
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,882,219 | Mastering Micro Frontends: A Deep Dive into Next-Gen Front-End Architecture | In the rapidly evolving landscape of front-end development, architects and engineers are continually... | 0 | 2024-06-09T16:41:42 | https://dev.to/yelethe1st/mastering-micro-frontends-a-deep-dive-into-next-gen-front-end-architecture-4mm3 | microfrontends, frontendarchitecture, scalabledevelopment, modularwebapplications |
In the rapidly evolving landscape of front-end development, architects and engineers are continually seeking innovative solutions to tackle the challenges of building large-scale, enterprise-grade applications. As a senior front-end engineer at a Fortune 500 company, I've had the privilege of leading teams in adopting... | yelethe1st |
1,880,790 | Go lang app containerized in Docker with Chainguard image | Welcome to Books CLI: Securely Search Books Using Chainguard Images Hey everyone, Amir... | 0 | 2024-06-09T16:41:11 | https://dev.to/bekbrace/go-lang-app-containerized-in-docker-with-chainguard-image-12bf | go, docker, chainguard, containers | # Welcome to Books CLI: Securely Search Books Using Chainguard Images
Hey everyone, Amir here! 🎉
I'm excited to introduce my latest project, **Books CLI**. This command-line application, built in Go, allows you to search for books by your favorite authors directly from your terminal. What sets this tool apart is its... | bekbrace |
1,882,216 | 12 React Best Practices Every Developer Should Know | Boost Your React Skills with These 12 Best Practices . 1 Use Ternary Operator for... | 0 | 2024-06-09T16:34:05 | https://dev.to/mayank_tamrkar/12-best-practices-every-developer-should-know-dle | react, coding, programming, webdev |
##Boost Your React Skills with These 12 Best Practices .
1 **Use Ternary Operator for Conditional Rendering:**
```jsx
import React from 'react';
const MyComponent = ({ isLoggedIn }) => {
return (
<div>
{isLoggedIn ? <p>Welcome, User!</p> : <p>Please login.</p>}
</div>
);
};
export default MyCom... | mayank_tamrkar |
1,882,112 | Searching with Umbraco Examine: Avoid these common filtering mistakes | With Umbracos Codegarden conference mere days away I am starting to feel the Codegarden spirit! And... | 0 | 2024-06-09T16:22:55 | https://dev.to/jemayn/searching-with-umbraco-examine-avoid-these-common-filtering-mistakes-1oin | umbraco, lucene | With Umbracos Codegarden conference mere days away I am starting to feel the Codegarden spirit! And that has helped motivate me to blog a bit again, at the top of my blogpost ideas list is something interesting I found a few months back about how you can filter in Examine - Umbracos API layer on top of Lucene.
# Setup... | jemayn |
1,882,206 | AWSKRUG Community Chronicles: Insights from a Community Hero (2/2) | Organizing Meetup Schedules Initially, meetups were primarily organized based on... | 27,649 | 2024-06-09T16:18:31 | https://dev.to/aws-heroes/awskrug-community-chronicles-insights-from-a-community-hero-22-2h0b | # Organizing Meetup Schedules
Initially, meetups were primarily organized based on location (gudi, gangnam). However, as meetups emerged based on technology categories (serverless, container, architecture, etc.), m... | taeseong_park | |
1,881,674 | Functional-programming tier list | 📹 Hate reading articles? Check out the complementary video, which covers the same content. If you... | 0 | 2024-06-09T16:18:04 | https://dev.to/zelenya/functional-programming-tier-list-4acl | functional, haskell, scala, ocaml | 📹 Hate reading articles? Check out [the complementary video](https://youtu.be/vhIQZ0px-Lc), which covers the same content.
---
If you have ever wondered which functional programming language is better than others, which one to pick, or which to learn — here is my subjective tier list.
> ⚠️ Note that I’m a bit biase... | zelenya |
1,882,205 | TronFc Cloud Mining Platform | TRONFC Cloud Mining Website Certification Platform✅ Sign up and get 38,000TRX 🎁 The minimum... | 0 | 2024-06-09T16:17:09 | https://dev.to/tronfcfun/tronfc-cloud-mining-platform-ikn | mining, usdt, tron |
TRONFC Cloud Mining Website Certification Platform✅
Sign up and get 38,000TRX 🎁 The minimum deposit to activa... | tronfcfun |
1,882,203 | Why You Should Try Low-Code/No-Code | Work smarter, not harder In a world where speed and flexibility are becoming essential in... | 0 | 2024-06-09T16:16:06 | https://dev.to/crossnetics/why-you-should-try-low-codeno-code-11kk | nocode, webdev, beginners, marketing | ## Work smarter, not harder
In a world where speed and flexibility are becoming essential in business, how can marketers, influencers, and entrepreneurs use the latest technology to amplify their campaigns? Have you ever wondered how much easier and more effective your marketing efforts can become using innovative Low... | crossnetics |
1,882,204 | I spent the last 6 months building LiveAPI Proxy: Here are 10 HARD-EARNED Engineering Lessons you can use now | How LiveAPI Taught me some important Lessons in engineering I have been working on a... | 0 | 2024-06-09T16:15:13 | https://dev.to/hexmos/i-spent-the-last-6-months-building-liveapi-proxy-here-are-10-hard-earned-engineering-lessons-you-can-use-now-1kc6 | webdev, proxy, api, apache2 |
## How LiveAPI Taught me some important Lessons in engineering
I have been working on a product named **LiveAPI**. Let me just give an idea of what this product does.

