это графическое приложение? Ответ такой же — использовать Docker!
В виду того, что на новой работе для обмена почтой исполь... | https://habr.com/ru/post/402781/ | null | ru | null |
# Django Gmap v3 Widget — геолокация с поиском, сохранение координат и адреса в JSONField
Привет. Была поставлена задача реализовать геолокацию (google maps v3) для пользователей в одном из проектов на django, хочу поделиться своим решением.
##### Необходимый функционал:
1. Вывод карты с маркером текущего положени... | https://habr.com/ru/post/141444/ | null | ru | null |
# ESP 8266: отправка данных на сайт методом Get запроса
Привет! Это мой первый пост здесь! Решил его написать, чтобы облегчить путь всем начинающим знакомство с ESP 8266.
Итак, у нас есть ESP-01.
И USB-UA... | https://habr.com/ru/post/543532/ | null | ru | null |
# Как в Datalake объединить слишком большое количество небольших файлов в несколько больших с помощью Apache Spark
Повышаем производительность ваших запросов чтения на больших датасетах
----------------------... | https://habr.com/ru/post/572522/ | null | ru | null |
# Уязвимость в Kohana?
Вчера наш портал, написанный на Kohana, подвергся успешной атаке. Мысль, что грешить надо именно на уважаемый фреймворк, безопасность в котором далеко не на последнем месте, сначала даже не обсуждалась. Программке, которой сканировали наш сайт, потребовалось порядка 95 тысяч запросов и 5 часов в... | https://habr.com/ru/post/150201/ | null | ru | null |
# Google Talk: борьба с глобальным потеплением
Ребята из Google заботятся об окружающей среде. Они подсчитали, что каждый символ, отсылаемый через Google Talk приводит к выбросу в атмосферу около 0.0000000000000000034 тонн углекислого газа (CO2). Поэтому, отныне и впредь, Google Talk будет конвертировать все наши сооб... | https://habr.com/ru/post/22694/ | null | ru | null |
# Новый облегчённый язык разметки текста на основе парных кавычек (pq)
Я не могу объяснить, откуда пришла идея такого языка разметки, но то, что получилось в итоге — весьма… занятно.
Не слишком-то рассчитываю на широкое практическое применение этой штуки, но некоторые идеи, использованные в этом языке разметки, впо... | https://habr.com/ru/post/348218/ | null | ru | null |
# Оживляем гексапода. Часть вторая
### Видео двигающегося гексапода
В сравнении с [предыдущей публикацией](https://habr.com/ru/post/488810/) ее [предшественница](https://habr.com/ru/post/485856/) получилась более зрелищная, благодаря большому количеству фотографий. Хочется заполнить пробел в этом вопросе и представит... | https://habr.com/ru/post/489672/ | null | ru | null |
# Как оставаться программистом, если у тебя память как у дрозофилы
Мой мадригал тем инструментам разработки, которые изменили мою жизнь
Программирование: срез за много лет
-----------------------------------
Программирование стало гораздо более многогранным ремеслом с тех пор, как в середине 1990-х я впервые попробо... | https://habr.com/ru/post/691908/ | null | ru | null |
# ReactJS in a nutshell. Часть 1
Добрый день, уважаемые читатели.
 В последнее время на Хабре всё чаще упоминается такой замечательный фреймворк, как [React.js](http://facebook.github.io/react/). Я работаю ... | https://habr.com/ru/post/222573/ | null | ru | null |
# Рассказ о том, почему в 2021 году лучше выбирать TypeScript, а не JavaScript
Недавно я, используя React Native, занимался разработкой мобильного приложения для медитации [Atomic Meditation](https://play.google.com/store/apps/details?id=com.doabledanny.atomicmeditation). Эта программа помогает тем, кто ей пользуется,... | https://habr.com/ru/post/556162/ | null | ru | null |
# Знакомимся с Javassist
Часть первая
------------
Всем большой привет! Перед началом стоит сказать, что библиотека Javassist довольно мощный инструмент, так как стирает почти все границы у того безграничного языка JAVA, позволяя разработчику осуществлять манипуляции связанные с байткодом.
Конечно, получив доступ к ... | https://habr.com/ru/post/664818/ | null | ru | null |
# Гайд для новичков. Как восстановить данные с iSCSI LUN диска QNAP TS-412
В этой статье для новичков, мы обсудим как вернуть данные со iSCSI LUN на примере устройства QNAP TS-412. Как восстановить сетевой диск или достать данные с поврежденного сетевого устройства.
. Сразу оговорюсь: что **работоспособность данной реализация напрямую зависит от типа NAT используемого Вашим провайдером, а также роутером**.
Итак, возникла у меня не... | https://habr.com/ru/post/482888/ | null | ru | null |
# Экстремальное программирование, знакомство с Behavior Driven Development и RSpec
#### Теория
Для начала, давайте разберемся, что же такое Behavior Driven Development(в дальнейшем BDD) и чем данная техника отличается от Test-Driven Development(в дальнейшем TDD)
Разрабо́тка че́рез тести́рование (англ. test-driven ... | https://habr.com/ru/post/52929/ | null | ru | null |
# Разбор задач Hacker Cup Qualification Round + перенос Facebook Hacker Cup Online Round I
Facebook Hacker Cup 2011 проходит в 4 раунда — квалификационный, два онлайн раунда и финальный, в главном офисе.
Квалификационный раунд, анонсированный [официально](http://www.facebook.com/hackercup "Официально") [Хабром](htt... | https://habr.com/ru/post/111898/ | null | ru | null |
# E2E-тестирование подключения по WalletConnect между DApp и мобильным приложением Metamask
Тестирование приложений через сквозные (end-to-end) тесты сейчас довольно популярно. Этот вид тестирования позволяет оценить работоспособность приложения со стороны пользователя. Поэтому компания, в которой я работаю, внедряет ... | https://habr.com/ru/post/693566/ | null | ru | null |
# 15 странностей в Ruby, о которых вам стоит знать
Ruby — замечательный язык со множеством интересных деталей, которые вы могли раньше и не видеть.
В этом посте я собрал несколько таких деталей в список.
1. Heredoc + Метод
------------------
Если у вас есть какие-то текстовые данные, которые вы хотите встроить ... | https://habr.com/ru/post/322508/ | null | ru | null |
# Ещё один способ использования python в браузере (и не только)
Предыстория
-----------
Весной 2020 года я впервые попробовал себя в разработке сайтов бэкенд я писал на питоне, а на фронте пришлось использовать js, и он вызвал у меня отторжение(тут надо уточнить, что я не считаю js ужасным языком, просто он мне не по... | https://habr.com/ru/post/535934/ | null | ru | null |
# добрый будильник на python
Прочитав статью на хабрахабре про [добрый будильник](http://habrahabr.ru/blogs/arbeit/72091/), решил попробовать на себе, и действительно, с ним просыпаться намного приятнее.
Основной принцип выражается в трех тезисах:
* звук будильника должен плавно увеличиваться
* Под музыку просып... | https://habr.com/ru/post/73444/ | null | ru | null |
# Новости из мира OpenStreetMap № 505 (17.03.2020-23.03.2020)
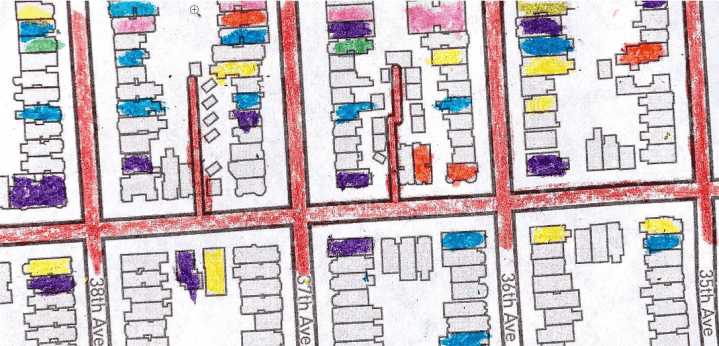
Детская раскраска с картами от Мэдисона Дрейпера [1](#wn505_22177) | map data OpenStreetMap contributors
Картографирование
---------... | https://habr.com/ru/post/495706/ | null | ru | null |
# А ваш CDN умеет так?

