
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,898,256 | Understanding Props, Parent, and Child Components in React Native using TypeScript. | In React Native, we often need to pass data from one component to another. This is where the concept... | 0 | 2024-06-24T01:17:02 | https://nehirugue.medium.com/understanding-props-parent-and-child-components-in-react-native-using-typescript-f91baaac88da | In React Native, we often need to pass data from one component to another. This is where the concept of props (short for properties) comes into play. Props are a way to pass data from a parent component to a child component.
Let’s start by creating a simple app that displays a list of posts.
**Step 1: Set up a new Re... | nehi_rugue | |
1,898,255 | Cutting Down Docker Image Sizes: Next.js Standalone Mode for Easy Kubernetes Deployments on EKS and AKS | A Developer's Deployment Dilemma So, you are all geared up and brimming with excitement to... | 0 | 2024-06-24T01:12:08 | https://dev.to/alessandrorodrigo/cutting-down-docker-image-sizes-nextjs-standalone-mode-for-easy-kubernetes-deployments-on-eks-and-aks-4pno | ## A Developer's Deployment Dilemma
So, you are all geared up and brimming with excitement to launch your newest and greatest super cool Next.js app. Except that Docker images are just too bloated, and everything becomes slow. How frustrating deployment delays are, correct? What if I told you there's a way to trim that... | alessandrorodrigo | |
1,898,097 | Sincronizando data entre tabs | Una de las cosas mas complicadas de entender y manejar en una aplicación es el estado de una... | 0 | 2024-06-24T01:10:26 | https://dev.to/dezkareid/sincronizando-data-entre-tabs-5951 | webdev, frontend, javascript | Una de las cosas mas complicadas de entender y manejar en una aplicación es el estado de una aplicación. Aunque tenemos herramientas como Redux, Zustand o cualquier otra biblioteca JS que salga en los próximos minutos que te tome leer este post.
Pero este post no se trata de bibliotecas, se trata de la plataforma y co... | dezkareid |
1,898,254 | Technical Dos attacks | Ethical Hacking - Dos attacks on different services. https://github.com/samglish/technicalDos The... | 0 | 2024-06-24T01:07:56 | https://dev.to/samglish/technical-dos-attacks-2982 | cybersecurity, ddos | Ethical Hacking - Dos attacks on different services.
[https://github.com/samglish/technicalDos](https://github.com/samglish/technicalDos)
**The different tools**
1. Metasploit
2. Nmap NSE
3. Exploit database
4. Scapy
**DOS/DDOS categories**
- Session abuse.
- Attacks based on packet volume.
- Protocol-based attacks.
... | samglish |
1,898,252 | Day 5: Collaborating with GitHub for DevOps | Welcome to Day 5 of our 90 Days of DevOps journey! Today, we'll explore GitHub collaboration, master... | 0 | 2024-06-24T01:02:14 | https://dev.to/arbythecoder/day-5-collaborating-with-github-for-devops-5oo | github, git, devops, cloud | Welcome to Day 5 of our 90 Days of DevOps journey! Today, we'll explore GitHub collaboration, master essential Git commands, and tackle real-life challenges in a straightforward manner.
#### Git Essentials for DevOps
**Mastering Git Commands:**
- **git init:** Start a new Git repository.
- **git add:** Add changes to... | arbythecoder |
1,898,251 | [Game of Purpose] Day 36 | Today I played around with sample projects: Lyria and Matrix. I wanted to see how professional game... | 27,434 | 2024-06-24T00:58:15 | https://dev.to/humberd/game-of-purpose-day-36-38ko | gamedev | Today I played around with sample projects: Lyria and Matrix. I wanted to see how professional game devs structure their code/blueprints. And oh boy I've seen so many nodes I can't wrap my head around. It took a lot of time for me to understand a function with 30 nodes, which would take me a minute if it was code.
Any... | humberd |
1,898,247 | Dev challenge - Algorithms | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-24T00:47:34 | https://dev.to/marimnz/dev-challenge-algorithms-ldi | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Algorithms are like a list with the necessary step-by-step instructions to solve a problem in the best way. It's like a good cake recipe, in which you can't bake it without first adding... | marimnz |
1,898,242 | Introduction to Game AI Development | Introduction In recent years, the development of artificial intelligence (AI) has... | 0 | 2024-06-24T00:34:33 | https://dev.to/kartikmehta8/introduction-to-game-ai-development-3oa4 | webdev, javascript, beginners, programming | ## Introduction
In recent years, the development of artificial intelligence (AI) has revolutionized the gaming industry. AI is used to create intelligent and lifelike characters in video games, making them more challenging and engaging. Game AI development involves using algorithms and techniques to simulate human-lik... | kartikmehta8 |
1,897,702 | Important things to know about the anchor tag <a> | Most of us are familiar with using the anchor tag to link to other pages on the web, but there's so... | 0 | 2024-06-23T23:35:39 | https://dev.to/douiri/important-things-to-know-about-the-anchor-tag-2hhi | html, webdev, learning, beginners | Most of us are familiar with using the anchor tag to link to other pages on the web, but there's so much more to this versatile element that often goes unnoticed by beginners. In this article, we'll explore some of the lesser-known features and functionalities of the anchor tag that can enhance your HTML skills and web... | douiri |
1,898,150 | Meet Chappy: Your Friendly, Quirky Chat Buddy - Next.js, Twilio API, Google Gemini, Assembly AI, & MongoDB, Hosted on Vercel | This is a submission for Twilio Challenge v24.06.12 Welcome to Chappy, your versatile chat... | 0 | 2024-06-24T00:08:58 | https://dev.to/ketanrajpal/chappy-your-friendly-and-quirky-chat-buddy-14pl | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
Welcome to Chappy, your versatile chat companion! You can access Chappy through your web browser or directly via WhatsApp, enjoying seamless synchronization from WhatsApp to WebApp.
Chappy is a true multitasker. Not only can it ... | ketanrajpal |
1,900,589 | Bye Copilot - How to Create a Local AI Coding Assistant for Free | TLDR: Create your own local AI Coding Assistant that integrates with VS Code. AI Coding... | 0 | 2024-06-26T23:22:03 | https://www.davegray.codes/posts/bye-copilot-how-to-create-a-local-ai-coding-assistant-for-free | ai, githubcopilot, codingassistant, codeassistant | ---
title: Bye Copilot - How to Create a Local AI Coding Assistant for Free
published: true
date: 2024-06-24 00:00:00 UTC
tags: ai,copilot,codingassistant,codeassistant
canonical_url: https://www.davegray.codes/posts/bye-copilot-how-to-create-a-local-ai-coding-assistant-for-free
cover_image: https://raw.githubuserconte... | gitdagray |
1,898,130 | Iteration - a Stream Generator for Recursive Minds | The Iterators For anyone having been in programming a couple of years, chances are you've... | 0 | 2024-06-23T23:54:23 | https://dev.to/fluentfuture/iteration-a-stream-generator-m75 | java, stream, functional | ## The Iterators
For anyone having been in programming a couple of years, chances are you've run into an interview question or an assignment like [iterator for binary tree](https://stackoverflow.com/questions/12850889/in-order-iterator-for-binary-tree).
There are variations like for the "pre-order", "post-order" or "... | fluentfuture |
1,898,229 | AI Journal App with WhatsApp Integration | This is a submission for Twilio Challenge v24.06.12 What I Built A mobile app that uses... | 0 | 2024-06-23T23:41:06 | https://dev.to/preveenraj/journal-app-with-ai-capabilities-and-whatsapp-integration-23dh | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
A mobile app that uses user-provided text, emojis and photos through WhatsApp to generate personalised daily journals. Journals are illustrated with user-uploaded photos or AI-generated images based on the user's ... | preveenraj |
1,898,230 | Join Me in Building an Exciting Tic-Tac-Toe Web App! | Hi everyone, I'm developing a React-based Tic-Tac-Toe web app and looking for passionate graphic... | 0 | 2024-06-23T23:36:24 | https://dev.to/mstechgeek/join-me-in-building-an-exciting-tic-tac-toe-web-app-3m0o | Hi everyone,
I'm developing a **React-based Tic-Tac-Toe web app** and looking for passionate graphic designers and front-end developers with JavaScript and React experience to join me!
