
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,886,778 | Semantic elements, Semantic elements in HTML, HTML style guide and declaring document types | What are Semantic Elements? A semantic element clearly describes its meaning to both the... | 0 | 2024-06-13T09:58:29 | https://dev.to/wasifali/semantic-elements-semantic-elements-in-html-html-style-guide-and-declaring-document-types-520l | webdev, css, learning, html | ## **What are Semantic Elements?**
A semantic element clearly describes its meaning to both the browser and the developer.
## **Examples of non-semantic elements**
`<div>` and `<span> `- Tells nothing about its content.
## **Examples of semantic elements**
`<form>`, `<table>`, and `<article>`
## **Semantic Elements i... | wasifali |
1,886,777 | Create A YouTube Homepage Clone in ReactJS and Tailwind CSS | Creating a clone of the YouTube homepage can be both enjoyable and helpful for enhancing your... | 0 | 2024-06-13T09:58:08 | https://www.codingnepalweb.com/create-youtube-homepage-tailwind-reactjs/ | react, tailwindcss, javascript, coding | Creating a clone of the YouTube homepage can be both enjoyable and helpful for enhancing your front-end development skills. This project offers a chance to work on a familiar design while getting practical experience with commonly used tools like [React.js](https://react.dev/) and [Tailwind CSS](https://tailwindcss.com... | codingnepal |
1,886,774 | Unlocking Opportunities: The Synergy of AI and Blockchain | Two groundbreaking technologies, artificial intelligence (AI) and blockchain, are converging to... | 0 | 2024-06-13T09:50:09 | https://dev.to/calyptus_ninja/unlocking-opportunities-the-synergy-of-ai-and-blockchain-4e97 | ai, blockchain, jobs | Two groundbreaking technologies, artificial intelligence (AI) and blockchain, are converging to reshape the future of business.
Picture a world where transactions occur directly between individuals, bypassing intermediaries. This vision is embodied in decentralised marketplaces, driven by the combined forces of AI and... | calyptus_ninja |
1,886,773 | LeetCode Meditations: Clone Graph | Let's start with the description for Clone Graph: Given a reference of a node in a connected... | 26,418 | 2024-06-13T09:48:28 | https://rivea0.github.io/blog/leetcode-meditations-clone-graph | computerscience, algorithms, typescript, javascript | Let's start with the description for [Clone Graph](https://leetcode.com/problems/clone-graph):
> Given a reference of a node in a **[connected](https://en.wikipedia.org/wiki/Connectivity_(graph_theory)#Connected_graph)** undirected graph.
>
> Return a [**deep copy**](https://en.wikipedia.org/wiki/Object_copying#Deep_c... | rivea0 |
1,886,772 | Key Changes In Oracle 23C Release Notes And How To Automate Testing | Oracle 23C release notes signify another step forward for businesses leveraging Oracle cloud... | 0 | 2024-06-13T09:48:12 | https://uktechnews.co.uk/2024/04/18/key-changes-in-oracle-23c-release-notes-and-how-to-automate-testing/ | automate, testing | 
Oracle 23C release notes signify another step forward for businesses leveraging Oracle cloud solutions. As with any major update, navigating the complexities of new features and functionalities necessitates a well-de... | rohitbhandari102 |
1,886,771 | The Convenience and Benefits of Online Medication Refills in Florida with Sonder Online Urgent Care | In the fast-paced world we live in, managing our health and staying on top of medication refills can... | 0 | 2024-06-13T09:45:56 | https://dev.to/sonder_clinic_c94481bd318/the-convenience-and-benefits-of-online-medication-refills-in-florida-with-sonder-online-urgent-care-433g | In the fast-paced world we live in, managing our health and staying on top of medication refills can often feel like a daunting task. Whether you are juggling a busy work schedule, family responsibilities, or other commitments, finding the time to visit a pharmacy for medication refills can be challenging. This is wher... | sonder_clinic_c94481bd318 | |
1,881,562 | Tools and Tool_Choice - Azure GPT4 | When it comes to integrating GPT into our products and especially if a chain of logical decisions are... | 0 | 2024-06-13T09:43:25 | https://dev.to/praveenr2998/tools-and-toolchoice-azure-gpt4-4f81 | ai, nlp, gpt3, machinelearning | When it comes to integrating GPT into our products and especially if a chain of logical decisions are made based on GPT's result then we have to worry about the unstructured nature of GPT's response.
There are several ways to solve this issue
1. Prompt Engineering - Emphasizing to return a structured output maybe as ... | praveenr2998 |
1,886,770 | your tube | Check out this Pen I made! | 0 | 2024-06-13T09:42:43 | https://dev.to/shivaji_gaikwad_45b3c1d0e/your-tube-14md | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Shivaji-Gaikwad/pen/NWVwjKb %} | shivaji_gaikwad_45b3c1d0e |
1,886,769 | UUID: A Profundidade dos Identificadores Únicos Universais | Introdução Em um mundo cada vez mais digital, a necessidade de identificadores únicos é... | 0 | 2024-06-13T09:42:12 | https://dev.to/iamthiago/uuid-a-profundidade-dos-identificadores-unicos-universais-2ced | webdev, uuid | ## Introdução
Em um mundo cada vez mais digital, a necessidade de identificadores únicos é crucial. Desde a identificação de usuários em sistemas de TI até a garantia de unicidade em transações financeiras, os Identificadores Únicos Universais (UUIDs) se destacam como uma solução eficiente e confiável. Neste artigo, e... | iamthiago |
1,886,768 | The Bug Bounty Dilemma: Are We Rewarding Skills or Exploits in Blockchain? | In the shadowy corners of the blockchain jobs world, where digital fortunes can be made or broken in... | 0 | 2024-06-13T09:40:09 | https://dev.to/calyptus_ninja/the-bug-bounty-dilemma-are-we-rewarding-skills-or-exploits-in-blockchain-1f1p | bugs, webdev | In the shadowy corners of the blockchain jobs world, where digital fortunes can be made or broken in a heartbeat, the saga of Avi Eisenberg serves as a modern cautionary tale. Convicted for a daring exploit of Mango Markets that netted him a cool $110 million, Eisenberg didn’t see himself as a criminal but as a shrewd ... | calyptus_ninja |
1,886,767 | Revolutionizing DeFi with Stellar Blockchain Development | The world of finance is undergoing a significant transformation, with decentralized finance (DeFi)... | 27,619 | 2024-06-13T09:38:08 | https://dev.to/aishik_chatterjee_0060e71/revolutionizing-defi-with-stellar-blockchain-development-4d7b | The world of finance is undergoing a significant transformation, with
decentralized finance (DeFi) emerging as a revolutionary force. DeFi
applications aim at empowering individuals by providing financial services
such as lending, borrowing, and trading, all without the requirement for
traditional intermediaries. As th... | aishik_chatterjee_0060e71 | |
1,886,765 | Odoo version 15 pip error | if you get error when running pip install -r requirements.txt as below thon38\Include... | 0 | 2024-06-13T09:33:11 | https://dev.to/jeevanizm/odoo-version-15-pip-error-1c09 | odoo | if you get error when running pip install -r requirements.txt as below
```
thon38\Include "-IC:\Program Files (x86)\Microsoft Visual Studio\2019\BuildTools\VC\Tools\MSVC\14.29.30133\include" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.19041.0\ucrt" "-IC:\Program Files (x86)\Windows Kits\10\include\10.0.190... | jeevanizm |
1,886,764 | Why Create an Engaging UI for In-Car Audiences | We are in a digital fray where UX UI design is an essential feature for every industry. One of the... | 0 | 2024-06-13T09:31:33 | https://www.peppersquare.com/blog/why-create-an-engaging-ui-for-in-car-audiences/ | We are in a digital fray where UX UI design is an essential feature for every industry. One of the industries where screen and user interface (UI) is having a makeover would be the automotive industry. It is a great way to create a seamless experience that has enabled manufacturers to produce lasting impressions.
