
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# У меня зазвонил телефон. Кто говорит?.. Поможет «слон»
Автоматическое определение клиента и его региона по входящему телефонному звонку стало неотъемлемой частью любой развитой HelpDesk или CRM-системы. Только **надо уметь делать это быстро** — тогда появляется масса возможностей.
Например, можно менеджеру сразу ... | https://habr.com/ru/post/514970/ | null | ru | null |
# JavaScript 2016, а можно попроще?
Последние полгода много пишут о неоправданной сложности клиентского JavaScript. Недавняя статья [How it feels to learn JavaScript in 2016](https://hackernoon.com/how-it-feels-to-learn-javascript-in-2016-d3a717dd577f#.l8ak5j3gz) и ее [перевод на хабре](https://habrahabr.ru/post/31202... | https://habr.com/ru/post/313234/ | null | ru | null |
# Проект Lazybones — «Лентяй», который работает за вас
Я не люблю Maven.
О моей пассионарной ненависти к этой штуке можно написать не одну статью, но сегодня я хочу поговорить об одной очень хорошей фиче Мавена — об архетипах. Что это такое можно прочитать [в официальной документации](https://maven.apache.org/guide... | https://habr.com/ru/post/218205/ | null | ru | null |
# Даже в Java 9 ArrayList всё ещё можно (и нужно) улучшать
Думаю, большинство джавистов согласится, что `java.util.ArrayList` — наиболее используемая коллекция в мире Java. Она появилась в версии 1.2 и быстро стала "коллекцией по умолчанию", ведь в большинстве случаев её возможностей вполне достаточно для повседневной... | https://habr.com/ru/post/348018/ | null | ru | null |
# PHPStorm + XDebug + Docker
Таких статей уже тысяча, зачем?Мне не подошла полностью ни одна. Я потратил около двух часов на весь процесс и за это время нашёл около десятка статей, в которых либо данные были неполные, либо просто устаревшие
Я ожидаю, что у вас уже есть проект с настроенным докером.
Шагов, на самом д... | https://habr.com/ru/post/712670/ | null | ru | null |
# Док в Леопарде с черным треугольником
Я уверен, что есть небольшое количество людей, которым нравится трехмерный док в Леопарде, но которые не могут вынести светящуюся точку, обозначающую запущенное приложение. Так же я уверен, что небольшое количество пользователей будут рады увидеть возвращение черного треугольног... | https://habr.com/ru/post/45811/ | null | ru | null |
# Мой конспект с Joker 2020
Вот и прошла конференция Joker 2020 для Java senior-ов. Для меня эта конференция стала особенной сразу по нескольким причинам — это первая "серьёзная" техническая конференция на которую я попал (в качестве зрителя), это моя первая онлайн-конференция, и это первая конференция, билет на котор... | https://habr.com/ru/post/531666/ | null | ru | null |
# Linux Unified Key Setup: как защитить флэшки и внешние диски от взлома

Посмотрим, как с помощью системы на базе спецификации Linux Unified Key Setup (LUKS) и утилиты Cryptsetup можно зашифровать флэш-накопители, внешние жёсткие ... | https://habr.com/ru/post/552040/ | null | ru | null |
# Удобный способ тестирования React-компонентов
Я написал построитель дополнительных отчетов (custom reporter) для Jest и выложил на [GitHub](https://github.com/gnemtsov/jest-snapshots-book). Мой построитель называется Jest-snapshots-book, он создает HTML-книгу снимков компонентов React-приложения.

Тут, казалось бы, хаотич... | https://habr.com/ru/post/586450/ | null | ru | null |
# Лайфхаки в веб-разработке

#### Ссылки открытия файлов в IDE
Это облегчит вам поиск нужного файла.
Вы сможете создавать ссылки на код прямо на странице ошибки. Или в журнале ошибок.
Сделайте ссы... | https://habr.com/ru/post/138496/ | null | ru | null |
# Консоль в массы. Переход на светлую сторону. Bash

