
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,888,835 | How To Install Next js and set up Visual Studio Code (VS Code) | Learn how to install Next.js and set up Visual Studio Code (VS Code) for a seamless development... | 0 | 2024-06-14T17:06:36 | https://dev.to/dimerbwimba/how-to-install-next-js-and-set-up-visual-studio-code-vs-code-dgl | tutorial, nextjs, vscode, typescript | {% embed https://youtu.be/Xsac_H9d2OM %}
Learn how to install Next.js and set up Visual Studio Code (VS Code) for a seamless development experience.
In this tutorial, we cover everything from installing Next.js to configuring VS Code with the best extensions and settings for Next.js development. Whether you're a beg... | dimerbwimba |
1,885,648 | How To Build an AI-Powered Voice Assistant With Twilio, Laravel, and OpenAI | Voice assistants, such as Amazon Alexa and Apple's Siri have become integral to people’s lives, as... | 0 | 2024-06-14T17:06:30 | https://www.twilio.com/en-us/blog/build-ai-powered-voice-assistant-twilio-laravel-openai | ai, openai, laravel, php | Voice assistants, such as Amazon Alexa and Apple's Siri have become integral to people’s lives, as they're so helpful with mundane tasks, such as setting reminders and turning on smart home devices. However, most voice assistants struggle with complex questions and queries, leaving users disappointed.
In this tutorial... | thatcoolguy |
1,888,833 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-14T17:06:03 | https://dev.to/lekocot138/buy-verified-cash-app-account-20db | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | lekocot138 |
1,888,832 | B.Sc. Nursing in Germany | Godzone Foreign Study offers an exceptional pathway for those pursuing a BSc in Nursing in Germany, a... | 0 | 2024-06-14T17:05:46 | https://dev.to/godzone_foreignstudy_6489/bsc-nursing-in-germany-3p5e | Godzone Foreign Study offers an exceptional pathway for those pursuing a [BSc in Nursing in Germany](https://godzoneforeignstudy.in/), a choice that promises a wealth of opportunities and experiences. Germany’s world-class education system, advanced healthcare infrastructure, and affordable tuition fees create an ideal... | godzone_foreignstudy_6489 | |
1,888,830 | WebTable Automation using Selenium | A dynamic table is a table where the number of rows and columns can change frequently. To manage... | 0 | 2024-06-14T17:01:35 | https://dev.to/divya_devassure/webtable-automation-using-selenium-p9h | webdev, beginners, selenium, testing | A dynamic table is a table where the number of rows and columns can change frequently. To manage these changes, advanced techniques are required to locate and interact with elements within a dynamic table in Selenium.
## Automate Dynamic Tables using Selenium
In this blog we will focus on automating dynamic tables. T... | divya_devassure |
1,888,831 | What is not machine learning ? | What is Not Machine Learning? In this video, we dive deep into the world of artificial... | 0 | 2024-06-14T17:00:07 | https://dev.to/dimerbwimba/what-is-not-machine-learning--4mhc | tutorial, ai, machinelearning, deeplearning | ## What is Not Machine Learning?
{% embed https://youtu.be/jV2SVEm1uNw %}
In this video, we dive deep into the world of artificial intelligence to clarify what machine learning is not. There's a lot of buzz around AI and machine learning, but it's crucial to understand the distinctions to avoid common misconceptions.... | dimerbwimba |
1,888,829 | HVAC experts | Discovering reliable heating and cooling solutions in Salt Lake City, Utah is crucial, especially... | 0 | 2024-06-14T16:52:19 | https://dev.to/waitetara/hvac-experts-17pb | Discovering reliable heating and cooling solutions in Salt Lake City, Utah is crucial, especially with the extreme weather conditions we experience. Fortunately, HVAC experts in the area are well-equipped to handle residential and industrial heating and cooling needs with precision and efficiency. If you're in need of ... | waitetara | |
1,888,828 | Day 18 of my progress as a vue dev | About today Today I coded the frontend of my audio editor project and defined the complete file... | 0 | 2024-06-14T16:49:45 | https://dev.to/zain725342/day-18-of-my-progress-as-a-vue-dev-17c4 | webdev, vue, typescript, tailwindcss | **About today**
Today I coded the frontend of my audio editor project and defined the complete file structure for the app. It was not the hard part but essential to be done properly in the beginning so that when it's time to dive in the functionality part of the project the frontend is at least not something to be conc... | zain725342 |
1,888,827 | Redeem Temu Coupon Code (acp856709) $100 off For All | To get $100 off Temu Coupon Code with a 30% discount, you can use the following codes: [acp856709]:... | 0 | 2024-06-14T16:47:58 | https://dev.to/subhamshooter/redeem-temu-coupon-code-acp856709-100-off-for-all-203g | To get $100 off Temu Coupon Code with a 30% discount, you can use the following codes:
[acp856709]: This code offers $100 off and a 30% special discount. It is applicable for both new and existing customers.
[acp856709] or [frf048797]: These codes provide $100 off and an additional 30% discount. They are also suitable ... | subhamshooter | |
1,888,826 | Create a Web API with MongoDB | Hello guys! Today I challenged myself to learn a little bit about MongoDB, so I created an API that... | 0 | 2024-06-14T16:45:18 | https://dev.to/vzldev/create-a-web-api-with-mongodb-16kn | mongodb, dotnet, api, csharp | Hello guys!
Today I challenged myself to learn a little bit about MongoDB, so I created an API that will connect to a MongoDB database.
## What is MongoDB?
MongoDB is a NOSQL database and NOSQL means "Not Only SQL". This is because MongoDB is not only a relational database. NOSQL can store unstructured data.
MongoDB... | vzldev |
1,888,870 | Web: Your Accessibility FAQ Guide | Ensuring that your website is accessible to all users, including those with disabilities, is not only... | 0 | 2024-06-14T18:15:08 | https://accessmeter.com/faqs/web-accessibility-faq/ | faqs, a11y, webaccessibility | ---
title: Web: Your Accessibility FAQ Guide
published: true
date: 2024-06-14 16:44:06 UTC
tags: FAQs,accessibility,faqs,webaccessibility
canonical_url: https://accessmeter.com/faqs/web-accessibility-faq/
---
Ensuring that your website is accessible to all users, including those with disabilities, is not only a legal ... | samuel_enyi_0f46ef94a1918 |
1,888,823 | Version Control Best Practices with Git and GitHub | Introduction: Efficient version control is the backbone of successful software... | 0 | 2024-06-14T16:43:33 | https://dev.to/haseebmirza/version-control-best-practices-with-git-and-github-364h | github, versioncontrol, git, tip | ## Introduction:
Efficient version control is the backbone of successful software development. Git and GitHub offer powerful tools for managing your codebase and collaborating with your team. In this article, we'll explore best practices to help you master these essential tools.
