
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Дино (Deno): Создать Rest API с помощью JWT
> **В преддверии старта курса** [**"Node.JS Developer"**](https://otus.pw/5GFJ/) **приглашаем всех желающих посмотреть открытый урок на тему** [**"Докеризация Node.js приложений"**](https://otus.pw/JUKY/)**.**
>
> *А сейчас делимся традиционным переводом полезного мат... | https://habr.com/ru/post/532582/ | null | ru | null |
# Расширение yii-debug-toolbar
Доброе время суток хабравчане.
Сегодня я хотел бы рассказать об одном замечательном расширении yii-debug-toolbar от Сергея Малышева.
Вкратце
-------
Это расширение добавляет очень симпатичную и удобную дебаг панель.
yii-debug-toolbar имеет 5 вкладок:* Server: отображает информа... | https://habr.com/ru/post/127234/ | null | ru | null |
# Всем лучшим учителям посвящаетя…
Я вырос в небольшой городке Алтайского края на берегу реки Бия, недалеко от того места, где она сливается с Катунью. Городок этот, в сущности, ничем не отличался от сотен других крошечных городов — бывших дореволюционных уездных центров, разросшихся однотипными блочными пятиэтажками ... | https://habr.com/ru/post/422233/ | null | ru | null |
# Разворачиваем виртуалку с Windows с пробросом виртуальной видеокарты с помощью QEMU и Intel GVT-g
Как заставить Intel GVT-g работать
==================================
Всем привет! Intel предложили отличное решение извечной проблемы: "у меня есть ноутбук на Linux и мне надо запускать Windows с аппаратным ускорением... | https://habr.com/ru/post/437270/ | null | ru | null |
# XFS, Reflink и Fast Clone. Созданы друг для друга
Как все мы знаем, XFS — это высокопроизводительная журналируемая файловая система, созданная в недрах Silicon Graphics. А высокопроизводительная она потому, что способна справляться с множеством параллельных потоков ввода-вывода. Так что если вам интересна файловая с... | https://habr.com/ru/post/508426/ | null | ru | null |
# Queries in PostgreSQL. Query execution stages
Hello! I'm kicking off another article series about the internals of PostgreSQL. This one will focus on query planning and execution mechanics.
This series will cover:
1. Query execution stages (this article)
2. Statistics
3. Sequential scan
4. Index scan
5. Nested-loo... | https://habr.com/ru/post/649499/ | null | en | null |
# Rust vs. C++ на алгоритмических задачах
Не так давно я стал присматриваться к языку программирования `Rust`. Прочитав [`Rustbook`](https://github.com/ruRust/rust_book_ru), изучив код некоторых популярных проектов, я решил своими руками попробовать этот язык программирования и своими глазами оценить его преимущества ... | https://habr.com/ru/post/344282/ | null | ru | null |
# 15 лучших советов разработчику по настройке быстродействия Oracle APEX
Всем горячий хабрапривет!
Сегодня нашей компании исполняется 28 лет, и в честь этого приятного события мы решили поделиться с вами новым материалом.
Благодарим за помощь с переводом нашего постоянного автора Юрия Пономарева [OBIEESupport]... | https://habr.com/ru/post/492862/ | null | ru | null |
# Категориальные признаки
*Не одним One-Hot единым...*
---
Привет, хабр! Хотел бы сделать краткий экскурс про работу с категориальными признаками, который часто на просторах интернета обходят стороной. В данной статье я постараюсь расширить базовые понятия по данной тематике и иллюстрировать их примерами.
> *Под*... | https://habr.com/ru/post/666234/ | null | ru | null |
# Как устроен мир семантической микроразметки
Я работаю в команде семантического веба в Яндексе. Мы занимаемся тем, что создаем продукты на основе семантической разметки, делаем свои расширения и участвуем в развитии стандарта Schema.org.
Мир семантической разметки устроен не вполне просто и на первый взгляд даже ... | https://habr.com/ru/post/211638/ | null | ru | null |
# OpenGL Mathematics (GLM) Обзор библиотеки
Данный текст является обзором библиотеки математических вычислений для OpenGL – GLM. Создан обзор дабы по мнению автора залатать брешь в информационном вакууме и направить умы несознательные по пути верному.
