
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Стандарт C++20: обзор новых возможностей C++. Часть 5 «Корутины»

25 февраля автор курса [«Разработчик C++»](https://praktikum.yandex.ru/cpp?utm_source=pr&utm_medium=content&utm_content=31_05_21&utm_campaign=pr_content_cpp_habr) в ... | https://habr.com/ru/post/559642/ | null | ru | null |
# Сборка (CI/CD) не-JVM проектов с использованием gradle/kotlin
В некоторых проектах сборке отводится роль Золушки. Основные усилия команда сосредоточивает на разработке кода. А самой сборкой могут заниматься люди, далёкие от разработки (например, отвечающие за эксплуатацию, либо за развёртывание). Если сборка хоть ка... | https://habr.com/ru/post/550654/ | null | ru | null |
# Создание сервлетов для чайников. Пошаговое руководство

Когда начинающий разработчик сталкивается с сервлетами, ему бывает очень сложно понять, как он работает и от чего зависит эта работа. Всё потому, что все примеры ... | https://habr.com/ru/post/333626/ | null | ru | null |
# Программная генерация скриптов для MSSQL
В силу частых и неупорядоченных изменений базы данных, большим числом пользователей, часто возникает вопросы о истории изменений. Речь не идет о тотально логирование всех изменений, которые происходят с базой в течение дня. Интерес представляют собой снимки структуры БД кажды... | https://habr.com/ru/post/145263/ | null | ru | null |
# Архитектура мобильного клиент-серверного приложения

К добавлению внешнего сервера рано или поздно приходит любой сложный проект. Причины, при этом, бывают совершенно различные. Одни, загружают дополнительные сведения из с... | https://habr.com/ru/post/246877/ | null | ru | null |
# Как привести в порядок историю ваших коммитов в Git
Публикуем перевод [статьи](https://hackernoon.com/how-to-clean-your-git-history-ryzb3ydv), которую мы нашли на hackernoon.com. Ее автор, Thiago Miranda, пишет о том, как сделать работу с Git более удобной и эффективной.
Аудио выход разведен не той стороной. Не баг, а фича.... | https://habr.com/ru/post/691936/ | null | ru | null |
# Держите данные под контролем
Не секрет, что пользовательским данным доверять нельзя. Поэтому однажды человек и придумал валидацию данных. Ну а я, интереса ради и пользы для, написал свою реализацию валидатора на PHP.
[Kontrolio](https://github.com/franzose/kontrolio) — «очередная библиотека валидации данных», спр... | https://habr.com/ru/post/306452/ | null | ru | null |
# Проблемы мониторинга дата-пайплайнов и как я их решал
Последние несколько лет я занимаюсь дата-инженерингом: строю пайплайны разного уровня сложности, добываю данные, нужные бизнесу, преобразую их и сохраняю, в общем, строю классические ETL.
В этом деле проблем можно ждать откуда угодно и на каждом шаге: источник д... | https://habr.com/ru/post/562520/ | null | ru | null |
# Quantum Computers Without Math and Philosophy
In this article, I will break down all the secrets of quantum computers piece by piece: what superposition (useless) and entanglement (interesting effect) are, whether they can replace classical computers (no) and whether they can crack RSA (no). At the same time, I will... | https://habr.com/ru/post/664810/ | null | en | null |
# Анализаторы Roslyn: повадки и места обитания
На днях объяснял одному товарищу что такое анализаторы Roslyn и как их писать. Ответ получился массивным, и я решил вынести его в отдельную публикацию.
Что такое анализаторы Roslyn? Если коротко — это отличный способ писать рефакторинги вроде Решарперовских. Постоянно ... | https://habr.com/ru/post/334582/ | null | ru | null |
# Python-шпаргалка. Часть 1 — Язык и Типы объектов

