
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,888,656 | How Entities and Symbols are displayed in HTML | HTML Entities Reserved characters in HTML must be replaced with entities: < (less than)... | 0 | 2024-06-14T14:29:00 | https://dev.to/wasifali/how-symbols-and-entities-are-displayed-in-html-50ko | webdev, css, learning, html | ## **HTML Entities**
Reserved characters in HTML must be replaced with entities:
< (less than) = <
> (greather than) = >
## **HTML Character Entities**
Some characters are reserved in HTML.
If you use the less than (<) or greater than (>) signs in your HTML text, the browser might mix them with tags.
Entity names... | wasifali |
1,888,655 | Hash Function 256 chars | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-14T14:26:43 | https://dev.to/fmalk/hash-function-256-chars-172m | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
A hash function takes a key or input data and maps it to a fixed-size, uniformely distributed value (hash), later used for data retrieval. It strives to be fast, only generate one poss... | fmalk |
1,888,654 | Recursion and Happy Birthday Alan Turing. | Recursion: A function that calls itself, solving problems by breaking them into smaller, identical... | 0 | 2024-06-14T14:24:02 | https://dev.to/wickley/recursion-and-happy-birthday-alan-turing-5hb9 | devchallenge, cschallenge, computerscience, beginners | Recursion: A function that calls itself, solving problems by breaking them into smaller, identical chunks. Think Russian nesting dolls, but for code. Perfect for tasks like navigating mazes or sorting data. Simplifies complex problems elegantly. | wickley |
1,888,640 | Streamline Your App Testing with Google Cloud CI and pCloudy | In the world of app development, ensuring the quality and reliability of applications is paramount.... | 0 | 2024-06-14T14:22:27 | https://dev.to/pcloudy_ssts/streamline-your-app-testing-with-google-cloud-ci-and-pcloudy-44mg | testautomation | In the world of app development, ensuring the quality and reliability of applications is paramount. Continuous Integration (CI) is a practice that helps teams detect and resolve issues early in the development process. Google Cloud provides a robust CI platform that allows developers to automate the testing of their ap... | pcloudy_ssts |
1,888,639 | Is Tech a Skill? | As I sit down to write this, I can't help but reflect on my journey into the world of technology.... | 0 | 2024-06-14T14:22:27 | https://blog.learnhub.africa/2024/06/14/is-tech-a-skill/ | beginners, programming, productivity, career |
As I sit down to write this, I can't help but reflect on my journey into the world of technology. Like many of you reading this, I was once a wide-eyed beginner, equally excited and intimidated by the prospect of entering this vast and ever-evolving field.
I was asked: Is tech truly a skill or something more? What ... | scofieldidehen |
1,888,627 | Enhancing Mobile and Web App Testing with Azure Pipeline and pCloudy | In the rapidly evolving world of mobile and web app development, ensuring the quality and reliability... | 0 | 2024-06-14T14:19:43 | https://dev.to/pcloudy_ssts/enhancing-mobile-and-web-app-testing-with-azure-pipeline-and-pcloudy-1h5i | automatethetestingprocess, webapptesting, devopstools | In the rapidly evolving world of mobile and web app development, ensuring the quality and reliability of applications is crucial for success. Testing plays a vital role in delivering a flawless user experience across various devices and platforms. To streamline and [automate the testing process](https://www.pcloudy.com... | pcloudy_ssts |
1,888,626 | Professional Furniture Removal in Dubai: Services | Moving to a new home or office in Dubai can be an exciting yet challenging experience, especially... | 0 | 2024-06-14T14:17:58 | https://dev.to/goal_achievers_ee2402e8c2/professional-furniture-removal-in-dubai-services-8ha | Moving to a new home or office in Dubai can be an exciting yet challenging experience, especially when it comes to transporting your furniture. Thankfully, professional **[Furniture removal in Dubai](https://eatransport.ae/wp-login.php)** services in Dubai offer comprehensive solutions to make your move smooth and stre... | goal_achievers_ee2402e8c2 | |
1,888,625 | error: Your local changes to the following files would be overwritten by merge | This error message occurs when you try to use git merge but there are uncommitted changes in your... | 0 | 2024-06-14T14:16:22 | https://dev.to/ajeetraina/error-your-local-changes-to-the-following-files-would-be-overwritten-by-merge-4hhm |
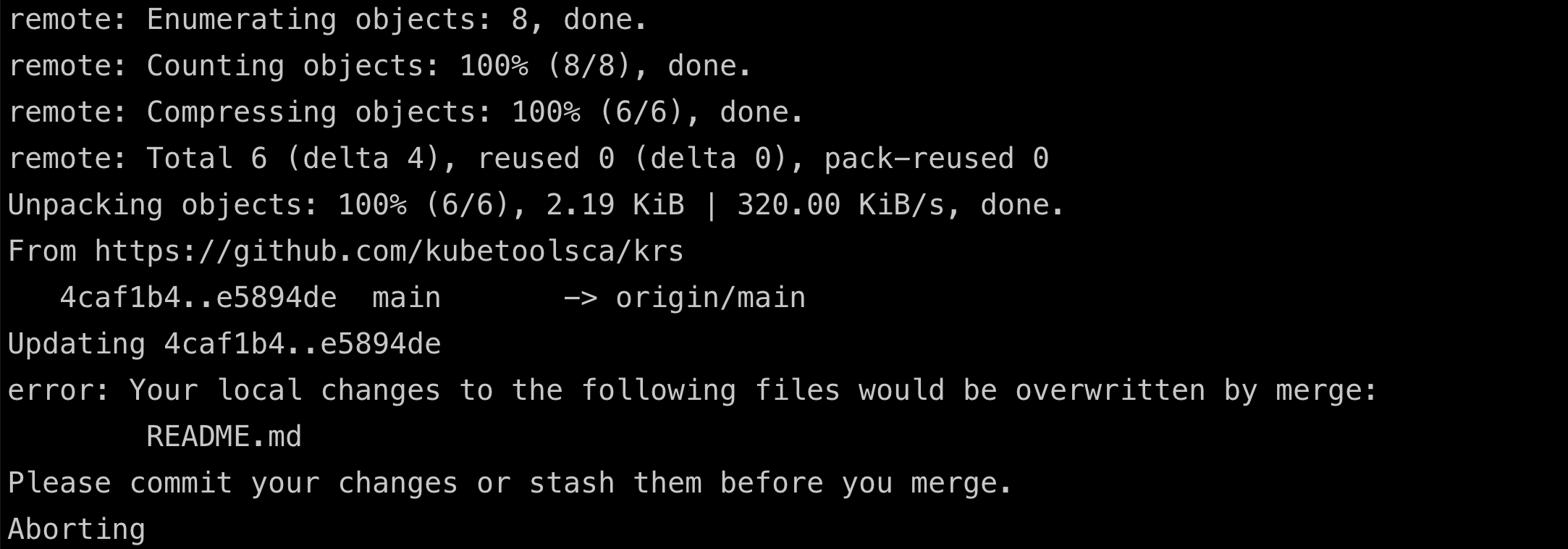
This error message occurs when you try to use `git merge` but there are uncommitted changes in your local repository that conflict with the incoming changes from the remote branch. Git prevents overwriting your local work w... | ajeetraina | |
1,888,624 | Streamlining Continuous Integration and Delivery with pCloudy-Bamboo Integration | In the world of app development, the ability to continuously integrate and deliver high-quality code... | 0 | 2024-06-14T14:15:03 | https://dev.to/pcloudy_ssts/streamlining-continuous-integration-and-delivery-with-pcloudy-bamboo-integration-58b3 | testautomationtools, functionaltesting, apptesting | In the world of app development, the ability to continuously integrate and deliver high-quality code is of paramount importance. To achieve this, developers rely on robust tools and processes that automate the build, test, and deployment phases. One such tool that has gained significant popularity is Bamboo CI. Bamboo ... | pcloudy_ssts |
1,888,623 | CSM Training In Hyderabad | CSM Training Courses | |Learnovative | We are the learning partners in your career growth journey. Our Agile and Scrum training programs... | 0 | 2024-06-14T14:11:43 | https://dev.to/learnovative/csm-training-in-hyderabad-csm-training-courses-learnovative-1n10 | csm, acsm, cspo, acspo | We are the learning partners in your career growth journey. Our Agile and Scrum training programs (CSM, CSPO, ACSM and ACSPO powered by international certification body Scrum Alliance) not only provide you with the required knowledge, but they also help you with practical insights that equip you for career development.... | learnovative |
1,888,615 | How I plan to (be able to) retire at 35 | Hi there! Some years ago, I was listening to an old interview with Agostinho da Silva, a Portuguese... | 0 | 2024-06-14T14:08:42 | https://diogodanielsoaresferreira.github.io/how-i-plan-to-be-able-to-retire-at-35/ | investing, financialindependence, fire, retirement | Hi there! Some years ago, I was listening to an old interview with Agostinho da Silva, a Portuguese philosopher who died 30 years ago, and he said something that has been in my mind ever since: "The Man is not born to work, the Man is born to create".
