
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Invisible.js — одни модели и на клиенте и на сервере
[Invisible.js](http://invisiblejs.github.io/) — библиотека, позволяющая использовать одни и те же модели данных как на клиенте, так и на сервере. На сервере работает поверх **express.js** на клиент отдается через [browserify](https://github.com/substack/node-brows... | https://habr.com/ru/post/206526/ | null | ru | null |
# Интеграция со службами каталогов при разработке корпоративных порталов на платформе LAMP
Решаемая бизнес-задача / сфера применения
-----------------------------------------
Веб-разработчики с завидной регулярностью получают заказы на создание корпоративных порталов. Под порталами в данном случае понимаются внутренн... | https://habr.com/ru/post/30182/ | null | ru | null |
# Приложение на основе микросервисов на Azure
Эта публикация посвящена двум приложениям на основе микросервисов, созданным и развернутым в Microsoft Azure Service Fabric и в службе контейнеров Azure. Хотя основное внимание уделяется приложениям на основе микросервисов, работающим в Azure Service Fabric и в службе конт... | https://habr.com/ru/post/326054/ | null | ru | null |
# JSON Web Token (JWT) — пример Java реализации на Spring Boot OAuth2 Resource Server 6.0
Доброе время!
Часть 2-я по открытому занятию нового учебного курса: реализация простого JWT через новый Spring Boot OAuth2 Resource Server (первая часть: [Spring Boot 3.0 — готовимся заранее](https://habr.com/ru/post/683936/)). ... | https://habr.com/ru/post/684270/ | null | ru | null |
# Двухфакторная аутентификация при монтировании зашифрованного раздела LUKS с помощью Yubikey 4
### Часть 3: Yubikey 4 и LUKS

### Введение
В статье рассматривается реализация двухфакторной аутентификации с помощью ключа Yub... | https://habr.com/ru/post/329648/ | null | ru | null |
# Архитектура и программирование компьютера Vectrex
*— А видеовыход у него есть?
— И как ты себе это представляешь?
(из разговора о Vectrex)*
[Vectrex](http://en.wikipedia.org/wiki/Vectrex) выпускался GCE в 1982 — 19... | https://habr.com/ru/post/313218/ | null | ru | null |
# .container больше не нужен
Все верстальщики в своих проектах используют div.container для центрирования контента и этот способ имеет некоторые особенности, от которых можно избавиться. Прочитав эту статью, Вы узнаете про способ, который позволит полностью отказаться от контейнера. Я попытаюсь рассказать о плюсах и м... | https://habr.com/ru/post/463923/ | null | ru | null |
# Средний цвет в JavaScript

По работе делал листалку фотографий. Сопровождающий текст было решено положить на усреднённый цвет фото. Тема среднего цвета заинтересовала, и я решил
посмотреть какие ещё варианты м... | https://habr.com/ru/post/419309/ | null | ru | null |
# Aero Framework — новое дыхание WPF. Поднимаемся выше MVVM
*Aero Framework* — передовая библиотека для промышленной и индивидуальной разработки кросс-платформенных *XAML*-ориентированных приложений с применением концепций *MVVM*-проектирования. Её основные достоинства — интуитивная ясность, предельная лаконичность, м... | https://habr.com/ru/post/268151/ | null | ru | null |
# Как создать игру, если ты ни разу не художник
В жизни каждого программиста бывали моменты, когда он мечтал сделать интересную игру. Многие программисты эти мечты реализовывают, и даже успешно, но речь сейчас не о них. Речь о тех, ... | https://habr.com/ru/post/445278/ | null | ru | null |
# Что нового в Java 20?
[](https://habr.com/ru/company/piter/blog/705478/)
Версия Java 20 [должна быть выпущена в марте 2023 года](https://openjdk.org/projects/jdk/20/), и ожидается, что в ней появится [целый ряд изменений и нов... | https://habr.com/ru/post/705478/ | null | ru | null |
# HackTheBox. Прохождение Remote. NFS, RCE в CMS Umbraco и LPE через UsoSvc

Продолжаю публикацию решений, отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu).
В данной статье копаемся в NFS ресур... | https://habr.com/ru/post/517876/ | null | ru | null |
# Иерархические модели в Qt
Продолжаю тему создания моделей с использованием Qt MV. В [прошлый раз](http://habrahabr.ru/post/171443/) была критическая статья по поводу того, как делать не надо. Переходим к позитивной части.
Для создания плоских моделей списков и таблиц можно использовать заготовки [QAbstractListMod... | https://habr.com/ru/post/172187/ | null | ru | null |
# Как на D писать под ARM
Доброго времени суток, Хабр!
Сегодня я хочу поделиться опытом разработки под миникомпьютеры на linux (RPI, BBB и другие) на языке программирования **D**. Под катом полная инструкция о том как сделать это без боли. Ну или почти… =)
.
Будет подробно рассказано, как внедриться в процесс игры, как изменить поток выполнения, приведено к... | https://habr.com/ru/post/446516/ | null | ru | null |
# Preview документов в программе на Python
В одной из систем, к которым я имею отношение, doc-файлы складываются в базу данных.
Мне стало интересно, можно ли пристроить в свою программку, работающую с базой, просмотр этих файлов.

