
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Расширение Web Essentials для Visual Studio: LESS, Zen Coding, CoffeeScript и многое другое
[](http://vswebessentials.com/)
Visual Studio – поистине потрясающий инструмент для разработки приложений вообще (чувствуете вс... | https://habr.com/ru/post/165735/ | null | ru | null |
# Сeph — от «на коленке» до «production» часть 2
(первая часть тут: <https://habr.com/ru/post/456446/>)
CEPH
====
### Введение
Поскольку сеть является одним из ключевых элементов Ceph, а она в нашей компании немного специфична — расскажем сначала немного о ней.
Тут будет сильно меньше описаний самого Ceph, в осн... | https://habr.com/ru/post/458390/ | null | ru | null |
# Коллекторный двигатель + Digispark = электровелосипед за 50$

Идея е-вела бередит меня уже с десяток лет, реализовал только сейчас!
**Спойлер**
Указанная сумма — средства на моториза... | https://habr.com/ru/post/415497/ | null | ru | null |
# Обзор маршрутизатора Draytek серии 2925. Часть вторая
В [первой части обзора](https://geektimes.ru/company/digitalangel/blog/280228/) серии маршрутизаторов Draytek 2925n, мы подробно рассмотрели, как устройство позиционируется на рынке, схему использования маршрутизатора, его ключевые функции и примеры их использова... | https://habr.com/ru/post/397537/ | null | ru | null |
# Защита сайта от сканирования и хаотичных интенсивных запросов
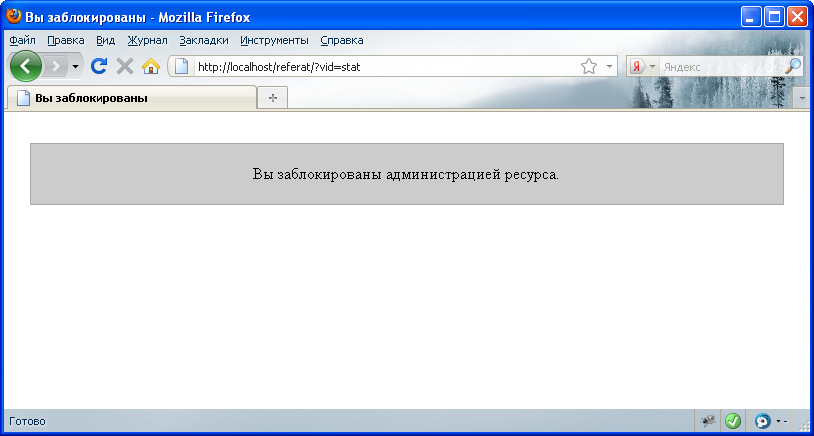
Хаотичные интенсивные запросы сильно нагружают сервера и транспортные каналы, существенно замедляя работу сайта. С помощью сканирования злоумышленники коп... | https://habr.com/ru/post/234729/ | null | ru | null |
# Kha vs HTML5: Компилируем JavaScript в C++
Предлагаю вашему вниманию перевод доклада Роберта Конрада с прошедшего в октябре прошлого года [HaxeUp Sessions 2019 Linz](https://haxe.org/videos/conferences/haxeup-sessions-2019/). Данный доклад посвящен процессу портирования на консоли игры [CrossCode](http://www.cross-c... | https://habr.com/ru/post/489974/ | null | ru | null |
# Эрланг для веб-разработки (1) -> Знакомство;

*Продолжение о базе данных и деплое во [второй статье](http://habrahabr.ru/post/274107/)*.
Я начинаю публиковать серию статей о веб-разработке на Эрланге. Многие хотят попро... | https://habr.com/ru/post/273979/ | null | ru | null |
# jQuery-сниппеты и плагины для iPad
Подборка простых jQuery-сниппетов и плагинов, которые помогут адаптировать сайт для отображения на iPad. Некоторые подойдут и для других тач-устройств.

### 1. Определение ориентаци... | https://habr.com/ru/post/158577/ | null | ru | null |
# Распаковка, редактирование и упаковка прошивок видеорегистраторов и IP камер от Xiong Mai
#### Предыстория
Не так давно приобрёл на Aliexpress IP камеру (чип Hi3516 платформа 53H20L) и 16-канальный гибридный видеорегистратор (чип Hi3521 платформа MBD6508E). Оба выполнены на чипсете от HiSilicon, так что проблем с с... | https://habr.com/ru/post/213411/ | null | ru | null |
# Шпаргалки по безопасности: Docker

Docker контейнеры — самая популярная технология для контейнеризации. Изначально она использовалась в основном для dev и test окружений, со временем перешла и в production. Docker контейнеры начали... | https://habr.com/ru/post/448704/ | null | ru | null |
# Электронное правительство, руки прочь от моих сайтов
Уже не в первый раз замечаю атаку на свои сервера из подсети «Ростелекома», относящейся к некоему «электронному правительству».
