
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# RubyMotion: нативные iOS приложения на Ruby (перевод)

В 2007 году Лоран Сансонетти, разработчик из Apple, основал проект с открытым исходным кодом MacRuby. Его целью было создание интерпретатора Ruby поверх среды испол... | https://habr.com/ru/post/143332/ | null | ru | null |
# Собеседования по алгоритмам: теория vs. практика
***tl;dr** За последние десятилетия мода на собеседования программистов менялась несколько раз, и каждая из них выглядит нелепо в ретроспективе. Либо мы наконец-то нашли настоящий секрет эффективных собеседований, либо увлеклись очередным модным течением, которое чере... | https://habr.com/ru/post/485596/ | null | ru | null |
# Книга «Java Concurrency на практике»
[](https://habr.com/ru/company/piter/blog/489038/) Привет, Хаброжители! Потоки являются фундаментальной частью платформы Java. Многоядерные процессоры — это обыденная реальность, а эффективн... | https://habr.com/ru/post/489038/ | null | ru | null |
# Борьба с 2D-физикой в Unity на примере бесконечной игры
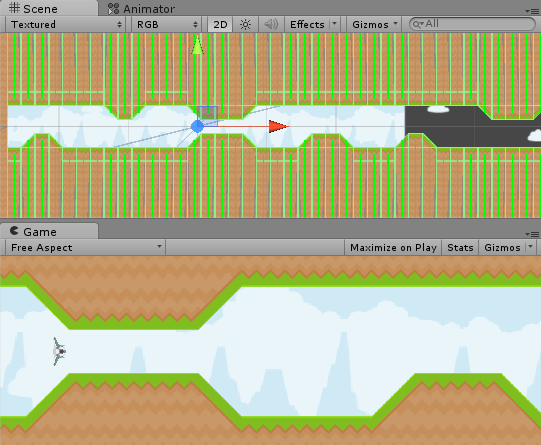
Мой странный творческий путь занес меня в разработку игр. Благодаря отличной студенческой программе от IT-компании, название которой СостоИт из одной Греческой МАленькой бук... | https://habr.com/ru/post/248391/ | null | ru | null |
# 9 основных принципов отзывчивого веб-дизайна

Отзывчивый дизайн — отличное решение проблемы корректного отображения сайта на разных экранах. Однако новичкам зачастую трудно понять основы, обучаясь только по книгам/статьям... | https://habr.com/ru/post/243247/ | null | ru | null |
# Мониторинг качества воздуха с использованием Raspberry Pi 4, датчика Sensirion SPS30 и Microsoft Azure
В материале, перевод которого мы публикуем сегодня, речь пойдёт о том, как подключить датчик качества воздуха Sensirion Particulate Matter Sensor SPS30 к Raspberry Pi 4, и о том, как, пользуясь возможностями Micros... | https://habr.com/ru/post/527234/ | null | ru | null |
# И javascript шаблонизатор
В наше время существует уже немалое количество таковых, не правда ли? Они даже неплохо справляются со своей работой, если надо, к примеру, сформировать HTML за сотые доли секунды – это довольно быстро, и пользователь не чувствует этой задержки. И почему же мы все не кидаемся вовсю использов... | https://habr.com/ru/post/104643/ | null | ru | null |
# International SEO | International SEO ranking factors
Let's say, your website offers content, products, or services for people from different regions or countries who speak different languages. Search engines will probably count this as duplicate content, leading to low rankings.

Начну с того, что уже много статей канули в небытие и иной раз сложно найти что-то актуальное. Бывает конечно и такое что оочень много информации по конкретной модели, но т.к. у меня возникли "затыки", то я решил написать себе статью, м.б.... | https://habr.com/ru/post/585822/ | null | ru | null |
# Когда код это данные
[](https://habr.com/ru/company/ruvds/blog/563568/)
> *«Представь, что люди как бы находятся в подземном жилище наподобие пещеры, где во всю её длину тянется широкий просвет. С малых лет у них на ногах и на шее око... | https://habr.com/ru/post/563568/ | null | ru | null |
# Пишем DSL в Koltin
### Небольшое вступление
Всем привет! Частенько зависаю на Medium и нахожу уйму полезных статей от зарубежных разработчиков. В один из таких дней искал для себя что-нибудь по DSL в Kotlin и наткнулся на серию статей о том, что такое DSL в Kotlin и как с этим работать. До прочтения я имел поверхно... | https://habr.com/ru/post/343730/ | null | ru | null |
# Новый функционал nanoCAD 6.0: нормативный аудит
Общеизвестно, что, выпуская новые версии, разработчики всегда говорят о множестве исправлений, улучшений и новом функционале. Тем не менее, вопреки всему, я рискну обратить ваше внимание на некоторые действительно уникальные инструменты nanoCAD 6.0, после которых мир С... | https://habr.com/ru/post/225063/ | null | ru | null |
# Когда появится следующий большой язык программирования с точки зрения Дарвина
*Good news everyone!
Futurama*
Следующего большого языка программирования не предвидится. По крайней мере, на то нет причин с точки зрения теории эволюции.
Эволюция работает не только в животном мире, но и в любой подходящей сре... | https://habr.com/ru/post/323550/ | null | ru | null |
# Как спарсить любой сайт?
Меня зовут [Даниил Охлопков](https://t.me/danokhlopkov), и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что испол... | https://habr.com/ru/post/579336/ | null | ru | null |
# Как мы измеряем скорость загрузки Яндекс.Почты
Если ваш сайт медленно грузится, вы рискуете тем, что люди не оценят ни то, какой он красивый, ни то, какой он удобный. Никому не понравится, когда все тормозит. Мы регулярно добавляем в Яндекс.Почту новую функциональность, иногда — исправляем ошибки, а это значит, у на... | https://habr.com/ru/post/244243/ | null | ru | null |
# Стеганография в GIF
#### Введение
Приветствую.
