
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как мы в X-Ray х64 завозили
Предисловие
===========
Доброго времени суток, речь пойдёт о игровом движке X-Ray, а точнее о его форке [X-Ray Oxygen](https://github.com/xrOxygen/xray-oxygen) В декабре 2016 года был опубликован проект X-Ray Oxygen. Тогда я разрабатывал его один и не мечтал о том, чем он стал на данный ... | https://habr.com/ru/post/421823/ | null | ru | null |
# Борьба с несбалансированностью классов с помощью модуля NEARMISS
В этой статье я расскажу об одном из методов для устранения дисбаланса предсказываемых классов. Важно уточнить, что многие методы, которые ст... | https://habr.com/ru/post/562322/ | null | ru | null |
# Погружение в разработку на Ethereum. Часть 4: деплой и дебаг в truffle, ganache, infura
В [прошлой статье](https://habrahabr.ru/post/339080/) мы рассмотрели разработанное приложение на Ethereum. Но обошли стороной вопрос как происходит процесс разработки. Ясно, что это не просто написание кода, который сразу работае... | https://habr.com/ru/post/348656/ | null | ru | null |
# Haskell — невозможное возможно?
Известно, что задача определения того, истинна ли некоторая функция `Integer -> Bool` хотя бы для одного числа вычислительно неразрешима. Однако, нечто, на первый взгляд кажущееся как раз таким оракулом (а именно, функцией `(Integer -> Bool) -> Maybe Integer`) будет описано в этой ста... | https://habr.com/ru/post/201446/ | null | ru | null |
# Почему "=" означает присваивание?
Давайте посмотрим на следующий код:
```
a = 1
a = a + 1
print(a)
```
В среде ФП часто критикуют данный момент императивного программирования: «Как так может быть, что a = a + 1? Это всё равно что сказать „1 = 2“. В мутабельном присваивании нет смысла».
Здесь мы наблюдаем нес... | https://habr.com/ru/post/353292/ | null | ru | null |
# «Мочим» объекты с помощью Cuckoo

*Пост написан по мотивам статьи [Mocking in Swift with Cuckoo](http://riis.com/blog/Mocking-in-Swift-with-Cuckoo/) by Godfrey Nolan*
По долгу своей "службы" мобильным разработчиком, предс... | https://habr.com/ru/post/322572/ | null | ru | null |
# Миссия AllMyChanges
Когда [наш проект](https://allmychanges.com/?utm_source=habrahabr&utm_campaign=our-mission) только зарождался, он базировался на гипотезе, что почти для любой библиотеки можно найти changelog, а если найти нельзя, то можно построить его из коммит-мессаджей. Но реальность оказалась не столь радужн... | https://habr.com/ru/post/260823/ | null | ru | null |
# Как подружить SRE с разработкой, а на сдачу улучшить качество сервиса
В декабре 2019-го в Dodo новые фичи стали выкатываться неприлично долго. Когда у разработчиков спросили, что им мешает держать высокую скорость поставки фич, в топе ответов оказались жалобы на нестабильную работу тестовых стендов и медленную обра... | https://habr.com/ru/post/583384/ | null | ru | null |
# Хакаем CAN шину авто. Виртуальная панель приборов

В первой статье [«Хакаем CAN шину авто для голосового управления»](https://habr.com/ru/post/399043/) я подключался непосредственно к CAN шине Comfort в двери своего авто и исслед... | https://habr.com/ru/post/442184/ | null | ru | null |
# C++ и Численные Методы: Приближенное интегрование по Ньютону-Котесу
**Методы Ньютона-Котеса** — это совокупность техник приближенного интегрирования, основанных на:
* разбиении отрезка интегрирования на равные промежутки;
* аппроксимации подинтегральной функции на выбранных промежутках многочленами;
* нахождении ... | https://habr.com/ru/post/479202/ | null | ru | null |
# Workers архитектуры Clean Swift
Привет, читатель!
Ранее мы разобрали как устроен **VIP** цикл и как совершать переходы между с ценами с передачей данных. Теперь нужно разобраться как разгрузить наш **Interactor** от переизбытка логики и вынести ее часть для повторного использования другими сценами. И в этом нам ... | https://habr.com/ru/post/465991/ | null | ru | null |
# Как писать на Objective-C в 2018 году. Часть 1
Большинство iOS-проектов частично или полностью переходят на Swift. Swift — замечательный язык, и за ним будущее разработки под iOS. Но язык нераздельно связан с инструментарием, а в инструментарии Swift есть недостатки.
