
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,886,443 | Taming the Evolving Beast: Understanding and Implementing API Versioning | In the ever-changing world of web development, APIs (Application Programming Interfaces) play a... | 0 | 2024-06-13T03:56:15 | https://dev.to/epakconsultant/taming-the-evolving-beast-understanding-and-implementing-api-versioning-1dhe | api | In the ever-changing world of web development, APIs (Application Programming Interfaces) play a crucial role in enabling communication between different applications. However, as APIs evolve and features are added or modified, a critical concept comes into play: API versioning.
## What is API Versioning?
API versioni... | epakconsultant |
1,886,433 | Unleashing the Power of ES6: Modernizing Your JavaScript Development | ES6, or ECMAScript 2015, marked a significant leap forward in JavaScript's capabilities. By embracing... | 0 | 2024-06-13T03:50:55 | https://dev.to/epakconsultant/unleashing-the-power-of-es6-modernizing-your-javascript-development-54k9 | javascript | ES6, or ECMAScript 2015, marked a significant leap forward in JavaScript's capabilities. By embracing its features, you can write cleaner, more maintainable, and expressive code. Here's a dive into how to effectively utilize ES6 in your development workflow:
1. Embrace Const and Let for Variable Declarations
Ditch th... | epakconsultant |
1,886,423 | Unpacking the Byte: The Tiny Titan of Data! | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T03:44:47 | https://dev.to/wanjala/byte-the-data-building-block-16ni | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Byte (B): A unit of digital information in computing, typically consisting of 8 bits. The smallest addressable unit of memory in most systems. Byt... | wanjala |
1,886,419 | Cloud and AI: The One-Two Punch Reshaping Media | A Transformation Beyond Belief Alright, folks, strap yourselves in 'cause the media industry is... | 0 | 2024-06-13T03:36:08 | https://dev.to/kevintse756/cloud-and-ai-the-one-two-punch-reshaping-media-3ck3 |
A Transformation Beyond Belief
Alright, folks, strap yourselves in 'cause the media industry is going through a transformation so mind-blowing, it'll make your jaw drop. And it's all thanks to two tech titans – cloud computing and Artificial Intelligence (AI). These game-changers are turning traditional approaches o... | kevintse756 | |
1,886,417 | Creating AI Applications with Pixie: A Step-by-Step Guide | Whether you're creative enthusiasts or seasoned developers, Pixie simplifies the creation of... | 0 | 2024-06-13T03:34:52 | https://dev.to/gptconsole/creating-ai-applications-with-pixie-a-step-by-step-guide-1bfn |

Whether you're creative enthusiasts or seasoned developers, Pixie simplifies the creation of intricate projects, including AI-driven applications such as text generation, image generation, and text-to-speech util... | vincivinni | |
1,886,416 | Node.js Timeouts and Memory Leaks | Introduction Issue Overview: The way Node.js handles timeouts can lead to significant... | 0 | 2024-06-13T03:34:16 | https://dev.to/srijan_karki/nodejs-timeouts-and-memory-leaks-3l64 | javascript, webdev, node |
#### Introduction
- **Issue Overview**: The way Node.js handles timeouts can lead to significant memory leaks.
- **Background**: The `setTimeout` API is commonly used in both browsers and Node.js. While it works similarly, Node.js returns a more complex object, which can cause problems.
#### Basic Timeout API
- **In ... | srijan_karki |
1,886,415 | Node.js Timeouts and Memory Leaks | - Memory Leak Issue: Node.js timeouts can easily create memory leaks. Timeout API: Unlike... | 0 | 2024-06-13T03:34:15 | https://dev.to/srijan_karki/nodejs-timeouts-and-memory-leaks-5g1p | webdev, javascript, node |
- **Memory Leak Issue**: Node.js timeouts can easily create memory leaks.
- **Timeout API**: Unlike browsers, where `setTimeout` returns a number, Node.js returns a `Timeout` object.
- **Timeout Object**: This o... | srijan_karki |
1,886,412 | Weaving the Web of Conversation: Implementing Chat Functionality in Your Web App | In today's fast-paced online world, real-time communication is key. Integrating chat functionality... | 0 | 2024-06-13T03:31:38 | https://dev.to/epakconsultant/weaving-the-web-of-conversation-implementing-chat-functionality-in-your-web-app-l0h | chat | In today's fast-paced online world, real-time communication is key. Integrating chat functionality into your web app can foster user engagement, build a strong community, and provide a valuable support channel. But where do you begin? Here's a roadmap to guide you through implementing chat in your web app:
1. Define Y... | epakconsultant |
1,886,411 | Power Up Your Web App: Implementing Subscription Management | Subscription-based models are booming, offering a steady revenue stream for businesses and flexible... | 0 | 2024-06-13T03:25:22 | https://dev.to/epakconsultant/power-up-your-web-app-implementing-subscription-management-3gpa | webdev, development | Subscription-based models are booming, offering a steady revenue stream for businesses and flexible access for users. If you're considering this approach for your web app, integrating a smooth subscription management system is crucial. Here's a breakdown of the key steps involved:
[Scripting and Coding Skills: PowerSh... | epakconsultant |
1,886,377 | Looking into GenAI | GenAI is a framework implementing design principles with the help of artificial intelligence. I... | 0 | 2024-06-13T02:29:41 | https://dev.to/christopherchhim/looking-into-genai-46g7 | webdev, ai, ux | GenAI is a framework implementing design principles with the help of artificial intelligence. I decided to look into GenAI because it helps me learn as to how we can design interfaces with the help of AI. AI is a tool meant to help and assist our abilities, but not replace them. GenAI has 6 key dimensions: discovery, a... | christopherchhim |
1,886,409 | Python Version Commodity Futures Moving Average Strategy | It is completely transplanted from the "CTP Commodity Futures Variety Moving Average Strategy". Since... | 0 | 2024-06-13T03:24:41 | https://dev.to/fmzquant/python-version-commodity-futures-moving-average-strategy-5aa0 | strategy, python, cryptocurrency, fmzquant | It is completely transplanted from the "CTP Commodity Futures Variety Moving Average Strategy". Since the Python version of the commodity futures strategy does not yet have a multi-variety strategy, the JavaScript version of the "CTP Commodity Futures Multi-Variable Moving Average Strategy" was ported. Providing some d... | fmzquant |
1,886,394 | [Docker] Laravel, Nginx MySQL | Dockerización PHP 8.2 Laravel 11 (Latest) Nginx (Latest) MySQL (Latest) Uso docker-compose... | 0 | 2024-06-13T03:16:42 | https://dev.to/jkdevarg/docker-laravel-nginx-mysql-4lp0 | docker, laravel, nginx, mysql | **Dockerización**
- PHP 8.2
- Laravel 11 (Latest)
- Nginx (Latest)
- MySQL (Latest)
**Uso**
- docker-compose build
- docker-compose up -d
**Config**
- Configurar el .env de laravel
---
**Dockerfile**
```
FROM php:8.2-fpm-alpine
# Update app
RUN apk update && apk add --no-cache tzdata
# Set timezone
ENV TZ="UTC... | jkdevarg |
1,886,392 | sweatandsocialdistance | Онлайн казино Вавада радует своих посетителей по-настоящему впечатляющим выбором игровых развлечений,... | 0 | 2024-06-13T03:11:09 | https://dev.to/sweatandsocialdistance/sweatandsocialdistance-67h | Онлайн казино [Вавада](https://sweatandsocialdistance.com/) радует своих посетителей по-настоящему впечатляющим выбором игровых развлечений, а также высочайшим уровнем сервиса и обслуживания. На официальном сайте этого надежного игорного заведения вы найдете все необходимые разделы и функции для по-настоящему комфортно... | sweatandsocialdistance | |
1,886,391 | Ghostface Text to Speech Mastery Guide 2024 | Discover the innovative Ghostface text to speech voice options for a unique creative experience.... | 0 | 2024-06-13T03:08:52 | https://dev.to/novita_ai/ghostface-text-to-speech-mastery-guide-2024-2l0 | ai, tts, ghostface |
Discover the innovative Ghostface text to speech voice options for a unique creative experience. Learn more on our blog.