Данная статья представляет собой очень краткую, но емкую выжимку всего, что должен знать начинающий разработчик или QA-инженер о языке Python. Надеюс... | https://habr.com/ru/post/312674/ | null | ru | null |
# zabbix_sender over HTTP — как послать данные в Zabbix по HTTP|S
В этой статье я приведу возможное решение проблемы для многих системных администраторов, которые используют систему мониторинга [Zabbix](http://www.zabbix.com/ru/). Особенно пригодится для тех, кто осуществляет мониторинг разных программ в Zabbix: систе... | https://habr.com/ru/post/253799/ | null | ru | null |
# JasperReport+ZK интеграция без одного потраченного цента
Доброго всем времени суток. Когда я начинал изучать этот превосходный [framework zk](http://zkoss.org), а было это года два назад, то конечно русских манов я не встретил, тогда я полез на всеми нами обожаемый хабр и таки нашел один вводный пост. Но он был наст... | https://habr.com/ru/post/128320/ | null | ru | null |
# Шифруем сообщения в сети XMPP/Jabber с помощью PGP
В этой статье я подробно опишу как использовать шифрование при передаче сообщений по сетям на основе XMPP с помощью пакета GnuPG. Показана процедура генерации ключевых пар под Windows, установка ключей в клиент Psi, проверка подписанного присутсвия, передача шифрова... | https://habr.com/ru/post/50982/ | null | ru | null |
# Как подружить конструктор лендингов Сайты24 с работающим ecom-проектом. Полет нормальный?
Всем привет, на связи снова AGIMA, а я ее тимлид — Дмитрий Матлах. Сегодня мы поделимся историей — расскажем о том, как избавились от одной очень назойливой боли. До недавнего времени эта боль преследовала нас постоянно: из мес... | https://habr.com/ru/post/532180/ | null | ru | null |
# Конференция DEFCON 16. Фёдор, хакер InSecure.org. NMAP-cканирование Интернет
Добрый день, меня зовут Фёдор, я из **InSecure.org** и я являюсь автором проекта сканера безопасности **Nmap**, выпущенного в свет в 1997 году. Я хотел бы поблагодарить всех, кто сюда пришёл, и сам **Defcon** за то, что меня сюда пригласили... | https://habr.com/ru/post/422767/ | null | ru | null |
# Парсим сайты с защитой от ботов
В этой статье мы разберемся, как работает типичная защита от роботов, рассмотрим подходы к автоматическому парсингу сайтов с такой защитой, и разработаем свое решение для её обхода. В конце статьи будет ссылка на гитхаб.
Речь не идет о каком-либо виде "взлома" или о создании повышенн... | https://habr.com/ru/post/710982/ | null | ru | null |
# Опыт применения глубокого обучения для идентификации видов цифровой модуляции по сырым I/Q отсчетам (Keras)
, автоматический генератор кода? Если еще нет, возможно, наш перевод откроет для вас новый полезный инструмент.

При разработке... | https://habr.com/ru/post/534686/ | null | ru | null |
# Видеосъёмка из браузера. HTML-код, который включает камеру на смартфоне

