
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Блоки. Внутреннее устройство файла базы данных Caché. Часть 2
Эта публикация – продолжение моей [статьи](http://habrahabr.ru/company/intersystems/blog/267951/), в которой я рассказал, как устроена база данных Caché изнутри. В ней я описал типы блоков, как они связаны, какое отношение имеют к глобалам. В той статье б... | https://habr.com/ru/post/268195/ | null | ru | null |
# Пагинатор (постраничная навигация) на XSLT
Время от времени всплывает умирающая технология XSLT и задаёт непростые вопросы. Как, например, взять максимум от 2 чисел в выражении или как организовать цикл. Соединением многих таких вопросов служит пагинатор — вывод навигации по нескольким страницам и, по возможности, у... | https://habr.com/ru/post/174977/ | null | ru | null |
# Другая реализация метафункции is_function<T> для C++98/03
Это небольшой отчет о том, как я решил написать метафункцию is\_function для С++98/03, таким образом, чтобы не нужно было создавать множество специализаций для разного количества аргументов.
Зачем, спросите вы, в 2016 году вообще подобным заниматься? Я... | https://habr.com/ru/post/277727/ | null | ru | null |
# Инстанциирование шаблонов функций по списку типов (Часть 1)
Случалось ли Вам писать шаблон функции, который должен быть инстанциирован для определённого набора типов и больше ни для чего? Если нет, то эта статья врядли покажется Вам интересной. Но если Вы всё ещё здесь, то тогда начнём.
Cтатья будет состоять из д... | https://habr.com/ru/post/235831/ | null | ru | null |
# БД мессенджера (ч.1): проектируем каркас базы
Как можно перевести бизнес-требования в конкретные структуры данных на примере проектирования «с нуля» базы для мессенджера.
* Часть 1: проектируем каркас базы
* [Часть 2: секционируем «наживую»](https://habr.com/ru/post/483170/)

В предыдущем посте я рассказал про то, как настроить и использовать php телеграм клиент madelineProto для парсинга постов. Но при использовании библиотеки я сто... | https://habr.com/ru/post/354000/ | null | ru | null |
# Почему принципы SOLID не являются надежным решением для разработки программного обеспечения
Фото от https://uns... | https://habr.com/ru/post/555862/ | null | ru | null |
# Проверяем исходный код WPF Samples от Microsoft
С целью популяризации анализатора кода PVS-Studio, который научился проверять помимо C++, ещё и C# проекты, мы решили проверить исходный код WPF примеров, предлагаемых компанией Microsoft.

Сегодня вышла финальная версия инструментов для разработчика [Opera Dragonfly 1.0](http://www.opera.com/dragonfly/), встроенных в браузер Opera. Открыть их проще простого: просто нажмите **Ctrl + Shift + I** ... | https://habr.com/ru/post/118735/ | null | ru | null |
# Автоверстка и стили в Unity: наш новый пайплайн и инструменты для UI
Начну с главного: мы сделали удобный инструмент для верстки и изменили пайплайн работы. Теперь по порядку.
В мобильных играх много разных интерфейсов, включая HUD и ... | https://habr.com/ru/post/462835/ | null | ru | null |
# Дистанционный съем показаний со счетчиков
При разработке домашней автоматизации ("умного дома") рано или поздно возникает задача дистанционного съема показаний с бытовых приборов учета (БПУ) электроэнергии, воды, тепла, газа. Если в БПУ нет специального интерфейса для считывания показаний, то такая задача решается с... | https://habr.com/ru/post/568314/ | null | ru | null |
# Асинхронные задачи в С++11
Доброго времени суток, хотел бы поделиться с сообществом своей небольшой библиотектой.
Я программирую на С/C++, и, к сожалению, в рабочих проектах не могу использовать стандарт C++11. Но вот пришли майские праздники, появилось свободное время и я решил поэкспериментировать и по-изучать ... | https://habr.com/ru/post/222227/ | null | ru | null |
# Создание меню с помощью программы FLProg

Добрый день. В программе FLProg начиная с версии 2.1. появились блоки конструктора меню. В данном уроке будет рассмотрено создание меню с помощью данных блоков.
Для того что бы было ин... | https://habr.com/ru/post/399097/ | null | ru | null |
# В PHP 5.5 возможно появится Finally
Не так давно, Никита Попов, один из активистов движения «ЗА PHP», опубликовал в своём твиттере сообщение:
> It very much looks like PHP 5.5 will have `finally` [t.co/Dy93CZaR](https://t.co/Dy93CZaR)
(Оригинал тут [twitter.com/nikita\_ppv/status/232930291625369600](https://twit... | https://habr.com/ru/post/149314/ | null | ru | null |
# Классический сапёр на html5 и LibCanvas

В этой статье я пошагово расскажу, как писать самый обычный, классический сапёр при помощи Html5 Canvas, AtomJS, и тайлового движка LibCanvas.