Вступление
----------
Удобство использования того или иного инструмента заключается в том, насколько он помогает в решении конкретной задачи. Также... | https://habr.com/ru/post/319670/ | null | ru | null |
# Symfony 2.0, RequestHandler Component
На сайте [Symfony Components](http://components.symfony-project.org/) про компонент **RequestHandler** сказано примерно следующее:
> Гибкое микро-ядро для быстрых фреймворков.
>
>
Так ли это и что из себя представляет **RequestHandler** в Symfony 2 я попробую рассмотреть... | https://habr.com/ru/post/89202/ | null | ru | null |
# Домашний Minecraft server в Azure часть 2 — Azure Automation
[В прошлой статье](https://habrahabr.ru/post/339034/) мы разворачивали майкрафт сервер в Azure с использованием 100% автоматизации процесса и прочих разных интересных современных практик DevOps. В этой статье мы ещё больше углубимся в **Azure IaaS** — в ча... | https://habr.com/ru/post/339906/ | null | ru | null |
# Кроссплатформенный многопоточный TCP/IP сервер на C++
Решил задаться целью написать простой в использовании и при этом быстрый многопоточного TCP/IP сервера на C++ и при этом кроссплатформенный — как минимум чтобы работал на платформах Windows и Linux без требования как-либо изменять код за пределами самописной библ... | https://habr.com/ru/post/503432/ | null | ru | null |
# Flexify плагин для выравнивания чего бы то ни было
Наверное каждый верстальщик, хотя бы раз в жизни сталкивался с версткой двух- или трех-колоночного макета. Хотя, сам макет сверстать несложно, если конечно колонки не различаются цветом фона, как например на хабре. А вот с разноцветными придется помучаться, потому ч... | https://habr.com/ru/post/47895/ | null | ru | null |
# Cоздание прототипа социальной сети на ExtJS. Первые и не последние проблемы с ExtJS 4
Постоянно меняющиеся требования и сжатые сроки подтолкнули нас к использованию ExtJS 4 для создания прототипа.
Проблемы в ExtJS, с которыми мы столкнулись при разработке, едва ли превысили опыт, который мы получили при препарир... | https://habr.com/ru/post/129080/ | null | ru | null |
# Клонирование игры Lode Runner с первого ПК в СССР «БК-0010» плюс несколько слов о программировании игр в конце 80-х

Недавно я оказался в не совсем обычной для себя ситуации вынужденного безделья. Пару недель поваляв дурака, я стал чувствовать, что это... | https://habr.com/ru/post/335968/ | null | ru | null |
# Установка Oracle JDK 7 в Ubuntu 12.04
Приветствую всех обновившихся и тех кто планирует.
Как многие из вас знают, проприетарная ява была выпилина из официальных репозитариев.
Взамен, юзерам предложили пользоваться *OpenJDK*.
Однако со стабильностью работы последней имеются серьезные проблемы.
Но обо всем... | https://habr.com/ru/post/143113/ | null | ru | null |
# Знакомство с Rome от создателей Babel — компилятор, сборщик, линтер, тесты в одном флаконе

Почти две недели назад вышла [запись в блоге](https://romefrontend.dev/blog/2020/08/08/introducing-rome.html) по поводу Rome.
Rome предс... | https://habr.com/ru/post/515914/ | null | ru | null |
# Среда разработки PHP на базе Docker
Решение, которое позволит создать на локальном компьютере универсальную среду разработки на **PHP** за **30 — 40 минут**.
Почему Docker?
--------------
* Docker не является VM-системой, он не моделирует аппаратное обеспечение компьютера. Используя Docker вы получите минимальное ... | https://habr.com/ru/post/519500/ | null | ru | null |
# История о том как SVN copy победил SVN merge
Итак, сразу опишу нашу ситуацию и потом объясню почему дал этой статье такое глупое название :-)
Наша команда из 4х человек работает на одном проекте (пока не буду говорить, что за проект, надеюсь, напишу о нем позже)
У нас было 3 SVN ветки: Production (стабильная в... | https://habr.com/ru/post/62185/ | null | ru | null |
# Локализация в Silverlight
Локализация когда-то приходит в ваш интернациональный дом. Что бы вы ни построили — большой небоскреб или хижину дяди Тома — надо уметь разговаривать на языке жителей этого дома.
Если ваш Silverlight дом нуждается в локализации, милости просим, я постараюсь дать краски и кисточку, а плак... | https://habr.com/ru/post/87450/ | null | ru | null |
# Шаблон Presenter в Laravel
Если вы используете Laravel в своем проекте достаточно долго, ваши модели, скорее всего, стали довольно большими. Со временем их становится все труднее поддерживать, т.к. они обрастают новым функционалом. Когда вы пишете код для каждого случая, где используются ваши модели, возникает собла... | https://habr.com/ru/post/309942/ | null | ru | null |
# Заделываем дыры в сервере приложений 1С и вокруг него

В сегодняшней статье я расскажу об уязвимостях сервера 1С в корпоративной сети.
Как показала практика, в инсталляциях с 1С все допускают одни и те же ошибки разной степени се... | https://habr.com/ru/post/349620/ | null | ru | null |
# Считаем скобочки на Oracle SQL

