
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Джавапокалипсис в отдельно взятой системе
*Эта статья ориентирована на ABAP-разработчиков в системах SAP ERP. Она содержит много специфических для платформы моментов, которые малоинтересны или даже спорны для разработчиков, использующих другие платформы.*
Есть такой эвфемизм: “исторически сложилось”.
Так вот, ... | https://habr.com/ru/post/275477/ | null | ru | null |
# Настройка аутентификации в сети L2TP с помощью Рутокен ЭЦП 2.0 и Рутокен PKI

Проблематика
============
Ещё совсем недавно многие не знали, как это — работать из дома. Пандемия резко изменила ситуацию в мире, все начали адаптирова... | https://habr.com/ru/post/506256/ | null | ru | null |
# Курс по Ruby+Rails. Часть 5. Паттерн MVC
MVC — это главный архитектурный принцип, вокруг которого строится не только Ruby on Rails, но и любой другой фреймворк, работающий со сложными структурами данных и и... | https://habr.com/ru/post/695880/ | null | ru | null |
# Добавляем в Go-проект конфигурацию на языке Terraform
Конфигурирование приложений — это интересная тема. Мало того, что форматов конфигурации в сообществе инженеров много, ситуация осложняется тем, что выбор того или иного языка определяет, как вашим приложением будут пользоваться люди. Инженеры, которые будут выкла... | https://habr.com/ru/post/692814/ | null | ru | null |
# Использование gpio-generic и irq_chip_generic для драйвера gpio
Данная статья является логичным продолжением предыдущей и её прочтение рекомендуется после ознакомления с [предшествующим материалом](https://habrahabr.ru/post/303060/). Текущая заметка необходима для понимания последующего материала, дополнительного по... | https://habr.com/ru/post/307840/ | null | ru | null |
# Кастомный ExpandableListView в Android
В данной статье хочу привести небольшой пример работы с кастомизацией **ExpandableListView** — двухуровневого списка.
То, что должно получиться в итоге
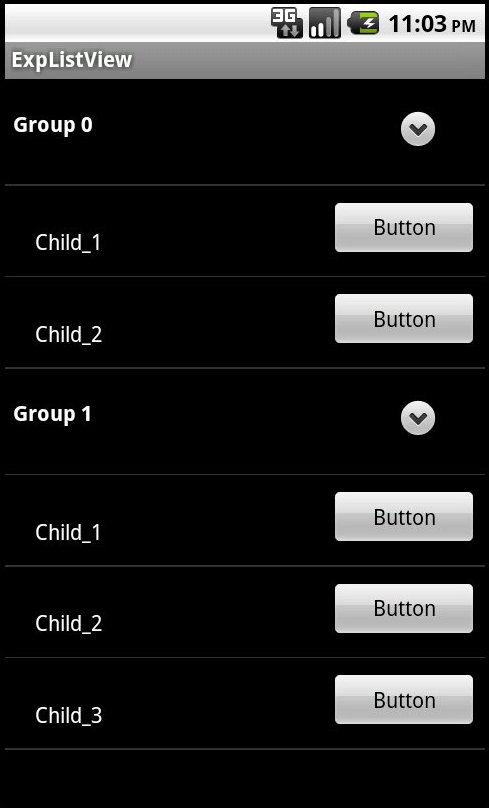
Приступим, соз... | https://habr.com/ru/post/147546/ | null | ru | null |
# Оптимизация и Generics в CLR
 *В этой статье Джон Скит будет описывать как простейшие конструкции языка замедляют вашу программу и как их можно ускорить.*
Как и в любой работе, сваязанной с производительностью приложе... | https://habr.com/ru/post/144193/ | null | ru | null |
# Добавление скриптинга в программу с помощью Lua

Lua это мощный, быстрый, легкий, встраиваемый язык сценариев. С его помощью можно легко и быстро добавить поддержку скриптинга в вашу программу.
Это может понад... | https://habr.com/ru/post/74382/ | null | ru | null |
# Salesforce Apex – как первый язык программирования. Плюсы и минусы
Моим первым языком программирования стал Apex. Это Java-подобный язык, который автоматизирует backend-логику в приложения на платформе [Salesforce.com](https://www.salesforce.com/).
Нельзя сказать, что я до этого не был знаком с ООП или другими язы... | https://habr.com/ru/post/536814/ | null | ru | null |
# TypeScript: не выходите за рамки
О том, как снизить риск дефектов программы на TypeScript, величину технического долга проекта и, одновременно, улучшить читаемость кода TypeScript.
### Фабрика кэша
Вычислив объект, нужный для работы программы, вы сталкиваетесь с характерным рисунком своих желаний: значение хочется... | https://habr.com/ru/post/654241/ | null | ru | null |
# Как генерировать правильную подпись (SIG) в API OK.RU. Работаем с ошибкой 104
Не так давно я столкнулся с трудностью. У меня не получалось при запросе по API в OK.RU (одноклассники) создать правильную SIG (ошибка 104). Как оказалось, я не единственный такой был, предлагаемые в сети рецепты не очень работали (провери... | https://habr.com/ru/post/468315/ | null | ru | null |
# Корректное завершение работы pod’ов в Kubernetes-кластере