Современные стандарты HTML и JavaScript дают разработчикам мощные инструменты для работы со смартфоном через браузер. Мы уже рассказывали о [трекинге движен... | https://habr.com/ru/post/692276/ | null | ru | null |
# Упрощение асинхронного кода на JavaScript с внедрением асинхронных функций из ES2016
Хотя мы еще продолжаем [работу над внедрением поддержки ES6/2015](http://blogs.windows.com/msedgedev/2015/05/12/javascript-moves-forward-in-microsoft-edge-with-ecmascript-6-and-beyond/), команда Chackra также смотрит за пределы ES20... | https://habr.com/ru/post/269871/ | null | ru | null |
# Степени — ключ к быстрой иерархии в реляционной БД
После публикации на Хабре [своей первой статьи](http://habrahabr.ru/post/165713/), об одном из способов организации иерархии в реляционной БД, у меня осталось чувство не доведенного до конца дела.
Судя по комментариям, кто-то принимал предложенный метод за друго... | https://habr.com/ru/post/166699/ | null | ru | null |
# Создаем эффективные стили для каруселей
Эта статья не о дизайне эффективных каруселей, а об эффективном создании стиля. Другими словами, речь пойдет не о UI-дизайне, а о конструкциях CSS – смене элементов карусели, их позиционировании и размерах.
**Зависимость от JavaScript с точки зрения взаимодействия, а не ст... | https://habr.com/ru/post/253111/ | null | ru | null |
# Программирование для начинающих. Моё знакомство с Processing
Доброго времени суток, уважаемые.
Цифровые электронные самоделки часто взаимодействуют с компьютером. Передают данные, либо управляются с него. В свете этого всегда был интерес к программированию.
Мой прошлый опыт в этой области связан с интерпретато... | https://habr.com/ru/post/260763/ | null | ru | null |
# Пробуем 3D с помощью jMonkeyEngine
Практически каждый, кто занимался геймдевом, понимает, что наилучшей производительности в этой области, по понятным причинам, можно добиться лишь на языках С/С++/asm. С данным утверждением в этой статье я спорить не буду, да и раньше даже как-то не задумывался о создании realtime-и... | https://habr.com/ru/post/88254/ | null | ru | null |
# Мне нравится vs like
Сейчас стало довольно популярно интегрировать на сайты социальные сервисы. Я думаю все видели социальные кнопки *tweet*, *like*, *Plus One* и множество других. Сегодня зашел на сайт Ubuntu.com и увидел следующую картину 
13 сентября 2022 года Microsoft [обновила](https://devblogs.microsoft.com/commandline/windows-terminal-preview-1-16-release/) превью... | https://habr.com/ru/post/688160/ | null | ru | null |
# Турецкие фокусы с червями, крысами… и фрилансером
Специалисты группы исследования угроз [экспертного центра безопасности Positive Technologies (PT Expert Security Center)](https://www.ptsecurity.com/ru-ru/research/pt-esc-threat-intelligence/) обнаружили вредоносную кампанию, которая активна по крайней мере с середин... | https://habr.com/ru/post/479998/ | null | ru | null |
# В который раз этот класс?
#### “А что это вы тут делаете?”
Сегодня в чате скайпа джентльмены вели задушевную беседу, размышляли о смысле жизни и, конечно же, говорили о погоде. В одном из сообщений этой душевной беседы проскочила [ссылка](http://demos.jquerymobile.com/1.4.2/) на мобильный фреймворк jquery. Немного ... | https://habr.com/ru/post/221063/ | null | ru | null |
# Не надо учить Machine Learning
#### Учитесь создавать софт, используя модели машинного обучения

*Дисклеймер: статья основана исключительно на моих наблюдениях за командами разработчиков в области машинного обучения и не является результатом... | https://habr.com/ru/post/504756/ | null | ru | null |
# Автоматический расчет ширины столбцов
#### Задача
Задача звучит просто – напечатать таблицу. Напечатать так, чтобы она выглядела красиво и, по возможности, не расползалась.
После некоторых раздумий, решено было воспользоваться [FOP](http://ru.wikipedia.org/wiki/Formatting_Objects_Processor) для генерации PDF. З... | https://habr.com/ru/post/167507/ | null | ru | null |
# Docker API + Portainer API = profit

Всем доброго времени суток! В этой статье хотел бы кратко в режиме смузи осветить возможности [Portainer](https://www.portainer.io/) API и применен... | https://habr.com/ru/post/482118/ | null | ru | null |
# gulpfile в 10 строк? Легко! — упрощаем создание типовых задач
Последнее время почти в любом проекте требуется сделать сборку less/sass/css/js/html и т.д. файлов. Gulp является отличным решением для выполнения этих задач, это глоток воздуха после grunt'a, но и он не идеален.
, и заодно начали оптимизировать код. А ещё перед этим читатели [обнаружили баг](... | https://habr.com/ru/post/101946/ | null | ru | null |
# IIS Request filtering против ddos-атаки
### Лежим
Заказчик, чьи сайты я поддерживал ранее, обратился с тем, что сайт лежит и отдает 500 ошибку. У него стандартный сайт на ASP.NET WebForms, не скажу, что очень нагруженный, но бывали проблемы с производительностью базы данных (MS SQL Server на отдельном сервере). Нед... | https://habr.com/ru/post/316550/ | null | ru | null |
# Пишем Telegram-бота на Rust, который будет запускать код на… Rust?
Доброй ночи! Сегодня хотелось бы кратко рассказать о том, как написать Telegram-бота на Rust, который будет запускать код на Rust. У статьи нет цели произвести полное погружение в API telegram\_bot, Serde, Telegram или в нюансы разработки на Rust. Он... | https://habr.com/ru/post/326830/ | null | ru | null |
# Разворачиваем MySQL: установка и настройка
MySQL на сегодняшний день является одной из наиболее распространенных в мире. Достаточно сказать, что по рейтингам 2021 года данная СУБД лишь немного уступала Orac... | https://habr.com/ru/post/712768/ | null | ru | null |
# Обзор физики в играх Sonic. Части 5 и 6: потеря колец и нахождение под водой

