
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,887,509 | Powershell to fix incorrect encoding of MP3 ID3 tags | This PowerShell script corrects the encoding of ID3 tags in MP3 files. It is specifically designed... | 0 | 2024-06-13T16:52:56 | https://dev.to/uyriq/powershell-to-fix-incorrect-encoding-of-mp3-id3-tags-5fca | powershell, pwsh, script, idv3tags | This PowerShell script corrects the encoding of ID3 tags in MP3 files. It is specifically designed for the case of a problem where tags encoded in WINDOWS-1251 have been saved to files as WINDOWS-1252 text, and so programs incorrectly output grainy characters (like this one"îñòðîâ") because they read the text as a West... | uyriq |
1,887,508 | Create Website with Login & Registration Form in HTML CSS and JavaScript | If you’re new to web development, creating a website with login and registration forms is an... | 0 | 2024-06-13T16:52:38 | https://www.codingnepalweb.com/create-website-login-registration-form-html/ | webdev, javascript, html, css | If you’re new to web development, creating a website with login and registration forms is an excellent way to learn and practice basic skills like designing a navigation menu bar, creating a website homepage, and building login and registration forms.
In this blog post, I’ll guide you through creating a responsive web... | codingnepal |
1,887,506 | Creative HTML Hero Section -- Digital Agency | Explore a stunning and dynamic HTML hero section designed for a digital agency. This pen showcases a... | 0 | 2024-06-13T16:45:53 | https://dev.to/creative_salahu/creative-html-hero-section-digital-agency-38lc | codepen, webdev, javascript, programming | Explore a stunning and dynamic HTML hero section designed for a digital agency. This pen showcases a creative, modern, and responsive layout perfect for web developers or agencies looking to make a bold statement.
Features:
Hero Section: Eye-catching design with a professional yet creative aesthetic.
Responsive Desig... | creative_salahu |
1,887,505 | Build an Antivirus with Python (Beginners Guide) | If you have been hit by a virus attack before, you will understand how annoying it is to lose your... | 0 | 2024-06-13T16:40:51 | https://blog.learnhub.africa/2024/06/13/build-an-antivirus-with-python-beginners-guide/ | python, programming, security, cybersecurity | If you have been hit by a virus attack before, you will understand how annoying it is to lose your files because the virus has corrupted them.
My first encounter with a virus attack was when all my apps stopped working, my laptop started malfunctioning, and my productivity slowed as I tried to figure out how to get my... | scofieldidehen |
1,887,504 | Implement JWT Refresh Token Authentication with Elysia JS and Prisma: A Step-by-Step Guide | In this comprehensive guide, we'll walk you through the process of integrating JWT refresh token... | 0 | 2024-06-13T16:39:03 | https://dev.to/harshmangalam/implement-jwt-refresh-token-authentication-with-elysia-js-and-prisma-a-step-by-step-guide-1dc | prisma, typescript, webdev, bunjs | In this comprehensive guide, we'll walk you through the process of integrating JWT refresh token authentication into your application using Elysia JS and Prisma.
## Authentication vs Authorization
Authentication is the process of verifying the identity of a user or system attempting to access a resource or service.
... | harshmangalam |
1,887,503 | Dev's connect here | Hey Dev's lets connect here....... | 0 | 2024-06-13T16:37:50 | https://dev.to/abhi0045/httpschatwhatsappcomehvjjh0lr2xkwyzasg6tq5-82c | [](https://chat.whatsapp.com/EhvJJH0Lr2XKwyzasg6tq5)Hey Dev's lets connect here.......
| abhi0045 | |
1,887,502 | HANCITOR - TRAFFIC ANALYSIS - SOL-LIGHTNET | let's start: Downloading the Capture File and Understanding the... | 0 | 2024-06-13T16:37:18 | https://dev.to/mihika/hancitor-traffic-analysis-sol-lightnet-1m7n | hancitor, wireshark, pcap, paloaltonetworks | ## let's start:
## Downloading the Capture File and Understanding the Assignment
1. Download the .pcap file from [PCAP](https://www.malware-traffic-analysis.net/2020/01/30/index.html)
2. Familiarize yourself with the assignment instructions.
## LAN segment data:
LAN segment range: 10.20.30[.]0/24 (10.20.30[.]0 throug... | mihika |
1,887,501 | Renowned Surgeon Professor Ali Al-Hussaini Honored With Honorary Professorship In Medical Science | The International Association for Quality Assurance in Pre-Tertiary & Higher Education (QAHE)... | 0 | 2024-06-13T16:35:52 | https://dev.to/aubss_edu/renowned-surgeon-professor-ali-al-hussaini-honored-with-honorary-professorship-in-medical-science-4bd8 | education, aubss, qahe, news |

The International Association for Quality Assurance in Pre-Tertiary & Higher Education (QAHE) and the American University of Business and Social Sciences (AUBSS) are pleased to announce that Professor Ali Al-Hussai... | aubss_edu |
1,887,500 | Oracle Global Trade Management Cloud Testing: The Comprehensive Guide | If your company carries out overseas trade, you deal with issues like conducting due diligence and... | 0 | 2024-06-13T16:35:45 | https://www.opkey.com/blog/oracle-global-trade-management-cloud-testing-the-comprehensive-guide | trade, management, cloud, testing | 
If your company carries out overseas trade, you deal with issues like conducting due diligence and managing changing compliance requirements. These shifting regulatory requirements, trade agreements, and process upda... | johnste39558689 |
1,887,499 | File Organizer Pro | import os import shutil import tkinter as tk from tkinter import filedialog, messagebox from pathlib... | 0 | 2024-06-13T16:33:57 | https://dev.to/dulanga/file-organizer-pro-4j3c | import os
import shutil
import tkinter as tk
from tkinter import filedialog, messagebox
from pathlib import Path
class FileOrganizerGUI:
def __init__(self, root):
self.root = root
self.root.title("File Organizer")
self.directory = tk.StringVar()
self.directory.set(str(Path.home() / ... | dulanga | |
1,887,497 | Code Refactoring | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T16:32:40 | https://dev.to/gamartya/code-refactoring-185p | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
Code Refactoring is like Oxford Comma. Ex:- Let's eat grandma vs Let's eat, grandma. In coding, first example is doing it's intended job. But, if you revisit after few months, you would be confused. By adding a comma ... | gamartya |
1,887,493 | Release 0.38.0 of Spellcheck (GitHub) Action - yet another maintenance release | The base images are always on the move | 0 | 2024-06-13T16:24:54 | https://dev.to/jonasbn/release-0380-of-spellcheck-github-action-yet-another-maintenance-release-16jm | githubaction, opensource, release | ---
title: Release 0.38.0 of Spellcheck (GitHub) Action - yet another maintenance release
published: true
description: The base images are always on the move
tags: githubaction, opensource, release
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-03-03 13:59 ... | jonasbn |
1,887,464 | Moving to WP Headless | In the rapidly evolving world of web development, WordPress (WP) remains a reliable and widely used... | 0 | 2024-06-13T16:23:33 | https://dev.to/francisco_scotta/moving-to-wp-headless-5a6o | webdev, wordpress, astro, headless | In the rapidly evolving world of web development, WordPress (WP) remains a reliable and widely used platform. However, as technology advances, improvements are necessary to keep up with the demand for faster, more efficient, and user-friendly websites. Transitioning from a traditional WordPress setup to a headless Word... | francisco_scotta |
1,887,463 | Navbar component | A post by kamalkant nawal | 0 | 2024-06-13T16:10:11 | https://dev.to/kamalkant_nawal_1c6234c37/navbar-component-2p5i | codesandbox | {% codesandbox 46hj5n %} | kamalkant_nawal_1c6234c37 |
1,887,462 | Counter-loop | A post by kamalkant nawal | 0 | 2024-06-13T16:08:34 | https://dev.to/kamalkant_nawal_1c6234c37/counter-loop-912 | codesandbox | {% codesandbox d92l5c %} | kamalkant_nawal_1c6234c37 |