```
$whois 109.207.13.1
...
inetnum: 109.207.0.0 - 109.207.15.255
netname: Electronic-government
descr: OJSC R... | https://habr.com/ru/post/191546/ | null | ru | null |
# Возможности PostgreSQL для тех, кто перешел с MySQL
*Крутой [varanio](https://habrahabr.ru/users/varanio/) буквально на прошлой неделе прочитал на DevConf забойный доклад для всех кто пересел на Посгрес с MySQL, но до сих пор не использует новую базу данных в полной мере. По мотивам выступления родилась эта публикац... | https://habr.com/ru/post/331460/ | null | ru | null |
# Установка шрифтов Groff
Здравствуй, Хабр!
Русские шрифты в Groff, пошаговая инструкция по установке. [Groff](https://www.gnu.org/software/groff/) - небольшой и очень-очень винтажный программный пакет, система набора текста, в каком-то смысле прадедушка TeX, LaTeX. Но если TeX создан [Дональдом Кнутом](https://ru.w... | https://habr.com/ru/post/657269/ | null | ru | null |
# Как работает JS: веб-воркеры и пять сценариев их использования
**[Советуем почитать] Другие 19 частей цикла**Часть 1: [Обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [О внутреннем устройстве V8 и оптимизации кода](https://habrahabr.ru/company/... | https://habr.com/ru/post/348424/ | null | ru | null |
# Установка и настройка LXD на OpenNebula
***Перевод статьи подготовлен в преддверии старта курса [«Администратор Linux»](https://otus.pw/0Q51/).***

---
В этой статье вы найдете пошаговое руководство по основам облачной системы... | https://habr.com/ru/post/508444/ | null | ru | null |
# Графы для самых маленьких: Ford & Bellman или как понять, что ты попал в бесконечно далекое прошлое
В предыдущих частях цикла мы рассмотрели алгоритмы [DFS](http://habrahabr.ru/post/200074/) и [BFS](http://habrahabr... | https://habr.com/ru/post/201588/ | null | ru | null |
# Как перенести электронную почту с cPanel на Zimbra Collaboration 8.0
Это инструкция по миграции электронной почты из cPanel в Zimbra 8.0.x 8.x. Прежде чем сделать какие-либо изменения на сервере, необходимо совершить резервное копирование.

Проект curl основан на фундаменте, заложенном в конце 1996 года инструментом под названием httpget.
ANSI C, ставший известным как C89
-----------------... | https://habr.com/ru/post/700382/ | null | ru | null |
# Пишем обёртку над SQLAlchemy Сore
Для асинхронного Python существует мало полноценных ORM, и им далеко до таких монстров-комбайнов, как DjangoOrm и SQLAlchemy.ORM. Бедность ORM-инструментария для асинхронного программирования заставила многих программистов отказаться от зачастую непонятной им работы с ORM и перейти ... | https://habr.com/ru/post/557638/ | null | ru | null |
# «Кандидат сбежал в слезах»: 5 главных вопросов для собеседования на Python разработчика
В июле и августе 1991 года я, с подачи [Гвидо Ван Россума](https://en.wikipedia.org/wiki/Guido_van_Rossum), проводил технические интервью на позицию *Middle Python Backend developer*. И, видимо, буду вынужден продолжать проводить... | https://habr.com/ru/post/700114/ | null | ru | null |
# Tracks Flow + Open Source = Simple File Storage
Рады сообщить, что проект [Tracks Flow](http://tracksflow.com/) начинает поддержку Open Source сообщества. Сегодня мы выкладываем в открытый доступ простенькую разработку — сервер хранения файлов на PHP с клиентской библиотекой на C#.
Просим строго не судить — этот ... | https://habr.com/ru/post/150514/ | null | ru | null |
# GUI на Golang: GTK+ 3
Решил я написать одно кроссплатформенное десктопное приложение на **Go**. Сделал **CLI**-версию, всё работает отлично. Да ещё и кросскомпиляция в **Go** поддерживается. Всё в общем отлично. Но понадобилась также и **GUI**-версия. И тут началось...
Крайне заманчивая конфигурация была недавно [анонсирована](https://blogs.oracle.com/cloud-infrastructure/post/moving-to-... | https://habr.com/ru/post/568386/ | null | ru | null |
# Визуальный редактор писем на React+Redux. Обзор, пример использования и расширения
Введение
--------
Всем привет! Не так давно мне поступила задача встроить визуальный редактор email в наш сервис внутренней рассылки, ибо людям надоело набирать html руками и компоновать валидные шаблоны для писем. Побродив по интерн... | https://habr.com/ru/post/329488/ | null | ru | null |
# Краткий обзор новых возможностей JPA-RS в EclipseLink
EclipseLink — это ORM фрэймворк с открытым исходным кодом, разрабатываемый Eclipse Foundation. В конце года запланирован выход версии 2.6.0. проекта. В преддверии этого, я хочу ознакомить вас с некоторыми новыми возможностями службы JPA-RS, которая является часть... | https://habr.com/ru/post/240769/ | null | ru | null |
# Про перевод «начал» и «начинаний» без begin, start и first
Если в переводном тексте кто-то что-то где-то **начинает** — то у меня сразу всплывают три дежурных варианта: **begin/beginning**, **start/starting**, **first/firstly**.
