
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Что нового в Rails 5.0. Можно планировать переезд
На 16 марта запланирован релиз Rails 5.0, самое время разобраться, что же нового и вкусного будет в новой версии рельсов (кроме нового логотипа и дизайна их официального сайта, я имею в виду).
.
>
>
В JUnit 5, чтобы написать тестовый код, который, как ожидается, вызовет исключение, мы должны использовать [Assertions.assertThrows()](http://junit.org/junit5/docs/current/api/... | https://habr.com/ru/post/591305/ | null | ru | null |
# Почему оптимизатор запросов не анализирует содержимое буферного пула
В SQL Server используется стоимостной оптимизатор запросов (cost-based optimizer), который ищет оптимальный план в течение времени, выдел... | https://habr.com/ru/post/649573/ | null | ru | null |
# Документация к cms Fine Cut Engine
Всем доброй пятницы!
[](http://finecut.info)
Может быть кому-нибудь пригодится: [Fine Cut Engine](http://finecut.info)?
Это админка для сайта-визитки.
В настоящий момент доку... | https://habr.com/ru/post/150582/ | null | ru | null |
# Вышел минималистичный Linux-дистрибутив Bottlerocket для запуска контейнеров. Самое главное о нём
Компания Amazon [объявила](https://aws.amazon.com/blogs/opensource/announcing-the-general-availability-of-bottlerocket-an-open-sou... | https://habr.com/ru/post/518290/ | null | ru | null |
# Julia и клеточные автоматы

Сегодня мы отправимся в красочное путешествие по миру клеточных автоматов, попутно изучая некоторые хитрые приемы их реализации, а также попытаемся понять, что скрывается за этой красотой — любопытная игра... | https://habr.com/ru/post/490454/ | null | ru | null |
# Начинаем работать с BACnet
Многие из нас, наверное, смотрели боевики и видели, как герои, сидя в темной комнате, удаленно управляют дверями в зданиях, открывая и закрывая их. Управляли освещением, лифтами, чтобы помочь кому-то ку... | https://habr.com/ru/post/680790/ | null | ru | null |
# Скорость флешек
Здравствуйте уважаемые любители железа!
#### Проблема
В сети невозможно найти информацию о скорости конкретной модели USB Flash накопителя(в простонародии флешки). Причина секретности этой информации мне не известна.
#### Наше решение
Была разработана утилита для проведения тестирования флешк... | https://habr.com/ru/post/95384/ | null | ru | null |
# 6 применений в «умном доме» платы USBasp. Нестандартное использование USBasp
[](http://homes-smart.ru/upload/habr/usb-nrf.jpg)
Иногда дешевле купить готовое устройство, чем собират... | https://habr.com/ru/post/208470/ | null | ru | null |
# MVP и Dagger 2 – скелет Android-приложения – часть 2
*Данная статья является результатом изысканий, побочным продуктом которых стало воплощение давней идеи в одном очень полезном и очень не хватавшем мне когда-то Android-приложении – [My Location Notifier](https://play.google.com/store/apps/details?id=com.caesar84mx... | https://habr.com/ru/post/434618/ | null | ru | null |
# Intel TXT vulnerability
### Короткая заметка проверки уязвимости Intel Trusted Execution Technology
В статье использовались: Ubuntu 16.04, tBoot 1.9.6, TPM 1.2.
Сначала проверим работает-ли intel txt на Ubuntu с ядром 4.10.0-28 командой:
`sudo txt-stat`
Привет, Хабр! Два года назад мы [писали](https://habr.com/company/badoo/blog/279047/) о том, как перешли на PHP 7.0 и сэкономили миллион долларов. На нашем профиле наг... | https://habr.com/ru/post/430722/ | null | ru | null |
# Генератор масок из интервалов DEF кодов для Asterisk
Что имеем на входе:
1. несколько SIP операторов для исходящей связи, причём у некоторых более «вкусные» тарифы на определенного мобильного оператора;
2. данные по DEF кодам на [rossvyaz.ru](http://www.rossvyaz.ru/docs/articles/DEF-9x.html) выделенным операторам... | https://habr.com/ru/post/150793/ | null | ru | null |
# Кондитерская программиста. Bon Appetit
Всем привет, в этой статье пойдёт речь о любопытных экспериментах с С++ и 3D графикой. Будем открывать свою собственную кондитерскую-программиста. Bon Appetit!
