
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Сколько инструкций процессора использует компилятор?
Месяц назад я [попытался сосчитать](https://habr.com/ru/post/503486/), сколько разных инструкций поддерживается современными процессорами, и насчитал 945 в Ice Lake. Комментаторы [затронули интересный вопрос](https://habr.com/ru/company/huawei/blog/503194/#comment... | https://habr.com/ru/post/506832/ | null | ru | null |
# Как мы при помощи WebAssembly в 20 раз веб-приложение ускорили
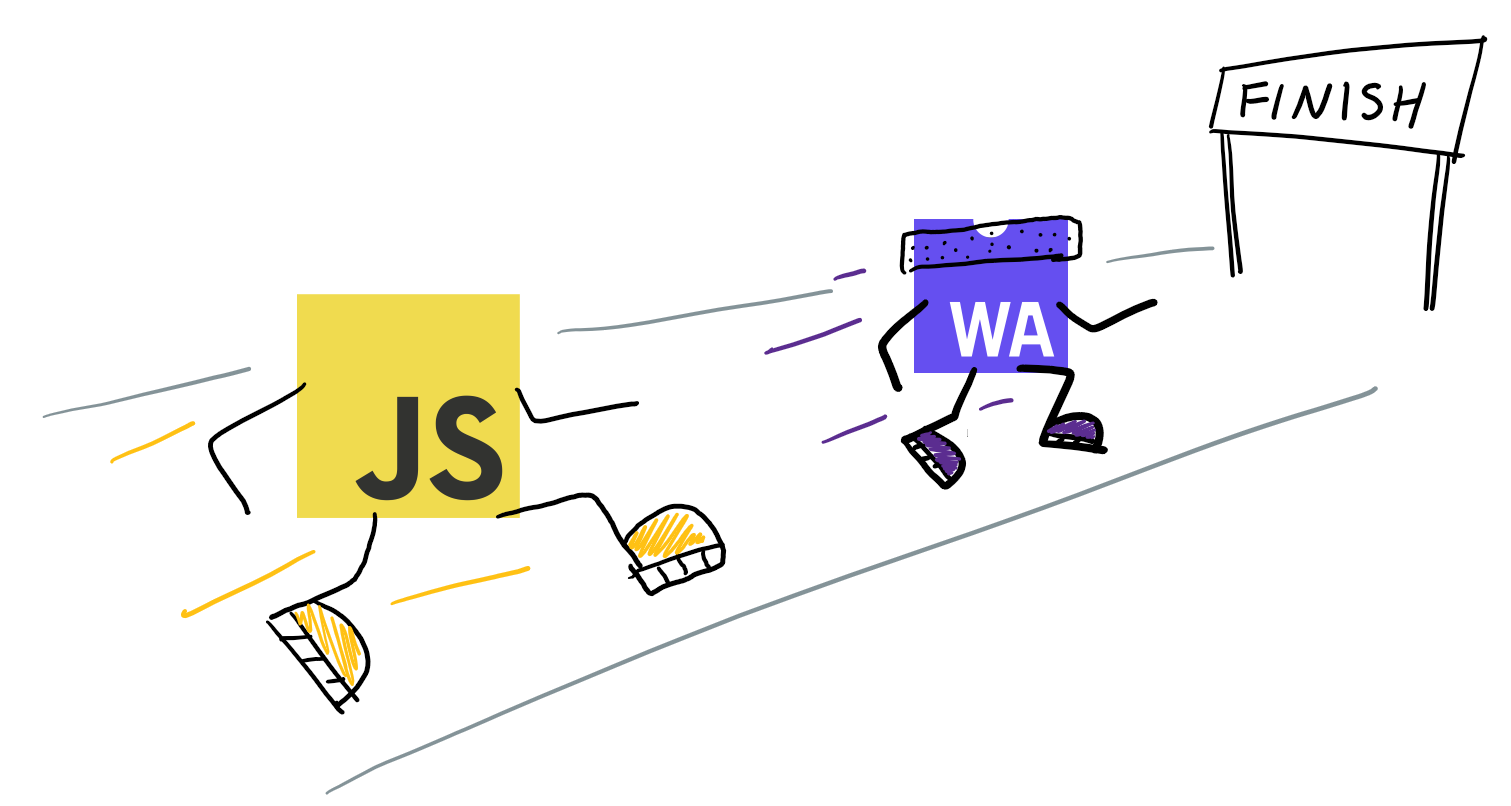
В этой статье рассматривается кейс по ускорению браузерного приложения через замену вычислений JavaScript на WebAssembly.
### WebAs... | https://habr.com/ru/post/452190/ | null | ru | null |
# Clustered index в InnoDB и оптимизация запросов
[](http://badoo.com/)В последнее время в сети часто пишут про clustered index в InnoDB и таблицах MySQL, но, несмотря на это, на практике используют довольно редко.