### Current Features:
- 🎮 Basic game logic for 3x3 Tic-Tac-Toe
- 🌐 Progressive Web App (PWA) implementation
- 🔊 Sound effects
- 🏆... | mstechgeek | |
1,897,385 | ⏱️ Mobitag Go Hackathon 2024-06-22 week-end 🤓 | 📢 Context Last week, optnc published the following post : ... | 27,823 | 2024-06-23T23:25:19 | https://dev.to/adriens/mobitag-go-hackathon-2024-06-22-week-end-2n16 | api, hackathon, showdev, go | ## 📢 Context
Last week, [optnc](https://dev.to/optnc) published the following post :
{% embed https://dev.to/optnc/mobitagnc-25-ans-plus-tard-des-sms-en-saas-via-apigee-2h9e %}
👉 This new blog post is all about **the inspiration it brought me the very next days.**
## 🎯 Week-end Hackathon pitch
I really love to ... | adriens |
1,892,580 | How to Build a Vue App To Show Your GitHub Repositories | Less than a year ago, I was a novice in programming with no background in computer science which is... | 0 | 2024-06-23T23:19:35 | https://dev.to/sheisbukki/how-to-build-a-vue-app-to-show-your-github-repositories-jef | vue, javascript, ionic, github | Less than a year ago, I was a novice in programming with no background in computer science which is why building this app was challenging but fulfilling. So, if you’re a beginner like me and everything seems overwhelming, I hope this motivates you to keep reading, practising, and building!
Prerequisites for building a... | sheisbukki |
1,897,462 | Building BellyFull: A Meal Suggestion Bot to Help Satisfy Your Cravings | This is a submission for the Twilio Challenge What I Built Ever had a craving for a... | 0 | 2024-06-23T23:15:07 | https://dev.to/sands_44/building-bellyfull-a-meal-suggestion-bot-to-help-satisfy-your-cravings-2oii | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
Ever had a craving for a particular meal, but had no idea where to find it or who sells it at a reasonable price?
Where I'm from, it's easy to find meals such as pizza, or maybe a burger and french fries, but harder t... | sands_44 |
1,889,943 | Learning about CustomPaint in Flutter | Something like a week ago I started to research about "how I can manually draw things in the Flutter... | 0 | 2024-06-23T23:09:54 | https://dev.to/josuestuff/learning-about-custompaint-in-flutter-4j69 | flutter, ui, beginners, learning | Something like a week ago I started to research about "how I can manually draw things in the Flutter canvas" and found information about `CustomPaint` and `CustomPainter`, which seems to be the main Flutter mechanism to allow devs draw specific things.
I'm not sure if there're more options or alternatives to achieve t... | josuestuff |
1,887,878 | FastAPI for Data Applications: Dockerizing and Scaling Your API on Kubernetes. Part II | Hey there, data enthusiasts and API aficionados! 🎉 If you joined us for the first part of this... | 27,835 | 2024-06-23T23:05:36 | https://dev.to/felipe_de_godoy/fastapi-for-data-applications-dockerizing-and-scaling-your-api-part-ii-4a53 | llmops, fastapi, eks, docker | Hey there, data enthusiasts and API aficionados! 🎉 If you joined us for the first part of this series, you already have your FastAPI application running smoothly on your local machine. Today, we're going to elevate that setup by deploying it to Amazon's Elastic Kubernetes Service (EKS). Get ready to scale those RESTfu... | felipe_de_godoy |
1,898,168 | AI Taxi Dispatch Operator | This is a submission for Twilio Challenge v24.06.12 What I Built Optimizing Business... | 0 | 2024-06-23T22:57:27 | https://dev.to/alaba_mustapha/ai-taxi-dispatch-operator-2kop | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
<!-- Share an overview about your project. -->
Optimizing Business Efficiency with AI Operators
Many businesses spend hours daily taking orders over the phone from prospective clients, leading to less productive e... | alaba_mustapha |
1,896,348 | Simplify Phone Screening with Twilio and AI Automation | This is a submission for the Twilio Challenge What I Built I explored several ideas for... | 0 | 2024-06-23T22:52:58 | https://dev.to/bibekkakati/simplify-phone-screening-with-twilio-and-ai-automation-3e8e | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
I explored several ideas for this challenge and did some research. Then, I found a LinkedIn post about how recruiters handle phone interviews for screening and the problems they face, like coordinating schedules betwee... | bibekkakati |
1,898,166 | A Journey into Microservices — Part 1 | Microservices have revolutionized how we build and manage software, but to fully appreciate their... | 0 | 2024-06-23T22:49:36 | https://dev.to/gervaisamoah/a-journey-into-microservices-part-1-4gck | microservices, architecture, softwaredevelopment, softwareengineering | Microservices have revolutionized how we build and manage software, but to fully appreciate their impact, we need to look at where we started and how we got here.
## The Journey from Monoliths to Microservices
### The Monolithic Era
In the beginning, there were monolithic applications. These were large, single-tiered... | gervaisamoah |
1,887,777 | The Magical World of Machine Learning at Hogwarts (Part #1) | 🌟✨ Welcome, young wizards and witches, to the mystical realm of machine learning! I am Professor Leo,... | 0 | 2024-06-23T22:43:23 | https://dev.to/gerryleonugroho/the-magical-world-of-machine-learning-at-hogwarts-part-1-2jp4 | machinelearning, ai, algorithms, beginners | 🌟✨ Welcome, young **wizards and witches**, to the **mystical realm** of **machine learning**! I am Professor Leo, a close friend of the great **Albus Dumbledore** and your guide on this magical journey through the wonders of machine learning. My son, **Gemika Haziq Nugroho**, is just like you — a budding wizard full o... | gerryleonugroho |
1,898,163 | Ieiejdj | Why does the chicken cross the road cause it had to get the other side ha ha ha | 0 | 2024-06-23T22:42:37 | https://dev.to/koesterslisahotmailcom/ieiejdj-191k | Why does the chicken cross the road cause it had to get the other side ha ha ha | koesterslisahotmailcom | |
1,898,158 | Sometimes all we need is a good safe word! Even ChatGPT! | Using Safe Words with ChatGPT to Solve Complex Problems: A Must-Have Technique When... | 0 | 2024-06-23T22:27:49 | https://dev.to/mbround18/sometimes-all-we-need-is-a-good-safe-word-even-chatgpt-2e82 | chatgpt, rust, devops, productivity | ## Using Safe Words with ChatGPT to Solve Complex Problems: A Must-Have Technique
When dealing with complex problems, communication clarity is crucial. In my recent experience, I found that using safe words with ChatGPT significantly enhanced my problem-solving process. Let me share how this simple technique can be a ... | mbround18 |
1,898,157 | Enhance Your React Applications with cards-slider-react-lib : A Feature-Rich Card Slider Library | cards-slider-react-lib: A Customizable and Responsive React Slider Component The... | 0 | 2024-06-23T22:26:08 | https://dev.to/victor_ajadi_21b5913f79f6/enhance-your-react-applications-with-cards-slider-react-lib-a-feature-rich-card-slider-library-m6m | webdev, javascript, beginners, programming | **cards-slider-react-lib: A Customizable and Responsive React Slider Component**
The `card-slider-react-lib` library provides a powerful and versatile React component for creating interactive and visually appealing card sliders in your web applications. This article delves into the features, usage, and customization o... | victor_ajadi_21b5913f79f6 |
1,898,149 | PNG vs AVIF: Understanding the Differences and Usage | What Are the Differences Between PNG and AVIF? PNG (Portable Network... | 0 | 2024-06-23T22:01:07 | https://dev.to/msmith99994/png-vs-avif-understanding-the-differences-and-usage-2j00 | ### What Are the Differences Between PNG and AVIF?
