
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Go против Excel на сотни тысяч строк
В этом году мы уже [писали на Хабре](https://habr.com/company/Voximplant/blog/346474/) про наш проект [SmartCalls.io](https://smartcalls.io/) – визуальный конструктор звонков, созданный для бизнес-пользователей. Проект решает задачу бизнеса по массовым обзвонам клиентов: создаетс... | https://habr.com/ru/post/424697/ | null | ru | null |
# Реверс-инжиниринг «Казаков», часть третья: напёрстки в LAN

На дворе конец 2016 года, наконец-то, ~~вызвав бурю восторга среди фанатов,~~ вышла третья часть «Казаков»… А мне всё не давала покоя странная ошибка в сетевой ко... | https://habr.com/ru/post/312686/ | null | ru | null |
# Становимся контрибьютером в PostgreSQL
 В этой статье я хотел бы рассказать о том, как выглядит процесс разработки PostgreSQL глазами одного из контрибьютеров в этот самый PostgreSQL. Занимать... | https://habr.com/ru/post/308442/ | null | ru | null |
# JUnit: тестирование методов, вызывающих System.exit()
### 1. Обзор
В определенных ситуациях нам может потребоваться, чтобы метод вызывал `System.exit()` и завершал работу приложения. Например, в случае есл... | https://habr.com/ru/post/701174/ | null | ru | null |
# #01 — И целого байта мало… | Какими бывают intro?
Дамы, господа, сегодня отличный день!
Скорее всего вы помните, что существует такая форма компьютерного искусства как **«демосцена»**, но если слышите это слово впервые — просто прочитайте тематический [**хаб**](https://habr.com/ru/hub/demoscene/) и [**теги**](htt... | https://habr.com/ru/post/495042/ | null | ru | null |
# Как отличить версию iPad в Safari
На днях встала задача: во что бы то ни стало, нужно было отличить iPad1 от iPad2 в браузере. iPad3 можно отличить с помощью window.devicePixelRatio, а вот с первыми двумя проблема. Детальное изучение всего объекта window результатов не дало. Появилась мысль попытаться отличить их по... | https://habr.com/ru/post/146769/ | null | ru | null |
# Функциональный подход обработки ошибок в Dart
При переходе на новую технологию, мы лишаемся привычных инструментов для разработки. В каких-то случая мы вынуждены смириться с их отсутствием из-за каких-то технических ограничений, но при возможности переносим инструменты с собой. Разрабатывая android приложения, за ос... | https://habr.com/ru/post/459757/ | null | ru | null |
# Строго-типизированный SignalSpy для тестирования Qt приложений
При написании юнит-тестов за правило хорошего тона считается проверка инвариантов класса посредством открытого интерфейса класса. В случае с Qt всё немного сложнее, так как функции-члены могут потенциально посылать сигналы, которые выходят «наружу» объек... | https://habr.com/ru/post/218729/ | null | ru | null |
# Кто добавил Python в последнее обновление Windows?
Несколько дней назад команда Windows [анонсировала майское обновление 2019 для Windows 10](https://blogs.windows.com/windowsexperience/2019/05/21/how-to-get-the-windows-10-may-2019-update/). В этом посте мы взглянем на то, что мы, команда Python, сделали для того, ч... | https://habr.com/ru/post/455337/ | null | ru | null |
# Делаем гирлянду с ребенком
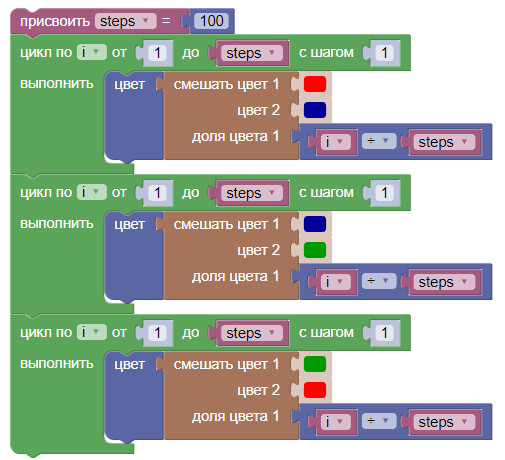
Уровень сложности: для начинающих.
