
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,887,939 | Today I learned about constant variables | <?php $a = 100 $b = 550 echo "$a + $b"; ?> Enter fullscreen mode Exit... | 0 | 2024-06-14T04:40:34 | https://dev.to/ahtshamajus/today-i-learned-about-constant-variables-4110 | webdev, php, beginners, backend |
```php
<?php
$a = 100
$b = 550
echo "$a + $b";
?>
```
| ahtshamajus |
1,887,938 | Test Data Generator: A Vital Tool in Software Development | In the realm of software development and quality assurance, one critical aspect that often... | 0 | 2024-06-14T04:39:17 | https://dev.to/keploy/test-data-generator-a-vital-tool-in-software-development-205k | data, webdev, javascript, ai |

In the realm of software development and quality assurance, one critical aspect that often determines the success or failure of a project is the quality of test data. The accuracy and robustness of testing directly ... | keploy |
1,887,937 | Tien Bao Dong Phuc | Công ty may đồng phục Tiến Bảo - chuyên may áo thun đồng phục, tạp dề đồng phục, quần áo bảo hộ, đồng... | 0 | 2024-06-14T04:36:06 | https://dev.to/rtdongphuctienbao/tien-bao-dong-phuc-3dbg | Công ty may đồng phục Tiến Bảo - chuyên may áo thun đồng phục, tạp dề đồng phục, quần áo bảo hộ, đồng phục học sinh, đồng phục công sở... giá xưởng tại hcm, miễn phí giao hàng, miễn phí may mẫu. Hotline 0902335112.
Website: https://dongphuctienbao.com/
Phone: 0902335112
Address: 276A Trần Thị Cờ, Tân Thới An, Quận 12, ... | rtdongphuctienbao | |
1,887,936 | Exploring the New Features in TypeScript 5.5 Beta | TypeScript 5.5 Beta introduces several exciting features and improvements aimed at enhancing the... | 0 | 2024-06-14T04:34:53 | https://www.jenuel.dev/blog/Exploring-the-New-Features-in-TypeScript-5-5-Beta | typescript, javascript | TypeScript 5.5 Beta introduces several exciting features and improvements aimed at enhancing the developer experience and increasing the language's flexibility and performance. Below, we delve into these new additions, providing detailed explanations and examples to illustrate their practical applications.
#### 1. **R... | jenueldev |
1,887,934 | Futuristic Worms Micelio | Check out this Pen I made! | 0 | 2024-06-14T04:32:47 | https://dev.to/kevgutierrez09_/futuristic-worms-micelio-112i | codepen, javascript, css | Check out this Pen I made!
{% codepen https://codepen.io/Kevin_Gutier09/pen/ExzKXbN %} | kevgutierrez09_ |
1,887,915 | Repositorio Institucional RIUCA | Check out this Pen I made! | 0 | 2024-06-14T04:19:52 | https://dev.to/kevgutierrez09_/repositorio-institucional-riuca-30fc | codepen, javascript | Check out this Pen I made!
{% codepen https://codepen.io/Kevin_Gutier09/pen/zYQEJwp %} | kevgutierrez09_ |
1,887,933 | A New Whatsapp Bot | Hey Guys I AM Turbo And I Am New To This Platform But I Wanted To Show You All About A Whatsapp Bot I... | 0 | 2024-06-14T04:23:57 | https://dev.to/toxic_turbo777/a-new-whatsapp-bot-4ip3 | showdev, node, docker, git | Hey Guys I AM Turbo And I Am New To This Platform But I Wanted To Show You All About A Whatsapp Bot I Made It's A Chatbot And Userbot I Made It's Using @whiskeysockets/baileys And This Was Built On Node Js Please Check Out My GitHub And Give A Star It Will Help Me To Continue
GitHub Repository: https://github.com/TUR... | toxic_turbo777 |
1,887,932 | Lô đề online là gì Cách chơi lô đề 123B hiệu quả | Việc đánh đề từ xưng đến nay luôn thu hút được rất nhiều người tham gia bởi lối chơi đa dạng và hấp... | 0 | 2024-06-14T04:23:47 | https://dev.to/123bonl/lo-de-online-la-gi-cach-choi-lo-de-123b-hieu-qua-2ce | 8us, lodeonline, lode |
Việc đánh đề từ xưng đến nay luôn thu hút được rất nhiều người tham gia bởi lối chơi đa dạng và hấp dẫn. Trò chơi này không chỉ đem lại nguồn thu nhập cho người chơi mà nó còn làm từ bộ môn số học đòi hỏi tính logic và tính suy luận cao.
Bên cạnh đó ngành công nghệ thông tin ngày càng phát triển mạnh mẽ nên hầu hết ... | 123bonl |
1,887,931 | LinkNetwork丨Scalability: The Ultimate Challenge for Public Chains | In the extensive field of blockchain technology applications, public chains, serving as the... | 0 | 2024-06-14T04:23:07 | https://dev.to/linknetwork/linknetworkgun-scalability-the-ultimate-challenge-for-public-chains-pjb |

In the extensive field of blockchain technology applications, public chains, serving as the foundational platforms for decentralized applications (DApps), have constantly faced a significant challenge in scalability... | linknetwork | |
1,887,930 | Animated Slider | Punishing Gray Graven #Team | Inspired by the pen about 'Stranger Things' by Ricardo Oliva Alonso Deaign Original. Adaptation:... | 0 | 2024-06-14T04:22:35 | https://dev.to/kevgutierrez09_/animated-slider-punishing-gray-graven-team-41ni | codepen, javascript, css, animation | Inspired by the pen about 'Stranger Things' by Ricardo Oliva Alonso
Deaign Original.
Adaptation: Kevin Gutiérrez
{% codepen https://codepen.io/Kevin_Gutier09/pen/WNBpWGM %} | kevgutierrez09_ |
1,887,905 | Best Practices for Migrating from Heroku to AWS | Migrating from Heroku to Amazon Web Services (AWS): Essential Considerations and Best... | 0 | 2024-06-14T03:50:22 | https://dev.to/emma_in_tech/best-practices-for-migrating-from-heroku-to-aws-11aa | ##Migrating from Heroku to Amazon Web Services (AWS): Essential Considerations and Best Practices
In today's cloud-centric era, businesses frequently face critical decisions when selecting the appropriate platform for hosting their applications. This article delves into the essential considerations, challenges, and be... | emma_in_tech | |
1,887,913 | argc, argv의 차이 | int argc argc = argument count argc는 운영체제가 이 프로그램을 실행했을 때 전달되는 인수의 갯수이다. 즉, main()함수에 전달되는 데이터의 갯수를... | 0 | 2024-06-14T04:16:17 | https://dev.to/sunj/argc-argvyi-cai-3aho | server | 1. int argc
- argc = argument count
- argc는 운영체제가 이 프로그램을 실행했을 때 전달되는 인수의 갯수이다.
- 즉, main()함수에 전달되는 데이터의 갯수를 의미한다.
2. char *argv[]
- argv = argument variable
- char *argv[]: 문자열의 주소를 저장하는 포인터 배열
- argv[0]은 프로그램의 실행경로이다.
- argv[1], argv[2] ... 에는 순서대로 사용자가 입력한 argument가 저장된다.
예를 들어, int main(int argc, char *argv[... | sunj |
1,887,912 | Mastering NextJS: Exploration of Its 12 Key Concepts | Introduction: In the realm of web development, NextJS has emerged as a powerful tool that simplifies... | 0 | 2024-06-14T04:13:37 | https://dev.to/vyan/mastering-nextjs-exploration-of-its-12-key-concepts-14e1 | webdev, beginners, nextjs, react | **Introduction:**
In the realm of web development, NextJS has emerged as a powerful tool that simplifies the process of building full-stack applications with just React. In this blog, we will delve into the 12 key concepts of NextJS, as outlined in a tutorial, to provide a comprehensive understanding of its capabilitie... | vyan |
1,887,911 | Documenting my pin collection with Segment Anything: Part 3 | In my last post, I showed how to use the Segment Anything Model with prompts to improve the... | 27,656 | 2024-06-14T04:11:08 | https://blog.feregri.no/blog/documenting-my-pin-collection-with-segment-anything-part-3/ | fastapi, segmentanything, imagesegmentation | In [my last post](https://dev.to/feregri_no/documenting-my-pin-collection-with-segment-anything-part-2-4pjc), I showed how to use the Segment Anything Model with prompts to improve the segmentation output, in it I decided that using bounding boxes to prompt the model yielded the best results for my purposes.