Все началось с того, что на сайте [codeforces.ru](http://codeforces.ru) в очередном Codeforces Round я увидел интересную задачку [“Скобочная последовательность”](http://codeforces.ru/cont... | https://habr.com/ru/post/151895/ | null | ru | null |
# Как поморгать 4 светодиодами на CortexM используя С++17, tuple и немного фантазии
Всем доброго здравия!
При обучении студентов разработке встроенного программного обеспечения для микроконтроллеров в университете я использую С++ и иногда даю особо интересующимся студентам всякие задачки для определения особо ~~бол... | https://habr.com/ru/post/457246/ | null | ru | null |
# Как сделать из сайта приложение и выложить его в Google Play за несколько часов. Часть 1/2: Progressive Web App
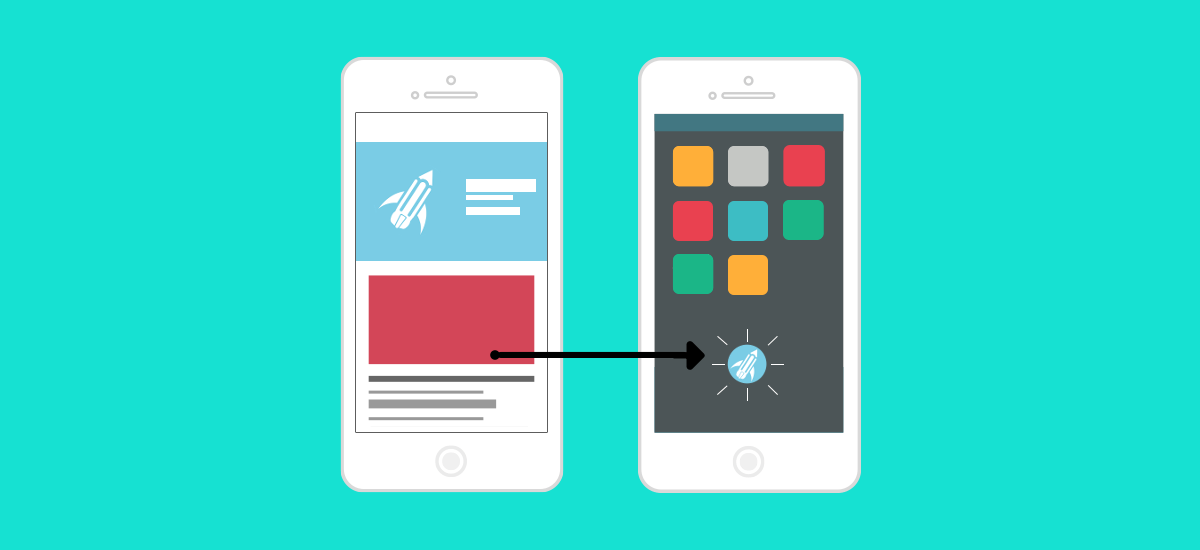
Наверное, все близкие к веб-разработке люди уже наслышаны о Progressive Web App. Ещё бы! Эта технология практически ур... | https://habr.com/ru/post/450504/ | null | ru | null |
# 30 полезностей для Firefox Developer Tools

Ниже приведены фичи и советы по использованию Firefox Developer Tools. Некоторые из них аналогичны возможностям инструментов в Chrome, для некоторых аналоги в д... | https://habr.com/ru/post/481036/ | null | ru | null |
# Как повысить качество кода в тестовом проекте
Качеством кода в тестах часто пренебрегают. Когда в совместной разработке участвуют десятки QA-инженеров, возникает острая необходимость ввести формализованные... | https://habr.com/ru/post/574320/ | null | ru | null |
# Как иногда плохой код и антипаттерн решают
Привет %username%!
Сегодня я хотел бы рассказать о том, как мне помог в проекте плохой код.
Кому интересно, прошу под кат.
Достался мне в наследство проект на сопровождение. Не знаю кем писался, но этому человеку икается и по сей день. Суть такая — есть приложение ... | https://habr.com/ru/post/271703/ | null | ru | null |
# Дамп ShadowBrokers: разбираемся в содержимом директории «swift»
Всем привет! В пятницу 14 апреля рано утром в публичном доступе появился новый дамп инструментов и документов Агенства Национальной Безопасности США, украденных APT-группировкой TheShadowBrokers. В данной статье мы попытаемся разобраться, что же содержи... | https://habr.com/ru/post/327114/ | null | ru | null |
# репостинг Twitter (или rss) в статус vkontakte.ru на Haskell
В данной статье речь пойдёт о небольшой программке, которая репостит твиты в статус во вконтакте.
Задача довольно простая и совершенно неоригинальная. Началось всё с того, что я прочитал статью на Хабре о том, как это [решается на python'е](http://habra... | https://habr.com/ru/post/85894/ | null | ru | null |
# Пишем Penguin Daycare Simulator на Go (Google App Engine) и Lua (Corona SDK)
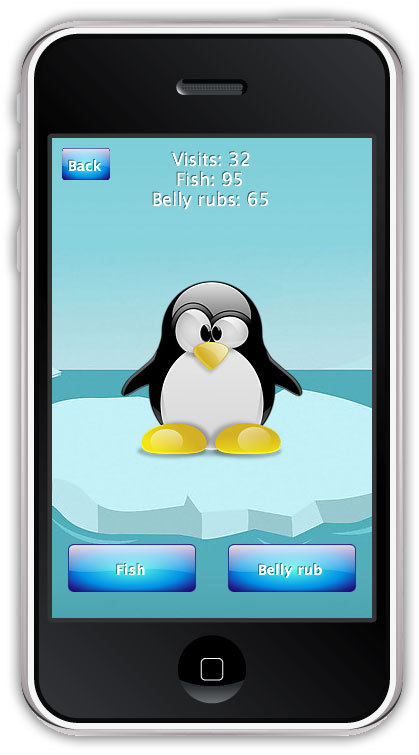
#### 1. Введение
Данный проект представляет собой простой пример использования Google App Engine в мобильном приложении.
... | https://habr.com/ru/post/220031/ | null | ru | null |
# История одного толстого бинарника
*Привет. Меня зовут Марко (я системный программист в Badoo). И я представляю вашему вниманию перевод поста по Go, который мне показался интересным. Go действител... | https://habr.com/ru/post/322880/ | null | ru | null |
# Автоматизация согласования сетевых доступов
Предыстория
-----------
Мы против умолчательного открытия доступов из неопределенных источников, поэтому если кто-то получает новую сеть либо сервер, ему придется открыть все необходимые сетевые доступы, по умолчанию обычно никакие сетевые доступы не выдаются для создавае... | https://habr.com/ru/post/571650/ | null | ru | null |
# Создаем датасет для распознавания счетчиков на Яндекс.Толоке

