
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Установка Django-проекта на VPS (centOS 7) [Для новичков]
Хочу поделиться практическим опытом по установке готового проекта на Django на VPS от Reg.ru. Данное руководство рассчитано на новичков, оно содержит ряд не самых лучших решений, но с ним вы сможете запустить своей проект на Django в течение часа.
Инструкц... | https://habr.com/ru/post/277653/ | null | ru | null |
# История про msdb размером в 42 Гб
 Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так. ... | https://habr.com/ru/post/273633/ | null | ru | null |
# БЭМ + React: гибкая архитектура дизайн-системы
[](https://habrahabr.ru/company/alfa/blog/340522/)
Дизайн — это фашизм. Фашизму нужна питательная среда. Он начинает раскрываться в полной мере только на крупных масштабах. Идеальная среда ... | https://habr.com/ru/post/340522/ | null | ru | null |
# Vulkan. Руководство разработчика. Вершинные буферы

Я начинаю перевод нового раздела Vulkan Tutorial ([vulkan-tutorial.com](https://vulkan-tutorial.com/Vertex_buffers/Vertex_input_description)), который называется Vertex buffers. С... | https://habr.com/ru/post/571944/ | null | ru | null |
# Компиляция Perl под Windows
Под Microsoft Windows существует несколько популярных дистрибутивов Perl.
Это Strawberry Perl и ActivePerl. Первый предназначен исключительно для Windows, второй собирается под различные платформы (полный список можно найти на официальном сайте). Важно учесть, что в ActivePerl, модули... | https://habr.com/ru/post/78034/ | null | ru | null |
# AppCode 2019.1: Swift 5, улучшенная работа подсветки, навигации и автодополнения, перемещение выражений и многое другое
Всем привет!
Неделю назад мы выпустили AppCode 2019.1 — поговорим об изменениях в нем. Под катом куча нового, полезного, исправленного и дополненного.
Ряд наших устройств имеет встроенный порт RS-485 для прямого подключения электросчётчиков, имеющих данный интерфейс. Для облегчения тестирования устройств мы разработали небольшую ... | https://habr.com/ru/post/576790/ | null | ru | null |
# Ускоряем OSB
Статья подготовлена Дмитрием Овчаренко, архитектором Департамента прикладных финансовых систем компании «Инфосистемы Джет»
#### Предвидя проблему
Приступая к разработке прокси-сервиса на Oracle Service Bus, следует принимать во внимание условия использования этого сервиса. Например, если разрабатыва... | https://habr.com/ru/post/269649/ | null | ru | null |
# Курс «Основы технологического предпринимательства» в ИТМО
С ноября этого года в университете ИТМО проходит курс «Основы технологического предпринимательства»[Technology Entrepreneurship]. Ведут его Кирилл Болгаров и Илья Березовский.
Кратко о курсе рассказывается на сайте [qdinvest.ru](http://qd.ifmo.ru/qd/bscho... | https://habr.com/ru/post/46686/ | null | ru | null |
# Создание инструмента для быстрого и эффективного написания автотестов на Selenium
> ***Фундаментальный строительный блок автоматизации – тестирование***
>
> *Род Джонсон*

Я не амбассадор автоматизации тестирования веб ... | https://habr.com/ru/post/450726/ | null | ru | null |
# Фаззинг в стиле 1989 года
С наступлением 2019 года хорошо вспомнить прошлое и подумать о будущем. Оглянемся на 30 лет назад и поразмышляем над первыми научными статьями по фаззингу: [«Эмпирическое исследование надёжности утилит UNIX»](ftp://ftp.cs.wisc.edu/paradyn/technical_papers/fuzz.pdf) и последующей работой 199... | https://habr.com/ru/post/435484/ | null | ru | null |
# Обновление одним файлом или объединяем несколько патчей
Большинство пользователей следят за обновлениями по безопасности и обновляют свои компьютеры и программы. Но как быть, если это локальная сеть, а интернет есть не у всех пользователей, а обновить Adobe продукты очень как хотелось бы? В данной статье будет расмо... | https://habr.com/ru/post/135190/ | null | ru | null |
# Помоги компилятору, и он поможет тебе. Тонкости работы с nullable reference типами в C#
Nullable reference типы появились в C# 3 года назад. За это время они смогли найти свою аудиторию. Но даже те, кто имеет дело с этим зверем, скорее всего, не знают всех его возможностей. Давайте разберёмся, как более качественно ... | https://habr.com/ru/post/706376/ | null | ru | null |
# Как защитить Python-приложения от внедрения вредоносных скриптов

