
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Строим отчет о членстве пользователей в группах AD: 4 проблемы в написании Powershell-скрипта

Билл Стюарт, scripting guru, в своей [статье на WindowsITPro](http://www.windowsitpro.com/content1/topic/auditing-active-dir... | https://habr.com/ru/post/148472/ | null | ru | null |
# Компьютерное зрение как альтернатива офисным пропускам

Сегодня я расскажу, как мы делали в офисе пропускную систему на основе сервиса распознавания лиц [Vision](https://biz.mail.ru/vision/). Сначала небольшая предыстория. Как в ... | https://habr.com/ru/post/473828/ | null | ru | null |
# Праздничный биатлон
С днем программиста, коллеги!
Предлагаю в честь праздника поразмять мозги и поучаствовать в биатлоне.
Виды спорта: алгоритмы, SQL. Для каждого из них будет две зада... | https://habr.com/ru/post/128289/ | null | ru | null |
# Облегчаем работу с SQL в go и при этом не отстреливаем себе ноги

Продолжаю [серию статей](https://habr.com/ru/company/first/blog/650187/) по программированию на Golang, в которой буду рассказывать о том, как упростить себе жизнь. ... | https://habr.com/ru/post/652697/ | null | ru | null |
# AngularJS для привыкших к jQuery
[AngularJS](http://angularjs.org) — прекрасный фреймворк для построения веб-приложений. У него замечательная документация, снабженная примерами. В обучающих «пробных» приложениях (вроде [TodoMVC Project](http://todomvc.com/)) он очень достойно показывает себя среди остальных прочих ф... | https://habr.com/ru/post/172975/ | null | ru | null |
# Дао роста полей
*Немного пятничного веселья.*
Поля ввода, *Textarea*, которые молчат, когда с ними ничего не делают, на самом деле хотят расти. Когда объём вводимых текстов превышает их размеры, их тайное... | https://habr.com/ru/post/148188/ | null | ru | null |
# Весь PHP в двух строчках
Я с гордостью хочу представить вам способ описать весь опыт программирования на PHP двумя строчками.
Двумя объявлениями функций из стандартной библиотеки PHP:
```
array_filter($input, $callback);
array_map($callback, $input);
```
Угумс. | https://habr.com/ru/post/148010/ | null | ru | null |
# Regexponline – интерактивный анализатор и редактор регулярных выражений
Есть одна бородатая шутка: «если у вас есть проблема, и вы собираетесь решать ее с использованием регулярных выражений, то у вас есть две проблемы». Действительно, регулярные выражения – очень мощный и гибкий инструмент, применяемый для решения ... | https://habr.com/ru/post/175179/ | null | ru | null |
# Решение задания с pwnable.kr 26 — ascii_easy. Разбираемся с ROP-гаджетами с нуля раз и навсегда

В данной статье решим 26-е задание с сайта [pwnable.kr](https://pwnable.kr/index.php) и разберемся с тем, что же такое ROP, как э... | https://habr.com/ru/post/479184/ | null | ru | null |
# Jira: когда дорогие плагины не нужны
кадр из анимационного фильма "Кунг-фу панда"При разработке крупного и длительного проекта зачастую использую... | https://habr.com/ru/post/683006/ | null | ru | null |
# Android in-app purchases, часть 1: конфигурация и добавление в проект
Всем привет, меня зовут Влад и я разработчик [Android SDK для обработки платежей в мобильных приложениях](https://github.com/adaptyteam/AdaptySDK-Android) в Adapty.
Внутренние покупки и в частности подписки являются наиболее популярным способом м... | https://habr.com/ru/post/568902/ | null | ru | null |
# Как мы делали приложение под Windows 10 с Fluent Design (UWP/C#)
Мы в ivi давно собирались обновить наше приложение под Windows 10 (которое для ПК и планшетов). Мы хотели сделать его эдаким «уютным» уголком для отдыха. И поэтому анонсированная недавно Microsoft-ом концепция [fluent design](https://fluent.microsoft.c... | https://habr.com/ru/post/343880/ | null | ru | null |
# CoffeeScript: Классы

В *ECMAScript* ~~пока~~ отсутствует понятие «класс», в классическом понимании этого термина, однако, в *CoffeeScript* такое понятие есть, поэтому сегодня мы расс... | https://habr.com/ru/post/146405/ | null | ru | null |
# Организация backup-сервера. Linux, ZFS и rsync
TL;DR:
Статья о настройке бекапа линуксовых серверов. В качестве хранилища используется раздел ZFS с включенными дедубликацией и компрессией. Ежедневно делаются снапшоты, которые сохраняются в течение недели (7 штук). Ежемесячные снапшоты хранятся в течение года (еще... | https://habr.com/ru/post/239513/ | null | ru | null |
# 10 советов по использованию ExecutorService
*Предлагаю читателям «Хабрахабра» перевод публикации [«ExecutorService — 10 tips and tricks»](http://www.nurkiewicz.com/2014/11/executorservice-10-tips-and-tricks.html).*

Аб... | https://habr.com/ru/post/260953/ | null | ru | null |
# Настройка Firefox в Linux
Решил написать о настройке Firefox для Linux. В интернете похожие статьи тоже есть, но в основном они по старым версиям браузера. Радикальных отличий в настройке Firefox для Linux или для Windows нет, однако есть свои особенности.