Так вышло, что я большой поклонник творчества [Уильяма Гибсона](https://en.wikipedia.org/wiki/William_Gibson). Моё знакомство с этим замечательным прозаиком случилось вследствие глубокого увле... | https://habr.com/ru/post/352050/ | null | ru | null |
# Cubieboard A10 как роутер и точка WiFi hotspot
Доброе время суток Хабра народ, я хотел бы показать реализацию роутера и точки WIFI доступа на базе miniPC Cubieboard A10. На данную тематику довольно много мануалов как на Хабре так и на просторах интернета но полностью рабочей инструкции так и не удалось отыскать.
... | https://habr.com/ru/post/215401/ | null | ru | null |
# [Перевод] Не стоит бояться функционального программирования
Представляю вашему вниманию перевод проскользнувшей недавно в ссылках [дайджеста](http://habrahabr.ru/post/228757/) [статьи](http://www.smashingmagazine.com/2014/07/02/dont-be-scared-of-functional-programming/) Джонатана Моргана о функциональном программиро... | https://habr.com/ru/post/228893/ | null | ru | null |
# Море, пираты — 3D онлайн игра в браузере
Приветствую пользователей Хабра и случайных читателей. Это история разработки браузерной многопользовательской онлайн игры с low-poly 3D графикой и простейшей 2D физикой.
Позади немало браузерных 2D мини-игр, но подобный проект для меня в новинку. В gamedev решать задачи, ... | https://habr.com/ru/post/509840/ | null | ru | null |
# Gulp.watch: ловим ошибки правильно
Во всех современных системах сборки фронтенда есть режим `watch`, при котором запускается специальный демон для автоматической пересборки файлов сразу после их сохранения. Также он есть и gulp.js, но с некоторыми особенностями, делающими работу с ним немного сложней. Работа gulp.js... | https://habr.com/ru/post/259225/ | null | ru | null |
# Umka. Жизнь статической типизации в скриптовом языке

В своё время посты на [Хабре](https://habr.com/ru/post/501002/) и [Reddit](https://www.reddit.com/r/ProgrammingLanguages/comments/gf5w0p/umka_a_new_statically_typed_scripting_la... | https://habr.com/ru/post/507510/ | null | ru | null |
# Дерево синтаксиса и альтернатива LINQ при взаимодействии с базами данных SQL

В этой статье, на примере простых логических выражений, будет показано, что такое абстрактное синтаксическое дерево и что с ним можно делать. Так же будет ... | https://habr.com/ru/post/524874/ | null | ru | null |
# Juniper routing instances
Routing Instance – это совокупность таблиц маршрутизации, интерфейсов и параметров протоколов маршрутизации. Протоколы маршрутизации контролируют информацию в таблицах маршрутизации, причем в одной routing instance могут быть как IPv4, так и IPv6 маршруты одновременно, а так же несколько фи... | https://habr.com/ru/post/275119/ | null | ru | null |
# Airconsole. Подключение к Console port Cisco по WiFi
Достаточно давно я пользуюсь iOS приложением для администрирования сетевого оборудования [Get-console](http://itunes.apple.com/us/app/get-console/id412067943?mt=8&ls=1) производства новозеландской CloudStore. Данное приложение, субъективно, лучшее для такого рода ... | https://habr.com/ru/post/189090/ | null | ru | null |
# Работаем с lightsquid или как сделать индивидуальную статистику для пользователей
Итак, появилась у меня задача на работе: дать каждому пользователю возможность смотреть свои логи посещения интернета. Вроде кажется и задача такая — должна уже со всех сторон на любом форуме обсудится и как минимум должно быть готовое... | https://habr.com/ru/post/548782/ | null | ru | null |
# Простой Telegram бот для поиска по сайту на WordPress без знаний программирования
Сразу на входе скажу - это инструкция не для разработчиков, это инструкция для тех, кто вообще ничего не понимает в программировании, но очень хочет сделать простого бота, который бы умел искать по сайту. Идея такой статьи появилась по... | https://habr.com/ru/post/659329/ | null | ru | null |
# NumPy, пособие для новичков. Часть 1
**NumPy** — это расширение языка Python, добавляющее поддержку больших многомерных массивов и матриц, вместе с большой библиотекой высокоуровневых математических... | https://habr.com/ru/post/121031/ | null | ru | null |
# PostgreSQL — Asynchronous Replication + Pooling + Failover
##### Вариант простой для понимания асинхронной master-slave репликации на базе Postgresql 9.1
Впервые встала задача единоличной реализации полноценной репликации и впервые был написан мини-мануал, который и хочу здесь представить.
Для системы репликации... | https://habr.com/ru/post/158731/ | null | ru | null |
# Как полиморфизм реализован внутри JVM
*Перевод данной статьи подготовлен специально для студентов курса [«Разработчик Java».](https://otus.pw/5HGh/)*