Математический функции в OpenGL никогда не были на высоте, а с п... | https://habr.com/ru/post/138731/ | null | ru | null |
# Транзакции InnoDB
InnoDB это транзакционный, реляционный движок работающий на основе MySQL сервера. Начиная с 2001 года он поставляется в стандартной сборке, а с версии 5.1 может устанавливаться в качестве плагина (без необходимости перекомпилировать ядро сервера). Синтаксис очень простой.
`START TRANSACTION;
... | https://habr.com/ru/post/57226/ | null | ru | null |
# Руководство по Node.js, часть 1: общие сведения и начало работы
Мы начинаем публикацию серии материалов, которые представляют собой поэтапный перевод [руководства](https://medium.freecodecamp.org/the-definitive-node-js-handbook-6912378afc6e) по Node.js для начинающих. А именно, в данном случае «начинающий» — это тот... | https://habr.com/ru/post/422893/ | null | ru | null |
# Создаем мобильную игру на Monogame, решая типичные проблемы начинающего разработчика
Целью данной статьи является систематизация материалов для создания простых игр на фреймворке [Monogame](http://www.monogame.net/). В статье будут рассмотрены решения типичных задач, с которыми приходится сталкиваться всем разработч... | https://habr.com/ru/post/307454/ | null | ru | null |
# Кунг-фу стиля Linux: о повторении кое-каких событий сетевой истории
В наши дни во встроенных системах часто имеется поддержка сети. Это может значительно их усложнить. Сетевая нагрузка на системы обычно не отличается высоким уровнем детерминированности, существуют разные варианты таких нагрузок. Порой в сетях происх... | https://habr.com/ru/post/568308/ | null | ru | null |
# Как легко и быстро поставить свой прелоадер на стандартный AJAX Битрикса?
#### Вступление
Посещаю Хабр уже давно, но на статью решился только сейчас. Да и то, не статья это вовсе, а так — скорее, заметка о том, как легко и без напряга, без правки ядра и заморочек с самим аяксом взять и заменить стандартное убогое о... | https://habr.com/ru/post/268221/ | null | ru | null |
# 9 полезных приёмов для тех, кто программирует на JavaScript
Автор материала, перевод которого мы сегодня публикуем, рассказывает о девяти полезных приёмах работы, которые могут пригодиться JavaScript-программисту. Он говорит о том, что эти приёмы позволяют экономить время, и о том, что ими пользуются профессионалы. ... | https://habr.com/ru/post/354676/ | null | ru | null |
# Обзор Google Play Billing 4.0.0
Всем привет. Я SDK Engineer вQonversion Мария Бордунова.
Сегодня речь пойдет о библиотеке [Google Play Billing Library 4.0.0](https://developer.android.com/google/play/billing/integrate), которая к концу этого года должна открыть новые возможности для приложений со встроенными покупк... | https://habr.com/ru/post/584780/ | null | ru | null |
# Пишем задачки на FBD. Пятнашки и Симпсон
Здравствуйте.
В этой статье будет показано, как на языке программирования [FBD](https://ru.wikipedia.org/wiki/FBD) написать простую программу, которая, тем не менее, будет делать что-то полезное. В нашем примере это будет игра в Пятнашки.
Для начала напомню правила [игр... | https://habr.com/ru/post/304416/ | null | ru | null |
# look-at — менеджер фокуса
Что такое look-at?
------------------
Это утилита, которая переключает фокус между окнами приложений из командной строки.
Зачем?
------
При работе с большим количеством открытых окон часто возникает проблема с тем, чтобы быстро переключиться в окно нужного приложения. Можно, конечно, п... | https://habr.com/ru/post/145018/ | null | ru | null |
# Оптимизация рендера в iOS: frame buffer, Render Server, FPS, CPU vs GPU
Render Loop крутится — кадры мутятся.
Доброго времени суток, уважаемые читатели. Здесь я начинаю свой цикл статей о работе с графикой в iOS.
В моих планах разобраться с работой базовых механик отрисовки и углубиться к таким вещам как AVFoundat... | https://habr.com/ru/post/647177/ | null | ru | null |
# Azure SDK for .NET: Story about a Difficult Error Search