### PNG (Portable Network Graphics)
PNG is a raster-graphics file format that supports lossless data compression. It was created as an improved, non-patented replacement for GIF (Graphics Interchange Format).
Here are some key characteristics of PNG:
**- Lossless C... | msmith99994 | |
1,854,427 | Dev: Web | A Web Developer is a professional responsible for designing, developing, and maintaining websites and... | 27,373 | 2024-06-23T22:00:00 | https://dev.to/r4nd3l/dev-web-4f7k | webdev, developer | A **Web Developer** is a professional responsible for designing, developing, and maintaining websites and web applications. Here's a detailed description of the role:
1. **Front-End Development:**
- Web Developers focus on front-end development, which involves creating the user interface, layout, and visual element... | r4nd3l |
1,893,030 | AI-Powered Loyalty Rewards Assistant: Amazon Bedrock Agent in Action | Generative AI is no longer a buzzword. It has become an integral part of our everyday conversations.... | 0 | 2024-06-23T21:48:30 | https://dev.to/girishmukim/generative-ai-assistant-for-loyalty-reward-system-using-amazon-bedrock-knowledge-bases-agent-1670 | aws, tutorial, ai, api | Generative AI is no longer a buzzword. It has become an integral part of our everyday conversations. Typically, new technologies spark excitement within the technical circle; however, Generative AI transcended that boundary and quickly became mainstream. Enterprises are also exploring its practical applications from a ... | girishmukim |
1,898,147 | The Growing Importance of Prompt Engineering | Introduction In the rapidly evolving landscape of artificial intelligence (AI), the role... | 27,673 | 2024-06-23T21:48:22 | https://dev.to/rapidinnovation/the-growing-importance-of-prompt-engineering-42df | ## Introduction
In the rapidly evolving landscape of artificial intelligence (AI), the role of
prompt engineering has emerged as a crucial element in harnessing the full
potential of AI technologies, particularly in the realm of language models. As
AI continues to integrate into various sectors, the ability to effecti... | rapidinnovation | |
1,894,033 | How to create LazyColumn with drag and drop elements in Jetpack Compose. Part 1. | Hello there! The subject of drag and drop elements isn't new and you can find many decisions of this... | 27,782 | 2024-06-23T21:45:47 | https://dev.to/mardsoul/how-to-create-lazycolumn-with-drag-and-drop-elements-in-jetpack-compose-part-1-4bn5 | android, compose | Hello there! The subject of drag and drop elements isn't new and you can find many decisions of this problem in the Internet. But the decision isn't so obviously like a creating drag and drop lists by RecyclerView. And I suppose my step-by-step guide will be useful.
#### Sources:
- [Make it Easy: How to implement Dra... | mardsoul |
1,897,915 | How to Create a Dark Mode in Figma and Not Die Trying | Alright, alright, you've been working on your design and prototyping in Figma for months, and due to... | 0 | 2024-06-23T21:42:41 | https://dev.to/amanda_montero/how-to-create-a-dark-mode-in-figma-and-not-die-trying-20pm | figma, uidesign, uxdesign, frontend |
Alright, alright, you've been working on your design and prototyping in Figma for months, and due to the nature of your project, a dark mode wasn't planned from the beginning. It's okay, it happens to all of us sometimes. Come on, you already had enough problems on your plate.
Don't worry, it's time to buckle up and ... | amanda_montero |
1,898,144 | Advanced Text Search Mastery with Apache Lucene: A Full Guide | Apache Lucene is an esteemed search library celebrated for its advanced text search capabilities. It... | 0 | 2024-06-23T21:31:29 | https://devtoys.io/2023/10/29/advanced-text-search-mastery-with-apache-lucene-a-full-guide/ | tutorial, backend, devtoys, java | ---
canonical_url: https://devtoys.io/2023/10/29/advanced-text-search-mastery-with-apache-lucene-a-full-guide/
---
Apache Lucene is an esteemed search library celebrated for its advanced text search capabilities. It is a vital resource for developers, data analysts, and SEO professionals, providing a robust query synt... | 3a5abi |
1,898,143 | AI is just excited to be here | Any software developer worth their salt can tell AI is just an excited pair programmer. In the early... | 0 | 2024-06-23T21:24:42 | https://dev.to/maurijhn/ai-is-just-excited-to-be-here-f10 | ai, computerscience | Any software developer worth their salt can tell AI is just an excited pair programmer.
In the early stages of ChatGPT, everybody was luring me into using the chatbot to help me as a software developer. Everything I heard about it was "heaven-like". When I started using it, I did feel its versatility for developers; e... | maurijhn |
1,898,129 | Enhancing Technical Skills by Writing: Learn in Public | Overview In this article, I will share the reasons why I write technical blog posts and... | 0 | 2024-06-23T21:20:03 | https://dev.to/godinhojoao/enhancing-technical-skills-by-writing-learn-in-public-42b7 | beginners, writing | ## Overview
- In this article, I will share the reasons why I write technical blog posts and my approach. I hope this will motivate and guide you to start writing about topics you are studying or already familiar with!
## Table of Contents
- [Reasons why I write technical blog posts](#reasons-why-i-write-technical-bl... | godinhojoao |
1,898,128 | [NestJS] API DockerHub + IA + PASETO (Local) | Proyecto en NestJS usando los endpoints de DockerHub (para buscar repositorios), utilizando... | 0 | 2024-06-23T21:13:43 | https://dev.to/jkdevarg/nestjs-api-dockerhub-ia-paseto-local-2n4n | nestjs, javascript, api, ai | Proyecto en NestJS usando los endpoints de DockerHub (para buscar repositorios), utilizando autenticación con Paseto y con la ayuda de IA (Geminis).
**Introducción:**
Es un proyecto que arme estando aburrido, mediante los endpoints de DockerHub obtengo datos de los repositorios, con ellos y usando IA Geminis creo un ... | jkdevarg |
1,898,127 | We were tired of bureaucracy, so we built an opensource repo for the best guides | Today we are launching Tramitit, a shared database on getting all those poor-UX local procedures done... | 0 | 2024-06-23T21:09:11 | https://ricardobatista.me/posts/we-were-tired-of-bureaucracy/ | Today we are launching [Tramitit](https://tramitit.com/), a shared database on getting all those poor-UX local procedures done in a much simpler way!
- **How it works**: The community provides detailed walkthroughs on every possible bureaucratic process you might go through.
- **For the community by the community**: T... | rbatista19 | |
1,898,125 | Custom Emails with Supertokens, Resend, and React Email | At Cerebral Valley we use Supertokens for authentication into our platform. Supertokens comes with a... | 0 | 2024-06-23T21:05:59 | https://dev.to/iporollo/custom-emails-with-supertokens-resend-and-react-email-2mi1 | At [Cerebral Valley](https://cerebralvalley.ai) we use [Supertokens](https://supertokens.com/) for authentication into our platform.
Supertokens comes with a default email template / design that is sent to users upon account creation, email confirmation, and other actions.