## Key Highlights
- Discover how to incorporate the distinctive Ghostface voice into your projects using advanced Text to Speech technology.
- Explore tips for selecting the best Ghostface Text to... | novita_ai |
1,886,390 | Accelerating Machine Learning with AWS SageMaker | Accelerating Machine Learning with AWS SageMaker Introduction to AWS... | 0 | 2024-06-13T03:02:23 | https://dev.to/virajlakshitha/accelerating-machine-learning-with-aws-sagemaker-44ln | 
# Accelerating Machine Learning with AWS SageMaker
### Introduction to AWS SageMaker
AWS SageMaker is a fully managed machine learning (ML) service that empowers data scientists and developers to build, train, and deploy ML models a... | virajlakshitha | |
1,886,389 | Deadlock | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T02:57:29 | https://dev.to/anshsaini/deadlocks-3h3n | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
When two or more processes are unable to proceed because each is waiting for another to release a resource. It results in a stalemate where none can progress, requiring intervention like resource reallocation or termi... | anshsaini |
1,886,388 | Explore Color Options for Jordan 4 Replicas | When it comes to Jordan 4 replicas, the world of color options is vast and exciting, offering sneaker... | 0 | 2024-06-13T02:51:45 | https://dev.to/dana_blair_91609e4d6908cf/explore-color-options-for-jordan-4-replicas-412b | design | When it comes to Jordan 4 replicas, the world of color options is vast and exciting, offering sneaker enthusiasts a chance to express their style through vibrant hues and unique combinations. Whether you're looking to match your favorite outfit or make a bold fashion statement, choosing the right color for your Jordan ... | dana_blair_91609e4d6908cf |
1,886,387 | Import Excel to MySQL, Create Tables Easily with One Click! This SQL Editor is All You Need | Required Tool SQLynx Pro ** (latest version 3.3.0 as of now) Steps SQLynx supports two modes for... | 0 | 2024-06-13T02:51:18 | https://dev.to/concerate/import-excel-to-mysql-create-tables-easily-with-one-click-this-sql-editor-is-all-you-need-3mb7 | **Required Tool**
**SQLynx Pro ** (latest version 3.3.0 as of now)
Steps
SQLynx supports two modes for importing Excel files: when the database has pre-created tables, or when tables need to be created. This guide introduces the process of importing data and creating tables directly when there are no pre-existing table... | concerate | |
1,882,873 | How to restore Ubuntu desktop UI After an Unexpected tty1 Boot without initial internet access | introduction My Ubuntu 24.04 desktop unexpectedly boot into tty1 presenting a shell... | 0 | 2024-06-13T02:48:40 | https://dev.to/sammybarasa/how-to-restore-ubuntu-desktop-ui-after-an-unexpected-tty1-boot-without-initial-internet-access-2g1j | ## introduction
My Ubuntu 24.04 desktop unexpectedly boot into tty1 presenting a shell interface to interact with on bootup.

The above image shows the tty1 output.
Sometimes this happens when one accidentally ... | sammybarasa | |
1,886,386 | The Ultimate Test Planning Guide: Ensure Software Excellence | In today’s competitive market, your software’s quality can be the deciding factor in its success. A... | 0 | 2024-06-13T02:47:32 | https://dev.to/elle_richard_232/the-ultimate-test-planning-guide-ensure-software-excellence-5bic | softwaredevelopment, testing | In today’s competitive market, your software’s quality can be the deciding factor in its success. A well-designed test plan is your roadmap to excellence. This guide offers the essential steps for creating a test plan that ensures your software functions flawlessly and meets all user expectations.
### What is Test Pla... | elle_richard_232 |
1,886,345 | You don't need `forEach()` | The most basic way to iterate over an array is the forEach method. However often times there is a... | 0 | 2024-06-13T02:46:19 | https://dev.to/read-the-manual/you-dont-need-foreach-1jif | javascript, beginners, webdev, programming | The most basic way to iterate over an array is the `forEach` method. However often times there is a better method for the job. Today we will take a look at common use cases and look at alternative array methods for reaching our goals.
Using `forEach` to solve problems often involves:
- declaring a variable outside of... | read-the-manual |
1,886,385 | Func Declaration vs Expression vs Statement vs Anonymous vs First Class | Functions in programming are like recipes in cooking. They are sets of instructions that we can reuse... | 27,558 | 2024-06-13T02:41:06 | https://dev.to/imabhinavdev/func-declaration-vs-expression-vs-statement-vs-anonymous-vs-first-class-2ogm | webdev, javascript, beginners, tutorial | Functions in programming are like recipes in cooking. They are sets of instructions that we can reuse whenever we need to perform a specific task. In JavaScript, functions are fundamental building blocks that allow us to organize code and make it reusable.
## Function Declaration
### Definition
Function declarations... | imabhinavdev |
1,886,381 | Coding Concepts | Analogies are a powerful learning tool because they allow us to understand unfamiliar concepts by... | 0 | 2024-06-13T02:32:25 | https://dev.to/ramdinesh/coding-concepts-4g03 | coding | Analogies are a powerful learning tool because they allow us to understand unfamiliar concepts by relating them to experiences or ideas we already know. Analogies can aid in learning complex concepts in accessible and practical ways.
Learning coding concepts through analogy can be a fun and effective way to understand... | ramdinesh |
1,886,379 | Recursion | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T02:32:21 | https://dev.to/ricco1973/recursion-1j68 | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Explainer
Recursion is a programming technique where a function calls itself with a smaller input until it reaches a base case. It's used to solve problems that can be broken down into smaller instances of the same problem. Eac... | ricco1973 |
1,886,380 | Simple DETR Object Detection with Python | DETR (DEtection TRansformer) is a deep learning model designed for object detection. It utilizes the... | 0 | 2024-06-13T02:32:21 | https://dev.to/chrisalexander0617/simple-detr-object-detection-with-python-539c | ai, machinelearning, python, objectdetection | DETR (DEtection TRansformer) is a deep learning model designed for object detection. It utilizes the Transformer architecture, initially created for natural language processing (NLP) tasks, as its core element to tackle the object detection challenge in an innovative and highly efficient way.