This goes contrary to the current belief in developed countries, wh... | diogodanielsoaresferreira |
1,888,620 | Redeem TEMU Code "aav67880" | The Temu discount code "aav67880" provides a $100 discount on your initial purchase. Here's all the... | 0 | 2024-06-14T14:01:31 | https://dev.to/akshansh090/redeem-temu-code-aav67880-950 | The Temu discount code "aav67880" provides a $100 discount on your initial purchase. Here's all the information you need to make the most of it. | akshansh090 | |
1,888,619 | Ultimate Guide to Boat Rentals in Abu Dhabi: Explore Luxury and Adventure | Introduction to Boat Rentals in Abu Dhabi Abu Dhabi's waters offer an escape from the hustle and... | 0 | 2024-06-14T14:00:46 | https://dev.to/pebino1779/ultimate-guide-to-boat-rentals-in-abu-dhabi-explore-luxury-and-adventure-23g9 | luxury, ultimate, adventure, webdev | Introduction to Boat Rentals in Abu Dhabi
Abu Dhabi's waters offer an escape from the hustle and bustle of city life. Renting a boat allows you to explore hidden coves, pristine beaches, and stunning coastal vistas. Whether you're celebrating a special occasion, enjoying a family outing, or simply wanting to unwind, a ... | pebino1779 |
1,880,770 | Como recuperar arquivos perdidos no Git utilizando o VSCode | O git é o sistema de controle de versão de código mais utilizado no mercado, normalmente nós... | 0 | 2024-06-14T14:00:00 | https://codigoaoponto.com/blog/como-recuperar-arquivos-perdidos-no-git-pelo-vscode | git, programming, webdev, tutorial | O git é o sistema de controle de versão de código mais utilizado no mercado, normalmente nós programadores apenas arranhamos a superfície do que essa ferramenta é capaz. No cotidiano, costumamos apenas realizar ações simples como pull, commit, merge e push.
No entanto, o git é uma ferramenta complexa, a sua incorreta ... | thiagonunesbatista |
1,888,684 | Code Sample: Integrating Azure OpenAI Search with #SemanticKernel in .NET | Hi! Today I’ll try to expand a little the scenario described in this Semantic Kernel blog post:... | 0 | 2024-06-18T15:52:12 | https://dev.to/azure/code-sample-integrating-azure-openai-search-with-semantickernel-in-net-223o | englishpost, azureaisearch, codesample | ---
title: Code Sample: Integrating Azure OpenAI Search with #SemanticKernel in .NET
published: true
date: 2024-06-14 13:59:42 UTC
tags: EnglishPost,AzureAISearch,CodeSample,EnglishPost
canonical_url:
---
Hi!
Today I’ll try to expand a little the scenario described in this Semantic Kernel blog post: “[Azure OpenAI O... | elbruno |
1,888,617 | Unlock $100 Off with Temu Coupon Code {aav67880} | Get $100 off Temu coupon code {aav67880} + 30% discount. You can receive a $100 discount on Temu by... | 0 | 2024-06-14T13:58:29 | https://dev.to/akshansh090/unlock-100-off-with-temu-coupon-code-aav67880-5dna | webdev, javascript, programming | Get $100 off Temu coupon code {aav67880} + 30% discount. You can receive a $100 discount on Temu by using the code. | akshansh090 |
1,876,338 | Sparky - hacking minikube with mini tool | TL; DR: How to deploy docker to minikube when one does not need anything fancy, but pure... | 0 | 2024-06-14T13:56:10 | https://dev.to/melezhik/sparky-hacking-minikube-with-mini-tool-3jl8 | k8s, raku, kubernetes | ---
Title: Sparky - hacking minikube with mini tool
Published: true
Description: How to deploy to minikube when you don't need anything fancy
Tags: k8s, Raku, Kubernetes
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-04 08:10 +0000
---
TL; DR: How to de... | melezhik |
1,888,614 | JDBC nedir ? | JDBC (Java Database Connectivity), Java programlama dili ile yazılmış uygulamaların ilişkisel... | 0 | 2024-06-14T13:55:21 | https://dev.to/mustafacam/jdbc-nedir--1fk1 | JDBC (Java Database Connectivity), Java programlama dili ile yazılmış uygulamaların ilişkisel veritabanları ile etkileşimde bulunmasını sağlayan bir API'dir. JDBC, Java uygulamaları ile veritabanları arasında bir köprü görevi görerek SQL sorgularını çalıştırmayı, veritabanı bağlantılarını yönetmeyi ve sonuçları işlemey... | mustafacam | |
1,888,613 | Code Refactoring: A Technical Guide to Improving Software Quality | Introduction Code refactoring is the process of restructuring existing computer code... | 0 | 2024-06-14T13:54:47 | https://dev.to/coderbotics_ai/code-refactoring-a-technical-guide-to-improving-software-quality-5fl | ### Introduction
Code refactoring is the process of restructuring existing computer code without changing its external behavior or functionality. It is a crucial step in software development that helps improve code quality, maintainability, and readability. In this blog, we will delve into the technical aspects of cod... | coderbotics_ai | |
1,873,913 | Laravel — PHP Artisan Serve Failed | Solve error “Failed to listen on 127.0.0.1:8000 (reason: ?)” when run “php artisan... | 0 | 2024-06-14T13:54:28 | https://dev.to/williammeier/laravel-php-artisan-serve-failed-2dh4 | php, laravel, artisan, tutorial |
Solve error “Failed to listen on 127.0.0.1:8000 (reason: ?)” when run “php artisan serve”
**Resolution**
Access your php.ini file in your PHP version folder. If you like me are using Laravel Herd on Windows you can access using the route "%USERPROFILE%\.config\herd\bin".
Now in your php.ini change the "variables_ord... | williammeier |
1,888,618 | State of AppExchange Salesforce Apps Market 2024 | Introduction to AppExchange Marketplace The Salesforce AppExchange is a marketplace filled... | 0 | 2024-06-14T18:20:23 | https://www.sfapps.info/salesforce-apps-stats-2024/ | appreviews, blog | ---
title: State of AppExchange Salesforce Apps Market 2024
published: true
date: 2024-06-14 13:53:27 UTC
tags: AppReviews,Blog
canonical_url: https://www.sfapps.info/salesforce-apps-stats-2024/
---
## Introduction to AppExchange Marketplace
The [Salesforce AppExchange](https://appexchange.salesforce.com/) is a marke... | doriansabitov |
1,888,611 | Error: Cannot find control with name: | I am using Angular 18. It is strange it cannot find first two controls in a... | 0 | 2024-06-14T13:51:25 | https://dev.to/tcj2001/error-cannot-find-control-with-name-206l | I am using Angular 18.