In this p... | feregri_no |
1,887,910 | PostgreSQL Full-Text Search in a Nutshell | If you ask me to choose a database for microservices, I would probably say PostgreSQL. On one hand,... | 0 | 2024-06-14T04:02:48 | https://dev.to/lazypro/postgresql-full-text-search-2dio | database, elasticsearch, tutorial, programming |
If you ask me to choose a database for microservices, I would probably say PostgreSQL.
On one hand, PostgreSQL is a popular open source database with many mature practices, both on the server side and the client side. On the other hand, PostgreSQL is very "scalable". Scalability of course includes non-functional requ... | lazypro |
1,887,908 | Alien: Defining New Freedoms and Ultimate Efficiency in Global Communication | In the current era of rapid globalization, communication technology plays an essential role.... | 0 | 2024-06-14T04:00:26 | https://dev.to/alien_web3/alien-defining-new-freedoms-and-ultimate-efficiency-in-global-communication-2h9d |

In the current era of rapid globalization, communication technology plays an essential role. However, despite the continuous advancements in technology, the global communication industry still faces numerous challen... | alien_web3 | |
1,886,848 | Mastering Version Control with Git: Beyond the Basics | _Welcome Aboard Week 2 of DevSecOps in 5: Your Ticket to Secure Development Superpowers! Hey there,... | 27,560 | 2024-06-14T03:48:00 | https://dev.to/gauri1504/mastering-version-control-with-git-beyond-the-basics-44ib | devops, devsecops, cloud, security |
_Welcome Aboard Week 2 of DevSecOps in 5: Your Ticket to Secure Development Superpowers!
Hey there, security champions and coding warriors!
Are you itching to level up your DevSecOps game and become an architect of rock-solid software? Well, you've landed in the right place! This 5-week blog series is your fast track... | gauri1504 |
1,887,904 | How Data Integration Is Evolving Beyond ETL | Forward-looking technologies are generally cutting-edge and used by early adopters, offering some... | 0 | 2024-06-14T03:47:11 | https://dev.to/seatunnel/how-data-integration-is-evolving-beyond-etl-4gn1 | datascience, dataintegration, opensource, etl | > Forward-looking technologies are generally cutting-edge and used by early adopters, offering some business value.

Image by GrumpyBeere from Pixabay.
When it comes to data integration, some people may wonder wh... | seatunnel |
1,887,902 | Introduction to Temporary Environments( Ephemeral Environments): A Beginner's Guide | The article examines the distinctions between conventional persistent staging environments and... | 0 | 2024-06-14T03:43:12 | https://dev.to/emma_in_tech/introduction-to-temporary-environments-ephemeral-environments-a-beginners-guide-2ecm | aws, devops, cloudcomputing, development | The article examines the distinctions between conventional persistent staging environments and contemporary ephemeral environments for software testing. It highlights the issues associated with shared persistent environments, such as infrastructure overhead, queueing delays, and the risk of significant changes. On the ... | emma_in_tech |
1,887,901 | O que é um mapeamento de estoque? | Mapeamento de estoque Um mapeamento de estoque eficaz envolve um conjunto de regras para garantir... | 0 | 2024-06-14T03:38:06 | https://dev.to/marlonjerold/o-que-e-um-mapeamento-de-estoque-1kmn | softwaredevelopment, projectideas | **Mapeamento de estoque**
Um mapeamento de estoque eficaz envolve um conjunto de regras para garantir que os processos relacionados a inventário e gestão de estoque sejam precisos e eficientes com o objetivo de suprir as necessidades da empresa.
Armazenamento e localização!
- Definição de locais de armazenamento (pr... | marlonjerold |
1,887,900 | How to connect MySQL using SQLynx | Query your MySQL data to safely and asily write, update, and delete without accidentally dropping... | 0 | 2024-06-14T03:37:25 | https://dev.to/concerate/how-to-connect-mysql-using-sqlynx-50g3 | Query your MySQL data to safely and asily write, update, and delete without accidentally dropping tables.
You can also inspect your schema, save and share queries, and run ad hoc analyses quickly.
SQLynx is a database IDE that is tailored to suit the specific needs of professional SQL developers.
SQLynx stands out as ... | concerate | |
1,887,899 | The Cutting-Edge Technology Behind DeepFasts Drilling Tools | DeepFasts Drilling Tools: The Future of Drilling. Introduction Have you previously seen a... | 0 | 2024-06-14T03:34:45 | https://dev.to/tahera_tabiya_2d8c7b907d0/the-cutting-edge-technology-behind-deepfasts-drilling-tools-3daf | DeepFasts Drilling Tools: The Future of Drilling.
Introduction
Have you previously seen a construction site where big and machines that are powerful through rocks and soil to lay the foundation of a building or a road? The machines they use are called drilling machines, and they make holes in the ground to extract res... | tahera_tabiya_2d8c7b907d0 | |
1,887,898 | Efficient Roofing Companies in Conroe TX for Quick Fixes | Looking to fix that pesky leak or replace your worn-out roof in Conroe, TX? Look no further!... | 0 | 2024-06-14T03:29:48 | https://dev.to/dbanerjee/efficient-roofing-companies-in-conroe-tx-for-quick-fixes-3ni4 | Looking to fix that pesky leak or replace your worn-out roof in Conroe, TX? Look no further! Efficient [roofing companies in Conroe TX](https://discount-roofing.com/roofing-companies-in-conroe-tx/) are the superheroes of quick fixes when it comes to protecting your home from the elements. In this blog post, we'll dive ... | dbanerjee | |
1,887,897 | Some Thoughts on the Logic of Crypto Currency Futures Trading | Problem scene For a long time, the data delay problem of the API interface of the crypto... | 0 | 2024-06-14T03:27:13 | https://dev.to/fmzquant/some-thoughts-on-the-logic-of-crypto-currency-futures-trading-2l3e | cryptocurrency, trading, futures, fmzquant | ## Problem scene
For a long time, the data delay problem of the API interface of the crypto currency exchange has always troubled me. I haven't found a suitable way to deal with it. I will reproduce the scene of this problem.
Usually the market order provided by the contract exchange is actually the counterparty price... | fmzquant |
1,546,828 | Compilado dicas de carreira - parte 3 | Dicas de engenharia de software parte 3 | 0 | 2024-06-14T03:26:11 | https://dev.to/hugaomarques/compilado-dicas-de-carreira-parte-3-4fd6 | iniciante, java, algoritmos, leetcode | ---
title: Compilado dicas de carreira - parte 3
published: true
description: Dicas de engenharia de software parte 3
tags: #iniciante #java #algoritmos #leetcode
---
## Dica #21: Nem tudo é só vitória
Cuidado ao achar que a galera que você segue com sucesso, trabalhando em grandes empresas, só teve vitórias na carre... | hugaomarques |
1,887,896 | AI Solutions: The Future of BFSI Innovation | Understanding BFSI AI Solutions Artificial Intelligence (AI) is rapidly transforming the Banking,... | 0 | 2024-06-14T03:21:48 | https://dev.to/avinashchander9077/ai-solutions-the-future-of-bfsi-innovation-190h | ai, bfsi, innovation, aisolutions | **Understanding BFSI AI Solutions**

Artificial Intelligence (AI) is rapidly transforming the Banking, Financial Services, and Insurance (BFSI) sector. AI solutions in BFSI leverage machine learning, natural language... | avinashchander9077 |
1,887,895 | Mastering Custom Hooks in React: A Comprehensive Guide | React hooks have revolutionized the way developers build components, making it easier to manage state... | 0 | 2024-06-14T03:21:15 | https://dev.to/hasancse/mastering-custom-hooks-in-react-a-comprehensive-guide-1bfb | webdev, javascript, programming, react | React hooks have revolutionized the way developers build components, making it easier to manage state and side effects. Custom hooks, in particular, provide a powerful mechanism to encapsulate logic and reuse it across components. In this blog post, we’ll explore how to create and use custom hooks in React, along with ... | hasancse |
1,887,884 | Dive into Kivy: Building User-Friendly Windows Apps with Python | The realm of app development can often seem daunting, shrouded in complex languages and frameworks.... | 0 | 2024-06-14T03:17:35 | https://dev.to/epakconsultant/dive-into-kivy-building-user-friendly-windows-apps-with-python-p2f | windows | The realm of app development can often seem daunting, shrouded in complex languages and frameworks. But what if you could leverage the power of Python to create user-friendly applications for Windows? Enter Kivy, a free and open-source framework that empowers you to build cross-platform apps, including those specifical... | epakconsultant |
1,887,882 | Demystifying Streamlit: Building Web Apps with Python in Minutes | Imagine transforming your Python scripts into interactive web apps within minutes. Streamlit, a... | 0 | 2024-06-14T03:13:01 | https://dev.to/epakconsultant/demystifying-streamlit-building-web-apps-with-python-in-minutes-2k3l | python | Imagine transforming your Python scripts into interactive web apps within minutes. Streamlit, a powerful open-source framework, makes this a reality. This article delves into the core concepts of Streamlit web apps, empowering you to craft user-friendly data visualizations and applications with ease.