### Prerequisites
I’d as... | chrisalexander0617 |
1,886,376 | Market quotes collector upgrade again | Supporting CSV format file import to provide custom data source Recently, a trader needs... | 0 | 2024-06-13T02:24:08 | https://dev.to/fmzquant/market-quotes-collector-upgrade-again-2f07 | market, trading, cryptocurrency, fmzquant | ## Supporting CSV format file import to provide custom data source
Recently, a trader needs to use his own CSV format file as a data source for FMZ platform backtest system. our platform's backtest system has many functions and is simple and efficient to use, so that as long as users have their own data, they can perfo... | fmzquant |
1,886,375 | Alternatives to npm: Exploring Different Package Managers for JavaScript Development | When it comes to managing dependencies in JavaScript projects, npm (Node Package Manager) is often... | 0 | 2024-06-13T02:20:38 | https://dev.to/vyan/alternatives-to-npm-exploring-different-package-managers-for-javascript-development-1h7g | webdev, javascript, beginners, npm | When it comes to managing dependencies in JavaScript projects, npm (Node Package Manager) is often the go-to choice. However, several other package managers can offer different features and benefits that might better suit your specific needs. In this blog, we will explore some popular alternatives to npm, including Yar... | vyan |
1,886,361 | Real vs Fake Jordan 4: Key Differences | The Jordan 4 is an iconic sneaker that often falls prey to counterfeiters. Identifying the... | 0 | 2024-06-13T02:14:46 | https://dev.to/dana_blair_91609e4d6908cf/real-vs-fake-jordan-4-key-differences-33pd | The Jordan 4 is an iconic sneaker that often falls prey to counterfeiters. Identifying the differences between real and [fake Jordan 4](https://www.colareps.com/collections/replica-air-jordan-4/)s is crucial for any collector or enthusiast. Here, we provide a detailed guide on how to distinguish authentic pairs from th... | dana_blair_91609e4d6908cf | |
1,886,360 | 中国区使用Docker官方镜像(非国内加速)Use official Docker images in China (not domestic acceleration) | 写在前面: Foreword: 1、本文使用中英语言,英文为机翻 1、This article is written in both Chinese and English. The English... | 0 | 2024-06-13T02:10:24 | https://dev.to/aionerljjj/zhong-guo-qu-shi-yong-dockerguan-fang-jing-xiang-fei-guo-nei-jia-su-use-official-docker-images-in-china-not-domestic-acceleration-2i4p | docker, vpn | 写在前面:
Foreword:
1、本文使用中英语言,英文为机翻
1、This article is written in both Chinese and English. The English version is machine-translated.
2、实测可用,完整复制命令即可使用,如有问题,请邮件至aionerljj@gmail.com
2、The instructions have been tested and are functional. Simply copy and use the commands as they are. If you encounter any issues, please ema... | aionerljjj |
1,886,359 | 中国区使用Docker官方镜像(非国内加速)Use official Docker images in China (not domestic acceleration) | 写在前面: Foreword: 1、本文使用中英语言,英文为机翻 1、This article is written in both Chinese and English. The English... | 0 | 2024-06-13T02:10:24 | https://dev.to/aionerljjj/zhong-guo-qu-shi-yong-dockerguan-fang-jing-xiang-fei-guo-nei-jia-su-use-official-docker-images-in-china-not-domestic-acceleration-5hfd | docker, vpn | 写在前面:
Foreword:
1、本文使用中英语言,英文为机翻
1、This article is written in both Chinese and English. The English version is machine-translated.
2、实测可用,完整复制命令即可使用,如有问题,请邮件至aionerljj@gmail.com
2、The instructions have been tested and are functional. Simply copy and use the commands as they are. If you encounter any issues, please ema... | aionerljjj |
1,886,358 | 中国区使用Docker官方镜像(非国内加速)Use official Docker images in China (not domestic acceleration) | 写在前面: Foreword: 1、本文使用中英语言,英文为机翻 1、This article is written in both Chinese and English. The English... | 0 | 2024-06-13T02:10:24 | https://dev.to/aionerljjj/zhong-guo-qu-shi-yong-dockerguan-fang-jing-xiang-fei-guo-nei-jia-su-use-official-docker-images-in-china-not-domestic-acceleration-4fjf | docker, vpn | 写在前面:
Foreword:
1、本文使用中英语言,英文为机翻
1、This article is written in both Chinese and English. The English version is machine-translated.
2、实测可用,完整复制命令即可使用,如有问题,请邮件至aionerljj@gmail.com
2、The instructions have been tested and are functional. Simply copy and use the commands as they are. If you encounter any issues, please ema... | aionerljjj |
1,885,507 | Fastest Way To Learn a Programming Language | Curiosity The greats love to learn. They love to grow. They never lose their holy... | 0 | 2024-06-13T02:10:00 | https://dev.to/thekarlesi/fastest-way-to-learn-a-programming-language-2kc3 | webdev, beginners, programming, html | ## Curiosity
The greats love to learn. They love to grow. They never lose their holy curiosity.
Look at Michael Jordan for example. He wasn't the best basketball player in his family. He says that his big brother was more skilled than him.
But he was curious.
Education is the game changer. When you invest in your l... | thekarlesi |
1,886,357 | Simple AI Smart Home Manager | The code for this post is all available here :... | 0 | 2024-06-13T02:09:34 | https://dev.to/aaronblondeau/simple-ai-smart-home-manager-3pck | genkit, ai, javascript | The code for this post is all available here : [https://github.com/aaronblondeau/genkit-smarthome](https://github.com/aaronblondeau/genkit-smarthome)
View the working app at [https://smarthome.aaronblondeau.com/](https://smarthome.aaronblondeau.com/)
Although I am working to de-google my life, I took note of the rece... | aaronblondeau |
1,886,356 | Essential Node.js backend examples for developers in 2024 | Boost your Node.js skills with these backend code snippets for 2024. Copy and paste them into your own projects to save time when building backends. | 0 | 2024-06-13T02:00:17 | https://snyk.io/blog/essential-node-js-backend-examples-2024/ | applicationsecurity, codesecurity, javascript, node | Node.js backend development continues to stand out in 2024 as a powerful and flexible runtime for building scalable and efficient applications, even more so with the rise of other runtimes such as Bun.
In this article, I wanted to provide a lightweight introduction to essential Node.js backend examples that demonstra... | snyk_sec |
1,886,229 | Awesome Open-Source 😎 | Welcome! 👋 Here you can find a curated list of all the best free and open-source software... | 27,705 | 2024-06-13T02:00:03 | https://dev.to/superp0sit1on/awesome-open-source-38h6 | opensource, community, productivity | ## Welcome! 👋
Here you can find a curated list of all the best free and open-source software for every need!
