
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Автоматизация однотипных операций при настройке коммутаторов через telnet без программирования
#### Вступление
Добрый день уважаемые хабражители!
Описанные ниже способ поможет сократить количество рутинной работы при настройке коммутаторов (например Planet, D-Link и др.) в случаях, когда необходимо выполнить нес... | https://habr.com/ru/post/180281/ | null | ru | null |
# Овладение Coordinator Layout
На презентации [Google I/O 15](https://www.youtube.com/watch?v=7V-fIGMDsmE), компания Google представила [новую версию библиотеки поддержки](http://android-developers.blogspot.com.es/2015/05/android-design-support-library.html) которая реализует несколько компонентов, сильно связанных со... | https://habr.com/ru/post/270121/ | null | ru | null |
# Оптимизация работы с PostgreSQL в Go: от 50 до 5000 RPS
Привет, меня зовут Иван, и я делаю Авито Доставку. Когда пользователь покупает товар с доставкой, мы показываем ему список отделений служб доставки с ценами. Цена доставки может меняться от отделения к отделению. Мы смотрим на область карты, где покупатель ищет... | https://habr.com/ru/post/525294/ | null | ru | null |
# Опыт применения технологии Рутокен для регистрации и авторизации пользователей в системе (часть 4)
Добрый день!
Итак, мы разобрались, каким образом будет происходить аутентификация пользователей в системе, а так же создали свой локальный удостоверяющий центр с корневым приватным ключом и корневым сертификатом. Т... | https://habr.com/ru/post/506934/ | null | ru | null |
# Модифицируем Python за 6 минут
Всем доброго и неумолимо наступающего!
Этот крайне насыщенный год подходит к своему завершению и у нас остался последний курс, который мы запускаем в этом году — "[Разработчик full-stack на Python](https://otus.pw/HqQW/)", чему, собственно, и посвящаем заметку, которая хоть и проско... | https://habr.com/ru/post/345526/ | null | ru | null |
# Самые быстрые числа с плавающей запятой на диком западе
В процессе реализации одной «считалки» возникла проблема с повышенной точностью вычислений. Расчетный алгоритм работал быстро на стандартных числах с плавающей запятой, но когда подключались библиотеки для точных вычислений, все начинало дико тормозить. В этой ... | https://habr.com/ru/post/423469/ | null | ru | null |
# «Новые Былины». Едим слона по частям
В этой статье я буду настраивать рабочее окружение для разработки игры "Былины", а также выполню разбиение самой игры на части, пригодные для использования в OpenFaaS. Все манипуляции буду дела... | https://habr.com/ru/post/482752/ | null | ru | null |
# Поиск и решение проблем масштабируемости на примере многоядерных процессоров Intel Core 2 (часть 2)
Продолжение статьи: [часть 1](http://habrahabr.ru/blogs/hi/107620/), [часть 3](http://habrahabr.ru/blogs/hi/107622/), [часть 4](http://habrahabr.ru/blogs/hi/107624/)
#### Эффективность использования кэш-линий
Пунк... | https://habr.com/ru/post/107621/ | null | ru | null |
# Лучший Pull Request
Относительно недавно мне посчастливилось присоединиться к команде разработки Bitbucket Server в Atlassian (до сентября [он был известен как Stash](https://confluence.atlassian.com/display/BitbucketServer/Bitbucket+rebrand+FAQ "en: Bitbucket rebrand FAQ")). В какой-то момент мне стало любопытно, к... | https://habr.com/ru/post/272531/ | null | ru | null |
# Nokia N900. Продолжаем разбираться или «Hack your Nokia N900»
Добрый день уважаемый читатель. Продолжаю свой цикл статей о Nokia N900. [Вот](http://habrahabr.ru/blogs/nokia/88129/), [вот](http://habrahabr.ru/blogs/nokia/85393/) и [вот](http://habrahabr.ru/blogs/nokia/82319/) — предыдущие мои публикации.
Сегодня п... | https://habr.com/ru/post/89651/ | null | ru | null |
# App Extensions на IOS, а в частности — Action Extension
Всем доброго времени суток!
Сегодня у меня выдался выходной на работе, который я решил посветить, собственно, рассказу о том, какая новая информация залетела в мою головушку.
Для затравки, хочу сделать небольшую ремарку - тема, которую я попытаюсь сегодня чу... | https://habr.com/ru/post/646299/ | null | ru | null |
# Новая программная модель чейнкода Hyperledger Fabric