It is strange it cannot find first two controls in a formGroup
**Html:**
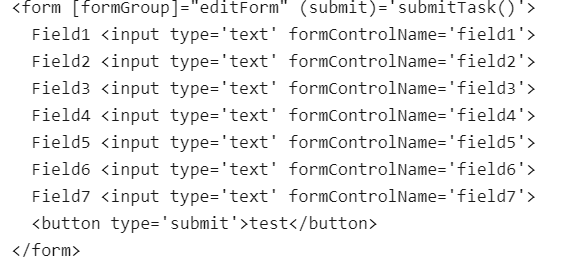
**Errors:**
Error: Cannot find control with name: 'field1'
Error: Cannot find control with name: 'field2'
Rest of fi... | tcj2001 | |
1,885,945 | Building a Cloud-Native Spreadsheet Copilot with Winglang and LangChain | The interest in building “AI copilots” is higher than ever before: Note: A copilot is an... | 0 | 2024-06-14T13:50:55 | https://dev.to/winglang/building-a-cloud-native-spreadsheet-copilot-with-winglang-and-langchain-68h | webdev, programming, opensource, typescript | The interest in building “AI copilots” is higher than ever before:
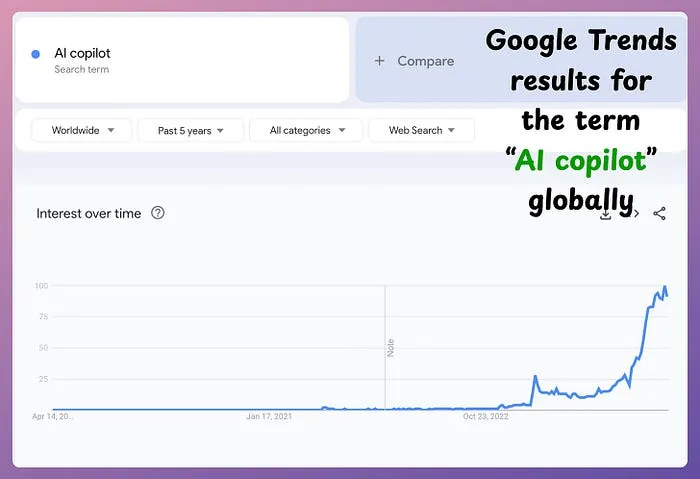
> Note: A copilot is an AI-powered application where users can ask questions in natural language and get responses specific to their context. The context cou... | avi_chawla |
1,888,609 | PM2 Add NodeJs Project In Process List | During the NodeJs project deployment we use the PM2 as process manager. PM2 monitor the application... | 0 | 2024-06-14T13:44:10 | https://dev.to/palchandu_dev/pm2-add-nodejs-project-in-process-list-1bk | During the NodeJs project deployment we use the [PM2](https://pm2.keymetrics.io/docs/usage/application-declaration/) as process manager.
PM2 monitor the application and restart it automatically while if app is crashing.
First install PM2 package
`$ npm install pm2@latest -g
# or
$ yarn global add pm2`
When managing... | palchandu_dev | |
1,888,607 | Exploring NFT Marketplaces in FinTech | Introduction The digital landscape is continuously evolving, and one of the... | 27,673 | 2024-06-14T13:39:14 | https://dev.to/rapidinnovation/exploring-nft-marketplaces-in-fintech-ogj | ## Introduction
The digital landscape is continuously evolving, and one of the most
significant advancements in recent years has been the rise of blockchain
technology. This innovation has paved the way for unique applications, one of
which is the creation and trading of Non-Fungible Tokens (NFTs). NFTs
represent a re... | rapidinnovation | |
1,888,606 | How To Install TestNG in Eclipse: Step By Step Guide | Test automation involves the use of specialized tools and frameworks to enhance the quality of the... | 0 | 2024-06-14T13:36:46 | https://dev.to/pcloudy_ssts/how-to-install-testng-in-eclipse-step-by-step-guide-14bo | exceptionhandling, testautomation, frameworks, junit | [Test automation](https://www.pcloudy.com/rapid-automation-testing/) involves the use of specialized tools and [frameworks ](https://www.pcloudy.com/top-10-test-automation-frameworks/)to enhance the quality of the application by writing and executing tests to verify the functionality of the application.
By automating... | pcloudy_ssts |
1,839,668 | Remote Startup Chaos: Do This and Thrive | Hi Coder, After the pandemic, we learned that people can be productive and efficient while working... | 0 | 2024-06-14T13:35:34 | https://dev.to/opensourceyllen/remote-startup-chaos-do-this-and-thrive-23j3 | workfromhome, remotework, startup, success | Hi Coder,
After the pandemic, we learned that people can be productive and efficient while working from the comfort of their homes. However, this flexibility comes with its own set of challenges and potential stress, especially when working remotely for a startup. That's why I decided to write this article: to help yo... | opensourceyllen |
1,888,604 | Hardening Your Multistage Builds: Security Considerations from Base Image to Final Artifact | Multistage builds are a powerful tool in Docker, allowing developers to create efficient and... | 0 | 2024-06-14T13:35:15 | https://dev.to/platform_engineers/hardening-your-multistage-builds-security-considerations-from-base-image-to-final-artifact-ihf | Multistage builds are a powerful tool in Docker, allowing developers to create efficient and optimized Docker images by breaking the build process into multiple stages. However, this complexity also introduces potential security risks if not properly managed. In this article, we will delve into the security considerati... | shahangita | |
1,888,535 | STEP BY STEP ON HOW TO DEPLOY AND CONNECT A VIRTUAL MACHINE ON AZURE CLOUD. | TABLE OF CONTENT Introduction Logging In Step 1 Configure Basic Settings Step 2 Configure Disk... | 0 | 2024-06-14T13:32:26 | https://dev.to/phillip_ajifowobaje_68724/step-by-step-on-how-to-deploy-and-connect-a-virtual-machine-on-azure-cloud-44oe | TABLE OF CONTENT
Introduction
Logging In
Step 1 Configure Basic Settings
Step 2 Configure Disk and Storage
Step 3 Networking
Step 4 Management
Step 5 Monitoring
Step 6 Review + Create
##
#### INTRODUCTION
There are various steps associated with the deployment and connection of a virtual machine in Azu... | phillip_ajifowobaje_68724 | |
1,888,603 | The Whole Manual for Using Odoo Services as Business Operating Solutions | Odoo's ERP software offers hardware support and application support, providing add-on functions like... | 0 | 2024-06-14T13:32:17 | https://dev.to/sandra_turner_fa105a2a6e4/the-whole-manual-for-using-odoo-services-as-business-operating-solutions-36ba | Odoo's ERP software offers hardware support and application support, providing add-on functions like sales, CRM, accounting, handling, and forecasting. Its modular approach ensures businesses can focus on relevant modules, making it versatile and useful. **[Odoo Implementation Services](https://www.bizople.com/odoo-imp... | sandra_turner_fa105a2a6e4 | |
1,888,601 | Oluyemi Akinyinka Awarded Doctor Of Management (Honoris Causa) By AUBSS And QAHE | Oluyemi Akinyinka, an esteemed Information Technology Project Manager, has been honored with the... | 0 | 2024-06-14T13:31:58 | https://dev.to/aubss_edu/oluyemi-akinyinka-awarded-doctor-of-management-honoris-causa-by-aubss-and-qahe-434k | education, aubss, news, qahe |

Oluyemi Akinyinka, an esteemed Information Technology Project Manager, has been honored with the prestigious title of Doctor of Management (Honoris Causa) by the American University of Business and Social Sciences ... | aubss_edu |
1,888,600 | Major Cross Browser Compatibility issues faced by the Developers | Introduction The digital world is constantly growing, and so are the browsers and devices. Customers... | 0 | 2024-06-14T13:26:41 | https://dev.to/pcloudy_ssts/major-cross-browser-compatibility-issues-faced-by-the-developers-g39 | crossbrowserstrategies, betteruserexperience, mdnsurvey2020 | Introduction
The digital world is constantly growing, and so are the browsers and devices. Customers are no more naive in choosing the best websites to fulfill their needs. So, it becomes necessary for the business to offer them the best user experience and services. There are so many browsers that come with new ver... | pcloudy_ssts |
1,888,599 | Top Magento Extensions for 2024: Must-Haves for Your eCommerce Site | Magento's flexibility and scalability make it a popular choice for eCommerce businesses. One of the... | 0 | 2024-06-14T13:26:01 | https://dev.to/thisuri_dewmini_63f59fbc8/how-to-implement-pwa-progressive-web-apps-in-magento-4go3 | webdev, magento, productivity, programming | Magento's flexibility and scalability make it a popular choice for eCommerce businesses. One of the key advantages of using [Magento is the vast array of extensions](https://www.neosolax.com.au/magento-agency/magento-extension-development/) available to enhance its functionality. As we move into 2024, here are some mus... | thisuri_dewmini_63f59fbc8 |
1,888,598 | New Member In Computer Science | HI! I'M A NEW MEMBER OF THE COMPUTER SCIENCE COMMUNITY. I WANT TO ASK THE PROFESSIONALS, HOW DO I... | 0 | 2024-06-14T13:23:08 | https://dev.to/xioreine/new-member-in-computer-science-50mf | newbie, learning, help, codenewbie | HI! I'M A NEW MEMBER OF THE COMPUTER SCIENCE COMMUNITY.