Идея возникла, когда под новый год сломалась старая гирлянда. Сын посмотрел на RGB-светодиодную ленту и спросил, можно ли сделать из нее гирлянду. Можно — сказа... | https://habr.com/ru/post/409449/ | null | ru | null |
# Оптимизации WordPress. Конкурс «ВПС на год за лучшие идеи!»
По данным [HackerTarget.com](http://hackertarget.com/wordpress-statistics-top-500k/) 20.9% сайтов из списка Alexa (104 684 из 500 000) работают на CMS WordPress. Из небольшого движка для блогов WordPress вырос в универсальную платформу для разработки сайтов... | https://habr.com/ru/post/231719/ | null | ru | null |
# Что такое фильтр Блума?
Всем привет! В этой статье я постараюсь описать, что такое фильтр Блума, рассказать о его назначении и показать сценарии, в которых его можно использовать. Я также реализую фильтр Блума на Pytho... | https://habr.com/ru/post/541378/ | null | ru | null |
# Ввод пароля или похитители времени

Не знаю, как вам, но мне в течении дня приходится часто отходить от рабочего места и блокировать мак. Чтобы не совершать несколько кликов мышкой, блокировку своего мака я «повесил» на к... | https://habr.com/ru/post/240647/ | null | ru | null |
# Nagios-светофор из китайских кубиков
UPD. Небольшое обновление по итогам 4 лет эксплуатации. За это время сломалась одна лампа и один конвертер USB-COM. Конвертер был просто заменен на другой, без малейшей попытки починить. Лампочка же была успешно отремонтирована, так как оказалась на удивление ремонтопригодна и ле... | https://habr.com/ru/post/353280/ | null | ru | null |
# Визуализация простой геометрии в WPF
Что такое геометрия модели
--------------------------
Для работы с 3D моделями мы используем специальные конвейеры обработки — [OpenGL](https://ru.wikipedia.org/wiki/OpenGL) и [DirectX](https://ru.wikipedia.org/wiki/DirectX). Когда конвейеры строят картину, они используют информ... | https://habr.com/ru/post/326406/ | null | ru | null |
# Модераторы
Я решил дать посту такой немногословный заголовок, чтобы даже те, кто читает нас через RSS, обратили на него внимание. Это не помешает, так как наши посты-анонсы о новых фичах набирают не так много просмотров (а беспокоить пользователей рассылками мы не очень-то любим).
 — инструмента для версионной миграции схемы базы данных под платформу .NET Core.
Карта Кипра с "рабочими местами" для цифровых кочевниковЕщё один небольшой pet-проект: про кафе и коворк... | https://habr.com/ru/post/694142/ | null | ru | null |
# Tcl/tk: интегрированная среда разработки TKproE-2.30
Прошло без малого пять лет как я впервые столкнулся с интегрированной средой разработки программ на tcl/tk [TKproE-2.20](https://habr.com/ru/post/343930/). В апреле 2021 года вышла ... | https://habr.com/ru/post/653129/ | null | ru | null |
# Активация поддержки многосайтовости в инсталляции Wordpress на VPS от Infobox за 5 минут
В этой статье мы рассмотрим, как быстро запустить несколько сайтов на [VPS](http://infobox.ru/vps/linux/) и [облачной VPS](http://infobox.ru/vps/cloud/) от Infobox. С тех пор, как появился проект [Wordpress MU](https://mu.wordp... | https://habr.com/ru/post/240161/ | null | ru | null |
# Погружение в автотестирование на iOS. Часть 2. Как взаимодействовать с ui-элементами iOS приложения в тестах
Привет, Хабр! В [прошлой статье](https://habr.com/ru/company/vivid_money/blog/533180/) мы разобр... | https://habr.com/ru/post/538708/ | null | ru | null |
# Promise.allSettled

На 71-м митинге Ecma TC39 будет рассматриваться проект и эталонная реализация `Promise.allSettled` — третьего из четырех основных комбинаторов промисов.
**Авторы**: Джейсон Вильямс (BBC), Роберт Памли (Bloomber... | https://habr.com/ru/post/459970/ | null | ru | null |
# Production-ready chatbot in GCP for less than a dollar

We have all been there — having a nice idea for a hackathon, hobby or a side project and having a burning desire to start coding as soon as pos... | https://habr.com/ru/post/510468/ | null | en | null |
# KVM (недо)VDI с одноразовыми виртуальными машинами с помощью bash
#### Кому предназначена данная статья
Данная статья может быть интересна системным администраторам, перед которыми вставала задача создать сервис «одноразовых» рабочих мест.
#### Пролог
В отдел ИТ сопровождения молодой динамично развивающейся ко... | https://habr.com/ru/post/462203/ | null | ru | null |
# Как уже снова не получить телефон (почти) любой красотки в Москве, или интересная особенность MT_FREE
**UPD0 14.03 8:21 — Телефон больше не получить. Остальные интересные данные пока остались.**
**UPD1 14.03 10:39 — Дабы не очернять ребят из *саппорта* MaximaTelecom**: Сообщил о ней я окольными путями, но раз пять ... | https://habr.com/ru/post/351114/ | null | ru | null |
# Назад в будущее с WebAssembly
Привет, Хабр! Представляю вашему вниманию перевод статьи [«Back To The Future With WebAssembly»](https://hmh.engineering/back-to-the-future-with-webassembly-9a12ab6ec33) автора Attila Vágó.