## 1. Understanding Version Control:
... | haseebmirza |
1,888,822 | Oracle Transportation Management Cloud Testing: The Comprehensive Guide | Businesses that ship, move, send, or receive goods on a regular basis require real-time tracking of... | 0 | 2024-06-14T16:41:56 | https://www.opkey.com/blog/oracle-transportation-management-cloud-testing-the-comprehensive-guide | cloud, testing | 
Businesses that ship, move, send, or receive goods on a regular basis require real-time tracking of their shipments. For this, they invest heavily in transport management solutions. One such solution is Oracle Transp... | johnste39558689 |
1,888,821 | The Future of Healthcare: AI and Automation | Accelerating Medical Discoveries AI's potential to accelerate medical discoveries is... | 27,673 | 2024-06-14T16:40:24 | https://dev.to/rapidinnovation/the-future-of-healthcare-ai-and-automation-42jk | ## Accelerating Medical Discoveries
AI's potential to accelerate medical discoveries is groundbreaking. AI systems
can analyze massive datasets from medical records, genetic information, and
scientific studies at unprecedented speeds. This can lead to new treatments,
disease predictors, and precision medicine approach... | rapidinnovation | |
1,888,800 | CVPR Pre-Show: Open3DSG: an Open-Vocabulary 3D Scene Graph Generation Method | With CVPR 2024 coming soon, check out this conversation between Harpreet Sahota (Hacker-in-Residence... | 0 | 2024-06-14T16:39:20 | https://dev.to/voxel51/unpublished-video-586k-4c4 | computervision, ai, machinelearning, datascience | With [CVPR 2024](https://cvpr.thecvf.com/) coming soon, check out this conversation between [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker-in-Residence at Voxel51) and Dr. [Jason Corso](https://www.linkedin.com/in/jason-corso/) (Prof of Robotics at the University of Michigan) with [Sebastian ... | jguerrero-voxel51 |
1,888,820 | Get $100 off Temu Coupon Code [acp856709] 30% off | You can get a $100 off Temu coupon code using the code {acp856709}. This Temu $100 Off code is... | 0 | 2024-06-14T16:38:51 | https://dev.to/subhamshooter/get-100-off-temu-coupon-code-acp856709-30-off-995 | beginners | You can get a $100 off Temu coupon code using the code {acp856709}. This Temu $100 Off code is specifically for new customers and can be redeemed to receive a $100 discount on your purchase.
Redeeming the coupon code (acp856709) is simple and hassle-free. Follow these steps to enjoy your $50 discount:
Visit Temu's We... | subhamshooter |
1,888,819 | Hire an excellent hacker to recover your money | I sent $130,000 to trade crypto assets on the website coinbitjzsc.top but when I tried to withdraw... | 0 | 2024-06-14T16:38:38 | https://dev.to/judy_leone_ac22c11b532d09/hire-an-excellent-hacker-to-recover-your-money-3j6l | I sent $130,000 to trade crypto assets on the website coinbitjzsc.top but when I tried to withdraw funds, I was told my account had been frozen because of “suspicious activity”. I provided proof of identification and proof that my funds had been transferred from their crypto asset account. The site then told me the ac... | judy_leone_ac22c11b532d09 | |
1,888,818 | Part 7: Connecting to a Database with Node.js | In the previous part of our Node.js series, we introduced Express.js, a powerful web application... | 0 | 2024-06-14T16:36:42 | https://dev.to/dipakahirav/part-7-connecting-to-a-database-with-nodejs-4be1 | node, mongodb, database | In the previous part of our Node.js series, we introduced Express.js, a powerful web application framework that simplifies server-side development. Now, let's take a significant step forward by integrating a database into our application. Databases are crucial for storing and retrieving persistent data. In this part, w... | dipakahirav |
1,888,817 | Day 8: Angular Signals and Infinite Scrolling | In today's blog post, we will explore the concepts of Angular Signals and Infinite Scrolling. These... | 0 | 2024-06-14T16:33:17 | https://dev.to/dipakahirav/day-8-angular-signals-and-infinite-scrolling-5e4f | angular, javascript, programming, webdev | In today's blog post, we will explore the concepts of Angular Signals and Infinite Scrolling. These two topics are crucial for building scalable and efficient Angular applications.
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewithDipak?sub_confirmation=1
) to support my channel and get more... | dipakahirav |
1,888,816 | 3d rotating octahedron | Check out this Pen I made! | 0 | 2024-06-14T16:31:46 | https://dev.to/kemiowoyele1/3d-rotating-octahedron-hfd | codepen | Check out this Pen I made!
{% codepen https://codepen.io/frontend-magic/pen/eYaeqdd %} | kemiowoyele1 |
1,888,808 | What's your keyboard layout? | This question comes up every now and then but it's always fun to see the different custom layouts... | 0 | 2024-06-14T16:31:41 | https://dev.to/jess/whats-your-keyboard-layout-bmb | discuss, watercooler | This question comes up every now and then but it's always fun to see the different custom layouts people use!
My friend Chris has been building out their new keyboard and shared this WIP pic with me:
 coming soon, check out this conversation between [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker-in-Residence at Voxel51) and Dr. [Jason Corso](https://www.linkedin.com/in/jason-corso/) (Prof of Robotics at the University of Michigan) with Dr. [Paola ... | jguerrero-voxel51 | |
1,888,812 | Day 5: Understanding Functions in JavaScript | Introduction Welcome to Day 5 of your JavaScript journey! Yesterday, we explored control... | 0 | 2024-06-14T16:26:52 | https://dev.to/dipakahirav/day-5-understanding-functions-in-javascript-55ji | javascript, webdev, programming, learning | #### Introduction
Welcome to Day 5 of your JavaScript journey! Yesterday, we explored control structures, learning how to make decisions and repeat actions in our code. Today, we'll dive into functions, which are essential for organizing and reusing code in JavaScript.