*Корректное завершение работы контейнеров в Kubernetes*
Это вторая часть [нашего пути](https://habr.com/ru/company/nixys/blog/489164/) (при... | https://habr.com/ru/post/489992/ | null | ru | null |
# DBX: попытка избавиться от составления MySQL запросов
Давным давно, когда я только начинал изучать PHP и тонкости составления запросов MySQL (2011 год) у меня возникла мысль написать обертку для MySQLi наподобие Doctrine для упрощения синтаксиса обращения к базе данных. На дворе уже 2019 и решил поделиться своим вел... | https://habr.com/ru/post/438762/ | null | ru | null |
# Инвентаризация в компании: Установка GLPI


. Есть продукты на любой вкус: хочешь прогу, чтобы просто конвертировать электронные презентации в HTML5? Да пожалуйста! Хочешь делать одностранични... | https://habr.com/ru/post/509234/ | null | ru | null |
# Истории аварий с Patroni, или Как уронить PostgreSQL-кластер
В PostgreSQL нет High Availability из коробки. Чтобы добиться HA, нужно что-то поставить, настроить — приложить усилия. Есть несколько инструментов, которые помогут повысить доступность PostgreSQL, и один из них — Patroni.
На первый взгляд, поставив Pat... | https://habr.com/ru/post/489206/ | null | ru | null |
# Python: коллекции, часть 3/4: объединение коллекций, добавление и удаление элементов
| [Часть 1](https://habrahabr.ru/post/319164/ "Python: коллекции, часть 1/4: классификация, общие подходы и методы, конвертация") | [Часть 2](https://habrahabr.ru/post/319200/ "Python: коллекции, часть 2/4: индексирование, срезы, со... | https://habr.com/ru/post/319876/ | null | ru | null |
# Составляем документацию разработчика пошагово без диет и тренировок
Недостаточно просто написать инструкции — важно, как, в каком порядке и где вы их разместите.
Привет! Это Теодора — технический писатель Платформы, жизненно важного департамента Ozon. Документация для нас имеет большое значение, потому что вся ком... | https://habr.com/ru/post/687024/ | null | ru | null |
# Эксперименты над олимпиадной задачей
Так получилось, что я попал в магистратуру, и как то гуляя мимо кафедры на глаза попалась олимпиадная задача по 1С. Кратко задача звучит так: «Есть записи продажи за каждый день, необходимо найти наибольший период когда план выполнялся». А потом когда я гулял со спящей дочкой у м... | https://habr.com/ru/post/327862/ | null | ru | null |
# Компенсация подсветки телевизора
[](https://habr.com/ru/company/ruvds/blog/693268/)
При просмотре телевизора я постоянно вижу красный. В прямом смысле – подсветка моего Panasonic частично не работает, что вызывает неравномерное роз... | https://habr.com/ru/post/693268/ | null | ru | null |
# В поисках пропавшего программиста. Новогодний квест

Всем здравствуйте.
Вот в преддверии нового года решил написать, такой экспериментально развлекательный пост-квест. Сил на серьезную статью уже нет, и мысленно находясь уже на ... | https://habr.com/ru/post/481956/ | null | ru | null |
# Обзор python-пакета yadirstat — самый простой способ получить статистику из API Яндекс Директ
Здравствуйте, мне приходится собирать статистику из Яндекс Директ и, чтобы упростить работу, я опубликовал свой python-пакет, с помощью которого это можно делать очень просто.
*Сначала вам следует получить токен для свое... | https://habr.com/ru/post/512902/ | null | ru | null |
# Sapper: Royal Engineer
Хабраразработчики, приветствую!
В данном посте я расскажу «историю» разработки и публикации первой нашей игры: как рисовался дизайн, как разрабатывали, с какими трудностями столкнулись, почему StackOverflow лучше Apple Dev Forums и т.д.
Игра делалась с целью формирования механизмов взаи... | https://habr.com/ru/post/221519/ | null | ru | null |
# Реализация простого видеочата на ASP.NET MVC

Доброго времени суток, господа хабраюзеры!
В данном топике я расскажу, как можно сделать простой видео-чат на ASP.NET MVC.
Но для начала предыстория. Мы запускаем серв... | https://habr.com/ru/post/154455/ | null | ru | null |
# Ещё немного про телефоны Xiaomi и борьбу с ними. Updated