## Summary 📋
- [Audio 🎧](#audio)
- [Development 💻](#development)
- [Game Development 🎮](#game-development)
- [Graphics 🖼️](#graphics)
- [Operational Systems 🖥️](#operational-systems)
- [Productivity 📎... | superp0sit1on |
1,886,352 | Ada Maurice : La Plateforme Éclatante de l'Art Mauricien | Ada Maurice se distingue comme une vitrine virtuelle éblouissante pour l'art contemporain de l'île... | 0 | 2024-06-13T01:53:08 | https://dev.to/joseph_wilson_/ada-maurice-la-plateforme-eclatante-de-lart-mauricien-4o9m | career, webdev | Ada Maurice se distingue comme une vitrine virtuelle éblouissante pour l'art contemporain de l'île Maurice. Cette plateforme en ligne dédiée à la promotion des talents locaux offre aux passionnés d'art du monde entier une opportunité unique de découvrir et d'acquérir des œuvres inspirantes qui captivent par leur origin... | joseph_wilson_ |
1,886,350 | Crafting a Long-term Sustainable Business: Your 2024 Continuity Checklist | In an ever-evolving economic landscape, the key to maintaining a thriving business is embracing... | 0 | 2024-06-13T01:50:05 | https://dev.to/bocruz0033/crafting-a-long-term-sustainable-business-your-2024-continuity-checklist-1i4f | riskmanagement, sustainability, businesscontinuity | In an ever-evolving economic landscape, the key to maintaining a thriving business is embracing adaptability while focusing on sustainability. The year 2024 presents new challenges and opportunities for business leaders committed to long-term success. Here's your [essential continuity checklist](https://getwpfunnels.co... | bocruz0033 |
1,886,349 | Importância da criação de ambientes virtuais. | Estudando sobre o uso de ambientes virtuais em Python, percebi que o principal motivo é evitar... | 0 | 2024-06-13T01:47:38 | https://dev.to/wallace_03/importancia-da-criacao-de-ambientes-virtuais-1ej8 | python, dicas, webdev | Estudando sobre o uso de ambientes virtuais em Python, percebi que o principal motivo é evitar conflitos entre as bibliotecas instaladas via Python. Por exemplo, se você tem um cliente com um site criado usando Django 2.2.2 e ele não quer atualizar para uma versão mais recente, mas ainda precisa de manutenção, você te... | wallace_03 |
1,886,348 | How to efficiently use drf_social_oauth2 and django_rest_framework_simplejwt | Hey guys!! So I was working on a rest api application with django and django rest framework but then... | 0 | 2024-06-13T01:43:40 | https://dev.to/codewitgabi/how-to-efficiently-use-drfsocialoauth2-and-djangorestframeworksimplejwt-23i5 | backend, django, oauth, tutorial | Hey guys!!
So I was working on a rest api application with django and django rest framework but then I happened to run into a lot of issues using drf_social_oauth2 and django_rest_framework_simplejwt. The issue was that the former strictly uses `Bearer` authentication header while the latter uses `any` authorization h... | codewitgabi |
1,886,339 | Gemika's Awesome Git Adventures: A Fun Guide to Coding Magic! 🧙♂️✨ | Greetings, young wizards and witches! Allow me to whisk you away into a tale of enchantment and... | 0 | 2024-06-13T01:43:16 | https://dev.to/gerryleonugroho/gemikas-awesome-git-adventures-a-fun-guide-to-coding-magic--4p49 | git, github, webdev, beginners | Greetings, young wizards and witches! Allow me to whisk you away into a tale of enchantment and wonder. I am Uncle Gerry, the proud father of the extraordinary young wizard, Gemika Haziq Nugroho. 🧙♂️✨ In the muggle world, I work my magic as a data-driven marketer and software engineer. This means I use numbers and my... | gerryleonugroho |
1,886,346 | Containers - DEV Computer Science Challenge | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-13T01:33:31 | https://dev.to/andresordazrs/containers-dev-computer-science-challenge-1576 | devchallenge, cschallenge, computerscience, beginners | _This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer._
## Containers
<!-- Explain a computer science concept in 256 characters or less. -->
Think of containers as take-out boxes. Each box contains everything an application needs to run and can be used anywhere. Just like take-out boxe... | andresordazrs |
1,886,347 | Simplifying Serverless Architecture with Terraform and AWS Lambda | I will detail how to automate serverless architecture using Terraform as Infrastructure as Code... | 0 | 2024-06-13T01:32:47 | https://dev.to/etorralbab/simplifying-serverless-architecture-with-terraform-and-aws-lambda-2o7n | serverless, apigateway, terraform, lambda | I will detail how to automate serverless architecture using Terraform as Infrastructure as Code (IaC), focusing on setting up an API Gateway and integrating it with AWS Lambda functions using TypeScript.
## TL;DR:
- **Project Setup**: Organize your project structure and initialize an npm project for managing dependenc... | etorralbab |
1,866,118 | Game Development Diary #11 : Second Day Back | 13/06/2024 - Thursday Today I will continue my GameDev.tv course. Here is what I’ve got from it: ... | 0 | 2024-06-13T01:30:15 | https://dev.to/hizrawandwioka/game-development-diary-11-second-day-back-59kd | gamedev, godot, godotengine, newbie | 13/06/2024 - Thursday
Today I will continue my GameDev.tv course. Here is what I’ve got from it:
##Improved Aiming and Smoothing
Vertical camera motion and using interpolate_with to smooth the camera.
##Custom Reticles
Learning how to use the _draw() virtual function and other draw functions to create custom 2D shap... | hizrawandwioka |
1,886,336 | Introduction to Transformer Models | NLP NLP is a field of linguistics and machine learning focused on understanding everything... | 0 | 2024-06-13T01:24:06 | https://dev.to/rohab_shabbir/introduction-to-transformer-models-1eon | machinelearning, beginners, learning |
### **NLP**
NLP is a field of linguistics and machine learning focused on understanding everything related to human language.
**What is NLP**
- Classifying whole sentences — sentiment analysis
- Classifying each word in a sentence — grammatically
- Generating text content — auto generated text
**Transformers and NL... | rohab_shabbir |
1,886,344 | Commodity Futures High Frequency Trading Strategy written by C++ | Summary The market is the battleground, the buyer and the seller are always in the game,... | 0 | 2024-06-13T01:22:21 | https://dev.to/fmzquant/commodity-futures-high-frequency-trading-strategy-written-by-c-2o2b | trading, strategy, cryptocurrency, fmzquant | ## Summary
The market is the battleground, the buyer and the seller are always in the game, which is also the eternal theme of the trading business. The Penny Jump strategy shared today is one of high-frequency strategies, originally derived from the interbank foreign exchange market, and is often used in mainstream fa... | fmzquant |
1,886,340 | AI to the world Care | This is a submission for the Twilio Challenge What I Built Demo ... | 0 | 2024-06-13T01:18:46 | https://dev.to/stromlight/ai-to-the-world-care-2lmj | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
<!-- Share an overview about your project. -->
## Demo
<!-- Share a link to your app and include some screenshots here. -->
## Twilio and AI
<!-- Tell us how you leveraged Twilio’s capabilities with AI -->
## Additi... | stromlight |
1,886,335 | Cloud deployment models | public Quick access to computing resources without a large upfront cost, with the public... | 0 | 2024-06-13T01:11:09 | https://dev.to/leonardosantosbr/cloud-deployment-models-368b | ## public
Quick access to computing resources without a large upfront cost, with the public cloud, your company purchases virtualized computing, storage, and networking services from a cloud service provider over the public internet.