We wanted to customize emails sent out from... | iporollo | |
1,898,124 | Small Forms Bundle | I've just released small/forms-bundle 1.0.0 and small/forms 1.1.2. small/forms provide input data... | 0 | 2024-06-23T21:03:31 | https://dev.to/sebk69/small-forms-bundle-3dc5 | php, symfony, showdev | I've just released small/forms-bundle 1.0.0 and small/forms 1.1.2.
small/forms provide input data validation and transformation.
small/forms-bundle implement it in Symfony normalizer.
git : [https://git.small-project.dev/lib/small-forms-bundle](https://git.small-project.dev/lib/small-forms-bundle)
packagist : [http... | sebk69 |
1,898,123 | "Traverse" in Computer Science | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T21:03:29 | https://dev.to/snipertomcat/traverse-in-computer-science-1mh9 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
The definition of the verb 'traverse' is to "travel across or through", and in the context of computer science simply refers to the read, write, or execution upon the members of a comp... | snipertomcat |
1,898,122 | "Traverse" in Computer Science | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T21:03:23 | https://dev.to/snipertomcat/traverse-in-computer-science-24lj | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
The definition of the verb 'traverse' is to "travel across or through", and in the context of computer science simply refers to the read, write, or execution upon the members of a comp... | snipertomcat |
1,898,118 | Wie man Wordpress lokal mit docker compose aufsetzt | Wieso so? Um eine reproduzierbare Entwicklungs - Umgebung zu haben, ist es gut das... | 0 | 2024-06-23T20:55:00 | https://dev.to/rubenvoss/wie-man-wordpress-lokal-mit-docker-compose-aufsetzt-3m33 | ## Wieso so?
Um eine reproduzierbare Entwicklungs - Umgebung zu haben, ist es gut das Aufsetzen dieser Umgebung automatisch tun zu können. Dazu kann man docker compose benutzen. Hier zeige Ich euch ein docker-compose.yml, welches ein guter Startpunkt ist für eine reproduzierbare Entwicklungsumgebung.
Wir Benutzen hier ... | rubenvoss | |
1,896,867 | WordPress Classic vs. Block Themes | WordPress, powering over 40% of the web, has seen significant transformations in its theme... | 0 | 2024-06-23T20:52:13 | https://dev.to/mikevarenek/wordpress-classic-vs-block-themes-4pi1 | webdev, wordpress, beginners | WordPress, powering over 40% of the web, has seen significant transformations in its theme development approach. From the early days of Classic themes to the revolutionary Block themes introduced with Full Site Editing (FSE), WordPress has continuously adapted to meet the needs of developers and users alike. As we stan... | mikevarenek |
1,898,117 | My 2024 Software Development Goals Update | It's been 170 days since I set my 2024 resolutions. It's been tough but the grind is worth it. At... | 0 | 2024-06-23T20:52:10 | https://melbite.com/melbite/My-2024-Software-Development-Goals-Update | career, programming, productivity, beginners | It's been 170 days since I set [my 2024 resolutions](https://melbite.com/Evans-Nyamai/Navigating-2024-with-Software-Development,-Tech-Training,-and-Open-Source-Aspirations). It's been tough but the grind is worth it.
At the beginning of the year, I promised self-growth, this includes:
- Growing [melbite](https://me... | evansifyke |
1,898,115 | Exploring the Power of CSS Variables | CSS variables, also known as custom properties, are a powerful feature that can significantly enhance... | 0 | 2024-06-23T20:49:09 | https://dev.to/kevin_asogwa/exploring-the-power-of-css-variables-1hn4 | webdev, css | CSS variables, also known as custom properties, are a powerful feature that can significantly enhance the way you write and manage your stylesheets. They allow you to store values in one place and reuse them throughout your CSS, making your code cleaner, more maintainable, and easier to read. Let's dive into some inter... | kevin_asogwa |
1,896,659 | Vue.js | Introduction Vue.js is a JavaScript framework used for creating user interfaces. Using... | 0 | 2024-06-23T20:40:45 | https://dev.to/allyn/vuejs-ffg | vue, javascript, beginners | ## Introduction
Vue.js is a JavaScript framework used for creating user interfaces. Using Vue.js, you can create components to efficiently build your program and enhance HTML with the template syntax provided that reflects the state of your component. When your state changes, Vue will automatically update the DOM upon ... | allyn |
1,898,113 | Deploying Django in Production. | This 5-step tutorial will guide you through deploying a Django application using Gunicorn behind a... | 0 | 2024-06-23T20:40:38 | https://dev.to/wassef911/deploying-django-in-production-b1p | django, nginx, webdev, python |

This 5-step tutorial will guide you through deploying a Django application using Gunicorn behind a reverse proxy (such as Nginx).
Its important to note that this greatly depends on the needs of your project, but ... | wassef911 |
1,898,102 | Introducing the Schengen Area Calculator: Plan Your European Travels Seamlessly | Are you planning a trip to Europe and worried about the 90/180-day Schengen visa rule? Meet the... | 0 | 2024-06-23T20:19:22 | https://dev.to/dany_trakhtenberg/introducing-the-schengen-area-calculator-plan-your-european-travels-seamlessly-398k | nextjs, react, tooling, firebase | Are you planning a trip to Europe and worried about the 90/180-day Schengen visa rule? Meet the [Schengen Area Calculator](https://schengenareacalc.web.app) – your ultimate tool for tracking stays and ensuring compliance with the Schengen visa regulations.
{% embed https://www.youtube.com/embed/TNb4ESWQzTQ?si=GuN3fdYY... | dany_trakhtenberg |
1,899,086 | Headlamp - k8s Lens open source alternative | Since Lens is not open source, I tried out monokle, octant, k9s, and headlamp1. Among them,... | 0 | 2024-06-27T03:16:28 | https://avilpage.com/2024/06/headlamp-k8s-lens-open-source-alternative.html | devops, kubernetes | ---
title: Headlamp - k8s Lens open source alternative
published: true
date: 2024-06-23 20:18:02 UTC
tags: devops,kubernetes
canonical_url: https://avilpage.com/2024/06/headlamp-k8s-lens-open-source-alternative.html
---
. You can practice your Rust skills in LabEx.
In this lab, we will learn about writing tests in Rust using attributes, macros, and assertions.
## How to Write Tests
Tests are Rust functions tha... | labby |
1,898,098 | AI is really here? | I've recently seen a craze about AI. Every application promises integrated AI. But for me, many are... | 0 | 2024-06-23T20:06:16 | https://dev.to/miplle_player1/ai-is-realy-here-1b62 | I've recently seen a craze about AI. Every application promises integrated AI. But for me, many are simply using it as marketing strategy. I tried using Jira, and it has an AI feature that supposedly just requires me to describe what I need in the search. But instead, I still have to set up the query filter in the same... | miplle_player1 | |
1,893,891 | Battleship Game in RUST | Hey! Amir here! 🌟 First of all: Thank you so much for the incredible interaction I had had when I... | 0 | 2024-06-23T20:03:38 | https://dev.to/bekbrace/battleship-game-in-rust-43ie | rust, gamedev, cli, programming |
Hey! Amir here! 🌟
First of all: Thank you so much for the incredible interaction I had had when I shared my Rust Full Course for Beginners last month.
I'm glad to know that it was helpful to you, even if just a bit.
Every opportunity to provide value and help you learn is something I cherish deeply.
I'll always b... | bekbrace |
1,898,096 | "Med-AI: Transforming Healthcare with AI Innovations" | This is a submission for Twilio Challenge v24.06.12 What I Built Med-AI is an innovative... | 0 | 2024-06-23T20:02:38 | https://dev.to/jyotika6221/med-ai-transforming-healthcare-with-ai-innovations-2e12 | twiliochallenge, ai, twilio, devchallenge | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
Med-AI is an innovative AI-driven healthcare application that harnesses artificial intelligence to enhance medical diagnostics, treatment planning, and healthcare delivery. It focuses on improving patient care an... | jyotika6221 |
1,898,091 | Concurrency and Parallelism in Ruby | Concurrency and Parallelism in Ruby In programming, concurrency and parallelism are... | 0 | 2024-06-23T19:46:42 | https://dev.to/francescoagati/concurrency-and-parallelism-in-ruby-1b9p | ruby, concurrency, parallelism, threads | ### Concurrency and Parallelism in Ruby
In programming, concurrency and parallelism are essential techniques for improving the performance and efficiency of code. Ruby, a popular programming language, offers various tools to handle these concepts. Let's explore these techniques using a simple example.