#### Данный пост является переводом статьи, в которой рассказывается о свойствах WebAssemly и ... | https://habr.com/ru/post/453008/ | null | ru | null |
# Вышел CoffeeScript 1.6.1 с поддержкой Source Maps
Случилось то, чего мы ждали уже давно. Благодаря усилиям [Jason Walton](http://github.com/jwalton) теперь [CoffeeScript поддерживает Source Maps](http://coffeescript.org/#source-maps), и мы можем отлаживать код на CoffeeScript прямо в браузере (Chrome, Firefox Nightl... | https://habr.com/ru/post/171649/ | null | ru | null |
# Sparta — комплекс для проведения тестирования на проникновение

При проведении тестирования на проникновение важным этапом является начальный сбор информации об объектах аудита и их взаимодействии. Для этого необходимо сос... | https://habr.com/ru/post/324560/ | null | ru | null |
# Вероятностные модели: сэмплирование
И снова здравствуйте! Сегодня я продолжаю серию статей в блоге Surfingbird, посвящённую разным методам рекомендаций, а также иногда и просто разного рода вероятностным моделям. Давным-давно, кажется, ~~в прошлую пятницу~~ летом прошлого года, я написал небольшой цикл о графических... | https://habr.com/ru/post/226677/ | null | ru | null |
# Аутентификации на Angular и Spring без Spring Security (сервер на Spring)
Часть 2. Сервер на Spring
=========================
О чем эта статья
----------------
В этой статье, я расскажу как написать простую аутентификацию без помощи готовых решений для данной задачи. Она может быть полезна для новичков, которые хо... | https://habr.com/ru/post/354862/ | null | ru | null |
# Введение в анализ социальных сетей на примере VK API
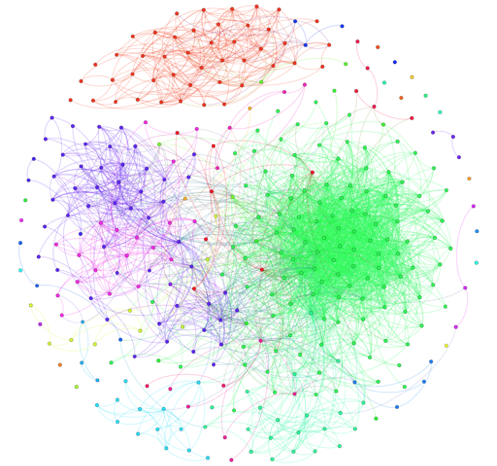
Данные социальных сетей — неисчерпаемый источник исследовательских и бизнес-возможностей. На примере Вконтакте API и языка Python мы сегодня разберем пару практических ... | https://habr.com/ru/post/263313/ | null | ru | null |
# Разработка нового сервиса в Android 7 | Кастомизация строки навигации

Представим себе следующую ситуацию: мы разрабатываем продукт, который требует очень специфические свойства которые или не сущес... | https://habr.com/ru/post/331900/ | null | ru | null |
# Штука для намотки трансформаторов. Без Arduino
В одном из проектов понадобилось намотать под сотню трансформаторов. Это стало поводом пересмотреть нелюбовь к моточным изделиям, которая тянулась ещё со школы... | https://habr.com/ru/post/682450/ | null | ru | null |
# import sphinxapi без танцев или простая установка sphinxapi.py через pip
Немного облегчил установку sphinxapi.py через pip.
Просто
```
pip install https://github.com/Romamo/sphinxapi/zipball/master
```
Используем
```
import sphinxapi
```
Когда я решил использовать Sphinxsearch для полнотекстового поиска... | https://habr.com/ru/post/220781/ | null | ru | null |
# Рисуем карту сервисов при помощи Qt Quick и GraphViz
Решил запрототипировать два представления в дополнение к стандартному Jaeger UI. Это
* построение карты сервисов по трейсу;
* просмотрщик логов без пикс... | https://habr.com/ru/post/689496/ | null | ru | null |
# Поиск случайной точки на PolygonCollider2D Unity
Привет, Habr. В данный момент я разрабатываю игру про животных, где они должны беспорядочно бегать по карте. Идеей является то, что есть несколько видов живо... | https://habr.com/ru/post/650379/ | null | ru | null |
# Карманный PaaS c Dokku
В своей [прошлой статье](http://habrahabr.ru/company/likeastore/blog/210000/) я упомянул Dokku, как важную составляющую нашей инфраструктуры и сегодня хочу раскрыть эту тему подробнее.