*Изображение взято с сайта [www.aerotime.aero](https://www.aerotime.aero/)*
Всем привет, меня зовут Семён, я руковожу разработкой партнёрских сервисов в ДомКлике. Недавно, работая над оптимизацией загрузки ... | https://habr.com/ru/post/521634/ | null | ru | null |
# Как заставить работать расширения yii-user и rights совместно?
Предисловие
-----------
Доброе время суток хабравчане.
Для начала представлюсь. Меня зовут Роман, и я занимаюсь разработкой сайтов (в основном на [php-фреймворке «yii»](http://www.yiiframework.com/ "Yii framework"), но проскакивают и другие php\pytho... | https://habr.com/ru/post/127052/ | null | ru | null |
# День рождения Perl и лучшие решения Golf от Moscow.pm
Сегодня [исполняется 27 лет](http://habrahabr.ru/post/245659/) со «дня рождения» одного из самых популярных на сегодня языков программирования — Perl. На нём создано несм... | https://habr.com/ru/post/246117/ | null | ru | null |
# Tutorial: how to port a project from Interop Word API to Open XML SDK
With the .NET5 release further development of some projects was questionable due to the complexity of porting. One can abandon small outdated libraries or find a replacement. But it's hard to throw away Microsoft.Office.Interop.Word.dll. Microsoft... | https://habr.com/ru/post/573860/ | null | en | null |
# Еще один беспроводной датчик температуры и влажности. Z-Wave плата Z-Uno + Sensirion SHT20
Как положено порядочному гигу у меня есть метеостанция, которую я собрал сам из DHT22, Raspberry Pi и экранчика Nokia, это решение на постоянном питании, передающее данные по Ethernet.
Но теперь мне понадобилась мобильная м... | https://habr.com/ru/post/404417/ | null | ru | null |
# Вышел финальный релиз PHP 5.6.0

