
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Геотрекинг в React Native
Мобильное приложение может выступать в роли «рабочего места» сотрудника, при этом бывает необходима передача географических координат и прочих данных. При кроссплатформенной разработке приложений на iOS и Android для этой задачи зачастую используют фреймворки, такие как Flutter или React Na... | https://habr.com/ru/post/493312/ | null | ru | null |
# Dynamic CDN for Low Latency WebRTC Streaming

Having analyzed earlier the capacity of standard [server configurations in Digital Ocean](https://habr.com/en/company/flashphoner/blog/476554/) in terms of WebRTC streaming, we have not... | https://habr.com/ru/post/477304/ | null | en | null |
# Шпаргалка по визуализации данных в Python с помощью Plotly
Plotly — библиотека для визуализации данных, состоящая из нескольких частей:
* Front-End на JS
* Back-End на Python (за основу взята библиотека Seaborn)
* Back-End на R
*В этой простыне все примеры разобраны от совсем простых к более сложным, так что раз... | https://habr.com/ru/post/502958/ | null | ru | null |
# Установка Redis и мониторинг с помощью Zabbix
Если вам нужна быстродействующая нереляционная СУБД типа «ключ-значение», то, возможно, подойдет [Redis (Remote Dictionary Server)](https://redis.io/). На базе ... | https://habr.com/ru/post/687916/ | null | ru | null |
# Анимация в WPF и Blend SDK
Всем добрый день! В этой статье я опишу простой способ запуска анимации с помощью инструмента Blend SDK от Microsoft.
С анимациями в WPF дела обстоят не очень легко и их стараются избежать по нескольким причинам. Первая — их тяжело запускать и сложно останавливать. Вторая — они не очен... | https://habr.com/ru/post/336692/ | null | ru | null |
# Auto dependency injection в Javascript
### Вступление
Как все мы знаем javascript это язык в котором очень просто выстрелить себе в ногу. Работая с этим языком уже почти пять лет, я не раз сталкивался с тем, что javascript предоставляет очень скудные инструменты для создания абстракций высокого уровня. А, создавая ... | https://habr.com/ru/post/149912/ | null | ru | null |
# Ковид-пандемия: взгляд ковидоскептика
> 
>
>
>
> Роман Левентов [leventov](https://habr.com/ru/users/leventov/)
>
> Довожу до вашего сведения, что я отправил ссылку на ваш пост в интернет-приемную sledcom.ru. За распростр... | https://habr.com/ru/post/564356/ | null | ru | null |
# Исследование сетевого трафика
> Специально для будущих студентов курса [**«Network engineer. Basic»**](https://otus.pw/hGTW/) наш эксперт - Александр Колесников подготовил интересный авторский материал.
>
> Также приглашаем принять участие в открытом онлайн-уроке на тему [**«STP. Что? Зачем? Почему?»**](https:/... | https://habr.com/ru/post/540546/ | null | ru | null |
# Кто же был на сервере?
Наступает момент, когда системному администратору необходимо определить дату последнего входа в систему каждого из пользователей, а также подготовить список тех аккаунтов, которые этого так и не сделали. Если б Вы ранее не знали команду **lastlog**, то удивились бы, насколько легко и быстро он... | https://habr.com/ru/post/270687/ | null | ru | null |
# Подарки для внимательных слушателей: какие аудиопасхалки прятали в «pre-gap» на Audio CD
Мы уже [рассказывали](https://www.audiomania.ru/content/art-7079.html) про сюрпризы, которые хранят в себе виниловые пластинки. Это был винил 1901 года, композиции Pink Floyd и The B-52's, небольшие программы и даже оптические э... | https://habr.com/ru/post/482288/ | null | ru | null |
# Чиним наследование?
Сначала здесь было долгое вступление про то, как я додумался до гениальной идеи (шутка, это [миксины в TS/JS](https://www.typescriptlang.org/docs/handbook/mixins.html) и [Policy в C++](https://en.wikipedia.org/wiki/Modern_C%2B%2B_Design#Policy-based_design)), которой и посвящена статья. Не буду т... | https://habr.com/ru/post/521866/ | null | ru | null |
# БЭМ on Rails

Здравствуй, <%= habrauser %>!