Судя по тому, что я вижу в присылаемых мне на проверку переводах, эта бедность речи наб... | https://habr.com/ru/post/501880/ | null | ru | null |
# Шустрый, удобный и кроссплатформенный профилировщик C++ кода
Всем привет. Несколько месяцев назад мы вместе с [victorzs](https://habrahabr.ru/users/victorzs/) решили сделать простой и удобный профилировщик *c++* кода (подразумевается *профилирование времени исполнения* участков кода, функций).
[ для программистов
О математике (так, чтобы было интересно) писать сложнее, чем о физике. Однако я надеюсь, что вы дочитаете хотя бы до примеров сумасшедших программ на C.

В этой статье продолжается обзор почтовых ящиков, начатый в предыдущей статье серии «Вся правда об ОСРВ».
Предыдущие статьи серии:
[... | https://habr.com/ru/post/431118/ | null | ru | null |
# k0s: Kubernetes в одном бинарном файле
> В нашей новой [переводной статье](https://medium.com/better-programming/k0s-kubernetes-in-a-single-binary-224bb43f4520) даем краткий обзор на новый дистрибутив Kubernetes. Надеемся, статья окажется интересной для читателей Habr'a.
Пару дней назад друг рассказал мне о новом д... | https://habr.com/ru/post/534490/ | null | ru | null |
# Получение id добавленной записи в PostgeSQL
Каким бы супер-пупер спецом вы не были — в процессе разработки эпизодически попадаются интересные и удобные вещи о которых, казалось бы, давно бы пора знать, но все никак не складывалось. Этакий ништячок, найдя который хочется воскликнуть: «Эврика!». Вот таким ништячком дл... | https://habr.com/ru/post/72590/ | null | ru | null |
# Руководство по модулю клавиатуры Python
Введение
--------
Python является одним из наиболее подходящих языков для автоматизации задач. Будь то повторяемый (этический) веб-скоб через некоторое время, запуск некоторых программ при запуске компьютера или автоматизацию отправки повседневных электронных писем, Python им... | https://habr.com/ru/post/579942/ | null | ru | null |
# Повышение продуктивности с Kotlin
Я недавно написал статью о нововведениях в Kotlin 1.4.20. И первый комментарий оказался немного несправедливым по отношению к Kotlin.
Он утверждал, что зачем мол Kotlin в ... | https://habr.com/ru/post/537362/ | null | ru | null |
# Сравнение производительности аналитических СУБД HPE Vertica и Exasol с использованием TPC-H Benchmark
 В данной статье я хочу продолжить тему сравнения баз данных, которые можно использовать для построения хранилища данных (D... | https://habr.com/ru/post/319902/ | null | ru | null |
# Псевдо 3D: Анимация вращения планет и других шароподобных объектов
Описание небольшого трюка по анимации вращения планет или других шарообразных штуковин. На написание этой статьи меня натолкнула статья [Сфера из двух треугольников](http://habrahabr.ru/post/180245/) (стоит почитать). А сам трюк основан на весьма про... | https://habr.com/ru/post/180353/ | null | ru | null |
# Добавляем в jsx циклы и условия
Если вы используете библиотеку React, то наверняка используете и jsx. Конечно, это не обязательно, и можно писать только js, используя `React.createElement`, но с jsx получится гораздо лаконичнее, что повышает читаемость. И всё замечательно до появления первой необходимости вывести да... | https://habr.com/ru/post/330172/ | null | ru | null |
# Админка для Private Docker Registry (Registry Admin)
Концепция контейнеризации на базе Docker, и ему подобных технологий, для многих разработчиков стала незаменимым инструментом доставки своих продуктов конечным пользователям в виде полностью подготовленной среды использования. В большинстве случаев, особенно это ка... | https://habr.com/ru/post/709988/ | null | ru | null |
# Удобная работа в консоли, или красим STDERR в красный цвет
#### Работа в консоли
Многие из нас пользуются консолью каждый день, и, наверное, каждый задавал себе вопрос: как я могу сделать свою работу в конс... | https://habr.com/ru/post/207768/ | null | ru | null |
# Четвертая бета Ruby on Rails 3
Вчера вечером DHH [написал](http://weblog.rubyonrails.org/2010/6/8/rails-3-0-beta-4-now-rc-in-days) в блоге Rails, что четвертая бета Rails 3 доступна для обновления, а релиз-кандидат выйдет в течение нескольких дней (в оригинале — «RC in days»).
Для обновления с прошлой беты, как ... | https://habr.com/ru/post/95971/ | null | ru | null |
# Почему IDEA лучше Eclipse
Священный спор
--------------
Принято считать, что есть «вечные» вопросы, на которые нет правильного ответа. Например, что лучше: Windows или Linux, Java или C#; Чужой против Хищника или Чак Норрис против Ван Дамма.
