
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Багобезопасный код: шаблон проектирования Null Safe
### Содержание
I. Описание проблемы
II. Обзор существующих решений
III. Вариант решения без применения аспектов.
IV. Решение на AspectJ
V. Динамические аспекты
VI. Послесловие.
VII. Ссылки и литература
### I.Описание проблемы
При программиров... | https://habr.com/ru/post/169827/ | null | ru | null |
# Чат вконтакта в качестве терминала
Вдохновлённый постом [«Простой диспетчер задач с веб-интерфейсом, написанный на языке GO для Unix-систем включая Android»](http://habrahabr.ru/post/247727/), языком Go и утилитой [simple status](https://github.com/cdarwin/simple_status), я решил написать в качестве забавного экспер... | https://habr.com/ru/post/251083/ | null | ru | null |
# Сравнение методов прогнозирования конверсии цепочек рекламных каналов
Самая суть [цепочек рекламных каналов](https://en.wikipedia.org/wiki/Attribution_(marketing)) вызывает непреодолимое желание узнать, что вероятнее всего произойдет дальше в цепочке. Будет конверсия или нет?
Но это похвальное стремление часто ут... | https://habr.com/ru/post/443562/ | null | ru | null |
# Настройка в OpenSearch аутентификации и авторизации пользователей через Active Directory по протоколу LDAP

В этой статье я расскажу о том, как я настраивал аутентификацию и авторизацию доменных пользователей Active Directory ... | https://habr.com/ru/post/664874/ | null | ru | null |
# Макросы в С и С++
Макросы - один из моих самых любимых инструментов в языках С и С++. Умные люди и умные книжки советуют по максимуму избегать использования макросов, по возможности заменяя их шаблонами, ко... | https://habr.com/ru/post/546946/ | null | ru | null |
# Переход на новую версию HP Application Lifecycle Management (ALM)
[](http://habrahabr.ru/company/hp/blog/263281/) Привет Хабр!
У каждого HP Application Lifecycle Management (ALM) администратора рано или п... | https://habr.com/ru/post/263281/ | null | ru | null |
# MindStream. Как мы пишем ПО под FireMonkey. Часть 4 Serialization
[Часть 1](http://habrahabr.ru/post/232955/).
[Часть 2](http://habrahabr.ru/post/234801/).
[Часть 3. DUnit + FireMonkey](http://habrahabr.ru/post/241301/).
[Часть 3.1. По мотивам GUIRunner](http://habrahabr.ru/post/241377/).
Ещё в начале ув... | https://habr.com/ru/post/245441/ | null | ru | null |
# Программируем прямо в Nginx

Nginx — великолепный веб-сервер. Все мы привыкли использовать его в связке с бекендами на разных языках программирования. Но оказывается можно писать простые программы прямо внутри конфигурационного ф... | https://habr.com/ru/post/504308/ | null | ru | null |
# Проблема трех раскладок в Linux
Имея одновременно три раскладки (английскую, русскую, украинскую) всегда в них путался, так как отличить их не глядя на индикатор не просто, а при потребности украинской раскладки, добавлять её и убирать каждый раз неудобно. Решается очень просто, расширением русской раскладки четырьм... | https://habr.com/ru/post/111059/ | null | ru | null |
# Анонс серии статей по настройке сервера Communigate Pro. Установка сервера
#### Всем привет!
Немного о наших разработках. Установка бесплатной версии.

Начиналось все с почтового сервера, но сейчас это уже полноценны... | https://habr.com/ru/post/185726/ | null | ru | null |
# Архивация по URL

Каждый год несколько процентов материалов, на которые я ссылаюсь, исчезают навсегда. Для человека, который старается не писать без пруфов, это неприемлемо, так что я разработал собственную стратегию борьбы с бит... | https://habr.com/ru/post/546342/ | null | ru | null |
# Безопасность OAuth2 и Facebook Connect уязвимости
Это — [сиквел моей сногсшибательной первой статьи](http://habrahabr.ru/post/150756/).
Готов поспорить что каждый веб разработчик сталкивался с фейсбук коннектом или вконтакте логином или аутенфикацией через твиттер. Все это по сути построено на основе OAuth1/2.
... | https://habr.com/ru/post/211362/ | null | ru | null |
# DDD на практике. Проектирование списка желаний
В интернете довольно много разрозненного материала по DDD. Если не считать синей книги, то в основном это короткие статьи с теорией, надёрганной из этой же книги, и которая мало пересекается с практикой. Возможно, конечно, что я просто плохо искал, но мне давно хотелось... | https://habr.com/ru/post/335834/ | null | ru | null |
# Математика в Gamedev по-простому. Триангуляции и Triangle.Net в Unity
Всем привет! Меня зовут Гриша, и я основатель CGDevs. Математика – очень крутой инструмент при разработке игр. Но если скажем без понимания [векторов](https://habr.com/post/430146/) и [матриц](https://habr.com/post/432544/) обойтись в принципе сло... | https://habr.com/ru/post/435374/ | null | ru | null |
# Категоризация веб-ресурсов при помощи… трансформеров?
Привет! Меня зовут Анвар, я аналитик данных RnD-лаборатории. Перед нашей исследовательской группой стоял вопрос проработки внедрения ИИ в сервис фильтрации веб-контента SWG-решения [Solar webProxy](https://rt-solar.ru/products/solar_webproxy/). В этом посте я рас... | https://habr.com/ru/post/690556/ | null | ru | null |
# Twitter открывает исходный код движка, заменяющего эмоджи на картинки
Речь здесь пойдёт о символах-картинках и о том, как отображать их.
По-японски они называются «絵文字» (где «絵» означает «картинка», ... | https://habr.com/ru/post/362825/ | null | ru | null |
# Как мы слили финал IT-Планеты по программированию
Не мы плохие, а багов много. Разработка искусственного интеллекта для игры “Хоккей” за ~7 часов.
Изначально статья планировалась о стратегиях участников, о том, что они успели сделать за конкурсное время и рады ли проделанной работой, но, опросив финалистов восемь... | https://habr.com/ru/post/472248/ | null | ru | null |
# Отладка приложений Node.js в Kubernetes?
#### Зачем вам это нужно?
При разработке кода на стороне сервера время от времени возникает проблема, которую очень трудно воспроизвести, наблюдаются утечки памяти ... | https://habr.com/ru/post/591903/ | null | ru | null |
# Построение моделей на панельных данных в Python, часть 2: метод «разность разностей» (diff-in-diff)
**Построение моделей на панельных данных в Python, часть 2: метод “разность разностей” (diff-in-diff).**
Привет, Хабр!
Данная статья является продолжением [статьи](https://habr.com/ru/post/710714/) “Построение моде... | https://habr.com/ru/post/710716/ | null | ru | null |
# Пиши на C как джентльмен