Не так давно, когда учился в университете, была курсовая по дисциплине «Программные методы защиты информации». По заданию требовалось сделать программу, внедряющую сообщение в файлы формата GIF. Решил делать на Java.
В данной статье я опишу некоторые теоретически... | https://habr.com/ru/post/128327/ | null | ru | null |
# Крошечная библиотека TFT для микроконтроллеров ATtiny
[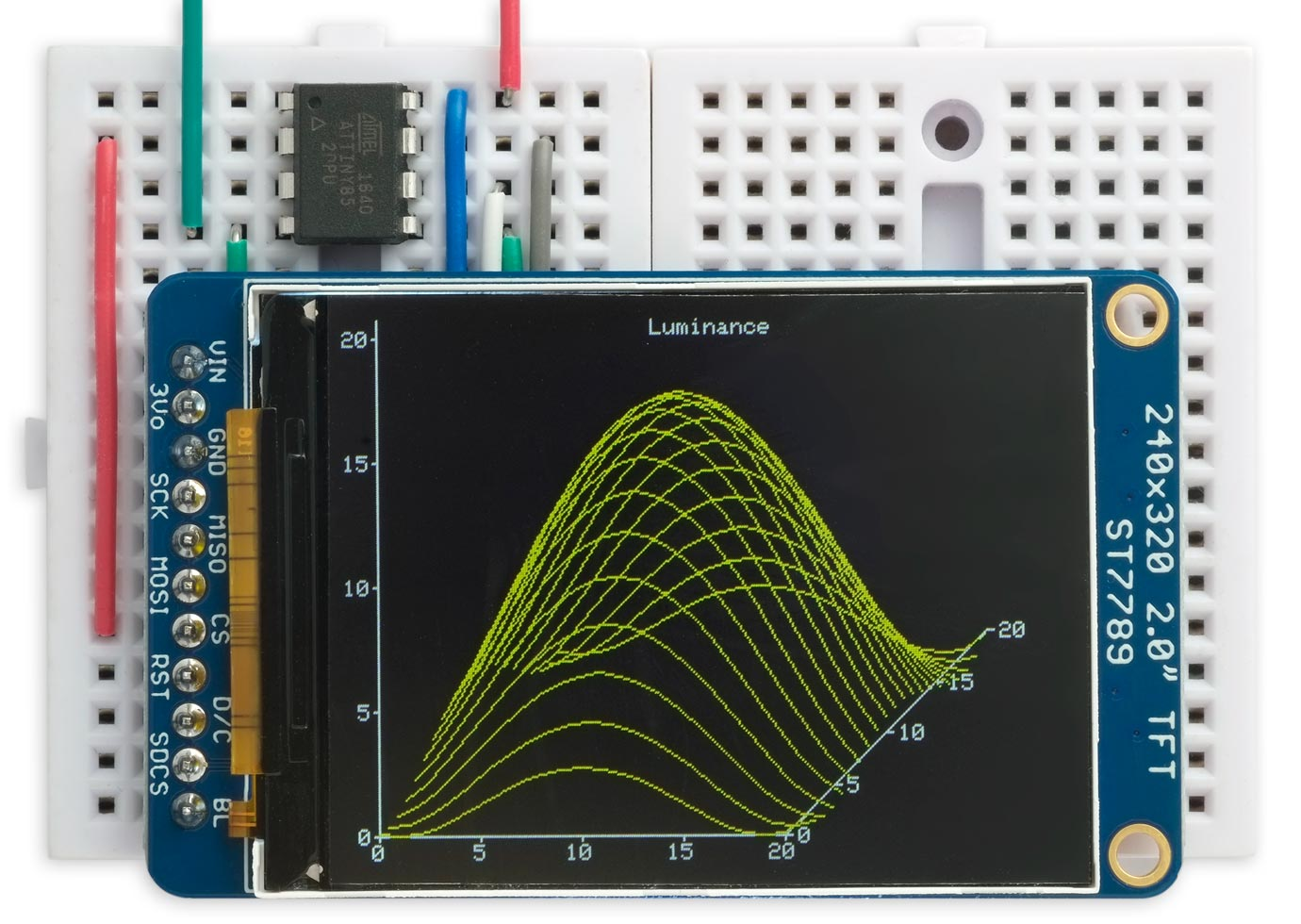](https://habr.com/ru/company/ruvds/blog/670612/)*Библиотека TFT на ATtiny85, управляющая цветным дисплеем Adafruit 2.0" 320x240*
В статье речь пойдёт о маленькой графической б... | https://habr.com/ru/post/670612/ | null | ru | null |
# [DotNetBook] Структура экземпляров типов и VMT
 С этой статьей я продолжаю публиковать целую серию статей, результатом которой будет книга по работе .NET CLR, и .NET в целом.