## Streamlit: Sim... | epakconsultant |
1,887,880 | How Sichuan DeepFast Oil Drilling Tools Co., Ltd is Revolutionizing the Oil Industry | The Revolutionary DeepFast Oil Drilling Devices coming from Sichuan are Changing the Oil Market.... | 0 | 2024-06-14T03:11:05 | https://dev.to/tahera_tabiya_2d8c7b907d0/how-sichuan-deepfast-oil-drilling-tools-co-ltd-is-revolutionizing-the-oil-industry-27da | The Revolutionary DeepFast Oil Drilling Devices coming from Sichuan are Changing the Oil Market.
Introduction
The oil fuel market was an resource important of income for several years, it proceeds to become in fantastic need around the world. Due to the require enhancing power, it is end up being essential towards che... | tahera_tabiya_2d8c7b907d0 | |
1,887,876 | Nice to join DEV | Hello, everyone! I am a game fan. welcome to chat with me! | 0 | 2024-06-14T03:08:25 | https://dev.to/huayaogames/nice-to-join-dev-1aif | gamedev, ai, webdev | Hello, everyone!
I am a game fan.
welcome to chat with me!
| huayaogames |
1,887,875 | Building Your Dream App: A Guide to Mobile App Development with Tapcart | In today's mobile-first world, a well-crafted app can be a game-changer for businesses. But... | 0 | 2024-06-14T03:04:58 | https://dev.to/epakconsultant/building-your-dream-app-a-guide-to-mobile-app-development-with-tapcart-45go | app | In today's mobile-first world, a well-crafted app can be a game-changer for businesses. But traditional app development can be expensive and time-consuming. Enter Tapcart, a powerful platform that empowers businesses to create native mobile apps without the hassle of complex coding. This article explores the world of T... | epakconsultant |
1,887,874 | Building Infrastructure as Code: Unlocking the Power of AWS CloudFormation | Building Infrastructure as Code: Unlocking the Power of AWS CloudFormation In the... | 0 | 2024-06-14T03:02:28 | https://dev.to/virajlakshitha/building-infrastructure-as-code-unlocking-the-power-of-aws-cloudformation-3273 | 
# Building Infrastructure as Code: Unlocking the Power of AWS CloudFormation
In the ever-evolving landscape of cloud computing, managing and provisioning cloud resources efficiently is paramount. AWS CloudFormation emerges as a powerf... | virajlakshitha | |
1,887,873 | The Big Three of UI/UX Design: Figma, Sketch, and Adobe XD | In today's digital landscape, crafting user-centric interfaces and experiences (UI/UX) is paramount.... | 0 | 2024-06-14T03:00:20 | https://dev.to/epakconsultant/the-big-three-of-uiux-design-figma-sketch-and-adobe-xd-2nno | uiux | In today's digital landscape, crafting user-centric interfaces and experiences (UI/UX) is paramount. Thankfully, a trio of powerful design tools has emerged, empowering designers to bring their visions to life: Figma, Sketch, and Adobe XD. Each boasts unique strengths, making the choice between them a thoughtful consid... | epakconsultant |
1,887,870 | Friction Liner/Gasket Manufacturers: Supporting Industrial Operations Worldwide | Friction Liner/Gasket Manufacturers: Supporting Industry Worldwide Introduction: Friction... | 0 | 2024-06-14T02:52:16 | https://dev.to/tahera_tabiya_2d8c7b907d0/friction-linergasket-manufacturers-supporting-industrial-operations-worldwide-poh | Friction Liner/Gasket Manufacturers: Supporting Industry Worldwide
Introduction:
Friction liner/gasket manufacturers are becoming required for commercial operations worldwide They offer an solution this really is gear definitely vital is ensuring helpful and production procedures run effortlessly This informative artic... | tahera_tabiya_2d8c7b907d0 | |
1,887,869 | Un buen libro para aprender y educar en programación | Hola. Recientemente he estado dandole forma a contenido educativo para enseñar programación y dar... | 0 | 2024-06-14T02:51:23 | https://dev.to/chema/un-buen-libro-para-aprender-y-educar-en-programacion-20li | books, programming, learning, spanish | Hola. Recientemente he estado dandole forma a contenido educativo para enseñar programación y dar unas mentorías. Y de paso, para recordar y reaprender los fundamentos.
En un punto me dio por recordar cómo fue que yo empecé a aprender, y cómo fue mi proceso 🤔.
Definitivamente no fue algo que podamos llamar "straight... | chema |
1,887,868 | Cube Therapy Billing - Stability and permanence | Cube Therapy Billing provides tailored RCM billing and credentialing solutions for ABA therapy... | 0 | 2024-06-14T02:45:35 | https://dev.to/cube-therapy-billing/cube-therapy-billing-stability-and-permanence-2730 | consulting, b2b, billing | Cube Therapy Billing provides tailored RCM billing and credentialing solutions for ABA therapy providers. Highly recommended to help you focus on your business and accelerate your revenue by taking your business to higher ground. Our services include pre-service support, claims management, and insurance credentialing.
... | cube-therapy-billing |
1,887,867 | Guide Wheel Liners for Mine Hoists: Precision Engineering for Reliability | photo_6284972798862540183_y.jpg Title: Guide Wheel Liners for Mine Hoists: Precision Engineering for... | 0 | 2024-06-14T02:42:26 | https://dev.to/tahera_tabiya_2d8c7b907d0/guide-wheel-liners-for-mine-hoists-precision-engineering-for-reliability-26id | photo_6284972798862540183_y.jpg
Title: Guide Wheel Liners for Mine Hoists: Precision Engineering for Reliability
Are you interested about guide wheel liners for mine hoists? Look no more. We'll explore the benefits of guide wheel linings, the development and safety they provide, their use and applications, in additio... | tahera_tabiya_2d8c7b907d0 | |
1,887,866 | Benefits of Having a High Google Page Ranking | Hello, everyone! Achieving a high ranking on Google's search results pages is more than just a badge... | 0 | 2024-06-14T02:39:28 | https://dev.to/juddiy/benefits-of-having-a-high-google-page-ranking-1g1j | seo, google, discuss | Hello, everyone!
Achieving a high ranking on Google's search results pages is more than just a badge of honor—it can significantly impact your online presence and business success. Here are several key benefits of having a high Google page ranking:
1. **Increased Visibility and Traffic**: Ranking higher on Google mea... | juddiy |
1,887,865 | Punk Rave Introduction | DESIGN CONCEPT Decorated with costume, inspired with behavior to meet those people with same”No... | 0 | 2024-06-14T02:38:27 | https://dev.to/ninawind/punk-rave-introduction-2h21 | DESIGN CONCEPT
Decorated with costume, inspired with behavior to meet those people with same”No depressed, never slavish” punk feeling just like PUNK RAVE.