В компиляторе Swift по-прежнему находятся баги, ... | https://habr.com/ru/post/431236/ | null | ru | null |
# STM32H7 — настройка тактирования без HAL
Не так давно компания STM выпустила на рынок очень мощную, по меркам микроконтроллеров, линейку кристаллов STM32H7. Что меня в ней привлекло:
* повышенная частота ядра до 400 МГц
* увеличенный объем ОЗУ, до 1 МБ
* 16 разрядный АЦП
* pin-to-pin совместимость с серий F7
Отл... | https://habr.com/ru/post/427435/ | null | ru | null |
# Что такое fluent-сеттер
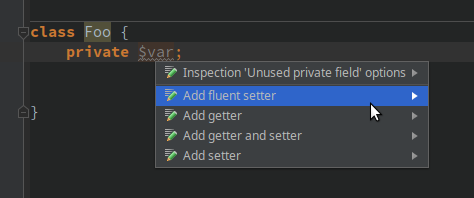
Сегодня в PhpStorm я создал приватную переменную и заметил, что IDE предлагает мне создать два вида сеттера: обычный setter и fluent setter.
Термин «fluent setter» мне раньше не встречался, поэтому ... | https://habr.com/ru/post/429020/ | null | ru | null |
# Использование XML-RPC в Drupal. Quickstart
В этой статье я расскажу как можно использовать эту замечательную технологию в не менее замечательной системе Друпал. В качестве примера попытаемся сделать систему, позволяющую отправлять сообщения на сайты под управлением Drupal из вашего jabber-клиента.
Чтобы сэкономит... | https://habr.com/ru/post/65714/ | null | ru | null |
# Массивы bash
*Предлагаю вашему вниманию перевод статьи Митча Фрейзера (Mitch Frazier) "[Bash Arrays](http://www.linuxjournal.com/content/bash-arrays)" с сайта linuxjournal.com.*
Если вы используете «стандартную» оболочку \*NIX-системы, возможно, вы не знакомы с такой полезной особенностью bash как массивы. Хотя м... | https://habr.com/ru/post/511608/ | null | ru | null |
# Hyper-V — дитя маркетинга или реальная альтернатива?
Привет, Хабр! Сейчас я задам вам вопрос, а вы задумайтесь: Что, очень популярное и когда-то вызывавшее трепет лично у вас, сегодня вспоминается только для «поностальгировать»? Наверняка, кто-то вспомнит Dendy или Super Nintendo, а некоторые свой пейджер. Так вот, ... | https://habr.com/ru/post/346776/ | null | ru | null |
# Как мы в Smart Engines учили Sailfish OS распознаванию

Всем привет! Как вы уже знаете по нашим статьям, мы в Smart Engines занимаемся распознаванием, причем распознавать мы стараемся на чем угодно и в лю... | https://habr.com/ru/post/352512/ | null | ru | null |
# Constraints в PostgreSQL, или о том, как попытаться спокойно жить
Данный материал был создан на основе одноимённого [доклада на PGConf.Online](https://pgconf.ru/2021/288643), вошедшего в число самых популярных выступлений конференции. Поскольку тема ограничений по-прежнему сохраняет свою актуальность, а смотреть вид... | https://habr.com/ru/post/672004/ | null | ru | null |
# Разблокировка ошибочно заблокированных джобов в DataStage
При работе с клиентом IBM WebSphere DataStage довольно нередки случаи краха приложения клиента, влекущие за собой блокировку джоба (будем называеть Job именно так, избегая более русского, но в то же время более общего термина **etl-процедуры** или **процедуры... | https://habr.com/ru/post/90718/ | null | ru | null |
# Храните ваши клятвы; Отношения с Node
Клятвы могут быть прекрасны. [Алексис Селлир](http://cloudhead.io/), сыскавший славу за разработку «LESS» (и «less.js»), начинает становиться звездой Open Source, выпустив в свет [**Vows**](http://vowsjs.org/), — каркас для разработки на Node.JS, управляемой асинхронным поведени... | https://habr.com/ru/post/98671/ | null | ru | null |
# MFC В 2022
Зачем и почему
--------------
Как бы мне не хотелось ответить на этот вопрос... Но ответа я не знаю. На рабочем проекте была задача написать редактор на MFC. Да, да... На MFC. Для тех, кто не знает, MFC - графическая библиотека от Microsoft, на которой стояли Microsoft Office и Visual Studio до 2010 года... | https://habr.com/ru/post/686980/ | null | ru | null |
# Как завладеть сетью /16 с помощью libpcap и libdnet. Работаем с протоколом SNMP
[](https://habr.com/ru/company/ruvds/blog/697854/)
Всем привет. Эксперименты с [эмуляцией сети](https://habr.com/ru/company/ruvds/blog/688314/) продолж... | https://habr.com/ru/post/697854/ | null | ru | null |
# Как перестать использовать MVVM

На недавнем [DroidCon Moscow 2016](http://droidcon.moscow/ru/#program) был доклад о MVVM c Databinding Library и доклад о библиотеке [Moxy](https://github.com/Arello-Mobile... | https://habr.com/ru/post/312548/ | null | ru | null |