Вся книга будет доступна на GitHub: [CLR Book](https://... | https://habr.com/ru/post/344556/ | null | ru | null |
# Автоматизированная проверка PHP кода при комитах
В свое время работая в узком кругу программистов, отдельными задачами и даже проектам, мы не задумывались о проблемах связанными с текучкой кадров. Точнее думать — думали, но ни каких мер не применяли, да и в целом коллектив был сплоченный никто не уходил и никого «не... | https://habr.com/ru/post/111977/ | null | ru | null |
# 10 фич для ускорения анализа данных в Python
*[Источник](https://pixabay.com/images/id-2123970/)*
Советы и рекомендации, особенно в программировании, могут быть очень полезны. Маленький шоткат, аддон или... | https://habr.com/ru/post/457302/ | null | ru | null |
# Разработка игры-бесконечной гонки для iOS при помощи Cocos2D-iphone
Сегодня я хочу вам рассказать о создании игры для iOS на основе Cocos2D на примере недавно вышедшей игры «Пчелогонки» (анг. – Bee Race).
Геймплей не содержит в себе ничего сложного – это по сути бесконечный ранер, в котором нужно собирать поинты ... | https://habr.com/ru/post/165601/ | null | ru | null |
# Работа с виртуальными машинами KVM. Подготовка хост-машины
#### Вступление
Как и было обещано в [предыдущей статье](http://habrahabr.ru/blogs/virtualization/120432/), сегодня мы поговорим о ... | https://habr.com/ru/post/120717/ | null | ru | null |
# Шаблон проекта многоязычного WPF приложения
##### Введение
Локализация приложения на WPF — не легкое занятие. Практически любое пособие по локализации WPF изобилует деталями и ручными шагами для реализации локализованного приложения.
##### Существующие решения
Локализация с помощью утилиты LocBaml, описанная в ... | https://habr.com/ru/post/118840/ | null | ru | null |
# Создание плагинов для AutoCAD с помощью .NET API (часть 6 – поиск и изменение объектов на чертеже)
Это шестая часть [цикла](http://habrahabr.ru/post/235723/) про разработку плагинов для AutoCAD. В ней поговорим про поиск объектов на чертеже, а также про их изменение.
```
public static string disclaimer = "Автор н... | https://habr.com/ru/post/262953/ | null | ru | null |
# Software Defined Radio — как это работает? Часть 4
Привет, Хабр.
В [третьей части](https://habr.com/ru/post/452390/) было рассказано, как получить доступ к SDR-приемнику посредством языка Python. Сейчас мы познакомимся с программой [GNU Radio](https://www.gnuradio.org/) — системой, позволяющей создать достаточно ... | https://habr.com/ru/post/453038/ | null | ru | null |
# HTML-controlbar для Flowplayer’a на основе стилей jQuery UI
Вопрос поиска хорошего flash-плеера с HTML-интерфейсом занимал и занимает многих. Только на хабре можно найти немало статей на похожую тему. Так сложилось, что для своих нужд я исп... | https://habr.com/ru/post/113912/ | null | ru | null |
# Отображение разработчикам статуса контроля качества исходного кода в SonarQube
SonarQube — это открытая платформа для обеспечения непрерывного контроля качества исходного кода, поддерживающая большое количество языков программирования и позволяющая получать отчеты по таким метрикам, как дублирование кода, соответств... | https://habr.com/ru/post/486904/ | null | ru | null |
# Oracle Database In-Memory
Данная статья подготовлена Алексеем Струченко, начальником отдела оптимизации СУБД и приложений компании «Инфосистемы Джет»
Вышедшая в июле 2014 года опция Database In-Memory является самой ожидаемой и самой обсуждаемой инновацией Oracle в семействе продуктов Oracle Database. За последн... | https://habr.com/ru/post/260455/ | null | ru | null |
# Функциональное мышление. Часть 2
Друзья, продолжаем разбираться в функциональном программировании. Во второй части из этой серии статей вы познакомитесь с основными принципами этой парадигмы разработки и поймёте, как этот подход отличается от объектно-ориентированного или императивного программирования.
Monticello and the Thomas Jefferson Foundation... | https://habr.com/ru/post/713510/ | null | ru | null |
# 25 видов «Цезаря» и английские слова
В мире криптографии есть много простых способов зашифровать сообщение. Каждый из них по-своему хорош. Об одном из них и пойдёт речь.
Ылчу Щзкгув
-----------
Или в переводе с «Шифра Цезаря» на русский — **Шифр Цезаря**.
.***

---
Корни деревьев виджетов во Flutter могут уходить очень глубоко…

Привет, Хабр!
Как [законодатели мод](https://www.piter.com/product_by_id/129958293) по [теме](https://www.piter.com/product_by_id/119628905) [Unity](https://www.piter.com/product_by_id/103057273) на ро... | https://habr.com/ru/post/455004/ | null | ru | null |
# Устройство NVRAM в UEFI-совместимых прошивках, часть четвертая
И снова здравствуйте, уважаемые читатели.