When we decided to search for errors in the Azure SDK for .NET project, we were pleasantly surprised by its size. «Three and a half million... | https://habr.com/ru/post/478978/ | null | en | null |
# Простой пример JDBC для начинающих
Здравствуйте! В этой статье я напишу простой пример соединения с базами данных на Java.Эта статья предназначена новичкам.Здесь я опишу каждую строчку объясню что зачем.
Но для начала немного теории.
JDBC (Java DataBase Connectivity — соединение с базами данных на Java) предна... | https://habr.com/ru/post/326614/ | null | ru | null |
# Радио с записью станций на языке Java
Привет всем! Как я уже говорил в своем [первом посте](https://habr.com/ru/company/itsoft/blog/547020/), я не программист, а скорее любитель. Пробовал писать свои поделки на разных языках, но начинал я с Java. Больше всего из семейства Java мне понравилась платформа JavaFX. Точне... | https://habr.com/ru/post/547908/ | null | ru | null |
# Lock-free структуры данных. Внутри. RCU

В этой статье я продолжу знакомить хабрасообщество с техниками, обеспечивающими написание lock-free контейнеров, попутно рекламируя (надеюсь, не слишком навязчиво)... | https://habr.com/ru/post/206984/ | null | ru | null |
# Делаем Новогодний колл-центр
> Внимание! Данная статья устарела. Вы можете ознакомиться с более свежими статьями здесь или почитать [блог на нашем сайте](https://voximplant.com/blog).
>
>
Приближается новый 2015 год и м... | https://habr.com/ru/post/247345/ | null | ru | null |
# Мои 5 копеек про Highload Cup 2017 или история 9го места
Про Higload Cup уже было несколько статей, поэтому о том, что это было писать не буду, кто пропустил можете почитать в [«История 13 места на Highload Cup 2017»](https://habrahabr.ru/post/337710/).
Так же постараюсь не повторяться и поделюсь интересными, с ... | https://habr.com/ru/post/337854/ | null | ru | null |
# Фундамент масштабируемости javascript приложения
*"Если хочешь идти быстро — иди один. Если хочешь идти далеко — идите вместе."* (с)
С этой лирической строки в данной статье я буду рассуждать о том, как правильно организовать код в вашем приложении, чтобы оно могло расти в высоту и в ширь. Если вы хотите, чтобы пр... | https://habr.com/ru/post/301020/ | null | ru | null |
# Якорная навигация на jQuery (graceful degradation)
Недавно я наткнулся на интересный плагин для jQuery: [BBQ — Back Button & Query Library](http://benalman.com/projects/jquery-bbq-plugin/).
И решил на ее основе сделать свой плагин для навигации на основе якорей. Задачи, которые я себе ставил:
1. нормальная раб... | https://habr.com/ru/post/82906/ | null | ru | null |
# Проектирование в PostgreSQL документо-ориентированного API: Полнотекстовый поиск и сохранение многих документов(Часть 2)
В [первой части этой серии статей](http://habrahabr.ru/post/272395/), я создал хорошую функцию сохранения, равно как и другую функцию, позволяющую создавать изменяемые документо-ориентированные та... | https://habr.com/ru/post/272411/ | null | ru | null |
# CUSTIS Labs. Развертываем инфраструктуру за минуты
Старт любого нашего проекта начинается с подготовки инфраструктуры. Времени на это порой уходит довольно много. Как минимум необходимо нарезать виртуалки ... | https://habr.com/ru/post/662005/ | null | ru | null |
# Optimistic UI, CQRS and EventSourcing
[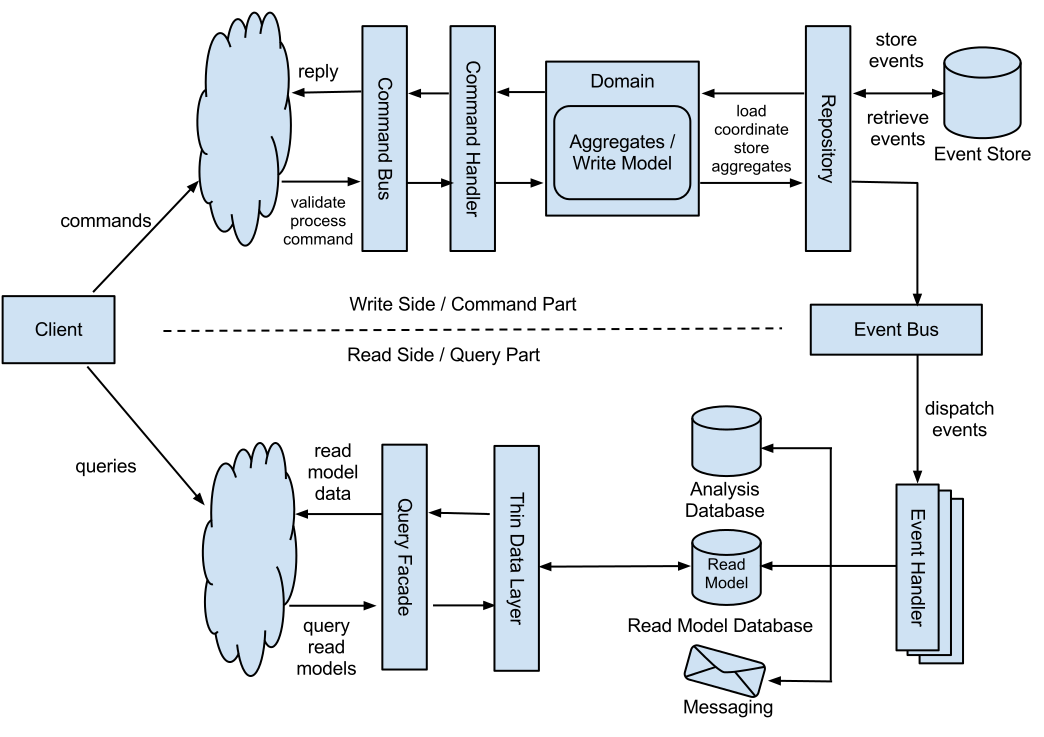](https://habrahabr.ru/company/devexpress/blog/350060/)
При разработке высоконагруженных веб-приложений для лучшего масштабирования часто применяется такой п... | https://habr.com/ru/post/350060/ | null | ru | null |
# Quake III Arena, Kubernetes (k3s) и Raspberry Pi
***Прим. перев.**: казалось бы, еще недавно сочетание из заголовка казалось невозможным безумием. Мир не стоит на месте, и это безумие стало не просто возможным, а даже по-настоящему простым в реализации. Подтверждение читайте ниже в переводе соответствующей инструкци... | https://habr.com/ru/post/532452/ | null | ru | null |
# Дампы LSASS для всех, даром, и пусть никто не уйдет обиженный
Здравствуйте, хабролюди!
Меня зовут [@snovvcrash](/users/snovvcrash), и я работаю в отделе анализа защищенности компании Angara Security. Отве... | https://habr.com/ru/post/661341/ | null | ru | null |
# Мониторинг и настройка сетевого стека Linux: получение данных