# Postgres-вторник №5: «PostgreSQL и Kubernetes. CI/CD. Автоматизация тестирования»

В конце минувшего года состоялся очередной прямой эфир российского PostgreSQL-сообщества [#RuPostgres](https://www.meetup.com/postgresqlrussia/), ... | https://habr.com/ru/post/479438/ | null | ru | null |
# Совершенная страница 404
Добрый день, уважаемые коллеги. Хочу поделиться с вами своей наработкой — [совершенная страница 404](http://sytchev.ru/404.zip). Это ни что иное, как дописанный код статьи Яна Ллойда «Совершенная страница 404» ([оригинал](http://www.alistapart.com/articles/perfect404/), [по русски](http://ww... | https://habr.com/ru/post/64250/ | null | ru | null |
# PipelineDB: работа с потоками данных

В предыдущих публикациях мы уже затрагивали проблему обработки событий в реальном масштабе времени. Сегодня мы хотели бы вновь вернутся к этой теме и рассказ... | https://habr.com/ru/post/306978/ | null | ru | null |
# Топология и комплексный анализ для ничего не подозревающего разработчика игр: сжатие единичных 3D-векторов
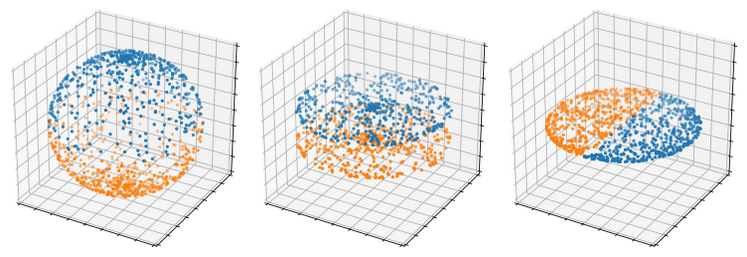
Как вы уже могли понять из моих предыдущих статей, мне нравится использовать разработку игр... | https://habr.com/ru/post/482348/ | null | ru | null |
# Компактная С++ библиотека для программирования конечно-разностных методов в операторном стиле. Часть 1. Семантика
Представлена семантика разработанной библиотеки pde++ для программирования конечно-разностных методов в операторном стиле. Основными объектами библиотеки являются сеточная функция, сеточная ячейка и сето... | https://habr.com/ru/post/442316/ | null | ru | null |
# Копируем заголовок и URL в удобном виде
Около года назад я опубликовал топик [Удобное дополнение к IE при написании обзоров](http://habrahabr.ru/blogs/ie/68067/), в котором рассказывал о своей небольшой программке, которая позволяет одним щелчком мыши скопировать заголовок и URL страницы в удобном виде. В комментари... | https://habr.com/ru/post/96518/ | null | ru | null |
# Советы начинающим веб-разработчикам
Я занимаюсь созданием сайтов в том или ином виде с 1995 года. После 25 лет работы, думаю, что накопил опыта и теперь располагаю достаточными знаниями. Ниже в произвольном порядке изложено несколько моментов, о которых я бы хотел, чтобы начинающие разработчики поразмыслили.
* По... | https://habr.com/ru/post/507476/ | null | ru | null |
# Как и зачем я сдавал сертификацию Oracle — Java SE 11 Developer
Меня зовут Аксёнов Вячеслав и я бэкенд разработчик, пишу на Java/Kotlin, расскажу про то, как я сдавал сертификацию на знания Java SE 11 от Oracle. И какие нюансы я понял в процессе подготовки.
.... | https://habr.com/ru/post/352686/ | null | ru | null |
# Особенности дизайна сайта для мобильных устройств
Речь пойдет о мобильных устройствах, которые на данное время занимают большой % на рынке WAP’a (телефоны без ОС, Symbian и прочие), об Android и iPhone сегодня говорить не будем
 ... | https://habr.com/ru/post/108498/ | null | ru | null |
# Veeam CDP для самых маленьких
Функция CDP (она же Continuous Data Protection) для многих сейчас видится манной небесной. Ведь она позволяет свести риски потери данных к около-нулевым значениям (RTO и RPO - единицы секунд), при этом не используя тормозящие всё вокруг себя снапшоты, и не зависеть от ограничений класси... | https://habr.com/ru/post/548900/ | null | ru | null |
# Основы создания 2D персонажа в Unity 3D 4.3. Часть 3: прыжки (и падения)
[Часть 1: заготовка персонажа и анимация покоя](http://habrahabr.ru/post/211472/)
[Часть 2: бегущий персонаж](http://habrahabr.ru/post/211847/)
**Часть 3: прыжки (и падения)**
Всем привет. Продолжаем серию уроков по созданию 2D персона... | https://habr.com/ru/post/212309/ | null | ru | null |
# Изменить сохранения Spark Часть вторая: реализация партишенера
***Автор:*** *Иван Калининский, участник профессионального сообщества Сбера SberProfi DWH/BigData.*
*Профессиональное сообщество SberProfi DWH/BigData отвечает за развитие компетенций в таких направлениях, как экосистема Hadoop, Teradata, Oracle DB, Gre... | https://habr.com/ru/post/583018/ | null | ru | null |
# О пересмотре результатов конкурса по программированию на JS
Спасибо участникам [конкурса по программированию](http://habrahabr.ru/company/hola/blog/270847/) за долготерпение. Я пишу этот пост, чтобы признать и исправить серьёзную ошибку, которую мы допустили при подведении итогов.