Besi... | pepper_square | |
1,886,762 | Best Artificial Intelligence institute in Ghaziabad | Softcrayons is widely recognized as the best Artificial Intelligence (AI) institute in Ghaziabad,... | 0 | 2024-06-13T09:30:42 | https://dev.to/nitish_sharma_e5f12c08cb6/best-artificial-intelligence-institute-in-ghaziabad-5576 | Softcrayons is widely recognized as the best [**Artificial Intelligence (AI)**](url) institute in Ghaziabad, offering a comprehensive and industry-relevant training program that equips students with the skills needed to excel in AI careers.
The [**AI course **](url)at Softcrayons covers a broad spectrum of topics essen... | nitish_sharma_e5f12c08cb6 | |
1,886,761 | CSS magic Hat and Wand | Check out this Pen I made! | 0 | 2024-06-13T09:30:34 | https://dev.to/kemiowoyele1/css-magic-hat-and-wand-19al | codepen | Check out this Pen I made!
{% codepen https://codepen.io/frontend-magic/pen/abMRXMJ %} | kemiowoyele1 |
1,885,522 | Unlocking AI Potential with Lambda Workstation | Introduction In recent years, artificial intelligence (AI) and deep learning have... | 0 | 2024-06-13T09:30:00 | https://dev.to/novita_ai/unlocking-ai-potential-with-lambda-workstation-2n89 | ## Introduction
In recent years, artificial intelligence (AI) and deep learning have revolutionized various industries, from healthcare and finance to entertainment and autonomous driving. These technologies rely on complex algorithms and vast amounts of data to mimic human intelligence and perform tasks such as image ... | novita_ai | |
1,886,758 | Wrap your SQL Database inside an AI Chatbot | We've always had the ability to connect your AI chatbot to your database. However, recently we've... | 0 | 2024-06-13T09:27:03 | https://ainiro.io/blog/wrap-your-sql-database-inside-an-ai-chatbot | ai, lowcode, productivity, openai | We've always had the ability to [connect your AI chatbot to your database](https://ainiro.io/blog/connect-chatgpt-to-your-sql-database). However, recently we've taken this to a completely new level, by connecting our CRUD generator to our machine learning features.
To understand what I mean, please watch the following... | polterguy |
1,886,620 | ازاي تمسح EBS غير مستخدمه عن طريق Lambda و EventBridge | كلنا عارفين عامل ال Cost ف AWS من العوامل المهمه اللي كتير مش بناخد بالنا منها.. سواء كنت بتسخدم ال... | 0 | 2024-06-13T09:26:53 | https://dev.to/muash10/zy-tmsh-ebs-gyr-mstkhdmh-n-tryq-lambda-w-eventbridge-om1 | python, cloud, cloudcomputing |
كلنا عارفين عامل ال Cost ف AWS من العوامل المهمه اللي كتير مش بناخد بالنا منها.. سواء كنت بتسخدم ال Service على مستوى شخصي كا تجربه او على مستوى Enterprise
و دي بتفرق كتير اوي ف اختياري للطريقه او Services اللي هستخدمها و انا ببني ال Solution بتاعي
اوقات كتير اوي بيبقى فيه Resources كتيره مش بنستخدمها او بننساها ... | muash10 |
1,886,757 | Artificial Intelligence institute in Ghaziabad | Softcrayons is recognized as a leading Artificial Intelligence (AI) institute in Ghaziabad, offering... | 0 | 2024-06-13T09:23:25 | https://dev.to/nitish_sharma_e5f12c08cb6/artificial-intelligence-institute-in-ghaziabad-39bf | Softcrayons is recognized as a leading **Artificial Intelligence (AI)** institute in Ghaziabad, offering top-notch training programs tailored to meet the needs of aspiring AI professionals. The institute is renowned for its comprehensive curriculum, expert faculty, and commitment to student success.With state-of-the-ar... | nitish_sharma_e5f12c08cb6 | |
1,886,716 | #2037. Minimum Number of Moves to Seat Everyone | https://leetcode.com/problems/minimum-number-of-moves-to-seat-everyone/description/?envType=daily-que... | 0 | 2024-06-13T09:18:47 | https://dev.to/karleb/2037-minimum-number-of-moves-to-seat-everyone-5dbg | https://leetcode.com/problems/minimum-number-of-moves-to-seat-everyone/description/?envType=daily-question&envId=2024-06-13
```js
/**
* @param {number[]} seats
* @param {number[]} students
* @return {number}
*/
var minMovesToSeat = function (seats, students) {
let res = 0
seats.sort((a, b) => b - a)
... | karleb | |
1,886,715 | BEST INSTITUTE FOR DATA SCIENCE TRAINING | Nowadays many IT aspirants are choosing data science as primary choice for starting their career and... | 0 | 2024-06-13T09:16:07 | https://dev.to/harshit_chauhan_a9aea06b0/best-institute-for-data-science-training-4bam | datascience, dataengineering, learning, training | Nowadays many IT aspirants are choosing data science as primary choice for starting their career and seeks for a perfect data science training institute. For those aspirants softcrayons tech training institute offer full packages, where one is exposed to preliminary and basic concepts in data science, data statistics, ... | harshit_chauhan_a9aea06b0 |
1,886,714 | What are the steps to build a basic PHP router? | In my last project, I have a direct mapping between a file path , address bar and a controller. If I... | 0 | 2024-06-13T09:14:27 | https://dev.to/ghulam_mujtaba_247/what-are-the-steps-to-build-a-basic-php-router-51ng | webdev, php, router, beginners | In my last project, I have a direct mapping between a file path , address bar and a controller. If I visit contact well, I have contact.php in address bar and sure enough contact.php in controller directory. But I want to change all of that.
Instead I want a single point of entry where I can be responsible for mapping... | ghulam_mujtaba_247 |
1,886,713 | Finding the Right Hardware Maintenance Provider: A Complete Guide | In today's rapidly evolving technological environment, the role of hardware maintenance is integral... | 0 | 2024-06-13T09:14:14 | https://dev.to/vadimyuriev/finding-the-right-hardware-maintenance-provider-a-complete-guide-22gi | In today's rapidly evolving technological environment, the role of hardware maintenance is integral to the seamless operation and longevity of [IT infrastructure](https://mdagrp.ru/). Choosing the right hardware maintenance provider is essential for enhancing organizational efficiency, productivity, and the overall IT ... | vadimyuriev | |
1,886,712 | Master Monopoly Go with These Free Dice Earning Tips | https://www.linkedin.com/pulse/new-monopoly-go-free-dice-links-2024-winbig-roshua-f-hadle-b2ruf https... | 0 | 2024-06-13T09:13:46 | https://dev.to/lisa_cute_e827b7731897c80/master-monopoly-go-with-these-free-dice-earning-tips-5c3m | https://www.linkedin.com/pulse/new-monopoly-go-free-dice-links-2024-winbig-roshua-f-hadle-b2ruf
https://www.linkedin.com/pulse/latest-monopoly-go-free-dice-links-2024-unlimited-rolls-f1bmf
https://www.linkedin.com/pulse/get-free-dice-monopoly-go-2024-todays-update-roshua-f-hadle-qmcbf
https://www.linkedin.com/pulse/ins... | lisa_cute_e827b7731897c80 | |
1,886,711 | #75. Sort Colors | https://leetcode.com/problems/sort-colors/description/?envType=daily-question&envId=2024-06-13 ... | 0 | 2024-06-13T09:10:18 | https://dev.to/karleb/75-sort-colors-12h0 | https://leetcode.com/problems/sort-colors/description/?envType=daily-question&envId=2024-06-13
```javascript
var sortColors = function(nums) {
let low = 0, mid = 0, high = nums.length - 1
while (mid <= high) {
if (nums[mid] === 0) {
[nums[low], nums[mid]] = [nums[mid], nums[low]]
low++
... | karleb | |
1,886,710 | HAVE YOU SPENT YOUR SAVINGS OR OPTED FOR A LOAN? | Getting your finances in order is a difficult feat that requires a great deal of effort, discipline,... | 0 | 2024-06-13T09:08:02 | https://dev.to/chintamani_finlease_08b6b/have-you-spent-your-savings-or-opted-for-a-loan-3o0k | loan, savings, financial, finance | Getting your finances in order is a difficult feat that requires a great deal of effort, discipline, and time. Buying a new home, planning a wedding, pursuing higher education, or starting a business all necessitate large sums of money.