А также смотрите продолжение — "... | https://habr.com/ru/post/168435/ | null | ru | null |
# 3D-фотографии Facebook изнутри: шейдеры параллакса

В последние несколько месяцев Facebook заполонили **3D-фотографии**. Если вам не довелось их увидеть, то объясню: 3D-фотографии — это изображения внутри по... | https://habr.com/ru/post/444706/ | null | ru | null |
# Стандарт C++20: обзор новых возможностей C++. Часть 2 «Операция ''Космический Корабль''»

25 февраля автор курса [«Разработчик C++»](https://praktikum.yandex.ru/cpp?utm_source=pr&utm_medium=content&utm_content=5_05_21&utm_campaign=... | https://habr.com/ru/post/555704/ | null | ru | null |
# Почему в Ember не нужны React-хуки
*От переводчика: Этот пост является продолжением* [*поста о реализация паттернов React-компонентов в Ember.js*](https://habr.com/ru/post/583436/)*. Автор рассматривает концепцию React-хуков для абстракции логики состояния (stateful logic) и сравнивает ее реализацию с реализацией в ... | https://habr.com/ru/post/583950/ | null | ru | null |
# Вычисление N-го знака числа Пи без вычисления предыдущих
С недавних пор существует элегантная формула для вычисления числа Пи, которую в 1995 году впервые опубликовали Дэвид Бэйли, Питер Борвайн и Саймон Плафф:

Продолжаем нашу серию статей про то, как влезть во внутренности игровых движков и вытаскивать из них всевозможное содержимое. Для тех, кто к нам только что присоединился, коротко... | https://habr.com/ru/post/309414/ | null | ru | null |
# Одноплатный компьютер для embedded программиста. Моргаем светодиодом на Qt
Введение
--------
Цель - моргать светодиодом на GPIO одноплатного компьютера в своём Qt проекте.
Первое, что приходит в голову - использовать готовое решение, такое как [wiringOP](https://github.com/orangepi-xunlong/wiringOP). Однако для м... | https://habr.com/ru/post/551342/ | null | ru | null |
# Автоматическое управление паролями в Active Directory
*Однажды мне всё это надоело…*
Вероятно, в большинстве случаев именно с этой фразы начинается творчество системных администраторов. В результате мы видим (хотя, правильнее сказать, даже и не замечаем) появление множества маленьких программ, которые выполняют с... | https://habr.com/ru/post/255197/ | null | ru | null |
# Пишем сериализатор для сетевой игры на C++11
Написать этот пост меня вдохновила замечательная [статья в блоге Gaffer on Games «Reading and Writing Packets»](http://gafferongames.com/building-a-game-network-protocol/reading-an... | https://habr.com/ru/post/303368/ | null | ru | null |
# Красота Go

[Gopher](https://blog.golang.org/gopher) — талисман Go
Некоторое время назад я начал изучать возможность использования Go в некоторых своих сторонних проектах и был просто поражен красотой этого языка программирования.
Д... | https://habr.com/ru/post/341302/ | null | ru | null |
# Немного о пустых интерфейсах. Быстрый взгляд изнутри
Всем привет!
**Warning:** статья не принесет ничего нового для профи, но будет полезна новичкам.
Если вы это читаете, значит ~~я уже мертв~~ вы, как минимум, интересуетесь языком Go. Следовательно, знаете, о такой вещи, как interface{}. А что будет, если я ... | https://habr.com/ru/post/315260/ | null | ru | null |
# От Web до Desktop за 2 недели: технология Electron на практике
Если у вас есть компьютер и вы используете его по назначению, то скорее всего вы так или иначе работали с приложениями на Electron (даже если ... | https://habr.com/ru/post/689980/ | null | ru | null |
# Слежка на экзаменах: программа ExamCookie
Мне стало известно, что датское правительство не просто [приостановило действие](https://www.version2.dk/artikel/digitale-proevevagt-totalovervaagning-elevers-computere-midlertidigt-trukket-tilbage-1087609) программы Digital Exam Monitor, которую мы проанализировали и полнос... | https://habr.com/ru/post/453536/ | null | ru | null |
# JQuery tooltip widget
Доброго времени суток.
Решил опубликовать пост, который принес инвайт.
