
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,882,039 | Where To Watch India vs Pakistan T20 World Cup Live In USA {Online} | Where To Watch India vs Pakistan T20 World Cup? If you want to catch the highly anticipated T20 World... | 0 | 2024-06-09T12:07:06 | https://dev.to/rameshchand/where-to-watch-india-vs-pakistan-t20-world-cup-live-in-usa-online-1okd | indiavspakistan, t20worldcup, usa, java | Where To Watch India vs Pakistan T20 World Cup? If you want to catch the highly anticipated T20 World Cup match between India and Pakistan, you can do so by subscribing to the Sling TV Willow Cricket package.
**[Watch India vs Pakistan T20 World Cup
](https://sling-tv.pxf.io/c/2960521/1575796/14334?sharedid=cricket_2... | rameshchand |
1,882,037 | How To Watch India vs Pakistan T20 World Cup Live In USA | Searching for how to watch the cricket World Cup live in the USA? then all the information is... | 0 | 2024-06-09T12:03:26 | https://dev.to/rameshchand/how-to-watch-india-vs-pakistan-t20-world-cup-live-in-usa-pm5 | t20world, t20worldcup, worldcup, indiavspakistan | Searching for how to watch the cricket World Cup live in the USA? then all the information is here.
[Click Here To Subscribe To Sling TV](https://sling-tv.pxf.io/c/2960521/1575796/14334?sharedid=cricket_2023)
The anticipation is building, and cricket fans across the United States are gearing up for the highly-awaited... | rameshchand |
1,881,744 | Highlight Specific Segment Block as Notice, Tip, Caution, Important & Warning in Markdown | Markdown is a very popular scripting language. It is used starting from writing documentation to even... | 0 | 2024-06-09T12:01:14 | https://dev.to/fahimfba/highlight-specific-segment-block-as-notice-tip-caution-important-warning-in-markdown-2ne8 | markdown, github | Markdown is a very popular scripting language. It is used starting from writing documentation to even creating a complete website. Therefore, almost all of us frequently use this scripting language every once in a while.
However, there are some limitations to this language as well. In some cases, we can not add that m... | fahimfba |
1,882,029 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-06-09T11:50:18 | https://dev.to/ayush16coder/my-pen-on-codepen-5gfi | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Nitin-Dongre/pen/zYXVqXV %} | ayush16coder |
1,880,822 | How I built a rhymes dictionary ? | Hi and welcome to this new article ! I've been working hard on my mobile dictionary Remède this last... | 0 | 2024-06-09T12:00:00 | https://remede.camarm.fr/2024/06/01/Rhymes-dictionary.html | mobile, french, ionic, javascript | Hi and welcome to this new article !
I've been working hard on my mobile dictionary Remède this last month (I released the `1.2.0-beta` version a week ago).
I've added many things but today I will focus on a special functionality.
I've added a **rhymes dictionary** which is completely running on your phone (or any b... | camarm |
1,882,034 | How to apply with MOI certificate at a UK University | How to apply with MOI What Is M.O.I The whole meaning of MOI is the medium of instruction . A... | 0 | 2024-06-09T11:59:17 | https://dev.to/educationhub/how-to-apply-with-moi-certificate-at-a-uk-university-3ibk | study, studyinukwith |

**How to apply with MOI**
What Is M.O.I
The whole meaning of MOI is the [medium of instruction](https://educationhub-bd.com/blog/How-to-apply-with-MOI-certificate-at-a-UK-University) . A medium of instruction is a... | educationhub |
1,882,032 | Building a Gym Management App with Laravel, Filament, Herd, and Blueprint | Hello friends, I recently took on the challenge of building a gym management application. Using... | 0 | 2024-06-09T11:54:56 | https://dev.to/hassanshahzadaheer/building-a-gym-management-app-with-laravel-filament-herd-and-blueprint-2b3m | Hello friends,
I recently took on the challenge of building a gym management application. Using Laravel along with some fantastic tools like Filament, Herd, and Blueprint, I was able to create a robust app in no time. If you find documentation hard to follow or just want a more guided experience, this post is for you.... | hassanshahzadaheer | |
1,882,031 | 3d rotating pyramid | Check out this Pen I made! | 0 | 2024-06-09T11:54:53 | https://dev.to/kemiowoyele1/3d-rotating-pyramid-2bdf | codepen | Check out this Pen I made!
{% codepen https://codepen.io/frontend-magic/pen/QWPLwYV %} | kemiowoyele1 |
1,882,030 | CSS spaceship | CSS and HTML spaceship | 0 | 2024-06-09T11:52:22 | https://dev.to/kemiowoyele1/css-spaceship-292g | codepen | <p>CSS and HTML spaceship</p>
{% codepen https://codepen.io/frontend-magic/pen/KKWNdMo %} | kemiowoyele1 |
1,882,026 | Companies with Red Logos: Exploring the Most Famous Red Logos | Red is a color that commands attention. It's bold, energetic, and associated with strong emotions... | 0 | 2024-06-09T11:44:25 | https://dev.to/akiburrahaman/companies-with-red-logos-exploring-the-most-famous-red-logos-5c97 | logo, brand, icon, webdev | 
Red is a color that commands attention. It's bold, energetic, and associated with strong emotions like love, passion, and even danger. Many companies use red in their logos to evoke these feelings and stand out in t... | akiburrahaman |
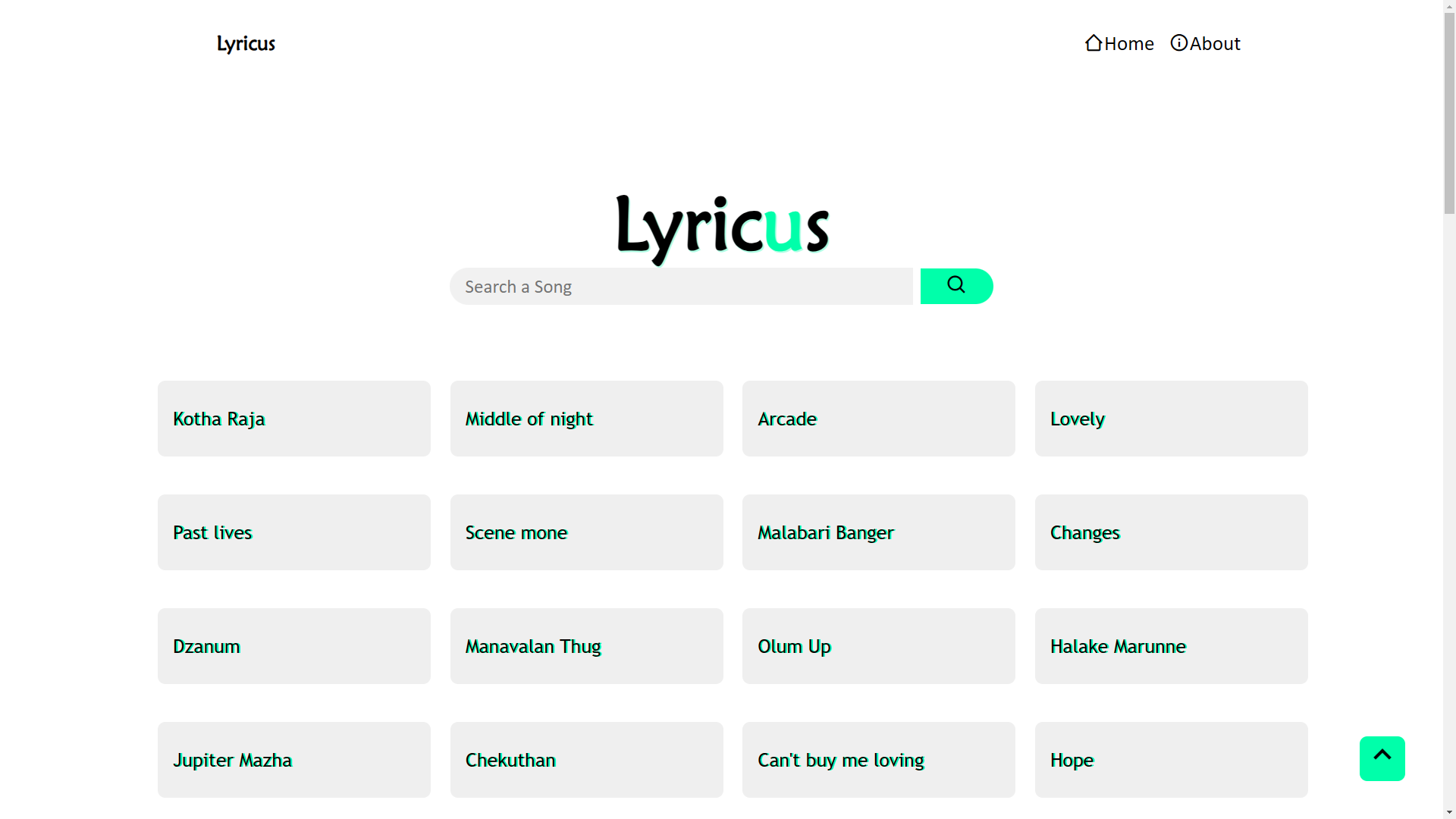
1,882,024 | I Hosted My first Website | I Hosted my first Website Lyricus😊😊. Here you can get 🎶song🎶 lyrics simply. take a look at... | 0 | 2024-06-09T11:37:10 | https://dev.to/shahan_k_5a525e24a07f6da6/i-hosted-my-first-website-2hle | webdev, javascript, firstweb, html | I Hosted my first Website Lyricus😊😊.