please subscribe to my [YouTube channel](https://... | dipakahirav |
1,851,553 | What is JSON ( Javascript Object Notation ) and how to use it | It's pretty common for newcomers in coding to struggle with many acronyms around their first weeks,... | 0 | 2024-06-14T16:26:34 | https://dev.to/henriqueleme/what-is-json-javacript-object-notation-and-how-to-use-it-2mhk | beginners, json, learning, programming | It's pretty common for newcomers in coding to struggle with many **acronyms** around their first weeks, today we'll talk about one that is very common to use in our profession, it's also really easy to understand trust me! In this article we'll talk about what does the JSON acronym mean, how can be used, what it looks ... | henriqueleme |
1,888,810 | Exploring Recursive Nets | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 27,893 | 2024-06-14T16:26:24 | https://dev.to/monish3004/exploring-recursive-nets-3a9e | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Recursive neural networks (RvNNs) are a class of artificial neural networks where the structure is applied recursively, particularly well-suited for hierarchical or structured data. Th... | monish3004 |
1,888,809 | Spring Data JPA nedir ? | Spring Data JPA, Spring Framework'ün bir alt projesi olan Spring Data'nın bir modülüdür ve Java... | 0 | 2024-06-14T16:25:46 | https://dev.to/mustafacam/spring-data-jpa-nedir--1lb1 | Spring Data JPA, Spring Framework'ün bir alt projesi olan Spring Data'nın bir modülüdür ve Java Persistence API (JPA) üzerine inşa edilmiştir. Amacı, JPA tabanlı veri erişim katmanlarının geliştirilmesini basitleştirmek ve hızlandırmaktır. Spring Data JPA, JPA'nın temel özelliklerini kullanarak veri erişim işlemlerini ... | mustafacam | |
1,888,777 | CVPR Pre-Show: A Closer Look at the Few-Shot Adaptation of Large Vision-Language Models | With CVPR 2024 coming soon, check out this conversation between Harpreet Sahota (Hacker-in-Residence... | 0 | 2024-06-14T16:25:24 | https://dev.to/voxel51/cvpr-pre-show-a-closer-look-at-the-few-shot-adaptation-of-large-vision-language-models-5cp4 | ai, computervision, machinelearning, datascience | With [CVPR 2024](https://cvpr.thecvf.com/) coming soon, check out this conversation between [Harpreet Sahota](https://www.linkedin.com/in/harpreetsahota204/) (Hacker-in-Residence at Voxel51) and Dr. [Jason Corso](https://www.linkedin.com/in/jason-corso/) (Prof of Robotics at the University of Michigan) with [Julio Silv... | jguerrero-voxel51 |
1,888,807 | jpa ve hibernate | Java Persistence API (JPA) ve Hibernate, Java ile ilişkisel veritabanlarına erişim ve yönetim için... | 0 | 2024-06-14T16:23:35 | https://dev.to/mustafacam/jpa-ve-hibernate-428m | Java Persistence API (JPA) ve Hibernate, Java ile ilişkisel veritabanlarına erişim ve yönetim için kullanılan teknolojilerdir. Her iki teknoloji de Object-Relational Mapping (ORM) yaklaşımını kullanarak, Java nesneleri ile veritabanı tabloları arasında bir köprü kurar. Ancak, JPA ve Hibernate arasında bazı önemli farkl... | mustafacam | |
1,888,806 | iphone 15 | Experience the iPhone 15 – your dynamic companion. Dynamic Island ensures you stay connected,... | 0 | 2024-06-14T16:21:55 | https://dev.to/amit29x/iphone-15-a3o | iphone, webdev, beginners, programming |

****
Experience the iPhone 15 – your dynamic companion. Dynamic Island ensures you stay connected, bubbling up alerts seamlessly while you're busy. Its durable design features infused glass and aerospace-grade alumi... | amit29x |
1,888,805 | The `never` type and `error` handling in TypeScript | One thing that I see more often recently is that folks find out about the never type, and start using... | 0 | 2024-06-14T16:21:53 | https://dev.to/stealc/the-never-type-and-error-handling-in-typescript-4k39 | typescript, nextjs, beginners, programming | One thing that I see more often recently is that folks find out about the never type, and start using it more often, especially trying to model error handling. But more often than not, they don’t use it properly or overlook some fundamental features of never. This can lead to faulty code that might act up in production... | stealc |
1,888,759 | Creating a windows 11 VM on Azure. | Creating a Windows 11 Virtual Machine (VM) on Azure involves several steps. Here's a step-by-step... | 0 | 2024-06-14T16:13:52 | https://dev.to/adeola_adebari/creating-a-windows-11-vm-on-azure-1gg3 |
Creating a Windows 11 Virtual Machine (VM) on Azure involves several steps. Here's a step-by-step guide to help you set up your VM:
## Prerequisites
1. Azure Subscription: You need an active Azure subscription. If you don't have one, you can sign up for a free account.
2. Azure Portal Access: Ensure you can log into ... | adeola_adebari | |
1,888,798 | Day 5: Creating Forms in HTML | Welcome to Day 5 of your journey to mastering HTML and CSS! Today, we will explore how to create... | 0 | 2024-06-14T16:11:56 | https://dev.to/dipakahirav/day-5-creating-forms-in-html-1oij | javascript, webdev, html, css | Welcome to Day 5 of your journey to mastering HTML and CSS! Today, we will explore how to create forms in HTML. Forms are essential for collecting user input, whether it's for a sign-up page, a search box, or feedback submission. By the end of this post, you'll be able to create and style various types of forms for you... | dipakahirav |
1,888,797 | spring data jdbc | Spring Data JDBC, Spring Framework'ün bir modülü olup, JDBC tabanlı veritabanı erişimini daha modern... | 0 | 2024-06-14T16:08:55 | https://dev.to/mustafacam/spring-data-jdbc-17e4 | Spring Data JDBC, Spring Framework'ün bir modülü olup, JDBC tabanlı veritabanı erişimini daha modern ve basit bir şekilde gerçekleştirmek için kullanılır. Spring Data JDBC, Spring Data'nın prensiplerini kullanarak veri erişimini daha kolay ve yönetilebilir hale getirir, ancak ORM araçlarının aksine doğrudan JDBC ile ça... | mustafacam | |
1,888,796 | GetBlock Offers Custom zkSync Nodes for Airdrop Management | As the ZK token airdrop gets closer, GetBlock takes measures to support crypto enthusiasts who... | 0 | 2024-06-14T16:08:27 | https://dev.to/getblockapi/getblock-offers-custom-zksync-nodes-for-airdrop-management-1l6f | zksync, airdrop, nodes, cryptocurrency |
As the ZK token airdrop gets closer, GetBlock takes measures to support crypto enthusiasts who participate in it. It offers free private zkSync RPC nodes that can be used to claim airdrop quickly. Due to high activity, network congestion is expected, but GetBlock users will avoid such issues.
## GetBlock zkSync nodes... | getblockapi |
1,888,795 | Advanced Git Workflows for Efficient Project Management – Part 7 | Introduction After mastering the basics and more intermediate topics like conflict... | 0 | 2024-06-14T16:08:09 | https://dev.to/dipakahirav/advanced-git-workflows-for-efficient-project-management-part-7-2k29 | webdev, github, git, learning | #### Introduction
After mastering the basics and more intermediate topics like conflict resolution, it's time to explore advanced Git workflows. These workflows are designed to enhance team collaboration, streamline project development, and maintain a clean and efficient project history. This installment will cover two... | dipakahirav |
1,885,062 | A Bit Saved is a Bit Earned | Unorthodox - the act of not orthodoxing A Wise Man Once Said A penny saved is a... | 0 | 2024-06-14T16:06:01 | https://dev.to/fonzacus/a-bit-saved-is-a-bit-earned-1k6m | beginners, learning | ###### _Unorthodox_ - the act of not orthodoxing
# A Wise Man Once Said
A penny saved is a penny earned, a great idiom to live by as we can minimize greed. My siblings and I grew up with the rich parents cheat code, but we are not too swayed by money. We are also trying to raise our kids the same way. Why I would bri... | fonzacus |
1,888,794 | CHANNEL LETTER SIGNS CHICAGO | Channel letter signs, including dimensional letter signage, backlit channel letters, and custom... | 0 | 2024-06-14T16:04:00 | https://dev.to/signfreaks_usa/channel-letter-signs-chicago-1752 | webdev | Channel letter signs, including dimensional letter signage, backlit channel letters, and custom [channel letter signs chicago](https://signfreaks.com/custom-signs/channel-letters-chicago/), serve as a vibrant embodiment of your brand’s identity. At SignFreaks, we specialize in crafting these three-dimensional signs, me... | signfreaks_usa |
1,888,793 | Rust Vs. Other Programming Languages: What Sets Rust Apart? | Introduction The rapid emergence of different programming languages in the technology... | 0 | 2024-06-14T16:02:00 | https://strapi.io/blog/rust-vs-other-programming-languages-what-sets-rust-apart |

## Introduction
The rapid emergence of different programming languages in the technology landscape may affect the programming language/tool choice while building a software product. Despite this, some program... | iamaamunir | |
1,888,792 | Unlocking the Power of Convex and Clerk: A Guide to Seamless Authentication and Data Management | As a web developer, discovering tools that simplify complex tasks and enhance productivity is always... | 0 | 2024-06-14T16:01:09 | https://dev.to/syedahmedullah14/unlocking-the-power-of-convex-and-clerk-a-guide-to-seamless-authentication-and-data-management-32h7 | webdev, javascript, clerk, programming | As a web developer, discovering tools that simplify complex tasks and enhance productivity is always exciting. Recently, I had the pleasure of exploring two incredible tools: Convex and Clerk. These tools are game-changers in the realms of data management and authentication. In this blog post, I’ll dive into what Conve... | syedahmedullah14 |
1,888,791 | The Essential Roles of Autonomous Agents in Modern API Integration | Seamless API integration is crucial for efficient and innovative business operations. Recent... | 0 | 2024-06-14T15:57:04 | https://dev.to/apidna/the-essential-roles-of-autonomous-agents-in-modern-api-integration-5b9m | webdev, programming, api, automation | Seamless API integration is crucial for efficient and innovative business operations.