Недавно закончил работу над виджетом для JS библиотеке [JQuery](http://jquery.com/). Конечно на данный момент есть аналоги, и даже некоторые приведены здесь. Но во всех реализациях есть определенные недостатки и недод... | https://habr.com/ru/post/76246/ | null | ru | null |
# Автономная работа frontend (заглушка, proxy_store, use_stale)
#### Введение
Технические работы неожиданно случаются у всех проектов и площадок — избежать нельзя, можно только подготовиться. В этом обзоре собран наш опыт перевода front фермы на автономный режим работы — без хранилища и backend.
* заглушка
* proxy... | https://habr.com/ru/post/162949/ | null | ru | null |
# Отчёты для NORD POS. Часть 1
### Берём данные, JasperReports и заполняем шаблон в iReport

Эта статья посвящена не столько, как это сделать красиво с точки зрения дизайна, а как с помощью имеющихся средств [JasperReports]... | https://habr.com/ru/post/247515/ | null | ru | null |
# Разработка web API
#### Интро
Это краткий перевод основных тезисов из брошюры «Web API Design. Crafting Interfaces that Developers Love» Брайана Маллоя из компании Apigee Labs. Apigee занимается разработкой различных API-сервисов и консталтингом. Кстати, среди клиентов этой компании засветились такие гиганты, как B... | https://habr.com/ru/post/181988/ | null | ru | null |
# Вейвлет — анализ.Часть 1
### Введение
Рассмотрим дискретное вейвлет – преобразования (DWT), реализованное в библиотеке PyWavelets [PyWavelets 1.0.3](https://pywavelets.readthedocs.io/en/latest/ref/signal-extension-modes.html#modes). PyWavelets — это бесплатное программное обеспечение с открытым исходным кодом, выпу... | https://habr.com/ru/post/451278/ | null | ru | null |
# Формирование Excel-документов средствами PHP
Возможность создания Excel-документов [в общих чертах уже была описана на Хабре](http://habrahabr.ru/blogs/php/31149/), но полной информации из этих статей мне получить не удалось. Пришлось заняться собственными изысканиями, результатами которых я хотел бы с Вами поделить... | https://habr.com/ru/post/55800/ | null | ru | null |
# Навигатор для проекта: MS Project + формулы + индикаторы
#### План – это не идеальная картина, а навигация по проекту
Почему когда вы едете на машине и попадаете в только что возникшую пробку, то ваш навигатор пересчитывает маршрут и время движения по нему, а управляя проектом, вы отказываетесь от такого полезного ... | https://habr.com/ru/post/218885/ | null | ru | null |
# Rust + CLion = Любовь

Привет, Хабр! В общем как я обещал вот рассказ о том как CLion в качестве IDE для Rust на MacOS использовать. Почему не IntelliJ IDEA? Потому что CLion может дебажить. Почему LLDB, а не GDB? Потому что LLDB у... | https://habr.com/ru/post/448820/ | null | ru | null |
# Как ваш браузер обрабатывает прикосновения к экрану телефона (js touch events)
→ [Ссылка на github](https://github.com/fakt309/imager)
### Вступление
Недавно я писал компонент для React минималистичной галереи картинок. Чтобы мой компонент обрабатывал всеми привычные touch события (такие как свайп влево/вправо, дл... | https://habr.com/ru/post/592317/ | null | ru | null |
# Реализация метода Куттера-Джордана-Боссена в MATLAB
##### Введение
Доброго времени суток, пользователи Хабра!
В этой статье речь пойдет о программной реализации стеганографического метода Куттера-Джордана-Боссена в MATLAB.
Для тех, кто не знает, поясню: стеганография — это наука о скрытой передаче информаци... | https://habr.com/ru/post/230747/ | null | ru | null |
# MASK-RCNN для поиска крыш по снимкам с беспилотников

В белом-белом городе на белой-белой улице стояли белые-белые дома… А как быстро вы можете найти все крыши домов на этой фотографии?
Все чаще можно ... | https://habr.com/ru/post/500752/ | null | ru | null |
# 256 строчек голого C++: пишем трассировщик лучей с нуля за несколько часов
Публикую очередную главу из моего [курса лекций по компьютерной графике](https://github.com/ssloy/tinyrenderer/wiki) (вот [тут можно читать](https://habr.com/ru/post/249139/) оригинал на русском, хотя английская версия новее). На сей раз тема... | https://habr.com/ru/post/436790/ | null | ru | null |
# Корзинка с сюрпризами — cпасите наши push'и
TLDR: Сделал [набор скриптов](https://github.com/lebedevsergey/BitbucketMercurialMigration) автоматизации миграции Bitbucket репозиториев с Mercurial на Git.