1,887,461 | Understanding Types and Interfaces in TypeScript: A Comprehensive Guide | TypeScript, a superset of JavaScript, introduces static typing to the language, which helps... | 0 | 2024-06-13T16:08:22 | https://dev.to/hasancse/understanding-types-and-interfaces-in-typescript-a-comprehensive-guide-1pm7 | webdev, javascript, programming, typescript | TypeScript, a superset of JavaScript, introduces static typing to the language, which helps developers catch errors early and write more maintainable code. Two of the most powerful features in TypeScript are types and interfaces. In this blog post, we'll explore the differences between types and interfaces, when to use... | hasancse |
1,883,448 | From Text Editors to Cloud-based IDEs - a DevEx journey | Remember the days of text-based editors like Vim? It’s a far cry from today’s sophisticated IDEs with features like code completion and debugging tools, and 'developer experience' is one of the biggest reasons why | 0 | 2024-06-13T16:07:00 | https://jmeiss.me/posts/ide-devex-journey-text-editor-to-cloud/ | devex, ide | ---
title: From Text Editors to Cloud-based IDEs - a DevEx journey
published: true
description: "Remember the days of text-based editors like Vim? It’s a far cry from today’s sophisticated IDEs with features like code completion and debugging tools, and 'developer experience' is one of the biggest reasons why"
tags: de... | jerdog |
1,887,460 | Diving Deeper into Generics in TypeScript | Hello everyone, السلام عليكم و رحمة الله و بركاته Generics in TypeScript offer more than just a way... | 0 | 2024-06-13T16:04:18 | https://dev.to/bilelsalemdev/diving-deeper-into-generics-in-typescript-2pal | typescript, programming, oop, solidprinciples | Hello everyone, السلام عليكم و رحمة الله و بركاته
Generics in TypeScript offer more than just a way to write flexible and reusable code; they provide a mechanism to create sophisticated and type-safe abstractions. By exploring advanced generic concepts, constraints, and real-world applications, you can unlock the ful... | bilelsalemdev |
1,887,459 | New session after a while | Its been while, while i was away. Today I had another session on other linux commands like who,last... | 0 | 2024-06-13T16:02:59 | https://dev.to/anakin/new-session-after-a-while-3c5d | linux | Its been while, while i was away. Today I had another session on other linux commands like who,last log for getting the login details. Other commands included details,mv,cp,rm,history,hostname,whoami,uptime. Through these commands I was able to move file, copy files, See the history of commands that I typed. See you to... | anakin |
1,887,458 | 🌟 Introducing MuscleMaven: Your Ultimate Fitness Companion! 💪 | Hello Dev Community! 👋 We are thrilled to introduce MuscleMaven, your go-to platform for all things... | 0 | 2024-06-13T16:02:25 | https://dev.to/puneetkumar2010/introducing-musclemaven-your-ultimate-fitness-companion-1cj9 | webdev, javascript, beginners, react | Hello Dev Community! 👋
We are thrilled to introduce *[MuscleMaven](https://musclemaven.onrender.com)*, your go-to platform for all things fitness. Whether you're a beginner or a seasoned athlete, MuscleMaven offers a range of features to help you stay fit and healthy. Let’s dive into what makes MuscleMaven stand out!... | puneetkumar2010 |
1,887,457 | Introduction to Sorting Algorithms in JavaScript | My Video and Written Content New Developer Docs Introduction to Sorting Algorithms in... | 0 | 2024-06-13T15:59:14 | https://dev.to/alexmercedcoder/introduction-to-sorting-algorithms-in-javascript-b60 | javascript, algorithms, sorting | - [My Video and Written Content](https://main.devnursery.com)
- [New Developer Docs](https://docs.devnursery.com)
# Introduction to Sorting Algorithms in JavaScript
## 1. Introduction
Sorting algorithms are fundamental to computer science and programming. They are essential tools for organizing data in a meaningful ... | alexmercedcoder |
1,887,456 | Currying function🤓 | Funny Samples: // 1. Phrase function gap(a) { return function(b) { return... | 0 | 2024-06-13T15:57:04 | https://dev.to/__khojiakbar__/currying-function-1f7a | javascript, currying, function | ## **Funny Samples:**
// 1. Phrase
```
function gap(a) {
return function(b) {
return function(c) {
return `${a[0].toUpperCase()}${a.slice(1)} ${b} ${c}`;
}
}
}
res = add('Hello')(['World'])('?');
console.log(res); // Hello World ?
```
// 2. Compliment generator
```
function make... | __khojiakbar__ |
1,887,455 | How to create School Management System Mobile App with React native | Creating a school management system using React Native involves several steps, from planning the... | 0 | 2024-06-13T15:56:14 | https://dev.to/nadim_ch0wdhury/how-to-create-school-management-system-mobile-app-with-react-native-2e4b | Creating a school management system using React Native involves several steps, from planning the features to implementing and testing the app. Here's a high-level guide to get you started:
### 1. Define the Features
First, outline the features you want in your school management system. Common features include:
- **U... | nadim_ch0wdhury | |
1,887,453 | Day 17 of my progress as a vue dev | About today Today was again one of those tricky days when I struggle to fully follow my daily routine... | 0 | 2024-06-13T15:49:41 | https://dev.to/zain725342/day-17-of-my-progress-as-a-vue-dev-1a9h | webdev, vue, typescript, tailwindcss | **About today**
Today was again one of those tricky days when I struggle to fully follow my daily routine properly and then start to question very decision I'm making and feeling a bit down. But, somehow I survived it and turned it around halfway through and I feel good about it. I ended up drawing an outline for the s... | zain725342 |
1,887,452 | Lazy-load Image - JavaScript & CSS | Dalam pembuatan web application, salah satu elemen yang paling banyak menyedot resource adalah image... | 0 | 2024-06-13T15:48:07 | https://dev.to/boibolang/lazy-load-image-javascript-css-3b5d | Dalam pembuatan web application, salah satu elemen yang paling banyak menyedot resource adalah image (gambar). Maka dari itu ada berbagai macam cara menyimpan gambar dalam sebuah web application. Kali ini kita akan belajar salah satu cara memanipulasi gambar yaitu lazy-load, lazy-load kita masih akan memakai intersecti... | boibolang | |
1,887,451 | The Role of Zakat in Islamic Finance | Understanding Zakat in Islamic Finance In Islamic finance, Zakat, one of the Five Pillars of Islam,... | 0 | 2024-06-13T15:48:04 | https://dev.to/aims_education_7843272be0/the-role-of-zakat-in-islamic-finance-4obl | Understanding Zakat in Islamic Finance
In Islamic finance, Zakat, one of the Five Pillars of Islam, holds significant importance. Zakat is a religious obligation for Muslims to give a portion of their wealth to those in need. This not only purifies the donor's wealth but also helps bring social welfare and economic equ... | aims_education_7843272be0 | |
1,887,450 | Dev | (https://www.dev.google) | 0 | 2024-06-13T15:44:16 | https://dev.to/alla_santoshpavankumar_/dev-5e0a | (https://www.dev.google) | alla_santoshpavankumar_ | |
1,887,448 | cash-frenzy-cash-frenzy | https://medium.com/@mollanadim24/cash-frenzy-cash-frenzy-free-coins-1m-free-coins-real-we651-c38c7496... | 0 | 2024-06-13T15:42:50 | https://dev.to/nadim_molla_1ac05706c2b4f/cash-frenzy-cash-frenzy-45o4 | https://medium.com/@mollanadim24/cash-frenzy-cash-frenzy-free-coins-1m-free-coins-real-we651-c38c74962de0
https://medium.com/@mollanadim24/best-cash-frenzy-casino-free-get-9999-coins-wef56-918bcd35eaa9
https://medium.com/@mollanadim24/free-bingo-blitz-free-credits-generator-unlimited-free-credits-2d89a1a5fc6a
https://m... | nadim_molla_1ac05706c2b4f | |
1,887,480 | A Tour of the Couchbase JetBrains Plugin for Developers | There is a Couchbase plugin available for use with any JetBrains IDE, including: IntelliJ IDEA,... | 0 | 2024-06-17T13:50:35 | https://www.couchbase.com/blog/a-tour-couchbase-jetbrains-plugin-developers/ | jetbrains, devtools, ide, couchbase | ---