В этой статье мы рассмотрим, как осуществляется приём пакетов на компьютерах под управлением ядра Linux, а также разберём вопросы мониторинга и настройки кажд... | https://habr.com/ru/post/314168/ | null | ru | null |
# Гениальность микропроцессоров RISC-V

Войны между RISC и CISC, проходившие в конце 1990-х, уже давно отгремели, и сегодня считается, что разница между RISC и CISC совершенно не имеет значения. Многие заявляют, что наборы ком... | https://habr.com/ru/post/534542/ | null | ru | null |
# WSL эксперименты. Часть 1
***Привет, хабр! В октябре OTUS запускает новый поток курса [«Безопасность Linux»](https://otus.pw/r2jnW/). В преддверии старта курса делимся с вами статьёй, которую написал один из наших преподавателей — Александр Колесников.***

Пояснительная часть
-------------------
Недавно мне попалась статья в журнале "Код" под названием ["Сравнение: классы против функций"](https://thecode.media/oop_battle/). Я прочитал ее и она показалось мне… странной. Журнал позиционирует себя как издание для начинаю... | https://habr.com/ru/post/513910/ | null | ru | null |
# Четыре простые настройки терминала Kubernetes, которые повысят вашу продуктивность

Я управлял эксплуатацией больших Kubernetes-кластеров более трёх лет, и хочу поделиться своим минималистичным подходом ... | https://habr.com/ru/post/520974/ | null | ru | null |
# Redux-Redents — (еще) один модуль для работы с серверными данными из React-Redux приложений.
React и Redux, в последнее время одни из самых популярных buzz-words в мире фронтенда. Поэтому когда мне потребовалось сделать веб-приложение, которое бы отображало данные, полученные с сервера, а также позволяло бы ими мани... | https://habr.com/ru/post/305074/ | null | ru | null |
# Топ 10 ошибок в проектах C# за 2019 год

Приветствуем всех любителей багов. Уже скоро наступит Новый год, так что самое время подвести итоги года уходящего. По традиции — рейтинг самых интересных... | https://habr.com/ru/post/481178/ | null | ru | null |
# Логирование в Java / quick start
В ходе моей работы в компании DataArt я, в числе прочего, занимаюсь менторской деятельностью. В частности это включает в себя проверку учебных заданий сделанных практикантами. В последнее время в заданиях наметилась тенденция «странного» использования логеров. Мы с коллегами решили в... | https://habr.com/ru/post/130195/ | null | ru | null |
# Продвинутое использование библиотеки PYTORCH: от подготовки данных до визуализации
PyTorch — современная библиотека машинного обучения с открытым исходным кодом, разработанная компанией Facebook. Как и др... | https://habr.com/ru/post/553716/ | null | ru | null |
# Повтор — тоже атака. Часть 1
Данная статья является первой из трех, которые будут рассказывать об инструментах, которые используются для тестирования внутренней инфраструктуры Windows Active Directory. Во в... | https://habr.com/ru/post/654383/ | null | ru | null |
# PHP-Дайджест № 97 – интересные новости, материалы и инструменты (14 – 27 ноября 2016)
[](https://habrahabr.ru/company/zfort/blog/316254/)
Предлагаем вашему вниманию очередную подборку со ссылками на ново... | https://habr.com/ru/post/316254/ | null | ru | null |
# Укрощаем UEFI SecureBoot
 Данные обещания надо выполнять, тем более, если они сделаны сначала в [заключительной части опуса о безопасности UEFI](http://habrahabr.ru/post/268423/), а потом повторены [со сцены ZeroNights 2015]... | https://habr.com/ru/post/273497/ | null | ru | null |
# IML TODO