#### Synchronou... | francescoagati |
1,896,839 | Mood-Based Music: A WhatsApp Chatbot That Curates Personalized Playlists | This is a submission for the Twilio Challenge What I Built I built a WhatsApp chatbot... | 0 | 2024-06-23T20:00:00 | https://dev.to/irensaltali/mood-based-music-a-whatsapp-chatbot-that-curates-personalized-playlists-n51 | devchallenge, ai, twilio, twiliochallenge | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
I built a WhatsApp chatbot using Twilio that generates a personalized playlist of 5 songs based on the user's current mood. When a user sends a message to +1 (856) 975-0130 starting with "Hi", the bot prompts them to s... | irensaltali |
1,898,094 | Facebook System Design Frontend | A post by Bidisha Das | 0 | 2024-06-23T19:58:54 | https://dev.to/officialbidisha/facebook-system-design-frontend-3i0j |
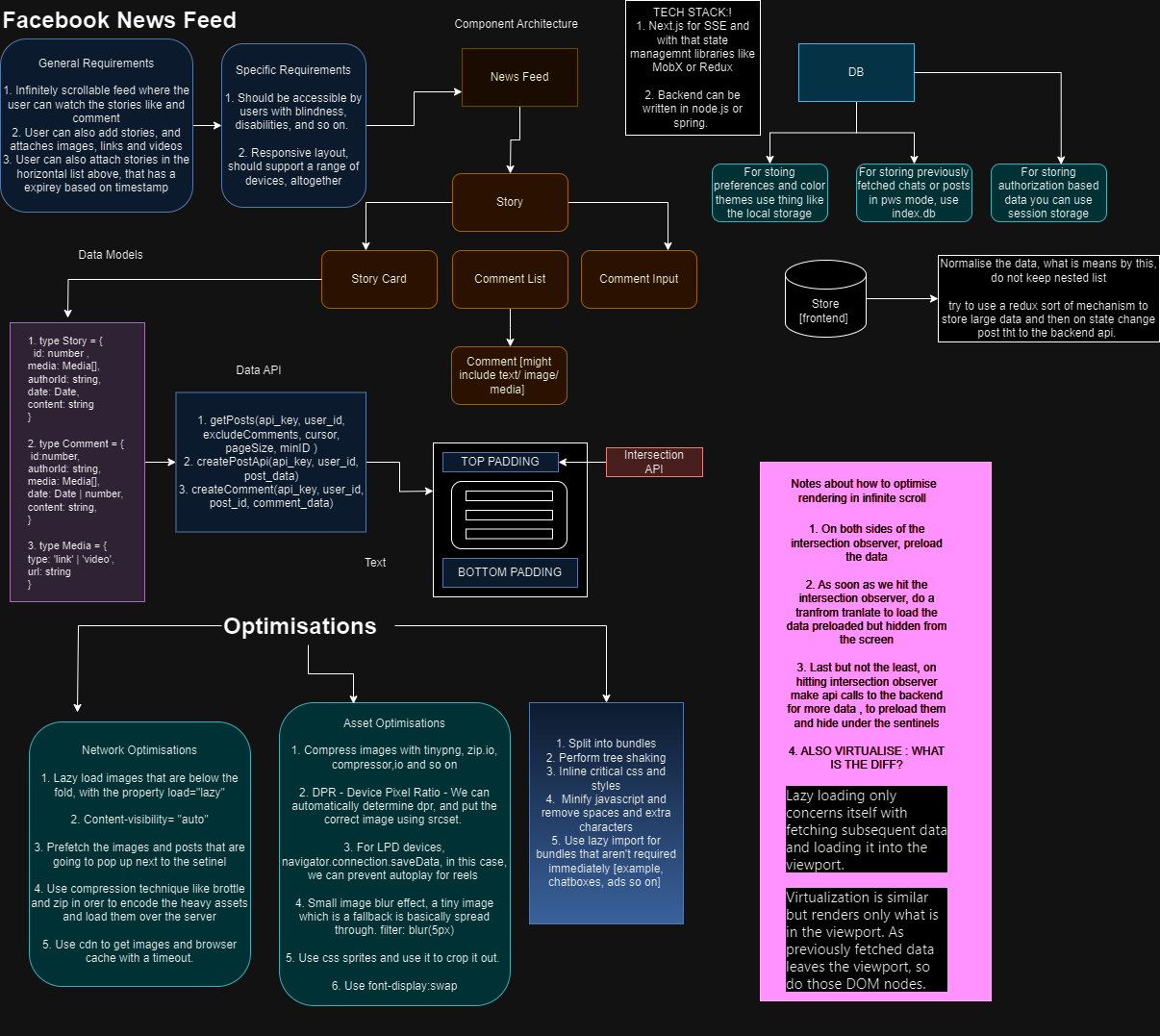
| officialbidisha | |
1,898,093 | Quick tip: Using picoGPT in the SingleStore portal | Abstract picoGPT is a simplified and minimal implementation of the GPT model. It... | 0 | 2024-06-23T19:56:06 | https://dev.to/singlestore/quick-tip-using-picogpt-in-the-singlestore-portal-24lf | singlestoredb, gpt2, picogpt | ## Abstract
[picoGPT](https://github.com/jaymody/picoGPT) is a simplified and minimal implementation of the GPT model. It demonstrates the core principles of the GPT architecture without the requirement for a full-scale implementation. Written in Python and consisting of a small quantity of code, picoGPT doesn't implem... | veryfatboy |
1,898,092 | The History of Large Language Models (LLM) | Large Language Models (LLMs) have evolved from simple N-Gram models to sophisticated transformers... | 0 | 2024-06-23T19:48:45 | https://dev.to/sgaglione/the-history-of-large-language-models-llm-82f | llm, python, ai | _Large Language Models (LLMs) have evolved from simple N-Gram models to sophisticated transformers like GPT-3, revolutionizing natural language processing. This article traces their development, highlighting key advancements such as Recurrent Neural Networks (RNNs) and the Transformer model, with practical Python examp... | sgaglione |
1,893,622 | Creating a Material Spinner with Pure and Simple CSS | Everyone has seen it hundreds, if not thousands of times, and it seems like this loader is very... | 0 | 2024-06-23T19:47:28 | https://dev.to/alekseiberezkin/creating-a-material-spinner-with-pure-and-simple-css-1b60 | webdev, css, material | {%codepen https://codepen.io/wvtyubnf-the-selector/pen/MWpGbre %}
Everyone has seen it hundreds, if not thousands of times, and it seems like this loader is very easy and natural. However, if you try to create it from scratch, you'll find it surprisingly challenging. The first problem is simply understanding the motio... | alekseiberezkin |
1,898,090 | Computer science | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T19:30:45 | https://dev.to/wafaberr/computer-science-1eaa | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Computer science is the study of computers, including their theoretical foundations, algorithms, hardware, and s... | wafaberr |
1,898,088 | Ondoarding new developers | Hey Devs! In our previous discussion, we highlighted the importance of a great onboarding process... | 0 | 2024-06-23T19:29:48 | https://dev.to/jwtiller_c47bdfa134adf302/ondoarding-new-developers-kmf | dotnet, onboarding | Hey Devs!