Для начала да... | https://habr.com/ru/post/650011/ | null | ru | null |
# Опыт создания загрузчика изображений
#### Предисловие
Всем привет. Я хочу рассказать о создании загрузчика изображений для своего первого web-проекта. Я постараюсь объяснить, какие решения я видел, и какие подводные камни встретились на моем пути. Ну и, собственно, как эти камни можно обойти. Надеюсь, мой опыт кому... | https://habr.com/ru/post/132489/ | null | ru | null |
# One Day in the Life of PVS-Studio Developer, or How I Debugged Diagnostic That Surpassed Three Programmers
Static analyzers' primary aim is to search for errors missed by developers. Recently, the PVS-Studio team again found an interesting example proving the power of static analysis.
Традиционно компиляторы реализуют вызовы виртуальных функций через двойную косвенную адресацию — если класс содержит хотя бы одну виртуальную функцию, то в начале каж... | https://habr.com/ru/post/248429/ | null | ru | null |
# Небольшие трюки с Elasticsearch
Небольшая заметка, скорее для себя, о мелких трюках по восстановлению данных в Elasticsearch. Как починить красный индекс если нет бэкапа, что делать если удалил документы, а копии не осталось — к сожалению в официальной документации об этих возможностях умалчивают.
Бэкапы
------
... | https://habr.com/ru/post/416955/ | null | ru | null |
# Dagaz: Сумма технологий
***Итак, технологии интересуют меня, так сказать, по необходимости: потому что всякая цивилизация включает и то, к чему общество стремилось, и то, чего никто не замышлял.
Порой, и довольно часто, ... | https://habr.com/ru/post/486082/ | null | ru | null |
# Туториал: Создание простейшей 2D игры на андроид
Этот туториал предназначен в первую очередь для новичков в разработке под андроид, но может быть будет полезен и более опытным разработчикам. Тут рассказано как создать простейшую 2D игру на анроиде без использования каких-либо игровых движков. Для этого я использовал... | https://habr.com/ru/post/330686/ | null | ru | null |
# Реализация Minecraft Query протокола в .Net Core
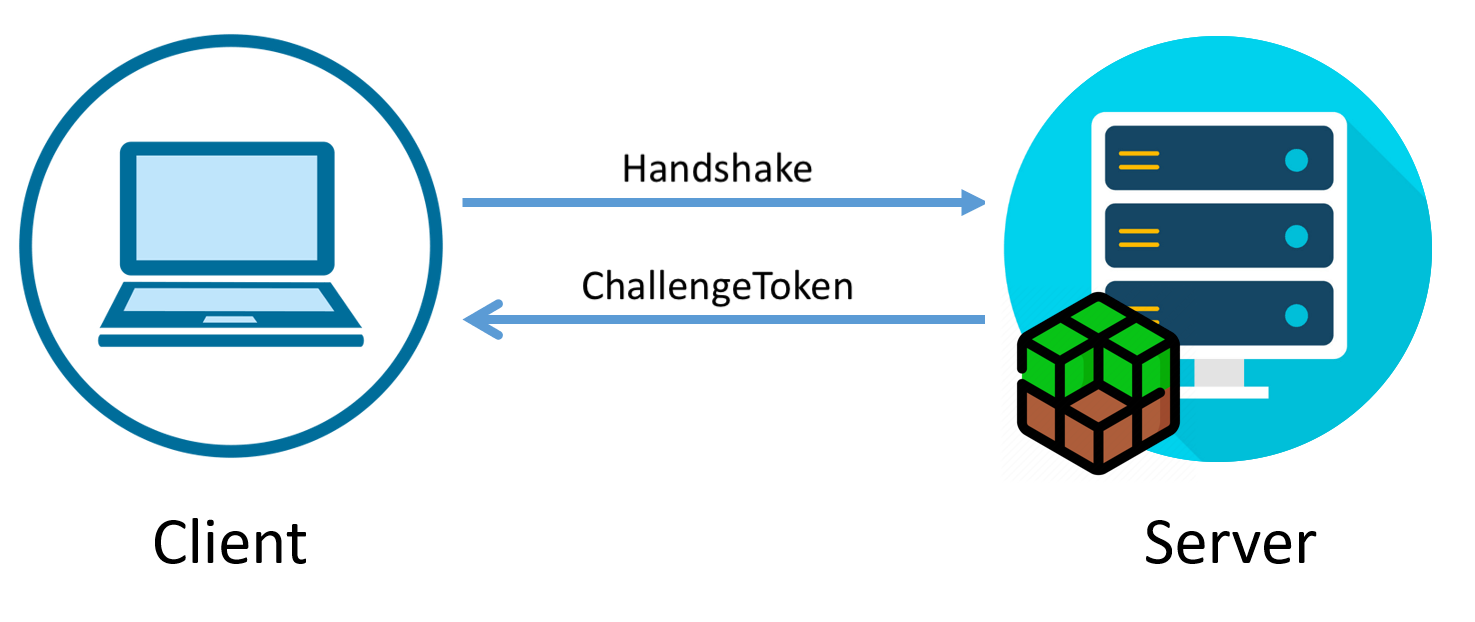**Minecraft Server Query** – это простой протокол, позволяющий получить актуальную информацию о состоянии сервера путём отправки пары-тройки незамысловатых U... | https://habr.com/ru/post/543798/ | null | ru | null |
# Адаптируем BDD для разработки на 1С совместно с cucumber и 1Script
Кто платит за тестирование решений? Особенно в случаях если заказчик (внутренний или внешний) просит запустить систему учета, и не указывает насколько плохая система ему нужна? Этот вопрос вызывает достаточно большую волну “священных войн” при любой ... | https://habr.com/ru/post/252473/ | null | ru | null |
# Знакомство с Koa или coroutine в nodejs
#### **Предисловие**
Меня уже очень давно привлекает javascript в качестве единого языка для веб-разработки, но до недавнего времени все мои изыскания оканчивались чтением документации nodejs и статей о том, что это callback`овый ад, что разработка на нем приносит лишь боль и... | https://habr.com/ru/post/238095/ | null | ru | null |
# Руководство по установке и тонкой настройке авиа-симулятора Microsoft Flight Simulator X (FSX)
На данный момент в мире существует всего два авиа-симулятора, которые способны приблизить виртуальный полёт к реальности — это [Microsoft Flight Simulator](http://habrahabr.ru/blogs/games/52713/) и [X-Plane](http://www.goo... | https://habr.com/ru/post/74630/ | null | ru | null |
