
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Предсказание растворимости молекул с помощью графовых сверточных нейросетей
Пару недель назад мы [начали рассказывать](https://habr.com/ru/company/hsespb/blog/563118/) о проектах, которые стали победителями [Школы по практическому программированию и анализу данных](https://spb.hse.ru/fmcs/programming/) НИУ ВШЭ — Сан... | https://habr.com/ru/post/565650/ | null | ru | null |
# Всё, что нужно знать о сборщике мусора в Python
Как правило, вам не нужно беспокоиться о сборщике мусора и работе с памятью когда вы пишете код на Python. Как только объекты больше не нужны, Python автоматически освобождает память из под них. Несмотря на это, понимание как работает GC поможет писать более качественн... | https://habr.com/ru/post/417215/ | null | ru | null |
# Миграция с Mongo на Postgres: опыт газеты The Guardian

The Guardian — одна из крупнейших британских газет, она основана в 1821 году. За без малого 200 лет существования архив накопился изрядный. По счастью, далеко не весь о... | https://habr.com/ru/post/436416/ | null | ru | null |
# Github включил ассемблер DCPU-16 в список официально поддерживаемых языков
В игре [0x10c](http://0x10c.com/) — новом проекте Нотча (автора Minecraft) — для управления космическим кораблём игроку придётся программировать ... | https://habr.com/ru/post/141883/ | null | ru | null |
# О подключении самописного Objective-C плагина к игровому движку Unity 3D