Here you can get 🎶song🎶 lyrics simply.
take a look at [lyricus.netlify.app](https://lyricus.netlify.app/).
Dont forget to tell your opinions(and problems😜).
| shahan_k_5a525e24a07f6da6 |
1,882,023 | Song Download: The Evolution, Impact, and Future of Digital Music Access. | The ability to download songs has transformed the way we experience music, providing unprecedented... | 0 | 2024-06-09T11:35:43 | https://dev.to/testing_email_9775839a60c/song-download-the-evolution-impact-and-future-of-digital-music-access-388i | The ability to download songs has transformed the way we experience music, providing unprecedented access to a vast array of tracks at our fingertips. This article explores the history, significance, and future of song downloads, delving into the technological advancements, cultural implications, and evolving trends th... | testing_email_9775839a60c | |
1,882,022 | Building a Diet Assistant using Lyzr SDK | In today’s fast-paced world, maintaining a balanced diet can be challenging. However, with the Diet... | 0 | 2024-06-09T11:35:32 | https://dev.to/akshay007/building-a-diet-assistant-using-lyzr-sdk-260i | ai, programming, diet, python | In today’s fast-paced world, maintaining a balanced diet can be challenging. However, with the **Diet Assistant** powered by **Lyzr SDK**, you can now effortlessly track and optimize your nutrition. This blog post will walk you through the incredible features of the Diet Assistant and how it can transform your dietary ... | akshay007 |
1,882,021 | i want to KNOW About PHONE | A post by Sami Niyigena | 0 | 2024-06-09T11:34:26 | https://dev.to/sami_niyigena/i-want-to-know-about-phone-1fel | sami_niyigena | ||
1,882,020 | i want to KNOW About PHONE | A post by Sami Niyigena | 0 | 2024-06-09T11:34:24 | https://dev.to/sami_niyigena/i-want-to-know-about-phone-4cg1 | sami_niyigena | ||
1,882,011 | The Ultimate beginners guide to open source – part 4: Why you should contribute to open source projects | Intro Getting involved in open source projects is a great way to improve your coding skills and work... | 0 | 2024-06-09T11:32:20 | https://dev.to/dunsincodes/the-ultimate-beginners-guide-to-open-source-part-4-why-you-should-contribute-to-open-source-projects-f3n | webdev, opensource, beginners, github | **Intro**
Getting involved in open source projects is a great way to improve your coding skills and work on real-world projects. By contributing to these projects, you can gain valuable experience that will make you a better developer. This blog will explore the benefits of contributing to open source, such as building... | dunsincodes |
1,882,010 | Building a Neat Node.js Project: Your Guide to a Clean Folder Structure 📂 | Starting a Node.js project? Keeping your codebase clean and organized is crucial. Let's talk about... | 0 | 2024-06-09T11:27:55 | https://dev.to/raksbisht/building-a-neat-nodejs-project-your-guide-to-a-clean-folder-structure-4eh6 | node, cleancode, tutorial | Starting a Node.js project? Keeping your codebase clean and organized is crucial. Let's talk about setting up a tidy folder structure for your project to make coding easier and collaboration smoother!
### Getting Started 🏗️
1. **Root Directory**: First things first, create a main folder for your project. This is wh... | raksbisht |
1,880,807 | AR Game ~ Location Information ~ | Table of contents Background Creation of AR game with location information Execution of the game... | 0 | 2024-06-09T11:25:57 | https://dev.to/takeda1411123/ar-game-location-information--1e8k | unity3d, gamedev, location, api | Table of contents
- Background
- Creation of AR game with location information
- Execution of the game
# Background
I will develop AR Game with Unity, AR foundation and so on. To learn AR development, I am researching about AR and the software related it. This blog shows the research and the process of developing ... | takeda1411123 |
1,882,008 | Understanding Throttling in JavaScript | Throttling is a technique in programming to ensure that a function is executed at most once in a... | 0 | 2024-06-09T11:21:26 | https://dev.to/dipakahirav/understanding-throttling-in-javascript-55jl | javascript, webdev, beginners, programming | Throttling is a technique in programming to ensure that a function is executed at most once in a specified time interval. This is particularly useful for controlling events that trigger multiple times in quick succession, like window resizing, scrolling, or mouse movements.
please subscribe to my [YouTube channel](htt... | dipakahirav |
1,882,007 | Simplifying Software Mechanics: A Clear Guide to Processes, Threads, Handles, Services and Applications | We, as computer science engineers specialized in various fields such as Cloud, Full-stack... | 0 | 2024-06-09T11:20:35 | https://dev.to/mahakfaheem/simplifying-software-mechanics-a-clear-guide-to-processes-threads-handles-services-and-applications-32bc | computerscience, programming, learning, community | We, as computer science engineers specialized in various fields such as Cloud, Full-stack development, Data Science, Machine Learning, Artificial Intelligence, and Cybersecurity, often know a lot about our domains. However, sometimes we struggle with the very basics, clinging to those doubts that couldn’t get clear in ... | mahakfaheem |
1,882,006 | Day 8 : Basic Git & GitHub for DevOps Engineers. | What is Git? Git is a free open source distributed version control system you can use to track... | 0 | 2024-06-09T11:20:30 | https://dev.to/oncloud7/day-8-basic-git-github-for-devops-engineers-4n99 | github, git, beginners, devops | **What is Git?**
Git is a free open source distributed version control system you can use to track changes in your files. You can work on all types of projects in Git, from small to large.
With Git, you can add changes to your code and then commit them (or save them) when you're ready. This means you can also go back ... | oncloud7 |
1,878,018 | AR Game ~ Applied AR to practice ~ | Table of contents Background Creation of applied AR Execution of the game Next Step ... | 0 | 2024-06-09T11:17:36 | https://dev.to/takeda1411123/ar-game-applied-ar-to-practice--1g25 | Table of contents
- Background
- Creation of applied AR
- Execution of the game
- Next Step
# Background
I will develop AR Game with Unity, AR foundation and so on. To learn AR development, I am researching about AR and the software related it. This blog shows the research and the process of developing AR game. If yo... | takeda1411123 | |
1,882,004 | EKS ZeroScaler | Scheduled auto-scaling to zero with Lambda GO client A seamless integration of Golang... | 0 | 2024-06-09T11:09:49 | https://dev.to/wardove/eks-zeroscaler-58nf | aws, tutorial, serverless, kubernetes | ## Scheduled auto-scaling to zero with Lambda GO client
A seamless integration of Golang Lambda kubernetes client, EventBridge, and EKS, all efficiently deployed with Terraform, for dynamic, cost-effective auto-scaling in development environments.