title: A Tour of the Couchbase JetBrains Plugin for Developers
published: true
date: 2024-06-13 15:40:29 UTC
tags: Jetbrains,devtools,IDE,couchbase
canonical_url: https://www.couchbase.com/blog/a-tour-couchbase-jetbrains-plugin-developers/
---
There is a [Couchbase plugin available for use with any JetBrains IDE](... | brianking |
1,880,255 | Announcing Live Preview for Storyblok’s Astro Integration | We are absolutely thrilled to announce that starting with version 4.1.0 our Astro integration... | 0 | 2024-06-13T15:31:35 | https://storyblok.com/mp/announcing-live-preview-for-storyblok-astro | astro, storyblok, webdev, headless | We are absolutely thrilled to announce that starting with version `4.1.0` our Astro integration [@storyblok/astro](https://github.com/storyblok/storyblok-astro) now officially supports the live preview functionality of Storyblok’s beloved Visual Editor. With this new feature, developers can empower editors to create co... | manuelschroederdev |
1,887,445 | This is my first time being in the community please can someone help me how to do | A post by Djouher Demmou | 0 | 2024-06-13T15:31:19 | https://dev.to/djouher_demmou_4b07dcc29a/this-is-my-first-time-being-in-the-community-please-can-someone-help-me-how-to-do-57ia | djouher_demmou_4b07dcc29a | ||
1,887,444 | How to Do Online Marketing for a Custom T-Shirt Printing Brand: A Comprehensive Guide | Online marketing is crucial for the success of any custom T-shirt printing brand. With the increasing... | 0 | 2024-06-13T15:26:44 | https://dev.to/saint_code_4a3e24bbc8242a/how-to-do-online-marketing-for-a-custom-t-shirt-printing-brand-a-comprehensive-guide-15od |
Online marketing is crucial for the success of any custom T-shirt printing brand. With the increasing popularity of personalized apparel, effectively marketing your brand online can help you reach a broad audience, increase sales, and build a loyal customer base. This article provides a detailed guide on how to market... | saint_code_4a3e24bbc8242a | |
1,887,443 | One-Byte: Last one: Big O Notation | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T15:25:03 | https://dev.to/stunspot/one-byte-last-one-big-o-notation-e1i | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Big O Notation: Defines algorithm efficiency as input size increases. O(1) is constant access, like finding an index. O(n) linear, like a list sea... | stunspot |
1,887,442 | PHP Mastery #1 - Pengenalan | Halo semuanya, selamat datang di seri belajar PHP yang saya sebut PHP Mastery. Dalam seri ini, kita... | 0 | 2024-06-13T15:23:12 | https://dev.to/fadlihdytullah/php-mastery-1-pengenalan-1e63 | php | Halo semuanya, selamat datang di seri belajar PHP yang saya sebut PHP Mastery. Dalam seri ini, kita akan mempelajari PHP dari tingkat dasar hingga mahir. Tujuan seri ini adalah untuk membangun fondasi yang kuat agar kita siap menguasai Laravel.
## PHP
PHP, yang merupakan singkatan dari PHP: HyperText Preprocessor (ya... | fadlihdytullah |
1,887,441 | Reduce Alert Fatigue | Alert fatigue is an increasingly common issue in cybersecurity that can have serious consequences.... | 0 | 2024-06-13T15:22:30 | https://dev.to/ddeeney/reduce-alert-fatigue-1977 | Alert fatigue is an increasingly common issue in cybersecurity that can have serious consequences. This article explores the causes and impacts of alert fatigue, as well as strategies for mitigating it. By implementing intelligent risk scoring, centralized alert management, context-driven prioritization, and other solu... | ddeeney | |
1,887,440 | PYTHON SELENIUM ARCHITECTURE | As we all know, Selenium is an automation tool used for web application testing, and Python is a... | 0 | 2024-06-13T15:22:17 | https://dev.to/jayshankark/python-selenium-architecture-5b3l |
As we all know, Selenium is an automation tool used for web application testing, and Python is a programming language. Selenium scripts can be written using only programming languages; the most commonly used programming languages are Java and Python.Pyhton and Selenium work together to create automation scripts and co... | jayshankark | |
1,887,439 | Unlocking the Power of Advanced Swarm Intelligence in Disaster Response | Introduction: In the realm of disaster response, every second counts. From earthquakes to... | 0 | 2024-06-13T15:21:16 | https://dev.to/chanda_simran/unlocking-the-power-of-advanced-swarm-intelligence-in-disaster-response-26a | markettrends, marketgrowth, marketstrategy |

**Introduction:**
In the realm of disaster response, every second counts. From earthquakes to hurricanes, natural calamities strike swiftly and without warning, leaving behind devastation and chaos. In such critica... | chanda_simran |
1,887,438 | Understanding Populating Referencing Fields in Mongoose | Introduction In MongoDB and Mongoose, referencing fields allow you to establish... | 0 | 2024-06-13T15:20:36 | https://dev.to/md_enayeturrahman_2560e3/understanding-populating-referencing-fields-in-mongoose-jhg | mongoose, node, express, javascript | ### Introduction
- In MongoDB and Mongoose, referencing fields allow you to establish relationships between different documents in your database. When you have a reference to another document (or multiple documents), populating those references means that you retrieve and include the actual referenced document(s) ins... | md_enayeturrahman_2560e3 |
1,887,434 | Detail implementation of Reports and Analytics | Sure! Below is an implementation for generating various reports for academic performance, attendance,... | 0 | 2024-06-13T15:19:36 | https://dev.to/nadim_ch0wdhury/detail-implementation-of-reports-and-analytics-1h77 | Sure! Below is an implementation for generating various reports for academic performance, attendance, and finances using Next.js, NestJS, and GraphQL.
### Backend (NestJS)
#### 1. Entities
We will use the entities defined previously for courses, assignments, submissions, fees, payments, and attendance.
#### 2. Serv... | nadim_ch0wdhury | |
1,887,432 | Detail implementation of Learning Management System | Sure! Below is an implementation for a Learning Management System (LMS) focusing on online course... | 0 | 2024-06-13T15:17:35 | https://dev.to/nadim_ch0wdhury/detail-implementation-of-learning-management-system-2dlp | Sure! Below is an implementation for a Learning Management System (LMS) focusing on online course management, assignment submission, and virtual classroom features using Next.js, NestJS, and GraphQL.
### Backend (NestJS)
#### 1. Entities
**Course Entity:**
```typescript
// course.entity.ts
import { Entity, Column, P... | nadim_ch0wdhury | |
1,887,431 | One-Byte: Concurrency | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T15:17:14 | https://dev.to/stunspot/one-byte-concurrency-370o | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Concurrency: Multiple tasks running simultaneously, not always parallel. Like multitasking on a computer. Optimizes CPU time and boosts responsive... | stunspot |
1,887,430 | pCloudy Desktop Assistant Launched- Easy to use and access important features of pCloudy at a single place | pCloudy Desktop Assistant Evolves – Easy Access & Enhanced Features in One Place! pCloudy has... | 0 | 2024-06-13T15:16:56 | https://dev.to/pcloudy_ssts/pcloudy-desktop-assistant-launched-easy-to-use-and-access-important-features-of-pcloudy-at-a-single-place-5665 | downloadthelatestpda200here | pCloudy Desktop Assistant Evolves – Easy Access & Enhanced Features in One Place!
pCloudy has been at the forefront of providing efficient solutions for mobile app testing. The pCloudy Desktop Assistant (PDA), initially launched with the 5.9 update, was a major utility that enabled users to access key features like ... | pcloudy_ssts |
1,887,429 | Setting Up a Node.js Environment 🚀 | Hey your instructor here #KOToka 😊 . "Let learn something today Ready to dive into Node.js... | 0 | 2024-06-13T15:16:55 | https://dev.to/erasmuskotoka/setting-up-a-nodejs-environment-176o | Hey your instructor here #KOToka 😊 .