Не так давно был выпущен [первый релиз](https://github.com/hyperledger/fabric-contract-api-go/releases/tag/v1.0.0) **fabric-contract-api-go** — реализации новой программной моде... | https://habr.com/ru/post/494880/ | null | ru | null |
# Выпущен Rust 1.4
Честно по графику встречаем [Rust 1.4](https://www.rust-lang.org/downloads.html). Релиз вобрал в себя 1200 патчей с момента последнего релиза. Основное внимание уделили стабилизации языка, а это уже серьёзный аргумент, в пользу того, что язык приобрёл понятные формы, синтаксис и стандартную библиоте... | https://habr.com/ru/post/269809/ | null | ru | null |
# Пишем симулятор медленных соединений на Go
В этой статье я хочу показать, как просто в Go можно делать достаточно сложные вещи, и какую мощь в себе несут интерфейсы. Речь пойдет о симуляции медленного соединения — но, в отличие от популярных решений в виде правил для iptables, мы реализуем это на стороне кода — так,... | https://habr.com/ru/post/251095/ | null | ru | null |
# Основы JAX-RS
#### Введение
Выросло данное API из [JSR 311: JAX-RS: The Java API for RESTful Web Services](http://jcp.org/en/jsr/summary?id=311 "JSR 311: JAX-RS: The Java API for RESTful Web Services") и вошло в Java EE 6 (планировалось в Java EE 5). Как видно из названия, предназначено оно для разработки RESTful в... | https://habr.com/ru/post/140181/ | null | ru | null |
# Did It Have to Take So Long to Find a Bug?
Have you ever wondered which type of project demonstrates higher code quality – open-source or proprietary? Our blog posts may seem to suggest that bu... | https://habr.com/ru/post/534136/ | null | en | null |
# STM32 fast start. Часть 2 Hello World на HAL, отладка в Atollic TrueSTUDIO
В прошлый раз мы осваивали создание нового проекта при помощи STM CubeMX первую часть можно найти [здесь.](https://habr.com/ru/post/442162/)
Для тех, кому лень перечитывать — закончилось все тем, что пустой проект успешно собрался.
 есть аналог mysql'ного [INSERT… ON DUPLICATE KEY UPDATE](http://dev.mysql.com/doc/refman/5.1/en/insert-on-duplicate.html) — upsert'ы (UPdate or inSERT).
Насколько быстро это делает mongodb?
Вопрос не праздный, так как при ups... | https://habr.com/ru/post/85804/ | null | ru | null |
# Пишем простую виртуальную машину на Python
Привет! Сейчас расскажу как написать простую виртуальную машину на Python. Надеюсь кто-то найдет эту статью интересной.
Мы не будем реализовывать парсер и компилятор, а сделаем пока что только машину-интерпретатор нашего ассемблера.
У нас будет стековая машина, и она ... | https://habr.com/ru/post/270797/ | null | ru | null |
# Quarkus: модернизация приложений на примере helloworld из JBoss EAP Quickstart
Привет всем в этом блоге, и с вами четвертый пост из серии про Quarkus! (Кстати, смотрите наш вебинар [«Это Quarkus – Kubernetes native Java фреймворк»](https://primetime.bluejeans.com/a2m/events/playback/61a77eb5-53ae-4dff-9ea6-92a9d66ca... | https://habr.com/ru/post/499524/ | null | ru | null |
# Kotlin и свои почти языковые конструкции
Скорее всего, из разработчиков, пользующихся Java, и в особенности Android-разработчиков многие уже знают про [Kotlin](http://kotlinlang.org/). Если нет, то никогда не поздно узнать. О... | https://habr.com/ru/post/266817/ | null | ru | null |
# Нет – взломам серверов! Советы по проверке и защите
Подозреваете, что Linux-сервер взломан? Уверены, что всё в порядке, но на всякий случай хотите повысить уровень безопасности? Если так – вот несколько простых советов, которые помогут проверить систему на предмет взлома и лучше её защитить.
[ о создании виджетов для дашборда я решил сделать ещё один несложный виджет. Он умеет всего лишь отображать [хаброметр](http://habrometr.ru/) выбранного в настройках пользователя.

Здравствуйте!
Хочу представить вам пошаговую инструкцию по деплою django проекта.
Сразу скажу, что используя мою краткую инструкцию вы не поймете механику развертывания. По сути, это просто список команд для деплоя. Тут не будет никаких подробностей каса... | https://habr.com/ru/post/645757/ | null | ru | null |
# Как я вырос без Кодабры
Двадцать лет назад я написал первую строчку кода: `10 CLS`. Именно так, не здороваясь с миром и не представляя, что меня ждет, я ввел следом `RUN` и электронная машина также бесцеремонно бросила мне первый вызов, стерев все на экране телевизора с насмешкой "ОК". Я был удивлен, но не тому, что... | https://habr.com/ru/post/316354/ | null | ru | null |
# Как я организовавывал связку apache+vmware
Продолжительное время на одном из серверов крутиться с десяток сайтов, все они подвержены риску взлома. Так как Apach+php стоит под Windows разграничить права на запись в ту или иную папку нет возможности. Обыкновенной командой можно вообще затереть все файлы на сервере.
... | https://habr.com/ru/post/63556/ | null | ru | null |
# Программирование для PlayStation 2 — старт

Каждый справляет новый год по разному.
Кто-то помнит его, а кто-то нет.
Я стоял на балконе и курил, наблюдая салют. Вобщем-то, я ждал когда запишетс... | https://habr.com/ru/post/135704/ | null | ru | null |
# Без реле, но и без Ардуины или Драка в песочнице