В дан... | https://habr.com/ru/post/135966/ | null | ru | null |
# Исправляем опечатки в поисковых запросах
Наверное, любой сервис, на котором вообще есть поиск, рано или поздно приходит к потребности научиться исправлять ошибки в пользовательских запросах. Errare humanum est; пользователи постоянно опечатываются и ошибаются, и качество поиска от этого неизбежно страдает — а с ним ... | https://habr.com/ru/post/433554/ | null | ru | null |
# Я просто оставлю это здесь
Я не ставлю цель ~~обо~~ очернить Перл. Я люблю Перл.
Просто **надо различать список и массив** в Перле.
```
use Perl or die;
```
```
#!/usr/bin/perl
use strict;
my $x = ('a', 'b');
print $x;
```
Вывод:
`b`
```
#!/usr/bin/perl
use strict;
my @a = ('a', 'b');
my $x = @a;
pr... | https://habr.com/ru/post/150140/ | null | ru | null |
# Linux/Cdorked.A: веб-серверы под управлением Lighttpd и nginx под угрозой
В прошлой части нашего исследования мы обещали опубликовать продолжение анализа инцидента заражений серверов под управлением Linux с участием бэкдора **Linux/Cdorked.A**. Мы уже [писали](http://habrahabr.ru/company/eset/blog/178197/), что спец... | https://habr.com/ru/post/179115/ | null | ru | null |
# Разработка через тестирование: улучшаем навыки
Тестирование важный навык, которым должен обладать каждый разработчик. Тем не менее, некоторые делают это неохотно.
Каждый из нас сталкивался с разработчиком, который утверждал, что тесты бесполезны, они требуют слишком много усилий, да и вообще его код настолько пре... | https://habr.com/ru/post/430128/ | null | ru | null |
# Hadoop и автоматизация: Часть 3
Ну что ж, Хабражители, пришло время подытожить **цикл статей** ([часть 1](http://habrahabr.ru/company/epam_systems/blog/222485/) и [часть 2](http://habrahabr.ru/company/epam_systems/blog/222653/)), посвященных моему приключению с автоматизацией развертывания **Hadoop** кластера.

It isn't real!
--------------
Почему так громко? Крик души. Возможно он мне не поддается, этот убунту, либо возможно `crooked_hands = On`. Не знаю.
### НО
Установив се... | https://habr.com/ru/post/25325/ | null | ru | null |
# Оптимизация запросов MySQL с использованием пользовательских переменных
**Введение.** В современном мире существует большое количество задач, в рамках которых приходится обрабатывать большие массивы однотипных данных. Яркими примерами являются системы для анализа биржевых котировок, погодных условий, статистики сете... | https://habr.com/ru/post/133781/ | null | ru | null |
# Сервелат, анимация и старый добрый code-behind
Решил немножко покопаться в Silverlight, да смастерить на нём что-нибудь прикольное. Это прикольное, конечно, должно шевелиться, переливаться и плавно подёргиваться, ибо вебдваноль у нас или где? :). И вот тут мне пришлось столкнуться с неплохой, по сути, системой анима... | https://habr.com/ru/post/109261/ | null | ru | null |
# Менять одежду на персонажах из MakeHuman в Unity3d
Цель статьи - перенести персонажа из Makehuman в Unity3d так, чтобы его одежду можно было снимать и надевать прямо во время игры.
Для этого нам понадобится [Makehuman](http://www.makehumancommunity.org/), [Blender3d](https://www.blender.org/), [Unity3d](https://uni... | https://habr.com/ru/post/544048/ | null | ru | null |
# HDD посвящается: усмиряем приложение, прожорливое на дисковое время
Корень всех зол
===============
Долгое время у меня была проблема — система очень сильно тормозила после старта. У меня ноутбук с жёстким диском (HDD) и **Ubuntu 14.04**.
Как выяснилось, причина крылась в одной лишь программе — демоне Dropbox. D... | https://habr.com/ru/post/282828/ | null | ru | null |
# Lego выпустит ваш конструктор, если за него проголосует 10 000 фанатов
Проект [Ideas.Lego](https://ideas.lego.com/) создан для того, чтобы любой желающий мог предложить свой конструктор. И если он наберет более 10 000 лайков, Лего его выпустит. Автор будет получать 1% от продаж.
, картинка оттуда же:

**TL;DR**... | https://habr.com/ru/post/430692/ | null | ru | null |
# WPF 4.0 — Отображение текста
Возможно, для многих этот топик не окажется откровением, но я лично узнал об этом совсем недавно. Однако, многим начинающим разработчикам он может быть полезным.