Начатый в [предыдущих](https://habrahabr.ru/post/281242/) [трех](https://habrahabr.ru/post/281412/) [частях](https:... | https://habr.com/ru/post/281901/ | null | ru | null |
# Юнит-тесты, BDD и сила текучих утверждений (fluent assertions) в 1С
#### Немного истории
Благодаря классному дядьке Кенту Беку (Kent Beck) родилась замечательная методология test-driven development. Не смотря на необычность подхода, переворачивающего привычный процесс написания кода с ног на голову (тест на функцио... | https://habr.com/ru/post/260013/ | null | ru | null |
# Автоматизация тестирования продуктовой аналитики в мобильных приложениях
Тестирование всех событий продуктовой аналитики перед каждым релизом обычно отнимает много времени. Это можно автоматизировать. Показываю, как им... | https://habr.com/ru/post/523018/ | null | ru | null |
# Новости из мира OpenStreetMap № 502 (25.02.2020-02.03.2020)
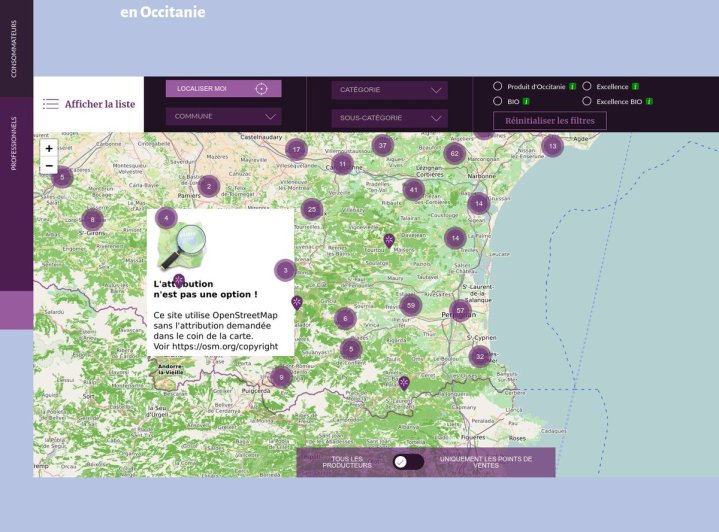
Сообщество OSM во Франции напоминает — «Атрибуция — это не опция!» [1](#wn502_22048) | Изображение [Кристиана Квеста](https://twitte... | https://habr.com/ru/post/492444/ | null | ru | null |
# Использование нескольких Persistent Store в Core Data
Всем iOS (да и MAC OS X) разработчикам известен такой системный фреймворк как Core Data. Эта штуковина представляет собой достаточно мощную ORM (по крайней мере для мобильной платформы).
Изначально в нашем приложении использовалась одна база данных для всей ин... | https://habr.com/ru/post/146896/ | null | ru | null |
# Ваш безлимит: как увеличить пропускную способность автомерджа

> *«Отыщи всему начало, и ты многое поймёшь»* (Козьма Прутков).
>
>
Меня зовут Руслан, я релиз-инженер в Badoo и Bumble. Недавно я столкнулс... | https://habr.com/ru/post/560228/ | null | ru | null |
# Четырёхмерный лабиринт с видом от первого лица
Существует более 30 игр с дополнительным пространственным измерением ([список на википедии](https://en.wikipedia.org/wiki/List_of_four-dimensional_games)), которые разнообразными способами визуализируют и пытаются сделать доступной для понимания наличие четвёртой коорди... | https://habr.com/ru/post/534964/ | null | ru | null |
# Обработка данных криптовалютного рынка в RavenDB с использованием временных рядов
Что если можно было бы хранить данные временных рядов вместе с «обычными» данными, избавившись от затрат времени, сил и ресурсов, связанных с использованием отдельной СУБД?
[RavenDB](https://ravendb.net/) — это документо-ориентирова... | https://habr.com/ru/post/657353/ | null | ru | null |
# Как Excel и VBA помогают отправлять тысячи HTTP REST API запросов
Работая в IoT-сфере и плотно взаимодействуя с одним из основных элементов данной концепции технологий – сетевым сервером, столкнулся вот с какой проблемой (задачей): необходимо отправлять много запросов для работы с умными устройствами на сетевой серв... | https://habr.com/ru/post/569468/ | null | ru | null |
# CPU-функции RDRAND и RDSEED стали доступнее
Всем привет!
Сам я криптографией не занимаюсь, но кому то вполне может пригодится мое небольшое исследование. Решил разобраться со встроенными в процессор функциями RDRAND и RDSEED. Компилятор Delphi сказал Undeclared identifier. Хмм. Уже давно существует BMI, BMI2, AVX... | https://habr.com/ru/post/441392/ | null | ru | null |
# Debian Server для новичка
Как-то обеспокоился наличием собственного FTP-сервака. Тем более под это дело «на помойку» был отдан комп этак десятилетней давности. Так как я человек хоть и виндовый, но начинал с чистого ДОСа (про книжки тов. Фигурнова кто помнит?), то я решил сделать все на линуксе. В линуксе я был ноль... | https://habr.com/ru/post/126944/ | null | ru | null |
# Higher-Kinded Data, или ещё один способ работать с сущностями базы данных (и не только)

Важный дисклеймер
-----------------
Перед началом хочу позволить себе небольшой, но важный дисклеймер.
*Я не с... | https://habr.com/ru/post/578070/ | null | ru | null |
# Так ли прост строковый оператор +
#### Введение
Строковый тип данных является одним из фундаментальных типов, наряду с числовыми (int, long, double) и логическим (bool). Тяжело себе представить хоть, сколько либо полезную программу, не использующую данный тип.
На платформе .NET строковый тип представлен в виде н... | https://habr.com/ru/post/220921/ | null | ru | null |
# Инверсная кинематика: простой и быстрый алгоритм
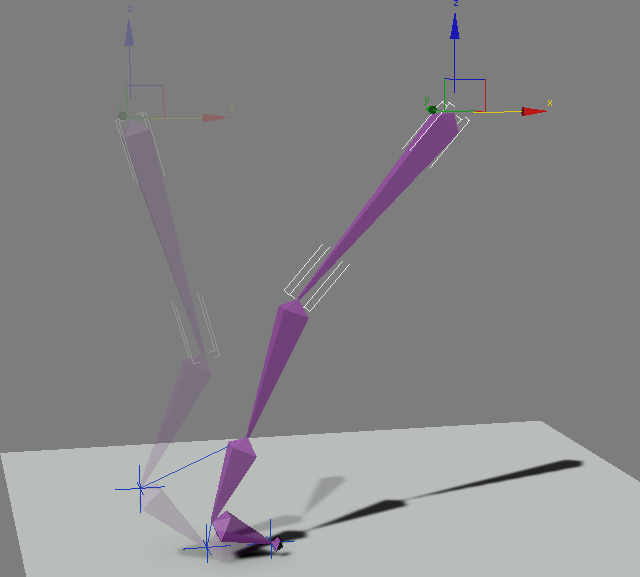Что такое «Инверсная кинематика»?