Я очень люблю фреймворк Ruby On Rails, он правда очень и очень крут. Он позволяет в кратчайшие сроки реализовать твои замыслы. Раньше я много писал на нем, но сегодня я fro... | https://habr.com/ru/post/192972/ | null | ru | null |
# Кабысдох – DoH-припарка от русского firewall
```
# wtf cf-hls-media.sndcdn.com
cf-hls-media.sndcdn.com is an alias for d1ws1c3tu8ejje.cloudfront.net.
d1ws1c3tu8ejje.cloudfront.net has address 13.33.240.123
❌ 13.33.240.123 заблокирован
```
С в очередной раз замолчавшего радио и [начался](https://twitter.com/mathemonk... | https://habr.com/ru/post/538806/ | null | ru | null |
# Начать с React и Bootstrap за 2 дня. День №1
Сразу скажу, что сайт будет быстрее работать, если заменить Bootstrap на чистый CSS и JS. Эта статья про то, как быстро начать разрабатывать красивые web-приложения, а оптимизация это уже отдельный вопрос, выходящий за пределы этой статьи.
Для начала надо хотя бы немно... | https://habr.com/ru/post/431826/ | null | ru | null |
# Как перестать замечать ограниченность траффика у бесплатных WiFi
Добрый день, уважаемые хабражители!
Этот пост, совмещенный с вопросом, посвящен попытке сделать работу с бесплатными WiFi удобной.
Пост написан про определенную сеть, но при простом допиле сгодится почти для всех. Во избежание проклятий скажу, чт... | https://habr.com/ru/post/181854/ | null | ru | null |
# Обработка ошибок в Go
Привет, хабровчане! Уже сегодня в ОТУС стартует курс [«Разработчик Golang»](https://otus.pw/Hjyy/) и мы считаем это отличным поводом, чтобы поделиться еще одной полезной публикацией по теме. Сегодня поговорим о подходе Go к ошибкам. Начнем!
Мы уже ознакомились с тем, [что нужно знать перед началом работы с Ansible](https://habr.com/ru/company/southbridge/blog/658201/).Теперь давайте разберем самые Часто Задаваемые Вопросы, или сокр... | https://habr.com/ru/post/659217/ | null | ru | null |
# GUI на Grafana для mgstat — утилиты мониторинга системы на InterSystems Caché, Ensemble или HealthShare
Добрый день! Данная статья является продолжением статьи "[Дружим Prometheus с Caché](https://habrahabr.ru/company/intersystems/blog/318940/)". Мы рассмотрим вариант визуализации результатов работы утилиты [^mgstat... | https://habr.com/ru/post/331594/ | null | ru | null |
# GitHub разблокирован
### Администрация сервиса пошла на условия Роскомнадзора
[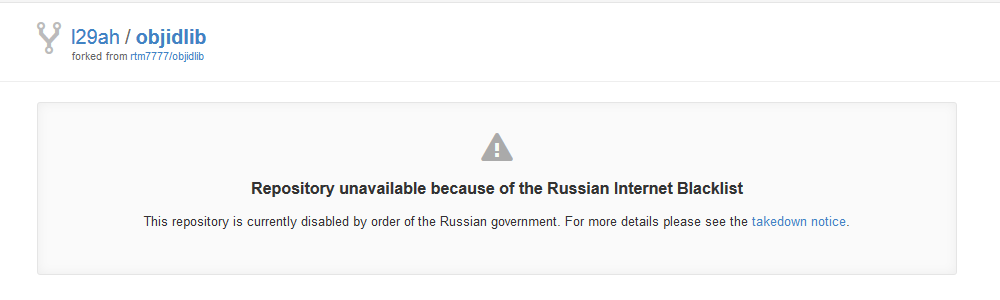](http://https:https://habrastorage.org/files/ea4/4de/623/ea44de6232e740109cec25c1822558c9.png)
GitHub закрыл для пользователей из России дост... | https://habr.com/ru/post/355742/ | null | ru | null |
# Мы опубликовали современный Voice Activity Detector и не только
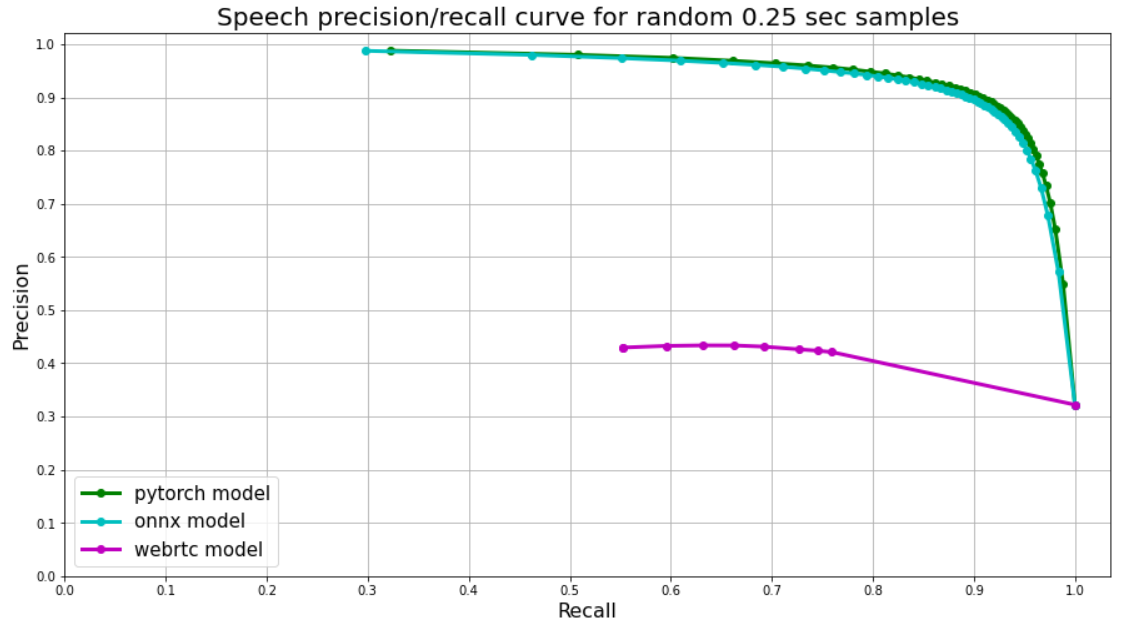
Всегда при работе с речью встает несколько очень "простых" вопросов, для решения которых нет большого количества удобных, открытых и про... | https://habr.com/ru/post/537274/ | null | ru | null |