Recent developments in autonomous agents have helped streamline complex processes, and enable businesses to effortlessly connect various services and systems without the need for extensive manual intervention.
At APIDNA, we have rec... | itsrorymurphy |
1,888,788 | How to transfer data between tabs using a Chrome extension | In today’s interconnected web, it’s common to need communication between different browser tabs, even... | 0 | 2024-06-14T15:55:27 | https://dev.to/bhaskar_sawant/how-to-transfer-data-between-tabs-using-a-chrome-extension-1ghn | typescript, softwareengineering, webdev, chrome | In today’s interconnected web, it’s common to need communication between different browser tabs, even if they come from different origins. Chrome extensions and the postMessage API make it easy to transfer data between tabs. You can create a Chrome extension using TypeScript to facilitate cross-origin communication. In... | bhaskar_sawant |
1,888,347 | HTML QUESTION AND ANSWER | Question1:What is the full meaning of HTML? Answer:HTML means Hyper Text Markup... | 0 | 2024-06-14T15:56:14 | https://dev.to/samweb281/html-question-and-answer-33nm |
**Question1:**What is the full meaning of **HTML**? **Answer:**HTML means Hyper Text Markup Language
**Question2:**What does it mean?
**Answer:**It is the computer language that is used to create and display pages on the internet.
**Question3:**What are **"HTML tags"**?
**Answer:**These are used for placing eleme... | samweb281 | |
1,885,017 | Step by Step Guide to Deploying and Connecting Window Virtual Machine in Azure | Contents What is Azure Virtual Machine How to Deploy Virtual Machines in Azure Step 1:... | 0 | 2024-06-14T15:56:00 | https://dev.to/celestina_odili/step-by-step-guide-to-deploying-and-connecting-to-azure-virtual-machine-c7d | cloudpractitioner, azure, microsoft, cloud | ##Contents <a name="Content"></a>
[What is Azure Virtual Machine] (#azure_VM)
[How to Deploy Virtual Machines in Azure] (#Deploy)
Step 1: Sign in to Azure Portal
Step 2: Create a Virtual machine
Step 3: Configure the Virtual Machine Basics
Step 4: Configure other Settings(optional)
Step 5: Review and Create (Deploy) th... | celestina_odili |
1,888,790 | java jdbc modules | Conclusion As we’ve seen now, there are several API’s and abstractions. Here’s a short list of what... | 0 | 2024-06-14T15:55:40 | https://dev.to/mustafacam/java-jdbc-modules-fng |
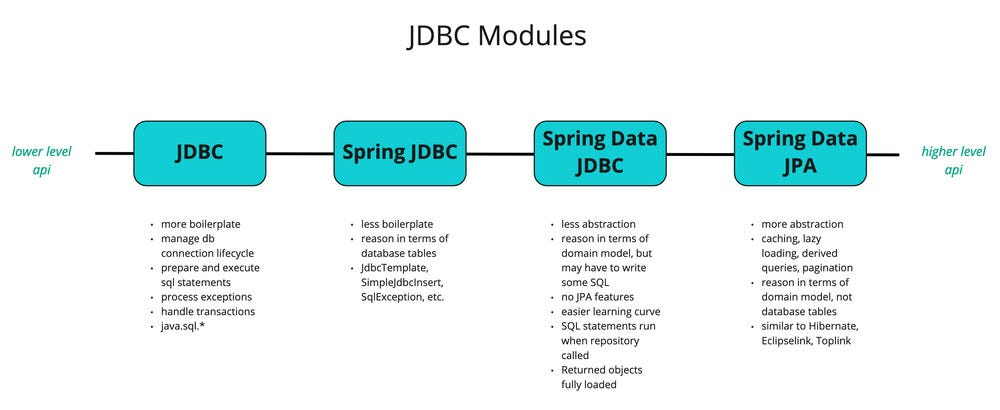
Conclusion
As we’ve seen now, there are several API’s and abstractions. Here’s a short list of what we covered:
**JDBC API**: The JDBC API is a low-level API to execute SQL queries on a database.
**JDBC Driver**:... | mustafacam | |
1,888,789 | One Byte Explainer - The Nibble | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-14T15:55:31 | https://dev.to/rafajrg21/one-byte-explainer-the-nibble-lp6 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Half a byte. Is a small unit of information used for more efficient use of memory & processing power when resources are limited.
## Additional Context
You could call this one a One N... | rafajrg21 |
1,864,934 | My Wins of the Week! 🪄 | 📰 I published a new post on DEV! ✨ Are Certificates From... | 0 | 2024-06-14T15:39:10 | https://dev.to/anitaolsen/my-wins-of-the-week-57hp | weeklyretro | <a href="https://www.glitter-graphics.com"><img src="http://dl10.glitter-graphics.net/pub/1527/1527890k6wfbn5d95.gif" width=550 height=30 border=0></a>
📰 I published a new post on DEV! ✨
{% embed https://dev.to/anitaolsen/are-certificates-from-code-learning-websites-worth-anything-3loh %}
💟 I received two ne... | anitaolsen |
1,888,787 | Mastering Type Guards in TypeScript: Ensuring Safe Type Checks | TypeScript is a powerful language that adds static types to JavaScript, enabling developers to write... | 0 | 2024-06-14T15:55:03 | https://dev.to/geraldhamiltonwicks/mastering-type-guards-in-typescript-ensuring-safe-type-checks-2ap0 | typescript, webdev, javascript, programming | TypeScript is a powerful language that adds static types to JavaScript, enabling developers to write safer and more maintainable code. One of the key features that enhance TypeScript’s robustness is type guards. Type guards allow us to narrow down the type of a variable within a conditional block, providing better type... | geraldhamiltonwicks |
1,888,978 | Shuffling the Deck: Learning Loops and Nested Loops in JavaScript | I’ve been diving into the world of JavaScript and having a blast revisitinvg different programming... | 0 | 2024-06-14T20:56:12 | https://medium.com/@rkconnections/shuffling-the-deck-learning-loops-and-nested-loops-in-javascript-f81cdc2f5d79 | ---
title: Shuffling the Deck: Learning Loops and Nested Loops in JavaScript
published: true
date: 2024-06-14 15:54:55 UTC
tags:
canonical_url: https://medium.com/@rkconnections/shuffling-the-deck-learning-loops-and-nested-loops-in-javascript-f81cdc2f5d79
---
.