The above API doc is ... | rijultp |
1,882,202 | 3D Tshirt Configurator With Three.js and Fabric.js | Hello Dev Community, I'm a non-code developer working on a pet project to create a 3D T-shirt... | 0 | 2024-06-09T16:13:10 | https://dev.to/apcliff/3d-tshirt-configurator-with-threejs-and-fabricjs-31j9 | Hello Dev Community,
I'm a non-code developer working on a pet project to create a 3D T-shirt configurator that allows users to customize a T-shirt model in real-time. The goal is to let users add text, images, and colors to a 3D T-shirt model, manipulate these elements, and interact with the 3D model itself. My targe... | apcliff | |
1,882,201 | Timeless June: The Animated Wall Clock in My Study Room | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration For the... | 0 | 2024-06-09T16:08:10 | https://dev.to/niketmishra/timeless-june-the-animated-wall-clock-in-my-study-room-2h2o | frontendchallenge, devchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
<!-- What are you highlighting today? -->
For the month of June, I drew inspiration from the long summer days and the importance of time in our daily lives. This led me to create an *... | niketmishra |
1,881,906 | AWSKRUG Community Chronicles: Insights from a Community Hero (1/2) | Currently, there are 24 meetups in the AWS Korea User Group(AWSKRUG). Most of the meetups are held... | 27,649 | 2024-06-09T16:06:26 | https://dev.to/aws-heroes/awskrug-community-chronicles-insights-from-a-community-hero-12-2c4h |
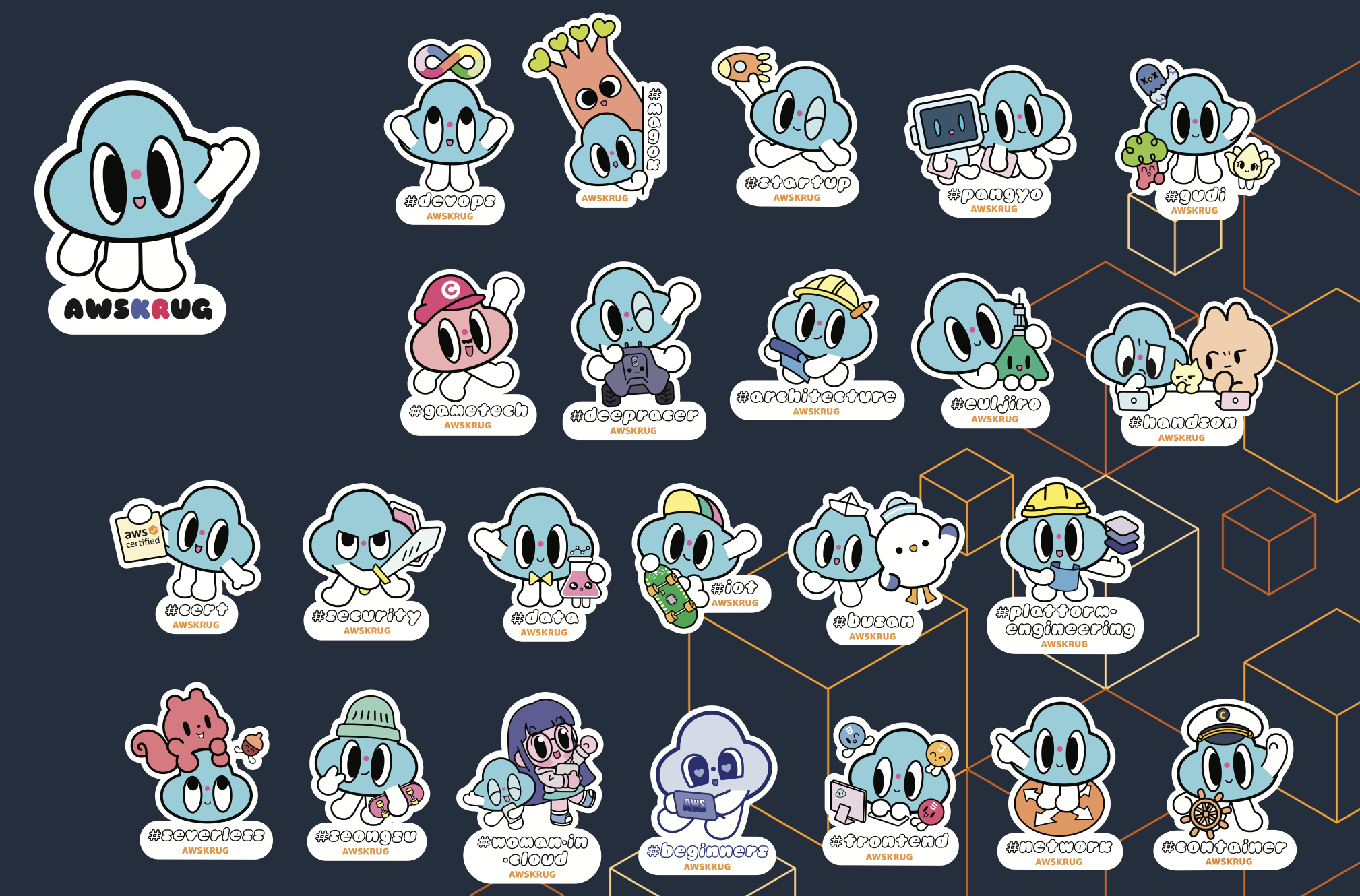
Currently, there are 24 meetups in the AWS Korea User Group(AWSKRUG).
Most of the meetups are held in Seoul, with some also in Pangyo, Gyeonggi-do, and Busan.
 is a cloud storage service that allows users to save, store, and... | 0 | 2024-06-09T16:00:56 | https://dev.to/teraboxdownloader/terabox-video-link-saver-4m6m | terabox, video, videosaver, teraboxlink | Terabox (formerly known as Dubox) is a cloud storage service that allows users to save, store, and manage their files online. If you want to save video links or videos from Terabox, follow these steps:
Saving Video Links
Log in to Terabox:
Open the Terabox website or app and log in to your account.
Upload Video:
Cli... | teraboxdownloader |
1,882,196 | Dynamically execute Tailwind CSS on multiple files with multiple outputs | Code snippet to dynamically execute Tailwind CSS in a given folder with multiple outputs for each file. | 0 | 2024-06-09T16:00:50 | https://dev.to/cbillowes/dynamically-execute-tailwind-css-on-multiple-files-with-multiple-outputs-38f2 | ---
title: Dynamically execute Tailwind CSS on multiple files with multiple outputs
published: true
description: Code snippet to dynamically execute Tailwind CSS in a given folder with multiple outputs for each file.
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# publi... | cbillowes | |
1,882,194 | Node.js vs. NestJS: A Comparative Analysis | In the world of web development, choosing the right framework or runtime can significantly impact the... | 0 | 2024-06-09T15:58:36 | https://dev.to/yelethe1st/nodejs-vs-nestjs-a-comparative-analysis-3f7o | webdev, javascript, node, nestjs |
In the world of web development, choosing the right framework or runtime can significantly impact the efficiency, scalability, and maintainability of your application. Node.js, a popular JavaScript runtime, and NestJS, a progressive Node.js framework, are two powerful options that developers often consider. This artic... | yelethe1st |
1,882,192 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-06-09T15:55:47 | https://dev.to/gabrialmillse432/buy-verified-paxful-account-27d6 | react, python, ai, devops | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\n \n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | gabrialmillse432 |
1,882,191 | Glam Markup Beaches | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration My love... | 0 | 2024-06-09T15:55:24 | https://dev.to/thabangrammitlwa/glam-markup-beaches-3ln3 | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
My love for summer and water
## Demo
I created an under the sea feeling with the mark up of the list to the top beaches in the world, as you click on each beach it reveals informatio... | thabangrammitlwa |
1,882,190 | CSS BORDERS | CSS Borders The CSS border properties allow you to specify the style, width, and color of... | 0 | 2024-06-09T15:54:04 | https://www.devwares.com/blog/css-borders/ | webdev, beginners, css, programming | ## CSS Borders
The CSS border properties allow you to specify the style, width, and color of an element's border.
## Border Width
The [border-width](https://www.devwares.com/tailwindcss/classes/tailwind-border-width/) property specifies the width of the four borders. The property can have from one to four values.
`... | hypercode |
1,877,693 | Advice for Intermediate developers | Prologue I wrote this blog five years ago when I was a junior developer. The tips I shared... | 0 | 2024-06-09T15:50:55 | https://dev.to/rampa2510/advice-for-intermediate-developers-4777 | software, community, developer, career | # Prologue
I wrote [this blog](https://dev.to/rampa2510/3-tips-for-new-developers-49hj) five years ago when I was a junior developer. The tips I shared back then are still rules I follow today and have become an integral part of me. I've grown a lot as a developer, so now I want to give back to the community as an int... | rampa2510 |
1,882,187 | HIRE FAST SWIFT CYBER SERVICES TODAY | I, David , a businessman from Colorado Springs , am forever indebted to , a team of exceptionally... | 0 | 2024-06-09T15:50:24 | https://dev.to/my_office_1803aad4fece944/hire-fast-swift-cyber-services-today-2a6e | cryptocurrency | I, David , a businessman from Colorado Springs , am forever indebted to
, a team of exceptionally skilled and efficient hackers, for their remarkable work in recovering my cryptocurrency that was mistakenly sent to t... | my_office_1803aad4fece944 |
1,882,186 | How to Use NgRx Selectors in Angular | In NgRx, when we want to get data from the store, the easiest way is by using store.select. It allows... | 0 | 2024-06-09T15:48:42 | https://www.danywalls.com/how-to-use-ngrx-selectors-in-angular | angular, ngrx, typescript, frontend | In [NgRx](https://ngrx.io/), when we want to get data from the store, the easiest way is by using [`store.select`](http://store.select). It allows us to get any slice of the state. Yes, it sounds funny, but any slice returns an `Observable<any>`.