Сразу скажу, что на старых ПК после настройки браузера к... | https://habr.com/ru/post/459880/ | null | ru | null |
# «Глупые» часы на FPGA
Привет всем!
Решил написать очередную статью, которая была бы полезна начинающим разработчикам в области ПЛИСоводства. Очень долго откладывал момент публикации, сам материал подготовил еще несколько месяцев назад, а вот сесть и написать всё это в целую статью как-то не доходили руки. Но вот ... | https://habr.com/ru/post/274843/ | null | ru | null |
# Почему я отказался от стандартной клавиатуры и никогда к ней не вернусь. Часть 1 (История клавиатуры)
### Предисловие
Сколько не совершенствуй свои клавиатурные навыки, не достигнешь значительного прогрес... | https://habr.com/ru/post/701494/ | null | ru | null |
# Разработка простого Eclipse RCP приложения
В данной статье я хотел рассказать о том, как создавать приложения при помощи Eclipse RCP (Rich Client Platform). Поводом для написания послужил тот факт, что на Хабре абсолютно отсутствуют статьи, описывающие данную платформу. В качестве примера мы создадим пользовательску... | https://habr.com/ru/post/139340/ | null | ru | null |
# Память в JavaScript — без утечек

То, как вы создаете и получаете доступ к своим данным, может повлиять на производительность вашего приложения. Посмотрим как.
### Вступление
JavaScript — это язы... | https://habr.com/ru/post/507758/ | null | ru | null |
# GTD на кухне: чем накормить голодного программиста
Итак, как и обещал в [первой части](http://habrahabr.ru/post/170499/), продолжаем упрощать бытовую жизнь хабражителя. Сегодня 8 марта (кстати, де... | https://habr.com/ru/post/172009/ | null | ru | null |
# Angular: пример использования NGRX

Эта статья является продолжением поста [«Angular: понятное введение в NGRX»](https://habr.com/ru/post/489674/)
Пример NGRX
-----------
В нашем примере будет список пользователей, страниц... | https://habr.com/ru/post/489758/ | null | ru | null |
# Почему нам нужен Delegate в iOS и WatchOS?
Около двух лет назад кто-то задал мне хороший вопрос: «Почему нам нужны делегаты для *UIViewControllers*?» Он думал, что Swift многое облегчил, но вся эта штука с делегатами кажется очень сложной. Почему просто нельзя посылать сообщения или инициализации между классами?
... | https://habr.com/ru/post/313242/ | null | ru | null |
# Аутентификация по-новому, или суперкуки
На сегодняшний день идея ухода от паролей и традиционных методов аутентификации на веб-ресурсах поднимается все чаще, причем этим озаботились такие гиганты IT-индустрии, как Google,... | https://habr.com/ru/post/185248/ | null | ru | null |
# Создание расширений в PostgreSQL

Здравствуйте, хабрачеловеки! Темой этой статьи будет создание расширений для **PostgreSQL**. В качестве примера, мы реализуем небольшую библиотеку для работы с 3D вектор... | https://habr.com/ru/post/198332/ | null | ru | null |
# Генеалогическое древо внутри Git
Поздравляю всех с днем программиста! Желаю больше ярких "коммитов", принятых "пулл-реквестов", меньше незапланированных "мержей" и чтобы ваши ветви жизни оставались актуальными как можно дольше. В качестве идейного подарка предлагаю реализацию генеалогического древа средствами систем... | https://habr.com/ru/post/351158/ | null | ru | null |
# С#: 10 распространенных ловушек и ошибок
Предлагаю вашему вниманию перевод [статьи](https://codeaddiction.net/articles/38/10-common-traps-and-mistakes-in-c) о «ловушках» в С#. Данная статья будет полезна начинающим программистам пока еще не знакомым с тонкостями языка.
Приятного чтения.