## Table of Contents <a name="Toc"></a>
1. [Introduction](#introduction... | wardove |
1,882,003 | Mastering SEO with Angular V18 | Introduction Search Engine Optimization (SEO) is crucial for the success of any website.... | 0 | 2024-06-09T11:06:35 | https://dev.to/aswinthgt/mastering-seo-with-angular-v18-5166 | angular, seo, webdev, javascript | ## Introduction
Search Engine Optimization (SEO) is crucial for the success of any website. While Angular is a powerful framework for building dynamic single-page applications, it presents unique challenges for SEO due to its reliance on JavaScript for rendering content. In this guide, we’ll explore best practices for ... | aswinthgt |
1,882,002 | If you could use notion to build an app/startup , what would you make? | I've been working hard on a framework that converts notion pages to usable apps. I wanted to know... | 0 | 2024-06-09T11:04:47 | https://dev.to/lilshake/if-you-could-use-notion-to-build-an-appstartup-what-would-you-make-5fgg | nocode, beginners, productivity, startup | I've been working hard on a framework that converts notion pages to usable apps. I wanted to know what use cases would be most popular.
This would be a purely **no code solution** (maximum code would be a simple DSL) and the focus is on actually getting an app out there that you've just built in notion.
If anyone is ... | lilshake |
1,882,001 | How I Was Introduced to DevOps: My Journey from Uncertainty to Passion | Intern To DevOps | 0 | 2024-06-09T11:02:36 | https://dev.to/ujjwalkarn954/how-i-was-introduced-to-devops-my-journey-from-uncertainty-to-passion-5la | devops, development, developer, iac | [Intern To DevOps](https://ujjwalkarn954.github.io/article2.html) | ujjwalkarn954 |
1,882,000 | App | रिऍक्ट-डॉक ची माहिती. बेस्ट एज्युकेशनल डॉक्युमेंटेशन आणि ब्लॉगिंग प्लॅटफॉर्म वॉज लोड ऑल इंडियन... | 0 | 2024-06-09T10:58:52 | https://dev.to/nandkishor_dhekane_0146dd/app-bg0 | रिऍक्ट-डॉक ची माहिती.
बेस्ट एज्युकेशनल डॉक्युमेंटेशन आणि ब्लॉगिंग प्लॅटफॉर्म वॉज लोड ऑल इंडियन स्टुडंट्स.
अँप लिंक : https://dev-reactdoc-app.pantheonsite.io/ | nandkishor_dhekane_0146dd | |
1,881,999 | How Captcha Solver Speeds Up Your reCAPTCHA Solving Process? | In today's digital age, security measures such as reCAPTCHA are essential to protect websites from... | 0 | 2024-06-09T10:58:32 | https://dev.to/media_tech/how-captcha-solver-speeds-up-your-recaptcha-solving-process-45io | In today's digital age, security measures such as reCAPTCHA are essential to protect websites from spam and malicious activities. However, solving reCAPTCHAs can often be a time-consuming process for users. This is where a Captcha Solver becomes invaluable. A Captcha Solver is a tool designed to automate the process of... | media_tech | |
1,881,998 | Understanding MongoDB Aggregation: A Simple Guide 🚀 | MongoDB, one of the most popular NoSQL databases, offers powerful tools for data aggregation.... | 0 | 2024-06-09T10:53:40 | https://dev.to/raksbisht/understanding-mongodb-aggregation-a-simple-guide-1g4a | mongodb, aggregation, aggregationframework, tutorial | MongoDB, one of the most popular NoSQL databases, offers powerful tools for data aggregation. Aggregation is a process that allows you to transform and analyze data in your MongoDB collections. Whether you’re summarizing, filtering, or transforming data, MongoDB’s aggregation framework is incredibly versatile and power... | raksbisht |
1,881,997 | Software Testing QA | What is Software Testing? Software testing is the process of verifying and validating whether a... | 0 | 2024-06-09T10:53:08 | https://dev.to/syedalia21/software-testing-qa-4590 | **What is Software Testing?**
Software testing is the process of verifying and validating whether a software web or application is bug-free and meet user requirements. The main aim of the software testing is to identify missing requirements or mistakes.
**Why Software Testing Important?**
Because if there are any bu... | syedalia21 | |
1,881,996 | Search & Replace Texts in DOCX | Hey guys, I have created a package name edit-office-file which can search & replace multiple... | 0 | 2024-06-09T10:53:00 | https://dev.to/satyajitnayak/search-replace-texts-in-docx-3o40 | javascript, editofficefile, docx, ooxml |
Hey guys, I have created a package name [edit-office-file](https://www.npmjs.com/package/edit-office-files) which can search & replace multiple text strings inside a DOCX file as well other office file... | satyajitnayak |
1,881,995 | Best Amazon Scraper APIs To Check Out in 2024 | The E-commerce Industry was valued at 25.93 trillion $ and is expected to rise at 18.4% CAGR from... | 0 | 2024-06-09T10:44:29 | https://dev.to/serpdogapi/best-amazon-scraper-apis-to-check-out-in-2024-4e81 | amazon, programming, beginners, news | The E-commerce Industry was valued at 25.93 trillion $ and is expected to rise at 18.4% CAGR from 2024 to 2030([source](https://www.grandviewresearch.com/industry-analysis/e-commerce-market)). With this exponential rise of the e-commerce industry, Amazon has become the industry leader with a current market capitalizati... | serpdogapi |
1,881,994 | Building a NL2GraphQL using Lyzr SDK | As technology continues to evolve, the need for seamless communication between humans and machines... | 0 | 2024-06-09T10:44:27 | https://dev.to/akshay007/building-a-nl2graphql-using-lyzr-sdk-148o | ai, graphql, programming, python | As technology continues to evolve, the need for seamless communication between humans and machines becomes increasingly crucial. In the realm of databases, particularly GraphQL, translating human intent into machine-readable queries can often be challenging. Here at Lyzr, we aim to bridge that gap with our innovative a... | akshay007 |
1,881,988 | Differences between primary, core and task nodes in Amazon EMR cluster | The key differences between primary, core, and task nodes in an Amazon EMR cluster are: Primary Node... | 0 | 2024-06-09T10:43:42 | https://dev.to/aws-builders/differences-between-primary-core-and-task-nodes-in-amazon-emr-cluster-pc6 | aws, emr, cluster, nodes | The key differences between primary, core, and task nodes in an Amazon EMR cluster are:
**Primary Node (also known as Master Node):**
- The primary node is responsible for coordinating the cluster and managing the execution of jobs.
- It runs the main Hadoop services, such as the JobTracker, NameNode, and ResourceMan... | nowsathk |
1,881,993 | JWT | JSON Web Token compact URL-safe means of representing claims to be transferred between two parties... | 0 | 2024-06-09T10:43:23 | https://dev.to/md_shariarhaque_11695a3/jwt-5d11 | JSON Web Token compact URL-safe means of representing claims to be transferred between two parties securely. These tokens are often used in authentication and authorization protocols.
1. Structure: JWTs consist of three parts separated by dots: Header, Payload, and Signature. These parts are base64url encoded JSON str... | md_shariarhaque_11695a3 | |
1,881,992 | ติดตั้ง thai locale ใน CenOS/Alma/Rocky linux ใน docker | วันนี้ลองเล่น almalinux 9.4 image แล้วมันไม่ได้มี locale thai มาให้ จะติดตั้งก็ง่ายๆด้วยคำสั่ง... | 0 | 2024-06-09T10:43:10 | https://dev.to/pramoth/tidtang-thai-locale-ain-cenosalmarocky-linux-ain-docker-19n4 | วันนี้ลองเล่น almalinux 9.4 image แล้วมันไม่ได้มี locale thai มาให้ จะติดตั้งก็ง่ายๆด้วยคำสั่ง `localectl` เพราะว่าอยู่ใน container จึง research หาสักพักเลย จึงจะ note ไว้หน่อยละกัน
almalinux image ไม่ได้ใส่ avialable locale มาให้เรามันมีแค่ POSIX locale ดังนั้นเราต้องติดตั้งเพิ่ม เราเช็คได้ว่ามันมี avialable locale อ... | pramoth | |
1,881,991 | Mastering CSS Unit Size Conversion: Simplify Your Workflow | When it comes to responsive web design, managing CSS unit sizes efficiently is crucial. Understanding... | 0 | 2024-06-09T10:43:02 | https://dev.to/gecschool/mastering-css-unit-size-conversion-simplify-your-workflow-112p | css, px, size | When it comes to responsive web design, managing CSS unit sizes efficiently is crucial. Understanding how to convert between different units can greatly enhance your design process. Among these conversions, px to rem is one of the most commonly used, especially for creating scalable and accessible web interfaces.
