
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# «Eppur si muove!»* или Работаем с таймзонами в Python
На нашей планете Земля, в одно и то же время, в разных географических точках планеты может быть разное время суток. Это следствие того, что наш мир — вращающийся геоид, а не плоский диск, а что наша Солнечная система имеет только одну звезду — Солнце. Ещё со школ... | https://habr.com/ru/post/242615/ | null | ru | null |
# Enumerable: How to yield a business value
This article is a brief explanation about how using a common language keywords might have an influence on the budget of IT-infrastructure of a project or help to achieve some limitations/restrictions of hosting infrastructure and, moreover, will be a good sing of the quality... | https://habr.com/ru/post/444358/ | null | en | null |
# Как сделать программу на Go быстрее на 42%, изменив один символ

Если вы прочитали заголовок и подумали «ну, ты, наверно, сделал сначала что-то глупое», то вы правы! Но что такое программирование, как не упражнения в глупых ошибках... | https://habr.com/ru/post/699538/ | null | ru | null |
# Быстрое индексное умножение по модулю
Введение
--------
Обычно данный материал приводится с обилием формул и рассчитан больше на математиков. Я постараюсь расписать его наиболее доступно на простых численных примерах с точки зрения применения этого метода в микроэлектронике на аппаратном уровне. В численных примера... | https://habr.com/ru/post/149273/ | null | ru | null |
# Неожиданное поведение фильтров исключений в C# 6
### Что такое фильтры исключений?
*Фильтры исключений (Exception Filters)* — новая фича C# 6, которая позволяет устанавливать специфические условия для блока `catch`. Этот блок будет исполнятся только в случае, если указанные условия выполнены. Проиллюстрируем синтак... | https://habr.com/ru/post/252437/ | null | ru | null |
# Несколько интересностей и полезностей для веб-разработчика #29
Доброго времени суток, уважаемые хабравчане. За последнее время я увидел несколько интересных и полезных инструментов/библиотек/событий, которыми хочу поделиться с Хабром.
#### [HumHub](https://github.com/humhub/humhub)
[.
Проще всего проиллюстрировать её назначение следующим примером.
До:
```
var name;
for (var i = 0; i < users.length; i++) {
if (users[i].id == 123) {
... | https://habr.com/ru/post/303624/ | null | ru | null |
# Эксперименты с нейронными сетями на данных сейсморазведки
Сложность интерпретации данных сейсмической разведки связана с тем, что к каждой задаче необходимо искать индивидуальный подход, поскольку каждый набор таких данных уникален. Ручная обработка требует значительных трудозатрат, а результат часто содержит ошибки... | https://habr.com/ru/post/482780/ | null | ru | null |
# «Heroes of Might and Magic IV»: баг с таверной или классика патчинга
Эта короткая история описывает одну из работ, проведенную в рамках проекта *«Equilibris»* — неофициального мода для игры «Heroes of Might and Magic IV». С точки зрения как реверс-инжиниринга, так и патчинга она не представляет особого интереса — не... | https://habr.com/ru/post/529188/ | null | ru | null |
# «Колотое целомудрие подергает ситечко» — или сложный пароль, но легкий для запоминания
Выполните подобный запрос у себя по таблице пользователей (*пароль хранится в sha1*):
`SELECT password, count( * ) FROM sys_users WHERE password = SHA1( '12345678' ) GROUP BY password HAVING count( * ) >1`У меня на данный момен... | https://habr.com/ru/post/124335/ | null | ru | null |
# Гайд по созданию Facebook Welcome Page и других кастомных табов
Facebook — самая большая социальная сеть и один и самых посещаемых сайтов в мире. В ней можно не только постить веселые статусы и лайкать фотографии, но и
использовать, как мощный маркетинговый инструмент. Все логично — миллиард пользователей, возмож... | https://habr.com/ru/post/141078/ | null | ru | null |
# Плагин tagSphere
Думаю, многие из вас видели плагин для [wordpress](http://domainingdomainers.com/domaining-tech/domain-o-sphere-active-flash-dynamic-tag-clouds-live-search-engine/2008/05/24/). Симпатичный шарик привлек мое внимание и мне захотелось его поковырять...
Разочарованию не было предела ― он оказался на... | https://habr.com/ru/post/47337/ | null | ru | null |
# Пишем клиент-серверную систему Backup-ов под *NIX OS
Всем добрый день.
Как говориться сисадмины деляться на тех кто делает бэкапы и тех кто их еще не делает.
Собственно снова о бэкапах.