Python-приложения используют множество скриптов. Этим и пользуются злоумышленники, чтобы подложить нам «свинью» — туда, где мы меньше всего ожидаем её увидеть.
... | https://habr.com/ru/post/516682/ | null | ru | null |
# Clarion. Процесс миграции Clarion приложения на Microsoft SQL 2019
Продолжаю повествовать о жизни с Clarion. В этом посте я опишу свой путь решения одной из частых задач, стоящих перед Clarion разработчиками, это миграция Clarion программы на СУБД Miscrosoft SQL.
. За это время было сделано много работы и получено много опыта, которым я хочу поделиться. Наибольшее количество изменений претерпели карты, большая ча... | https://habr.com/ru/post/145575/ | null | ru | null |
# Jerminal — эмулятор терминала для Java-программ
### Вступление
Привет, хабраюзеры! Решил поведать вам о мини-библиотеке Jerminal. Я сейчас работаю над большим коммерческим проектом на Groovy/Java. Ну и мне пришло задание — написать консольку для приложения. К сожалению, было поставлено условие: никаких сторонних ре... | https://habr.com/ru/post/327234/ | null | ru | null |
# Введение в FreeSWITCH, часть вторая
[О FreeSWITCH](http://deepwalker.habrahabr.ru/blog/50091/)
[Первая часть](http://deepwalker.habrahabr.ru/blog/50140/)
Номерной план
-------------
Итак, у FreeSWITCH можно подкрутить множество настроек, но основное действо будет происходить в номерном плане. Номерной план ра... | https://habr.com/ru/post/50240/ | null | ru | null |
# Меняем PID процесса в Linux с помощью модуля ядра
В этой статье мы попытаемся создать модуль ядра, способный изменить PID уже запущенного процесса в ОС Linux, а так же поэкспериментировать с процессами, получившими измененный PID.
 Сегодня ночью, проводя очередной code-review в наших проектах, наткнулся на большой кусок проявления чистейшего, кристализованного копипаста. Он не очень пришелся мне ... | https://habr.com/ru/post/137875/ | null | ru | null |
# Знакомство с JMS 2.0
Не так давно, 12 июня 2013, миру [был представлен релиз Java EE 7](http://www.oracle.com/us/corporate/press/1957557). Одним из ключевых моментов в этом релизе было появление JMS версии 2.0, которая не обновлялась с 2002 года.
Данный текст является вольным переводом начала [статьи](http://www.... | https://habr.com/ru/post/184460/ | null | ru | null |
# .NET-обёртки нативных библиотек на C++/CLI
Предисловие переводчика
=======================
Данная статья представляет собой перевод главы 10 из книги Макруса Хиге (Marcus Heege) «Expert C++/CLI: .NET for Visual C++ Programmers». В этой главе разобрано создание классов-обёрток для нативных классов C++, начиная от тр... | https://habr.com/ru/post/318224/ | null | ru | null |
# Заглядываем под капот нового Gmail
Полгода назад Google [представила](https://www.theverge.com/2018/4/25/17277360/gmail-redesign-live-features-google-update) обновленную версию своего почтового сервиса. Несмотря на то что многие пользователи были недовольны редизайном, в том числе и [на Хабре](https://habr.com/post/... | https://habr.com/ru/post/429506/ | null | ru | null |
# ObjectScript API, интеграция с C++. Часть 3: подключение модуля с функциями на C++
ObjectScript — новый объектно-ориентированный язык программирования с открытым исходным кодом. ObjectScript расширяет возможности таких языков, как JavaScript, Lua и PHP.
Часть 3: подключение модуля с функциями на C++
-------------... | https://habr.com/ru/post/153021/ | null | ru | null |
# Wi-Fi термометр на ESP8266 + DS18B20 всего за 4$

В последнее время всё большую популярность набирают Wi-Fi модули на основе ESP8266. Я тоже решил приобщиться к прекрасному, задумав реализовать термометр, отдающий данные ... | https://habr.com/ru/post/252481/ | null | ru | null |
# Suspending over blocking
This article aims to show how to use [Kotlin Coroutines](https://kotlinlang.org/docs/reference/coroutines-overview.html) and remove [Reaxtive eXtensions (Rx)](http://reactivex.io/).
Benefits
--------
To start let's consider four benefits of Coroutines over Rx:
### Suspending over Blocking... | https://habr.com/ru/post/465529/ | null | en | null |
# Нужна система с низкими задержками? Выбираем Java вместо C++
Все разработчики знают, что есть два способа сделать дело: первый — вручную, медленно, нервно, сложно, либо второй – автоматизировано, быстро и е... | https://habr.com/ru/post/586870/ | null | ru | null |
# Weapon wheel в Doom 1993
Приветствую.
Многие из нас с теплотой относятся к олдскульным видеоиграм, вышедшим на стыке веков. У них превосходная атмосфера, бешеная динамика и множество оригинальных решений, которые не устарели спустя десятилетия. Однако в наши дни видение интерфейса игр несколько изменилось — на с... | https://habr.com/ru/post/508800/ | null | ru | null |
# Захват сигнала мышечной активности в систему машинного обучения
Около полугода назад ко мне пришла идея создания открытого фреймворка для нейроинтерфейсов.
На данном видео захват [ЭМГ](https://ru.wikipedia.org/wiki/%D0%AD%D0%BB%D0%B5%D0%BA%D1%82%D1%80%D0%BE%D0%BC%D0%B8%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F) с... | https://habr.com/ru/post/437888/ | null | ru | null |
# Terraformer — Infrastructure To Code