Да простят меня читатели, но это реплика на реплику. А началось всё с интересной [статьи](http://geektimes.ru/post/258850/), где автор познакомил нас со своей разработкой н... | https://habr.com/ru/post/367627/ | null | ru | null |
# YouTubeDrive: хранение файлов на YouTube

Хостинг неограниченного размера? Звучит как нечто фантастическое и невозможное по законам природы. Примерно как вечный двигатель. Но что, если такое возможно? (не вечный двигатель, конечно,... | https://habr.com/ru/post/676282/ | null | ru | null |
# Отслеживание хода выполнения в R
Неважно, отдаем ли мы себе в этом отчет, но когда нужно подождать, мы волнуемся и сгораем от нетерпения. Особенно это касается ожидания «вслепую», т.е. когда неизвестно, сколько же еще придется мучиться. Как выяснил Брэд Аллан Майерс, считающийся изобретателем индикатора состояния в ... | https://habr.com/ru/post/317314/ | null | ru | null |
# MSBuild — в Open Source на github
Сегодня мы особенно рады сообщить что [MSBuild](https://github.com/Microsoft/msbuild) (наверное, самая часто используемая и самая таинственная по документированности — прим. перев.) — теперь доступен на [github](https://github.com/Microsoft/msbuild) и мы вносим его в список [.NET Fo... | https://habr.com/ru/post/253589/ | null | ru | null |
# Основы теории вычислительных систем: машина с конечным числом состояний
Теория вычислительных систем — это то, что позволяет нам программировать. Однако, можно писать программы и без представления о концепциях, скрывающихся за вычислительными процессами. Не то, чтобы это было плохо — когда мы программируем, то работ... | https://habr.com/ru/post/169373/ | null | ru | null |
# RE: Занимательная задачка
Копаясь в поиске сайта, наткнулся на [занимательную задачку](http://mako.habrahabr.ru/blog/38728/) и не смог отказать себе в удовольствии потратить 10 минут времени для решения её на полюбившемся мне прологе.
> `*% ((((1?2)?3)?4)?5)?6*
> **solve**(*Formula*) :-
> *Signs* **=** [... | https://habr.com/ru/post/51644/ | null | ru | null |
# Двоичное кодирование вместо JSON
Кодируйте одни и те же данные гораздо меньшим количеством байт.
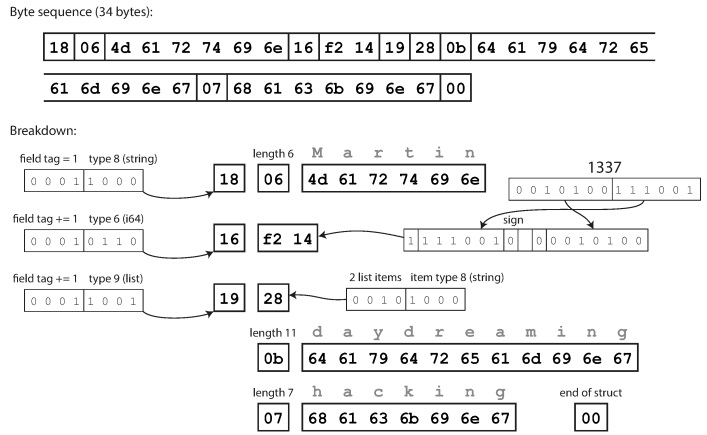
### Почему меня это должно волновать
Данные хранятся в памяти в ... | https://habr.com/ru/post/509902/ | null | ru | null |
# Индикатор искусственного горизонта на HTML5 canvas
Ниже будет представлено воплощение средствами HTML5 одной из необычных идей по визуализации пространственного положения управляемого объекта. Код может использоваться в браузерных играх, имитирующих управление транспортным средством в трехмерном пространстве. Способ... | https://habr.com/ru/post/530334/ | null | ru | null |
# Ещё один инструмент для проверки ваших npm зависимостей — wtfwith
Вы как-нибудь задумывались, сколько версий одной и той же библиотеки затягивает ваша клиентская или серверная сборка? Мне вот в какой-то момент стало интересно. Навскидку найти для этого готовый инструмент не получилось, а смотреть глазами package-loc... | https://habr.com/ru/post/353912/ | null | ru | null |
# Книга «Head First. Kotlin»
[](https://habr.com/ru/company/piter/blog/473614/)Привет, Хаброжители! У нас вышла книга для изучения Kotlin по методике Head First, выходящей за рамки синтаксиса и инструкций по решению конкретных за... | https://habr.com/ru/post/473614/ | null | ru | null |
# Легкая верстка в вынужденных местах: хелперы, декораторы, элементы форм
Многие уже знают о том что во вьюхах не рекомендуется использовать логику и вообще какие-либо манипуляции с данными. Для этого подобный код выносят в [декораторы](https://github.com/drapergem/draper), [кастомные элементы формы](https://github.co... | https://habr.com/ru/post/184528/ | null | ru | null |
# Создаем простой gradient background creator на React
*Disclaimer: Безусловно, эта статья для начинающих кодеров на React. Опытный и не очень react-разработчик не найдет тут ничего полезного. Разве что может указать на ошибки(буду благодарен).*
**Построение и декомпозиция проекта.**
Никакой сложной архитектуры и де... | https://habr.com/ru/post/677286/ | null | ru | null |
# Программируем управление освещением по датчикам движения и освещения на Node-RED
В русскоязычном интернете пока мало статей о такой среде программирования как [Node-RED](http://nodered.org/). Данная статья приоткроет тайну завесы об этом продукте и покажет на примере создания алгоритма управления освещением по датчи... | https://habr.com/ru/post/396985/ | null | ru | null |
# В помощь маркетологу: пишем автоматическую выгрузку данных из Adfox с визуализацией
В [прошлой статье](http://habrahabr.ru/post/265383/) был рассмотрен пример настройки автоматической выгрузки данных из Яндекс Метрики. Это облегчает регулярную выгрузку, но способ получается полуавтоматическим: надо запускать скрипт,... | https://habr.com/ru/post/266307/ | null | ru | null |
# Объединяем Code Coverage от PHPUnit и phpspec
Сегодня та или иная библиотека на Github, у которой нет тестов, уже не воспринимается серьезно. Тесты помогают нам смело делать рефакторинг и быть уверенными, что модуль, класс или функция работают так, как это задумывалось. Они позволяют нам тестировать наш код на разны... | https://habr.com/ru/post/316210/ | null | ru | null |
# Типичное использование Observable объектов в Angular 4
Представляю вашему вниманию типичные варианты использования Observable объектов в компонентах и сервисах Angular 4.

