
_id string | text string | title string |
|---|---|---|
205201 | من در حال حاضر یک کارآموز در یک پیمانکار دولتی هستم و این احساس را دارم (به طور غیرقابل اجتنابی) که Word استاندارد واقعی در فرآیند توسعه نرم افزار است. فرمت باینری آن کار را در اسناد بسیار دشوار می کند، همانطور که من به همکاری بر اساس کد عادت دارم. استفاده از نشانهگذاری متن ساده (با زبانهایی مانند LaTeX، Markdown، Re... | چرا زبانهای نشانهگذاری متن ساده (مانند LaTeX یا Markdown) در فرآیند توسعه نرمافزار محبوبتر نیستند؟ |
206793 | از من خواسته شد که کد منبع (همراه با کاربران موجود) برنامه کاربردی کوچکی را که سال ها پیش ایجاد کردم، بفروشم. من بررسی کرده ام که چگونه برای کد منبع قیمت گذاری کنم، اما تاکنون راه حل خوبی پیدا نکرده ام. من تو نت سرچ کردم ولی چیز مفیدی پیدا نکردم سپس با چند نفر دیگر روبرو شدم که کد منبع خود را نیز با کاربران فروختند، ام... | چگونه برای کد منبع خود قیمت گذاری می کنید؟ |
161777 | من این عکس کمیک را در وبلاگ استیو هانوف پیدا کردم: 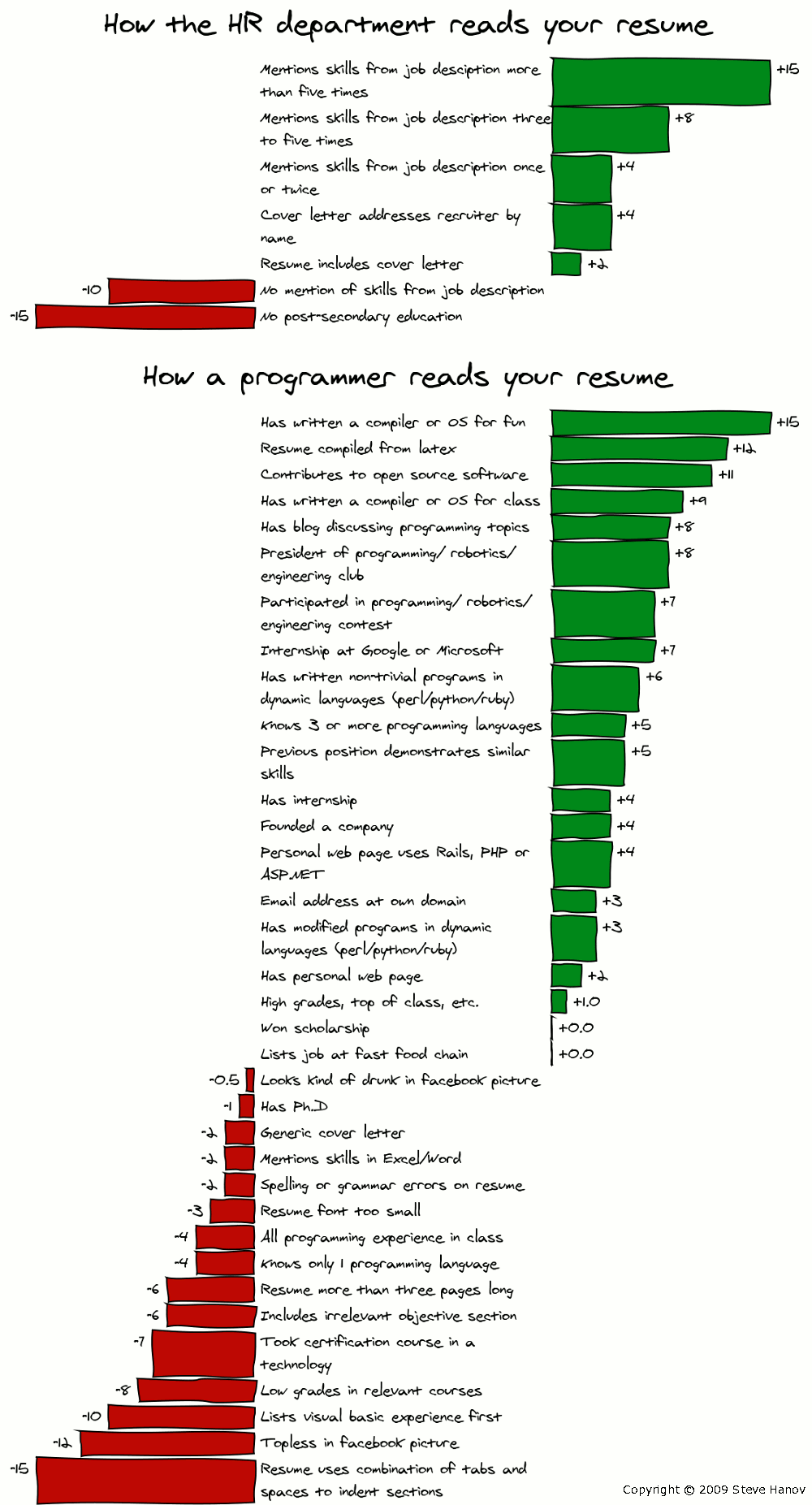 واضح است که بسیاری از نکات درست است. چیزی که من نمی توانم درک کنم این است که چرا _دکتری داشتن یک چیز بد محسوب می شود؟  ن... | چرا برنامه نویس با مدرک دکترا نامزد بدی برای کارفرماست؟ |
171124 | من در حال کار بر روی یک افزونه وردپرس برای مدیریت داده های صخره نوردی هستم و باید راهی برای ذخیره نمرات سنگ نوردی از همه سیستم های مختلف به روشی یکپارچه بیاندیشم. سیستم های مختلفی وجود دارد که همه آنها دارای سیستم عددی هستند. مقایسه همه سیستمها: http://en.wikipedia.org/wiki/Grade_(climbing)#Comparison_tables آیا راه و... | ذخیره و تجزیه و تحلیل دشواری صخره نوردی |
83986 | من در حال حاضر با یک دوراهی با بررسی عملکرد آینده روبرو هستم. زمانی که حدود 1 سال پیش با شرکتم شروع به کار کردم، سعی کردم تا حد امکان در درک خود از مجموعه مهارت و دانش برنامه نویسی خود صادق باشم. من مهارت های درک شده خود را بر اساس توانایی برنامه نویسی خود نسبت به کسانی که به نظرم برنامه نویسان و توسعه دهندگان خوبی هست... | افزایش حقوق در طول بررسی عملکرد |
88896 | در پرسش همکار قدیمی من، افراد مختلفی درباره استراتژیهایی برای برخورد با همکارانی که تمایلی به ادغام گردش کار خود با تیم ندارند، بحث کردند. مایلم، در صورت امکان، راهبردهایی را برای آموزش همکار که صرفاً از تکنیک ها و ابزارهای مدرن بی اطلاع است و احتمالاً کمی بی تفاوت است، یاد بگیرم. من کارم را با یک برنامه نویس شروع کرد... | الهام بخشیدن به یک همکار برای اتخاذ شیوه های کدنویسی بهتر؟ |
213898 | من برای یک شرکت تولید نرم افزار کار می کنم. ما مشتریان سازمانی بزرگی داریم که محصول ما را پیاده سازی می کنند و از آنها پشتیبانی می کنیم. به عنوان مثال، اگر نقصی وجود داشته باشد، ما پچ ها و غیره را ارائه می دهیم. به عبارت دیگر، این یک راه اندازی نسبتا معمولی است. اخیراً، بلیطی در رابطه با استثنایی که مشتری در یک فایل گز... | آیا اصرار بر بازتولید هر نقص قبل از تشخیص و رفع آن معقول است؟ |
188152 | من کدی با استفاده از یک کتابخانه شخص ثالث، QrCode.Net، در قالب یک فایل «dll» دارم. این کتابخانه تحت مجوز MIT مجوز دارد. اگر از کد منبع استفاده نکردم یا آن را تغییر ندادم، باید مجوز را در پروژه خود لحاظ کنم؟ * * * متن مجوز کامل: > ## مجوز MIT (MIT) > > حق چاپ (ج) 2011 جورج مامالادزه > > بدینوسیله به هر شخصی که نسخه ای ا... | آیا باید مجوز یک کتابخانه شخص ثالث وارد شده به عنوان یک DLL را اضافه کنم؟ |
19278 | (در ابتدا در Stack Overflow ارسال شد اما در آنجا بسته شد و بیشتر مربوط به اینجا بود) بنابراین ما ابتدا با یک مرد برای یک نقش فنی مصاحبه کردیم و او بسیار خوب بود. قبل از مصاحبه دوم، ما او را در گوگل جستجو کردیم و صفحه MySpace او را یافتیم که می تواند، به بیان ملایم، نامناسب تلقی شود. فقط برای روشن شدن شکی وجود نداشت که ... | آیا زمانی که شخصی برای استخدام به عنوان برنامه نویس در نظر می گیرد، چیزی که در اینترنت منتشر می کند، بازی منصفانه است؟ |
161370 | ما در حال حاضر از سیستم کنترل نسخه خود سوء استفاده می کنیم و از آن ... تقریباً به عنوان یک FTP برای ذخیره باینری های انتشار بزرگ (4+ گیگابایت) استفاده می کنیم. ما به دنبال دوری از این رویه وحشتناک هستیم که منابع IT را در اختیار دارد و ادامه می دهد و بیشتر و بیشتر از منابع IT را می گیرد و در عین حال فرآیندهای یکپارچه سا... | استفاده از بیت تورنت برای مدیریت انتشار داخلی |
110746 | میشه یکی توضیح بده این یعنی چی؟ > یونیکد فضای کدی از 1114112 نقطه کد را در محدوده 0hex تا > 10FFFFhex تعریف می کند. http://en.wikipedia.org/wiki/Unicode | توضیح یونیکد مورد نیاز است |
246021 | من به دنبال راهی مناسب (*) با فضای کارآمد برای رمزگذاری اعشار با دقت دلخواه (مثلا BigDecimal) هستم، به گونهای که هنگام مرتبسازی الگوی بیت رمزگذاریها به صورت واژگانی، اعداد به صورت عددی مرتب شوند. این مربوط به این سوال Stackoverflow است. یک رویکرد ساده و ساده برای این کار تبدیل عدد به نمایشی شبیه IEEE با توان 8 بایتی... | رمزگذاری ساده قابل مرتب سازی برای اعشار با دقت دلخواه |
250104 | من در حال توسعه یک سرور رسانه هستم، عملکرد اصلی این است که یک تصویر را ارائه دهد، که به روش زیر انجام می شود /media/:id که در آن :id شناسه تصویر است. ممکن است بخواهید اندازه خاصی را بخواهید، با قوانینی که من ارائه خواهم کرد. به عنوان مثال: /media/:id/50x50 /media/:id?witdh=50&height=50 سوال: به نظر شما کدام گزینه بهتر ... | آدرسهای اینترنتی با رشتههای پرس و جو متغیر و حافظه پنهان |