В один непрекрасный день мой любимый хостинг репозиториев Bitbucket [объявил](https://bitbucket.org/blog/sunsett... | https://habr.com/ru/post/488038/ | null | ru | null |
# Чудеса тригонометрии с использованием canvas
Давно хотел начать изучение HTML5 canvas, и наконец решительно за него взялся. Первое что я решил попробовать это отображение различных фигур с помощью стандартных линий в «псевдо 3D». Когда-то давно я подсмотрел очень интересный способ в плагине к winamp'у и решил реализ... | https://habr.com/ru/post/142720/ | null | ru | null |
# Простое обнаружение объектов по цвету
Доброго времени суток.
В этом коротком посте хотел показать простой способ поиска объектов по цвету с [OpenCV](https://ru.wikipedia.org/wiki/OpenCV).
Для экспериментов использовал камеру Logitech WebCam C270
**Итак начнем**
Подключаем всё нужное
```
#include
#inc... | https://habr.com/ru/post/245139/ | null | ru | null |
# Анимация перехода от глобуса к двумерной карте
Хочу поделиться с хабром своим картографическим экспериментом, а именно анимацией перехода от [Ортографической](https://en.wikipedia.org/wiki/Orthographic_projection_(cartography) "Orthographic projection") проекции (глобус) к [Равнопромежуточной](https://en.wikipedia.o... | https://habr.com/ru/post/198300/ | null | ru | null |
# Разработка REST API-сервиса на платформе WSO2
В [прошлой статье](https://habr.com/ru/company/rosbank/blog/578468/) мы рассказывали, как у нас в банке работает платформа WSO2. Мы предоставляем ее как сервис, как интеграционный слой, следим за его стабильностью, а разработкой на платформе занимаются уже команды из под... | https://habr.com/ru/post/592805/ | null | ru | null |
# Опытные мелочи Windows-админа
Всегда имел желание написать цикл постов, где был бы понемногу изложены разные интересные мелочи и задачи, которые приходилось решать в повседневной рутине системного администратора.
Возможно, кое-что из описанного будет полезно другим сисадминам.
Сразу оговорюсь, что в качестве и... | https://habr.com/ru/post/121801/ | null | ru | null |
# Vue.js: Хуки жизненного цикла ваших и сторонних компонентов

Lifecycle hooks (Хуки жизненного цикла) — это очень важная часть любого компонента. Нам, нашему приложению, часто нужно знать что происходит с компонентом, когда он соз... | https://habr.com/ru/post/482030/ | null | ru | null |
# Тестирование GWT приложений архитектуры MVP
Добрый день!
В этой статье я рассмотрю unit/integration тестирование в GWT с использованием UI компонентов GWT и GXT и MVP (с Passive View) архитектуры для разделения логики и внешнего вида приложения.
GWT и GXT здесь выделены не случайно — Google разработал нескольк... | https://habr.com/ru/post/246285/ | null | ru | null |
# Рецепт приготовления Xubuntu, или нетбук для супруги
С момента написания статьи вышли новые версии Xubuntu. Статья устарела. Писал, в основном, для собственной памяти и актуальность поддерживаю там где удобнее. [Актуальный вариант](http://cleaner-lab.blogspot.com/2011/10/xubuntu-1110.html) и [продолжение темы](http:... | https://habr.com/ru/post/130763/ | null | ru | null |
# Безопасно рисуем иконки в ПЗУ и ловим UB в C++ коде на IAR компиляторе
Доброго времени суток хабровчане. Давненько я не писал, был довольно сильно занят семьей, начались тренировки и нужно каждый день возить детей. Но вот наконец-то есть время чтобы немного вспомнить про разработку ПО.
Сегодня будем выводить иконку... | https://habr.com/ru/post/593347/ | null | ru | null |
# Установка и начала использования библиотеки MPI
Иногда необходимо запустить приложение на нескольких машинах (или процессорах), чтобы улучшить производительность (т.е. уменьшить время выполнения). Можно создать компьютерную сеть для последующего запуска приложения распределённо по всем узлам. При разработке такого п... | https://habr.com/ru/post/47795/ | null | ru | null |
# Просто о Прологе
Привет, трудящиеся. Не буду надолго задерживать ваше внимание объяснением декларативного подхода, попробую предложить решить еще одну задачку используя язык логического программирования, как вариант декларативного взгляда на формулировку проблем и их решений.