---
*«Это все мелочи,... | https://habr.com/ru/post/322394/ | null | ru | null |
# Установка MeteorJS на Raspberry Pi B+ под управлением Arch Linux ARM

Если найдётся ещё кто-нибудь, кто как и я вдруг решить использовать RPI в качестве домашнего или тестового сервера с развёрнутым meteor-приложением, над... | https://habr.com/ru/post/249677/ | null | ru | null |
# Введение в IBM DB2
По работе пришлось в течение некоторого времени разбираться с СУБД IBM DB2. Т.к. система коммерческая, то в интернете не так много информации на русском языке, поэтому решил описать некоторые особенности работы этой СУБД.
#### Точка входа
Начнем со входной точки в СУБД. В SQL SERVER конечной т... | https://habr.com/ru/post/128932/ | null | ru | null |
# Как обработать deep link со сложным path? Вот так
Всем привет! Эта статья получилась совершенно случайно. Когда мы готовили Deep Dive Into Deep Link ([habr](https://habr.com/ru/post/686990/), [mobius](https://2022spring.mobiusconf.com/talks/327f5418c684d5f102fd59732cf0ac19/) в 2022 году), пришли к выводу:
> Не сущ... | https://habr.com/ru/post/707864/ | null | ru | null |
# MessagePack аналог JSON, но быстрее и меньше
MessagePack это эффективный сериализатор данных в бинарное представление.

Используя данную библиотеку вы можете обмениваться сообщениями между вашими компонентами системы ... | https://habr.com/ru/post/251177/ | null | ru | null |
# Как на Python подобрать экипировку для игрового перса
Учимся находить лучшее для своего разбойника при помощи программирования. Также разбираемся, не водит ли нас программа «за нос».
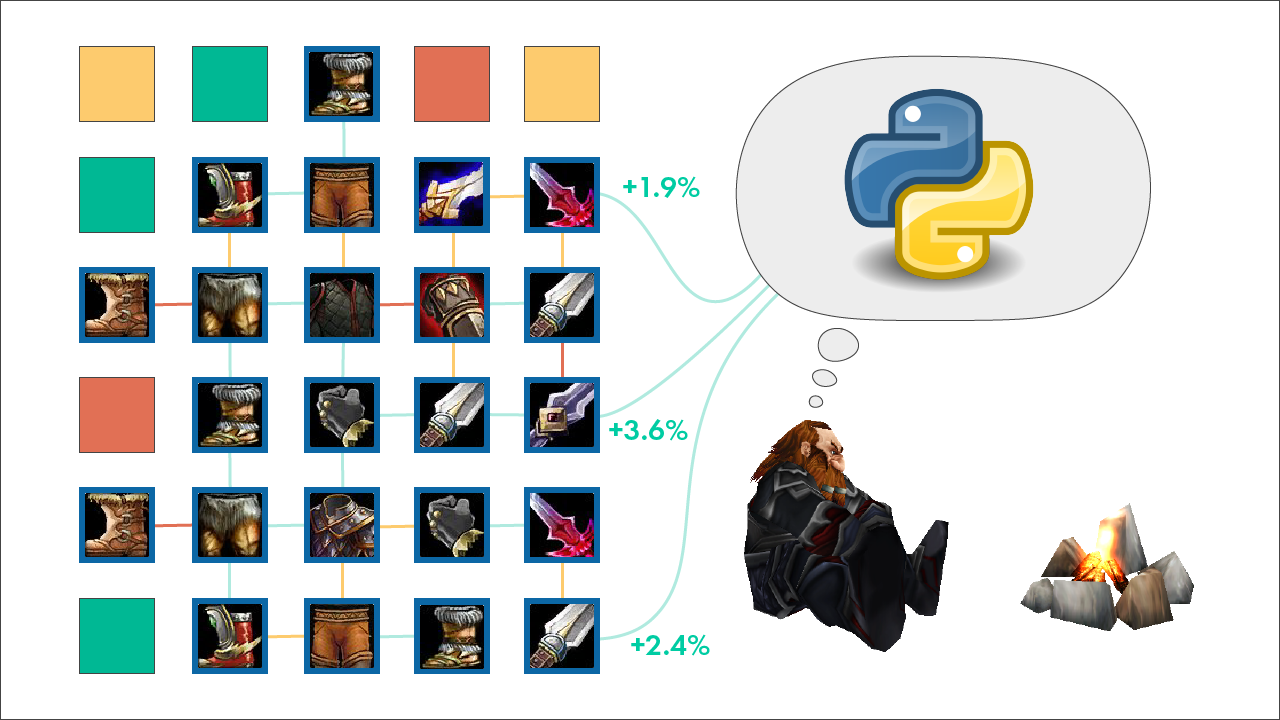
**Цель:** научиться поэтапно моделирова... | https://habr.com/ru/post/495774/ | null | ru | null |
# Redis Best Practices, часть 3
Заключительный перевод разделов [Redis Best Practices](https://redislabs.com/redis-best-practices/) с официального сайта «Redis Labs». Самое необычное и интересное сегодня под катом!