*Продолжение цикла статей о физике в играх про Соника. В этом посте рассматриваются потеря колец и нахождение под водой.*
**Ссылки на другие ... | https://habr.com/ru/post/305312/ | null | ru | null |
# ML-задача на 30 минут: гадаем по cookie
«Я тебя по IP вычислю!» – помните такую угрозу из интернета времен нулевых годов? Мы в [Big Data МТС](https://career.habr.com/companies/mts/vacancies) решили выяснить, можно ли составить хотя бы приблизительное представление о человеке, обладая информацией о сайтах, которые он... | https://habr.com/ru/post/709602/ | null | ru | null |
# Легким движением руки UITabBarController превращается в UISplitViewController
Доброй ночи/утра/дня/вечера
Как видно из названия статьи я расскажу вам о том, как потратив минимум сил и времени, превратить iPhone`ский UITabBarController в iPad`овский “UISplitViewController”
Для этого нам понадобится: проект(под ... | https://habr.com/ru/post/92593/ | null | ru | null |
# Timers in .Net
В последнее время не в первый раз сталкиваюсь с тем, что разработчики не до конца понимают как работает один из стандартных таймеров в .NET — System.Threading.Timer.
Т.е. в общем-то они вроде понимают что таймер что-то выполняет, скорее всего в ThreadPool — и если его использовать для периодическог... | https://habr.com/ru/post/195814/ | null | ru | null |
# И снова Яндекс.Погода для сайта: время суток, направление ветра и прочие параметры
В продолжении поста о погоде [«Яндекс.Погода для сайта в деталях»](http://habrahabr.ru/post/232529/). Прочитав данный пост, я пришел к выводу, что тема еще актуальна, и хотел бы дополнить выше упомянутую статью своими наработками.
... | https://habr.com/ru/post/233243/ | null | ru | null |
# Наследование компонентов в Angular: простой способ решить проблему с Dependency Injection
Итак, собственно проблема: порой у нас в проекте есть много похожих компонентов, с одинаковой логикой, одинаковыми DI, свойствами итд и возникает мысль: а почему бы не вынести все это дело в базовый компонент (точнее директиву)... | https://habr.com/ru/post/544590/ | null | ru | null |
# Расширение помощника CAPTCHA для Codeigniter

Недавно, от наличия свободного времени и желания сделать что то полезное, решил написать расширение для ~~убогого~~ хелпера капчи в Codeigniter.
Если Вам доводилось име... | https://habr.com/ru/post/161635/ | null | ru | null |
# Издание собственной книги: от А до Я
[](http://speedupyourwebsite.ru/books/speed-up-your-website/)После [заметки о выходе книги](http://habrahabr.ru/blogs/speedupyou... | https://habr.com/ru/post/54886/ | null | ru | null |
# NVIDIA прекращает выпуск драйверов для Windows 7 и 8.1 в этом году

Представители компании NVIDIA [заявили](https://nvidia.custhelp.com/app/answers/detail/a_id/5201/related/1), что в октябре 2021 года с поддержки компании будут сня... | https://habr.com/ru/post/562628/ | null | ru | null |
# Типажи и анонимные функции в PHP. Кря-кря!
В данной статье я не буду рассказывать, что такое Типажи, не буду описывать синтаксис, или разбирать всякие тонкости, связанные с разрешением имен и наследованием Типажей. На эту... | https://habr.com/ru/post/180333/ | null | ru | null |
# Android + Gradle + CI + CD или Как настроить кормушку для котов