Хотел бы рассказать про новый CLI tool который я написал для решения одной старой проблемы.
### Проблема
Terraform уже давно стал стандартом в Devops/Cloud/... | https://habr.com/ru/post/450410/ | null | ru | null |
# Telegram-бот, webhook и 50 строк кода
Как, опять? Ещё один туториал, пережёвывающий официальную документацию от Telegram, подумали вы? Да, но нет! Это скорее рассуждения на тему того, как построить функциональный бот-сервис используя *Python3.5+*, *asyncio* и *aiohttp*. Тем интереснее, что заголовок на самом деле лу... | https://habr.com/ru/post/322078/ | null | ru | null |
# LiveReload — обновление javascript без полной перезагрузки страницы (на примере mithril)
#### Вступление
Не так давно я начал пользоваться такой полезной штукой как livereload (для тех, кто не знает, что это — [есть статья на хабре](http://habrahabr.ru/post/168091/)). Livereload отслеживает изменения в коде веб-при... | https://habr.com/ru/post/260173/ | null | ru | null |
# Карты в браузере без сети: open source наносит ответный удар
Как-то давно я [писал о том как можно в вебе использовать карты без сети](http://habrahabr.ru/post/141707/) и пытался сделать это с помощью гугло карт. К сожалению условия использования запрещали модифицировать ресурсы, а написанный мною код работал только... | https://habr.com/ru/post/170129/ | null | ru | null |
# И еще немного об автоподстройке высоты textarea
Редизайня один «смартфонный» проект, я наткнулся на страницу чата с textarea, не умеющей ресайзиться в зависимости от количества строк. Не составило проблемы найти и подключить небольшой плагин ([autoResize](http://www.xiper.net/examples/js-plugins/forms/autoresize/js/... | https://habr.com/ru/post/269325/ | null | ru | null |
# Управляем ЖК дисплеем HD44780 с помощью ассемблера
В университете на одном профильном предмете начали изучать стенд на основе микроконтроллера МК-51, дисплея HD44780, клавиатуры. Все это дело программируется через COM порт с помощью ассемблера. На тот момент я изучат микроконтроллеры семейства AVR (а именно Atmega8)... | https://habr.com/ru/post/166735/ | null | ru | null |
# Concurrency и паттерны ошибок, скрытые в коде: Deadlock
Наверняка, многие слышали, а кто-то встречал на практике, такие слова, как взаимные блокировки(deadlock) и гонки(race condition). Эти понятия относятся к разряду ошибок в использовании concurrency. Если я задам вам вопрос, что такое дедлок, вы с большой вероятн... | https://habr.com/ru/post/442448/ | null | ru | null |
# Внедрение Airflow для управления Spark-джобами в ivi: надежды и костыли
Задача деплоя моделей машинного обучения в продакшн — это всегда боль и страдания, потому что очень некомфортно вылезать из уютного jupyter notebook в мир мониторинга и отказоустойчивости.
Мы уже писали про [первую итерацию рефакторинга](http... | https://habr.com/ru/post/456630/ | null | ru | null |
# Тюнинг MySQL — thread_cache_size
Параметр thread\_cache\_size играет немаловажную роль в производительности нагруженного MySQL-сервера. В некоторых случаях можно увеличить производительность на 30-50%.
Этот параметр указывает количество тредов, уходящих в кеш при отключении клиента. При новом подключении тред исп... | https://habr.com/ru/post/159085/ | null | ru | null |
# Для чего нужно интеграционное тестирование?
Эта статья является конспектом книги «[Принципы юнит-тестирования](https://www.litres.ru/vladimir-horikov/principy-unit-testirovaniya-pdf-epub-64083637/)». Материал статьи посвящен интеграционным тестам.
Юнит-тесты прекрасно справляются с проверкой бизнес-логики, но прове... | https://habr.com/ru/post/556002/ | null | ru | null |
# В конце этого года наступит эпоха вмешательства сайтов в контекстное меню браузеров посредством HTML5
Всякий, кто читал сколько-нибудь недавний черновик стандарта HTML5 и доходил там до подраздела 4.11.4.3 («[Context menus](http://www.w3.org/TR/html5/interactive-elements.html#context-menus)»), уж конечно видал в нём... | https://habr.com/ru/post/126478/ | null | ru | null |
# OpenCV. Видео с камеры. Пишем в файл