## private
A private cloud is hosted in a data center and maintained by IT staff, t... | leonardosantosbr | |
1,886,334 | Real-Time Communication with WebSockets: A Complete Guide | Unlock the power of WebSockets for real-time communication in web applications. This complete guide... | 0 | 2024-06-13T01:07:02 | https://dev.to/dipakahirav/real-time-communication-with-websockets-a-complete-guide-32g4 | javascript, webdev, websocket, programming | Unlock the power of WebSockets for real-time communication in web applications. This complete guide covers everything from the basics to advanced features, helping you implement efficient, scalable, and real-time updates in your projects. Perfect for developers aiming to master WebSocket technology.
please subscribe t... | dipakahirav |
1,886,333 | Mobile Bumper Repair: Convenience and Quality at Your Doorstep | Introduction In today's fast-paced world, convenience is key, and this extends to car... | 0 | 2024-06-13T00:52:12 | https://dev.to/max_silva_312126221f27e00/mobile-bumper-repair-convenience-and-quality-at-your-doorstep-10dl |
## Introduction
In today's fast-paced world, convenience is key, and this extends to car maintenance and repair. Mobile bumper repair services bring professional, high-quality repair work right to your doorstep, saving you time and hassle. This post explores the benefits of mobile bumper repair, how it works, and w... | max_silva_312126221f27e00 | |
1,886,332 | Hello DEV Community! 👋 | Hello DEV Community! 👋 I'm thrilled to be joining this dynamic and inspiring community! My name is... | 0 | 2024-06-13T00:51:46 | https://dev.to/techgirlkaydee/hello-dev-community-4mb2 | **Hello DEV Community! 👋**
I'm thrilled to be joining this dynamic and inspiring community! My name is Khadisha, and I'm in the midst of an exciting transition from business lending to cloud engineering. Here’s a bit about my journey, my new interests, and what I hope to achieve moving forward.
**A Leap from Business... | techgirlkaydee | |
1,886,330 | One-shot migration from Create React App to Vite | Introducing Viejct: A tool for migrating your React app from react-scripts (Create React App) to Vite. | 0 | 2024-06-13T00:49:46 | https://dev.to/bhbs/one-shot-migration-from-create-react-app-to-vite-f3 | react, vite | ---
title: One-shot migration from Create React App to Vite
published: true
description: Introducing Viejct: A tool for migrating your React app from react-scripts (Create React App) to Vite.
tags: react, vite
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ax73j8b1q2ad92hrim37.jpeg
# published_at... | bhbs |
1,886,331 | code | Python | 0 | 2024-06-13T00:49:07 | https://dev.to/mrjam/code-ojg | Python | mrjam | |
1,886,303 | Making Serverless 15x Cheaper | We’ve often heard developers working on stateful applications say that they want to adopt serverless... | 0 | 2024-06-13T00:41:35 | https://dev.to/dbos/making-serverless-15x-cheaper-751 | aws, cloud, typescript, postgres | We’ve often heard developers working on stateful applications say that they want to adopt serverless technology to more easily deploy to the cloud, but can’t because it’s prohibitively expensive. For clarity, by “stateful applications” we mean applications that manage persistent state stored in a database (for example,... | kraftp |
1,886,329 | Why I Recommend SQLynx as the Best SQL IDE | I used to be a loyal Navicat、DataGrip user, but after deeply using SQLynx for a while, I can never go... | 0 | 2024-06-13T00:40:30 | https://dev.to/concerate/why-i-recommend-sqlynx-as-the-best-sql-ide-316l | I used to be a loyal Navicat、DataGrip user, but after deeply using SQLynx for a while, I can never go back. I feel like shouting: This is the SQL IDE/Editor that should be used in 2024.
If I were to sum up SQLynx in one sentence, it would be: "What you don't have, I have; what you have, I excel in."
For instance, in ... | concerate | |
1,886,328 | Fraud Detection and Prevention in Finance | Fraud detection and prevention is crucial for safeguarding financial assets and maintaining customer... | 0 | 2024-06-13T00:37:08 | https://dev.to/miniailive/fraud-detection-and-prevention-in-finance-5fmd | webdev, androiddev, machinelearning, ai | Fraud detection and prevention is crucial for safeguarding financial assets and maintaining customer trust. Businesses face increasing threats from cybercriminals who use sophisticated methods to commit fraud. Implementing robust fraud detection systems helps identify suspicious activities early. Techniques like machin... | miniailive |
1,886,327 | Abstraction | Abstraction is simplifying concepts to ease our work. Instead of code being specific to hardware, it... | 0 | 2024-06-13T00:34:41 | https://dev.to/mpreams/abstraction-1hdb | cschallenge | Abstraction is simplifying concepts to ease our work. Instead of code being specific to hardware, it depends on the abstract concept of the solution. | mpreams |
1,886,325 | Building a Real-Time Chat Application with Firebase | Introduction In today's fast-paced world, real-time communication has become a crucial... | 0 | 2024-06-13T00:32:29 | https://dev.to/kartikmehta8/building-a-real-time-chat-application-with-firebase-23k9 | webdev, javascript, beginners, programming | ## Introduction
In today's fast-paced world, real-time communication has become a crucial aspect of our daily lives. Building a real-time chat application has become essential for businesses, organizations, and even individuals. Firebase, a popular Backend as a Service (BaaS) platform, offers an easy and efficient sol... | kartikmehta8 |
1,886,324 | APIs | Application Programming Interfaces (API) are how we can write programs that get and post information... | 0 | 2024-06-13T00:26:27 | https://dev.to/mpreams/apis-2bnk | cschallenge | Application Programming Interfaces (API) are how we can write programs that get and post information with another live source of data. It's like a menu at your favorite restaurants. | mpreams |
1,885,012 | Elixir Process, what is? how work? What is linked & monitored process | One of some difficult to understand from other languages go to Elixir is process (a lightweight/green... | 0 | 2024-06-13T00:22:38 | https://dev.to/manhvanvu/elixir-process-what-is-how-work-bgj | One of some difficult to understand from other languages go to Elixir is process (a lightweight/green thread, not OS process) and people usually ignore it to use libraries.
Actually, Elixir process is very powerful thing, If go to work with large scale system we need to do with process a lot.
I have long time work wi... | manhvanvu | |
1,886,311 | Let’s Build Small AI Buzz, Offer ‘Claim Processing’ to Mid/Big Companies | Discover How AI Can Transform Businesses, Every Details Spelled Out. Full Article Artificial... | 0 | 2024-06-13T00:18:25 | https://dev.to/exploredataaiml/lets-build-small-ai-buzz-offer-claim-processing-to-midbig-companies-3dkn | llm, rag, machinelearning, genai | Discover How AI Can Transform Businesses, Every Details Spelled Out.
[Full Article] (https://medium.com/@learn-simplified/lets-build-small-ai-buzz-offer-claim-processing-to-mid-big-companies-d589f008d724)
Artificial Intelligence (AI) is rapidly reshaping business landscapes, promising unprecedented efficiency and acc... | exploredataaiml |
1,886,307 | Simple way to obtain largest Number in an array or slice in golang | 🚀 Step-by-Step Guide to Find the Largest Number in an Array in Go Finding the largest... | 0 | 2024-06-13T00:09:08 | https://dev.to/toluwasethomas/simple-way-to-obtain-largest-number-in-an-array-or-slice-in-golang-2o06 | webdev, beginners, go, arrays | # 🚀 Step-by-Step Guide to Find the Largest Number in an Array in Go
Finding the largest number in an array is a common task in programming. Let's walk through a simple yet effective approach to accomplish this in Go.