Как известно, с самого рождения WPF болел проблемами с отображением текста. Особенно это было заметно на не крупных шрифтах... | https://habr.com/ru/post/109313/ | null | ru | null |
# Устали от глупых шуток о JS? Напишите свою библиотеку
В JavaScript есть немало моментов, вызывающих вопрос «Чего???». Несмотря на то что у большинства из них есть логическое объяснение, если вы вникнете, они всё равно могут удивлять. Но JavaScript точно не заслуживает возмутительных шуток. Например, иногда мы видим ... | https://habr.com/ru/post/535138/ | null | ru | null |
# Учим язык, смотря сериалы: vlc + lua + stardict + wordnet + anki = l'amour
Очень уж мне нравится смотреть сериалы, а еще я учу с их помощью языки. И если раньше я прилежно останавливал видео на непонятном месте, перематывал назад, включал субтитры и забивал незнакомые слова в Анки, то сейчас я делаю то же самое. Раз... | https://habr.com/ru/post/169351/ | null | ru | null |
# Vim и кириллица: парочка приёмов

Раньше для редактирования обычных русскоязычных текстов, я обычно откладывал Vim в сторонку и прибегал к помощи других редакторов. Причиной этому была парочка очень ... | https://habr.com/ru/post/98393/ | null | ru | null |
# Что собой представляют образы Docker none:none?
*Предлагаю вашему вниманию перевод статьи [What are Docker none:none images?](https://www.projectatomic.io/blog/2015/07/what-are-docker-none-none-images/) из блога Project Atomic.*
Последние несколько дней я потратил на упражнения с образами Docker `:`. Чтобы объяснит... | https://habr.com/ru/post/304134/ | null | ru | null |
# DOM Storage window broadcast
В статье речь пойдет об интересном DOM Storage эвенте, который позволяет выполнять броадкаст общение между окнами обраузера одного домена не подозревающих об существовании друг друга.

*Традиционная модель валидации ресурсов*
Разработчики из Google вчера [объявили](https://blog.chromium.org/2017/01/reload-reloa... | https://habr.com/ru/post/357676/ | null | ru | null |
# Вышел Pidgin 2.6.1, устанавливаем из исходников
В репозиториях версии программ обновляются не моментально, а ждать иногда не хочется :) поэтому собираем pidgin вручную.
На самом деле в какую-то из последних «акций» AOL по отпугиванию от аськи отваживанию пользователей с альтернативными клиентами мне нужно было по... | https://habr.com/ru/post/67477/ | null | ru | null |
# Используем функционал Podman вместо docker-compose на примере Gitea
В своем порыве использовать только технологии компании Red Hat, я решила освоить их first-party контейнерный стек. В основе стека лежит `podman`- движок для контейнеров, работающий без демон-процесса и без root привилегий по умолчанию. `podman`интег... | https://habr.com/ru/post/705614/ | null | ru | null |
# Оптимизация образов Docker
Образы Docker могуть быть очень большими. Многие превышают 1 Гб в размере. Как они становятся такими? Должны ли они быть такими? Можем ли мы сделать их меньше, не жертвуя функциональностью?
В CenturyLink Lab мы много работали над сборкой различных [docker-образов](https://registry.hub.d... | https://habr.com/ru/post/234829/ | null | ru | null |
# Плагины в Python
Сегодня я расскажу, как построить плагиновую архитектуру в python на include'ах.

Наше приложение будет получать команды и раздавать их плагинам в надежде, что какой-нибудь плагин ее да... | https://habr.com/ru/post/79513/ | null | ru | null |
# Новинки Opera 19 для разработчиков
Догоняя релиз [Opera 19 для Андроида](http://www.opera.com/mobile/android) на прошлой неделе, выходит [Opera 19 для Mac и Windows](http://www.opera.com/computer) (на основе Chromium 32). Дальше о том, что это значит для разработчиков.