PUNK RAVE Gothic romantic classicism feelings are spelled with the punk-like rebel’s strong personality, combined with the contemporary characteristics of the scen... | ninawind | |
1,887,824 | Steps to create Azure Virtual Machine | First things first, you can create an Azure Virtual Machine through the Azure portal. A simple... | 0 | 2024-06-14T02:36:56 | https://dev.to/ikay/steps-to-create-azure-virtual-machine-5a74 | azure, virtualmachine, networking, datacenter | First things first, you can create an Azure Virtual Machine through the Azure portal. A simple browser-based user interface can help you create virtual machines along with all the additional resources. With this quick step-by-step guide, you can deploy your own Azure Virtual Machine.
Before getting started, make sure ... | ikay |
1,887,864 | Exploring Material Innovations in Friction Liner/Gasket Manufacturing | photo_6284972798862540181_y.jpg Exploring the Wonders of the New Friction Liner/Gasket Material... | 0 | 2024-06-14T02:31:07 | https://dev.to/tahera_tabiya_2d8c7b907d0/exploring-material-innovations-in-friction-linergasket-manufacturing-3p2c | photo_6284972798862540181_y.jpg
Exploring the Wonders of the New Friction Liner/Gasket Material Innovations
Friction liner/gaskets are essential components in machines and equipment help prevent leakage and ensure a seal tight. A years few, friction liners/gaskets were made of traditional materials like rubber, asbest... | tahera_tabiya_2d8c7b907d0 | |
1,887,863 | Enhanced analysis tool based on Alpha101 grammar development | Summary The FMZ platform launched a trading factor analysis tool based on "WorldQuant... | 0 | 2024-06-14T02:30:27 | https://dev.to/fmzquant/enhanced-analysis-tool-based-on-alpha101-grammar-development-3ekp | analysis, trading, fmzquant, cryptocurrency | ## Summary
The FMZ platform launched a trading factor analysis tool based on "WorldQuant Alpha101", which provides a new weapon for developers of quantitative trading strategies. Through analysis factors, it helps everyone better understand the market and gain insight into the opportunities behind the financial market.... | fmzquant |
1,887,862 | Test | Test | 0 | 2024-06-14T02:30:00 | https://dev.to/testingwebfree/test-3a9j | webdev, beginners | #Test | testingwebfree |
1,887,861 | Synthesis of Peptide Nucleic Acids (PNA) | Peptide nucleic acid (PNA) synthesis is the process of creating PNA oligomers in the laboratory. The... | 0 | 2024-06-14T02:26:14 | https://dev.to/creativepeptides/synthesis-of-peptide-nucleic-acids-pna-3o5e | Peptide nucleic acid (PNA) synthesis is the process of creating PNA oligomers in the laboratory. The synthesis of peptide nucleic acid is a synthetic nucleic acid analogue that has a pseudopeptide backbone, making it resistant to enzymatic degradation and stable under a wide range of conditions.
The [synthesis of PNA]... | creativepeptides | |
1,887,860 | The relationship between 5G and LED display | Displays and 5G seem to have no direct relationship, but in fact, the two are closely related. LED... | 0 | 2024-06-14T02:24:34 | https://dev.to/sostrondylan/the-relationship-between-5g-and-led-display-50gl | 5g, led, display | Displays and 5G seem to have no direct relationship, but in fact, the two are closely related. [LED display](https://sostron.com/products/) industry relies on the advancement of network technology to achieve today's development. With the advent of the 5G era, the full opening of the Internet of Everything will bring ne... | sostrondylan |
1,887,859 | Guide Wheel Liners for Mine Hoists: Ensuring Smooth Movement and Control | photo_6284972798862540183_y.jpg Title: Making Mine Hoists Safer and More Efficient with Guide Wheel... | 0 | 2024-06-14T02:22:55 | https://dev.to/tahera_tabiya_2d8c7b907d0/guide-wheel-liners-for-mine-hoists-ensuring-smooth-movement-and-control-3pdg | photo_6284972798862540183_y.jpg
Title: Making Mine Hoists Safer and More Efficient with Guide Wheel Liners
Introduction
Guide Wheel Liners are an innovative development in the area of mine technology hoisting. They provide a variety of benefits, such as ensuring movement control smooth improving safety, and prolongin... | tahera_tabiya_2d8c7b907d0 | |
1,887,853 | Unveiling URI, URL, and URN | This guide provides an overview of URI, URL, and URN, explaining their differences and use... | 0 | 2024-06-14T02:12:55 | https://blog.logto.io/unveiling-uri-url-and-urn/ | webdev, coding, programming, opensource | This guide provides an overview of URI, URL, and URN, explaining their differences and use cases.
---
When developing web apps, we often need to call different web services. When configuring the communication and connection of different web services, we frequently encounter the concepts of URI, URL, and URN. Usually, ... | palomino |
1,887,850 | Ready, Set, LAUNCH!! How to Launch and Connect to an AWS EC2 Instance. | AWS EC2 (Amazon Elastic Compute Cloud) is a popular service that provides scalable computing capacity... | 0 | 2024-06-14T01:49:07 | https://dev.to/techgirlkaydee/ready-set-launch-how-to-launch-and-connect-to-an-aws-ec2-instance-1jbj | aws, compute, ec2, cloudcomputing | [AWS EC2 (Amazon Elastic Compute Cloud)](https://aws.amazon.com/ec2/) is a popular service that provides scalable computing capacity in the cloud. Whether you're setting up a server for the first time or just need a refresher, this guide will walk you through launching an EC2 instance and connecting to it.
---
## **P... | techgirlkaydee |
1,887,849 | Help! my husband is Spying on My iPhone from his Computer - What should I do? | Yesterday, after work, I made a shocking discovery that left me feeling completely violated and... | 0 | 2024-06-14T01:49:07 | https://dev.to/brittany_jones/help-my-husband-is-spying-on-my-iphone-from-his-computer-what-should-i-do-1m4a | news | Yesterday, after work, I made a shocking discovery that left me feeling completely violated and betrayed. I found out that my husband has been remotely spying on my iPhone from his Mac computer.
I never imagined that my own spouse would be invading my privacy in such a blatant manner. It has left me feeling confused a... | brittany_jones |
1,887,846 | SQLynx-A web-based SQL IDE that can run centrally | A web-based SQL IDE that can run centrally provides the convenience of accessing database management... | 0 | 2024-06-14T01:37:43 | https://dev.to/concerate/sqlynx-a-web-based-sql-ide-that-can-run-centrally-3ni1 | A web-based SQL IDE that can run centrally provides the convenience of accessing database management tools through a web browser, allowing for centralized administration and collaboration without the need for local installations.
SQLynx is not a online SQL IDE(SaaS), You still need to deploy SQLynx in your own environ... | concerate | |
1,887,684 | Laravel 11.x Sanctum SPA authentication with Postman! | For those who are unfamiliar with Laravel, it is a very popular monolithic PHP web framework similar... | 0 | 2024-06-14T01:32:37 | https://dev.to/prismlabsdev/laravel-11x-sanctum-spa-authentication-with-postman-3ji0 | laravel, authentication, postman | For those who are unfamiliar with [Laravel](https://laravel.com/), it is a very popular monolithic PHP web framework similar to others like [Ruby on Rails](https://rubyonrails.org/). It is known for its ease of use, rapid development and making PHP development far more enjoyable haha!
, and best practices for secure authentication.
### What is an API Key?
An API key is a unique identifier used to authentic... | mochafreddo |
1,887,843 | Teach you to upgrade the market collector backtest the custom data source | Previous article Teach you to implement a market quotes collector taught you how to implement a... | 0 | 2024-06-14T01:24:51 | https://dev.to/fmzquant/teach-you-to-upgrade-the-market-collector-backtest-the-custom-data-source-efm | market, data, backtest, fmzquant | Previous article [Teach you to implement a market quotes collector](https://www.fmz.com/digest-topic/5692) taught you how to implement a market collector. We have implemented a robot program that collects market quotes together.
How to use market data after we collected it? it will be using for the backtest system. Re... | fmzquant |
1,885,209 | Mastering PostgreSQL JSONB type in one article | Learn how to use PostgreSQL's JSONB type to efficiently store, query, and manipulate JSON... | 0 | 2024-06-14T01:19:31 | https://blog.logto.io/mastering-postgresql-jsonb/ | webdev, programming, postgressql, database | Learn how to use PostgreSQL's JSONB type to efficiently store, query, and manipulate JSON data.