[Dokku](https://github.com/progrium/dokku) это средство простого трансформирования Ubuntu сервера, в мини-... | https://habr.com/ru/post/211016/ | null | ru | null |
# Интеграция AdMob в Cocos2d-x
Уважаемые хабражители, в этой статье я хочу поделиться своим опытом по интеграции баннерной сети AdMob в игру для Android, написанную с использованием движка Cocos2d-x.

##### Введение
... | https://habr.com/ru/post/161891/ | null | ru | null |
# Реверс-инжиниринг приложений после обфускации (Часть 2)
Введение
--------
*Данная публикация направлена на изучение некоторых приемов реверс-инжиниринга. Все материалы представлены исключительно в ознакомительных целях и не предназначены в использовании в чьих-либо корыстных целях.*
Рекомендуется к прочтению по... | https://habr.com/ru/post/445126/ | null | ru | null |
# Простые модели экономической динамики на Python
### Введение
В моих публикациях [1,2] экономические задачи рассматривались в статике без учёта времени. В задачах оптимизации экономической динамики анализируются изменение экономических параметров и их взаимосвязей во времени. В моделях экономической динамики время м... | https://habr.com/ru/post/336946/ | null | ru | null |
# Шейдерный эффект дудла
В этом туториале я расскажу о том, как с помощью шейдеров воссоздать популярный спрайтовый эффект дудла в Unity. Если для вашей игры необходим такой стиль, то из этой статьи вы узнаете, как достичь его без отрисовки кучи дополнительных изображений.
Последние несколько лет этот стиль станови... | https://habr.com/ru/post/449540/ | null | ru | null |
# PostgreSQL 9.5: что нового? Часть 1. INSERT… ON CONFLICT DO NOTHING/UPDATE и ROW LEVEL SECURITY
[Часть 2. TABLESAMPLE](http://habrahabr.ru/post/266759/)
[Часть 3. GROUPING SETS, CUBE, ROLLUP](http://habrahabr.ru/post/269849/)
[В 4 квартале 2015 года](http://www.postgresql.org/developer/roadmap/) ожидается рели... | https://habr.com/ru/post/264281/ | null | ru | null |
# Нефункциональное модульное тестирование — «главное чтобы блестел». Часть 2
В прошлом году я написал [небольшую заметку](http://community.livejournal.com/ru_perl/383519.html) о нефункциональном тестировании — т.е. о тестах пытающихся выявить уродливый и сложный в сопровождении код. Конечно такие тесты не гарантируют ... | https://habr.com/ru/post/111655/ | null | ru | null |
# Объектно-ориентированный дизайн… в CSS
Предупрежу заранее, что я совершенно не считаю себя экспертом HTML/CSS/JS. Но, как архитектору, мне всегда была интересна организация и систематизация кода в самых разных его проявлениях, в том числе и представленных в виде CSS. Особенно сильно этот интерес был подогрет БЭМом, ... | https://habr.com/ru/post/171437/ | null | ru | null |
# Написание бота для игры в Шарики 2.0
Недавно наткнулся на простенькую [игрушку](https://vk.com/app3197585), где необходимо стрелять шариком в группы одного цвета. Хотя в игры я играю очень редко, минут 30 я с ней посидел.
Захотелось автоматизировать этот процесс. Знаний для игры не требуется, да игр таких много. ... | https://habr.com/ru/post/165297/ | null | ru | null |
# Причины и следствия
Здесь я хочу поделиться с вами тремя примерами неадекватного кода. И в то же время постараюсь разобрать и классифицировать каждый случай. Тем самым расскажу не только «что такое плохо?», но и «почему?»
#### Недостаток знаний/опыта.
Не так давно пришлось воскрешать некогда очень популярный в с... | https://habr.com/ru/post/46196/ | null | ru | null |
# MVCC in PostgreSQL-6. Vacuum
We started with problems related to [isolation](https://habr.com/ru/company/postgrespro/blog/467437/), made a digression about [low-level data structure](https://habr.com/ru/company/postgrespro/blog/469087/), then discussed [row versions](https://habr.com/ru/company/postgrespro/blog/4776... | https://habr.com/ru/post/484106/ | null | en | null |
# Быстрый пул для php+websocket без прослойки nodejs на основе lua+nginx

Кратко: nginx не умеет пулить websockets, а php работает per request. Нужна прослойка которая будет держать... | https://habr.com/ru/post/338614/ | null | ru | null |
# Пишем систему рекомендаций музыки на основе ML
К старту [курса по ML и DL](https://skillfactory.ru/machine-learning-i-deep-learning?utm_source=habr&utm_medium=habr&utm_campaign=article&utm_content=data-sci... | https://habr.com/ru/post/585182/ | null | ru | null |
# Android Remote Debugger — удаленная отладка Android приложений
Отладка является важным этапом разработки программного обеспечения. Поиск и исправление ошибок позволяют разрабатывать качественные продукты.