Подписка на параметр роутера и мапинг на другой Obse... | https://habr.com/ru/post/337512/ | null | ru | null |
# Node.js на службе разработчика электроники: создаём библиотеки микросхем
Всем привет! Сегодня мы поговорим о схемотехнике. А чтобы было интереснее, приплетем сюда Node.js. Внимательный читатель тут же спросит, какая же между ними связь? А такая, что мы попытаемся, используя современные технологии, немного облегчить ... | https://habr.com/ru/post/271051/ | null | ru | null |
# Odesk-client перестал снимать скриншоты (OS X Lion)?
Если вы зарабатываете деньги через [Odesk](http://www.odesk.com), то после обновления на OS X Lion, скорее всего заметили, что перестали сниматься скриншоты. Выглядит это примерно вот так:

Это оказалось не так просто, как казалось.
Для начала сделаем небольшой файл-шаблончик с нужными картинками. Это ф... | https://habr.com/ru/post/72493/ | null | ru | null |
# Двенадцать простых начальных шагов разработки модуля для Node.js
![[Аристотель]](https://habrastorage.org/r/w780q1/getpro/habr/post_images/101/328/cf0/101328cf0c1248b20ec5b675fc43a677.jpg)**«Начало — более чем половина всего».**
Это очень древний GTD-принцип: возраст его, вероятно, исчисляется тысячелетиями. (Нап... | https://habr.com/ru/post/262057/ | null | ru | null |
# Updated Razor support in Visual Studio Code, now with Blazor support
Some days ago we announced improved Razor tooling support in Visual Studio Code with the latest C# extension. This latest release includes improved Razor diagnostics and support for tag helpers and Blazor apps.
 получилась очень быстрой и маленькой, но интерес хабражителей к теме, судя по опросу «стоит ли продолжать?», который висят в... | https://habr.com/ru/post/164805/ | null | ru | null |
# Говорить нельзя молчать: от яслей до офиса
Неопределенность — всегда неудобно. Особенно это напрягает на работе, где со всех сторон ожидается продуктивность, многозадачность и прочий позитив. Типичная ситуация: сотрудник не знает и тревожится, а руководитель загружен и ему не до ответов. А бывает наоборот: информаци... | https://habr.com/ru/post/461771/ | null | ru | null |
# Готовим ASP.NET5, выпуск №2 – повторим азы для самых начинающих
Друзья, перед вами второй выпуск колонки про ASP,NET5, в которой мы знакомимся с разными интересными вещами из мира веб-разработки на новой версии открытой платформы ASP.NET5.
 {
const ... | https://habr.com/ru/post/475260/ | null | ru | null |
# IoT в моей жизни. Как создать умный офис, а также отслеживать рост картофеля у себя в квартире благодаря IoT
Приветствую вас, Хабровчане!
В 2020-м году все мы знаем что такое Интернет Вещей и для чего он нужен. Но как много из нас знакомы с облачными платформами, которые представляют один из наиболее значимых пл... | https://habr.com/ru/post/504564/ | null | ru | null |
# Установка и сборка образа Angstrom Linux для платы TechNexion Thunder
#### Набор разработчика от TechNexion Thunderpack

Здравствуй уважаемый читатель. Недавно мне довелось поработать с набором дл... | https://habr.com/ru/post/218991/ | null | ru | null |
# Новинки ноября в Opera: версия для планшетов и синхронизация