# Решение проблемы ограничения PTRACE_ATTACH в контейнерах Docker

В последние два года мы широко используем Docker как для разработки, так и для выполнения систем в производственной среде, и все текущие продукты для наших клиен... | https://habr.com/ru/post/334016/ | null | ru | null |
# Шрифты в вебе, обзор от 2016 года

#### Предисловие
Статья — не про всё возможное, связанное с типографикой и текстами, вроде letter-spacing и max-height. Это скорее некоторый список занятных возможностей, которые могут б... | https://habr.com/ru/post/310044/ | null | ru | null |
# Как я Google API с CodeIgniter A3M подружить пытался и что из этого вышло

Недавно возникла задача прикрутить к библиотеке [A3M](https://github.com/donjakobo/A3M) (это довольно популярная библиотека аутентификации для Cod... | https://habr.com/ru/post/266339/ | null | ru | null |
# PostGIS + Mapnik + TileCache во FreeBSD
Привет! Появилась необходимость на одном из серверов в нашей сети сделать «что-то вроде openstreetmap.org», но так, чтобы все это продолжало работать и без подключения к Интернету.
К сожалению я не нашел хорошего мануала на «Великом и Могучем» о том, как это реализовать, по... | https://habr.com/ru/post/138791/ | null | ru | null |
# Автоматизация импортов в Python
| До | После |
| --- | --- |
|
```
import math
import os.path
import requests
# 100500 other imports
print(math.pi)
print(os.path.join('my', 'path'))
print(requests.get)
```
|
```
import smart_imports
smart_imports.all()
print(math.pi)
print(os_path.join('my', 'path'))
print(r... | https://habr.com/ru/post/459930/ | null | ru | null |
# Переход от режима Hand в Intel RealSense SDK R4 (v6.0) к режиму Cursor в Intel RealSense SDK 2016 R1

После появления камеры Intel RealSense [SR300](https://software.intel.com/en-us/RealSense/SR300Camera) и пакета [Intel ... | https://habr.com/ru/post/306010/ | null | ru | null |
# Разносим S3 бакеты по разным пулам в Ceph Luminous
В процессе настройки нового кластера на Ceph Luminous появилась задача разнести разные S3 бакеты по разным устройствам хранения (в моем случае SSD и HDD). В интернете много инструкций как это сделать в Ceph Jewel, но в случае с Luminous процесс претерпел большие изм... | https://habr.com/ru/post/351894/ | null | ru | null |
# Impress Application Server простыми словами
Это не первая вводная статья про [Impress](https://www.npmjs.com/package/impress) на Хабре, но за последний год я получил много вопросов и приобрел некоторый опыт в объяснении архи... | https://habr.com/ru/post/247543/ | null | ru | null |
# Про LL-парсинг: Подход к синтаксическому анализу через концепцию нарезания строки
Приветствую уважаемое сообщество!
Повторение — мать учения, а разбираться в синтаксическом анализе — очень полезный навык для любого программиста, поэтому хочу еще раз поднять эту тему и поговорить в этот раз про анализ методом реку... | https://habr.com/ru/post/412905/ | null | ru | null |
# Кана-капча на PHP — это просто!

В этом топике я кратко расскажу о кана-капче, что она из себя представляет, как она работает и как ее сделать средствами PHP.