Мы получили множество замечаний ... | https://habr.com/ru/post/274961/ | null | ru | null |
# Отслеживание ошибок в приложении React с помощью Sentry

Сегодня я расскажу вам об отслеживании ошибок в реальном времени в приложении React. Приложение внешнего интерфейса обычно не используется для отслеживания ошибок. Некоторые ... | https://habr.com/ru/post/511676/ | null | ru | null |
# Как я получил первый опыт разработки игры на Android

В этой статье я хочу поделиться своим опытом создания первой игры для платформы Android, рассказать весь путь от зарождения идеи до публикации.
#### Предыстория... | https://habr.com/ru/post/274277/ | null | ru | null |
# Использование платформы Intel Edison для создания видеоровера
[](http://geektimes.ru/company/intel/blog/268648/)
[Intel Edison](http://www.intel.com/content/www/us/en/do-it-yourself/edison.html) — это умная вычислительная... | https://habr.com/ru/post/371559/ | null | ru | null |
# Time Travel Debugging в новом WinDbg
Возможно, вы уже слышали о том, что Microsoft выпустила обновлённую версию своего известного отладчика WinDbg, который и раньше был хорош, но слишком уж отстал по интерфейсу от современных тенденций. Новая версия WinDbg, к счастью, не пошла настолько далеко, чтобы получить новомо... | https://habr.com/ru/post/340744/ | null | ru | null |
# Core Data + Swift для самых маленьких: необходимый минимум (часть 2)
Это вторая часть трилогии о Core Data, первая доступна здесь: [Core Data + Swift для самых маленьких: необходимый минимум (часть 1)](https://habrahabr.ru/post/303512/).
В первой части мы познакомились с общими сведениями о Core Data, основными к... | https://habr.com/ru/post/303798/ | null | ru | null |
# Мои маленькие реле: Тройной Brainfuck, или что такое безумие

*Рис.1: Релейный компьютер BrainfuckPC на фоне его автора*
Продолжая славную традицию ежегодного дайджеста моих самых безумных компьютерных проектов, представляю ва... | https://habr.com/ru/post/442732/ | null | ru | null |
# Рост хоккеистов: анализируем данные всех чемпионатов мира в текущем веке
[](http://image.spreadshirtmedia.com/image-server/v1/designs/13069879,width=280,height=280?mediaType=png)
На днях завершился очередной чемпионат мира п... | https://habr.com/ru/post/301340/ | null | ru | null |
# Hashing
It is an efficient searching technique. Searching is a widespread operation on any data structure. Hashing is used to search specific records from a large domain of records. If we can efficiently search a record out of many records, we easily perform different operations on that data. Hashing is storing and... | https://habr.com/ru/post/563664/ | null | en | null |
# Обновляемые смарт-контракты Ethereum
Почти перед каждым программистом, который пишет смарт-контракты Ethereum встают вопросы: «Что делать, если нужно будет расширить функционал контрактов? Как быть, если в контракте найдется баг, который повлечет за собой потерю средств? Что делать, если обнаружится уязвимость в ком... | https://habr.com/ru/post/342200/ | null | ru | null |
# Rust новости #3 (ноябрь 2018)

Предлагаю вашему вниманию субъективную подборку ржавых новостей за ноябрь. В этой подборке: Rust 2018, RustRush, видео с конференций, Amazon Lambda и Firecracker, квизы, переход exonu... | https://habr.com/ru/post/432250/ | null | ru | null |
# Менеджер пакетов для XCode
Сегодня обнаружил достойный внимания всех разработчиков, пишущих под iOS/Mac OS и использующих XCode, проект – менеджер плагинов для XCode. Имя этому проекту – [Alcatraz](http://bit.ly/ZNRgJM). Увидев это чудо, я незамедлительно захотел его протестировать, благо установка выполняется тремя... | https://habr.com/ru/post/177775/ | null | ru | null |
# Введение в детерминированные сборки на С/С++. Часть 1
*Перевод статьи подготовлен специально для студентов курса [«Разработчик С++»](https://otus.pw/6G2d/).*

---
### Что такое детерминированная сборка?
Детерминированная сборк... | https://habr.com/ru/post/467741/ | null | ru | null |
# Отучаем Chrome кушать винчестеры
Нравится мне Chrome, но надоело мне что он скрипит винчестером так как будто они не ломаются. Решил я его отучить это делать. Получилось, теперь делюсь рецептурой.