Как-то два года назад, случайно включив телевизор, я увидел интересный [сюжет](https://www.vesti.ru/doc.html?id=2921101) в программе "Вести". В нём рассказывали о том,... | https://habr.com/ru/post/469633/ | null | ru | null |
# Трепещущий Kivy. Обзор возможностей фреймворка Kivy и библиотеки KivyMD

[Kivy](https://github.com/kivy/kivy) и [Flutter](https://github.com/flutter/flutter) — два фреймворка с открытым исходным кодом для кроссплатформенной разрабо... | https://habr.com/ru/post/546684/ | null | ru | null |
# Курс MIT «Безопасность компьютерных систем». Лекция 14: «SSL и HTTPS», часть 3
### Массачусетский Технологический институт. Курс лекций #6.858. «Безопасность компьютерных систем». Николай Зельдович, Джеймс Микенс. 2014 год
Computer Systems Security — это курс о разработке и внедрении защищенных компьютерных систем.... | https://habr.com/ru/post/427787/ | null | ru | null |
# Организация деплоя в множество k8s окружений с помощью helmfile
[Helmfile](https://github.com/roboll/helmfile) — обёртка для [helm](https://github.com/helm/helm/), которая позволяет в одном месте описывать множество helm релизов, параметризовать их чарты для нескольких окружений, а также задавать порядок их деплоя.
... | https://habr.com/ru/post/491108/ | null | ru | null |
# Zabbix 3.X: мониторинг контролеров Adaptec в Windows Server (Hyper-V Core)
Доброго времени суток, %habrauser%! Сегодня займемся укрощением своих кривых ручонок и попробуем настроить мониторинг контролеров Adaptec на Hyper-V (core 2012r2) хостах при помощи Zabbix 3.2, PowerShell и консольной утилиты [Adaptec RAID Con... | https://habr.com/ru/post/323042/ | null | ru | null |
# DI для полностью переиспользуемых JSX-компонентов

Привет, меня зовут Сергей и мне интересна проблема переиспользования компонент в вебе. Глядя на то, как [пытаются](https://habrahabr.ru/company/docsvision... | https://habr.com/ru/post/338666/ | null | ru | null |
# Маршрутизация в socks. Еще один способ
Рассмотрим еще один способ маршрутизации локальной сети через «socks-прокси». В отличии от [предыдущего способа](http://habrahabr.ru/post/345418/) с «redsocks», в этом, будет рассмотрена возможность маршрутизации на сетевом уровне (сетевой модели OSI), по средствам пакета «badv... | https://habr.com/ru/post/347168/ | null | ru | null |
# 12 малоизвестных фактов о CSS
*Предлагаю читателям «Хабрахабра» перевод статьи [«12 Little-Known CSS Facts (The Sequel)»](http://www.sitepoint.com/12-little-known-css-facts-the-sequel/). Она совсем недавно была упомянута в [дайджесте интересных материалов из мира веб-разработки и IT](http://habrahabr.ru/company/zfor... | https://habr.com/ru/post/263169/ | null | ru | null |
# Различия асинхронной и многопоточной архитектуры на примере Node.js и PHP
В последнее время наблюдается рост платформ, построенных на асинхронной архитектуре. На асинхронной модели построен самый быстрый в мире веб-сервер nginx. Активно развивается шустрый серверный javascript в лице Node.js. Чем же хороша эта архит... | https://habr.com/ru/post/150788/ | null | ru | null |
# Гибкая авторизация с помощью Casbin и PERM. Практический пример
После написания предыдущей статьи по [языку PERM и библиотеке Casbin](https://habr.com/ru/post/539778/), возникли [вопросы](https://habr.com/ru/post/539778/#comment_22609026). Причем не у одного человека, и я хотел ответить сначала в комментарии, но пон... | https://habr.com/ru/post/540454/ | null | ru | null |
# PVS-Studio впечатлен качеством кода Abbyy NeoML