245613 | آیا دلیل خاصی وجود دارد که این امر زبان را از نظر مفهومی می شکند یا دلیل خاصی وجود دارد که در برخی موارد از نظر فنی غیرممکن است؟ ~~کاربرد با اپراتور جدید خواهد بود.~~ **ویرایش:** من میخواهم امید خود را برای دریافت مستقیم اپراتور جدید و اپراتور جدید قطع کنم و مستقیم باشم. نکته سوال این است: چرا سازنده ها _خاص_ هستند؟ ال... | چرا C++ به شما اجازه نمی دهد که آدرس یک سازنده را بگیرید؟ |
215822 | همانطور که ما قبل از توسعه طراحی و تجزیه و تحلیل می کنیم، آیا تولید کلاس های جاوا از نمودار کلاس راحت نیست؟ این طراحی جامع تر و کدهای بهتر را ترویج می کند، درست است؟ عجیب است که چرا گوگل هزاران ابزار را برای تولید نمودار کلاس از کلاسهای جاوا برمیگرداند، اما نه برعکس. | آیا تولید کلاس های جاوا از نمودار کلاس منطقی است؟ |
215827 | این وضعیت مستعد بن بست فرآیندهای یک سیستم عامل است و من می خواهم آن را با حداقل سمافورها حل کنم. اساساً سه فرآیند همکاری وجود دارد که همه داده ها را از یک دستگاه ورودی می خوانند. هر فرآیند، هنگامی که دستگاه ورودی را دریافت می کند، باید دو داده متوالی را بخواند. من می خواهم از طرد متقابل برای انجام این کار استفاده کنم. ... | تئوری سیستم عامل -- با استفاده از حداقل تعداد سمافورها |
175173 | من تعدادی پروژه منبع باز دارم که مورد استفاده قابل توجهی قرار گرفته اند و مایلم نگهبانان مشترکی پیدا کنم تا وقتی صحبت از درخواست های تعمیر و نگهداری و پشتیبانی به میان می آید و دیدگاه های دیگری در مورد چگونگی پیشرفت پروژه به میان می آید، گلوگاه نباشم. کجا باید به دنبال نگهدارنده مشترک بگردم، چه چیزی را در یک نگهدارنده ... | یافتن پشتیبان برای پروژه های منبع باز |
96386 | من گاهی اوقات اصطلاح Bootstrapper را می بینم. من آن را آخرین بار در هنگام ایجاد چند تمرین یادگیری برای Prism دیدم. من به طور تصادفی با کلاس UnityBootstrapper آشنا شدم. سوال من این است: چه زمانی یک کلاس را Bootstrapper می نامید؟ چرا؟ در مورد کلاس چه می گوید؟ | بوت استرپر در برنامه نویسی چیست؟ |
161378 | من به شغل آزاد و ساختن وب سایت در اوقات فراغتم فکر می کنم. من در C#/ASP.NET، JavaScript/jQuery و همچنین HTML/CSS و SQL تجربه دارم. بنابراین، احساس میکنم دانش کافی در زمینه فناوریهای وب برای رفتن به این مسیر را دارم. چیزی که من از آن مطمئن نیستم این است که آیا ابزاری وجود دارد که بتوان از آن برای ساده کردن زندگی یک تو... | ابزارهای توسعه دهنده وب آزاد |
214155 | من یک رابط TableSqlBuilder دارم که دارای روش getCreateTableSql است. این رابط در برخی کلاس های دیگر به شرح زیر استفاده می شود: تابع createTable( $tableDefinition ) { $sql = $this->tableSqlBuilder->getCreateTableSql( $tableDefinition ); $this->db->execute( $sql ); } رابط TableSqlBuilder چندین پیاده سازی دارد،... | کلاس های خاصی تزریق کنید یا نه |
254905 | این کد میراث را در نظر بگیرید: رابط عمومی IPersistentCollection { IPersistentCollection cons(Object o); } ژنریک شده در جاوا، می تواند چیزی شبیه به این شود: رابط عمومی IPersistentCollection<T> { IPersistentCollection<T> cons(T o); } واضح است که افزودن یک آیتم جدید به یک مجموعه جاوا قابل تغییر نباید نوع مجموعه مو... | انواع جاوا پارامتری (عمومی) |
234787 | فرض کنید برای یک شرکت کار می کنید و کاری که انجام می دهید توسعه نرم افزار برای آنهاست. شما هیچ ایده ای از تصویر بزرگ یا شاید جزئی ندارید. آنچه شما دارید وظایفی است که از طریق سیستم ردیابی مشکل به شما محول می شود. وظایفی به شما داده می شود، آنها را به روشی که وظیفه توصیف می کند کار می کنید، آنها را پس می فرستید. مانند ا... | مبارزه با بدهی فنی به عنوان کمترین توسعه دهنده؟ |
253442 | برای متدهایی که **هرگز به متغیر نمونه یا متغیر ایستا دسترسی ندارند** و درست مانند یک تابع (با فاصله نام) عمل میکنند و فقط بر اساس آرگومانهای ورودی قطعی هستند، میخواهم بپرسم که آیا اگر همه را تغییر دهم، توجهی وجود دارد. از آنها به روش استاتیک؟ من مدام می شنوم که مردم می گویند روش استاتیک ضعیف است، اما من به دنبال نمو... | اشکال استفاده از روش استاتیک |
105412 | با تیمی متشکل از 3 توسعه دهنده وب دیگر، اکنون یک سال است که عنوان توسعه دهنده وب پیشرو را دارم. این اولین کار من به عنوان سرپرست است. من کاملا در مورد اینکه چه نقشی از مدیریت انجام می دهم تنظیم شده ام. من کنجکاو هستم که توسعه دهندگان سطح ارشد دیگر چه می کنند. من در درجه اول کنجکاو هستم که مسئولیت های دیگران به عنوان مد... | نقش توسعه دهنده ارشد وب در تیم چیست؟ |
142196 | من بسیار علاقه مند به یادگیری برنامه نویسی هستم، اما مطمئن نیستم که آیا می خواهم به سمت توسعه وب یا برنامه نویسی نرم افزار گرایش داشته باشم. یا برنامه نویسی کامپیوتری هر دو را در پوسته مهره پوشش می دهد؟ از کجا یا چگونه باید شروع کنم؟ | من میخوام برنامه نویسی کنم! |
171128 | وضعیت معمولی در طراحی رابط کاربری: شما طراحی برخی از UI را انجام میدهید و، مثلاً، ایدههای جدید درخشانی مانند «روبان» یا «پیمایش جنبشی گذشته» به ذهنتان خطور میکند. استراتژی در مورد چنین چیزی چه خواهد بود؟ ثبت اختراع، آن را دوست ندارید، اما به هر حال می خواهم بپرسم: چقدر طول می کشد تا همه این کارها انجام شود و به طور ... | اثر نویسنده و حق چاپ. در طراحی UI |