#### Катакана
В японском языке для записи используются две слоговы... | https://habr.com/ru/post/121029/ | null | ru | null |
# Была ли жизнь до Audio CD? Программный декодер PCM
В [прошлой статье](https://habr.com/ru/post/497666/) мы рассказали про динамические QR коды, которые записывали на VHS кассеты. Эпидемия PCM зацепила и меня, так что пришло время поковырять этот формат.
 мы рассказали, как построили работу серверов и оптимизировали изображения в нашем [агрегаторе презентаций](https://slide-share.ru/). Это помогло. Дискам стало легче, страницы сайта начали загружаться быстрее. После того, как контент... | https://habr.com/ru/post/713974/ | null | ru | null |
# Мой друг Netmiko. Часть 3: один скрипт для разных устройств Huawei
Мы уже разобрали в прошлых частях как накатить на сетевые устройства Huawei список команд из внешнего файла. И это работает, если у нас сеть состоит из одинаковых устройств. Конечно, в реальной практике такое встречается редко. В этой работе мы рассм... | https://habr.com/ru/post/657981/ | null | ru | null |
# PostgreSQL отложенные SQL ограничения
На Хабре уже было несколько статей упоминающих deferred constraints.
* [Postgres: bloat, pg\_repack и deferred constraints](https://habr.com/ru/company/miro/blog/499444/)
* [Ограничения (сonstraints) PostgreSQL: exclude, частичный unique, отложенные ограничения и др](https://... | https://habr.com/ru/post/526042/ | null | ru | null |
# Подготовка и публикация приложений в Marketplace
Недавно мне невероятно повезло участвовать в вебинаре Microsoft Стаса Павлова и Юлии Щегловой "[Windows Phone для стартапов. Ответы на ваши вопросы](http://www.techdays.ru/videos/4270.html)" (запись доступна на [techdays](http://www.techdays.ru/videos/4270.html)).
... | https://habr.com/ru/post/142469/ | null | ru | null |
# Назад к микросервисам вместе с Istio. Часть 2

***Прим. перев.**: [Первая часть](https://habr.com/ru/company/flant/blog/438426/) этого цикла была посвящена знакомству с возможностями Istio и их демонстрации в действии. Теперь же ре... | https://habr.com/ru/post/440378/ | null | ru | null |
# Google Sheets API + Python. Чтение и запись с Сервисным Аккаунтом Google Cloud
*Google Sheet* и *Sheets API* - классный (простой, бесплатный и универсальный) способ организовать хранение и анализ данных пол... | https://habr.com/ru/post/575160/ | null | ru | null |
# Автоматизация замены дисков с помощью Ansible

Всем привет. Я работаю ведущим системным администратором в ОК и отвечаю за стабильную работу портала. Хочу рассказать о том, как мы выстроили процесс автоматической замены дисков, а ... | https://habr.com/ru/post/452110/ | null | ru | null |
# Получение параметров команды из человеческой фразы
Хотя мне и [удалось разобраться](https://habrahabr.ru/post/348224/) с классификацией интента, осталась более сложная задача — выцепить из фразы дополнительные параметры. Я знаю, что это делается с помощью тегов. Один раз я уже успешно применил [sequence\_tagging](ht... | https://habr.com/ru/post/350222/ | null | ru | null |
# Алгоритмы в индустрии: теория формальных языков и чат-боты
Популярность диалоговых систем тесно связана с термином “искусственный интеллект”. Такие системы обычно основаны на нейросетях и других моделях машинного обучения.
Однако, такой подход порождает неожиданные трудности
, и нашли решение проблемы с активацией, которая преследовала пользова... | https://habr.com/ru/post/315702/ | null | ru | null |
# Allure-Android. Информативные отчеты для мобильной автоматизации
*Статья публикуется от имени Иванова Андрея и Батеевой Екатерины, [neifmetus](https://habr.com/ru/users/neifmetus/)*
Автоматизация мобильных приложений довольно молодая сфера: фреймворков много и многие проекты сталкиваются с проблемой выбора самого... | https://habr.com/ru/post/433756/ | null | ru | null |
# Использование DSP-сопроцессора DM8168 с помощью фреймворка C6Accel

В этой статье мы познакомимся с отладочной платой DM816x/C6A816x/AM389x и фреймворком C6Accel (он же C6EZAccel), а также рассмотрим инструкции по наладке... | https://habr.com/ru/post/248591/ | null | ru | null |
# Выборочный обход блокировок на маршрутизаторах с прошивкой Padavan и Keenetic OS
Инструкций с разными вариантами обхода блокировок Интернет-ресурсов опубликовано огромное количество. Но тема не теряет актуальности. Даже всё чаще звучат инициативы на законодательном уровне заблокировать статьи о методах обхода блокир... | https://habr.com/ru/post/428992/ | null | ru | null |
# Требования ACID на простом языке
Мне нравятся книги из серии [Head First O`Reilly](https://okiseleva.blogspot.com/2020/01/head-first-oreilly.html) — они рассказывают просто о сложном. И я стараюсь делать также.