#### Промисы в JavaScript
[Так называемые «... | https://habr.com/ru/post/210588/ | null | ru | null |
# Как уязвимость в REG.RU позволяла получить данные регистрации любого домена
Сегодня я хочу рассказать о том, как в далеком 2012 году я нашел уязвимость в системе регистрации доменов компании REG.RU. Очень часто я вижу истории, в которых авторы рассказывают об уязвимостях при этом упоминая, что компания не уделила на... | https://habr.com/ru/post/429280/ | null | ru | null |
# Заходим в личный кабинет на zakupki.gov.ru без Internet Explorer и другие полезные советы при работе с КриптоПро
В этой заметке я постараюсь обобщить опыт использования криптопровайдера КриптоПро для доступа к закрытой ча... | https://habr.com/ru/post/326718/ | null | ru | null |
# Как бороться с «темами» в документе MS Visio
Суть проблемы
-------------
В MS Visio начиная с версии 2007 появилась возможность называемая «[темы](https://learn.microsoft.com/ru-ru/archive/blogs/visio_ru/60)» (со слов разработчиков она предназначена «для придания схеме профессионального вида»)…
> As we started wo... | https://habr.com/ru/post/697172/ | null | ru | null |
# Как снять данные с весового модуля со своей спецификацией протокола передачи данных и отправить на MQTT сервер
Данная статья написана для начинающих, тех кто на начальном уровне знает Python и немного разбирается в АСУ ТП. Задача достаточно распространенная, надо взять данные со старого, со своей спецификой оборудов... | https://habr.com/ru/post/712050/ | null | ru | null |
# Мониторинг систем видеонаблюдения с помощью Zabbix

Система мониторинга Zabbix уже давно зарекомендовала себя как простое в установке и настройке решение, которое помогает поддерживать работоспособность серверов, сайтов, сети и т... | https://habr.com/ru/post/371325/ | null | ru | null |
# Работа со структурами или как я учился писать читабельный код
#### С чего все началось
Я студент технического университета и учусь по направлению: «Высшая математика, информатика и математическое моделирование». Так как я учусь только на втором курсе — мой код совершенным назвать очень сложно. В прошлом семестре мы... | https://habr.com/ru/post/168075/ | null | ru | null |
# Как неправильно протестировать производительность NoSQL БД в Amazon
Пост рассказывает о моем ~~неудачном~~ тесте производительности, а также показывает пару ~~неправильных~~ цифр производительности [ARDB](https://github.com/yinqiwen/ardb) c встраиваемой БД [LMDB](https://symas.com/lmdb/) в Amazon EC2 контейнерах.
... | https://habr.com/ru/post/341778/ | null | ru | null |
# Статический анализ больших объёмов Python-кода: опыт Instagram. Часть 2
Сегодня публикуем вторую часть перевода материала, посвящённого статическому анализу больших объёмов серверного Python-кода в Instagram.
[](https://habr.com/... | https://habr.com/ru/post/473770/ | null | ru | null |
# Спектральный анализ сервера
Что будет, если к **Perfmon** применить быстрое преобразование Фурье? Или функцию корреляции? Получится *#черте\_что!*
У меня есть сервер, на котором идет много периодических процессов. Если записать его CPU с разрешением 1 секунда, то получится примерно вот что:

В этой статье я хочу показать, как настроить Stunnel на использование российских криптографических алгоритмов в протоколе TLS. В качестве бонуса покажу, как шифровать TLS-ка... | https://habr.com/ru/post/477650/ | null | ru | null |
# Грамотное адаптивное выравнивание шапки сайта
Зачастую вроде бы простые задачи верстки требуют сложной структуры HTML-разметки и использования CSS-трюков. Центрирование элементов или выравнивание контента может быть очень утомительным. Одна из таких задач — это выравнивание элементов верхней части сайта так, чтобы л... | https://habr.com/ru/post/188150/ | null | ru | null |
# Организация музыкального сопровождения торгового зала
Добрый день, вечер или ночь, все зависит от времени суток в который вам довелось прочитать мою статью.
В связи с открытием торгового зала была поставлена задача, организовать фоновую музыку в торговом зале, а именно:
— Трансляция из главного офиса подгото... | https://habr.com/ru/post/345266/ | null | ru | null |
# Как создать Minecraft на Python? Обзор библиотеки Ursina Engine

Среди любителей Minecraft много энтузиастов: пока одни просто играют, другие запускают целые серверы и пишут модификации. А кто-то идет дальше и разрабатывает собстве... | https://habr.com/ru/post/704040/ | null | ru | null |
# Дождались: поддержка YAML и Ansible (без коров) в dapp
В начале этого года мы посчитали, что наша Open Source-утилита для сопровождения процессов CI/CD — dapp версии 0.25 — обладает достаточным набором функций и была начата работа... | https://habr.com/ru/post/351838/ | null | ru | null |
# Распределенное выполнение Python-задач с использованием Apache Mesos. Опыт Яндекса
Подготовка релиза картографических данных включают в себя запуск массовой обработки данных. Некоторые задачи хорошо ложатся на идеологию Map-Reduce. В этом случае задача инфраструктуры традиционно решается использованием Hadoop или [Y... | https://habr.com/ru/post/306548/ | null | ru | null |
# Gosuslugi.ru: получение загранпаспорта. Monkey business solution
Да, я знаю, эта тема обсуждалась еще год назад. Но, данная статья не о тестировании нового интерфейса сайта gosuslugi, и не описание конкретного случая. Это полное прохождение одного квеста. Одного из многих других квестов — наших в с вами взаимодейств... | https://habr.com/ru/post/119098/ | null | ru | null |
# PHP-Дайджест № 188 (7 – 21 сентября 2020)
[](https://habr.com/ru/post/519960/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 8 Beta 4, инициатива по консолидации PHP-сообщества, концепт PHP для GraalVM, предл... | https://habr.com/ru/post/519960/ | null | ru | null |
# Отличный плагин для проверки верстки
Существует множество способов тестировать верстку. Большинство из них были описаны в статьях или комментариях хабра. Упоминаний данного способа я не нашел.