Возникла ситуация, когда нужно было иметь под рукой всегда свежий бэкап с большого количества
удаленных хостов. Причем ... | https://habr.com/ru/post/133051/ | null | ru | null |
# Создание псевдотрёхмерной гоночной игры

В детстве я редко ходил в залы аркадных автоматов, потому что особо в них не нуждался, ведь дома у меня были потрясающие игры для C64… но есть три аркадные игры, ... | https://habr.com/ru/post/499252/ | null | ru | null |
# Обзор литературы прочитанной за два года
Привет Хабра! Когда я только начинал заниматься веб-разработкой, то даже не мог представить, сколько литературы нужно прочесть и какой объем знаний получить, чтобы стать нормальным специалистом. Кроме того, сфера постоянно меняется, и знания устаревают.
Анимация при наведении – прекрасный способ сделать приложение динамичным и отзывчивым. Это мелочь, но именно такие детали в итоге могут сделать... | https://habr.com/ru/post/670234/ | null | ru | null |
# Тестирование в React Native
Эта статья – большущий гайд по технологиям, которые мы в СДЭК используем для проверки наших внутренних приложений, написанных на React Native. Часть из этих подходов вполне можно... | https://habr.com/ru/post/683026/ | null | ru | null |
# Прикручиваем ActiveRecord к сайту
##### Введение
В процессе создания более ли мене сложного сайта приходится задумываться об организации доступа к БД(базе данных). Если сайт создается на базе существующего фреймворка или CMS, то там как правило имеются встроенные механизмы ORM (с англ. — Объектно-реляционное отобра... | https://habr.com/ru/post/211913/ | null | ru | null |
# Node.js + face-recognition.js: простое и надёжное распознавание лиц с помощью глубокого обучения

*Перевод статьи [Node.js + face-recognition.js: Simple and Robust Face Recognition using Deep Learning](https://medium.com/@muehler.v/node-js... | https://habr.com/ru/post/351586/ | null | ru | null |
# Пишем 2d-игру на Java
Доброго времени суток всем!
В этой статье будет описываться создание 2D игры на Java. Сразу предупреждаю, вы должны хотя бы базово знать язык Java, поскольку на подробное объяснение каждой строки у меня нету времени. И очень прошу вас, не списывать просто код, а пытаться понять что означает ... | https://habr.com/ru/post/326032/ | null | ru | null |
# Инкапсуляция для настоящих самураев, или нюансы, связанные с ключевым словом internal в C#
Пролог: internal is new public
------------------------------
Каждый из нас мечтал о проекте, где всё будет сделано правильно. Это кажется вполне естественным. Как только ты узнаёшь о самой возможности писать хороший код, как... | https://habr.com/ru/post/445804/ | null | ru | null |
# На память о 2017-м: лучшие посты в нашем блоге за год

*[Pixel Jeff](http://pixeljeff.tumblr.com/)*
Новогодние традиции — это святое. Оливье, шампанское, мандарины, ёлка и подведение итогов за год. В 2017-м мы опубликовали 212 пос... | https://habr.com/ru/post/345790/ | null | ru | null |
# Мобильные устройства изнутри. Что такое GPT?
Что такое GPT?
--------------
**ОГЛАВЛЕНИЕ**[1. Введение](#1)
[2. Структура GPT](#2)
[3. Что такое GPT-раздел типа Intel?](#3)
[3.1. Структура заголовка нового GPT-раздела](#31)
[3.2. Структура записи описания нового GPT-раздела](#32)
[4. Заключение.](#4... | https://habr.com/ru/post/347738/ | null | ru | null |
# То, что вам никто не говорил о z-index в статье «То, что вам никто не говорил о z-index»
Почти два года назад вышла статья «[What no one told you about z-index](http://philipwalton.com/articles/what... | https://habr.com/ru/post/225721/ | null | ru | null |
# Наконец-то!
На хабре появился нормальный редактор комментариев. Теперь не надо будет каждый раз прописывать руками все коды. Сколько лет его все ждали.
Теперь можно удалить все надстройки для браузеров, дублирующие этот функционал.
Где анонс этого апдейта и какие-либо комментарии от администрации? Может ещё ка... | https://habr.com/ru/post/113590/ | null | ru | null |
# Объединяя C++ и Python. Тонкости Boost.Python. Часть первая
Boost.Python во всех отношениях замечательная библиотека, выполняющая своё предназначение на 5+, хотите ли вы сделать модуль на С++ для Python либо хотите построить скриптовую обвязку на Python для нативного приложения написанного на С++.