`ls:` List files and directories.
`ls -l:` Long format, shows detailed information.
`ls -a:` List all files, including hidden files.
`ls -lh:` Long format wit... | oncloud7 |
1,888,783 | What is Test Monitoring and Test Control? | Introduction In the realm of application testing, the ability to monitor and control the execution... | 0 | 2024-06-14T15:47:23 | https://dev.to/pcloudy_ssts/what-is-test-monitoring-and-test-control-46cb | automatedseleniumtestingt, applicationtesting, testmonitoring | Introduction
In the realm of [application testing](https://www.pcloudy.com/blogs/how-to-accelerate-app-testing-using-continuous-testing-cloud/), the ability to monitor and control the execution of your test suite is fundamental to the successful delivery of high-quality software. These essential strategies allow man... | pcloudy_ssts |
1,888,756 | HTML TAGS | Question1:What is the full meaning of HTML? Answer:HTML means Hyper Text Markup... | 0 | 2024-06-14T15:46:30 | https://dev.to/michweb/html-tags-2h3o | **Question1:**What is the full meaning of **HTML**?
**Answer:**_HTML means Hyper Text Markup Language_
**Question2:**What does it mean?
**Answer:**_It is the computer language that is used to create and display pages on the internet_.
**Question3:**What are **"HTML tags"**?
**Answer:**These are used to place elements... | michweb | |
1,888,536 | What it's like to be a woman developer | As a woman developer, my journey in the tech industry has been a blend of unique challenges and... | 0 | 2024-06-14T15:46:24 | https://dev.to/webdevqueen/what-its-like-to-be-a-woman-developer-4d0 | womenintech, career, beginners, discuss | As a woman developer, my journey in the tech industry has been a blend of unique challenges and rewarding experiences. Despite numerous initiatives promoting gender diversity, women, especially those in backend development roles, remain underrepresented. Here’s a glimpse into my personal experience navigating this male... | webdevqueen |
1,888,782 | spring jdbc nedir ? | Spring JDBC, Spring Framework'ün bir parçası olan ve JDBC (Java Database Connectivity) kullanarak... | 0 | 2024-06-14T15:46:11 | https://dev.to/mustafacam/spring-jdbc-nedir--419m | Spring JDBC, Spring Framework'ün bir parçası olan ve JDBC (Java Database Connectivity) kullanarak ilişkisel veritabanlarıyla etkileşimi kolaylaştıran bir modüldür. Spring JDBC, ham JDBC API'sinin kullanımını basitleştirir, tekrarlanan kodları ortadan kaldırır ve kaynak yönetimini otomatikleştirir. Bu sayede geliştirici... | mustafacam | |
1,888,160 | Using Power Automate Flow for Exporting and Importing Solutions | In today's post, I'll show you an easy way to export and import your Power Platform solutions using... | 0 | 2024-06-14T15:43:23 | https://dev.to/fernandaek/using-power-automate-flow-for-exporting-and-importing-solutions-3d7b | powerplatform, powerautomate, powerfuldevs, powerapps | In today's post, I'll show you an easy way to export and import your Power Platform solutions using Power Automate 😉
This method is a simpler alternative to pipelines in Power Platform and helps you keep everything in sync across your environments without the need for managed environments (though managed environments... | fernandaek |
1,888,779 | JavaScript: JWT Token | JWT Token Procedure -> Basically when a client sends request to the server for the first... | 0 | 2024-06-14T15:39:48 | https://dev.to/alamfatima1999/javascript-cookies-jwt-token-25kf | **_<u>JWT Token</u>_**
Procedure ->
1. Basically when a client sends request to the server for the first time-> Authentication.
2. It sends it's username and password to get authenticated by the server.
3. The server uses this information to generate a token -> JWT Token(Access Token) which has expiry time defined.
... | alamfatima1999 | |
1,724,835 | What was your win this week? | Heyo! Hope you all had a wonderful week. Looking back on this past week, what was something you... | 0 | 2024-06-14T15:38:55 | https://dev.to/devteam/what-was-your-win-this-week-5116 | weeklyretro | ---
title: What was your win this week?
published: true
description:
tags: weeklyretro
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/lj45j9daeu40yn1r7m7a.jpg
---
Heyo!
Hope you all had a wonderful week.
Looking back on this past week, what was something you were proud of accomplishing?
All ... | jess |
1,888,778 | Best Selenium Python Frameworks for Test automation | According to a recent Developer Survey by Stack Overflow, Python is considered the most sought-after... | 0 | 2024-06-14T15:38:53 | https://dev.to/pcloudy_ssts/best-selenium-python-frameworks-for-test-automation-29ic | seleniumpythonframeworks, browsertesting, gherkinlanguage, seleniumtesting | According to a recent Developer Survey by Stack Overflow, Python is considered the most sought-after programming language among developers. It is the most accessible and simplified programming language that provides an extensive support system for test automation frameworks. With more and more implementation of Artific... | pcloudy_ssts |
1,888,776 | L'Open Source et Moi | Je m'appelle Firmin Nganduli et je suis développeur full stack. Pendant trois mois du 11 mars au 11... | 0 | 2024-06-14T15:35:06 | https://dev.to/firminfinva/lopen-source-et-moi-5im | opensource, wiki, mediawiki, goma | Je m'appelle Firmin Nganduli et je suis développeur full stack. Pendant trois mois du 11 mars au 11 juin 2024, mon intérêt pour l'open source a été éveillé grâce à Kali Academy, une organisation dédiée à cette philosophie. Attiré par le développement logiciel et désireux d'explorer l'open source, j'ai décidé de postul... | firminfinva |
1,888,775 | The Art of Learning from Tutorials | Watching the whole tutorial isn't important, understanding what you're watching is. Pay attention to... | 0 | 2024-06-14T15:34:19 | https://dev.to/tamilvanan/the-art-of-learning-from-tutorials-2l8k | tutorial |
- Watching the whole tutorial isn't important, understanding what you're watching is.
- Pay attention to understanding the concepts, not just finishing the tutorial.
- Write down key points and ideas as you go. This helps reinforce learning.
- Take breaks to think about what you’ve learned and how it applies to your ... | tamilvanan |
1,887,510 | Deploy an Amazon Lex Chatbot to your own website. | Why a chatbot? For professionals, integrating a chatbot into your website is more than... | 0 | 2024-06-14T15:33:57 | https://dev.to/monica_escobar/deploy-an-amazon-lex-chatbot-to-your-own-website-e18 | aws, automation, ai, lex | ## Why a chatbot?
For professionals, integrating a chatbot into your website is more than just a cool tech feature; it’s a way to showcase your commitment to innovation and user experience. It reflects a forward-thinking approach and shows that you value your visitors’ time and needs. By offering instant, personalised... | monica_escobar |
1,888,764 | Free Website Checker Monkey | Keeping your website problem-free is hard. When you change something, you often don't know if... | 0 | 2024-06-14T15:30:20 | https://dev.to/irfanahmadin/free-website-checker-monkey-57f6 | webdev, testing, website, qa | Keeping your website problem-free is hard. When you change something, you often don't know if something is wrong until you check every part yourself.
what if there is a virtual monkey checking your website and score it as per best practices?