Зачем? Во-первых, винчестер — не железный, в смысле — железный, конечно, но ломаться умеет и чем больше его долбят —... | https://habr.com/ru/post/61616/ | null | ru | null |
# Лазерное шоу своими руками. Часть 2
Теперь, когда вы прочитали(или не прочитали) всю эту скучную теорию из [первой части](http://habrahabr.ru/post/176527/) – займёмся практическими экспериментами. Если у вас в хозяйстве завалялся аналоговый осциллограф, то вы сможете не прилагая почти никаких усилий вывести на него ... | https://habr.com/ru/post/176539/ | null | ru | null |
# Внешняя сортировка с O(1) дополнительной памяти
Прочитав [эту статью](http://habrahabr.ru/post/266557/), я вспомнил, как писал внешнюю сортировку, которая использовала O(1) внешней памяти. Функция получала бинарый файл и максимальный размер памяти, которую она могла выделить под массив:
```
void ext_sort(const st... | https://habr.com/ru/post/268535/ | null | ru | null |
# Автоматизация поддержания соответствия между названиями слоев в редакторе и коде с помощью CodeDom
При работе с [Unity](https://unity3d.com/ru/) очень часто приходится обращаться к сущностям Unity (слоям коллизий, сортировочным слоям, тэгам, осям ввода, сценам) по их названиям. Если какую-то из них, например, переим... | https://habr.com/ru/post/309128/ | null | ru | null |
# «И швец и жнец» или обзор полезных расширений для XWiki

Вот уже второй год, как мы используем XWiki вместо Confluence.
За это время я к ней привык и даже в некотором роде полюбил. Поэтому не могу пройт... | https://habr.com/ru/post/708792/ | null | ru | null |
# Чистая архитектура в Python: пошаговая демонстрация. Часть 2

**Содержание*** [Часть 1](https://habrahabr.ru/post/319126/)
* *Часть 2*
* [Часть 3](https://habrahabr.ru/post/319898/)
* [Часть 4](https://habrahabr.ru/post/32... | https://habr.com/ru/post/319202/ | null | ru | null |
# Самые простые фракталы на JavaScript
Представляю сообществу страничку на JavaScript, которая позволяет строить, рисовать, создавать простые фрактальные фигуры, основанные на самоподобии. На самом деле это мой первый опыт использования HTML/CSS/JS. При обширном опыте программирования, я до сих пор пропускал веб-разра... | https://habr.com/ru/post/187780/ | null | ru | null |
# Вышел FindBugs 3.0.1

Новая версия FindBugs [доступна для скачивания](https://sourceforge.net/projects/findbugs/) на официальном сайте. Несмотря на то что поменялась только третья цифра в номере версии, в... | https://habr.com/ru/post/251749/ | null | ru | null |
# npm для простых смертных

Эта статья предназначена для тех, кто не очень дружит с Node.js, но хочет использовать приложения вроде Grunt, Gulp и тому подобные. Процесс работы с этими приложениями подразумевает редактирован... | https://habr.com/ru/post/243335/ | null | ru | null |
# Natas Web. Прохождение CTF площадки, направленной на эксплуатацию Web-уязвимостей

В данной статье мы разберемся с эксплуатацией некоторых WEB-узвимостей на примере прохождения варгейма [Natas](http://overthewire.org/wargames/... | https://habr.com/ru/post/464111/ | null | ru | null |
# Насколько крепка дружба между Java и С внутри Dalvik VM?
 В данной статье попытался очень подробно описать свои шаги при исследовании кода андроида и его выполнения в Dalvik VM. Мне было очень интересно узнать... | https://habr.com/ru/post/126356/ | null | ru | null |
# 14 вещей, которые я хотел бы знать перед началом работы с MongoDB
***Перевод статьи подготовлен в преддверии старта курса [«Нереляционные базы данных»](https://otus.pw/ZRL1/).***

---
Основные моменты:
* Крайне важно разрабо... | https://habr.com/ru/post/520412/ | null | ru | null |
# Calltracking в Minecraft или как быстро сделать трехмерный UI
Пару месяцев назад назад я показал детям Minecraft, а чуть позже — купил им [книгу](https://habrahabr.ru/company/piter/blog/269757/) по программированию в MineCraft. Правда, детям купил, чес-слово. Ну сам взял полистить, ну написал пару скриптов…
На эт... | https://habr.com/ru/post/278995/ | null | ru | null |
# CS Cart или через терни к черной дыре костылей и оптимизаций
Совсем недавно, я стал разработчиком модулей для CS Cart. Случилось это по воле случая: меня взяли на работу в Петербургскую сеть интернет магазинов, торгующих вейпами и всякими интересными штуками для удовлетворения потребностей физического характера стра... | https://habr.com/ru/post/558778/ | null | ru | null |
# Russian AI Cup 2017 — история второго места
Привет! В этой статье я хотела бы рассказать вам о своем участии в соревновании по написанию игровых ботов [Russian AI Cup](http://russianaicup.ru/) CodeWars, на котором мне удалось занять 2 место, и что и как для этого было сделано.