Сегодня, 28 августа, команда разработчиков PHP [объявила](http://php.net/archive/2014.php#id2014-08-28-1) об релизе версии 5.6.0!
**Основные нововведения PHP 5.6.0:**
* [Скалярные вы... | https://habr.com/ru/post/234899/ | null | ru | null |
# Доверять Джини или нет: вот в чем вопрос
Коэффициент Джини (или индекс Джини), кривая Лоренца, TPR (true positive rate) и FPR (false positive rate) – одни из самых популярных атрибутов экономических задач, ... | https://habr.com/ru/post/654907/ | null | ru | null |
# Производительность Raspberry Pi: добавляем ZRAM и изменяем параметры ядра
Пару недель назад я опубликовал [обзор Pinebook Pro](https://haydenjames.io/pinebook-pro-my-first-impressions-and-setup-tips/). Поскольку Raspberry Pi 4 тоже основана на ARM, то для неё вполне подходят некоторые из оптимизаций, упомянутых в пр... | https://habr.com/ru/post/504468/ | null | ru | null |
# Как не пересчитывать суммы и средние каждый раз
Представим, что у нас электронная платёжная система, а в ней в базе данных таблица операций. И мы хотим посчитать, например, какого размера средняя операция. Легко, вот запрос, только долго выполняется:
`> SELECT avg(amount) FROM transfer;
65.125965782378
gene... | https://habr.com/ru/post/139622/ | null | ru | null |
# TypeScript: разрабатываем WebAssembly-компилятор

Привет, друзья!
Представляю вашему вниманию перевод [этой замечательной статьи](https://blog.scottlogic.com/2019/05/17/webassembly-compiler.html), в которой автор рассказывает о то... | https://habr.com/ru/post/660607/ | null | ru | null |
# Проброс USB в виртуалку по сети средствами UsbRedir и QEMU

На сегодняшний день существет довольно много способов пробросить USB-устройство на другой компьютер или виртуалку по сети.
Из наиболее популярных — железячные ... | https://habr.com/ru/post/265065/ | null | ru | null |
# У дизайнера новая идея? Что может быть проще
Привет, *хабровчанин!* Дизайнеры люди идейные, а заказчики с их бизнес-требованиями, тем более.
Представь, что ты сваял свой самый лучший UIkit на свете на самом крутом %вставить свое% JS фреймворке. Казалось бы, там есть все, что нужно проекту. Теперь-то ты сможешь п... | https://habr.com/ru/post/438834/ | null | ru | null |
# Удалённый мониторинг датчиков: разные типы связи в зависимости от расстояния

*Картинка [Wallpapersafari](https://img.wallpapersafari.com/desktop/1920/1080/53/80/8UC7qH.jpg)*
С каждым днём количество подключённых к интерн... | https://habr.com/ru/post/674884/ | null | ru | null |
# Анонимные функции в Swift
Эта публикация является конспектом соответствующего раздела замечательной книги [«iOS 8 Programming Fundamentals with Swift»](http://shop.oreilly.com/product/0636920034278.do) Matt Neuburg, O'Reilly, 2015. Статья, описывающая использование анонимных функций, может быть интересной новичкам и... | https://habr.com/ru/post/256127/ | null | ru | null |
# Почти-web-сервер своими руками
В последнее время появилось несколько постов по привлечению внимания к определённым языкам программирования на примере написания некоего несложного «web-сервера». Раз уж пошла такая пьянка perl пока не затронули, то добавлю и свои пять копеек :)
Будем писать несложное серверное прил... | https://habr.com/ru/post/69411/ | null | ru | null |
# Анонс React Native

Не так давно в Калифронии прошла [конференция по React.js](http://conf.reactjs.com/) (доклады с этой конференции уже размещены [на канале facebook разработчиков в youtube](https://www.youtube.com/chann... | https://habr.com/ru/post/249393/ | null | ru | null |
# Восемь причин перейти на новый API Яндекс.Кассы
В октябре 2017 года у Яндекс.Кассы появились новый платёжный протокол и третья версия API. Мы уже [рассказывали](https://habr.com/ru/company/yamoney/blog/340210/) о том, как и почему к этому пришли, а сейчас напомним ключевые причины перейти на него для тех, кто этого ... | https://habr.com/ru/post/453174/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.