Честно признаться, у меня не было планов писать и публиковать эту статью, но, после того, как за два месяца увидел в ближнем кругу коллег 5 ... | https://habr.com/ru/post/320612/ | null | ru | null |
# Что нового в Selenium 4 — ключевые особенности и отличия
Сегодня для каждого бизнеса требуется высококачественное программное обеспечение в сжатые сроки, чтобы достигнуть этого организациям необходимо прово... | https://habr.com/ru/post/649615/ | null | ru | null |
# QtCreator: Qt кросс-компиляция из linux 64 в linux 32, win32, win64 и Mac OS X; upx, usb, dmg, etc

Библиотека [Qt](http://qt-project.org/) позволяет делать действительно кроссплатформенные приложения. Ед... | https://habr.com/ru/post/198142/ | null | ru | null |
# Справа налево. Как перевернуть интерфейс сайта под RTL

Мы недавно перевели онлайн-версию 2ГИС на арабский язык, и в [прошлой статье](https://habr.com/company/2gis/blog/358148/) я рассказал о необходимой для этого теории — что... | https://habr.com/ru/post/416635/ | null | ru | null |
# Вышел релиз GitLab 13.0 с кластерами Gitaly, иерархией эпиков на дорожных картах и автоматическим развертыванием для ECS

Что изменилось со времени 12.0
-------------------... | https://habr.com/ru/post/506658/ | null | ru | null |
# Профайлинг NUnit-тестов .NET Framework 4

С профайлингом приложений наверняка сталкивался каждый, но как часто вам приходилось профайлить тесты?
Как показал мой личный опыт, чтобы успешно выполнить эту задачу для сборки, соб... | https://habr.com/ru/post/128338/ | null | ru | null |
# Глубокое обучение для новичков: распознаем рукописные цифры
Представляем первую статью в серии, задуманной, чтобы помочь быстро разобраться в технологии *глубокого обучения*; мы будем двигаться от базовых принципов к нетривиальным особенностям с целью получить достойную производительность на двух наборах данных: MNI... | https://habr.com/ru/post/314242/ | null | ru | null |
# Пятничный JS: единственно верный способ вычисления факториала
### Введение
Вычисление факториала — одна из традиционных программистских задач для собеседований. Если вдруг кто забыл, факториал натурального числа N обозначается как N! и равняется произведению всех натуральных чисел от единицы до N включительно. Напр... | https://habr.com/ru/post/327544/ | null | ru | null |
# Stimulus 1.0: скромный JavaScript фреймворк для HTML, который у вас уже есть
*От переводчика: [Давид Хейнемейер Ханссон](https://twitter.com/dhh) написал небольшой текст о том, почему он и его команда Ruby on Rails разработала свой собственный Javascript фреймворк. [Оригинал текста](https://github.com/stimulusjs/sti... | https://habr.com/ru/post/346132/ | null | ru | null |
# От Java 8 до Java 15 за 10 минут
Данный пост является [переводом статьи](https://medium.com/swlh/from-java-8-to-java-15-in-ten-minutes-f42d422a581e) с некоторыми уточнениями.
В этой статье я хочу рассмотреть основные возможности, добавленные в Java начиная с 7 версии по 15. Я затрону как минимум одно крупное улучше... | https://habr.com/ru/post/589605/ | null | ru | null |
# Подробное руководство по инверсии зависимостей. Часть 1
Инверсия зависимостей - один из принципов SOLID, который лежит в основе построения гексагональной архитектуры приложения. Существует множество статей... | https://habr.com/ru/post/582588/ | null | ru | null |
# Мобильные сервисы, блобы и Windows 8. Храним данные в облаке

Добрый день.
Мы живем в мире тотальной глобализации как в реальной жизни, так и в виртуальной. Я имею в виду, что нам хочется иметь одни и те же данные, о... | https://habr.com/ru/post/157641/ | null | ru | null |
# Vulkan. Руководство разработчика. Краткий обзор

Я работаю техническим переводчиком ижевской IT-компании CG Tribe, которая предложила мне внести свой вклад в сообщество и начать публиковать переводы интересных статей и руководств. ... | https://habr.com/ru/post/524992/ | null | ru | null |
# Особенности получения пакетов через raw socket в Linux

Linux (в отличии, к примеру, от FreeBSD) позволяет использовать сырые сокеты не только для отправки, но и для получения данных. В этом месте существуют интересные ... | https://habr.com/ru/post/183316/ | null | ru | null |
# Learn OpenGL. Урок 6.1. PBR или Физически-корректный рендеринг. Теория