**Un... | gecschool |
1,881,990 | lá số tử vi | Tử Vi, hay Tử Vi Đẩu Số, là một bộ môn huyền học được dùng với các công năng chính như: luận đoán về... | 0 | 2024-06-09T10:35:38 | https://dev.to/dongphuchh023/la-so-tu-vi-189e | Tử Vi, hay Tử Vi Đẩu Số, là một bộ môn huyền học được dùng với các công năng chính như: luận đoán về tính cách, hoàn cảnh, dự đoán về các " vận hạn" trong cuộc đời của một người đồng thời nghiên cứu tương tác của một người với các sự kiện, nhân sự.... Chung quy với mục đích chính là để biết vận mệnh con người.
Lấy lá ... | dongphuchh023 | |
1,881,989 | Comprehensive Guide to Debouncing in JavaScript: Improve Your Code Efficiency | Learn how to implement debouncing in JavaScript with practical examples and tips. Master the debounce... | 0 | 2024-06-09T10:34:54 | https://dev.to/dipakahirav/understanding-debouncing-in-javascript-5g30 | javascript, webdev, programming, debouncing | Learn how to implement debouncing in JavaScript with practical examples and tips. Master the debounce function and improve your web performance.
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewithDipak?sub_confirmation=1
) to support my channel and get more web development tutorials.
In this... | dipakahirav |
1,881,987 | Understand the Liskov substitution principle using a simple example. | Imagine you're building a delivery system. Consider an entity class Vehicle and its subclass... | 0 | 2024-06-09T10:24:44 | https://dev.to/muhammad_salem/understand-the-liskov-substitution-principle-using-a-simple-example-3apo | Imagine you're building a delivery system.
Consider an entity class Vehicle and its subclass Car.
```csharp
public class Vehicle
{
public virtual void StartEngine()
{
// General engine start logic
}
public virtual void LoadCargo(int weight)
{
// General cargo loading logic
}
}
... | muhammad_salem | |
1,881,936 | Buy Verified Paxful Account | Buy Verified Paxful Account There are several compelling reasons to consider purchasing a... | 0 | 2024-06-09T09:22:12 | https://dev.to/hafazakiyaha79/buy-verified-paxful-account-4mi3 | Buy Verified Paxful Account
There are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various tran... | hafazakiyaha79 | |
1,881,953 | Best Omegle Alternatives for 2023 | Omegle has been a go-to platform for random video and text chatting with strangers. However, concerns... | 0 | 2024-06-09T10:16:22 | https://dev.to/raza_strom_010020543a0dc6/best-omegle-alternatives-for-2023-44ie | Omegle has been a go-to platform for random video and text chatting with strangers. However, concerns over safety, moderation, and user experience have led many to seek better alternatives. Here are some of the [best Omegle alternatives for 2023](https://talkwithstranger.com/free-chat-rooms/omegle-alternative-stranger-... | raza_strom_010020543a0dc6 | |
1,881,952 | Ponytail Hair Extensions: A Perfect Solution for Instant Glamour | One of the concerns often associated with traditional hair extensions is the potential for damage to... | 0 | 2024-06-09T10:12:27 | https://dev.to/cskeisari665/ponytail-hair-extensions-a-perfect-solution-for-instant-glamour-1g45 | One of the concerns often associated with traditional hair extensions is the potential for damage to natural hair caused by adhesive bonds, heat application, or constant tension. Ponytail extensions, however, provide a damage-free solution that allows you to enjoy the benefits of longer, fuller hair without compromisin... | cskeisari665 | |
1,881,951 | Image Scraping with HtmlAgilityPack: A Practical Guide Using ConsoleWebScraper | Image Scraping with HtmlAgilityPack: A Practical Guide Using ConsoleWebScraper Web scraping is a... | 0 | 2024-06-09T10:11:00 | https://dev.to/themysteriousstranger90/image-scraping-with-htmlagilitypack-a-practical-guide-using-consolewebscraper-57km | csharp, dotnet, webscraping, webdev | **Image Scraping with HtmlAgilityPack: A Practical Guide Using ConsoleWebScraper**
Web scraping is a valuable tool for automating the collection of information from websites. My simple, open-source ConsoleWebScraper application, available on [GitHub](https://github.com/TheMysteriousStranger90/ConsoleWebScraper) and [S... | themysteriousstranger90 |
1,881,950 | How do you create a full CRUD GraphQL API for posts in Nest JS? | Sure! I'll guide you through creating a GraphQL API endpoint for posts in an existing NestJS project.... | 0 | 2024-06-09T10:10:32 | https://dev.to/nadim_ch0wdhury/how-do-you-create-a-full-crud-graphql-api-for-posts-in-nest-js-4l1k | Sure! I'll guide you through creating a GraphQL API endpoint for posts in an existing NestJS project. Here are the steps you need to follow:
1. **Install necessary dependencies:**
First, ensure you have the necessary GraphQL dependencies installed in your NestJS project. Run the following command in your project d... | nadim_ch0wdhury | |
1,881,487 | Debouncing in JavaScript | Debouncing in General term Debouncing is a technique in programming that helps prevent... | 0 | 2024-06-09T10:03:10 | https://dev.to/mrhimanshusahni/debouncing-in-javascript-2p3o | javascript, webdev, learning, tutorial | ## Debouncing in General term
**Debouncing** is a technique in programming that helps prevent time-consuming tasks from being triggered so frequently that they slow down the performance of a web page. In simpler terms, it controls how often a function is called.
## What is Debouncing in JavaScript? 🤔
In JavaScript... | mrhimanshusahni |
1,881,948 | Top 10 Laravel Collection Methods You Have Never Used. | In this article series, we go a little deeper into parts of Laravel we all use, to uncover functions... | 27,571 | 2024-06-09T10:03:08 | https://backpackforlaravel.com/articles/tips-and-tricks/top-10-collection-methods-you-have-never-used | laravel, php, programming | In this article series, we go a little deeper into parts of Laravel we all use, to uncover functions and features that we can use in our next projects... if only we knew about them!
Here are a few lesser-known collection methods that can be quite handy in various real-world scenarios:
1. **macro()**: This lets you ad... | karandatwani92 |
1,881,945 | How to Download Files from Firebase Storage Using JavaScript | Learn how to programmatically download files from Firebase Storage using JavaScript, complete with code snippets and practical explanations. | 0 | 2024-06-09T10:00:32 | https://dev.to/itselftools/how-to-download-files-from-firebase-storage-using-javascript-4292 | javascript, firebase, webdev, programming |
Through our experience at [itselftools.com](https://itselftools.com), where we have built over 30 applications using technologies like Next.js and Firebase, we've gained significant expertise in handling common but critical tasks efficiently. One such task is downloading files from Firebase Storage, which is something... | antoineit |
1,881,943 | أدوات لإنشاء منتجات التجميع وإدارتها بسهولة | الميزات الرئيسية عند انشاء متجر الكتروني بـ مكلف تم تصميم برنامج مكلف مع مراعاة المرونة والوظائف ،... | 0 | 2024-06-09T09:55:10 | https://dev.to/engmuhammed_alsulami_e46/dwt-lnsh-mntjt-ltjmy-wdrth-bshwl-3n02 | الميزات الرئيسية عند [انشاء متجر الكتروني](https://mukalaf.com.sa/) بـ مكلف
تم تصميم [برنامج مكلف](https://mukalaf.com.sa/) مع مراعاة المرونة والوظائف ، مما يوفر لك أدوات لإنشاء منتجات التجميع وإدارتها بسهولة.
[انشاء منتج مجمع](https://mukalaf.com.sa/) : يتضمن برنامج مكلف واجهة سهلة الاستخدام تتيح لك [إنشاء منتجات ال... | engmuhammed_alsulami_e46 | |
1,881,941 | Effortless – Free Tailwind CSS Website Template | Effortless is your go-to solution for crafting a sleek and modern landing page with minimal... | 0 | 2024-06-09T09:54:47 | https://dev.to/mikevarenek/effortless-free-tailwind-css-website-template-5ghd | webdev, tailwindcss, beginners | Effortless is your go-to solution for crafting a sleek and modern landing page with minimal effort.