Одним из таких [холиваров](http://lurkmore.to/%D0%A5%D0%BE%D0%BB%D0%B8... | https://habr.com/ru/post/112749/ | null | ru | null |
# Golang daemon
Около года назад мне понадобилось написать linux демона, реализующего небольшой сетевой сервис. В то время я активно изучал Go и мне очень нравился этот язык, поэтому взвесив все за и против я решил реализовать задачу на нем. К тому же, Go уже был стабильным и имел версию 1.0.1.
О том, с какими подв... | https://habr.com/ru/post/187668/ | null | ru | null |
# Установка DataContext вложенным невизуальным объектам в WPF/Silverlight

При разработке [DXScheduler for WPF](http://www.devexpress.com/Products/NET/Controls/WPF/Scheduler/) мы получили от пользователя сценарий, в котором и... | https://habr.com/ru/post/115104/ | null | ru | null |
# Когда простого пунктира мало: как подружить Java AWT Stroke и 10 приказ Минэкономразвития РФ
Мы тут в ИТМО занимаемся созданием всяких ГИС на заказ. И вот пришел к нам заказчик и попросил сделать демку с отображением генерального плана города и с некоторой аналитикой по ней.
Сам генеральный план - это куча геоданны... | https://habr.com/ru/post/524588/ | null | ru | null |
# Как на самом деле работает mod_rewrite. Пособие для продолжающих
Эта статья выросла из идеи продвинутого обучения наших сотрудников технической поддержки работе с mod\_rewrite. Практика показала, чт... | https://habr.com/ru/post/129560/ | null | ru | null |
# Выбор зависимостей для проекта
***Салют, хабровчане. В преддверии старта курса [«Fullstack разработчик JavaScript»](https://otus.pw/Rq6w/), подготовили для вас еще один полезный перевод.***

---
Каждый веб-разработчик сталкива... | https://habr.com/ru/post/507270/ | null | ru | null |
# Включаем HTTP/2 в NGINX для сайта
В этой статье мы расскажем, как включить HTTP/2 для сайта в NGINX, размещенного на [VPS от Infobox](http://infobox.ru/vps/linux/) и какие преимущества это даст вашему сайту. Поддержка HTTP/2 была добавлена в релиз [NGINX 1.9.5](https://www.nginx.com/blog/nginx-1-9-5/).
[
Это четвёртая подборка советов про Python и программирование из моего авторского канала [@pythonetc](http://t.me/pythonetc).
Предыдущие подборки:
* [Август 2018](https://habr.com/company/mailru/b... | https://habr.com/ru/post/425125/ | null | ru | null |
# Использование Typescript с React – руководство для новичков
Друзья, в преддверии выходных хотим поделиться с вами еще одной интересной публикацией, которую хотим приурочить к запуску новой группы по курсу [«Разработчик JavaScript»](https://otus.pw/rqAj/).

 ***— Для начала, ты должен понять главное…
— Что главное?
— Нет никакой ложки!
"[Матрица](http://www.kinopoisk.ru/film/301/)"***
Как я уже неоднокра... | https://habr.com/ru/post/259611/ | null | ru | null |
# JavaScript метод insertAdjacentHTML и beforeend
Перевод статьи «JavaScript insertAdjacentHTML and beforeend», David Walsh.
Если вы не знали: чертов DOM очень медленный. А по мере того, как наши сайты становятся все более динамичными и AJAX-использующими, нам становиться все важнее управлять DOM древом с наименьши... | https://habr.com/ru/post/235333/ | null | ru | null |
# Уйти от jQuery к Svelte, как это было
Всем привет.
Это отчёт в продолжение статьи "[Уйти от jQuery к Svelte, без боли](https://habr.com/ru/post/486646/)".
Ниже я расскажу о трудностях с которыми столкнулся, их было не много, и только одна была настолько фундаментальной, где без [поддержки сообщества](http://tg... | https://habr.com/ru/post/491388/ | null | ru | null |
# Брошенная корзина Mailchimp: гайд для ленивых
Сначала немного разглагольствований :) Рано или поздно перед любым интернет-магазином встает вопрос настройки брошенной корзины. Статистика и сосущее под ложечкой ощущение упущенных денег не щадят никого.