# Обновление прошивки HP P2000 G3 MSA Array System

HP MSA P2000 — популярный дисковый массив начального уровня компании HP (на самом деле Dothill). Простой, надежный, относительно недорогой, с приемлемой скоростью рабо... | https://habr.com/ru/post/258007/ | null | ru | null |
# Бюджетный вариант виртуальной АТС с не бюджетными возможностями
В этом топике я попробую рассказать про попытку организовать бюджетный `виртуальный телефонный офис`.
И так, изначально имеется:
* пара десятков мелких офисов (арендаторы).
* телефония приходящая им по сипу
* пользовательские SIP телефоны и софтфо... | https://habr.com/ru/post/135845/ | null | ru | null |
# Как я делал парсинг расписания
Привет Habr!
Дорогой читатель! Если тебя интересует парсинг html и разработка под Android, то эта статья для тебя. Надеюсь ты найдешь в ней много интересного и полезного. В ней я хочу поделиться своим опытом в данной сфере.
Описание проблемы
-----------------
Немного обо мне. Я ... | https://habr.com/ru/post/483284/ | null | ru | null |
# Интернационализация поиска по городским адресам. Реализуем русскоязычный Soundex на Sphinx Search
Как много в вашем городе иностранных туристов? В моём мало, но встречаются, как правило стоят потерянные посреди улицы и повторяют одно единственное слово – название чего бы то ни было. А прохожие пытаются им на пальцах... | https://habr.com/ru/post/547652/ | null | ru | null |
# Systemd и контейнеры: знакомство с systemd-nspawn

Контейнеризация сегодня — одна из самых актуальныx тем. Количество публикаций о таких популярных инструментах, как LXC или Docker, исчисляется т... | https://habr.com/ru/post/271957/ | null | ru | null |
# Улучшаем border-radius.htc
Думаю многим верстальщикам известно решение, которое заставляет IE рисовать скругленные уголки: «[curved-corner](http://code.google.com/p/curved-corner/)» (или border-radius.htc).
В этой статье я расскажу, как избавиться от ошибок «Invalid argument» при его использовании, а также как в ... | https://habr.com/ru/post/102904/ | null | ru | null |
# Свои потоки ввода-вывода в C++ с помощью std::streambuf
*В статье на примерах объясняется, как реализовать поддержку потокового ввода-вывода из стандартной библиотеки () для своих классов.
В тексте статьи будет часто встречаться слово «поток», что означает именно поток ввода-вывода ((i/o)stream), но не поток выпо... | https://habr.com/ru/post/326578/ | null | ru | null |
# Трансляция запросов в SQL с использованием LinqToSql в тестах
Мы уже несколько лет делаем наш продукт автоматизации маркетинга, и пилить фичи с высокой скоростью нам помогает CI, а точнее — большое количество автоматических тестов.
В продукте примерно 700 000 строк кода со всеми кастомизациями, и на это всё мы им... | https://habr.com/ru/post/322604/ | null | ru | null |
# Быстрый старт на React Native
Какие горизонты открывает React? Single Page Application (и веб-приложения, и десктопные приложения на Electron) — это цветочки. Очень заманчиво выглядит разработка мобильных приложений на React Native. Лозунг "learn once, write anywhere" стоит того, чтобы приложить некоторые усилия. Go... | https://habr.com/ru/post/327668/ | null | ru | null |
# Scrolling в web slices или как впихать невпихуемое
 Одна из новых возможностей IE 8 — это web slices, фрагменты веб-страниц, которые можно просматривать браузером не открывая всю страницу целиком.