##### XPrecise
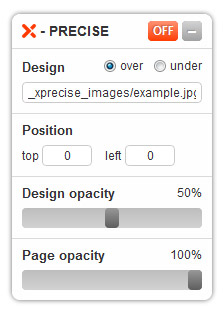
Утили... | https://habr.com/ru/post/152115/ | null | ru | null |
# Умная кормушка: Machine Learning, Raspberry Pi, Telegram, немножко магии обучения + инструкция по сборке
Всё началось с того, что жена захотела повесить кормушку для птиц. Идея мне понравилась, но сразу захотелось оптимизировать. Световой день зимой короткий — сидеть днём и смотреть на кормушку времени нет. Значит н... | https://habr.com/ru/post/322520/ | null | ru | null |
# Композитный «datasource»-объект и элементы функционального подхода
Как-то раз я (ну ладно, даже не я) столкнулся с задачей добавить в `[UICollectionView](https://developer.apple.com/documentation/uikit/uicollectionview)` с определенным типом ячеек одну ячейку совершенно другого типа, причем делать это лишь в особенн... | https://habr.com/ru/post/442138/ | null | ru | null |
# OCaml и RESTful JSON API с использованием Eliom
Привет, Хабр! Представляю вашему вниманию перевод руководства [RESTful JSON API using Eliom](http://ocsigen.org/tuto/4.0/manual/rest).
В этом руководстве рассказывается, как создать простой, но полный REST API с использованием JSON в качестве формата сериализации. ... | https://habr.com/ru/post/336336/ | null | ru | null |
# Разработка модуля создания финансовых сообщений для АРМ КБР/ АРМ КБР-СПФС
Привет, Хабр!
Это моя первая небольшая статья про небольшую разработку финансовой программы, прошу строго не судить.
Поскольку не все государственные компании реализовали у себя обмен финансовыми сообщениями через систему передачи финан... | https://habr.com/ru/post/523318/ | null | ru | null |
# PostSharp. Решение задач логгирования и аудита
 И снова здравствуйте! В прошлый раз при обсуждении АОП, мы с вами говорили о решении задач кэширования. Сегодня мы поговорим о не менее часто встречающейся задаче – задаче логгировани... | https://habr.com/ru/post/124860/ | null | ru | null |
# Динамические окружения GitLab vs self-service портал. Что выбрать?
**Как все члены наших проектных команд вдруг стали немножко DevOps’ами**
Привет, Хабр! Мы недавно с коллегами читали [статью компании Flant](https://habr.com/ru/company/flant/blog/571482/) о динамических окружениях в GitLab и хотели бы поделиться с ... | https://habr.com/ru/post/586698/ | null | ru | null |
# Расширяем и используем Flatpages в Django. Встраиваем CKEditor
Здравствуйте, сегодня я хотел бы вам рассказать о том, как сделать модель, которая хранит в себе обычные страницы, а не отдельные записи в базе данных (для ListView, TemplateView и тд). Речь пойдёт о том, как расширить и дополнить существующие в Django f... | https://habr.com/ru/post/340686/ | null | ru | null |
# data.table: выжимаем максимум скорости при работе с данными в языке R
На эксклюзивных условиях представляем для вас полный вариант [статьи](https://xakep.ru/2016/10/03/r-data-table-speed/) из журнала [Хакер](https://habrahabr.ru/company/xakep/), посвященной разработке на R. Под катом вы узнаете, как выжать максимум ... | https://habr.com/ru/post/316032/ | null | ru | null |
# Введение в геномику для программистов
Об авторе. Энди Томасон — ведущий программист [Genomics PLC](https://www.genomicsplc.com/). Он с 70-х годов занимается графическими системами, играми и компиляторами; специализация — производительность кода.
#### Гены: краткое введение
[Геном человека](https://en.wikipedia.... | https://habr.com/ru/post/452622/ | null | ru | null |
# Как легко и быстро сделать создание snapshot'ов и их автоматическое удаление
История о том, как у меня была задача на решение которой ушло 2 дня. Обнаружилось несоответствие в документации и реальном мире яндекс облака в Яндекс писалось, но ответа не получилось.