"Let learn something today
Ready to dive into Node.js development? Setting up your environment is the
first step! 🌟 Here’s a quick guide to get you started:
1. Install Node.js: Download and install Node.js from the official website. This will also install npm (Node Packa... | erasmuskotoka | |
1,887,428 | Panduan Lengkap Bermain Game Pragmatic di Platform Online: Kiat Sukses | Pengenalan Permainan Pragmatis dan Platform Online Pragmatic Games, yang ditawarkan oleh... | 0 | 2024-06-13T15:15:25 | https://dev.to/sugiharasaki/panduan-lengkap-bermain-game-pragmatic-di-platform-online-kiat-sukses-1778 | Pengenalan Permainan Pragmatis dan Platform Online
--------------------------------------------------
... | sugiharasaki | |
1,887,427 | Event Modeling: Another Game-Changing Technique You Wish You Knew Sooner! | Have you ever started a new project where everything looked shiny and the work was easy and... | 0 | 2024-06-13T15:14:49 | https://dev.to/iwooky/event-modeling-another-game-changing-technique-you-wish-you-knew-sooner-4on8 | learning, architecture, programming, productivity | Have you ever started a new project where everything looked shiny and the work was easy and enjoyable?
A honeymoon phase, right? But then, suddenly, after 6 months, it becomes unrealistically hard, business starts to complain and every change takes years to integrate.
_If this sounds all too familiar, then you're i... | iwooky |
1,886,756 | It's been a long time since I posted but I am back. The challenge restarts. Day 1 of 30 | So today I covered some React.JS and refreshed my mind on the concepts I learned with a small... | 0 | 2024-06-13T15:14:49 | https://dev.to/francis_ngugi/its-been-a-long-time-since-i-posted-but-i-am-back-the-challenge-restarts-day-1-of-30-1kn5 | webdev, react, beginners, adhd | So today I covered some React.JS and refreshed my mind on the concepts I learned with a small project. It was not easy, but I learned a lot and got a better understanding of react and how the front end works. And also I managed to do some reading of my past hacking notes since it has been a long time since I did sth re... | francis_ngugi |
1,887,425 | Functional and Non functional testing | Functional Testing Objective: To verify that the software functions according to the specified... | 0 | 2024-06-13T15:13:56 | https://dev.to/abarna/functional-and-non-functional-testing-1eon | Functional Testing
Objective: To verify that the software functions according to the specified requirements.
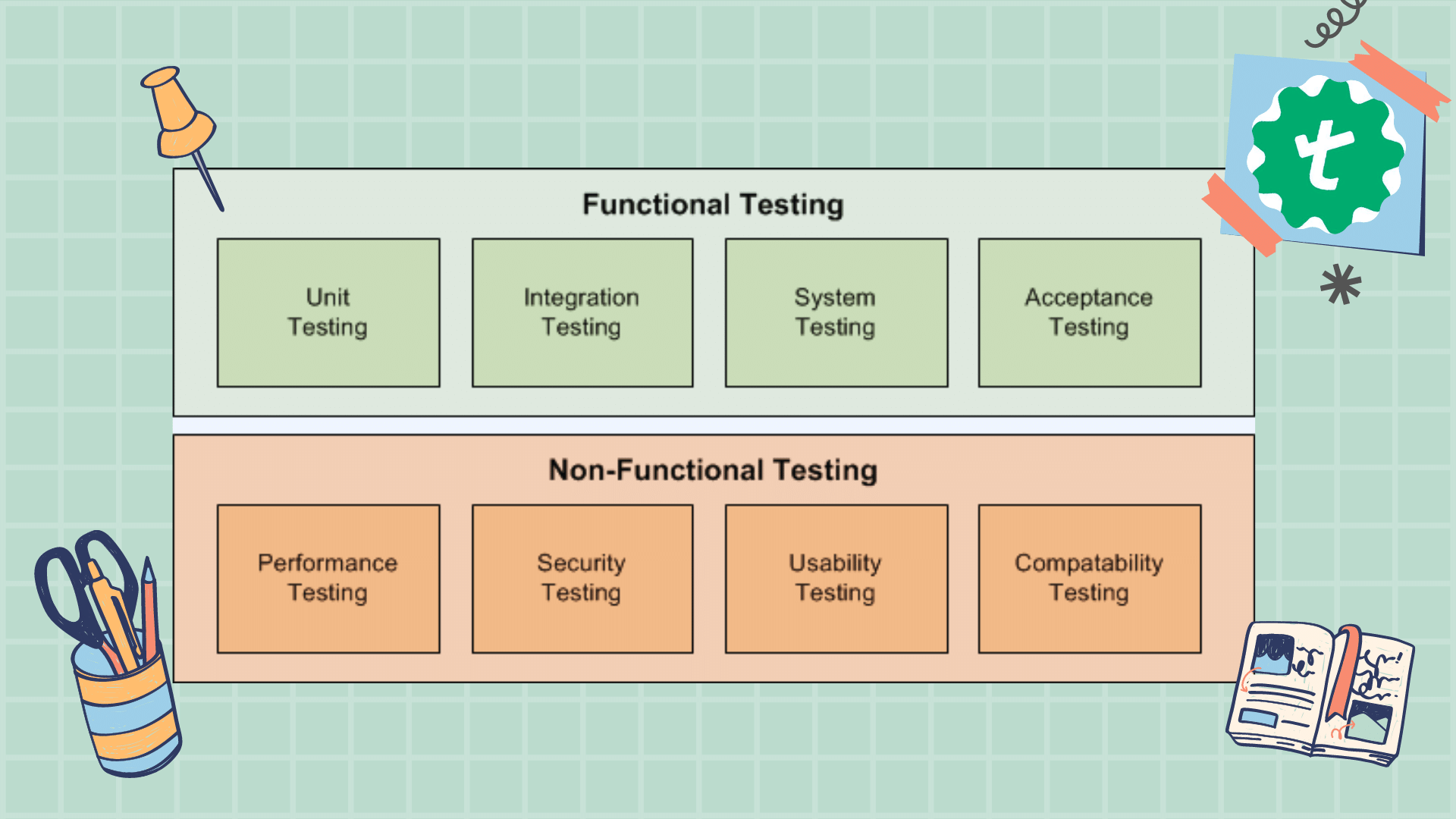
Key Focus Areas:
Features and Functions: Ensures each feature works correctly.
User Interface: Verifies... | abarna | |
1,887,424 | Detail implementation of Financial Management | Here's an implementation for a Financial Management system focusing on fee management, billing,... | 0 | 2024-06-13T15:13:27 | https://dev.to/nadim_ch0wdhury/detail-implementation-of-financial-management-5hif | Here's an implementation for a Financial Management system focusing on fee management, billing, payments, and financial report generation using Next.js, NestJS, and GraphQL.