И все бы хорошо, вот только одна неприятная мелочь — в p... | https://habr.com/ru/post/55310/ | null | ru | null |
# 3 простых совета, которые сделают ваше Rails приложение быстрее, часть #3
Заключительная статья по оптимизация Ruby on Rails приложения.
[Совет #1: Приберите ваш статический контент](http://habrahabr.ru/blogs/ruby/50840/)
[Совет #2: Уберите все лишнее](http://habrahabr.ru/blogs/ruby/50946/)
[Совет #3: Кэшир... | https://habr.com/ru/post/51042/ | null | ru | null |
# CPrompt — интерпретатор языка си
С июня 2009 года я занимаюсь разработкой интерпретатора Си. (я уже упоминал об этом [в статье о вызовах функций](http://habrahabr.ru/blogs/cpp/78886/)).
Сейчас уже реализовано достаточно много конструкций: циклы, выбор, вычисление выражений, вызовы функций (как объявленных пользов... | https://habr.com/ru/post/80141/ | null | ru | null |
# Визуализация пересечений и перекрытий с помощью Python
### Изучение вариантов решения одной из самых сложных задач визуализации данных
Преобладающая задача в любом анализе данных — сравнение нескольких наборов чего-либо. Это могут быть списки IP-адресов для каждой целевой страницы вашего сайта, клиенты, которые куп... | https://habr.com/ru/post/536228/ | null | ru | null |
# Создание сапера при помощи модуля Tkinter
День добрый. Почти каждый начинающий программист стремится к созданию своей первой игры. Спустя пол года ~~ленивого~~ кропотливого обучения я решился написать сапера. Языком написания был выбран Python, модулем для добавления интерфейса tkinter, потому как уже имелся опыт ра... | https://habr.com/ru/post/326358/ | null | ru | null |
# Кроссбраузерный <progress>-бар
Доброе время суток, Хабро-сообщество!
Совсем недавно по работе мне попалась интересная задачка, которую я всё же [реализовал](http://css-live.ru/Primer/progress-ba... | https://habr.com/ru/post/140167/ | null | ru | null |
# Не Dagger'ом едины
В последнее время многим программистам очень понравилась библиотека для реализации внедрения зависимостей Dagger2. Хотя, как мне кажется, из-за неочевидной работы под капотом и большим семейством аннотаций Dagger долго заходил в комьюнити. И так получается что сейчас куда не глянь многие использую... | https://habr.com/ru/post/352352/ | null | ru | null |
# Триггерные рассылки
Последнее время в Email-маркетинге все чаще используются автоматические рассылки определенным группам потребителей. Типичные задачи: * поздравить с днем рожденья
* позвать на сайт, если потребитель на него долго не заходил
* сделать персонализированное предложение (делим потребителей на сегменты ... | https://habr.com/ru/post/251915/ | null | ru | null |
# 42 строки кода для выхода из лимба
Вы ведь знаете, как это бывает: большой проект долго проектируется, долго пишется, порой вымучивается и в конце концов сдается. Проходит месяц другой «горячей отладки», и после наступает благоговейная тишина. От заказчика ничего не слышно. И не потому что он разорился благодаря ваш... | https://habr.com/ru/post/313422/ | null | ru | null |
# Last.Backend открывает свои двери первым посетителям
Всем привет!
Праздники пролетели незаметно и пришла пора и поработать. А что бы работать вам было в радость, мы решили запустить Last.Backend в бету. Правда решили делать это не сразу а постепенно. Как нынче модно — идём путём agile со итерациями в 2 недели. ... | https://habr.com/ru/post/222477/ | null | ru | null |
# Очередные уязвимости нулевого дня в различных роутерах
Похоже, начало года не задалось для производителей роутеров. Буквально сегодня я сообщал о [критических уязвимостях в роутерах различных производителей](http://habrahabr.ru/post/168613/), связанных с небезопасной обработкой протокола UPnP. И вот ещё одна новость... | https://habr.com/ru/post/168683/ | null | ru | null |
# Пробел в знаниях основ веб-разработки
Вчера я разговаривал с другом, который ищет разработчика на открытую вакансию. Он выразил некоторое разочарование, которое я тоже испытываю в последнее время:
> У меня проблемы с поиском фрон... | https://habr.com/ru/post/341626/ | null | ru | null |