*> «Code Monkey like Fritos
>
> Code Monkey like Tab and Mountain Dew
>
> Code Monkey very simple man
>
> With big warm fuzzy secret heart:
>
> Code Monkey like you
>
> Code M... | https://habr.com/ru/post/325678/ | null | ru | null |
# Всё и сразу: автоматическая проверка размера бандла
Привет всем, меня зовут Илья. В ИТ я работаю около 6 лет, последние 2 года — в компании «Яндекс.Деньги» фронтенд-разработчиком. В обязанности входит поддерживать/развивать части приложений, в данный момент проект «Личный кабинет» (и нет, это не просто «в ие неправи... | https://habr.com/ru/post/488754/ | null | ru | null |
# Cloud9 и OpenShift. Разработка и развертывание приложений в облаках
Так уж получилось, что сейчас я стажируюсь в одной компании, где очень тяжело выбить простую программку себе на десктоп, а тем более IDE, порой это даже превращается в целые недельные квесты. Но в то же время, в свободное от работы время, я очень лю... | https://habr.com/ru/post/165303/ | null | ru | null |
# Пишем документацию для Ruby on Rails проектов с помощью YARD
Добрый день, хабражители! Обнаружил, что на сайте нет статьи о том, как можно организовать процесс создания документации для Ruby on Rails п... | https://habr.com/ru/post/215879/ | null | ru | null |
# Минималистичный issue tracker на Django
В этой статье рассказывается, как за короткое время решить с помощью фреймворка Django, простую, но интересную задачу: создание системы баг-трекинга (система тикетов) для своего проекта. Наша система будет интегрирована с системой аутентификации пользователей Django и админист... | https://habr.com/ru/post/234307/ | null | ru | null |
# Передача цветного изображения с помощью Intel RealSense SDK

Вы задумали создать простое приложение с потоком цветного изображения, использующее [камеру Intel RealSense](https://software.intel.com/en-us/realsense/devkit) ... | https://habr.com/ru/post/279285/ | null | ru | null |
# Хабрачтец или как я сделал этим летом
Здравствуйте!
Вдохновленный постами о том, что нужно начать делать и все получится, в данном материале я хотел бы поделиться рассказом о результате многочисленных вдохновений и моём опыте разработки приложения для ОС Андроид. Постараюсь описать процесс от возникновения идеи д... | https://habr.com/ru/post/129738/ | null | ru | null |
# Java Challengers #3: Полиморфизм и наследование
Java Challengers #3: Полиморфизм и наследование
===============================================
*Мы продолжаем перевод серии статей с задачками по Java. [Прошлый пост про строки](https://habr.com/company/otus/blog/428449/) вызвал на удивление [бурную дискуссию](https:... | https://habr.com/ru/post/429120/ | null | ru | null |
# Мой друг Netmiko. Часть 2: Три улучшения Python-скрипта
Продолжаю ковырять автоматизацию рутины на сети из Huawei коммутаторов. На этот раз изыскания, которые позволили сократить код в 3 раза, а именно: хосты и команды перенесены в отдельные файлы, пароль и имя пользователя больше не хранятся в открытом тексте. Есть... | https://habr.com/ru/post/648127/ | null | ru | null |
# Меры центральности в Network Science
Привет, Хабр!
Меня зовут Сергей Коньков, я Data Scientist и участник [профессионального сообщества NTA.](https://newtechaudit.ru/) За последние 10 лет интерес к науке Network Science неимоверно возрос, что повлекло за собой закономерное развитие всевозможных инструментов для исс... | https://habr.com/ru/post/715386/ | null | ru | null |
# Двухуровневый CI-процесс PHP-проекта
Непрерывная интеграция (CI, англ. Continuous Integration) — это практика разработки программного обеспечения, которая заключается в выполнении частых автоматизированных ... | https://habr.com/ru/post/714514/ | null | ru | null |
# Управление VirtualBox с помощью консоли
Виртуализация… виртуализация…
Сейчас все пытаются выжать из своих аппаратных ресурсов как можно больше. Иметь несколько отдельных компьютеров с различными ОС немного накладно и не все организации пойдут на это. Но выход есть, можно использовать виртуальные машины. И возможн... | https://habr.com/ru/post/60325/ | null | ru | null |
# Создание Ultimate Hacking Keyboard
*Перевод истории задумки и создания Ultimate Hacking Keyboard – необычной клавиатуры, проект которой вскоре планируют запустить на Kickstarter.*
#### Как я решил построить идеальную клавиатуру для разработчика с нуля
В августе 2007 на работе я заметил, насколько далека от идеал... | https://habr.com/ru/post/376919/ | null | ru | null |
# Как Android-троян Gustuff снимает сливки (фиат и крипту) с ваших счетов