##### Приветствую!
В прошлых уроках:
[OpenCV. Вывод видео](http://lockdog.habrahabr.ru/blog/76723/)
[OpenCV (компьютерное зрение). Установка под MSVS... | https://habr.com/ru/post/78150/ | null | ru | null |
# Как преодолеть страх и начать использовать Azure Machine Learning
Я знаю многих Data Scientist-ов — да и пожалуй сам к ним отношусь — которые работают на машинах с GPU, локальных или виртуальных, расположенных в облаке, либо через Jupyter Notebook, либо через какую-то среду разработки Python. Работая в течение 2 лет... | https://habr.com/ru/post/485338/ | null | ru | null |
# Тестирование радиомодемов LoRa/LoRaWAN RN2483. Часть 2, LoRaWAN
[В предыдущей части](https://geektimes.ru/post/281286/) рассказывалось, как подключить модемы RN2483 в режиме LoRa. Сейчас перейдем к следующей, более сложной части — подключению к сети LoRaWAN.
### Что такое LoRaWAN?
, так что по традиции небольшая интересная статья для вас.
Поехали
В этом практическом руководстве мы рассмотрим, как интегрировать мониторинг... | https://habr.com/ru/post/358588/ | null | ru | null |
# Вывод формулы n-ного члена для рекуррентной последовательности на примере задачи из квеста Амнезия
> Пеленгский фермер Бух'ерик разводит хрякоплюхов. Эти животные размножаются так быстро, что их поголовье ежедневно возрастает в 3 раза. Но, начиная со второго дня, на ферму повадилась нападать стая страшных зверей дол... | https://habr.com/ru/post/345420/ | null | ru | null |
# Индикатор Futaba M204SD02AJ в последовательном режиме

В этой статье я хочу поделиться опытом использования индикатора FUTABA MSD204AJ в режиме последовательного интерфейса. Будем программировать на ардуине.
Для ... | https://habr.com/ru/post/392757/ | null | ru | null |
# pfBlockerNG для домашней сети
pfBlockerNG - пакет pfSense для фильтрации IP трафика и DNSBL блокировки по готовым фидам с некоторыми дополнительными функциями и обширными возможностями по конфигурированию в... | https://habr.com/ru/post/581208/ | null | ru | null |
# Тестирование с использованием BDD
#### Введение
Современные проекты все чаще предъявляют высокие требования к покрытию автоматическими тестами. В наше время писать тесты не просто признак хорошего тона, но одно из требований, которое предъявляется к коду. Все чаще мы слышим такие аббревиатуры, как TDD (Test Driven ... | https://habr.com/ru/post/139674/ | null | ru | null |
# Основы Kubernetes
В этой публикации я хотел рассказать об интересной, но незаслуженно мало описанной на Хабре, системе управления контейнерами Kubernetes.

#### **Что такое Kubernetes?**
Kuberne... | https://habr.com/ru/post/258443/ | null | ru | null |
# Техники в Elixir для начинающих: Метод проб и ошибок (перевод)

Перевод статьи [Coding A.I. Techniques in Elixir: The Generate and Test Algor... | https://habr.com/ru/post/310744/ | null | ru | null |
# Вы яндекс не видали?
Кто-то воспользовался недавней дырой в BGP?
Дело не в DNS и т.п. если сделать tracert то дальше пограничного маршрутизатора вашего провайдера пакеты не знают куда идти :) Все гораздо серьезнее.
Или атака, или халатность. Т.е. проблема также не связана с нагрузкой.
Прямо как солнечное за... | https://habr.com/ru/post/40932/ | null | ru | null |
# Встраиваем PVS-Studio в Eclipse CDT (macOS)
После появления цикла статей о встраивании PVS-Studio в различные IDE под Linux ([Eclipse](https://habrahabr.ru/post/316670/), [Anjuta](https://habrahabr.ru/post/316720/)), появилось желание запустить PVS-Studio для проверки своих проектов, разрабатываемых в Eclipse под ma... | https://habr.com/ru/post/317518/ | null | ru | null |
# 5 функций объекта Console, о которых Вы не знали
Не все знают, что `console.log()` можно использовать не только для логирования, но и для еще нескольких полезных операций. Я выбрал 5 наиболее интересных методов использования Console, подходящих для повседневной жизни.
*Все описанные функции прекрасно работают в G... | https://habr.com/ru/post/253081/ | null | ru | null |
# Ферма SharePoint 2013 в Windows Azure. SQL Server 2012