На днях компания ABBYY опубликовала исходный код своего фреймворка NeoML. Нам предложили проверить эту библиотеку с помощью PVS-Studio. Это интер... | https://habr.com/ru/post/509182/ | null | ru | null |
# Интеграция Siri или «Вот что мне удалось найти в вашем приложении»

На WWDC 2016 Apple представила миру SiriKit — API для работы с голосовым помощником.
Если вы не смотрели [WWDC сессию про SiriKit](https://developer.a... | https://habr.com/ru/post/303886/ | null | ru | null |
# Полезности Mercurial
Думаю, почти все читающие знают, что такое Mercurial — это распределённая система контроля версий, для исходного кода и других (преимущественно текстовых) файлов. Многие ей пользуются, и знают основные команды, как то удаление/добавление файлов, создание коммита и отправка локальных изменений в ... | https://habr.com/ru/post/188418/ | null | ru | null |
# Негативный опыт заказа iPhone 4 в Apple Store UK — как разочаровать клиента
Решил поделиться впечатлениями от заказа нескольких iPhone 4 в английском Apple Store, больно и обидно ударившим меня сразу об четыре бампера.
Все начиналось хорошо: сайт Apple Store предлагал немедленно приобрести iPhone 4 и получить ег... | https://habr.com/ru/post/98641/ | null | ru | null |
# Беспроводные локальные сети или как работает Wi-Fi по стандарту IEEE 802.11. Лабораторная работа в Packet Tracer
**Введение**
В данной статье в лабораторных работах изучается технология беспроводных локальных сетей по стандарту IEEE 802.11. Стандарт IEEE был разработан институтом инженеров по электротехнике и эле... | https://habr.com/ru/post/351564/ | null | ru | null |
# Как я создавал файл конфигурации DHCP из таблицы Excel при помощи Python
Я решил поставить DHCP сервер на Linux, но была небольшая проблема, у нас не было текущего DHCP сервера (все ip были статическими), карты сети, списка ip и mac адресов. Я сканировал сеть получил список mac и ip, распечатал и мы с коллегой пошли... | https://habr.com/ru/post/682558/ | null | ru | null |
# Простой многопользовательский текстовый редактор с end-to-end шифрованием
### Введение
На сегодняшний день защита информации является одной из приоритетных задач IT-индустрии, особенно учитывая то, что для прослушивания трафика в наше время практически не нужно иметь специализированных знаний – в Интернете достаточ... | https://habr.com/ru/post/485430/ | null | ru | null |
# «Слабые» ссылки в CPython
Модуль weakref позволяет создавать "слабые" ссылки на объекты.
"Слабой" ссылки не достаточно, чтобы объект оставался "живым": когда на объект ссылаются только "слабые" ссылки, сборщик мусора удаляет объект и использует память для других объектов. Однако, пока объект не удалён, "слабая" ссы... | https://habr.com/ru/post/599411/ | null | ru | null |
# (Архив) Matreshka.js — Введение
**Статья устарела. В [новой документации](http://ru.matreshka.io/) содержится самая актуальная информация из этого поста. См. [bindNode](http://ru.matreshka.io/#Matreshka-bindNode) и [on](http://ru.matreshka.io/#Matreshka-bindNode).**
Приветствую всех читателей и писателей хабра. ... | https://habr.com/ru/post/196146/ | null | ru | null |
# Как с помощь Raspberry PI вырастить фасоль, и снять TimeLapse видео
Приветствую вас господа!