Первая часть н... | https://habr.com/ru/post/506594/ | null | ru | null |
# Как мы мигрировали критичную БД с Oracle в CockroachDB
### … простите, мигрировали куда? Туда!
CockroachDB — PostgreSQL-совместимая (по SQL-синтаксису DML) распределенная СУБД с открытым кодом (ну, почти). Ее название символизирует, что она, как таракан, выживает в любых экстремальных ситуациях. Лично мне крайне им... | https://habr.com/ru/post/669208/ | null | ru | null |
# Когда акторный фреймворк превращается в «черный ящик» и что мы можем с этим сделать?
Модель акторов — это хороший подход к решению некоторых типов задач. Готовый акторный фреймворк, особенно в случае языка C++, может очень сильно облегчить жизнь разработчика. С программиста снимается изрядная часть забот по управлен... | https://habr.com/ru/post/352176/ | null | ru | null |
# Raspbery Pi Pico для управления адресуемыми светодиодами

Если вам нужно сделать гирлянду, где переливается десяток-сотня светодиодов, то эта статья будет вам мало полезна. А вот если у вас несколько десятков тысяч светодиодов и ... | https://habr.com/ru/post/694598/ | null | ru | null |
# Редактирование видео в MPC с помощью шейдеров
**Есть задача:** Изменить видео “на лету” при воспроизведении — поменять местами правую и левую часть. Не отразить, а именно поменять, т.е. разрезать картинку на две части и поменять их местами. Можно, конечно, сделать с помощью фреймсервера типа [AviSynth'a](https://hab... | https://habr.com/ru/post/434856/ | null | ru | null |
# Как я уместил систему управления товарами на сайте Presta Shop в пяти кнопках
Внимание!Прочитав статью, может сложиться впечатление, что я люблю БДСМ или что-то такое, но это вам только кажется.
#### Проблемы в работе магазина
Я работаю в обычном велосипедном магазине в центре Варшавы. Торгуем как стационарно, так... | https://habr.com/ru/post/555696/ | null | ru | null |
# Можно ли войти в закрытую дверь, или как патчат уязвимости
В мире каждый день публикуются десятки CVE (по данным компании [riskbasedsecurity.com](http://riskbasedsecurity.com) за 2017 год было опубликовано 20832 CVE). Однако производители стали с большим пониманием и вниманием относиться к security-репортам, благода... | https://habr.com/ru/post/353108/ | null | ru | null |
# Инженерный подход к разработке ПО
Как проверить идеи, архитектуру и алгоритмы без написания кода? Как сформулировать и проверить их свойства? Что такое model-checkers и model-finders? Требования и спецификации — пережиток прошлого?
Привет. Меня зовут Васил Дядов, сейчас я работаю программистом в Яндексе, до этого р... | https://habr.com/ru/post/457810/ | null | ru | null |
# Ожидаемые новые возможности JavaScript, о которых полезно знать
С момента выхода стандарта ECMAScript 2015 (его ещё называют ES6) JavaScript серьёзно изменился и улучшился. Это очень хорошая новость для всех JS-разработчиков. Более того, теперь новая версия ECMAScript выходит каждый год. Возможно, вы не обратили осо... | https://habr.com/ru/post/475244/ | null | ru | null |
# Основы Flutter для начинающих (Часть VII)
Большинство мобильных приложений содержат различные картинки.
А как же без них? Картинки делают насыщенным и более понятным пользовательский интерфейс пользователя.
Flutter имеет встроенную поддержку картинок. Наиболее часто используемым является класс Image, который мы и... | https://habr.com/ru/post/561614/ | null | ru | null |
# Zimbra: удаление случайных или ненужных писем
Тема, возможно, избита и не очень актуальна, если настроено автоматическое удаление писем по истечению определенного срока.
Но если случается, что один сотрудник вместо того, чтобы отправить очень приватно-пикантное сообщение другому, отправляет его (сообщение) всему ... | https://habr.com/ru/post/277117/ | null | ru | null |
# Обзор компактного IP телефона Escene ES205
[](http://habrahabr.ru/company/digitalangel/blog/266951/) Рост курса и, как следствие, увеличение стоимости оборудования существенно сокращает число моделей IP теле... | https://habr.com/ru/post/266951/ | null | ru | null |
# Бенчмарк Prometheus vs VictoriaMetrics на метриках node_exporter
> *Для будущих студентов* [*курса «DevOps практики и инструменты»*](https://otus.pw/pySW/) *подготовили перевод интересного материала.