Доброго всем дня.
Начнем собственно с того что такое Unity 3d В кратце это трехмерный игровой движок. На официальном сайте доступна бесплатн... | https://habr.com/ru/post/162991/ | null | ru | null |
# Выбор элементов recylerView при помощи dataBinding'а
Всем привет. На днях столкнулся с проблемой реализации выбора нескольких элементов в RecyclerView с использованием dataBinding'а.
### Сразу за дело
Для начала напишем базовый адаптер, поддерживающий dataBinding.
```
/**
* Универсальный адаптер для data bindin... | https://habr.com/ru/post/531166/ | null | ru | null |
# Чтение официальных данных о численности муниципальных образований с параметрами форматирования текста с помощью библиотеки xlrd
Для одного общественного проекта (визуализация бюджетов поселений и районов) мне потребовались данные об иерархии муниципальных образований и их численности.
Нужные данные я [нашел](http... | https://habr.com/ru/post/182548/ | null | ru | null |
# Как написать игру в стиле Tower Defense
Жанр Tower Defence один из самых популярных жанров игр на iOS. Причиной тому веселое времяпрепровождение, сдобренное постройкой башен для создания последней точки обороны против орд монстров, пытающихся эту самую оборону прорвать.
Представляю вашему вниманию перевод статьи,... | https://habr.com/ru/post/162733/ | null | ru | null |
# Отрицательные отступы — путь к универсальности
Я часто сталкиваюсь с ситуацией, когда в череде блоков с одинаковыми отступами и общим контейнером, у первого или последнего блока нет отступа или он отличается от остальных. Какое–то время для решения этой «проблемы» я использовал «костыли», вроде классов first или las... | https://habr.com/ru/post/23748/ | null | ru | null |
# Krumo — помощник для отладки php кода
Довольно часто для отладки кода приходится просматривать содержимое переменных, как правило для этого используется такие команды как echo, print\_r(), var\_dump(). Но тут много неудобств, бывает что переменных много, бывает что вобще не знаем какие переменные используются (напри... | https://habr.com/ru/post/47698/ | null | ru | null |
# Liquibase и changeset’ы на чистом SQL
Не все знают, но начиная с версии 2.0 Liquibase поддерживает возможность использования файлов с «чистым SQL» в качестве файлов changeset’ов. Под катом хочу немного описать, из чего они состоят.
Для определения метаданных в файлах SQL используются комментарии, каждый файл chan... | https://habr.com/ru/post/251617/ | null | ru | null |
# Линейная регрессия и градиентный спуск
Пусть в некоторой предметной области исследуются показатели X и Y, которые имеют количественное выражение.
При этом есть все основания полагать, что показатель Y зависит от показателя X. Это положение может быть как научной гипотезой, так и основываться на элементарном здрав... | https://habr.com/ru/post/471458/ | null | ru | null |
# Кот под колпаком. Часть 2

Всем привет! В [прошлой части](https://habr.com/ru/post/445740/) мы рассказали про существующие решения для «оркестрации» параллельных задач «взлома хешей» на hashcat.
В этой части продолжаем рассказ... | https://habr.com/ru/post/446922/ | null | ru | null |
# Среднеквадратичное приближение функций
На днях нужно было написать программу, вычисляющую среднеквадратичное приближение функции, заданной таблично, по степенному базису — методом наименьших квадратов. Сразу оговорюсь, что тригонометрический базис я не рассматривал и в этой статье его брать не буду. В конце статьи м... | https://habr.com/ru/post/131335/ | null | ru | null |
# Мой «Hello World!» на FPGA или очередная версия UART

Наконец-то у меня дошли руки до изучения ПЛИС. А то как-то неправильно получается: драйвера на железо под Linux пишу, микроконт... | https://habr.com/ru/post/427011/ | null | ru | null |
# Изучаем и реализуем алгоритм работы правильного observer паттерна для react компонентов

Итак продолжаем развивать observer-паттерн. В [предыдущей](https://habrahabr.ru/post/348960/) статье от старого и очень простого паттерна "obser... | https://habr.com/ru/post/349022/ | null | ru | null |
# Python consumes a lot of memory or how to reduce the size of objects?
A memory problem may arise when a large number of objects are active in RAM during the execution of a program, especially if there are restrictions on the total amount of available memory.
Below is an overview of some methods of reducing the size... | https://habr.com/ru/post/458518/ | null | en | null |
# Недокументированные возможности Microsoft SQL Server: STATISTICS_ONLY, DBCC AUTOPILOT и SET AUTOPILOT
Как известно, оптимизатор запросов SQL Server, для построения оптимального плана выполнения запроса, использует оценку стоимости. SQL Server строит и оценивает множество планов и выбирает среди них план с минимально... | https://habr.com/ru/post/168597/ | null | ru | null |
# Excel «Всемогущий» и Redmine: как генерировать задачи прямо в Excel

В далёких от IT проектных организациях Excel часто используется в качестве инструмента обработки бог весть каких данных.
Передо мной встала задача в о... | https://habr.com/ru/post/318198/ | null | ru | null |
# Онлайн доступ к закладкам Google Chrome

Когда-то столкнулся с проблемой просмотра закладок Google Chrome онлайн. К сожалению, Google пока не дает возможности просмотра закладок браузера через веб, как это делает,... | https://habr.com/ru/post/146656/ | null | ru | null |
# Использование DPDK для обеспечения высокой производительности прикладных решений (часть 0)
Kernel is the root of all evil ⊙.☉
==================================
Сейчас вряд ли кого-то удивить использованием [epoll()](https://ru.wikipedia.org/wiki/Epoll)/[kqueue()](http://www.opennet.ru/base/dev/kqueue_overview.txt.... | https://habr.com/ru/post/267591/ | null | ru | null |
# Работа с ANSI консолью
[](http://alexsnet.ru/wp-content/uploads/2008/11/picture-12.png)Часто ли нужно сделать програму для консоли? Не так часто, да? А вот я последнее время только этим и занимаюсь… Поэтому сделал класс (на самом деле сдел... | https://habr.com/ru/post/45041/ | null | ru | null |
# Плагин Veeam для бэкапа и восстановления баз данных SAP HANA
В этом сезоне разработчики Veeam представили решение для бэкапа и восстановления серверов и баз данных SAP HANA. Читатели нашего блога проявили интерес к новинке — а тут как раз подоспела и полезная статья от моего коллеги Клеменса Зербе. Сегодня поделюсь ... | https://habr.com/ru/post/461951/ | null | ru | null |
# Как с помощью Python создать полностью автоматизированную трейдинговую систему на базе ИИ
Можно ли с помощью ИИ автоматизировать набор правил, по которым действуют на бирже профессиональные трейдеры? Кома... | https://habr.com/ru/post/669462/ | null | ru | null |
# Знакoмство с flex sdk
Все мы во время разработок сталкивались с проблемой тестирования или дебагинга (то есть отлова ошибок). Сегодня я расскажу как это можно делать без специальных IDE, используя только инструменты непосредственно входящие в пакет flex sdk.
Итак для начала мы наберем текст нашей программы, котор... | https://habr.com/ru/post/137117/ | null | ru | null |
# Применение AOP для отладки чужой библиотеки
На Хабре уже [поднималась](http://habrahabr.ru/search/?q=aop) тема [аспектно-ориентированного программирования](http://ru.wikipedia.org/wiki/%D0%90%D1%81%D0%BF%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%B... | https://habr.com/ru/post/138755/ | null | ru | null |
# Простая публикация геоданных на собственной карте на базе 2ГИС
Недавно передо мной встала интересная задача — отображать на сайте карту, с различными объектами, причем этих объектов могут быть десятки и сотни, а управлять ими должен уметь любой менеджер ниже среднего звена.
Более формально задача сводилась к тому... | https://habr.com/ru/post/204228/ | null | ru | null |
# WPF, WinForms: рисуем Bitmap c >15000 FPS. Хардкорные трюки ч.1
Сразу уточнение: Bitmap 200x100 на компе с быстрой памятью и i7 3930K на 1366. Но, это честный System.Drawing.Bitmap.
Вводная: приложение типа осциллографа. Ссылка на готовый проект с фронтэндом в конце статьи.
Как же быстро рисовать его на экран?... | https://habr.com/ru/post/164705/ | null | ru | null |
# Закладки в Media Player Classic Home Cinema
Если выбрать в настройках ведение истории и сохранение позиций просмотра, MPC HC может автоматически сохранять до 20-ти закладок на последнее место просмотра видеофайлов и столько же закладок для DVD. При возобновлении просмотра плеер будет начинать воспроизведение с после... | https://habr.com/ru/post/149436/ | null | ru | null |
# Как я дал вторую жизнь некроноуту Fujitsu Siemens amilo pro v2035 с помощью lubuntu
Ещё со студенческой скамьи у меня остался ноутбук Fujitsu выпуска 2005 года(!), который тогда верой и правдой мне служил для постижения азов Паскаля и Си, серфинга интернетов и героев 3.
Рука не поднялась его выбросить или продать, ... | https://habr.com/ru/post/651625/ | null | ru | null |
# Вот вообще этим не занимался, и тут раз, и Data Science
Машинное обучение. Все о нём говорят. Много кто. Большая тема – но покрытая этой жуткой мистикой. Как магия – есть дар, сможешь что угодно сделать. Если нет... вообще не понятно, как подступиться. Постоянно фигурируют какие-то numpy, pandas, scikit-learn. На ка... | https://habr.com/ru/post/536518/ | null | ru | null |
# Руководство по разработке облачных приложений с помощью SAP Cloud Platform и Cloud Foundry
Cloud Foundry (CF) является глобальным стандартом разработки облачных приложений, который позволяет разработчикам уделять больше внимания поставленным задачам и облегчает процесс развертывания и управления приложениями.
В э... | https://habr.com/ru/post/350690/ | null | ru | null |
# Автоматизированный шаблон для front-end проектов

Человек изобрел компьютеры, чтобы они выполняли за нас большую часть повторяющихся задач. Это позволяет нам экономить много времени и использовать его с максимальной поль... | https://habr.com/ru/post/239573/ | null | ru | null |
# Сортировка в одну строку
Имеем обычный «пузырек»:
```
for(int i = 0; i < n - 1; i++ )
for(int j = i + 1; j < n; j++)
if(ar[i] > ar[j])
{
int temp = ar[i];
ar[i] = ar[j];
ar[j] = temp;
}
```
Задача №1: Избавиться от временной переменной. Делается это вот таким макаром:
```
ar[i] ^= ar... | https://habr.com/ru/post/144510/ | null | ru | null |
# Управление RGB лентой с помощью Arduino и драйвера L298N
Здравствуйте Хабр-сообщество.
В данное время стали доступны светодиодные ленты с изменяемым цветом свечения. Они классно выглядят, не дорого стоят и их можно хорошо приспособить для декоративной подсветки интерьера, рекламы, и т.д.
К таким лентам можно ... | https://habr.com/ru/post/224621/ | null | ru | null |
# Интегрируем clojure-библиотеку в java-приложение
Язык Clojure отличается очень тесной интеграцией с Java. Прямое использование Java-библиотеки в приложении на Clojure — дело совершенно простое и обыденное. Обратная интеграция несколько сложнее. В этой статье указаны некоторые варианты интеграции кода на Clojure в Ja... | https://habr.com/ru/post/171361/ | null | ru | null |
# Как взломать двухфакторную аутентификацию Яндекса
Наконец-то Яндекс запилил двухфакторную аутентификацию. Я не ждал подвоха, но, похоже, зря.
Как работает двухфакторная аутентификация Яндекса?
В браузере отображается QR-код, юзер сканирует его специальным приложением, браузер сразу это чувствует и авторизует п... | https://habr.com/ru/post/249757/ | null | ru | null |
# Определяем пользователей VPN (и их настройки!) и прокси со стороны сайта