---
In modern application development, handling and storing unstructured data is becoming increasingly common. PostgreSQL's JSONB type provides a powerful tool for developers to efficiently store and query JSON data. In th... | palomino |
1,887,838 | Un octet : la brique élémentaire du numérique | Un octet, symbolisé par "o", est l'unité de base de l'information en informatique. Il représente 8... | 0 | 2024-06-14T01:15:37 | https://dev.to/marc14444/un-octet-la-brique-elementaire-du-numerique-f9k | devchallenge, cschallenge, computerscience, beginners | Un octet, symbolisé par "o", est l'unité de base de l'information en informatique. Il représente 8 bits, soit 8 chiffres binaires (0 ou 1).
Combinés, ces 8 bits permettent de coder 256 valeurs différentes, ce qui suffit pour représenter des caractères, des nombres, des instructions et bien plus encore.
C'est l'unité ... | marc14444 |
1,887,836 | I don't know if that's illegal or not (Sorry FBI) | const accountCheck = () => { if (mybalance < moneyneeded) { const money =... | 0 | 2024-06-14T01:14:18 | https://dev.to/shafayeat/i-dont-know-if-thats-illegal-or-not-sorry-fbi-hfo | discuss, javascript |
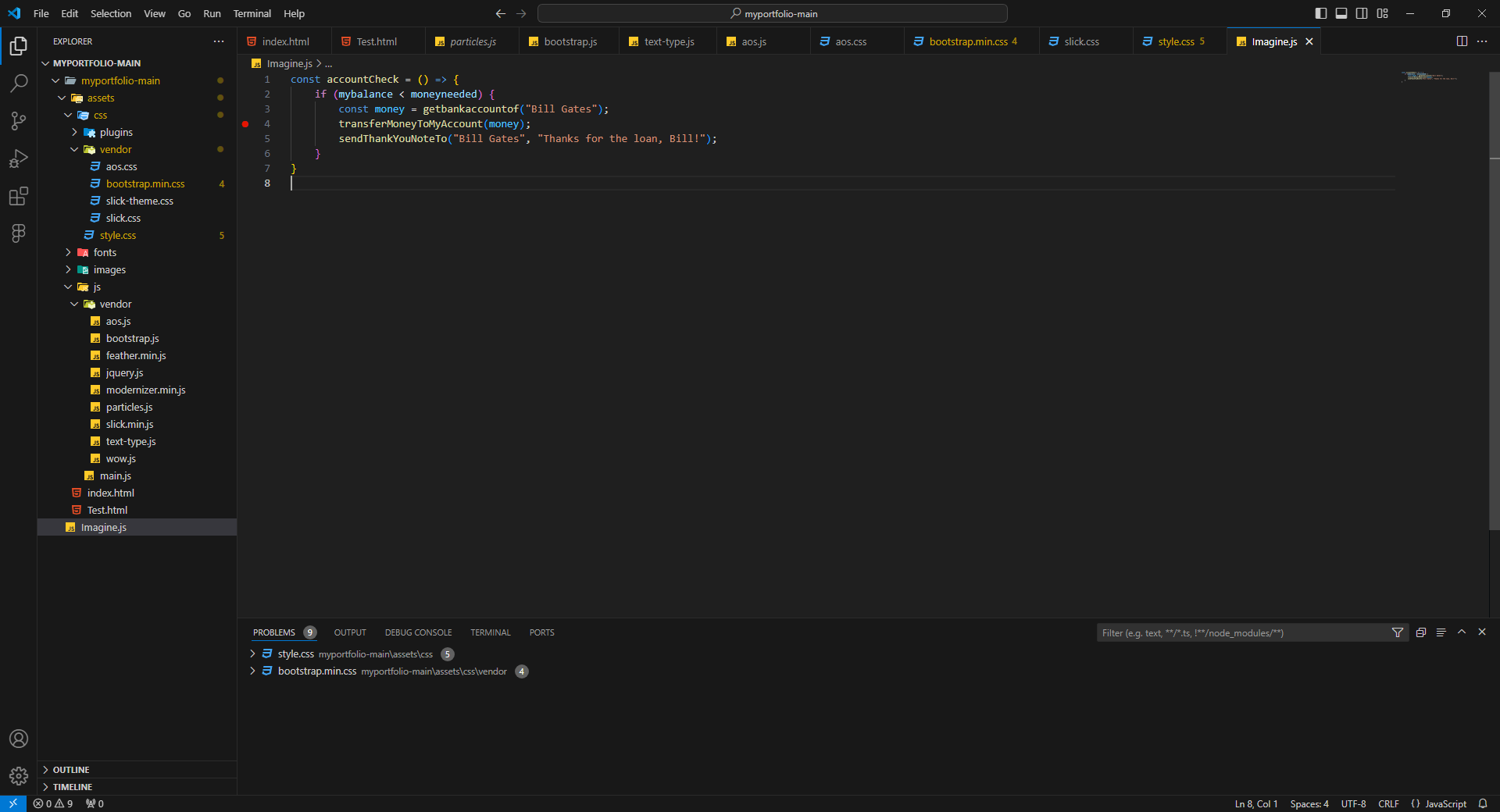
```JavaScript
const accountCheck = () => {
if (mybalance < moneyneeded) {
const money = getbankaccountof("Bill Gates");
transferMoneyToMyAccount(money);
sendThankYouNoteTo("Bill Gates", ... | shafayeat |
1,887,781 | FastAPI for Data Applications: From Concept to Creation. Part I | In this blog post, we'll explore how to create an API using FastAPI, a modern Python framework... | 27,835 | 2024-06-14T00:58:11 | https://dev.to/felipe_de_godoy/fastapi-for-data-applications-from-concept-to-creation-part-i-15ia | fastapi, dataengineering, datascience, llmops | In this blog post, we'll explore how to create an API using FastAPI, a modern Python framework designed for building APIs with high performance. We will create a simple API that allows users to add, update, and query items stored temporarily in memory. Alongside this, we'll discuss how you can extend this example to ex... | felipe_de_godoy |
1,887,832 | vipsosyalbayim smm panel ınstagram tiktok twitter | Takipçi Satın Al Sosyal Medya Takipçi Satın Al Ucuz Takipçi Satın Al Güvenilir Takipçi Satın... | 0 | 2024-06-14T00:53:08 | https://dev.to/takipcisatinal34/e-4c66 | Takipçi Satın Al
Sosyal Medya Takipçi Satın Al
Ucuz Takipçi Satın Al
Güvenilir Takipçi Satın Al
Organik Takipçi Satın Al
Instagram Takipçi Satın Al
Instagram Ucuz Takipçi Satın Al
Instagram Organik Takipçi Satın Al
Instagram Aktif Takipçi Satın Al
Instagram Hızlı Takipçi Satın Al
| takipcisatinal34 | |
1,887,774 | Create an App with EXPO (1) | Hi,guys,after finishing my fullstack project with Nest.j/Typeorm/Mysql/Aws/Vue3, I am going to start... | 0 | 2024-06-13T23:43:42 | https://dev.to/alexander6/create-an-app-with-expo-1-28g9 | Hi,guys,after finishing my fullstack project with Nest.j/Typeorm/Mysql/Aws/Vue3, I am going to start a new application with React Native. what is this app for? I don't know for now. the first function that comes to my mind is that it should support chatting and posting.
### So let't start it.
As my past experience, w... | alexander6 | |
1,887,680 | Create Window 11 virtual machine in Azure portal | Table of contents Sign in to Azure Create virtual machine Connect to virtual machine Install... | 0 | 2024-06-14T00:49:36 | https://dev.to/emeka_moses_c752f2bdde061/create-window-11-virtual-machine-in-azure-portal-4p53 | azure, virtualmachine, window11, cloud | Table of contents
- Sign in to Azure
- Create virtual machine
- Connect to virtual machine
- Install windows 11
- View the windows 11 welcome page
- Clean up resources.
- Delete a reources.