Когда речь идёт о базах данных, могут всплыть магические слова «Требования ACID». На собеседовании или в ... | https://habr.com/ru/post/555920/ | null | ru | null |
# Android navigation component. Простые вещи, которые приходится делать самому
Всем привет! Хочу рассказать об особенностях в работе [Navigation Architecture Component](https://developer.android.com/topic/libraries/architecture/navigation/), из-за которых у меня сложилось неоднозначное впечатление о библиотеке.
Эт... | https://habr.com/ru/post/429152/ | null | ru | null |
# Как мы настраивали миграции для бизнес-процессов в Битрикс24
Для автоматизации своих операций бизнес часто использует Битрикс24. В этой статье рассказываем о некоторых возможных проблемах при изменении бизнес-процессов и о том, как мы их решали.
.
И вот когда я в один прекрасный момент задумался о мониторинге в своем... | https://habr.com/ru/post/394333/ | null | ru | null |
# Уголок Java-разработчика: библиотеки на каждый день
За все время, проведенное в написании кода на Java, у меня сформировался определенный набор полезных **cторонних** библиотек, которые прочно засели в classpath, и без которых не обходится ни один день разработки, будь то написание чего-либо «на коленке» или работа ... | https://habr.com/ru/post/46687/ | null | ru | null |
# AWS Route53: DNS Failover теперь с поддержкой Elastic Load Balancer
Привет, друзья! 
Совсем недавно вышла [статья](http://habrahabr.ru/post/170471/) [astlock](http://habrahabr.ru/users/astlock/) о фейловере DNS. Фи... | https://habr.com/ru/post/181942/ | null | ru | null |
# Настройка DNS сервера на FreeBSD

Довольно часто возникает вопрос о внедрении своего ДНС сервера, который мог бы не только обслуживать запросы внешних пользователей к приобретенным ДНС именам, но и ... | https://habr.com/ru/post/68350/ | null | ru | null |
# Особенности функций Mikrotik script. Сode из :parse
Исследование функций и скриптов в Mikrotik script. Рассматриваются разные способы создания и вызова функций и скриптов с передачей в них параметров. Оператор :parse и особый тип данных code.
1. Что такое функция в Mikrotik script?
---------------------------------... | https://habr.com/ru/post/650795/ | null | ru | null |
# Разбор конкурса-квиза по React со стенда HeadHunter на HolyJs 2018
Привет. 24–25 сентября в Москве прошла конференция фронтенд-разработчиков HolyJs <https://holyjs-moscow.ru/>. Мы на конференцию пришли со своим стендом, на котором проводили quiz. Был основной квиз — 4 отборочных тура и 1 финальный, на котором были р... | https://habr.com/ru/post/431492/ | null | ru | null |
# Бюджетный мониторинг температуры в Cерверной комнате (MP707+nettop c Linux+PRTG)
Свою первую статью на Хабре интересно написать по материалу, основанному на личном опыте и действиях. Для этот как раз подходит раздел DIY или Сделай сам.
Нижеописанная система уже работает больше года практически без перерыва.
##... | https://habr.com/ru/post/417327/ | null | ru | null |
# Использование шейдеров во Flutter. Часть 1
*Привет! На связи Юрий Петров, Flutter Team Lead в* [*Friflex*](https://friflex.com/?utm_source=habr_article&utm_medium=link_main_rus_30012023&utm_campaign=Ispolzovanie_shejderov_vo_Flutter_CHast_1)*. Мы разрабатываем кроссплатформенные мобильные приложения для бизнеса и сп... | https://habr.com/ru/post/713298/ | null | ru | null |
# jTap — событие клика для сенсорных устройств

Привет, **%username%**!
Начну с того, что с каждым новым днем волна мобильных устройств все более накрывает людей. И, как повелось, практически... | https://habr.com/ru/post/191078/ | null | ru | null |
# zx – bash скрипты на javascript

Bash широко используется в программировании и является превосходным инструментом, но и у него есть свои недостатки. Поэтому Google разработал пакет zx, который позволяет использовать bash внутри j... | https://habr.com/ru/post/563312/ | null | ru | null |
# 64-битная арифметика в браузере и WebAssembly
 WebAssembly активно разрабатывается и уже достиг состояния, когда собранный модуль можно попробовать в Chrome Canary и Firefox Nightly, включив флажок в настройках.