*We can save the day from dark, from bad
There's no one we need*
Многие из вас используют VPN или прокси в повседн... | https://habr.com/ru/post/216295/ | null | ru | null |
# Nuxt.js app от UI-кита до деплоя. Часть 3: Мультиязычность
Привет!
Это третья часть цикла статей о создании современного блога на Nuxt.js. Сегодня реализуем мультиязычность в приложении, которое мы написали в [первой](https://habr.com/ru/company/timeweb/blog/543090/) и [второй](https://habr.com/ru/company/timeweb... | https://habr.com/ru/post/550144/ | null | ru | null |
# Нормализация текста в задачах распознавания речи
При решении задач, связанных с распознаванием (Speech-To-Text) и генерацией (Text-To-Speech) речи важно, чтобы транскрипт соответствовал тому, что произнёс говорящий — то есть реально **устной** речи. Это означает, что прежде чем **письменная** речь станет нашим транс... | https://habr.com/ru/post/491260/ | null | ru | null |
# Несколько рецептов открытия множества ссылок

Если вы любите автоматизировать свою работу и постоянно ищете способы сэкономить 5 минут здесь и 10 минут там, — эта статья расскажет о том, как можн... | https://habr.com/ru/post/179003/ | null | ru | null |
# Введение в 3D Touch
С выходом iPhone 6s и iPhone 6s Plus компания Apple представила нам совершенно новый способ взаимодействия с нашими телефонами: жест сильного нажатия. Как вы знаете, эта функция уже доступна на Apple Watch и MacBook и в MacBook Pro под названием Force Touch. Это — буквально — добавило новое понят... | https://habr.com/ru/post/271291/ | null | ru | null |
# Полиморфные связи
На днях в блоге [Ruby on Rails](http://habrahabr.ru/blogs/ror/) появилась [статья](http://habrahabr.ru/blogs/ror/79389/) о полиморфных связях, в которой автор писал всякие разные вещи, но при этом забыл упоминуть, как их использовать и зачем они нужны (потом, конечно же, исправился, но все равно на... | https://habr.com/ru/post/79431/ | null | ru | null |
# Как работает RBAC в Kubernetes
RBAC (Role-based access control) — это система распределения прав доступа к различным объектам в кластере Kubernetes.
**Объекты** в кластере Kubernetes — это YAML-манифесты, а **права доступа** определяют, какому **пользователю** можно только просматривать манифесты, а кто может их со... | https://habr.com/ru/post/655409/ | null | ru | null |
# Assembler. Установка интерпретатора и запуск первой программы через DOSBox
В данной статье разбирается способ установки интерпретатора и запуск файла EXE через DOSBox. Планировалось погрузить читателя в особенности программирования на TASM, но я согласился с комментаторами. Есть много учебников по Ассемблер и нет см... | https://habr.com/ru/post/564898/ | null | ru | null |
# Отладка как процесс
Существует мнение, что разработка занимает около 10% времени, а отладка — 90%. Возможно, это утверждение утрировано, но любой разработчик согласится с тем, что отладка — крайне затратный по ресурсам процесс, особенно в больших многопоточных системах.
Таким образом, оптимизация и систематизация... | https://habr.com/ru/post/420793/ | null | ru | null |
# IPSec всемогущий
Добрый день, друзья. Не секрет, что многим из нас хоть раз, но пришлось столкнуться с необходимостью настройки VPN. Являясь активным читателем Хабра я заметил, что несмотря на обилие статей про IPSec, многим он всё равно представляется чем-то сложным и перегруженным. В данной статье я попытаюсь разв... | https://habr.com/ru/post/504484/ | null | ru | null |
# Сравнение сортировок обменами
[](https://habr.com/post/415691/)
[Сферические алгоритмы в вакууме](https://habr.com/post/414653/) — это прекрасно. Однако давайте спустимся с небес на грешную землю и посмотрим как вся эта теоретическ... | https://habr.com/ru/post/415691/ | null | ru | null |
# Загрузка и хранение фотографий в Web приложениях
#### Почему это важно?
На современных web сайтах объем картинок может составлять от 30% до 70% всего размера страницы. Например, объем изображений [на Хабре](http://i.onthe.io/test?url=habrahabr.ru) обычно составляет несколько мегабайт.