Yandex.Cloud
Задача:
По расписанию, создават... | https://habr.com/ru/post/513884/ | null | ru | null |
# Почему функциональное программирование такое сложное
Я несколько раз начинал читать статьи из серии «Введение в функциональное программирование», «Введение в Теорию Категорий» и даже «Введение в Лямбда Исчисление». Причем и на русском, и на английском. Каждый раз впечатление было очень сходным: во-первых, много новы... | https://habr.com/ru/post/505928/ | null | ru | null |
# А давайте это отфильтруем
Стилизация элементов пользовательского интерфейса в экосистеме .net/WPF «*позволяет разработчикам и дизайнерам создавать визуально привлекательные эффекты и согласованный внешний вид своих продуктов»* [[docs.microsoft.com](https://docs.microsoft.com/ru-ru/dotnet/desktop/wpf/controls/styles-... | https://habr.com/ru/post/666582/ | null | ru | null |
# Лампа для слежения за фазами Луны на Raspberry Pi и Python
Лампа для слежения за фазами Луны, об изготовлении которой я хочу рассказать, это — развитие моего [проекта](https://python.plainenglish.io/a-raspberry-pi-powered-snapology-origami-sunrise-lamp-night-light-and-disco-ball-a12ea6dcb2fa) лампы, воспроизводящей ... | https://habr.com/ru/post/566098/ | null | ru | null |
# Почему концепция Exception в C# — зло
В этой короткой заметке я поделюсь наблюдениями о проблемах концепции exception в языке C#, именно о тех, которые возникают от самого факта наличия такой ее реализации... | https://habr.com/ru/post/551326/ | null | ru | null |
# Как упаковывать и дистрибутировать модели машинного обучения с помощью MLFlow
*MLFlow - это инструмент для управления всеми стадиями жизненного цикла модели машинного обучения. Более того, в статье рассматр... | https://habr.com/ru/post/698130/ | null | ru | null |
# Часть 0. Требуется эльф для работы в Матрице. Возможна релокация
**Внимание: содержит системное программирование. Да, в сущности, ничего другого и не содержит.**
Давайте представим, что вам дали задание написать фэнтезийно-фантастическую игру. Ну там про эльфов. И про виртуальную реальность. Вы с детства мечтали на... | https://habr.com/ru/post/452592/ | null | ru | null |
# Настройка BGP Looking glass на базе OpenBSD 6.1
Мы уже давно использовали связку OpenBSD+OpenBGPD+bgplg для предоставления публичного сервера bgp looking glass. Было принято обновить OpenBSD до свежей версии.
В процессе настройки выяснилось несколько ньюансов, не раскрытых в полной мере в официальной документаци... | https://habr.com/ru/post/332694/ | null | ru | null |
# Как работать с секретами в Golang, чтобы минимизировать хаос
Над менеджментом секретов нужно задумываться с самого начала работы над проектом. Кто-то может со мной не согласиться, ведь на стадии разработки возникает куча первостепенных задач, и проблема хранения секретов уходит на второй план. Попытаюсь развеять ваш... | https://habr.com/ru/post/679546/ | null | ru | null |
# Магия виртуализации: вводный курс в Proxmox VE

Сегодня речь пойдет о том, как быстро и достаточно просто на одном физическом сервере развернуть несколько виртуальных серверов с разными операционными системами. Любому системному ад... | https://habr.com/ru/post/483236/ | null | ru | null |
# Загрузка файлов в AngularJS
Давно писал модуль для загрузки файлов и всё он был не идеальным. И тут подумал, если сейчас не опубликую, то никогда не опубликую, идеал-то не достижим!
При составлении АПИ руководствовался принципом — как можно проще. Поэтому сначала несколько мыслей о загрузке файлов:
**Загрузка ... | https://habr.com/ru/post/191464/ | null | ru | null |
# Kotlin и стоимость разработки игры (+ немного оффтопика)
Добрый день. Сегодня я хочу рассказать о разработке игры с использованием языка программирования Kotlin. Также приведу небольшой пример работы с RxJava в конце статьи.
Первый commit для этой игры случился 4 июня сего года, то есть до открытой беты я дошёл ... | https://habr.com/ru/post/331976/ | null | ru | null |
# Убираем лишние запятые из javascript-кода
Когда пишешь на js, часто возникают ситуации, когда то тут, то там остаются строчки вида ",)" или ",}" или ",]". В ff, chrome код с такими фрагментами работает, а вот в IE нет.
Лекарство для вима:
`autocmd BufWritePre *.js :%s/\(.*\),\(\s*\n*\s*\)\(\}\|\]\|)\)/\1\2\3/e... | https://habr.com/ru/post/114435/ | null | ru | null |
# Как создать нагрузочный тест с помощью Apache Jmeter
В этом посте я опишу, как создать нагрузочный тест веб-приложения с помощью инструмента для проведения нагрузочного тестирования, разрабатываемого в рамках Apache Jakarta Project — **JMeter**.