Здравстуй дорогой читатель. Если тебе незнакомы понятия Continuous integration (CI), Continuous delivery (CD) или же у тебя нет представления как и зачем их ну... | https://habr.com/ru/post/328326/ | null | ru | null |
# Караоке на HTML5 canvas

Решил я попробовать сделать web-караоке, но чтобы текст красиво отображался — не по-буквенно, а плавно. Решение оказалось более простым, чем я думал.
По-буквенный вариант совсем прост — достаточ... | https://habr.com/ru/post/248783/ | null | ru | null |
# Экспорт и импорт личных данных телефона
Столкнулся с проблемой, что нужно было забрать свои контактные телефоны и все события в календаре с телефона и перекинуть на другой. Ходя по разным сервисам ничего не нашёл. Пришлось написать все самому.
Не буду показывать весь код программы, покажу лишь как забирать и запи... | https://habr.com/ru/post/81726/ | null | ru | null |
# Buildbot в примерах
Потребовалось мне настроить процесс сборки и доставки на сайт пакетов программ из Git-репозитария. И увидев, ни так давно, тут на Хабре статью по buildbot (ссылка в конце) решил для этого попробовать его и применить.
Так как buildbot — это распределённая система, то будет логичным под каждую арх... | https://habr.com/ru/post/464489/ | null | ru | null |
# Адаптация Jetpack Compose в hh.ru
Представьте: теплый осенний вечер, на столе чашечка чего-нибудь вкусного, за окном порхают пожелтевшие листья и тонко насвистывает ветер. Но на душе скребутся коварные мыши. И вам точно известно, откуда эти мыши растут: еще летом вышел стабильный Jetpack Compose, а вы таки не затащи... | https://habr.com/ru/post/679448/ | null | ru | null |
# TVGuardian. Задача: заменить ругательства в реальном времени

*«Он похож на зануду?» Реплика также может быть оценена, будто Уоллеса сравнивают с клячей, старой лошадью. [Видеоролик Джерри Ноулза](https://www.youtube.com/watch?v=... | https://habr.com/ru/post/715518/ | null | ru | null |
# Android Vitals — Это холодный старт?
Эта серия блогов посвящена мониторингу стабильности и производительности приложений Android в продакшне. В последних двух постах я описал то, что происходит с момента, к... | https://habr.com/ru/post/593743/ | null | ru | null |
# Апгрейд для ленивых: как PostgreSQL 12 повышает производительность

[PostgreSQL 12](https://www.postgresql.org/), последняя версия «лучшей в мире реляционной базы данных с открытым исходным кодом», выходит через пару-тройку недель (если вс... | https://habr.com/ru/post/466727/ | null | ru | null |
# Всё познаётся в сравнении, или реализация одной простенькой задачи на python и tcl
В силу исторических причин, у нас в конторе, используется старенькая АТС Panasonic TDA200. И, как известно, журнал звонков она выводит в последовательный порт, для чтения данных из которого, на сервере использовалась одна программульк... | https://habr.com/ru/post/335842/ | null | ru | null |
# Сказ о Cocos2d-android
Так уж получилось, что мне пришлось портировать игру с ios. Фреймворк выбирать не пришлось, им стал Cocos2d. До момента использования фреймворка мне довелось почитать отзывы о нем и они настораживали. Но как всегда надеялся на лучшее. И так, о своем опыте портирования и применения данного фрей... | https://habr.com/ru/post/136968/ | null | ru | null |
# Создание пакета для Laravel
Привет Хабр!
Фреймворк Laravel быстро набирает популярность и уже обрел большую армию фанатов. В этой статье я опишу разработку простого пакета для Laravel, а так же публикацию созданного нами пакета на сайте packagist.org для того, чтобы добавлять наш пакет в проект одной строчкой в c... | https://habr.com/ru/post/241423/ | null | ru | null |
# Data acquisition, часть 2
В [первой части](http://habrahabr.ru/blogs/net/93958) моего рассказа про data acquisition, я написал про то, какой инструментарий используется для получения HTML из интернета. В этом посте я более детально расскажу про то, как из этого HTML получать нужные данные, и как эти данные трансформ... | https://habr.com/ru/post/94128/ | null | ru | null |
# Чистая архитектура в Go-приложении. Часть 2
От переводчика: данная статья [написана Manuel Kiessling](http://manuel.kiessling.net/2012/09/28/applying-the-clean-architecture-to-go-applications/) в сентябре 2012 года, как реализация [статьи Дядюшки Боба](http://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architec... | https://habr.com/ru/post/270351/ | null | ru | null |
# RVM — подробно