So try this https://labs.checkops.com
Check sample report :https://labs.che... | irfanahmadin |
1,888,761 | organized dotfiles | Tried my dotfiles workflow w/ stow command, check it out. | 27,725 | 2024-06-14T15:29:34 | https://dev.to/kenkoro/dotfiles-w-stow-4kh2 | opensource, learning, linux, showdev | Tried my dotfiles workflow w/ stow command, [check it out][dotfiles].
[dotfiles]: https://github.com/kenkoro/dotfiles | kenkoro |
1,888,762 | Best Unit Testing Frameworks to Automate your Desktop Web Testing using Selenium | Introduction Selenium is the most preferred tool of all times when it comes to automating web... | 0 | 2024-06-14T15:28:40 | https://dev.to/pcloudy_ssts/best-unit-testing-frameworks-to-automate-your-desktop-web-testing-using-selenium-2d0b | seleniumframework, testng, functional, endtoend | Introduction
Selenium is the most preferred tool of all times when it comes to automating web applications. Selenium supports various unit testing frameworks based on multiple programming languages like Java, C#, PHP, Ruby, Perl, JavaScript, and Python. These frameworks are used for executing test scripts on web app... | pcloudy_ssts |
1,886,038 | JavaScript30 - 5 Flex Panels Image Gallery | Well here we are! Back with another update on my progress through Wes Bos's JavaScript 30. In this... | 0 | 2024-06-14T15:27:13 | https://dev.to/virtualsobriety/javascript30-5-flex-panels-image-gallery-2n3k | javascript, beginners, learning, javascript30 | Well here we are! Back with another update on my progress through Wes Bos's [JavaScript 30](https://javascript30.com/). In this challenge I had to take 5 pre-selected images with some "motivational" words and update them with flexbox and CSS to make them grow and shrink as well as reveal other words when clicked. Be... | virtualsobriety |
1,888,677 | Taming the Microservices Beast: Container Orchestration with Amazon ECS and EKS | Taming the Microservices Beast: Container Orchestration with Amazon ECS and... | 0 | 2024-06-14T15:05:39 | https://dev.to/virajlakshitha/taming-the-microservices-beast-container-orchestration-with-amazon-ecs-and-eks-5fgn | 
# Taming the Microservices Beast: Container Orchestration with Amazon ECS and EKS
Microservices architectures have revolutionized the way we design, develop, and deploy software. This approach breaks down monolithic applications int... | virajlakshitha | |
1,887,716 | .NET Core WebAPI (Auto)Binding Parameters When Calling Via JavaScript Fetch | Get the Source Code For This Article All of the source code for this article is located at... | 0 | 2024-06-14T15:27:13 | https://dev.to/raddevus/net-core-webapi-autobinding-parameters-when-calling-via-javascript-fetch-31e4 | ## Get the Source Code For This Article
All of the source code for this article is [located at my github repo](https://github.com/raddevus/BindApi). It's all C# .NET Core 8.x and JavaScript code.
## Introduction
This is a fast article with multiple examples of how to leverage the user of .NET Core WebAPI Auto-Binding ... | raddevus | |
1,888,755 | Joining dev | Hi, I am very excited to work with you thanks, working with you, it's my honour | 0 | 2024-06-14T15:24:00 | https://dev.to/ibrahim_08f006e885b7d5590/joining-dev-2p1a | Hi, I am very excited to work with you thanks, working with you, it's my honour | ibrahim_08f006e885b7d5590 | |
1,888,754 | Joining dev | Hi, I am very excited to work with you thanks, working with you, it's my honour | 0 | 2024-06-14T15:23:57 | https://dev.to/ibrahim_08f006e885b7d5590/joining-dev-161p | Hi, I am very excited to work with you thanks, working with you, it's my honour | ibrahim_08f006e885b7d5590 | |
1,888,753 | I need an web developer who can create website for my college project for free. please | A post by Umar Zaib | 0 | 2024-06-14T15:23:54 | https://dev.to/umarzzaib/i-need-an-web-developer-who-can-create-website-for-my-college-project-for-free-please-22p5 | umarzzaib | ||
1,884,979 | Introduction to Docker Integration in GitLab CI/CD Pipelines | Introduction Brief Overview of Docker Docker is a platform that allows developers to... | 0 | 2024-06-14T15:22:08 | https://dev.to/arbythecoder/introduction-to-docker-integration-in-gitlab-cicd-pipelines-4lg6 | beginners, gitlab, cicd, docker | #### Introduction
**Brief Overview of Docker**
Docker is a platform that allows developers to package applications and their dependencies into a standardized unit called a container. Containers are lightweight, portable, and can run on any environment that supports Docker, ensuring consistency across development, test... | arbythecoder |
1,888,683 | Real-Time Sentiment Analysis using PySpark and FastAPI | ⏱ Real-Time Sentiment Analysis using PySpark and FastAPI In today's landscape, many APIs, including... | 0 | 2024-06-14T15:15:49 | https://dev.to/raghavtwenty/real-time-sentiment-analysis-using-pyspark-and-fastapi-19jl | bigdata, spark, python, fastapi | ⏱ Real-Time Sentiment Analysis using PySpark and FastAPI
In today's landscape, many APIs, including Twitter's, often require payment for real-time streaming access.
💻 To overcome this hurdle, I've developed my own FastAPI solution capable of delivering string values akin to Twitter's API and most of the APIs. Levera... | raghavtwenty |
1,888,682 | Discussion: What makes good Content on DEV Community? 🚀🌟 | Hello fellow dev, I hope you are all doing great. I've been wondering 🤔 what makes a post... | 0 | 2024-06-14T15:15:19 | https://dev.to/jennavisions/discussion-what-makes-good-content-on-dev-community-56im | watercooler, discuss, community, learning |
Hello fellow dev,
I hope you are all doing great.
I've been wondering 🤔 what makes a post beneficial to the DEV community.
There are many great posts out here, but I've noticed a mix of quality.
For example; incomplete posts, some relevant ones contain grammar and punctuation mistakes, while others seem unrelate... | jennavisions |
1,888,681 | LeetCode Day8 String Part.2 | LeetCode No.151 Reverse Words in a String Given an input string s, reverse the order of... | 0 | 2024-06-14T15:11:17 | https://dev.to/flame_chan_llll/leetcode-day8-string-part2-5bcg | leetcode, java, algorithms | ##LeetCode No.151 Reverse Words in a String
Given an input string s, reverse the order of the words.
A word is defined as a sequence of non-space characters. The words in s will be separated by at least one space.
Return a string of the words in reverse order concatenated by a single space.