Сравним прои... | https://habr.com/ru/post/308874/ | null | ru | null |
# Короткая заметка про шаблоны и смешание выведение типа и явного его задания
Намедни решил написать свою библиотеку для работы с [FITS](https://ru.wikipedia.org/wiki/FITS)-файлами. Да, я знаю, что есть [CCFITS](http://heasarc.gsfc.nasa.gov/fitsio/CCfits/), но хотелось изобрести свой велосипед с… сами знаете.
Одна ... | https://habr.com/ru/post/216901/ | null | ru | null |
# Распознавание жестов движений на Android используя Tensorflow

Введение
--------
В сегодняшние дни есть много разных способов взаимодействия со смартфонами: тач-скрин, аппаратные кнопки, сканер отпечатков пальцев, видео камера (например систем... | https://habr.com/ru/post/346766/ | null | ru | null |
# Windows: достучаться до железа
Меня всегда интересовало низкоуровневое программирование – общаться напрямую с оборудованием, жонглировать регистрами, детально разбираться как что устроено... Увы, современн... | https://habr.com/ru/post/527006/ | null | ru | null |
# Реферальная система в Telegram ботах
Всем привет! Наверняка вы видели в различных ботах реферальную ссылку типа https://t.me/<юзернейм\_бота>?start=<число>. Обычно в качестве числа указывается Telegram ID реферера. В этой статье я расскажу как обрабатывать такие ссылки в своем боте.
Для разработки ботов я использую... | https://habr.com/ru/post/561112/ | null | ru | null |
# Windows 8.1 Kernel Patch Protection — PatchGuard
Периодически, как правило во вторую среду месяца, можно услышать истории о том, что Windows после очередного обновления перестает загружаться, показывая синий экран смерти... | https://habr.com/ru/post/246841/ | null | ru | null |
# Чек-лист устранения SQL-инъекций
В прошлой статье мы уже рассматривали тему SQL-инъекций.
SQL-инъекции' union select null,null,null --Современные веб-приложения имеют сейчас довольно сложную структуру. Вм... | https://habr.com/ru/post/546232/ | null | ru | null |
# Плагин perl-support для vim
#### Установка плагина
```
mkdir ~/.vim
cd ~/.vim
curl http://www.vim.org/scripts/download_script.php?src_id=21048 -o perl-support.zip
unzip perl-support.zip
rm perl-support.zip
echo "filetype plugin on" >> ~/.vimrc
yum install perl-Perl-Critic perltidy
```
#### Создание нового файл... | https://habr.com/ru/post/208492/ | null | ru | null |
# Начинаем изучать STM32: Что такое регистры? Как с ними работать?
### Продолжаем рассмотрение базовых вопросов
В [предыдущем уроке](https://habr.com/post/406889/) мы рассмотрели работу с битовыми операциями и двоичными числами, тем самым заложив основу для рассмотрения новой темы. В этом уроке мы с Вами рассмотрим о... | https://habr.com/ru/post/407083/ | null | ru | null |
# OpenWRT, или Что еще можно сделать со своим роутером
Здравствуйте, на написание данной статьи меня натолкнула [аналогичная](http://habrahabr.ru/post/191854/), но в качестве сервера выступала Raspberry Pi. По моему мнению использовать эту маленькую, но при этом достаточно мощную платку в этих целях немного не целесоо... | https://habr.com/ru/post/191990/ | null | ru | null |
# API индивидуализированного изучения грамматики
Индивидуальное обучение иностранному языку всегда работает лучше, чем обучение по общим программам и по материалам, которые “подходят всем”. Действительно, программисту и... | https://habr.com/ru/post/370689/ | null | ru | null |
# Developing a symbolic-expression library with C#. Differentiation, simplification, equation solving and many more
Hello!