I WANT TO ASK THE PROFESSIONALS, HOW DO I START MY JOURNEY TO BE A PROGRAMMER AND A GAME DEVELOPER.
I HAVE NO EXPERIENCE BUT I HAVE DO SOME KNOWLEDGE IN THE CODING INDUSTRY.
CAN SOMEONE GUIDE ME TO BE A GOOD PROGRAMMER. | xioreine |
1,888,597 | Finding a Reliable Ride: Your Guide to Taxi Services Near You | In a busy world, hailing a taxi can be a lifesaver. Whether you're running late for an appointment or... | 0 | 2024-06-14T13:21:29 | https://dev.to/clocktowercars/finding-a-reliable-ride-your-guide-to-taxi-services-near-you-3hi | travel, taxi, uk, london | In a busy world, hailing a taxi can be a lifesaver. Whether you're running late for an appointment or simply don't feel like dealing with traffic, a taxi service offers a convenient and comfortable way to get around. But with so many options available, how do you find the right taxi service near you?
## Researching Ta... | clocktowercars |
1,888,222 | Automating the Building of VMs with Packer | Introduction There are many reasons why one might need a VM, for example: Learning new... | 0 | 2024-06-14T13:20:34 | https://dev.to/krjakbrjak/automating-the-building-of-vms-with-packer-420 | packer, automaton, qemu, virtualization | ## Introduction
There are many reasons why one might need a VM, for example:
1. **Learning new tools** like [Kubernetes](https://kubernetes.io/) and explore different ways of installing it, experimenting with various plugins, etc. If these tools are installed natively on the host and something goes wrong, it might re... | krjakbrjak |
1,888,583 | AWS Launches Two New AI Certifications: A Leap Forward for AI Enthusiasts - Coming August 2024 | AWS Launches Two New AI Certifications: A Leap Forward for AI Enthusiasts Amazon Web Services (AWS)... | 0 | 2024-06-14T13:16:34 | https://dev.to/stevewoodard/aws-launches-two-new-ai-certifications-a-leap-forward-for-ai-enthusiasts-coming-august-2024-210m | aws, ai, certification, training | AWS Launches Two New AI Certifications: A Leap Forward for AI Enthusiasts
Amazon Web Services (AWS) recently unveiled two new certifications focused on artificial intelligence (AI) and machine learning (ML). These certifications—AWS Certified AI Practitioner and AWS Certified Machine Learning Engineer – Associate—aim ... | stevewoodard |
1,888,585 | Navigating the Evolving Marketing Landscape: Harnessing AI for Strategic Success | In today's dynamic business environment, the integration of technology has become synonymous with... | 0 | 2024-06-14T13:14:28 | https://dev.to/linda0609/navigating-the-evolving-marketing-landscape-harnessing-ai-for-strategic-success-1jh4 | marketresearch | In today's dynamic business environment, the integration of technology has become synonymous with innovation and growth. Among the myriad of technological advancements driving change across industries, Artificial Intelligence (AI) stands out as a transformative force reshaping traditional marketinag methodologies and o... | linda0609 |
1,887,400 | Integrating React QuillJs with React Hook Form | Quilljs is a free, open-source library that lets developers easily add rich text editing capabilities... | 0 | 2024-06-14T13:10:29 | https://dev.to/arnaudfl/integrating-react-quilljs-with-react-hook-form-2ghj | react, quilljs, typescript, reacthookform | **Quilljs** is a free, open-source library that lets developers easily add rich text editing capabilities to their web applications. It provides a familiar WYSIWYG (What You See Is What You Get) editing experience, similar to popular word processors, allowing users to format text, add images, and create interactive con... | arnaudfl |
1,888,582 | Handling Actions Class in Selenium and its usage | Selenium is considered one of the best testing tools for automating web applications. It is a... | 0 | 2024-06-14T13:08:35 | https://dev.to/pcloudy_ssts/handling-actions-class-in-selenium-and-its-usage-3c86 | besttestingtools, multipleinteractions, selenium, seleniumwebdriver | [Selenium ](https://www.pcloudy.com/selenium-testing-for-effective-test-automation/)is considered one of the [best testing tools](https://www.pcloudy.com/top-10-test-automation-frameworks-in-2020/) for automating web applications. It is a powerful tool with built-in features to support all types of actions related to t... | pcloudy_ssts |
1,888,572 | How I Replaced Gaming with Coding | Are you a gamer looking to transition into coding? In this video, I share my personal journey of how... | 0 | 2024-06-14T13:08:32 | https://dev.to/proflead/how-i-replaced-gaming-with-coding-3hh1 | webdev, beginners, coding, story | Are you a gamer looking to transition into coding? In this video, I share my personal journey of how I replaced gaming with coding and became a web developer.
💬 Comment below with your own experiences or questions about transitioning from gaming to coding.
Follow me for daily updates and coding tips:
- [https://pro... | proflead |
1,888,581 | One Byte Explainer: What is a quine? | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-14T13:08:29 | https://dev.to/rivea0/one-byte-explainer-what-is-a-quine-4gi9 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
The answer is "The answer is".
Also called a _self-replicating program_, a quine is a computer program that outputs its own source code. The sentence above tries to mimic one. Its prac... | rivea0 |
1,888,580 | Game Dev Digest — Issue #237 - Graphics Programming, Animation, and more | Issue #237 - Graphics Programming, Animation, and more This article was originally... | 4,330 | 2024-06-14T13:08:11 | https://gamedevdigest.com/digests/issue-237-graphics-programming-animation-and-more.html | gamedev, unity3d, csharp, news | ---
title: Game Dev Digest — Issue #237 - Graphics Programming, Animation, and more
published: true
date: 2024-06-14 13:08:11 UTC
tags: gamedev,unity,csharp,news
canonical_url: https://gamedevdigest.com/digests/issue-237-graphics-programming-animation-and-more.html
series: Game Dev Digest - The Newsletter About Unity ... | gamedevdigest |
1,886,323 | Function fitting in Go | In Go, as in most programming languages, the return value of a function g() can be used as an... | 0 | 2024-06-14T13:07:39 | https://dev.to/qustavo/function-fitting-in-go-210f | go, programming, coding | In Go, as in most programming languages, the return value of a function `g()` can be used as an argument of another function `f()`.