Note that s may contain l... | flame_chan_llll |
1,888,679 | Decorators and Generators in Python | Decorators and Generators in Python Python is a versatile and powerful programming... | 0 | 2024-06-14T15:10:05 | https://dev.to/romulogatto/decorators-and-generators-in-python-ejl | # Decorators and Generators in Python
Python is a versatile and powerful programming language that offers various features to simplify code organization and improve performance. Two such features are decorators and generators, which allow you to add functionality to your code and create iterable objects, respectively.... | romulogatto | |
1,888,678 | How to Enhance Your Business with Custom Gift Display Boxes? | If you care about maintaining the quality of your high-end beauty items, sturdy custom display boxes... | 0 | 2024-06-14T15:08:02 | https://dev.to/allien/how-to-enhance-your-business-with-custom-gift-display-boxes-4paa | If you care about maintaining the quality of your high-end beauty items, sturdy **[custom display boxes](https://imhpackaging.com/product-category/display-boxes/)** are the way to go. Customer satisfaction and loyalty will rise dramatically if the things they purchase from you are in good condition. In addition, having... | allien | |
339,400 | Weekly Journal :: Retro Style | Like many of you, I have read my fair share of productivity and time management books. I repeatedly s... | 0 | 2020-05-20T01:09:10 | https://dev.to/dev0928/weekly-journal-retro-style-34gh | productivity, career | Like many of you, I have read my fair share of productivity and time management books. I repeatedly see many of them suggesting one habit - writing a daily journal. As soon I finish reading a book (well… sometimes even halfway through the book), I get pumped up and start writing a journal with a brand new notebook. Fir... | dev0928 |
1,888,676 | Mailing Made Easy: Cardboard Boxes, Postage Bags, and Paper Bags Explained | In our everyday activities, we often find ourselves in need of suitable packaging—whether it's for... | 0 | 2024-06-14T15:03:11 | https://dev.to/adnan_jahanian/mailing-made-easy-cardboard-boxes-postage-bags-and-paper-bags-explained-31h3 |
In our everyday activities, we often find ourselves in need of suitable packaging—whether it's for sending parcels, organising a party, or simply storing items. Understanding the different types of packaging available can help you make the best choice for your needs. Let's delve into some popular packaging options and... | adnan_jahanian | |
1,888,675 | Debugging HTTP Traffic in kubectl port-forward with KFtray v0.11.7 | KFtray is a application that can be integrated into the system tray for easy interaction with... | 0 | 2024-06-14T15:01:40 | https://dev.to/hcavarsan/debugging-http-traffic-in-kubectl-port-forward-with-kftray-v0117-2p1d | kubernetes, devops, development, rust | KFtray is a application that can be integrated into the system tray for easy interaction with kubectl port-forward commands. A additional feature has joined recently in new version 0.11.7, one that can make HTTP traffic traces logs; this is an new method that simplifies debugging. This article provides a short guide o... | hcavarsan |
1,883,447 | NumPy's Argmax? How it Finds Max Elements from Arrays | NumPy is most often used to handle or work with arrays (multidimensional, masked) and matrices. It... | 0 | 2024-06-14T15:00:00 | https://geekpython.in/numpy-argmax-function-in-python | numpy, python | [NumPy](https://numpy.org/doc/stable/user/whatisnumpy.html) is most often used to handle or work with arrays (multidimensional, masked) and matrices. It has a collection of functions and methods to operate on arrays like statistical operations, mathematical and logical operations, shape manipulation, linear algebra, an... | sachingeek |
1,888,673 | Updates from the 102nd TC39 meeting | There were several items on the agenda, this post focuses on feature proposals and their progress... | 0 | 2024-06-14T14:57:17 | https://dev.to/hemanth/updates-from-the-102nd-tc39-meeting-i4i | There were several items on the agenda, this post focuses on feature proposals and their progress from the 101th TC39 meeting [11-13th June 2024].
__Stage 2:__
* [Error.isError](https://github.com/tc39/proposal-is-error): `Error.isError` tests if a value is an `Error` instance, irrespective of its Realm origin.
* [E... | hemanth | |
1,888,672 | Generate a SSL with certbot on digitalocean droplet | Install Certbot for SSL # Install python3 virtual environment apt install... | 0 | 2024-06-14T14:56:11 | https://dev.to/sokngoun/generate-a-ssl-with-certbot-on-digitalocean-droplet-2h5f | ## **Install Certbot for SSL**
```
# Install python3 virtual environment
apt install python3-venv
# Create a virtual environment
sudo python3 -m venv /opt/certbot/
```
```
# Upgrade pip
sudo /opt/certbot/bin/pip install --upgrade pip
# Using pip to install certbot & certbot-nginx
sudo /opt/certbot/bin/pip instal... | sokngoun | |
1,888,671 | Securely Importing Customer Data to Your Azure SaaS Product | In the realm of data-driven insights and analytics, integrating customer data securely and... | 0 | 2024-06-14T14:52:13 | https://dev.to/vaibhavi_shah/securely-importing-customer-data-to-your-azure-saas-product-444c | In the realm of data-driven insights and analytics, integrating customer data securely and efficiently into your SaaS product hosted on Azure is crucial. Many SaaS providers face the challenge of securely importing data from their customers’ Azure accounts while maintaining data integrity and compliance with regulatory... | vaibhavi_shah | |
1,888,491 | 🎨 Melhore Seu Tema Favorito no VSCode em Minutos! | Se você é uma pessoa como eu era, que mudava de tema a todo momento no VSCode 😅, chegando ao ponto de... | 0 | 2024-06-14T14:50:35 | https://dev.to/maiquitome/modifique-qualquer-tema-no-vscode-3fch | vscode, tema, braziliandevs | Se você é uma pessoa como eu era, que mudava de tema a todo momento no VSCode 😅, chegando ao ponto de pensar em criar seu próprio tema, mas desistiu por falta de tempo ou preguiça de colocar tanto esforço nisso, eu tenho uma solução bem mais fácil que vai resolver esse problema!
Você vai conseguir alterar aquele tema... | maiquitome |
1,888,670 | "Explurger.app: app for travelers make your journey effective" | App for travelers is platform to make your travel journey effective. Using this app create your own... | 0 | 2024-06-14T14:46:58 | https://dev.to/appfortravelers/explurgerapp-app-for-travelers-make-your-journey-effective-1nbi | [App for travelers](https://www.explurger.com/
) is platform to make your travel journey effective. Using this app create your own bucket list, start your journey and make your journey a memorable . Install this app r... | appfortravelers | |
1,888,657 | OverflowBox and videos in Flutter | Recently I was working on something with Flutter when I encountered with a small problem: how can I... | 0 | 2024-06-14T14:45:51 | https://dev.to/josuestuff/overflowbox-and-videos-in-flutter-1kk8 | flutter, ui, beginners, learning | Recently I was working on something with Flutter when I encountered with a small problem: how can I make a video to fill up all the available space inside a Container widget?
Well, today I’m gonna explain how I did it and how the _[“Understanding constraints”](https://docs.flutter.dev/ui/layout/constraints)_ Flutter d... | josuestuff |
1,888,669 | Content modeling in a headless CMS: Structuring BCMS by content types | Content modeling refers to the process of defining the structure of content. Each type is described... | 0 | 2024-06-14T14:45:09 | https://dev.to/momciloo/content-modeling-in-a-headless-cms-structuring-bcms-by-content-types-m92 | [Content modeling](https://thebcms.com/blog/content-modeling-basics) refers to the process of defining the structure of content. Each type is described by its attributes, and broken down into individual components. Headless architecture is how you manage that content.