For example:
Download | ** How to Download: Dulces Sueños Spanish Pop (Sample Packs) Elevate Your Music... | 0 | 2024-06-09T15:44:59 | https://dev.to/kala_plugins_7b320d218402/dulces-suenos-spanish-pop-sample-packsdownload-5d2f | music, production, vstplugins, download |

**
## How to Download: Dulces Sueños Spanish Pop (Sample Packs)
**Elevate Your Music Production with Authentic Latin Vocals .Unlock the essence of Latin pop with the **Dulces Sueños: Spanish Pop** sample pack, a ... | kala_plugins_7b320d218402 |
1,882,181 | LOST BITCOIN RECOVERY SERVICE DIGITAL HACK RECOVERY | Digital Hack Recovery has emerged as a leading force in the intricate landscape of Bitcoin recovery,... | 0 | 2024-06-09T15:43:09 | https://dev.to/liam_jones_9ae8cbbf5c29e7/lost-bitcoin-recovery-service-digital-hack-recovery-1ejo | Digital Hack Recovery has emerged as a leading force in the intricate landscape of Bitcoin recovery, offering invaluable assistance to individuals and companies grappling with the loss or theft of their digital assets. In an era where the adoption of virtual currencies like Bitcoin is on the rise, the need for reliable... | liam_jones_9ae8cbbf5c29e7 | |
1,882,178 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-09T15:42:33 | https://dev.to/gabrialmillse432/buy-verified-cash-app-account-32ap | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | gabrialmillse432 |
1,882,173 | Cloud Scalability: The Key to Business Agility in a Changing World | The business world today is a whirlwind of change. New technologies emerge constantly, customer... | 0 | 2024-06-09T15:34:07 | https://dev.to/marufhossain/cloud-scalability-the-key-to-business-agility-in-a-changing-world-2iad | The business world today is a whirlwind of change. New technologies emerge constantly, customer expectations shift rapidly, and competition is fiercer than ever. To survive and thrive in this dynamic environment, businesses need to be agile. Agility means being adaptable, responsive, and innovative. It's about being ab... | marufhossain | |
1,871,634 | JavaScript Essentials | Introduction JavaScript is a versatile programming language essential for adding... | 27,559 | 2024-06-09T15:32:00 | https://dev.to/suhaspalani/javascript-essentials-5e44 | webdev, javascript, beginners, programming | #### Introduction
JavaScript is a versatile programming language essential for adding interactivity to web pages. It is one of the core technologies of the web, alongside HTML and CSS. Learning JavaScript fundamentals is crucial for any web developer.
#### JavaScript Basics
**Data Types and Variables:**
- **Primitive ... | suhaspalani |
1,882,170 | How to Handle Side Effects in Angular Using NgRx Effects | Side-effects! They are one of the most common tasks in our applications. In Angular, but build... | 0 | 2024-06-09T15:31:28 | https://www.danywalls.com/how-to-handle-side-effects-in-angular-using-ngrx-effects | angular, ngrx, frontend, typescript | Side-effects! They are one of the most common tasks in our applications. In Angular, but build application if we don't take care the component ends with a lot of responsability, like get, process and render the data. But in Angular most of time when we need to get data from an API, instead of put the logic to handle ev... | danywalls |
1,882,169 | Unlocking the Power of the Cloud: A Comprehensive Guide to Cloud Computing | What is Cloud Computing? Cloud computing is a transformative technology that allows businesses and... | 0 | 2024-06-09T15:29:50 | https://dev.to/mcckeown/unlocking-the-power-of-the-cloud-a-comprehensive-guide-to-cloud-computing-4cc4 | beginners, webdev | **What is Cloud Computing?**
Cloud computing is a transformative technology that allows businesses and individuals to access and use computing resources over the internet. Instead of owning and maintaining physical servers and data centers, users can leverage cloud services to store data, run applications, and perform ... | mcckeown |
1,882,168 | How To Add HTTP Headers to Requests with Functional Interceptors in Angular | When we work with request data in Angular to an external API, sometimes we need to add or send... | 0 | 2024-06-09T15:29:21 | https://www.danywalls.com/how-to-add-http-headers-to-requests-with-functional-interceptors-in-angular | javascript, angular, frontend | When we work with request data in Angular to an external API, sometimes we need to add or send headers. The idea of repeating the code in each request is not something to feel proud of.
For example, when working with the [**ball don't lie API**](https://www.balldontlie.io/), it requires sending the `Authorization` hea... | danywalls |
1,882,167 | Dominando o Angular: Guia Completo para Iniciantes | Enter fullscreen mode Exit fullscreen mode O Angular é uma das... | 0 | 2024-06-09T15:27:59 | https://dev.to/mayra_machado_f50e69498d7/dominando-o-angular-guia-completo-para-iniciantes-3l5p |
```
```
O Angular é uma das frameworks mais populares para desenvolvimento de aplicações web. Neste guia, exploraremos os fundamentos do Angular e como você pode começar a criar aplicações robustas e escaláveis.
Desenvolvido pela Google, o Angular foi lançado em 2010 e desde então tem evoluído significativamente, ... | mayra_machado_f50e69498d7 | |
1,882,166 | A crash course in using Bunjs instead of Node.js on Linux | Transitioning from Node.js to Bun on Linux: A Complete Guide Introduction In... | 0 | 2024-06-09T15:23:54 | https://dev.to/chovy/a-crash-course-in-using-bunjs-instead-of-nodejs-on-linux-56bi | linux, bunjs, node, tutorial | # Transitioning from Node.js to Bun on Linux: A Complete Guide
## Introduction
In the evolving world of JavaScript, Bun is quickly making a name for itself as a high-performance runtime environment that's compatible with Node.js but significantly faster. This guide will walk you through the basics of getting started ... | chovy |
1,882,131 | Web accessibility, how to design web pages for everyone | As developers, how can we make at least the web more accessible for all? That’s the main question of... | 0 | 2024-06-09T15:18:43 | https://dionarodrigues.dev/blog/web-accessibility-how-to-design-web-pages-for-everyone | a11y, webacessibility, webdev, inclusion | **As developers, how can we make at least the web more accessible for all? That’s the main question of this article and here we’ll explore some ideas to make our websites more inclusive, a place where people with disabilities can also use the internet to learn something new, acquire some different skill, buy products a... | dionarodrigues |
1,882,127 | How to configure Server-Side Encryption (SSE-S3) in Amazon S3? | Introduction Amazon S3 offers various encryption options to secure your data at rest.... | 0 | 2024-06-09T15:15:56 | https://dev.to/siddhantkcode/how-to-configure-server-side-encryption-sse-s3-in-amazon-s3-3nlk | aws, s3, security, encryption |
## Introduction
Amazon S3 offers various encryption options to secure your data at rest. Among these options, Server-Side Encryption (SSE) is a powerful feature where Amazon S3 automatically encrypts your objects. This blog post will guide you through configuring SSE-S3 to encrypt objects added to an S3 bucket using ... | siddhantkcode |
1,857,408 | Say "Oui" to Global Users: Localize Your Flutter App with Gemini | Why localize your app? Think about it, ignoring international users is like making a fire meme and... | 0 | 2024-06-09T15:09:41 | https://dev.to/koukibadr/fast-localization-with-gemini-on-flutter-4keh | flutter, gemini | Why localize your app? Think about it, ignoring international users is like making a fire meme and forgetting to post it online - what's the point? But don't worry, we hear you screaming Fear not, for Gemini is here to be your Yoda in the localization swamp. We'll tackle all your app translation woes, so buckle up ... | koukibadr |
1,882,129 | pottery-chicago | bachelorette parties | 0 | 2024-06-09T15:07:18 | https://dev.to/potterychicago1/pottery-chicago-4mbh | [bachelorette parties](https://pottery-chicago.com/bachelorette-party-chicago) | potterychicago1 | |
1,882,128 | Setting Up Emacs for Go Development on macOS | Introduction Emacs is a highly customizable text editor with powerful features for programming. In... | 0 | 2024-06-09T15:05:41 | https://dev.to/yas8say/setting-up-emacs-for-go-development-on-macos-g04 | go | **Introduction**
Emacs is a highly customizable text editor with powerful features for programming. In this guide, we’ll walk through installing Emacs on macOS, setting it up for Go development, and using it effectively.