---
В моей предыдущей статье [Everything About Method Overloading vs Method ... | https://habr.com/ru/post/467197/ | null | ru | null |
# Как реализовать отслеживание местоположения андроид устройства на своем сайте
Занимаюсь грузоперевозками на своей газели, и у меня родилась идея сделать функцию отслеживания своего местоположения для всех посетителей своего сайта. Это очень удобно для тех, кто следит за своим грузом или тех, кто ждет машину. У меня ... | https://habr.com/ru/post/546286/ | null | ru | null |
# Прохождение капчи «Лабиринт» на Javascript
Существует не слишком широко известная браузерная игра. Игровой процесс в ней очень простой и монотонный, что способствует появлению ботов. Для борьбы с ними в игру введена капча, время от времени вылезающая во время боя. На угадывание даётся 50 секунд, если угадать за 20, ... | https://habr.com/ru/post/164887/ | null | ru | null |
# Правильный вывод полей в Drupal 7
Перевод статьи от [ComputerMinds](http://www.computerminds.co.uk/): [Rendering Drupal 7 fields (the right way)](http://www.computerminds.co.uk/articles/rendering-drupal-7-fields-right-way)
##### Краткий ответ
Используйте field\_view\_field()!
##### Полный ответ
Drupal 7 дает... | https://habr.com/ru/post/163501/ | null | ru | null |
# Vivado: Picasso mode
Аннотация
---------
*Безумию все возрасты покорны*
При проектировании каких-либо модулей на ПЛИС невольно иногда приходит в голову мысль о не совсем стандартном использовании самой среды проектирования и инструментов, которые она предоставляет для проектирования. В этой небольшой заметке мы ра... | https://habr.com/ru/post/477974/ | null | ru | null |
# Марсоход, Инициализация
[](https://habrahabr.ru/post/314544/)
В этой серии статей мы строим программное обеспечение марсохода в [соответствии со следующими спецификациями](https://habrahabr.ru/post/314536/). Это позволит п... | https://habr.com/ru/post/314544/ | null | ru | null |
# Основное про API-шлюз в Kubernetes
Существует множество альтернатив для доступа к модулю извне кластера. Шлюз API - это определенно новинка этой области, и потому выбран темой этой статьи.
Ранее мы описыв... | https://habr.com/ru/post/690934/ | null | ru | null |
# Программа конференции Lua in Moscow 2019

Как мы сообщали в [предыдущем анонсе](https://habr.com/ru/company/mailru/blog/437492/), 3 марта (воскресенье) в офисе Mail.ru Group пройдёт третья международная конференция Lua in Moscow ... | https://habr.com/ru/post/441364/ | null | ru | null |
# Обзор фреймворка CodeIgniter
Здравствуй всеми уважаемый хабрахабр. В этой статье речь пойдёт о замечательном PHP фреймворке CodeIgniter (сокращённо CI). CodeIgniter — популярный PHP фреймворк с открытым исходным кодом, позволяющий создавать многофункциональные и безопасные веб-приложения с MVC архитектурой. Разработ... | https://habr.com/ru/post/168015/ | null | ru | null |
# jQuery Video Extend — расширение возможностей HTML5 видео плеера
Часто вижу, что владельцы сайтов и разработчики используют видео-плееры вроде [VideoJS](http://www.videojs.com/), [Flowplayer](http://flowplayer.org/), [Uppod](http://uppod.ru/) и т.д., но очень редко вижу стандартные HTML5 плееры на сайтах. Мне это ка... | https://habr.com/ru/post/264719/ | null | ru | null |
# НЕрадиоуправляемые модели: вперед к беспроводным подлодкам на пульте
> *“Мы можем исключительно много, но до сих пор мы так и не поняли, что из того, что мы можем, нам действительно нужно” (С) АБС, “Улитка на склоне”*
>
>
**Приветствую вас, глубокоуважаемые!**
Мы тут опять решили проблему, о существовании которо... | https://habr.com/ru/post/550910/ | null | ru | null |
# Пакеты, системы, модули, библиотеки — КАКОГО?

