
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как сжать модель fastText в 100 раз
Модель fastText — одно из самых эффективных векторных представлений слов для русского языка. Однако её прикладная польза страдает из-за внушительных (несколько гигабайт) размеров модели. В этой статье мы показываем, как можно уменьшить модель fastText с 2.7 гигабайт до 28 мегабайт... | https://habr.com/ru/post/489474/ | null | ru | null |
# Выразить иерархически: вопрос как увидеть хамелеона
**Проблема** нейросетей - невозможность обучаться на единичных примерах. Справиться может табличное RL, но обучаться на данных большой размерности - иная неразрешимая сторона этой парадигмы <https://habr.com/ru/post/437020/>. **Решение** только в одном: видеть мир ... | https://habr.com/ru/post/690518/ | null | ru | null |
# Разработка UI с помощью Flutter
Привет, Хабр! Представляем вашему вниманию перевод статьи "[Building Layouts](https://flutter.io/docs/development/ui/layout#whats-the-point)".
Сегодня мы узнаем:
------------------
* Как работают механики построения UI на Flutter
* Как верстать экраны горизонтально и вертикально
*... | https://habr.com/ru/post/433256/ | null | ru | null |
# Контролируем переполнение ячейки таблицы с помощью max-width

Допустим, мы хотим сделать двухколоночную раскладку с помощью свойства table-cell. Левая колонка будет занимать всю доступную ширину, правая ж... | https://habr.com/ru/post/217911/ | null | ru | null |
# Псевдо Lens Flare
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Pseudo Lens Flare»](http://john-chapman-graphics.blogspot.com/2013/02/pseudo-lens-flare.html) автора John Chapman.

**L... | https://habr.com/ru/post/439408/ | null | ru | null |
# FaaS и serverless-решения на примере PoC kubeless-функции
Первая ассоциация, которая приходит на ум при упоминании serverless-решений, — это облачные сервисы вроде AWS Lambda, Azure Functions или Google F... | https://habr.com/ru/post/556832/ | null | ru | null |
# Разбор ошибок в игровом движке Stride
Stride – это мощный, бесплатный и активно развивающийся игровой движок, реализованный на C#. Он вполне может стать альтернативой Unity, но насколько качественный исходный код Stride? Узнаем это с помощью статического анализатора PVS-Studio.
У вас никогда не возникало ощущения, что в языке X, на котором вы в данный момент программируете чего-то не хватает? Какой-нибудь небольшой, но приятной плюшки, которая может и не с... | https://habr.com/ru/post/133340/ | null | ru | null |
# Prometheus in Action: from default counters to SLO-related queries
A Gentle Intro
--------------
All Prometheus metrics are based on **time series** - streams of timestamped values belonging to the same me... | https://habr.com/ru/post/538692/ | null | en | null |
# ТОП-10 ошибок, найденных в C#-проектах за 2020 год

Наконец-то столь нелёгкий 2020 подходит к концу, а это значит, что пришло время подвести итоги! За этот год командой PVS-Studio было написано ... | https://habr.com/ru/post/534834/ | null | ru | null |
# Фильтрация изображения на FPGA

Данная статья является продолжением моей предыдущей [статьи о детектировании движения на ПЛИС](https://habrahabr.ru/post/323258/). В ней я хочу рассмотреть реализацию трёх алгоритмов фильтр... | https://habr.com/ru/post/324070/ | null | ru | null |
# Анализ производительности отдельных подсистем программы по Linux perf report
Обычно для подготовки отчета по профилированию на Linux я использовал только самые простые варианты запуска `perf report` (сами данные по производительности должны быть получены до запуска `perf report` командой `perf record`, вот [тут можн... | https://habr.com/ru/post/305188/ | null | ru | null |
# ATtiny85: прототип беспроводного сенсора
Обычно, для перехода от идеи к реализации, необходим прототип устройства, удобный для проверки и отладки на месте, что особенно важно для мобильного устройства. Далее постараюсь максимально подробно разобрать процесс создания прототипа беспроводного сенсора на базе ATtiny85.
... | https://habr.com/ru/post/388079/ | null | ru | null |
# Совершенно секретно или статичный IP на Windows Phone
Понадобилось мне недавно сделать статичным IP на своем Windows Phone.