В этой статье я хочу поговорить об отладке именно Android приложений. Android Studio предоставляет нам различны... | https://habr.com/ru/post/488514/ | null | ru | null |
# Android, Ubuntu и Python: автоматизация записи интернет-радио и синхронизация on-air
Привет всему сообществу Хабра!
Наверняка многие по дороге 'дом' <--> 'работа' слушают в пути музыку со своего Android-фона. Я тоже частенько досыпаю в метро под бодрый breaks лишние 10-20 минут. В очередной поездке до места опера... | https://habr.com/ru/post/146272/ | null | ru | null |
# «Звезда» — оптимальная структура данных при переходе на российский BI
Бизнес-аналитика — интереснейшее направление работы с данными. С одной стороны пользователи хотят видеть красивые дашборды и простые self-service платформы, а с другой стороны, для организации всего этого порой требуется колоссальная работа по орг... | https://habr.com/ru/post/678346/ | null | ru | null |
# Message dispatching на D
Многие разработчики игр сталкиваются с проблемой описания и реализации протокола общения клиента и сервера, особенно если пишут свои велосипеды для работы с сокетами. Ниже я расскажу о моей попытке решить задачу как можно элегантнее и удобнее для дальнейшего использования и масштабирования п... | https://habr.com/ru/post/149809/ | null | ru | null |
# Путеводитель по ID для JPA сущностей. Часть 1: ID, генерируемые на сервере
Разработка инструментария – очень познавательное занятие, потому что заставляется задуматься над теми вещами, которые в процессе ра... | https://habr.com/ru/post/653843/ | null | ru | null |
# Понятно про CSS Masking и Shapes Modules, или Будущая революция дизайна контента
Доброго времени суток уважаемые хабражители. На сегодняшний день с помощью CSS можно создать множество различных элементов. Это безусловно очень радует, вспоминая веб несколько лет назад. Но порой так «устаешь» от всех этих изощрений с ... | https://habr.com/ru/post/190246/ | null | ru | null |
# Как предсказать гипероним слова (и зачем). Моё участие в соревновании по пополнению таксономии
Как может машина понимать смысл слов и понятий, и вообще, что значит — понимать? Понимаете ли вы, например, что такое спаржа? Если вы скажете мне, что спаржа — это (1) травянистое растение, (2) съедобный овощ, и (3) сельск... | https://habr.com/ru/post/507228/ | null | ru | null |
# В поисках идеальной системы отзывов для интернет-магазина
[](http://habrahabr.ru/post/256993/) **Привет, Хабр!** В [предыдущем посте](http://habrahabr.ru/company/cackle/blog/255477/) мы погово... | https://habr.com/ru/post/256993/ | null | ru | null |
# 50 оттенков matplotlib — The Master Plots (с полным кодом на Python)
Те, кто работает с данными, отлично знают, что не в нейросетке счастье — а в том, как правильно обработать данные. Но чтобы их обработать, необходимо сначала проанализировать корреляции, выбрать нужные данные, выкинуть ненужные и так далее. Для под... | https://habr.com/ru/post/468295/ | null | ru | null |
# Обзор Asterisk REST Interface (ARI)
В начале времен единственным "поставщиком" функционала Asterisk были модули, многие из которых расширяли арсенал приложений и функций плана набора.
Тогда, в начале времен, все эти команды и функции далеко опережали свое время, и благодаря им Asterisk "уделывал" по функционалу мн... | https://habr.com/ru/post/308652/ | null | ru | null |
# Смотрим любое кино мгновенно
**Disclaimer: я не призываю незаконно скачивать контент, пиратство - наказуемо и является преступлением**
После ареста серверов [Moonwalk](https://4pda.ru/2019/10/22/363190/) жить стало в разы труднее. Лично я уже совсем отвык от торрентов. Нужно что-то качать, ждать, чем-то открывать, ... | https://habr.com/ru/post/545784/ | null | ru | null |
# Запрещаем использование известных UserJS
#### Введение
UserJS предоставляет пользователям удобный и простой механизм модификации веб-страниц, именно благодаря этому многие пользователи автоматизирую свои действия с помощью UserJS, а иногда и обходят слабые системы защиты.