Как-то раз, ребенку в школе задали вырастить фасоль, чтобы посмотреть во что она прорастает и как из боба вырастает расте... | https://habr.com/ru/post/180227/ | null | ru | null |
# Интегрируем Webpack в Visual Studio 2015
В статье я расскажу как сделать работу с webpack из Visual Studio удобнее, а именно: автоматический запуск webpack при открытии проекта, бандлинг при изменении файлов и... | https://habr.com/ru/post/278103/ | null | ru | null |
# Новые версии Mail.Ru Агента
`в течение последних суток запустили сразу три новых версии клиентов Mail.Ru Агента - для Windows (5.5), J2ME (3.5) и Symbian. все они уже доступны для загрузки с официального сайта.
**Windows*** возможность использования произвольного количества учетных записей Mail.Ru и ICQ одновреме... | https://habr.com/ru/post/60922/ | null | ru | null |
# Композиция протоколов для инъекции зависимостей
Мне нравится использовать композицию и инъекцию зависимостей, но когда каждая сущность начинает инъектится несколькими зависимости, получается некое нагромождение.
Проект растет и приходится инъектить все больше зависимостей в объекты, рефакторить методы помногу раз, ... | https://habr.com/ru/post/326712/ | null | ru | null |
# Какое тестовое задание выдать джависту? Лучше просто поговорить
Всем привет, меня зовут Сергей, я руковожу группой серверных программистов студии Whalekit и активно занимаюсь наймом в эту группу. Сервер пиш... | https://habr.com/ru/post/658435/ | null | ru | null |
# Книга «Node.js в действии. 2-е издание»
[](https://habrahabr.ru/company/piter/blog/351602/) Второе издание «Node.js в действии» было полностью переработано, чтобы отражать реалии, с которыми теперь сталкивается каждый Node-разр... | https://habr.com/ru/post/351602/ | null | ru | null |
# Zabbix 2.2: Мониторинг температуры процессора Windows машины
 **Немного о себе и о рабочей среде**Работаю инженером в компании из двух человек, обслуживаем десяток муниципальных и коммерческих предприятий с ... | https://habr.com/ru/post/228095/ | null | ru | null |
# Развертывание Mercurial репозиториев через FastCGI с использованием Nginx на FreeBSD
Поддался я влиянию моды и захватывающим перспективам DVCS с недавних пор. Это вытолкнуло меня с наезженной колеи Subversion + Trac и заставило искать новые схемы как хранить исходные тексты в разных компаниях. И предоставлять для ни... | https://habr.com/ru/post/90066/ | null | ru | null |
# Ввод в программу иерархического списка
Появилась задача — вводить в web-приложение элементы иерархического списка (например КЛАДР).
Когда работал с [drupal](http://drupal.org), видел там модуль [Hierarchical Select](http://drupal.org/project/hierarchical_select), реализующий эту функциональность.
Но хотелось с... | https://habr.com/ru/post/132594/ | null | ru | null |
# 8 недооцененных команд Git, которые должен знать каждый программист (помимо привычных pull, push, add, commit)
### 1. Переименовываем локальную ветку
Если вы сделали опечатку, когда вводили имя ветки, вам ... | https://habr.com/ru/post/567706/ | null | ru | null |
# Делаем консоль чуточку удобнее
Практически все Javascript-программисты пользуются консолью в браузерах. Консоль встроена в Хром, Оперу, IE и устанавливается с Firebug в Фоксе.
Но у неё есть пару неудобств, которые ... | https://habr.com/ru/post/116852/ | null | ru | null |
# WD MyBook Live — расширение стандартной функциональности
Не секрет, что в данное время наличие дома нескольких компьютеров и прочих устройств, работающих с сетью в той или иной мере (телефоны, телевизоры, iptv-приставки, медиаплееры, etc) стало для многих нормой вещей. Обычно, в таком случае всё подобное железо соед... | https://habr.com/ru/post/141120/ | null | ru | null |
# Создаем прототип для Sentiment Analysis с помощью Python и TextBlob

Что важно для команды разработчиков, которая только начинает строить систему, базирующуюся на машинном обучении? Архитектура, компоненты, возможности тести... | https://habr.com/ru/post/457168/ | null | ru | null |
# Сто раз сломай, один раз поправь или Как мы улучшали тестирование отказоустойчивости и восстановления API
Привет, хабровчане!
Меня зовут Нурыев Асхат, я ведущий инженер по автоматизации в DINS. За время ра... | https://habr.com/ru/post/647137/ | null | ru | null |
# jBitTorrent API 1.0, исправленный и дополненный
Недавно я [описывал библиотеку jBitTorrent](http://habrahabr.ru/blogs/java/117116/#habracut) для Java, с помощью которой можно работать с файлами по протоколу BitTorrent.
В той же статье был блок описания проблем, встречанных при использовании этой библиотеки, ведь ... | https://habr.com/ru/post/117526/ | null | ru | null |
# Руководство по решению проблем с памятью в Ruby

Наверняка есть везучие Ruby-разработчики, которые никогда не страдали от проблем с памятью. Но всем остальным приходится тратить невероятно много сил, чтобы разобраться, по... | https://habr.com/ru/post/305426/ | null | ru | null |
# Сохранность Registry своими руками
Недавно пострадал от потери NTUser.dat и с ним всего HKCU под Windows7 да так, что Windows Restore не помог — пришлось подниматься из бакапа месячной давности. В результате сильно озаботился вопросом резервирования реестра. Как выяснилось, Win7/Vista никакого резервирования «чисто»... | https://habr.com/ru/post/142558/ | null | ru | null |
# Эта база данных в огне…