[**UPD from 12.06.2021**: if you're looking for a symbolic algebra library, AngouriMath is actively developed. It's on [Github](https://github.com/asc-community/AngouriMath) and has a [website]... | https://habr.com/ru/post/486496/ | null | en | null |
# Проверяем IronPython и IronRuby с помощью PVS-Studio
Совсем недавно мы выпустили новую версию нашего анализатора PVS-Studio с поддержкой проверки C# проектов. Пока на время релиза дальнейшая разработка продукта была приостановлена, я занимался тестированием анализатора. В качестве проектов для своих экспериментов я ... | https://habr.com/ru/post/274863/ | null | ru | null |
# Введение в веб-компоненты. Часть 1
*От переводчика: Представляю вашему вниманию перевод многообещающего [стандарта Веб-компонентов](http://dvcs.w3.org/hg/webcomponents/raw-file/tip/explainer/index.html) от Google, который может стать трендом в ближайшие несколько лет. В данный момент, знание этого стандарта не несёт... | https://habr.com/ru/post/152001/ | null | ru | null |
# Solutions to Bug-Finding Challenges Offered by the PVS-Studio Team at Conferences in 2018-2019

Hi! Though the 2019 conference season is not over yet, we'd like to talk about the bug-finding challe... | https://habr.com/ru/post/476268/ | null | en | null |
# Разбор решения занявшего второе (пока что) место в конкурсе Hola по программированию почтовых фильтров на JavaScript
В ноябре прошлого (уже) года, Hola объявила [конкурс по программированию почтовых фильтров на js](http://habrahabr.ru/company/hola/blog/270847/), и недавно опубликовала [его результаты](http://habraha... | https://habr.com/ru/post/274935/ | null | ru | null |
# Не знаешь что посмотреть? Посмотри лучшие видео с TED
Наткнулся на очень [интересный пост](http://blog.postrank.com/2010/05/and-the-most-engaging-ted-talk-is/), где небольшим скриптом народ составил топ самых обсуждаемых докладов с [TED](http://www.ted.com). А так как сериалы становятся все тупее и тупее, решил запо... | https://habr.com/ru/post/115405/ | null | ru | null |
# Система наблюдения в автомобиле за ним же на Raspberry Pi. Часть 2
В прошлой [статье](http://habrahabr.ru/post/202012/) я описал:
* создание на одном Raspberry Pi домашнего VPN-сервера;
* установку и настройку на втором Raspberry Pi OpenVPN-клиента, Node.JS и 3G-модема.
В этот раз настроим и подключим GPS-приёмн... | https://habr.com/ru/post/202334/ | null | ru | null |
# Надежное программирование в разрезе языков. Часть 2 — Претенденты
Первая часть с функциональными требованиями [тут](https://habr.com/ru/post/437830/).
Заявленные как языки программирования с прицелом на надежность.
В алфавитном порядке — Active Oberon, Ada, BetterC, IEC 61131-3 ST, Safe-C.
Сразу дисклеймер ... | https://habr.com/ru/post/442372/ | null | ru | null |
# Фрагментация блобов Azure Blob Storage в сценариях загрузки и скачивания данных
Введение
--------
Если вы работали с облачными технологиями Microsoft Azure то наверняка сталкивались, или как минимум читали, про Azure Storage Account и его составляющие – Tables, Queues и Blobs.
В данной статье я хотел бы рассмотре... | https://habr.com/ru/post/652337/ | null | ru | null |
# Редкий SQL
Вводная
-------
Когда часто сталкиваешься с какой-либо технологией, языком программирования, стандартом, формируется некая картина их возможностей, границы, в которых они используются. Так может продолжаться достаточно долго, пока на глаза не попадаются примеры, которые расширяют затвердевшие горизонты з... | https://habr.com/ru/post/321504/ | null | ru | null |
# Детский HTTP DOS
Часто администраторы настраивают LAMP «из коробки». Для домашних страничек и тестовых стендов в этом нет ничего страшного.
Полноценный DDOS — это не самое дешевое удовольствие для атакующего и, если Ваш портал заказали, то должны найтись ресурсы для защиты от атаки.
Куда большую опасность пр... | https://habr.com/ru/post/125300/ | null | ru | null |
# Хранение данных в облаке
С восходом социальных приложений, таких, как Facebook, Instagram, YouTube и многих других, управление сгенерированным пользователями контентом стало проблемой, а проблемы нужно решать. Amazon AWS S3, Google Storage, Rackspace Cloud Files и другие похожие сервисы стали появляться, как грибы п... | https://habr.com/ru/post/173939/ | null | ru | null |
# Характерные особенности языка Dart
Dart был разработан так, чтобы выглядеть знакомо для программистов на таких языках, как Java и JavaScript. Если постараться, можно писать на Dart практически так же, как на одном из них. Если *оче... | https://habr.com/ru/post/130120/ | null | ru | null |
# Размеры Java-объектов разного типа
Введение
========
Содержит ли Java-объект:
* поля, объявленные в суперклассе?
* private поля, объявленные в суперклассе?
* методы?
* элементы массива?
* длину массива?
* другой объект (в себе)?
* hash-код?
* тип (свой)?
* имя (своё)?
Ответы на эти (и другие) вопросы можно полу... | https://habr.com/ru/post/470441/ | null | ru | null |
# Реверс-инжиниринг аркадного автомата: записываем Майкла Джордана в NBA Jam

Прошлым летом меня пригласили на тусовку в Саннивейле. Оказалось, что у хозяев в гараже есть аркадный автомат NBA JAM Tournament... | https://habr.com/ru/post/473660/ | null | ru | null |
# Авторизация в Redmine с другого сайта
На сайте [centos-admin.ru](http://centos-admin.ru) дизайнер придумал очень здоровский эффект для формы логина. Идея формы состоит в том, что пользователь вводит свои логин и пароль в [Redmine](http://www.redmine.org/) и попадает авторизованным на свою страничку.