**disclaimer**: статья является ответом на критику (которая обрушилась на [хабре](http://habrahabr.ru/post/214293/)), раскрывая потенциал IML на примере популярного приложения [ToDo MVC](h... | https://habr.com/ru/post/214963/ | null | ru | null |
# Symfony CLI — новый инструмент для локальной разработки
В декабре 2018-го, на конфиренции Lisbon SymfonyCon Фабиэн Потансье — создетель фреймворка Symfony представил некий symfony.phar — инструмент для быстрого создания Symfony-приложений на основе официальных шаблонов проекта: [skeleton](https://github.com/symfony/... | https://habr.com/ru/post/451138/ | null | ru | null |
# Regex и Win cmd, простенький пример
Заметил, что здесь много сложных и интересных статей про Win cmd и Regex, но гораздо меньше чего-то простого, с чего можно начать знакомство с этими мощными инструментами.
Идея написания этого урока возникла, когда я понял, что наверняка такие же задачи пытается решить еще кто-... | https://habr.com/ru/post/218267/ | null | ru | null |
# Входите! Вход без логина и пароля
#### Кто виноват?
Одна из часто встающих задач при разработке web-проектов — пустить пользователя на сайт без ввода логина и пароля, при этом авторизовав его.
Вот некоторые примеры таких ситуаций:
* Ссылка на активацию аккаунта только что зарегистрированным пользователем.
* С... | https://habr.com/ru/post/109421/ | null | ru | null |
# Макросы в Emacs'е: формируем отряды для обработки
*Не забывай свои корни, помни, есть вещи на порядок выше…
Каста здесь*
История из жизни
================
Многие начинали свою компьютерную жизнь с игр. Кто не начи... | https://habr.com/ru/post/281499/ | null | ru | null |
# Арифметическое переполнение в ПЛК AllenBradley
Недавно на работе столкнулись с интересной ситуацией, о которой захотелось написать тут, потому что случай довольно интересный, хотя как и оказалось простой. На одном из агрегатов, управляемым контроллером от Allen Bradley Compact Logix L33ER, в контроллере постоянно сы... | https://habr.com/ru/post/701806/ | null | ru | null |
# Работа с формами
Известное дело — разработку любого веб-приложения можно поделить на этапы, а сами этапы — на типовые задачи. Одной из наиболее часто встречающихся типовых задач является *работа с формами*. Каждый раз, когда программисту приходится сталкиваться с ней, можно словить некоторое уныние, если надоевшая р... | https://habr.com/ru/post/85123/ | null | ru | null |
# Организуем релевантный поиск по разнородным данным с помощью Sphinx
В одном из текущих проектов возникла задача поиска по данным разного типа, которая была успешно решена с помощью зарекомендовавшей... | https://habr.com/ru/post/47908/ | null | ru | null |
# Побеждаем широковещательный флуд в корпоративной локальной вычислительной сети
#### Симптомы
Случилось у нас в организации, страшное дело – сеть работала, работала и вдруг, вроде без особых на то причин, стала работать нестабильно. Выглядело всё это очень странно (впервые столкнулся с проблемой сабжа) – некоторые к... | https://habr.com/ru/post/162135/ | null | ru | null |
# Используем NLog 2.0 в Silverlight или как я стал опенсорсником
Началось все достаточно банально — с того, что мне понадобился logging в моем проекте на Silverlight.
Под «взрослым» .NET-ом я всегда пользовался NLog-ом от Ярека Ковальского. А почему не log4net, спросят многие из вас.
Все, конечно, достаточно су... | https://habr.com/ru/post/105889/ | null | ru | null |
# Игровой контроллер для ПК на Android
Всем привет! В данной статье я хочу рассказать о том, как можно сделать из своего Adndroid смартфона игровой контроллер (в простонародье — джойстик) для обычного ПК, а именно **руль**.
#### Описание задачи
Поведение руля будет эмулироваться с помощью акселерометра. Для этого... | https://habr.com/ru/post/111511/ | null | ru | null |
# К социальным кнопкам на сайтах теперь можно добавить кнопку Skype

Как известно, в июне этого года [запустилась](http://geektimes.ru/post/252010/) веб-версия Skype, которая доступна по адресу we... | https://habr.com/ru/post/386177/ | null | ru | null |
# Приемы и особенности работы с Microsoft Power Platform
Добрый день, друзья! В данной статье хотелось бы поделиться различными приемами работы с Microsoft Power Platform и рассказать, как с помощью базовых возможностей Power Apps, Power Automate и других сервисов линейки Microsoft Power Platform можно делать различны... | https://habr.com/ru/post/598079/ | null | ru | null |
# Динамическая система Лоренца и вычислительный эксперимент