Пошел я искать решение в гугл. Все, что я там нашел, было связано непосредственно с настройкой роутера или полностью рутованными телефонами (мой рут накрылся после обновления до Tango), поэт... | https://habr.com/ru/post/173325/ | null | ru | null |
# Mkcert: валидные HTTPS-сертификаты для localhost

В наше время использование HTTPS становится обязательным для всех сайтов и веб-приложений. Но в процессе разработки возникает проблема корректного тестирования. Естественно, Let’s E... | https://habr.com/ru/post/435476/ | null | ru | null |
# Портирование WPF приложений на netcore 3.0
Ожидаемый релиз netcore 3.0 позволяет запускать wpf на netcore. Процедура перевода для одного несложного проекта занимает один-два дня. Каждый последующий — много быстрее.

Подготовка и к... | https://habr.com/ru/post/470401/ | null | ru | null |
# Компоненты-агностики в Angular
Когда работаешь над библиотекой переиспользуемых компонентов, вопрос API встает особенно остро. С одной стороны, нужно сделать надежное, аккуратное решение, с другой — удовлетворить массу частных случаев. Это относится и к работе с данными, и к внешним особенностям различных кейсов исп... | https://habr.com/ru/post/473108/ | null | ru | null |
# 22 совета Angular-разработчику. Часть 1
Автор статьи, первую часть перевода которой мы публикуем, говорит, что он уже около двух лет работает над крупномасштабным Angular-приложением в [Trade Me](https://preview.trademe.co.nz/). В течение последних нескольких лет команда разработчиков приложения постоянно занимается... | https://habr.com/ru/post/425661/ | null | ru | null |
# Проблемы пакетной обработки запросов и их решения (часть 2)

Это продолжение статьи [«Проблемы пакетной обработки запросов и их решения»](https://habr.com/ru/company/custis/blog/460291). Рекомендуется сначала ознакомиться с перво... | https://habr.com/ru/post/467919/ | null | ru | null |
# Lombok. Полное руководство
Здесь изложен необходимый минимум информации, которую нужно изучить, если хочешь приступить к использованию проекта Lombok. Рассмотрим, как интегрировать его в вашу IDE и исполь... | https://habr.com/ru/post/676394/ | null | ru | null |
# Рефакторинг функций расширения в Kotlin: использование объекта-компаньона
В Kotlin есть отличная возможность использовать функции расширения, позволяющие писать более выразительный и компактный код. Под капотом это просто статические ... | https://habr.com/ru/post/575550/ | null | ru | null |
# Наслаждайтесь миллиардами цветов с 10-битным HEVC
Человеческий глаз способен видеть намного больше цветов, чем показывают ему современные видео дисплеи. Каким бы навороченным не был компьютер, он все равно может воспроизвести лишь конечное количество цветов. В этой статье мы расскажем об использовании 10-битной глуб... | https://habr.com/ru/post/330568/ | null | ru | null |
# Часть I. InterSystems GlobalsDB .Net — разведка боем с заглядыванием под капот

Наконец-то вместо уговоров подождать еще немного, на вопрос “Есть ли InterSystems GlobalsDB/Caché Extreme под Microsof... | https://habr.com/ru/post/141546/ | null | ru | null |
# CDD — Cli Driven Development
Все-таки самоизоляция не проходит бесследно. Сидишь себе дома, а в голову разные мысли приходят. Как, чем осчастливить человечество? И вот оно: CDD! (И еще PDD / SOLID / KISS / ... | https://habr.com/ru/post/550488/ | null | ru | null |
# GObject: инкапсуляция, инстанциация, интроспекция
… а также другие страшные слова! (с)
Прежде чем мы познакомимся с некоторыми продвинутыми возможностями объектной системы типов GLib, необходимо поговорить о ряде моментов, которые мы не затронули в предыдущих двух статьях. В этот раз мы познакомимся ближе с базов... | https://habr.com/ru/post/418443/ | null | ru | null |
# По мотивам GUIRunner
[Часть 1](http://habrahabr.ru/post/232955/).
[Часть 2](http://habrahabr.ru/post/234801/).
[Часть 3](http://habrahabr.ru/post/241301/).