Больше всего от использования UserJS пол... | https://habr.com/ru/post/107396/ | null | ru | null |
# Невизуальные методы защиты сайта от спама. Часть 3. Повторы
Продолжение статьи [Невизуальные методы защиты сайта от спама](https://habrahabr.ru/company/cleantalk/blog/282586/)
Часть 3. Повторы подстрок
=========================
Как уже говорилось, невизуальные методы защиты сайта от спама используют анализ текст... | https://habr.com/ru/post/301302/ | null | ru | null |
# Одностраничный магазин на Phalcon PHP + AngularJS. Работа над ошибками
##### Введение
Всем привет! Не так давно я написал публикацию [«Одностраничный магазин с корзиной на Phalcon + AngularJS + Zurb Foundation»](htt... | https://habr.com/ru/post/246733/ | null | ru | null |
# Модальное окно bootstrap для редактирования форм
Возникла необходимость использовать плагин bootstrap-modal.js для редактирования формы. Казалось бы тривиальная задача, но пришлось столкнуться с некоторыми сложностями. В данной статье поделюсь с вами своим решением, более изящные решения и здоровая критика приветств... | https://habr.com/ru/post/179211/ | null | ru | null |
# В Safari 15.4 добавили более 70 дополнений к WebKit
В Safari 15.4 [добавлено](https://webkit.org/blog/12445/new-webkit-features-in-safari-15-4/) более 70 дополнений к WebKit, а также иные обновления и исправления. Это первый большой выпуск WebKit в 2022 году. Safari 15.4 доступен сегодня для macOS Monterey 12.3, iPa... | https://habr.com/ru/post/655743/ | null | ru | null |
# Легковесный модуль для HTTP запросов
Все началось с того, что передо мной встала задача написать бота для Telegram, здесь, я первый раз столкнулся с их [API](https://core.telegram.org/bots/api). Для работы с ним я выбрал популярный на сегодняшний день модуль [Request](https://github.com/request/request).
Бот был... | https://habr.com/ru/post/264583/ | null | ru | null |
# Как сделать полнотекстовую поисковую машину на 150 строках кода Python
Полнотекстовый поиск — неотъемлемая часть нашей жизни. Разыскать нужные материалы в сервисе облачного хранения документов, найти фильм ... | https://habr.com/ru/post/551000/ | null | ru | null |
# Scroll Views внутри Scroll Views
В данной статье я хочу представить [*OLEContainerScrollView*](https://github.com/ole/OLEContainerScrollView), который является потомком *UIScrollView* и позволяет вам добавлять несколько scroll views, таблиц (*UITableView*) или коллекций (*UICollectionView*) в один контейнер.
####... | https://habr.com/ru/post/224815/ | null | ru | null |
# Облегчаем себе жизнь
При разработке проектов используем БД PostgreSQL, благодаря ее открытости, бесплатности и довольно большого функционала. По принятой архитектуре, для таблиц создаем вьюшки (представления) и приложения работают уже с ними. Во многих случаях вьюшки один в один копируют таблицы, но каждую из них на... | https://habr.com/ru/post/215373/ | null | ru | null |
# Не заставляйте слушателей рефлексировать
Введение
--------

В процессе разработки очень часто возникает необходимость создать экземпляр класса, имя которого хранится в конфигурационном XML файле, или вызвать метод, название которо... | https://habr.com/ru/post/447022/ | null | ru | null |
# Какие ссылки использовать: абсолютные или относительные?
Имеется в виду: какие адреса использовать для переходов внутри сайта? Допустим, мы хотим создать на домене site.ru с уже работающим сайтом другой подсайт, файлы которого будут находиться в папке shop. URL этого подсайта будет такой:
```
http://site.ru/shop... | https://habr.com/ru/post/310286/ | null | ru | null |
# Установка Archlinux на телефон с Android во второй раздел SD или просто подпапку системной карты памяти

Привет всем. Тут уже была [статья](http://habrahabr.ru/company/xakep/blog/208518/) на тему Bo... | https://habr.com/ru/post/221543/ | null | ru | null |
# Анализ CSS хаков для различный версий браузеров
День добрый, уважаемые.
Хочу предупредить что это моя оригинальная статья, это не репост с чужого блога.
Предлагаю к рассмотрению обзор хаков для верстки. Хаки были отобраны с различных ресурсов и заботливо систематизированы. Зачем я это сделал и почему? Да, хаки... | https://habr.com/ru/post/79820/ | null | ru | null |
# Модели Sequence-to-Sequence Ч.1
Всем добрый день!
И у нас снова открыт новый поток на доработанный курс [«Data scientist»](https://otus.pw/LlGz/): ещё один [отличный преподаватель](https://otus.pw/lH7g/), чуть доработанная исходя из обновлений программа. Ну и как обычно интересные [открытые уроки](https://otus.pw... | https://habr.com/ru/post/430780/ | null | ru | null |
# Лучшие практики Go, шесть лет в деле
В 2014 году я выступил на открытии конференции GopherCon с докладом под названием «Go: [Best Practices for Production Environments](https://peter.bourgon.org/go-in-production)». В [SoundCloud](https://soundcloud.com/) мы были одними из первых пользователей Go и к тому времени уже... | https://habr.com/ru/post/301036/ | null | ru | null |
# Android — Сontinuous Integration. Часть 2
Первая часть, рассказывающая для чего все это нужно [здесь](http://habrahabr.ru/post/145907/).