Это продолжение цикла статей, посвященного созданию фермы SharePoint 2013 в Windows Azure. Первые главы вы можете найти по следующим ссылкам:
* [Ферма SharePoin... | https://habr.com/ru/post/153453/ | null | ru | null |
# Geeknote — консольный клиент для Evernote
Приветствую, коллеги!
Хочу рассказать вам о нашем проекте — [Geeknote](http://www.geeknote.me/). Это консольный клиент для Evernote. Проект Open Source и исходные коды доступны на Github. Geeknote позволяет работать с Evernote из командной строки. Реализованы все основные... | https://habr.com/ru/post/147448/ | null | ru | null |
# Deep Dive Into Deep Link. Часть 5. Нюансы: port, mime, path, диспетчеризация, обратная совместимость
Сюда дошли лишь самые стойкие… Для тех кто впервые:
`HTTP/1.1 303 See other`
`Location_1:` <https://habr.com/ru/post/686990/>
`Location_2:` <https://habr.com/ru/post/691220/>
`Location_3:` <https://habr.com/ru/... | https://habr.com/ru/post/701148/ | null | ru | null |
# CredSSP encryption oracle remediation – ошибка при подключении по RDP к виртуальному серверу (VPS / VDS)
Начиная с 8 мая 2018 года, после установки обновлений на свой персональный компьютер, многие пользователи [виртуальных серверов](https://vps.house) под управлением ОС Windows Server столкнулись с ошибкой «[CredSS... | https://habr.com/ru/post/358190/ | null | ru | null |
# Генерация приглашений, похожих на инвайты сайта habrahabr
Скрипт генерирует приглашения для регистрации на сайте в виде картинки 51x51 пикселей формата PNG, написан на PHP, в качестве базы данных использует MySQL. Сделан ради интереса, будет интересен только новичкам.
С помощью библиотеки [GD](http://www.boutell.... | https://habr.com/ru/post/121921/ | null | ru | null |
# Основы LibCanvas — практика

Это продолжение [статьи про основы LibCanvas](http://habrahabr.ru/blogs/canvas/121046/). Если первая часть затрагивала теоретические засады, то в этой части мы перейдём к практике и постараемся реализ... | https://habr.com/ru/post/121047/ | null | ru | null |
# Script-server. WebUI для удалённого запуска ваших скриптов
Всем привет. В данной статье я бы хотел рассказать про свой домашний проект. Если коротко: Script server является веб-сервером для предоставления пользователям доступа к вашим скриптам через web-интерфейс. Сервер и скрипты запускаются локально, а параметризу... | https://habr.com/ru/post/309518/ | null | ru | null |
# Разработка настоящих компонентов: блок сообщения Facebook Messenger
Смесь любопытства и тяги к исследованиям снова привели меня к системе обмена сообщениями Facebook. Я уже изучал компоненты Facebook и [писал](https://ishadeed.com/article/building-real-life-components/) об этом. Сейчас я обратил внимание на то, что ... | https://habr.com/ru/post/587724/ | null | ru | null |
# Пользовательская документация и GitHub
Сталкивались ли вы когда нибудь с долгим поиском документации к используемой библиотеке или пакету? Я считаю странным, что исходный код не распространяется с пользовательской документацией. Ведь она такая же важная часть кода, как тесты или зависимости. Без хорошей пользователь... | https://habr.com/ru/post/269883/ | null | ru | null |
# Всё, что вы должны знать о прототипах, замыканиях и производительности
#### Не всё так просто
На первый взгляд, JavaScript может показаться достаточно простым языком. Возможно, это из-за достаточно гибкого синтаксиса. Или из-за схожести с другими известными языками, например, с Java. Ну или из-за достаточно малого ... | https://habr.com/ru/post/223027/ | null | ru | null |
# Веб-сервисы в Oracle