Сегодня дописал [пост](http://habrahabr.ru/post/241301/) о том, как мы решили написать свой GUIRunner для FireMonkey. В комментарии к посту в одной из с... | https://habr.com/ru/post/241377/ | null | ru | null |
# WWDC 2019: Custom Instruments и SF Symbols, а также новые подходы к разработке iOS-приложений

В народе говорят, что везение — это результат упорного и длительного труда. Наверное, отчасти это правда. Двое наших сотрудников выигр... | https://habr.com/ru/post/470736/ | null | ru | null |
# Как «взломать» RedBull
На самом деле правильнее назвать статью «как накрутить себе баллы в конкурсе, чтобы выиграть целый холодильник RedBull». У нас, кстати, в офисе уже стоит такой холодильник с напитками.
. Одним из примечательных нововведений этой версии являются квазицитаты — удобный механизм для описания синтаксических деревьев Scala с помощью разбираемых во время компиляции строк; очевидно, что в перв... | https://habr.com/ru/post/224229/ | null | ru | null |
# Техническая реализация REST & user friendly уведомлений после редиректов
Иногда есть необходимость показывать пользователю уведомления после редиректа уже на новой странице.
В статье описаны достоинства и недостатки нескольких реализаций таких уведомлений,
... | https://habr.com/ru/post/69894/ | null | ru | null |
# Сыграем в DOOM на серверах
[](https://habr.com/ru/company/ruvds/blog/522314/)
У меня возникла безумная идея – это сыграть в классический DOOM по сети установленный на VPS под управлением Windows. В целом, это задумывалось как тес... | https://habr.com/ru/post/522314/ | null | ru | null |
# Mono 2.10.1 и MonoDevelop 2.6 с работающим дизайнером форм в extras-testing репозиториях для N900
А вдруг я ещё не всех задолбал?
В общем, с помощью чёрной магии, лома и какой-то матери мне таки удалось заставить Mono собираться под скрэтчбоксом, а MonoDevelop довести до вменяемого состояния, так что теперь норма... | https://habr.com/ru/post/118435/ | null | ru | null |
# Сенсорная крышка для мусорного ведра своими руками

В статье расскажу, как превратить обычное ведро с крышкой в автоматическое.
Подошел к ведру — крышка открылась, положил в него что надо, отошел... | https://habr.com/ru/post/197070/ | null | ru | null |
# Кто умнее чем IDEA?
Два года назад я вызвался постоять на стенде нашей компании JetBrains на последней конференции [JBreak](https://2018.jbreak.ru/) в Новосибирске. Перед конференцией мне спустили сверху вот такие карточки:

И ска... | https://habr.com/ru/post/489156/ | null | ru | null |
# Диаграммы в LaTeX
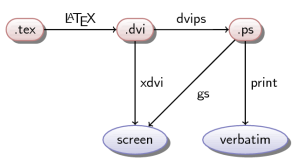Многие достаточно часто сталкиваются с необходимостью создания различных диаграмм, графов, деревьев для удобного представления информации. Особенно важным этот вопрос может оказаться при со... | https://habr.com/ru/post/81751/ | null | ru | null |
# Обзор Cool Dates — сервиса анонсов будущих событий
[](http://cooldates.ru)
На прошлой неделе [someone](https://geektimes.ru/users/someone/), в своем посте [«Уведомления о событиях»](http://someone.habrahabr.ru/blog/58105/) представил идею по созданию сервиса-уведомит... | https://habr.com/ru/post/58446/ | null | ru | null |
# Пишем Ruby gem для Yandex Direct API
Очень хотелось изучить Ruby получше, а рабочего проекта не было. И я попробовал написать gem для работы с Yandex Direct API.