# ExtJS 7 и Spring Boot 2. Как построить SPA, взаимодействующее с вашим API и внешними ReactJS плагинами?
Последние версии Ext JS, особенно Modern Toolkit снизили порог вхождения во фреймворк (примеры Kitchen Sink), упростили создание нужного интерфейса (привет Sencha Architect) и добились минимального размера веб-при... | https://habr.com/ru/post/479676/ | null | ru | null |
# Исследуем активность кибергруппировки Donot Team

APT-группа Donot Team (также известная как APT-C-35, SectorE02) активна по крайней мере с 2012 года. Интерес злоумышленников направлен на получение конфиденциальной информации и инт... | https://habr.com/ru/post/476740/ | null | ru | null |
# Автоматическая проверка орфографии в EXCEL
Доброе время суток Хаброжители.
Буквально на днях, ко мне и моим коллегам обратились «опытные пользователи» Excel. По специфике работы «опытные пользователи» часто используют офисный пакет для оформления документации. Как ни странно, таблицы Excel так же часто встречаютс... | https://habr.com/ru/post/136520/ | null | ru | null |
# Мега-Учебник Flask, Часть XIX: Развертывание на основе Docker-контейнеров
(издание 2018)
--------------
### *Miguel Grinberg*
---
 [Туда](https://habrahabr.ru/post/352830/) [Сюда](https://habrahabr.ru/post/353804/) . Это встраиваемая аналитическая технология и набор инструме... | https://habr.com/ru/post/335586/ | null | ru | null |
# Как добавить Isar в проект на Flutter
Первое время при работе с Flutter мне хватало Hive. Быстро, удобно, но возможностей Hive мне стало не хватать. На странице <https://pub.dev/packages/hive> разработчики посоветовали попробовать Isar и я решила рискнуть. Много звездочек, но он совсем свежий, ошибки не гуглятся, а ... | https://habr.com/ru/post/673068/ | null | ru | null |
# С++23 — feature freeze близко
Прошло четыре месяца с [прошлой онлайн-встречи](https://habr.com/ru/company/yandex/blog/561104/) ISO-комитета, а значит, настало время собраться опять.

В этот раз в черновик нового стандарта C++23 ... | https://habr.com/ru/post/580880/ | null | ru | null |
# Vuex: структурирование больших проектов и работа с модулями
Vuex — это официальная, отлично документированная библиотека для управления состоянием приложений, разработанная специально для фреймворка Vue.js. Автор материала, перевод которого мы сегодня публикуем, полагает, что пользоваться этой библиотекой гораздо пр... | https://habr.com/ru/post/420357/ | null | ru | null |
# Скриптуем на WebAssembly, или WebAssembly без Web

Представлять WebAssembly не нужно — поддержка уже есть в современных браузерах. Но технология годится не только для них.
WebAssembly — кроссплатформенный байткод. Значит, этот бай... | https://habr.com/ru/post/344246/ | null | ru | null |
# Воспроизведение звука на Intel Edison через Bluetooth с использованием Advanced Audio Distribution Profile (A2DP)
В ходе реализации проектов на плате Intel Edison иногда возникает необходимость воспроизвести звук. В последних версиях образа Yocto добавлена поддержка Alsa, и можно воспользоваться USB аудиокартой. Но ... | https://habr.com/ru/post/258157/ | null | ru | null |
# Представляем Entity Framework Core 7 Preview 6: Улучшение производительности
Пакет Entity Framework 7 (EF7) Preview 6 опубликован и доступен для загрузки через [nuget.org](https://devblogs.microsoft.com/dotnet/announcing-ef7-preview6/#how-to-get-ef7-previews) (в конце поста есть ссылки на индивидуальные компоненты п... | https://habr.com/ru/post/678738/ | null | ru | null |
# Как я Magento изменял, или Меняем базовый функционал на простом примере
При разработке интерфейса магазина передо мной стояла задача не просто привести все к нужному виду и логике, но и обеспечить обновление версий движка, поэтому редактирование основных програмных модулей я исключил сразу. В качестве платформы был ... | https://habr.com/ru/post/63902/ | null | ru | null |
# Проверяем эмулятор GPCS4, или сможем ли когда-нибудь поиграть в «Bloodborne» на PC
Эмулятор – это приложение, способное имитировать запуск программы, предназначенной для одной платформы, на другой. Примером эмулятора является GPCS4, предназначенный для запуска игр для PS4 на PC. Недавно состоялся первый релиз GPCS4,... | https://habr.com/ru/post/671754/ | null | ru | null |
# Советы и секреты №3
#### Как сжать Windows 10 и освободить место. Самый удобный аудио- и видеотранскодер под Windows, Mac и Linux. Аналог GitHub для внутреннего использования
**Как сжать Windows 10**
В июле 2016 года Microsoft выпустила для Windows 10 новый механизм компрессии [Compact OS](https://msdn.microsoft... | https://habr.com/ru/post/396555/ | null | ru | null |
# Итоги 21-го конкурса IOCCC
Объявлены [победители](http://www.ioccc.org/2012/README.html) 21-го международного конкурса обфусцированного кода на C. Как обычно, участники удивили способностью втиснуть совершенно невероятные ... | https://habr.com/ru/post/155335/ | null | ru | null |
# Динамическая таблица поверх Google Maps
Введение
========
Вам когда-нибудь нужно было отображать крупные массивы данных с привязкой к карте? Мне на работе понадобилось отображать заказы сгруппированные по широте и долготе. И не просто статической таблицей, а динамической, с разной детализацией для разного приближен... | https://habr.com/ru/post/330920/ | null | ru | null |
# Streaming API. Небольшой пример на PHP
Летом проходил конкурс от ВКонтакте на тему «Streaming API Contest». Я решил поучаствовать, но так как нормальной идеи для реализации всех возможностей Streaming API я не нашел, то решил просто выводить записи по указанным правилам.