[Веб-сервисы](https://ru.wikipedia.org/wiki/%D0%92%D0%B5%D0%B1-%D1%81%D0%BB%D1%83%D0%B6%D0%B1%D0%B0) широко применяются для интеграции между компонентами одной системы или между различными системами. Популярно... | https://habr.com/ru/post/502030/ | null | ru | null |
# Web Open Font Format в Firefox 3.6
*Эта статья написана Джоном Даггеттом(John Daggett) — сотрудником компании Mozilla, который много работал с дизайнерами шрифтов и web программистами чтобы улучшить положение шрифтов в web. Статья представляет из себя поверхностный обзор новых возможностей и содержит некоторые приме... | https://habr.com/ru/post/72991/ | null | ru | null |
# Как подружить Redis Cluster c Testcontainers?
В [26-м выпуске](https://anchor.fm/npcomplete/episodes/NP-complete-26----1-2-e11fhsi) NP-полного подкаста я рассказывал, что начал переводить один из своих сервисов из Redis Sentinel на Redis Cluster. На этой неделе я захотел потестировать данный код, и, конечно же, выбр... | https://habr.com/ru/post/563650/ | null | ru | null |
# Работают ли SPF, DKIM и DMARC?
Появилась вчера на Хабре такая вот [статья](https://habr.com/ru/company/globalsign/blog/650485/) . Когда компания, занимающаяся ИТ-безопасностью заявляет, что spf/dkim/dmarc не работают и существует минимум 18 способов подменить адрес на (вашем!) почтовом сервере, это вызывает озабочен... | https://habr.com/ru/post/650687/ | null | ru | null |
# Particles System в моделировании толпы (2)
Продолжаем разговор от 07.04.2014 ([Particles System в моделировании толпы](http://habrahabr.ru/post/218473/)).
**В этой части добавляю:**
1. медленные персонажи (это будут крупные стрЕлки)
2. огибание в пути медленных стрелок быстрыми
3. взрывы (с разбрасыванием тел)... | https://habr.com/ru/post/218697/ | null | ru | null |
# Домашний «облачный» сервер на 10 Ватт? Вполне!
Привет пользователям Хабра.
Сегодня хочу рассказать про домашний веб-сервер, который одновременно прекрасно выполняет функции домашнего медиа-центра (mp3, ip-tv, video, uPnP и т.д.).
Все началось с того, что я уже некоторое время использовал для внутренних нужд се... | https://habr.com/ru/post/198492/ | null | ru | null |
# Обзор мобильного приложения Drive
Ранее в нашем блоге мы рассказывали об on-premise решениях [Zextras Team Pro](https://habr.com/ru/company/zimbra/blog/538014/) и [Zextras Drive](https://habr.com/ru/company/zimbra/blog/541570/), позволяющих создать корпоративное хранилище файлов, а также корпоративный групповой чат ... | https://habr.com/ru/post/548306/ | null | ru | null |
# Структуризация проекта в WordPress, Laravel Blade и не только
WordPress можно любить, можно не любить, но сложно не согласиться с тем, что он решает проблемы. В последнее время разработка под WordPress ушла далеко от создания примитивных блогов с 4-5 информационными страницами. Все больше и больше компаний использую... | https://habr.com/ru/post/301848/ | null | ru | null |
# Разрабатываем систему real-time fulltext-поиска по error-логам на основе ClickHouse от Яндекса
**UPDATE из будущего:** Не используйте этот подход! Для поиска логов намного лучше подходит простой поиск по регулярному выражению или подстроке встроенными средствами ClickHouse. Эта статья была написана давно, как интере... | https://habr.com/ru/post/304602/ | null | ru | null |
# Обновление ДубльГИС консольными средствами Linux
#### Введение

Очень часто пользователи просят установить ДубльГИС (не сочтите за рекламу) справочник, особенно если пользователь ездит в командиров... | https://habr.com/ru/post/135528/ | null | ru | null |
# Руководство по использованию Dependency Injection в Symfony2
В данной статье приводится пример создания простого сайта-блога с использованием паттерна [Dependency Injection](http://ru.wikipedia.org/wiki/Внедрение_зависимости). Применяется подход с внедрением зависимостей во все возможные компоненты Symfony: контролл... | https://habr.com/ru/post/165237/ | null | ru | null |
# Реактивное программирование под Android
Отказоустойчивость, отзывчивость, ориентированность на события и масштабируемость — четыре принципа нынче популярного [реактивного программирования](http://www.reactivemanifesto.org/). Именно следуя им создаётся backend больших систем с одновременной поддержкой десятков тысяч ... | https://habr.com/ru/post/228125/ | null | ru | null |
# Реактивная обработка стрима логов с RxJava — Часть 1
***[Reactive log stream processing with RxJava — Part l](https://balamaci.ro/reactive-log-processing/)***
В предыдущем посте автор рассматривал случаи использования [ELK](http://www.elasticsearch.org/) стека и сбора логов.
С учетом движения в сторону микросерв... | https://habr.com/ru/post/329894/ | null | ru | null |
# Путаница зависимостей. Как я взломал Apple, Microsoft и десятки других компаний
С тех пор как я начал учиться программировать, я восхищаюсь уровнем доверия, который мы вкладываем в простую команду, подобну... | https://habr.com/ru/post/550380/ | null | ru | null |
# Облегчаем внедрение зависимостей и модульное тестирование с помощью асинхронных функций
Очень часто подготовка кода к модульному (или юнит-) тестированию имеет обыкновение идти рука об руку с работой по раз... | https://habr.com/ru/post/651495/ | null | ru | null |
# HHVM (hip-hop): Сравнительное тестирование и настройка