*Данный пост является продолжением моей статьи [1] на Хабрахабре об аттракторе Лоренца. Здесь рассмотрим метод построения приближенных решен... | https://habr.com/ru/post/229959/ | null | ru | null |
# Некоторые возможности Python о которых вы возможно не знали
#### Предисловие
Я очень полюбил Python после того, как прочитал книгу Марка Лутца «Изучаем Python». Язык очень красив, на нем приятно писать и выражать собственные идеи. Большое количество интерпретаторов и компиляторов, расширений, модулей и фреймворков ... | https://habr.com/ru/post/196382/ | null | ru | null |
# Домашняя BigData. Часть 1. Практика Spark Streaming на кластере AWS
Здравствуйте.
В данной статье мы в домашних условиях произведем установку на платформу EC2 AWS (Amazon Web Services) Apache Kafka, Apache Spark, Zookeeper, Spark-shell и научимся всем этим пользоваться.
### Знакомство с платформой Amazon Web S... | https://habr.com/ru/post/443912/ | null | ru | null |
# Ещё один способ обновления торрентов
На одном трекере я являюсь активным сидером. Но когда приходит время обновлять раздачи, для меня начинается ужас: некоторые раздачи имеют разные название в торрент-клиенте и на трекере, раздач с идентичным названием на трекере очень много, да и искать какую-то конкретную раздачу ... | https://habr.com/ru/post/135874/ | null | ru | null |
# Making python's dream of multithreading come true
Intro
=====
So you are writing some CPU-intensive code in Python and really trying to find ways out of its single-threaded prison. You might be looking towards Numba's "nopython parallel" mode, you might be using forked processes with multiprocessing, you might be w... | https://habr.com/ru/post/526002/ | null | en | null |
# CDN-провайдер Cloudflare внедрял содержимое памяти своего сервера в код произвольных веб-страниц
Специалисты по безопасности из Google обнаружили [неприятный баг](https://bugs.chromium.org/p/project-zero/issues/detail?id=1139... | https://habr.com/ru/post/322500/ | null | ru | null |
# Анализ исходного кода Doom 3

23 ноября 2011 года id Software поддержала собственную традицию и опубликовала исходный код своего предыдущего движка.
На сей раз настало время [idTech4](http://en.wikipedia.org/wiki/Id_Tech_4), который использовался в Prey, в... | https://habr.com/ru/post/333836/ | null | ru | null |
# Spotify: миграция подсистемы событий в Google Cloud (часть 3)
В [первой статье](https://habrahabr.ru/company/google/blog/319772/) этой серии мы говорили о том, как работает старая система доставки сообщений и некоторых выводах, которые мы сделали по итогам ее работы. Во [второй](https://habrahabr.ru/company/google/b... | https://habr.com/ru/post/323908/ | null | ru | null |
# Электрические схемы средствами LaTeX и TikZ
Иногда в LaTeX нужно нарисовать несложную электрическую схему. Далее рассказано как это сделать без привлечения стороннего ПО средствами самого LaTeX. То что будет написано далее рассчитано на тех, кто уже знаком с таким средством создания векторной для LaTeX как TikZ. В п... | https://habr.com/ru/post/250541/ | null | ru | null |
# Миграция Bing's Workflow Engine на .NET 5
> *Материал переведен.* [*Ссылка на оригинальную статью*](https://devblogs.microsoft.com/dotnet/migration-of-bings-workflow-engine-to-net-5/)
>
>
Bing работает с... | https://habr.com/ru/post/565464/ | null | ru | null |
# Анализируем числовые последовательности

Иногда, если имеешь дело с числовыми последовательностями или бинарными данными, возникает желание “пощупать” их, понять, как они устроены, подвержены ли сжатию, если зашифрованы... | https://habr.com/ru/post/183786/ | null | ru | null |
# Батлрояль за 2 месяца: как мы обновили сетевой код и на 20% сократили траты на сервера
Оптимизация сетевого кода онлайн-шутера — это не только экономия на серверах и трафике, но еще и создание комфорта для ... | https://habr.com/ru/post/568848/ | null | ru | null |
# Цензура в интернете. Когда базовых мер недостаточно — I2P
В [прошлой статье](https://habr.com/ru/post/543202/) я рассказал, какие выкрутасы можно сделать одним только браузером. Нам потребуются эти знания далее
Жаркий август 2020 показал, что базовые меры — это слишком мало и неэффективно. Нужно что-то большее
Выб... | https://habr.com/ru/post/544516/ | null | ru | null |
# Планирование в Go: Часть I — Планировщик ОС
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Scheduling In Go: Part I — OS Scheduler»](https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part1.html) автора Билла Кеннеди, о том, как работает внутренний планировщик Go.
Это первый пост в серии из трех... | https://habr.com/ru/post/478168/ | null | ru | null |
# Arduino в Linux: копаемся в кишках проекта
Введение
========
В [предыдущей статье](https://geektimes.ru/post/295469/) был описан процесс превращения Qt Creator в полноценную IDE для проектов на платформе Arduino. Шаги были описаны подробно, но без описания смысла происходящего, поэтому эффект от такой статьи неболь... | https://habr.com/ru/post/408379/ | null | ru | null |
# Yii 2.0.16

Команда PHP-фреймворка Yii выпустила версию 2.0.16, содержащую [более сотни исправлений и немного улучшений](https://github.com/yiisoft/yii2/blob/2.0.16/framework/CHANGELOG.md). Исправлены несколько проблем с безопасность... | https://habr.com/ru/post/438394/ | null | ru | null |
# Скриншоты сервиса Samsung Apps
Samsung пытается продвигать собственный [сервис публикации](http://seller.samsungapps.com/) приложений для Android.