Буквально на днях Group-IB [сообщала](https://www.group-ib.ru/media/gustuff/) об активности мобильного Android-трояна Gustuff. Он работает исключительно на ме... | https://habr.com/ru/post/446948/ | null | ru | null |
# Строим надёжный процессинг данных — лямбда архитектура внутри Google BigQuery
В этой статье хочу поделиться способом, который позволил нам прекратить хаос с процессингом данных. Раньше я считал этот хаос и последующий ре-процессинг неизбежным, а теперь мы забыли что это такое. Привожу пример реализации на BiqQuery, ... | https://habr.com/ru/post/279491/ | null | ru | null |
# Опыт внедрения 2fa на linux с duosecurity
На недавно прошедшей конференции [Zeronights](https://2016.zeronights.ru/program/defensive-track/) я рассказывал про двухфакторную аутентификацию, и какие проблемы могут быть при ее внедрении. К сожалению, времени выступления для полного погружения в тему было мало, поэтому ... | https://habr.com/ru/post/322544/ | null | ru | null |
# Организация онлайн-вещания подкаста
Для [последней презентации Apple](http://tjournal.ru/paper/apple-october-event) мы решили расширить наши текстовые трансляции и добавить аудиоподкаст в реальном времени. С... | https://habr.com/ru/post/202226/ | null | ru | null |
# Модальные окна на CSS
В наше время для различных сайтов нормой стали всевозможные всплывающие модальные окна — popup'ы — для регистрации, авторизации, информационные окна, — всевозможных форм и размеров. Также существует огромное количество плагинов к тому же jQuery для простого и удобного создания таких попапов — т... | https://habr.com/ru/post/136351/ | null | ru | null |
# Асинхронное программирование в приложениях ASP.NET MVC 4
Прочитав [статью](http://habrahabr.ru/post/142318/) об изучении MVC и увидев [комментарий](http://habrahabr.ru/post/142318/#comment_4764117) пользователя [RouR](http://habrahabr.ru/users/rour/), я очень заинтересовался данной темой, ну и на ходу решил перевест... | https://habr.com/ru/post/142372/ | null | ru | null |
# Как не нужно использовать Node.js Stream API
В интернете опять кто-то не прав – во вчерашнем [Node Weekly](https://nodeweekly.com/issues/261) была ссылка [на пост](https://itnext.io/streams-for-the-win-a-performance-comparison-of-nodejs-methods-for-reading-large-datasets-pt-2-bcfa732fa40e) в котором автор пытается и... | https://habr.com/ru/post/427901/ | null | ru | null |
# Алгоритм Форчуна, подробности реализации
Последние несколько недель я работал над реализацией [алгоритма Форчуна](https://en.wikipedia.org/wiki/Fortune%27s_algorithm) на C++. Этот алгоритм берёт множество 2D-точек и строит из них [диаграмму Вороного](https://en.wikipedia.org/wiki/Voronoi_diagram). Если вы не знаете,... | https://habr.com/ru/post/430628/ | null | ru | null |
# Pebble: пример использования Android-компаньона
 Благодаря официальному мобильному приложению Pebble отлично справляются с информированием о состоянии вашего смартфона — показывают входящие сообщения, информацию о вызовах и п... | https://habr.com/ru/post/249167/ | null | ru | null |
# IPv6 теория и практика: виды пакетов и автоконфигурация
Эта вторая статья, продолжающая цикл, посвященный IPv6. В [первой](http://habrahabr.ru/post/210100/) вводной статье речь шла о структуре IPv6 пакета, з... | https://habr.com/ru/post/210224/ | null | ru | null |
# Модуль PowerShell для Intel IoT Gateway
Шлюзы Intel для интернета вещей могут работать под управлением различных операционных систем. Одна из них – Windows 10 IoT. Сегодня мы поговорим о модуле для PowerShell **IntelIoTGatewaySetup**, который создан специально для поддержки IoT-шлюзов в среде Microsoft Windows.
[... | https://habr.com/ru/post/304046/ | null | ru | null |
# Поиск подстроки и смежные вопросы
Здравствуйте, уважаемое сообщество! Недавно на Хабре проскакивала неплохая обзорная [статья](http://habrahabr.ru/blogs/algorithm/111449/) о разных алгоритмах поиска подстроки в строке. К сожалению, там отсутствовали подробные описания каких либо из упомянутых алгоритмов. Я решил вос... | https://habr.com/ru/post/113266/ | null | ru | null |
# DevTips: Советы веб-разработчику (1-16)
Команда браузера [Google Chrome](https://www.google.ru/chrome/browser/desktop/) проделывает огромную работу для того, чтобы разработчикам жилось лучше. [Chrome DevTools](https://developer.chrome.com/devtools) — пример замечательного инструмента, сильно упрощающего отладку ваше... | https://habr.com/ru/post/268519/ | null | ru | null |
# Big O Notation
Asymptotic notations are used to represent the complexity or running time of an algorithm. It is a technique of defining the upper and lower limits of the run-time performance of an algorithm. We can analyze the runtime performance of an algorithm with the help of asymptotic notations. Asymptotic not... | https://habr.com/ru/post/559518/ | null | en | null |
# Знакомство с Apache Mahout
*Привет.
Моя первая [статья](http://habrahabr.ru/post/188350/) на Хабре показала, что не многие знают о библиотеке Mahout. (Может быть, конечно, я в этом ошибаюсь.) Да и ознакомительного материала по этой теме здесь нет. Поэтому я решил написать пост, рассказывающий о возможностях библ... | https://habr.com/ru/post/189098/ | null | ru | null |
# Загрузка классов в серверах приложений, особенности JBoss AS 7
Java характеризуется динамической загрузкой классов. Для поиска и загрузки используется механизм делегирующих classloader'ов. В Java SE окружении их количество ограничивается 2-3, но в серверах приложений оно приближается к 10 иерархическим classloader'а... | https://habr.com/ru/post/140133/ | null | ru | null |
# Yapf — причесываем код Python автокорректором
В эпоху все большей популярности различных js и css linter'ов, не удивительно появление удобного линтера с автокоррекцией для Python.
Приветствуйте, [Yapf](https://github.com/google/yapf/) — готовое решение, для превращения каши из строк во вполне читаемый код. И пове... | https://habr.com/ru/post/324336/ | null | ru | null |
# Система настроек и смена версий программ: эволюция жизнеспособных форм
*Константно-переменный дуализм.*
Настройки у программ существуют давно, от самых древних ассемблерных программ, имеющих в своём коде... | https://habr.com/ru/post/133989/ | null | ru | null |
# Nemesida WAF: защита сайта и API от атак и паразитного трафика
За прошедшие выходные мы зафиксировали всплеск атак на веб-ресурсы, уверен, с этим столкнулись и вы. И пока зарубежные вендоры решают, кто из них уходит, кто - нет, мы продолжаем работать на отечественном рынке, улучшать механизмы работы Nemesida WAF и д... | https://habr.com/ru/post/654409/ | null | ru | null |
# Минимальная Arduino своими руками
Arduino — это хорошо, когда хочется быстро реализовать идею, не заморачиваясь мелочами. Но когда идея проверена, лишняя функциональность начинает просто мешать.
Собирая робота на гусеничном шасси, я столкнулся с тем, что бутерброд из Arduino + MotorShield + Sensor Shield плюс ко ... | https://habr.com/ru/post/131589/ | null | ru | null |
# Паттерн BIF: чистый код фронтенда и удобная работа с серверными данными
В материале, перевод которого мы сегодня публикуем, речь пойдёт о том, что делать в ситуации, когда данные, получаемые с сервера, выглядят не так, как нужно клиенту. А именно, сначала мы рассмотрим типичную проблему такого рода, а потом разберём... | https://habr.com/ru/post/416011/ | null | ru | null |
# Не блокчейн
Чуть больше 10 лет назад, 3 января 2009 года был создан genesis block Биткойна. Так началась история блокчейна, обещавшая перевернуть мир, создать новую экономику, сделать существующие банки реликтами прошлого.
10 лет — достаточно долгий срок, чтобы подвести итоги, поговорить почему ничего подобного н... | https://habr.com/ru/post/438104/ | null | ru | null |
# Как сделать костыль для Тинькофф Инвестиций своими руками или уведомления об action required for take profit / stop loss
Есть такой брокер — Тинькофф Банк. И есть проблема в том, что на текущий момент этот брокер не имеет приказов take profit / stop loss. Поэтому, если вы хотите торговать более активно, то вам нужно... | https://habr.com/ru/post/442734/ | null | ru | null |
# Динамические Linq-запросы или приручаем деревья выражений
#### Введение
Linq to Entity позволяет очень выразительно со статической проверкой типов писать сложные запросы. Но иногда надо нужно сделать запросы чуть динамичнее. Например, добавить сортировку, когда имя колонки задано строкой.
Т.е. написать что то вр... | https://habr.com/ru/post/181065/ | null | ru | null |
# Заполнить виджет градиентом, изображением или гифкой с помощью ShaderMask
Один из наиболее популярных способов сделать элемент UI выразительным и аутентичным состоит в том, чтобы заполнить его картинкой, ... | https://habr.com/ru/post/703218/ | null | ru | null |
# Соотношение сторон и масштабирование изображений в Image компоненте
Адаптированный переводСогласно правилам Хабра я указал ссылку на оригинальную статью. Но хочу отметить, что данный перевод является адапта... | https://habr.com/ru/post/714438/ | null | ru | null |
# ROS: карта глубин на Raspberry Pi «малой кровью»
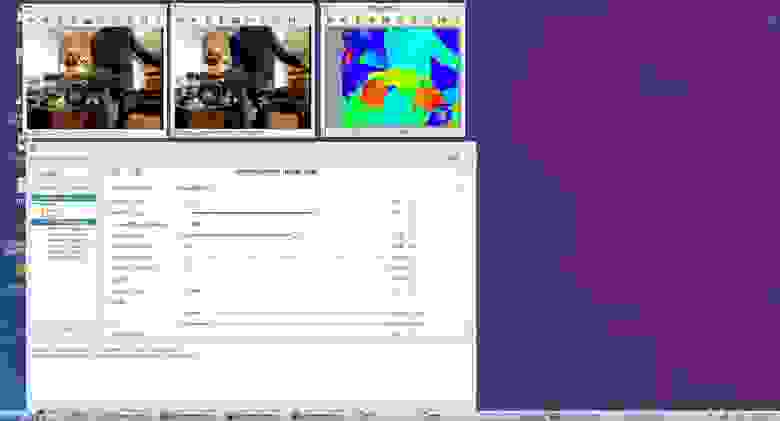
Если вы используете ROS при создании роботов, то наверняка знаете, что в ней есть поддержка работы со стереокамерами. Можно построить, например, карту глубин видимой части пр... | https://habr.com/ru/post/431092/ | null | ru | null |
# Всепротокольный бот на PHP за 10 минут, или как Microsoft Bot Framework и Azure Functions облегчают нам жизнь
Абсолютно невозможно отрицать, что развитие естественных паттернов в интерфейсах дало фантастический толчок к развитию всей ИТ-индустрии в целом. И речь не только и не столько о голосовых интерфейсах, скольк... | https://habr.com/ru/post/325130/ | null | ru | null |
# Очень долгая компиляция проекта .NET Framework под Windows CE и решение.
Если ваш несложный, казалось бы, проект, который вы пишете в MS Visual Studio 2005/2008 под ОС Windows CE собирается очень долго (у меня время сборки было примерно минут 5), то вы пришли по адресу. У меня была такая проблема, но всемогущий гуге... | https://habr.com/ru/post/41218/ | null | ru | null |
# Пришло время Java 12! Обзор горячих JEP-ов