## 📝 Steps to Follow
### 1️⃣ Loop through Each Value
Iterate through each element of the array or ... | toluwasethomas |
1,886,306 | CODER CYBER SERVICES // RECOVER STOLEN CRYPTOCURRENCY | In cyberspace, where promises gleam like diamonds but often lead to deceptive traps, one can easily... | 0 | 2024-06-12T23:56:36 | https://dev.to/christine_kradolfer_891e5/coder-cyber-services-recover-stolen-cryptocurrency-5p5 | In cyberspace, where promises gleam like diamonds but often lead to deceptive traps, one can easily lose themselves. I found myself ensnared in this digital maze when a seemingly promising investment opportunity turned into a nightmare. It all began innocuously enough with an invitation to join a Telegram group promisi... | christine_kradolfer_891e5 | |
1,886,305 | Anyone who likes games | I have a fun game for everyone to play eaglercraft.com its unblocked and free | 0 | 2024-06-12T23:55:18 | https://dev.to/scarlett_exe/anyone-who-likes-games-25pc | I have a fun game for everyone to play eaglercraft.com its unblocked and free | scarlett_exe | |
1,886,304 | Day 969 : keep | liner notes: Professional : So...no code was written today. haha I was in meetings, responding to... | 0 | 2024-06-12T23:55:04 | https://dev.to/dwane/day-696-keep-5c5h | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : So...no code was written today. haha I was in meetings, responding to community questions, booking a hotel room and filling out a visa. But got it all done.
- Personal : Went through some tracks for the radio show. Played around with the settings of the highlight video creator and I thi... | dwane |
1,886,302 | How to Prepare for Driving School in Vienna | Preparing for driving school is a crucial step toward becoming a confident and responsible driver.... | 0 | 2024-06-12T23:44:00 | https://dev.to/novadriving_school_eaa910/how-to-prepare-for-driving-school-in-vienna-3fg4 | Preparing for driving school is a crucial step toward becoming a confident and responsible driver. Whether you're gearing up for your first driving lesson or refreshing your skills, adequate preparation is key to success. In this guide, we'll delve into the essential steps to prepare for [driving school in Vienna](http... | novadriving_school_eaa910 | |
1,407,116 | Why batch jobs are so difficult? | The detail data produced in the business system usually needs to be processed and calculated to our... | 0 | 2023-03-19T23:54:33 | https://dev.to/jbx1279/why-batch-jobs-are-so-difficult-155e | database, bigdata, sql, programming | The detail data produced in the business system usually needs to be processed and calculated to our desired result according to a certain logic so as to support the business activities of enterprise. In general, such data processing will involves many tasks, and it needs to calculate in batches. In the bank and insuran... | jbx1279 |
1,886,301 | Recursion | Recursion can be referred to as a function in programming that calls itself to solve some part of the... | 0 | 2024-06-12T23:40:51 | https://dev.to/ismailajat14162/recursion-4jnh | devchallenge, cschallenge, computerscience, beginners | Recursion can be referred to as a function in programming that calls itself to solve some part of the problem or task in a repeated manner until its reach optimal solution. Example sorting random numbers in descending order by comprising each number at a time.
| ismailajat14162 |
1,886,299 | [JavaScript] Generate Unique Code | Script que genera código único. El script se basa en las siguientes condiciones: Debe tener una... | 0 | 2024-06-12T23:30:06 | https://dev.to/jkdevarg/javascript-generate-unique-code-2jlj | javascript, beginners, programming, github | Script que genera código único.
El script se basa en las siguientes condiciones:
- Debe tener una longitud de 6 caracteres
- Debe empezar con las siguientes letras "M", "B", "L"
- Debe ser todo en mayuscula
- No debe contener el número 1
- No se pueden repetir
- Se deben generar 10,000 códigs en 20 archivos de texto
... | jkdevarg |
1,886,298 | What is Data Governance? | Introduction Image Credit: Spiceworks In an era where data is considered the new oil,... | 0 | 2024-06-12T23:25:03 | https://dev.to/kellyblaire/what-is-data-governance-54fo | sql, database, datascience, sqlserver | #### Introduction
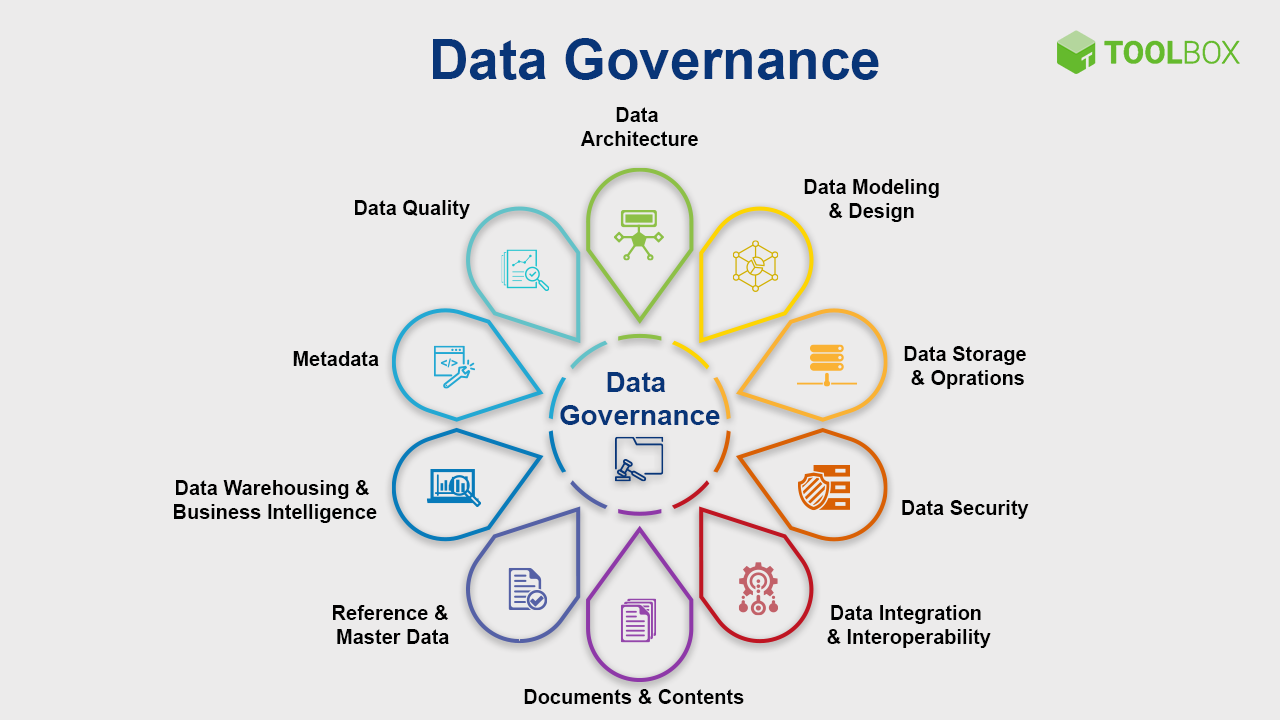
_Image Credit: [Spiceworks](https://www.spiceworks.com/tech/big-data/articles/what-is-data-governance-definition-importance-and-best-practices/)_
In an era where data is considered the new oil, ef... | kellyblaire |
1,886,297 | Vscode Android | if you are looking for visual studio code for android for free, just download VHEditor. its available... | 0 | 2024-06-12T23:23:43 | https://dev.to/collinsomega/vscode-android-45le | if you are looking for visual studio code for android for free, just download VHEditor. its available on playstore. | collinsomega | |
1,886,256 | Certificate at codsoft 🚀 | A post by Alyan Sheikh | 0 | 2024-06-12T22:54:03 | https://dev.to/alyan_sheikh_e1f7c955a630/certificate-at-codsoft-100a |
 | alyan_sheikh_e1f7c955a630 | |
1,886,296 | Api Architecture Styles using GraphQL | Applications need data to function, these are in a database within a server They have a client which... | 0 | 2024-06-12T23:22:06 | https://dev.to/marioflores7/api-architecture-styles-using-graphql-efi | Applications need data to function, these are in a database within a server
They have a client which is the view and a server where the data logic is.