>
> Также приглашаем всех желающих поучаствовать в* [*открытом вебинаре на тему «Prometheus: быстрый старт».*](h... | https://habr.com/ru/post/541640/ | null | ru | null |
# Основы работы отечественных МК 1986ВЕ1Т с болгарскими отладчиками OLIMEX ARM-USB-OCD-H. Часть 2 — RAM & Interruptions
Преамбула
---------
Изначально вторая глава задумывалась только, как шпаргалка по работе из оперативной памяти, но делать и разбираться в этом не очень трудно. Основная "запара" может настигнуть нес... | https://habr.com/ru/post/657533/ | null | ru | null |
# ПЛК — что это такое?
Доброго времени суток, уважаемые жители Хабра!
Прочитав [пост про программирование ПЛК Siemens серии S7](http://habrahabr.ru/blogs/controllers/139180/), я залез в поиск по Хабру, и был весьма удивлен, что тема промышленной автоматики вообще, и программирования ПЛК в частности, освещена весьма... | https://habr.com/ru/post/139425/ | null | ru | null |
# Заканчивается 2022 год, а я всё ещё использую Flash
В 2020 году Adobe прибила Flash Player, но я не захотел, чтобы мои Flash-игры пропали навечно.
С разными промежутками я делал игры всю свою жизнь, но людям особенно нравилась серия Hapland, поэтому я решил, что неплохо было бы исправить их для релиза в Steam. Мо... | https://habr.com/ru/post/707934/ | null | ru | null |
# Hubot: универсальный бот на CoffeeScript от разработчиков Github
[](http://hubot.github.com/)
Разработчики Github на работе занимаются не только основным делом, но и [посторонними проектами](http://zachholman.com/posts/why-githu... | https://habr.com/ru/post/131256/ | null | ru | null |
# Помогаем Queryable Provider разобраться с интерполированными строками
### Тонкости Queryable Provider
Queryable Provider не справляется вот с этим:
```
var result = _context.Humans
.Select(x => $"Name: {x.Name} Age: {x.Age}")
.Where(x => x != "")
... | https://habr.com/ru/post/442460/ | null | ru | null |
# Использование Java смарт-карт для защиты ПО. Глава 4. Пишем первый апплет

#### 1. Введение
В данном цикле статей пойдет речь об использовании Java смарт-карт (более дешевых аналогов электронных ключей) для защиты программно... | https://habr.com/ru/post/255535/ | null | ru | null |
# Пишем многопользовательскую змейку на tornado
Какое-то время назад решил написать небольшое приложение, чтобы потренироваться работе с вебсокетами. Из питоновских фреймворков мне показалось удобней изкоробочная поддержка их в tornado. Поскольку игрушка предельно простая, может кому-то показаться полезной как пример.... | https://habr.com/ru/post/346696/ | null | ru | null |
# Emacs: дрессируем курсор (продолжение)
*Не бойтесь совершенства. Вам его не достичь!*
```
Сальвадор Дали
```
Взгляв в прошлое
----------------
В [предыдущей статье](http://habrahabr.ru/post/265531/), речь шла о том, как можно заставить курсор Emacs сохранять позицию в ... | https://habr.com/ru/post/266073/ | null | ru | null |
# Тестирование смарт-контрактов Ethereum на Go: прощай, JavaScript

*Я хочу поблагодарить коллег: Сергея Немеша, Михаила Попсуева, Евгения Бабича и Игоря Титаренко за консультации, отзывы и тестирование. Я также хочу сказать спасибо ком... | https://habr.com/ru/post/445254/ | null | ru | null |
# Блокировка состояний Terraform в Яндекс.Облаке
Данный вопрос возник при миграции облачных ресурсов в Яндекс.Облако. [Официальная документация](https://cloud.yandex.ru/docs/tutorials/infrastructure-management/terraform-state-storage), к сожалению, не даёт ответа на этот счёт, как и гуглёж. Однако, можно применить под... | https://habr.com/ru/post/711982/ | null | ru | null |
# Использование rebar3 для управления проектами на Erlang

Rebar3 — это инструмент для языка программирования Erlang, который позволяет легко и удобно управлять проектами, написанными на Erlang (иногда и на Elixir).