Самое сложное в... | https://habr.com/ru/post/168083/ | null | ru | null |
# О чем говорит YouTube
На заре машинного обучения большинство решений выглядели очень странно, обособленно и необычно. Сегодня множество ML алгоритмов уже выстраиваются в привычный для программиста ... | https://habr.com/ru/post/433532/ | null | ru | null |
# Как устроено автоматическое тестирование в Почте Mail.Ru под iOS

Некоторое время назад мы рассказали вам об [автоматическом тестировании нашей Почты на Android](https://habrahabr.ru/company/mailru/blog/306236/) и полу... | https://habr.com/ru/post/325552/ | null | ru | null |
# PostgreSQL Antipatterns: статистика всему голова
Для выбора наиболее эффективного плана выполнения запроса [PostgreSQL пользуется накопленной статистикой](https://postgrespro.ru/docs/postgresql/12/planner-stats) о распределении значений данных в целевых таблицах.
Она обновляется с помощью явного запуска команд **... | https://habr.com/ru/post/479656/ | null | ru | null |
# Очистка заражённых файлов сайта от вредоносного кода
Добрый день, уважаемые Хабраюзеры!
Некоторое время назад, около месяца, на сервере нашей компании появился вирус. На одном из крупных проектов были поражены все \*.js файлы. Ситуация обычная — в конец файлов был дописан вредоносный код. Яндекс выдавал предупреж... | https://habr.com/ru/post/141710/ | null | ru | null |
# Гид по предварительной обработке текста с помощью BERT
Современные NLP-приложения, например, для [анализа настроения](https://analyticsindiamag.com/guide-to-build-a-simple-sentiment-analyzer-using-tensorflow-hub/), поиска [ответов на вопросы](https://analyticsindiamag.com/guide-to-question-answer-retrieval-with-mult... | https://habr.com/ru/post/579518/ | null | ru | null |
# Программируем Pololu 3pi на Ubuntu/Debian, для начинающих
Вы только что приобрели робота от Pololu и в качестве операционной системы используете Linux Ubuntu или Debian, тогда эта статья для вас. В первую очередь статья рассчитана на новичков, которые решили попробовать себя в р... | https://habr.com/ru/post/103227/ | null | ru | null |
# Импорт координат из текстового файла в чертёж nanoCAD на классическом .NET API
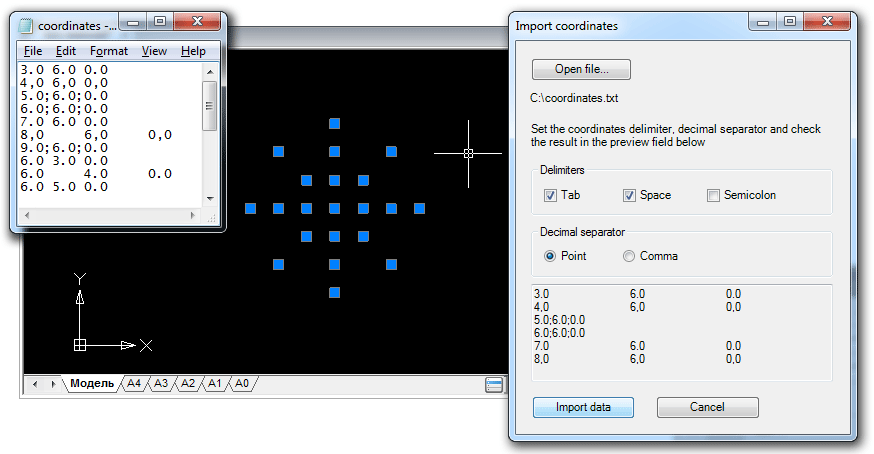
Одним из наиболее популярных вопросов по программированию под nanoCAD является «Как мне импортировать точки из текстового фа... | https://habr.com/ru/post/188188/ | null | ru | null |
# Особенности использования MongoDB

Чуть больше года назад меня попросили поучаствовать в развитии одной известной в узких кругах (но не всегда с хорошей стороны) социальной сети. В то время я уже был фана... | https://habr.com/ru/post/229129/ | null | ru | null |
# Как находить проблемы с интернетом и кто виноват ч.2 — домашняя работа
Перед тем, как обращаться к провайдеру, необходимо разобраться - а всё ли хорошо в доме. Без этой проверки есть риск превратиться в мальчика, который постоянно кричал ~~"у меня потери пакетов"~~ "волки".