У меня есть много [хобби-проектов](https://github.com/aschmelyun?tab=repositories) в GitHub. Некоторые из них довольно популярны, поэтому к ним время от времени постят issues. Проблема в ... | https://habr.com/ru/post/675874/ | null | ru | null |
# Хватит делать сайты с бесконечной прокруткойǃ
TL;DR. Хотя бесконечная прокрутка подходит для некоторых случаев, но она может создать проблемы.
Бесконечная прокрутка может быть дезориентирующей, неконт... | https://habr.com/ru/post/427615/ | null | ru | null |
# Получение root доступа к смарт-телевизорам LG на ОС webOS
**Обновление поста от 04.11.2022 г.**
LG заблокировала данный способ получения рута, новый вариант доступен [тут](http://webos-forums.ru/post158462.html#p158462).
Наверное, многие слышали про получение рут доступа к девайсам на Android. Благодаря ему вы... | https://habr.com/ru/post/335504/ | null | ru | null |
# Креативное использование веб-шрифтов

С помощью CSS-магии мы можем создавать красивые типографические эффекты и забыть о использовании изображений, в большинстве случаев. В этой статье мы создадим ряд симпатичных приме... | https://habr.com/ru/post/151453/ | null | ru | null |
# Не CDN единым
В последнее время стало модно говорить о доступности при разработке сайтов, писать rel, alt, делать версию для слабовидящих и так далее, однако почему бы сначала не подумать о нормальных пользователях. Подключая jQuery из CDN:
```
```
… многие забывают очень важную деталь.
Конечно же, нужно не... | https://habr.com/ru/post/250663/ | null | ru | null |
# Новости из мира OpenStreetMap № 483 (15.10.2019-21.10.2019)
[Картографируют каждый божий день](https://osmstats.neis-one.org/?item=boards) [1](#wn483_21154) | [altogetherlost.com](http://altoge... | https://habr.com/ru/post/473888/ | null | ru | null |
# Задача о 8-ми ферзях. Свежий взгляд. Шаг первый. Сокращаем количество шагов перебора в три раза
Казалось бы, что можно добавить на тему о популярной задачке о расстановке ферзей на шахматной доске стандартной размерности 8x8 клеток? Но как оказалось и тут можно внести свою толику программистской мысли.
Классически ... | https://habr.com/ru/post/679200/ | null | ru | null |
# Tips and Tricks по программированию на Android

Летом друг подкинул пару заказов по разработке для Android. Первое это streaming проигрыватель видео для одного французского телевидени... | https://habr.com/ru/post/78570/ | null | ru | null |
# Свой tor2web-сервис при помощи Nginx и Lua

Обсудим, как сделать шлюз из Интернета в скрытые сайты Tor.
Сеть [Tor](https://www.torproject.org) — это система прокси-серверов, позволяющая устанавливат... | https://habr.com/ru/post/243055/ | null | ru | null |
# Новый алгоритм трассировки пути для оптимизации работы GPU: Wavefront Path Tracing

В этой статье мы исследуем важную концепцию, используемую в недавно выпущенной платформе Lighthouse 2. [Wavefront path tracing](https://research.nv... | https://habr.com/ru/post/461017/ | null | ru | null |
# Google Earth Engine (GEE) как общедоступный суперкомпьютер
Сервис [Google Earth Engine](https://code.earthengine.google.com) предоставляет возможность бесплатно работать с огромными массивами пространственной информации. К примеру, в считанные минуты можно получить композитную мозаику (сборное изображение) по миллио... | https://habr.com/ru/post/548292/ | null | ru | null |
# Поточная конвертация баз Firebird 2.5 в формат ODS12 (Firebird 3.0)
У каждой версии Firebird есть собственная версия формата дисковых структур базы данных – O(n)D(isk)S(tructure). До версии 2.5 включительно, движок Firebird мог работать с ODS предыдущих версий, то есть базы от старых версий открывались новой версией... | https://habr.com/ru/post/445204/ | null | ru | null |
# Операция «B.A.T.M.A.N.»: добавление модулей ядра в Yocto на Intel Edison
Недавно меня спросили о том, как добавить поддержку batman-adv в Yocto. В результате завязалась переписка, которая стала основой для этого поста. Итак, как же это сделать? Давайте разбираться вместе.