По моим наблюдениям, минимум раз в неделю в списке [c.l.l](http://groups.google.com/group/comp.lang.lisp) или другом Lisp-списке [«новички»](http://ru.wikipedia.org/wiki/%D0%9D%D0%... | https://habr.com/ru/post/146574/ | null | ru | null |
# Установка новой инфраструктуры Active Directory в Windows Azure
В ходе данной статьи я расскажу о развертывании нового сервиса Windows Azure Active Directory и присоединении новых виртуальных машин. Перед тем, как приступить к развертыванию Active Directory необходимо:
• Настроить **Virtual Networking**, включая ... | https://habr.com/ru/post/158211/ | null | ru | null |
# Графика для эдвенчуры с DALL-E 2
Недавно я получил доступ к OpenAI [DALL-E 2](https://openai.com/dall-e-2/). Конечно, очень весело создавать с его помощью котиков на аватарки, но ведь модель можно использовать и в других видах творческой работы.
О сильных и слабых сторонах DALL-E рассказано неоднократно, поэтому я ... | https://habr.com/ru/post/683282/ | null | ru | null |
# Кроссплатформенный сервер с неблокирующими сокетами. Часть 4
Эта статья продолжает мои предыдущие:
[Простейший кросcплатформенный сервер с поддержкой ssl](http://habrahabr.ru/post/211474/)
[Кроссплатформенный https сервер с неблокирующими сокетами](http://habrahabr.ru/post/211661/)
[Кроссплатформенный http... | https://habr.com/ru/post/213301/ | null | ru | null |
# Что нам стоит автоматизацию построить. Использование HTTP API в Google Sheets
В эпоху повальной автоматизации пользователям хочется «нажать на кнопку и получить ответ». Ну или дополнительно немного подвигать мышкой. Автоматизация же отчетов и других штук, которые удобно представить в виде таблички, часто строится в ... | https://habr.com/ru/post/326906/ | null | ru | null |
# Пишем веб сервис на Go (часть первая)
В этой статье, я хотел бы рассказать вам, как можно достаточно быстро и легко написать небольшое веб-приложение на языке Go, который, не смотря на юный возраст, успел завоевать расположение у многих разработчиков. Обычно, для подобных статей пишут искусственные приложения, вроде... | https://habr.com/ru/post/208680/ | null | ru | null |
# Конфигурация программ на Go

Всем привет! После пяти лет программирования на Go я обнаружил себя достаточно
ярым приверженцем определенного подхода к конфигурации программ. В этой
статье я попытаюсь раскрыть е... | https://habr.com/ru/post/479882/ | null | ru | null |
# Подборка занимательных CSS рецептов «Голые пятницы #2»
Привет, Хабр! В этот раз мы поговорим о стилизации инпутов без картинок и JS, особенностях вертикальных отступов, CSS счетчиках, необъятных возможностях в именовании классов, а также расскажем, как улучшить анимацию на слабых устройствах.
 Aarch64 — это 64-битная архитектура от ARM (иногда её называют arm64). В этой статье я расскажу, чем она отличается от "обычных" (32-битных) ARM и насколько сложно портировать на него свою систему.
Эта ст... | https://habr.com/ru/post/463417/ | null | ru | null |
# Отображение данных в формате json на структуру C++
В идеале хотелось бы определить структуру С++
```
struct Person {
std::string name;
int age;
bool student;
} person;
```
передать экземпляр person в метод отображения вместе с данными json\_data
```
map_json_to_struct(person, json_data)
```
после чего просто ... | https://habr.com/ru/post/506506/ | null | ru | null |
# Эксперимент с бинарным кодом в Glimmer
Перевод статьи об [эксперименте с бинарным кодом в Glimmer](https://engineering.linkedin.com/blog/2017/12/the-glimmer-binary-experience), соавторы публикации: Сара Клаттербак, Чад Хиетала и Том Дейл.
Чуть более года назад [Ember.js](https://engineering.linkedin.com/blog/2016... | https://habr.com/ru/post/348586/ | null | ru | null |
# Группы асинхронных задач в Python 3.11
Вчера на официальном сайте был опубликован первый релиз-кандидат Python 3.11, который принесет важные оптимизации и доработки в возможности языка. Релиз планируется в ... | https://habr.com/ru/post/681560/ | null | ru | null |
# Learn OpenGL. Урок 5.5 – Normal Mapping