Задачей инверсной кинематики является поиск такого набора конфигураций сочленений, который обеспечил бы максимально мягко... | https://habr.com/ru/post/222689/ | null | ru | null |
# Программирование DeFi: Uniswap. Часть 2
Введение
--------
Это вторая часть серии статей о программировании DeFi смарт-контрактов. [В предыдущей части](https://habr.com/ru/post/572034/) мы впервые соприкоснулись с Uniswap, его основной механикой и начали создавать смарт-контракт Биржи, который может принимать ликвид... | https://habr.com/ru/post/572126/ | null | ru | null |
# MS SQL 2005, Parameter Sniffing, тормозящий Stored Procedure
Недавно столкнулся с проблемой: скрипт запущенный в Query Analyzer отрабатывал за секунду, а он же в виде хранимой процедуры аж 50 секунд. Оказалось всему виной Parameter Sniffing который призван… оптимизировать запрос. [:)](http://lurkmore.ru/%D0%B2%D0%BD... | https://habr.com/ru/post/109580/ | null | ru | null |
# Функциональный Kotlin. Часть 2. Каррированные функции и где они обитают
Введение
--------
В [прошлой статье](https://habr.com/ru/post/539992/) мы рассмотрели основу современного функционального программирования - функции высшего порядка. Настало время познакомиться с ними чуть глубже, узнав про каррирование.
Опре... | https://habr.com/ru/post/649817/ | null | ru | null |
# Как автоматизировать развертывание баз данных с помощью Liquibase?
> Перевод материала подготовлен в рамках курса [**«Экспресс-курс по управлению миграциями (DBVC)».**](https://otus.pw/3yKP/)
>
>

---
... | https://habr.com/ru/post/557008/ | null | ru | null |
# Back/Forward Cache — механизм кеширования страниц в браузере
Начиная с версии 1.5, в Firefox появился механизм кеширования, сохраняющий состояние страницы в памяти. Кеширование действует на одну сессию браузера. Перемещаясь по посещенным страницам с использованием кнопок «Назад/Вперёд», нет необходимости загружать с... | https://habr.com/ru/post/225091/ | null | ru | null |
# Опыт использования утилиты logman для сбора метрик производительности приложения в Windows
Введение
========
Добрый день!
В своем первом посте я хотел бы поделитьcя опытом использования такой утилиты как **logman**, с помощью которой можно собирать информацию о потреблении ресурсов (и не только) приложением под ... | https://habr.com/ru/post/203692/ | null | ru | null |
# DDIA book (книга с кабанчиком) — сделай level up в понимании баз данных
Несколько месяцев назад на одной из ретроспектив мы решили попробовать совместное чтение.
Наш формат:
1. Выбираем книгу.
2. Определяем часть, которую необходимо прочитать за неделю. Выбираем небольшой объем.
3. В пятницу обсуждаем прочитан... | https://habr.com/ru/post/423981/ | null | ru | null |
# Симулятор машинок Брайтенберга
Просто захотелось написать симулятор машинок Брайтенберга. Корни у этой вещи растут из идей построения простеньких роботов, но также она интересна с точки зрения развития сложных систем.
[](https://ha... | https://habr.com/ru/post/342154/ | null | ru | null |
# Атака SWEET32: Исследователи обнаружили новый способ взлома шифров 3DES и Blowfish
[](https://habrahabr.ru/company/pt/blog/308746/)
Исследователи информационной безопасности Картикеян Баргаван (Karthikeyan Bhargavan) и Гае... | https://habr.com/ru/post/308746/ | null | ru | null |
# Система контроля библиотеки на Flask-Potion, Часть 0: готовим всё, что понадобится
Введение
========
В своей работе я уже некоторое время использую [Flask-Potion](https://potion.readthedocs.io) — фреймворк, основными достоинствами которого являются: весьма удобная интеграция с SQLAlchemy моделями, автогенерация cru... | https://habr.com/ru/post/472018/ | null | ru | null |
# Intel Threading Building Blocks 4.4 – что нового?
Недавно вышло большое обновление Intel® Parallel Studio XE 2016, и вместе с ним Intel® Threading Building Blocks 4.4. В новой версии появилось несколько интересных дополнений:
* Глобальный контроль для управления ресурсами, в первую очередь, количеством рабочих по... | https://habr.com/ru/post/266587/ | null | ru | null |
# Qt и Android Market или вторая жизнь Анаграмм
В конце ноября мне стукнула моча в голову и я написал достаточно глупый и несуразный пост об одном из своих приложений, находящийся [здесь](http://habrahabr.ru/blogs/mobiledev/133403/). Тогда пост был заминусован, что в принципе логично, учитывая то, какого качества он б... | https://habr.com/ru/post/138743/ | null | ru | null |
# Простая имитация разрушений с использованием Unity и Blender
Всем привет! недавно задался вопросом насчет разрушений в Unity, поискал в интернете что есть на эту тему, но увы я нашел лишь кучу вопросов и обсуждений.