While these are anticipated expenses, many people face unexpected financial obliga... | chintamani_finlease_08b6b |
1,886,709 | Branch and Bound Algorithm to Solve the Traveling Salesman Problem | In this blog post, we are going to take a look at how to use the Branch and Bound algorithm to solve... | 0 | 2024-06-13T09:05:57 | https://dev.to/jospin6/branch-and-bound-algorithm-to-solve-the-traveling-salesman-problem-3ce6 | algorithms, datastructures, ruby | In this blog post, we are going to take a look at how to use the Branch and Bound algorithm to solve the Traveling Salesman Problem and how to implement it using ruby.
First what is Branch and Bound algorithm? according to [geeksforgeeks](https://www.geeksforgeeks.org/branch-and-bound-algorithm/) The Branch and Bound ... | jospin6 |
1,886,708 | What is memoization | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T09:04:40 | https://dev.to/codewitgabi/what-is-memoization-2o99 | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Say I go to a store to get some groceries, the price of my items is calculated but then I decide to add a new item, the new price is added to the ... | codewitgabi |
1,886,707 | How to unleash the Creativity of Siri Voice Generator | Transform your projects with Siri Voice Generator. Add a touch of playfulness and imagination to your... | 0 | 2024-06-13T09:03:26 | https://dev.to/novita_ai/how-to-unleash-the-creativity-of-siri-voice-generator-1738 | ai, voicegenerator, tts | Transform your projects with Siri Voice Generator. Add a touch of playfulness and imagination to your work with this versatile tool.
## Key Highlights
- AI technology to generate Siri voices that sound natural and engaging.
- Text-to-speech technology is at the core of these Siri voice generator AI, allowing users to... | novita_ai |
1,886,706 | FMZ simulation level backtest mechanism explanation | Backtest architecture The FMZ platform backtest program is a complete control process, and... | 0 | 2024-06-13T09:03:10 | https://dev.to/fmzquant/fmz-simulation-level-backtest-mechanism-explanation-133 | fmzquant, backtest, cryptocurrency, trading | ## Backtest architecture
The FMZ platform backtest program is a complete control process, and the program is polling non-stop according to a certain frequency. The data returned by each market and trading API also simulates the actual running time according to the calling time. It belongs to the onTick level, not the o... | fmzquant |
1,886,705 | Tech Stack for Minimalists [FTMHP] 👌 | What is the most minimal Tech stack ? I hope you have this question in your mind before reading this... | 0 | 2024-06-13T09:02:44 | https://dev.to/rudransh61/tech-stack-for-minimalists-ftmhp-1n48 | webdev, javascript, beginners, productivity | What is the most minimal Tech stack ?
I hope you have this question in your mind before reading this and in this post I am going to tell you my favorite tech stack which is only for minimalists like me ...
Yeah I love React ... But sometimes it feels very heavy tool for a small task ....
Yeah I love nodejs ... But ... | rudransh61 |
1,886,704 | Why Quality Assurance is Essential | Quality Assurance has been a lifesaver for BaunIT. It has helped us reach new heights. QA will have... | 0 | 2024-06-13T09:02:28 | https://dev.to/martinbaun/why-quality-assurance-is-essential-1iab | productivity, career, softwaredevelopment, developer | Quality Assurance has been a lifesaver for [BaunIT.](https://baunit.com/) It has helped us reach new heights. QA will have you finally accepting the annoying accidental feature is a bug.
Here are seven reasons why I take **Quality Assurance** seriously;
## 1. Fast and Cost-Efficient Development
Detecting and fixing ... | martinbaun |
1,883,316 | Random and fixed routes with Apache APISIX | My ideas for blog posts inevitably start to dry up after over two years at Apache APISIX. Hence, I... | 0 | 2024-06-13T09:02:00 | https://blog.frankel.ch/fixed-routes-apisix/ | routes, splitraffic, apigateway, apacheapisix | My ideas for blog posts inevitably start to dry up after over two years at [Apache APISIX](https://apisix.apache.org/). Hence, I did some triage on the [APISIX repo](https://github.com/apache/apisix/issues). I stumbled upon this one question:
>We have a requirement to use a plugin, where we need to route the traffic o... | nfrankel |
1,886,695 | Awesome GitHub Profile | This is my Personal Customized GitHub Profile created through markdown and a little bit of HTML. I... | 0 | 2024-06-13T09:01:56 | https://dev.to/zemerik/awesome-github-profile-5bc5 | github, markdown | This is my Personal Customized GitHub Profile created through markdown and a little bit of HTML. I have different features in this README for different purposes, such as Banner, Dropdown, Socials, Badges, and more!
The **10** features of this Profile which I have shown in the video are:
➡️ 1. Banner
➡️ 2. Dropdown
➡️ ... | zemerik |
1,886,702 | Monorepos: Proposing a Monorepo to your team (Q&A) | This post follows a demo I did for my team leaders, where I explained what a monorepo is and how it... | 26,284 | 2024-06-13T09:01:26 | https://dev.to/codenamegrant/monorepos-2dj | learning, architecture, software, monorepo | This post follows a demo I did for my team leaders, where I explained what a monorepo is and how it could address the problems we are currently facing with web frontend dev. TODO insert link
The team leaders include a mix of senior developers and business analysists. So some questions are more technical and some are mo... | codenamegrant |
1,886,701 | Post AKU Care Services | Alkaptonuria (AKU) may be a rare disorder of chromosome recessive inheritance. it's caused by a... | 0 | 2024-06-13T09:01:03 | https://dev.to/delhihomehealthcare/post-aku-care-services-4j25 | delhihomehealthcare, nursingservices, postakucareservices |

Alkaptonuria (AKU) may be a rare disorder of chromosome recessive inheritance. it's caused by a mutation in a very sequence that ends up in the buildup of acid (HGA). Characteristically, the surplus HGA means that ... | delhihomehealthcare |
1,886,700 | Mastering SAP Project Systems (PS) | In the world of enterprise resource planning (ERP), SAP Project Systems (PS) stands out as a... | 0 | 2024-06-13T09:01:01 | https://dev.to/mylearnnest/mastering-sap-project-systems-ps-21m8 | sap, sapps | In the world of [enterprise resource planning (ERP)](https://www.mylearnnest.com/best-sap-ps-course-in-hyderabad/), SAP Project Systems (PS) stands out as a comprehensive and robust solution for managing and executing projects. With over a decade of experience in implementing and optimizing SAP PS, I have witnessed fir... | mylearnnest |
1,886,793 | Building a Sustainable Web: a practical exploration of Open Source tools and strategies | Introduction In the past few years I've been deeply concerned about climate change. My... | 27,706 | 2024-06-13T10:25:38 | https://tech.sparkfabrik.com/en/blog/building-a-sustainable-web/ | opensource, sustainability, envsustainability | ---
title: Building a Sustainable Web: a practical exploration of Open Source tools and strategies
published: true
date: 2024-06-13 09:00:00 UTC
tags: opensource,sustainability,envsustainability
canonical_url: https://tech.sparkfabrik.com/en/blog/building-a-sustainable-web/
series: Sustainability
cover_image: https://d... | vallss |
1,886,699 | RAG Explained | Using Retrieval-Augmented Generation to Build Semantic Search | Large language models (LLMs) have captured the public sphere of imagination in the past few years... | 0 | 2024-06-13T08:59:48 | https://orkes.io/blog/rag-explained-building-semantic-search/ | rag, ai, orchestration, llm | Large language models (LLMs) have captured the public sphere of imagination in the past few years since OpenAI first launched ChatGPT to the world in late 2022. After the initial fascination amongst the public, businesses followed suit to find use cases where they could potentially deploy LLMs.