_Step 1: Install Emacs_
First, ensure you have Emacs installed on your system. You can download i... | yas8say |
1,882,126 | JavaScript Client-Side Development: Tips and Tools for Mastery 🚀 | Welcome to our forum dedicated to mastering JavaScript for client-side development! Whether you're a... | 0 | 2024-06-09T15:00:10 | https://dev.to/timetinker/javascript-client-side-development-tips-and-tools-for-mastery-5b4 | javascript, webdev, tutorial, python | Welcome to our forum dedicated to mastering JavaScript for client-side development! Whether you're a beginner looking to learn the basics or a seasoned developer aiming to sharpen your skills, this is the place for you. Join us to explore essential tools, frameworks, and libraries that enhance your JavaScript developme... | timetinker |
1,882,075 | Bash Scripting for Software Engineers - A Beginner's Guide | It's your first day at your new job. You've been handed a computer running Linux, and you were told... | 27,654 | 2024-06-09T15:00:00 | https://dev.to/alexindevs/bash-scripting-for-software-engineers-a-beginners-guide-1j65 | programming, bash, shell, linux | It's your first day at your new job. You've been handed a computer running Linux, and you were told to locate all the files containing the word "key". It's a simple enough task, right? The catch is, there are thousands of files on that system, and you've never written a shell script before.
Shell scripting, the langu... | alexindevs |
1,882,113 | JavaScript Coding Interview Questions | Q1. Reverse this string let str = "Hello, World!"; let s =... | 0 | 2024-06-09T14:27:46 | https://dev.to/alamfatima1999/javascript-interview-questions-576j | Q1. Reverse this string
```JS
let str = "Hello, World!";
let s = str.split("").reverse().join("");
console.log(s);
```
Q2. Remove duplicates
```JS
let arr = [1,2,3,4,5,6,6];
//let s = new Set();
let s = new Set(arr);
s.add(...arr);
for(let i =0;i<arr.length;i++){
s.add(arr[i]);
}
console.log(s);
```
Q3. Can yo... | alamfatima1999 | |
1,882,125 | Understanding DNS: The Backbone of the Internet | Understanding DNS: The Backbone of the Internet Hey, developers! Today, we're diving into... | 0 | 2024-06-09T14:59:09 | https://dev.to/elizabethsobiya/understanding-dns-the-backbone-of-the-internet-49d7 | # Understanding DNS: The Backbone of the Internet
Hey, developers! Today, we're diving into a fundamental yet often overlooked part of the internet: the Domain Name System (DNS). Whether you're a seasoned developer or just starting out, understanding DNS is crucial for navigating the web and creating robust applicatio... | elizabethsobiya | |
1,882,124 | How to Deploy and Host Your Website Cost-Effectively with Vercel 💰💰 | Creating and deploying a portfolio website can often seem like a intimidating task, especially when... | 0 | 2024-06-09T14:57:37 | https://dev.to/itsfarhankhan28/how-to-deploy-and-host-your-website-cost-effectively-with-vercel-5ejk | vercel, deployment, hosting, website | Creating and deploying a portfolio website can often seem like a intimidating task, especially when you're trying to minimize costs without compromising on quality. Recently, I had the opportunity to develop a simple yet effective single-page portfolio for a client, and I found an efficient way to deploy it using Verce... | itsfarhankhan28 |
1,882,122 | It’s free real (e)state | Let’s talk about States, in context of building user interfaces be it a web application, desktop or... | 0 | 2024-06-09T14:55:44 | https://dev.to/ishar19/its-free-real-estate-3jip | react, flutter, webdev, mobile |
Let’s talk about States, in context of building user interfaces be it a web application, desktop or mobile applications.
What is a state? Why do we use it, need it? How should we use it? And why/ where should we not use it?
### Act 1: What
A state can be representative of your UI at any given point of time, whatev... | ishar19 |
1,882,121 | BEST RECOVERY EXPERTS FOR LOST/STOLEN CRYPTOCURRENCY LEE ULTIMATE HACKER | LEEULTIMATEHACKER@ AOL. COM Support @ leeultimatehacker . com. telegram:LEEULTIMATE wh@tsapp +1 ... | 0 | 2024-06-09T14:53:22 | https://dev.to/jackie_hjelm_8cea8a4e5c17/best-recovery-experts-for-loststolen-cryptocurrency-lee-ultimate-hacker-1e9j | LEEULTIMATEHACKER@ AOL. COM
Support @ leeultimatehacker . com.
telegram:LEEULTIMATE
wh@tsapp +1 (715) 314 - 9248
https://leeultimatehacker.com
In the cacophony of voices heralding cryptocurrencies as the next big thing, I found myself swept up in the frenzy, eager to partake in the promise of untold riches. Fr... | jackie_hjelm_8cea8a4e5c17 | |
1,882,119 | Beginners Guide on How to Contribute to Open Source Projects | What Exactly is Open Source? Open source refers to software that is freely available to... | 0 | 2024-06-09T14:47:03 | https://dev.to/idungstanley/beginners-guide-on-how-to-contribute-to-open-source-projects-3344 |

## What Exactly is Open Source?
Open source refers to software that is freely available to the public to use, modify, and distribute. This software comes with source code that anyone can inspect, enhance, and adap... | idungstanley | |
1,882,118 | Using Phoenix.PubSub as a message-bus for Elixir cluster | In my sharing session about using Phoenix.PubSub as message-bus for Elixir cluster, it quite simple... | 0 | 2024-06-09T14:44:45 | https://dev.to/manhvanvu/simple-using-phoenixpubsub-as-a-message-bus-for-elixir-cluster-l3c | elixir, cluster, messagebus, pubsub | In my sharing session about using Phoenix.PubSub as message-bus for Elixir cluster, it quite simple and effective way for small & medium system. Now I recap it.