246785 | در مکانی که من کار می کنم از کلاس SafeReader استفاده می کنیم که IDataReader را می پوشاند. یکی از ویژگی ها این است که اگر فیلدی که می خواهید به آن دسترسی پیدا کنید در پرس و جو نبود، فقط یک مقدار پیش فرض را برمی گرداند. بنابراین، من با کدی کار میکنم که از قبل در جای خود قرار دارد، اما ظاهراً هرگز به طور کامل کار نمیکند... | اگر فیلدی در یک پرس و جو یافت نشد، بازگشت یک مقدار پیش فرض ایده خوبی است؟ |
245614 | من در حال نوشتن یک مترجم برای یک زبان برنامه نویسی کاربردی هستم که قرار است در مرورگر اجرا شود. نیازی به گفتن نیست، عملکرد تنها نگرانی در این برنامه است. Emscripten یک کامپایلر LLVM→ JavaScript است که ادعا می کند برنامه هایی را تولید می کند که تنها 2 تا 3 برابر کندتر از بومی اجرا می شوند. با توجه به اینکه برنامه های جا... | آیا با کدنویسی یک برنامه به زبان C و سپس کامپایل در جاوا اسکریپت، عملکرد بهتری خواهید داشت؟ |
57205 | آیا زمان خوبی برای انتشار یک برنامه وجود دارد؟ آیا لحظه بدی برای انتشار یک برنامه وجود دارد؟ برای مثال، شاید بهار/تابستان به اندازه پاییز/زمستان فروش نداشته باشد. به این معنا که بچههایی که از مدرسه خارج میشوند زمان کمتری را جلوی صفحه نمایش میگذرانند، زمان بیشتری را بیرون از خانه میگذرانند، و غیره. نظری در این مورد ... | لحظه انتشار یک برنامه در اپ استور |
207116 | گاهی اوقات در کد GitHub تگ های cc، vv و ^^ را می بینم. آیا اینها معنای خاصی دارند؟ مثال: // cc MaxTemperatureMapper Mapper برای مثال حداکثر دما // vv MaxTemperatureMapper import java.io.IOException; واردات org.apache.hadoop.io.IntWritable; واردات org.apache.hadoop.io.LongWritable; وارد کردن org.apache.... | آیا cc، vv، ^^ معنای خاصی در کد دارند؟ |
82293 | چه زمانی بین جداول رابطهای و فیلدهایی که مقادیر متعددی از یک نوع خاص را در خود دارند، خط میکشید. اجازه دهید در مثال زیر توضیح دهم که در آن یک PokeMaster می تواند به چندین پوکمون با تعداد ناشناخته مرتبط شود. TablePokeMasters PokeMasterId PokeMasterName TablePokeMastersToPokemon <- سوال جانبی، یک قرارداد ... | آرگومان هایی برای ذخیره انجمن های باینری در یک فیلد واحد در مقابل جدول نگاشت؟ |
158315 | این ممکن است یک سوال احمقانه باشد، اما من روی الگوریتمی کار می کنم که فواصل متغیرها را در برخی از محدودیت ها محاسبه می کند. به عنوان مثال تابعی به نام propagateValues وجود دارد و شرح آن عبارت است از انتشار محدوده های مقدار برای محدودیت های داده شده دقیقاً منظور از انتشار ارزش چیست؟ الگوریتمی که من کار می کنم اساساً س... | انتشار ارزش به چه معناست؟ |
2541 | هنگام برنامه نویسی وقتی چیزی شما را عصبانی می کند چه می کنید؟ من معمولاً موس را محکم روی میزم می زنم و می روم قهوه یا هر چیز دیگری بخورم، فقط برای اینکه آرام باشم | چگونه می توانم به طور سازنده و حرفه ای با خشم در هنگام کار کنار بیایم؟ |
97528 | من اغلب می شنوم که اسکالا توانایی انتقال تابع به عنوان پارامتر به تابع دیگر را دارد. میخواهم تفاوت بین ارسال یک مقدار بهعنوان پارامتر در مقابل عبور خود تابع به عنوان پارامتر را بدانم. چگونه روش دوم مزیتی را برای برنامه نویسی به ارمغان می آورد. اگر توابع به عنوان پارامتر ارسال شوند چگونه ارجاعات شیء ایجاد می شوند زیرا... | تفاوت بین ارسال یک مقدار در مقابل ارسال یک تابع به عنوان پارامتر در مقیاس |
250101 | آیا مالک محصول در حالت ایده آل باید به عنوان بخشی از تیم مدیریت محصول باشد؟ اگر صاحب محصول خارج از تیم مدیریت محصول باشد، چگونه می توان با ذینفعان داخلی برخورد کرد؟ از آنجایی که صاحب محصول در تیم مدیریت محصول نبود و درگیریهای زیادی وجود داشت، مشکلاتی داشتیم. | آیا مالک محصول باید در تیم مدیریت محصول باشد |
97385 | کجا توصیف خوبی از استفاده از کلمه scope در علوم کامپیوتر وجود دارد؟ در این پست از یک سوال در مورد کلمه رزرو شده نهایی جاوا، یک پاسخ دهنده نشان می دهد که محدوده متنی است، بنابراین هر تکرار یک حلقه for باعث می شود یک محدوده به عنوان فعلی از سر گرفته شود. یکی دیگر از پاسخدهندهها حاکی از آن است که دامنه وابسته به زمان اس... | کجا توصیف خوبی از استفاده از کلمه scope در علوم کامپیوتر وجود دارد؟ |
158311 | من می خواستم اعلان فشار زمان واقعی را در یکی از برنامه های نوشته شده در RoR پیاده سازی کنم. من هیچ تجربه ای با nodejs، nowjs، express یا socketio ندارم. ساده ترین راه برای پیاده سازی سیستم اعلان فشار بیدرنگ چیست؟ | ساده ترین راه برای پوش نوتیفیکیشن |
82834 | من می دانم که این ممکن است یک سوال بارگذاری شده باشد. به عنوان مثال، در Sql Server 2008، انجام «DECLARE @someNum NUMERIC(10);» به این معنی است که محدوده متغیر با 10 رقم محدود خواهد شد. در زبان های دیگر مانند C، جاوا و غیره استانداردهای نمایش اعداد کامل و کسری متفاوت است. محدوده مقادیر توسط چند بایت برش داده می شود و ای... | چرا دقت عددی SQL به عنوان تعداد ارقام مشخص می شود؟ |
64196 | من عملکردی را به وب سایت خود اضافه می کنم که فرآیندهای طولانی مدت را به صورت ناهمزمان با استفاده از MSMQ انجام می دهد. با این حال، انجام این ansynch به این معنی است که باید کاربران را هنگام تکمیل درخواستهایشان مطلع کنیم. با استفاده از الگوی فرمان، یک رابط* به نام INotify ایجاد کردم و آن را در کلاس پیام ایجاد کردم، بنا... | «از جریانها عبور نکنید» به اشیاء پایگاه داده مستقل از ردیف داده در معماری N-Tier دسترسی پیدا میکند؟ |