В честь выхода своей книги "[Thing Explainer](http://geektimes.ru/post/260306/)" Рэндел Манро выпустил «маленькую» игру [Hoverboard](http://xkcd.com/1608/) — поле, по которому вы... | https://habr.com/ru/post/367133/ | null | ru | null |
# Samsung AllShare и Linux
Купили телевизор Samsung и обнаружили на нём AllShare, но совершенно не хочется ставить ради использования этой функции Windows? Тогда читаем ниже.
Что такое AllShare, при более близком рассмотрении, и с чем её едят? Ну у корейцев видимо всё не как у людей и оттого они обозвали то, что вс... | https://habr.com/ru/post/139412/ | null | ru | null |
# Relinx — ещё одна реализация .NET LINQ методов на C++, с поддержкой «ленивых вычислений»

**(ОБНОВЛЕНО!)**
Среди многих реализаций LINQ-подобных библиотек на C++, есть много интересных, полез... | https://habr.com/ru/post/303538/ | null | ru | null |
# WireGuard для подключения к домашней Raspberry pi и использование домашнего интернета удалённо
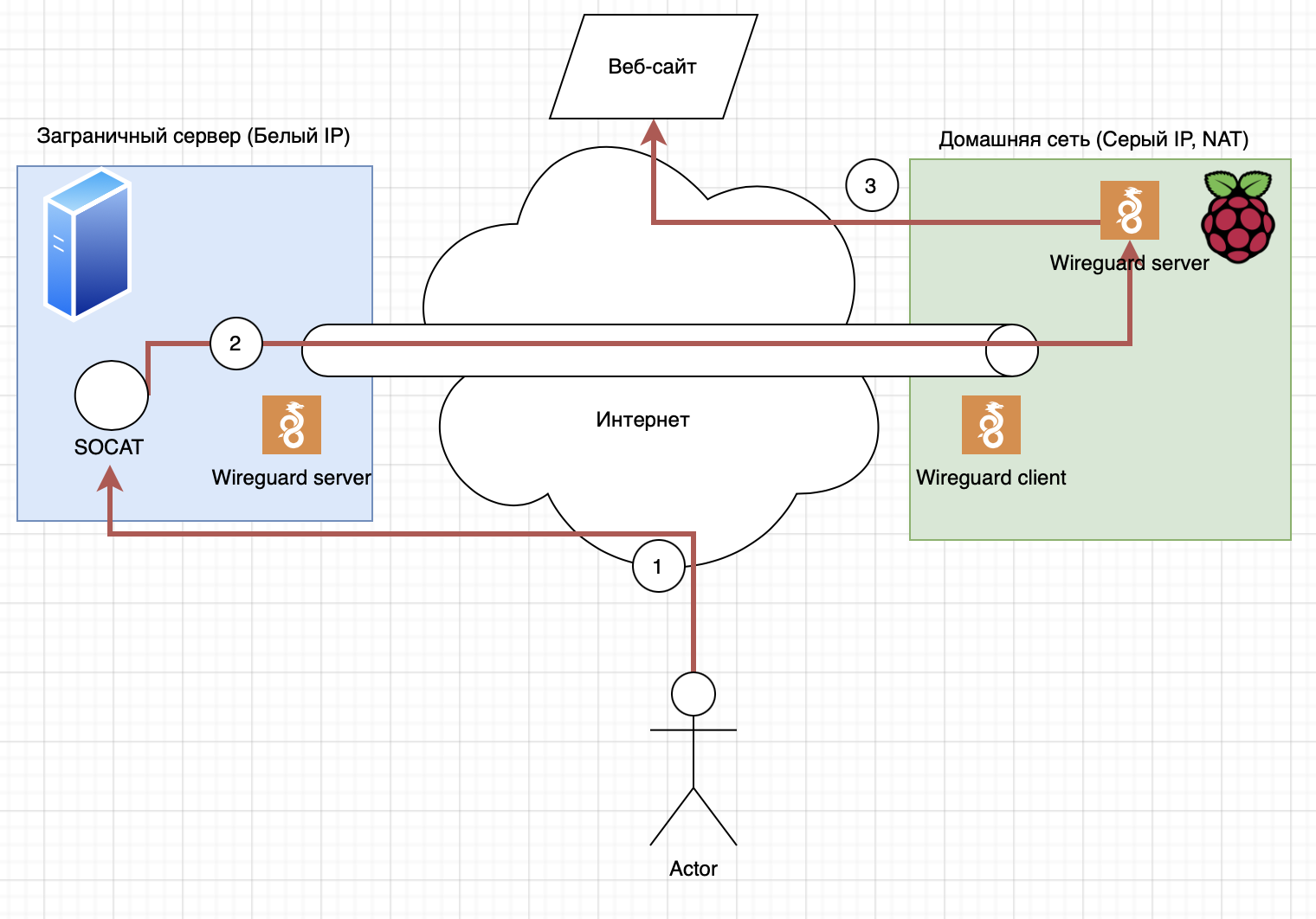Wireguard удобный инструмент ~~(хотя и легко определяеться на DPI, но мы сейчас не об этом)~~ сегодня я хочу ра... | https://habr.com/ru/post/572796/ | null | ru | null |
# Распознаем простые фигуры по массиву точек
В данной статье рассматривается простой алгоритм распознавания нарисованного пользователем многоугольника. Алгоритм преобразует набор точек, предоставленный пользователем, в точки многоугольника, удаляя точки находящиеся на прямых. Так же алгоритм может на базовом уровне ра... | https://habr.com/ru/post/597449/ | null | ru | null |
# Руководство по обновлению до MongoDB 5.0 и Rocket.Chat 4.0 в Docker