---
*В настоящее время, у пользователей ... | https://habr.com/ru/post/531082/ | null | ru | null |
# Новые возможности векторизации и распараллеливания в Intel® Parallel Composer

В начале апреля стартовала программа по тестированию Intel® Parallel Composer beta, которая заканчивается в конце августа. Напомню основные компоненты композера:
* Intel C++ Compiler:
* ... | https://habr.com/ru/post/97011/ | null | ru | null |
# Добавляем голосовое управление на русском языке в VR-проект
Тема виртуальной, дополненной реальности, метавселенных набирает обороты. Но что это такое, как должно выглядеть, как этим пользоваться, никто толком пока не знает. Однако, как в своё время переход от десктопных приложений к мобильным, миграция в VR принесё... | https://habr.com/ru/post/670588/ | null | ru | null |
# Анализируем локальные функции в C# 7
Добавление локальных функций в языке C# первоначально для меня было излишним. Прочитав статью в блоге [SergeyT](https://habrahabr.ru/users/sergeyt/), я понял, что эта фича действительна нужна. Итак, кто сомневается в надобности локальных функций и кто еще не знает что это, вперед... | https://habr.com/ru/post/346174/ | null | ru | null |
# Создание столбчатых диаграмм с помощью JavaScript
[](https://habr.com/ru/company/ruvds/blog/711728/)
Современный мир буквально переполнен данными, и нам желательно уметь представлять их графически для быстроты и удобства восприятия... | https://habr.com/ru/post/711728/ | null | ru | null |
# Часть 2: Использование блоков UDB контроллеров PSoC фирмы Cypress для уменьшения числа прерываний в 3D-принтере

[В прошлый раз](https://habr.com/post/433800/) мы рассмотрели вариант генерации импульсов для шаговых двигателей, ча... | https://habr.com/ru/post/434742/ | null | ru | null |
# Простой переводчик на Ruby
С помощью mechanize и hpricot написал класс очень полезного переводчика.
На даный момент доступно 3 сервера для перевода translate.meta.ua, translate.google.com и pereklad.online.ua
##### Пример кода:
`def initialize(url=:meta)
Hpricot.buffer_size = 2621444
@agent = WWW::Mech... | https://habr.com/ru/post/62856/ | null | ru | null |
# Переносим свою картину мира в чат-бота на базе GPT-3
Думаю, все уже наслышаны о потрясающих возможностях ChatGPT и GPT-3, многие уже вдоволь наигрались с ними, а новые стартапы на их основе льются на нас каждый день проливным дождём! Возможности ChatGPT в решении некоторых текстовых задач потрясают, порой кажется, ч... | https://habr.com/ru/post/712534/ | null | ru | null |
# Контейнеры внедрения зависимостей и выгоды от их использования
### От переводчика
Всем привет! Я продолжаю серию переводов, в которой мы по косточкам разбираем, что такое Dependency Injection.
В [предыдущих статьях серии](#series) речь шла о «внедрении зависимостей» как подходе к проектированию приложений и возм... | https://habr.com/ru/post/350708/ | null | ru | null |
# Рекурсивное программирование на ЛИСП – решатель формул
Решатель формул сам по себе очень интересная тренировка, и в определённый момент эта тренировка может очень пригодиться в другой задаче – конструировании новой формулы, автоматической её проверке (погрешность, просчёт значений по списку координат)… И excel вам н... | https://habr.com/ru/post/74280/ | null | ru | null |
# О сложностях мониторинга работающих процессов в Linux
Все знают о том, как наблюдать за работающими процессами в Linux-системе. Но почти никто не добивается в подобных наблюдениях высокой точности. На самом деле, всем методам мониторинга процессов, о которых пойдёт речь в этом материале, чего-то не хватает.
[, посвящённой разработке REST-серверов на Go. Здесь мы поговорим о middleware. У меня есть [материал](https://eli.thegreenplace.net/2021/life-of-an-http-request-in-a-go-server/),... | https://habr.com/ru/post/566198/ | null | ru | null |
# Десять возможностей C++11, которые должен использовать каждый C++ разработчик
В данной статье рассматривается ряд возможностей С++11, которые все разработчики должны знать и использовать. Существует много новых дополнений к языку и стандартной библиотеке, эта статья лишь поверхностно охватывает часть из них. Однако,... | https://habr.com/ru/post/182920/ | null | ru | null |
# Слабая связность
**NB**: это черновик двух новых глав [моей книги](https://twirl.github.io/The-API-Book/docs/API.ru.html), посвященной дизайну API. В тексте встречаются отсылки к предыдущим главам.