#### Процент брошенных корзин с 2006 по 2017

> I now have a new shiny blog. Read this article with the latest updates there <https://blog.goncharov.page/react-lifting-state-up-is-killing-your-app>
Have you heard about "liftin... | https://habr.com/ru/post/471300/ | null | en | null |
# Как верстать красиво или чем плохи css-фреймворки
Преимущества дивной вёрстки, семантичной разметки и разделения содержимого и дизайна описаны десятки, сотни раз, но все-равно находятся люди, которые не понимают самой идеи html и css, пишут в коде такие ужасные вещи, как
```
```
, когда хотят расскасить текст в... | https://habr.com/ru/post/108142/ | null | ru | null |
# Перевод с человеческого на ботовский
Началось все с того, что я, как и многие другие, захотел написать бота. Предполагалось, что бот мне будет напоминать всякие разные вещи, которые я постоянно забываю — первый сценарий, который предполагалось реализовать, это чтобы бот мне в 10 вечера говорил о том, чтобы я прочита... | https://habr.com/ru/post/347496/ | null | ru | null |
# “Сигма дельта” или как сделать хорошую звуковую карту из STM32F401
Жене мешают смотреть последние новости из телефона и телевизора приходящие поесть (первично ?) и поиграть на компьютере (вторично?) внуки. Она их конечно любит , но звуки их взаимодействия с компьютером ее сильно раздражают. Пришлось надеть на внуков... | https://habr.com/ru/post/662141/ | null | ru | null |
# Мошенничество с USB флешками на eBay
Предлагаю вашему вниманию личный опыт покупки USB флешек на eBay. Надеюсь эта заметка поможет кому-то не попасться в лапы мошенникам.
Скорее всего аналогичные флешки продаются и в других местах, будьте внимательны при покупке!
, которые сделают их ПО для организации VPN-туннелей частью ядра Linux... | https://habr.com/ru/post/419769/ | null | ru | null |
# Сам себе DynDNS или реализация Managed DNS посредством PowerShell
На улице сейчас прекрасные солнечные дни, так что большую часть своего времени я стал проводить вне своего дома с широким каналом, а где-нибудь в парке с нетбуком и 4g модемом. Это несомненно лучше для моего здоровья, но, тем не менее, большие файлы с... | https://habr.com/ru/post/146079/ | null | ru | null |
# Как мы следим за скоростью регресса
### Зачем мониторить время прохождения тестов?
Для начала разберёмся, почему мы вообще решили отслеживать скорость прохождения регрессионных тестов. Если бы у нас их был... | https://habr.com/ru/post/657025/ | null | ru | null |
# Пережить отпуск
Многие в нашей сфере не очень то любят отдыхать. Интернет развивается семимильными шагами, порой 2-х недельный отпуск может обернуться «опазданием» старта очередного проекта и как следствием — потери денег.
Однако лично я уверен, что отпуск это святое =) Я не очень то люблю море и пляжи, но с удо... | https://habr.com/ru/post/15120/ | null | ru | null |
# Лог файлы Linux по порядку
Невозможно представить себе пользователя и администратора сервера, или даже рабочей станции на основе Linux, который никогда не читал лог файлы. Операционная система и работающие приложения постоянно создают различные типы сообщений, которые регистрируются в различных файлах журналов. Умен... | https://habr.com/ru/post/332502/ | null | ru | null |
# Разбираем редкого зверя от Nvidia — DGX A100

Крупные IT-компании располагают дорогими «игрушками», которые скрыты от взоров большинства пользователей. Сегодня мы приоткроем завесу тайны и расскажем про систему, которая оптимизиров... | https://habr.com/ru/post/578230/ | null | ru | null |
# Экономим время на подключении шрифтов в проект

Всем привет!
Сегодняшний пост о спонтанно появившемся сайте со шрифтами.
Все началось после того, как мне в очередной раз пришел макет с нестанд... | https://habr.com/ru/post/147616/ | null | ru | null |
# Хакеры используют PuTTY для заражения крупных компаний
Они используют троянскую версию SSH-клиента PuTTY и KiTTY SSH для развертывания бэкдора под названием «AIRDRY.V2» в системах крупных компаний. Первый известный пострадавший — Amazon. Кибератака приписывается группировке UNC4034 (также известна под названием Herm... | https://habr.com/ru/post/688572/ | null | ru | null |
# How to set up PVS-Studio in Travis CI using the example of PSP game console emulator

Travis CI is a distributed web service for building and testing software that uses GitHub as a source code hosti... | https://habr.com/ru/post/464641/ | null | en | null |
# Как мы делали очередной конструктор чат-ботов. Часть 1

Привет, Хабромир! Последний год мы с командой провели, создавая свой стартап «Конструктор чат-ботов для бизнеса Botlify», и я хотел бы поделиться с аудиторией небольшой исто... | https://habr.com/ru/post/487340/ | null | ru | null |
# Используем Chrome без мыши
После перехода на Хром с Оперы мне не хватало одной вещи: использования браузера без мыши — передвижения по странице, переход по ссылкам и прочее. Часто, когда таскаю ноутбук, бывает необходимость работать без мыши. Увы, тачпаду на моем x350 далеко до «яблочного», поэтому становилось очень... | https://habr.com/ru/post/137690/ | null | ru | null |
# Управление настройками ReSharper в команде
Сегодня я хочу рассказать о том, как можно централизованно управлять настройками ReSharper на уровне команды разработчиков. Под настройками я понимаю настройки форматтера, Live Templates и настройки ReSharper. Они могут быть экспортированы и упакованы в так называемые [Decl... | https://habr.com/ru/post/262383/ | null | ru | null |
# Подборка полезных репозиториев на GitHub

В последнее время у меня собралось много отмеченных репозиториев на GitHub со всякими разными, полезными и не очень кусками кода. Решил их как структурировать для себя, так и поделиться с общественностью.