Прошло полгода, а значит — [время устанавливать новую Java](https://mail.openjdk.java.net/pipermail/jdk-dev/2019-March/002718.html)! Это был долгий путь, и до конца добрались немногие. Из и... | https://habr.com/ru/post/444434/ | null | ru | null |
# Создание софтверного движка 2.5D
В настоящее время интерес к софтверным движкам, как из игр Quake, DOOM или Duke Nukem 3D практически нулевой. Однако, эти движки имели своё очарование и мне, например, очень нравится графика именно таких вот движков с нереалистичными текстурами на стенах. Конечно, такие текстуры можн... | https://habr.com/ru/post/329972/ | null | ru | null |
# Кеширование данных в LINQ-to-SQL, в т.ч. и NULL
Хочу поделиться с хабрасообществом парочкой классов, которые я использую в своих ASP.NET проектах. Один является обёрткой для объекта Cache, другой содержит расширяющие методы для кеширования результатов запросов LINQ-to-SQL.
Итак, задача: кешировать запросы LINQ-to... | https://habr.com/ru/post/106958/ | null | ru | null |
# React, AbortController и асинхронные onClick вызовы
Добрый день, читатели Хабра, представляю вашему вниманию перевод статьи [**React, Abort Controller and onClick async calls**](https://medium.com/@cis.bart/react-abort-controller-and-onclick-async-calls-aa4776772262)**.**
Что такое Abort Controller в JavaScript Web... | https://habr.com/ru/post/588799/ | null | ru | null |
# Структурированное сопоставление с шаблонами в Python 3.10
Версия [Python 3.10](https://www.python.org/dev/peps/pep-0619/), работа над которой началась 25 мая 2020 года, запланирована к выпуску 4 октября 2... | https://habr.com/ru/post/555804/ | null | ru | null |
# Самописный таймер в виде функции для промышленного контроллера Simatic S7-1200
Еще для серии S7-300 и S7-400 под Step 7 классических версий предлагаемых разработчику таймеров вполне хватало — это и стандартные таймеры IEC, реализованные в виде функциональных блоков, и таймеры S5 (которые, к слову, до сих пор существ... | https://habr.com/ru/post/491200/ | null | ru | null |
# Дайджест событий для HR-специалистов в IT-области на август 2017