Недавно вышел [Rocket.Chat 4.0.0](https://github.com/RocketChat/Rocket.Chat/releases/tag/4.0.0), и, честно говоря, перейти на новую версию с предыдущей не так-то ... | https://habr.com/ru/post/590323/ | null | ru | null |
# Первые впечатления о Laravel API Resources

Прошлой ночью [Taylor Otwell](https://medium.com/@taylorotwell) наконец представил что может стать началом замены Fractal при разработке API на фреймворке ... | https://habr.com/ru/post/336432/ | null | ru | null |
# Обходим лимит поиска LinkedIn, играя с API
Лимит
-----
Есть на LinkedIn такое ограничение — [Лимит коммерческого использования](https://www.linkedin.com/help/linkedin/answer/52950/commercial-use-limit?lang=en). Крайне вероятно, что вы, как и я до недавнего времени, никогда не сталкивались и не слышали о нем.
 это современный фреймворк для разработки систем управления роботов, ориентированный на машинное обучение. Isaac SDK появился в начале 2019г. и уже имеет несколько релизов. Разрабатывается фреймворк компание... | https://habr.com/ru/post/531538/ | null | ru | null |
# Чего нам ждать от Ruby 2.1?
Несколько дней назад Константин Хаасе, один из ключевых людей в сообществе Ruby, опубликовал [запись в своём блоге](http://rkh.im/ruby-2.1), посвящённую анонсу предварительной версии Ruby 2.1. Изменений между версиями 2.0 и 2.1 накопилось достаточно, чтобы вчитаться в его изложение, и луч... | https://habr.com/ru/post/195844/ | null | ru | null |
# Рендеринг в веб
Как разработчики, мы часто сталкиваемся с решениями, которые влияют на всю архитектуру наших приложений. Одно из основных решений, которое должны принять веб-разработчики - это где реализовывать логику и рендеринг в своем приложении. Это может быть непросто, так как существует множество различных вар... | https://habr.com/ru/post/548382/ | null | ru | null |
# В зоне доступа. Находим расстояние от точки до области и сокращаем запросы обратного геокодинга

Мне не раз приходилось реализовывать функционал расчета расстояния от некоторой географической точки до области на карте — например, д... | https://habr.com/ru/post/486066/ | null | ru | null |
# How I gave my old laptop second life
*17-19 min read*
Hi y'all, my name is Labertte and I use Arch btw.
Probably like every other Linux user, I'd like to buy a ThinkPad, put some lightweight distribution like Arch or Gentoo on it, and then ~~go to Starbucks, get a soy latte and tell everyone that I use "linux"~~.... | https://habr.com/ru/post/682148/ | null | en | null |
# Автоматизированное тестирование веб-приложения (MS Unit Testing Framework + Selenium WebDriver C#). Часть 2.1: Selenium API wrapper — Browser
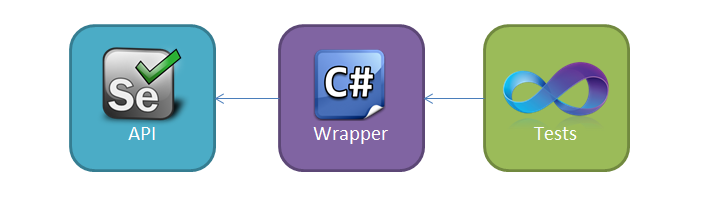
##### Введение
Снова здравствуйте! Представляю ... | https://habr.com/ru/post/180047/ | null | ru | null |
# Мой умный дом на .NET
В последнее время на хабре много статей про умный дом. В основном все они касаются взаимодействия с домашними устройствами. Для автоматического принятия решений используют [MajorDoMo](h... | https://habr.com/ru/post/214387/ | null | ru | null |
# IDS Bypass at Positive Hack Days 11: writeup and solutions
The IDS Bypass contest was held at the Positive Hack Days conference for the third time (for retrospective, here's . This year we created six gam... | https://habr.com/ru/post/673226/ | null | en | null |
# Python на максималках: расширения на языках Rust и Cython
Python — лучший выбор для анализа данных и машинного обучения. Его производительность в большинстве случаев более чем достаточна. Но как быть, если объемы ваших данных растут значительно быстрее, чем имеющиеся ресурсы, и требуется повышение производительности... | https://habr.com/ru/post/697034/ | null | ru | null |
# Smart плинтус 1.0

Озаботила меня одна проблема – темный коридор по пути из спальни на кухню. Ну, знаете, люблю ночью на кухню ходить, но в потемках некомфортно, а т.к. коридор относительно ширины достаточно длинный, то велика вер... | https://habr.com/ru/post/369123/ | null | ru | null |
# Документирование программ
На определенном этапе развития программной системы неизбежно возникает задача разработки пользовательской документации. И тут возникает технический вопрос выбора форматов и инструментов разработки документации.
### 1.1. Выходные форматы
С выбором конечного формата обычно проблем не возн... | https://habr.com/ru/post/250155/ | null | ru | null |
# С++ exception handling под капотом. Часть 3
Продолжаем перевод серии статей об обработки исключений в C++
[1 часть](https://habrahabr.ru/post/279111/)
[2 часть](https://habrahabr.ru/post/279151/)
C++ exceptions под капотом: поиск верного landing pad
=====================================================
Это... | https://habr.com/ru/post/279149/ | null | ru | null |
# Тёмный путь