[ — всё в тума... | https://habr.com/ru/post/532628/ | null | ru | null |
# Postgresso 8-9 (45-46)

*По некоторым причинам этот номер сдвоенный, дальше Postgresso продолжит выходить в обычном, ежемесячном режиме.*
---
### Релизы Postgres
#### PostgreSQL 15 — Beta 3-4, RC 1-2 и, теперь GA
Свершилось... | https://habr.com/ru/post/683810/ | null | ru | null |
# MPCMeter — индикация прогресса просмотра видео. Arduino + JavaScript
#### **Вместо введения**
Спасибо моему анонимному хабрадедуморозу за [подарочек](http://habrahabr.ru/post/249843/#comment_8278907) (*pro mini*). Долго колебался, что с ней делать. Махнул рукой и заказал в дополнение китайскую посылочку…
Спустя ... | https://habr.com/ru/post/254911/ | null | ru | null |
# Оптимизация сайта для GooglePage Speed (учтены все особенности после его обновления) Часть 1
Эта статья будет интересна, кто столкнулся с разного рода проблемами после обновления Google PageSpeed и претензиям со стороны заказчиков или начальника, почему упал бал или возникло такое количество замечаний. А так же тем,... | https://habr.com/ru/post/436966/ | null | ru | null |
# Новые источники данных для Teiid, часть 1: используем DDL
Те, кто сталкивались с необходимостью объединения нескольких источников данных, наверное, уже знают о [JBoss Teiid](http://www.jboss.org/teiid "JBoss Teiid"), вводная статья о нём есть даже на [хабре](http://habrahabr.ru/post/142580/). Коротко говоря, эта сис... | https://habr.com/ru/post/150765/ | null | ru | null |
# Введение в HDInsight
HDInsight Services for Windows Azure — это сервис, позволяющий работать с кластером Apache Hadoop в Облаке, предоставляющий программную среду для операций управления, анализа и отчетности по Большим Данным.
Я не буду подробно останавливаться на возможностях Hadoop. Он был впервые представлен... | https://habr.com/ru/post/165185/ | null | ru | null |
# Пишем кроссбраузерный UserJS. Пример №2: переопределяем alert()
Начало: [Пример №1: меняем логотип Яндексу](http://habrahabr.ru/blogs/GreaseMonkey/73901/)
Прошлый раз меня спросили: "[А из UserJS есть доступ к переменным страницы?](http://habrahabr.ru/blogs/GreaseMonkey/73901/#comment_2129699)".
Ответ: да.
... | https://habr.com/ru/post/73928/ | null | ru | null |
# Новая система nooLite-F с обратной связью и шифрованием

На днях в лабораторию Hi-Lab.ru поступили модули новой системы **nooLite-F** компании [Ноотехника](http://www.noo.com.by/) для тестирования и интеграции с ... | https://habr.com/ru/post/370383/ | null | ru | null |
# Импортозамещение на практике. Часть 6. Пользовательские рабочие места
Эта статья довольно долго не могла увидеть свет, по ряду причин, от проблем со здоровьем после COVID (я отупел), до отсутствия времени. ... | https://habr.com/ru/post/695284/ | null | ru | null |
# Интеграция CI/CD для нескольких сред с Jenkins и Fastlane. Часть 1
> В преддверии старта курса ["iOS Developer. Basic"](https://otus.pw/xhV24/) традиционно подготовили для вас интересный перевод, а также приглашаем записаться на бесплатный вебинар, в рамках которого наши эксперты подробно расскажут о программе курса... | https://habr.com/ru/post/526394/ | null | ru | null |
# Установка и настройка: Nginx + php5-fpm
В данной заметке, будет показано как поставить связку Nginx + php5-fpm (php5.3) на Debian Lenny и настроить безопасную конфигурацию.### Установка и настройка