Normal Mapping
==============
Все сцены, которые мы используем состоят из многоугольников, в свою очередь состоящих из сотен, тысяч абсолютно плоских треугольников. Нам уже удал... | https://habr.com/ru/post/415579/ | null | ru | null |
# Обзор интересных программ от Microsoft Research
[Microsoft Research](http://research.microsoft.com/) (MSR) — подразделение корпорации Microsoft, созданное в 1991 году для исследования различных вопросов и тем в области информатики. Microsoft Research объединяет 800 исследователей в шести глобальных лабораториях по в... | https://habr.com/ru/post/83177/ | null | ru | null |
# Шаблонизация в JavaScript с использованием Razor
В силу всё большего и большего усложнения веб-приложений на стороне клиента, хочется иметь шаблонизаторы, которые работали бы прямо на клиенте. И таких средств, надо сказать, появилось не мало. Но так как ~~я легких путей не ищу~~ все они мне не нравятся, я решил сдел... | https://habr.com/ru/post/142475/ | null | ru | null |
# Небольшой скрипт на bash для пингования хостов
Как одновременно держать руку на пульсе у нескольких серверов и управляемых свичей? Я решил автоматизировать этот процесс. Вот что вышло.
Сам скрипт
==========
> `1. #!/bin/bash
> 2. #Версия 0.2pre alfa
> 3. #Скрипт поддерживает четыре ключа: 1) -s режим тишины, 2) ... | https://habr.com/ru/post/75590/ | null | ru | null |
# Несколько интересностей и полезностей для веб-разработчика #13
Доброго времени суток, уважаемые хабравчане. За последнее время я увидел несколько интересных и полезных инструментов/библиотек/событий, которыми хочу поделиться с Хабром.
#### [Colour Schemes](https://github.com/daylerees/colour-schemes)
[ рассматривались базовые понятия Storm.
Разные классы задач предъявляют различные требования к надежности. Одно дело пропустить пару записей при подсчете статистики посещений, где счет идет на сотни тысяч и особая точность не нужн... | https://habr.com/ru/post/186436/ | null | ru | null |
# ХабраВойны — python-robots
[Драфт течпревью](http://code.google.com/p/python-robots/source/browse/) игры для программистов. (очень грязный, опубликовал, чтобы собрать мнения и замечания, не минусуйте сильно, пожалуйста) По мотивам
[habrahabr.ru/blogs/sport\_programming/74536](http://habrahabr.ru/blogs/sport_progr... | https://habr.com/ru/post/74550/ | null | ru | null |
# Мега-Учебник Flask, Часть 7: Unit-тестирование
Это седьмая статья в серии, где я описываю свой опыт написания веб-приложения на Python с использованием микрофреймворка Flask.
Цель данного руководства — разработать довольно функциональное приложение-микроблог, которое я за полным отсутствием оригинальности решил н... | https://habr.com/ru/post/223783/ | null | ru | null |
# Простой сайт на D
На хабре уже упоминался язык D. Но популярности он не получил из-за невозможности практического использования, а точнее большинству он просто не нужен.Сегодня хочу рассказать вам об одном полезном фреймворке для D. Большинство программистов хоть раз писали веб-сервер на компилируемом языке, но эти ... | https://habr.com/ru/post/181548/ | null | ru | null |