*Предлагаю вашему вниманию перевод [оригинальной статьи](http://blog.cleancoder.com/uncle-bob/2017/01/11/TheDarkPath.html) Роберта С. Мартина.*
За последние несколько месяцев я попробовал два новых языка.... | https://habr.com/ru/post/324122/ | null | ru | null |
# Linux, безопасность и все такое… (вдогонку)
Навеяло [вот этим](http://habrahabr.ru/blogs/linux/81724/) топиком. Автор задал правильные вопросы, но к сожалению не дал правильных ответов.
На самом деле это общая грустная тенденция. Почему-то все свято уверены, что раз вирусов под линуксом нету, то и безопасность с... | https://habr.com/ru/post/81889/ | null | ru | null |
# Анонс публичной бета-версии NGINX Amplify
[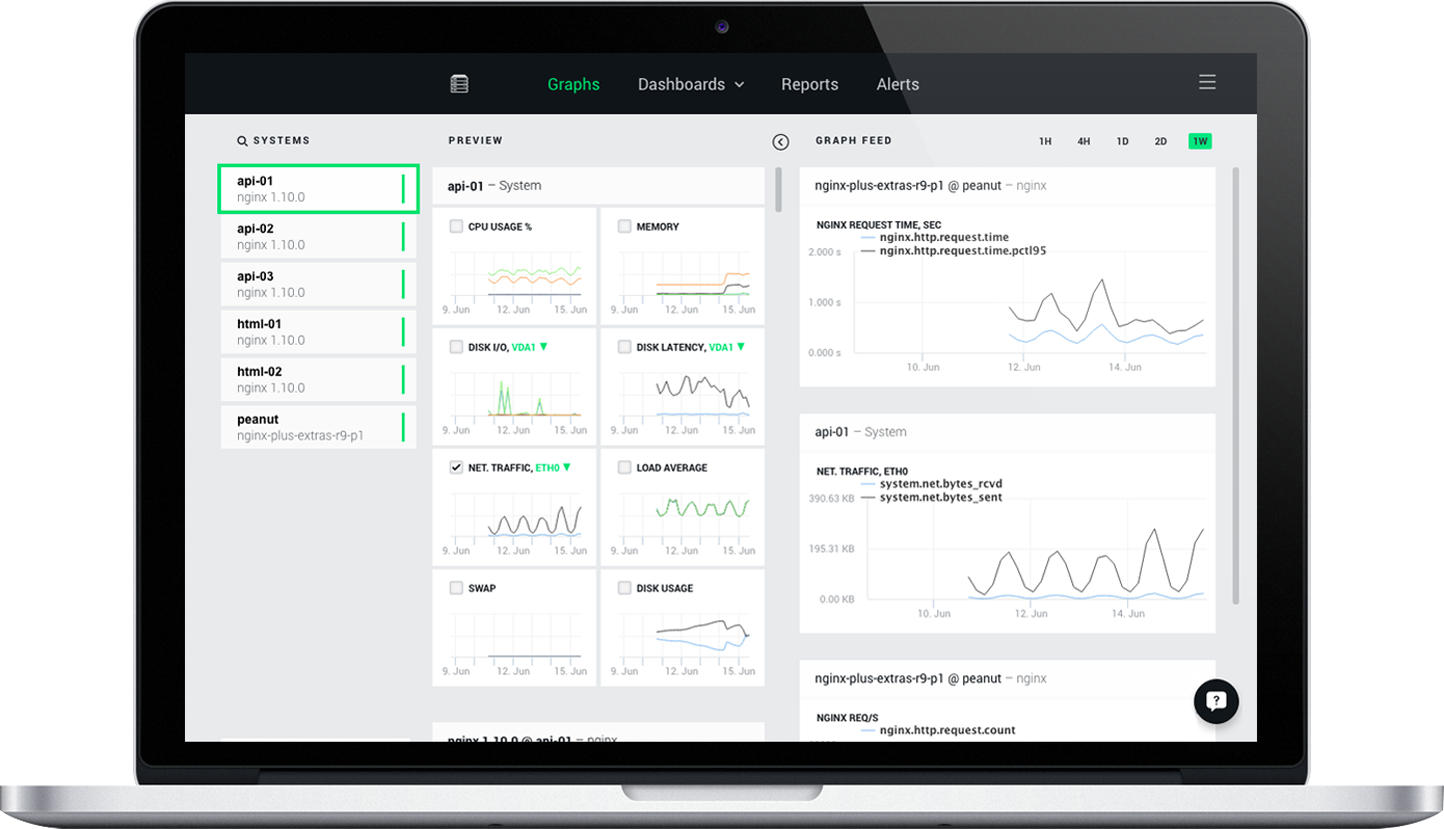](https://www.nginx.com/amplify/)
Мы рады представить бету NGINX Amplify, нашего нового инструмента для мониторинга NGINX и [NGINX Plus](https://www.nginx.com/pr... | https://habr.com/ru/post/305384/ | null | ru | null |
# Telegram бот для службы поддержки (часть 1)

В этом цикле статей мы реализуем службу поддержки для онлайн-чатов. Система должна уведомлять команду операторов о новом сообщении, делить нагрузку на команду любого размера, д... | https://habr.com/ru/post/303528/ | null | ru | null |
# Декларативное описание структур данных в RDBMS
Лет 6 назад я задавался вопросом "[Как правильно организовать распределенное проектирование БД?](https://habr.com/ru/post/263053/)" Тогда ответа на свой вопрос я так и не получил, но за прошедшее с тех пор время я встретился с вариантом, наиболее близко подобравшимся к ... | https://habr.com/ru/post/575254/ | null | ru | null |
# Сверхэффективная обработка текста
Не важно, пишете ли вы книгу, верстаете веб-страницу или редактируете исходные коды программ, порой возникает целый ряд разнообразных рутинных задач, которые отнимают много времени, но обязательны к выполнению.
В этой статье я хочу продемонстрировать несколько сценариев, которые ... | https://habr.com/ru/post/231929/ | null | ru | null |
# Блокчейн аналитика в Dune Analytics на примере Uniswap
Есть такая платформа блокчейн‑аналитики [Dune](https://dune.com/), с помощью которой можно дергать различные данные из блокчейна. В декабре 2022го в коллаборации с Uniswap они запустили курс [12DaysOfDune](https://www.notion.so/12-Days-of-Dune-2022-2c30c5a875ce4... | https://habr.com/ru/post/715600/ | null | ru | null |
# Linux Mint 16 «Petra»
Спустя полтора месяца после [выхода](http://habrahabr.ru/post/198020/) Ubuntu 13.10, состоялся релиз новой версии дистрибутива Linux Mint с кодовым именем Petra.