JMeter является очень мощным инструментом нагрузочного тестирования ... | https://habr.com/ru/post/165159/ | null | ru | null |
# Как уронить космическую станцию
Когда "Наука" креативно избавлялась от остатков топлива, разворачивая МКС вокруг своей оси, мне стало любопытно: если расположение случайно включившегося двигателя было бы максимально неудачным, **сколько потребовалось бы времени, топлива и тяги, чтобы свести станцию с орбиты**?
). Во второй части немного будет рассказано о философии языка, о поддержке пространств имен и о типе **id**. Судя по ... | https://habr.com/ru/post/138640/ | null | ru | null |
# Как уменьшить размер бандла — стратегия однобуквенных классов в css-modules
Улучшаем компрессию бандлов на 40% от размера файла, путём замены стандартного хеширования на однобуквенный префикс + хеш пути файла.
Css-modules позволяют написать компоненты Bird и Cat, со стилями в файлах с одинаковым именем styles.css... | https://habr.com/ru/post/499162/ | null | ru | null |
# О трэйлинг вайтспейсах замолвите слово
Значит так. Властью, данной мне хабраредактором, я объявляю этот топик местом праведного гнева, ярости, местом вселенской скорби и бессильной ненависти, которые возникают в благородных мужах при виде подобной картины:
](https://habr.com/post/414369/)
Настоящий админ может спать спокойно лишь тогда, когда у него всё бэкапится, мониторится и дублируется. ~~Или когда он работает в хорошей команде, где... | https://habr.com/ru/post/414369/ | null | ru | null |
# Сказания Великого Ктулху. Чак Норрис
Великому Ктулху было скучно. Он смотрел на вечность, а Вечность смотрела на него. Ни одна из сторон не желала уступать. А так как Великий Ктулху и есть вечность, то смотрел он сам на себя. И это продолжалось вечно.
Вы спросите, когда это было? Я отвечу никогда. Великий Ктулху е... | https://habr.com/ru/post/682142/ | null | ru | null |
# Яндекс-деньги стали проводить часть интернет-платежей по пластиковой карте ЯД как снятие в банкомате
Всем добрый день.
Поскольку за адекватное время (почти неделя) дождаться ответа от поддержки ЯД не удалось, а отбивка о создании тикета пришла исправно, пишу тут с целью предупредить общественность о такой (доволь... | https://habr.com/ru/post/160751/ | null | ru | null |
# Работа с Microsoft Kinect в приложениях на C++
Введение
--------
Совсем недавно Microsoft выпустили beta-версию инструментария для работы с Kinect – Microsoft Research Kinect SDK. В инструментарии доступны заголовочные файлы, библиотека, а также примеры использования в приложениях на C++. Но наличие самого SDK не р... | https://habr.com/ru/post/123588/ | null | ru | null |
# GraphQL + Typescript = любовь. TypeGraphQL v1.0
[](https://habr.com/ru/company/ruvds/blog/516634/)
ЗTypeGraphQL v1.0
=================
19 августа вышел в релиз фреймворк TypeGraphQL, упрощающий работу с GraphQL на Typescript. За д... | https://habr.com/ru/post/516634/ | null | ru | null |
# Использование объединений в константных выражениях под С++11
Возможно, вы уже знакомы с [обобщёнными константными выражениями](http://ru.wikipedia.org/wiki/C%2B%2B11#.D0.9E.D0.B1.D0.BE.D0.B1.D1.89.D1.91.D0.BD.D0.BD.D1.8B.D... | https://habr.com/ru/post/164037/ | null | ru | null |
# Spring в действии — пробуем opensource CMS на Java
В данной статье речь пойдёт о системе управления содержимым *Riot*, написанной на *Java*. Система основана на *Spring Framework*, использует *Ajax*.