**Подробнее о правилах**Правило — это набо... | https://habr.com/ru/post/337874/ | null | ru | null |
# Практический пример создания собственного View-компонента

Мне нравится [Dribbble](https://dribbble.com/). Там есть много крутых и вдохновляющих диз... | https://habr.com/ru/post/433782/ | null | ru | null |
# Построение выпуклой 3D оболочки
Что? Зачем?
===========
Всем привет!
Я хотел бы рассмотреть задачу вычислительной геометрии, а именно **построение выпуклой 3D оболочки**. Как мне кажется, это и не самый сложный, и не самый простой алгоритм, который было бы очень интересно и полезно разобрать.
Если Вы никогда не с... | https://habr.com/ru/post/529352/ | null | ru | null |
# Геометрические фигуры на CSS
[Отличная подборка](http://css-tricks.com/examples/ShapesOfCSS/), как нарисовать различные геометрические фигуры одним элементом HTML.
Квадрат
=======

```
#square {
width: 100px;
height: 100px... | https://habr.com/ru/post/126207/ | null | ru | null |
# Как установить лицензионную защиту кода на Python и обезопасить данные с помощью HASP?
Всем привет, я Вячеслав Жуйко – Lead команды разработки Audiogram в MTS AI.
При переходе от On-Cloud размещений ПО на... | https://habr.com/ru/post/678928/ | null | ru | null |
# Продолжение истории про «Сердце» электронного устройства или простейшее программирование Silicon Labs C8051F320
Не так давно я написал статью про [мою поделку](http://habrahabr.ru/blogs/DIY/132295/) на основе микроконтроллера Silicon Labs C8051F320. Пришло время рассказать и про программирование данного мк под прост... | https://habr.com/ru/post/133856/ | null | ru | null |
# Заметки о вращении вектора кватернионом
#### Структура публикации
* Получение кватерниона из вектора и величины угла разворота
* Обратный кватернион
* Умножение кватернионов
* Поворот вектора
* Рысканье, тангаж, крен
* Серия поворотов
#### Получение кватерниона из вектора и величины угла разворота
Ещё раз – что т... | https://habr.com/ru/post/255005/ | null | ru | null |
# Инструкция по обновлению ПО и первичной настройке Nokia 7750 (SR-7 | SR-12)
Данная статья продолжает тему первичной настройки оборудования Nokia (ранее Alcatel-Lucent). Она будет полезна тем, кто не имеет большого опыта эксплуатации данного оборудования, но в ближайшей перспективе планирует связать свои рабочие часы... | https://habr.com/ru/post/306168/ | null | ru | null |
# Импакт-анализ на примере Android-проекта
Одной из самых дорогих по времени операций на CI-сервере является прогон автотестов. Есть множество способов их ускорения, например, распараллеливание выполнения по нескольким CI-агентам и/или эмуляторам, полная эмуляция внешнего окружения(backend/сервисы Google/вебсокеты), т... | https://habr.com/ru/post/647519/ | null | ru | null |
# Thunderargs: практика использования. Часть 2
[История создания](http://habrahabr.ru/post/223041/)
[Часть 1](http://habrahabr.ru/post/224705/)
Добрый день. Вкратце напомню, что thunderargs — библиотека, которая даёт использовать аннотации для обработки входящих аргументов.