Вот [уже 2 года]... | https://habr.com/ru/post/202380/ | null | ru | null |
# apache+nginx+gzip_static+yuicompressor
В этой статье я опишу принципиальные различия Apache и Nginx, архитектуру фронтэнд-бэкэнд, установку Apache в качестве бэкэнда и Nginx в качестве фронтэнда. А также опишу технологию, позволяющую ускорить работу веб-сервера: gzip\_static+yuicompressor.
### Nginx
**Nginx** – ... | https://habr.com/ru/post/108211/ | null | ru | null |
# Веб-безопасность 200
В информационной безопасности есть казалось бы очевидные вещи. Но они все еще часто встречаются, в том числе в крупных компаниях и государственных организациях. На эту тему эксперт по ... | https://habr.com/ru/post/570032/ | null | ru | null |
# Пишите код так, как будто сопровождать его будет склонный к насилию психопат, который знает, где вы живёте
..., даже если проект не планируется развивать и вы не собираетесь делиться исходными кодами, потому что через 20 лет какой-нибудь маньяк будет изучать и дорабатывать машинный код вашего продукта, и он может за... | https://habr.com/ru/post/302570/ | null | ru | null |
# Защита от DDOS атаки подручными средствами. Получение доступа к своему серверу
За последнее время, наш сайт часто подвергается достаточно мощным DDOS атакам, к слову последняя атака была самой крупной за последнее время, размер ботнета по нашим оценкам — около 10 тысяч машин, мощность — 100 Mbits/s.
Атаку заметил... | https://habr.com/ru/post/128526/ | null | ru | null |
# Управление учетными записями в Linux. Часть 1. Хранение учетных данных
#### Файлы и их хозяева
Файлы в операционках семейства Linux можно назвать основой всего. Для Linux все есть файл. Другими словами, фа... | https://habr.com/ru/post/689416/ | null | ru | null |
# Рисуем диаграммы Mermaid.js в README-файлах GitHub
14 февраля 2022 года GitHub [объявила](https://habr.com/ru/news/t/651569/) о старте нативной поддержки диаграмм Mermaid.js в README-файлах GitHub. Нововведение помогло быстрее и эффективнее оформлять блок-схемы и графики для документации. До этого диаграммы вставлял... | https://habr.com/ru/post/652867/ | null | ru | null |
# Поймут даже дети: простое объяснение async/await и промисов в JavaScript
Привет, Хабр! Представляю вашему вниманию перевод статьи [«JavaScript Async/Await and Promises: Explained like you’re five years old»](https://medium.com/javascript-in-plain-english/javascript-async-await-and-promises-explained-like-youre-five-... | https://habr.com/ru/post/474726/ | null | ru | null |
# Возможности Matlab для разработки и тестирования механистических торговых систем
Думаю, обосновывать необходимость тщательного тестирования и подбора параметров торговых стратегий нет необходимости… Лучше поясню, почему именно Matlab.
В торговом терминале MetaTrader есть встроенная система тестирования и настройк... | https://habr.com/ru/post/260635/ | null | ru | null |
# Rust: for и итераторы
([предыдущая статья](https://habrahabr.ru/post/306582/))

В данной статье мы обсудим **for** циклы, а так же родственные понятия итераторов и «итерируемых объектов».
В зависимости от вашего пред... | https://habr.com/ru/post/306702/ | null | ru | null |
# Обзор систем сборок для Raspberry Pi
В прошлом мой выбор пал на OpenEmbedded (OE) и по заслугам, она одна из лучших систем сборок. К выбору на тот момент не подходил осознанно и захотел исправить это, поэтому решил посмотреть на текущие решения.
Мысль бы не пришла в голову, если под руками не оказалась плата Rasp... | https://habr.com/ru/post/172349/ | null | ru | null |
# 33 способа ускорить ваш фронтенд в 2017 году