With more and more LLMs... | livw |
1,886,698 | KleverList | Discover KleverList for WooCommerce: the ultimate plugin that perfectly integrates your online store... | 0 | 2024-06-13T08:56:09 | https://dev.to/malik_hamid_311d4b4c65819/kleverlist-4adh | email, marketing, wordpress | [](https://kleverlist.com/)
Discover KleverList for WooCommerce: the ultimate plugin that perfectly integrates your online store with leading email marketing platforms such as AWeber, Mailchimp, and Sendy. This powerful tool will help your email marketing campaigns by offering advanced data integration features that en... | malik_hamid_311d4b4c65819 |
1,886,697 | Algorithmic Trading: The Future of Best Prop Firm EAs? 2024 | Algorithmic Trading: The Future of Best Prop Firm EAs? 2024 In recent years, the financial markets... | 0 | 2024-06-13T08:55:47 | https://dev.to/prop_firmea_ee6232ddef3e/algorithmic-trading-the-future-of-best-prop-firm-eas-2024-1ai8 | webdev, javascript, programming, beginners | Algorithmic Trading: The Future of Best Prop Firm EAs? 2024
In recent years, the financial markets have undergone a great deal of change due to the ever-changing landscape. Increasingly influenced by technological advances. Approaches and techniques used in trading have been shaped by these influences. A recent trend h... | prop_firmea_ee6232ddef3e |
1,886,696 | Physiotherary Care Services | Specialized physiotherapists at Delhi Home HealthCare Services give glorious physiotherapy services... | 0 | 2024-06-13T08:55:16 | https://dev.to/delhihomehealthcare/physiotherary-care-services-4g7a | delhihomehealthcare, nursingservices | Specialized physiotherapists at Delhi Home HealthCare Services give glorious physiotherapy services through out Delhi and NCR.

Physiotherapy helps to restore movement and function when someone is affected by inju... | delhihomehealthcare |
1,886,691 | Object-oriented programming in PHP | Object-oriented programming (OOP) in PHP is a powerful way to structure and manage your code. Here’s... | 0 | 2024-06-13T08:51:51 | https://dev.to/zouhairghaidoud/oop-in-php-3hja | webdev, php, laravel, oop | Object-oriented programming (OOP) in PHP is a powerful way to structure and manage your code. Here’s a basic introduction to help you get started:
## 1. Classes and Objects
Classes are blueprints for objects. They define properties (variables) and methods (functions) that the objects created from the class will have.
... | zouhairghaidoud |
1,886,690 | Stroke Care Services | This is physically and emotionally challenging to caring for someone who is paralysed. Preparation,... | 0 | 2024-06-13T08:51:06 | https://dev.to/delhihomehealthcare/stroke-care-services-lm1 | strokecareservices, healthcareservices, delhihomehealthcare | This is physically and emotionally challenging to caring for someone who is paralysed. Preparation, management and patience are key to For successfully caring for completely paralysed patient.

Our Delhi Home Healt... | delhihomehealthcare |
1,886,689 | Tracheostomy Care Services | Tracheostomy Care Services Delhi Home HealthCare Services Provides best Male/Female Nurses Who... | 0 | 2024-06-13T08:46:59 | https://dev.to/delhihomehealthcare/tracheostomy-care-services-5gn8 | tracheostomycareservices, healthcareservices | **Tracheostomy Care Services**

Delhi Home HealthCare Services Provides best Male/Female Nurses Who expert to handle critical situation of Patient. Provides best Male/Female Nurses Who expert to handle critical situ... | delhihomehealthcare |
338,397 | Building a calendar in Swift | In this post, I wanted to walk through an approach I used when building a calendar view in Swift for... | 0 | 2020-05-18T18:15:35 | https://chrisharding.io/building-a-calendar-in-swift | swift, ios | In this post, I wanted to walk through an approach I used when building a calendar view in Swift for an iOS app I’m working on. The requirements were as follows:
* Should start from the current day, and then scroll backwards through time
* Each month is it’s own section, with corresponding header
* Days should be a se... | chrisharding |
1,886,688 | PROTECT JUSTİCE | Communities, N.G.O.s , Organisations and Advocates of Justice like yourselves play an important... | 0 | 2024-06-13T08:46:12 | https://dev.to/eroldi/protect-justice-4lje | sustanable, development | Communities, N.G.O.s , Organisations and Advocates of Justice like yourselves play an important role in encouraging community to find constructive ways for sustainable growth to achieve a decent life for all.
The symbol of one of the economic monument in Sfax was in process of unfair, unjust bankcruptcy deci... | eroldi |
1,886,687 | Todo Tomorrow for VS Code ✅ | My new Visual Studio Code extension that highlights TODO and FIXME comments | 0 | 2024-06-13T08:43:48 | https://dev.to/sapegin/todo-tomorrow-for-vs-code-1kio | vscode, projects, extensions, javascript | ---
title: Todo Tomorrow for VS Code ✅
published: true
description: "My new Visual Studio Code extension that highlights TODO and FIXME comments"
tags: vscode, projects, extensions, javascript
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/l588irq5mannqvxazldv.png
# Use a ratio of 100:42 for best... | sapegin |
1,886,686 | ReductStore v1.10.0: downsampling and optimization | We are pleased to announce the release of the latest minor version of ReductStore, 1.10.0.... | 0 | 2024-06-13T08:42:36 | https://www.reduct.store/blog/news/reductstore-v1_10_0-released | news, reductstore, database |
We are pleased to announce the release of the latest minor version of [**ReductStore**](https://www.reduct.store/), [**1.10.0**](https://github.com/reductstore/reductstore/releases/tag/v1.10.0). ReductStore is a time series database designed for storing and managing large amounts of blob data.
To download the latest ... | atimin |
1,886,685 | Attendant Services | Attendant Services There are many diseases which prevent the patient from taking care of him/her... | 0 | 2024-06-13T08:41:22 | https://dev.to/delhihomehealthcare/attendant-services-4pak | delhihomehealthcare, nursingbureau, athomeservices | **Attendant Services**
There are many diseases which prevent the patient from taking care of him/her self. Delhi Home HealthCare Services provides Male/Female carefully trained Medical Attendant or Patient Care Taker can help the patients who are disabled, chronically ill or cognitively impaired as well as elderly pa... | delhihomehealthcare |
1,886,684 | How to use Excel-like editing in your DataGrid | Excel-like editing is a very popular request we had. In this short article, we show you how to... | 0 | 2024-06-13T08:39:08 | https://infinite-table.com/blog/2024/06/13/how-to-use-excel-like-editing-in-datagrid | frontend, javascript, html, webdev |
Excel-like editing is a very popular request we had. In this short article, we show you how to configure Excel-like editing in the Infinite React DataGrid.