Кроме того, она даёт возможность до... | https://habr.com/ru/post/190088/ | null | ru | null |
# Re: Проблема «maximum-subarray» на примере курса доллара
После прочтения недавней статьи [«Проблема «maximum-subarray» на примере курса доллара»](http://habrahabr.ru/blogs/algorithm/129576/) 3 раза, мне захотелось плеваться. *В статье предлагается найти промежуток дат, за который можно было заработать больше всего н... | https://habr.com/ru/post/129755/ | null | ru | null |
# Google Tag Manager: неочевидные и полезные настройки триггеров
Маркетолог в [Otzyvmarketing](https://otzyvmarketing.ru/) Станислав Романов рассказал, как с помощью диспетчера тегов Google Tag Manager (GTM) настроить аналитику и отслеживать скачивание файлов с сайта. Статья для тех, кто знает основы языка JavaScript ... | https://habr.com/ru/post/475608/ | null | ru | null |
# Используем Twitter по назначению
Однажды мне было очень скучно. Настолько, что я решил достать все детали своего «конструктора» и собрать что-нибудь.

В закромах нашлось следующее: Arduino совместимая плата, роутер ... | https://habr.com/ru/post/181852/ | null | ru | null |
# Вычисление выражений на Nemerle и Mono.
За weekend на хабре появились три статьи по разбору математических выражений: [Компилятор выражений](http://habrahabr.ru/blogs/development/50139), [Парсер математических выражений](http://habrahabr.ru/blogs/net/50158/) и [Вычисление значения выражения](http://habrahabr.ru/blog... | https://habr.com/ru/post/48945/ | null | ru | null |
# DoH в картинках
Угрозы конфиденциальности и безопасности в интернете становятся серьёзнее. Мы в Mozilla внимательно их отслеживаем. Считаем своей обязанностью сделать всё возможное для защиты пользователей Firefox и их данных.
Нас беспокоят компании и организации, которые тайно собирают и продают пользовательские... | https://habr.com/ru/post/413515/ | null | ru | null |
# Как я разрабатывал игру fly bird 2
Это гифка, которую я сделал, чтобы показать вступление и как началась история путешествия птички. У меня есть друг, который не боится рисовать, даже если он не обучался рисованию ... | https://habr.com/ru/post/662559/ | null | ru | null |
# Простая космическая симуляция с помощью Python и Box2D
Привет, Хабр.
На данную статью меня вдохновила недавняя публикация [Моделируем Вселенную](https://habr.com/ru/post/494546/), где автор показал весьма интересное моделирование разных космических явлений. Однако представленный там код непрост для начинающих. Я ... | https://habr.com/ru/post/500568/ | null | ru | null |
# Особенности тестирования Android без Google-сервисов
Привет! Меня зовут Мария Лещинская, я QA-специалист [в Surf](https://surf.ru/). Наша компания разрабатывает мобильные приложения с 2011 года. В этом материале поговорим о тестировании устройств Android, на которых нет поддержки Google Services.
Huawei без Google-... | https://habr.com/ru/post/559106/ | null | ru | null |
# Создаём простую нейросеть

*Перевод [Making a Simple Neural Network](https://becominghuman.ai/making-a-simple-neural-network-2ea1de81ec20)*
Что мы будем делать? Мы попробуем создать простую и совсем маленькую нейронную сеть, к... | https://habr.com/ru/post/423647/ | null | ru | null |
# Github actions и кросс-платформенное построение
Привет, Хабр. Это статья о том как настроить построение на всех платформах с помощью github actions.
Предыстория
-----------
Написал я простенькое приложение на electron, сам я пользовался linux-ом но мой друг предпочитал macos. Когда я попытался скомпилировать на с... | https://habr.com/ru/post/466501/ | null | ru | null |
# Книга «JavaScript для глубокого обучения: TensorFlow.js»
[](https://habr.com/ru/company/piter/blog/566226/) Привет, Хаброжители! Пора научиться использовать TensorFlow.js для построения моделей глубокого обучения, работающих не... | https://habr.com/ru/post/566226/ | null | ru | null |
# Разработка угловой стабилизации квадрокоптера
Данная статья скорее логическое продолжение моей статьи о балансере: [«Создание робота балансера на arduino»](http://habrahabr.ru/post/220989/).
В ней будут очень кратко освещены: простая модель угловой стабилизации квадрокоптера с использованием кватернионов, линеари... | https://habr.com/ru/post/240221/ | null | ru | null |
# Анализ данных с использованием Python

Язык программирования **Python** в последнее время все чаще используется для анализа данных, как в науке, так и коммерческой сфере. Этому способствует простота языка, а также большое разнообра... | https://habr.com/ru/post/353050/ | null | ru | null |
# Анализ исходного кода Another World

Я потратил две недели на чтение и реверс-инжиниринг [исходного кода Another World](https://github.com/fabiensanglard/Another-World-Bytecode-Interpreter) (в Север... | https://habr.com/ru/post/324550/ | null | ru | null |
# Снижение производительности SharePoint при увеличении уникальных Security Scopes на больших списках
Всем привет!