[facebook/three20
==... | https://habr.com/ru/post/93117/ | null | ru | null |
# JWT аутентификация в CLI приложении на Linux
> JSON Web Token — это открытый стандарт для создания токенов доступа, основанный на формате JSON. Как правило, используется для передачи данных для аутентификации в клиент-серверных приложениях. [Wikipedia](https://ru.wikipedia.org/wiki/JSON_Web_Token)
>
>
Когда речь ... | https://habr.com/ru/post/524622/ | null | ru | null |
# TinyML — машинное обучение на микроконтроллерах

В настоящее время мы все, так или иначе, пользуемся последними достижениями в сфере так называемого «искусственного интеллекта», который на самом деле представляет собой зачастую про... | https://habr.com/ru/post/665932/ | null | ru | null |
# Поговорим о централизованном логировании
Эта статья – продолжение [текста о мониторинге](https://habr.com/ru/post/551264/). Здесь предлагаю нам с вами поговорить о роли логов в оценке состояния наблюдаемой площадки, посмотреть, что они способны нам дать, а также затронуть вопрос – «можно ли отрывать логи от метрик?»... | https://habr.com/ru/post/551582/ | null | ru | null |
# Оптимизация mysql комплексная
Доброго времени суток, уважаемые хабровчане.
Сегодня речь пойдет опять и снова про mySQL. Разберемся в оптимизации и поговорим про множество параметров сервера.
Давайте приступать.
Начало
------
Сервер у нас пусть будет на **CentOS**. Оптимизировать будем методом правки ко... | https://habr.com/ru/post/539792/ | null | ru | null |
# Реализация навигации в Android приложениях с помощью Navigation Architecture Component
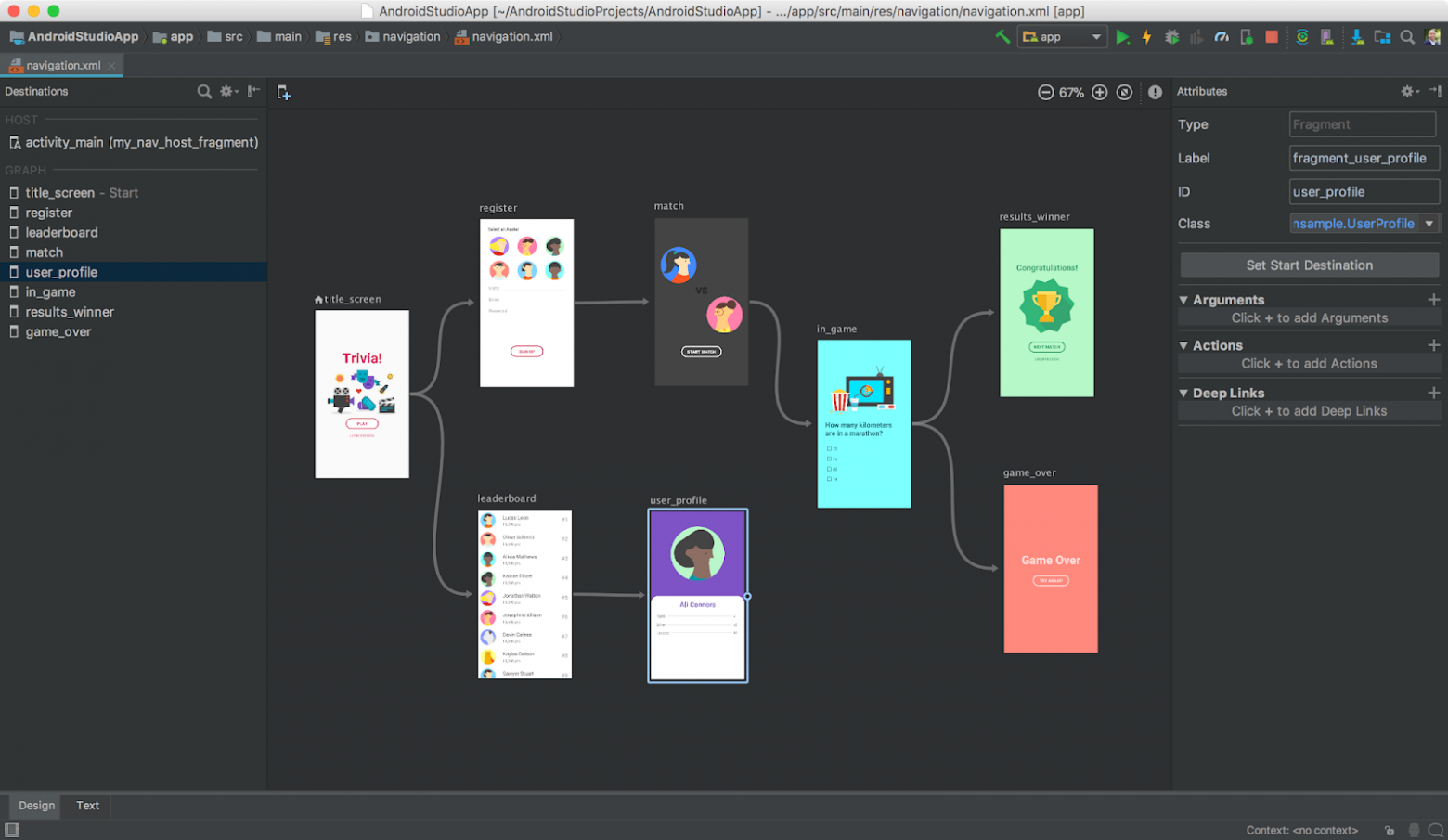
От переводчика
--------------
Здравствуйте, хабрчане. Это перевод [статьи-документации](https://developer.androi... | https://habr.com/ru/post/416025/ | null | ru | null |
# В двух словах о самом разном
Итак, напишу о том, как пофиксить дрожание в IE при эмуляции position:absolute; (без фоновой картинки), устроить склонение слов, решить проблемы с вопросиками в Mysql и про остальные неважные, но иногда полезные хитрости.