Click on a cell and start typing
{% codesandbox y6xtw6 %}
This behavior is achieved by using the [Instant Edit keyboard shorcut](https://infinite-table.com/docs/... | radubrehar |
1,886,683 | Transforming Healthcare Engagement with AI 2.0 | Digital Shift and the Need for Personalized Engagement The healthcare sector has... | 27,619 | 2024-06-13T08:37:40 | https://dev.to/aishik_chatterjee_0060e71/transforming-healthcare-engagement-with-ai-20-1l9n | ## Digital Shift and the Need for Personalized Engagement
The healthcare sector has experienced a digital transformation, accelerated by
the COVID-19 pandemic, necessitating new methods for engaging with healthcare
professionals (HCPs). AI 2.0 offers a compelling solution by merging machine
learning with deep human in... | aishik_chatterjee_0060e71 | |
1,886,682 | Understanding Data Sharing Agreements: A Guide for Business Owners | Introduction: In today's interconnected digital landscape, data sharing is inevitable and... | 0 | 2024-06-13T08:33:15 | https://dev.to/bocruz0033/understanding-data-sharing-agreements-a-guide-for-business-owners-41fl | datasharing, intellectualproperty, datasecurity | ## Introduction:
In today's interconnected digital landscape, data sharing is inevitable and crucial for businesses looking to enhance operations, innovate, and collaborate with other organizations. However, navigating through data sharing agreements (DSAs) can be daunting for business owners. This guide aims to demyst... | bocruz0033 |
1,886,681 | Delhi Home Healthcare Services In Noida | Welcome To Delhi Home HealthCare Services Delhi Home Health Care Services May Be A Leading... | 0 | 2024-06-13T08:30:48 | https://dev.to/delhihomehealthcare/delhi-home-healthcare-services-in-noida-26i3 | homehealthcareservices, delhihomehealthcare, nursingservices | **[Welcome To Delhi Home HealthCare Services](http://delhihomehealthcare.in)**

Delhi Home Health Care Services May Be A Leading Organization To Produce Nursing Services Like Patient Care, Attendants, New Born Baby ... | delhihomehealthcare |
1,886,680 | FindAll - Automated analysis of network security emergency response tools. | 🔍 FindAll FindAll is a dedicated emergency response tool designed for network security... | 0 | 2024-06-13T08:30:48 | https://dev.to/xutaotaotao/findall-automated-analysis-of-network-security-emergency-response-tools-1plf | programming, security, tooling, electron | ## 🔍 FindAll
FindAll is a dedicated emergency response tool designed for network security blue teams to help team members respond to and analyze network security threats effectively. It integrates advanced information gathering and automated analysis capabilities to improve the efficiency and accuracy of security inci... | xutaotaotao |
1,886,679 | Elevate Your E-commerce Presence: Unleashing the Potential of a Full-Service Amazon PPC Agency | In today's hyper-competitive e-commerce landscape, standing out amidst the crowd requires more than... | 0 | 2024-06-13T08:30:20 | https://dev.to/jimmydev/elevate-your-e-commerce-presence-unleashing-the-potential-of-a-full-service-amazon-ppc-agency-47cp | In today's hyper-competitive e-commerce landscape, standing out amidst the crowd requires more than just a great product; it demands a strategic approach to marketing and advertising. This is where the expertise of a **[full service Amazon PPC agency UK](https://myteamz.co.uk/)** comes into play, offering a comprehensi... | jimmydev | |
1,886,678 | Continuous Integration (CI) Testing: Enhancing Software Development through Automation | In today’s fast-paced software development environment, the need for rapid delivery of high-quality... | 0 | 2024-06-13T08:29:20 | https://dev.to/keploy/continuous-integration-ci-testing-enhancing-software-development-through-automation-2j23 | ci, testing, webdev, devops |

In today’s fast-paced software development environment, the need for rapid delivery of high-quality software is more critical than ever. Continuous Integration (CI) testing has emerged as a pivotal practice that hel... | keploy |
1,886,677 | Nikmati Ragam Permainan Slot Gacor123 Online Gampang Maxwin | Selamat datang di dunia seru dan mengasyikkan dari permainan slot online! Jika kamu mencari keseruan... | 0 | 2024-06-13T08:28:58 | https://dev.to/valeriee/nikmati-ragam-permainan-slot-gacor123-online-gampang-maxwin-2co4 | javascript, beginners, webdev, tutorial | Selamat datang di dunia seru dan mengasyikkan dari permainan slot online! Jika kamu mencari keseruan dan keuntungan dalam satu tempat, maka Slot Gacor123 adalah pilihan yang tepat. Dengan berbagai jenis permainan yang menarik, peluang untuk meraih kemenangan besar juga semakin terbuka lebar. Ayo simak informasi lengkap... | valeriee |
1,886,676 | Introduction to Digital Identity Verification | Digital identity verification is crucial for confirming the authenticity of an individual's identity... | 27,619 | 2024-06-13T08:27:30 | https://dev.to/aishik_chatterjee_0060e71/introduction-to-digital-identity-verification-eoh | Digital identity verification is crucial for confirming the authenticity of an
individual's identity in the digital realm. As the world increasingly moves
online, the need to establish a person's identity accurately and securely has
become paramount. This process is fundamental in various sectors, including
banking, he... | aishik_chatterjee_0060e71 | |
1,886,674 | Medieval Security: Authentication vs. Authorization. | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T08:25:57 | https://dev.to/ynvshashank/medieval-security-authentication-vs-authorization-5f9o | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
In medieval times, visiting the king's palace, only nobles and royals can enter the Castle (**Authentication**) and Only royals can access the royal library (**Authorization**). Authentication verifies identity, while... | ynvshashank |
1,886,660 | Unlocking the Power of AI: Webbuddy Agency's Comprehensive AI Development Services | In an era defined by technological innovation, artificial intelligence (AI) stands out as one of the... | 0 | 2024-06-13T08:19:22 | https://dev.to/piyushthapliyal/unlocking-the-power-of-ai-webbuddy-agencys-comprehensive-ai-development-services-469p | aidevelopment, webdev, aiservices | In an era defined by technological innovation, artificial intelligence (AI) stands out as one of the most transformative forces reshaping industries and societies worldwide. Webbuddy Agency, a leader in digital solutions, is at the forefront of harnessing AI's potential to drive meaningful change. In this comprehensive... | piyushthapliyal |
1,886,659 | Looking for Partners to Bring in Web3 Clients and Grow Together! | Hello everyone! I’m on the lookout for some awesome people to help me bring in clients for my... | 0 | 2024-06-13T08:18:53 | https://dev.to/muratcanyuksel/looking-for-partners-to-bring-in-web3-clients-and-grow-together-176j | networking, blockchain, web3, news | Hello everyone!
I’m on the lookout for some awesome people to help me bring in clients for my blockchain development business. If you’re great at networking and want to earn some serious commission, this is your chance!
I'm a full stack blockchain developer focusing on EVM based chains with a couple of years experi... | muratcanyuksel |
1,886,132 | Kubernetes - An Operator Overview | Kubernetes is a powerful open-source platform for automating the deployment, scaling, and management... | 0 | 2024-06-13T08:18:22 | https://dev.to/rostenkowski/kubernetes-an-operator-overview-34gl | kubernetes, devops, aws, eks | Kubernetes is a powerful open-source platform for automating the deployment, scaling, and management of containerized applications.
This article provides a concise overview of Kubernetes, focusing on its essential components for operators managing containerized applications and AWS EKS.
## Control Plane
The control ... | rostenkowski |
1,886,658 | The Ultimate Guide to the Best Eyeglasses for Men | Finding the perfect pair of eyeglasses is more than just a necessity for vision correction—it's also... | 0 | 2024-06-13T08:15:57 | https://dev.to/vinay_rana_43480f9c429870/the-ultimate-guide-to-the-best-eyeglasses-for-men-bjd | eyeglasses |
Finding the perfect pair of eyeglasses is more than just a necessity for vision correction—it's also a fashion statement and a reflection of your personality. With countless styles, materials, and brands available, choosing the right eyeglasses can be overwhelming. This guide will help you navigate the options to find... | vinay_rana_43480f9c429870 |
1,886,657 | Buy Cheap Software | Buy cheap software online at cdrbsoftwares.com for unbeatable prices on top brands. Get the latest... | 0 | 2024-06-13T08:15:11 | https://dev.to/cdrbsoftwares/buy-cheap-software-47jg | Buy cheap software online at cdrbsoftwares.com for unbeatable prices on top brands. Get the latest software solutions without breaking the bank.
[https://www.cdrbsoftwares.com/](https://www.cdrbsoftwares.com/) | cdrbsoftwares | |
1,886,656 | Solving a layout issue with `grid-auto-flow: column` | In a recent project, I encountered a layout issue that was elegantly solved by the CSS Grid property... | 0 | 2024-06-13T08:14:51 | https://dev.to/alebarbaja/solving-a-layout-issue-with-grid-auto-flow-column-1hnh | css, webdev, learning | In a recent project, I encountered a layout issue that was elegantly solved by the CSS Grid property `grid-auto-flow: column`. Let's dive into the problem and the solution.