### Backend (NestJS)
#### 1. Entities
**Fee Entity:**
```typescript
// fee.entity.ts
import { Entity, Column, PrimaryGeneratedColumn, ManyToOne... | nadim_ch0wdhury | |
1,887,423 | Different Techniques Of Debugging Selenium Based Test Scripts | Different Techniques Of Debugging Selenium Based Test Scripts Writing and maintaining the test... | 0 | 2024-06-13T15:11:08 | https://dev.to/pcloudy_ssts/different-techniques-of-debugging-selenium-based-test-scripts-4e4c | montemedialibrary, simplescreenrecorder, seleniumtestautomation | Different Techniques Of Debugging Selenium Based Test Scripts
Writing and maintaining the test automation code is not always a piece of cake. As a matter of fact, we frequently face [many scenarios](https://www.pcloudy.com/blogs/testing-scenarios-you-should-avoid-while-automating-with-selenium/) where automated t... | pcloudy_ssts |
1,887,422 | Detail implementation of Communication Tools | Sure! Below is an implementation for communication tools including a messaging system, email... | 0 | 2024-06-13T15:10:24 | https://dev.to/nadim_ch0wdhury/detail-implementation-of-communication-tools-31ji | Sure! Below is an implementation for communication tools including a messaging system, email notifications, and announcements/notices using Next.js, NestJS, and GraphQL.
### Backend (NestJS)
#### 1. Entities
**Message Entity:**
```typescript
// message.entity.ts
import { Entity, Column, PrimaryGeneratedColumn, ManyT... | nadim_ch0wdhury | |
1,887,421 | One-Byte: Public Key Cryptography | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T15:10:00 | https://dev.to/stunspot/one-byte-public-key-cryptography-emi | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Public Key Cryptography: Uses two keys – one public for encryption, one private for decryption. Secures internet communication, digital signatures... | stunspot |
1,887,415 | Creating a Secure NestJS Backend with JWT Authentication and Prisma | In this tutorial, we will create a secure backend application using NestJS, Prisma, and JWT-based... | 0 | 2024-06-13T15:09:51 | https://dev.to/tharindufdo/creating-a-secure-nestjs-backend-with-jwt-authentication-and-prisma-2of9 | nestjs, prisma, jwt, typescript | In this tutorial, we will create a secure backend application using NestJS, Prisma, and JWT-based authentication. Our application will include CRUD operations for managing books, with endpoints protected by JWT authentication.
## Prerequisites
Before we start, ensure you have the following installed on your machine:
... | tharindufdo |
1,887,644 | Alfred: The AI Assistant for Modern Developer Portals | Enhance developer experience by allowing easier API discovery and saving developers’s time on API... | 0 | 2024-06-18T11:41:45 | https://blog.treblle.com/alfred-the-ai-assistant-for-modern-developer-portals/ | ai, apiobservability, api, digitaltransformation | ---
title: Alfred: The AI Assistant for Modern Developer Portals
published: true
date: 2024-06-13 15:08:53 UTC
tags: AI,APIObservability,APIs,DigitalTransformation
canonical_url: https://blog.treblle.com/alfred-the-ai-assistant-for-modern-developer-portals/
---
![Alfred: The AI Assistant for Modern Developer Portals]... | cindreta |
1,887,420 | Detail implementation of Academic Management | Certainly! Below is an implementation for Academic Management, including features for class and... | 0 | 2024-06-13T15:08:17 | https://dev.to/nadim_ch0wdhury/detail-implementation-of-academic-management-m2 | Certainly! Below is an implementation for Academic Management, including features for class and subject management, timetable creation and management, and attendance tracking and reporting using Next.js, NestJS, and GraphQL.
### Backend (NestJS)
#### 1. Entities
**Class Entity:**
```typescript
// class.entity.ts
imp... | nadim_ch0wdhury | |
1,887,402 | Built replies generation application with Angular | Introduction I built a replies generation application four times using different large... | 27,661 | 2024-06-13T15:06:33 | https://www.blueskyconnie.com/built-replies-generation-application-with-angular/ | angular, tutorial, generativeai, frontend | ##Introduction
I built a replies generation application four times using different large language models, APIs, frameworks, and tools. I experimented with different tools and models to find my preferred stack to build Generative AI applications.
###Create a new Angular Project
```bash
ng new ng-prompt-chaining-demo
... | railsstudent |
1,887,446 | Countdown to js13kGames 2024 | Another year, another countdown. This time though we’ll have a thirteenth edition of js13kGames - our... | 0 | 2024-06-13T15:41:57 | https://medium.com/js13kgames/countdown-to-js13kgames-2024-64ae3dbfab4d | codegolf, competition, javascript, gamedev | ---
title: Countdown to js13kGames 2024
published: true
date: 2024-06-13 15:05:25 UTC
tags: codegolf,competition,javascript,gamedev
canonical_url: https://medium.com/js13kgames/countdown-to-js13kgames-2024-64ae3dbfab4d
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/8fckfl1lg0vu5me39f9h.png
---
A... | end3r |
1,887,419 | Streamlining Your Software Delivery with AWS CodePipeline | Streamlining Your Software Delivery with AWS CodePipeline In today's fast-paced software... | 0 | 2024-06-13T15:05:08 | https://dev.to/virajlakshitha/streamlining-your-software-delivery-with-aws-codepipeline-23ek | 
# Streamlining Your Software Delivery with AWS CodePipeline
In today's fast-paced software development landscape, delivering high-quality applications at speed is paramount. Continuous Integration and Continuous Delivery (CI/CD) p... | virajlakshitha | |
1,887,418 | One-Byte: Virtualization | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T15:04:49 | https://dev.to/stunspot/one-byte-virtualization-4bkk | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Virtualization: Creating virtual hardware/OS within a system. Like running a different OS on the same machine. Optimizes resources, adds flexibili... | stunspot |
1,887,417 | Detail implementation of User Management | Certainly! Below is a detailed implementation for user management, including user registration,... | 0 | 2024-06-13T15:04:39 | https://dev.to/nadim_ch0wdhury/detail-implementation-of-user-management-36nn | Certainly! Below is a detailed implementation for user management, including user registration, login, profile management, and role-based access control using Next.js, NestJS, and GraphQL.
### Backend (NestJS)
#### 1. User Entity
```typescript
// user.entity.ts
import { Entity, Column, PrimaryGeneratedColumn } from '... | nadim_ch0wdhury | |
1,887,416 | Process for developing School Management System using Next js, Nest js & GraphQl API! | Developing a comprehensive School Management System using Next.js, NestJS, and GraphQL involves... | 0 | 2024-06-13T15:02:18 | https://dev.to/nadim_ch0wdhury/process-for-developing-school-management-system-using-next-js-nest-js-graphql-api-ad8 | Developing a comprehensive School Management System using Next.js, NestJS, and GraphQL involves several steps and considerations. Here's a high-level overview of how you can approach this project:
### Technology Stack:
- **Frontend:** Next.js (React framework)
- **Backend:** NestJS (Node.js framework)
- **API:** Graph... | nadim_ch0wdhury | |
1,887,401 | 🚴♂️Speeding up with JS one liners | I will write more, I promise. I've been doing some leetcode and practicing my typing. So I pretend to... | 0 | 2024-06-13T15:01:05 | https://dev.to/girordo/speeding-up-with-js-one-liners-2m3 | javascript, webdev, beginners, programming | I will write more, I promise.
I've been doing some leetcode and practicing my typing. So I pretend to write more about these two subjects.
I'm also not generating these stuff with ChatGPT and pretend to write more of my thoughts instead just being some random subject IA generated.
BUT I'm guiding through other articles... | girordo |
1,887,414 | CSS: Best Practices for Multi-Level Navigation | Just get to the point, the key is to use the CSS adjacent sibling selector (the + selector), child... | 0 | 2024-06-13T15:00:49 | https://dev.to/taufik_nurrohman/css-best-practices-for-multi-level-navigation-2d7f | css, webdev, beginners | Just get to the point, the key is to use the CSS adjacent sibling selector (the `+` selector), child selector (the `>` selector) and the new `:focus-within` pseudo-class selector:
``` css
/*
* Hide sub-menu(s) by default.