Задача 391. [Perfect Rectangle](https:/... | https://habr.com/ru/post/450466/ | null | ru | null |
# Поэтический дискурс с привкусом реверс-инжиниринга
*«Старик Ассемблер нас заметил,
И в гроб сходя, благословил»*

Однажды я решил написать программу, сочиняющую стихи. Алгоритм придумался быстро – в конце сочиняе... | https://habr.com/ru/post/323034/ | null | ru | null |
# Производство Material иконок для MacOSX приложения Home Assistant на Electron
В [первой серии](https://habr.com/ru/post/496856/) я заварил умный дом на Home Assistant. В процессе я влюбился в Home Assistant и подумал, не написать ли десктопное приложение для этой системы. У Home Assitant есть прекрасный web-интерфей... | https://habr.com/ru/post/497880/ | null | ru | null |
# Gnuplot и с чем его едят
[](https://habr.com/ru/company/ruvds/blog/517450/)
Наверняка многие из вас листая западные научные издания видели красивые и простые графики. Возможно некоторые из вас задумывались в чём же эти учёные мужи ... | https://habr.com/ru/post/517450/ | null | ru | null |
# React: разработка реального приложения с помощью React Query

Привет, друзья!
Представляю вашему вниманию перевод [этой замечательной статьи](https://www.smashingmagazine.com/2022/01/building-real-app-react-query/), в которой расс... | https://habr.com/ru/post/702876/ | null | ru | null |
# Трояны и бэкдоры в кнопочных мобильных телефонах российской розницы
**TL;DR:** немалое количество простых кнопочных телефонов, присутствующих в российских магазинах, содержат нежелательные недокументированные функции. Они могут совершать автоматическую отправку СМС-сообщений или выходить в интернет для передачи факт... | https://habr.com/ru/post/575626/ | null | ru | null |
# Симулятор электронных схем Qucs-S снова жив
Qucs-S является программой с открытым исходным кодом для моделирования электронных схем. Qucs-S кроссплатформенный (поддерживаются Linux, Windows и FreeBSD), написан на С++ с использованием набора библиотек Qt и разрабатывается полностью в частном порядке (в отличие, напри... | https://habr.com/ru/post/678526/ | null | ru | null |
# Использование контролёров для того, чтобы удержать ErlyBank на плаву
Это четвертая статья в [серии «Введение в ОТП»](http://habrahabr.ru/tag/otp%20introduction/). Если вы только что присоединились к нам, рекомендую [начать с первой части](http://habrahabr.ru/blogs/erlang/55708/), в которой говорится о gen\_server и ... | https://habr.com/ru/post/129277/ | null | ru | null |
# Sphinx для ASP.NET через jTemplates

Есть у нас хобби — развивать интернет-магазин по продаже напитков и продуктов оптом.
Товары у нас появляются путем привлечения поставщиков и размещения их товаров в... | https://habr.com/ru/post/208236/ | null | ru | null |
# Полнотекстовый поиск в Grails
Подключить полнотекстовый поиск в [Grails](http://grails.org/) — задача довольно легкая. Для этого используется плагин [Searchable](http://www.grails.org/plugin/searchable), который делает все сущности Grails-приложения индексируемыми. Searchable позволяет абстрагировать весь процесс ин... | https://habr.com/ru/post/114363/ | null | ru | null |
# Ускоряем pow
В этой статье я хочу поделиться несколькими нестандартными алгоритмами для быстрого возведения числа в степень, а также продемонстрировать их реализацию и сравнить их быстродействие в C++, C# и Java.
, притом в первую очередь под Windows.
Последний раз модуль для питона на C++ я писал в 2004 году. Модуль к мертворожденной (... | https://habr.com/ru/post/139790/ | null | ru | null |
# Saga: проверяем покрытие кода тестами
Если вы пишете на javascript и покрываете код юнит-тестами, то, вполне вероятно, вам будет интересно насколько хорошо он покрыт. А если в проекте используется Maven, то хочется получать эту информацию при каждой сборке.
Итак, [Saga](http://timurstrekalov.github.com/saga/) — а... | https://habr.com/ru/post/143172/ | null | ru | null |
# Тесты для кода и код для тестов
В динамических языках, вроде python и javascript, возможно прямо во время работы заменять методы и классы в модулях. Это очень удобно для тестов — можно просто ставить "заплатки", которые будут исключать тяжёлую или ненужную логику в контексте данного теста.