```go
package main
func g() int { return 42 }
func f(n int) { println(n) }
func main() {
f(g()) // prints `42`
}
```
Now, what happens when `g()` returns more than one value, can we ... | qustavo |
1,888,579 | Test Data Management: Ensuring Quality and Efficiency in Software Testing | In the landscape of software development, ensuring the quality and reliability of applications is... | 0 | 2024-06-14T13:07:34 | https://dev.to/keploy/test-data-management-ensuring-quality-and-efficiency-in-software-testing-21mh | javascript | In the landscape of software development, ensuring the quality and reliability of applications is paramount. One of the critical components in achieving this goal is effective test data management (TDM). Test data management encompasses the processes, tools, and strategies used to create, maintain, and manage the data ... | keploy |
1,888,578 | pip Trends newsletter | 15-Jun-2024 | This week's pip Trends newsletter is out. Interesting stuff by John Franey, Nimrita Koul, Mike... | 0 | 2024-06-14T13:06:50 | https://dev.to/tankala/pip-trends-newsletter-15-jun-2024-423b | python, programming, news, beginners | This week's pip Trends newsletter is out. Interesting stuff by John Franey, Nimrita Koul, Mike Driscoll, Kris Jenkins, Ian Eyre, Trey Hunner & Tech Talks Weekly are covered this week
{% embed https://newsletter.piptrends.com/p/offline-speech-to-text-logging-with %} | tankala |
1,888,492 | Conditional Statement In Javascript | we use conditional statement in javascript when we want to perform different actions based on... | 0 | 2024-06-14T13:04:07 | https://dev.to/peter_akojede/conditional-statement-in-javascript-3pb9 | webdev, javascript, programming, coding |

we use conditional statement in javascript when we want to perform different actions based on different conditions. They are the fundamental part of programming and use when certain conditions are either true or fa... | peter_akojede |
1,888,576 | Moodcare: India’s Premier Intimate Wellness Online Store | At Moodcare, we recognize the critical importance of a fulfilling intimate life. This understanding... | 0 | 2024-06-14T12:58:37 | https://dev.to/moodcare/moodcare-indias-premier-intimate-wellness-online-store-4bh6 | webdev, moodcare, intimate, productivity | At Moodcare, we recognize the critical importance of a fulfilling intimate life. This understanding drives us to offer products that are not only effective but also safe and backed by extensive research. We believe that intimate wellness should be accessible to everyone, which is why we offer a wide range of products d... | moodcare |
1,888,574 | Object Oriented Programming | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-14T12:56:33 | https://dev.to/efpage/object-oriente-programming-4c8a | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Class based OOP is a paradigm that uses classes as templates for reusable code modules (objects). Objects can have their own private data and functions. Inheriting child classes is the... | efpage |
1,888,573 | Top Web Development Company in UK | Web Development Services in UK | Sapphire Software Solutions is Top Web Development Company in UK. Our web developers are skilled at... | 0 | 2024-06-14T12:55:39 | https://dev.to/samirpa555/top-web-development-company-in-uk-web-development-services-in-uk-4i00 | softwaredevelopment, softwaredevelopmentservices, softwaredevelopmentcompany | Sapphire Software Solutions is **[Top Web Development Company in UK](https://www.sapphiresolutions.net/top-web-development-company-in-uk)**. Our web developers are skilled at building websites, software and custom-built mobile apps that guarantee a seamless user experience through our best web development services in U... | samirpa555 |
1,888,571 | Multifunctional IDE using Neovim (3 of 3) | God mode activation Ok, here is the last section, let's summarize what we will do here.... | 0 | 2024-06-14T12:52:55 | https://dev.to/alekanteri/multifunctional-ide-using-neovim-3-of-3-1d62 | neovim, javascript, rust, code | ### God mode activation
Ok, here is the last section, let's summarize what we will do here. First, we will add a start page, just for beauty; if you use _Obsidian_, then it can be integrated into _vim_, this is also on our plan today; we will add a preview of `.md` files; cli for working with _git_; a very large and c... | alekanteri |
1,888,569 | OPAL Fetcher using GraphQL and Neon | As an enthusiastic student passionate about leveraging cutting-edge technologies, I participated in... | 0 | 2024-06-14T12:51:21 | https://dev.to/nithamitabh/opal-fetcher-using-graphql-and-neon-394b | python, postgressql, quine, graphql | - As an enthusiastic student passionate about leveraging cutting-edge technologies, I participated in the Medium Track of the OPAL challenge. My submission focuses on developing a custom GraphQL data fetcher for the **OPAL policy engine**, seamlessly integrated with a Neon _serverless Postgres_ database. This project n... | nithamitabh |
1,888,568 | Step-by-Step Guide: How to Create and Connect a Windows 11 Pro Azure Virtual Machine | ``Table of contents Step 1: Create an Azure Account Step 2: Create a Virtual Machine Step 3:... | 0 | 2024-06-14T12:51:04 | https://dev.to/mabis12/step-by-step-guide-how-to-create-and-connect-a-windows-11-pro-azure-virtual-machine-44kn | azure, windows, cloudcomputing, vm | ``**Table of contents**
Step 1: Create an Azure Account
Step 2: Create a Virtual Machine
Step 3: Choosing VM Configuration
Step 4: Review and Validation
Step 5: Deploying the Virtual Machine
Step 6: Download Key Pair (For SSH Access):
Step 7: Connect to virtual machine
Step 8: Clean up resources
In this blog, I'll be... | mabis12 |
1,888,563 | Best Practices for API Testing with Playwright in a Software Development Company | Modern software development hinges on the seamless interaction between various components and... | 0 | 2024-06-14T12:50:34 | https://dev.to/jessicab/best-practices-for-api-testing-with-playwright-in-a-software-development-company-5dmk | api, apitesting, playwright, softwaredevelopment | Modern software development hinges on the seamless interaction between various components and external services. Application Programming Interfaces (APIs) serve as the communication layer facilitating this exchange. While their presence may be subtle, their role is undeniable.
Therefore, a software development company... | jessicab |
1,888,567 | 2024'te Modern Web Geliştirme: Bilmeniz Gereken Trendler | 2024'te Modern Web Geliştirme: Bilmeniz Gereken Trendler Web geliştirme dünyası hızla... | 0 | 2024-06-14T12:50:26 | https://dev.to/alikaanyasa/2024te-modern-web-gelistirme-bilmeniz-gereken-trendler-30e7 | webdev, beginners | # 2024'te Modern Web Geliştirme: Bilmeniz Gereken Trendler
Web geliştirme dünyası hızla değişiyor. 2024 yılında hangi trendler ve araçlar öne çıkıyor? Bu yazıda, modern web geliştirme trendlerini ve bu alanda başarılı olmanın yollarını inceleyeceğiz.
## Web Geliştirme Trendleri
2024 yılında web geliştirme dünyasında... | alikaanyasa |
1,888,566 | Multifunctional IDE using Neovim (2 of 3) | Let's make it better We are done with the basic settings, now let's move on to improving... | 0 | 2024-06-14T12:50:22 | https://dev.to/alekanteri/multifunctional-ide-using-neovim-2-of-3-4off | neovim, javascript, rust, code | ### Let's make it better
We are done with the basic settings, now let's move on to improving our working environment. We will add convenient file navigation, a search engine and much more.
let's start with the explorer, everything is pretty standard here, we install the required plugin and write its configuration in ... | alekanteri |
1,887,773 | Type-Safe Env Vars With Vite - A Modern Approach | This post is a revamp of my previous one where I showed you how to use Zod and TS to create a... | 0 | 2024-06-14T12:49:46 | https://dev.to/seasonedcc/type-safe-env-vars-in-remix-a-modern-approach-with-arktype-11k9 | typescript, remix, advanced, vite | This post is a revamp of my [previous one](https://dev.to/seasonedcc/type-safe-environment-variables-on-both-client-and-server-with-remix-54l5) where I showed you how to use Zod and TS to create a type-safe environment variable system that works on both the client and server.
If you haven't read it yet, **go check it ... | gugaguichard |
1,888,565 | Multifunctional IDE using Neovim (1 of 3) | Introduction Hello everyone, my dear programmers, today we will step by step make from the... | 0 | 2024-06-14T12:49:29 | https://dev.to/alekanteri/multifunctional-ide-using-neovim-1-of-3-3a8g | neovim, javascript, rust, code | ## Introduction
Hello everyone, my dear programmers, today we will step by step make from the standard vim, a full-fledged tool capable of replacing VSCode if desired.
I often hear this question from my friends. Why not use a ready-made config like _LazyVim_ or _NVChad_? Well, firstly, I am the kind of person who lik... | alekanteri |
1,888,561 | How to find your forgotten software engineer tasks | Do you ever wonder how many software engineering tasks have fallen through the cracks? How many times... | 0 | 2024-06-14T12:47:22 | https://www.beyonddone.com/blog/posts/how-to-find-your-forgotten-tasks | productivity, softwareengineering, career, agile | Do you ever wonder how many software engineering tasks have fallen through the cracks? How many times you've let your coworkers down?
It is extremely easy for this to happen, especially for mentions of your username scattered across various platforms like GitHub, Jira, Google Docs, Slack, and so many others. Each of t... | sdotson |
1,888,560 | Join our discord builder's server | hey there folks, we're Tonic-AI We started off as an accidental community , but we're... | 0 | 2024-06-14T12:45:14 | https://dev.to/tonic-ai/join-our-discord-builders-server-48m9 | community, ai, buildinpublic, programming | ### hey there folks, we're Tonic-AI
We started off as an accidental community , but we're growing and supporting eachother, "building in public" and basically learning and ton and publishing a ton of demos and stuff.
- sounds good ?