Azure virtual machines (VMs) can be created through the Azure portal. This method provides a browser-based user interface to cre... | emeka_moses_c752f2bdde061 |
1,887,826 | Turbocharge Your OpenDevin Development: A Deep Dive into a Time-Saving Bash Script | Introduction Embarking on your OpenDevin journey? This innovative platform opens doors to endless... | 0 | 2024-06-14T00:42:04 | https://dev.to/tosin2013/turbocharge-your-opendevin-development-a-deep-dive-into-a-time-saving-bash-script-3p31 | opendevin, ai, opensource, development |
**Introduction**
Embarking on your [OpenDevin](https://opendevin.github.io/OpenDevin/) journey? This innovative platform opens doors to endless possibilities, but the initial setup can sometimes be a time sink. What if I told you there's a way to skip the tedious configuration and dive straight into coding? Meet our... | tosin2013 |
1,887,827 | Introduction to Ethical Hacking with Kali Linux | Introduction Ethical hacking is the practice of using advanced computer skills and... | 0 | 2024-06-14T00:32:13 | https://dev.to/kartikmehta8/introduction-to-ethical-hacking-with-kali-linux-1fl4 | webdev, javascript, programming, beginners | ## Introduction
Ethical hacking is the practice of using advanced computer skills and techniques to identify potential vulnerabilities in a computer system. It is carried out with the permission of the system owner in order to find and fix any security flaws. Kali Linux is a popular operating system used by ethical ha... | kartikmehta8 |
1,887,825 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-06-14T00:22:26 | https://dev.to/aditya_singh2109/my-pen-on-codepen-27ln | codepen | Check out this Pen I made!
{% codepen https://codepen.io/adjmcvgz-the-typescripter/pen/qBGVOpr %} | aditya_singh2109 |
1,887,783 | BSides Knoxville 2024: A Community Celebrating A Decade of Cybersecurity | Knoxville is home to multiple famous institutions, such as the University of Tennessee, the Tennessee... | 0 | 2024-06-14T00:03:49 | https://dev.to/gitguardian/bsides-knoxville-2024-a-community-celebrating-a-decade-of-cybersecurity-2mpf | security, cybersecurity, ai, llms | Knoxville is home to multiple famous institutions, such as the [University of Tennessee](https://www.utk.edu/?ref=blog.gitguardian.com), the [Tennessee Valley Authority (TVA)](https://www.tva.com/?ref=blog.gitguardian.com), and [Dolly Parton](https://en.wikipedia.org/wiki/Dolly_Parton?ref=blog.gitguardian.com). Visuall... | dwayne_mcdaniel |
1,888,781 | Using FFmpeg & the Command Line To Repurpose Video Content into a Podcast — Rob Kleiman | The Adventure Begins Embark on a thrilling journey with me as we delve deep into the heart... | 0 | 2024-06-14T15:43:37 | https://medium.com/@rkconnections/using-ffmpeg-the-command-line-to-repurpose-video-content-into-a-podcast-rob-kleiman-c97592058e4f | ---
title: Using FFmpeg & the Command Line To Repurpose Video Content into a Podcast — Rob Kleiman
published: true
date: 2024-06-14 00:00:58 UTC
tags:
canonical_url: https://medium.com/@rkconnections/using-ffmpeg-the-command-line-to-repurpose-video-content-into-a-podcast-rob-kleiman-c97592058e4f
---
### The Adventure... | rkrevolution | |
1,888,964 | Docker Dadbod Ui | In normal mode, invoke :DBUI, establish a new connection with A. When prompted to enter a connection... | 0 | 2024-06-28T17:31:56 | https://blog.waysoftware.dev/blog/docker-dadbod-ui/ | ---
title: Docker Dadbod Ui
published: true
date: 2024-06-14 00:00:00 UTC
tags:
canonical_url: https://blog.waysoftware.dev/blog/docker-dadbod-ui/
---
In normal mode, invoke `:DBUI`, establish a new connection with `A`. When prompted to enter a connection string, follow the[PG spec](https://www.postgresql.org/docs/cu... | johnmcguin | |
1,888,965 | Shell into Containerized PostgreSQL Database | Shell into the running container: docker exec -it <container-id> /bin/bash Enter... | 0 | 2024-06-28T17:32:14 | https://blog.waysoftware.dev/blog/docker-psql-shell/ | ---
title: Shell into Containerized PostgreSQL Database
published: true
date: 2024-06-14 00:00:00 UTC
tags:
canonical_url: https://blog.waysoftware.dev/blog/docker-psql-shell/
---
Shell into the running container:
```
docker exec -it <container-id> /bin/bash
```
Run psql to connect to the database:
```
psql -d <d... | johnmcguin | |
1,888,687 | When "The Best" isn't good enough | I am a beekeeper. This won't be of much surprise to anyone who's spent any time with me, or who... | 0 | 2024-07-02T09:29:09 | https://simonemms.com/blog/2024/06/14/when-the-best-isnt-good-enough | culture, development, questions | ---
title: When "The Best" isn't good enough
published: true
date: 2024-06-14 00:00:00 UTC
tags: culture,development,questions
canonical_url: https://simonemms.com/blog/2024/06/14/when-the-best-isnt-good-enough
---

I am a beekeeper.
... | mrsimonemms |
1,888,886 | FIX: Git Bash is Slow and has Strange Random Characters in VS Code | TLDR: If you're using git bash in VS Code and notice it slows down and/or starts printing random... | 0 | 2024-06-19T17:58:04 | https://www.davegray.codes/posts/git-bash-vs-code-slow-strange-random-characters | gitbash, vscode | ---
title: FIX: Git Bash is Slow and has Strange Random Characters in VS Code
published: true
date: 2024-06-14 00:00:00 UTC
tags: gitbash,vscode
canonical_url: https://www.davegray.codes/posts/git-bash-vs-code-slow-strange-random-characters
cover_image: https://raw.githubusercontent.com/gitdagray/my-blogposts/main/imag... | gitdagray |
1,888,286 | Modules Status Update | Hello Again!! As another Friday draws to a close, I hope this message finds you well.... | 0 | 2024-06-14T17:36:43 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-14-modules-status-update/ | puppet, community | ---
title: Modules Status Update
published: true
date: 2024-06-14 00:00:00 UTC
tags: puppet,community
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-14-modules-status-update/
---
## Hello Again!!
As another Friday draws to a close, I hope this message finds you well. Reflect... | puppetdevx |
1,888,487 | Boost Your Git Productivity with Aliases: Start Saving Time Today! | Tired of spending precious time typing out those long, repetitive Git commands? You're not alone. Git... | 26,070 | 2024-06-14T11:25:45 | https://ionixjunior.dev/en/boost-your-git-productivity-with-aliases-start-saving-time-today/ | git | ---
title: Boost Your Git Productivity with Aliases: Start Saving Time Today!
published: true
date: 2024-06-14 00:00:00 UTC
tags: git
canonical_url: https://ionixjunior.dev/en/boost-your-git-productivity-with-aliases-start-saving-time-today/
cover_image: https://ionixjuniordevthumbnail.azurewebsites.net/api/Generate?ti... | ionixjunior |
1,888,287 | DevX Status Update | Belfast Summer Party The team had a great afternoon out with all of our colleages... | 0 | 2024-06-14T17:37:39 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-14-devx-status-update/ | puppet, community | ---
title: DevX Status Update
published: true
date: 2024-06-14 00:00:00 UTC
tags: puppet,community
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2024-06-14-devx-status-update/
---
## Belfast Summer Party
The team had a great afternoon out with all of our colleages completing a tour... | puppetdevx |
1,887,780 | Exploring ssh | Most people who have worked on remote servers are probably familiar with ssh, which let's us securely... | 0 | 2024-06-13T23:58:55 | https://dev.to/georg4313/exploring-ssh-20oj | ssh, servers | Most people who have worked on remote servers are probably familiar with [ssh](https://medium.com/@aqeelabbas3972/introduction-to-ssh-secure-shell-0d07e18d3149), which let's us securely communicate and control our remote environments.
Other than basic use, I think it is important to dive deeper and also use the speci... | georg4313 |
1,887,740 | Github - Organization(Demo) | Step by Step approach to create an organization in GitHub Step 1 : Click on the icon of... | 27,667 | 2024-06-13T22:44:59 | https://dev.to/learnwithsrini/github-organizationdemo-3p89 | github, organization, teams | ###Step by Step approach to create an organization in GitHub
**Step 1** : Click on the icon of your profile and which is highlighted in the below picture
**Step 2** : Select organization
.