Август — время отпусков и отдыха, но HR-специалистам некогда отдыхать. Хотя событий в августе меньше, чем обычно, «Мой круг» публикует для всех, кто ещё... | https://habr.com/ru/post/334732/ | null | ru | null |
# Codeigniter: делаем сессии наконец стабильными (прежде всего для авторизаций)
Сессии в Codeigniter хороши всем. Правда, очень удобно сделаны, особенно когда вы храните сессии в БД (что я считаю единственно верным). Куки шифрованные, в куках ничего, кроме идентификатора нету. Они привязываются к user\_agent и, опцион... | https://habr.com/ru/post/130853/ | null | ru | null |
# Обзор ретро-футуристичного КПК DevTerm с Linux
[](https://habr.com/ru/company/ruvds/blog/655123/)
Команда ClockworkPI выпустила интересный карманный девайс с ОС Linux, который легко собирается без паяльника, имеет экран с разрешени... | https://habr.com/ru/post/655123/ | null | ru | null |
# Операционные системы с нуля; Уровень 0
 Добрый день/вечер/ночь/утро! Есть один экспериментальный курс по операционным системам. Есть он в Стэнфордском университете. Но часть материалов доступно всем желающим. Помимо слайдов доступны по... | https://habr.com/ru/post/349248/ | null | ru | null |
# Насильственная оптимизация запросов PostgreSQL
Что делать, когда имеется приложение с закрытым исходным кодом, которое обращается к БД не самым оптимальным образом? Как потюнить запросы, не меняя приложение, а возможно и саму БД?
Если вы не задавались такими вопросами — вы очень успешный и строгий DBA.
Ну а ес... | https://habr.com/ru/post/432944/ | null | ru | null |
# adb: tap, swipe и два дымящихся event'а
Разработчики приложений для Android, а также тестировщики знают про команды `adb shell input tap X Y` и `adb shell input swipe X1 Y1 X2 Y2 [DurationMs]`. Но у каждой из них есть свой фатальный недостаток. Что это за недостатки, как их исправить с помощью event'ов и о нюансах я... | https://habr.com/ru/post/712374/ | null | ru | null |
# Я давно хотел открыть свою страницу на vkontakte.ru
и наконец я смогу это сделать! теоретически…
итак, основная идея — использовать данные моего профайла на сайте vkontakte.ru при формировании моей домашней страницы (она естественно не требует никакой аутентификации и видна всему интернету — в это и заключается с... | https://habr.com/ru/post/44660/ | null | ru | null |
# Automation: быстрый старт или «А ну-ка, Excel, пиши за меня сам!»
Небольшой топик-шпаргалка для быстрого написания скриптов для автоматической обработки документов ms office'а. А так же для помощи в преодолении синдрома чистого листа.
Как правильно заметили в недавнем [топике](http://habrahabr.ru/blogs/net/139706... | https://habr.com/ru/post/139850/ | null | ru | null |
# Как стереть данные так, чтобы их не смогли восстановить спецслужбы?