*/
nav li ul {
display: none;
}
/*
* Image 1: Adjacent sibling selector to show the
* clos... | taufik_nurrohman |
1,887,413 | How many types of feature should be available in a School Management System Full Stack app? | A comprehensive School Management System (SMS) Full Stack app should include a variety of features to... | 0 | 2024-06-13T15:00:39 | https://dev.to/nadim_ch0wdhury/how-many-types-of-feature-should-be-available-in-a-school-management-system-full-stack-app-58h9 | A comprehensive School Management System (SMS) Full Stack app should include a variety of features to handle all aspects of school administration and academic management. Here are the key types of features that should be available:
1. **User Management:**
- Admin Dashboard
- Role-Based Access Control (Admin, Tea... | nadim_ch0wdhury | |
1,887,412 | Using Spectron for Electron Apps | The Speed at which Technologies and companies are growing today are quite unfathomable. We have come... | 0 | 2024-06-13T14:59:37 | https://dev.to/pcloudy_ssts/using-spectron-for-electron-apps-34e0 | electronapplication, electron, spectron, chromedriver | The Speed at which Technologies and companies are growing today are quite unfathomable. We have come a long way from the digital age of the 1970s to the information age of the 21st century in such a short span of time. The rate at which technologies around the world are evolving things that we thought impossible is sta... | pcloudy_ssts |
1,887,411 | One-Byte: CAP Theorem | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T14:59:24 | https://dev.to/stunspot/one-byte-cap-theorem-107i | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
CAP Theorem: In distributed systems, you can have Consistency, Availability, or Partition Tolerance, but only two at a time. It's a trade-off tria... | stunspot |
1,887,410 | AI-based body pose detection to extend telehealth software | This post is a quick overview of an Abto Software blog article. Telehealth adoption, being... | 0 | 2024-06-13T14:58:05 | https://dev.to/abtosoftware/ai-based-body-pose-detection-to-extend-telehealth-software-2phf | ai, datascience, computerscience, algorithms | _This post is a quick overview of an Abto Software [blog article](https://www.abtosoftware.com/blog/ai-based-body-pose-detection-to-extend-telehealth-software)._
Telehealth adoption, being influenced by the coronavirus pandemic, drastically changed healthcare delivery. Administrational processes, including registratio... | abtosoftware |
1,887,409 | X is about to start hiding all likes | A corporate source claims that X is launching private likes as soon as today. This implies that... | 0 | 2024-06-13T14:56:51 | https://dev.to/sophia78/x-is-about-to-start-hiding-all-likes-1fl5 | trending, usa, viral, news | A corporate source claims that X is launching private likes as soon as today. This implies that platform preferences will be concealed by default, something that X's Premium subscribers can currently do. Elon Musk, the owner of X, reshared a screenshot of the story after it was published, stating that it's "important t... | sophia78 |
1,887,408 | Where is the most random place you figuring out your code / bug? | Mine: In a dream 🤣. Share yours in the comment. | 0 | 2024-06-13T14:56:13 | https://dev.to/syakirurahman/where-is-the-most-random-place-you-figuring-out-your-code-bug-14jp | bug, meme, discuss | Mine: In a dream 🤣.
Share yours in the comment. | syakirurahman |
1,887,406 | Why is Appium Preferred Over Other Mobile App Test Automation Tools? | Has a thought ever struck you about why people choose Appium over other mobile app test automation... | 0 | 2024-06-13T14:52:00 | https://dev.to/pcloudy_ssts/why-is-appium-preferred-over-other-mobile-app-test-automation-tools-359d | mobileautomationtesting, mobileapplicationtesting, appiumautomation | Has a thought ever struck you about why people choose Appium over other mobile app test automation tools? If you still wonder, come to us!
[Mobile automation testing](https://www.pcloudy.com/mobile-automation-testing-on-real-devices/) has become a crucial aspect of a robust procedure of mobile software development, t... | pcloudy_ssts |
1,887,405 | Pandas and Its Powerful Features — Tips That Might Help You | **DataFrame, Series, and Grouping Operations: When to Use Each One? **In my day-to-day Python... | 0 | 2024-06-13T14:51:34 | https://dev.to/edulon/pandas-and-its-powerful-features-tips-that-might-help-you-18jl | python, beginners, datascience, development | **DataFrame, Series, and Grouping Operations: When to Use Each One?
**In my day-to-day Python development, I often encounter various ways to achieve the same result when manipulating data. Pandas, a powerful library for data analysis, offers incredible tools such as DataFrame, Series, and grouping operations. But when ... | edulon |
1,887,404 | Comprehensive Guide to Gutter Installation: Protecting Your Home From Water Damage | Gutter installation plays a crucial role in maintaining the integrity of your home by efficiently... | 0 | 2024-06-13T14:51:24 | https://dev.to/allic47re/comprehensive-guide-to-gutter-installation-protecting-your-home-from-water-damage-42h7 | Gutter installation plays a crucial role in maintaining the integrity of your home by efficiently directing rainwater away from its foundation, walls, and landscaping. This detailed guide covers everything you need to know about **[gutter installation](https://alllitchfieldgutters.com)**, including types of gutters, ma... | allic47re | |
1,887,403 | Design Pattern #2 - Facade Pattern | Let’s continue our quest on learning new the trending design patterns for front-end developers.... | 27,620 | 2024-06-13T14:49:55 | https://www.superviz.com/design-pattern-2-facade-pattern-for-frontend-developers | javascript, architecture, learning, webdev | Let’s continue our quest on learning new the trending design patterns for front-end developers.
After discussing the [Singleton pattern in our first article](https://dev.to/superviz/design-pattern-1-singleton-for-frontend-developers-14p9), we now turn our attention to the Facade pattern in this second article. The Fa... | vtnorton |
1,887,399 | Exploratory Testing, A Guide Towards Better Test Coverage | Exploratory Testing is a black box testing technique which lays out the freedom to testers to think... | 0 | 2024-06-13T14:47:16 | https://dev.to/pcloudy_ssts/exploratory-testing-a-guide-towards-better-test-coverage-il8 | functionaltestexecution, pcloudyscertifayafeatures | Exploratory Testing is a black box testing technique which lays out the freedom to testers to think out of the box with a minimal dependency on pre-designed answers and step on a process of investigation and discovery to improve the quality of application under test. In layman terms, Exploratory testing is said to be a... | pcloudy_ssts |
1,887,395 | One Byte: Gödel's Incompleteness | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T14:45:17 | https://dev.to/stunspot/one-byte-godels-incompleteness-34dh | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Gödel's Incompleteness: In consistent formal systems, some truths are unprovable within them. Limits math/logical systems. Influences computing, c... | stunspot |
1,876,332 | PyCon US 2024: A roundup of writeups | If you read just one, check Kati's thorough recap! 22nd May 2024 Echos of the People API user... | 0 | 2024-06-13T14:41:55 | https://dev.to/hugovk/pycon-us-2024-a-roundup-of-writeups-26hj | python, pycon, pyconus, 2024 | If you read just one, check [Kati's thorough recap](https://katherinemichel.github.io/portfolio/pycon-us-2024-recap.html)!
22nd May 2024
* [Echos of the People API user guide](https://nedbatchelder.com/blog/202405/echos_of_the_people_api_user_guide.html) by [Ned Batchelder](https://mastodon.social/@nedbat@hachyderm.i... | hugovk |
1,887,392 | Here are 17 developer tools which makes you productive | Here are 17 developer tools that can help keep you productive, with images and titles: Code... | 0 | 2024-06-13T14:38:52 | https://dev.to/akshansh090/here-are-17-developer-tools-which-makes-you-productive-21c3 | Here are 17 developer tools that can help keep you productive, with images and titles:
1. Code Editor
!https://github.com/microsoft/vscode/blob/master/images/logo.png
Visual Studio Code
2. Version Control
!https://git-scm.com/images/logo.png
Git
3. Browser DevTools
!https://developer.chrome.com/docs/devtools/logo.pn... | akshansh090 | |
1,887,380 | LeetCode Day7 String Part.1 | LeetCode No.344 Reverse String Write a function that reverses a string. The input string... | 0 | 2024-06-13T14:37:32 | https://dev.to/flame_chan_llll/leetcode-day8-string-3mln | leetcode, java, algorithms | ## LeetCode No.344 Reverse String
Write a function that reverses a string. The input string is given as an array of characters s.