Люди уже давно знакомые с... | https://habr.com/ru/post/319950/ | null | ru | null |
# Управление сложностью в проектах на ruby on rails. Часть 3
В [предыдущей части](https://habrahabr.ru/post/267233/) я рассказал про контроллеры и роутинг. Теперь поговорим про формы. Довольно часто требуется реализовать формы, которым не соответствует ни одна модель. Или добавить валидацию, которая имеет смысл только... | https://habr.com/ru/post/321034/ | null | ru | null |
# Оформление изображений на CSS3
При использовании свойств box-shadow или border-radius непосредственно на изображении, браузеры могут некорректно отображать заданные нами CSS стили, из-за чего внешний вид блока будет существенно отличаться от задуманного. Однако если использовать изображение в качестве фона, то этой ... | https://habr.com/ru/post/129313/ | null | ru | null |
# Как PVS-Studio защищает от поспешных правок кода, пример N2

Большое количество ошибок программистами допускается просто по невнимательности или из-за спешки. Хорошо это видно ... | https://habr.com/ru/post/646227/ | null | ru | null |
# PHP – компилируемый язык?! PVS-Studio ищет ошибки в PeachPie

PHP широко известен как интерпретируемый язык программирования, использующийся в основном для разработки сайтов. Однако немногие знают, что для PHP есть ещё и компилят... | https://habr.com/ru/post/573296/ | null | ru | null |
# Передаю привет разработчикам компании Yandex

Приблизительно раз в полгода нам пишет кто-то из сотрудников компании Yandex, интересуется лицензированием PVS-Studio, качает триал и... | https://habr.com/ru/post/337182/ | null | ru | null |
# 5 способов полезного использования Raspberry Pi
Привет Хабр.
Raspberry Pi наверное есть дома почти у каждого, и рискну предположить, что у многих она валяется без дела. А ведь Raspberry это ~~не только ценный мех~~, но и вполне мощный fanless-компьютер с Linux. Сегодня мы рассмотрим полезные возможности Raspberry... | https://habr.com/ru/post/472778/ | null | ru | null |
# Знакомство с SwiftUI: Создание простого приложения с использованием TableView
Во время проведения WWDC 2019, одним из самым больших и захватывающих моментом был анонс релиза SwiftUI. **SwiftUI** — это совершенно новый фреймворк, который позволяет проектировать и разрабатывать пользовательские интерфейсы с написанием... | https://habr.com/ru/post/461645/ | null | ru | null |
# DBA: перенос значений SEQUENCE между базами PostgreSQL
Как можно перенести в другую PostgreSQL-базу **последнее назначавшееся значение** «автоинкремент»-поля типа serial, если в таблице могли быть какие-то удаления, и «просто подставить max(pk)» уже не подходит?
Мало кто знает, что хоть PG и не предоставляет до в... | https://habr.com/ru/post/483424/ | null | ru | null |
# Сравнительное тестирование работы PostgreSQL с большими страницами Linux
 Ядро Linux предоставляет широкий спектр параметров конфигурации, которые могут повлиять на производительность. Это все о получении правильной конфигурации для... | https://habr.com/ru/post/458910/ | null | ru | null |
# Тюнинг консольного клиента MySQL
Мне довольно часто, даже постоянно приходится обращаться к разным базам данных MySQL. Испробовав немало разных GUI клиентов я понял, что они все меня не удовлетворяют. То проблемы с кодировкой, то отсутствует автодополнение кода, то не работает история запросов. В общем пришел я к ис... | https://habr.com/ru/post/82402/ | null | ru | null |
# Настройка OpenVPN шлюза в интернет на Debian, который на OpenVZ
Итак господа, приближается первое августа, поэтому задумался я над тем чтобы заиметь себе ip страны, в которой попроще с законодательством в сфере p2p, а именно Нидерландов. После достаточно долгих поисков нашел провайдера, который обещал два ядра от E3... | https://habr.com/ru/post/188474/ | null | ru | null |
# Без ансамбля

Решили мы однажды заняться автоматизацией наших рутинных рабочих моментов. Создать у себя ансамбль(ansible) или что-нибудь в этом роде. Я полез на сайт ансамбля, посмотрел как он работает *… подключается к удаленному ... | https://habr.com/ru/post/428439/ | null | ru | null |
# Swift. KeyChain. Property wrapper
XcodeНекоторое время назад была опубликована [статья](https://habr.com/ru/post/670378/) на тему хранения данных пользователя. В этой статье было представлено р... | https://habr.com/ru/post/670490/ | null | ru | null |
# Кодируем и декодируем сообщение для внеземных цивилизаций
Привет Хабр.