Причин было несколько. Среди них: Yandex Direct API очень типичен для Яндекса и современных REST-сервисов вообще. Если разобраться и преодолеть типичные о... | https://habr.com/ru/post/311512/ | null | ru | null |
# Клиент Caché ODBC в Linux
Несколько лет назад заказчик, крупный медицинский центр федерального значения, поручил нам разработать софт, обслуживающий информационные киоски. Внешне киоск напоминает платёжный терминал (только без купюроприёмника), его основная функция, как следует из названия, — предоставление пациента... | https://habr.com/ru/post/156321/ | null | ru | null |
# Борьба с «плохими» URI, спамерами и php-шеллами — личный опыт
Полагаю, все веб-программисты проходят в той или иной степени одинаковый путь. Я основываюсь на своем личном опыте. Для меня в начале постижения этой науки создание сайта было на первом месте. Только по прошествии значительного времени я осознал, что сайт... | https://habr.com/ru/post/264017/ | null | ru | null |
# Мелкая питонячая радость #13: стойкие пароли, гибкие уведомления и вменяемые тесты API
Создатель Python и пенсионер Гвидо Ван Россум был вынужден снова выйти на работу, на этот раз в Майкрософт. Нет, Гвидо ... | https://habr.com/ru/post/528046/ | null | ru | null |
# «20 тысяч IOPS на узел — хорошие показатели с учётом задержек в 5 мс». Для OLTP — нет

Поводом написать эту статью стал весьма достойный обзор [Как мы тестировали VMware vSAN...](https://habr.com/company/croc/blog/414125) компа... | https://habr.com/ru/post/414269/ | null | ru | null |
# Языки, которые почти стали CSS
*Привет, Хабр! Предлагаю вашему вниманию перевод статьи [The Languages Which Almost Became CSS](https://eager.io/blog/the-languages-which-almost-were-css/) автора Zack Bloom про языки, которые могли бы стать CSS, сложись история немного иначе.*
. Кроме своих основных функций этот роутер может служить принт-сервером и файлопомойкой благодаря наличию двух ... | https://habr.com/ru/post/44391/ | null | ru | null |
# Добавить системный вызов. Часть 4 и последняя
*```
- Что-то беспокоит меня Гондурас...
- Беспокоит? А ты его не чеши.
```*
В предыдущих частях о... | https://habr.com/ru/post/268409/ | null | ru | null |
# Кэширование в Android, Telegram для групп, улучшение callback, multicast, showlist и другие нововведения

Достаточно крупное обновление исправляющее ошибки в андроид клиенте, улучшение безопасности получ... | https://habr.com/ru/post/262571/ | null | ru | null |
# CoinRoad: Как мы сделали приложение на базе кастомных пушей в Android
Сегодня я хочу рассказать вам об интересном и в некотором смысле новом способе взаимодействия с пользователем – кастомных пушах в Android. Именно его мы использовали как основу своего мобильного приложения CoinRoad для отображения графиков и котир... | https://habr.com/ru/post/534260/ | null | ru | null |
# Человеческим языком про метрики 1: Потерянное введение
Однажды мне понадобилось внедрить метрики в сервисы своей команды. С самого начала я не понимал, что именно хочу получить: одно дело — прикрутить библи... | https://habr.com/ru/post/683608/ | null | ru | null |
# «Божественный» код (GOD'S code)

«Божественный» код — громкий термин, который может показаться желтым заголовком, но всё же именно о таком коде будет идти речь: из каких частей он состоит и как его писать. Это история о моих стар... | https://habr.com/ru/post/414201/ | null | ru | null |
# Асинхронное программирование — тестирование событий
Иногда приходится писать тесты для событий, и делать это неудобно – очень быстро начинают плодиться дополнительные методы и поля. О том, как тестировать события в C# я и хочу рассказать.
Для начала пример. У меня есть API, который асинхронно скачивает веб-страни... | https://habr.com/ru/post/71410/ | null | ru | null |
# Срезаем пики с RRD графиков на примере Munin
Любой linux администратор наверняка наблюдал аномальные пики на RRD графиках. Пики появляются вследствие нарушения процесса сбора отслеживаемой величины и портят картину на графике. Это нормальное явление для RRD.
На графике трафика пики могут появится после перезапуск... | https://habr.com/ru/post/92406/ | null | ru | null |
# Никогда не «не делай» того, о чем пожалеешь или умный дом с CCU.IO
На хабре последнее время появляется много статей об автоматизации дома. Какие-то статьи с пространными размышлениями на тему умного дома, не несущие полезной нагрузки. Какие-то с конкретной реализацией на конкретном проприетарном железе, но им не хва... | https://habr.com/ru/post/227435/ | null | ru | null |
# Корутины в C++20 — что это и как с ними работать
*Прим. Wunder Fund: В статье описаны базовые подходы к работе с корутинами в 20м стандарте С++, на паре практических примеров разобраны шаблоны классов для п... | https://habr.com/ru/post/582000/ | null | ru | null |
# HTML 5. Работа с Web SQL базой данных
В HTML 5 есть много новых возможностей, которые позволяют web разработчикам создавать более мощные и насыщенные приложения. К этим возможностям относятся и новые способы хранения данных на клиенте, такие как web storage(поддерживается в IE8) и web SQL database.