Можно сравнить функционал сервиса с [Google Play](https://play.google.com/store).
На главной странице профиля видна о... | https://habr.com/ru/post/146557/ | null | ru | null |
# Решение задания с pwnable.kr 04 — flag. Упакованные исполяемые файлы

В данной статье разберем: как и для чего применяется упаковка исполняемых файлов, как их обнаружить и распаковать, и решим 4-е задание с сайта [pwnable.kr](... | https://habr.com/ru/post/460028/ | null | ru | null |
# Уроки, полученные при создании первой игры, и почему я хочу написать свой движок

Недавно я выпустил свою первую игру [BYTEPATH](http://store.steampowered.com/app/760330/BYTEPATH/) и мне показалось, ... | https://habr.com/ru/post/353656/ | null | ru | null |
# HTML5 Prefetching — Предварительная загрузка документов
Аж в 2003 году Mozilla представила новый механизм для оптимизации загрузки страниц. И существует большой шанс, что технология войдет в HTML5.
Суть же метода в том, что на любой странице браузеру можно указать документы (страница, файл стилей, картинка), кот... | https://habr.com/ru/post/104766/ | null | ru | null |
# Отладка Hadoop приложений
Сколько бы ни говорили, что логи способны полностью заменить отладку, увы и ах — это не совсем так, а иногда — совсем не так. Действительно, иногда и в голову не придет, что надо было писать в лог именно *эту* переменную — в то же время, в режиме отладки можно часто просмотреть сразу нескол... | https://habr.com/ru/post/89365/ | null | ru | null |
# Интеграция Ruby в Nginx

Уже достаточно давно существует всем известная связка Nginx + Lua, в том числе здесь был ряд статей. Но время не стоит на месте. Примерно год назад появилась первая версия модуля,... | https://habr.com/ru/post/225313/ | null | ru | null |
# Как работать с логами Zimbra OSE
Логирование всех происходящих событий — одна из наиболее важных функций любой корпоративной системы. Логи позволяют решать возникающие проблемы, проводить аудит работы информационных систем, а также расследовать инциденты информационной безопасности. Zimbra OSE также ведет подробные ... | https://habr.com/ru/post/523238/ | null | ru | null |
# Затачиваем старый код под новые реалии
В данной статье я расскажу об одном из способов, позволяющих с наименьшими усилиями трансформировать программный код на C/C++ в код, написанный на C#. Впроче... | https://habr.com/ru/post/101653/ | null | ru | null |
# Как сделать бота, который превращает фото в комикс. Часть третья. Бесплатный serverless + GPU хостинг модели
[⇨ Часть 1](https://habr.com/ru/post/479218/)
[⇨ Часть 2](https://habr.com/ru/post/483168/)
Ну, отдохнули и хватит. С возвращением!
В предыдущих сериях мы с вами собрали данные и обучили свою первую мод... | https://habr.com/ru/post/485824/ | null | ru | null |
# Насколько данные для обучения модели (не)похожи на тестовую выборку?
Рассмотрим один из сценариев, при котором ваша модель машинного обучения может быть бесполезна.
Есть такая поговорка: *«Не сравнивайте яблоки с апельсинами»*. Но что делать, если нужно сравнить один набор яблок с апельсинами с другим, но распред... | https://habr.com/ru/post/422185/ | null | ru | null |
# Новое в SObjectizer-5.5.23: исполнение желаний или ящик Пандоры?