Мотивом для этой статьи, на самом деле, послужил грустный повод. Всемирно известный радиотелескоп обсерватории Аресибо в Пуэрто-Рико [разрушился](https://www.bbc.com/news/world-us-canada-55147973) и восстановлению не подлежит. Многие годы это ... | https://habr.com/ru/post/530882/ | null | ru | null |
# Майнинг на микроконтроллере ESP32 оказался не очень выгоден

20-летний немецкий программист Джейк описал [свой эксперимент](https://blog.ja-ke.tech/2019/03/16/esp32-bitcoin.html) по майнингу на микроконтр... | https://habr.com/ru/post/444454/ | null | ru | null |
# Сравнение производительности ASP.NET Core-проектов на Linux и Windows в службе приложений Azure
Что быстрее — [ASP.NET Core](https://docs.microsoft.com/ru-ru/aspnet/core/?view=aspnetcore-5.0)-приложение, развёрнутое в Docker-контейнере на Linux, или такая же программа, но запущенная на Windows-сервере, учитывая то, ... | https://habr.com/ru/post/555650/ | null | ru | null |
# Настройка GitLab CI для загрузки java проекта в maven central

Данная статья рассчитана на java разработчиков, у которых возникла потребность быстро публиковать свои продукты в репозиториях sonatype и/или maven central с использова... | https://habr.com/ru/post/449664/ | null | ru | null |
# День рождения программиста, который не хотел денег, но создал проект на миллиарды долларов

27 сентября исполняется 68 лет Ларри Уоллу — программисту, разработавшему популярный клиент rn — newsreader для групп новостей Usenet, [в... | https://habr.com/ru/post/689804/ | null | ru | null |
# Эволюция real-time Web: примеры из практики (или с чем Lua справляется лучше JS)
Карантин и переход на удаленку наводят на ностальгические воспоминания о полном жизни офисе, когда вместо звонков и трансляций мы работали и собирались на хакатонах в одной комнате с коллегами. Сегодня вспомним хакатон, где мы писали ве... | https://habr.com/ru/post/508420/ | null | ru | null |
# Создаём сложные интерфейсы и спецэффекты на базе Qt. Часть II
© Х.ф. «Матрица»Привет, Хабр! Меня зовут Михаил Полукаров, я занимаюсь разработкой desktop-версии в команде ... | https://habr.com/ru/post/701382/ | null | ru | null |
# Миграция с ISA 2004/2006 на Forefront TMG
На смену Internet Security & Acceleration (ISA) Server пришел Forefront Threat Management Gateway (TMG).
В данном переводе мы рассмотрим процесс перехода с ISA 2004/2006 на For... | https://habr.com/ru/post/135438/ | null | ru | null |
# Почему инлайнить стили — плохо
Стилизовать страницу можно разными способами: [встроить стили](https://htmlacademy.ru/courses/307/run/15?utm_source=habr&utm_medium=special&utm_campaign=inline200821) прямо в HTML, импортировать, создать с помощью JavaScript или подключить из отдельного файла. Среди разработчиков хорош... | https://habr.com/ru/post/573768/ | null | ru | null |
# Методы расширения в Java

В таких языках программирования, как C#, Kotlin, Groovy, Scala есть возможность расширять класс путем добавления нового функционала, при этом не требуется наследование или изменение самого изначального кла... | https://habr.com/ru/post/527688/ | null | ru | null |
# Текст любой ценой: WCBFF и DOC
Несколько позже, чем хотелось, но продолжаем наш разговор о получении текста из разных форматов данных. Мы с вами уже познакомились с тем, как работать с изначально XML-base файлами (docx и odt), прочитали текст из pdf, преобразовали содержимое rtf в plain-text. Теперь перейдём в вкусн... | https://habr.com/ru/post/72745/ | null | ru | null |
# Regex for lazy developers
Регулярные выражения – это система обработки текста, основанная на специальной системе записи образцов. Проще говоря представляет программистам возможность легко обрабатывать и валидировать строки. Представляет имплементацию принципа DRY (Don’t Repeat Yourself), почти во всех поддерживаемых... | https://habr.com/ru/post/577534/ | null | ru | null |
# Криптография в Java. Класс Certificate
Привет, Хабр! Представляю вашему вниманию перевод заключительной статьи "Java Certificate" автора Jakob Jenkov из [серии статей для начинающих](http://tutorials.jenkov.com/java-cryptography/index.html), желающих освоить основы криптографии в Java.
Оглавление:
-----------
1. [... | https://habr.com/ru/post/446888/ | null | ru | null |
# Встраиваем качественный звук в Qt приложение (Qt + FMOD)
Помню время, когда я обрадовался мультимедийным возможностям Qt… phonon хорош, это да. Но помню и время разочарования: слишком мало всего умеет этот самый phonon. Как минимум, он не умеет воспроизводить два звука одновременно. Да и интерфейсы у него хромают… ... | https://habr.com/ru/post/103346/ | null | ru | null |
# Как улучшить межсерверное взаимодействие и сэкономить время разработчика
Привет! Я Алексей, Java-разработчик. Хочу поделиться опытом внедрения подхода Contract-First в backend.
#### Что такое контракт
Представим продакшн и три группы участников: мобильное приложение, бэкенд и фронтенд.