**Key Features:**
- Sticky Menu: Navigate with ease as the sticky menu ensures your main navigation is always accessible, providing a smooth and user-friendly experience.
- Hero Section: Make a bold first imp... | mikevarenek |
1,881,865 | Learning by Doing: Event Loop in Rust | Before you read, concepts like: concurrency, traits, Arc/Mutex and Rust Channles (crossbeam lib)... | 0 | 2024-06-09T09:53:56 | https://dev.to/luisccc/learning-by-doing-event-loop-in-rust-hf1 | rust, programming, tutorial, learning |
Before you read, concepts like: concurrency, traits, Arc/Mutex and Rust Channles (crossbeam lib) should be clear for you.
Image by [Huso112](https://www.deviantart.com/huso112)
# Discover rust using known concepts
As a seasoned Java software developer, I’m always on the lookout for new challenges to further my und... | luisccc |
1,881,942 | GitOps for CloudFront and S3 | Front-end deployments in GitOps style This strategy uses ArgoCD, EKS, and AWS services... | 0 | 2024-06-09T09:51:24 | https://dev.to/wardove/gitops-for-cloudfront-and-s3-5c7o | aws, devops, terraform, react | ## Front-end deployments in GitOps style
This strategy uses ArgoCD, EKS, and AWS services like CloudFront and S3 to streamline deployments, improve performance, and maintain best practices.
## Table of Contents <a name="Toc"></a>
1. [Introduction](#introduction)
2. [Building and Syncing to S3](#sync-s3)
3. [Deploying ... | wardove |
1,881,939 | 6 Cutting-Edge AI Tools that will transform Your Workflow | In the fast-paced world of technology, staying ahead means embracing innovation that can streamline... | 0 | 2024-06-09T09:49:53 | https://dev.to/hr21don/6-cutting-edge-ai-tools-that-will-transform-your-workflow-1am0 | ai, productivity, career, webdev | In the fast-paced world of technology, staying ahead means embracing innovation that can streamline your workflow and boost productivity.
And here is the curated list:
## 1. [AIHumanizer.ai](https://aihumanizer.ai/)
AIHumanizer is an AI tool that transforms your AI text into human content instantly.
, renowned for their iconic designs and exceptional quality. From the luxurious sophistication of Gucci and Chanel to the innovative sportswear of Nike and Adidas, these brands set global fashion trends. Discover the... | hazrat_sultan_f11769 | |
1,881,563 | TEST | testing going on here | 0 | 2024-06-08T20:14:38 | https://dev.to/bug_hunter_bafbe6b69fd53a/test-4f0o | testing going on here
| bug_hunter_bafbe6b69fd53a | |
1,881,918 | Navigating the Testing Challenges in Machine Learning Systems | Hey there! Let's dive into the world of Testing Machine Learning (ML) Systems. It's a bit different... | 0 | 2024-06-09T09:22:08 | https://dev.to/pravinkumar/navigating-the-testing-challenges-in-machine-learning-systems-1o5c | testing, ai, machinelearning, challenge | Hey there! Let's dive into the world of _**Testing Machine Learning (ML) Systems**_. It's a bit different from what you might be used to with regular software testing. With ML, we're dealing with complex algorithms that use data to make decisions, making it tricky to figure out what's right and wrong.
> Imagine trying... | pravinkumar |
1,881,922 | SOLID Principles for Android | As a developer, there comes a time when we have to learn principles for moving ahead in career. For... | 27,686 | 2024-06-09T09:19:25 | https://dev.to/rishi2062/solid-principles-for-android-4f62 | android, androiddev, opensource, solidprinciples | 
As a developer, there comes a time when we have to learn principles for moving ahead in career. For some this topic might be new, for some they are already experienced on these principles. I will try to ma... | rishi2062 |
1,881,921 | Use CSS to Remove PNG Image Background Color | In CSS you can remove the white background color form your PNG image by using only one CSS property... | 0 | 2024-06-09T09:18:36 | https://dev.to/yasminsardar/use-css-to-remove-png-image-background-color-460h | beginners, tutorial, css, devops | In CSS you can remove the white background color form your PNG image by using only one CSS property called mix-blend-mode. Below example:
```js
img { mix-blend-mode: multiply;}
```
If you want to remove white or background color from an image, this CSS property is perfect for you. Additionally, it works on all image... | yasminsardar |
1,881,920 | Behind the Scenes of Rosewood: Meet the Stellar Cast | Take a peek behind the curtains of "Rosewood tv show" and get acquainted with its talented cast. With... | 0 | 2024-06-09T09:17:56 | https://dev.to/jhon_snow_bee41c17043d868/behind-the-scenes-of-rosewood-meet-the-stellar-cast-1nah | Take a peek behind the curtains of "[Rosewood tv show](https://www.hbtrl.com/articles/rosewood-tv-show-cast/)" and get acquainted with its talented cast. With Morris Chestnut and Jaina Lee Ortiz at the forefront, this ensemble delivers an electrifying mix of drama and suspense. Each actor breathes life into their chara... | jhon_snow_bee41c17043d868 | |
1,881,919 | Quick Steps to Recover Your Stolen Bitcoin or Cryptocurrency | I feel what makes most of us vulnerable to this types of attack is ignorance generally in the crypto... | 0 | 2024-06-09T09:17:02 | https://dev.to/dani_walsh_57e8c2ddf87df2/quick-steps-to-recover-your-stolen-bitcoin-or-cryptocurrency-19b3 | bitcoin, cryptocurrency, university | I feel what makes most of us vulnerable to this types of attack is ignorance generally in the crypto space. In January 2023, I lost about 300k USD in form of Bitcoin to scammers! All i did wrong was to click a link (a phishing website) and in less than 10 minutes, all my fortune went down the drain. Some important less... | dani_walsh_57e8c2ddf87df2 |
1,881,916 | Understanding the JavaScript Event Loop 🚀 | Event Loop is another important concept in JavaScript that often comes up in technical... | 0 | 2024-06-09T09:12:41 | https://dev.to/shahabmalikk/understanding-the-javascript-event-loop-44ij | webdev, javascript, frontend, softwareengineering | Event Loop is another important concept in JavaScript that often comes up in technical interviews
JavaScript is single-threaded, meaning it can only perform one task at a time. This might make you wonder how JavaScript handles asynchronous operations like fetching data from an API, setTimeout, or event listeners. The ... | shahabmalikk |
1,881,913 | Enriching Event Listings with Microformats/Microdata for a Better User Experience | TLDR: Use microdata/microformats to add more meaning to event listings on your website, enabling... | 0 | 2024-06-09T09:07:59 | https://dev.to/netsi1964/enriching-event-listings-with-microformatsmicrodata-for-a-better-user-experience-5bgl | microdata, eventlistings, ux, webdev | > TLDR: Use microdata/microformats to add more meaning to event listings on your website, enabling users to easily add events to their calendars and providing a better user experience.
Many websites have lists of events which they in the best intention want their users to know about. But maybe they could get feedback ... | netsi1964 |
1,881,912 | Buy verified cash app account | Buy verified cash app account Cash app has emerged as a dominant force in the realm of mobile banking... | 0 | 2024-06-09T09:07:50 | https://dev.to/hafazakiyaha79/buy-verified-cash-app-account-27j2 | Buy verified cash app account
Cash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with ... | hafazakiyaha79 | |
1,881,911 | Movie Finder | This is a program that I made as a portfolio project during my studies on computer science at... | 0 | 2024-06-09T09:06:26 | https://dev.to/andychild1/movie-finder-1jn9 | python, movies, algorithms | This is a program that I made as a portfolio project during my studies on computer science at Codecademy.
It is a recommendation software that help the user to find movies based on the related category.