153096 | من حدود 15 قالب دارم (این رشد خواهد کرد) و هر الگو حدود 10-15 سوال خواهد داشت. هر سوال میتواند پاسخهایی در قالبهای مختلف داشته باشد، مانند کادر متن، کادر فهرست، کشویی، دکمه رادیویی و غیره. من باید یک الگو را در هر صفحه بر اساس ورودیهایی که دریافت میکنم نشان دهم. بهترین رویکرد طراحی برای این کار چه خواهد بود؟ 1. ... | بهترین طراحی برای ایجاد مجموعه پویا از سوالات (کنترل ها) در برنامه وب silverlight؟ |
191349 | اینها قوانین رابرت سی. مارتین برای TDD هستند: * شما مجاز به نوشتن هیچ کد تولیدی نیستید مگر اینکه برای قبولی در آزمون واحد ناموفق باشد. * شما مجاز به نوشتن یک آزمون واحد بیش از حد کافی برای شکست خوردن نیستید. و شکست های کامپایل شکست هستند. * شما مجاز به نوشتن کد تولید بیش از حد کافی برای قبولی در آزمون یک واحد مرد... | در TDD، اگر من یک تست بنویسم که بدون تغییر کد تولید قبول شود، به چه معناست؟ |
97382 | * کدام آزمون (ها) برای صدور گواهینامه جاوا از Oracle باید داده شود. * آیا امتحان Oracle 1Z0-851 SCJP قدیمی است؟ * کتابی را که امتحان Oracle 1Z0-851 را پوشش می دهد توصیه کنید؟ | گواهی Oracle Java SE |
167720 | استدلال ** شفاهی قابل خواندن !== درک سریعتر ** در http://ryanflorence.com/2011/case-against-coffeescript/ واقعا قوی و جالب است. من و من مطمئن هستم که دیگران به شواهدی که علیه این استدلال می کنند بسیار علاقه مند خواهیم بود. شواهد روشنی برای این وجود دارد و من آن را باور دارم. مردم به طور طبیعی به تصاویر فکر می کنند، ن... | طراحی زبان: آیا زبان هایی مانند Python و CoffeeScript واقعا قابل درک تر هستند؟ |
150670 | من در حال طراحی یک برنامه بسیار استاندارد Spring MVC هستم، و سعی می کنم بفهمم مسئولیت مدیریت تراکنش در کجا باید باشد. من استراتژیهای طراحی تراکنشهای جاوا را خواندهام، و بهترین راهبردی که فکر میکنم مناسبتر است، سرور نماینده است، که در آن کنترلکننده تراکنشها را مدیریت میکند و سرویسها و DAOها از تراکنشها غافل ه... | الگوی طراحی تراکنش برای MVC و محل مسئولیت؟ |
97521 | به نظر می رسد بین آنچه که از کسی که چند سال در دانشگاه برنامه نویسی خوانده است و آنچه واقعاً می داند، انتظار دارم، اختلاف زیادی وجود دارد. احساس نمیکنم در مصاحبهها سؤالات پیچیدهای میپرسم. برخی از سوالات معمول من عبارتند از: * تفاوت بین نوع مرجع و نوع ارزش چیست؟ اگر به نظر میرسد که مصاحبهشونده واقعاً پاسخ خود را ... | آیا باید انتظار داشته باشم که فارغ التحصیلان اخیر با مفاهیم اولیه برنامه نویسی آشنا باشند؟ |
117775 | من در حال حاضر به آینده شغلی خارج از حوزه برنامه نویسی خودم علاقه مند هستم. به طور خاص، من یک توسعهدهنده وب هستم، اما میخواهم به برنامهنویسی برنامههای دسکتاپ روی بیاورم. چگونه باید رزومه خود را تنظیم کنم تا نشان دهم که قادر به توسعه این نوع نرم افزار هستم در حالی که هیچ تجربه قبلی با آن نداشته ام؟ این سوال همچنین م... | رزومه خود را برای تغییر شغل در برنامه نویسی تنظیم کنید |
14315 | مشابه سوال من در مورد علائم هشدار دهنده به راحتی قابل مشاهده در کد، فکر می کنم گاهی اوقات نظرات برنامه نویسان می تواند در مدت زمان کوتاهی چیزهای زیادی (از چیزهای نه خوب) در مورد آنها به شما بگوید. ترسناک ترین چیزی که اخیراً (از یک ارشد) شنیده ام این است: > می توانم از کنترل منبع استفاده کنم، اما سرعتم را کاهش می دهد، ه... | وقتی یک برنامه نویس آنها را می گوید، کدام نظرات فوراً زنگ خطر را به صدا در می آورند؟ |
195912 | من روی یک برنامه بزرگ جنگو کار می کنم که از CouchDB به عنوان پایگاه داده و couchdbkit برای نگاشت اسناد CouchDB به اشیاء در پایتون، مشابه ORM پیش فرض جنگو، استفاده می کند. ده ها کلاس مدل و صد یا دو نمایش CouchDB دارد. این برنامه به کاربران اجازه می دهد تا یک دامنه ثبت کنند، که به آنها یک URL منحصر به فرد حاوی نام دامنه ... | آیا این انتزاع بیش از حد است؟ (و آیا اسمی برای آن وجود دارد؟) |
19273 | با خواندن نیکلاوس ویرث، می توان متوجه شد که علیرغم محبوبیت پاسکال، او خوشحال نیست که اوبرون (به عنوان جانشین «صیقل خورده» پاسکال و مدولا) محبوبیت زیادی کسب نکرده است. من هرگز کاری در Oberon انجام ندادم، اما با خواندن صفحه Oberon For Pascal Developers واقعاً بسیاری از تغییرات را به عنوان یک توسعه دهنده دلفی/پاسکال دوست ... | آیا اوبرون واقعا پاسکال بهتری است؟ |
238364 | این احتمالاً یک سؤال احمقانه لعنتی است، که من از آن عذرخواهی می کنم، اما به نظر نمی رسد که برای یافتن پاسخ، نحو گوگل را به درستی دریافت کنم. یک Property مانند این را تصور کنید: private int _type public int Type { get { return _type; } set { _type = value; //رویدادی را به زبان یا فناوری انتخابی خود افزایش ده... | معماری مبتنی بر واحد |
102523 | اخیراً موردی توسط مالک محصول به بک لاگ محصول اضافه شده است که می گوید وقتی از صفحه x به صفحه ورود می روم، خطایی می بینم. می خواهم آن خطا حذف شود. به نظر من این یک مورد استفاده نیست، و نباید یک PBI (مورد عقب مانده محصول) باشد. با این حال، وقتی در مورد آن بحث کردم، اسکرام مستر به من گفت که داستانهای کاربر PBI نیستند و P... | PBI در مقابل داستان کاربر |