Сегодня мы делимся результатами тестирования php скрипта с и без HHVM на скорость, а также сразу смотрим, как это внедряется, например на Fedor... | https://habr.com/ru/post/223815/ | null | ru | null |
# Как рассылать Push уведомления с контроллера умного дома
В хит-параде самых полезных функций систем автоматизации оповещения о всевозможных событиях стабильно входят в первую тройку. И если несколько лет назад самым удобных способом для этого были смс и email, то в последнее время их дополнили Push нотификации.
... | https://habr.com/ru/post/370485/ | null | ru | null |
# Модульное тестирование и Python

Меня зовут Вадим, я ведущий разработчик в Поиске Mail.Ru. Я поделюсь нашим опытом проведения модульного тестирования. Статья состоит из трёх частей: в первой расскажу, чего мы вообще добиваемся с ... | https://habr.com/ru/post/418929/ | null | ru | null |
# PHD VI: как у нас угнали дрона
[](https://habrahabr.ru/company/pt/blog/302490/)
В этом году на [PHDays](http://www.phdays.ru/) был представлен новый конкурс, где любой желающий мог перехватить управление квадрокоптером Syma X5C. П... | https://habr.com/ru/post/302490/ | null | ru | null |
# Стабильность develop в Android
Всем привет! Меня зовут Костя, я тимлид платформенной мобильной команды в hh.ru. Мы уже рассказывали о практиках, которые помогают нам выпускать еженедельные релизы мобильных приложений: автоматизация тестирования, Release Train, GitHub Flow, Continuous Integration. И нам стали задават... | https://habr.com/ru/post/591223/ | null | ru | null |
# Немного о программировании ESP8266 на C под FreeRTOS
***Тут должна быть КДПВ, но на нее не хватило бюджета.***
Замотивировавшись ответом от [Tarson](https://geektimes.ru/users/tarson/) на мой комментарий к [Программирование и обмен данными с «ARDUINO» по WI-FI посредством ESP8266](https://geektimes.ru/post/292801... | https://habr.com/ru/post/406813/ | null | ru | null |
# Как ускорить реакцию на нажатие ссылок в WebView под Android
Приветствую всех Хабровчан!
Излагаю суть проблемы: есть приложение на Андроид — его суть — просто обертка вокруг WebView.
Весь функционал вынесен в PHP (на сервере) и JavaScript (на клиентских страницах).
Основная цель — на страницах много кнопо... | https://habr.com/ru/post/141476/ | null | ru | null |
# Градиентный спуск по косточкам
В интернете есть много статей с описанием алгоритма градиентного спуска. Здесь будет еще одна.
8 июля 1958 года [The New York Times писала](https://www.nytimes.com/1958/07/08/archives/new-navy-device-learns-by-doing-psychologist-shows-embryo-of.html): «Психолог показывает эмбрион комп... | https://habr.com/ru/post/467185/ | null | ru | null |
# Автоматическая оптимизация алгоритмов с помощью быстрого возведения матриц в степень
Пусть мы хотим вычислить десятимиллионное [число Фибоначчи](https://ru.wikipedia.org/wiki/%D0%A7%D0%B8%D1%81%D0%BB%D0%B0_%D0%A4%D0%B8%D0%B1%D0%BE%D0%BD%D0%B0%D1%87%D1%87%D0%B8) программой на Python. Функция, использующая тривиальный... | https://habr.com/ru/post/236689/ | null | ru | null |
# Обзор FlashDevelop 3.1.0 RTM