И нет я не заявляю что моя статья единственная в своем роде, потому что метод довольно прост, но п... | https://habr.com/ru/post/518420/ | null | ru | null |
# (Архив) Вышла первая версия фреймворка Matreshka.js
[](http://matreshka.io/)
[Репозиторий на Github](https://github.com/finom/matreshka)
Всем привет! Спешу сообщить радостную новость. Наконец, выш... | https://habr.com/ru/post/253909/ | null | ru | null |
# Быстрая разработка приложения на Angular + Ag-Grid
В один из дней как обычно попивая кофе, мне приходит сообщение в Skype о том что нужно в кратчайшие сроки сделать приложение с нехитрым функционалом. Нужно было иметь таблицу с сортировкой и пагинацией, возможность фильтровать по слову, дате и.т.п. Так же иметь стра... | https://habr.com/ru/post/339232/ | null | ru | null |
# Пример веб-производительности
В любой сложной системе процесс оптимизации по большей части состоит из распутывания связей между различными слоями системы, каждый из которых обладает собственным набором ограничений. До сих пор мы рассматривали ряд отдельных сетевых компонентов детально — различные физические средства... | https://habr.com/ru/post/226289/ | null | ru | null |
# Golang-дайджест № 19 (1 – 31 июля 2022)
Свежая подборка новостей и материалов
#### Интересное в этом выпуске
* Выпущены версии 1.18.4 и 1.17.12;
* Выпущен GoLand 2022.2;
* Go To Memory;
* Что нового в Go ... | https://habr.com/ru/post/680418/ | null | ru | null |
# Первые шаги с STM32 и компилятором mikroC для ARM архитектуры — Часть 2, продолжение
Разобравшись с таймером, попробуем использовать его для чего, то кроме генерации временных интервалов. Чаще всего при помощи таймера генерируется ШИМ сигнал. Что это такое можно почитать на просторах Сети, например во всеведающий [В... | https://habr.com/ru/post/319256/ | null | ru | null |
# Конвертируем и загружаем на YouTube
Доброго времени суток!
Итак начнём. В статье я опишу краткий проект на [django](http://www.djangoproject.com), который конвертирует/загружает видео-ролики на Ваш канал YouTube.
Пару слов об истории проблемы… Я работаю в небольшой региональной телевизионной компании, которой ... | https://habr.com/ru/post/124508/ | null | ru | null |
# «Дуров, верни стену» или «Хабрахабр + Geektimes + Мегамозг» в одной ленте
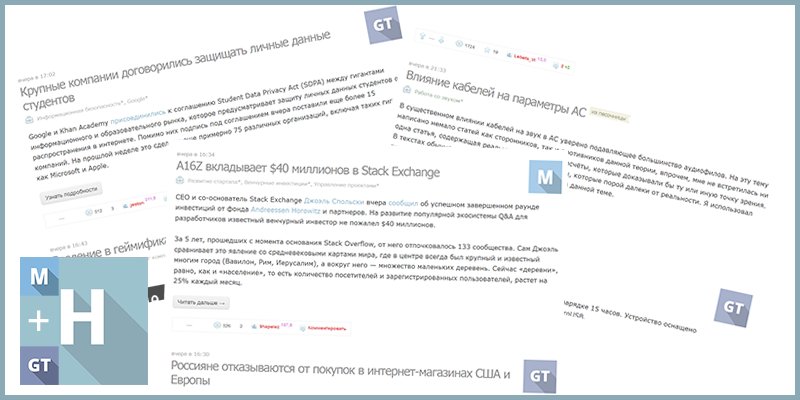
Когда разбушевался Роскомнадзор и Хабр по вынужденным причинам разделился, [появился «младший брат»](http://habrahabr.ru/company/tm/blog/240135/), ... | https://habr.com/ru/post/248599/ | null | ru | null |
# Восстановление знаков пунктуации и заглавных букв — теперь и на длинных текстах
[](https://colab.researc... | https://habr.com/ru/post/594565/ | null | ru | null |
# Bash-скрипты, часть 3: параметры и ключи командной строки
> [Bash-скрипты: начало](https://habrahabr.ru/company/ruvds/blog/325522/)
>
> [Bash-скрипты, часть 2: циклы](https://habrahabr.ru/company/ruvds/blog/325928/)
>
> [Bash-скрипты, часть 3: параметры и ключи командной строки](https://habrahabr.ru/company/ru... | https://habr.com/ru/post/326328/ | null | ru | null |
# Смартфон управляет игрушечным автомобилем
За прошедшее десятилетие у многих появилось один два смартфона лежащих без дела, так и у меня. Решил применить смартфон для управления чем-нибудь, ну например, автомобилем.