Но что делать в C++? Go? ... | https://habr.com/ru/post/452702/ | null | ru | null |
# Почему в основе каждого нового веб-приложения в PayPal лежит TypeScript?
Недавно мы опубликовали [материал](https://habr.com/ru/company/ruvds/blog/437464/), в котором Эрик Эллиот критиковал TypeScript. Сегодня мы представляем вашему вниманию перевод статьи Кента Доддса. Тут он рассказывает о том, почему в PayPal пер... | https://habr.com/ru/post/437986/ | null | ru | null |
# Веселая Квартусель, или как процессор докатился до такой жизни

При отладке обычных программ, точки останова можно ставить почти везде и в достаточно больших количествах. Увы. Когда программа исполняется на контроллере, это прави... | https://habr.com/ru/post/464795/ | null | ru | null |
# Контейнер в linux, linux в egg, egg в python

Hello, {{username}}
Я DevOps и очень люблю Linux. Понятное дело, что с такой связкой я просто не мог не полюбить LinuX Containers (тем... | https://habr.com/ru/post/256647/ | null | ru | null |
# Что ещё необходимо узнать про OpenCL C перед тем, как на нём писать
| | |
| --- | --- |
| Как было написано |
```
float4 val = (0, 0, 0, 0);
```
|
| Что хотел написать автор |
```
float4 val = (float4)(0, 0, 0, 0);
```
|
| Как нужно было написать |
```
float4 val = 0;
```
|
Если Вы сталкивались с OpenCL ... | https://habr.com/ru/post/345984/ | null | ru | null |
# Бесплатный скрипт для Photoshop: экспорт векторных слоев из PSD в SVG
Использование готового и бесплатного скрипта, о котором пойдет речь, значительно упрощает и ускоряет процесс переноса исходников из Photoshop в Sketch. Но я думаю, скрипт может пригодится и для тех, кто с указанной программой не работает. Он экспо... | https://habr.com/ru/post/277673/ | null | ru | null |
# Как подружить ltree и Laravel
Я участвую в разработке ERP системы, в детали посвящать вас не буду, это тайна за семью печатями, но скажу лишь одно, древовидных справочников у нас много и вложенность их не ограничена, кол-во в некоторых составляет несколько тысяч, а работать с ними надо максимально эффективно и удобн... | https://habr.com/ru/post/539244/ | null | ru | null |
# Docker и костыли в продакшене

Навеяно публикацией [«Понимая Docker»](http://habrahabr.ru/post/253877/), небольшой пример костылей вокруг докера для запуска веб-приложений.
Я пробовал разные технологии обвязок, но некот... | https://habr.com/ru/post/253999/ | null | ru | null |
# T-SQL. Формирование XML со списком значений

### Небольшая заметка по формированию XML
### FOR XML PATH
Для формирования структуры XML-документа со списком значений можно воспользоваться режимом PATH для FOR XML в T-SQL.
```... | https://habr.com/ru/post/506942/ | null | ru | null |
# Разработка чат-бота для Facebook Messenger
В настоящее время наблюдается, действительно, бум чат-мессенджеров. Один за другим платформы для обмена мгновенными сообщениями объявляют о запуске платформы для разработки ботов.
Не стал и исключением Facebook. 12 апреля на конференции F8 Facebook представила платформу ... | https://habr.com/ru/post/281559/ | null | ru | null |
# Представляем Tartiflette: реализацию GraphQL с открытым исходным кодом для Python 3.6+
Друзья, в преддверии майских праздников мы решили не заваливать вас сложными техническими статьями, поэтому нашли довольно интересный, а главное, легкий в прочтении материал, переводом которого с радостью делимся с вами. Данный ма... | https://habr.com/ru/post/449526/ | null | ru | null |
# Как запустить email-рассылки и не попасть в спам?
[](https://habr.com/ru/company/dashamail/blog/478344/)
*Изображение: [Pixabay](https://pixabay.com/photos/spam-sausage-ham-ham-tin-909485/)*
Email-маркетинг – эффективный инстр... | https://habr.com/ru/post/478344/ | null | ru | null |
# Взлом госуслуг: мифы и реальность
В последнее время в СМИ обсуждаются множественные случаи взлома портала "Госуслуги". В этой статье я постараюсь выяснить что из этого миф и выдумки, а что является правдой, а для этого придется самому взломать госуслуги.