In our previous discussion, we highlighted the importance of a great onboarding process and shared some of your best experiences and practices. Today, let's delve deeper into what makes an onboarding process truly exceptional and how tools like [RazorSharp](https://razorsharp.dev) can enhance this crucial ph... | jwtiller_c47bdfa134adf302 |
1,898,087 | Mastering Debouncing in JavaScript: Improve Performance with Ease | Debouncing is a simple yet powerful technique in JavaScript that helps optimize performance by... | 0 | 2024-06-23T19:27:39 | https://dev.to/dev_habib_nuhu/mastering-debouncing-in-javascript-improve-performance-with-ease-1n4p | webdev, javascript, programming, react |

Debouncing is a simple yet powerful technique in JavaScript that helps optimize performance by limiting the rate at which a function is executed. This is especially useful for handling events like window resizing,... | dev_habib_nuhu |
1,898,086 | AI assistant/chatbot for use/support | This is a submission for the Twilio Challenge What I Built I built an SMS/whatsapp/call... | 0 | 2024-06-23T19:25:14 | https://dev.to/tophepzz1/ai-assistantchatbot-for-usesupport-jei | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
<!-- Share an overview about your project. -->
I built an SMS/whatsapp/call Assistant that you can chat with and it will still retain context, a conversational AI.
it keeps an history of the conversation so in as much ... | tophepzz1 |
1,898,085 | Elevate Your Dining Experience with Padded Dining Chairs | Description Transform your dining area into a haven of comfort and style with our exquisite [padded... | 0 | 2024-06-23T19:22:17 | https://dev.to/mani_dia_8c53345aa4e95886/elevate-your-dining-experience-with-padded-dining-chairs-1ojl | Description
Transform your dining area into a haven of comfort and style with our exquisite [padded dining chairs] https://www.elegantcollections.com.au/products/copy-of-set-of-2-aleah-velvet-black-rubberwood-upholstered-dining-chairs-tufted-back. These chairs are not just a seat but an experience, offering unparallel... | mani_dia_8c53345aa4e95886 | |
1,897,934 | STR Fasa 3 Tarikh dan Jumlah | Pengenalan STR Fasa 3 Sumbangan Tunai Rahmah (STR Fasa 3) untuk rakyat Malaysia telah... | 0 | 2024-06-23T16:23:02 | https://dev.to/str2024/str-fasa-3-5fie | ## Pengenalan STR Fasa 3
Sumbangan Tunai Rahmah ([STR Fasa 3](https://semakanstr.com/str-fasa-3/)) untuk rakyat Malaysia telah diumumkan dan dijangka akan diagihkan tidak lama lagi. Berikut adalah maklumat terkini:
STR Fasa 3 adalah sebahagian daripada inisiatif Payung Rahmah yang bertujuan untuk membantu golongan ya... | str2024 | |
1,897,763 | Importance of Soft Skills for Job Interviews | Most of the time, while preparing for job interviews, most candidates try to demonstrate their... | 0 | 2024-06-23T19:21:07 | https://dev.to/m_midas/the-importance-of-soft-skills-5 | webdev, beginners, programming, career | Most of the time, while preparing for job interviews, most candidates try to demonstrate their technical abilities, or hard skills. Hard skills are no doubt essential, but soft skills play an equally important role and can literally make or break an opportunity. Learning and working on soft skills will not only help in... | m_midas |
1,898,059 | A Comprehensive Guide to Effective Backlink Strategies | Introduction Embarking on an SEO journey can be both exciting and challenging. Backlinks... | 0 | 2024-06-23T19:18:56 | https://dev.to/gohil1401/a-comprehensive-guide-to-effective-backlink-strategies-36mm | webdev, beginners, tutorial, seo |
## Introduction
Embarking on an SEO journey can be both exciting and challenging. Backlinks are a crucial component of SEO, helping to improve your website's authority and search engine ranking. In this comprehensive guide, we'll explore various backlink strategies, tools like the Moz Bar Chrome extension, and differ... | gohil1401 |
1,898,036 | Throttling in JS | Throttling Throttling in JavaScript is a technique used to control the rate at which a... | 0 | 2024-06-23T19:16:10 | https://dev.to/margish288/throttling-in-js-j44 | throttling, javascript, webdev, learndev | ## Throttling
-
**Throttling** in JavaScript is a technique used to control the rate at which a function is executed.
- This is especially useful in scenarios where a function could be called frequently, such as during **scroll events**, **window resizing**, or **handling user input** in real-time.
- By throttlin... | margish288 |
1,898,058 | Happy to be a part | Just Singned up and and excited to be part of this community. Im currently working as full stack web... | 0 | 2024-06-23T19:15:49 | https://dev.to/shadabfalak/happy-to-be-a-part-4bna | Just Singned up and and excited to be part of this community. Im currently working as full stack web developer and recently made website [77Links](https://77links.com/).
Im also interested in developing Mobile Apps. My colllegyes introduced me Flutter framework so im here to follow flutter giants to learn more this new... | shadabfalak | |
1,898,057 | An Intro to blockchain | Blockchain Blockchain is a distributed immutable ledger that is completely transparent. Let's break... | 0 | 2024-06-23T19:14:48 | https://dev.to/arsh_the_coder/an-intro-to-blockchain-32h1 | **Blockchain**
Blockchain is a distributed immutable ledger that is completely transparent. Let's break that down. Distributed means it is not available on a single machine, hence not centrally controlled. Immutable refers to the fact that it can't be changed (we'll see that later). Ledger means it contains a record o... | arsh_the_coder | |
1,898,056 | code error need help plz | <!DOCTYPE html> My Website - Help Needed! <!-- Oops, forgot to... | 0 | 2024-06-23T19:13:02 | https://dev.to/shadabfalak/code-error-need-help-plz-2fdd | <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>My Website - Help Needed!</title>
<link rel="stylesheet" href="styles.css">
<script src="script.js"></script>
<!-- Oops, forgot to close the head tag -->
<body>
<header>
<h1>Welcome to My Website</h1>
<!-- Navb... | shadabfalak | |
1,898,055 | 18 dicas para se destacar como engenheiro de software | Postado originalmente no Dev na Gringa Substack. Quer receber futuros artigos no seu e-mail? Assine... | 0 | 2024-06-23T19:12:51 | https://dev.to/lucasheriques/18-dicas-para-se-destacar-como-engenheiro-de-software-junior-4857 | braziliandevs, career, beginners | Postado originalmente no [Dev na Gringa Substack](https://devnagringa.substack.com/p/18-dicas-para-se-destacar-na-carreira?utm_source=devto). Quer receber futuros artigos no seu e-mail? [Assine gratuitamente aqui](https://devnagringa.substack.com/subscribe?utm_source=devto).
---
Nesse artigo, vou falar sobre dicas qu... | lucasheriques |
1,898,054 | Marquage vehicule Essonne | Le marquage des véhicules est une technique publicitaire de plus en plus prisée par les entreprises... | 0 | 2024-06-23T19:12:31 | https://dev.to/esrcompany08/marquage-vehicule-essonne-3nfc | Le marquage des véhicules est une technique publicitaire de plus en plus prisée par les entreprises cherchant à accroître leur visibilité et à renforcer leur image de marque. À Paris et en Essonne, cette méthode offre une opportunité unique de toucher un large public grâce à une publicité mobile. Cet article explore le... | esrcompany08 | |
1,898,053 | Magical Stories for All: Journey into Fantasy with Our StoryTeller Bot! | This is a submission for Twilio Challenge v24.06.12 Ever wanted to go back to your childhood, when... | 0 | 2024-06-23T19:11:43 | https://dev.to/shubrah_gupta_107/get-enchanted-by-the-good-old-storyteller-5g6h | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
Ever wanted to go back to your childhood, when grandma told you stories about animals and birds, adding her own little twists while you sat in wonder about what would happen next? Ever felt bored and wished someone would read you... | shubrah_gupta_107 |
1,898,052 | Your personal fitness trainer at your service! | This is a submission for Twilio Challenge v24.06.12 I used to be hesitant about fitness, worrying... | 0 | 2024-06-23T19:11:41 | https://dev.to/shubrah_gupta_107/your-personal-fitness-trainer-at-your-service-4144 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
I used to be hesitant about fitness, worrying about how much effort it would take and what might happen if I did an exercise wrong. I thought it would be too much work, but then I just went for it. Guess what? It's awesome! Fitne... | shubrah_gupta_107 |
1,898,050 | Tired of Messy Code?🥴 | Want to Make Your Code Look Pretty and Well-Organized? Try the 𝗣𝗿𝗲𝘁𝘁𝗶𝗲𝗿 extension in VS Code!💡 𝗪𝗵𝗮𝘁... | 0 | 2024-06-23T19:10:56 | https://dev.to/aurnab990/tired-of-messy-code-36h0 | vscode, prettier, vscodextention, vscodesettings | Want to Make Your Code Look Pretty and Well-Organized?