Для начала выбрал игрушечный автомобиль из Лего. Он может двигаться вперед и назад, поворачивать в... | https://habr.com/ru/post/424945/ | null | ru | null |
# Движение объекта к точке в Unity3D
Введение
========
Предположим, что у нас есть объект, который должен двигаться к точке. Задачка-то простенькая, использовать интерполяцию, например. Но что, если наш объект может поворачиваться на случайный угол? Как тогда задать точку для интерполирования? Ведь наверняка наша усл... | https://habr.com/ru/post/347904/ | null | ru | null |
# Подготовка Nexus Player (FUGU) к работе с SoCWatch
Польза от оптимизации энергопотребления Android-приложений, которые рассчитаны на мобильные устройства, видна невооружённым взглядом. Меньше потребление энергии – дольше время между перезарядками. Но у энергопотребления есть и другие стороны. Стационарное «железо», ... | https://habr.com/ru/post/266843/ | null | ru | null |
# Восстанавливаем поврежденные таблицы Innodb
Предположим, вы работаете с MySQL таблицами Innodb, и в один ~~прекрасный~~ не самый хороший момент подводит глючное железо, драйвер, бажит ядро, отключается элек... | https://habr.com/ru/post/257627/ | null | ru | null |
# Sourcery для автоматического конвертирования в структуры объектов Realm
В [интернете](https://realm.io/docs/swift/latest/), да и даже на [Хабре](https://habr.com/ru/post/272393/), есть куча статей о том, как работать с Realm. Эта база данных достаточно удобная и требует минимальных усилий для написания кода, если ей... | https://habr.com/ru/post/460867/ | null | ru | null |
# Кеширование блоков с помощью nginx
[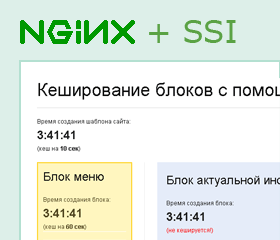](http://linux.ria.ua/SsiBlocks/src/bin/index.php)Многим разработчикам знакома ситуация когда кешировать страницы сайта, скажем, на 5-10 минут нельзя всего из-за одного... | https://habr.com/ru/post/95613/ | null | ru | null |
# FZF. Нечеткий поиск или как быстро ставить npm пакеты и убивать процессы
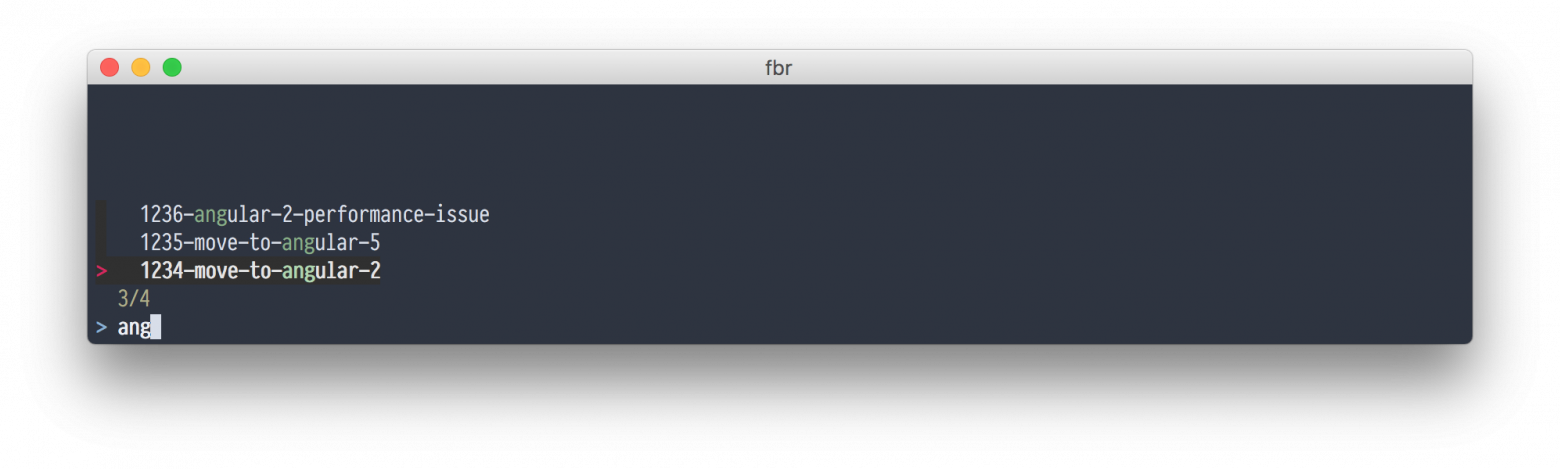
Я работаю в MacOS, почти не использую Finder и все время провожу в консоли. Именно поэтому стараюсь сделать работу из консоли как можно более удобной.
Отно... | https://habr.com/ru/post/344770/ | null | ru | null |
# Унификация правил валидации на примере Asp core + VueJS

*В статье описывается простой способ унификации правил валидации пользовательского ввода клиент-серверного приложеия. На примере простого проекта, я покажу как это можно сдел... | https://habr.com/ru/post/473776/ | null | ru | null |
# Кушать подано, садитесь подключать, пожалуйста
Сегодня Intel Edison с набором датчиков и актюаторов поможет нам сделать следующее: сыграть песенку «В траве сидел кузнечик», определить, хорошо ли течет вода, горит ли огонь, перекачать воду, проверить есть ли в воздухе пары спирта, пыльная ли комната, проследить, как ... | https://habr.com/ru/post/261123/ | null | ru | null |
# Восстановление контроллера домена из резервной копии с помощью Veeam
Продолжаем публикацию серии статей, написанных коллегой для корпоративного блога и посвященных резервному копированию и восстановлению контроллеров домена и собственно Active Directory.
В предыдущей [статье](https://habrahabr.ru/company/veeam/bl... | https://habr.com/ru/post/313570/ | null | ru | null |
# LFS: Темная сторона силы. Часть 2
Предисловие
===========
Итак, в [предыдущей статье](http://habrahabr.ru/post/257663/) мы начали собирать LFS, остановившись на том, что собрали временную систему, располагающую всем необходимым для дальнейшей сборки инструментарием.