 на основе виртуального кластера Kubernetes, чтобы обнаруживать попытки взлома K8s-инфраструктуры. Также в статье рассматриваются отличия низкоинтерактивных и высокои... | https://habr.com/ru/post/695390/ | null | ru | null |
# Настраиваем удобную сборку проектов в Visual Studio
Эта статья является руководством по настройке сборки C++ проектов Visual Studio. Частично она сводилась из материалов разрозненных статей на эту тему, частично является результатом реверс-инжениринга стандартных конфигурационных файлов Студии. Я написал ее в основн... | https://habr.com/ru/post/448216/ | null | ru | null |
# Инструкция: Как создавать ботов в Telegram
24 июня разработчики Telegram [открыли](https://core.telegram.org/bots) платформу для создания ботов. Новость кого-то обошла стороной Хабр, однако многие уже начали разрабатывать викторины. При этом мало где указаны хоть какие-то примеры работающих ботов.
Прежде всего, б... | https://habr.com/ru/post/262247/ | null | ru | null |
# React: разрабатываем хук для загрузки дополнительных данных

Привет, друзья!
В этой статье я хочу поделиться с вами опытом разработки хука для загрузки дополнительных данных (авось кому-нибудь пригодится).
На самом деле, хуков бу... | https://habr.com/ru/post/584862/ | null | ru | null |
# Аддоны Kodi используются для распространения криптомайнеров
Если вы используете Kodi, то могли заметить, что популярный голландский репозиторий аддонов XvBMC был [закрыт](https://www.technadu.com/kodi-addon-repository-xvbmc-nl-taken-down-brein-anti-piracy-complaint/38165/) из-за нарушения авторских прав. После этого... | https://habr.com/ru/post/423541/ | null | ru | null |
# Аутентификация в Django при помощи Metamask
Сегодня мы напишем простой сниппет для аутентификации пользователей на сайте при помощи кошелька Metamask. Замечу, что данное решение максимально изолировано от фреймворка. Вы сможете легко адаптировать его не только к Django, но и к Flask, Sanic, Starlette, Aiohttp и т.п.... | https://habr.com/ru/post/684958/ | null | ru | null |
# Докеризация MySQL в Uber

Разработанная инженерами Uber система хранения данных [Schemaless](https://eng.uber.com/schemaless-part-one/) используется в нескольких самых важных и крупных сервисах нашей компании (например, [M... | https://habr.com/ru/post/322142/ | null | ru | null |
# PyGMTSAR (Python GMTSAR) — Спутниковая интерферометрия для всех
[](https://github.com/mobigroup/gmtsar/actions/workflows/macos.yml)[](htt... | https://habr.com/ru/post/692334/ | null | ru | null |
# NGINX как балансировщик нагрузки для MySQL или MariaDB Galera Cluster
*Данная статья является переводом оригинальной [статьи](http://severalnines.com/blog/nginx-database-load-balancer-mysql-or-mariadb-galera-cluster) с сайта Severalnines.*
Nginx хорошо известен всем за свои расширенные возможности и эффективность... | https://habr.com/ru/post/271467/ | null | ru | null |
# Как я парсил всю базу данных игр Metacritic-а
***Metacritic** — англоязычный сайт-агрегатор, собирающий отзывы о музыкальных альбомах, играх, фильмах, телевизионных шоу и DVD-дисках.* (с википедии).
Использованные библиотеки: **lxml**, **asyncio**, **aiohttp** (lxml — библиотека разбора HTML страниц с помощью Pyt... | https://habr.com/ru/post/319966/ | null | ru | null |
# Метаклассы в Python
Привет, Хабр! У нас продолжается [распродажа в честь черной пятницы](https://habr.com/ru/company/piter/news/t/590621/). Там вы найдете много занимательных книг.
Возможен вопрос: а что ... | https://habr.com/ru/post/592127/ | null | ru | null |
# Отладка C на ZX Spectrum
клон ZX Spectrum harlequin 128k c ethernet адаптеро... | https://habr.com/ru/post/575134/ | null | ru | null |
# Быстрое создание MVP (minimum viable product) на базе Microsoft Azure и Xamarin.Forms
> *Друзья! Мы открываем в нашем блоге колонку на тему разработки мобильных приложений на Xamarin. И первая публикация от Вячеслава Черникова — руководителя отдела разработки компании «Binwell» затрагивает нюансы кроссплатформенной ... | https://habr.com/ru/post/281897/ | null | ru | null |
# О первоклашках, дистанционке и асинхронном программировании

Я дауншифтер. Так получилось, что последние три года мы с женой и младшим ребёнком наслаждаемся сельским пейзажем за окном, свежим воздух... | https://habr.com/ru/post/533102/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.