Позвольте мне рассказать техническую историю.
Много лет назад я разрабатывал приложение со встроенными в него функциями совместной работы. Это был удобный экспериментальный стек, в котором использовалс... | https://habr.com/ru/post/522672/ | null | ru | null |
# Проверка проекта Microsoft Orleans с помощью PVS-Studio
Введение
--------
Всем доброго времени суток.
Вначале маленький Disclaimer для сомневающихся: да, за этот пост я, возможно, получу лицензию на PVS-Studio для проверки открытого проекта Microsoft Orleans. А может и не получу, как фишка ляжет-с. Нет, с компан... | https://habr.com/ru/post/276727/ | null | ru | null |
# Книга «Spring Boot 2: лучшие практики для профессионалов»
[](https://habr.com/ru/company/piter/blog/506872/)Привет, Хаброжители! Хотите повысить свою эффективность в разработке корпоративных и облачных Java-приложений?
Увели... | https://habr.com/ru/post/506872/ | null | ru | null |
# Ошибка, которая сохранилась в Windows с 1974 года
Сейчас 2018 год, а это сообщение — ошибка, сохранившаяся с 1974 года. Ограничение, которое встречается даже в самой последней Windows 10, появилось ещё ДО «ЗВЁЗДНЫХ ВОЙН». Баг древний как Уотергейт.

В те врем... | https://habr.com/ru/post/428734/ | null | ru | null |
# Насколько хорошо у вас настроен OSPF/IS-IS или помогатор для сетевых инженеров
Коллеги-сетевики, привет. К написанию данной статьи меня сподвигли задачи, с которыми приходилось сталкиваться во время работы с OSPF/IS-IS и тот набор решений, к которому я в конечном итоге пришел. Речь идет о насущном вопросе сетевых ин... | https://habr.com/ru/post/680048/ | null | ru | null |
# WAL in PostgreSQL: 4. Setup and Tuning
So, we got acquainted with the structure of the [buffer cache](https://habr.com/ru/company/postgrespro/blog/491730/) and in this context concluded that if all the RAM contents got lost due to failure, the [write-ahead log (WAL)](https://habr.com/ru/company/postgrespro/blog/4942... | https://habr.com/ru/post/496150/ | null | en | null |
# Основы работы с базой данных RIPE