**Внимание! Данный текст является описанием возможности в экс... | https://habr.com/ru/post/569370/ | null | ru | null |
# Децентрализируй это. Создание сетей хранения без единого центра на Go
Сеть Интернет по своей архитектуре допускает возможность прямого обмена трафиком между любыми узлами, но все же в большинстве сценариев ... | https://habr.com/ru/post/700808/ | null | ru | null |
# Иерархический буфер глубин

Краткий обзор
=============
Иерархический буфер глубин — это многоуровневый буфер глуби (Z-буфер), используемый как ускоряющая структура (acceleration structure) для запросов глубин. Как и в случае mip-... | https://habr.com/ru/post/494376/ | null | ru | null |
# Быстрая работа с JSON в Swift
Работа с форматом JSON в Swift на первый взгляд не представляет особых сложностей, с одной стороны в стандартном наборе есть класс NSJSONSerialization который умеет парсить файлы, с другой стороны множество сторонних библиотек обещающих сделать этот процесс проще, а код нагляднее. В рам... | https://habr.com/ru/post/274809/ | null | ru | null |
# Memory and Span pt.2
[](https://github.com/sidristij/dotnetbook)
### Span usage examples
A human by nature cannot fully understand the purpose of a certain instrument until he or she gets some experience. So, let’s turn to some exa... | https://habr.com/ru/post/443976/ | null | en | null |
# Вышел Microsoft Edge для Linux
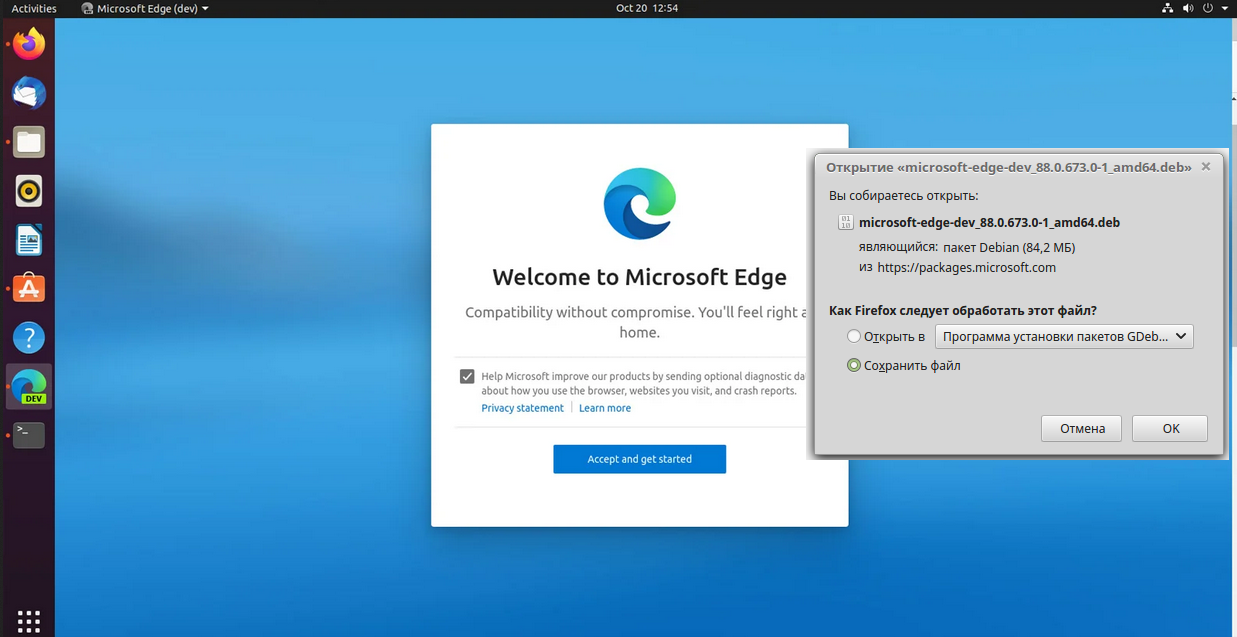
20 октября 2020 года в канале Dev программы Microsoft Edge Insider для разработчиков стала [доступна](https://www.microsoftedgeinsider.com/ru-ru/?form=MO12HB&OCID=MO12HB) первая сборка браузера Micro... | https://habr.com/ru/post/524396/ | null | ru | null |
# Новый Technorati: теперь не только блоги
Механизм поиска блогов [Technorati](http://www.technorati.com/) кардинально обновился: изменения затронули как содержание, так и внешний вид.