** join us! **
[discord](https://discord.gg/ZbXm7YHsA7) | tonic |
1,888,555 | 5 Unique Features that Put Goleko Ahead of the Game | Project management platforms are requisite tools when it comes to structuring and assigning tasks,... | 0 | 2024-06-14T12:45:05 | https://dev.to/odhiambo_ouko/5-unique-features-that-put-goleko-ahead-of-the-game-3o0d | productivity, productmanagement, programming, discuss | Project management platforms are requisite tools when it comes to structuring and assigning tasks, promoting collaborations, sharing files, and, of course, boosting productivity. The need for project management solutions is even higher today, given the increasing number of remote and distributed teams around the world.... | odhiambo_ouko |
1,888,590 | Video: LLMs from the trenches | In the last year, I have met about 250 customers, most of them in person, and I have learned a few... | 0 | 2024-06-16T08:01:01 | https://julsimon.medium.com/video-llms-from-the-trenches-c31ee6f1bf12 | machinelearning, opensource, llm, ai | ---
title: Video: LLMs from the trenches
published: true
date: 2024-06-14 12:44:59 UTC
tags: machinelearning,opensource,llm,ai
canonical_url: https://julsimon.medium.com/video-llms-from-the-trenches-c31ee6f1bf12
---
In the last year, I have met about 250 customers, most of them in person, and I have learned a few thin... | juliensimon |
1,888,559 | Python beginner. | A post by Chiel | 0 | 2024-06-14T12:44:40 | https://dev.to/sammandro/python-beginner-5d6l | python, beginners | sammandro | |
1,888,558 | (React App for Review Sentiment Analysis) | Check out this Pen I made! A React application that dynamically highlights text in reviews based on... | 0 | 2024-06-14T12:44:20 | https://dev.to/aditya_singh2109/react-app-for-review-sentiment-analysis-3ane | codepen | Check out this Pen I made! A React application that dynamically highlights text in reviews based on sentiment analysis. Each highlight comes with a tooltip for additional context, making it easier to understand the sentiment and key topics in the reviews. Check it out! 🚀 #ReactJS #SentimentAnalysis #WebDevelopment #Te... | aditya_singh2109 |
1,888,557 | Best Clone Scripts from Appysa Technologies | Elearning Script Udemy Clone LMS Clone Lynda Clone Coursera Clone Rental Script Airbnb Clone Vrbo... | 0 | 2024-06-14T12:41:00 | https://dev.to/appysa/best-clone-scripts-from-appysa-technologies-340d | [Elearning Script](https://appysa.com/elearning-script/)
[Udemy Clone](https://appysa.com/udemy-clone/)
[LMS Clone](https://appysa.com/lms-clone/)
[Lynda Clone](https://appysa.com/lynda-clone/)
[Coursera Clone](https://appysa.com/coursera-clone/)
[Rental Script](https://appysa.com/rental-script/)
[Airbnb Clone](ht... | appysa | |
1,888,556 | What is Microservices Architecture? Examples, Challenges, Benefits and Best Practices | Microservices architecture is a software development approach that structures an application as a... | 0 | 2024-06-14T12:38:01 | https://dev.to/hyscaler/what-is-microservices-architecture-examples-challenges-benefits-and-best-practices-10be | Microservices architecture is a software development approach that structures an application as a collection of loosely coupled services, which can be developed, deployed, and scaled independently. It contrasts with the traditional monolithic architecture, where the entire application is built as a single unit.
## Exa... | rajatp | |
1,888,554 | Khong bang lai Phat bao nhieu | Không bằng lái phạt bao nhiêu? ô tô bị phạt tới 12 triệu, xe máy bị phạt tối đa tới 5 triệu đồng, vì... | 0 | 2024-06-14T12:33:07 | https://dev.to/kbanglaiphatbn/khong-bang-lai-phat-bao-nhieu-25oi | Không bằng lái phạt bao nhiêu? ô tô bị phạt tới 12 triệu, xe máy bị phạt tối đa tới 5 triệu đồng, vì thế hãy mang đầu đủ giấy phép và bằng lái.
#khongbanglaiphatbaonhieu, #nuoixevn, #chiphinuoixe
Gmail: nuoixevn@gmail.com
Website: https://nuoixe.vn/tin-tuc/khong-bang-lai-phat-bao-nhieu
Phone: 0338751746
Address: Số 70... | kbanglaiphatbn | |
1,888,553 | Nodemon is not for production! | What is Nodemon? Nodemon is a utility that automatically restarts your Node.js application... | 0 | 2024-06-14T12:32:42 | https://dev.to/kameshoff/nodemon-is-not-for-production-3mdj | ## What is Nodemon?
Nodemon is a utility that automatically restarts your Node.js application when file changes in the directory are detected. It is very useful during development because it allows developers to see the effects of their changes immediately without having to manually stop and restart the server.
## Wh... | kameshoff | |
1,888,552 | Introduction to MongoDB Queries | MongoDB, a popular NoSQL database, provides a flexible and efficient way to manage data.... | 0 | 2024-06-14T12:30:20 | https://dev.to/saumya27/introduction-to-mongodb-queries-3a8h | mongodb, webdev | MongoDB, a popular NoSQL database, provides a flexible and efficient way to manage data. Understanding basic MongoDB queries is crucial for interacting with your database effectively. This guide will walk you through the fundamental operations to get you started with querying MongoDB collections.
**What are Basic Mong... | saumya27 |
1,887,676 | Ağ Keşif - SNMP v3 Profili Nasıl Oluşturulur? | SNMP Keşif Oluşturma SNMP Bilgisi OLuştur butonu ile açılan ekranda gerekli bilgilerin girilmesi... | 0 | 2024-06-14T12:24:36 | https://dev.to/aciklab/ag-kesif-snmp-v3-profili-nasil-olusturulur-24hp | liman, snmp, linux, network | [SNMP Keşif Oluşturma](https://dev.to/aciklab/ag-kesif-snmp-kesif-olusturma-3e0h)

**SNMP Bilgisi OLuştur** butonu ile açılan ekranda gerekli bilgilerin girilmesi gerekir.
. Our collection features:
**Luxurious Designs:** Elegant and sophisticated designs to elevate ... | jawariya_shoukatali_ | |
1,888,550 | 10 Best Payment Gateways to Use with Gravity Forms Booking in 2024 | This article explores the symbiotic relationship between payment gateways and Gravity Booking,... | 0 | 2024-06-14T12:24:23 | https://dev.to/leo99/10-best-payment-gateways-to-use-with-gravity-forms-booking-in-2024-3ob5 |
This article explores the symbiotic relationship between [payment gateways](https://gravitybooking.com/set-up-and-use-mollie-payment-gateway/) and Gravity Booking, highlighting their important roles in seamless online transactions.
Importance of Payment Gateways in E-commerce
Discover why payment gateways are cruc... | leo99 | |
1,888,549 | explanation is "Hash Function in Computer Science." | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. Explainer A... | 0 | 2024-06-14T12:22:43 | https://dev.to/creation_world/explanation-is-hash-function-in-computer-science-5e1f | devchallenge, cschallenge, computerscience, beginners | This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer.](https://dev.to/challenges/cs)
**Explainer**
A hash function maps data of any size to a fixed-size value. It's used in data structures like hash tables to quickly find data. A good hash function minimizes collisions, where differe... | creation_world |
1,888,548 | TypeScript Enums are *more than ok* | As long as you use text-based ones. In TypeScript, enums by default assign numbers as the values in... | 0 | 2024-06-14T12:21:01 | https://dev.to/boscodomingo/typescript-enums-are-more-than-ok-ed6 | webdev, javascript, programming, typescript | **As long as you use text-based ones**.
In TypeScript, enums by default assign numbers as the values in the order the keys are defined. This means that changing existing enums can lead to unwanted changes:
```ts
enum Enum {
key0, // 0
key1 // 1
}
// Later commit, disaster strikes
enum Enum {
key0, // 0
key2, // ... | boscodomingo |
1,888,520 | Ağ Keşif - SNMP Keşif Oluşturma | Liman MYS arayüzünde Keşif oluşturulması işlemini ele alacağız. Ağ Keşif eklentimizin Keşif... | 0 | 2024-06-14T12:18:54 | https://dev.to/aciklab/ag-kesif-snmp-kesif-olusturma-3e0h | liman, snmp, linux, network | Liman MYS arayüzünde Keşif oluşturulması işlemini ele alacağız.