*Данная статья задумывалась как отправная точка, которая поможет новичкам быстро вникнуть в суть работы с БД RIPE, чтобы в голове сложилась целостная картина и понимание... | https://habr.com/ru/post/526508/ | null | ru | null |
# Пишем игру для Android c помощью AndEngine. Часть 3
Всем привет!
Вот и долгоданное продолжение цикла статей о том как создать для андроид ~~не очень~~ простую игру с помощью [AndEngine](http://www.andengine.org/).
Уже ознакомились с предыдущими статьями?
[Часть 1](http://habrahabr.ru/blogs/android_developme... | https://habr.com/ru/post/123367/ | null | ru | null |
# Пишем приложение для удаленного управления плеером MPV из RetroOrangePi
Многие пользователи медиацентра KODI, входящего в состав RetroOrangePi, наверняка заметили, что там используется внешний плеер MPV, который, в отличии от штатного, имеет поддержку аппаратного декодирования. Это позволяет проигрывать контент 1080... | https://habr.com/ru/post/423765/ | null | ru | null |
# Ущербно-ориентированное программирование
Ущербно-ориентированное программирование — это набор подходов, поощряющий повторное использование кода и гарантирующий долгосрочное использование производимого программистами кода в боевых системах. Количество строк кода является повсеместно применяемым показателем значимости... | https://habr.com/ru/post/203646/ | null | ru | null |
# Логгирование приложения на C# в базу данных FireBird Embedded с помощью NLog 2.0
Приступая к своему первому десктопному приложению на С#, я задался вопросом ведения логов. Изучив предложения по данной теме, за хорошие отзывы и отсутствие платы за использование, мой выбор пал на NLog 2.0. После чтения документации на... | https://habr.com/ru/post/133763/ | null | ru | null |
# Избавляемся от «vk.com/away.php» или переход по ссылкам здорового человека
Переходя по ссылкам, размещенным во Вконтакте, можно заметить, что как и в остальных социальных сетях, сначала происходит переход на «безопасную» ссылку, после чего социальная сеть решает: нужно ли пускать пользователя дальше или нет. Большин... | https://habr.com/ru/post/453904/ | null | ru | null |
# Kali Linux: виды проверок информационных систем
→ Часть 1. [Kali Linux: политика безопасности, защита компьютеров и сетевых служб](https://habrahabr.ru/company/ruvds/blog/338338/)
→ Часть 2. [Kali Linux: фильтрация трафика с помощью netfilter](https://habrahabr.ru/company/ruvds/blog/338480/)
→ Часть 3. [Kali L... | https://habr.com/ru/post/339636/ | null | ru | null |
# Black [O]lives Matter: раса, криминал и огонь на поражение в США. Часть 2
В [первой части статьи](https://habr.com/ru/post/517776/) я описал предпосылки для исследования, его цели, допущения, исходные данные и инструменты. Сейчас можно без дальнейших разглагольствований сказать гагаринское...
Поехали!
--------
Имп... | https://habr.com/ru/post/517782/ | null | ru | null |
# Конвертер аудио / видео файлов FFmpeg
1 Введение
Каждый пользователь хотя бы раз использовал компьютер для просмотра фильмов или прослушивания музыки. Большинство из Вас знает о существовании различных форматов как аудио-, так и видеоинформации. Каждый формат предназначен для своей цели.
Так MP4 удобен для в... | https://habr.com/ru/post/119834/ | null | ru | null |
# Обнаружение пересекающихся сообществ в Instagram для определения интересов пользователей
Сколько может рассказать о человеке профиль в соцсети? Фотографии, посты, комментарии, подписки – непаханное поле для анализа. Сегодня поговорим о том, как мы определяем интересы пользователей на основе их подписок в сети Instag... | https://habr.com/ru/post/470634/ | null | ru | null |
# Пишем аудио-разведчик своими руками
Было бы здорово иногда иметь под рукой программку, которая в наше отсутствие умеет записывать звук со встроенного микрофона нашего ноутбука и передавать его по сети на другой наш комьютер. А тот, в свою очередь, этот звук умел бы воспроизводить в режиме реального времени. Давай по... | https://habr.com/ru/post/660861/ | null | ru | null |
# Mikrotik, Telegram и не только…
Здравствуйте, друзья!
Сегодня я хочу рассказать вам, как открыл для себя новый язык программирования, среду исполнения, а ещё готовый фронт-энд. И всё это без кучи фреймвор... | https://habr.com/ru/post/686252/ | null | ru | null |
# Автоматическое разблокирование корневого LUKS-контейнера после горячей перезагрузки
Зачем вообще люди шифруют диски своих персональных компьютеров, а иногда — и серверов? Понятное дело, чтобы никто не украл с диска фотографии их любимых домашних котиков! Вот только незадача: зашифрованный диск требует при каждой заг... | https://habr.com/ru/post/457396/ | null | ru | null |
# Rust 1.59.0: встроенный ассемблер, деструктурирующее присваивание, отключение инкрементальной компиляции
Команда Rust публикует новую версию языка — 1.59.0. Rust — это язык программирования, позволяющий каждому создавать надёжное и эффективное программное обеспечение.
---
[политическое сообщение удалено из-за прав... | https://habr.com/ru/post/653565/ | null | ru | null |
# Основы Ansible, без которых ваши плейбуки — комок слипшихся макарон
Я делаю много ревью для чужого кода на Ансибл и много пишу сам. В ходе анализа ошибок (как чужих, так и своих), а так же некоторого количества собеседований, я понял основную ошибку, которую допускают пользователи Ансибла — они лезут в сложное, не о... | https://habr.com/ru/post/508762/ | null | ru | null |
# Openwrt сниффер витой пары
Всем доброго времени суток, моя не большая история началась с того как мы с другом спорили о стандартах 10BASE-T и 100BASE-T о полных и халф-дуплексах в итоге решил на примере готового устройства показать ему что слушать с пар можно.
Прочитав [статью](https://habr.com/ru/post/90678/) вз... | https://habr.com/ru/post/512468/ | null | ru | null |
# Универсальный бот для игры Flood-It

*Рисунок 1. Игровое поле.*
Однажды, попалась мне на глаза одна [статейка](http://habrahabr.ru/blogs/gdev/129117/). Сразу же после прочтения заголовка, в голове появились деся... | https://habr.com/ru/post/136380/ | null | ru | null |
# Переводим студентов на удаленку за 1 день

Еще 16 марта мы сидели в уютном оупенспейсе, а уже на следующий день весь офис переехал на удаленку, домой. На хабре достаточно подобных историй. Но специфика нашей ситуации заключает... | https://habr.com/ru/post/495820/ | null | ru | null |
# Миграция схемы данных без головной боли: идемпотентность и конвергентность для DDL-скриптов
Язык SQL и реляционные базы с нами уже более сорока лет. За это время стандарт SQL прошёл через множество ревизий, и, судя по всему, процесс развития на этом не останавливается. Реляционные базы в качестве хранилищ данных дес... | https://habr.com/ru/post/337816/ | null | ru | null |
# Имитируем иридисценцию: шейдер CD-ROM
Этот туториал посвящён **иридисценции**. В этом туториале мы исследуем саму природу света, чтобы понять и воссоздать поведение материала, создающего цветные отражения. Туториал предназначен для разработчиков игр на Unity, однако описанные в нём техники можно запросто реализовать... | https://habr.com/ru/post/346852/ | null | ru | null |
# Автоматическое управление номером версии c помощью Azure DevOps
В этой статье я расскажу, как мы организовали последовательное автоматическое увеличение номера версии приложения при выполнении коммита в ветку main с помощью Azure DevOps Pipeline.
Мы делаем этого для того, чтобы все пользователи и разработчики могл... | https://habr.com/ru/post/576464/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.