both communicate through an API, the best known is REST
Graphql allow queries to be made on the client side, not on the server side, it is like doing sql on the fronte... | marioflores7 | |
1,886,259 | Neural Networks | A neural network is like a lasagna. Each layer (like noodles, cheese, sauce) adds something special.... | 0 | 2024-06-12T23:07:19 | https://dev.to/architjoshi/neural-networks-2862 | cschallenge, neuralnetworks, lasagna, machinelearning | A neural network is like a lasagna. Each layer (like noodles, cheese, sauce) adds something special. The first layer takes in info (ingredients), middle layers mix and change it (cooking), and the last layer gives the final result (a yummy lasagna).
 tool that allows you to... | 0 | 2024-06-12T22:38:45 | https://dev.to/hassan_aftab/understanding-terraform-a-guide-to-effective-iac-practices-28pn | programming, devops, terraform, infrastructureascode | ## What is Terraform?
<br>
Terraform is an infrastructure as code (IaC) tool that allows you to build, change, and version cloud and on-premises resources safely and efficiently.
With Terraform, you define your infrastructure using human-readable configuration files, which can be **versioned, reused, and shared**.
... | hassan_aftab |
1,886,252 | The Ultimate Guide to Professional Legal Translation Services | Welcome to our comprehensive guide on professional legal translation services. At our agency, we... | 0 | 2024-06-12T22:37:48 | https://dev.to/alexaandrew/the-ultimate-guide-to-professional-legal-translation-services-jkb | Welcome to our comprehensive guide on professional legal translation services. At our agency, we understand the critical importance of accurate and reliable translations in the legal field. Whether you’re a law firm, corporate entity, or government agency, we are here to meet your legal translation needs with precision... | alexaandrew | |
1,886,251 | Clean Code With AI | Mastering Clean Code with ChatGPT and Gemini TL;DR: This is my talk a at Tech Excellence on... | 18,654 | 2024-06-12T22:36:57 | https://dev.to/mcsee/clean-code-with-ai-4kck | cleancode, ai, chatgpt, refactoring | *Mastering Clean Code with ChatGPT and Gemini*
> TL;DR: This is my talk a at Tech Excellence on combining Artificial Intelligence and Clean Code
# Summary
How can you leverage ChatGPT, Gemini, Copilot and other assistants to write clean code? What instructions should you provide them? How do you configure them to as... | mcsee |
1,886,204 | shadcn-ui/ui codebase analysis: Dashboard example explained. | In this article, we will learn about Dashboard example in shadcn-ui/ui. This article consists of the... | 0 | 2024-06-12T20:51:12 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-dashboard-example-explained-42a1 | javascript, nextjs, opensource, shadcnui | In this article, we will learn about [Dashboard](https://ui.shadcn.com/examples/dashboard) example in shadcn-ui/ui. This article consists of the following sections:
, a base implementation of `HttpAsyncClient` that also imple... | jonathan-dev |
1,886,228 | run.bash & migrate.bash - Pimpe deine .bashrc auf 🔝🔥 | Deine .bashrc Deine .bashrc Datei ist ein Skript, das jedes mal bei deinem Shellzugriff... | 0 | 2024-06-12T21:56:40 | https://dev.to/rubenvoss/runbash-migratebash-pimpe-deine-bashrc-auf-307h | ## Deine .bashrc
Deine .bashrc Datei ist ein Skript, das jedes mal bei deinem Shellzugriff aufgerufen wird. Hier kannst du verschiedene Werte setzen & Dein Leben dadurch leichter machen. Wir werden am Beispiel django jetzt Skripte für dein Projekt entwickeln, die dir den Start deines Projekts erleichtern. Außerdem werd... | rubenvoss | |
1,886,226 | Navigating the Cross-Platform App Development Landscape: What You Need to Succeed in 2024 | Cross-platform app development has become increasingly popular in recent years as businesses seek to... | 0 | 2024-06-12T21:36:11 | https://dev.to/ritesh12/navigating-the-cross-platform-app-development-landscape-what-you-need-to-succeed-in-2024-5365 | Cross-platform app development has become increasingly popular in recent years as businesses seek to reach a wider audience with their mobile applications. This approach allows developers to create apps that can run on multiple operating systems, such as iOS, Android, and Windows, using a single codebase. By doing so, ... | ritesh12 | |
1,886,225 | Workflow and Internal Mechanics of CSS with PostCSS and Vite | In modern web development, tools such as Vite and PostCSS are essential for optimizing CSS,... | 0 | 2024-06-12T21:31:46 | https://dev.to/dev_raghvendra/workflow-and-internal-mechanics-of-css-with-postcss-and-vite-9o1 | javascript, beginners, css, vite |
In modern web development, tools such as Vite and `PostCSS` are essential for optimizing CSS, particularly within frameworks like React. This article explores the setup and optimization of CSS using PostCSS plugins like Tailwind CSS and AutoPrefixer within a project powered by Vite. ... | dev_raghvendra |
1,886,222 | Essentials Fear of GOd Hoodies | Essentials Hoodies are your go-to for comfort and style. We have versatile, cozy, and perfect... | 0 | 2024-06-12T21:21:51 | https://dev.to/essentialsclothing11/essentials-fear-of-god-hoodies-53jo | essentails, hoodie, trackcsuit | [Essentials Hoodies](https://essentialsukclothing.com/essentials-hoodie/) are your go-to for comfort and style. We have versatile, cozy, and perfect hoodiess for any occasion. You can upgrade your wardrobe effortlessly with your premium collection. | essentialsclothing11 |
1,886,210 | Seeking for A SKILLED Golang Developer (URGENT HIRING *) | Job Title: Principal Software Engineer (Golang Developer) Location: Fully Remote Job Type:... | 0 | 2024-06-12T21:19:19 | https://dev.to/andrew_king_cd5fbd2e15d08/seeking-for-a-skilled-golang-developer-urgent-hiring--3il4 | go | **Job Title:** Principal Software Engineer (Golang Developer)
**Location:** Fully Remote
**Job Type:** Full-time
**Department:** Engineering/Technology
**Salary:** Negotiable
**Job Summary**
We are in search of a distinguished Principal Software Engineer with a minimum of 15 years of extensive experience in soft... | andrew_king_cd5fbd2e15d08 |
1,886,207 | Exploring Destructuring in JS | Hello, my name is Daniel and I'm a beginner at coding. I am an active student at Flatiron School. In... | 0 | 2024-06-12T21:15:32 | https://dev.to/daniel_trejo14/exploring-destructuring-in-js-114j | Hello, my name is Daniel and I'm a beginner at coding. I am an active student at Flatiron School. In phase-2 we delve heavily into react and all the amazing things it can do. Today I decided to talk about Destructuring a little because it is a super simple yet amazing piece of code. Destructuring allows for a more conc... | daniel_trejo14 | |
1,886,206 | Singleton Design Pattern, TypeScript example | What is Singleton Pattern, use cases and critics. Example of Singleton Pattern in TypeScript. | 0 | 2024-06-12T21:13:07 | https://dev.to/artem/singleton-design-pattern-typescript-example-443e | designpatterns, typescript | ---
title: Singleton Design Pattern, TypeScript example
published: true
description: What is Singleton Pattern, use cases and critics. Example of Singleton Pattern in TypeScript.