## The Problem
I was working on a responsive design where I needed to display a set of data items. On smaller screens, these items should stack v... | alebarbaja |
1,886,655 | Git and Version Control Systems | Git is a distributed version control system used to track changes in files. It allows collaboration... | 0 | 2024-06-13T08:14:33 | https://dev.to/namesaditya/git-and-version-control-systems-56h9 | devchallenge, cschallenge, computerscience, beginners | Git is a distributed version control system used to track changes in files. It allows collaboration among developers, maintaining a history of edits, facilitating team coordination, and enabling the rollback to previous versions if needed. | namesaditya |
1,886,653 | How to create a scroll to top button with Tailwind CSS and JavaScript | Remember the scroll to top button that we did with only Tailwind CSS then with Alpine JS? Well today... | 0 | 2024-06-13T08:12:54 | https://dev.to/mike_andreuzza/httpslexingtonthemescomtutorialshow-to-create-a-scroll-to-top-button-with-tailwind-css-and-javascript-2i0k | javascript, tailwindcss, tutorial | Remember the scroll to top button that we did with only Tailwind CSS then with Alpine JS? Well today we are recreating it with vainilla JavaScript.
[Read the article,See it live and get the code](https://lexingtonthemes.com/tutorials/how-to-create-a-scroll-to-top-button-with-tailwind-css-and-javascript/)
| mike_andreuzza |
1,886,651 | What's the Best Way to Conduct Keyword Research to Boost Your Website's SEO? | Hey everyone! When it comes to SEO, keyword research is a crucial step. Choosing the right keywords... | 0 | 2024-06-13T08:10:30 | https://dev.to/juddiy/whats-the-best-way-to-conduct-keyword-research-to-boost-your-websites-seo-2l04 | seo, discuss, learning | Hey everyone!
When it comes to SEO, keyword research is a crucial step. Choosing the right keywords can significantly improve your website's ranking in search engine results and attract more targeted traffic. So, what's the best way to conduct keyword research to help your website's SEO?
1. **Use Professional Tools**... | juddiy |
1,886,650 | Learning JavaScript | what is the First thing i can do to Master JavaScript guys?? huhu I don't know how to start it.... | 0 | 2024-06-13T08:09:20 | https://dev.to/emzthug/learning-javascript-1kip | javascript, beginners, webdev, tutorial | what is the First thing i can do to Master JavaScript guys?? huhu I don't know how to start it. please Help me i got stuck in here.:(( | emzthug |
1,886,637 | How to Build a Strong Brand with PR Firms in Italy | Building a strong brand is essential for businesses and organizations aiming to establish... | 0 | 2024-06-13T07:50:36 | https://dev.to/top_pragencyeurope_0c86/how-to-build-a-strong-brand-with-pr-firms-in-italy-305e | <p style="text-align: justify;">Building a strong brand is essential for businesses and organizations aiming to establish credibility, attract customers, and differentiate themselves in competitive markets. Public relations (PR) firms in Italy play a pivotal role in helping clients craft compelling brand narratives, en... | top_pragencyeurope_0c86 | |
1,886,649 | The Differences Between "Test Coverage" and "Code Coverage" | As developers, we often hear terms like "test coverage" and "code coverage" thrown around in... | 0 | 2024-06-13T08:06:54 | https://dev.to/accreditly/the-differences-between-test-coverage-and-code-coverage-20fc | webdev, programming, tutorial, learning | As developers, we often hear terms like "test coverage" and "code coverage" thrown around in discussions about software quality. While they may sound similar, they represent different aspects of testing and development. Understanding the nuances between these two concepts is essential for improving code quality and ens... | accreditly |
1,886,648 | Creando un Tetris con JavaScript II: rotando las piezas | Insertrix: un tetris ligeramente distinto. | 27,594 | 2024-06-13T08:06:28 | https://dev.to/baltasarq/creando-un-tetris-con-javascript-ii-rotando-las-piezas-2nf6 | spanish, gamedev, javascript, tutorial | ---
title: Creando un Tetris con JavaScript II: rotando las piezas
published: true
series: JavaScript Tetris
description: Insertrix: un tetris ligeramente distinto.
tags: #spanish #gamedev #javascript #tutorial
cover_image: https://upload.wikimedia.org/wikipedia/commons/4/46/Tetris_logo.png
# Use a ratio of 100:42 for ... | baltasarq |
1,886,646 | Building Accessible React Components with React Aria | Creating accessible and interactive web applications is a challenge that many developers face today.... | 0 | 2024-06-13T08:04:05 | https://dev.to/webdevlapani/building-accessible-react-components-with-react-aria-55l8 |
Creating accessible and interactive web applications is a challenge that many developers face today. Ensuring that your components are not only functional and visually appealing but also accessible to all users, including those with disabilities, requires a deep understanding of various web standards and best practice... | webdevlapani | |
1,886,644 | Elevate Your Online Presence with Expert Web Development Services from WebBuddy Agency | In today's digital age, having a strong online presence is essential for businesses to thrive and... | 0 | 2024-06-13T08:02:03 | https://dev.to/piyushthapliyal/elevate-your-online-presence-with-expert-web-development-services-from-webbuddy-agency-1lne | webdev, websitedevelopmentservices, webbuddy | In today's digital age, having a strong online presence is essential for businesses to thrive and succeed. Your website serves as the virtual face of your brand, often forming the first impression potential customers have of your business. Therefore, investing in professional **[web development services](https://www.we... | piyushthapliyal |
1,885,836 | TW Elements - TailwindCSS Colors. Free UI/UX design course | Colors Colors in Tailwind CSS are defined as classes that you can apply directly to your... | 25,935 | 2024-06-13T08:00:00 | https://dev.to/keepcoding/tw-elements-tailwindcss-colors-free-uiux-design-course-528i | tailwindcss, html, tutorial, beginners | ##Colors
Colors in Tailwind CSS are defined as classes that you can apply directly to your HTML elements. In this lesson, we'll learn how they work.
##Color utility classes
Tailwind CSS comes with a wide variety of predefined colors. Each color has different shades, ranging from 100 (lightest) to 900 (darkest). You ... | keepcoding |
1,852,619 | Don't worry! Deploy! Metis has your database covered. | As developers, we all strive to write the best code that performs great when deployed. It is true... | 0 | 2024-06-13T08:00:00 | https://www.metisdata.io/blog/dont-worry-deploy-metis-has-your-databases-covered | sql, database, observability | As developers, we all strive to write the best code that performs great when deployed. It is true when we’re writing our application code, and the same applies when it comes to our databases! Wouldn’t it be great if you could feel confident when changing your code? Would you like to deploy with no stress? Would you lik... | adammetis |
1,886,642 | Importance of CyberSecurity | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T07:58:56 | https://dev.to/deepesh_patil_611/importance-of-cybersecurity-11h1 | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Cybersecurity is vital for protecting sensitive data from cyberattacks, ensuring privacy, and maintaining the integrity of financial systems, heal... | deepesh_patil_611 |
1,886,641 | Revolutionizing Business with Mobile App Development | In the modern digital era, mobile app development stands as a cornerstone for business innovation and... | 0 | 2024-06-13T07:57:55 | https://dev.to/piyushthapliyal/revolutionizing-business-with-mobile-app-development-393g | mobileappdevelopment, appdevelopment | In the modern digital era, **[mobile app development](https://www.webbuddy.agency/services/mobile)** stands as a cornerstone for business innovation and growth. With a surge in mobile device usage, businesses across various sectors are leveraging mobile apps to enhance customer engagement, streamline operations, and bo... | piyushthapliyal |
1,886,638 | One Byte Explainer: Recursion | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T07:52:02 | https://dev.to/jonrandy/one-byte-explainer-recursion-9hn | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
To understand recursion, see [here](https://dev.to/jonrandy/one-byte-explainer-recursion-9hn).
| jonrandy |
1,886,639 | CVA vs. Tailwind Variants: Choosing the Right Tool for Your Design System | When building a design system, choosing the right tool to manage styles and variants is crucial for... | 0 | 2024-06-13T07:52:01 | https://dev.to/webdevlapani/cva-vs-tailwind-variants-choosing-the-right-tool-for-your-design-system-12am |
When building a design system, choosing the right tool to manage styles and variants is crucial for maintainability and scalability. Two popular libraries that help manage CSS styles in modern applications are CVA (Class Variance Authority) and Tailwind Variants. This blog post will compare these tools, highlighting t... | webdevlapani | |
1,886,636 | Creating a Face Swapping Application with Python and OpenCV | Introduction Hello! 😎 In this tutorial I will teach you how to create a face-swapping... | 0 | 2024-06-13T07:46:51 | https://ethan-dev.com/post/creating-a-face-swapping-application-with-python-and-opencv | python, beginners, tutorial, opencv | ## Introduction
Hello! 😎
In this tutorial I will teach you how to create a face-swapping application using Python, OpenCV and dlib.