So, **content modeling in a headless CMS** interse... | momciloo | |
1,888,668 | Therapeutic Triumphs: Advances in Internal Medicine Treatments with Dr. Jaspaul S. Bhangoo | In the realm of healthcare, the field of internal medicine plays a pivotal role in diagnosing,... | 0 | 2024-06-14T14:43:30 | https://dev.to/drjaspaulsbhangoo01/therapeutic-triumphs-advances-in-internal-medicine-treatments-with-dr-jaspaul-s-bhangoo-1cbh | In the realm of healthcare, the field of internal medicine plays a pivotal role in diagnosing, treating, and managing a wide range of conditions that affect the internal organs and systems of the body. With advancements in medical research and technology, the landscape of internal medicine treatments has evolved signif... | drjaspaulsbhangoo01 | |
1,888,667 | The Puzzle of Pathogens: Understanding Microbes in Internal Medicine with Dr. Jaspaul S. Bhangoo | In the realm of internal medicine, the intricate interplay between pathogens and the human body... | 0 | 2024-06-14T14:42:12 | https://dev.to/drjaspaulsbhangoo01/the-puzzle-of-pathogens-understanding-microbes-in-internal-medicine-with-dr-jaspaul-s-bhangoo-4j09 | In the realm of internal medicine, the intricate interplay between pathogens and the human body presents a complex puzzle for healthcare professionals to decipher. Infectious diseases, caused by a diverse array of microbes, challenge clinicians to diagnose and treat ailments ranging from common colds to life-threatenin... | drjaspaulsbhangoo01 | |
1,885,866 | Navigating Success: Setting up Vue Router in your Project. | Introduction In the ever-growing tech space of today, a seamless navigation experience can either... | 0 | 2024-06-14T14:42:05 | https://dev.to/chidinma_nwosu/navigating-success-setting-up-vue-router-in-your-project-4el0 | javascript, beginners, learning, vue | **Introduction**
In the ever-growing tech space of today, a seamless navigation experience can either make or break your web application. That is why our journey begins with understanding Vue and the Vue router.
**What is Vue ?**
[Vue](vuejs.org) also pronounced as 'view', was created by [Evan You](https://evanyou.me... | chidinma_nwosu |
1,888,666 | $All and $ElemMatch in MongoDB | Using $All and $ElemMatch in MongoDB $all The $all operator is used with... | 0 | 2024-06-14T14:41:52 | https://dev.to/kawsarkabir/all-and-elemmatch-in-mongodb-4od6 | webdev, database, mongodb, kawsarkabir | ## Using $All and $ElemMatch in MongoDB
### $all
The `$all` operator is used with arrays. Let's say you have an array field called `interests`. If you want to find documents where the `interests` include "Travelling", you can easily do that:
```javascript
// array field
"interests" : [ "Travelling", "Gaming", "Readi... | kawsarkabir |
1,888,660 | Object / pipe function / currying | 0bject Objectlar bu keys va value yani kalitlar va qiymatlarni o'z ichiga olgan ma'lumotlar... | 0 | 2024-06-14T14:32:22 | https://dev.to/bekmuhammaddev/object-pipe-function-currying-29ek | javascript, object, webdev | **0bject**
Objectlar bu keys va value yani kalitlar va qiymatlarni o'z ichiga olgan ma'lumotlar to'plami.Ob'ektlar yordamida siz ko'p turdagi ma'lumotlarni bitta strukturada saqlashingiz mumkin.Ob'ektlar JavaScriptning asosiy tushunchalaridan biri bo'lib, ular ko'pincha dasturda turli ma'lumotlarni guruhlash va ular... | bekmuhammaddev |
1,888,665 | Containment Strategies: Preventing Outbreaks in Internal Medicine Settings with Dr. Jaspaul S. Bhangoo | In the field of internal medicine, healthcare professionals face the constant challenge of preventing... | 0 | 2024-06-14T14:40:37 | https://dev.to/drjaspaulsbhangoo01/containment-strategies-preventing-outbreaks-in-internal-medicine-settings-with-dr-jaspaul-s-bhangoo-ob8 | In the field of internal medicine, healthcare professionals face the constant challenge of preventing and containing infectious diseases within clinical settings. With the potential for outbreaks to occur, especially in settings such as hospitals and clinics where patients with various medical conditions converge, it i... | drjaspaulsbhangoo01 | |
1,888,664 | Updating Non-Primitive Data Dynamically in Mongoose | Introduction When working with MongoDB and Mongoose, updating documents is straightforward... | 0 | 2024-06-14T14:35:31 | https://dev.to/md_enayeturrahman_2560e3/updating-non-primitive-data-dynamically-in-mongoose-17h2 | javascript, mongodb, node, express | ### Introduction
When working with MongoDB and Mongoose, updating documents is straightforward for primitive fields. However, handling nested or non-primitive fields requires a more nuanced approach to ensure that the data is updated correctly without overwriting existing fields. In this blog post, we'll explore how ... | md_enayeturrahman_2560e3 |
1,888,663 | Unified Project Development Environment: ServBay is Enough | Introduction The current development environment is not fully unified, with some... | 0 | 2024-06-14T14:34:12 | https://dev.to/servbay/unified-project-development-environment-servbay-is-enough-20pl | webdev, beginners, programming, php | ### Introduction
The current development environment is not fully unified, with some differences in details that, while not affecting 90% of the work, occasionally cause issues due to environment and version discrepancies.
**1. Dependency Issues**
- Different development environments might install different versio... | servbay |
1,888,662 | Decoding the Linux Command Line: 52 Indispensable Utilities Explained | Top 50 Linux Commands Every Regular User Must Know As a regular Linux user, mastering... | 0 | 2024-06-14T14:32:58 | https://dev.to/mnamesujit/decoding-the-linux-command-line-52-indispensable-utilities-explained-34kk | cmd, terminal, linux | # Top 50 Linux Commands Every Regular User Must Know
As a regular Linux user, mastering these essential commands can greatly enhance your productivity and efficiency. Let's dive into the top 52 Linux commands with practical examples.
1. **ls (List)**
- `ls` - List files and directories in the current directory.
... | mnamesujit |
1,888,570 | AWS GameDay: Frugality Fest | AWS GameDay is an engaging, hands-on learning event where participants tackle real-world technical... | 0 | 2024-06-14T14:32:42 | https://dev.to/aws-builders/aws-gameday-frugality-fest-4889 | gameday, awsusergroup, awscommunity, communitybuilder | AWS GameDay is an engaging, hands-on learning event where participants tackle real-world technical challenges using AWS solutions in a team-based environment. Unlike traditional workshops, GameDays are open-ended and encourage creative problem-solving.
To foster collaboration among AWS User Groups in Romania, we organ... | lp |
1,888,659 | How to create an API endpoint in astro | Introduction What's the setup? 1. Ready your Astro project 2. SSR 2.1 Adapter 2.2 server or... | 0 | 2024-06-14T14:32:12 | https://daniel.es/blog/how-to-create-an-api-endpoint-in-astro/ | astro, webdev, typescript, javascript | - [Introduction](#introduction)
- [What's the setup?](#whats-the-setup)
- [1. Ready your Astro project](#1-ready-your-astro-project)
- [2. SSR](#2-ssr)
- [2.1 Adapter](#21-adapter)
- [2.2 `server` or `hybrid`](#22-server-or-hybrid)
- [2.3 A note on environment variables](#23-a-note-on-environment-variab... | onticdani |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.