### Сильная связность и сопутствующие проблемы
В предыдущих разделах мы старались приводить теоретические правила и п... | https://habr.com/ru/post/554632/ | null | ru | null |
# Решение проблемы конфликтов имен CSS классов в приложении на React с помощью webpack лоадера
Приветствую вас, друзья!
Началось всё с того, что я замыслил разработать кое-что так сказать для души. React приложение должно было рендериться поверх чего-то другого, например какого-то сайтика, встал вопрос того, что возм... | https://habr.com/ru/post/344974/ | null | ru | null |
# Функциональное программирование с PHP-генераторами

Генераторы классные. Они облегчают написание итераторов, определяя функции вместо создания целых классов, реализующих `Iterator`. Также генераторы помогают создавать ленивые списк... | https://habr.com/ru/post/351818/ | null | ru | null |
# Динамический импорт модулей в Python
Давайте представим ситуацию, когда вам нужно установить на все виртуальные машины (агенты сервера сборки) определенный пакет Python. Но вы не можете изменить образ аген... | https://habr.com/ru/post/681680/ | null | ru | null |
# TorrentMonitor и снова здравствуйте
Полтора года назад я уже писал здесь о своей разработке [TorrentMonitor](http://habrahabr.ru/post/157319/). Кто-то может быть уже читал и давно пользуется, а кто-то может быть даже и не слышал, поэтому хочу поведать вам о ней ещё раз, тем более что полтора года я не сидел сложа ру... | https://habr.com/ru/post/210548/ | null | ru | null |
# Istio Circuit Breaker: отключаем неисправные контейнеры
Праздники завершились, и мы возвращаемся с нашим вторым постом из серии по Istio Service Mesh.

Сегодняшняя тема – Circuit Breaker, что в переводе на русский электротехниче... | https://habr.com/ru/post/483262/ | null | ru | null |
# Самые полезные новинки C++ 20

В сентябре прошлого года профильный комитет ISO утвердил [С++ 20](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2020/) в качестве текущей версии международного стандарта. Предлагаю ознакомиться с... | https://habr.com/ru/post/553456/ | null | ru | null |
# Speed Dial для Google Chrome
Всем меня радует Chrome, и достаточно прочно занимает место основного браузера под Windows. Однако с момента введения «самых посещаемых сайтов» как основы для каждой новой вкладки меня одолевала мысль о том что она слишком примитивна — до по... | https://habr.com/ru/post/78697/ | null | ru | null |
# Знакомимся с Web Animations API
Доброго времени суток, друзья!
Веб API постоянно эволюционируют. Некоторые из них, такие как Console или Canvas, хорошо поддерживаются всеми браузерами, другие по-прежнему находятся на стадии разработки.
Одним из API, находящимся на стадии разработки, является Web Animations API... | https://habr.com/ru/post/486454/ | null | ru | null |
# Устранение дублирования Where Expressions в приложении
Допустим, у вас есть товары и категории. В какой-то момент клиент сообщает, что для категорий с рейтингом > 50 необходимо использовать другие бизнес-процессы. У вас достаточно опыта и вы понимаете, что где сегодня 50 завтра будет 127.37 и хотите избежать появлен... | https://habr.com/ru/post/313394/ | null | ru | null |
# Краткое руководство по работе с данными с помощью Miller

Привет, друзья!
Представляю вашему вниманию перевод [этой замечательной статьи](https://www.smashingmagazine.com/2022/12/guide-command-line-data-manipulation-cli-miller/), ... | https://habr.com/ru/post/711246/ | null | ru | null |
# Named Capturing Group и Backreferences
Данная заметка не предназначена для начинающих изучать регулярные выражения, для начинающих я бы посоветовал книгу Ben Forta "Teach Yourself Regular Expressions in 10 Minutes" (ISBN: 0-672-32566-7).