Let's see a quick start coding guide using Go, Evans, and gRPC
... | andrefsilveira1 |
1,887,778 | Computer Science Concept: Hash Function | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T23:51:33 | https://dev.to/sweta_kangurisonulkar_/computer-science-concept-hash-function-gm5 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
**Computer Science Concept: Hash Function**
A hash function converts input data of any size into a fixed-size value, typically used in hash tables for fast data retrieval. It's crucial... | sweta_kangurisonulkar_ |
1,887,776 | Tree Loving Care, LLC | For expert tree care services in Viroqua, WI, turn to Tree Loving Care, LLC. With our passion for... | 0 | 2024-06-13T23:44:11 | https://dev.to/treelovingcarellc/tree-loving-care-llc-1ald |

For expert tree care services in Viroqua, WI, turn to Tree Loving Care, LLC. With our passion for trees and dedication to excellence, we ensure your trees receive the utmost care. Contact us today for a compliment... | treelovingcarellc | |
1,887,775 | Tree Loving Care, LLC | For expert tree care services in Viroqua, WI, turn to Tree Loving Care, LLC. With our passion for... | 0 | 2024-06-13T23:44:00 | https://dev.to/treelovingcarellc/tree-loving-care-llc-163m |

For expert tree care services in Viroqua, WI, turn to Tree Loving Care, LLC. With our passion for trees and dedication to excellence, we ensure your trees receive the utmost care. Contact us today for a compliment... | treelovingcarellc | |
1,887,772 | 01 - to tech Html,Css,Javascript project | 1- https://youtu.be/eUuDmIrhW1k?si=PeVva2ZQXIF45Ars 2- https://youtu.be/-FAjw3aLP80?si=FMiE0gICPzxf-... | 0 | 2024-06-13T23:37:52 | https://dev.to/hussein09/first-day-to-tech-htmlcssjavascript-project-2h89 | html, css, javascript, webdev |
1-
https://youtu.be/eUuDmIrhW1k?si=PeVva2ZQXIF45Ars
2-
https://youtu.be/-FAjw3aLP80?si=FMiE0gICPzxf-GLo
**I will upload more than 150 projects** from the series of programming languages: html, css, js, and we will develop them at a later time. | hussein09 |
1,887,771 | Gemika's Awesome Git Adventures: A Fun Guide to Coding Magic! 🧙♂️✨" | Hey, Little Buddy! Meet Uncle Gerry and the Magic World of GitHub 🪄✨ Hello there, little... | 0 | 2024-06-13T23:27:44 | https://dev.to/gerryleonugroho/gemikas-awesome-git-adventures-a-fun-guide-to-coding-magic--25go | git, github, webdev, beginners | ### Hey, Little Buddy! Meet Uncle Gerry and the Magic World of GitHub 🪄✨
Hello there, little one! Let me tell you a story. I'm Uncle Gerry, the father of the amazing Gemika Haziq Nugroho. I do some really cool stuff as a data-driven marketer and software engineer. That means I help people use numbers and magic comput... | gerryleonugroho |
1,887,770 | Movers and Packers in Dubai Marina | Relocating homes inside Dubai Marina is an example of accepting change in the middle of a busy city.... | 0 | 2024-06-13T23:23:39 | https://dev.to/scarlett_6341cae31964617a/movers-and-packers-in-dubai-marina-1876 | Relocating homes inside Dubai Marina is an example of accepting change in the middle of a busy city. But with the careful attention to detail provided by **[movers and packers Dubai Marina](https://madomovers.com/movers-in-dubai-marina/)**, the transfer can go as smoothly as the peaceful seas around this energetic loca... | scarlett_6341cae31964617a | |
1,887,746 | Building a Real-Time Streaming Chatbot with Kotlin and Ollama AI | In the ever-evolving landscape of artificial intelligence, creating a chatbot capable of handling... | 0 | 2024-06-13T23:18:49 | https://dev.to/josmel/building-a-real-time-streaming-chatbot-with-kotlin-and-ollama-ai-2m7h | ollama, kotlin, chatbot, streaming | In the ever-evolving landscape of artificial intelligence, creating a chatbot capable of handling real-time conversations with streaming responses is a fascinating challenge. In this blog post, we'll walk you through the process of building a Kotlin-based chatbot using Ollama AI. We'll cover everything from setting up ... | josmel |
1,887,738 | DEV Computer Science Challenge v24.06.12 : Recursion | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T22:44:29 | https://dev.to/therbstar/dev-computer-science-challenge-v240612-recursion-28ik | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
**Recursion**: A process where a function calls itself as a subroutine. This enables it to perform repetitive tasks efficiently, with each step working on a smaller problem, until a ba... | therbstar |
1,887,744 | [Game of Purpose] Day 26 | Today I made propellers animation start and end smoothly, instead of instantly. In my BP_Propeller... | 27,434 | 2024-06-13T23:12:04 | https://dev.to/humberd/game-of-purpose-day-26-3091 | gamedev | Today I made propellers animation start and end smoothly, instead of instantly. In my `BP_Propeller` Blueprint I used a Timeline node, where I specified a curve. In this case it ramps up in 2 seconds non-linearly.
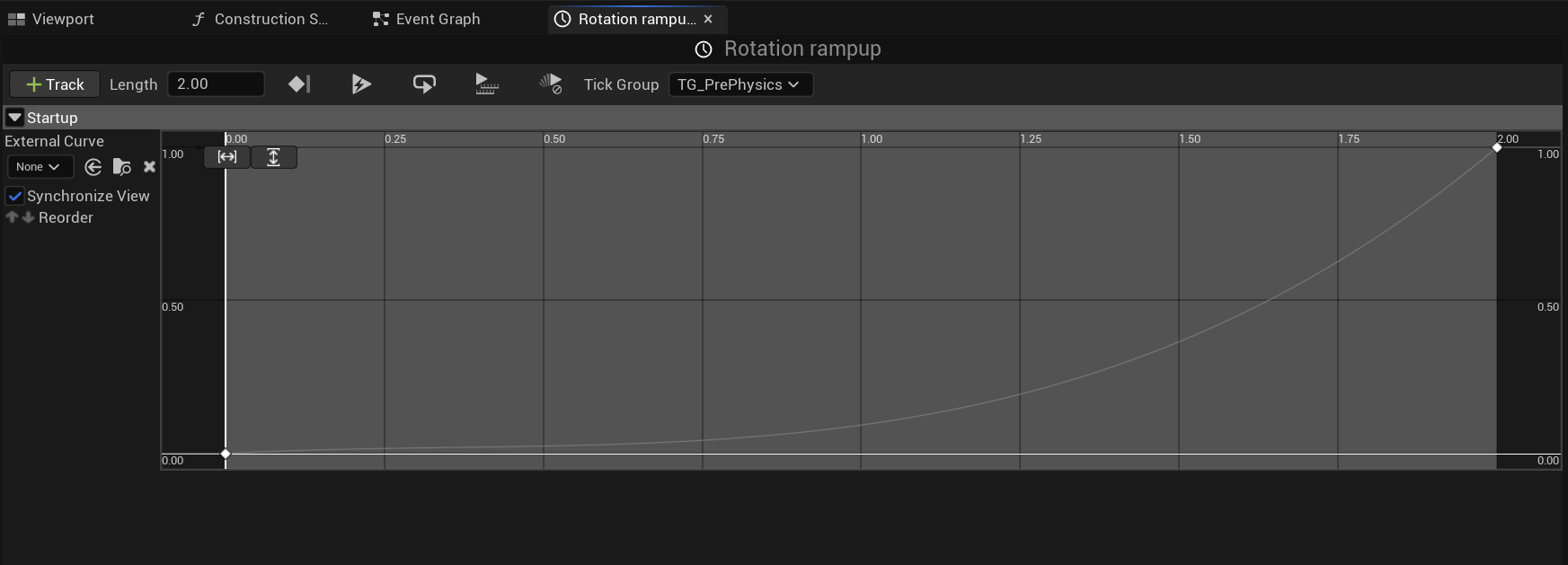
... | humberd |
1,886,544 | Build your AI Travel Agent with GPT-4o using Python | Imagine planning your dream vacation, but instead of spending hours searching online, an intelligent... | 0 | 2024-06-13T23:10:00 | https://dev.to/spiff/build-your-ai-travel-agent-with-gpt-4o-using-python-3mmg | ai, beginners, python, programming | Imagine planning your dream vacation, but instead of spending hours searching online, an intelligent assistant arranges everything for you. Sounds like a fantasy, right? What if I said you could build this AI travel agent with just a few lines of [Python](https://www.python.org/) code? Yes, it's that simple. In this gu... | spiff |
1,863,797 | Cyclic has shut down and I am migrating my data to another service | A few weeks ago, I wrote an article on deploying your full-stack application, which you can find... | 23,487 | 2024-06-13T23:00:00 | https://dev.to/devlawrence/cyclic-has-shut-down-and-i-am-migrating-my-data-to-another-service-4nj6 | webdev, javascript, programming, learning | A few weeks ago, I wrote an article on deploying your full-stack application, which you can find
[here](https://dev.to/devlawrence/how-to-deploy-your-fullstack-website-my-approach-3f6l).