tags: #designpatterns #typescript
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2... | artem |
1,886,205 | Learn GO: Creating Variables in GO Lang | I just started learning Go and I want myself to be fully committed to it. So, I thought may be should... | 0 | 2024-06-12T20:55:27 | https://dev.to/ivewor/learn-go-creating-variables-in-go-lang-5dim | go, beginners, tutorial, programming | I just started learning Go and I want myself to be fully committed to it. So, I thought may be should start writing about it. It will help me to basically learn each part in some more details and will also help me to track the progress.
I won't be talking about why you should or should not use this language. I just fi... | ivewor |
1,886,203 | Build Your Own Chatbot in Kotlin with GPT: A Step-by-Step Guide | In this post, I'll guide you through a practical example of how to integrate GPT (Generative... | 0 | 2024-06-12T20:47:34 | https://dev.to/josmel/build-your-own-chatbot-in-kotlin-with-gpt-a-step-by-step-guide-27fd | ai, gpt3, kotlin | In this post, I'll guide you through a practical example of how to integrate GPT (Generative Pre-trained Transformer) into a Kotlin application to create a basic chatbot. This chatbot will be able to respond to user queries naturally and efficiently.
### Setting Up the Project
**Step 1: Set Up Dependencies**
First, m... | josmel |
1,886,202 | css girl | pure CSS image of a girl with blue eyes and blue hair | 0 | 2024-06-12T20:31:44 | https://dev.to/kemiowoyele1/css-girl-adc | codepen | pure CSS image of a girl with blue eyes and blue hair
{% codepen https://codepen.io/frontend-magic/pen/pojYRjB %} | kemiowoyele1 |
1,609,168 | Building RESTful APIs with Express.js | Welcome to a journey into the world of web architecture! Whether you're a seasoned developer or... | 0 | 2024-06-12T20:29:18 | https://dev.to/labank_/building-restful-apis-with-expressjs-he1 |

Welcome to a journey into the world of web architecture! Whether you're a seasoned developer or just dipping your toes into the vast sea of software development, understanding the core concepts and tools that power the we... | labank_ | |
1,884,848 | GDSC at Mbeya University of Science and Technology: A Community History | Overview of the GDSC Chapter Introduction to GDSC and Its Mission Google Developer Student... | 0 | 2024-06-12T20:26:22 | https://dev.to/fareedcodez/gdsc-at-mbeya-university-of-science-and-technology-a-community-history-44cd | gdsc, career, community | ## Overview of the GDSC Chapter
**Introduction to GDSC and Its Mission**
Google Developer Student Clubs are university based community groups for students interested in Google developer technologies. Students from all undergraduate or graduate programs with an interest in growing as a developer are welcome. By joining ... | fareedcodez |
1,886,201 | Debugging 101 - How to Fix Software Errors Efficiently | If debugging is the process of removing software bugs, then programming must be the process of... | 0 | 2024-06-12T20:22:48 | https://dev.to/alexindevs/debugging-101-how-to-fix-software-errors-efficiently-5hm2 | webdev, debugging, javascript, programming | > If debugging is the process of removing software bugs, then programming must be the process of putting them in.
You’re sitting at your desk, staring (glaring, rather) at your laptop. It’s 2 am. Your code just isn’t working and you’re not sure why. You’ve tried everything you can think of, but the bug is still there,... | alexindevs |
1,873,358 | Advanced JavaScript | Introduction JavaScript has evolved significantly since its inception, becoming one of the... | 27,559 | 2024-06-12T20:21:00 | https://dev.to/suhaspalani/advanced-javascript-f4l | webdev, javascript, programming, beginners | #### Introduction
JavaScript has evolved significantly since its inception, becoming one of the most powerful and flexible programming languages for web development. Understanding advanced JavaScript concepts is crucial for building complex and efficient applications. This week, we'll dive into some of these advanced t... | suhaspalani |
1,886,188 | L1SLOAD el nuevo opcode para Keystores seguras y escalables | Las funciones de abstracción de cuentas cross-chain serán posibles gracias a los Keystores. Los... | 0 | 2024-06-12T20:18:56 | https://dev.to/turupawn/l1sload-el-nuevo-opcode-para-keystores-seguras-y-escalables-50of | ---
title: L1SLOAD el nuevo opcode para Keystores seguras y escalables
published: true
description:
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-06 15:00 +0000
---
Las funciones de abstracción de cuentas cross-chain serán posibles gracias a lo... | turupawn | |
1,879,464 | How to use L1SLOAD, the Keystore backbone | Seamless cross-chain account abstraction features will be possible thanks to Keystores. Were users... | 0 | 2024-06-12T20:18:44 | https://dev.to/filosofiacodigoen/how-to-use-l1sload-the-keystores-backbone-25ah | ---
title: How to use L1SLOAD, the Keystore backbone
published: true
description:
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-06 15:00 +0000
---
Seamless cross-chain account abstraction features will be possible thanks to [Keystores](https://... | turupawn | |
1,886,189 | Estudos em Quality Assurance (QA) - Como Reportar um Bug | Título: Um título claro e conciso que descreve o problema de forma sucinta. Prioridade: Classifique... | 0 | 2024-06-12T20:14:32 | https://dev.to/julianoquites/estudos-em-quality-assurance-qa-como-reportar-um-bug-2f69 | qa, testing, learning, testedesoftware | **Título:** Um título claro e conciso que descreve o problema de forma sucinta.
**Prioridade:** Classifique a prioridade do bug de acordo com sua gravidade, usando escalas como P0 (crítico) a P3 (menos crítico).
**Resumo:** Uma breve descrição do bug, incluindo informações adicionais relevantes.
**Passos para Reprod... | julianoquites |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.