Сегодня мы хотим рассказать про наши ноябрьские новинки последних дней: новую версию Opera 18 для компьютеров, мобильную Opera 18 для планшет... | https://habr.com/ru/post/202918/ | null | ru | null |
# Создаём процедурные глобусы планет
*Искажения, бесшовный шум и как с ними работать.*
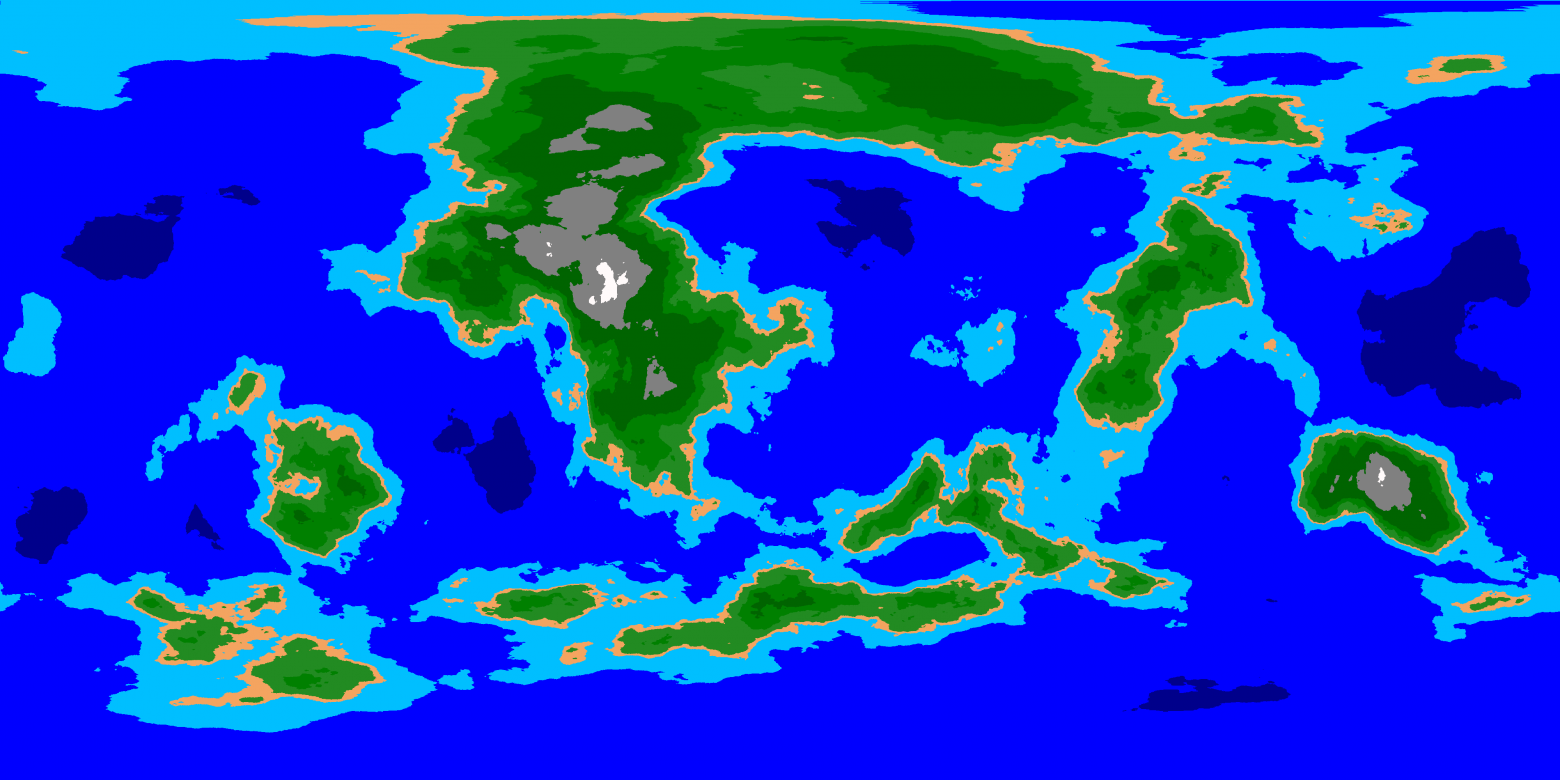
### Генерируем планету
Один из простейших способов генерации планеты — использование шума. Если мы решим выбр... | https://habr.com/ru/post/448324/ | null | ru | null |
# XSS на yandex.ru
Вчера один мой друг (LMaster) нашел пассивную XSS на Яндексе. Специально сформированный адрес, переданный жертве, позволяет похитить cookies. Не фильтруется GET-параметр add. Для срабатывания скрипта не требуется никаких действий пользователя.
Запрос:
`_http://www.yandex.ru/?add=3188">&edit=1`... | https://habr.com/ru/post/64774/ | null | ru | null |
# 1\. Обучение пользователей основам ИБ. Борьба с фишингом
На сегодняшний день сетевой администратор или инженер ИБ тратит уйму времени и сил, чтобы защитить периметр сети предприятия от различных угроз, осва... | https://habr.com/ru/post/521252/ | null | ru | null |
# GlassRAT: анализ трояна из Китая с помощью RSA Security Analytics и RSA ECAT