Физически-корректный рендеринг
------------------------------
PBR, или физически-корректный рендеринг (physically-based rendering) это набор техник... | https://habr.com/ru/post/426123/ | null | ru | null |
# У нас проблемы с промисами
*Разрешите представить вам перевод статьи Нолана Лоусона «[У нас проблемы с промисами](http://pouchdb.com/2015/05/18/we-have-a-problem-with-promises.html)», одной из лучших по теме из тех, что мне доводилось читать.*
### У нас проблемы с промисами
Дорогие JavaScript разработчики, наста... | https://habr.com/ru/post/269465/ | null | ru | null |
# Strategy Design Pattern
Всем привет, друзья. Меня зовут **Alex**, я профессиональный разработчик и создатель программных продуктов в веб индустрии. Много лет изучаю языки, делюсь опытом с другими.
Сегодня хочу с вами поговорить про шаблон проектирования **Стратегия (Strategy).** Постараюсь донести до вас принципы ... | https://habr.com/ru/post/552278/ | null | ru | null |
# Ubiquitous Language и Bounded Context в DDD
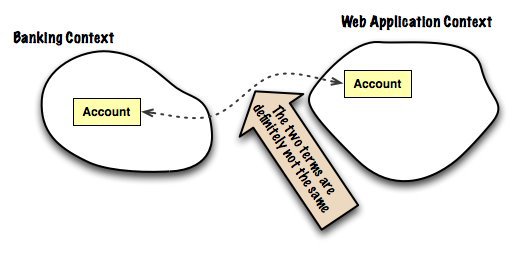
[Domain-Driven Design: Tackling Complexity in the Heart of Software](http://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software/dp/0321125215) Эванса — лучшая книг... | https://habr.com/ru/post/232881/ | null | ru | null |
# Получение root на роутере Tenda Nova MW6
Началось всё с того, что польстившись на распродажу и новые buzz words — я приобрел wifi mesh систему, дабы покрыть все уголки загородного дома и прилегающего участка. Все бы ничего, но одна проблема раздражала. А с учетом того, что я сел на больничный на несколько дней — дов... | https://habr.com/ru/post/460591/ | null | ru | null |
# .Net: Затраты на многопоточность
Недавно получил простую задачу: написать windows-сервис для обработки пользовательских запросов. Вопрос про то, какие эти запросы и по какому протоколу работает сервис, выходит за рамки этой статьи. Более интересным мне показался другой фактор, многопоточную ли делать обработку запро... | https://habr.com/ru/post/58931/ | null | ru | null |
# Пять простых шагов для понимания JSON Web Tokens (JWT)

Представляю вам мой довольно вольный перевод статьи [5 Easy Steps to Understanding JSON Web Tokens (JWT)](https://medium.com/vandium-software/5-ea... | https://habr.com/ru/post/340146/ | null | ru | null |
# EDC-устройство для сисадмина: Linux в кармане
У каждого админа, пожалуй, был случай, когда что-то внезапно ломается, а ты где-нибудь в дороге: едешь на машине, садишься на поезд или, банально, сидишь где-то на скамейке в парке и срываться и куда-то нестись желания нет ни малейшего. А чинить надо. Или, как минимум, о... | https://habr.com/ru/post/409945/ | null | ru | null |
# Какова оптимальная длина пароля?
Конечно, чем больше, тем лучше. И с помощью менеджера паролей можно очень легко генерировать и автоматически заполнять пароли любой длины. Но нужно ли делать пароли длиной в сотни символов, или есть какой-то эмпирический разумный минимум?
Вот интерфейс типичного [генератора пароле... | https://habr.com/ru/post/515064/ | null | ru | null |
# Обзор примера применения обучения с подкреплением с использованием TensorFlow
Всем привет!
Я думаю, что многие слышали о [Google DeepMind](http://deepmind.com/). О том как они... | https://habr.com/ru/post/274597/ | null | ru | null |
# Модули Laurent и Умный дом (часть 2). Arduino и AMS
Это вторая статья из цикла о интеграции модулей Laurent (Лоран) компании [KernelChip](http://www.kernelchip.ru/) в системы домашней автоматизации и в этой части речь пойдёт об интеграции этих модулей с экосистемой Ардуино. В [первой части](http://geektimes.ru/post/... | https://habr.com/ru/post/387205/ | null | ru | null |
# Возможно, вам не нужен Kubernetes

*Девушка на скутере. Иллюстрация [freepik](https://www.freepik.com/free-photos-vectors/car), логотип Nomad от [HashiCorp](https://www.nomadproject.io/)*
Kubernetes — это 300-... | https://habr.com/ru/post/445030/ | null | ru | null |
# Визуализация статических и динамических сетей на R, часть 1
Очень многие системы и явления представимы в виде сетей, т.е. набора объектов и связей между ними. Сеть — не только абстракция, но и наглядный инструмент визуализации данных. Можно отобразить важность того или иного объекта, вес каждой связи, указать ключев... | https://habr.com/ru/post/262079/ | null | ru | null |
# Мега-Учебник Flask, Часть XIII: I18n и L10n (издание 2018)
### *Miguel Grinberg*
---
 [Туда](https://habrahabr.ru/post/349604/) [Сюда](https://habrahabr.ru/post/350626/) 
По работе пришлось столкнуться с задачей обработки xls файлов средствами python. Немного по гуглив, я натолкнулся на несколько библиотек, с пом... | https://habr.com/ru/post/99923/ | null | ru | null |
# Умные погодные приложения с Flink SQL
Иногда требуется получать, маршрутизировать, преобразовывать, запрашивать и анализировать все данные о погоде в Соединенных Штатах - по мере появления этих данных. С FL... | https://habr.com/ru/post/547050/ | null | ru | null |
# OAuth аутентификация в приложении Flask
Эта статья является бонусом к новому циклу статей [Flask Mega-Tutorial (2018)](https://habrahabr.ru/post/346346/).
Автор тот же Мигель Гринберг. Статья не новая, но не утратила своей актуальности.
[blog.miguelgrinberg.com](http://blog.miguelgrinberg.com "blog.miguelgrinbe... | https://habr.com/ru/post/346918/ | null | ru | null |
# Как не создать с нуля криптовалюту за 3 года