При этом если ... | https://habr.com/ru/post/84654/ | null | ru | null |
# Хоткеи в приложенях Ruby on Rails
**Mousetrap** — javascript-библиотека, позволяющая легко и непринужденно добавлять хоткеи на сайты, появилась не так давно. Но уже успела полюбиться мне... | https://habr.com/ru/post/152057/ | null | ru | null |
# Использование фильтров из Box2D в Libgdx
В [прошлой](http://habrahabr.ru/post/162079/) статье рассматривалась работа с `ContactListener`. Вот только примеры, которые я использовал, были не совсем верно выбраны. В Box2D есть намного более удобные средства для фильтрации столкновений, а именно – фильтры. О них и напиш... | https://habr.com/ru/post/163885/ | null | ru | null |
# Поиск RSS новостных сайтов

Покопался я ещё в своих старых и не очень проектах и нашёл одну интересную программку. Она ищет RSS ссылки новостных сайтов. Задача которая стояла — это найти как можно бо... | https://habr.com/ru/post/203210/ | null | ru | null |
# JSF + DynamicFaces = AJAX
##### Кратко о JSF
JSF — компонентный MVC фреймворк для веб-приложений на java. Основная его задача — упростить разработку интерфейса и связывание его с серверной частью. JSF содержит валидаторы и конвертеры, также вы можете добавить свои компоненты и изменять существующие.
О JSF подроб... | https://habr.com/ru/post/36927/ | null | ru | null |
# На вкус и цвет 2 – не RGB единым
Приветствую всех читателей. Попробуем продолжить нашу затею, начало которой [здесь](http://habrahabr.ru/post/254797/#first_unread).
Итак, мы имеем кастомную View с разноцветным кружочком, из которого теперь необходимо выдернуть выбранный пользователем цвет. Перед тем как окунуться... | https://habr.com/ru/post/254895/ | null | ru | null |
# Погружение в службы Android

Перевод статьи ["Deep Dive into Android Services"](https://proandroiddev.com/deep-dive-into-android-services-4830b8c9a09) от Nazmul Idris. Я оставил оригинальное название автора, хотя это скорее не "... | https://habr.com/ru/post/349102/ | null | ru | null |
# Особенности работы с API Google Drive
Недавно нам нужно было сделать простое приложение для Google Drive. Приложение должно было формировать список пользователей, на которых расшарены документы в указанной папке с возможностью редактирования. Задача, в принципе, простая, поэтому недолго думая развернул болванку прое... | https://habr.com/ru/post/241209/ | null | ru | null |
# Автоматизация go get — больше не нужно запоминать названия библиотек
Всем привет! Когда я начинал писать на Go, я стартовал и забрасывал с десяток мелких пет-проектов. Большинство из них использовали [fasthttp](https://github.com/valyala/fasthttp) и его [fasthttp/router](https://github.com/fasthttp/router). И пакет ... | https://habr.com/ru/post/713482/ | null | ru | null |
# OpenSceneGraph: Основы работы с текстурами

Введение
========
Мы уже рассматривали [пример](https://habr.com/ru/post/430212/), где раскрашивали квадрат во все цвета радуги. Тем не менее существует и другая технология, а име... | https://habr.com/ru/post/437624/ | null | ru | null |
# Как npm стал самым популярным пакетным менеджером в мире
Со [вступительной речью](https://www.youtube.com/watch?v=mY3DyBT55do) на конференции [Node.js Interactive](http://events.linuxfoundation.org/event... | https://habr.com/ru/post/319724/ | null | ru | null |
# Категории программных тестов
 *Перевод был сделан как ответ на некоторые комментарии к переводу [Настройка IDE для автоматического запуска тестов](http://habrahabr.ru/blogs/testing/64737/). Прочитав статью... | https://habr.com/ru/post/64874/ | null | ru | null |
# UNIX-way и генератор заданий по архитектуре компьютерных сетей
Прошлой зимой на нашей любимой кафедре произошло одно замечательное событие — курс проектирования компьютерных сетей был переформирован, в результате чего вместо одного семестра практических занятий образовались два семестра занятий лабораторных. С одной... | https://habr.com/ru/post/131949/ | null | ru | null |