**Важно:** все команды от root'а.
Добавляем репозитарии и генерируем ключи:
>
> ```
> echo "deb http://backports... | https://habr.com/ru/post/113101/ | null | ru | null |
# Заметки о Unix: небольшая странность семейства вызовов exec*()
Я недавно [писал](https://utcc.utoronto.ca/~cks/space/blog/unix/FindExecImplementationShows) об опции `-exec` команды `find` и ненароком упомянул о «семействе системных вызовов `exec()`». Это — странное выражение, обычно о Unix-вызовах так не говорят, та... | https://habr.com/ru/post/553070/ | null | ru | null |
# NiFi по красоте: HTTPS/LDAP/NiFi Registry/NiFi Cli + CI/CD
### Вступление
Давайте, я сразу объясню свою баянистость. Да, в интернетах полно мануалов. Да, полно пошаговых прохождений. Да, можете сказать, что все жевано пережевано. Но конкретно в моем случае, как это всегда и бывает, оказалась горстка "но":
Есть ман... | https://habr.com/ru/post/553756/ | null | ru | null |
# Анонс Rust 1.0
Сегодня мы с гордостью представляем [релиз Rust версии 1.0](https://github.com/rust-lang/rust/blob/master/RELEASES.md#version-100-may-2015), нового языка программирования для создания более надёжных и эффективных систем. **Раст объединяет в себе низкоуровневый контроль над производительностью с удобст... | https://habr.com/ru/post/258069/ | null | ru | null |
# Please come back to me in Casablanca

Несколько недель назад Microsoft презентовал свою новую разработку — проект Casablanca. Для того, чтобы понять что это, нужно вернуться еще чуть дальше в прошлое, к прошедшей конфе... | https://habr.com/ru/post/144925/ | null | ru | null |
# Что такое AXON
[AXON](http://intellimath.bitbucket.org/axon) — это нотация для сериализованного представления объектов, документов и данных в текстовой форме. Она объединяет в себе *простоту* [JSON](http://www.json.org), *расширяемость* [XML](http://www.w3.org/xml) и *удобочитаемость* [YAML](http://www.yaml.org).
... | https://habr.com/ru/post/304516/ | null | ru | null |
# Цифровая фильтрация на ПЛИС – Часть 2
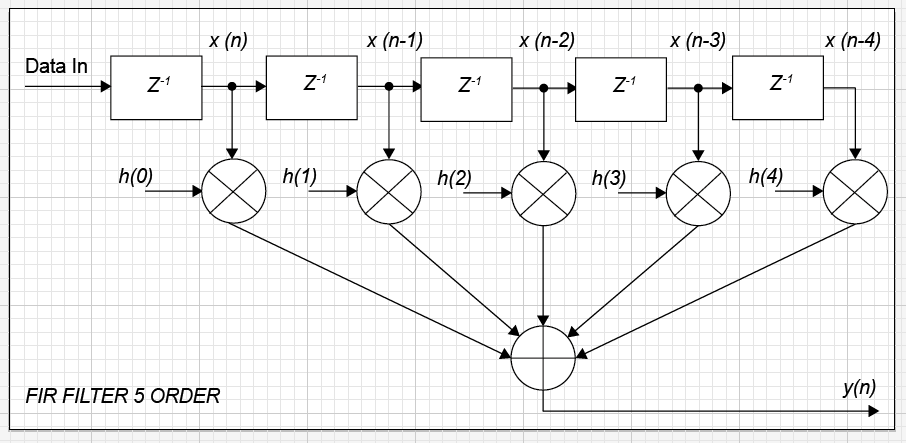
Всем привет!
Это вторая публикация на тему «Цифровая фильтрация на ПЛИС». Вторая часть будет посвящена практической реализации КИХ фильтров на FPGA. В процессе подготовки материал... | https://habr.com/ru/post/274847/ | null | ru | null |
# Домашка по арифметике
*Лёшенька, Лёшенька, сделай одолжение!
Выучи, Алёшенька, таблицу умножения !*
**Агния Барто**

Сначала задачка для первоклассника. Дано некоторое положительное число. Нужно умножить на него другое ... | https://habr.com/ru/post/485786/ | null | ru | null |
# Visual Studio Mobile Center: Деплоим мобильный софт с помощью devops-конвейера Microsoft
В [прошлой статье](https://habrahabr.ru/company/microsoft/blog/325184/) мы рассмотрели автоматизацию сборки мобильных приложений с помощью Bitrise, разобрались со сборкой Android- (и iOS-) приложения, подключили Xamarin Test Clo... | https://habr.com/ru/post/329908/ | null | ru | null |
# Обзор ECMAScript 6, следующей версии JavaScript
Для начала, ликбез и несколько фактов:
* ECMAScript — это официальный стандарт языка JavaScript (Слово JavaScript не могло быть использовано, потому что слово Java являлось торговой маркой компании Sun) Т.е. JavaScript — это имплементация стандарта ECMAScript.
* TC3... | https://habr.com/ru/post/175371/ | null | ru | null |
# «Kubernetes как часть data platform»
Привет, Хабр! Меня зовут Денис, в компании oneFactor я занимаю позицию архитектора, и одна из моих обязанностей — это развитие технического стека компании. В этой статье я расскажу про нашу data platform’у (далее просто DP или платформа) и про мотивацию внедрения в неё Kubernetes... | https://habr.com/ru/post/671334/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.