Специалистами RSA Research была обнаружена троянская программа GlassRAT для удаленного администрирования (Remote Administration Tool — RAT) с «... | https://habr.com/ru/post/274245/ | null | ru | null |
# Эволюция модульного JavaScript

Скорее всего, когда Брендан Айк проектировал JavaScript, он не представлял, как эволюционирует его проект спустя двадцать лет. На данный момент вышло уже шесть основных спецификаций языка, ... | https://habr.com/ru/post/192874/ | null | ru | null |
# Миграция Laravel Nova с PostgreSQL на CockroachDB. Наш опыт и решение
Часто бывает, при ближайшем рассмотрении некоторая проблема выявляет более глубокую, погружаясь в решение которой находишь для себя много интересного.
О такой ситуации на одном из наших проектов и пойдет речь.
. Аналогично AutoCAD, для AutoCAD Architecture возможно написани... | https://habr.com/ru/post/265617/ | null | ru | null |
# Патчим прошивку Android за 5 минут
### Задача
Все началось с того, что я захотел установить на планшет Digma Optima 7.61 игру GTA San Andreas. К сожалению, виртуальная SD-карта планшета имеет объем менее 1 Гб, а кэш игры весит порядка 2-3 Гб. На планшете установлен Android 4.4.2 и возможность просто взять и сменить... | https://habr.com/ru/post/330566/ | null | ru | null |
# Создание Single Page Application на Marko.js — ZSPA Boilerplate
В данной статье вы познакомитесь с [Marko.js](https://markojs.com/) актуальной на данный момент пятой версии. Пару лет назад на Хабре уже была отличная [статья](https://habr.com/ru/post/529320/) (за авторством [apapacy](https://habr.com/ru/users/apapacy... | https://habr.com/ru/post/647641/ | null | ru | null |
# Большие файлы и Sinatra
Недавно столкнулся с интересной проблемой, когда попытка отдать большой файл через `Sinatra::Helpers.send_file` приводила к отжиранию всей оперативной памяти (типичный размер файла — 14Gb).
Исследование показало, что [Sinatra](http://www.sinatrarb.com/) сама читает и отдает файл кусками по... | https://habr.com/ru/post/120305/ | null | ru | null |
# Оптимизация кода для платформы Эльбрус на простых примерах
*"Обычно хакер пишет программы не ради выгоды,
а ради собственного удовольствия. Такая программа
может оказаться полезной, а может остаться
всего лишь игрой интеллекта."
Генри С. Уоррен. Алгоритмические трюки для программистов [1]*
Сегодня мы пр... | https://habr.com/ru/post/317672/ | null | ru | null |
# uid.me — сервис личных страниц (технические детали inside)
*Добрый день, Хабр!*
*Мы хотим сделать обзорный пост, посвящённый нашему новому проекту. Обзор затронет как функционал, так и техническую часть, надеемся, это сделает статью интересной как профессиональным разработчикам, так и тем, кто читает Хабр с целью... | https://habr.com/ru/post/205066/ | null | ru | null |
# Модульный подход к разработке web-приложений с использованием JavaScript: AMD и RequireJS
При разработке приложений с модульной структурой на JavaScript возникает две проблемы:* описание и удовлетворение зависимос... | https://habr.com/ru/post/152833/ | null | ru | null |
# Авторизация из приложения C# на портале BlaBlaCar.ru
Зачем ?
-------
Из кода Вашего приложения Вы можете авторизоваться на любом web-портале. Это может быть нужно когда Вы хотите получить доступ к ресурсам... | https://habr.com/ru/post/532788/ | null | ru | null |
# Создание движка для блога с помощью Phoenix и Elixir / Часть 7. Добавляем комментарии / Новогодний анонс в заключении

От переводчика: «*Elixir и Phoenix — прекрасный пример того, куда движется современная веб-разработка. ... | https://habr.com/ru/post/318790/ | null | ru | null |
# Распознавание с нестандартного микрофона
Некоторые сталкиваются с тем что необходимо распознать речь перевести её в текст и обработать. Проблема описывалась много раз как впрочем и пути её решения так что Google в помощь, но вот я столкнулся на собственном опыте с проблемой которая потребовала нетривиального решения... | https://habr.com/ru/post/214635/ | null | ru | null |
# Разрабатываем Telegram-бота для отслеживания фильмов на NodeJS и TypeScript