[Dropbox](https://www.dropbox.com/home) — чрезвычайно популярный облачный сервис. Если вы давно им пользуетесь, то скорее всего, не искали... | https://habr.com/ru/post/134466/ | null | ru | null |
# 2D магия в деталях. Часть первая. Свет

Игры большие и трехмерные уже давно радуют глаз реалистичным освещением, мягкими тенями, бликами и прочей осветительной красотой. В двумерных же играх — во главе стола прямые руки ху... | https://habr.com/ru/post/305252/ | null | ru | null |
# Отладка шейдеров на Java + Groovy

Подсветка синтаксиса шейдеров. Связь между шейдерами и внешними структурами данных. Юнит-тесты для шейдеров, дебаг, рефакторинг, статический анализ кода, и вообще полная поддержка IDE. О ... | https://habr.com/ru/post/269591/ | null | ru | null |
# Как создавать и использовать словари в ClickHouse

Если вы открыли эту ~~дверь~~ статью, то наверняка, вы уже имели дело с ClickHouse и можно упустить интересные подробности об его удобстве и скорости, а перейти сразу к делу – собств... | https://habr.com/ru/post/513972/ | null | ru | null |
# NLP. Проект по распознаванию адресов. Natasha, Pullenti, Stanza
Многие аналитики данных сталкиваются с задачей распознавания адресов, напечатанных на документах. Для решения этой задачи я обратился к инстру... | https://habr.com/ru/post/667442/ | null | ru | null |
# Разбираемся с концепцией аутентификации в HTTP
Я часто путаю понятия авторизации и аутентификации между собой, поэтому решил создать материал, который закрепил бы эти понятия через какой-то практический опы... | https://habr.com/ru/post/682170/ | null | ru | null |
# Загрузка картинок на сервер с использованием HTML5+jQuery+PHP
Доброго времени суток!
Наверняка многие видели в движке WP функцию переноса файлов с рабочего стола в окно браузера и их дальнейшую загрузку на сервер. Когда я увидел такое, мне стало интересно как же это организовано. Тогда я полез в дебри, чуть было ... | https://habr.com/ru/post/136694/ | null | ru | null |
# Измеряем power consumption для цифровых блоков микросхемы ASIC (еще до изготовления)
[](http://habrahabr.ru/company/metrotek/blog/264389/)
В последнее время на **Хабрахабр** появилось много статей посвященных разработке д... | https://habr.com/ru/post/264389/ | null | ru | null |
# Сигнатура Snort для уязвимости CVE-2017-9805 в Apache Struts
Друзья, добрый день!
7–8 сентября в СМИ и блогах стали появляться сообщения о взломе одного из крупнейших бюро кредитных историй Equifax. Представители американской компании сообщили, что «утекли» данные 143 миллионов человек: имена, адреса, номера соци... | https://habr.com/ru/post/337734/ | null | ru | null |
# Обзор онлайн-курса по Arduino/робототехнике от МФТИ (вторая неделя)

*Мы продолжаем публикацию обзора онлайн-курса "Строим роботов и другие устройства на Arduino", начало [здесь](https://geektimes.ru/company/makeitlab/blo... | https://habr.com/ru/post/403029/ | null | ru | null |
# Структурное логирование в .NET на примере Serilog
Все мы знаем, что логирование - вещь очень полезная для современного проекта. С помощью него можно быстро локализовать и устранить ошибку в продукте, восстановить кейс, который к ней привёл, посмотреть историю действий пользователя.
Существует несколько видов логиро... | https://habr.com/ru/post/712384/ | null | ru | null |
# Учим поросёнка на моноидах верить в себя и летать
В [одной](https://habr.com/post/429530/) из предыдущих статей я рассказывал о том, как можно построить исполнитель программ для виртуальной стековой машины, используя подходы функционального и языково-ориентированного программирования. Математическая структура языка ... | https://habr.com/ru/post/430956/ | null | ru | null |
# Как сделать магический шар на Three.js
### Анимированный объём при помощи встроенного шейдера
Конечно же, после [смерти Flash](https://habr.com/ru/company/skillfactory/blog/540292/) веб не превратился в пр... | https://habr.com/ru/post/570592/ | null | ru | null |
# Лезем в сорцы компилятора — как работает goscheduler (Часть I)

Каждый раз, когда я открываю новую книжку о golang, обязательно лезу в главу о горутинах и в очередной раз читаю, как беспощадно прекрасен голанг. Подумать только, вме... | https://habr.com/ru/post/581158/ | null | ru | null |
# Тестирование продукта RuScanner: как заставить отладчик Android работать во благо тестирования
Всем привет, меня зовут Дарья Чернышева, я инженер по обеспечению качества команды RuScanner.
В этом посте я р... | https://habr.com/ru/post/668990/ | null | ru | null |
# Возможные утечки персональных данных или как Дом.ru даёт полный доступ к личному кабинету по ссылке из http
> Впервые уязвимость была обнаружена еще 26.06.2020, о чем автор тут же сообщил техподдержке Дом.ru. Автор долго и упорно пытался решить проблему непублично, но встретил полное её непонимание техническими спец... | https://habr.com/ru/post/510146/ | null | ru | null |
# Простой генератор DGML-файла графа переходов машины состояний
Допустим, есть проект WPF/MVVM, в котором необходимо реализовать шаблон State Machine, позволяющий управлять поведением объекта (в данном случае, ViewModel) в зависимости от того состояния, в котором он находится. При этом необходимо получить простую реал... | https://habr.com/ru/post/269983/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.