156405 | من یک توسعه دهنده سی شارپ هستم. من قصد دارم C++ را یاد بگیرم. (امیدوارم بتوانم از مفاهیم OOP از سی شارپ استفاده کنم] من یک دستگاه ویندوز 7 دارم. 1. ابزارهایی که برای توسعه C++ باید نصب کنم چیست؟ 2. آیا آموزش های خوبی برای تغییر به C++ وجود دارد. یک توسعه دهنده سی شارپ؟ | شروع برنامه نویسی C++ (برای یک برنامه نویس C#) |
251274 | از من خواسته شده است که IDisposable را بر روی اشیایی که 100% منابع مدیریت شده هستند، بدون جریان و منابع بزرگ پیاده سازی کنم. من اهمیت دفع درست منابع بزرگ و منابع مدیریت نشده را میدانم، اما طرف دیگر معادله چطور؟ برای شیای که از پیادهسازی IDisposable (اشیاء کوچک کاملاً مدیریتشده) سود نمیبرد، در صورت وجود، GC.Suppres... | آیا GC.SuppressFinalize می تواند مشکلات عملکردی ایجاد کند؟ |
87320 | من پایگاه داده را اینجا جستجو کردم و هیچ پاسخی برای سوالم پیدا نکردم. استانداردی برای دانستن یک برنامه نویس php چیست؟ منظورم این است که به معنای واقعی کلمه، فرد باید چه گروهی از توابع، مکانیسم ها و متغیرهای زبان را بشناسد تا خود را یک برنامه نویس (خوب) php بداند؟ (من می دانم که خوب بودن فراتر از نحو زبان است، هنوز هم ف... | چه برنامه نویس php باید بداند؟ |
190432 | من مبتلا به سندرم آسپرگر هستم و تأثیر آسپرگر برای من این است که درک مفاهیم از خواندن مطالب برای من دشوار است مگر اینکه ایده یا تجسم ذهنی در مورد آنچه می خوانم داشته باشم - که اغلب ممکن نیست زیرا اکثر زمانی که چیزی را می خوانیم زیرا از ابتدا درباره آن چیزی نمی دانیم. اما، باید بتوانم چیزی را به صورت بصری در ذهنم درک کنم... | برنامه نویس آسپرگر و مشکلات یادگیری. بهترین راه برای غلبه بر آنها؟ |
252999 | در حین مرور در SO، به پاسخی برخوردم که پیشنهاد میکرد از عبارت «سعی کنید-در نهایت» برای رفع مشکلی که داشت استفاده کنید. (یک اشکال نادر که گاهی برای کاربرانش اتفاق می افتاد). یکی نظر داد که راه حل معتبری است اما گفت برای کد تولید توصیه نمی شود. > آیا این درست است؟ چرا برای کد تولید توصیه نمی شود؟ اگر برای گرفتن استثناها... | آیا یک عبارت try-catch-finally برای کد تولید مناسب است؟ |
244534 | من به HTML و CSS مسلط هستم اما هنوز در مورد جاوا اسکریپت بسیار متزلزل هستم. با این اوصاف، من توانسته ام یک سایت با استفاده از کتابخوان بایگانی اینترنتی بسازم که به reader.js متکی است در اینجا یک کپی از یکی از نسخه های من از reader.js https://gist.github.com/dylan-k آمده است. /ed4efed2384e221d46cc سایت خوبی است، اما متو... | سوال تازه کار جاوا اسکریپت: متغیرها را درون خطی تعریف کنید |
96650 | آیا می توانیم تغییرات روی یک مصنوع خاص را کنترل کنیم در حالی که ابزار مدیریت پیکربندی ما به درستی کار نمی کند؟ آیا خودمان می توانیم این کار را انجام دهیم؟ | اهمیت استفاده از ابزارهای مدیریت پیکربندی در پروژه نرم افزاری برای کنترل تغییرات |
153094 | من اکنون در حال یادگیری Gerrit هستم (که اولین ابزار بررسی کدی است که استفاده می کنم). Gerrit به یک تغییر بازنگری شده نیاز دارد تا متشکل از یک commit باشد. شاخه ویژگی من حدود 10 commit دارد. روشی که گریت ترجیح می دهد این است که آن 10 تعهد را در یک کامیت له کنید. اما به این ترتیب اگر commit در شاخه هدف ادغام شود، تاریخچه... | Gerrit، git و بررسی کل شاخه |
165380 | من می دانم که با یادگیری یک زبان، می توانید به سادگی یک کتاب بخرید، مثال ها را دنبال کنید و در صورت امکان تمرین ها را امتحان کنید. اما چیزی که من واقعاً به دنبال آن هستم این است که چگونه پس از یادگیری زبان به آن تسلط پیدا کنید. اکنون می دانم که تجربه یکی از عوامل اصلی است، اما در مورد یادگیری درونیات زبان، ساختار زیربن... | چگونه می توانم واقعاً به یک زبان برنامه نویسی تسلط داشته باشم؟ |
17136 | ...در درصد به عنوان مثال 60/40 یا 90/10 یا 100/0. فرضیه من این است که هر چه نسبت زمانی که صرف فکر کردن میکنید بیشتر باشد، در نتیجه کد شما کوچکتر میشود (و زمان کمتری برای نوشتن آن نیاز خواهد بود). به عبارت دیگر بیشتر فکر کنید، کمتر بنویسید. به نظر شما درست است؟ به عنوان یک یادداشت جانبی، فکر می کنم در شرکت های نرم اف... | زمان کار شما چگونه بین کدنویسی و تفکر تقسیم می شود؟ |
209123 | من داشتم یک برنامه پایتون برای اندازه گیری رشد codereview.SE می ساختم. رویکرد من این بود که آمار سایت را در صفحه اول نشان دهم و آنها را روی هارد دیسکم ذخیره کنم. من قصد دارم هر روز یک بار این کار را انجام دهم. تا به حال من به اندازه کافی برای دریافت آمار و اضافه کردن آنها به یک فایل متنی ساخته ام. اسکریپت پایتون را می ... | چه زمانی باید استفاده از پایگاه داده بر تجزیه داده ها از یک فایل متنی ترجیح داده شود؟ |
251277 | من مدرک دانشگاهی در CS دارم و در مورد جاوا و OCaml یاد گرفتم. جاوا به عنوان مقدمه مورد استفاده قرار گرفت و در اکثر CS کلاس ها به جز موارد نظری استفاده شد. OCaml بخشی از یادگیری یک الگوی برنامه نویسی متفاوت بود. از آنجایی که OCaml یک ورودی موفق در CV من نبود، من به یک برنامه نویس جاوا بهتر تبدیل شدم. همچنین اکثر مشاغل م... | قبل از شروع نوشتن C چه کاری باید انجام دهم و بدانم؟ |
96380 | ما در حال حاضر در شرایطی هستیم که بین استفاده از یک نقشهبردار شی-رابطهای خارج از جعبه یا استفاده از خودمان یک انتخاب داریم. یک برنامه قدیمی (ASP.NET + SQL Server) داریم که در آن لایه داده و کسبوکار -لایه ها متاسفانه با هم له می شوند. این سیستم از نظر دسترسی به داده ها چندان پیچیده نیست. این داده ها را از یک گروه بزر... | آیا نوشتن لایه دسترسی به داده / داده نقشه برداری ایده خوبی است؟ |