I've chosen Nodes and Linked List as the main data structure where the Movie class act as a common Node class and the... | andychild1 |
1,881,910 | Seeking Spiritual Connections: Embrace Guidance from Local Mediums | Explore the profound world of spiritual mediums near you to uncover guidance and solace. Whether... | 0 | 2024-06-09T09:00:19 | https://dev.to/rick_henry_d0eb318d5211b6/seeking-spiritual-connections-embrace-guidance-from-local-mediums-1m1j | Explore the profound world of [spiritual mediums near you](https://www.haqbahu.com/articles/spritual-miediums-near-me/) to uncover guidance and solace. Whether you're navigating life's challenges or seeking communication with departed loved ones, these gifted individuals serve as conduits between realms. Through their ... | rick_henry_d0eb318d5211b6 | |
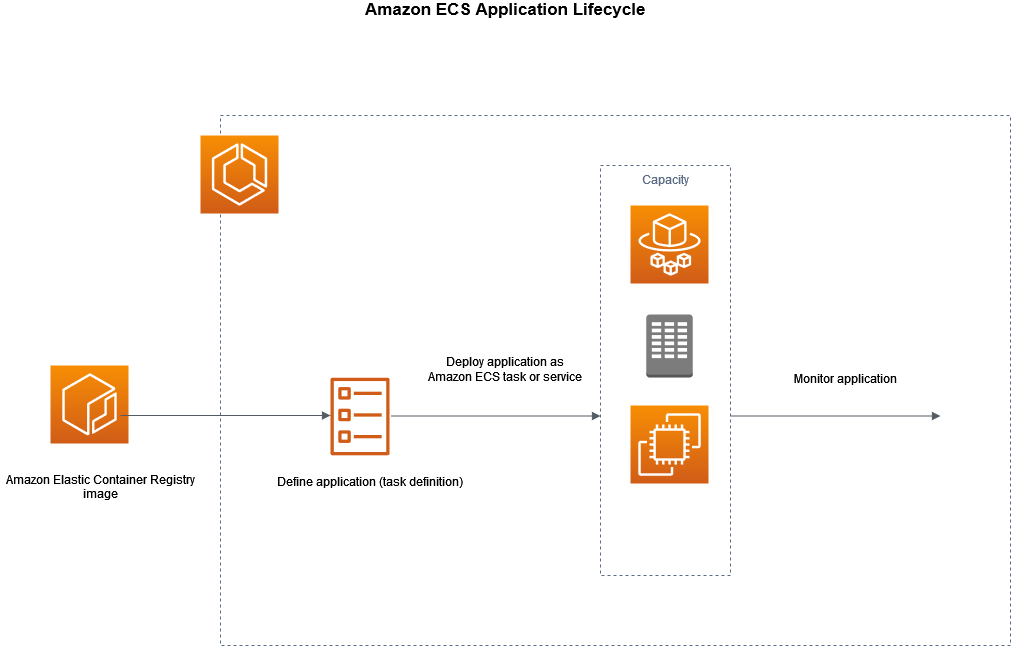
1,881,909 | Running a python script as a standalone task in ECS | Architecture Prepare docker Image Dockerfile - A Dockerfile is a text file... | 0 | 2024-06-09T08:58:56 | https://dev.to/harsh_vardhansingh_69340/running-a-python-script-as-a-standalone-task-in-ecs-317l | ecs, docker, aws | ## Architecture
## Prepare docker Image
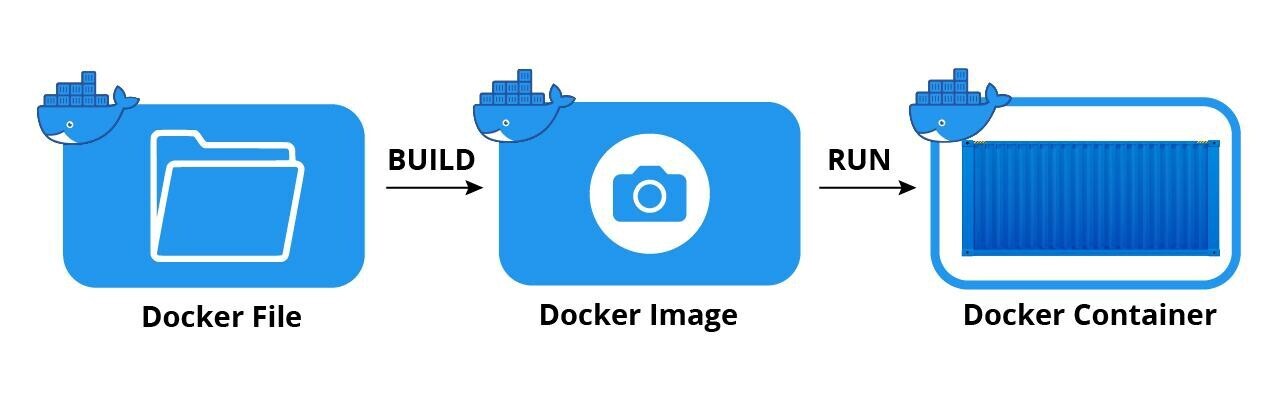
- Dockerfile - A Dockerfile is a text file that contains a series o... | harsh_vardhansingh_69340 |
1,881,908 | Revolutionizing Web Development: Harnessing the Power of React.js for Modern Web Applications | In the heart of India’s tech industry, a web development company in Bangalore is revolutionizing the... | 0 | 2024-06-09T08:57:44 | https://dev.to/ranjit_reddy_cdb410e64ad8/revolutionizing-web-development-harnessing-the-power-of-reactjs-for-modern-web-applications-2535 | In the heart of India’s tech industry, a web development company in Bangalore is revolutionizing the digital landscape. Leveraging the capabilities of React.js, these companies are crafting modern web applications that are not only visually appealing but also highly functional and scalable. This article explores how Re... | ranjit_reddy_cdb410e64ad8 | |
1,881,907 | Auto suggest vscode plugins for your team through the settings in your repo. | A less known feature is the ability to suggest what plugins should be installed to best work with... | 27,650 | 2024-06-09T08:57:29 | https://dev.to/matthewbill/auto-suggest-vscode-plugins-for-your-team-through-the-settings-in-your-repo-1l6m | vscode, webdev, plugins, developer | A less known feature is the ability to suggest what plugins should be installed to best work with your repo, by by using the `extensions.json` file in the `/.vscode` folder.
```
{
"recommendations": [
"dbaeumer.vscode-eslint",
"esbenp.prettier-vscode",
"mikestead.dotenv",
"hediet.vscode-drawio",
... | matthewbill |
1,881,905 | TK66⭐️ Link Trang Chủ Tk66.pro Số #1 Châu Á | TK66 là nhà cái cá cược online uy tín nhất Việt Nam hiện nay. Tk88pro sở hữu các sản phẩm hấp dẫn, đa... | 0 | 2024-06-09T08:48:39 | https://dev.to/tk66pro/tk66-link-trang-chu-tk66pro-so-1-chau-a-nff | TK66 là nhà cái cá cược online uy tín nhất Việt Nam hiện nay. Tk88pro sở hữu các sản phẩm hấp dẫn, đa dạng với tỉ lệ trả thưởng cực kỳ cao.
Địa Chỉ: 44 Đường Thị Mười, Tân Thới Hiệp, Quận 12, Thành phố Hồ Chí Minh, 70000, Việt Nam
Email: b4gapampresn@gmail.com
Website: https://tk66.pro/
Điện Thoại: (+63) 9854570443
#t... | tk66pro | |
1,881,904 | Building a Audience Analyzer using Lyzr SDK | In the fast-paced world of marketing, understanding your audience is key to success. However,... | 0 | 2024-06-09T08:48:03 | https://dev.to/akshay007/building-a-audience-analyzer-using-lyzr-sdk-1kb6 | In the fast-paced world of marketing, understanding your audience is key to success. However, crafting tailored strategies that resonate with your target demographic can be a daunting task. Enter **Audience Navigator**, a groundbreaking app powered by **Lyzr Automata**, designed to revolutionize the way marketing strat... | akshay007 | |
1,881,902 | .gitignore file IGNORED my .env file | I'm learning React. So while developing a project on React, I was using some Appwrite... | 0 | 2024-06-09T08:35:09 | https://dev.to/bkaush/gitignore-file-ignored-my-env-file-3lgf | tutorial, react, programming, javascript | I'm learning React.
So while developing a project on React, I was using some Appwrite functionalities to do the backend stuff easily.
I created a .env file and saved all the necessary keys inside it.