Для тестирования и отладки регулярных выражений идеально подходит программа... | https://habr.com/ru/post/54681/ | null | ru | null |
# Делаем автоматизированный обзвон для нотификаций или опросов
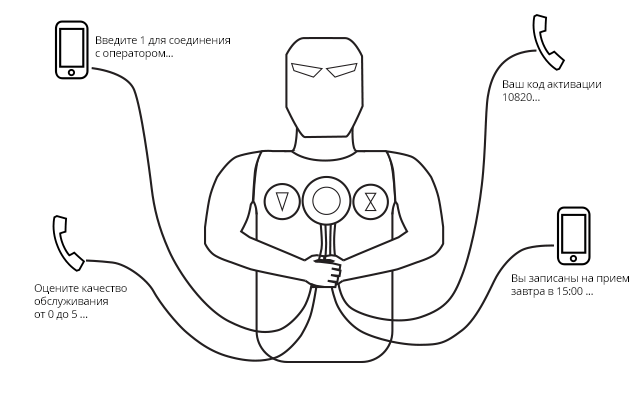В ряде случаев у компании может возникнуть необходимость обзвонить каких-то из своих клиентов и сообщить им о чем-то, или, например, провести опрос про качеству обс... | https://habr.com/ru/post/243809/ | null | ru | null |
# IPv6 — это весело, часть 2
**Введение:** Добрый день или вечер, или даже ночь дорогие хабравчане. В данной статье продолжим изучать особенности протокола IPv6 и его отличия от IPv4. В данной статье будет минимальное количество теории и максимальное количество настройки. Начнем с настройки DHCPV6 и рассмотрим особенн... | https://habr.com/ru/post/254293/ | null | ru | null |
# Программируем под Pebble. Урок второй: Камешек, дающий ответы, игральные кости и секс-кубики
[Часы](http://habrahabr.ru/company/avi/blog/204338/) — это конечно хорошо, но ими забит весь сайт. Надо сделать что-то более интересное.

Электронная коммерция — одна из самых больших и быстро растущих областей, в связи с чем она привлекает внимание как исследователей информационной безопасности, так... | https://habr.com/ru/post/517268/ | null | ru | null |
# Заметки про motd
motd — message of the day, сообщение отображаемое при входе в Linux-систему (на примере Ubuntu).
Раньше файл, содержащий приветствие располагался в `/etc/motd`, сейчас же это набор скриптов, располагающихся в каталоге `/etc/update-motd.d/`:
```
# ls -alh /etc/update-motd.d/
total 56K
drwxr-xr-x 2... | https://habr.com/ru/post/529746/ | null | ru | null |
# Развертывание Windows UEFI с использованием Foreman
**Автор: DevOps Team Leader компании** [**Hostkey**](https://hostkey.ru/) **Егор Гараджа**
[В прошлой статье](https://habr.com/ru/company/hostkey/blog/70... | https://habr.com/ru/post/706448/ | null | ru | null |
# PUSH в GIT как средство доставки в прод, или как сэкономить время на развертывании и обновлении сервисов
Программисты любят программировать. Но если вы – программист, и результат вашего творения делается не “в стол”, рано или поздно наступит момент, когда нужно показать его миру: заказчику, пользователям, инвесторам... | https://habr.com/ru/post/700620/ | null | ru | null |
# Почему каждый Data Scientist должен знать Dask
Здравствуйте, коллеги!
Возможно, название сегодняшней публикации лучше смотрелось бы с вопросительным знаком — сложно сказать. В любом случае, сегодня мы хотим предложить вам краткий экскурс, который познакомит вас с библиотекой [Dask](http://docs.dask.org/en/latest/... | https://habr.com/ru/post/454262/ | null | ru | null |
# Как попасть в Microsoft, Amazon или Twitter без диплома престижного колледжа
Эта статья для тех, кто готовится искать работу и, возможно, тревожится о том, что в топовые компании без диплома Стэнфордского университета по информатике не пробьешься. Вам наверняка говорили, что вас никто не возьмет в Facebook или Micro... | https://habr.com/ru/post/353462/ | null | ru | null |
# Настройка SSL для приложения в Windows Azure
[](http://windowsazure.com/ru-ru/)
Протокол шифрования SSL (Secure Socket Layer) — это самый распространенный способ защиты данных в Интернете. В этом примере будет пока... | https://habr.com/ru/post/149939/ | null | ru | null |
# Amazon выпустил фикс для инстансов работающих под Windows Server 2012 R2, предотвращающий потерю сетевых подключений
Сегодня утром получил [уведомление](http://aws.amazon.com/windows/2012r2-network-drivers/) от службы поддержки AWS.
В уведомлении сообщается, что функция «Plug and Play Cleanup» из Windows Server 2... | https://habr.com/ru/post/235609/ | null | ru | null |
# Управление освещением и голосовое оповещение о погоде на Raspbery Pi
Управление освещением и голосовое оповещение о погоде. Пример кода и электрическая схема подлючения реле к Raspberry Pi.