RVM — Ruby Version Manager
Программа для управления версиями Ruby.
Как быть если один проект использует Ruby 1.8.7, а другой 1.9.2? А что если при этом у вас 2 проекта под версией 1.9.2, но с разными набор... | https://habr.com/ru/post/120504/ | null | ru | null |
# Domain Driven Design: Value Objects и Entity Framework Core на практике
На Хабре и не только написано приличное количество статей про Domain Driven Design — как в общем про архитектуру, так и с примерами на .Net. Но при этом зачастую слабо упоминается такая важнейшая часть этой архитектуры, как Value Objects.
В ... | https://habr.com/ru/post/443770/ | null | ru | null |
# Ожидание длиной в 15 лет. Nginx Application Server
Начиная с момента появления Nginx в 2004 году, мы все задавались вопросом: когда же на nginx можно будет запускать приложения? Мы запускали PHP в php-fpm и на апаче, запускали Python через uWSGI, иногда жили с Apache, а если нам нужны были разные версии PHP — жили с... | https://habr.com/ru/post/337346/ | null | ru | null |
# Ко-вариантность и типы данных
Тема вариантов в программировании вызывает кучу сложностей в понимании, по мне это проблема в том, что в качестве объяснения берут не всегда успешные метафоры - контейнеры.
Я надеюсь что может у меня получиться объяснить эту тему с другой стороны используя метафоры “присвоения” в разре... | https://habr.com/ru/post/560936/ | null | ru | null |
# Подземелья Qt: Рецепты приготовления монстров (Часть 1. Редактирование разнородных данных)

Всякому профессиональному разработчику приложений, использующему Qt, довольно часто приходится использовать связку mo... | https://habr.com/ru/post/276419/ | null | ru | null |
# Создание шейдеров
Освоить создание графических шейдеров — это значит взять под свой контроль всю мощь видепроцессора с его тысячами параллельно работающих ядер. При таком способе программирования требуется другой образ мышления, но раскрытие его потенциала стоит потраченных усилий.
Практически в любой современной... | https://habr.com/ru/post/333002/ | null | ru | null |
# CSS: системные цвета, шрифты и кое-что ещё
Думаю, все мы, в целом, знакомы с таким способом описания CSS-цветов:
```
color: OldLace;
background: rebeccapurple;
```
Полагаю, их обычно называют «[именованными цветами](https://css-tricks.com/snippets/css/named-colors-and-hex-equivalents/)».
[](http://habrahabr.ru/post/274689/)
[Расчет биномиальных коэффициентов с использованием Фурье-преобразований](http://habrahab... | https://habr.com/ru/post/274911/ | null | ru | null |
# Использование SPI из Python на Raspberry Pi
Приведенная в этой статье информация получена в процессе подключения трансивера [nRF24L01+](http://www.nordicsemi.com/eng/Products/2.4GHz-RF/nRF24L01P) к RPi. Естественно, все это можно использовать и для работы с другими SPI устройствами.
Для включение аппаратного инте... | https://habr.com/ru/post/214901/ | null | ru | null |
# Знакомство фронтендера с WebGL: первые наброски (часть 2)
Это история в несколько частей:
* [Знакомство фронтендера с WebGL: почему WebGL? (часть 1)](https://habr.com/ru/post/567052/)
* Знакомство фронтендера с WebGL: первые наброски (часть 2)
* [Знакомство фронтендера с WebGL: четкие линии (часть 3)](https://habr.... | https://habr.com/ru/post/567082/ | null | ru | null |
# Встречайте Envoyer.io (часть 2)
[Envoyer](https://envoyer.io/) — новый сервис от Тэйлора Отвелла, создателя Laravel. Уже сейчас можно посмотреть [серию скринкастов на Laracasts](https://laracasts.com/series/envoyer) про этот сервис. Это вторая и последняя часть описания этого сервиса.
[Встречайте Envoyer.io (част... | https://habr.com/ru/post/253278/ | null | ru | null |
# Создание patch’ей на Wix при помощи PatchWiz