Если Вы матёрый веб-технолог, можете не читать: ничего нового н... | https://habr.com/ru/post/47088/ | null | ru | null |
# Как замкнуть переменную в C# и не выстрелить себе в ногу
Еще в далеком 2005 с выходом стандарта C# 2.0 появилась возможность передачи переменной в тело анонимного делегата посредством ее захвата (или замыкания, кому как угодно) из текущего контекста. В 2008 вышел в свет новый стандарт C# 3.0, принеся нам лямбды, пол... | https://habr.com/ru/post/320588/ | null | ru | null |
# Линтер на все случаи жизни — GitHub Super Linter

Команда DevOps инженеров из GitHub поделились своим универсальным решением для проверки качества кода. С ним можно настроить [линтер](https://github.com/github/super-linter) для 17 яз... | https://habr.com/ru/post/507528/ | null | ru | null |
# FineReader, Tesseract и EasyOCR или нужно ли срочно менять инструмент для OCR
*По сравнению со старшими товарищами, EasyOCR очень молодой проект, но с большими амбициями. В статье приводится сравнение качества работы, удобства работы, особенности установки и производительности трёх инструментов.*
Одна из популярных... | https://habr.com/ru/post/573030/ | null | ru | null |
# Приватные классы. Сокрытие в php
В php как и в большинстве других ООП языков существуют модификаторы видимости. Это ключевые слова public, protected и private. Но они применимы исключительно к свойствам, методам или константам. Данные модификаторы тесно связаны с возможностью инкапсуляции данных. Стоит заметить, что... | https://habr.com/ru/post/435894/ | null | ru | null |
# Развертывание тестового кластера VMware Virtual SAN 6.2
Введение
--------
Передо мной была поставлена задача — развернуть кластер VMware Virtual SAN 6.2 для тестирования производительности, анализа возможностей, особенностей и принципов работы гиперконвергентной программной СХД от VMware.
Кроме того, созданный т... | https://habr.com/ru/post/318258/ | null | ru | null |
# Тестирование дешевых виртуальных серверов
У многих хостеров есть в продаже дешевые виртуальные серверы, к тому же в последнее время стали в большом количестве появляться рекламные тарифы с различными ограничениями (например, возможностью заказа одного такого виртуального сервера для одного аккаунта), цена на которые... | https://habr.com/ru/post/467953/ | null | ru | null |
# VolgaCTF глазами участника

15 апреля завершился отборочный этап соревнований в области информационной безопасности [VolgaCTF-2012](http://volgactf.ru/), в котором принимали участие 29 команд из различных городов П... | https://habr.com/ru/post/142131/ | null | ru | null |
# Синхронность — это миф
Привет всем!
Сегодня вас ждет длинный текст без картинок (слегка сокращенный по сравнению с оригиналом), где подробно разобран тезис, вынесенный в заголовок. Ветеран компании Майкрософт [Терри Кроули](https://www.zdnet.com/article/microsoft-big-brains-terry-crowley/) описывает суть асинхрон... | https://habr.com/ru/post/423573/ | null | ru | null |
# PDFsharp and MigraDoc Foundation (Основы)
Так как статья, из-за которой я получил инвайт куда-то пропала, хочу опубликовать ее снова.
Ввиду небольшого количества бесплатных библиотек для работы с PDF в .Net а также недостаточного освещения их на русском языке хочу рассказать о работе с такой замечательной библиот... | https://habr.com/ru/post/150059/ | null | ru | null |
# У Вас есть дети? Давайте меняться!
На днях закончил делать новый сервис по обмену детскими вещами. К этому моменту у самого накопилась целая куча этого добра.