В этой статье я опишу то, как я один написал криптовалюту с нуля, какие интересные технологии я оттуда вынес, с каким опытом ушел и что произошло потом. Это не туториал, а просто... | https://habr.com/ru/post/505330/ | null | ru | null |
# Padding Oracle Attack: криптография по-прежнему пугает
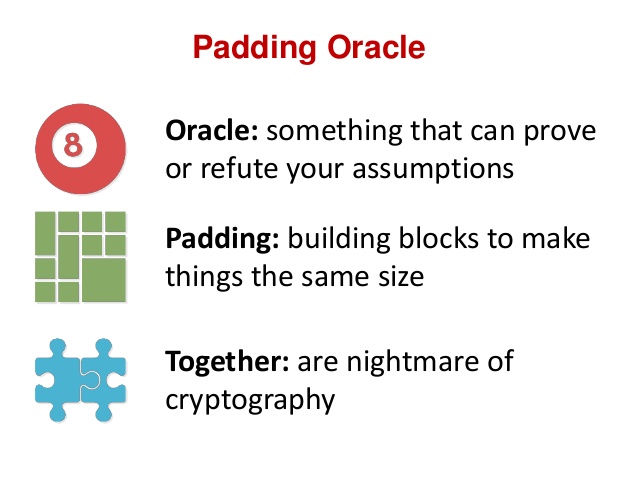### Эту уязвимость чинят уже пятнадцать лет
В хабрапереводе текста четырёхгодовалой давности [«Padding Oracle Attack или почему криптография пугает»](... | https://habr.com/ru/post/338072/ | null | ru | null |
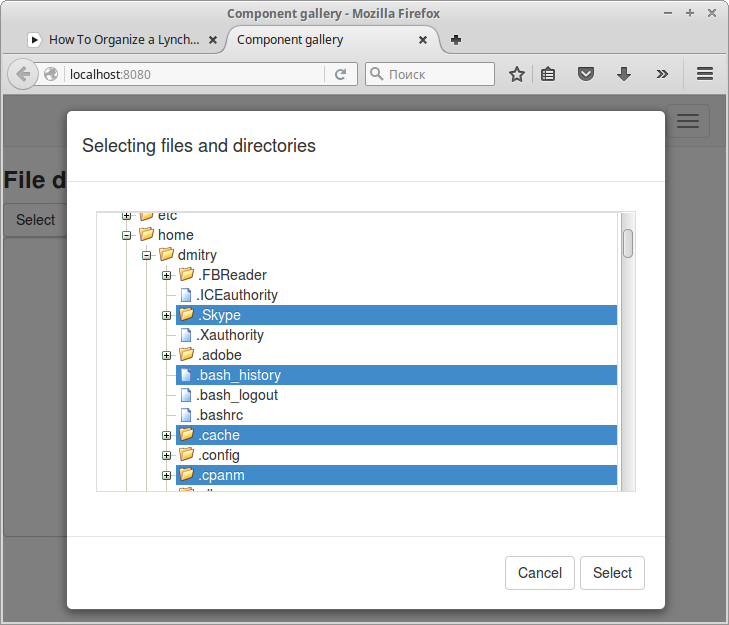
# Диалог выбора файлов на Wt
По работе пришлось сделать несколько своих компонентов на Wt: визард, диалог выбора каталогов и файлов на устройстве. Решил выложить на [GitHub](https://github.com/RPG-18/WtComponents), может ко... | https://habr.com/ru/post/275453/ | null | ru | null |
# Unsafe.AsSpan: Span<T> как замена указателям?