(Simple case for using P... | manhvanvu |
1,882,116 | The Frontend Challenge: 1980s/Miami style Glam Up Beaches Around the World | This is a submission for [Frontend Challenge... | 0 | 2024-06-09T14:42:53 | https://dev.to/darrellroberts/the-frontend-challenge-1980smiami-style-glam-up-beaches-around-the-world-59kf | devchallenge, frontendchallenge, css, javascript | _This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
## What I Built
<!-- Tell us what you built and what you were looking to achieve. -->
I created a place where the user can easily locate on a world map where the best beaches in the wo... | darrellroberts |
1,882,115 | easiest way to print sqls in entity framework | Let say you have DbContext like below public class Database(DbContextOptions<Database>... | 0 | 2024-06-09T14:42:52 | https://dev.to/ozkanpakdil/easiest-way-to-print-sqls-in-entity-framework-4nag | Let say you have DbContext like below
```C#
public class Database(DbContextOptions<Database> options) : DbContext(options)
{
public DbSet<Todo> Todos => Set<Todo>();
}
```
Just want to print generated SQLs use below class
```C#
public class Database(DbContextOptions<Database> options) : DbContext(options)
{
pub... | ozkanpakdil | |
1,881,591 | Integrando sua API com front React e Axios | Ao se desenvolver uma API, é ideal que os dados resultantes no lado do servidor dela sejam consumidos... | 0 | 2024-06-09T14:42:51 | https://dev.to/tuliopss/como-integrar-sua-api-com-seu-frontend-cg8 | api, programming, fullstack, react | Ao se desenvolver uma API, é ideal que os dados resultantes no lado do servidor dela sejam consumidos em algum lugar de forma dinâmica e intuitiva, diferentemente de um software de teste manual, como o Postman, por exemplo. Para isso, o desenvolvimento do frontend se faz necessário, permitindo a interação e visualiza... | tuliopss |
1,882,114 | PACX ⁓ Working with solutions | PAC CLI provides a rich namespace dedicated to working with Dataverse solutions. The commands... | 0 | 2024-06-09T14:39:57 | https://dev.to/_neronotte/pacx-working-with-solutions-5fil | powerplatform, dataverse, github, opensource | [PAC CLI provides a rich namespace](https://learn.microsoft.com/en-us/power-platform/developer/cli/reference/solution) dedicated to working with Dataverse solutions.
The commands provided there are really powerful, and designed to **drive a code-first approach to solution management**, that personally I ❤️ a lot.
Bef... | _neronotte |
1,882,096 | Why You Need a Portfolio Website | Having a portfolio website is crucial for professional growth in today's competitive job market.... | 0 | 2024-06-09T14:20:11 | https://dev.to/abdullah_ali_eb8b6b0c2208/why-you-need-a-portfolio-website-445l | webdev, programming, jobs, tutorial | Having a portfolio website is crucial for professional growth in today's competitive job market. Here's why
**heres my portfolio website link drop a review and shares yours
https://abdullahs-portfolio.vercel.app/**
**Showcase Your Profile
**
- First Impressions Matter: A well-designed portfolio site makes a strong fi... | abdullah_ali_eb8b6b0c2208 |
1,882,091 | Frontend Challenge CSS Beach | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. ... | 27,653 | 2024-06-09T14:17:43 | https://dev.to/syedmuhammadaliraza/frontend-challenge-css-beach-3lih | frontendchallenge, css, dev, devchallenge | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Demo
<!-- Show us your CSS Art! You can directly embed an editor into this post (see the FAQ section of the challenge page) or you can share an image of your project and share a public link to ... | syedmuhammadaliraza |
1,882,090 | DIGITAL WEB RECOVERY AGAENCY FOR CRYPTOCURRENCY FRAUD RECOVERY | Fraudulent activities are on the rise, and individuals like me often find themselves in devastating... | 0 | 2024-06-09T14:13:58 | https://dev.to/nicole_treacy_be8c5c9d0b3/digital-web-recovery-agaency-for-cryptocurrency-fraud-recovery-1j4e | Fraudulent activities are on the rise, and individuals like me often find themselves in devastating situations, feeling helpless and alone. However, my experience with Digital Web Recovery has been nothing short of a miraculous turnaround. In March, I fell victim to a fraudulent binary options website, which left me in... | nicole_treacy_be8c5c9d0b3 | |
1,882,089 | Key Features of the Best Infant Carriers | Comfort and Support: The best infant carriers provide optimal comfort and support for both you and... | 0 | 2024-06-09T14:10:50 | https://dev.to/cris_eagles_2b77808a25111/key-features-of-the-best-infant-carriers-1gn9 |
**Comfort and Support:** The best infant carriers provide optimal comfort and support for both you and your baby. Look for carriers with wide, padded shoulder straps and a supportive waist belt to distribute your baby’s weight evenly. Ensure that the carrier has a sturdy, adjustable seat that supports your baby’s hips... | cris_eagles_2b77808a25111 | |
1,882,088 | Frontend Challenge Submission | This is a submission for Frontend Challenge v24.04.17, CSS Art: June. ... | 0 | 2024-06-09T14:09:57 | https://dev.to/syedmuhammadaliraza/frontend-challenge-submission-i01 | frontendchallenge, devchallenge, css | _This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Demo
<!-- Show us your CSS Art! You can directly embed an editor into this post (see the FAQ section of the challenge page) or you can share an image of your project and share a public link to ... | syedmuhammadaliraza |
1,881,618 | Environment Variables in Docker and Docker Compose - Part 2. Options and Properties | Introduction This document summarizes command options and properties of compose.yaml. ... | 0 | 2024-06-09T00:41:56 | https://dev.to/zundamon/enviroment-variables-in-docker-2od3 |
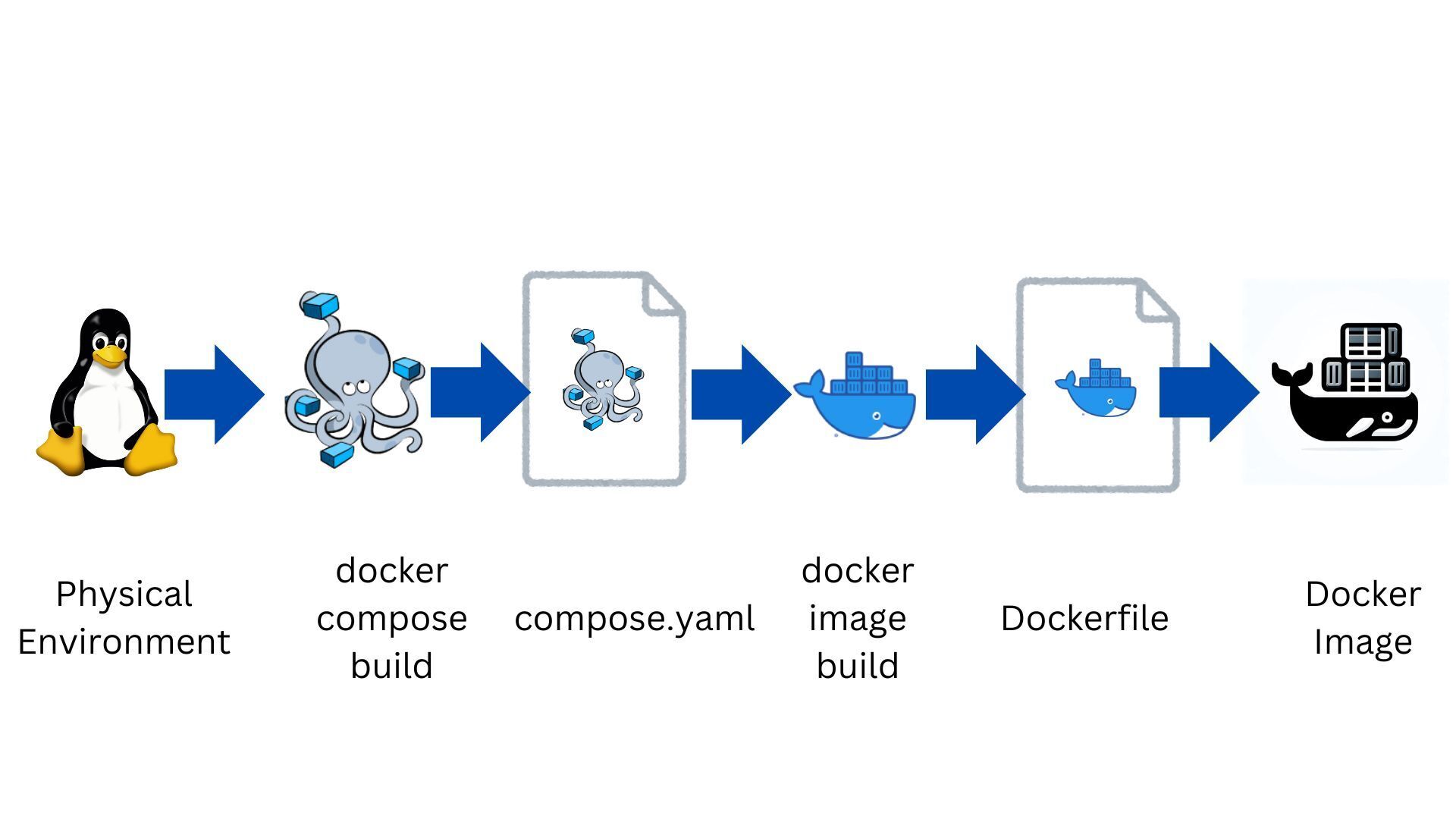
## Introduction
This document summarizes command options and properties of `compose.yaml`.