#### Содержание
* Подготовка
* Maven
+ Root
- Build profiles
- Plugins
+ App
- Resource filtering
+ Lib
+ Test
* Заключение
* Ссылки
Пост рассчитан на читат... | https://habr.com/ru/post/152279/ | null | ru | null |
# Когда старый компьютер лучше нового
[](https://dilbert.com/strip/2012-04-05)
*[© dilbert](https://dilbert.com/strip/2012-04-05)*
Наметилась странная тенденция. Возникает впечатление, что с каждым годом компьютеры *замедляются*. ... | https://habr.com/ru/post/557752/ | null | ru | null |
# PickMeUp — хороший jQuery datepicker plugin
#### Проблема
Начиная работу над очередным сайтом понадобился datepicker. Самый известный такой datepicker — в jQuery UI, но так как jQuery UI в проекте не использовался — тянуть даже его часть не хотелось, принялся за поиски достойной альтернативы.
Требования следующи... | https://habr.com/ru/post/202640/ | null | ru | null |
# Visual Tcl. Разработка графического пользовательского интерфейса для утилит командной строки (Продолжение)
В [предыдущей статье](https://habrahabr.ru/post/332924/) в качестве инструментария для создания графического интерфейса для утилит командной строки на базе Tcl/Tk был рассмотрен конструктор tkBuilder. Конструкт... | https://habr.com/ru/post/333742/ | null | ru | null |
# Теория и практика использования ClickHouse в реальных приложениях. Александр Зайцев (2018г)

Несмотря на то, что данных сейчас много почти везде, аналитические БД все еще довольно экзотичны. Их плохо знают и еще хуже умеют эффективно... | https://habr.com/ru/post/512304/ | null | ru | null |
# Шифрование/дешифрование данных на стороне клиента в web-ориентированных системах
В наши дни всё больше программ переводятся в так называемый «web-ориентированный» вид, то есть используется принцип клиент-сервер, что позволяет хранить данные удалённо и получать к ним доступ через тонкий клиент (браузер).
Одновреме... | https://habr.com/ru/post/130085/ | null | ru | null |
# Blitz.Engine: Ассетная система

Прежде чем разбираться в том, как работает ассетная система движка **Blitz.Engine**, нам необходимо определиться с тем, что такое ассет и что именно мы будем понимать под ассетной системой. Согласн... | https://habr.com/ru/post/498300/ | null | ru | null |
# Простая математическая задача, которую мы все еще не в состоянии решить
> Сергей Жестков - преподаватель МФТИ и по совместительству эксперт OTUS, приглашает всех желающих на бесплатный демо-урок [продвинутого курса "Математика для Data Science"](https://otus.pw/WXEe/), по теме: [«Отображения, их матрица и диагонализ... | https://habr.com/ru/post/527270/ | null | ru | null |
# Win 8.1 App использование HTML & WinJS
Я предполагаю, что эта статья будет интересна тем, кто знает и умеет HTML&JavaScript, но не пробовал силы в разработке приложений для Win8. Для того, чтобы пройти эту статью и кодить в сласть необходимо иметь на борту VS 2013.
В статье будут рассмотрены ключевые аспекты разр... | https://habr.com/ru/post/216135/ | null | ru | null |
# Оптимизация расхода батареи

#### Введение
В этой статье приводится несколько советов по оптимизации расхода батареи приложениями.