Данная статья является продолжением опубликованной месяц назад статьи-размышлении "[Легко ли добавлять новые фичи в старый фреймворк? Муки выбора на примере развит... | https://habr.com/ru/post/426983/ | null | ru | null |
# Что такое RxJS и почему о нём полезно знать
В этом материале мы поделимся с вами переводом интервью с руководителем проекта RxJS 5+, инженером Google [Беном Лешем](https://medium.com/@benlesh).
В огромном мире фронтенд-разработки существует множество интересных инструментов. Я стремлюсь найти правильный подход к ... | https://habr.com/ru/post/341880/ | null | ru | null |
# Итераторы и генераторы на основе функций
Поддержка итераторов и генераторов в качестве языковых конструкций появилась в javascript только в версии 1.7, и об использовании этих чудесных вещей в браузерах еще долго можно будет только мечтать. Однако использовать итераторы и генераторы в виде паттернов проектирования в... | https://habr.com/ru/post/122739/ | null | ru | null |
# Используем $_COOKIE как $_SESSION
Тема пришла из далекого детства, когда я только начинал программировать, разбирал особенности PHP. На тот момент меня удивляла такая несправедливость: c сессией можно было работать как с обычным ассоциативным массивом(**$\_SESSION**), а для кукисов необходимо было использовать функц... | https://habr.com/ru/post/134870/ | null | ru | null |
# ExtJS и PHP в примере
Добрый день,
Когда я начинал писать на ExtJS, именно примеров с PHP кодом в интернете не хватало, статьи были, но все они сводились к тому, что был код ExtJS (переводы книг) без PHP. Поэтому я и решил написать эту статью.
Для начала, **несколько советов начинающим ExtJSникам:**
**В пер... | https://habr.com/ru/post/91155/ | null | ru | null |
# Количество Биткоинов не будет 21.000.000
Откуда появляются новые Биткоины
--------------------------------
Биткоин имеет ограниченное предложение и еще не все монеты находятся в [циркуляции](https://telegra.ph/Cirkuliruyushchee-predlozhenie-09-05). Единственный способ создать новые монеты, это ***майнинг*** — механ... | https://habr.com/ru/post/689792/ | null | ru | null |
# Типичные уязвимости на сайтах, со статистикой
##### Этот топик будет посвящен:
* статистике встречаемости уязвимостей
* реакции администрации(скорости и адекватности)
* опасности
и всяческим другим факторам. Будут приведены примеры.
#### Что послужило толчком
Пост можно начать так: «дело было вечером, делать б... | https://habr.com/ru/post/192122/ | null | ru | null |
# Внутренности движка QML. Часть 1: Загрузка файлов
В [этой](http://www.kdab.com/category/blogs/qmlengineseries/) ([2 часть в переводе](http://habrahabr.ru/post/150133/)) серии статей мы заглянем под капот движка QML и раскроем некоторые из особенностей его внутренней работы.Статьи основаны на Qt5 версия QtQuick, QtQu... | https://habr.com/ru/post/150064/ | null | ru | null |
# Анализ протоколов работы пультов ДУ
При создании HTPC одним из вопросов является способ управления оболочкой. Думаю, не стоит рассказывать о том, что традиционные устройства ввода — клавиатура и мышь не подходят для данной задачи. Гораздо удобнее управлять HTPC так же как и другой бытовой электроникой — с помощью ПД... | https://habr.com/ru/post/204906/ | null | ru | null |
# Знакомимся с Needle, системой внедрения зависимостей на Swift
Привет! Меня зовут Антон, я iOS-разработчик в Joom. Из этой статьи вы узнаете, как мы работаем с DI-фреймворком Needle, и реально ли он чем-то выгодно отличается от аналогичных решений и готов для использования в production-коде. Это всё — с замерами прои... | https://habr.com/ru/post/514784/ | null | ru | null |
# Блочные устройства QEMU

В QEMU есть несколько способов подключить блочное устройство для виртуальной машины. Изначально это было реализовано следующим способом:
```
-hda /dev/sda1
```
Таким образом... | https://habr.com/ru/post/412825/ | null | ru | null |
# Разбор «лохотрона» на игральных картах
##### Вместо вступления
В стандартной колоде для покера 54 карты. Без двух джокеров, которые не участвуют в игре, выходит 52 карты. Если вы хорошенько перемешаете колоду, то, возможно, создадите уникальную комбинацию из карт, которую никогда никто не создавал до вас. Потому чт... | https://habr.com/ru/post/179319/ | null | ru | null |
# Применение смарт-аккаунтов и смарт-ассетов Waves в финансовых инструментах

*В предыдущей [статье](https://habr.com/ru/company/waves/blog/442238/) мы рассмотрели несколько кейсов применения смарт-аккаунтов в бизнесе – включая ... | https://habr.com/ru/post/443836/ | null | ru | null |
# Маленький Hello World для маленького микроконтроллера — в 24 байта (и чужое решение в 12 байт)
Классической тестовой программой для большинства программистов на системах, имеющих хоть какой-то дисплей, является Hello World. Такая традиция была введена Керниганом и Ритчи в [1978 году.](https://ru.wikipedia.org/wiki/%... | https://habr.com/ru/post/240183/ | null | ru | null |
# Windows и case-sensitive filesystem
Давным-давно, на заре своего рождения Windows использовала файловую систему FAT. Потом ей на смену Microsoft и IBM разработали NTFS. В те давние времена возникло два противоположных подхода к файловой системе. В Linux используется case-sensitive файловая система, а в Microsoft — c... | https://habr.com/ru/post/414239/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.