82831 | من یک سیستم آسان برای آپلود پایگاه داده های MS Access قابل جستجو در وب پیدا کردم - به نام Caspio Online (http://www.caspio.com/). با این حال، من ترجیح می دهم هزینه ماهانه را فقط برای آپلود پایگاه های داده در وب سایت خود پرداخت نکنم. آیا کسی جایگزین منبع باز می داند که به من اجازه دهد پایگاه داده MS Access 2007 را در یک... | آپلود پایگاه داده MS Access در وب |
167235 | با خواندن منابع مختلف در مورد قدرت رمز عبور، سعی می کنم الگوریتمی ایجاد کنم که تخمین تقریبی از میزان آنتروپی یک رمز عبور را ارائه دهد. من سعی می کنم الگوریتمی ایجاد کنم که تا حد امکان جامع باشد. در این مرحله من فقط شبه کد دارم، اما الگوریتم موارد زیر را پوشش می دهد: * طول رمز عبور * کاراکترهای تکراری * الگوها (منطقی) *... | چگونه می توانم آنتروپی رمز عبور را تخمین بزنم؟ |
148642 | من یک فایل .c دارم که اساساً پایگاه داده کوچک خود را از افراد مدیریت می کند. توابع افزودن، حذف، ویرایش و جستجو در میان برخی دیگر وجود دارد. دارای یک آرایه استاتیک است که از آن برای ذخیره داده ها استفاده می کند. راه خوبی برای آزمایش واحد یک فایل مانند این چیست؟ چون آرایه ثابت است نمی توانم در داده های خودم قرار دهم. آیا... | آزمایش فایلی که به شدت به یک آرایه استاتیک متکی است |
102528 | من می خواهم بدانم چه روش استانداردتری برای فراخوانی عبارت منظم به صورت کوتاه وجود دارد. من هر دو را دیده ام، regex و regexp. گوگل می گوید که regex تقریباً 2 بازدید به اندازه regexp دارد، اما بستگی به روش جستجوی من دارد (زمانی که عبارت منظم را بعد از کلمه اضافه می کنم، regex تبدیل به regex regular expression می شود، نتی... | کوتاه کردن استانداردتر برای «بیان منظم»، «regex» یا «regexp» چیست؟ |
9554 | خواندن کد منبع SQLite ماموریت IMO غیرممکن است. با این حال، این یک قطعه قابل استفاده از نرم افزار بسیار پیچیده است (این یک پایگاه داده جاسازی شده کامل است) که می تواند دانلود، کامپایل و از کدهای دیگران استفاده شود و دائماً به روز می شود. چگونه مردم موفق به نوشتن و حفظ چنین کدهای بسیار پیچیده و سخت خوانی می شوند؟ | چگونه مردم قادر به نوشتن و حفظ کدهای بسیار پیچیده و سخت خوان هستند؟ |
99745 | Git و Mercurial از مدل های مشابه پیروی می کنند و اصطلاحات مشابهی دارند. انتشار اولیه Mercurial تنها 12 روز پس از Git's بود. چگونه این دو پروژه، در توسعه اولیه در همان زمان، تا این حد شبیه به هم شدند؟ کسی از تاریخچه خبر داره؟ | چگونه Git و Mercurial به طور همزمان توسعه یافتند؟ |
64198 | من حدود 3-4 سال است که برنامه نویسی می کنم (مدرک تحصیلی خود را در CS به پایان رساندم که در آنجا زبان برنامه نویسی جاوا به ما آموزش داده شد). حالا سوال من این است: > آیا برای بسیاری از مردم دانستن نحوه نوشتن کد از حالت خاموش > کار دشواری است؟ منظور من از این این است که وقتی به یک کار نزدیک میشوم، معمولاً در گوگل جستجو ... | چگونه می توانم در دانستن نحوه نوشتن کد مستقیماً بهتر باشم؟ |
179489 | بنابراین من در مدرسه در مورد الگوهای طراحی یاد می گیرم. بسیاری از آنها ایده های کوچک احمقانه ای هستند، اما با این وجود برخی از مشکلات تکراری را حل می کنند (تک تک، آداپتورها، نظرسنجی ناهمزمان، و غیره). اما امروز به من در مورد به اصطلاح الگوی طراحی نمونه اولیه گفته شد. من باید چیزی را از دست بدهم، زیرا هیچ فایده ای از آن... | هدف الگوی طراحی پروتوتایپ چیست؟ |
201222 | من می خواهم بدانم چگونه می توان یک پروژه بزرگ با اجزای متعدد را با سیستم مدیریت کنترل نسخه مدیریت کرد. در پروژه فعلی من 4 بخش اصلی وجود دارد. 1. وب 2. سرور 3. کنسول مدیریت 4. پلتفرم. قسمت وب و سرور از 2 کتابخانه استفاده می کند که من نوشتم. در مجموع 5 مخزن git و 1 مخزن جیوه وجود دارد. اسکریپت ساخت پروژه در مخزن پلتفر... | طرحبندی پروژه بزرگ: افزودن ویژگی جدید در چندین پروژه فرعی |
99295 | من می خواهم یک کلاینت توییتر با کلاینت ضخیم، دسکتاپ و منبع باز بسازم. من اتفاقاً از داتنت بهعنوان زبان و توییتر بهعنوان بستهبندی OAuth/Twitter استفاده میکنم و برنامه من احتمالاً بهعنوان منبع باز منتشر خواهد شد. برای دریافت رمز OAuth، چهار اطلاعات مورد نیاز است: 1. Access Token (نام کاربری توییتر) 2. Access Secret... | چگونه کلید و راز مصرف کننده OAuth v1 را برای یک کلاینت دسکتاپ منبع باز توییتر بدون فاش کردن آن برای کاربر ذخیره کنم؟ |
195149 | من در حال تولید اسناد برای یک پروژه آینده بوده ام. یکی از ویژگی های داده های موجود در این پروژه این است که بازنگری می شود (یا حداقل بخش های بزرگی از آن خواهد بود). من با سرصفحه HTTP Accept-Datetime (آنطور که می فهمم، بسیار جدید است) برخوردم. این برای فعال کردن دسترسی به داده های تجدید نظر شده با استفاده از رابط های موج... | بازبینی وب و هدر Accept-Datetime |
96657 | بنابراین ... من یک سیستم عامل هستم. موارد متعددی وجود دارد که اسکریپتنویسی مفید است (عمدتاً مدیریت کاربر ... ایجاد گروهها، اختصاص مجوزها، حذف حسابهای منقضی شده، و غیره)، و من میخواهم یک برنامه کامل بسازم. اما من حتی نمی دانم از کجا شروع کنم. **ویرایش** بسیاری از نظرات در امتداد خطوط یاد بگیرید آنچه را که می خواهید ... | تازه وارد برنامه نویسی، از کجا شروع کنم؟ |