Теперь мы будем собирать основную систему, вып... | https://habr.com/ru/post/257941/ | null | ru | null |
# Трудности, с которыми мы столкнулись при модуляризации нашего приложения. Часть 2
[**Первая часть**](https://habr.com/ru/company/otus/blog/701688/)
### Наши дальнейшие действия
В итоге мы провели ревизию ... | https://habr.com/ru/post/705292/ | null | ru | null |
# Графический формат JNG — чем полезен, как устроен, чем сконвертить, посмотреть и загрузить
 На картинке изображенна турецкая снайперская винтовка с очень подходящим названием — JNG. В статье, как вы уже догадались — речь п... | https://habr.com/ru/post/155547/ | null | ru | null |
# Qt на Android: как мы дали вторую жизнь приложению с авторскими медитациями
 Краткое лирическое вступление — в 2017 году мне случилось очень плотно заинтересоваться медитациями. Этому способствовала целая цепочка событий, благоприятны... | https://habr.com/ru/post/501456/ | null | ru | null |
# Книга «Python для сетевых инженеров. Автоматизация сети, программирование и DevOps»
[](https://habr.com/ru/company/piter/blog/681618/) Привет, Хаброжители!
Сети образуют основу для развертывания, поддержки и обслуживания пр... | https://habr.com/ru/post/681618/ | null | ru | null |
# КлассикAI жанра: ML ищет себя в поэзии
 Сейчас в прессе часто встречаются новости вида “AI научился писать в стиле автора Х”, или “ML создает искусство”. Посмотрев на это, мы решили – было бы здорово, если эти громкие заявления... | https://habr.com/ru/post/419745/ | null | ru | null |
# Nanc — backend-agnostic CMS с Flutterлюшками
Intro
-----
Привет! Сегодня я хочу представить вам плод моего многомесячного труда по ночам и выходным, призванный улучшить опыт управление контентом и привнести в мир разработки Flutter-приложений дополнительные возможности.
Далее речь пойдет о Nanc (читается как Нэнс,... | https://habr.com/ru/post/714076/ | null | ru | null |
# Особенности формирования тактовых частот в PSoC 5LP

При разработке аппаратной части комплекса REDD, описанного в [этой статье](https://habr.com/ru/post/440156/), мы рассматривали различные варианты реализации. PSoC рассматривалс... | https://habr.com/ru/post/443554/ | null | ru | null |
# Трассировка JS ↔ DOM, или Туда и обратно
Поиск утечек памяти в Chrome 66 стал гораздо удобней. DevTools теперь могут проводить трассировку, делать снапшоты DOM-объектов из C++, отображать все доступные DOM-объекты из JavaScript вместе со ссылками на них. Появление этих возможностей стало следствием нового механизма ... | https://habr.com/ru/post/351620/ | null | ru | null |
# Реализация длииииииинной арифметики на C++
В большинстве современных языков программисту уже не нужно заботиться о числах, с которыми процессор непосредственно манипулировать не может. Где-то, как в Python или Haskell, поддержка длинных целочисленных типов встроена прямо в ядро языка, где-то, как в Java или C#, реал... | https://habr.com/ru/post/172285/ | null | ru | null |
# Разложение матрицы аффинного преобразования
Не так давно в процессе разработки редактора 2D-графики возникла задача разложить матрицу аффинного преобразования на плоскости, на произведение матриц простых преобразований с тем, чтобы отобразить их пользователю и предложить какую-то более-менее адекватную интерпретацию... | https://habr.com/ru/post/278597/ | null | ru | null |
# JavaParser. Корёжим код легко и непринуждённо
В мире существует множество клёвых маленьких библиотек, которые как бы и не знаменитые, но очень полезные. Идея в том, чтобы потихоньку знакомить Хабр с такими вещами. Сегодня расскажу о JavaParser.
JavaParser — это набор инструментов для парсинга, анализа, трансформаци... | https://habr.com/ru/post/348710/ | null | ru | null |
# Новая утечка истории браузера через favicon
Недавно наткнулся на это исследование [pdf](http://web.archive.org/web/20210210122008/https://www.cs.uic.edu/~polakis/papers/solomos-ndss21.pdf) (по его мотивам уже была [статья](https://habr.com/ru/company/itsumma/blog/542734/) на хабре), после прочтения, решил поискать б... | https://habr.com/ru/post/543282/ | null | ru | null |
# Организация делителя частоты с дробным коэффициентом деления в объёме ПЛИС
*Статья посвящена актуальной задаче деления тактовых частот, стоящей перед разработчиками широкого спектра цифровых устройств на основе ПЛИС. Предложенные технические решения могут оказаться полезными при проектировании заказных и серийных СБ... | https://habr.com/ru/post/306132/ | null | ru | null |
# Dancer2 или современное web-приложение на PERL. Часть III
Современные web-приложения в большинстве случаях хранят данные в SQL базах данных. Для доступа к этим данным используются объекты модели, которые по... | https://habr.com/ru/post/579668/ | null | ru | null |
# Руководство по NestJS. Часть 2

Привет, друзья!
Данная серия статей представляет собой мои заметки о [NestJS](https://nestjs.com/) — фреймворке для разработки эффективных и масштабируемых серверных приложений на [Node.js](https:... | https://habr.com/ru/post/666470/ | null | ru | null |
# Vibrant.kt — быстрое прототипирование и разработка распределенных приложений (DApps) на JVM
Нихао!
------
### Введение
Я долго ничего не писал, потому что ЕГЭ само себя не сдаст, но к [Балтийскому конкурсу](http://baltkonkurs.ru) я не мог не написать чего-нибудь классное. Хороших идей из ниоткуда я выдавить не мог... | https://habr.com/ru/post/347080/ | null | ru | null |
# checkm8 для Lightning-видеоадаптеров Apple

Появление эксплойта `checkm8` можно назвать одним из важнейших событий прошедшего года для исследователей продукции Apple. Ранее мы уже [опубликовали технический анализ](https://habr.com/... | https://habr.com/ru/post/485216/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.