У вас бывало такое, что вы приходите в кино и смотрите трейлеры перед началом фильма, при этом некоторые из них цепляют вас достаточно сильно и вы даете с... | https://habr.com/ru/post/443876/ | null | ru | null |
# Настройки Windows 10: часть III, или куда приводят скрипты
Здравствуйте, товарищи! Прошло чуть больше полугода после выхода предыдущей [статьи](https://habr.com/post/465365) о [Windows 10 Sophia Script](ht... | https://habr.com/ru/post/553800/ | null | ru | null |
# Делаем из Linux From Scratch свой универсальный дистрибутив
Так уж случилось, что пару лет назад по долгу службы на команду разработчиков, к которой я отношусь, свалилась неожиданная задача — разработка системы управления оборудованием (в этом-то как-раз неожиданности нет, ибо направление разработок такое) с управля... | https://habr.com/ru/post/122179/ | null | ru | null |
# Структура блогов
Создать некоторую структуру блогов (иерархию, например) на основе смыловой нагрузки.
Объясню суть идее на примере:
Есть блоги:
[OS Inferno](http://www.habrahabr.ru/blog/os_inferno/) [Haiku OS](http://www.habrahabr.ru/blog/haiku/)
[Операционные системы](http://www.habrahabr.ru/blog/os/) ... | https://habr.com/ru/post/8965/ | null | ru | null |
# Exposable паттерн. Независимые инжекции путём экспанирования
*Disposable* паттерн (интерфейс *IDisposable*) предполагает возможность высвобождения некоторых ресурсов, занимаемых объектом, путём вызова метода *Dispose*, ещё до того момента, когда все ссылки на экземпляр будут утрачены и сборщик мусора утилизирует его... | https://habr.com/ru/post/256629/ | null | ru | null |
# Пишем бота на JavaScript для Minecraft (1.8-1.18) / Часть 10-14
Здравствуйте, уважаемые читатели Хабра! Продолжаем писать бота для Minecraft(1.8 - 1.18) с помощью библиотеки mineflayer. С прошлыми уроками можете ознакомиться [ТУТ](https://habr.com/ru/post/695372/).
Часть 10 (Взаимодействие с коровами)
-------------... | https://habr.com/ru/post/701056/ | null | ru | null |
# Ответственный подход к JavaScript-разработке, часть 2
В апреле этого года мы опубликовали перевод [первого материала](https://habr.com/ru/company/ruvds/blog/447576/) из цикла, посвящённого ответственному подходу к JavaScript-разработке. Там автор размышлял о современных веб-технологиях и об их рациональном использов... | https://habr.com/ru/post/460797/ | null | ru | null |
# Оптимизация JavaScript и jQuery из-под HTML и CSS при разработке сайта
Доброго времени суток, Хабражители. Хочу поделиться неким опытом (советами) при работе с JavaScript + jQuery (по сути, вместо jQuery можете подставить любой другой JS фреймворк). Статья будет интересна новичкам JS и jQuery, но и ~~динозаврам~~ оп... | https://habr.com/ru/post/196580/ | null | ru | null |
# Эластичные шаблоны
[](http://www.voprosoff.net/test/)
Большинство дизайнов ориентировано на использование фиксированных значений при верстке: ширина и высота блоков, размер шрифта. Это позволяет сверстанному шаблону «не разваливаться» при изменении... | https://habr.com/ru/post/21209/ | null | ru | null |
# Строим систему распознавания лиц на основе Golang и OpenCV

OpenCV — библиотека, разработанная для проектов по компьютерному зрению. Ей уже около 20 лет. Я использовал ее еще в колледже и до сих пор приме... | https://habr.com/ru/post/462159/ | null | ru | null |
# Статическое константное дерево на шаблонах C++
Поиск и структуры данных
------------------------
Поиск можно считать одной из наиболее нужных и часто используемых операций при разработке программного обеспечения. На сегодняшний день известно большое количество алгоритмов и структур данных, обеспечивающих высокую ск... | https://habr.com/ru/post/645363/ | null | ru | null |
# JavaScript Augmented Reality — тест JSARToolkit