Добрый день всем! Хочется поделиться со всеми своим опытом создания системы для генерации патчей (да простит меня читатель за использование этого слова). Про wix довольно мн... | https://habr.com/ru/post/190546/ | null | ru | null |
# Рано закапывать Java

Много было сказано про «красоту» кода на Java, но на мой взгляд, главное — не инструмент, а умение им пользоваться. Под катом попытка написать декларативный DSL для вёрстки под... | https://habr.com/ru/post/331790/ | null | ru | null |
# Спор о первом языке программирования: окончательное решение
Некоторые относятся к спору о выборе первого языка программирования примерно так:

Говорят, на выбор влияет миллион фаторов и спорить по этому поводу не имеет никаког... | https://habr.com/ru/post/488200/ | null | ru | null |
# Дружим Prometheus с Caché
[Prometheus](https://prometheus.io/) – одна из систем мониторинга, адаптированных под сбор [time series данных](https://en.wikipedia.org/wiki/Time_series_database).
Она достаточно проста в инсталляции и первоначальной настройке. Имеет встроенную графическую подсистему для отображения д... | https://habr.com/ru/post/318940/ | null | ru | null |
# Учебный курс по React, часть 18: шестой этап работы над TODO-приложением
В сегодняшней части перевода учебного курса по React вам предлагается продолжить работу над Todo-приложением и сделать так, чтобы щелчки по флажкам воздействовали бы на состояние компонента.
[
Кроссплатформенная разработка мобильных приложений была очень популярна в свое время. Данный подход использовали большинство компаний во время становления мобильной отрасли.... | https://habr.com/ru/post/277705/ | null | ru | null |
# Использование Facebook Graph API в Java
**Добрый день, Хаброжители!**
Сегодня я расскажу Вам историю собственного велосипеда.
Передо мной стала задача работы с Facebook Graph API в Java, меня интересовали 3 функции: логин, получение информации о пользователе, публикация сообщения на стене.
Работающей библио... | https://habr.com/ru/post/129614/ | null | ru | null |
# Открытый интернет-мессенджер Tox
На фоне всеобщей истерии с АНБ всё большее число людей чувствует необходимость в защищенной связи. Разработчики Tox обещают все, сразу и «из коробки».
Предупреждаю сразу: проект только начал развиваться и пока обещает намного больше, чем готов дать.

→ Часть 2. [Kali Linux: фильтрация трафика с помощью netfilter](https://habrahabr.ru/company/ruvds/blog/338480/)
→ Часть 3. [Kal... | https://habr.com/ru/post/338480/ | null | ru | null |
# Переход с CruiseControl.NET на Jenkins в команде разработчиков PVS-Studio
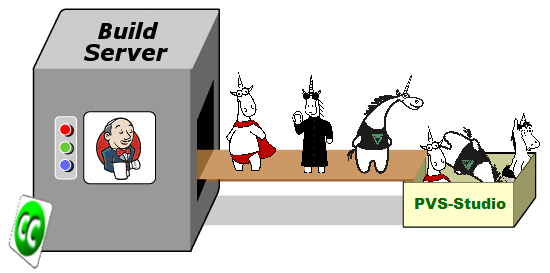
Сейчас трудно представить разработку программного обеспечения без автоматизированных сборок проекта и тестирования. Для ... | https://habr.com/ru/post/321346/ | null | ru | null |
# ML.NET: впечатления от Model Builder и не только
Доброго времени суток и мое почтение, читатели Хабра!
Предыстория
-----------
У нас на работе принято обмениваться интересными находками в командах разработки. На очередной встрече, обсуждая будущее .NET и **.NET 5** в частности, мы с коллегами заострили внимание на... | https://habr.com/ru/post/476052/ | null | ru | null |
# Процедурная генерация многоэтажных 3D-подземелий