You must do this by modifying the input array in-place with O(1) extra memory.
Example 1:
Input: s = ["h","e","l","l","o"]
Output: ["o","l","l","e","h"]
Example 2:
Input: s = ["H","a"... | flame_chan_llll |
1,887,389 | Embark on Your Machine Learning Journey | Machine learning (ML) is rapidly transforming our world, from personalized recommendations on... | 27,619 | 2024-06-13T14:37:02 | https://dev.to/aishik_chatterjee_0060e71/embark-on-your-machine-learning-journey-1i76 | Machine learning (ML) is rapidly transforming our world, from personalized
recommendations on shopping platforms to intelligent assistants that
anticipate our needs. But have you ever wondered how these seemingly magical
systems work? The answer lies in practical projects that allow you to learn by
doing. This blog pos... | aishik_chatterjee_0060e71 | |
1,887,387 | Deploying and Connecting to a Virtual Machine in Azure. | **Step 1: **Create a Virtual Machine Log in to the Azure portal and navigate to the Virtual... | 0 | 2024-06-13T14:36:55 | https://dev.to/tojumercy1/deploying-and-connecting-to-a-virtual-machine-in-azure-373o | azure, tutorial, virtualmachine, ai | **Step 1: **Create a Virtual Machine
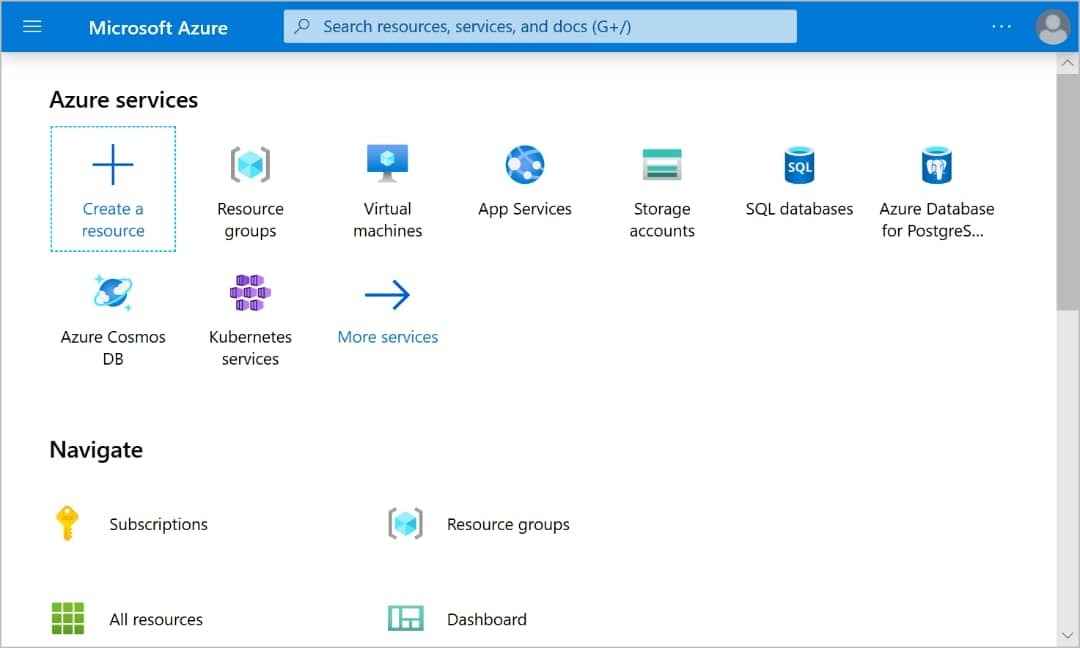
1. Log in to the Azure portal and navigate to the Virtual machines page.
2. Click on "Create" and select "Virtual machine" from the options.
Step 2: Configure Virtual Machine ... | tojumercy1 |
1,887,388 | 🚀 Disaster Recovery Solution Using AWS Backups 🌐 | Recently, I implemented an innovative Disaster Recovery (DR) solution to support our Amazon RDS... | 0 | 2024-06-13T14:36:05 | https://dev.to/alerabello/disaster-recovery-solution-using-aws-backups-2p28 | aws, cloud | Recently, I implemented an innovative Disaster Recovery (DR) solution to support our Amazon RDS backups using the powerful tools provided by AWS. Here's a brief overview of the project:
🔹 Challenge: Ensure that our RDS database backups are securely and efficiently replicated across different AWS accounts and regions.... | alerabello |
1,887,386 | DEV Computer Science Challenge Submission | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T14:35:49 | https://dev.to/jershdev/dev-computer-science-challenge-submission-32nj | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Formal logic is the foundation for why humans can write instructions for the computer. It is the reason why certain sequence of symbols hold mean... | jershdev |
1,887,385 | API Testing: A Comprehensive Guide | Here is a comprehensive guide to API testing ¹: Uses: Validate responses and data... | 0 | 2024-06-13T14:35:02 | https://dev.to/akshansh090/api-testing-a-comprehensive-guide-38ap | Here is a comprehensive guide to API testing ¹:
Uses:
- Validate responses and data reliability.
- Identify bugs, inconsistencies, or deviations from the anticipated behavior.
Benefits:
- API testing contributes to the success of software development.
- API testing allows teams to detect defects early in the developmen... | akshansh090 | |
1,887,384 | Setting up twin.macro with Vite + React | Introduction Recently, I encountered a project which worked with twin macro. My first... | 0 | 2024-06-13T14:34:16 | https://dev.to/franklivania/setting-up-twinmacro-with-vite-react-18na | react, tailwindcss, javascript, vite | ## Introduction
Recently, I encountered a project which worked with twin macro. My first thought was that Tailwind is already perfect, so why want more? Then I started to use twin.macro, and I have gotten addicted to it. Not only does it have massive flexibility in styling, but you can also use it with emotion, or sty... | franklivania |
1,887,383 | Trending News Today X is about to start hiding all likes | A corporate source claims that X is launching private likes as soon as today. This implies that... | 0 | 2024-06-13T14:34:10 | https://dev.to/newsbelltoday08/trending-news-todayx-is-about-to-start-hiding-all-likes-3epm | news, newsong, trending, usa | A corporate source claims that X is launching private likes as soon as today. This implies that platform preferences will be concealed by default, something that X's Premium subscribers can currently....**Read More** - https://shorturl.at/667f8 | newsbelltoday08 |
1,887,382 | Метрология ДМ-317 | Основные задачи метрологии – обеспечение единства измерений; – установление системы... | 0 | 2024-06-13T14:34:01 | https://dev.to/void_1nside/mietrologhiia-dm-317-39hg | ### Основные задачи метрологии
– обеспечение единства измерений;
– установление системы единиц физической величины (ФВ), государственных эталонов и образцовых средств измерений;
– обеспечение исследований, производства и эксплуатации технических устройств;
– разработка методов оценки погрешностей, состояние средств... | void_1nside | |
1,887,381 | How to train ChatGPT on your Data [Step-by-Step Guide] | Hello devs 🙌🏼 I've seen a lot of people looking to customize ChatGPT for their projects. So today, I... | 0 | 2024-06-13T14:32:54 | https://dev.to/creativetim_official/how-to-train-chatgpt-on-your-data-step-by-step-guide-4hd | ai, python | Hello devs 🙌🏼
I've seen a lot of people looking to customize ChatGPT for their projects. So today, I just wanted to share some info about how you can train it on your website data.