Восстановление и уничтожение данных — две стороны одной медали. Чтобы знать, когда и как можно вернуть себе информацию, надо понимать и как она может... | https://habr.com/ru/post/151554/ | null | ru | null |
# Готовим Helm с GitLab, KinD и Chart-Testing
В этой статье мы рассмотрим, как более-менее прилично организовать процесс тестирования и публикации чартов, встреченные при этом подводные камни, а также рассмо... | https://habr.com/ru/post/574496/ | null | ru | null |
# Битва двух якодзун, или Cassandra vs HBase. Опыт команды Сбербанка
Это даже не шутка, похоже, что именно эта картинка наиболее точно отражает суть этих БД, и в конце будет понятно почему:

Согласно DB-Engines Ranking, две самых ... | https://habr.com/ru/post/484096/ | null | ru | null |
# Пентест вебсайта с помощью Owasp Zap

Сегодня защита веб-приложения имеет решающее значение, поэтому осваивать пентест инструменты приходится и самим разработчикам. О мощном фреймворке [WPScan](https://habr.com/ru/company/alexhost/... | https://habr.com/ru/post/530110/ | null | ru | null |
# Добавили возможность встраивать JS-скрипты в доски. Как мы делаем свою систему управления проектами
Первого апреля системе YouGile исполнился год. Нешуточный срок для проекта, который начался с мысли — «А давайте на выходных сделаем себе удобную систему управления проектами». Сейчас несколько тысяч пользователей, в ... | https://habr.com/ru/post/325608/ | null | ru | null |
# Классификатор обращений пользователей (1C + python)
1. Описание задачи
------------------
В нашей компании очень много пользователей и каждый день они шлют массу обращений на самые разные темы. У нас есть ... | https://habr.com/ru/post/569206/ | null | ru | null |
# Система мониторинга OpenNMS
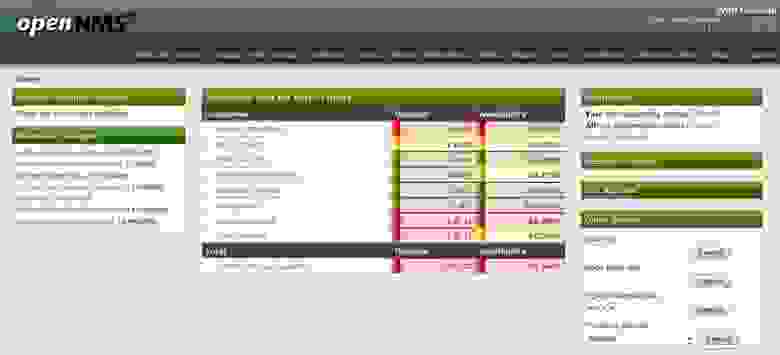
Ни в малейшей степени не желаю показаться непатриотичным, но исторически сложилось так, что при выборе корпоративной системы мониторинга сетевой инфраструктуры у нас на ... | https://habr.com/ru/post/193682/ | null | ru | null |
# Подключение дисплея DVD плеера к микроконтроллеру