# Групповое редактирование ресурсов (документов) с помощью MIGXDB
Не устаю удивляться возможностям, которые предоставляет компонент [MIGX](http://modx.com/extras/package/migx) от [Bruno17](https://github.com/Bruno17) для **M... | https://habr.com/ru/post/196396/ | null | ru | null |
# Интернет на магнитах 2 — Гипертекст
[](https://habrahabr.ru/post/141307/) Пора дать волю гипертексту и расширить возможности его распространения не только классическим клиент-серверным способом, но и в одноранговых ... | https://habr.com/ru/post/141307/ | null | ru | null |
# Универсальный контейнер данных
В последние лет 5 я, по большей части, имею дело с приложениями на базе Magento, в основу которой заложены идеи максимальной гибкости, расширяемости и адаптивности. Популярность Magento в e-commerce и количество сторонних модулей расширений к ней говорят о том, что эта платформа и реал... | https://habr.com/ru/post/273261/ | null | ru | null |
# И опять атака на сайты Wordpress — перебор + XMLRPC
С полудня субботы на моем сервере, где хостится около 25 сайтов на Wordpress, начались дикие тормоза. Так как мне удалось пережить предыдущие атаки ([атака 1 — ровно год назад](http://habrahabr.ru/post/188932/), [атака 2 — в марте](http://habrahabr.ru/post/215543/)... | https://habr.com/ru/post/232129/ | null | ru | null |
# Инфраструктура открытых ключей: GnuPG/SMIME и токены PKCS#11 с поддержкой российской криптографии
Неумолимо приближается час «Ч»: «использование схемы подписи ГОСТ Р 34.10-2001 для формирования подписи после 31 декабря 2018 года не до... | https://habr.com/ru/post/417735/ | null | ru | null |
# Elementary OS. Наводим чистоту и порядок в Applications
Здравствуйте!
Когда впервые зашла на хабр, поняла, что я дома. Home, Sweet Home.…
Всё не решалась написать. Вот, решилась! Пишу. Хорошо иль плохо, но пишу.
 ... | https://habr.com/ru/post/242751/ | null | ru | null |
# Dagaz: Пинки здравому смыслу (часть 4)
***Пусть же вихрем сабля свищет!
Мне Костаки не судья!
Прав Костаки, прав и я!
…
[Козьма Прутков](https://ru.wikiquote.org/wiki/%D0%9A%D0%BE%D0%B7%D1%8... | https://habr.com/ru/post/253397/ | null | ru | null |
# Теория кэша (часть вторая, практическая, дополненная)
Это вторая, дополнительная (upd: дополненная), часть моей статьи посвященной кэшированию информации при веб-разработке. Первая имеет название [Теория кэша](http://habrahabr.ru/blogs/webdev/38771/).
**UPD:** После многочисленных коментариев я сильно переработал... | https://habr.com/ru/post/38911/ | null | ru | null |
# Для чего на самом деле нужны стрелочные функции в JavaScript
Привет, Хабр! Представляю вашему вниманию перевод статьи [«The real reason why JavaScript has arrow functions»](https://medium.com/front-end-weekly/the-real-reason-why-javascript-has-arrow-functions-8a2da3bbb559) автора Martin Novák.