`C#` — невероятно гибкий язык. На нем можно писать не только бэкэнд или десктопные приложения. Я использую `C#` для работы, в том числе, и с научными данными, которые накладывают определ... | https://habr.com/ru/post/465077/ | null | ru | null |
# Surf Studio: машинное обучение в production
*Представляем гостевой пост от компании Surf Studio ([Certified Google Developer Agency](https://developers.google.com/agency/directory/)).*
Привет, Хабр. Меня зовут Александ... | https://habr.com/ru/post/325896/ | null | ru | null |
# Сказ о том, как я Home Assistant настраивал

**Home Assistant** — это популярная система умного дома, которая автоматизирует привычные бытовые процессы и работает на YAML файлах. В этой статье я расскажу, как настроить Home Assistant... | https://habr.com/ru/post/546072/ | null | ru | null |
# Установка Jenkins и Bonobo Git Server под ОС Windows для сборки Android приложений
Добрый день. ~~Не имея времени копаться в Linux~~Столкнувшись с пробелами в информации при поиске по сети инструкций по установке и настройке под ОС Windows сервера непрерывной сборки Jenkins для приложений Android, Git сервера и их и... | https://habr.com/ru/post/313564/ | null | ru | null |
# Защищаем трафик при помощи Comodo TrustConnect и DNSCrypt
Раньше я не уделял должного внимания шифрованию, так как данные передаваемые в общественных местах не имели большой важности, но сегодня я увидел в этом и оборотную сторону медали. В институте, как обычно, на паре информатики, студенты сидели вконтакте, хабре... | https://habr.com/ru/post/141825/ | null | ru | null |
# Что происходит, когда вы отправляете SMS
Это третья статья в цикле [full-stack dev](https://scottbot.net/tag/full-stack-dev/) о секретной жизни данных. Она посвящена сложному и длинному маршруту SMS: набор, сохранение, отправка, получение и отображение. Добавлю немного истории и контекст, чтобы разбавить перечень пр... | https://habr.com/ru/post/437510/ | null | ru | null |
# Как мы переходили с InboxSDK на Gmail.js
Для разработки своего решения для поддержки клиентов мы выбрали сервис Gmail, так как это один из самых популярных почтовых клиентов. А для расширения его возможностей — готовую библиотеку InboxSDK. На момент разработки она обладала нужным нам функционалом, и такое решение по... | https://habr.com/ru/post/335874/ | null | ru | null |
# Одним махом 100 миллионов убивахом. Или lock-free распределитель памяти
#### Постановка задачи
Один из алгоритмов, который я реализовывал, имел интересные особенности при работе с памятью:
* Могло выделяться огромное количество, до десятков и сотен миллионов небольших объектов одного типа.
* Объекты представляли... | https://habr.com/ru/post/182722/ | null | ru | null |
# Вред макросов для C++ кода

Язык C++ открывает обширные возможности для того, чтобы обходиться без макросов. Так давайте попробуем использовать макросы как можно реже!
Сразу оговорюсь, что я не являюсь фанатиком и не приз... | https://habr.com/ru/post/444612/ | null | ru | null |
# Вышел React v16.0
Это перевод поста Эндрю Кларка о выходе столь ожидаемой версии React. Оригинальный пост в [блоге React](https://facebook.github.io/react/blog/2017/09/26/react-v16.0.html).
Мы с удовольствием сообщаем о выходе React v16.0! Среди изменений некоторые давно ожидаемые нововведения, например [**фрагмент... | https://habr.com/ru/post/338932/ | null | ru | null |
# Friendly Open Space JS: Рендеринг на стороне клиента и создание враппера
### «Friendly Open Space» — очень молодой фреймворк, но бегать уже умеет :-)
В данной статье по освоению «Friendly Open Space», мы освоим рендеринг шаблона в браузере и запуск приложения на локальной файловой БД.
Ядро фреймворка поддерживае... | https://habr.com/ru/post/473154/ | null | ru | null |
# В Kubernetes 1.21 отключили вывод managed fields для kubectl get
Сегодня наши инженеры заметили, казалось бы, незначительное [изменение](https://github.com/kubernetes/kubernetes/pull/96878) в [Kubernetes 1.21](https://kubernetes.io/docs/setup/release/notes/)… но оно порадовало столь многих внутри компании, что сразу... | https://habr.com/ru/post/556324/ | null | ru | null |
# Чистый код для TypeScript — Часть 1
Наткнувшись на материал по принципам чистый код для [TypeScript](https://github.com/labs42io/clean-code-typescript) и прочитав его решил взяться за его перевод. Здесь я хочу поделиться с вами некоторыми выдержками из этого перевода, так как некоторые моменты чистого кода для TypeS... | https://habr.com/ru/post/484402/ | null | ru | null |
# Вышел GitLab 11.2: предпросмотр в Web IDE и импорт проектов под Android