Начну с предыстории, зачем же мне все это нужно. Я задался целью сделать себе HTPC компьютер на базе корпуса от DVD плеера Daewoo DV-500, внешне он мне нравится, и свободного мест... | https://habr.com/ru/post/231735/ | null | ru | null |
# HTTP-заголовки в I2P. Почему HTTP-прокси предпочтительнее SOCKS
Для выхода в скрытую сеть [I2P](https://habr.com/ru/post/552072/) необходимо программное обеспечение — I2P-роутер: [i2pd](https://i2pd.website/) (C++) или [I2P](https://geti2p.net/ru) (Java). Данное приложение содержит в себе всю внутреннюю логику I2P и... | https://habr.com/ru/post/594823/ | null | ru | null |
# Зачем нужно понимать ООП
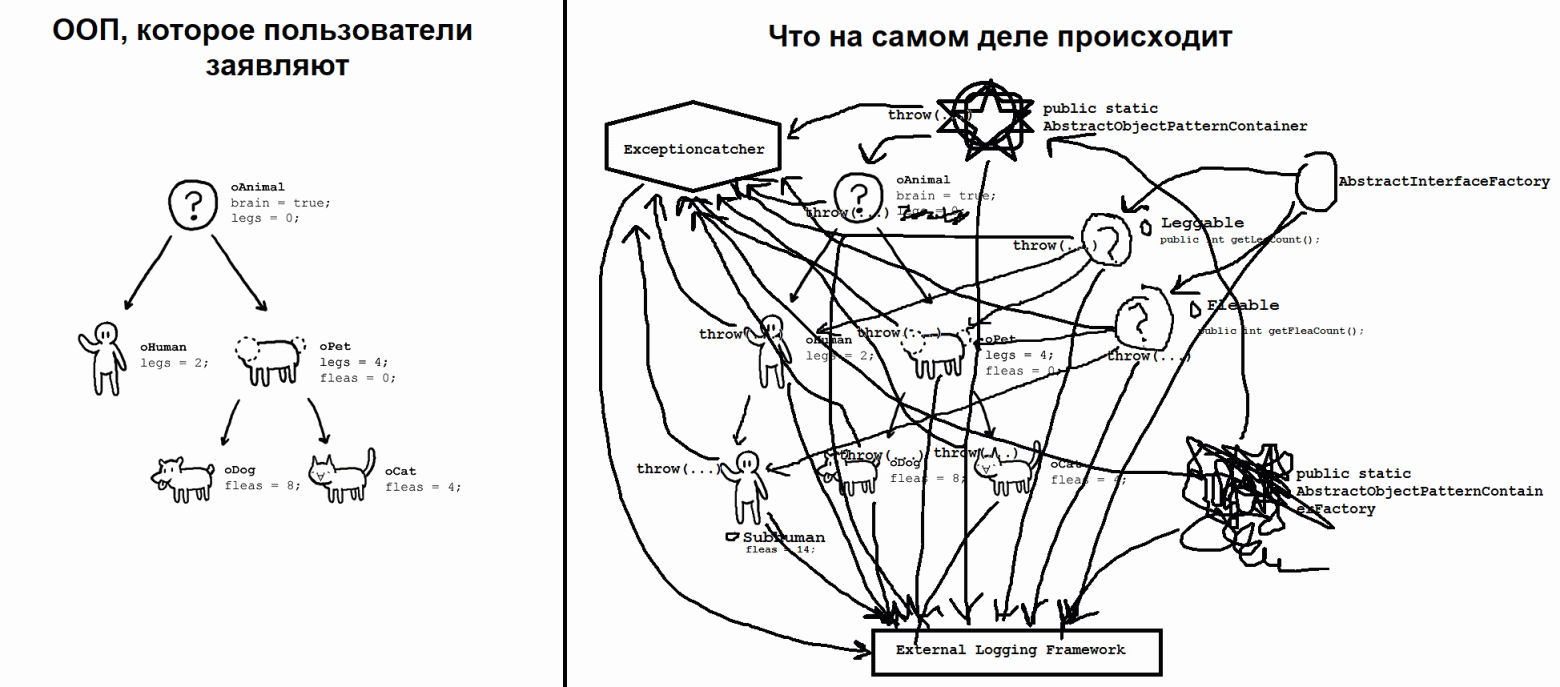
Часто я встречаю разработчиков, которые пишут код на объектно-ориентированном языке программирования, но не понимают принципов ООП. Это могут быть начинающие девелоперы, которые еще на собеседованиях сталк... | https://habr.com/ru/post/479640/ | null | ru | null |
# Оптимизация GUI на Qt
Как правило, при создании desktop-приложений на платформе Qt не возникает проблем, связанных с медленностью работы GUI. Qt – платформа достаточно надежная, неплохо вылизанная по всем параметрам, в том числе и по скорости работы. Однако всё же иногда бывают ситуации, когда из-за обилия виджетов ... | https://habr.com/ru/post/672962/ | null | ru | null |
# Разбираемся с синтаксисом шаблонов в Angular2