Ağ Keşif eklentimizin **Keşif** sekmesinde karşılaştığımız başlıklar:
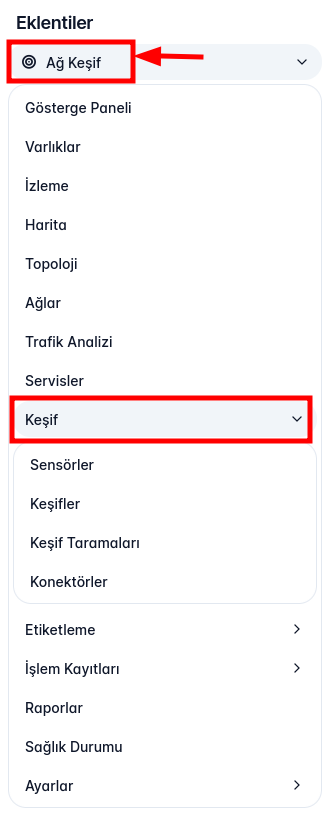
**Sensörler:** Bu sekmede sisteminizdeki sensörleri görüntüleyebilir, yönetebil... | yarensari |
1,888,544 | Organize your business with the best billing software in India | Visit: https://eazybills.com/blog/choose-best-billing-software-in-india The billing method is the... | 0 | 2024-06-14T12:17:02 | https://dev.to/eazy_bills_3c661bacbecc65/organize-your-business-with-the-best-billing-software-in-india-59kn | billing, software, gst, free | Visit: https://eazybills.com/blog/choose-best-billing-software-in-india
The billing method is the tool that sends the invoice to the clients with a detailed explanation of the goods and services provided and the payable amount. This type of billing method is generally used in business-to-business transactions as it h... | eazy_bills_3c661bacbecc65 |
1,888,543 | Unveiling the Mystical Energy of Himalaya Quartz | The world of crystals and gemstones is vast and varied, each stone imbued with unique properties and... | 0 | 2024-06-14T12:17:01 | https://dev.to/crystals_andreiki_211532/unveiling-the-mystical-energy-of-himalaya-quartz-32hg | himalayanquartz, crystal, reiki, himalayan | The world of crystals and gemstones is vast and varied, each stone imbued with unique properties and energies. Among these, Himalaya Quartz stands out, not only for its stunning beauty but also for its potent energy. Sourced from the majestic heights of the Himalayan mountains, Himalaya Quartz is renowned for its power... | crystals_andreiki_211532 |
1,888,542 | What are the cost structures typically associated with SaaS product development services? | Development and design expenses, cloud hosting and infrastructure fees, continuing maintenance and... | 0 | 2024-06-14T12:15:29 | https://dev.to/richard21266663/what-are-the-cost-structures-typically-associated-with-saas-product-development-services-57kc | saas, saasdevelopment, discuss | Development and design expenses, cloud hosting and infrastructure fees, continuing maintenance and support costs, marketing and sales costs, and subscription management charges are common cost structures for SaaS product development. In addition, there are fees for user training, customer support, security, and complia... | richard21266663 |
1,888,540 | Data-Driven Dapps Storage: Filecoin, Sia, & Arweave Compared | Introduction Welcome to Dapp Mentors! In this article, we'll explore decentralized... | 0 | 2024-06-14T12:12:46 | https://dev.to/daltonic/data-driven-dapps-storage-filecoin-sia-arweave-compared-g78 | web3, dapps, blockchain, news | ## Introduction
Welcome to [**Dapp Mentors!**](https://www.youtube.com/@dappmentors?sub_confirmation=1) In this article, we'll explore decentralized blockchain storage networks, a crucial aspect of building decentralized applications (dApps). Unlike regular blockchain networks, which focus on financial transactions, d... | daltonic |
1,888,539 | Elevate Your Home with Carrigaline Furniture and Carpet Selections | Whether you are looking to warm up your living room with an ultra-soft carpet or modernise your... | 0 | 2024-06-14T12:11:45 | https://dev.to/carrigalinefurniture/elevate-your-home-with-carrigaline-furniture-and-carpet-selections-2g29 | furniture, carpets | Whether you are looking to warm up your living room with an ultra-soft carpet or modernise your kitchen with super sleek Karndean LVT, with our extensive range of beautiful flooring and accessories to choose from, you’ll find the perfect style, comfort level and price (whether your looking for cheap vinyl flooring or l... | carrigalinefurniture |
1,888,537 | How to evaluate GenAI-based assistive search responses? | Many organizations around the world are adopting GenAI technologies in their workflow to make their... | 0 | 2024-06-14T12:10:15 | https://dev.to/ragavi_document360/how-to-evaluate-genai-based-assistive-search-responses-2jgi | Many organizations around the world are adopting GenAI technologies in their workflow to make their teams more productive and to achieve business outcomes that drive business growth.
Technical writers have a huge role in the GenAI era in ensuring trust in GenAI system-generated responses. Technical writers can produce... | ragavi_document360 | |
1,888,534 | Case Study: Web Crawler | This case study develops a program that travels the Web by following hyperlinks. The World Wide Web,... | 0 | 2024-06-14T12:08:44 | https://dev.to/paulike/case-study-web-crawler-2c6b | java, programming, learning, beginners | This case study develops a program that travels the Web by following hyperlinks. The World Wide Web, abbreviated as WWW, W3, or Web, is a system of interlinked hypertext documents on the Internet. With a Web browser, you can view a document and follow the hyperlinks to view other documents. In this case study, we will ... | paulike |
1,887,393 | Introducing Houdini Swap; A Privacy first cross-chain liquidity aggregator | TL; DR Move ETH to Mode in one-click privately and compliantly only on Houdini Swap. On the road... | 0 | 2024-06-14T12:07:08 | https://dev.to/modenetwork/introducing-houdini-swap-a-privacy-first-cross-chain-liquidity-aggregator-7ak | blockchain, privacy | > **_TL; DR_**
> Move ETH to Mode in one-click privately and compliantly only on [Houdini Swap](https://houdiniswap.com/).
On the road to making cryptocurrency, blockchain tools, and blockchain protocols user-friendly enough for mass adoption, we’ve had innovation and solutions around scalability and security issues... | modenetwork |
1,888,533 | How To Import Mail from Mac Outlook to Windows Outlook? – Solved | Should you be among the individuals seeking to import messages from Mac Outlook to Windows Outlook.... | 0 | 2024-06-14T12:06:14 | https://dev.to/cillian_61c2f5868ed268d07/how-to-import-mail-from-mac-outlook-to-windows-outlook-solved-4afg | outlook, mac, olm | Should you be among the individuals seeking to import messages from Mac Outlook to Windows Outlook. This article will then demonstrate how to rapidly complete it. The mailbox data is saved in different types of data files on Mac OS and Windows OS, even though the MS Outlook email application can be used on both platfor... | cillian_61c2f5868ed268d07 |
1,888,532 | 🚀 Open-Sourcing Truss Networks: Be Part of the Professional Networking Revolution! 🚀 | At Truss Networks, we’re all about community and transparency. Today, we're ecstatic to share a... | 0 | 2024-06-14T12:06:03 | https://dev.to/kiplangatkorir/open-sourcing-truss-networks-be-part-of-the-professional-networking-revolution-226a | opensource, webdev, javascript, programming | At Truss Networks, we’re all about community and transparency. Today, we're ecstatic to share a game-changing announcement: We are open-sourcing the development of Truss Networks!
Why Are We Open-Sourcing?