### ◯ Overview
#### 1. Flow of Passing Environment Variables
, CSS Art: 09-June-2024
## Inspiration
It's my first time doing something out of my comfort zone. I'm excited to participate in this challenge and eager to take on even more challenges to improve my skills.
<!-- What ... | nishanthi_s |
1,882,084 | Level Up: Developing Engaging JavaScript Games for the Web🚀 | Creating web games with JavaScript has become increasingly popular and accessible, offering... | 0 | 2024-06-09T14:02:04 | https://dev.to/dharamgfx/level-up-developing-engaging-javascript-games-for-the-web-18e3 | webdev, javascript, gamedev, programming |
Creating web games with JavaScript has become increasingly popular and accessible, offering developers a variety of tools and techniques to craft engaging experiences. This post will guide you through the essential components of web game development, covering everything from APIs and technologies to techniques and tu... | dharamgfx |
1,882,083 | Java 8 Lambda Expressions and Functional Interfaces | Overview : Java 8 introduced Lambda Expressions and Functional Interfaces, which bring functional... | 0 | 2024-06-09T14:01:39 | https://dev.to/abhishek999/java-8-lambda-expressions-and-functional-interfaces-3403 | java, java8, lambda, functionalinterfaces | **Overview :**
Java 8 introduced Lambda Expressions and Functional Interfaces, which bring functional programming capabilities to Java. These features allow for more concise and readable code, especially when working with collections and performing common tasks like filtering, mapping, and reducing
By the end of this... | abhishek999 |
1,882,082 | Why Creating an ERD is Essential Before Starting Your Backend Project. | In the intricate realm of software development, meticulous planning is as critical as the execution... | 0 | 2024-06-09T14:00:09 | https://dev.to/yelethe1st/why-creating-an-erd-is-essential-before-starting-your-backend-project-40c1 | backenddevelopment, databasedesign, erd, projectplanning | In the intricate realm of software development, meticulous planning is as critical as the execution itself. One foundational step that often gets overlooked in the rush to code is the creation of an Entity-Relationship Diagram (ERD). This diagram serves as a blueprint for the database architecture, ensuring clarity, ef... | yelethe1st |
1,882,077 | Compile your NodeJS application to single file executable | Hi great developers :) In this article, I am trying to share with you my small experience about... | 0 | 2024-06-09T13:59:07 | https://dev.to/sudospace/compile-your-nodejs-application-to-single-file-executable-5aoe | typescript, javascript, node | Hi great developers :)
In this article, I am trying to share with you my small experience about converting nodeJS projects to single file executable.
In short, there are methods that you can use.
1. NodeJS single file executable built-in feature
Here I link [NodeJS documentation](https://nodejs.org/api/single-executab... | sudospace |
1,882,081 | Kevlar Motorcycle Shirts: The Ultimate Blend of Style and Protection | Riding a motorcycle is an exhilarating experience, but safety should always be a priority.... | 0 | 2024-06-09T13:57:57 | https://dev.to/terryjohn/kevlar-motorcycle-shirts-the-ultimate-blend-of-style-and-protection-f6d | beginners, productivity | Riding a motorcycle is an exhilarating experience, but safety should always be a priority. Traditional leather jackets have been the go-to for many riders, but a new trend is emerging: Kevlar motorcycle shirts. These shirts, also known as Kevlar riding shirts or Kevlar armored shirts, combine style with cutting-edge pr... | terryjohn |
1,882,080 | Mastering JavaScript MathML: Writing Mathematics with MathML | Mathematical Markup Language (MathML) allows you to write complex mathematical expressions in web... | 0 | 2024-06-09T13:55:53 | https://dev.to/dharamgfx/mastering-javascript-mathml-writing-mathematics-with-mathml-1fll | webdev, beginners, javascript, programming |
Mathematical Markup Language (MathML) allows you to write complex mathematical expressions in web pages seamlessly. This guide will take you through the essential topics to get started with MathML and explore its various elements.
## MathML First Steps
### What is MathML?
- **Definition**: MathML (Mathematical Markup... | dharamgfx |
1,882,079 | Taruhan Olahraga dan Kasino Sunmory33 | Dalam dunia permainan online yang menarik, Sunmory33 telah muncul sebagai tujuan utama bagi... | 0 | 2024-06-09T13:53:26 | https://dev.to/withorwithout02/taruhan-olahraga-dan-kasino-sunmory33-2j0p |

Dalam dunia permainan online yang menarik, Sunmory33 telah muncul sebagai tujuan utama bagi penggemar taruhan olahraga dan kasino. Baik Anda penggemar berat olahraga yang ingin memasang taruhan pada tim favorit An... | withorwithout02 | |
1,882,078 | We Also Provide You Reviews At A Very Reasonable Price | Buy TrustPilot Reviews Trustpilot Reviews From US And Benefit Your Business Online sales of a... | 0 | 2024-06-09T13:46:50 | https://dev.to/alicia1fka/we-also-provide-you-reviews-at-a-very-reasonable-price-42kk | javascript, webdev, beginners, tutorial | Buy TrustPilot Reviews
Trustpilot Reviews From US And Benefit Your Business
Online sales of a particular company depend a lot on the reviews posted by the customers. In fact it has been observed that as many as 92% of the people rely on these reviews when they are making purchases. It is for this reason you will see th... | alicia1fka |
1,882,060 | Negative Indexing in Python, with Examples 🐍 | Python is known for its simplicity and readability, making it a popular choice for beginners and... | 0 | 2024-06-09T13:41:36 | https://dev.to/hichem-mg/negative-indexing-in-python-with-examples-1ind | python, beginners, coding |
Python is known for its simplicity and readability, making it a popular choice for beginners and seasoned developers alike. One of the features that contributes to its flexibility is negative indexing.