Многие впервые увидев синтаксис шаблонов Angular2 начинают причитать, мол ужас какой сделали, неужто нельзя было как в Angular1 хотя-бы. Зачем нужно было вводить это разнообр... | https://habr.com/ru/post/274743/ | null | ru | null |
# Смена пола и расы на селфи с помощью нейросетей

Привет, Хабр! Сегодня я хочу рассказать вам, как можно изменить свое лицо на фото, используя довольно сложный пайплайн из нескольких генеративных нейросетей и не только. Модные недавно пр... | https://habr.com/ru/post/340154/ | null | ru | null |
# В апреле выйдет GNU Compiler Collection 12
Смягчение уязвимости Trojan Source, оптимизация функций приведения типов, многомерный оператор `[]`, подавление предупреждений о вендорных атрибутах — вот лишь нек... | https://habr.com/ru/post/662932/ | null | ru | null |
# Заканчивается поддержка Python 3.6
Приблизительно через 3 недели истекает срок поддержки Python 3.6. Больше никаких исправлений багов и безопасности. При этом [сегодня](https://pypistats.org/packages/__all_... | https://habr.com/ru/post/595477/ | null | ru | null |
# Мобильная Установка Доказательства Актуальности Контроля Измерений. Часть 1. «Хороший человек идет на войну»
Итак, надоело! Даже, не так, ДОСТАЛО! А точнее, за.... Впрочем, не буду прибегать к ненормативной лексике. Квартира, купленная 2.5 года назад - это не квартира, а какое-то вечное испытание. Да такое, что Форт... | https://habr.com/ru/post/535202/ | null | ru | null |
# Размещение кучи FreeRTOS в разделе CCMRAM для STM32
При разработке одного девайса на базе STM32F407 столкнулся с проблемой нехватки оперативной памяти. Назначение самого девайса не принципиально, но важно, что изначальный код писался для десктопной системы и его нужно было просто портировать на микроконтроллер под у... | https://habr.com/ru/post/546670/ | null | ru | null |
# Проверяем исходный код FlashDevelop с помощью PVS-Studio
Для проверки качества диагностик нашего статического анализатора и его рекламы мы регулярно анализируем проекты с открытым исходным кодом. Разработчик... | https://habr.com/ru/post/305718/ | null | ru | null |
# Логические поля в базах данных, есть ли противоядие

Часто в таблицах содержится большое количество логических полей, проиндексировать все из них нет возможности, да и эффективность такой индексации низка. Тем не менее, для работ... | https://habr.com/ru/post/483056/ | null | ru | null |
# Перенаправление данных из COM-порта в Web
Недавно на хабре была статья [«Отображаем данные из Serial в Chrome Application»](http://habrahabr.ru/company/amperka/blog/263505/) о том, как красиво представить данные, отправляемые Arduin-кой в Serial. По-моему, ребята предложили очень красивое решение, которое с одной ст... | https://habr.com/ru/post/264663/ | null | ru | null |
# Использование сервисов и обработка их результатов в Xamarin
Продолжим обсуждать различные задачи для Xamarin с которыми приходится регулярно сталкиваться, так как статьи по данной тематике появляются не очень часто. Данная статья больше будет полезна начинающим разработчикам, но и более опытным тоже может быть интер... | https://habr.com/ru/post/540304/ | null | ru | null |
# Разработка игр для детей с использованием Intel Perceptual Computing. Пример «Приключений Клифорда»

Предлагаем вам сокращенный перевод статьи, освещающей разработку серии интерактивных развивающих игр для детей младшего ... | https://habr.com/ru/post/237227/ | null | ru | null |
# Онлайн-чемпионат SIBUR Challenge 2021 для аналитиков данных
Привет, Хабр!
Мы с AI Community и AI Today проводим онлайн-чемпионат по анализу данных **Sibur Challenge 2021**. Участвовать могут все, кто занимается машинным обучением. Призовой фонд в 650 000 рублей между собой разделят 5 первых мест:
1 место – 250 000... | https://habr.com/ru/post/593027/ | null | ru | null |
# Как написать UI-автотесты, если не умеешь программировать?
Всем привет! В этой статье пойдет речь о том, как написать простые UI-тесты на языке Java. Это будет интересно тем, кто давно хотел попробовать себя в автоматизации или добавить новенького в свой текущий проект.
В этой статье не будет большой остановки на ... | https://habr.com/ru/post/707710/ | null | ru | null |
# Как сделать два приложения из одного. Опыт Тинькофф Джуниор
Привет, меня зовут Андрей и я занимаюсь приложениями Тинькофф и Тинькофф Джуниор для платформы Android. Хочу рассказать о том, как мы собираем два похожих приложения из одной кодовой базы.
`Тинькофф Джуниор — это мобильное банковское приложение, ориент... | https://habr.com/ru/post/454128/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.