Face swapping involves taking the face from one image and seamlessly blending it onto another face in a different image.
This tutorial is beginner-friendly and will guide you through t... | ethand91 |
1,886,635 | The Essential Role of Chatbots and AI in Modern Hospitality | In the ever-changing world of the hospitality business, technology advances are constantly... | 0 | 2024-06-13T07:45:58 | https://dev.to/niajaix/how-ai-chatbots-benefit-hotel-guest-experiences-1906 | hotel, ai, chatbot, guest | In the ever-changing world of the hospitality business, technology advances are constantly transforming how hotels and other service providers operate. Among these advancements, chatbots and artificial intelligence (AI) have emerged as critical tools for improving passenger experience and optimising operations. This ar... | niajaix |
1,886,634 | How to Test Local Website on Mobile Devices | When building a website, developers often need to test if their site is responsive, optimized, and... | 0 | 2024-06-13T07:45:28 | https://www.codingnepalweb.com/test-local-website-on-mobile-devices/ | webdev, coding, productivity, beginners | When building a website, developers often need to test if their site is responsive, optimized, and works well on mobile devices. Testing this can be frustrating if they don't know an easy and proper way to do this.
In this blog post, I’ll show you how to test local websites on mobile devices in three simple steps. Alt... | codingnepal |
1,886,633 | Decoding Recursion | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T07:44:06 | https://dev.to/mitchiemt11/decoding-recursion-ic1 | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
**Recursion** is a technique where a function calls itself, breaking a problem into smaller sub-problems. It simplifies tasks like sorting and tre... | mitchiemt11 |
1,886,632 | Cursor Animation : Creating Smooth Hover Effects in CSS | Check out this short video on YouTube for a quick demonstration on how to create smooth hover effects... | 0 | 2024-06-13T07:43:38 | https://dev.to/dipakahirav/cursor-animation-creating-smooth-hover-effects-in-css-4lho | javascript, webdev, coding, css | Check out this short video on YouTube for a quick demonstration on how to create smooth hover effects in CSS:
[Watch the video](https://youtube.com/shorts/YM5hPXuk-Cs?si=hn6BdQJNMxXdfYos)
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewithDipak?sub_confirmation=1
) to support my channel and ... | dipakahirav |
1,886,631 | Introduction to Digital Twins in Industry 4.0 | Digital twins have emerged as a cornerstone technology in the era of Industry 4.0, revolutionizing... | 27,619 | 2024-06-13T07:43:31 | https://dev.to/aishik_chatterjee_0060e71/introduction-to-digital-twins-in-industry-40-4ffe | Digital twins have emerged as a cornerstone technology in the era of Industry
4.0, revolutionizing how industries operate, design, and maintain their
systems. Industry 4.0 represents the fourth industrial revolution,
characterized by the integration of digital technologies into industrial
sectors. Digital twins play a ... | aishik_chatterjee_0060e71 | |
1,886,630 | Simplifying TailwindCSS with Tailwind Variants in React | TailwindCSS is a powerful utility-first CSS framework that allows you to build modern websites... | 0 | 2024-06-13T07:43:19 | https://dev.to/webdevlapani/simplifying-tailwindcss-with-tailwind-variants-in-react-2mo7 |
TailwindCSS is a powerful utility-first CSS framework that allows you to build modern websites quickly. However, managing complex styles can sometimes be a challenge, especially when dealing with responsive design, multiple component states, and variant configurations. This is where **Tailwind Variants** comes in hand... | webdevlapani | |
1,886,629 | Mastering Advanced Techniques to Elevate Your Frontend Development | JavaScript Jedi: Master the Advanced Practices Needed for Frontend Development... | 0 | 2024-06-13T07:41:42 | https://dev.to/jinesh_vora_ab4d7886e6a8d/mastering-advanced-techniques-to-elevate-your-frontend-development-42 | webdev, javascript, programming, ai | ## JavaScript Jedi: Master the Advanced Practices Needed for Frontend Development Mastery
JavaScript or JS is especially strong in the Force when it comes to frontend development. One can very well get started with a basic understanding, but only advanced techniques can ensure a transition from a Padawan to a true Jav... | jinesh_vora_ab4d7886e6a8d |
1,886,628 | Laser hair removal machine | Diode laser machine for permanent hair reduction uses semiconductor technology that produces a... | 0 | 2024-06-13T07:41:21 | https://dev.to/coolpretty/laser-hair-removal-machine-3k23 | laser, hair, removal, webdev | [Diode laser machine for permanent hair reduction](https://coolprettygroup.com/) uses semiconductor technology that produces a coherent projection of light in the visible to infrared range. It uses a light beam with a narrow spectrum to target specific chromophores in the skin. | coolpretty |
1,886,619 | Unstyled Component Libraries in React: A Guide for Developers | Unstyled Component Libraries in React: A Guide for Developers Unstyled component libraries... | 0 | 2024-06-13T07:29:05 | https://dev.to/webdevlapani/unstyled-component-libraries-unstyled-component-libraries-in-react-a-guide-for-developers-k98 |
# Unstyled Component Libraries in React: A Guide for Developers
Unstyled component libraries in React provide the core functionality and structure of UI components without any predefined styles, allowing developers to implement their own custom designs. These libraries offer flexibility and are ideal for projects wh... | webdevlapani | |