# Чем Linux HugePages важны для серверов баз данных?
Часто пользователи рассказывают нам о сбое базы данных по вине Out Of Memory Killer. Он завершает процессы PostgreSQL и остается причиной большинства отказов этой БД. Память на хост-компьютере может закончиться по нескольким причинам, наиболее распространенные из ни... | https://habr.com/ru/post/655887/ | null | ru | null |
# Одержимость производительностью или опыт профилирования в виртуальной среде
Давайте будем откровенны: неэффективно работающее приложение у большинства разработчиков вызывает дискомфорт. Подчас погоня за производительностью имеет почти спортивную природу, не связанную с прямыми обязанностями. На хабре, как и в жизни ... | https://habr.com/ru/post/192176/ | null | ru | null |
# Разбор базового решения для задачи привязки аэроснимков к местности с Цифрового Прорыва

20 сентября состоялся очередной [релиз](https://www.kali.org/news/kali-linux-2017-2-release/) популярного дистрибутива для проведения тестирования на проникновение Kali Li... | https://habr.com/ru/post/338460/ | null | ru | null |
# Рецепт полезного код-ревью от разработчика из Яндекса

Привет. Меня зовут Сергей, последние пять лет я работаю в Яндексе. За это время участвовал в разработке одиннадцати проектов. Писал код на JavaScript, Python и C++. Некоторые... | https://habr.com/ru/post/422143/ | null | ru | null |
# Как рендерится кадр Middle Earth: Shadow of Mordor
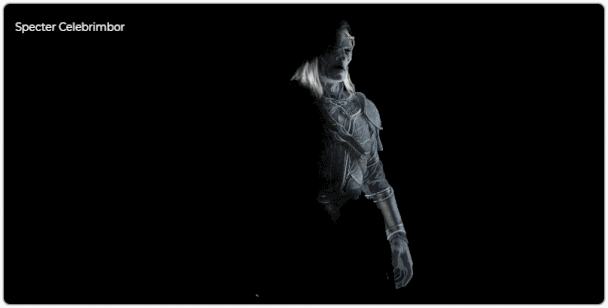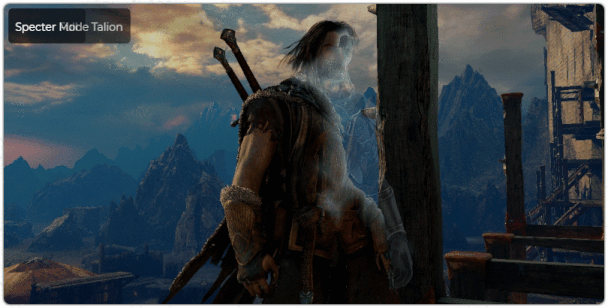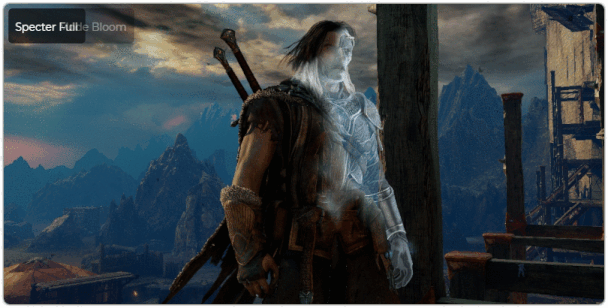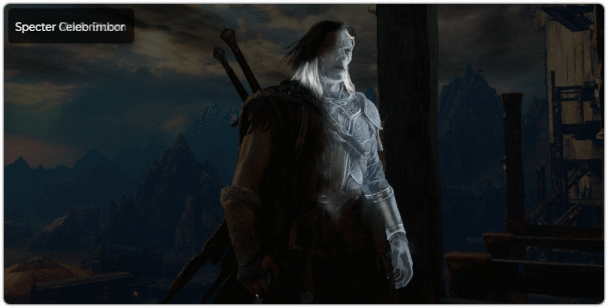
[Middle Earth: Shadow of Mordor](https://en.wikipedia.org/wiki/Middle-earth:_Shadow_of_Mordor) была выпущена в 2014 году. Сама игра стала большим сюрпризом, и то, что она была спин-оффом ... | https://habr.com/ru/post/430518/ | null | ru | null |
# RxJava. Убираем магию
Я долго боялся использовать RxJava в production. Её назначение и принцип работы оставались для меня загадкой. Чтение исходного кода не добавляло ясности, а статьи только путали. Под катом попытка ответить на вопросы: «Какие задачи эта технология решает лучше аналогов?» и «Как это работает?» с п... | https://habr.com/ru/post/317928/ | null | ru | null |
# Истории успеха Kubernetes в production. Часть 3: GitHub
Продолжаем рассказывать об успешных примерах использования Kubernetes в production. Новый кейс — совсем свежий. Подробная информация о нём появилась только вчера. А что ещё более значимо, речь пойдёт про крупный онлайн-сервис, с которым наверняка так или иначе ... | https://habr.com/ru/post/335814/ | null | ru | null |