Technorati теперь не сфокусирован только на блогах, но также осуществляет поиск мультимедийных данных. Как отметил [в своем блоге](... | https://habr.com/ru/post/8794/ | null | ru | null |
# Руководство по JavaScript, часть 8: обзор возможностей стандарта ES6
Сегодня, в восьмой части перевода руководства по JavaScript, мы сделаем обзор возможностей языка, которые появились в нём после выхода стандарта ES6. Мы, так или иначе, сталкивались со многими из этих возможностей ранее, где-то останавливаясь на ни... | https://habr.com/ru/post/431074/ | null | ru | null |
# Настройка DKIM, SPF и DMARC в Zimbra Collaboration Suite
Если при попытке отправить сообщение на почтовые сервера Gmail вы вдруг получили ошибку типа «Our system has detected that this message is 550-5.7.1 likely unsolicited mail. To reduce the amount of spam sent to Gmail, 550-5.7.1 this message has been blocked.»,... | https://habr.com/ru/post/339296/ | null | ru | null |
# 10 причин почему ваш проект должен использовать Dojo Toolkit
Dojo Toolkit это одновременно самый мощный и наименее используемый JavaScript фреймворк. В то время, как почти каждый JavaScript фреймворк или тулкит обещает сделать все на свете и даже больше, Dojo Toolkit предоставляет наиболее убедительные аргументы в д... | https://habr.com/ru/post/189576/ | null | ru | null |
# ZoG на стероидах
Когда я [писал](http://habrahabr.ru/post/212237/) о разработке игры "[Thud!](https://github.com/GlukKazan/ZoG/blob/master/Rules/02.Thud.zrf)", я уже сетовал на некоторую избыточность получе... | https://habr.com/ru/post/214713/ | null | ru | null |
# «Осторожно, печеньки!»: советы начинающим тестировщикам в сфере безопасности
Привет, меня зовут Вика Бегенчева, я QA-инженер в Redmadrobot. Я расскажу, как злоумышленники крадут наши данные, и что можно сде... | https://habr.com/ru/post/544198/ | null | ru | null |
# Как я blakecoin майнер делал

Не знаю кому как, а меня прошедший 2017 год шокировал стремительным взлетом биткоина. Сейчас, конечно, ажиотаж уже ушел, а в 17-м году про криптовалюты говорили и писали все кому не лень.
Я видел,... | https://habr.com/ru/post/351118/ | null | ru | null |
# Ansible playbook для управления Windows/Linux агентами Zabbix
Данная статья про написание простых ansible плейбуков для автоматической установки агентов на хосты с Linux/Windows и регистрации хостов через API Zabbix, включая SNMP хосты. Будут использоваться готовые роли и модули Ansible Galaxy Zabbix.
Zabbix подгот... | https://habr.com/ru/post/555458/ | null | ru | null |
# Swift Generics: cтили для UIView и не только #2
Данная публикация является продолжением [выпуска](https://habrahabr.ru/post/327662/), где была затронута тема декорирования объектов. Ознакомление с первой публикацией поможет лучше вникнуть в текущий контекст, т.к. упомянутые ранее термины и решения буду описываться с... | https://habr.com/ru/post/339048/ | null | ru | null |
# Использование Data Transformers в Symfony2
Формы – в Symfony2 один из самых мощных инструментов, они представляют множество возможностей. Много секретов работы с Symfony2 описано в [Книге рецетов](http://symfony.com/doc/current/cookbook/index.html). Хочу представить вам перевод одного рецепта работы с формами, в Sym... | https://habr.com/ru/post/152539/ | null | ru | null |
# Физик и ролики
Предисловие
-----------
Однажды я купил слишком бюджетный велосипед и с самого начала с ним стали постоянно возникать какие-то проблемы: то развалится сиденье, то слетит цепь, то лопнут спи... | https://habr.com/ru/post/584848/ | null | ru | null |
# Учебник Thymeleaf: Глава 14. Еще несколько страниц нашей бакалеи
[Оглавление](https://habrahabr.ru/post/350862/)
14 Еще несколько страниц нашей бакалеи
--------------------------------------
Теперь мы много знаем об использовании Thymeleaf и можем добавить некоторые новые страницы на наш сайт для управления зака... | https://habr.com/ru/post/352536/ | null | ru | null |
# Снижение сложности вычислений при операциях с векторами и матрицами
### Введение
Ввиду того, что при решении задач оптимизации, дифференциальных игр, и в ***2D*** и ***3D*** расчётах, а вернее при написании софта, который проводит вычисления для их решения одними из наиболее часто выполняемых операций являются вект... | https://habr.com/ru/post/350924/ | null | ru | null |
# Элегантная обработка ошибок в JavaScript с помощью монады Either
Давайте немного поговорим о том, как мы обрабатываем ошибки. В JavaScript у нас есть встроенная функция языка для работы с исключениями. Проблемный код мы заключаем в конструкцию `try...catch`. Это позволяет прописать нормальный путь выполнения в разде... | https://habr.com/ru/post/457098/ | null | ru | null |
# Включение внешних языков в программы на Haskell
В данной статье приведено краткое описание техники, которое позволяет использовать в программах на Haskell библиотеки, написанные на других языках программирования. При этом нет необходимости ни переписывать эти библиотеки на Haskell, ни писать бесчисленные обертки на ... | https://habr.com/ru/post/269939/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.