In this tutorial, I will go through what negative indexing is, how it works, and its practical applications in Pytho... | hichem-mg |
1,882,074 | Identifying Container Image Vulnerabilities with Docker Scout | A guide on how to maintain a more secure containerized software. | 0 | 2024-06-09T13:39:54 | https://dev.to/plutov/identifying-container-image-vulnerabilities-with-docker-scout-503o | docker, security, cicd, kubernetes | ---
title: Identifying Container Image Vulnerabilities with Docker Scout
published: true
description: A guide on how to maintain a more secure containerized software.
tags: Docker, Security, CICD, Kubernetes
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/2kcgwo2gueldysu9l05q.jpeg
---

1. First the path to the require module is resolved and the file is loaded.

#TronFcRegister now: http://tronfc.fun
#TronFcOfficial Telegram Channel: https://t.me/TronFc_Mining8
#TronFcOffi... | tronfc |
1,881,914 | Symfony 7 vs. .NET Core 8 - Routing; part 3 | Disclaimer This is a tutorial or a training course. Please don't expect a walk-through... | 0 | 2024-06-09T13:25:30 | https://dev.to/awons/symfony-7-vs-net-core-8-routing-part-3-n6 | symfony, dotnetcore, routing | ## Disclaimer
This is a tutorial or a training course. Please don't expect a walk-through tutorial showing how to use ASP.NET Core. It only compares similarities and differences between Symfony and ASP.NET Core. Symfony is taken as a reference point, so if features are only available in .NET Core, they may never get t... | awons |
1,882,067 | A way to speed up Next.js dynamic SSR | Let's say you have a React server component that fetches data on a server and renders a list of... | 27,652 | 2024-06-09T13:23:12 | https://dev.to/pavelkrasnov/a-way-to-speed-up-nextjs-dynamic-ssr-27ga | Let's say you have a React server component that fetches data on a server and renders a list of items:
```
import PokemonList from "./PokemonList";
async function fetchPokemon(id: number) {
const response = await fetch(`https://pokeapi.co/api/v2/pokemon/${id}`);
return response.json();
}
const pokemonIds = A... | pavelkrasnov | |
1,882,064 | Level Up Your Coding Skills for Free! | Explore these fantastic free resources for web development, backend development, data, APIs, DevOps, and programming languages. | 0 | 2024-06-09T13:19:24 | https://dev.to/iamatifriaz/level-up-your-coding-skills-for-free-3p7j | webdev, codenewbie | ---
title: Level Up Your Coding Skills for Free!
published: true
description: Explore these fantastic free resources for web development, backend development, data, APIs, DevOps, and programming languages.
tags: webdev, codenewbies
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/36qspkqsqmp7lfueuy... | iamatifriaz |
1,882,062 | Setting up a Local Kafka Environment on Windows | Setting up a Local Kafka Environment on... | 0 | 2024-06-09T13:14:33 | https://dev.to/codegreen/setting-up-a-local-kafka-environment-on-windows-1h8c | java, kafka, zookeeper | ##Setting up a Local Kafka Environment on Windows##
===============================================
**Note:** It's recommended to place Kafka and ZooKeeper folders in the root directory (C:/Windows) without any spaces in the folder names to avoid potential issues.
Prerequisites
-------------
* [Java Development Ki... | manishthakurani |
1,881,937 | Learn Bun.sh in Simple ways | Bun.sh is a modern JavaScript runtime similar to Node.js, but it promises better performance and... | 0 | 2024-06-09T13:13:11 | https://dev.to/aakash10802/learn-bunsh-in-simple-ways-41l9 | webdev, bunjs, beginners, tutorial | Bun.sh is a modern JavaScript runtime similar to Node.js, but it promises better performance and built-in tools for tasks such as bundling, transpiling, and running scripts.
10 Facts about Bun.sh
[](https://youtu.be/eTB0UCDnMQo)
1. Bun.sh is a modern JavaScript runtime designed for better performance than Node.js.
2.... | aakash10802 |
1,882,061 | Java Records | All About Java Records : Overview : Java Records, introduced in Java 14 as a preview feature and... | 0 | 2024-06-09T13:12:41 | https://dev.to/abhishek999/java-records-1bil | java, record | **All About Java Records :**
**Overview :**
Java Records, introduced in Java 14 as a preview feature and finalized in Java 16, provides a concise way to model immutable data. They simplify the boilerplate code needed for data-carrying classes by automatically generating methods like equals(), hashCode() and toString... | abhishek999 |
1,882,054 | The Importance of Good Health for Indie Developers | Indie development is an exciting and sometimes, rewarding field as it offers the freedom to create... | 0 | 2024-06-09T13:03:23 | https://dev.to/leonardsangoroh/the-importance-of-good-health-for-indie-developers-55o2 | programming, programmers, mentalhealth, developers | Indie development is an exciting and sometimes, rewarding field as it offers the freedom to create and innovate. However, it also comes with unique challenges, especially when it comes to maintaining good health. In this post, we will explore why good health is crucial for us, Indie Developers, and look at how we can a... | leonardsangoroh |
1,881,664 | Hello ? | A post by Prgull Kamal | 0 | 2024-06-09T00:41:35 | https://dev.to/prgull/hello--44ln | prgull | ||
1,882,059 | Test | Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test... | 0 | 2024-06-09T12:44:51 | https://dev.to/petrache/test-3144 | Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test Test ... | petrache | |
1,882,057 | Types vs Interfaces in TypeScript | To describe complex types, we can use two TypeScript entities: types or interfaces. In the post we... | 0 | 2024-06-09T12:43:11 | https://dev.to/betelgeuseas/types-vs-interfaces-in-typescript-2ebo | javascript, typescript | To describe complex types, we can use two TypeScript entities: types or interfaces. In the post we will look into their differences and similarities.
Both allow us to create reusable structures for variables, function parameters, return types, and more. In many cases, types and interfaces are interchangeable and can b... | betelgeuseas |
1,882,053 | You're doing state wrong | Implementing component state as a combination of booleans may seem like the easiest way to do it, but... | 0 | 2024-06-09T12:40:51 | https://nabiltharwat.com/blog/2024-06-08-youre-doing-state-wrong | webdev, javascript, programming, typescript | Implementing component state as a combination of booleans may seem like the easiest way to do it, but let's do something different.
_Cover by Namroud Gorguis on Unsplash_
> This article is framework- and language- agnostic. Code examples presented are written in a generic form.
## Consider a music player
That can p... | kl13nt |
1,882,055 | Accessibility on TV | There are all these rules for accessibility on websites, which admittedly most sites don't follow,... | 0 | 2024-06-09T12:45:29 | https://blog.nicm42.co.uk/accessibility-on-tv | a11y | ---
title: Accessibility on TV
published: true
date: 2024-06-09 12:39:32 UTC
tags: accessibility
canonical_url: https://blog.nicm42.co.uk/accessibility-on-tv
---
There are all these rules for accessibility on websites, which admittedly most sites don't follow, but theoretically they should. However that's not the case... | nicm42 |
1,882,043 | Intro to MultiversX blockchain interactions with JavaScript SDK | Writing low-level code for blockchain applications is one thing, but you must also write tools to... | 27,816 | 2024-06-09T12:39:19 | https://www.julian.io/articles/multiversx-js-sdk-intro.html | multiversx, blockchain, web3, javascript | Writing low-level code for blockchain applications is one thing, but you must also write tools to interact with the protocol and smart contracts. What is the best programming language for that? A couple exist, but what's quickest to pick up, especially with a great SDK? Of course, JavaScript.