Мы с воодушевлением представляем вам новые возможности версии 11.2, которые помогут вам быстрее ста... | https://habr.com/ru/post/422473/ | null | ru | null |
# Чистый AutoML для “грязных” данных: как и зачем автоматизировать предобработку таблиц в машинном обучении
Или “Мне бы такую работу, чтобы поменьше работы.”:)
В данном посте хотелось бы затронуть такую очень известную и много где описанную тему как предобработка табличных данных в Data Science. Вы можете задать воп... | https://habr.com/ru/post/657525/ | null | ru | null |
# Никто не умеет обрабатывать ошибки
Из одной книги в другую, из статьи в статью кочует мнение о том, что выражение
```
try {
//do something
}
catch(Exception ex) {
}
```
является плохой практикой. Возврат кодов – также плохая практика. Но становится ли нам, программистам, жить легче с этими знаниями и так уж... | https://habr.com/ru/post/221723/ | null | ru | null |
# Первые шаги в BI-аналитике. Роль Data Engineering
Добрый день, уважаемые читатели! Материал носит теоретический характер и адресован исключительно начинающим аналитикам, которые впервые столкнулись с BI-аналитикой.
Что традиционно понимается под этим понятием? Если говорить простым языком, то это комплексная систем... | https://habr.com/ru/post/555388/ | null | ru | null |
# Как стать Zend PHP 5 Certified Engineer
Свершилось, ура! Теперь [я](http://www.zend.com/store/education/certification/yellow-pages.php#show-ClientCandidateID=ZEND010589) имею почетный статус ZCE :)
Поэтому хотел бы поделиться своим опытом подготовки к сертификации, ну и заодно провести небольшой ликбез на тему [с... | https://habr.com/ru/post/61215/ | null | ru | null |
# PHPixie 3.0 ORM или новый взгяд на ActiveRecord
 Уже закончен долгообещанная третья версия [PHPixie](http://phpixie.com) ORM компонента. Он теперь полностью независим от фреймворка и может спокойно испо... | https://habr.com/ru/post/252305/ | null | ru | null |
# Динамическое создание Windows и Web CRUD-интерфейсов и не только для бизнес приложений с XAF + Entity Framework. Часть 1
У нас есть старенькое веб приложение DXLibrary для учета литературы и поиска интересных пополнений в местной библиотеке, написанное много лет назад за пару часов одним из разработчиков на DevExpre... | https://habr.com/ru/post/271331/ | null | ru | null |
# Как работает ViewEncapsulation и ng-deep в Angular
*Перевод (а точнее оригинал) моей статьи опубликованной* [*здесь*](https://dev.to/mprojs/how-viewencapsulation-and-ng-deep-work-in-angular-5gm1)
Многие A... | https://habr.com/ru/post/665040/ | null | ru | null |
# Сказ о том как я свой REST фреймворк с веб-сокетами писал
Эта статья посвящена очередному REST фреймворку (для Python 3), особенностью которого является использование веб-сокетов для обмена данными между клиентом и сервером. О том откуда пришла идея, с чем мне пришлось столкнулся при написании своей первой библиотек... | https://habr.com/ru/post/274353/ | null | ru | null |
# Использование SPI механизма для создания расширений
Архитектура большинства Java(и не только) приложений сегодня предусматривает возможность расширения функционала посредством различного рода ~~магических~~ воздействий на код. В последнее время это также стало возможно, если использовать какой-нибудь модный [фреймво... | https://habr.com/ru/post/118488/ | null | ru | null |
# Исследователи восстановили утерянную игру для NES с 30-летних дискет

Привет, я основатель Video Game History Foundation Фрэнк Сифалди. Сегодня мы с Ричем Уайтхаусом расскажем вам историю о том, как восстановили и собрали заново *Days of T... | https://habr.com/ru/post/506102/ | null | ru | null |
# OData REST API — мелкие хитрости (часть 3)
Продолжаем серию постов об особенностях использования протокола OData (см. [часть 1](http://habrahabr.ru/company/databoom/blog/262937/), [часть 2](http://habrahabr.ru/company/databoom/blog/263167/) ).
OData оговаривает что объекты можно создавать и апдейтить используя с... | https://habr.com/ru/post/263435/ | null | ru | null |
# Best App Development Practices To Follow In 2020

As per the stats, there were around 6 billion mobile app users in 2018-19. With increased demand for mobile apps, the number of mobile users has increased exponentially as compared ... | https://habr.com/ru/post/477504/ | null | en | null |
# PHP 5.3.7 released, но обновление содержит критическую ошибку
18 Августа была анонсирована версия 5.3.7
22 Августа анонсирован Upgrade Warning который не рекомендует установку/апгрейд этой версии.
Вкратце: при использовании функции crypt() для хэшей MD5 выдаётся только соль.
Получается вот такая очень непр... | https://habr.com/ru/post/126857/ | null | ru | null |
# Автоматизация квартиры с HomePod, Raspberry Pi и Node.js

Перевели для вас [статью Криса Хокинса](https://medium.com/@chrishawkins/automating-my-home-with-homepod-raspberry-pi-and-node-js-b56b39780499), в которой он рассказывает о превращен... | https://habr.com/ru/post/438292/ | null | ru | null |
# Четыре приема быстрой разработки на Unity3D
Больше гибкости, меньше кода — продуктивнее разработка.
Уже долгое время [Unity3D](https://unity.com/) — мой любимый инструмент разработки игр, которым я пользу... | https://habr.com/ru/post/531882/ | null | ru | null |
# Машинное обучение: с чего начать или как построить первую модель