I was about to commit the changes when I saw that the .env file was not showing in dark grayish color, instead showin... | bkaush |
1,881,901 | Automating and Integrating Testing into Your CI/CD Pipeline: Because Who Needs Sleep Anyway? | Today, we're going to dive into the wild world of automating and integrating testing into a CI/CD... | 0 | 2024-06-09T08:34:04 | https://dev.to/spantheslayer/automating-and-integrating-testing-into-your-cicd-pipeline-because-who-needs-sleep-anyway-3bea | devops, cicd, aws, testing | Today, we're going to dive into the wild world of automating and integrating testing into a CI/CD pipeline. Buckle up, because testing is the unsung hero of the CI/CD pipeline—like a superhero with no cape, ensuring your deployments don't go down in flames.
Testing is one of the most important parts of a CI/CD pipelin... | spantheslayer |
1,881,900 | Discover Your Soulmate: Nearby Muslim Marriage Bureau | On the hunt for a Muslim marriage bureau close to home to help in your search for a life partner?... | 0 | 2024-06-09T08:30:31 | https://dev.to/hazradec0a5b51c71236/discover-your-soulmate-nearby-muslim-marriage-bureau-mco | On the hunt for a [Muslim marriage bureau close to home](https://articles.hazratsultanbahu.com/muslim-marriage-bureau-near-me/) to help in your search for a life partner? Look no further! Our nearby Muslim marriage bureau is at your service, committed to assisting members of the Muslim community in finding their perfec... | hazradec0a5b51c71236 | |
1,881,893 | AI Projects in Python for Beginners: A Step-by-Step Introduction to Artificial Intelligence | Start your journey into artificial intelligence with our beginner-friendly AI projects in Python.... | 0 | 2024-06-09T08:17:05 | https://dev.to/hazradec0a5b51c71236/ai-projects-in-python-for-beginners-a-step-by-step-introduction-to-artificial-intelligence-41de | python, ai | Start your journey into artificial intelligence with our beginner-friendly [AI projects in Python](https://3tiatech.com/ai-projects-in-python-for-beginners/). These projects are designed to make learning AI accessible, guiding you through the development of simple applications like chatbots, image classifiers, and sent... | hazradec0a5b51c71236 |
1,881,891 | Awesome | AI open-framework | Ehy Everybody 👋 It’s Antonio here, CEO & Founder at Litlyx. Today Subject is...... | 0 | 2024-06-09T08:13:11 | https://dev.to/litlyx/awesome-ai-open-framework-2j6j | discuss, beginners, opensource, learning | ## Ehy Everybody 👋
It’s Antonio here, CEO & Founder at [Litlyx](https://litlyx.com).
```bash
Today Subject is... **AI!**
```
I come back to you with a curated **Awesome List of resources** that you can find interesting.
I will contribute to this community as much as I can because I love it.
Share some love to ou... | litlyx |
1,881,867 | Sticky Element - JavaScript & CSS | Halo semua, 2 bulan ini absen posting dikarenakan kesibukan yang padat. Mari kita mulai belajar lagi... | 0 | 2024-06-09T08:08:25 | https://dev.to/boibolang/sticky-element-javascript-css-2fnh | Halo semua, 2 bulan ini absen posting dikarenakan kesibukan yang padat. Mari kita mulai belajar lagi seputar JavaScript dan CSS, kali ini kita akan membahas dan membuat _sticky element_. _Sticky element_ paling sering kita temukan pada navigation bar sebuah website, ada banyak cara untuk membuat sticky element, pada po... | boibolang | |
1,867,387 | Database Sharding for System Design Interview | A complete guide of database sharding for system design, why use it and how it works for your system design interview. | 0 | 2024-06-09T08:05:27 | https://dev.to/somadevtoo/database-sharding-for-system-design-interview-1k6b | programming, systemdesign, development, softwaredevelopment | ---
title: Database Sharding for System Design Interview
published: true
description: A complete guide of database sharding for system design, why use it and how it works for your system design interview.
tags: programming, systemdesign, development, softwaredevelopment
# cover_image: https://direct_url_to_image.jpg
# ... | somadevtoo |
1,881,888 | RECOVER STOLEN CRYPTO AFTER FALLING FOR SCAM / BOTNET CRYPTO RECOVERY | Get in Touch with them via info below WhatsApp +12249352948 Website:... | 0 | 2024-06-09T08:03:24 | https://dev.to/charlotte_luarel_c2580e7d/recover-stolen-crypto-after-falling-for-scam-botnet-crypto-recovery-5d9l |
Get in Touch with them via info below
WhatsApp +12249352948
Website: https://botnetcryptorecovery.info/
Email: chat@botnetcryptorecovery.info
My recent experience with B O T N E T C R Y P T O R E C O V E R Y has... | charlotte_luarel_c2580e7d | |
1,881,887 | Deployment Strategies: All at Once, Rolling Deploys, Blue-Green, and Canary Releases | In this post, we'll dive into the chaotic world of deployment strategies—where "All at Once" is like... | 0 | 2024-06-09T07:54:14 | https://dev.to/spantheslayer/deployment-and-delivery-strategies-all-at-once-rolling-deploys-blue-green-and-canary-releases-fd5 | In this post, we'll dive into the chaotic world of deployment strategies—where "All at Once" is like jumping off a cliff, "Rolling Deploys" are a slow burn, "Blue-Green" is the responsible adult, and "Canary Releases" are like sending the interns into the fire first.
#### All at Once Deployment
In the high-risk, high... | spantheslayer | |
1,881,886 | Stop Using TypeScript Interfaces | Why You Should Use Types Instead Join our Vibrant Discord Community for exclusive... | 0 | 2024-06-09T07:40:26 | https://dev.to/afzalimdad9/stop-using-typescript-interfaces-1lc2 | javascript, webdev, programming, typescript | ## Why You Should Use Types Instead

Join our [Vibrant Discord Community](https://discord.com/invite/C2PXBMqpuV) for exclusive information and insightful discussions
**Types and Interfaces** are ... | afzalimdad9 |
1,881,882 | A Comprehensive Guide to TypeScript’s `any`, `unknown`, and `never` Types | TypeScript is a superset of JavaScript that adds static type definitions, enabling developers to... | 0 | 2024-06-09T07:35:00 | https://dev.to/dipakahirav/a-comprehensive-guide-to-typescripts-any-unknown-and-never-types-4ba7 | typescript, javascript, webdev, programming | TypeScript is a superset of JavaScript that adds static type definitions, enabling developers to catch errors early during the development process. Among its many features, TypeScript includes several special types—`any`, `unknown`, and `never`—each serving a distinct purpose. Understanding the differences and proper u... | dipakahirav |
1,881,954 | Integrating Confluence with Azure OpenAI for Seamless Updates | This Blog post will tell you how easy it will be to integrate external data into Copilot in a quick... | 0 | 2024-06-23T17:27:50 | https://blog.bajonczak.com/how-to-index-confluence-with-azure-ai-search/ | ai, githubcopilot, groundingdata, confluence | ---
title: Integrating Confluence with Azure OpenAI for Seamless Updates
published: true
date: 2024-06-09 07:30:13 UTC
tags: AI,Copilot,GroundingData,Confluence
canonical_url: https://blog.bajonczak.com/how-to-index-confluence-with-azure-ai-search/
---
 { /* no-op */ } static void... | 0 | 2024-06-09T07:29:03 | https://dev.to/kasid_khan_98865d77a5fe2e/why-there-are-so-many-assertall-methods-in-junit-class-assertall-what-is-the-use-of-each-17gk | junit | ```
class AssertAll {
private AssertAll() {
/* no-op */
}
static void assertAll(Executable... executables) {
assertAll(null, executables);
}
static void assertAll(String heading, Executable... executables) {
Preconditions.notEmpty(executables, "executables array must not be null or empty");
Precondition... | kasid_khan_98865d77a5fe2e |
1,881,880 | Join GitHub Education | Table of Contents Introduction to GitHub Education Qualification Before you begin Drop a... | 0 | 2024-06-09T07:28:08 | https://dev.to/g_venkatasandeepreddy_b/join-github-education-1cge | github, git, student, education | ## Table of Contents
* [Introduction to _GitHub Education_](#introduction)
* [Qualification](#qualification)
* [Before you begin](#before)
* [Drop a Application](#application)
* [Advantages of GitHub Education](#advantage)
## Introduction to GitHub Education<a name="introduction"></a>
**_GitHub Education_** is the con... | g_venkatasandeepreddy_b |
1,881,861 | Toca Boca Mod APK: A New Frontier in Digital Playtime | Toca Boca World Mod APK in the world of digital play, has captured the imagination of children and... | 0 | 2024-06-09T06:56:56 | https://dev.to/tyuiljf/toca-boca-mod-apk-a-new-frontier-in-digital-playtime-26h2 | tocaboca, tocalifeworld, tocalifestories, charactersgame | Toca Boca World Mod APK in the world of digital play, has captured the imagination of children and parents alike with its creative and engaging apps. Known for fostering imagination, creativity, and learning, [Toca Boca Mod APK](https://tocalifesworld.com/
) games offer a safe and ad-free environment for children to ex... | tyuiljf |
1,881,879 | How to create a testimonial carousel with Tailwind CSS and JavaScript | Let's recreate a carousel with Tailwind CSS and JavaScript. Same thing as the previous with... | 0 | 2024-06-09T07:27:02 | https://dev.to/mike_andreuzza/how-to-create-a-testimonial-carousel-with-tailwind-css-and-javascript-4bl3 | javascript, tailwindcss, tutorial | Let's recreate a carousel with Tailwind CSS and JavaScript. Same thing as the previous with Alpine.js, but with JavaScript.