Привет!
Пару месяцев назад я писал пост, о том как научить [webpack для spa](https://habrahabr.ru/post/265801/).
С того момента инструмент шагнул вперед и оброс дополнитель... | https://habr.com/ru/post/278503/ | null | ru | null |
# Поддержка флеша в Chromium под Linux
На Ubuntu Forums [появилась информация](http://ubuntuforums.org/showthread.php?t=1207863) о том, что Chromium научился цеплять Adobe Flash Plugin. Для установки достаточно сделать символическую ссылку на установленную библиотеку:
`$ cd /usr/lib/chromium-browser/plugins
$ su... | https://habr.com/ru/post/64560/ | null | ru | null |
# ARM аccемблер
Привет всем!
По роду деятельности я программист на Java. Последние месяцы работы заставили меня познакомиться с разработкой под Android NDK и соответственно написание нативных приложений на С. Тут я столкнулся с проблемой оптимизации Linux библиотек. Многие оказались абсолютно не оптимизированы под ... | https://habr.com/ru/post/133808/ | null | ru | null |
# Накрутки на КиноПоиске, посмотрим на аккаунты поближе
По мотивам последних новостей о взломе аккаунтов на КП захотелось побаловаться со статистикой оценок, которую можно частично подсмотреть на сайте.
Примечательно, что уже 18 сентября, в интернете писали, что другим фильмам, выходящим 28 сентября скручивают рейт... | https://habr.com/ru/post/407067/ | null | ru | null |
# Пара полезных исключений из правил по форматированию исходного кода
Плоский дизайн (flat design), это сейчас модно и красиво. Внесем же наш маленький вклад в общую тенденцию, применим немного flat-форматированного кода
#### Отступ лесенкой
Вложенные секции кода рекомендуется писать с отступом относительно внешне... | https://habr.com/ru/post/208750/ | null | ru | null |
# Новости из мира OpenStreetMap № 469 (09.07.2019-15.07.2019)
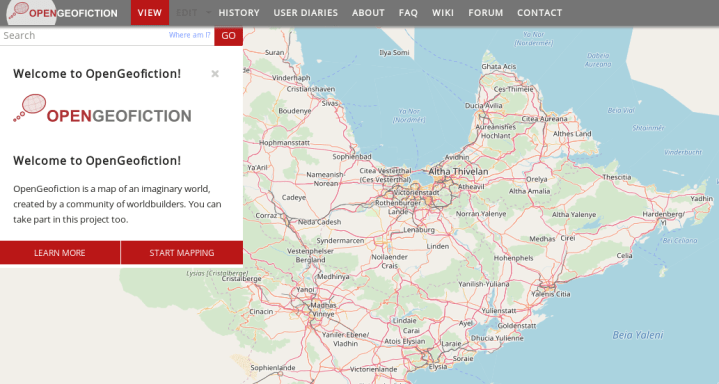
Cайт OpenGeofiction (OGF) сделан на программной платформе OpenStreetMap [1](#wn469_20513) |
Картографирование
-----------------
* Франсуа Л... | https://habr.com/ru/post/461093/ | null | ru | null |
# CodeIgniter + lighttpd = ЧПУ
Имеем новый проект «domen.com», который будет работать на php-фреймворке [codeigniter](http://codeigniter.com/) и вебсервере [lighttpd](http://www.lighttpd.net/).
За... | https://habr.com/ru/post/65408/ | null | ru | null |
# Вышла 4 версия Font Awesome
Добрый день,
Вышла 4-ая версия бесплатного набора шрифтов [Font-Awesome](http://fortawesome.github.io/Font-Awesome/). Изменился дизайн сайта, добавился кроме всего прочего знак рубля, но самое главное — изменились имена классов у иконок. Сейчас нужно везде использовать тэг *и вместо п... | https://habr.com/ru/post/199008/ | null | ru | null |
# Реализация мультизагрузки файлов с индикаторами выполнения на ASP.NET
В этой статье Марк Салливан рассказывает, как с помощью ASP.NET и библиотек Uploadify реализовать мультизагрузку файлов с динамическими индикаторами выполнения. Созданный в процессе класс Http-обработчика, наряду с классом элемента управления, под... | https://habr.com/ru/post/341366/ | null | ru | null |
# MongoDB: $or VS $in — что работает быстрее?
По катом будет совсем небольшое сравнение производительности MongoDB в случаях использования $or и $in логических операций в запросах. Надеюсь, что данная заметка сэкономит кому-нибудь рабочее время.
Тесты запускались на MongoDB 2.4.9
Допустим в MongoDB есть коллекци... | https://habr.com/ru/post/219913/ | null | ru | null |
# Selenium + AutoIT. Автоматизация тестирования Windows окон
Меня зовут Иван Сидоренко, я инженер по тестированию в компании Digital Design.
Передо мной стояла задача разработки авто-тестов для одного из наших проектов с помощью инструмента Selenium WebDriver на языке Java. Подробнее про это вы можете прочитать в м... | https://habr.com/ru/post/489502/ | null | ru | null |
# Интегрируем смартконтракт в веб-приложение на Nodejs
Если вам интересна тема разработки продуктов использующих смартконтракты, но вы хотите понять полный цикл создания таких приложений, то этот урок специально для вас (надеюсь). Из него вы узнаете как разработать, оттестировать, залить в сеть и интегрировать в ваше ... | https://habr.com/ru/post/343744/ | null | ru | null |
# Получение статистики по всем клиентам из API Яндекс Директ в разрезе дней с помощью Python
В работе часто использую короткую статистику в разрезе дней чтобы отслеживать отклонения трафика.
Более подробно о написании запросов написал в [статье « Получение рекламных кампаний Яндекс Директ с помощью API в DataFrame... | https://habr.com/ru/post/449392/ | null | ru | null |
# Разбираем декораторы ES2016