I want to cover interacti... | julian-io |
1,881,622 | HashiCorp Vault Quickstart | https://github.com/darkedges/quickstart-hashicorp-vault This is a sample project to initialise a... | 0 | 2024-06-08T23:56:17 | https://dev.to/darkedges/hashicorp-vault-quickstart-26g6 | https://github.com/darkedges/quickstart-hashicorp-vault
This is a sample project to initialise a [HashiCorp Vault](https://www.vaultproject.io/) instance with a PKI Instance and generate some secrets that can be used by the ForgerRock Identity Platform.
It uses [HashiCorp Terraform](https://www.terraform.io/) to prov... | darkedges | |
1,882,038 | Swift Custom Array Implementation Using UnsafeMutablePointer | In this article, we explore a custom array implementation in Swift using UnsafeMutablePointer. This... | 0 | 2024-06-09T12:33:58 | https://dev.to/binoy123/swift-custom-array-implementation-using-unsafemutablepointer-fl5 | swift, customearray, architecture, beginners | In this article, we explore a custom array implementation in Swift using UnsafeMutablePointer. This implementation offers insights into manual memory management, dynamic resizing, and conformance to protocols such as CustomDebugStringConvertible and Sequence. The goal is to provide a detailed overview of the internal w... | binoy123 |
1,882,044 | YOLOv10 on Custom Dataset | What is YOLO? You Only Look Once (YOLO) is a state-of-the-art, real-time object detection... | 0 | 2024-06-09T12:33:41 | https://dev.to/wydoinn/yolov10-on-custom-dataset-4dld | ai, machinelearning, deeplearning, python | ## What is YOLO?
**You Only Look Once (YOLO)** is a state-of-the-art, real-time object detection algorithm .
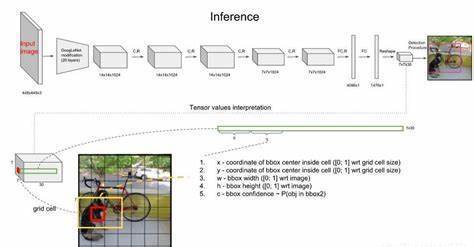
## What makes YOLO popular?
- Speed
- Detection accuracy
- Good generalization
- Open-source
Goog... | wydoinn |
1,882,052 | How to setup Deep Links for Android applications | Deep links are special URIs that take users directly to specific content within a mobile app, rather... | 0 | 2024-06-09T12:24:12 | https://wannabedev.io/guides/how-to-setup-deep-links-for-android-applications | android, mobile, learning, deeplinks | Deep links are special URIs that take users directly to specific content within a mobile app, rather than just launching the app or opening a webpage in a browser.
These links enhance user experience by letting users navigate to precise content or a particular section of the app with just one click.
## Types of links... | rmmgc |
1,882,051 | Postmortem: A Guide to Learning from Failure | Introduction In the world of software development, postmortems are a crucial step in... | 0 | 2024-06-09T12:23:33 | https://dev.to/ferdi_code/postmortem-a-guide-to-learning-from-failure-1bbm | ## Introduction
In the world of software development, postmortems are a crucial step in ensuring that we learn from our mistakes and improve our processes. A postmortem is a detailed analysis of a project or incident that identifies what went wrong, what went right, and what we can do better next time. In this blog, w... | ferdi_code | |
1,882,027 | Integrating AI into Your Website: A Step-by-Step Guide with ReactJS and OpenAI | Integrating AI into your website can significantly enhance user experience, especially when dealing... | 0 | 2024-06-09T12:22:58 | https://dev.to/limacodes/integrating-ai-into-your-website-a-step-by-step-guide-with-reactjs-and-openai-46b8 | ai, openai, react, nextjs | **Integrating AI into your website can significantly enhance user experience, especially when dealing with customer support.**
In this article, we will walk you through the process of integrating OpenAI’s latest model into a Next.js React application to create an intelligent FAQ hub for a support company.
> This AI ... | limacodes |
1,882,025 | I’ve worked in IT for over 10 years. Here are 5 things I wish I knew when I started | Hello, dear Dev.to community. I need to get some things off my chest, so here I am, hoping to share... | 0 | 2024-06-09T12:22:22 | https://dev.to/vorniches/ive-worked-in-it-for-over-10-years-here-are-5-things-i-wish-i-knew-when-i-started-43pe | burnout, productivity, beginners, career | Hello, dear Dev.to community. I need to get some things off my chest, so here I am, hoping to share something useful with young IT professionals. Over my career, I’ve gone through freelancing, internships, corporate jobs, career changes, and even launching my own SaaS (a story for another time…). I’ve made countless mi... | vorniches |
1,882,045 | How to Manage Services in Linux: systemd and SysVinit Essentials - DevOps Prerequisite 8 | Service and Daemon Management in Linux: Mastering systemd and SysVinit Effective... | 0 | 2024-06-09T12:19:00 | https://dev.to/iaadidev/how-to-manage-services-in-linux-systemd-and-sysvinit-essentials-devops-prerequisite-8-1jop | linux, commnads, services, daemon | ## Service and Daemon Management in Linux: Mastering systemd and SysVinit
Effective management of services and daemons is a critical aspect of Linux system administration. Services and daemons are background processes that perform essential functions, such as handling network requests, managing hardware, and running s... | iaadidev |
1,882,042 | Kubernetes: Hello World | Introduction Deploying software can be a daunting and unpredictable task. Kubernetes,... | 0 | 2024-06-09T12:14:45 | https://dev.to/pratikjagrut/kubernetes-hello-world-268d | kubernetes, containers | ### Introduction
Deploying software can be a daunting and unpredictable task. Kubernetes, often referred to as ***K8s***, serves as a proficient navigator in this complex landscape. It is an open-source container orchestration platform, that automates the deployment, scaling, and management of applications within cont... | pratikjagrut |
1,882,041 | How to configure a Disk on a virtual machine from Azure Cloud and Install windows features using PowerShell. | *Step 1: Login to Azure portal * _Click on virtual machines and create _ **Step 2: a. Select... | 0 | 2024-06-09T12:13:37 | https://dev.to/busybrain/how-to-configure-a-disk-on-a-virtual-machine-from-azure-cloud-and-install-windows-features-using-powershell-3m54 | **Step 1: Login to Azure portal **
**_Click on virtual machines and create _**
_**_**Step 2:
a. Select the... | busybrain | |
1,882,028 | react js useEffect hook | The useEffect hook is used to handle function side effects in React. A function side effect in... | 0 | 2024-06-09T11:50:06 | https://dev.to/kemiowoyele1/react-js-useeffect-hook-1a5l | react, useeffect, javascript, webdev | The useEffect hook is used to handle function side effects in React. A function side effect in JavaScript is any effect outside the function’s local variable. Examples of function side effect include;
I. Making network request
II. Manipulating the DOM
III. Fetching data from an API
IV. Changing the value of a variable ... | kemiowoyele1 |
1,882,040 | EKS Secret Management — with Golang, AWS ParameterStore and Terraform | Table of Contents Introduction InitContainer with GO binary OIDC Federated Access for... | 0 | 2024-06-09T12:08:38 | https://dev.to/wardove/eks-secret-management-with-golang-aws-parameterstore-and-terraform-4h24 | aws, terraform, go, security | ## Table of Contents <a name="Toc"></a>
1. [Introduction](#introduction)
2. [InitContainer with GO binary](#part-1)
3. [OIDC Federated Access for EKS Pods](#part-2)
4. [Farewell](#farewell)
## Introduction <a name="introduction"></a>
Hey Folks! In this article, we are going to delve into a robust approach to Kubernete... | wardove |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.