Дети растут зачастую быстрее, чем изнашивается их одежда и обувь. Не говоря уже о стерилизаторах, игрушках, колясках, качельках, велосипедах и книжках, ст... | https://habr.com/ru/post/61585/ | null | ru | null |
# Фактор рефакторинга
Код зависим от данных и моделей, а значит от абстракций используемых в них, поэтому рефакторинг неминуем сегодня. Почему? Обычно под рефакторингом подразумевают реорганизацию кода из соображений необходимости использовать данные по-новому. Мы поговорим о самом частом и нелюбимом типе рефакторинга... | https://habr.com/ru/post/576326/ | null | ru | null |
# Что сейчас происходит с RDF-хранилищами?
Semantic Web и Linked Data подобны ближнему космосу: жизни там нет. Чтобы отправиться туда на более-менее длительный срок… ну, не знаю, что говорили вам в детстве в ответ на «хочу стать космонавтом». Но понаблюдать за происходящим можно и находясь на Земле; стать астрономом-л... | https://habr.com/ru/post/451206/ | null | ru | null |
# Приятное тестирование с Espresso

Хочу представить вашему вниманию библиотеку для тестирования Android приложений от Google. Espresso была анонсирована 23 апреля прошлого года на Google Test Automat... | https://habr.com/ru/post/212425/ | null | ru | null |
# Java для HPC. Расчёт скалярного произведения векторов
Здравствуйте,
Данный пост — продолжение [первого](http://habrahabr.ru/blogs/java/105021/) поста по теме.
*Данный пост является краткой выжимкой из статьи «Java for High Performance Computing», которая будет представлена мной на университетской конференции Т... | https://habr.com/ru/post/105408/ | null | ru | null |
# Аутентификация в rails-приложениях с помощью facebook, vkontakte
Аутентификация в rails-приложениях через facebook, vkontakte
============================================================

В данной статье будет рассказа... | https://habr.com/ru/post/142128/ | null | ru | null |
# MVVM Framework для Windows Phone своими руками. Часть 1
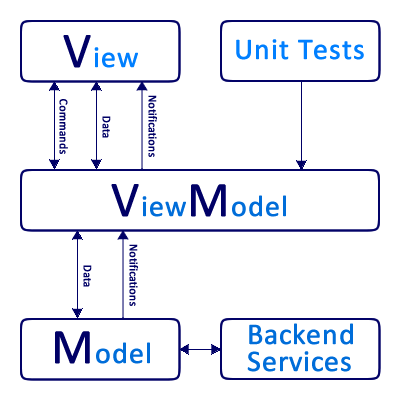 Разработка приложений для платформ WPF, Silverlight, Windows Store и Windows Phone, почти всегда подразумевает использование паттерна MVVM. Это законо... | https://habr.com/ru/post/221077/ | null | ru | null |
# Python: коллекции, часть 4/4: Все о выражениях-генераторах, генераторах списков, множеств и словарей
| [Часть 1](https://habrahabr.ru/post/319164/ "Python: коллекции, часть 1/4: классификация, общие подходы и методы, конвертация") | [Часть 2](https://habrahabr.ru/post/319200/ "Python: коллекции, часть 2/4: индексиро... | https://habr.com/ru/post/320288/ | null | ru | null |
# Умные алгоритмы обработки строк в ClickHouse
В ClickHouse постоянно возникают задачи, связанные с обработкой строк. Например, поиск, вычисление свойств UTF-8 строк или что-то более экзотическое, будь то поиск типа учёта регистра или поиск по сжатым данным.
Всё началось с того, что руководитель разработки ClickHouse... | https://habr.com/ru/post/466183/ | null | ru | null |
# Установка squid+sams+ntlm на centos 6.4 по шагам
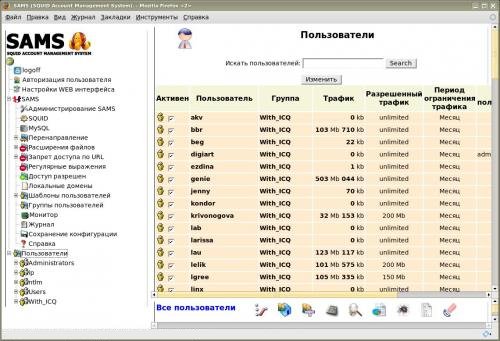
Добрый день господа, думаю, я не открою Америку рассказывая про проект SAMS (Squid Accaunt Management System), статьи о нем достаточно распространены, в ... | https://habr.com/ru/post/199302/ | null | ru | null |
# Простой подход к работе с отзывчивыми изображениями
[Спецификация](http://usecases.responsiveimages.org) по отзывчивым изображениям — это фантастический документ, в котором описано множество вариантов использования таких изображений. Но опыт подсказывает мне, что чаще всего при работе с ними нужно знать лишь о том, ... | https://habr.com/ru/post/500292/ | null | ru | null |
# VPN без VPN или рассказ об нетрадиционном использовании SSH
По данным ssh.com и Wikipedia, первая версия и реализация протокола SSH увидела свет в 1995 году. Задачей автора было разработать безопасную альтернативу использовавшимся тогда для удалённого администрирования rlogin, telnet и rsh. Любопытно, что появлению ... | https://habr.com/ru/post/441806/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.