Training ChatGPT on your own website data can be done the traditional way by scraping your site's content, cleaning the data, and fine-... | creativetim_official |
1,887,376 | Google Chrome Tips and Tricks and New Hidden Features | Google Chrome Tips and Tricks and New Hidden Features Discover the top 5 Google Chrome tips and... | 0 | 2024-06-13T14:30:10 | https://dev.to/proflead/google-chrome-tips-and-tricks-and-new-hidden-features-39b1 | chrome, webdev, google, beginners | Google Chrome Tips and Tricks and New Hidden Features
Discover the top 5 Google Chrome tips and tricks to boost your productivity and uncover hidden features you never knew existed! From secret shortcuts to powerful extensions, this video has everything you need to become a Chrome power user. Don't miss out on these g... | proflead |
1,887,379 | How to Calculate ROI on Test Automation? | If you are a software developer, you already know how software testing is indispensable for your... | 0 | 2024-06-13T14:29:46 | https://dev.to/jamescantor38/how-to-calculate-roi-on-test-automation-1m4f | calculateroi, testautomation, testgrid | If you are a software developer, you already know how software testing is indispensable for your development process. Testing helps you identify bugs and glitches during the early stages of development and lets you proactively rectify such issues before the product launch.
Software testing helps you deliver reliable ... | jamescantor38 |
1,887,378 | Boating in Style: Top Picks for Boats for Sale in Abu Dhabi | Abu Dhabi, with its stunning coastline and crystal-clear waters, offers a perfect backdrop for... | 0 | 2024-06-13T14:28:04 | https://dev.to/tagesep646/boating-in-style-top-picks-for-boats-for-sale-in-abu-dhabi-3b9m | boats, business, travel, webdev | Abu Dhabi, with its stunning coastline and crystal-clear waters, offers a perfect backdrop for boating enthusiasts. Picture yourself gliding across the waves, feeling the warm sun on your face, and the cool breeze in your hair. It's not just about owning a boat; it's about embracing a lifestyle that combines luxury [Bo... | tagesep646 |
1,887,377 | One-Byte: Qubits | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T14:25:00 | https://dev.to/stunspot/one-byte-qubits-10j6 | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Qubits: Fundamental units of quantum computing, unlike classical bits. Can be 0, 1, or both (superposition) and link ("entangle") for complex calc... | stunspot |
1,886,654 | Metadata-as-API with Macula Data Sources | When building media-rich apps or websites, we often need to add some kind of textual information,... | 0 | 2024-06-13T14:24:00 | https://dev.to/kelp_digital/metadata-as-api-with-macula-data-sources-47cp | webdev, metadata, api | When building media-rich apps or websites, we often need to add some kind of textual information, such as date, photo parameters, or camera information. One way of doing this is by directly grabbing the metadata from images with a package like exif-js. Depending on the complexity of your UI, this can work just fine, bu... | alxwnth |
1,887,300 | Terraform Functions Guide: Complete List with Detailed Examples | Terraform functions are essential for creating effective infrastructure code. They help automate... | 0 | 2024-06-13T14:12:31 | https://www.env0.com/blog/terraform-functions-guide-complete-list-with-examples | terraform, devops, aws, cloud | Terraform functions are essential for creating effective infrastructure code. They help automate tasks like generating resource names, calculating values, and managing data structures.
In this blog post, we will explore using [Terraform CLI](https://www.env0.com/blog/what-is-terraform-cli)'s built-in functions in dif... | env0team |
1,887,299 | Continuing Education Requirements: Meeting Professional Development Needs in Chiropractic Practice with Dr.Tom Herchakowski | In the dynamic field of chiropractic practice, practitioners face a myriad of challenges in managing... | 0 | 2024-06-13T14:12:10 | https://dev.to/drtomherchakowski/continuing-education-requirements-meeting-professional-development-needs-in-chiropractic-practice-with-drtom-herchakowski-387 | In the dynamic field of chiropractic practice, practitioners face a myriad of challenges in managing their clinics effectively. Among these challenges, meeting continuing education requirements stands out as a critical aspect of maintaining licensure, staying abreast of advancements in the field, and ensuring high-qual... | drtomherchakowski | |
1,887,298 | Breaking Records | Prepare your favorite cup of coffee, because we are about to enter the fantastic world of Breaking... | 0 | 2024-06-13T14:09:26 | https://dev.to/kecbm/breaking-records-55ji | javascript, beginners, programming, tutorial | *Prepare your favorite cup of coffee*, because we are about to enter the fantastic world of **Breaking records**.
## The problem

 in their solutions.
However, an under explored part of Generative AI is the managing resiliency. It is easy to build on a API provided by a LLM vendor lik... | aravind |
1,887,297 | Meilleures pratiques pour créer une application Express.js | Partie 2 : Meilleures pratiques et fonctionnalités avancées pour créer une application... | 0 | 2024-06-13T14:07:54 | https://dev.to/land-bit/meilleures-pratiques-pour-creer-une-application-expressjs-1e5b | backend, webdev, javascript, tutorial | # Partie 2 : Meilleures pratiques et fonctionnalités avancées pour créer une application Express.js
#### Introduction
Pour la 1ère partie, je vous invite à visité l'article où j'ai parler de [l'introduction d'express et ses concepts fondamentaux](https://dev.to/land-bit/meilleures-pratiques-pour-creer-une-application... | land-bit |
1,887,437 | What’s New in C# 13 for Developers? | TL;DR: Explore the latest features in C# 13! From enhanced params collections to modernized thread... | 0 | 2024-06-19T13:08:08 | https://www.syncfusion.com/blogs/post/whats-new-csharp-13-for-developers | web, blazor, csharp, development | ---
title: What’s New in C# 13 for Developers?
published: true
date: 2024-06-13 14:05:05 UTC
tags: web, blazor, csharp, development
canonical_url: https://www.syncfusion.com/blogs/post/whats-new-csharp-13-for-developers
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/l1z4yyuc3upx2fqb03if.jpeg
---
... | gayathrigithub7 |
1,887,294 | Ownership in Rust | Introduction All programs have to manage the way they use the computer's memory while they... | 0 | 2024-06-13T14:04:21 | https://damiencosset.dev/posts/what-is-ownership-rust/ | rust, learning |
## Introduction
All programs have to manage the way they use the computer's memory while they run. Rust is obviously no different. In this article, I'll try to understand how it works.
Rust uses something that they call *Ownership*. *Ownership* is a set of rules that define how a Rust program manages memory. If you ... | damcosset |
1,883,398 | Signals vs. ngOnChanges for better Angular state management | Written by Lewis Cianci✏️ You know what framework just hasn’t stayed still lately? Angular. For a... | 0 | 2024-06-13T14:01:14 | https://blog.logrocket.com/signals-vs-ngonchanges-angular-state-management | angular, webdev | **Written by [Lewis Cianci](https://blog.logrocket.com/author/lewiscianci/)✏️**
You know what framework just hasn’t stayed still lately? Angular. For a long time, nothing really seemed to change, and now we’re smack-bang in the middle of what some are calling the Angular Renaissance.
First up, we received signals, t... | leemeganj |
1,887,293 | Unlocking the Power of EC2 Auto Scaling using Lifecycle Hooks | In a previous article in which I wrote about EC2 auto scaling, I failed to talked about instance... | 0 | 2024-06-13T14:01:02 | https://dev.to/aws-builders/unlocking-the-power-of-ec2-auto-scaling-using-lifecycle-hooks-12fk | aws, autoscaling, ec2, cloud | In a previous article in which I wrote about EC2 auto scaling, I failed to talked about instance lifecycle hooks and how AWS practitioners can utilize them to optimize their infrastructure. This article is my way of showing you that I have learned from that mistake.
A little recap of what auto scaling is: It's a proce... | brandondamue |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.