Try the 𝗣𝗿𝗲𝘁𝘁𝗶𝗲𝗿 extension in VS Code!💡
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗣𝗿𝗲𝘁𝘁𝗶𝗲𝗿?
↳ Prettier is a tool that makes your code look neat and consistent.
↳ It works by checking your code and fixing its style according to set rules.
↳ Prettier supports many programmi... | aurnab990 |
1,892,028 | Understanding Dispose and Garbage Collection in .NET 🗑️ | Dispose vs Close | Garbage... | 0 | 2024-06-23T19:06:53 | https://dev.to/ipazooki/understanding-dispose-and-garbage-collection-in-net-3ach | dotnet, csharp, gc, tutorial | {% embed https://youtu.be/HnvOllctapI?si=XwXVtCbp1ers_2lc %}
## Introduction
Hello, tech enthusiasts! 🌟 Today, we're diving into the fascinating world of memory management in .NET, focusing on the `Dispose` method and the Garbage Collector (GC). These concepts are crucial for ensuring your applications run efficientl... | ipazooki |
1,897,978 | Dynamic Programming, Design and Analysis of Algorithms | Dynamic Programming Dynamic programming (DP) is a method used in computer science and... | 0 | 2024-06-23T19:05:48 | https://dev.to/harshm03/dynamic-programming-design-and-analysis-of-algorithms-2pf2 | coding, interview, algorithms, dsa | ## Dynamic Programming
Dynamic programming (DP) is a method used in computer science and mathematics to solve complex problems by breaking them down into simpler subproblems. It involves solving each subproblem just once and storing their solutions – typically using a data structure like an array or a table – to avoid... | harshm03 |
1,898,049 | First Post | Hello everyone at the Dev community! I have just joined and wanted to say hello. I am fairly new to... | 0 | 2024-06-23T19:04:45 | https://dev.to/paul_8bd971efd08cf4d64c7d/first-post-5c6h | webdev, beginners | Hello everyone at the Dev community!
I have just joined and wanted to say hello. I am fairly new to web development. Currently, I am learning the ropes with Scrimba, ZTM, and Frontend Mentor. I have been learning for almost 2 months currently, and at the moment, I try to spend most of my time just coding and getting m... | paul_8bd971efd08cf4d64c7d |
1,898,047 | I a Avid Vim User, Finally Migrated to Neovim! How does it work, what do I gain from it? | Having migrated to Neovim, I will give you some feedback and give you the keys to understanding and... | 0 | 2024-06-23T19:00:05 | https://dev.to/umairk/i-a-avid-vim-user-finally-migrated-to-neovim-how-does-it-work-what-do-i-gain-from-it-3a24 | productivity, devops, opensource, linux | Having migrated to Neovim, I will give you some feedback and give you the keys to understanding and succeeding in your migration to Neovim! First of all, a little context and history.
## Vim, the essential
Who doesn't know Vim, if only through jokes about how to quit it? And for good reason Vim - or often its predeces... | umairk |
1,898,046 | What is Recursion? | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-23T18:58:58 | https://dev.to/00gizem00/what-is-recursion-145e | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
When defining an object or a function, using itself within its own definition is called recursion.
## Additional Context
It is a very powerful problem-solving strategy. | 00gizem00 |
1,898,045 | Working of Web and DNS - Day 1/? | The way I finished my last blog was sad, I was so damn tired but I wanted to finish the publishing... | 27,813 | 2024-06-23T18:55:17 | https://dev.to/theshakeabhi/re-learning-the-basics-of-web-day-1-34gh | The way I finished my last blog was sad, I was so damn tired but I wanted to finish the publishing website part, but couldn't yet still manage to skim through it and complete it. But today will be going through that again and reading more carefully
## Day 1: Publishing of website and How does web works and Beyond
- W... | theshakeabhi | |
1,898,044 | Why Downtime and Reliability Top the List of Backend Performance Concerns for Engineers | Last week we asked our community what aspect of backend performance concerns them the most. Almost... | 0 | 2024-06-23T18:53:06 | https://dev.to/apitoolkiti/why-downtime-and-reliability-top-the-list-of-backend-performance-concerns-for-engineers-30mh | backendreliability, applicationdowntime, sitereliabilityengineering, apitoolkit | Last week we asked our community what aspect of backend performance concerns them the most. Almost 80% of engineers say downtime and reliability are their most pressing concerns.
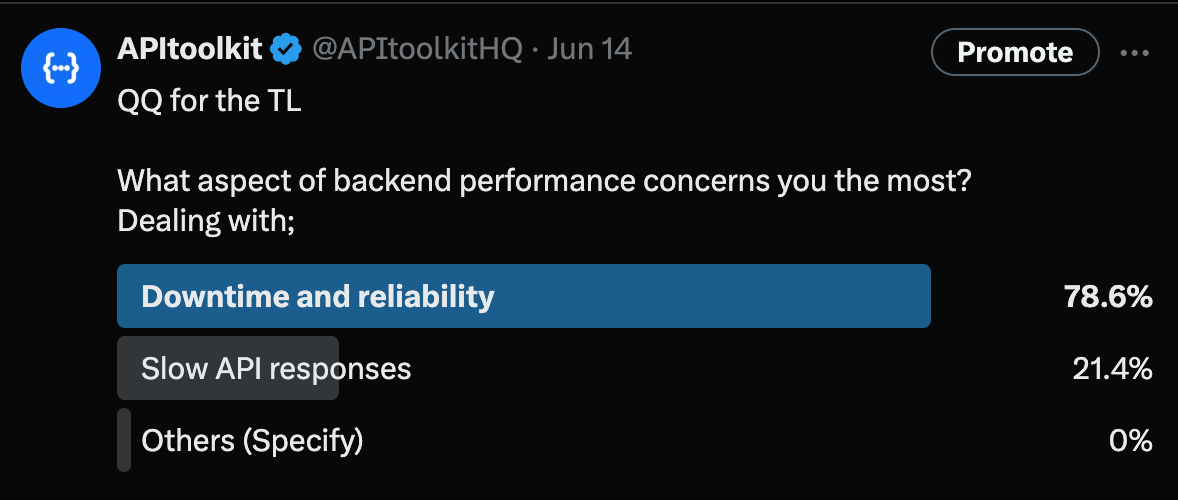
The results were telling: a whopping... | apitoolkit |
1,898,042 | geojson-faker: fake geodata in GeoJSON format | geojson-faker is a tool for generating fake geodata in GeoJSON format. What problem does... | 0 | 2024-06-23T18:51:27 | https://dev.to/impocode/geojson-faker-fake-geodata-in-geojson-format-3oho | python, geojson, faker, pydantic | [geojson-faker](https://github.com/impocode/geojson-faker) is a tool for generating fake geodata in GeoJSON format.