В этой статье мы решили поделиться своими жизненными наблюдениями за проблемой производительности больших списков в SharePoint.
Итак, мы достаточно часто сталкиваемся с ситуациями, когда есть списо... | https://habr.com/ru/post/211735/ | null | ru | null |
# Ускоряем восстановление бэкапов в PostgreSQL

*Мои ощущения от процесса работы*
Недавно я решил заняться ускорением восстановления нашей базы данных в dev-окружении. Как и во многих других проектах, база вначале была не... | https://habr.com/ru/post/328056/ | null | ru | null |
# Тестирование флеш СХД. Violin 6232 Series Flash Memory Array
Продолжаем тему, начатую в статьях "[Тестирование флеш СХД. Теоретическая часть](http://itg-td.blogspot.com/2014/04/ibm-ramsan-flashsystem-820.html)" и "[Тестирование флеш СХД. IBM RamSan FlashSystem 820"](http://itg-td.blogspot.com/2014/05/ibm-ramsan-flas... | https://habr.com/ru/post/231057/ | null | ru | null |
# Квантификаторы в регулярных выражениях
Регулярные выражения — это арифметика для алгоритмов. Они доступны во многих языках программирования, редакторах и настройках приложений. Как и сложение с умножени... | https://habr.com/ru/post/68345/ | null | ru | null |
# Глубокое обучение и Raspberry PI
> «Что у нас есть?» — спросил горбоносый поворачиваясь.
>
> «Алдан-3», — сказал бородатый.
>
> «Богатая машина, — сказал я.”[1]
Недавно я решил заняться изучением глубокого обучения. На работе мне выдали новую карточку с поддержкой CUDA и шеф выразил пожелание что эта вершин... | https://habr.com/ru/post/400141/ | null | ru | null |
# Понимаем декораторы в Python'e, шаг за шагом. Шаг 1

*###### На Хабре множество раз обсуждалась тема декораторов, однако, на мой взгляд, данная статья (выросшая из одного [вопроса на stackoverflow](http://stackoverflow.... | https://habr.com/ru/post/141411/ | null | ru | null |
# ONLYOFFICE Community Server: как баги способствуют возникновению проблем с безопасностью

В наши обзоры ошибок программ с отрытым исходным кодом редко попадают серверные сетевые приложения. Наве... | https://habr.com/ru/post/533496/ | null | ru | null |
# AWS: RDS Micro инстансы теперь доступны и в VPC
Привет! 
Совсем [недавно](http://habrahabr.ru/company/epam_systems/blog/154179/) RDS стали доступными на инстансах типа t1.micro бесплатно в рамках пакета Free Tier. ... | https://habr.com/ru/post/161447/ | null | ru | null |
# Linux: Листинг директории без ls (list files without ls)
Выяснилось что в моем zte 531 b стоит урезанный linux. Однако полноценному его изучению мешает отсутствие в стандартной поставке командочки ls. Оказывается листинг директории можно получить и без нее:
`> echo *
CVS bin dev etc lib linuxrc mnt proc sbin u... | https://habr.com/ru/post/51245/ | null | ru | null |
# Главное — скорость. Новый графический формат QOI в 20−50 раз быстрее PNG

Современные форматы кодирования изображений — это настоящая магия, в которой не разобраться без нескольких лет погружения в специфические алгоритмы. Даже опе... | https://habr.com/ru/post/592699/ | null | ru | null |
# Jupyter for .NET. «Like Python»
A few months ago Microsoft [announced](https://habr.com/ru/company/microsoft/blog/487532/) about the creation of Jupyter for .NET. However, people are barely interested in it despite how attractive the topic is. I decided to make a LaTeX wrapper for the `Entity` class from a symbolic ... | https://habr.com/ru/post/528816/ | null | en | null |
# Начало работы с TI CC13xx-CC26xx и Contiki под Code Composer Studio
Последнее время тематика интернета вещей становится все более и более горячей — однако в большинстве случаев, если речь заходит о работе с какими-то базовыми аппаратными решениями, то беседа сводится либо к готовым модулям, либо, реже, к чипам выпус... | https://habr.com/ru/post/390815/ | null | ru | null |
# Верстаем flex-календарик
Идет 2018 год, модные пацаны давно уже верстают на grid, а я все на третьем бутстрапе сижу с **col-md** кочерячусь, мельком поглядывая на четвертый.
Решил я, что это не дело, и стоит немного знания освежить, но у **grid** вроде как поддержка пока хромает, а вот **flex** технологию уже даже ... | https://habr.com/ru/post/353664/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.