# Деплой php+MySQL на heroku
Всем доброго времени суток. Хочу поделиться с вами своим опытом развертывания php+mysql приложения на сервисе [heroku](http://www.heroku.com). Если вы первый раз о таком слышите, вам [сюда](https://ru.wikipedia.org/wiki/Heroku).
#### Поехали
Итак, представим, что у нас есть уже готовое... | https://habr.com/ru/post/236211/ | null | ru | null |
# Магия IBDesignable или расширяем функциональность Interface Builder в Xcode

Interface Builder в Xcode с некоторого времени экономит мне много времени в работе по стандартному лайауту элементов интерфейса и иногда помогает... | https://habr.com/ru/post/274687/ | null | ru | null |
# Hg Init: Часть 5. Процесс слияния
Это пятая часть из серии **Hg Init: Учебное пособие по Mercurial** от Джоэля Спольски ([Joel Spolsky](http://www.joelonsoftware.com/)). Предыдущие части:
* [«Переобучение для пользователей Subver... | https://habr.com/ru/post/109203/ | null | ru | null |
# Как написать и поместить на сайт фотобанк на > 100 000 картин
Допустим, у вас есть >100'000 изображений, которые надо рассортировать и удобно выложить в веб для массового просмотра. Это может быть что угодно — галерея всего созданного человечеством искусства (в задаче которую я делал), или исторический фотоархив гор... | https://habr.com/ru/post/509604/ | null | ru | null |
# Параллельные запросы в PostgreSQL

В современных ЦП очень много ядер. Годами приложения посылали запросы в базы данных параллельно. Если это отчетный запрос ко множеству строк в таблице, он выполняется быстрее, когда задействует не... | https://habr.com/ru/post/446706/ | null | ru | null |
# Создание небольшого API на Deno
В этом посте я хотел бы рассказать и показать процесс создания небольшого API с помощью Deno. Deno — новейшая среда для запуска Javascript и Typescript, разработанная создателем Node.js — Райаном Далем.
 и подробно разобраны в [следующем цикле статей](http://habrahabr.ru/users/makeman/topics/)
В этой статье я расск... | https://habr.com/ru/post/210778/ | null | ru | null |
# Как реализовать загрузку изображений в список в отдельном потоке на Android

По просьбам трудящихся, статья о методе загрузки изображений в список в отдельном потоке на Android.... | https://habr.com/ru/post/78747/ | null | ru | null |
# Реализация union типов в Java
При разработке кода иногда нужно чтобы объект в определенный момент содержал значения одного типа или значения другого типа. Языки программирования, которые поддерживают концепцию объединений, позволяют в определенный момент сохранять текущее значение в одной области памяти.