## What problem does the library solve
If your product is related to geodata, then there is often a need to generate a large amount of this data. For example, in order to run tests or prepare a demonstr... | impocode |
1,898,214 | Setting Up TanStack File-Based Router with a Vite React App | Integrating a file-based router in your Vite React application can streamline your development... | 0 | 2024-06-30T05:44:48 | https://iamdipankarpaul.hashnode.dev/setting-up-tanstack-file-based-router-with-a-vite-react-app | react, tanstack, vite, projects | ---
title: Setting Up TanStack File-Based Router with a Vite React App
published: true
date: 2024-06-23 18:46:19 UTC
tags: React,tanstack,vite,projects
canonical_url: https://iamdipankarpaul.hashnode.dev/setting-up-tanstack-file-based-router-with-a-vite-react-app
---
Integrating a file-based router in your Vite React ... | dipankarpaul |
1,898,040 | Twilio challenge - Environmental Bot | This is a submission for Twilio Challenge v24.06.12 What I Built This project provides an... | 0 | 2024-06-23T18:44:55 | https://dev.to/imkarthikeyan/twilio-challenge-environmental-bot-jm1 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
<!-- Share an overview about your project. -->
This project provides an AI-driven air quality alert system using Twilio and OpenAI. Users can send their location via WhatsApp and receive alerts based on the curren... | imkarthikeyan |
1,898,038 | Supervised Learning: Algorithms and Applications | Imagine you're training a puppy. You show it a ball and say "fetch," then throw it. Each time the... | 0 | 2024-06-23T18:41:10 | https://dev.to/abhinav_yadav_554cab962bb/supervised-learning-algorithms-and-applications-348h | supervised, machinelearning, ai, beginners | Imagine you're training a puppy. You show it a ball and say "fetch," then throw it. Each time the puppy retrieves the ball, it learns to associate the word "fetch" with the action. That's supervised learning in a nutshell!
## Table Of Content
- Introduction to Supervised Learning
- Types of Supervised Learning
- Pop... | abhinav_yadav_554cab962bb |
1,898,035 | Structured Approach to Designing an Airline Management System | First, I want to emphasize that you should Use these characteristics as a guideline, not a rigid set... | 0 | 2024-06-23T18:38:22 | https://dev.to/muhammad_salem/structured-approach-to-designing-an-airline-management-system-47if | First, I want to emphasize that you should Use these characteristics as a guideline, not a rigid set of rules. Your judgment and experience will play a crucial role in making informed decisions during OOA.
Here's how I can help you identify valid objects during Object-Oriented Analysis (OOA) and refine the selection ... | muhammad_salem | |
1,898,033 | Deploying an Application Using Apache as a Web Server | Deploying an application using Apache as a web server is a fundamental skill for web developers and... | 0 | 2024-06-23T18:33:59 | https://dev.to/iaadidev/deploying-an-application-using-apache-as-a-web-server-1f9j | apache, deployment, webdev, beginners |
Deploying an application using Apache as a web server is a fundamental skill for web developers and system administrators. Apache, an open-source HTTP server, is renowned for its robustness, flexibility, and widespread use. This blog will guide you through the steps to deploy a web application using Apache, with rele... | iaadidev |
1,898,032 | I utilized Twilio’s powerful SMS and Voice APIs to build the reminder system: | What I Built I developed an automated reminder system that leverages Twilio's SMS and Voice APIs to... | 0 | 2024-06-23T18:32:41 | https://dev.to/aditya_kushwaha_0a7aa61d6/i-utilized-twilios-powerful-sms-and-voice-apis-to-build-the-reminder-system-2bcc | twiliochallenge | What I Built
I developed an automated reminder system that leverages Twilio's SMS and Voice APIs to send appointment reminders via text messages and voice calls. This system includes basic AI functionality to handle user interactions, such as confirming or rescheduling appointments through SMS and IVR (Interactive Voic... | aditya_kushwaha_0a7aa61d6 |
1,898,031 | Event Booking System with Twilio and OpenAi | This is a submission for the Twilio Challenge What I Built I built an event booking... | 0 | 2024-06-23T18:32:20 | https://dev.to/toubielawbar/event-booking-system-with-twilio-and-openai-15m3 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
<!-- Share an overview about your project. -->
I built an event booking system built using Twilio and AI allows users to book events through various communication channels like SMS and voice calls.
## Demo
<!-- Share... | toubielawbar |
1,897,903 | AWS Summit TokyoのAWS Jamに参加しました | AWS Jamの紹介 AWS... | 0 | 2024-06-23T18:30:39 | https://dev.to/regent0ro/aws-summit-tokyonoaws-jamnican-jia-simasita-50n7 | aws, awssummit, awsjam | ## AWS Jamの紹介
AWS JamとはAWSのユースケースに基づいた問題をチームで解決に取り組むイベントです。問題を解決するとチームに得点が入り、チーム対抗で得点を競うようなゲーム形式で、楽しくAWSを学ぶことができます。
AWS Jamは AWS クラスルームトレーニングまたはAWS re:inventやAWS re:inforceなどのグローバルイベントでも開催されいます。
AWS Summit Tokyoでも毎年AWS Jamが開催されていて、セッションの申し込み開始からすぐ満席になるほど大人気なセッションの一つとなっています。私の場合も最初の申し込みでは申し込めませんでしたが、追加枠の申し込みで幸い参加することがで... | regent0ro |
1,898,029 | Get Personalized tasks extracted, and sent to you, from your meeting room! | This is a submission for the Twilio Challenge What I Built Get Personalized tasks... | 0 | 2024-06-23T18:29:37 | https://dev.to/santhosh_0484000/get-personalized-tasks-extracted-and-sent-to-you-from-your-meeting-room-2gj7 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
Get Personalized tasks extracted, and sent to you, from your meeting room! Using meeting transcripts
## Demo
https://github.com/santosh8309/twilio_challenge.git
.*
## Explainer
Machine Learning (ML) is a subset of AI that enables systems to learn and improve from experience without explicit programming. ML algorithms use data to identify patterns, make decisio... | selvadharshini |
1,898,026 | Unlock Your Web Development Potential: Essential Skills for Success | Unlock Your Web Development Potential: Essential Skills for Success HTML & CSS - The foundation... | 0 | 2024-06-23T18:24:09 | https://dev.to/ridoy_hasan/unlock-your-web-development-potential-essential-skills-for-success-2in6 | webdev, programming, productivity, learning | Unlock Your Web Development Potential: Essential Skills for Success
HTML & CSS - The foundation of any website. Learn to structure and style effectively.
JavaScript - Bring your site to life with dynamic and interactive features.
Responsive Design - Ensure your site looks great on all devices.
Version Control (Git)... | ridoy_hasan |
1,897,977 | Migrando Microservicios de NestJS con TypeScript a Go: Una Semana de Descubrimientos | En la última semana, me he sumergido en el mundo de Go con el objetivo de migrar nuestros microservicios desarrollados en NestJS con TypeScript. Esta travesía ha sido un ejercicio intenso de desaprender ciertos paradigmas y adoptar otros, comprendiendo las diferencias fundamentales entre estos dos ecosistemas de desarr... | 0 | 2024-06-23T18:18:19 | https://dev.to/devjaime/migrando-microservicios-de-nestjs-con-typescript-a-go-una-semana-de-descubrimientos-4585 | nestjs, go, spanish | ---
title: Migrando Microservicios de NestJS con TypeScript a Go: Una Semana de Descubrimientos
published: true
description: En la última semana, me he sumergido en el mundo de Go con el objetivo de migrar nuestros microservicios desarrollados en NestJS con TypeScript. Esta travesía ha sido un ejercicio intenso de desa... | devjaime |
1,897,975 | Getting Started with Colud Acquisition | A post by Bhogadi Vidhey | 0 | 2024-06-23T18:09:52 | https://dev.to/vidheyb/getting-started-with-colud-acquisition-4m1g | vidheyb | ||
1,897,974 | AWS Billing and Cost Management | A post by Bhogadi Vidhey | 0 | 2024-06-23T18:09:18 | https://dev.to/vidheyb/aws-billing-and-cost-management-10da | vidheyb |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.