225609 | آیا الگوی استانداردی در OOP برای بهروزرسانی «اتمی» یک جفت شی، مانند یک جفت حساب بانکی در یک تراکنش وجود دارد؟ من میخواهم یک متد عمومی واحد را در معرض دید قرار دهم که همه این کارها را یکباره انجام میدهد، اما فقط میتواند با ایجاد _دو_ فراخوانی متدهای عمومی برای بهروزرسانی اشیاء جداگانه، راههایی برای انجام آن پیدا ک... | الگویی برای به روز رسانی اتمی یک جفت شی |
186667 | این ممکن است بسیار ساده لوحانه باشد، اما من متعجب بودم، این متن درختان دوتایی (ساده، مرتب شده و متعادل)، از همه انواع پیمایش است: * عمق-اول پیش سفارش * عمق-اول به ترتیب * عمق-اول پست -order * width-first کاربرد واقعی نسخه های قبل و بعد از سفارش چیست؟ منظورم این است که آیا نوعی و/یا پیکربندی درخت باینری وجود دارد که در ... | سودمندی پیمایش پیش و پس از سفارش درختان باینری |
153327 | یکی از مزایای سیستم های کنترل نسخه قدیمی مانند CVS و SVN در توسعه سازمانی این است که هر کسی می تواند به کنترل منبع متصل شود و تمام پروژه هایی که شرکت دارد را ببیند. این میتواند به شما کمک کند تا دیدی در سطح بالایی از پیشرفتهایی که در خارج از سرعت شما اتفاق میافتد را آسانتر کنید و همچنین همه چیز را در یک مکان نگه می... | مدیریت (بسیاری) پروژه های متعدد در Git در یک محیط سازمانی |
64192 | من کمی بیش از 10 سال تجربه توسعه دارم. در چند سال گذشته، من بیشتر به صورت انفرادی کار میکردم و اگرچه این کار مزایای خود را دارد، اما احساس میکنم که رشد من را محدود کرده است. من به دنبال انتخاب یک کار قراردادی برای بازگشت به یک محیط تیم هستم. من چند فرصت را سنجیده ام: شرکت A از جدیدترین ابزارها استفاده می کند (NET 4، ... | کدام فرصت شغلی بهتر است؟ یکی با بیشترین پتانسیل یادگیری یا بیشترین پتانسیل تدریس؟ |
153328 | ما در حال بررسی استخدام یک پیمانکار یا کارآموز هستیم تا با ما در پروژه iOS ما کار کند، اما این باعث میشود که من واقعاً پارانویا شوم که به کسی که برای شرکت کار نمیکند اجازه دسترسی به پایگاه کد ارزشمند ما را میدهیم. منظورم این است که من فقط میتوانم به آنها اجازه دسترسی به کلاسهایی را بدهم که میخواهم روی آنها کار ... | هنگام کار با پیمانکاران/کارورزان، تا چه حد باید از پایگاه کد شما محافظت شود؟ |
63165 | آیا راهی برای ایفای نقش جاوا اسکریپت با زبان دیگری مانند سی شارپ وجود دارد؟ یکی از راههایی که به ذهنم خطور کرد این است که silverlight را نصب کردهام، از سی شارپ به جای جاوا اسکریپت برای تمام اسکریپتهای سمت کلاینت استفاده کنم (اگرچه C# یک زبان برنامهنویسی نیست). آیا ممکن است؟ من در مورد چیزی مانند GWT (جاوا) یا اسکری... | آیا راهی برای ایفای نقش جاوا اسکریپت با زبان دیگری مانند سی شارپ وجود دارد؟ |
119743 | سوالات اخلاقی بیشتر و بیشتر در اخبار مطرح می شوند و می توانند هسته اصلی زندگی توسعه دهندگان نرم افزار باشند. در این سال چندین بار از من برای پاسخ به سؤالات اخلاقی در زمینه برنامه نویسی رایانه ای خواسته شد، و از اینکه دیدم چقدر سؤالات ناراحت کننده و مشکلی که به نظر من بی اهمیت می دانم می تواند منجر به آن شود، شگفت زده ش... | آیا کسی کاربرد اخلاق در برنامه نویسی را آموزش می دهد؟ |
191344 | من خیلی گیج شدم من حتی نمی توانم درک کنم که چگونه MVC خارج از توسعه وب پیاده سازی می شود. این ممکن است یک سوال خیلی کلی به نظر برسد، اما چگونه می توان MVC را اعمال کرد. من سؤالات کلی زیر را دارم: 1. آیا M، V و C قرار است هر کدام یک کلاس باشند یا چند. اگر تعدادشان زیاد باشد، چگونه کار می کند. 2. بیشتر کلاس هایی که قب... | نحوه استفاده از MVC در عمل |
198398 | پس از خواندن چند روز در مورد مشخصات GPLv3 و به طور خاص AGPLv3، من یک سوال در مورد توزیع و به چه کسی دارم. اگر من یک برنامه وب (سرور و مشتری) برای یک مشتری ایجاد کنم. آنها به من پول می دهند، من همه منبع و مالکیت را تحویل می دهم. برنامه وب در حال حاضر فقط برای کارمندان و پیمانکاران قابل دسترسی است. اما برای بحث، از آنجای... | چه کسی با agpl به کد منبع دسترسی پیدا می کند |
161998 | من از سابقه ساخت وبسایتهای MVC و برنامههای HTML5 آمدهام و اخیراً تصمیم گرفتهام به چیزهایی بپردازم که در دانشگاه به آنها آموزش داده نشدهاند، یعنی چیزهایی که بیشتر مردم در دورههای علوم کامپیوتر میآموزند. من در حال مطالعه کتابی در مورد الگوریتمها بودهام و اولین موردی که به آن اشاره میکند، مرتبسازی درج بود. من ... | مقایسه مرتبسازی درج خودم در مقابل الگوریتم استاندارد |
96383 | من می دانم که استثنا در برنامه به این معنی است که اتفاق غیرقابل پیش بینی رخ داده است (اما نه آنقدر بد که به طور اجتناب ناپذیر برنامه از کار بیفتد!). دنباله try-catch-finally من را ناراحت می کند زیرا خواندن برنامه سخت تر است (یک سطح دیگر از براکت های فرفری) و درک آن سخت تر است (پرش از هر جایی برای گرفتن در صورت بروز است... | آیا کنترل کننده onError بهتر از استثناها است؟ |
246397 | آیا استفاده قانونی برای هک های دستکاری بیت در زبان های سطح بالاتر مانند جاوا وجود دارد؟ می توانم ببینم که آنها در برنامه های سطح پایین و محاسباتی حساس به سرعت مفید هستند، به عنوان مثال. پردازش گرافیکی یا توابع رمزنگاری حدس میزنم به همین دلیل است که همه مجموعههای آنها به زبان C هستند. با این حال، برای فکر کردن به آنه... | در جاوا، وقتی تکنیک غیر بیتی خواناتر است، چرا از هک بیت استفاده کنیم؟ |