Все бы здоров... | https://habr.com/ru/post/267921/ | null | ru | null |
# Как на самом деле изменится жизнь после нововведений в ГК ч.4
Какие перемены приготовил нам законодатель в грядущих поправках к Гражданскому кодексу? Прежде, чем вступать в шумные [споры до рыготы](http://habrahabr.ru/blogs/copyright/51360/), предлагаю прочесть текст этих поправок [в первоисточнике](http://www.cons... | https://habr.com/ru/post/284408/ | null | ru | null |
# Angular 2.0.0-alpha для тех, кто не в силах ждать

Совсем недавно (5-6 марта) прошла конференция [ng-conf](http://www.ng-conf.org), и много докладов на ней было посвящено грядущему релизу Angular 2, на нескольких из них да... | https://habr.com/ru/post/253469/ | null | ru | null |
# Suricata как IPS
#### Предисловие
Печально видеть, что статьи о предупреждении или предотвращении вторжений на хабре столь непопулярны.
[Курс молодого бойца: защищаемся маршрутизатором. Продолжение: IPS](/post/60769/) — **5** плюсов.
[SNORT как сервисная IPS](/post/123474/) — **25** плюсов.
[OSSEC: Большой... | https://habr.com/ru/post/192884/ | null | ru | null |
# Геокодер OSM на Java
Привет, дорогие читатели хабра. В этой статье поговорим
* Про адреса и хранилища данных с нечеткой схемой
* Про обработку геоданных на java, а именно про Java Topology Suite
* Про стоимость «простоты» для разработчика
* Про pure Java nosql документную бд / движок полнотекстового поиска — Ela... | https://habr.com/ru/post/222875/ | null | ru | null |
# Облако в штанах

В сети сейчас большое количество различных т.н. «облачных» систем хранения данных. Созданы они, в большинстве своём, для удобства доступа к данным для рядового пользователя из любого кон... | https://habr.com/ru/post/224961/ | null | ru | null |
# А Вы как представляете себе Product?
Данные, данные, данные… Постоянно приходится с ними работать и, конечно же, хотелось бы иметь для этого максимально комфортные условия.
Предположим есть у нас табличка в базе данных:
Product: id int — первичный ключ, name varchar(256), description text, is\_visible bit.
... | https://habr.com/ru/post/42215/ | null | ru | null |
# Entropy — Неточный язык программирования
 В комментариях к недавнему посту про [неточный процессор](http://habrahabr.ru/post/144144/#comment_4836943), хабраюзер [lol2Fast4U](http://habrahabr.ru/users/lol2fast4u/) привел с... | https://habr.com/ru/post/144300/ | null | ru | null |
# Рисуем графики (диаграммы) в Django

Многие веб-разработчики время от времени сталкиваются с необходимостью визуализировать сравнительно большое количество данных при помощи диаграмм (... | https://habr.com/ru/post/126704/ | null | ru | null |
# Как оценить производительность Linux-сервера: открытые инструменты для бенчмаркинга
Мы в [1cloud.ru](https://1cloud.ru?utm_source=habrahabr&utm_medium=cpm&utm_campaign=bench3&utm_content=site) подготовили подборку инструментов и скриптов для оценки производительности процессоров, СХД и памяти на Linux-машинах: Iomet... | https://habr.com/ru/post/462777/ | null | ru | null |
# Открытый проект файловой системы для внутренней памяти STM32H
Зачем ставить внешнюю IC памяти или SD карту если в микроконтроллере осталось много свободной Flash памяти!
Микроконтроллеры семейства STM32H снабжены... | https://habr.com/ru/post/584156/ | null | ru | null |
# Angular c Clarity Design System от VmWare

Поработав с [Angular Material 2](https://material.angular.io/), в какой то момент пришел к выводу, что продукт сыро... | https://habr.com/ru/post/339294/ | null | ru | null |
# Применение FitNesse для .Net приложений
Привет, хабр.
Я думаю, многие из вас слышали про такую штуку, как [FitNesse](http://fitnesse.org/). Это одна из технологий тестирования, где тесты создаются как wiki-разметка (т.е. каждый тест — это web страница), и потом запускаются на определенной технологии [(Java, .Net,... | https://habr.com/ru/post/228967/ | null | ru | null |
# Бэкап файловых и SQL баз 1С (в облако и с шифрованием)
В этой статье я хочу поделиться опытом резервного копирования файловых и SQL баз 1С в локальное, сетевое и облачное (на примере Google Drive) хранилище с помощью Effector Saver.
ПО является платным: 2500₽.
Переход на новую версию (с 3 на 4) также является... | https://habr.com/ru/post/474944/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.