Многие из нас, наверное, уже устали от этой шумихи вокруг последних стандартов ECMAScript. ES6, ES7 ECMAScript Harmony… Кажется, что у каждого свое мнение на счет того, как правильно называть J... | https://habr.com/ru/post/277021/ | null | ru | null |
# Система наблюдения в автомобиле за ним же на Raspberry Pi. Часть 1
#### Введение
Добрый день.
Однажды я приобрёл Raspberry Pi без каких-то на то целей — как только начались упоминания о нём на хабре. Начал бесцельно запускать фтп-сервера, пробовать Node.js и прочие мелкие серверные дела, пока не приобрёл новый а... | https://habr.com/ru/post/202012/ | null | ru | null |
# Компилируем Spring Boot-приложение в нативное с помощью GraalVM
***Перевод статьи подготовлен в преддверии старта курса [«Разработчик на Spring Framework»](https://otus.pw/rRY9/).***

---
Привет, любители Spring’а! Добро пожало... | https://habr.com/ru/post/503328/ | null | ru | null |
# PVS-Studio: 25 подозрительных фрагментов кода из CoreCLR

Корпорация Microsoft выложила в открытый доступ исходный код движка CoreCLR, который является ключевым элементом .NET Core. Эта новость, конечно ж... | https://habr.com/ru/post/253280/ | null | ru | null |
# Пишем и слушаем разговоры в 3CX
Запись разговоров одна из наиболее востребованных функций в телефонной станции. В 3CX данная функция уже встроена и доступна для 100% абонентов для любой коммерческой лицензии.
**Как записывать?**
3CX пишет все звонки на конкретного абонента, входящие/исходящие/внешние/внутренн... | https://habr.com/ru/post/263531/ | null | ru | null |
# Находим ошибки в коде компилятора GCC с помощью анализатора PVS-Studio
Я регулярно проверяю различные открытые проекты, чтобы продемонстрировать возможности статического анализатора кода PVS-Studio (C, C+... | https://habr.com/ru/post/308946/ | null | ru | null |
# Для повышения надежности и безопасности банковского программного обеспечения используйте PVS-Studio

Среди наших клиентов постепенно начинают появляться организации, занимающиеся разра... | https://habr.com/ru/post/336898/ | null | ru | null |
# Implementation of a Simple Ternary System
Three-valued Logic
==================
**List of accomplishments**
* Basic ternary logic gates: T\_NOT, T\_OR, T\_AND, T\_NAND, T\_NOR, T\_XOR and more
* Synthesis, Minimization and Realization for Ternary Functions
* Ternary half adder, Ternary full adder, Ternary ripple c... | https://habr.com/ru/post/431726/ | null | ru | null |
# Собеседование. Сегодня

В сферу моих профессиональных обязанностей входит проведение собеседования для соискателей на должность PHP разработчика. И дальше речь пойдет о собеседовании…
*Два го... | https://habr.com/ru/post/67963/ | null | ru | null |
# HowTo: continuous integration Django в Jenkins с помощью Selenium
Это шпаргалка раскрывающая раздел «Интеграция Selenium тестов» статьи [Настройка Jenkins для django проекта с нуля](http://habrahabr.ru/blogs/django/132521/). А именно как запускать `Selenium` тесты на удалённом сервере `Jenkins` у которого нет монито... | https://habr.com/ru/post/138784/ | null | ru | null |
# Учим MS SQL Server Reporting Services 2008 R2 показывать HTML в отчетах
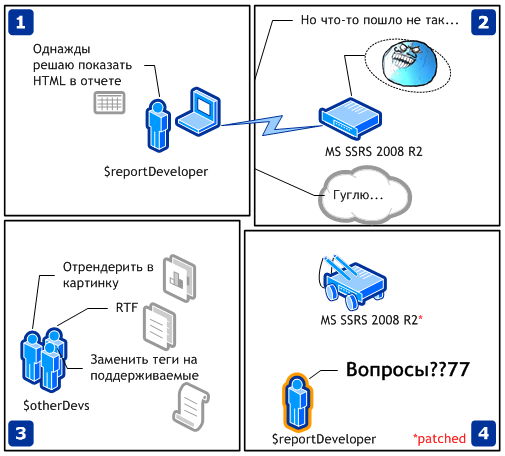
#### Проблема
Недавно столкнулся с необходимостью показать в отчете SSRS 2008 R2 HTML-таблицы, хранящиеся в базе данных.
И здесь на сцену стат... | https://habr.com/ru/post/142597/ | null | ru | null |
# Контекст выполнения и стек вызовов в JavaScript
Если вы — JavaScript-разработчик или хотите им стать, это значит, что вам нужно разбираться во внутренних механизмах выполнения JS-кода. В частности, понимание того, что такое контекст выполнения и стек вызовов, совершенно необходимо для освоения других концепций JavaS... | https://habr.com/ru/post/422089/ | null | ru | null |
# Готовим ASP.NET Core: создаем собственный Tag Helper
> *Мы продолжаем нашу колонку по теме ASP.NET Core публикацией от Станислава Ушакова ( [JustStas](https://habrahabr.ru/users/juststas/)) — team lead из компании DataArt. В статье Стас рассказывает о способах создания своих собственных тег-хелперов в ASP.NET Core. ... | https://habr.com/ru/post/278251/ | null | ru | null |
# Блеск и нищета стандартных селектов
[](http://habrahabr.ru/company/htmlacademy/blog/257743/)**Примечание переводчика**: *Мы продолжаем публиковать материалы, которые будут полезны веб-разработчикам, дизайнерам и верстальщикам... | https://habr.com/ru/post/257743/ | null | ru | null |
# Внутреннее устройство llst, часть 1. Введение в Smalltalk
Доброго времени суток. Предлагаю вашему вниманию вторую статью из цикла о Low Level Smalltalk (LLST). Кто не в курсе о чем идет речь, тем рекомендую ... | https://habr.com/ru/post/164769/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.