195285 | مدتی در یک شرکت توسعه وب کوچک (3 برنامه نویس) کار می کنم. در طول سال گذشته، شرکت روزهای سختی را پشت سر گذاشت (پروژه های کمتر) و تعدادی از همکاران از جمله مدیر تولید ما اخراج شدند. بیرون بودن این فرد از تیم برای ما به این معنی است که باید بیشتر و بیشتر با روسای شرکت (مالکین) سر و کار داشته باشیم. این آنها هستند که با مش... | چگونه با کارکنان مدیریتی (مالک شرکت) که تأثیر تغییرات مشخصات را کم اهمیت می دانند، برخورد کنیم؟ |
48024 | یکی از دوستان بسیار خوب من و یک برنامه نویس مشتاق اخیرا درگذشت. او نزدیک به 40 پروژه را در BitBucket به جا گذاشت. اکثر آنها عمومی هستند، اما تعداد کمی از آنها به عنوان خصوصی علامت گذاری شده اند. من تصمیم گرفته ام به جای اینکه کار او را ناپدید کنم، وظایف سرپرستی پروژه ها را بر عهده بگیرم. اگر شما هم در چنین شرایطی بوده ... | سرپرستی پروژه های دوستان درگذشته |
64191 | من در حال مناظره با یکی از همکارانم در مورد استفاده صحیح (در صورت وجود) از trigger_error در زمینه روش های جادویی هستم. اولاً، من فکر میکنم که باید از «خطا_راهاندازی» اجتناب شود _به جز این مورد. فرض کنید کلاسی داریم با یک متد 'foo()' class A { public function foo() { echo 'bar'; } } اکنون بگویید میخواهیم دقیق... | trigger_error در مقابل throw Exception در زمینه متدهای جادویی PHP |
251278 | در حال حاضر ما از یک سیستم بسیار ساده برای کنترل نسخه استفاده می کنیم. ما یک مخزن اصلی کاملاً مسطح برای کل خط تولید خود داریم. همانطور که پایگاه کد ما رشد می کند و محصولات بیشتری را به خط تولید اضافه می کنیم، این شروع به ایجاد برخی از اشکالات جدی می کند. ما می خواهیم از این موضوع فاصله بگیریم، به خصوص بدون سبک مسطح، ام... | نحوه مدیریت فایل های تکراری در کنترل نسخه |
140085 | مشتری ما از ما می خواهد که یک برنامه سفارشی برای او بنویسیم که بتواند روی تعداد انگشت شماری از آیپدهای شرکتش استفاده کند. این برنامه احتمالا فقط برای این یک مشتری مفید است (شاید برای دو یا سه مورد دیگر در آینده، اما فقط پس از سفارشی سازی اضافی). خواندم که اگر مشتری در برنامه خرید حجمی اپل مشترک شود، میتوانیم یک برنامه... | به عنوان یک شرکت اروپایی، آیا می توان یک برنامه کاربردی iPad سفارشی برای مشتری نوشت؟ |
194433 | من در مورد Big O Notation و نحوه محاسبه آن بر اساس نحوه نگارش یک الگوریتم اطلاعات بیشتری کسب کرده ام. من با مجموعه جالبی از قوانین برای محاسبه الگوریتم Big O روبرو شدم و میخواستم ببینم آیا در مسیر درستی هستم یا راه را ترک میکنم. **نشانگذاری Big O: N** function(n) { For(var a = 0; i <= n; i++) { // N است زیرا فقط یک ح... | آیا این یک قانون مناسب برای شناسایی نماد Big O یک الگوریتم است؟ |
235208 | من Yeoman را برای ساختن نمونههای اولیه به صورت محلی و ماکتهای استاتیک که میتوانم با یک تیم به اشتراک بگذارم بسیار مفید یافتم. با این حال، به نظر میرسد که گنجاندن ساختار دایرکتوری آن در چارچوب یک چارچوب بزرگتر مانند Rails، Django، .NET بسیار دشوار خواهد بود، و من نمیتوانم تصور کنم که یک گردش کار کارآمد میتواند چه... | آیا قراردادی برای استفاده از Yeoman در زمینه یک چارچوب وب بزرگتر وجود دارد؟ |
79091 | من علاقه مندم که درباره نحوه کار خدمات وب دانلود آهنگ زنگ بیشتر بدانم. من برنامه نویسی وب را در جاوا انجام می دهم و می خواهم وب سرویسی بسازم که وقتی کاربر برای وب سرویس پیامک می فرستد آهنگ زنگ به تلفن همراه کاربر ارسال می کند. * آیا کسی با این نوع خدمات آشنایی دارد؟ * برای اینکه بتوانم چنین چیزی ایجاد کنم به چه چیز... | خدمات وب برای دانلود آهنگ های زنگ چگونه کار می کنند؟ |
149512 | من سعی میکنم راه خوبی برای مدیریت محتوای ارسالشده توسط کاربر پیدا کنم و روشی ایجاد کنم تا مشخص کنم چه زمانی محتوای ناخواسته/ ضعیف باید پنهان شود. هدف این است که رای دادن به نظرات مشابه با نظرات لایک/نپسندیدن در یوتیوب ایجاد شود و اگر امتیاز خوب است نظرات را نشان دهید، در غیر این صورت آنها نامرئی هستند. **رویکرد** فکر... | چگونه یک سیستم برای مخفی کردن محتوای اسپم شده کاربر پیاده سازی کنیم؟ |
167906 | من در حال بازنویسی یک کتابخانه کلاینت/پراکسی PHP هستم که یک رابط برای یک سرویس وب .Net مبتنی بر SOAP فراهم میکند، و در این فرآیند میخواهم آزمایشهای واحد و یکپارچهسازی را اضافه کنم تا تغییرات بعدی ریسک کمتری داشته باشند. کاری که کتابخانه ای که من روی آن کار می کنم انجام می دهد این است که تماس ها به وب سرویس را جمع آ... | سرویس گیرنده پروکسی وب سرویس تست واحد/ادغام |
79098 | برای هر پروژه وب استاندارد، کد سمت سرور، صفحات سرور، جاوا اسکریپت و فایل های CSS را به عنوان دارایی های کد خود خواهید داشت. داشتن یک مجموعه آزمایشی و یک فرآیند ساخت اسکریپت شده برای کامپایل/بسته بندی/ استقرار کد، یک روش کاملاً استاندارد برای کدهای سمت سرور است. بیلدها معمولاً پس از آزمایش و تأیید کد در یک محیط QA بر اس... | آیا اجازه میدهید کد لایه ارائه خارج از چرخه ساخت اجرا شود؟ |
196481 | من در حال نوشتن یک «InputStream» هستم که جریانهای داده حاوی دادههای «تریلر» را پردازش میکند. یعنی، **_n_** بایت های نهایی جریان، قطعه ای از داده است که باید به طور جداگانه مدیریت شود و نباید از روش های «خواندن» بازگردانده شود. کلاس من یک آرایه بایت داخلی با طول **_n_** را حفظ می کند و داده ها را در این آرایه بایت از... | بایت ها را از طریق یک بافر با اندازه ثابت جابجا کنید |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.