Вышла новая версия FlashDevelop, замечательного редактора кода для as3 и haXe. Самое приятное в новой версии это то, что появилась возможность использовать Debuger и Pro... | https://habr.com/ru/post/91883/ | null | ru | null |
# Три мелкие но полезные плюшки в Laravel 5.2.22
Совсем недавно состоялся релиз минорной версии 5.2.22 нашего любимого фреймворка Laravel. Наряду с некоторыми небольшими исправлениями, есть несколько новых функций, давайте посмотрим на них.
##### 1. Проверка уникальности массива
Новое правило для проверки, имеет л... | https://habr.com/ru/post/278557/ | null | ru | null |
# История одного SSL рукопожатия
Привет, Хабр!
Недавно мне пришлось прикручивать SSL с двухсторонней аутентификацией (mutual authentication) к Spring Reactive Webclient. Казалось бы, дело нехитрое, но вылилось оно в блуждание в исходниках JDK с неожиданным финалом. Опыта набралось на целую статью, которая может ока... | https://habr.com/ru/post/414909/ | null | ru | null |
# RBKmoney Payments под капотом — инфраструктура платежной платформы

Привет, Хабр! Описание работы [внутренностей](https://habr.com/ru/company/rbkmoney/blog/447440/) большой платежной платформы логично будет продолжить описанием тог... | https://habr.com/ru/post/451814/ | null | ru | null |
# Детальное сравнение WordPress и October CMS
*Меня зовут Павел Ловцевич, я сооснователь и CTO веб-студии LOVATA. Одной из основных платформ, на которой мы разрабатываем проекты для наших заказчиков, является October CMS, с которой мы работаем уже почти 6 лет.
Эта CMS несколько опередила свое время и не сразу сниск... | https://habr.com/ru/post/509098/ | null | ru | null |
# Наследование в JavaScript с точки зрения занудного ботаника: Фабрика Конструкторов
Это история об одной очень специальной части JavaScript, [самого используемого](https://githut.info/) искусственного ... | https://habr.com/ru/post/470994/ | null | ru | null |
# Ruby + Shoes = Миленький GUI
Статья изначально публиковалась для личного блога, но думаю те кто начинают изучать Ruby, или просто хотят написать GUI к приложению сочтут ее полезной.
Вступлений не будет. Тема сегодня — **Shoes**. Такой небольшой kit, для создания GUI к приложениям на Ruby. Впервые я о ~~нем~~ них ... | https://habr.com/ru/post/60075/ | null | ru | null |
# Цветовая идентификация
`function get_username_html_color($username )
{
return '#' . substr( md5($username ), 0, 6 );
}`
Я, например, вот такой **subz**. Первые попавшиеся под руку %username%: **rost**, **anvar**, **navosha**.
Пытливым умам посчитать хватит ли краски для всех хабраюзеров.
Спасиб... | https://habr.com/ru/post/26386/ | null | ru | null |
# Все врут: эпопея с NVMe-серверами и Hi-CPU
[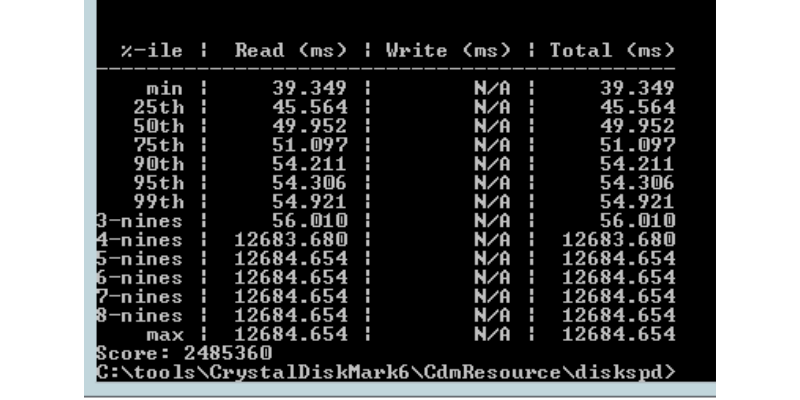](https://habr.com/ru/company/ruvds/blog/560404/)*Diskspd лучше использовать вместо CrystalDiskMark, потому что код первой на стыке с GUI второй даёт забавный баг*
У нас, в RUVDS, не хват... | https://habr.com/ru/post/560404/ | null | ru | null |
# Нам требовался мониторинг покрытия проекта автотестами. Для этого мы разработали сервис Coverage Manager
**Summary: Игорь Зубцов, руководитель автоматизированного тестирования в направлении омниканальных ре... | https://habr.com/ru/post/707148/ | null | ru | null |
# Мой первый Eclipse-плагин
Приветствую, дорогие хаброчитатели!
Некоторое время назад мне выпала интересная задача – написать плагин для Eclipse. Причем плагин не простой, а с хитрой задумкой.
Опыта написания плагинов для Eclipse у меня никогда не было, но надо – так надо, а что из этого получилось – под хаброка... | https://habr.com/ru/post/243297/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.