[Read the article,See it live and get the code](https://lexingtonthemes.com/tutorials/how-to-create-a-carousel-with-tailwind-css-and-javascript/)
| mike_andreuzza |
1,881,878 | The Power of Personas and How Might We Questions in User-Centric Design | During my recent project, two concepts that resonated with me deeply were the creation of personas... | 0 | 2024-06-09T07:26:02 | https://victorleungtw.com/2024/06/09/usercentric/ | innovation, personas, brainstorming, usercentric | During my recent project, two concepts that resonated with me deeply were the creation of personas and the use of "how might we" questions. These concepts proved essential in shaping a user-centric approach that directly addressed our client's challenges and needs.
. It is a widely used data format for electronic dat... | bytecodesky |
1,881,876 | Promise: How to Use and Some Notes! | It would be a glaring omission not to talk about Promise in JavaScript. In fact, there have been many... | 0 | 2024-06-09T07:24:44 | https://2coffee.dev/en/articles/promise-how-to-use-and-some-notes | javascript, node, promise | It would be a glaring omission not to talk about Promise in JavaScript. In fact, there have been many articles written about Promise, which you can find through Google or occasionally come across in a programming-related community. But because Promise is an important concept and everyone has a different way of explaini... | hoaitx |
1,881,875 | Glam Up My Markup: Beaches | This is a submission for Frontend Challenge v24.04.17, Glam Up My Markup: Beaches What I... | 0 | 2024-06-09T07:22:26 | https://dev.to/rith1x/glam-up-my-markup-beaches-4fn8 | devchallenge, frontendchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
## What I Built
For the Frontend Challenge v24.04.17, I transformed the provided HTML markup into a visually appealing and interactive website without modifying the given template. The ... | rith1x |
1,881,869 | amit29x follow me in all social's media accounts | he top 23 social media apps and platforms for 2024 Facebook — amit29x WhatsApp — YouTube... | 0 | 2024-06-09T07:08:20 | https://dev.to/amit29x/amit29x-follow-me-in-all-socials-media-accounts-325m |

he top 23 social media apps and platforms for 2024
1. Facebook — amit29x
2. WhatsApp —
3. YouTube —amit29x
4. Instagram — amit29x
5. WeChat —
6. TikTok —
7. Telegram — amit29x
8. Snapchat — amit29x
9. Kuaishou — ... | amit29x | |
1,881,461 | useState() Hooks In react , How it Works ? | 👉 useState() Hooks In React useState() hooks is a function that allows you to add a state in... | 0 | 2024-06-09T07:05:43 | https://dev.to/pervez/usestate-hooks-in-react-how-it-works--1oh4 | webdev, javascript, programming, beginners | 👉 **useState() Hooks In React**
useState() hooks is a function that allows you to add a state in functional components. When you call useState() hooks, it returns an array with two elements.
➡️ **State Variable:** The current value of the state.
➡️ **State Updater Function:** This function allows you to update the ... | pervez |
1,881,862 | How To Manage Amazon Inspector in AWS Organizations Using Terraform | Introduction Over the past two months, I have published numerous blog posts on managing... | 27,647 | 2024-06-09T07:02:52 | https://blog.avangards.io/how-to-manage-amazon-inspector-in-aws-organizations-using-terraform | aws, terraform, security | ## Introduction
Over the past two months, I have published [numerous blog posts on managing different AWS security services in AWS Organizations using Terraform](https://dev.to/acwwat/series/27647). In this blog post, I will cover one remaining AWS service, AWS Inspector, for native vulnerability management. The Terra... | acwwat |
1,881,864 | Glam up my markup: beaches | This is a submission for Frontend Challenge v24.04.17, Glam Up My Markup: Beaches What I... | 0 | 2024-06-09T07:01:34 | https://dev.to/filoxo/glam-up-my-markup-beaches-1e56 | devchallenge, frontendchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
## What I Built
i set out to build a page that felt worth sharing with a friend, neighbor, or even stranger! imagining the beach always evokes a sense of happiness and freedom for me, a... | filoxo |
1,881,863 | How-to make SSL (IONOS cert) Web redirect own apache server | Hi, I come to you as I don't know what to do more to make SSL working on my domain handle by IONOS... | 0 | 2024-06-09T07:00:48 | https://dev.to/philaupatte/how-to-make-ssl-ionos-cert-web-redirect-own-apache-server-8k1 | help | Hi,
I come to you as I don't know what to do more to make SSL working on my domain handle by IONOS with redirection. (IONOS don't support customer running their own server)
**On IONOS :**
- I have a domain *.philaupatte.com
- I have SSL certificate (cer, key and intermediate)
- I have a redirection to the box of my I... | philaupatte |
1,881,860 | How to Use a Sentence Rephraser to Avoid Plagiarism? A Complete Guide | Crafting unique, plagiarism-free content can feel like a never-ending battle. Staring at a screen,... | 0 | 2024-06-09T06:55:14 | https://dev.to/ray_parker01/how-to-use-a-sentence-rephraser-to-avoid-plagiarism-a-complete-guide-3n35 | ---
title: How to Use a Sentence Rephraser to Avoid Plagiarism? A Complete Guide
published: true
---

Crafting unique, plagiarism-free content can feel like a never-ending battle. Staring at a screen, searching for fr... | ray_parker01 | |
1,881,859 | I created my own search engine | I have created my own search engine and I'll tell you how it works. First of all, I created my own... | 0 | 2024-06-09T06:42:44 | https://dev.to/schbenedikt/i-created-my-own-search-engine-go4 | bootstrap, python, webdev, programming |
I have created my own search engine and I'll tell you how it works.
First of all, I created my own web crawler. It runs on Python and stores various meta data in a mysql database.
{% embed https://github.com/SchBenedikt/web-crawler %}
The search engine, which I created with Bootstrap, then retrieves the results from... | schbenedikt |
1,881,858 | ilogo.fun - Free Download Vector Svg Logo Icon | WE HAVE MILLIONS OF SVG FILES: LOGO ICON ILLUSTRATIONS ALL SVG IS DOWNLOADED FOR... | 0 | 2024-06-09T06:37:28 | https://dev.to/ilogofun/ilogofun-free-download-vector-svg-logo-icon-21o | svg, logo, icon | WE HAVE MILLIONS OF SVG FILES: LOGO ICON ILLUSTRATIONS
ALL SVG IS DOWNLOADED FOR FREE
https://ilogo.fun/
 | ilogofun |
1,881,857 | laravel-nuxt-template | This repository provides a starter template for building web applications using Laravel as the... | 0 | 2024-06-09T06:33:40 | https://dev.to/akramghaleb/laravel-nuxt-template-1c6j | This repository provides a starter template for building web applications using Laravel as the backend and Nuxt.js as the frontend framework.
## This project built with Laravel 11 + Nuxt 3 <br>
- This template build with Laravel v11.0 & Nuxt v3.11
- This template Support Pinia State Management
- If you like this wo... | akramghaleb |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.