В последнее время я играл в несколько roguelike, поэтому решил попробовать написать собственный процедурный генератор подземелий. Существует множество способов решения этой задачи, и я ... | https://habr.com/ru/post/481218/ | null | ru | null |
# Мониторинг производительности дисковой подсистемы при помощи zabbix и block stat
Вряд ли кто-то будет спорить, что наблюдение за производительностью дисковой подсистемы — чуть ли не важнейшая задача для всех высоконагруженных систем хранения и баз данных. Я изначально столкнулся с этим давным-давно, еще когда приход... | https://habr.com/ru/post/377757/ | null | ru | null |
# Веб-аналитика с помощью Google Tag Manager

Относительно недавно, мы проводили редизайн и оптимизацию нашего сайта и наткнулись на ряд проблем связанных со скриптами и кодами отслеживания от Google. А им... | https://habr.com/ru/post/203622/ | null | ru | null |
# Опыт внедрения PSR стандартов в одном легаси проекте
Всем привет!
В этой статье я хочу рассказать о своем опыте переезда на “отвечающую современным трендам” платформу в одном legacy проекте.
Все началось примерно год назад, когда меня перекинули в “старый” (для меня новый) отдел.
До этого я работал с Symfony/... | https://habr.com/ru/post/337692/ | null | ru | null |
# Сравнительный анализ языков C# и C++
Давайте взглянем на эти два языка внимательнее. Что важно для прилежного программиста? Чтобы его код был удобочитамым, дабы в любой момент, спустя любое время можно было изменить этот код.
C++
---
Чему учит нас C++, что он нам говорит, какие парадигмы он воздвигает?
1. Чт... | https://habr.com/ru/post/273331/ | null | ru | null |
# Насколько быстр AMP на самом деле?
Проект Accelerated Mobile Pages (AMP) от Google вызвал определённый переполох по идеологическим причинам, но саму технологию так и не разобрали подробно. Несколько недель назад Ферди Кристант писал про [несправедливое преимущество, которое получает контент AMP за счёт предзагрузки]... | https://habr.com/ru/post/353256/ | null | ru | null |
# Что можно найти в чужом коде? Подборка полезных материалов по .NET
Привет, Хабр! Наш коллега, Скотт Хансельман, считает, что в рамках изучения языка программирования важно не только кодить и практиковаться в написании, но и изучать чужой код. «Читайте чужой код» говорит Скотт и приводит полезные материалы, которые о... | https://habr.com/ru/post/418519/ | null | ru | null |
# Веб-разработка с нуля: руководство для молодых команд по созданию инфраструктуры CI/CD и процесса разработки
Чуть больше года назад я столкнулся с тем, что на внутреннем проекте совсем не айтишной компании вырос целый отдел веб-разработки, которым мне и довелось руководить. Рабочий процесс вроде как устаканился и вс... | https://habr.com/ru/post/526440/ | null | ru | null |
# Dagaz: Быстрее, Лучше, Умнее…
***— Как взмывают ангелы дружно в ряд…
— Дружно в ряд, дружно в ряд…
— Поднимают головы! И летят! И летят!..
сэр Терри Пратчетт «Ночная стража»***
Рано или позд... | https://habr.com/ru/post/349516/ | null | ru | null |
# A new writing method/technology (“dendrowriting”), as exemplified by the YearVer site
Several years have passed since the appearance of [the first text markup language that supports “dendrowriting”](https://pqmarkup.org), but no worthwhile piece of text demonstrating the advantages of the new writing method/technolo... | https://habr.com/ru/post/648913/ | null | en | null |
# Поля класса доступные по имени с setter и getter в C++
Как известно, в C++ нет средства описания полей класса с контролируемым доступом, как например property в C#. На Хабрахабре уже пробегала [статья](http://habrahabr.ru/blogs/cpp/121799/) частично на эту тему, но мне решительно не нравится синтаксис. К тому же оче... | https://habr.com/ru/post/125880/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.