Предварительно установите **mplayer** и **alsa**:
```
sudo apt-get install alsa-utils
sudo apt-get install mplayer
```
... | https://habr.com/ru/post/362075/ | null | ru | null |
# ELK Stack для хранения логов Django приложения
Каждый из проектов, который перерастает этап прототипа, нуждается в организации логирования. Грамотное логирования решает уйму проблем и помогает понять состояние проекта. На начальном этапе логирование в файл меня устраивало пока проект не разросся и поиск по логам не ... | https://habr.com/ru/post/421819/ | null | ru | null |
# Запросить 100 серверов нельзя оптимизировать код. Ставим запятую
Можно выделить ряд алгоритмов, которые являются базовыми и лежат в основе практически каждой строчки программ, написанных на языках высокого уровня. Хорошо иметь под руками классический многотомный труд Дональда Кнута ["The Art of Computer Programming"... | https://habr.com/ru/post/562906/ | null | ru | null |
# Пожалуйста, прекратите писать shell-скрипты
Когда вы автоматизируете какую-либо задачу, например, упаковываете свое приложение для Docker, то часто сталкиваетесь с написанием shell-скриптов. У вас может быт... | https://habr.com/ru/post/657841/ | null | ru | null |
# Немного об арифметике
Вы когда-нибудь задумывались о том, как мы считаем? Как устроен счет на низком уровне? Например, как выглядят на прямой единичные отрезки в выражении 1 + 1 = 2. Или что такое квадратный корень из  информацию о множественных dll hijacking уязвимостях в продуктах Microsoft Office, а какой-либо реакции не наблюдается. Ни CV... | https://habr.com/ru/post/272487/ | null | ru | null |
# Дизайн и эволюция constexpr в C++
`constexpr` - одно из самых магических ключевых слов в современном C++. Оно дает возможность создать код, который будет выполнен еще до окончания процесса компиляции, что я... | https://habr.com/ru/post/579490/ | null | ru | null |
# Сервер авторизации для микросервисов на Spring Boot
В этой статье рассмотрим, как реализовать аутентификацию с помощью централизованного сервера авторизации (Authorization Server) и API-шлюза (API Gateway).... | https://habr.com/ru/post/681448/ | null | ru | null |
# Разработка приложения на основе протокола oAuth для Twitter API на PHP

В этой статье расскажу про работу с Twitter API по протоколу OAuth на PHP.
Протокол OAuth предоставляет приложению доступ к данным пользователя без пере... | https://habr.com/ru/post/103548/ | null | ru | null |
# Простая реализация модели MVC с поддержкой иерархии шаблонов
В данной статье показывается пример реализации модели MVC средствами PHP. Предлагаемая реализация является предельно простой как для понимания, так и для исполнения. Полезными особенностями являются легкая расширяемость и поддержка иерархии шаблонов. Все э... | https://habr.com/ru/post/232089/ | null | ru | null |
# Property Injection своими руками (Xamarin/.Net)
В данной статье мы рассмотрим, чем отличается Property Injection от Constructor Injection и реализуем первое в дополнение к последнему на базе небольшого DI-контейнера в исходниках.
Это обучающий материал начального уровня. Будет полезен тем, кто ещё не знаком с DI-... | https://habr.com/ru/post/352304/ | null | ru | null |
# Как я сократил время загрузки GTA Online на 70%

GTA Online [печально известна](https://www.reddit.com/r/gtaonline/comments/9vgo0g/how_the_fuck_are_20_minute_load_times_acceptable/) своей медленной скоростью загрузки. Запуст... | https://habr.com/ru/post/544764/ | null | ru | null |
# Бенчмарк как основание для принятия решения об изменении кода
Билл Кеннеди в одной из лекций своего замечательного курса [Ultimate Go programming](https://www.safaribooksonline.com/library/view/ultimate-go-programming/9780134757476/) сказал:
> Многие разработчики стремятся оптимизировать свой код. Они берут строч... | https://habr.com/ru/post/438446/ | null | ru | null |
# Подходы к созданию скриптового языка описания настольных игр
Так уж случилось, что игры я писал лишь для себя, и профессионально этим никогда не занимался.
А вот опыт писать DSL (Domain Specific language) для уменьшения рутины написания совершенно разного кода хоть какой-то есть.
Именно этим и хочется поделитс... | https://habr.com/ru/post/247405/ | null | ru | null |
# Безопасно ускоряем Erlang приложение c помощью NIF на Rust
В статье освещен вопрос интеграции Erlang и Rust на примере реализации вероятностной структуры данных Бёртона Блума, позволяющей проверить принадлежность элемента множеству с необходимой точностью.