Отключая фоновые сервисы обновлений при потере соединения или уменьшая частоту... | https://habr.com/ru/post/134828/ | null | ru | null |
# Дистанционное управление громкостью IP TV приставки при помощи Attiny13A
Как-то мне позвонили из Ростелекома и предложили подключить IP TV. Ну что же, решил я, пусть жена с сыном смотрят в спальне мультики и согласился. И вот принесли мне заветную коробочку. Т.к. отдельного телевизора для неё у меня нет, то решил я ... | https://habr.com/ru/post/524592/ | null | ru | null |
# Разделяем интерфейс и реализацию в функциональном стиле на С++
Разделяем интерфейс и реализацию в функциональном стиле на С++
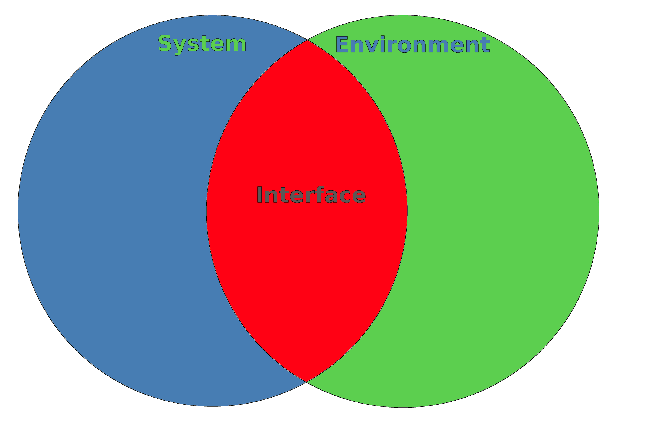
В языке С++ для разделения объявлений структур данных (классов) используются заголовочные файлы. В н... | https://habr.com/ru/post/312148/ | null | ru | null |
# NetLogo: И взрослым, и детям
Многие сложные системы удается исследовать только моделированием. Для систем, состоящих из большого количества независимых объектов, такие как поведение толпы, развитие много... | https://habr.com/ru/post/220589/ | null | ru | null |
# Как мы CRM Битрикс24 с кучей всего интегрировали
У нас был сложный сайт с личным кабинетом клиентов, устаревшая, переписанная 1С-ка, десяток маркетинговых сервисов, и телефония на Asterisk.
Единственное, что вызывало у меня опасение — это учётная система, написанная на .net. Ничто в мире не бывает более беспомощным... | https://habr.com/ru/post/697800/ | null | ru | null |
# Delinking и Lisp
Экономический термин delinking впервые (насколько я смог отследить) использовал [Самир Амин](https://ru.wikipedia.org/wiki/%D0%90%D0%BC%D0%B8%D0%BD,_%D0%A1%D0%B0%D0%BC%D0%B8%D1%80) в работе 1984-го года [Delinking: Towards a Polycentric World](https://www.goodreads.com/book/show/390264.Delinking) дл... | https://habr.com/ru/post/656081/ | null | ru | null |
# jPlayer — плагин для проигрывания аудио и видео
[](http://www.jplayer.org/)Я уже писал про скрипт [audio.js](http://habrahabr.ru/blogs/javascript/110906/), позволяющий проигрывать аудио файлы использую возможно... | https://habr.com/ru/post/112776/ | null | ru | null |
# Союз R и PostgreSQL. Анализируем работу аэропортов, рассчитываем пенсии
Часть I. R извлекает и рисует
-----------------------------
Конечно, PostgreSQL с самого начала создавалась как универсальная СУБД, а не как специализированная OLAP-система. Но один из больших плюсов Постгреса — в поддержке языков программирова... | https://habr.com/ru/post/427571/ | null | ru | null |
# NCBI Genome Workbench: научные исследования под угрозой
Современные компьютерные технологии, технические и программные решения — всё это сильно облегчает и ускоряет проведение различных научных исследований... | https://habr.com/ru/post/430476/ | null | ru | null |
# Очень кратенький обзор Orange Pi 5
Всем привет и с наступающим !
Дома живут две raspberry pi 4 на одном из которых живет в DMZ nexcloud + некоторое публичное барахлишко, а на другом home assistant. Есть так же один raspberry pi 3 с octoprint для управления 3д принтера. Брал до. Сейчас цены на малинку вообще не гума... | https://habr.com/ru/post/708766/ | null | ru | null |
# Обход проактивной защиты Agnitum Outpost Security Suite в 2 строчки
Ранее я уже [заявлял об этом](http://www.securitylab.ru/blog/personal/shanker/24993.php) и даже делился видео-демонстрацией, но не раскрывая подробности. К сожалению, Разработчик ~~забил болт~~ так и не отреагировал на моё письмо о проблеме (моё обр... | https://habr.com/ru/post/161393/ | null | ru | null |
# Netapp — реальность против маркетинга
###### Доброго дня

Так уж получилось, что я занимаюсь системами хранения данных последние 5 лет, 4 года из которых я посвятил системам среднего уровня компани... | https://habr.com/ru/post/212453/ | null | ru | null |
# Маскируем класс под граф Boost. Часть 2: Завершаем реализацию поддержки концепций
[Пролог: Концепции Boost](http://habrahabr.ru/post/210838/)
[Часть 1: Подключение ассоциированных типов без вмешательс... | https://habr.com/ru/post/212089/ | null | ru | null |
# Введение в разработку картографических и геолокационных мобильных приложений с применением QtMobility.location
Этот пост участвует в конкурсе „[Умные телефоны за умные посты](http://habrahabr.ru/company/Nokia/blog/132522/)“
Никогда ранее не приходилось участвовать в разработке картографических и геолокационных мо... | https://habr.com/ru/post/133447/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.