В качестве первой задачи для машинного обучения возьмем что-то понятное и простое, например, прогноз стоимости жилья. Готовый датасет можно найти на сайте kaggle. На... | https://habr.com/ru/post/505516/ | null | ru | null |
# Идиомы С++. Type erasure
Хотите получить представление о том, как устроен *boost::function*, *boost::any* “под капотом”? Узнать или освежить в памяти, что скрывается за непонятной фразой “стирание типа”? В этой статье я постараюсь кратко изложить мотивацию, стоящую за этой идиомой и ключевые элементы реализации.
... | https://habr.com/ru/post/207294/ | null | ru | null |
# Адаптивный антивирус A3 самостоятельно обнаружил и исправил уязвимость ShellShock за 4 минуты
IT-специалисты из Университета Юты создали пакет программ, который не только выявляет и удаляет неизвестные ранее вирусы, но и исправляет последствия их работы. Проект под названием A3 (Advanced Adaptive Applications, а по-... | https://habr.com/ru/post/356568/ | null | ru | null |
# Dagger 2. Subcomponents. Best practice. Part 2
Всем привет! В прошлый раз [мы разобрались с реализацией Subcomponent и случаями использования его на примере отдельно взятого экрана](https://habrahabr.ru/post/334710/). Здесь будет несколько отсылок к той статье, поэтому лучше сначала ознакомиться с ней.
Сегодня же... | https://habr.com/ru/post/337070/ | null | ru | null |
# Место Java в мире HFT
В статье автор пытается проанализировать почему существуют торговые системы написанные на Java. Как может Java соперничать в области высокой производительности с C и C++? Далее размещены небольшие раз... | https://habr.com/ru/post/331608/ | null | ru | null |
# Красивые формы для приёма банковских карт с CardInfo.js
> **UPD. CardInfo больше не работает. Используйте BinKing.**
> ----------------------------------------------------------
>
>
>
> Гайд по использованию: https://habr.com/ru/post/527796/
>
> Сайт сервиса: https://binkng.io
Всем кто верстал, верстает и... | https://habr.com/ru/post/324738/ | null | ru | null |
# PHP: атрибуты vs аннотации: оптимизируем метадату Doctrine
```
php
#[ORM\Entity, ORM\Table(name: 'item_price')]
class ItemPrice
{
#[ORM\Id, ORM\Column(type: 'integer'), ORM\GeneratedValue]
private int $id;
#[
ORM\ManyToOne(targetEntity: Item::class, inversedBy: 'prices'),
ORM\JoinColumn(... | https://habr.com/ru/post/686796/ | null | ru | null |
# Релиз CLion 2016.1: новые инструменты и новые языки
Привет, Хабр!
У нас сегодня отличные новости — вышел очередной релиз нашей кросс-платорфменной среды для разработки на C и C++, CLion 2016.1.

Вер... | https://habr.com/ru/post/279625/ | null | ru | null |
# Добавляем поддержку ECMAScript 2015 в ExtJS6
Добрый день, мир не стоит на месте, в прошлом году состоялся релиз ECMAScript 2015 (он же ES6), который привнес множество [нововведений](https://github.com/lukehoban/es6features), огорчает лишь одно ExtJS и Sencha cmd пока не научились поддерживать данную спецификацию. Пр... | https://habr.com/ru/post/281240/ | null | ru | null |
# Веб-контроль Raspberry Pi GPIO
Доброго времени суток! В этом посте я хочу показать, как управлять электроникой через Интернет используя Raspberry Pi. Выглядеть это будет примерно вот так.

**Краткое описание**:
*... | https://habr.com/ru/post/162651/ | null | ru | null |
# Синхронизация музыки и игровых событий на Unity

*Пример редактора уровня в игре.*
Если вы когда либо играли в игры типа Guitar Hero, Osu или Bit Trip Runner вы знаете, как сильно погружает в «поток» простая зависи... | https://habr.com/ru/post/242631/ | null | ru | null |
# Обработка большого количества задач при помощи delayed_job
Я большой фанат [resque](https://github.com/defunkt/resque), который использует [Redis](http://redis.io) в качестве хранилища, однако если есть необходимость быстро выполнить большое количество фоновых задач, в некоторых случаях **delayed\_job** может работа... | https://habr.com/ru/post/145899/ | null | ru | null |
# SysAdmin Anywhere: Используем UDP Hole Punching для реализации удаленного рабочего стола
#### Введение
 Системные администраторы по своей природе — люди ленивые. Не любят они по сто раз одно и то же делать. Хотят все авт... | https://habr.com/ru/post/142858/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.