One of the hosting services I discussed was Cyclic. Unfortunately, Cyclic has since shut down. In this article, I'll explore why I... | devlawrence |
1,887,741 | Docker + MariaDB | Database popular among developers. Get container pull. docker pull "mariadb" ... | 0 | 2024-06-13T22:46:14 | https://dev.to/thiagoeti/docker-mariadb-4n2c | docker, mariadb | Database popular among developers.
#### Get container **pull**.
```console
docker pull "mariadb"
```
#### Create **network** for data.
```console
docker network create "mariadb"
```
#### Create **volume** for data.
```console
docker volume create "mariadb"
ln -s "/var/lib/docker/volumes/mariadb" "/data/volume/"
`... | thiagoeti |
1,887,736 | Understanding the differences between micro-service and monolithic architecture. | One of the initial decisions you'll face when building an application is choosing the right... | 0 | 2024-06-13T22:38:59 | https://dev.to/xcoder03/understanding-the-differences-between-micro-service-and-monolithic-architecture-14dc | webdev, softwareengineering, learning, discuss | One of the initial decisions you'll face when building an application is choosing the right architecture. This choice will significantly impact your application's scalability, maintainability, and overall success. Two popular architecture approaches are monolithic and microservice architecture. This article will explai... | xcoder03 |
1,887,735 | Vanilla CSS Animations Suck 👎 But I fixed them... | Creating animations using vanilla CSS can be a daunting task for developers. While animations add a... | 0 | 2024-06-13T22:32:35 | https://dev.to/max_prehoda_9cb09ea7c8d07/vanilla-css-animations-suck-but-i-fixed-them-4jhm | Creating animations using vanilla CSS can be a daunting task for developers. While animations add a touch of flair and interactivity to web projects, the process of crafting them from scratch can be time-consuming and frustrating.
One of the primary hurdles is the syntax. CSS animations come with a plethora of propert... | max_prehoda_9cb09ea7c8d07 | |
1,887,720 | 📚 How to Handle Multiple MSW Handlers in Storybook Stories | Handling multiple states in Storybook stories can often be problematic, especially when different... | 0 | 2024-06-13T22:27:37 | https://dev.to/enszrlu/how-to-handle-multiple-msw-handlers-in-storybook-stories-2mo2 | storybook, webdev, frontend, programming | Handling multiple states in Storybook stories can often be problematic, especially when different handlers are required to simulate various states. This tutorial will guide you through the process of managing these handlers effectively to ensure each story showcases the correct state without persistent issues.
## 1. P... | enszrlu |
1,887,733 | Day 970 : Chosen | liner notes: Professional : So many meetings... again. Learned that my Visa application was denied... | 0 | 2024-06-13T22:25:24 | https://dev.to/dwane/day-970-chosen-1ek3 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : So many meetings... again. Learned that my Visa application was denied because there was another option that I should have chosen that I guess is new. Refilled out the long form again only to find out I need some form that I have no clue how to get. Hopefully the organizer knows how to g... | dwane |
1,887,723 | Introducing jekyll-crypto-donations: Easily Add Crypto Donation Blocks to Your Jekyll Site | Hello Dev Community! I'm excited to share the release of my new Jekyll plugin,... | 0 | 2024-06-13T22:18:11 | https://dev.to/madmatvey/introducing-jekyll-crypto-donations-easily-add-crypto-donation-blocks-to-your-jekyll-site-3557 | staticwebapps, jekyll, ruby, cryptocurrency | Hello Dev Community!
I'm excited to share the release of my new Jekyll plugin, `jekyll-crypto-donations`. This gem allows you to seamlessly integrate cryptocurrency donation blocks into your Jekyll-generated websites. Whether you're a blogger, content creator, or developer, this plugin can help you receive support fro... | madmatvey |
1,887,722 | Secure your enterprise critical assets from secret sprawl | Understand the risks of secret sprawl, embracing shift-left and strategies to secure secret leaks in... | 0 | 2024-06-13T22:02:23 | https://dev.to/security-and-technology/secure-your-enterprise-critical-assets-from-secret-sprawl-4ajj | enterprise, cybersecurity, secrets, shiftleft | Understand the risks of secret sprawl, embracing shift-left and strategies to secure secret leaks in the modern software development lifecycle.
---
## Secret sprawl:
Enterprises often need help with the uncontrolled proliferation of secrets across their IT infrastructure. The unchecked proliferation is called a secr... | security-and-technology |
1,854,419 | Dev: AI | An AI Developer, also known as an Artificial Intelligence Developer, is a professional specializing... | 27,373 | 2024-06-13T22:00:00 | https://dev.to/r4nd3l/dev-ai-29ll | ai, developer | An **AI Developer**, also known as an Artificial Intelligence Developer, is a professional specializing in the design, development, and implementation of artificial intelligence (AI) systems and algorithms. Here's a detailed description of the role:
1. **Understanding of Artificial Intelligence:**
- AI Developers p... | r4nd3l |
1,887,721 | Creating an AI-driven experience using Twilio | Creating an AI-driven experience using Twilio can open up many possibilities for interactive and... | 0 | 2024-06-13T21:55:56 | https://dev.to/hussein09/creating-an-ai-driven-experience-using-twilio-31he | devchallenge, ai, twilio | Creating an AI-driven experience using Twilio can open up many possibilities for interactive and automated services. One compelling application is setting up an AI-powered SMS chatbot that can handle customer inquiries, book appointments, or provide information. Here’s a step-by-step guide on how to build this experien... | hussein09 |
1,878,548 | Let's Build HTTP Client From Scratch In Rust | Previously, we dived into how to make an HTTP parser with no dependencies. In this blog let's extend... | 0 | 2024-06-13T21:45:26 | https://dev.to/hiro_111/lets-build-http-client-from-scratch-in-rust-46ad | rust, dns, http | [Previously](https://dev.to/hiro_111/lets-build-http-parser-from-scratch-in-rust-5gih), we dived into how to make an HTTP parser with no dependencies. In this blog let's extend our knowledge further by building an HTTP client CLI😉
(I call our brand-new CLI [`fetch`](https://github.com/hirotake111/rust_fetch), by the ... | hiro_111 |
1,887,719 | Babylon.js Browser MMORPG - DevLog - Update #10- Entities interpolation | Hey! Last two days I was working on syncing server and client clocks. On top of it I implemented... | 0 | 2024-06-13T21:44:55 | https://dev.to/maiu/babylonjs-browser-mmorpg-devlog-update-10-entities-interpolation-2a9g | babylonjs, indiegamedev, indie, mmorpg | Hey!
Last two days I was working on syncing server and client clocks. On top of it I implemented entity interpolation. On the video I'm presenting You situation when server network tick is set to 4 which means it sends messages to players each 250ms, which is simulating quite significant lags.
Without interpolation ... | maiu |
1,887,296 | Contributing to ODK: the go-to mobile form data collection tool | This is a post with very little code, but instead a higher level retrospective on contribution to a... | 0 | 2024-06-13T21:36:16 | https://dev.to/spwoodcock/contributing-to-odk-the-go-to-mobile-form-data-collection-tool-3mco | This is a post with very little code, but instead a higher level retrospective on contribution to a mature open-source project.
## Intro to ODK
[ODK](https://getodk.org) is a collection of open-source tools that are used to collect data via forms designed for a mobile phone.
It is at the forefront of tools available... | spwoodcock |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.