Выбор языка
-----------
Тесты производительности, основан... | https://habr.com/ru/post/349398/ | null | ru | null |
# Как быстрее всего сфоткать 35 билбордов в Москве
Идеи, чем заняться на выходных, ITшники черпают из сотни разных источников. Я, к примеру, недавно увидел конкурс Открытого чемпионата школ по Экономике, заключающегося в том, чтобы **сфотографировать максимальное число билбордов Чемпионата**. Адреса организаторы любез... | https://habr.com/ru/post/324864/ | null | ru | null |
# Экстремальное кодирование аудио
Вы никогда не задумывались, как поведут себя существующие форматы сжатия с потерями в совершенно ненормальных условиях? Обычно они удачно маскируют удаляемую ин... | https://habr.com/ru/post/89885/ | null | ru | null |
# Локальные репозитории пакетов
Всем привет! Сегодня хочу поделиться нашими мыслями относительно того, как можно защитить свою разработку от некоторых потенциальных рисков в современных условиях. Собственно,... | https://habr.com/ru/post/657881/ | null | ru | null |
# Как использовать Prometheus для обнаружения аномалий в GitLab

Одной из базовых функций языка запросов Prometheus является агрегация [временных рядов](https://prometheus.io/docs/prometheus/latest/querying... | https://habr.com/ru/post/499032/ | null | ru | null |
# Производительность фронтенда: разбираем важные метрики
Обычно под производительностью понимают количество операций за определенный интервал времени и чем их больше, тем лучше. Но такое определение, да и подход в целом, мало применим к... | https://habr.com/ru/post/454920/ | null | ru | null |
# Интерфейсы классов и коллекции
Вопрос о том, какими должны быть хорошие интерфейсы классов, непрост. Какие методы включить в интерфейс, какими должны быть их параметры, не надо ли вообще разбить данный интерфейс на несколько? Что будет с интерфейсом по мере развития проекта, потребуется ли его изменять? Наверняка по... | https://habr.com/ru/post/150448/ | null | ru | null |
# Dock панель для сайта. Выбор подходящего jQuery плагина и руководство по установке

#### Красота спасет мир
Обладатели компьютеров Apple давно пользуются красивой и удобной dock панелью. В отличие от этих сч... | https://habr.com/ru/post/95877/ | null | ru | null |
# Подключаем Facebook SDK для Xamarin.Forms
Социальные сети, и особенно Facebook, уже давно используются в мобильных приложениях. Сегодня мы рассмотрим, как подключить нативные Facebook SDK к проекту на базе Xamarin.Forms (iOS и Android) для удобной авторизации пользователей и получения о них базовой информации. Вы та... | https://habr.com/ru/post/321454/ | null | ru | null |
# Raphaël
Привет, Хабр
------------
В этом коротком очерке хотел бы рассказать о маленькой (по словам авторов) библиотеки на JavaScript — Raphaël. Данная библиотека использует для работы SVG и VML и служит, как не сложно догадаться для облегчения работы с векторная графикой в вебе.
Так же по утверждению создателе... | https://habr.com/ru/post/59386/ | null | ru | null |
# TiKV — распределённая база данных key-value для cloud native

28 августа организация CNCF (Cloud Native Computing Foundation), стоящая за Kubernetes, Prometheus и другими Open Source-проектами для современных облачных приложений, [... | https://habr.com/ru/post/421903/ | null | ru | null |
# Собственный «Кто звонил?» на базе Мультифона
На какие вопросы вы найдёте ответы в этой статье:
* как отправлять USSD через GSM/3G/4G-модем и читать ответы;
* как отправлять SMS через Мультифон;
* как использовать Яндекс SpeechKit в автоответчике на Asterisk.
На какие вопросы вы не найдёте ответов:
* зачем нуж... | https://habr.com/ru/post/278679/ | null | ru | null |
# SynchronizationContext — когда MSDN подводит
Не знаю почему, но информации об этом новом класса в .NET Framework, действительно немного. Документация MSDN почти ничего не говорит о способах использования SynchronizationContext. Должен сказать, изначально я и сам плохо представлял назначение этого класса и как его ис... | https://habr.com/ru/post/232169/ | null | ru | null |
# Фишинг «своими руками». Опыт компании «Актив», часть вторая

В [первой](https://habrahabr.ru/company/aktiv-company/blog/329470/) статье я рассказал о теории вопроса, теперь же от теории перейдем к практике. Итак, мы успешно... | https://habr.com/ru/post/329538/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.