Вы уже используете прогрессивную загрузку? А как насчёт технологий **Tree Shaking** и **разбиения кода** в React и Angular? Вы настроили сжатие Brotl... | https://habr.com/ru/post/320558/ | null | ru | null |
# Конспектируем Книгу Rust:: Времена и структуры
Продолжаем работать с [10.3](https://doc.rust-lang.ru/book/ch10-03-lifetime-syntax.html).
КМБ.- Двойная жизнь.- Восстание мертвецов.- Ошибка в документации.- Ужасающие подробности из The Rustonomicon.- Архитектурные озарения.- Развязка.
* **Предыдущая часть**: [Време... | https://habr.com/ru/post/569496/ | null | ru | null |
# Генератор ocmod-файла для интернет-магазина на Opencart
Реально ли при разработке модификаций для распространенного движка интернет-магазинов Opencart сосредоточиться на своих алгоритмах, а подготовку файла для подгрузки в эту CMS дать на откуп специальным скриптам? Собственно, это то, что сильно облегчило бы жизнь ... | https://habr.com/ru/post/529186/ | null | ru | null |
# Третья жизнь пет-проекта по распознаванию рукописных цифр
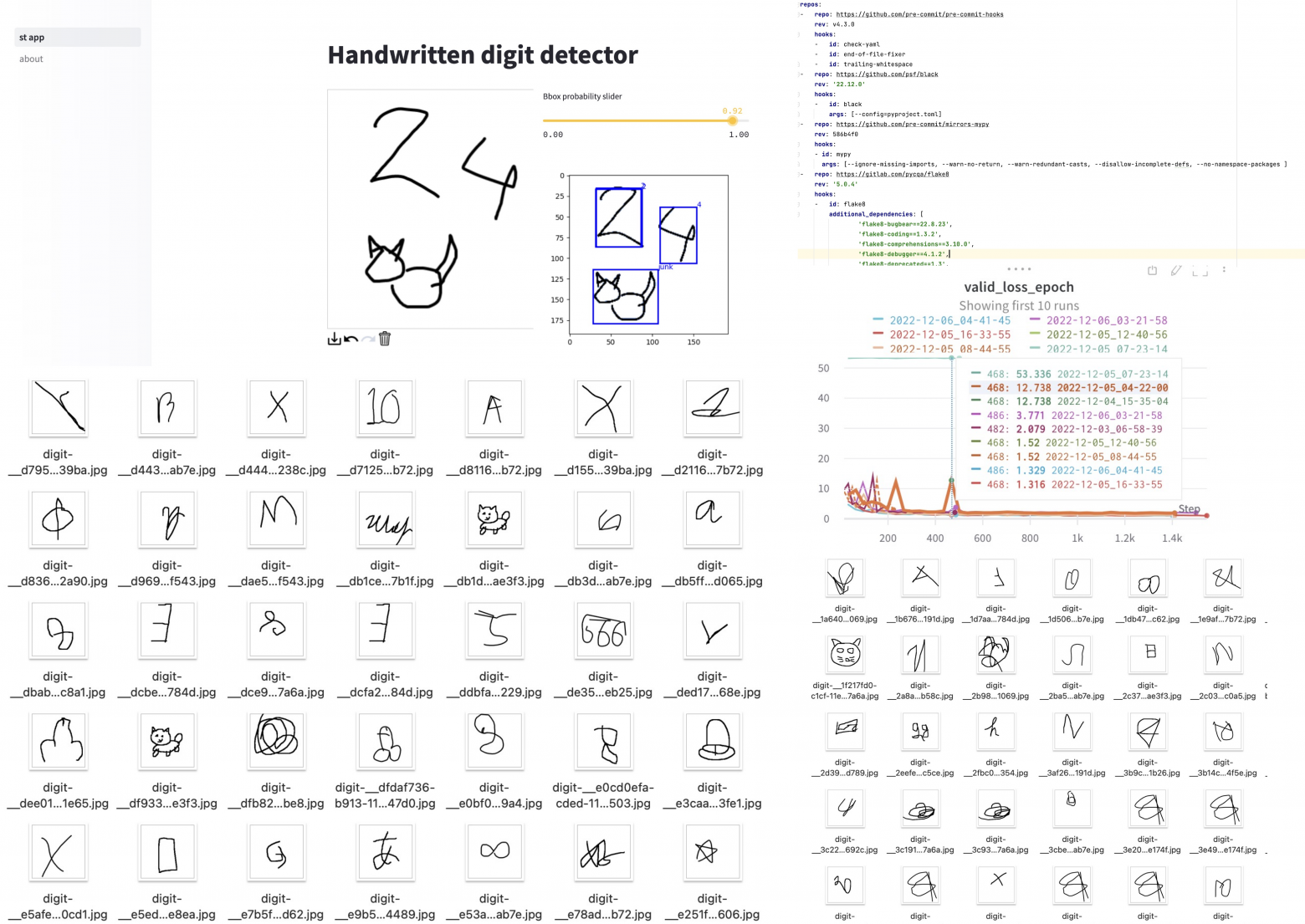В этом блогпосте я поделюсь историей о том, как я обновлял свой старенький пет-проект по распознаванию цифр, как делал разметку для него, и почему м... | https://habr.com/ru/post/707046/ | null | ru | null |
# Бесплатные тензорные процессоры от Google в облаке Colaboratory
Недавно Google предоставил бесплатный доступ к своим [тензорным процессорам](https://cloud.google.com/tpu/) (tensor processing unit, TPU) на облачной платформе для машинного обучения [Colaboratory](https://colab.research.google.com). Тензорный процессор... | https://habr.com/ru/post/428117/ | null | ru | null |
# Считывание контроллера nes (dendy) на ассемблере
В предыдущей статье Я рассказывал вам бо основах ассемблера 6502 о некоторых участках памяти и как с ними работать, до сегодняшнего дня у меня стояли следующий ряд задач: считывание контроллера, анимация, таймер. Ниже под катом Я расскажу как научился читать контролле... | https://habr.com/ru/post/552604/ | null | ru | null |
# Simplify working with parallel tasks in C# (updated)

No doubts that `async/await` pattern has significantly simplified working with asynchronous operations in C#. However, this simplification relates... | https://habr.com/ru/post/349352/ | null | en | null |
# Устанавливаем и настраиваем cGit на Ubuntu
С помощью данной статьи (пошаговой инструкции) вы сможете сделать себе собственный Git репозиторий, с веб-интерфейсом на базе [cGit](http://hjemli.net/git/cgit/).
Вот так, просто и лаконично, выглядит стандартный cGit (кликабельно):
[А помните ли вы свой первый мобильный телефон? Для меня это была Nokia 3310, неубиваемая «трубка», неустанно радовавшая меня скудным набором развлечений в виде игры в змейк... | https://habr.com/ru/post/538028/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.