🔍 Transparency: We’re committed to building a trustworthy platform. Open-sourcing our code means our developmen... | kiplangatkorir |
1,887,734 | What is a Ledger and why you need to learn about it? | Portuguese Version What is Ledger Series What is a Ledger and why you need to learn... | 0 | 2024-06-14T12:05:47 | https://dev.to/woovi/what-is-a-ledger-and-why-you-need-to-learn-about-it-4d0g | javascript, mongodb | [Portuguese Version](https://daniloab.substack.com/p/o-que-e-ledger-e-por-que-voce-precisa)
## What is Ledger Series
1. [What is a Ledger and why you need to learn about it?](https://dev.to/woovi/what-is-ledger-and-why-does-it-need-idempotence-18n9)
2. [What is Ledger and why does it need Idempotence?](https://dev.to/... | daniloab |
1,888,531 | Innovative Python Development Solutions for Your Business | Harness the power of Python with our expert development services. We specialize in creating custom,... | 0 | 2024-06-14T12:05:30 | https://www.karandeeparora.com/ | Harness the power of Python with our expert development services. We specialize in creating custom, scalable solutions tailored to your business needs. From web applications to data analysis and automation, our team delivers high-quality, efficient, and robust Python solutions. Partner with us to transform your ideas i... | karandeeparora | |
1,888,530 | Avoiding Beginner Mistakes Hampering You to Scale Backend⚡️ | This blog covers how I unlocked performance that allowed me to scale my backend from 50K requests →... | 0 | 2024-06-14T12:05:21 | https://dev.to/rikenshah/scaling-backend-to-1m-requests-with-just-2gb-ram-4m0c | go, devops, backend, postgres |
This blog covers how I unlocked performance that allowed me to scale my backend from 50K requests → 1M requests (~16K reqs/min) on minimal resources (2 GB RAM 1v CPU and minimal network bandwidth 50-100 Mbps).

It will take you... | rikenshah |
1,888,529 | How Cloud Kitchen Business Models Have Transformed the Food Delivery Industry? | The rise of cloud kitchens has sparked a profound change in the food industry in recent years. This... | 0 | 2024-06-14T12:03:12 | https://dev.to/hazeljohnson/how-cloud-kitchen-business-models-have-transformed-the-food-delivery-industry-4281 |
The rise of cloud kitchens has sparked a profound change in the food industry in recent years. This radically new idea has challenged and transformed the traditional restaurant model. This provides restaurants... | hazeljohnson | |
1,888,528 | Exploring the Powerful Features of Ubuntu | Introduction Ubuntu stands as a prominent and robust operating system that has garnered immense... | 0 | 2024-06-14T12:03:00 | https://dev.to/rose_rusell_8839af0b0bba5/exploring-the-powerful-features-of-ubuntu-4c6c | ubuntu, vscode | Introduction
Ubuntu stands as a prominent and robust operating system that has garnered immense popularity within the tech community. This article delves into the powerful features of Ubuntu, highlighting its versatility and capability to cater to a wide range of computing needs.
The synergy of Ubuntu, a prominent Lin... | rose_rusell_8839af0b0bba5 |
1,888,527 | How Deutsche Telekom MMS optimizes Ansible Playbooks with Steampunk Spotter | Managing Ansible code quality across multiple teams and projects can be challenging. We talked to... | 0 | 2024-06-14T11:58:47 | https://steampunk.si/blog/how-deutsche-telekom-mms-optimizes-ansible-playbooks-with-spotter/ | ansibleplaybooks, successstory, automation | Managing Ansible code quality across multiple teams and projects can be challenging. We talked to **Andreas Hering, System Engineer at Deutsche Telekom MMS** that shared how he and his team handle the complexities of managing diverse Ansible environments with the help of Steampunk Spotter. They not only achieved signif... | xlab_steampunk |
1,888,526 | Will AI Take the Jobs of Employees in the Near Future? | The Impact of AI on Employment The rise of artificial intelligence (AI) has sparked significant... | 0 | 2024-06-14T11:58:35 | https://dev.to/balananujith/will-ai-take-the-jobs-of-employees-in-the-near-future-3ipe | **The Impact of AI on Employment**
The rise of artificial intelligence (AI) has sparked significant discussions about its potential impact on the job market. One concern that often emerges is whether AI will take the jobs of employees in the near future. While AI is poised to transform various industries, its effect o... | balananujith | |
1,888,525 | Common Mistakes to Avoid During Air Conditioning Repair | Introduction Repairing your air conditioning system requires careful attention to detail and... | 0 | 2024-06-14T11:58:27 | https://dev.to/affanali_offpageseo_a5ec6/common-mistakes-to-avoid-during-air-conditioning-repair-1126 |
Introduction
Repairing your air conditioning system requires careful attention to detail and adherence to best practices. Making mistakes during the repair process can lead to further damage, safety hazards, and costly repairs. This guide highlights common mistakes to avoid during [air conditioning repair](https://a... | affanali_offpageseo_a5ec6 | |
1,888,524 | Create your game with Octokit: The first ever Text-to-game AI generator | Octokit - One of the pioneers in text-to-game AI technology AI technology has been... | 0 | 2024-06-14T11:57:48 | https://dev.to/bui/create-your-game-with-octokit-the-first-ever-text-to-game-ai-generator-502b | ## Octokit - One of the pioneers in text-to-game AI technology
AI technology has been advancing at the speed of light and brought in a new era of discovery and innovation. AI algorithms, capable of processing and analyzing vast amounts of data with exceptional speed and accuracy, are transforming scientific research ac... | bui | |
1,888,523 | One Byte Explainer: Deadly Embrace | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. Deadly... | 0 | 2024-06-14T11:57:08 | https://dev.to/miketalbot/deadly-embrace-24jh | devchallenge, cschallenge, computerscience | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer.
Deadly embrace stops the world dead when one function holds a "lock" that is also required by a function it calls directly or indirectly. Neither can proceed so it's game over. It can be tough to find and debug.
| miketalbot |
1,888,522 | LP Propane Conversion Guide: Step-by-Step Instructions | 
```
Converting your appliances to LP propane can bring numerous benefits, including cost savings, increased energy efficiency, and environmental friendliness. This step-by-step guide will walk you through the [L... | affanali_offpageseo_a5ec6 | |
1,888,521 | 12 Best Google Play Store Alternatives in 2024 | 12 Best Google Play Store Alternatives in... | 0 | 2024-06-14T11:56:15 | https://dev.to/sh20raj/12-best-google-play-store-alternatives-in-2024-5chi | play, google, playstore, googleplaystorealternatives | # 12 Best Google Play Store Alternatives in 2024
> https://www.reddit.com/r/DevArt/comments/1dgbgiu/12_best_google_play_store_alternatives_in_2024/
The Google Play Store is the go-to marketplace for Android apps, but it’s not the only option out there. Whether you're looking for a broader selection, fewer restricti... | sh20raj |
1,880,402 | A quick guide to get started with Meteor.js community | Hello, there! So you just started with Meteor.js or you have been using it for a while, but maybe now... | 8,874 | 2024-06-14T11:55:54 | https://dev.to/storytellercz/a-quick-guide-to-get-started-with-meteorjs-community-43jp | meteor, javascript, beginners, tutorial | Hello, there! So you just started with Meteor.js or you have been using it for a while, but maybe now you want to find some help, talk to other people who use it or a good OSS developer/user want to get at least knowledgeable about the community. This guide/tutorial will introduce you to the basics of Meteor.js communi... | storytellercz |
1,888,519 | Objective C Interview Questions and Answers | Objective-C — the language that powers iOS and macOS development. Whether you’re a fresh-faced... | 0 | 2024-06-14T11:55:09 | https://dev.to/lalyadav/objective-c-interview-questions-and-answers-47nh | objectivec, programming, developer, objectivecinterviewquestions | Objective-C — the language that powers iOS and macOS development. Whether you’re a fresh-faced enthusiast or an aspiring developer, unlocking the secrets of Objective-C opens doors to creating powerful and intuitive applications. **[top interview questions and answers](https://www.onlineinterviewquestions.com/objective... | lalyadav |
1,888,517 | 5 Exciting HTML & Web Development Tutorials on LabEx 🚀 | The article is about 5 exciting HTML and web development tutorials from the LabEx platform. It covers a range of topics, including how to use the `<mark>` tag to highlight text, building a web-based TCP port scanner, leveraging the `<div>` tag and CSS for page layout and styling, showcasing sample code output with the ... | 27,723 | 2024-06-14T11:54:32 | https://dev.to/labex/5-exciting-html-web-development-tutorials-on-labex-4460 | coding, programming, tutorial, html |
Dive into the world of web development with this captivating collection of 5 HTML and web-based tutorials from the LabEx platform. Whether you're a beginner or an experienced programmer, these hands-on labs will equip you with the skills to create stunning web pages, build powerful web applications, and explore the la... | labby |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.