[JSARToolkit](https://github.com/kig/JSARToolKit) это JavaScript библиотека, портированн... | https://habr.com/ru/post/115485/ | null | ru | null |
# Любите квесты, любите и свои персональные данные в паблике находить
Несколько дней назад со мной произошло ровно то, что написано в заголовке. В далеком 2014 году (а именно 28 декабря в 17:00) мы с женой и друзьями играли в перформанс-квест «Коллекционер» от «Клаустрафобии» и уже давно про это забыли, но «Клаустрафо... | https://habr.com/ru/post/446372/ | null | ru | null |
# MicroProfile и его экосистема
Совсем недавно вышла новая версия MicroProfile - [4.1](https://github.com/eclipse/microprofile/releases/tag/4.1). Я бы хотел рассказать, что вообще такое MicroProfile, для чего... | https://habr.com/ru/post/574958/ | null | ru | null |
# Интеграция библиотеки на Swift в UE4
Недавно возникла задача интеграции кода, который был написан только на Swift в проект на UE4. При этом вариант "давайте быстренько перепишем все на Objective C" не рассматривался. Готового решения нигде не нашел, пришлось, как это часто бывает, копать и вширь и вглубь. Задача был... | https://habr.com/ru/post/522746/ | null | ru | null |
# Автоматизация рыбной ловли для World of Warcraft
Познакомился с World of Warcraft очень давно и люблю его весь, но одна вещь больше всего не давала мне покоя — рыбная ловля. Это нудное повторяющееся действие, где ты просто нажимаешь на кнопку рыбной ловли и тыкаешь на поплавок раз в 5-15 секунд. Мой навык разработки... | https://habr.com/ru/post/335580/ | null | ru | null |
# Установка, настройка и использование сканера уязвимостей chkrootkit
В предыдущей моей публикации про [сканер уязвимостей rkhunter](http://habrahabr.ru/company/first/blog/242865/) в комментариях хабрапользователем [Indexator](http://habrahabr.ru/users/indexator/) был упомянут сканер chrootkit. При схожем функционале ... | https://habr.com/ru/post/243487/ | null | ru | null |
# Лечение битых файлов, закачки и докачки
В этом топике вы узнаете как:
* восстановить повреждённую закачку, даже если файла нет в торрентах и других источниках, что содержат хеш его фрагментов;
* скачать файл с докачкой, даже если она не поддерживается сервером;
* докачивать, если сервер не даёт прямых ссылок, отд... | https://habr.com/ru/post/48496/ | null | ru | null |
# Dagger 2. Subcomponents. Best practice
На хабре уже было несколько хороших статей по установке и работе с [**Dagger 2**](https://github.com/google/dagger):
* [1 часть: Основы](https://habrahabr.ru/post/279125/)
* [2 часть: Subcomponent'ы](https://habrahabr.ru/post/279641/)
Я же хочу поделиться своим опытом испол... | https://habr.com/ru/post/334710/ | null | ru | null |
# Битрикс в связке Nginx+PHP-FPM, настройка ЧПУ, а так же композитный кэш с отдачей через nginx. Доработанная конфигурация
**Цель:** Предоставить конфигурацию виртуального сервера Nginx для работы Битрикс-cms в связке Nginx+PHP-FPM. Который в прочем подойдёт и для связки Nginx+Apache2, с небольшими доработками.
**Ц... | https://habr.com/ru/post/438604/ | null | ru | null |
# Простой способ добавить поддержку файлов лицензий в Ваше приложение .Net
Некоторое время назад приятель попросил автоматизировать часть рутинной работы его бизнеса. На тот момент я предвкушал наступление грядущего сокращения и с удовольствием согласился.
Разработка заняла три полных цикла и сейчас подходит к кон... | https://habr.com/ru/post/62315/ | null | ru | null |
# Самодельный компьютер из платы АОНа
В последнее время на Хабре появилось несколько статей про самодельные компьютеры, созданные из различных нестандартных компонентов. Я тоже решил рассказать о своем компьютере, созданном в далеком 1993 году. На волне всеобщего увлечения синклерами, мне захотелось иметь полностью ор... | https://habr.com/ru/post/497092/ | null | ru | null |
# Усатый стрелок из двадцати трёх полигонов
А давайте отвлечёмся немного и напишем игру в google play? И не такую огромную и неподъёмную фигню, про которую я обычно пишу статьи, а что-нибудь простое и милое сердцу?
На само... | https://habr.com/ru/post/322262/ | null | ru | null |
# Загрузчик фотографий как vkontakte на Flex
Неделю назад мои знания action script ограничивались тем, как добавить событие onclick на баннер перед загрузкой в баннерную сеть. В качестве загрузчика файлов я использовал swfupload, и очень не хотел влезать внутрь swf-ника и разбираться в коде. Мне не нравится flash, я н... | https://habr.com/ru/post/80954/ | null | ru | null |
# Следующий уровень автоматизации Kubernetes. Создаем свой оператор
Оператором в Kubernetes принято называть развертывание, которое самостоятельно управляет ресурсами кластера, регистрирует новые Custom Resou... | https://habr.com/ru/post/669806/ | null | ru | null |
# Вышел NHibernate 3.3.3.GA
Всем привет. Буквально несколько минут назад мы выпустили NHibernate 3.3.3.GA. Забрать можно с [sf.net](http://sourceforge.net/projects/nhibernate/?source=directory) или установить с помощью менеджера пакетов [NuGet](http://nuget.org/packages/NHibernate/3.3.3.4000).
Это минорный релиз, н... | https://habr.com/ru/post/173137/ | null | ru | null |
# Порядок выполнения событий в DOM
Столкнулся с проблемой в своём [календарике](http://kurapov.name/calendar/) — есть два элемента, один из которых позиционируется абсолютно на весь экран, полупрозрачная затемняющая занавеска а второй — форма. Вы наверняка видели такие решения при показе картинок в lightbox или аутиде... | https://habr.com/ru/post/22142/ | null | ru | null |
# Кто вы, Mr. Noob? Или попытка классификации новичков, обитающих в Internet, по их манере задавать вопросы! (Часть 1)
Здравствуй, Хабраленд! Узнал о твоем существовании и сразу захотел посетить тебя. Но ты оказался под замком. Я был опечален таким исходом, но быстро понял, что ты лучшее, что я видел, а значит – ты зн... | https://habr.com/ru/post/91967/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.