1,886,627 | AI Development Services by WebBuddy: Transforming Your Business with Cutting-Edge AI Solutions | In today's rapidly evolving digital landscape, businesses must leverage advanced technologies to stay... | 0 | 2024-06-13T07:38:42 | https://dev.to/piyushthapliyal/ai-development-services-by-webbuddy-transforming-your-business-with-cutting-edge-ai-solutions-d2f | aidevelopment, ai, aidevelopmentservices | In today's rapidly evolving digital landscape, businesses must leverage advanced technologies to stay ahead of the competition. Artificial Intelligence (AI) is at the forefront of this technological revolution, offering unprecedented opportunities for innovation, efficiency, and growth. At WebBuddy, we specialize in pr... | piyushthapliyal |
1,886,626 | In Excel, Concatenate the Top 3 Members in Each Group into a String | Problem description & analysis: Below is a grouped table having detailed data under each... | 0 | 2024-06-13T07:38:00 | https://dev.to/judith677/in-excel-concatenate-the-top-3-members-in-each-group-into-a-string-24l1 | beginners, programming, tutorial, productivity | **Problem description & analysis**:
Below is a grouped table having detailed data under each group:
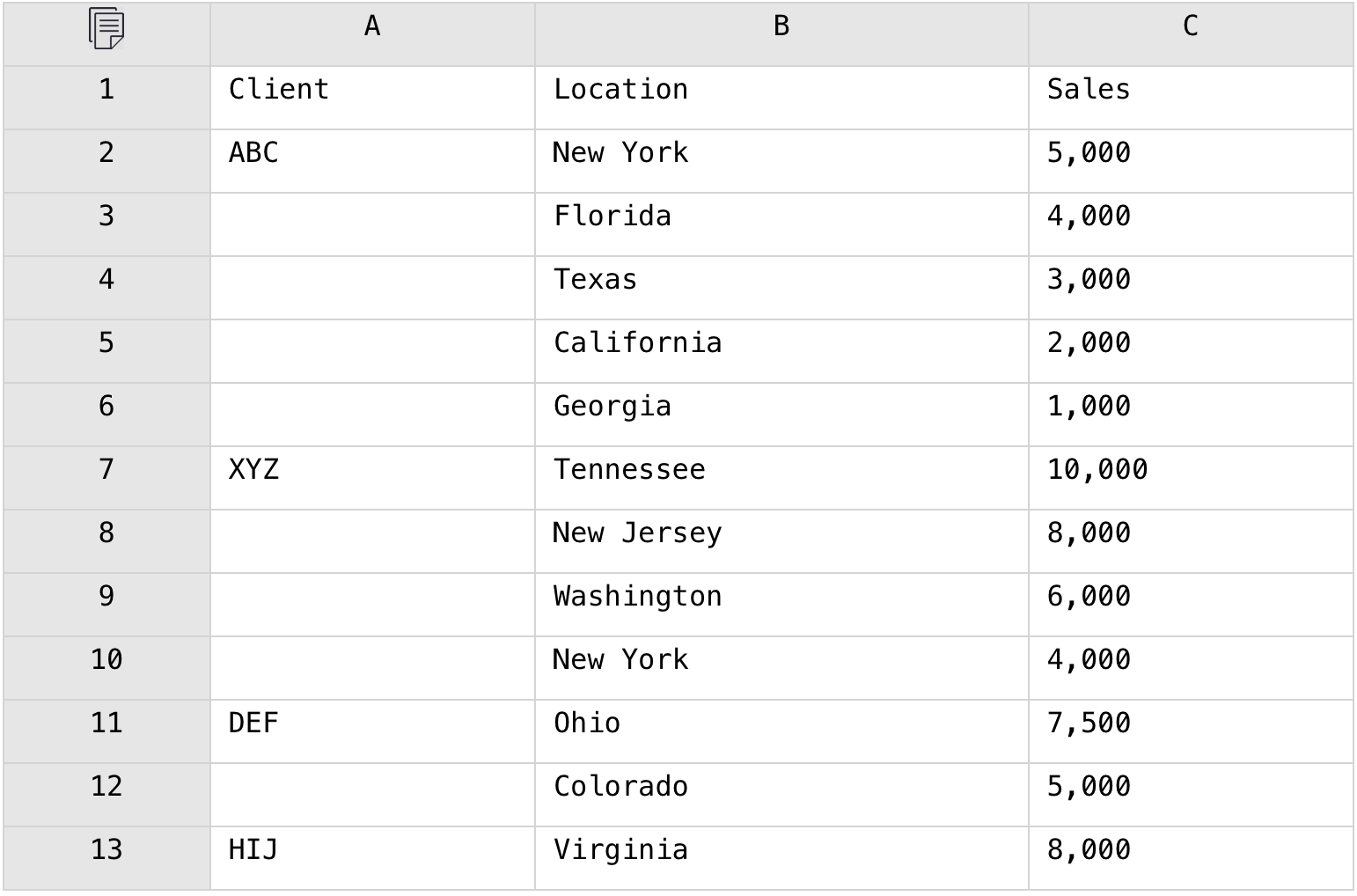
We need to concatenate the top 3 locations in each group into a string with the comma and display them along with... | judith677 |
1,886,625 | Winning Tips and Tricks in 3 Patti | Tips and Tricks to Maximize Winning Chances in 3 Patti Games 3 Patti, also known as Teen... | 0 | 2024-06-13T07:35:10 | https://dev.to/sultan_khan_a412f27a485c3/winning-tips-and-tricks-in-3-patti-2k4b | teenpatti, 3patti, 3pattiblu | ## Tips and Tricks to Maximize Winning Chances in 3 Patti Games
3 Patti, also known as Teen Patti, is a popular card game, often compared to poker. It involves strategy, skill, and a bit of luck. Whether you are a novice or an experienced player, the following tips and tricks can help you enhance your game and increas... | sultan_khan_a412f27a485c3 |
1,886,624 | The best way to install and upgrade FMZ docker on Linux VPS | Note "One-click Rent a docker VPS" is a expensive way of running FMZ docker, we usually... | 0 | 2024-06-13T07:34:30 | https://dev.to/fmzquant/the-best-way-to-install-and-upgrade-fmz-docker-on-linux-vps-58kd | docker, linux, trading, fmzquant | ## Note
- "One-click Rent a docker VPS" is a expensive way of running FMZ docker, we usually don't recommend it, it designed mainly for new users to get familiar with our platform.
- One docker can run multiple robots.
- A VPS server can run multiple dockers, but generally not necessary.
- If prompted that Python canno... | fmzquant |
1,886,622 | Smile On Click: Your Hashtag Printer Photo Booth for Every Event | In an era dominated by digital connections, there's a growing nostalgia for authentic, human... | 0 | 2024-06-13T07:32:59 | https://dev.to/rohan_sahani_8c237b05a6f5/smile-on-click-your-hashtag-printer-photo-booth-for-every-event-l9d |
In an era dominated by digital connections, there's a growing nostalgia for authentic, human interactions. Smile On Click understands this longing and brings it to life through their innovative [hashtag printer photo booths](https://www.smileonclick.com/hashtag-printer-photo-booth/
). These booths blend the charm of t... | smileonclick | |
1,886,617 | Introduction to Blockchain and Rust | Blockchain technology, a decentralized digital ledger, has revolutionized data storage and... | 27,619 | 2024-06-13T07:28:22 | https://dev.to/aishik_chatterjee_0060e71/introduction-to-blockchain-and-rust-782 | Blockchain technology, a decentralized digital ledger, has revolutionized data
storage and transaction recording across multiple industries. Its
transparency, security, and efficiency make it pivotal in today's digital age.
Rust, a programming language known for its safety and performance, is
increasingly popular for d... | aishik_chatterjee_0060e71 | |
1,886,616 | 20 Essential Tips for Frontend Developers🚀 | Introduction Frontend development is a dynamic and exciting field. To excel, it's crucial... | 0 | 2024-06-13T07:26:20 | https://dev.to/dharamgfx/20-essential-tips-for-frontend-developers-3a4o | webdev, beginners, tips, frontend |
## Introduction
Frontend development is a dynamic and exciting field. To excel, it's crucial to stay updated and follow best practices. Here are 20 essential tips to help you become a better frontend developer.
## Tips
### 1. **Master HTML, CSS, and JavaScript**
- **Explanation**: These are the building blocks o... | dharamgfx |
1,886,615 | Tỉ lệ kèo nhà cái mới nhất | https://kenhkeonhacai.org/cac-keo-nha-cai-pho-bien-tai-euro-2024/ Tỷ lệ kèo nhà cái bóng đá: Euro... | 0 | 2024-06-13T07:26:14 | https://dev.to/keonhacaiorg1/ti-le-keo-nha-cai-moi-nhat-mfk | https://kenhkeonhacai.org/cac-keo-nha-cai-pho-bien-tai-euro-2024/ Tỷ lệ kèo nhà cái bóng đá: Euro 2024, C1✔️Ngoại Hạng Anh✔️La Liga✔️Bundesliga✔️Ligue 1
https://keonhacaiorg1.zohosites.com
https://hashnode.com/@keonhacaiorg1
https://hackmd.io/@keonhacaiorg1
https://kenhkeonhacai.org/cac-keo-nha-cai-pho-bien-tai-euro-20... | keonhacaiorg1 | |
1,886,613 | Registered Diagnostic Cardiac Sonographer (RDCS) | What are Radionuclide Drug Conjugates (RDCs)? Coupling drugs combine precise targeting and potent... | 0 | 2024-06-13T07:22:05 | https://dev.to/alexbrowns/registered-diagnostic-cardiac-sonographer-rdcs-49l3 | What are Radionuclide Drug Conjugates (RDCs)?
Coupling drugs combine precise targeting and potent killing properties, has become a widely recognized form of medication in recent years. Radioactive drug conjugates (RDCs), as a particular form of coupling drugs, are formed by combining radioactive isotopes with disease-... | alexbrowns |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.