Наприме... | https://habr.com/ru/post/465097/ | null | ru | null |
# Многозначное шифрование с использованием хеш-функций
В последнее время приходится все больше задумываться о сохранности анонимности и безопасности относительно прав на информационную собственность. В этой заметке я предло... | https://habr.com/ru/post/147857/ | null | ru | null |
# Solidity: комментарии
Комментарии используются для того, чтобы объяснить что делает код. [Роберт С. Мартин](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%80%D1%82%D0%B8%D0%BD,_%D0%A0%D0%BE%D0%B1%D0%B5%D1%... | https://habr.com/ru/post/655403/ | null | ru | null |
# Cloud-based WebRTC streaming on DigitalOcean

Popular cloud hosting DigitalOcean has recently launched its new marketplace selling preconfigured images that can help to quickly deploy an application server. It’s much like AWS, but D... | https://habr.com/ru/post/476554/ | null | en | null |
# Получить выписку ЕГРН из Росреестра с помощью python, минуя api
### Не первое знакомство с порталом Росреестра
Любой юрист когда-либо обращался с запросом в Росреестр (Федеральная служба государственной регистрации, кадастра и картографии). Времена, когда для запроса надо было бежать в отделение Росреестра и подав... | https://habr.com/ru/post/460040/ | null | ru | null |
# Кросс-вмный (CLR/JVM) код на Python
Это узкоспециализированная короткая заметка про то, как я запинывал write once, run everywhere тесты для библиотеки, портированной с C# на Java, при помощи Python.
Смысл в следующем: есть большая, толстая и красивая библиотека, которая была по коммерческим соображениям портиро... | https://habr.com/ru/post/148473/ | null | ru | null |
# Советы по работе с Gradle для Android-разработчиков
Всем привет! Я пишу приложения под Android, в мире которого система сборки Gradle является стандартом де-факто. Я решил поделиться некоторыми советами по работе с системой с теми, у кого нет чёткого понимания, как правильно структурировать свои проекты и писать bui... | https://habr.com/ru/post/544630/ | null | ru | null |
# Временное решение для блокировки рекламы
Для себя временно решил использовать некэширующий веб-прокси [Privoxy](http://www.privoxy.org) — очень простая настройка, работоспособен под всеми системами, позволяет расширять фильтры, и слету рубит рекламу на Хабре (да, мне стыдно :-) ).
Установил не совсем дефолтно — п... | https://habr.com/ru/post/38941/ | null | ru | null |
# Кластеризуем миллионы планов PostgreSQL
Как найти самые "горячие" запросы на вашем PostgreSQL-сервере? Поискать их в логе и проанализировать план или воспользоваться расширением [pg\_stat\_statements](https://postgrespro.ru/docs/postgresql/12/pgstatstatements).
А если в лог попадает миллион запросов за сутки?.. Тог... | https://habr.com/ru/post/577646/ | null | ru | null |
# Темы приложений для Xamarin.Forms
Все основные ОС теперь поддерживают темные и светлые темы приложений, и появился Xamarin.Forms 4.7, чтобы упростить добавление этой фичи в ваши приложения. Фактически, если вы ничего не сделаете, ваши приложения Xamarin.Forms будут соответствовать предпочтениям ОС пользователя. Заче... | https://habr.com/ru/post/511642/ | null | ru | null |
# Unity Auto Registration
#### Unity Auto Registration
Unity Auto Registration расширяет возможности Unity контейнера, предоставляя fluent interface для автоматической регистрации типов по установленным правилам. Используя всего несколько строк кода вы можете отсканировать указанную сборку и зарегистрировать все соот... | https://habr.com/ru/post/74757/ | null | ru | null |
# Пишем на картинках
В течение последнего времени что-то часто стали мелькать статьи про обработку изображений на php. Скругленные края уже были, тени были, мокрый пол был, еще куча всего было.
А вот надписей вроде еще не было. Значит будут. :-)
Представляю вашему вниманию не большой, но в тоже время достаточно ... | https://habr.com/ru/post/43744/ | null | ru | null |
# Поиск пути через NavMesh на ActionScript – CrossBridge-порт Recast Navigation

В этой статье я расскажу об опыте переноса C++ кода на ActionScript с помощью [FlasCC](http://www.adobe.com/devnet-docs/flascc/README.html) ком... | https://habr.com/ru/post/233631/ | null | ru | null |
# Android Studio. Kotlin. Подключение Google календаря через Content Provider
Безысходность и отчаяние я испытывал много дней подряд, пытаясь "подключить" Google календарь к своему приложению. Так долго и так тяжело, как тогда, я не буксовал ни над одной фичей... Я сделал это! Прошло более двух месяцев, пока я и мои п... | https://habr.com/ru/post/664876/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.